开启智能时代:深度解析智能文档分析技术的前沿与应用
开启智能时代:深度解析智能文档分析技术的前沿与应用
本章主要介绍文档分析技术的理论知识,包括背景介绍、算法分类和对应思路。通过本文学习,你可以掌握:1. 版面分析的分类和典型思想 2. 表格识别的分类和典型思想 3. 信息提取的分类和典型思想。
作为信息承载工具,文档的不同布局代表了各种不同的信息,如清单和身份证。文档分析是一个从文档中阅读、解释和提取信息的自动化过程。文档分析常包含以下几个研究方向:
- 版面分析模块: 将每个文档页面划分为不同的内容区域。该模块不仅可用于划定相关区域和不相关区域,还可用于对其识别的内容类型进行分类。
- 光学字符识别 (OCR) 模块: 定位并识别文档中存在的所有文本。
- 表格识别模块: 将文档里的表格信息进行识别和转换到excel文件中。
- 信息提取模块: 借助OCR结果和图像信息来理解和识别文档中表达的特定信息或信息之间的关系。
由于OCR模块在前面的章节中进行了详细的介绍,接下来将针对上面版面分析、表格识别和信息提取三个模块做单独的介绍。对于每一个模块,会介绍该模块的经典或常用方法以及数据集。
1. 版面分析
1.1 背景介绍
版面分析主要用于文档检索,关键信息提取,内容分类等,其任务主要是对文档图像进行内容分类,内容的类别一般可分为纯文本、标题、表格、图片和列表等。但是文档布局、格式的多样性和复杂性,文档图像质量差,大规模的带标注的数据集的缺少等问题使得版面分析仍然是一个很有挑战性的任务。
版面分析任务的可视化如下图所示:

现有的解决办法一般是基于目标检测或语义分割的方法,这类方法基将文档中不同的板式当做不同的目标进行检测或分割。
一些代表性论文被划分为上述两个类别中,具体如下表所示:
| 类别 | 主要论文 |
|---|---|
| 基于目标检测的方法 | Visual Detection with Context,Object Detection,VSR |
| 基于语义分割的方法 | Semantic Segmentation |
1.2 基于目标检测的方法
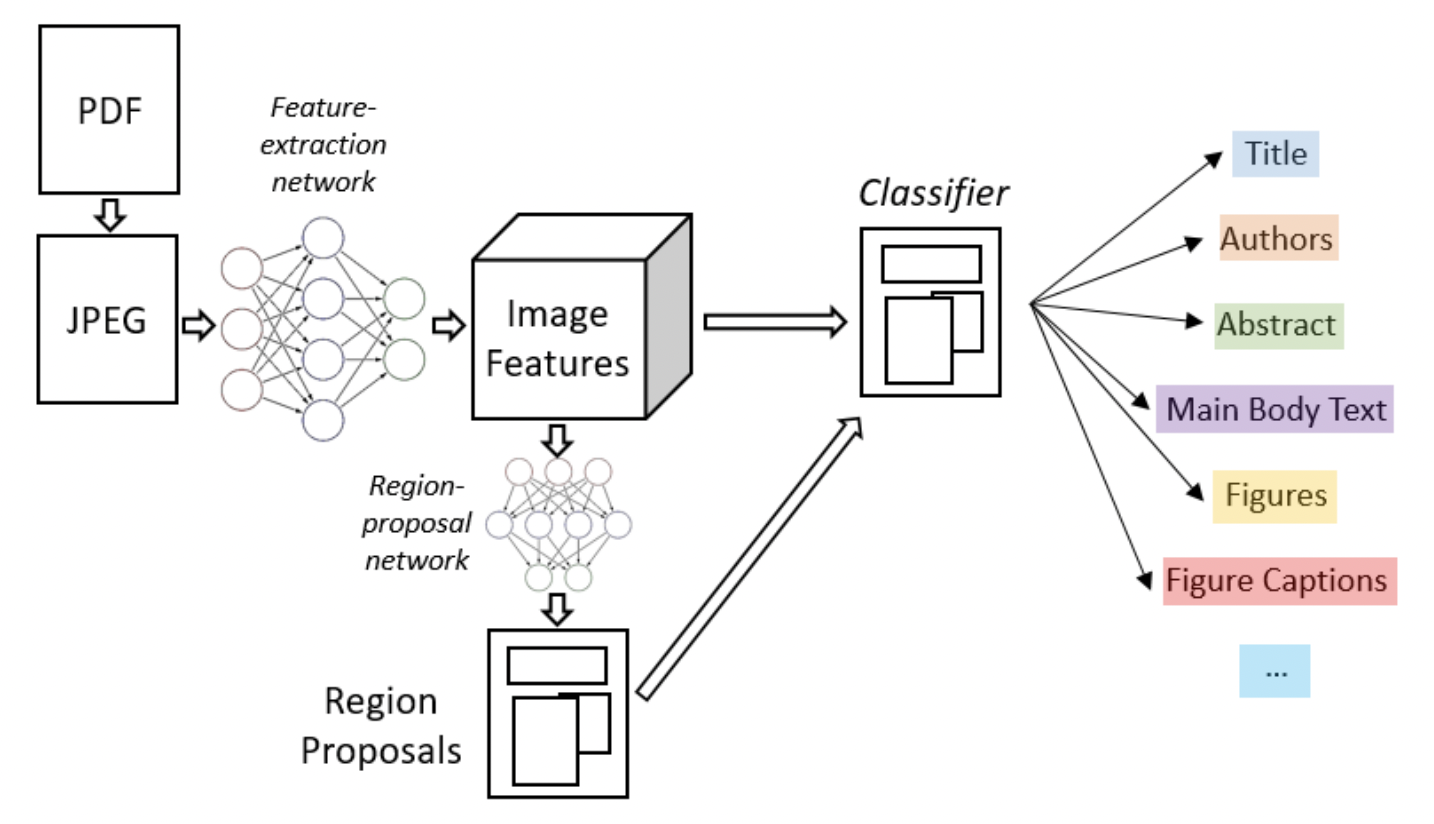
Soto Carlos[1]在目标检测算法Faster R-CNN的基础上,结合上下文信息并利用文档内容的固有位置信息来提高区域检测性能。Li Kai [2]等人也提出了一种基于目标检测的文档分析方法,通过引入了特征金字塔对齐模块,区域对齐模块,渲染层对齐模块来解决跨域的问题,这三个模块相互补充,并从一般的图像角度和特定的文档图像角度调整域,从而解决了大型标记训练数据集与目标域不同的问题。下图是一个基于目标检测Faster R-CNN算法进行版面分析的流程图。
1.3 基于语义分割的方法
Sarkar Mausoom[3]等人提出了一种基于先验的分割机制,在非常高的分辨率的图像上训练文档分割模型,解决了过度缩小原始图像导致的密集区域不同结构无法区分进而合并的问题。Zhang Peng[4]等人结合文档中的视觉、语义和关系提出了一个统一的框架VSR(Vision, Semantics and Relations)用于文档布局分析,该框架使用一个双流网络来提取特定模态的视觉和语义特征,并通过自适应聚合模块自适应地融合这些特征,解决了现有基于CV的方法不同模态融合效率低下和布局组件之间缺乏关系建模的局限性。
1.4 数据集
虽然现有的方法可以在一定程度上解决版面分析任务,但是该类方法依赖于大量有标记的训练数据。最近也有很多数据集被提出用于文档分析任务。
- PubLayNet[5]: 该数据集包含50万张文档图像,其中40万用于训练,5万用于验证,5万用于测试,共标记了表格,文本,图像,标题和列表五种形式
- HJDataset[6]: 数据集包含2271张文档图像, 除了内容区域的边界框和掩码之外,它还包括布局元素的层次结构和阅读顺序。
PubLayNet数据集样例如下图所示:


参考文献:
[1]:Soto C, Yoo S. Visual detection with context for document layout analysis[C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019: 3464-3470.
[2]:Li K, Wigington C, Tensmeyer C, et al. Cross-domain document object detection: Benchmark suite and method[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 12915-12924.
[3]:Sarkar M, Aggarwal M, Jain A, et al. Document Structure Extraction using Prior based High Resolution Hierarchical Semantic Segmentation[C]//European Conference on Computer Vision. Springer, Cham, 2020: 649-666.
[4]:Zhang P, Li C, Qiao L, et al. VSR: A Unified Framework for Document Layout Analysis combining Vision, Semantics and Relations[J]. arXiv preprint arXiv:2105.06220, 2021.
[5]:Zhong X, Tang J, Yepes A J. Publaynet: largest dataset ever for document layout analysis[C]//2019 International Conference on Document Analysis and Recognition (ICDAR). IEEE, 2019: 1015-1022.
[6]:Li M, Xu Y, Cui L, et al. DocBank: A benchmark dataset for document layout analysis[J]. arXiv preprint arXiv:2006.01038, 2020.
[7]:Shen Z, Zhang K, Dell M. A large dataset of historical japanese documents with complex layouts[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. 2020: 548-549.
2. 表格识别
2.1 背景介绍
表格是各类文档中常见的页面元素,随着各类文档的爆炸性增长,如何高效地从文档中找到表格并获取内容与结构信息即表格识别,成为了一个亟需解决的问题。表格识别的难点总结如下:
- 表格种类和样式复杂多样,例如不同的行列合并,不同的内容文本类型等。
- 文档的样式本身的样式多样。
- 拍摄时的光照环境等
表格识别的任务就是将文档里的表格信息转换到excel文件中,任务可视化如下:

现有的表格识别算法根据表格结构重建的原理可以分为下面四大类:
- 基于启发式规则的方法
- 基于CNN的方法
- 基于GCN的方法
- 基于End to End的方法
一些代表性论文被划分为上述四个类别中,具体如下表所示:
| 类别 | 思路 | 主要论文 |
|---|---|---|
| 基于启发式规则的方法 | 人工设计规则,连通域检测分析处理 | T-Rect,pdf2table |
| 基于CNN的方法 | 目标检测,语义分割 | CascadeTabNet, Multi-Type-TD-TSR, LGPMA, tabstruct-net, CDeC-Net, TableNet, TableSense, Deepdesrt, Deeptabstr, GTE, Cycle-CenterNet, FCN |
| 基于GCN的方法 | 基于图神经网络,将表格识别看作图重建问题 | GNN, TGRNet, GraphTSR |
| 基于End to End的方法 | 利用attention机制 | Table-Master |
2.2 基于启发式规则的传统算法
早期的表格识别研究主要是基于启发式规则的方法。例如由Kieninger[1]等人提出的T-Rect系统使用自底向上的方法对文档图像进行连通域分析,然后按照定义的规则进行合并,得到逻辑文本块。而之后由Yildiz[2]等人提出的pdf2table则是第一个在PDF文档上进行表格识别的方法,它利用了PDF文件的一些特有信息(例如文字、绘制路径等图像文档中难以获取的信息)来协助表格识别。而在最近的工作中,Koci[3]等人将页面中的布局区域表示为图(Graph)的形式,然后使用了Remove and Conquer(RAC)算法从中将表格作为一个子图识别出来。

2.3 基于深度学习CNN的方法
随着深度学习技术在计算机视觉、自然语言处理、语音处理等领域的飞速发展,研究者将深度学习技术应用到表格识别领域并取得了不错的效果。
Siddiqui Shoaib Ahmed[12]等人在DeepTabStR算法中,将表格结构识别问题表述为对象检测问题,并利用可变形卷积来进更好的进行表格单元格的检测。Raja Sachin[6]等人提出TabStruct-Net将单元格检测和结构识别在视觉上结合起来进行表格结构识别,解决了现有方法由于表格布局发生较大变化而识别错误的问题,但是该方法无法处理行列出现较多空单元格的问题。

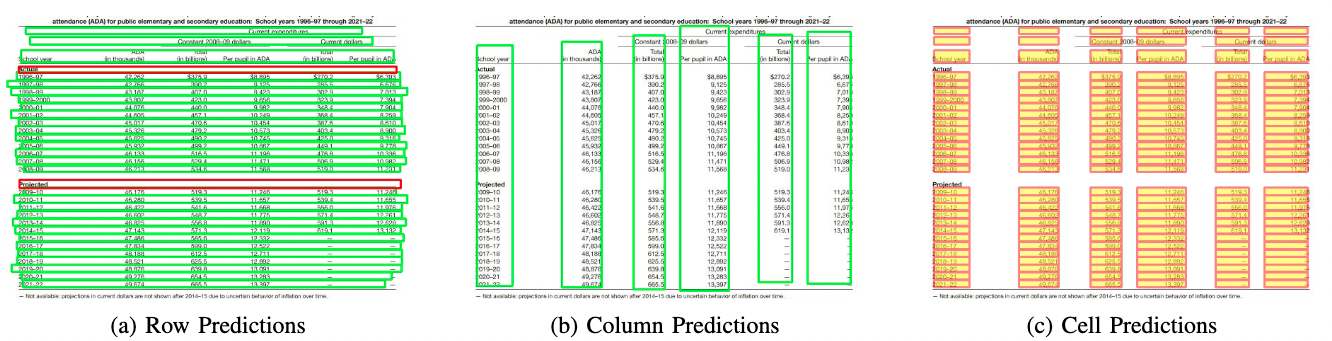
之前的表格结构识别方法一般是从不同粒度(行/列、文本区域)的元素开始处理问题,容易忽略空单元格合并的问题。Qiao Liang[10]等人提出了一个新框架LGPMA,通过掩码重评分策略充分利用来自局部和全局特征的信息,进而可以获得更可靠的对齐单元格区域,最后引入了包括单元格匹配、空单元格搜索和空单元格合并的表格结构复原pipeline来处理表格结构识别问题。
除了以上单独做表格识别的算法外,也有部分方法将表格检测和表格识别在一个模型里完成,Schreiber Sebastian[11]等人提出了DeepDeSRT,通过Faster RCNN进行表格检测,通过FCN语义分割模型用于表格结构行列检测,但是该方法是用两个独立的模型来解决这两个问题。Prasad Devashish[4]等人提出了一种基于端到端深度学习的方法CascadeTabNet,使用Cascade Mask R-CNN HRNet模型同时进行表格检测和结构识别,解决了以往方法使用独立的两个方法处理表格识别问题的不足。Paliwal Shubham[8]等人提出一种新颖的端到端深度多任务架构TableNet,用于表格检测和结构识别,同时在训练期间向TableNet添加额外的空间语义特征,进一步提高了模型性能。Zheng Xinyi[13]等人提出了表格识别的系统框架GTE,利用单元格检测网络来指导表格检测网络的训练,同时提出了一种层次网络和一种新的基于聚类的单元格结构识别算法,该框架可以接入到任何目标检测模型的后面,方便训练不同的表格识别算法。之前的研究主要集中在从扫描的PDF文档中解析具有简单布局的,对齐良好的表格图像,但是现实场景中的表格一般很复杂,可能存在严重变形,弯曲或者遮挡等问题,因此Long Rujiao[14]等人同时构造了一个现实复杂场景下的表格识别数据集WTW,并提出了一种Cycle-CenterNet方法,它利用循环配对模块优化和提出的新配对损失,将离散单元精确地分组到结构化表中,提高了表格识别的性能。
基于CNN的方法对跨行列的表格无法很好的处理,因此在后续的方法中,分为了两个研究方法来解决表格中跨行列的问题。
2.4 基于深度学习GCN的方法
近些年来,随着图卷积神经网络(Graph Convolutional Network)的兴起,也有一些研究者尝试将图神经网络应用到表格结构识别问题上。Qasim Shah Rukh[20]等人将表格结构识别问题转换为与图神经网络兼容的图问题,并设计了一种新颖的可微架构,该架构既可以利用卷积神经网络提取特征的优点,也可以利用图神经网络顶点之间有效交互的优点,但是该方法只使用了单元格的位置特征,没有利用语义特征。Chi Zewen[19]等人提出了一种新颖的图神经网络GraphTSR,用于PDF文件中的表格结构识别,它以表格中的单元格为输入,然后通过利用图的边和节点相连的特性来预测单元格之间的关系来识别表格结构,一定程度上解决了跨行或者跨列的单元格识别问题。Xue Wenyuan[21]等人将表格结构识别的问题重新表述为表图重建,并提出了一种用于表格结构识别的端到端方法TGRNet,该方法包含单元格检测分支和单元格逻辑位置分支,这两个分支共同预测不同单元格的空间位置和逻辑位置,解决了之前方法没有关注单元格逻辑位置的问题。
GraphTSR表格识别算法示意图:

2.5 基于端到端的方法
和其他使用后处理完成表格结构的重建不同,基于端到端的方法直接使用网络完成表格结构的HTML表示输出
 |  ) ) |
|---|---|
| 图 10:端到端方法的输入输出 | 图 11:Image Caption示例 |
端到端的方法大多采用Image Caption(看图说话)的Seq2Seq方法来完成表格结构的预测,如一些基于Attention或Transformer的方法。
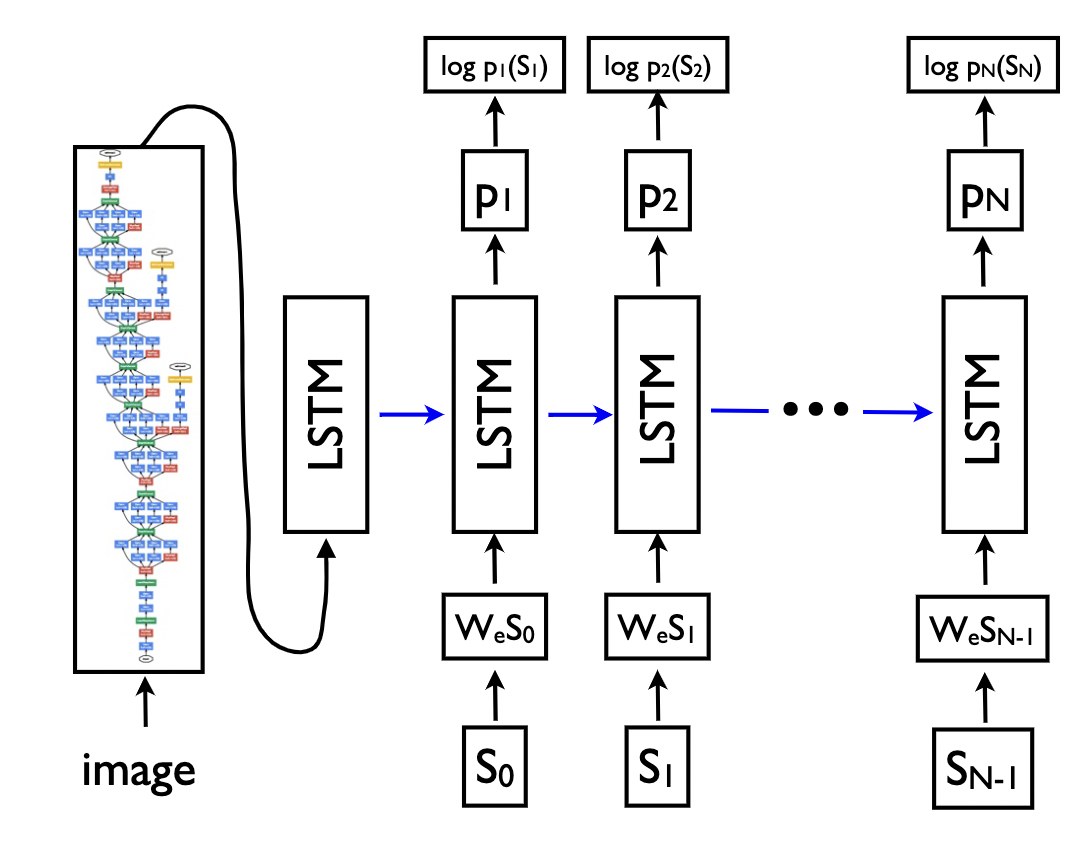
Ye Jiaquan[22]在TableMaster中通过改进基于Transformer的Master文字算法来得到表格结构输出模型。此外,还添加了一个分支进行框的坐标回归,作者并没有在最后一层将模型拆分为两个分支,而是在第一个 Transformer 解码层之后就将序列预测和框回归解耦为两个分支。其网络结构和原始Master网络的对比如下图所示:
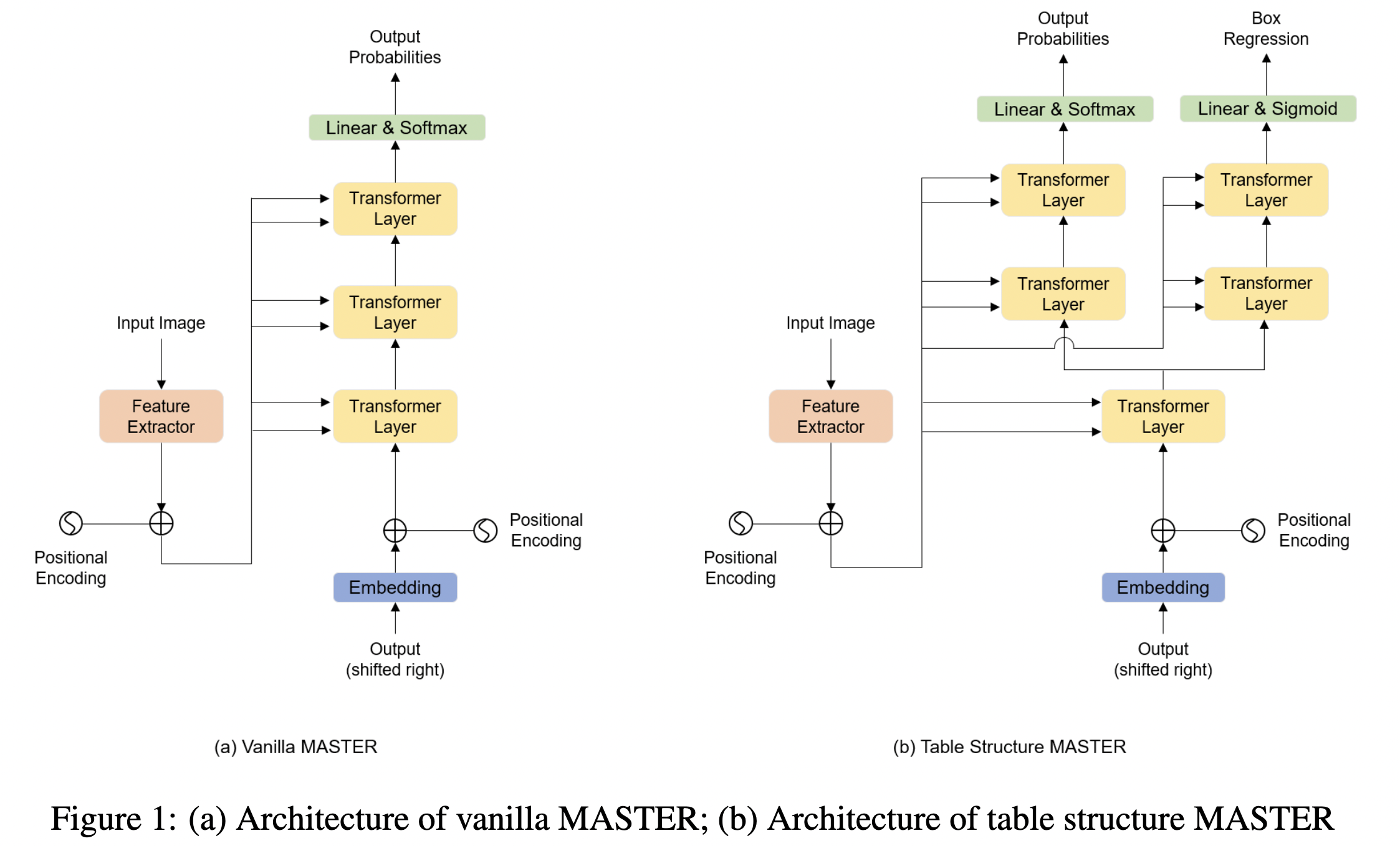
2.6 数据集
由于深度学习方法是数据驱动的方法,需要大量的标注数据对模型进行训练,而现有的数据集规模偏小也是一个重要的制约因素,因此也有一些数据集被提出。
- PubTabNet[16]: 包含568k表格图像和相应的结构化HTML表示。
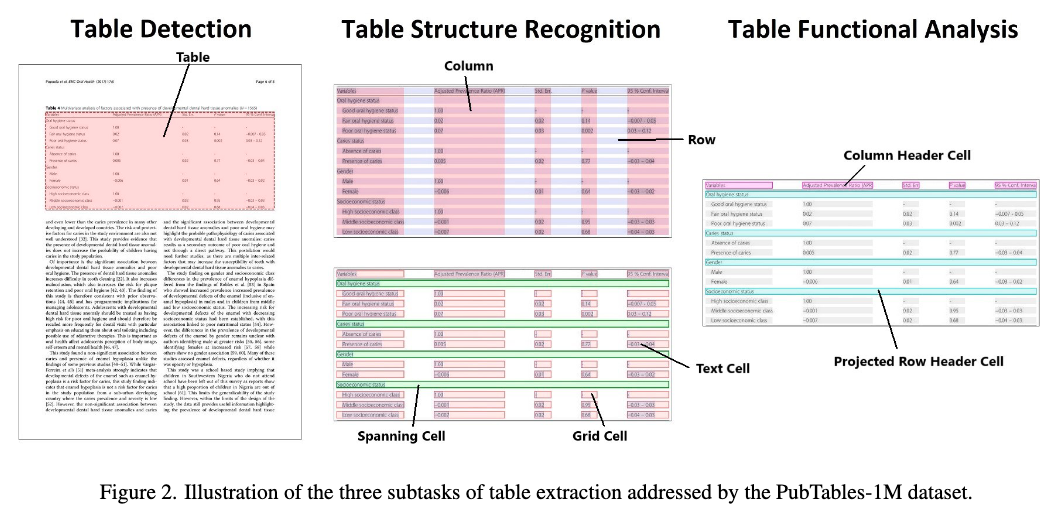
- PubMed Tables(PubTables-1M)[17]:表格结构识别数据集,包含高度详细的结构注释,460,589张pdf图像用于表格检测任务, 947,642张表格图像用于表格识别任务。
- TableBank[18]: 表格检测和识别数据集,使用互联网上Word和Latex文档构建了包含417K高质量标注的表格数据。
- SciTSR[19]: 表格结构识别数据集,图像大部分从论文中转换而来,其中包含来自PDF文件的15,000个表格及其相应的结构标签。
- TabStructDB[12]: 包括1081个表格区域,这些区域用行和列信息密集标记。
- WTW[14]: 大规模数据集场景表格检测识别数据集,该数据集包含各种变形,弯曲和遮挡等情况下的表格数据,共包含14,581 张图像。
数据集示例

3. Document VQA
3.1 背景介绍
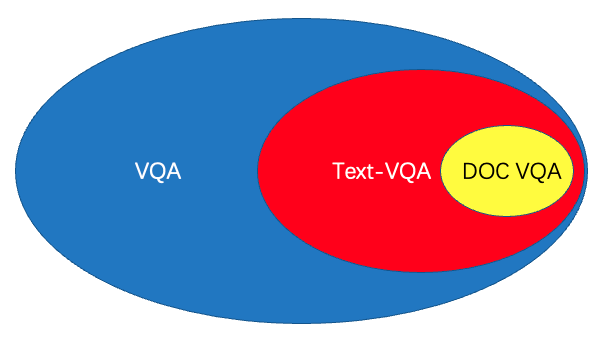
在VQA(Visual Question Answering)任务中,主要针对图像内容进行提问和回答,但是对于文本图像来说,关注的内容是图像中的文字信息,因此这类方法可以分为自然场景的Text-VQA和扫描文档场景的DocVQA,三者的关系如下图所示。
VQA,Text-VQA和DocVQA的示例图如下图所示。
| 任务类型 | VQA | Text-VQA | DocVQA |
|---|---|---|---|
| 任务描述 | 针对图片内容提出问题 | 针对图片上的文字内容提出问题 | 针对文档图像的文字内容提出问题 |
| 示例图片 |  |  |  |
DocVQA由于其更加贴近实际应用场景,涌现出了大批学术界和工业界的工作。在常用的场景中,DocVQA里提问的问题都是固定的,比如身份证场景下的问题一般为
- 公民身份号码是什么?
- 姓名是什么?
- 名族是什么?

基于这样的先验知识,DocVQA的 研究开始偏向Key Information Extraction(KIE)任务,本次我们也主要讨论KIE相关的研究,KIE任务主要从图像中提取所需要的关键信息,如从身份证中提取出姓名和公民身份号码信息。
KIE通常分为两个子任务进行研究
- SER: 语义实体识别 (Semantic Entity Recognition),对每一个检测到的文本进行分类,如将其分为姓名,身份证。如下图中的黑色框和红色框。
- RE: 关系抽取 (Relation Extraction),对每一个检测到的文本进行分类,如将其分为问题和的答案。然后对每一个问题找到对应的答案。如下图中的红色框和黑色框分别代表问题和答案,黄色线代表问题和答案之间的对应关系。

一般的KIE方法基于命名实体识别(Named Entity Recognition,NER)[4]来研究,但是这类方法只利用了图像中的文本信息,缺少对视觉和结构信息的使用,因此精度不高。在此基础上,近几年的方法都开始将视觉和结构信息与文本信息融合到一起,按照对多模态信息进行融合时所采用的的原理可以将这些方法分为下面三种:
- 基于Grid的方法
- 基于Token的方法
- 基于GCN的方法
- 基于End to End 的方法
一些代表性论文被划分为上述三个类别中,具体如下表所示:
| 类别 | 思路 | 主要论文 |
|---|---|---|
| 基于Grid的方法 | 在图像上多模态信息的融合(文本,布局,图像) | Chargrid |
| 基于Token的方法 | 利用Bert这类方法进行多模态信息的融合 | LayoutLM, LayoutLMv2, StrucText, |
| 基于GCN的方法 | 利用图网络结构进行多模态信息的融合 | GCN, PICK, SDMG-R,SERA |
| 基于End to End的方法 | 将OCR和关键信息提取统一到一个网络 | Trie |
3.2 基于Grid的方法
基于Grid的方法在图像层面进行多模态信息的融合。Chargrid[5]首先对图像进行字符级的文字检测和识别,然后通过将类别的one-hot编码填充到对应的字符区域(下图中右图的非黑色部分)内来完成对网络输入的构建,输入最后通过encoder-decoder结构的CNN网络来进行关键信息的坐标检测和类别分类。


相比于传统的仅基于文本的方法,该方法能够同时利用文本信息和结构信息,因此能够取得一定的精度提升,但是该方法对文本和结构信息的融合只是做了简单的嵌入,并没有很好的将二者进行融合
3.3 基于Token的方法
LayoutLM[6]将2D位置信息和文本信息一起编码到BERT模型中,并且借鉴NLP中Bert的预训练思想,在大规模的数据集上进行预训练,在下游任务中,LayoutLM还加入了图像信息来进一步提升模型性能。LayoutLM虽然将文本,位置和图像信息做了融合,但是图像信息是在下游任务的训练中进行融合,这样对三种信息的多模态融合并不充分。LayoutLMv2[7]在LayoutLM的基础上,通过transformers在预训练阶段将图像信息和文本,layout信息进行融合,还在Transformer中加入空间感知自注意力机制辅助模型更好地融合视觉和文本特征。LayoutLMv2虽然在预训练阶段对文本,位置和图像信息做了融合,但是由于预训练任务的限制,模型学到的视觉特征不够精细。StrucTexT[8]在以往多模态方法的基础上,在预训练任务提出Sentence Length Prediction (SLP) 和Paired Boxes Direction (PBD)两个新任务来帮助网络学习精细的视觉特征,其中SLP任务让模型学习文本段的长度,PDB任务让模型学习Box方向之间的匹配关系。通过这两个新的预训练任务,能够加速文本、视觉和布局信息之间的深度跨模态融合。
 |  ) ) |
|---|---|
| 图 21:transformer算法流程图 | 图 22:LayoutLMv2算法流程图 |
3.4 基于GCN的方法
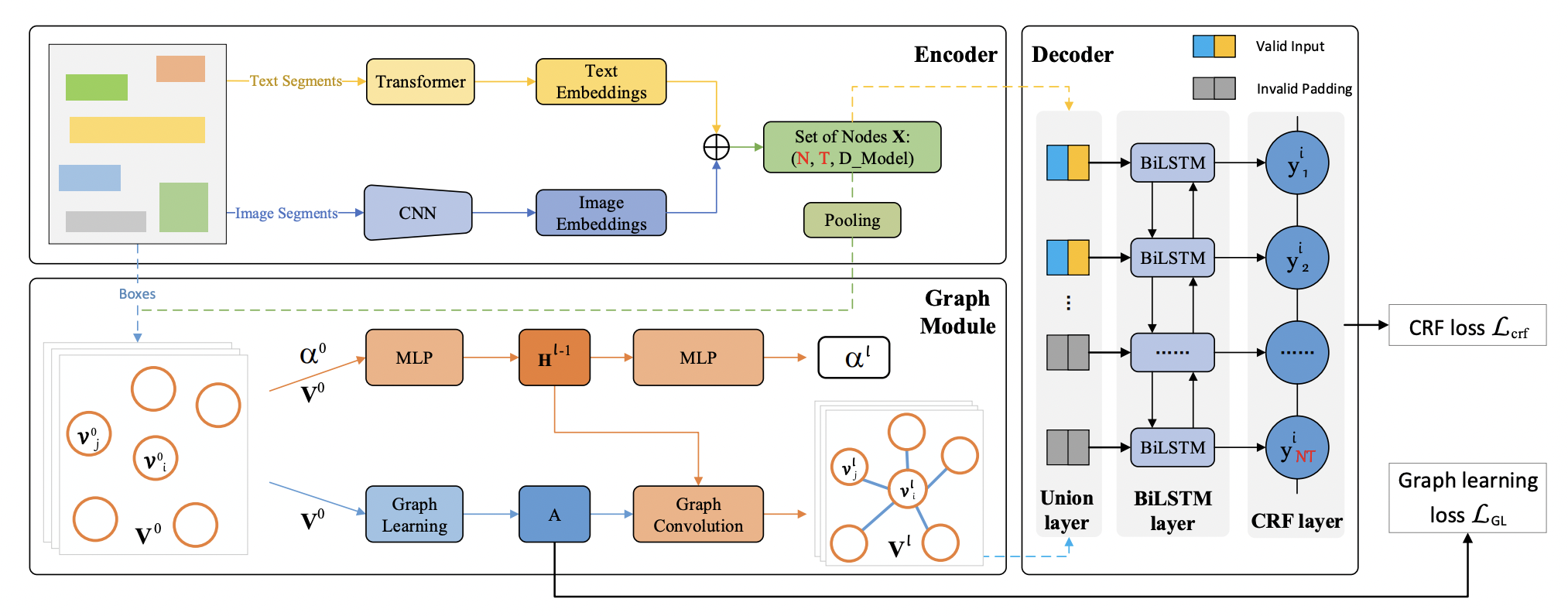
现有的基于GCN的方法[10]虽然利用了文字和结构信息,但是没有对图像信息进行很好的利用。PICK[11]在GCN网络中加入了图像信息并且提出graph learning module来自动学习edge的类型。SDMG-R [12]将图像编码为双模态图,图的节点为文字区域的视觉和文本信息,边表示相邻文本直接的空间关系,通过迭代地沿边传播信息和推理图节点类别,SDMG-R解决了现有的方法对没见过的模板无能为力的问题。
PICK流程图如下图所示:
SERA[10]将依存句法分析里的biaffine parser引入到文档关系抽取中,并且使用GCN来融合文本和视觉信息。

3.5 基于End to End 的方法
现有的方法将KIE分为两个独立的任务:文本读取和信息提取,然而他们主要关注于改进信息提取任务,而忽略了文本读取和信息提取是相互关联的,因此,Trie[9]提出了一个统一的端到端网络,可以同时学习这两个任务,并且在学习过程中相互加强。
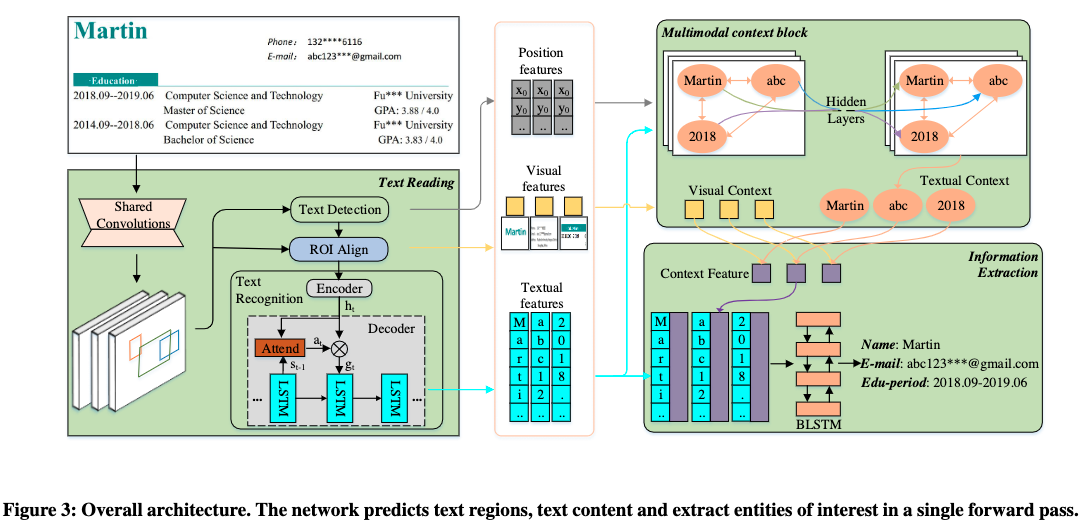
3.6 数据集
用于KIE的数据集主要有下面两个:
- SROIE: SROIE数据集[2]的任务3旨在从扫描收据中提取四个预定义的信息:公司、日期、地址或总数。数据集中有626个样本用于训练,347个样本用于测试。
- FUNSD: FUNSD数据集[3]是一个用于从扫描文档中提取表单信息的数据集。它包含199个标注好的真实扫描表单。199个样本中149个用于训练,50个用于测试。FUNSD数据集为每个单词分配一个语义实体标签:问题、答案、标题或其他。
- XFUN: XFUN数据集是微软提出的一个多语言数据集,包含7种语言,每种语言包含149张训练集,50张测试集。
 |  ) ) |
|---|---|
| 图 26: sroie示例图 | 图 27: xfun示例图 |
参考链接
https://aistudio.baidu.com/education/group/info/25207
https://github.com/PaddlePaddle/PaddleOCR/tree/release/2.7
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。
相关文章:
开启智能时代:深度解析智能文档分析技术的前沿与应用
开启智能时代:深度解析智能文档分析技术的前沿与应用 本章主要介绍文档分析技术的理论知识,包括背景介绍、算法分类和对应思路。通过本文学习,你可以掌握:1. 版面分析的分类和典型思想 2. 表格识别的分类和典型思想 3. 信息提取的…...
高级时钟项目
高级时钟项目 笔者来介绍一下一个简单的时钟项目,主要功能就是显示时间 1、背景 2、数码管版本(第一版) 3、OLED屏幕版本(第二版) 3.1、Boot 3.2、app 3.3、上位机 界面一:时间天气显示 界面二 &…...

跨境海淘攻略:如何实现自己批量养买家账号海淘
近年来,随着互联网的发展,网购已经成为人们日常生活中不可或缺的一部分。不仅在国内购买商品,在跨境电商行业越来越成熟,很多的消费者开始选择购买国外平台商品,价格相比国内专柜来说会更为优惠。因此,海淘…...

【lua】在微软 windows 系统上安装 lua
https://sourceforge.net/projects/luabinaries...

系统学习Linux-PXE无人值守装机(附改密)
目录 pxe实现系统自动安装pxe工作原理 大致的工作过程如下: PXE的组件: 一、配置vsftpd 二、配置tftp 三、准备pxelinx.0文件、引导文件、内核文件 四、配置dhcp 配置ip 配置dhcp 五、创建default文件 六、新建测试主机用来测试装机效果 七、…...

关于web3.0平台的详细说明
Web3.0是指下一代互联网的发展阶段,它以区块链技术为基础,具有去中心化、安全性强、用户数据私密性保护等特点。在Web3.0的社交平台中,人们可以更好地掌控自己的数据,并获得更加开放和透明的社交体验。 以下是一些关于Web3.0社交…...

Git命令简单使用
1、上传仓库到 git 上传仓库到 git 上之前需要配置用户名和邮箱 git config --global user.name "user_name" git config --global user.email "email_id"在本地仓库中使用名称初始化 git init使用下面的命令将文件添加到仓库 # 添加一个或多个文件到暂…...
网络请求和文件)
Flutter(十)网络请求和文件
目录 文件操作网络请求1.Dio库2.websocket3.JSON转Dart Model 文件操作 APP目录 Android 和 iOS 的应用存储目录不同,PathProvider (opens new window)插件提供了一种平台透明的方式来访问设备文件系统上的常用位置。该类当前支持访问两个文件系统位置:…...
Unity RenderStreaming 云渲染-黑屏
🥪云渲染-黑屏 网页加载出来了,点击播放黑屏 ,关闭防火墙即可!!!!...
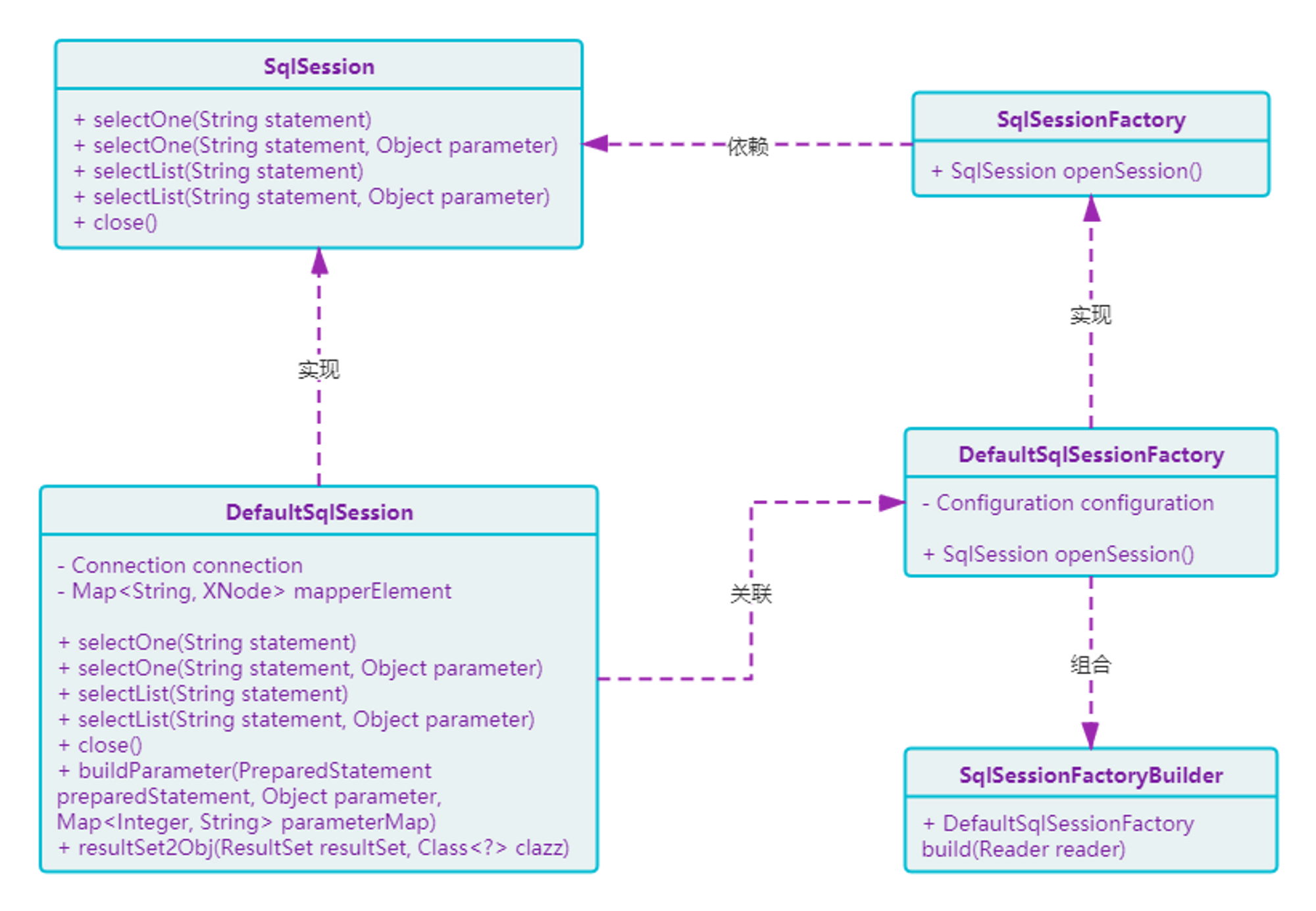
Java设计模式:四、行为型模式-04:中介者模式
文章目录 一、定义:中介者模式二、模拟场景:中介者模式三、违背方案:中介者模式3.1 工程结构3.2 创建数据库3.3 JDBC工具类3.4 单元测试 四、改善代码:中介者模式4.1 工程结构4.2 中介者工程结构图4.3 资源和配置类4.3.1 XML配置对…...

【GO】LGTM_Grafana_Tempo(1)_架构
最近在尝试用 LGTM 来实现 Go 微服务的可观测性,就顺便整理一下文档。 Tempo 会分为 4 篇文章: Tempo 的架构官网测试实操跑通gin 框架发送 trace 数据到 tempogo-zero 微服务框架使用发送数据到 tempo 第一篇是关于,tempo 的架构ÿ…...

MFC 与 QT“常用控件”对比
1、 常用控件 MFC QT 1.静态文本框/标签 CStatic QLabel 按钮 CButton包含了3种样式的按钮,Push Button,Check Box,Radio Box 4种不同的类 2.按钮:推动按钮 Push Button(同一个类CButton) QPushButton 3.按钮…...

linux 下安装chrome 和 go
1. 安装google-chrome 1.1 首先下载google-chrome.deb安装包 之后 安装 gdebi包 sudo apt install gdebi 1.2 安装所要安装的软件 sudo gdebi code_1.81.1-1691620686_amd64.deb 1.3 解决Chrome无法启动问题 rootubuntu:~/Downloads# whereis google-chrome google-chrome…...
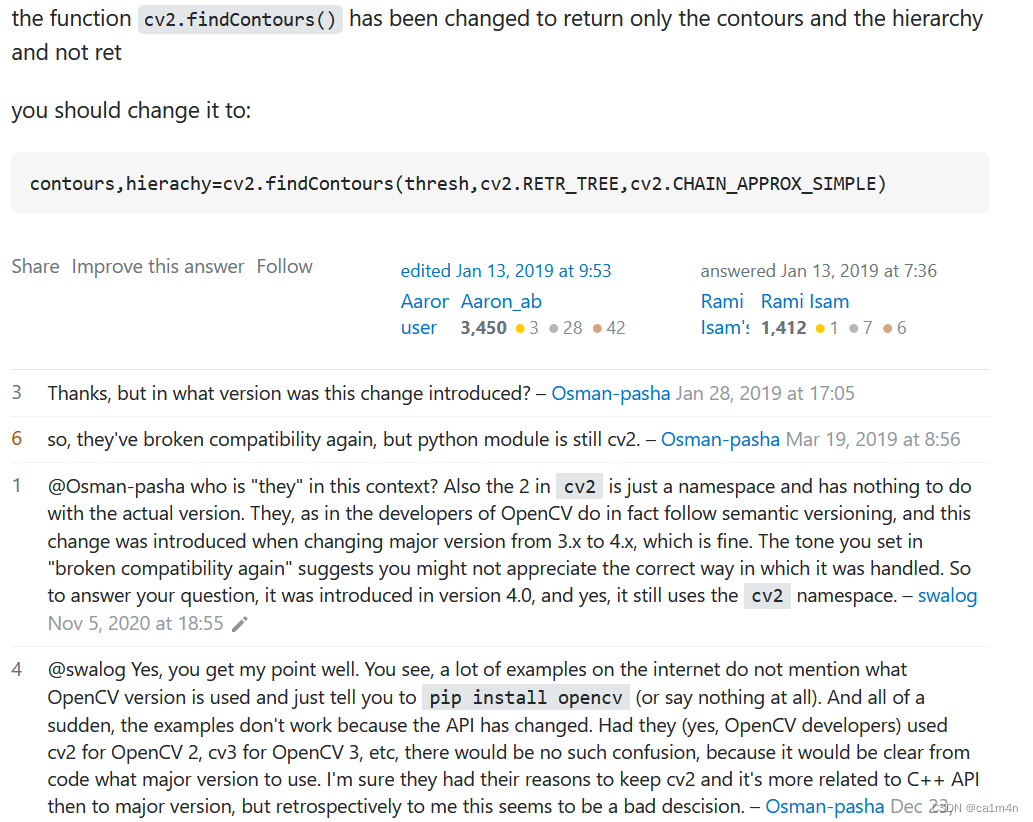
OpenCV: cv2.findContours - ValueError: too many values to unpack
OpenCV找轮廓findContours报错 ValueError: not enough values to unpack (expected 3,got 2) 问题指向这行代码👇 binary, cnts, hierarchy cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE ) 报错的意思是需要3个返回值但只给了两…...

Vue框架--Vue概述
1.vue概述 Vue是一个渐进式JavaScript 框架,用于动态构建用户界面。 2.vue的特点 (1).遵循MVVM模式 MVVM是Model-View-ViewModel的简写。它本质上就是MVC的改进版 (2).采用组件化模式,提高代码的复用率,且让代码更好的维护。 组件化:简单的说就是使用xxx.vue模式包含一个页面…...

Fiddler安装与使用教程(1) —— 软测大玩家
😏作者简介:博主是一位测试管理者,同时也是一名对外企业兼职讲师。 📡主页地址:【Austin_zhai】 🙆目的与景愿:旨在于能帮助更多的测试行业人员提升软硬技能,分享行业相关最新信息。…...
Ubuntu 22.04安装 —— Win11 22H2
目录 Ubuntu使用下载UbuntuVmware 安装图示安装步骤图示 Ubuntu使用 系统环境: Windows 11 22H2Vmware 17 ProUbutun 22.04.3 Server Ubuntu Server documentation | Ubuntu 下载 Ubuntu 官网下载 建议安装长期支持版本 ——> 可以选择桌面版或服务器版(仅包…...

【STM32】IIC的初步使用
IIC简介 物理层 连接多个devices 它是一个支持设备的总线。“总线”指多个设备共用的信号线。在一个 I2C 通讯总线中,可连接多个 I2C 通讯设备,支持多个通讯主机及多个通讯从机。 两根线 一个 I2C 总线只使用两条总线线路,一条双向串行数…...

音视频 ffmpeg命令参数说明
主要参数: -i 设定输入流 -f 设定输出格式(format) -ss 开始时间 -t 时间长度 音频参数: -aframes 设置要输出的音频帧数 -b:a 音频码率 -ar 设定采样率 -ac 设定声音的Channel数 -acodec 设定声音编解码器,如果用copy表示原始编解码数据必须…...

Go学习第十天
打印报错堆栈信息 安装errors包 go get github.com/pkg/errors 具体使用 // 新生成一个错误, 带堆栈信息 func New(message string) error//只附加新的信息 func WithMessage(err error, message string) error//只附加调用堆栈信息 func WithStack(err error) error//同时附…...
)
ArcGIS Pro脚本工具实战:5分钟用arcpy给要素批量‘改名’(保姆级参数配置指南)
ArcGIS Pro脚本工具实战:5分钟用arcpy给要素批量‘改名’(保姆级参数配置指南) 当你在处理上百个GIS图层时,是否曾被重复的"右键-属性-修改别名"操作折磨到崩溃?上周我接手一个城市管网项目,需要…...

3种高级策略突破AI编辑器限制:Cursor Pro逆向工程技术解析
3种高级策略突破AI编辑器限制:Cursor Pro逆向工程技术解析 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your…...

3个高效方法解决抖音素材管理难题:从零散文件到有序素材库
3个高效方法解决抖音素材管理难题:从零散文件到有序素材库 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback s…...

光学萌新看过来:用Lighttools 8.4.0配合Solidworks做光机设计,第一步安装和环境配置怎么做?
光学与机械协同设计:Lighttools 8.4.0与Solidworks环境配置全指南 在光机一体化设计领域,光学仿真软件与机械建模工具的协同工作已成为行业标配。对于刚接触光学设计的机械工程师,或是需要将光学分析融入机械设计流程的团队而言,掌…...

计算机数值型数据表示:从二进制到浮点数与字符编码的底层原理
1. 项目概述:从“0”和“1”到万千世界我们每天都在和计算机打交道,无论是刷短视频、处理文档,还是运行复杂的科学计算。你有没有想过,屏幕上那些生动的图像、动听的音乐、精确的数值,在计算机的“大脑”——CPU和内存…...

Python实战:基于InsightFace构建实时人脸识别系统
1. 环境准备与InsightFace初探 第一次接触人脸识别系统开发时,我被各种算法和框架搞得晕头转向,直到发现了InsightFace这个宝藏库。它就像瑞士军刀一样集成了人脸检测、对齐、识别全套功能,而且对Python开发者特别友好。记得当时用OpenCVDlib…...
)
不止图表引用!VSCode+LaTeX完整编译链配置指南(含BibTeX文献处理)
VSCodeLaTeX高效工作流:从交叉引用到文献管理的全栈配置指南 当你第一次在VSCode中尝试用LaTeX撰写学术论文时,是否曾被那些顽固的"??"标记困扰?这些问号背后隐藏着LaTeX编译机制的核心逻辑——交叉引用需要多轮编译才能正确解析…...

模型切换总报错?Trae 在模块四迁移中解决 3 类兼容性问题的配置要点
1. 模型切换总报错?不是模型的问题,是配置没对齐上下文契约 我在三个中型项目里反复遇到同一个现象:刚切完模型,Trae 就在右下角弹出红色提示——“Context initialization failed” 或 “Model adapter mismatch: expected Claude-3-haiku, got DeepSeek-VL-4”。不是模型…...

RT-Thread裁剪实战:从98KB到28KB的嵌入式系统瘦身指南
1. 项目概述:为什么我们需要裁剪RT-Thread?如果你是一名嵌入式软件工程师,或者正在学习RT-Thread,那么“裁剪”这个词对你来说一定不陌生。RT-Thread作为一款优秀的国产开源实时操作系统,其标准版(或称完整…...

OPNsense-从零部署:硬件选型与虚拟机安装实战
1. 为什么选择OPNsense? 第一次听说OPNsense是在三年前帮朋友公司排查网络问题时。当时他们用的某商业防火墙频繁死机,我试着在旧服务器上部署了OPNsense临时救急,没想到这台"临时工"不仅稳定运行了两年多,还解锁了流量…...