最佳实践:TiDB 业务读变慢分析处理
作者:李文杰 网易游戏计费 TiDB 负责人

在使用或运维管理 TiDB 的过程中,大家几乎都遇到过 SQL 变慢的问题,尤其是查询相关的读变慢问题。读变慢的问题大部分情况下都遵循一定的规律,通过经验的积累可以快速的定位和优化,不好排查的问题需要从读 TiDB 的每个过程一一排查和分析处理。
本文针对读 TiDB 集群的场景,总结业务 SQL 在查询突然变慢时的分析和排查思路,旨在沉淀经验、共享与社区。
一. 读原理
业务 SQL 从客户端发送到 TiDB 集群后,主要经历解析、生成执行计划、执行查询、返回查询结果这几个流程。如下所示是 TiDB 读过程的架构简图:
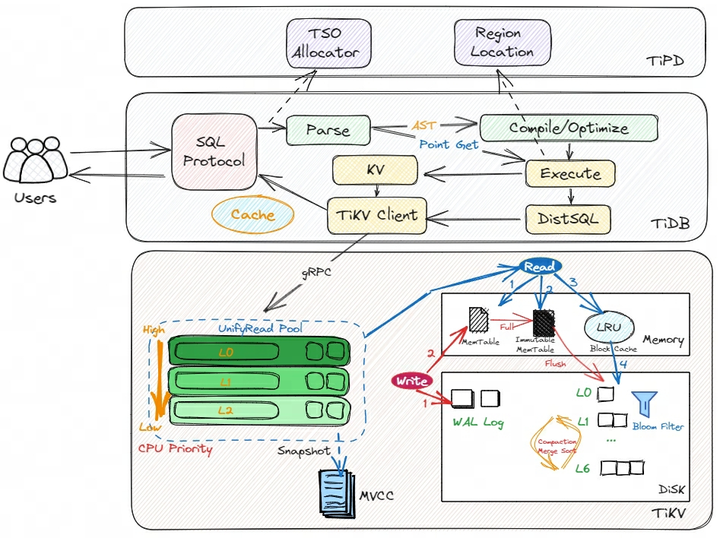
来自客户端的每个读取数据的操作,TiDB 也会将其封装为读事务,通常情况下事务在执行的过程分别会与 TiDB Server、TiPD Server 和 TiKV Server 进行交互。
TiDB Server
● 用户提交的业务 SQL 经过 Protocol Layer 进行 SQL 协议转换后,内部 PD Client 向 TiPD Server 申请到一个 TSO,此 TSO 即为读事务的开始时间 txn_start_tso,同时也是该读事务在全局的唯一 ID。
● TiDB Server 在解析前会将 SQL 做分类,分为 KV 点查询(唯一键查询,Point Get)和 DistSQL 复杂查询(非点查,Copprocessor )。
○ KV 点查询跳过执行计划优化阶段,直接到查询层,对于在线交易相关的 TP 场景,会大大降低响应延迟。
○ 复杂的 SQL 查询会被解析、转为抽象语法树 AST、编译、基于 RBO/CBO 等优化,会生成真正可以执行的计划。最终生成一个个对单个表访问的数据请求。
● TiKV Client 模块负责和存储层进行交互,查询请求经过 gRPC 调用,会优先进入 Unified Read Pool 线程池。
TiKV Server
● Unified Read Pool 线程池负责确认查询的数据 Snapshot 和统一调度查询优先级。
○ 新来的查询请求其优先级是最高的,落在 L0 队列里。随着查询时间越久,为了保证系统整体吞吐量,慢查询的优先级会不断降低,即会从 L0 调低到 L1、L2 等,随着优先级调低其分配到的 CPU 会减少。
○ 也就是说,一个大查询它越慢,它的优先级就会不断调低,优先级不断调低其执行的时间可能会更久。所以,尽可能减少大查询事务。
● 查询请求读取 RocksDB 数据
○ 先去 LSM Tree 的 MemTable 查找,最新的数据会写在这里,如果命中则返回。
○ 如果没找到,继续到 Immutable Memory Table 查找,找到则返回。
○ 如果再找不到,则搜查 SST 文件的缓存 Block Cache,找到则返回。
○ 如果还没找到,则会开始读取磁盘 SST 文件,会依次搜索 L0 至 L6 各个层级的内容。每一层的文件都会配备一个布隆过滤器。
过滤器对一个 Key 如果判断不存在,那么它一定不存在这个 SST 文件内,此时可以跳过这个文件;
如果判断在文件内则它可能在可能不在,无法判断准确,此时会直接去查文件内容,由于 SST 文件严格有序,所以在文件内是效率较高的二分查找。
○ 直到找到数据后,通过 gRPC 调用返回查询结果。
上面描述的过程,大致就是一个查询请求在 TiDB 集群内部的流转步骤,这也是我们在遇到读慢时的分析步骤。
二. 读变慢排查思路
2.1 读慢常规分析
业务的 SQL 变慢后,我们在 TiDB Server 的 Grafana 面板可以看到整体的或者某一百分位的请求延迟会升高,我们根据现象先确认方向性的问题:是整体变慢,还是某个 SQL 变慢。
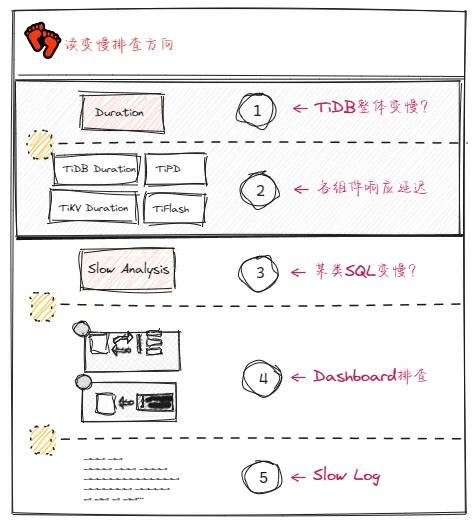
● 是否整体变慢
○ 分析各个组件 TiDB、TiKV、TiPD 的响应延迟情况
● 整体如果是正常的,继续分析是不是某类 SQL 变慢
○ 到 Dashboard 查一查慢查询,看一看集群热力图,分析一下 Top SQL
根据上面的思路,通常就可以对读变慢的问题有一个整体的把握。
接着,和写入变慢的分析一样,我们可以依次排查物理硬件环境、是否有业务变更操作等情况,直到定位清楚问题。如下图所示,业务读 SQL 变慢的分析思路可以有下面步骤:
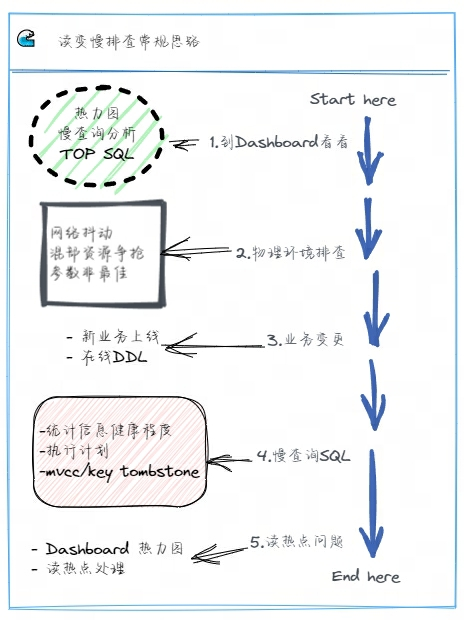
● 遇到问题我们应该养成习惯,要先到 Dashboard 看看,对集群运行状况有个整体的把握
○ 查看集群热力图,关注集群高亮的区域,分析是否有读热点出现,如果有则确认对应的库表、Region 等信息
热点问题处理 ( https://docs.pingcap.com/zh/tidb/stable/troubleshoot-hot-spot-issues#tidb-热点问题处理 )
○ 排查慢 SQL 情况,查看集群慢查询结果,分析 SQL 慢查询原因
○ 查看 TOP SQL 面板,分析集群的 CPU 消耗与 SQL 关联的情况
● 物理硬件排查
○ 排查客户端与集群之间、集群内部 TiDB 、TiPD、TiKV 各组件之间的网络问题
○ 排查集群的内存、CPU、磁盘 IO 等情况,尤其是混合部署的集群,确认是否存在资源相互竞争、挤兑的场景出现
○ 排查操作系统的内核操作是否与官方建议的最佳实践值是否一致,确认 TiDB 集群运行在最优的系统环境内
● 业务变更
○ 确认是否是新上线业务
○ 查看集群的 DDL Jobs,确认是否由于在线 DDL 导致的问题,特别是大表加索引的场景,会消耗集群较多的资源,从而干扰集群正常的访问请求
2.2 读慢全链路排查
常规分析思路可以解决绝大部分的问题,对于剩下那些无法确认的或较为复杂业务的问题,这时候可以分析读请求从 TiDB Server 到 TiKV Server 、到读 RocksDB 的整个过程,对全部查询的链路逐一进行排查,从而确认查询慢所在的节点,定位到原因后再进行优化即可,这一过程大致如下图所示。
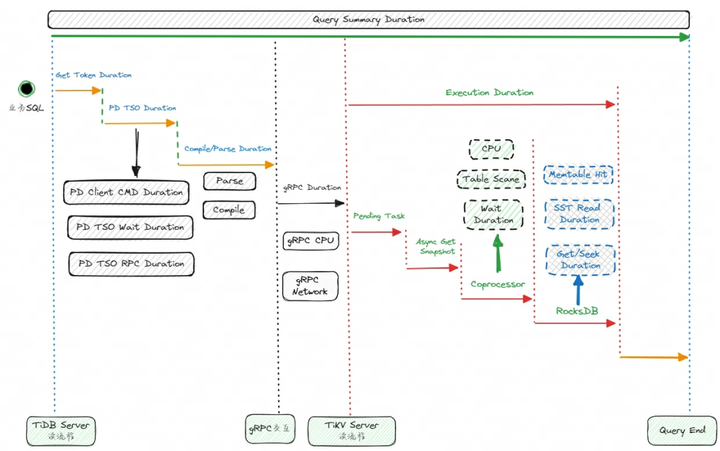
同样地,这个是一个兜底的排查思路,适用范围较广、通用性较强,但是排查起来要花费更多的时间和精力,也要求管理员对数据库本身的运行原理有一定的掌握。上面的排查步骤还是很复杂的,对用户很不友好。
但是,目前官方已经推出的 Dashboard 慢查询分析功能,已经帮我们集成和记录了各个环节的延迟,再也不用一个一个去查找 Grafana 面板来确认和分析了,极大地降低排查难度和缩短问题解决时长,是 TiDB 用户的一大福音。
下面是一个慢查询执行时长分析的例子,可以看到慢查询是因为 TiKV 执行 Coprocessor 任务的累计处理时间比较久,所以导致整个查询较慢, 我们再继续针对性分析和优化 Coprocessor 算子即可。

三. 总结
● 了解 TiDB 的读过程,有助于我们掌握数据库的底层执行原理,遇到问题时可以快速定位和分析原因,也能引导我们更好地使用数据库,发挥其最好的性能。
● TiDB Dashboard 是对用户非常友好的一个官方工具,它使得我们分析慢查询 SQL 变得更轻松和快速,大大降低了问题处理的时间,强烈建议使用。
● 下面的官方文档,在分析此类问题时推荐优先查看:
○ 集群读写延迟增加排查 ( 读写延迟增加 | PingCAP 文档中心 )
○ 热点问题处理 ( TiDB 热点问题处理 | PingCAP 文档中心 )
○ 定位慢查询 ( 慢查询日志 | PingCAP 文档中心 )
○ 分析慢查询 ( 分析慢查询 | PingCAP 文档中心 )
相关文章:
最佳实践:TiDB 业务读变慢分析处理
作者:李文杰 网易游戏计费 TiDB 负责人 在使用或运维管理 TiDB 的过程中,大家几乎都遇到过 SQL 变慢的问题,尤其是查询相关的读变慢问题。读变慢的问题大部分情况下都遵循一定的规律,通过经验的积累可以快速的定位和优化ÿ…...

【ES6】Getter和Setter
JavaScript中的getter和setter方法可以用于访问和修改对象的属性。这些方法可以通过使用对象字面量或Object.defineProperty()方法来定义。 以下是使用getter和setter方法的示例: <!DOCTYPE html> <script>const cart {_wheels: 4,get wheels(){retu…...

3DS Max中绘制圆锥箭头
3DS Max中绘制圆锥箭头 绘制结果绘制过程步骤一:绘制立体圆锥方法1方法2 步骤二:圆锥体调参(模型尺寸设置)1圆锥体参数说明2圆锥体参数调整 步骤三:绘制圆柱体步骤四:圆柱体调参步骤五:圆锥与圆…...

虚拟机Ubuntu20.04 网络连接器图标开机不显示怎么办
执行以下指令: sudo service network-manager stop sudo rm /var/lib/NetworkManager/NetworkManager.state sudo service network-manager start...
你真的知道什么是USB Server吗?一分钟了解
很多公司都在用USB Server,效率大幅提高,但也还有不少人不知道USB Server到底是什么、干嘛用的。 USB Serve是帮助企业远程连接和集中管控USB设备的服务器 它的主要用途就是异地远程连接USB。 如,虚拟化环境的加密狗、前置机连接࿰…...
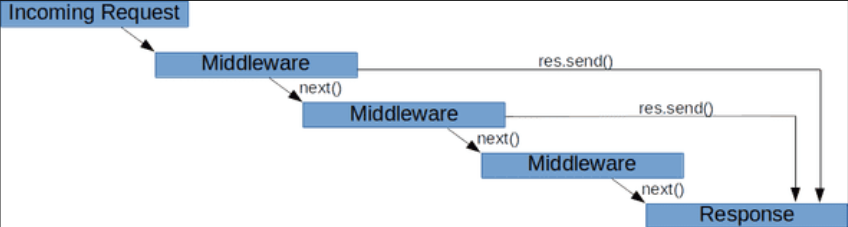
Node.js 中间件是怎样工作的?
express自带路由功能,可以侦听指定路径的请求,除此之外,express最大的优点就是【中间件】概念的灵活运用,使得各个模块得以解耦,像搭积木一样串起来就可以实现复杂的后端逻辑。除此之外,还可以利用别人写好…...
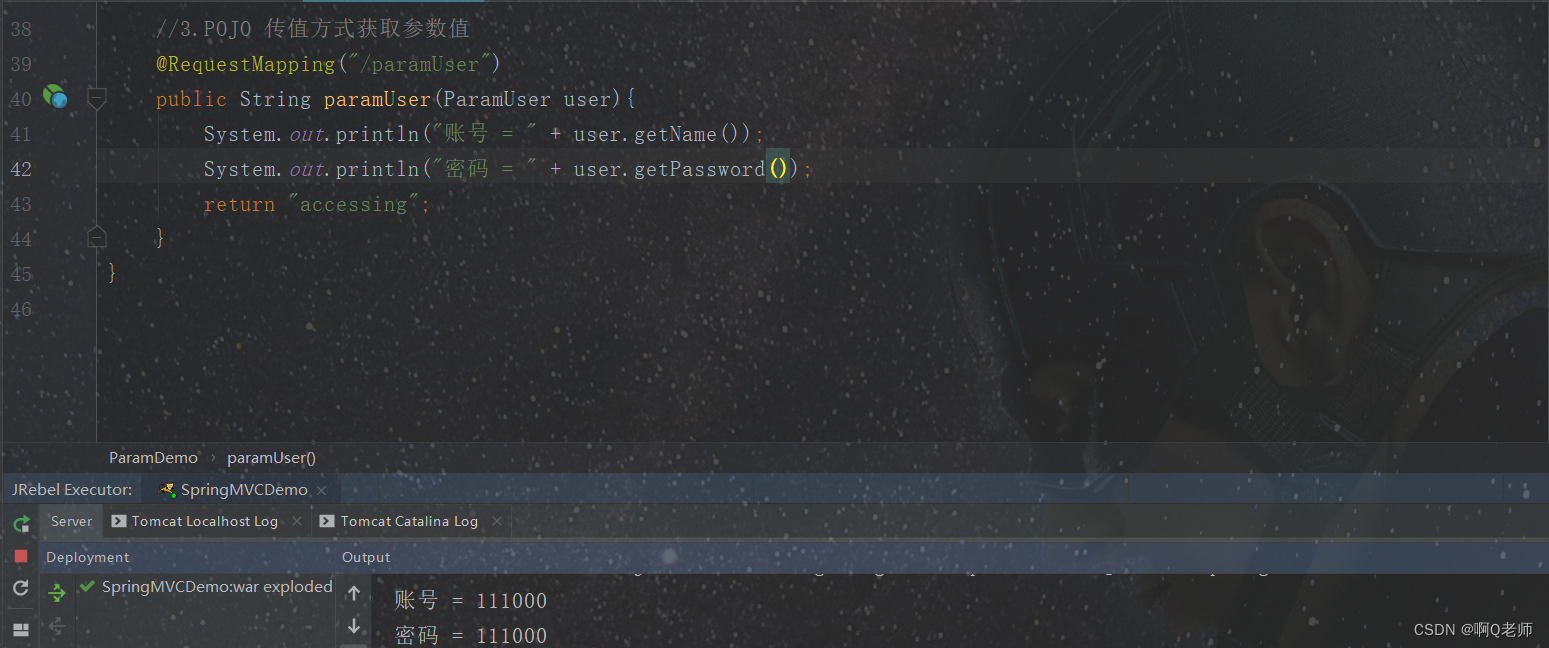
Spring MVC: 请求参数的获取
Spring MVC 前言通过 RequestParam 注解获取请求参数RequestParam用法 通过 ServletAPI 获取请求参数通过实体类对象获取请求参数附 前言 在 Spring MVC 介绍中,谈到前端控制器 DispatcherServlet 接收客户端请求,依据处理器映射 HandlerMapping 配置调…...

别再头疼反弹Shell失败了,这篇文章带你找到问题根源
别再头疼反弹Shell失败了,这篇文章带你找到问题根源 在渗透测试中,反弹shell失败的原因可以有多种。以下是一些常见的原因: **1.防火墙和网络过滤器:**目标系统可能配置了防火墙或网络过滤器,以限制对外部系统的连接…...
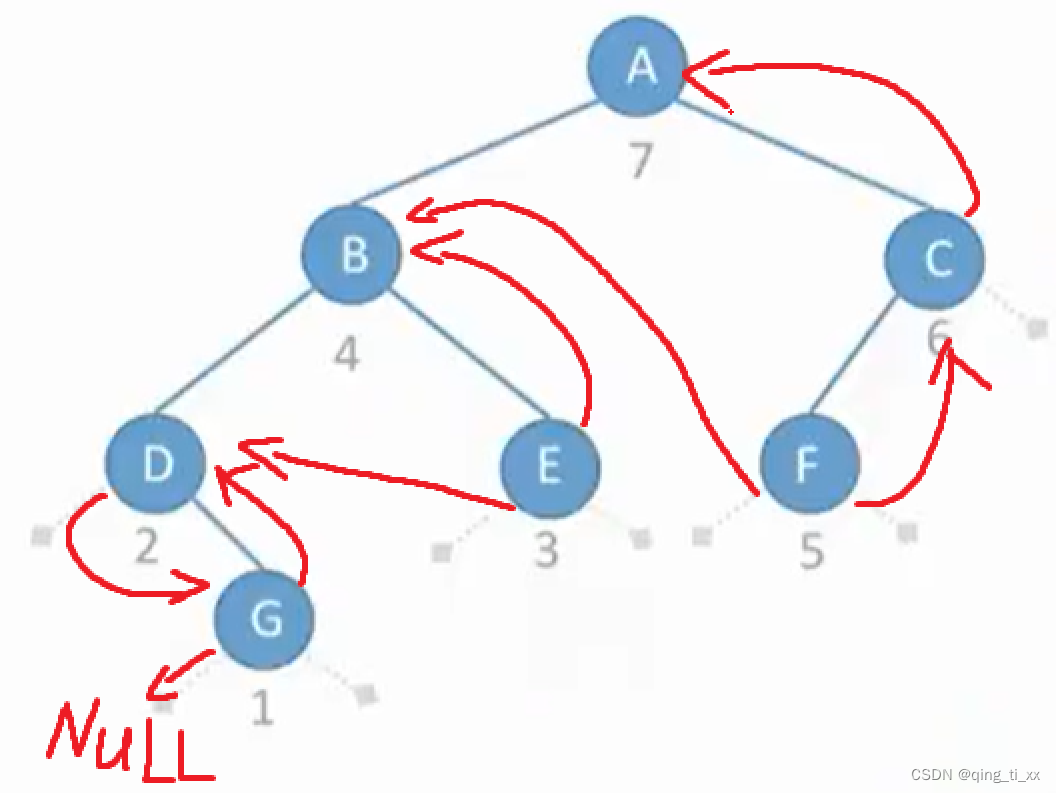
第五章 树与二叉树 四、线索树(手算与代码实现)
一、定义 1.线索树是一种二叉树,它在每个节点上增加了两个指针,分别指向其前驱和后继。 2.这些指针称为“线索”,因此线索树也叫做“线索化二叉树”。 3.在线索树中,所有的叶子节点都被线索化,使得遍历树的过程可以…...

服务器前后端学习理解
个人兴趣,突然想起来记录一下 1. 背景 想做一个最简单的网页,点击按钮后,访问服务器的redis数据库,读取一个为hello的值并显示 首先用js写了一个脚本,使用redis包,读取到了数据,并使用consol.l…...
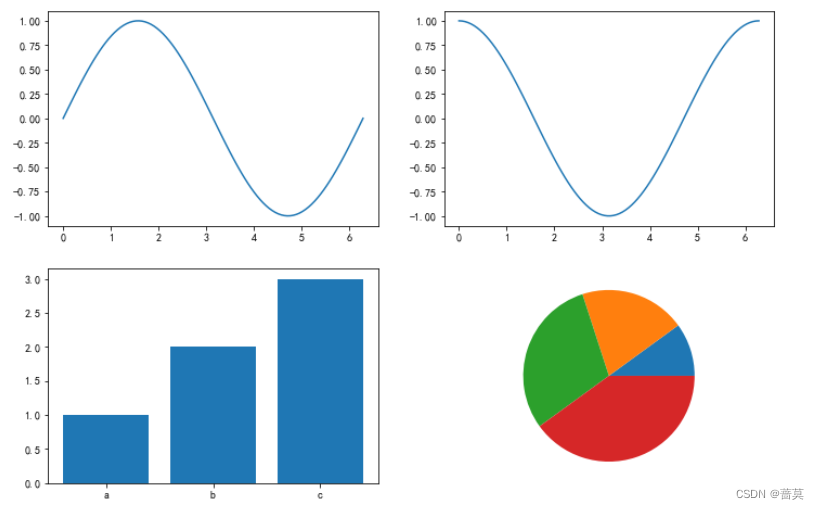
python-数据分析-numpy、pandas、matplotlib的常用方法
一、numpy import numpy as np1.numpy 数组 和 list 的区别 输出方式不同 里面包含的元素类型 2.构造并访问二维数组 使用 索引/切片 访问ndarray元素 切片 左闭右开 np.array(list) 3.快捷构造高维数组 np.arange() np.random.randn() - - - 服从标准正态分布- - - …...
ChatGPT⼊门到精通(5):ChatGPT 和Claude区别
⼀、Claude介绍 Claude是Anthropic开发的⼀款⼈⼯智能助⼿。 官⽅⽹站: ⼆、Claude能做什么 它可以通过⾃然语⾔与您进⾏交互,理解您的问题并作出回复。Claude的主要功能包括: 1、问答功能 Claude可以解答⼴泛的常识问题与知识问题。⽆论是历史上的某个事件,理科…...
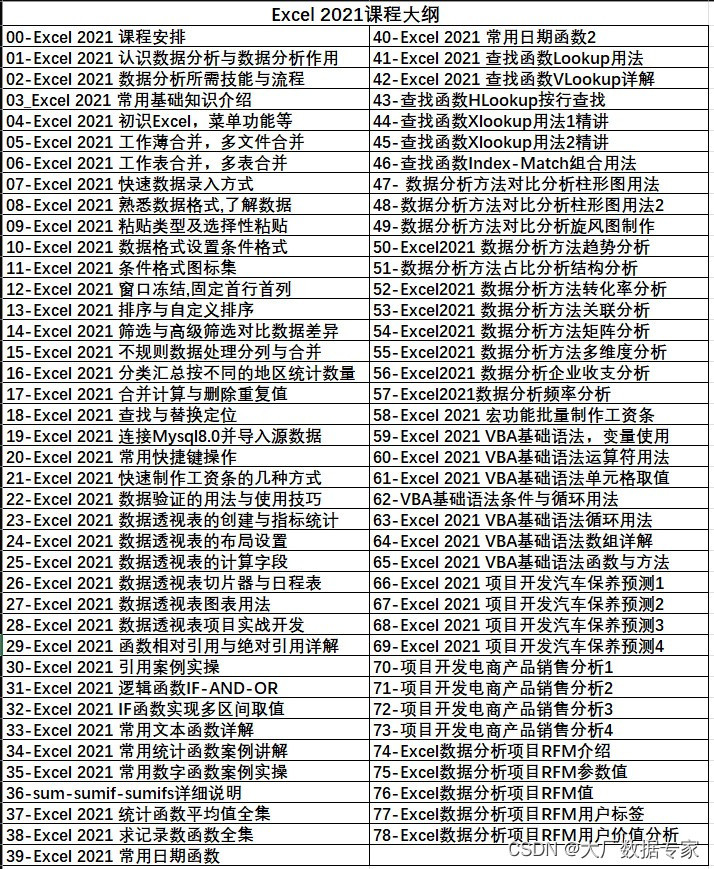
ChatGPT 总结数据分析的所有知识点
ChatGPT功能非常多,特别是对某个行业,某个方向,某个技术进行总结那是相当专业的。 如下图。 直接用一个指令便总结出来数据分析当中的所有知识点内容。 AIGC ChatGPT ,BI商业智能, 可视化Tableau, PowerBI, FineReport, 数据库Mysql Oracle, Office, Python ,ETL Ex…...
hadoop-HDFS
1.HDFS简介 2.1 Hadoop分布式文件系统-HDFS架构 2.2 HDFS组成角色及其功能 (1)Client:客户端 (2)NameNode (NN):元数据节点 管理文件系统的Namespace元数据 一个HDFS集群只有一个Active的NN ÿ…...

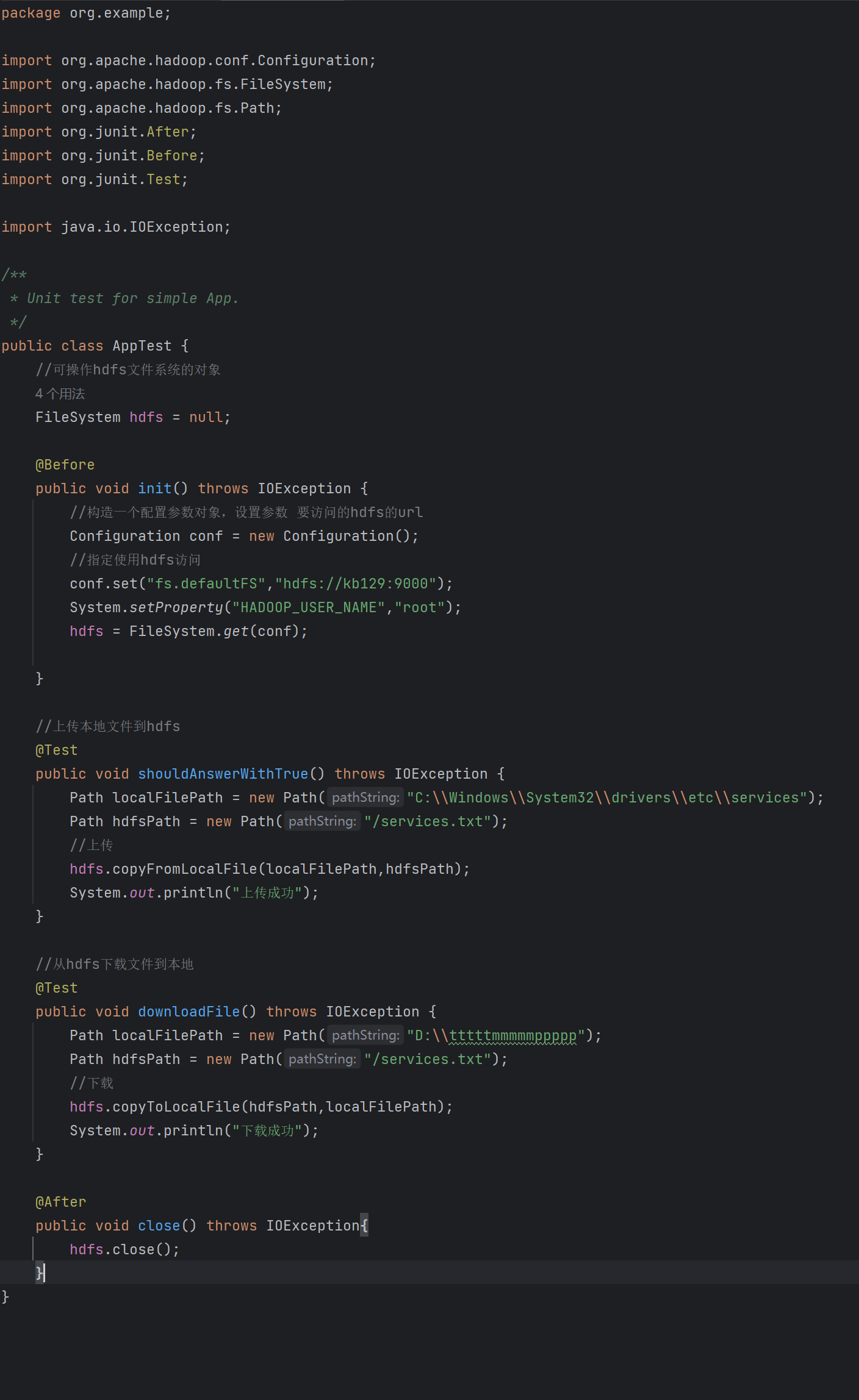
0202hdfs的shell操作-hadoop-大数据学习
文章目录 1 进程启停管理2 文件系统操作命令2.1 HDFS文件系统基本信息2.2 介绍2.3 创建文件夹2.4 查看指定文件夹下的内容2.5 上传文件到HDFS2.6 查看HDFS文件内容2.7 下载HDFS文件2.8 HDFS数据删除操作 3 HDFS客户端-jetbrians产品插件3.1 Big Data Tools 安装3.2 配置windows…...

生活小记-挂号信
"挂号信"通常指的是在邮寄过程中通过挂号邮寄服务寄送的信件,相对于普通信件有一些特殊的特点和服务。以下是挂号信与其他信件(例如普通信件)之间的区别: 跟踪和确认: 挂号信:通过挂号邮寄服务寄…...
)
3D点云处理:基于PCA的计算点云位姿(占位待整理)
文章目录 文章目录:3D视觉个人学习目录微信:dhlddxB站: Non-Stop_...
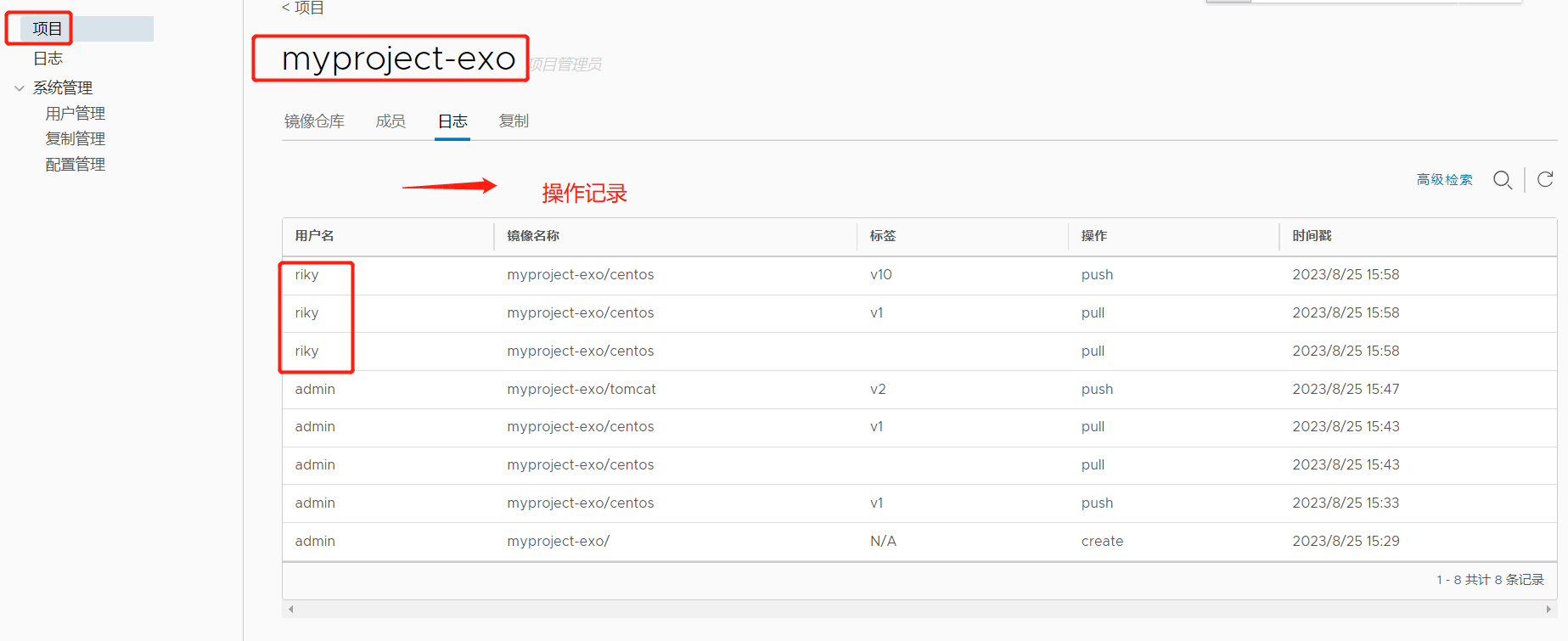
本地私有仓库、harbor私有仓库部署与管理
本地私有仓库、harbor私有仓库部署与管理 一、本地私有仓库1.本地私有仓库简介2.搭建本地私有仓库3.容器重启策略介绍 二、harbor私有仓库部署与管理1.什么是harbor2.Harbor的特性3.Harbor的构成4.harbor部署及配置5.客户端测试 三、Harbor维护1.创建2.普通用户操作私有仓库3.日…...

尚硅谷SpringMVC (5-8)
五、域对象共享数据 1、使用ServletAPI向request域对象共享数据 首页: Controller public class TestController {RequestMapping("/")public String index(){return "index";} } <!DOCTYPE html> <html lang"en" xmln…...

jupyter notebook中查看python版本的解决方案
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的…...

内存计算芯片技术:相变存储器与混合信号架构解析
1. 内存计算芯片技术概述内存计算(In-Memory Computing)技术正在重塑现代计算架构的格局。传统冯诺依曼架构中,数据需要在处理器和存储器之间频繁搬运,这种"存储墙"问题已成为制约计算效率的主要瓶颈。根据IEEE的实测数…...

ncmdump项目:网易云音乐NCM文件解密解决方案
ncmdump项目:网易云音乐NCM文件解密解决方案 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾经在网易云音乐下载了喜欢的歌曲,却发现只能在特定客户端播放,无法在其他设备或播放器上享受&…...

在微服务架构中利用 Taotoken 实现多模型 API 的动态切换与调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在微服务架构中利用 Taotoken 实现多模型 API 的动态切换与调用 面向后端架构师或开发负责人,当微服务系统需要集成多种…...

5分钟搭建拼多多商品数据采集系统:电商从业者的完整解决方案
5分钟搭建拼多多商品数据采集系统:电商从业者的完整解决方案 【免费下载链接】scrapy-pinduoduo 拼多多爬虫,抓取拼多多热销商品信息和评论 项目地址: https://gitcode.com/gh_mirrors/sc/scrapy-pinduoduo 在电商竞争日益激烈的今天,…...

Perplexity搜索响应延迟突增2100ms?内部API调用链路拆解,开发者必看避坑清单
更多请点击: https://codechina.net 第一章:Perplexity搜索响应延迟突增2100ms?现象复现与影响定性 近期监控系统捕获到Perplexity搜索API端点( /v1/search)在UTC时间2024-06-12T08:14:22Z起出现持续约17分钟的P99延迟…...

从ZEMAX到SOLIDWORKS:手把手教你搞定红外平行光管的跨软件光机设计流程
从ZEMAX到SOLIDWORKS:红外平行光管光机协同设计全流程解析 在光学工程领域,红外平行光管的设计往往需要跨越光学仿真与机械实现两大专业领域。这种"光机协同设计"过程既考验工程师对光学原理的理解,又要求熟练掌握专业软件间的数据…...

3种创新方案解决抖音视频保存难题
3种创新方案解决抖音视频保存难题 【免费下载链接】douyin_downloader 抖音短视频无水印下载 win编译版本下载:https://www.lanzous.com/i9za5od 项目地址: https://gitcode.com/gh_mirrors/dou/douyin_downloader 你是否曾遇到过这样的困扰:在抖…...

QQ音乐解析终极指南:如何免费获取全网音乐资源
QQ音乐解析终极指南:如何免费获取全网音乐资源 【免费下载链接】MCQTSS_QQMusic QQ音乐解析 项目地址: https://gitcode.com/gh_mirrors/mc/MCQTSS_QQMusic 你是否厌倦了音乐平台的层层限制?想要畅听所有歌曲却不想支付高昂的会员费?Q…...

5个核心功能技巧:用MPh实现COMSOL仿真自动化
5个核心功能技巧:用MPh实现COMSOL仿真自动化 【免费下载链接】MPh Pythonic scripting interface for Comsol Multiphysics 项目地址: https://gitcode.com/gh_mirrors/mp/MPh 你是一个文章写手,你负责为开源项目写专业易懂的文章。今天我们要介绍…...

【Perplexity法规查询功能深度解密】:20年合规专家亲授3大避坑指南与5步精准检索法
更多请点击: https://codechina.net 第一章:Perplexity法规查询功能的核心定位与演进逻辑 Perplexity法规查询功能并非通用搜索引擎的简单延伸,而是面向法律合规、金融风控与企业治理场景构建的垂直智能体。其核心定位在于实现“可溯源、可验…...