Python 操作 MongoDB 数据库介绍
MongoDB 是一款面向文档型的 NoSQL 数据库,是一个基于分布式文件存储的开源的非关系型数据库系统,其内容是以 K/V 形式存储,结构不固定,它的字段值可以包含其他文档、数组和文档数组等。其采用的 BSON(二进制 JSON )的数据结构,可以提高存储和扫描效率,但空间开销会有些大。今天就为大家简单介绍下在 Python 中使用 MongoDB 。
安装 PyMongo 库
在 Python 中操作 MongoDB ,需要使用 PyMongo 库,执行如下命令安装:
pip3 install pymongo连接 MongoDB 数据库
连接时需要使用 PyMongo 库里面的 MongoClient 模块,有两种方式可以创建连接,默认只需要传入IP和端口号即可。如果数据库存在账号密码,则需要指定连接的数据库,并进行鉴权才能连接成功。
#导入 MongoClient 模块from pymongo import MongoClient, ASCENDING, DESCENDING# 两种方式#1. 传入数据库IP和端口号mc = MongoClient('127.0.0.1', 27017)#2. 直接传入连接字串mc = MongoClient('mongodb://127.0.0.1:27017')# 有密码的连接# 首先指定连接testdb数据库db = mc.testdb# 通过authenticate方法认证账号密码db.authenticate('username','password')# 检查是否连接成功,输出以下结果表示连接成功print(mc.server_info())# {'version': '4.2.1', 'gitVersion': 'edf6d45851c0b9ee15548f0f847df141764a317e', 'modules': [], 'allocator': 'tcmalloc', 'javascriptEngine': 'mozjs', 'sysInfo': 'deprecated', 'versionArray': [4, 2, 1, 0], 'openssl': {'running': 'OpenSSL 1.1.1 11 Sep 2018', 'compiled': 'OpenSSL 1.1.1 11 Sep 2018'}, ……省略 , 'ok': 1.0}
MongoDB 数据库操作
成功连接数据库,接下来我们开始介绍通过 MongoClient 模块如何对 mongoDB 数据库进行 CURD 的操作。
获取数据库和集合
首先要指定需要操作的数据库和集合,这里的数据库可以对应为 Mysql 的 DataBase,集合对应为 Mysql 的 Table。需要注意的是在 mongoDB 中,不需要提前创建数据库和集合,在你操作它们时如果没有则会自动创建,但都是延时创建的,在添加 Document 时才会真正创建。
# 指定操作数据库的两种方式#1. 获取 testdb 数据库,没有则自动创建db = mc.testdb#2. 效果与上面 db = mc.testdb 相同db = mc['testdb']# 打印出testdb数据库下所有集合(表)print(db.collection_names())# 指定操作集合的两种方式#1. 获取 test 集合,没有则自动创建collection = db.test#2. 效果与 collection = db.test 相同collection = db['test']# 打印集合中一行数据print(collection.find_one())
数据的插入操作
在 MongoDB 中,每条数据其实都有一个 _id 属性作为唯一标识。如果没有显式指明该属性,MongoDB 会自动产生一个 ObjectId 类型的 _id 属性,insert() 方法会在执行后返回 _id 值。不过在 PyMongo 3.x 版本中,官方已经不推荐使用 insert() 方法,而是推荐使用insert_one() 和 insert_many() 方法来分别插入单条记录和多条记录。
# 要插入到集合中的对象book = {'name' : 'Python基础','author' : '张三','page' : 80}# 向集合中插入一条记录collection.insert_one(book)# 返回结果:{'_id': ObjectId('5de4c7b90ae08431839ac2a7'), 'name': 'Python基础', 'author': '张三', 'page': 80}# 对于insert_many()方法,我们可以将数据以列表形式传递参数book1 = {'name' : 'Java基础','author' : '李白','page' : 100}book2 = {'name' : 'Java虚拟机','author' : '王五','page' : 100}# 创建 book_list 列表book_list = [book1, book2]# 向集合中插入多条记录collection.insert_many(book_list)# 返回结果:<pymongo.results.InsertManyResult object at 0x7f80a39fa408>
数据的查询操作
查询需要使用 find_one() 或 find() 方法,其中 find_one() 查询得到的是单个结果,即一条记录,find() 则返回一个生成器对象。下面我们就来查询上面刚插入的数据,如果查询不到数据则返回 None ,代码如下:
# 通过条件查询一条记录,如果不存在则返回Noneres = collection.find_one({'author': '张三'})print (res)# 打印结果:{'_id': ObjectId('5de4c7b90ae08431839ac2a7'), 'name': 'Python基础', 'author': '张三', 'page': 80}# 通过条件查询多条记录,如果不存在则返回Noneres = collection.find({'page': 100})print (res)#打印结果:<pymongo.cursor.Cursor object at 0x7f80a39daa58># 使用 find() 查询会返回一个对象# 遍历对象,并打印查询结果for r in res:print(r)#打印结果:# {'_id': ObjectId('5de4c8ae0ae08431839ac2a8'), 'name': 'Java基础', 'author': '李白', 'page': 100}# {'_id': ObjectId('5de4c8ae0ae08431839ac2a9'), 'name': 'Java虚拟机', 'author': '王五', 'page': 100}# 查询page大于50的记录res = collection.find({'page': {'$gt': 50}})# 通过遍历返回对象,结果如下:# {'_id': ObjectId('5de4c7b90ae08431839ac2a7'), 'name': 'Python基础', 'author': '张三', 'page': 80}# {'_id': ObjectId('5de4c8ae0ae08431839ac2a8'), 'name': 'Java基础', 'author': '李白', 'page': 100}# {'_id': ObjectId('5de4c8ae0ae08431839ac2a9'), 'name': 'Java虚拟机', 'author': '王五', 'page': 100}
上面查询条件中我们用到了 $gt 的比较运算符,关于查询条件中的比较运算符和功能运算符对照表如下:
| 符号 | 含义 | 举例 |
|---|---|---|
| $gt | 大于 | {'page': {'$gt': 50} |
| $lt | 小于 | |
| $lte | 小于等于 | |
| $gte | 大于等于 | |
| $ne | 不等于 | |
| $in | 在范围内 | {'page': {'$in': [50, 100]}} |
| $nin | 不在范围内 | {'page': {'$nin': [50, 100]}} |
| $regex | 匹配正则表达式 | {'name': {'$regex': '^张.*'}} |
| $exists | 属性是否存在 | {'name': {'$exists': True}} |
| $type | 类型判断 | {'name': {'$type': 'string'}} |
| $mod | 数字模操作 | {'page': {'$mod': [80, 10]}} |
| $text | 文本查询 | {'$text': {'$search': 'Java'}} |
| $where | 高级条件查询 | {'$where': 'obj. author == obj. full_name'} |
数据的更新操作
更新操作和插入操作类似,PyMongo 提供了两种更新方法,即 update_one() 和 update_many() 方法,其中 update_one() 方法只会更新满足条件的第一条记录。
注意:
如果使用 $set,则只更新 book 对象内存在的字段,如果更新前还有其他字段,则不更新也不删除。
如果不使用 $set,则会把更新前的数据全部用 book 对象替换,如果原本存在其他字段则会被删除。
# 查询一条记录book = collection.find_one({'author': '张三'})book['page'] = 90# 更新满足条件{'author', '张三'}的第一条记录res = collection.update_one({'author': '张三'}, {'$set': book})# 更新返回结果是一个对象,我们可以调用matched_count和modified_count属性分别获得匹配的数据条数和影响的数据条数。print(res.matched_count, res.modified_count)#打印结果:1 1# 更新满足条件 page>90 的所有记录,page 字段自加 10res = collection.update_many({'page': {'$gt': 90}}, {'$inc': {'page': 10}})# 打印更新匹配和影响的记录数print(res.matched_count, res.modified_count)#打印结果:2 2book3 = {'name':'Python高级', 'author':'赵飞', 'page': 50}#upsert=True表示如果没有满足更新条件的记录,则会将book3插入集合中res = collection.update_one({'author': '赵飞'}, {'$set': book3}, upsert=True)print(res.matched_count, res.modified_count)#打印结果:0 0# 查询所有记录,并遍历打印出来res = collection.find()for r in res:print(r)#打印结果:# {'_id': ObjectId('5de4c7b90ae08431839ac2a7'), 'name': 'Python基础', 'author': '张三', 'page': 90}# {'_id': ObjectId('5de4c8ae0ae08431839ac2a8'), 'name': 'Java基础', 'author': '李白', 'page': 110}# {'_id': ObjectId('5de4c8ae0ae08431839ac2a9'), 'name': 'Java虚拟机', 'author': '王五', 'page': 110}# {'_id': ObjectId('5de4d76f71aa089d58170a92'), 'author': '赵飞', 'name': 'Python高级', 'page': 50}
集合的删除操作
删除数据同样推荐使用两个方法 delete_one() 和 delete_many() ,其中 delete_one() 为删除第一条符合条件的记录。具体操作代码如下:
# 删除满足条件的第一条记录result = collection.delete_one({'author': '张三'})# 同样可以通过返回对象的 deleted_count 属性查询删除的记录数print(result.deleted_count)# 打印结果:1# 删除满足条件的所有记录,以下为删除 page < 90 的记录result = collection.delete_many({'page': {'$lt': 90}})print(result.deleted_count)# 打印结果:1
其他数据库操作
除了以上标准的数据库操作外,PyMongo 还提供了以下通用且方便的操作方法,比如 limit() 方法用来读取指定数量的数据skip() 方法用来跳过指定数量的数据等,具体请看如下代码:
# 查询返回满足条件的记录然后删除result = collection.find_one_and_delete({'author': '王五'})print(result)# 打印结果:{'_id': ObjectId('5de4c8ae0ae08431839ac2a9'), 'name': 'Java虚拟机', 'author': '王五', 'page': 110}# 统计查询结果个数# 全部结果个数collection.find().count()# 返回结果:1# 满足条件结果个数collection.find({'page': 100}).count()# 返回结果:0# 查询结果按字段排序# 升序results = collection.find().sort('page', ASCENDING)# 降序results = collection.find().sort('page', DESCENDING)# 下面查询结果是按page升序排序,只返回第二条记录及以后的两条结果results = collection.find().sort('page', ASCENDING).skip(1).limit(2)print(results)
注意:在数据量在在千万、亿级别庞大的时候,查询时最好
skip()的值不要太大,这样很可能导致内存溢出。
数据索引操作
默认情况下,数据插入时已经有一个 _id 索引了,当然我们还可以创建自定义索引。
# unique=True时,创建一个唯一索引,索引字段插入相同值时会自动报错,默认为Falsecollection.create_index('page', unique= True)# 打印结果:'page_1'# 打印出已创建的索引print(collection.index_information())# 返回结果:{'_id_': {'v': 2, 'key': [('_id', 1)], 'ns': 'testdb.test'}, 'page_1': {'v': 2, 'unique': True, 'key': [('page', 1)], 'ns': 'testdb.test'}}# 删除索引collection.drop_index('page_1')#删除集合collection.drop()
总结
本文为大家介绍了 Python 中如何创建连接 MongoDB 数据库,并通过代码的方式展示了对 MongoDB 数据的增删改查以及排序索引等操作,通过以上学习个人感觉操作起来还是比较简单方便的。今天就先介绍到这里,以后还会为大家介绍其他数据库的操作。
相关文章:

Python 操作 MongoDB 数据库介绍
MongoDB 是一款面向文档型的 NoSQL 数据库,是一个基于分布式文件存储的开源的非关系型数据库系统,其内容是以 K/V 形式存储,结构不固定,它的字段值可以包含其他文档、数组和文档数组等。其采用的 BSON(二进制 JSON &am…...

【ES6】Generator 函数
Generator 函数是 ES6 引入的一种新的函数类型,它既可以生成一个序列,又可以在某个条件下停止执行,并在需要时恢复执行。Generator 函数非常适合处理那些需要按需计算的场景,例如处理大数据、生成随机数等。 Generator 函数的基本…...
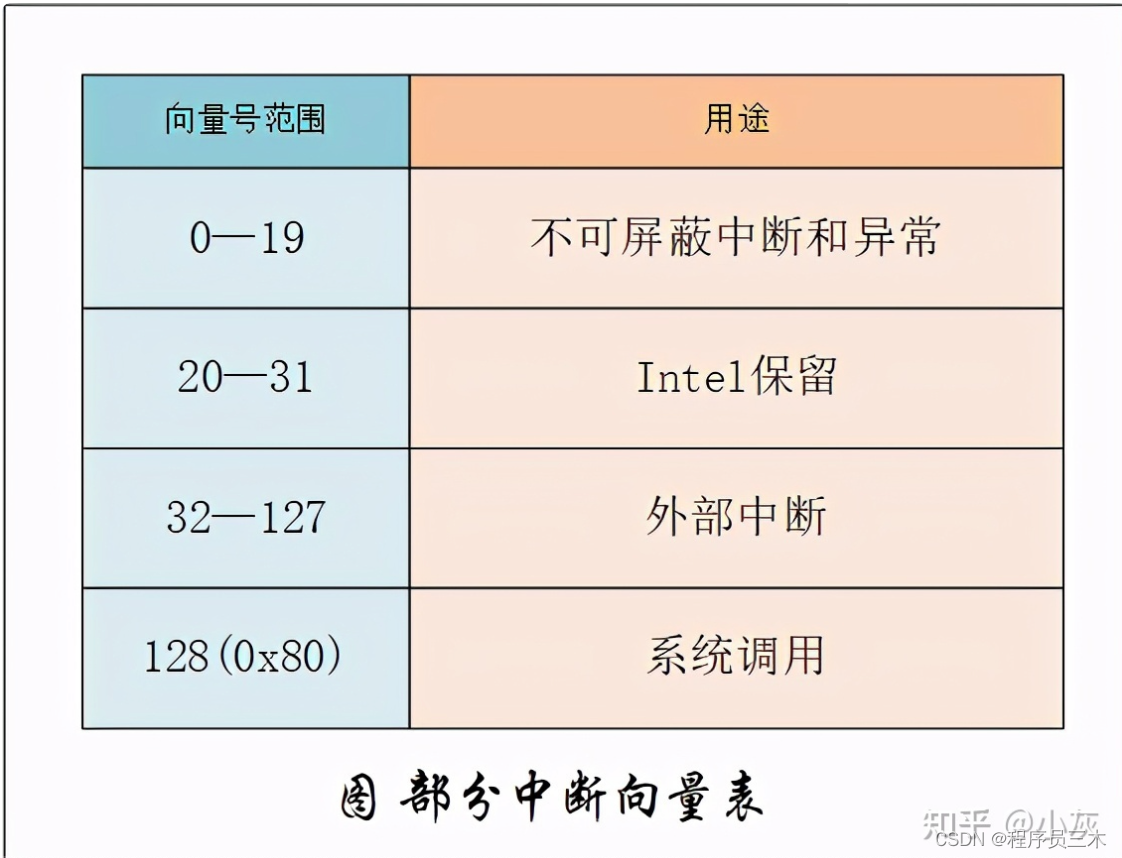
「操作系统」1. 基础
前言:操作系统基础八股文 文章目录 一 、操作系统基础1.1 什么是操作系统?1.2 什么是系统调用1.3 什么是中断 🚀 作者简介:作为某云服务提供商的后端开发人员,我将在这里与大家简要分享一些实用的开发小技巧。在我的职…...

Docker安装Oracl数据库!
安装Docker 查看是否安装docker: yum list installed | grep docker 安装docker: yum -y install docker 启动docker: systemctl start docker 查看docker启劝状态: systemctl status docker 查看docker版本: docker --version 设置docker开机自启动: systemctl en…...


leecode 数据库:1158. 市场分析 I
数据导入: SQL Schema: Create table If Not Exists Users (user_id int, join_date date, favorite_brand varchar(10)); Create table If Not Exists Orders (order_id int, order_date date, item_id int, buyer_id int, seller_id int); Create tab…...
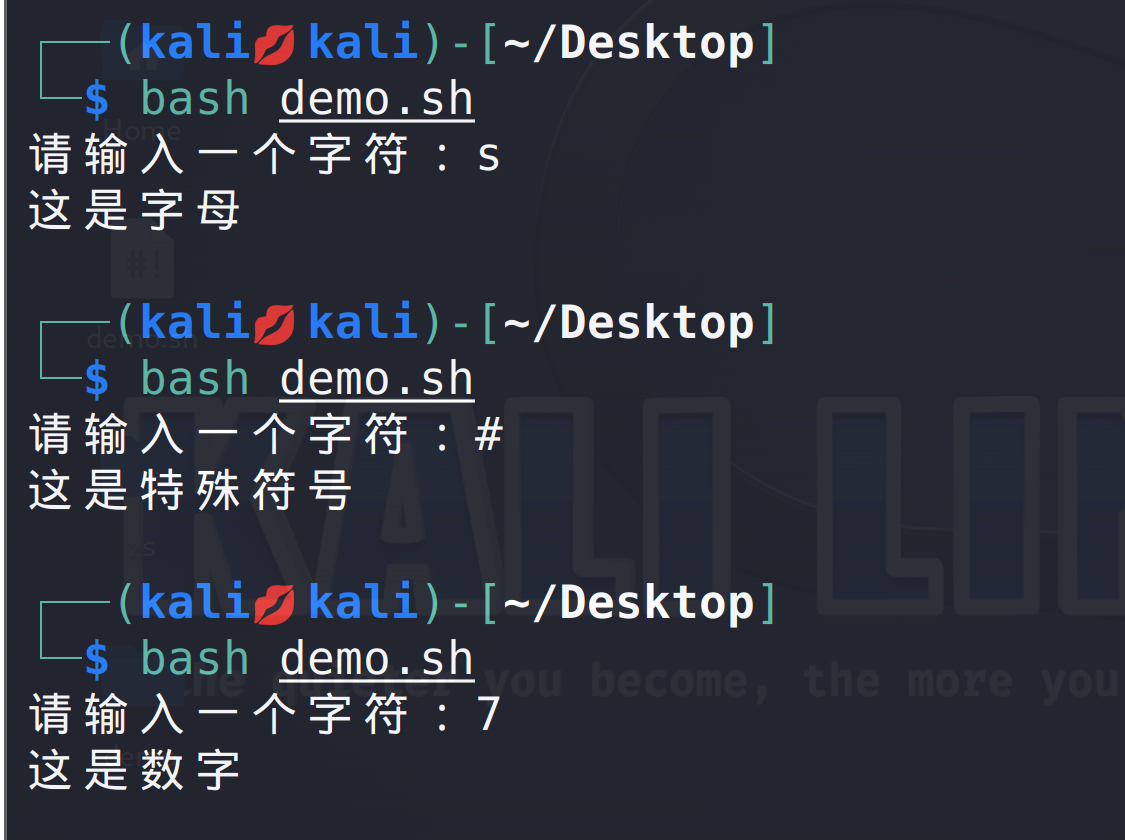
简单shell脚本的编写
文章目录 简单使用shell脚本参数判断整数的比较运算符字符串的比较运算shell脚本流程控制shell脚本循环for循环批量添加用户批量ping IP地址检测同一局域网,多台主机存活情况检测同一局域网,多台主机存活情况多线程检测主机存活情况 while循环case选择语…...

汽车售后接待vr虚拟仿真实操演练作为岗位培训的重要工具和手段
汽车虚拟仿真教学软件是一种基于虚拟现实技术的教学辅助工具。它能够模拟真实的汽车环境和操作场景,让学生能够通过虚拟仿真来学习和实践汽车相关知识和技能。与传统的教学方式相比,汽车虚拟仿真教学软件具有更高的视觉沉浸感和互动性,能够更…...
登录校验-Filter-登录校验过滤器
目录 思路 登录校验Filter-流程 步骤 流程图 登录校验Filter-代码 过滤器类 工具类 测试登录 登录接口功能请求 其他接口功能请求 前后端联调 思路 前端访问登录接口,登陆成功后,服务端会生成一个JWT令牌,并返回给前端࿰…...

Vue3列表竖向滚动(包含使用swiper的翻页效果)
一、使用element-plus表格进行滚动: 可以满足的需求:表格一行一行竖向滚动,类似走马灯。 不能满足的需求:表格分页竖向滚动,有翻页的效果。 代码: <template><el-table:data"tableData"…...

OS 死锁处理
如果P先申请mutex 则mutex从1置零,假设申请到的empty 0则empty变成-1阻塞态 同理C中mutex从0变为-1,那么如果想离开阻塞态,那么就需要执行V(empty)但是如果执行V(empty)就需要P(mu…...
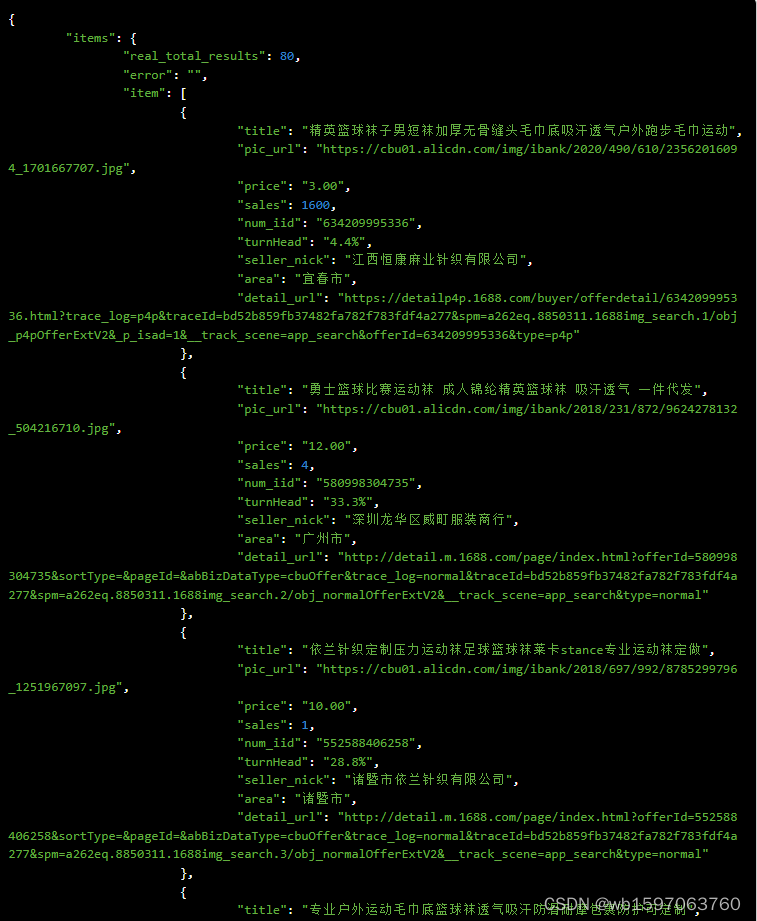
Java实现根据按图搜索商品数据,按图搜索获取1688商品详情数据,1688拍立淘接口,1688API接口封装方法
要通过按图搜索1688的API获取商品详情跨境属性数据,您可以使用1688开放平台提供的接口来实现。以下是一种使用Java编程语言实现的示例,展示如何通过1688开放平台API获取商品详情属性数据接口: 首先,确保您已注册成为1688开放平台…...
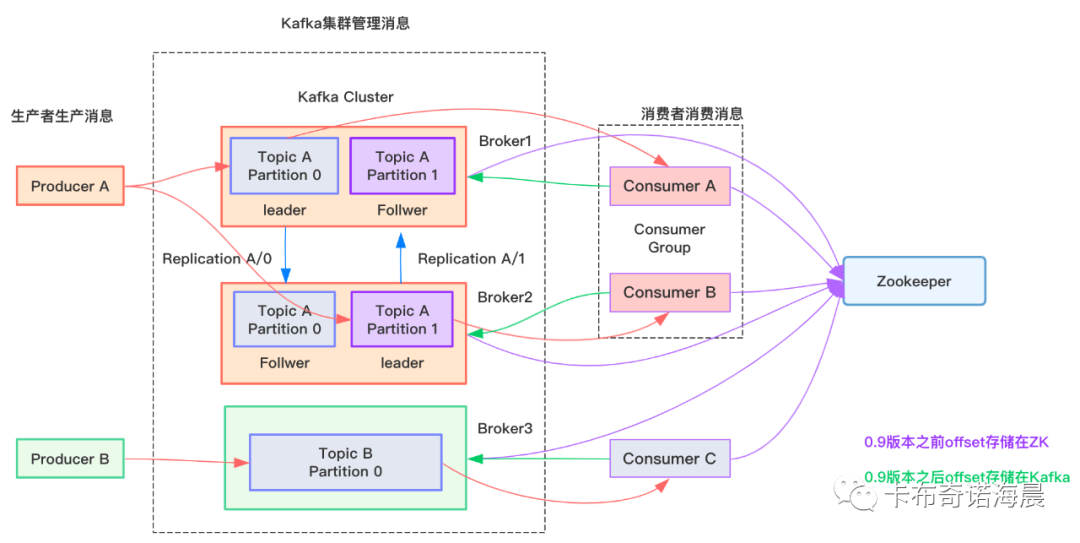
如何避免重复消费消息
博主介绍:✌全网粉丝3W,全栈开发工程师,从事多年软件开发,在大厂呆过。持有软件中级、六级等证书。可提供微服务项目搭建与毕业项目实战,博主也曾写过优秀论文,查重率极低,在这方面有丰富的经验…...
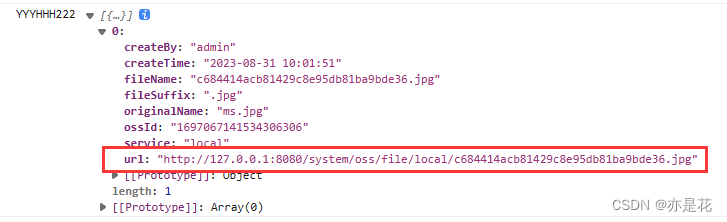
【若依框架RuoYi-Vue-Plus 图片回显不显示问题,OSS文件上传或者本地上传】
一、问题 1.设计表 product(商品表) 有 id (id) name(商品名)icon(图标) 2.使用若依代码生成功能,导入product表,代码生成。 3.将生成的代码导入到项目中得到…...

docker搭建rocketmq环境
准备局域网 nameserver和broker在同一网段才能够互相访问,我们先创建一个局域网。 创建rocketmq-network,让nameserver、broker在同一个网段: docker network create --driverbridge \ --subnet192.168.2.10/24 rocketmq-network安装names…...

uwsgi部署多进程django apscheduler与问题排查
💖 作者简介:大家好,我是Zeeland,开源建设者与全栈领域优质创作者。📝 CSDN主页:Zeeland🔥📣 我的博客:Zeeland📚 Github主页: Undertone0809 (Zeeland)&…...
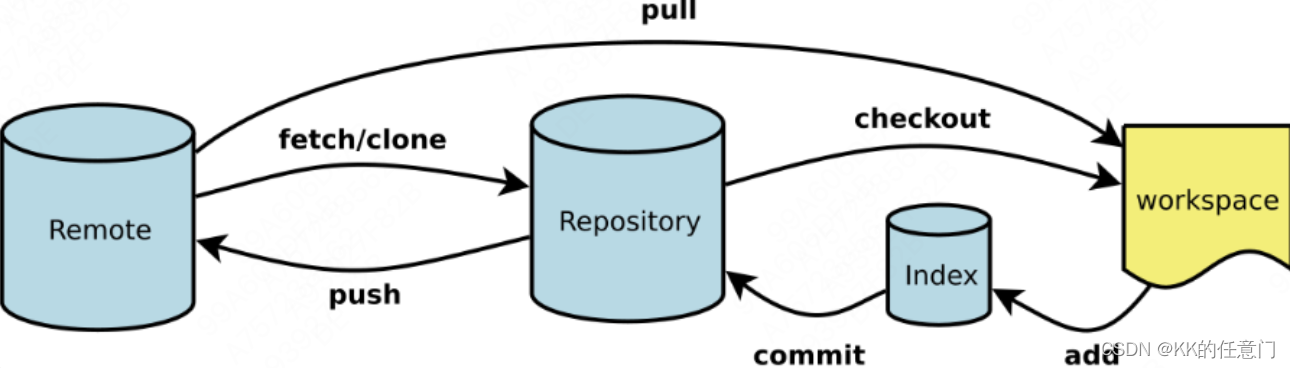
git difftool对比差异,避免推送不相关内容
问题 在利用git进行版本管理的时候,经常会由于对其他不相关的代码,做了一些小改动,例如删除了一个空行,多了一个缩进等。 为避免将这些不相关的改动也提交到远程,对PR造成不必要的影响,可以利用git diff命…...

Java设计模式:一、六大设计原则-05:接口隔离原则
文章目录 一、定义:接口隔离原则二、模拟场景:接口隔离原则三、违背方案:接口隔离原则3.1 工程结构3.2 英雄技能调用3.2.1 英雄技能接口3.2.2 英雄:后裔3.2.3 英雄:廉颇 3.3 单元测试 四、改善代码:接口隔离…...
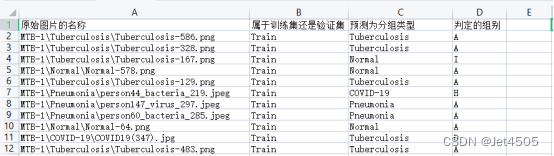
第63步 深度学习图像识别:多分类建模误判病例分析(Tensorflow)
基于WIN10的64位系统演示 一、写在前面 上两期我们基于TensorFlow和Pytorch环境做了图像识别的多分类任务建模。这一期我们做误判病例分析,分两节介绍,分别基于TensorFlow和Pytorch环境的建模和分析。 本期以健康组、肺结核组、COVID-19组、细菌性&am…...

OpenCv读/写视频色差 方案
OpenCv read / write video color differenceOpenCv读/写视频色差 感谢博主: OpenCv读/写视频色差答案 - 爱码网 有没有办法让 OpenCV 使用正确的转换?? 是的,使用 GStreamer 后端而不是 FFmpeg 后端,颜色看起来很完…...
)
别再复制粘贴了!手把手教你用C语言实现MODBUS CRC-16校验(附5种算法对比)
MODBUS CRC-16校验算法实战指南:从原理到最优实现选择 在工业自动化领域,MODBUS协议因其简单可靠而广泛应用,而CRC-16校验则是保障数据完整性的关键环节。许多开发者习惯直接复制网络上的校验代码,却常常遇到内存溢出、性能瓶颈或…...

GEE数据流转实战:如何用Google Drive和Assets搭建你的遥感数据处理流水线
GEE数据流转实战:构建云端遥感数据处理流水线 当遥感数据处理遇上云计算平台,一场关于效率的革命正在悄然发生。Google Earth Engine(GEE)作为全球领先的地理空间分析平台,与Google Drive和Assets的深度整合࿰…...

手把手教你用Vivado配置Xilinx SEM IP 3.1:从IP Catalog到Tera Term串口调试全流程
手把手教你用Vivado配置Xilinx SEM IP 3.1:从IP Catalog到Tera Term串口调试全流程 在FPGA开发中,软错误缓解(SEM)IP核是确保设计可靠性的关键组件。对于使用Xilinx Artix-7系列芯片的工程师来说,掌握SEM IP的完整配置…...

5步掌握AlienFX Tools:开源Alienware控制的终极指南
5步掌握AlienFX Tools:开源Alienware控制的终极指南 【免费下载链接】alienfx-tools Alienware systems lights, fans, and power control tools and apps 项目地址: https://gitcode.com/gh_mirrors/al/alienfx-tools 厌倦了Alienware Command Center&#…...

PotPlayer字幕翻译插件终极指南:3步实现跨语言视频无障碍观看
PotPlayer字幕翻译插件终极指南:3步实现跨语言视频无障碍观看 【免费下载链接】PotPlayer_Subtitle_Translate_Baidu PotPlayer 字幕在线翻译插件 - 百度平台 项目地址: https://gitcode.com/gh_mirrors/po/PotPlayer_Subtitle_Translate_Baidu 还在为外语视…...

避坑指南:在Simplicity Studio 5中为BLE工程添加串口控制与软定时器时,我踩过的那些雷
Simplicity Studio 5 BLE开发实战:串口控制与软定时器的七个关键陷阱与解决方案 当你在Simplicity Studio 5中完成基础BLE工程搭建后,真正挑战才刚刚开始。我曾在一个智能照明项目中,需要同时处理BLE连接、串口指令控制和LED定时闪烁功能&…...

给你的Alienware设备一次真正的解放:轻量级控制工具完全指南
给你的Alienware设备一次真正的解放:轻量级控制工具完全指南 【免费下载链接】alienfx-tools Alienware systems lights, fans, and power control tools and apps 项目地址: https://gitcode.com/gh_mirrors/al/alienfx-tools 你是否曾经为Alienware Comman…...

告别插线!用ESP32的OTA Web Updater实现无线烧录,保姆级避坑指南
ESP32无线固件更新全攻略:从零构建OTA Web Updater系统 引言:为什么需要无线更新? 想象一下,你精心设计的智能温室控制系统已经安装在屋顶的密闭箱体中,突然发现需要修复一个关键的温度传感器逻辑错误。传统方式需要…...

OpenCV实战:工业相机Bayer数据高效转换与图像处理全流程
1. 工业相机Bayer格式基础解析 第一次接触工业相机输出的Bayer格式数据时,我盯着那些看起来像黑白噪点的图像完全摸不着头脑。后来才发现,这其实是工业视觉领域最常见的原始数据格式之一。Bayer格式的本质是单通道马赛克阵列,每个像素点只记录…...

C166编译器内联展开机制与嵌入式性能优化
1. C166编译器运行时库函数的内联展开机制解析在嵌入式开发领域,C166架构因其高效的实时性能被广泛应用于工业控制领域。作为长期使用Keil C166工具链的开发者,我发现编译器对标准库函数的内联优化处理直接影响着代码的执行效率和内存占用。本文将深入剖…...