第63步 深度学习图像识别:多分类建模误判病例分析(Tensorflow)
基于WIN10的64位系统演示
一、写在前面
上两期我们基于TensorFlow和Pytorch环境做了图像识别的多分类任务建模。这一期我们做误判病例分析,分两节介绍,分别基于TensorFlow和Pytorch环境的建模和分析。
本期以健康组、肺结核组、COVID-19组、细菌性(病毒性)肺炎组为数据集,基于TensorFlow环境,构建mobilenet_v2多分类模型,因为它建模速度快。
同样,基于GPT-4辅助编程,这次改写过程会简单展示。
二、误判病例分析实战
使用胸片的数据集:肺结核病人和健康人的胸片的识别。其中,健康人900张,肺结核病人700张,COVID-19病人549张、细菌性(病毒性)肺炎组900张,分别存入单独的文件夹中。
直接分享代码:
######################################导入包###################################
from tensorflow import keras
import tensorflow as tf
from tensorflow.python.keras.layers import Dense, Flatten, Conv2D, MaxPool2D, Dropout, Activation, Reshape, Softmax, GlobalAveragePooling2D, BatchNormalization
from tensorflow.python.keras.layers.convolutional import Convolution2D, MaxPooling2D
from tensorflow.python.keras import Sequential
from tensorflow.python.keras import Model
from tensorflow.python.keras.optimizers import adam_v2
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.python.keras.preprocessing.image import ImageDataGenerator, image_dataset_from_directory
from tensorflow.python.keras.layers.preprocessing.image_preprocessing import RandomFlip, RandomRotation, RandomContrast, RandomZoom, RandomTranslation
import os,PIL,pathlib
import warnings#设置GPU
gpus = tf.config.list_physical_devices("GPU")warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号################################导入数据集#####################################
data_dir = "./MTB-1"
data_dir = pathlib.Path(data_dir)
image_count = len(list(data_dir.glob('*/*')))
print("图片总数为:", image_count)batch_size = 32
img_height = 100
img_width = 100# 创建一个数据集,其中包含所有图像的路径。
list_ds = tf.data.Dataset.list_files(str(data_dir/'*/*'), shuffle=True)
# 切分为训练集和验证集
val_size = int(image_count * 0.2)
train_ds = list_ds.skip(val_size)
val_ds = list_ds.take(val_size)class_names = np.array(sorted([item.name for item in data_dir.glob('*') if item.name != "LICENSE.txt"]))
print(class_names)def get_label(file_path):parts = tf.strings.split(file_path, os.path.sep)one_hot = parts[-2] == class_namesreturn tf.argmax(one_hot)def decode_img(img):img = tf.image.decode_image(img, channels=3, expand_animations=False) # 指定 channels 参数img = tf.image.resize(img, [img_height, img_width])img = img / 255.0 # normalize to [0,1] rangereturn img# 在创建数据集时,添加一个新的元素:数据集类型
def process_path_with_filename_and_dataset_type(file_path, dataset_type):label = get_label(file_path)img = tf.io.read_file(file_path)img = decode_img(img)return img, label, file_path, dataset_typeAUTOTUNE = tf.data.AUTOTUNE# 在此处对train_ds和val_ds进行图像处理,包括添加文件名信息和数据集类型信息
train_ds_with_filenames_and_type = train_ds.map(lambda x: process_path_with_filename_and_dataset_type(x, 'Train'), num_parallel_calls=AUTOTUNE)
val_ds_with_filenames_and_type = val_ds.map(lambda x: process_path_with_filename_and_dataset_type(x, 'Val'), num_parallel_calls=AUTOTUNE)# 合并训练集和验证集
all_ds_with_filenames_and_type = train_ds_with_filenames_and_type.concatenate(val_ds_with_filenames_and_type)# 对训练数据集进行批处理和预加载
train_ds_with_filenames_and_type = train_ds_with_filenames_and_type.batch(batch_size)
train_ds_with_filenames_and_type = train_ds_with_filenames_and_type.prefetch(buffer_size=AUTOTUNE)# 对验证数据集进行批处理和预加载
val_ds_with_filenames_and_type = val_ds_with_filenames_and_type.batch(batch_size)
val_ds_with_filenames_and_type = val_ds_with_filenames_and_type.prefetch(buffer_size=AUTOTUNE)# 在进行模型训练时,不需要文件名和数据集类型信息,所以在此处移除
train_ds = train_ds_with_filenames_and_type.map(lambda x, y, z, t: (x, y))
val_ds = val_ds_with_filenames_and_type.map(lambda x, y, z, t: (x, y))for image, label, path, dataset_type in train_ds_with_filenames_and_type.take(1):print("Image shape: ", image.numpy().shape)print("Label: ", label.numpy())print("Path: ", path.numpy())print("Dataset type: ", dataset_type.numpy())train_ds = train_ds.prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.prefetch(buffer_size=AUTOTUNE)plt.figure(figsize=(10, 8)) # 图形的宽为10高为5
plt.suptitle("数据展示")for images, labels, paths, dataset_types in train_ds_with_filenames_and_type.take(1):for i in range(15):plt.subplot(4, 5, i + 1)plt.xticks([])plt.yticks([])plt.grid(False)plt.imshow(images[i].numpy())plt.xlabel(class_names[labels[i]])
plt.show()######################################数据增强函数################################data_augmentation = Sequential([RandomFlip("horizontal_and_vertical"),RandomRotation(0.2),RandomContrast(1.0),RandomZoom(0.5, 0.2),RandomTranslation(0.3, 0.5),
])def prepare(ds, augment=False):ds = ds.map(lambda x, y, z, t: (data_augmentation(x, training=True), y, z, t) if augment else (x, y, z, t), num_parallel_calls=AUTOTUNE)return ds# 注意这里变量名的更改
train_ds_with_filenames_and_type = prepare(train_ds_with_filenames_and_type, augment=True)# 在进行模型训练时,不需要文件名和数据集类型信息,所以在此处移除
train_ds = train_ds_with_filenames_and_type.map(lambda x, y, z, t: (x, y))
val_ds = val_ds_with_filenames_and_type.map(lambda x, y, z, t: (x, y))train_ds = train_ds.prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.prefetch(buffer_size=AUTOTUNE)###############################导入mobilenet_v2################################
#获取预训练模型对输入的预处理方法
from tensorflow.python.keras.applications import mobilenet_v2
from tensorflow.python.keras import Input, regularizers
IMG_SIZE = (img_height, img_width, 3)base_model = mobilenet_v2.MobileNetV2(input_shape=IMG_SIZE, include_top=False, #是否包含顶层的全连接层weights='imagenet')inputs = Input(shape=IMG_SIZE)
#模型
x = base_model(inputs, training=False) #参数不变化
#全局池化
x = GlobalAveragePooling2D()(x)
#BatchNormalization
x = BatchNormalization()(x)
#Dropout
x = Dropout(0.8)(x)
#Dense
x = Dense(128, kernel_regularizer=regularizers.l2(0.1))(x) # 全连接层减少到128,添加 L2 正则化
#BatchNormalization
x = BatchNormalization()(x)
#激活函数
x = Activation('relu')(x)
#输出层
outputs = Dense(4, kernel_regularizer=regularizers.l2(0.1))(x) # 添加 L2 正则化,改变输出层的神经元数量为4
#BatchNormalization
outputs = BatchNormalization()(outputs)
#激活函数
outputs = Activation('softmax')(outputs) # 使用softmax激活函数,因为是多分类问题
#整体封装
model = Model(inputs, outputs)
#打印模型结构
print(model.summary())
#############################编译模型#########################################
#定义优化器
from tensorflow.python.keras.optimizers import adam_v2, rmsprop_v2optimizer = adam_v2.Adam()#编译模型
model.compile(optimizer=optimizer,loss='sparse_categorical_crossentropy', # 因为是多分类问题,所以损失函数选择sparse_categorical_crossentropymetrics=['accuracy'])#训练模型
from tensorflow.python.keras.callbacks import ModelCheckpoint, Callback, EarlyStopping, ReduceLROnPlateau, LearningRateSchedulerNO_EPOCHS = 50
PATIENCE = 10
VERBOSE = 1# 设置动态学习率
annealer = LearningRateScheduler(lambda x: 1e-5 * 0.99 ** (x+NO_EPOCHS))# 设置早停
earlystopper = EarlyStopping(monitor='loss', patience=PATIENCE, verbose=VERBOSE)#
checkpointer = ModelCheckpoint('mtb_jet_best_model_mobilenetv3samll-1.h5',monitor='val_accuracy',verbose=VERBOSE,save_best_only=True,save_weights_only=True)train_model = model.fit(train_ds,epochs=NO_EPOCHS,verbose=1,validation_data=val_ds,callbacks=[earlystopper, checkpointer, annealer])#保存模型
#model.save('mtb_jet_best_model_mobilenet-1.h5')
#print("The trained model has been saved.")###########################误判病例分析#################################
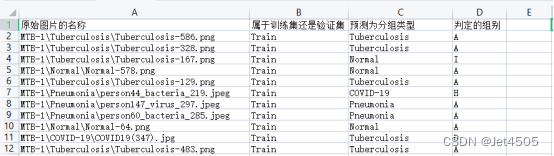
import pandas as pd# 提取图片的信息并预测
data_list = []
for image, label, path, dataset_type in all_ds_with_filenames_and_type:# 获取图片名称、类别信息path_parts = path.numpy().decode('utf-8').split('/')dataset_type = dataset_type.numpy().decode('utf-8')true_class = class_names[label.numpy()]image_name = path_parts[-1]# 使用模型预测图片的类别img_array = np.expand_dims(image, axis=0)predictions = model.predict(img_array)pred_class = class_names[np.argmax(predictions)]# 根据预测结果判断所属的组别if true_class == pred_class:group = 'A'elif true_class == 'COVID-19':if pred_class == 'Normal':group = 'B'elif pred_class == 'Pneumonia':group = 'C'elif pred_class == 'Tuberculosis':group = 'D'elif true_class == 'Normal':if pred_class == 'COVID-19':group = 'E'elif pred_class == 'Pneumonia':group = 'F'elif pred_class == 'Tuberculosis':group = 'G'elif true_class == 'Pneumonia':if pred_class == 'COVID-19':group = 'H'elif pred_class == 'Normal':group = 'I'elif pred_class == 'Tuberculosis':group = 'J'elif true_class == 'Tuberculosis':if pred_class == 'COVID-19':group = 'H'elif pred_class == 'Normal':group = 'I'elif pred_class == 'Pneumonia':group = 'J'# 保存图片的信息和预测结果data_list.append([image_name, dataset_type, pred_class, group])# 将结果转化为DataFrame并保存为csv文件
result = pd.DataFrame(data_list, columns=["原始图片的名称", "属于训练集还是验证集", "预测为分组类型", "判定的组别"])
result.to_csv("result-m-t.csv", index=False)三、改写过程
先说策略:首先,先把二分类的误判病例分析代码改成四分类的;其次,用咒语让GPT-4帮我们续写代码已达到误判病例分析。
策略的理由:之前介绍过,做误判病例分析是需要读取图片的路径信息。悲剧的是,我们之前在读取数据的时候使用的是“image_dataset_from_directory”函数,它不提供路径信息。因此,在二分类的误判病例分析的教程中,我们修改了数据读取的代码,因此,在此基础上进行修改,效率最高!
提供咒语如下:
①改写{代码1},改变成4分类的建模。代码1为:{XXX};
②在{代码1}的基础上改写代码,达到下面要求:
(1)首先,提取出所有图片的“原始图片的名称”、“属于训练集还是验证集”、“预测为分组类型”;文件的路劲格式为:例如,“MTB-1\Normal\XXX.png”属于Normal,“MTB-1\COVID-19\XXX.jpg”属于COVID-19,“MTB-1\Pneumonia\XXX.jpeg”属于Pneumonia,“MTB-1\Tuberculosis\XXX.png”属于Tuberculosis;
(2)其次,根据样本预测结果,把样本分为以下若干组:(a)预测正确的图片,全部判定为A组;(b)本来就是COVID-19的图片,预测为Normal,判定为B组;(c)本来就是COVID-19的图片,预测为Pneumonia,判定为C组;(d)本来就是COVID-19的图片,预测为Tuberculosis,判定为D组;(e)本来就是Normal的图片,预测为COVID-19,判定为E组;(f)本来就是Normal的图片,预测为Pneumonia,判定为F组;(g)本来就是Normal的图片,预测为Tuberculosis,判定为G组;(h)本来就是Pneumonia的图片,预测为COVID-19,判定为H组;(i)本来就是Pneumonia的图片,预测为Normal,判定为I组;(j)本来就是Pneumonia的图片,预测为Tuberculosis,判定为J组;(k)本来就是Tuberculosis的图片,预测为COVID-19,判定为H组;(l)本来就是Tuberculosis的图片,预测为Normal,判定为I组;(m)本来就是Tuberculosis的图片,预测为Pneumonia,判定为J组;
(3)居于以上计算的结果,生成一个名为result-m.csv表格文件。列名分别为:“原始图片的名称”、“属于训练集还是验证集”、“预测为分组类型”、“判定的组别”。其中,“原始图片的名称”为所有图片的图片名称;“属于训练集还是验证集”为这个图片属于训练集还是验证集;“预测为分组类型”为模型预测该样本是哪一个分组;“判定的组别”为根据步骤(2)判定的组别,从A到J一共十组选择一个。
(4)需要把所有的图片都进行上面操作,注意是所有图片,而不只是一个批次的图片。
代码1为:{XXX}
③还需要根据报错做一些调整即可,自行调整。
最后,看看结果:
四、数据
链接:https://pan.baidu.com/s/1rqu15KAUxjNBaWYfEmPwgQ?pwd=xfyn
提取码:xfyn
相关文章:
第63步 深度学习图像识别:多分类建模误判病例分析(Tensorflow)
基于WIN10的64位系统演示 一、写在前面 上两期我们基于TensorFlow和Pytorch环境做了图像识别的多分类任务建模。这一期我们做误判病例分析,分两节介绍,分别基于TensorFlow和Pytorch环境的建模和分析。 本期以健康组、肺结核组、COVID-19组、细菌性&am…...

OpenCv读/写视频色差 方案
OpenCv read / write video color differenceOpenCv读/写视频色差 感谢博主: OpenCv读/写视频色差答案 - 爱码网 有没有办法让 OpenCV 使用正确的转换?? 是的,使用 GStreamer 后端而不是 FFmpeg 后端,颜色看起来很完…...
【传输层】网络基础 -- UDP协议 | TCP协议
再谈端口号端口号范围划分netstatpidof UDPUDP的特点面向数据报UDP的缓冲区 基于UDP的应用层协议 TCP认识TCP协议的报头理解封装解包理解可靠性TCP工作模式16位窗口大小6位标志位URGACKPSHRSTSYNFIN 再谈端口号 端口号(Port)标识了一个主机上进行通信的不同的应用程序 在TCP/I…...
Android开发之性能测试工具Profiler
前言 性能优化问题,在我们开发时都会遇到,但是在小厂和对自己要求不严格的情况下,我都很少去做性能优化; 在性能优化上,基本大家都是通过自己的开发经验和性能分析工具来发现问题,今天给大家分享一下小编最…...

SpringBoot初级开发--多环境配置的集成(9)
在Springboot的开发中,我们经常要切换各种各样的环境配置,比如现在是开发环境,然后又切换到生产环境,这个时候用多环境配置就是一个明智的选择。接下来我们沿用上一章的工程来配置多环境配置工程。 1.准备多环境配置文件 这里我…...
(数学) 剑指 Offer 39. 数组中出现次数超过一半的数字 ——【Leetcode每日一题】
❓ 剑指 Offer 39. 数组中出现次数超过一半的数字 难度:简单 数组中有一个数字出现的次数超过数组长度的一半,请找出这个数字。 你可以假设数组是非空的,并且给定的数组总是存在多数元素。 示例 1: 输入: [1, 2, 3, 2, 2, 2, 5, 4, 2] 输…...
如何用PS把roughness贴图转换成Smoothness,并放入Metallic贴图的a通道。
1:用PS打开Roughness贴图 2:选择反相,装换成Smoothness贴图 3:新建一个大小相等的psd文件,或者打开Metallic贴图 4:如果没有金属度贴图,就把新建的图画成纯黑色 5:选择图层蒙版->…...

了解XSS攻击与CSRF攻击
什么是XSS攻击 XSS(Cross-Site Scripting,跨站脚本攻击)是一种常见的网络安全漏洞,它允许攻击者在受害者的浏览器上执行恶意脚本。这种攻击通常发生在 web 应用程序中,攻击者通过注入恶意脚本来利用用户对网站的信任&…...

安全测试-django防御安全策略
django安全性 django针对安全方面有一些处理,学习如何进行处理设置,也有利于学习安全测试知识。 CSRF 跨站点请求伪造(Cross-Site Request Forgery,CSRF)是一种网络攻击方式,攻击者欺骗用户在自己访问的网…...

7.react useReducer使用与常见问题
useReducer函数 1. useState的替代方案.接收一个(state, action)>newState的reducer, 并返回当前的state以及与其配套的dispatch方法2. 在某些场景下,useReducer会比useState更加适用,例如state逻辑较为复杂, 且**包含多个子值**,或者下一个state依赖于之前的state等清楚us…...
)
c#泛型(generic)
概述: C#中的泛型(Generics)是一种允许在编写类、方法和委托时使用参数化类型的机制。泛型允许我们编写更通用、可重用的代码,可以避免类型转换和重复编写类似的代码。 泛型的基本语法如下所示: class ClassName<…...
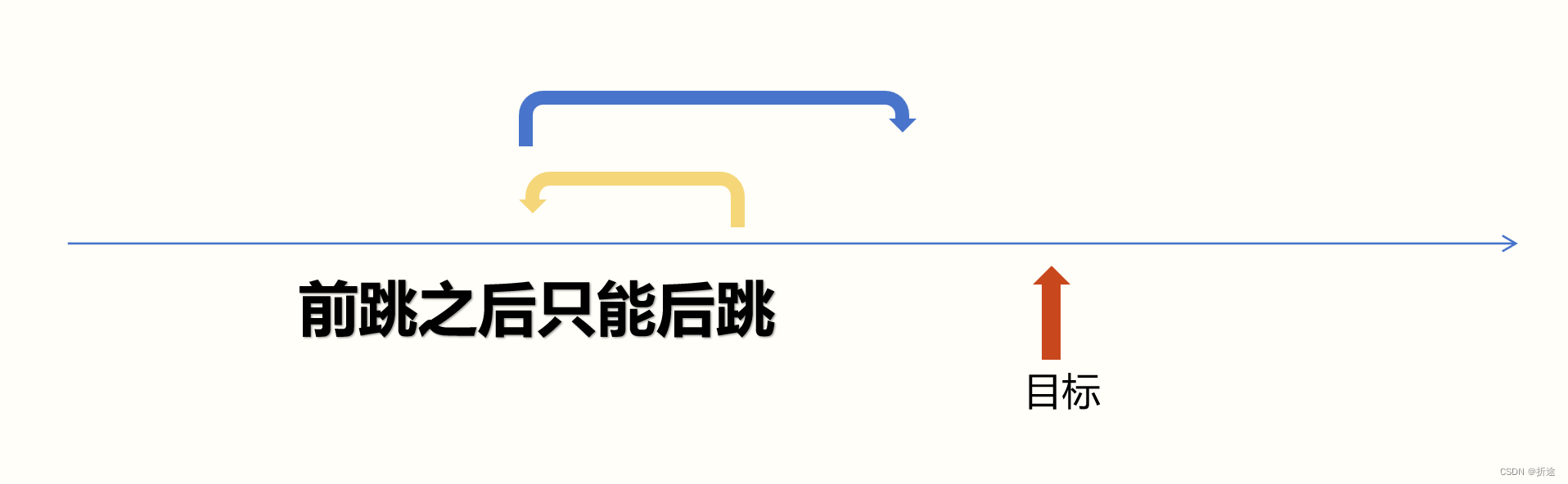
【力扣每日一题】2023.8.30 到家的最少跳跃次数
目录 题目: 示例: 分析: 代码: 题目: 示例: 分析: 题目给我们一只跳蚤,我们可以操控它前跳 a 格或是后跳 b 格,不能跳到小于0的位置,有一些被禁止的点不…...
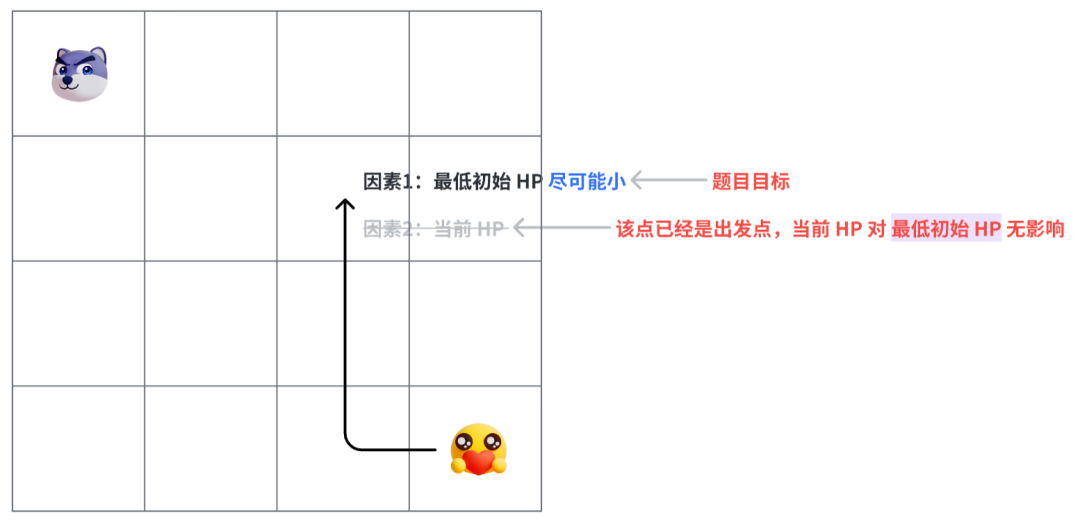
精读《算法题 - 地下城游戏》
今天我们看一道 leetcode hard 难度题目:地下城游戏。 恶魔们抓住了公主并将她关在了地下城 dungeon 的 右下角 。地下城是由 m x n 个房间组成的二维网格。我们英勇的骑士最初被安置在 左上角 的房间里,他必须穿过地下城并通过对抗恶魔来拯救公主。 骑士…...

随记-Kibana Dev Tools,ES 增删改查 索引,Document
索引 创建索引 创建索引 PUT index_test创建索引 并 修改分片信息 # 创建索引 并 修改分片信息 PUT index_test2 { # 必须换行, PUT XXX 必须独占一行,类似的 其他请求也需要独占一行 "settings": {"number_of_shards": 1, # 主分片"…...

什么是架构,架构的本质是什么
不论是开发人员还是架构师,我们都一直在跟软件系统打交道,架构是在工作中出现最频繁的术语之一。那么,到底什么是架构?你可能有自己的答案,也有可能没有答案。对“架构”的理解需要我们不断在实践中思考、归纳、演绎&a…...
Python爬虫(十七)_糗事百科案例
糗事百科实例 爬取糗事百科段子,假设页面的URL是: http://www.qiushibaike.com/8hr/page/1 要求: 使用requests获取页面信息,用XPath/re做数据提取获取每个帖子里的用户头像连接、用户姓名、段子内容、点赞次数和评论次数保存到json文件内…...

Ae 效果:CC Threads
生成/CC Threads Generate/CC Threads CC Threads(CC 编织条)效果基于当前图层像素生成编织条图案和纹理。可以用在各种设计中,如背景设计、图形设计、文字设计等。 ◆ ◆ ◆ 效果属性说明 Width 宽度 设置编织的宽度。 默认值为 50。值越大…...
)
Kotlin 协程 - 多路复用 select()
一、概念 又叫选择表达式,是一个挂起函数,可以同时等待多个挂起结果,只取用最快恢复的那个值(即多种方式获取数据,哪个更快返回结果就用哪个)。 同时到达 select() 会优先选择先写子表达式,想随…...
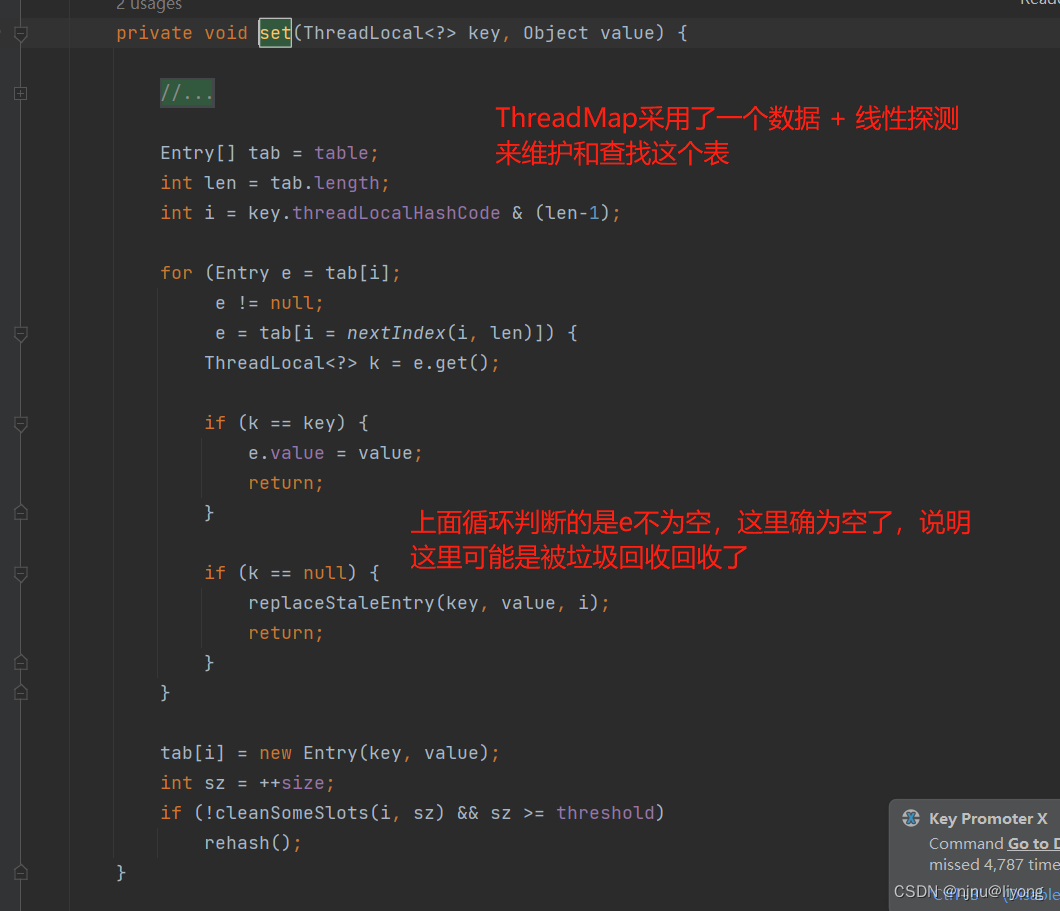
学习笔记-ThreadLocal
ThreadLocal 什么是ThreadLocal? ThreadLocal 是线程本地变量类,在多线程并行执行过程中,将变量存储在ThreadLocal中,每个线程中都有独立的变量,因此不会出现线程安全问题。 应用举例 解决线程安全问题:例…...

python利用pandas统计分析—groupby()函数的使用
文章目录 一、groupby使用场景二、groupby基本原理三、groupby分组运算基础聚合操作:只能选择一种聚合操作agg 聚合操作:可以针对同列选择不同聚合方法transformapply 四、groupby分组后去重统计nunique()五、groupby分组后重命名列名rename()直接重新命…...

OpenClaw 环境搭建|可视化操作零门槛
📌 OpenClaw 一键安装包|一键部署,告别复杂环境配置 适配系统:Windows10/11 64 位当前版本:v2.7.5(虾壳云版) ⭐ 核心优势 全程可视化操作,无需命令行、无需手动配置 Python/Node…...
)
不止于点灯:用STM32F103和JDY-23蓝牙,打造你的第一个智能家居原型(附OLED状态显示)
从原型到产品:基于STM32F103与JDY-23的智能家居开发实战 在创客圈里,用单片机控制LED灯可能是最入门的实验之一。但如何将一个简单的点灯Demo升级为具备产品思维的原型系统?这正是本文要探讨的核心。我们将以STM32F103C8T6为主控,…...

如何在5分钟内制作专业滚动歌词?LRC Maker免费在线工具终极指南
如何在5分钟内制作专业滚动歌词?LRC Maker免费在线工具终极指南 【免费下载链接】lrc-maker 歌词滚动姬|可能是你所能见到的最好用的歌词制作工具 项目地址: https://gitcode.com/gh_mirrors/lr/lrc-maker 你是否曾为制作歌词时间轴而烦恼&#x…...

期货合约乘数与最小变动价位:从 Quote 读规格做下单预算
前言 写天勤量化下单逻辑时,若手数、保证金和盈亏对不上账,我一般会先查合约规格有没有读错。乘数、最小变动价位(一跳)、涨跌停价都在 Quote 里,用统一字段做预算,比手算或硬编码合约表更不容易在换月后踩…...

STM32固件防抄攻略:手把手教你用Programmer CLI读取芯片ID并实现简易加密
STM32固件防抄实战:基于芯片ID的低成本加密方案设计与实现 在硬件产品开发中,固件安全往往是被忽视的一环。许多中小团队在产品量产前夕才意识到,精心设计的电路和算法可能因为固件被轻易复制而失去竞争优势。STM32系列MCU凭借其丰富的产品线…...
)
别再硬编码了!用Unity动画事件实现音效与攻击判定的动态解耦(附完整C#脚本)
告别硬编码:Unity动画事件驱动的模块化开发实战 在游戏开发中,动画系统与游戏逻辑的耦合常常成为后期维护的噩梦。想象一下这样的场景:每次调整动画帧数都需要同步修改代码中的硬编码数值,或者音效资源路径被直接写在脚本里导致资…...

AArch64架构TLB管理机制与优化实践
1. AArch64 TLB管理机制概述TLB(Translation Lookaside Buffer)是现代处理器内存管理单元(MMU)的核心组件,负责缓存虚拟地址到物理地址的转换结果。在AArch64架构中,TLB管理机制尤为复杂,涉及多…...

RTX 40系列显卡需求强劲的背后:技术迭代、AI驱动与市场理性回归
1. 项目概述:从“矿难”到“复苏”,显卡市场的十字路口“显卡最坏的日子过去了?”——这大概是过去两年里,每一个关注PC硬件、游戏或者内容创作的玩家和从业者,心里反复掂量过无数次的问题。从2020年底开始,…...

SolidWorks插件开发避坑指南:手把手教你搞定工具栏图标和菜单注册表清理
SolidWorks插件开发深度优化:图标管理与注册表清理实战 当你在SolidWorks插件开发中精心设计了功能完备的工具栏,却遭遇图标显示异常、工具栏名称重复或旧插件残留等问题时,那种挫败感每个开发者都深有体会。这些看似简单的界面问题背后&…...

MCP39F501电能计量芯片:高精度单相计量方案与工程实践详解
1. 项目概述:为什么我们需要一颗专用的电能计量芯片?在智能家居、工业物联网和新能源领域,精确测量交流电(AC)的用电参数——比如电压、电流、功率、电能——是底层最核心的需求之一。你可能觉得,用个高精度…...