linux————ELK(日志收集系统集群)
目录
一、为什么要使用ELK
二、ELK作用
二、组件
一、elasticsearch
特点
二、logstash
工作过程
INPUT(输入)
FILETER(过滤)
OUTPUTS(输出)
三、kibana
三、架构类型
ELK
ELKK
ELFK
ELFKK
EFK
四、构建ELk集群
一、环境配置
二、安装node1与node2节点的elasticsearch
三、在node1安装elasticsearch-head插件
四、node1服务器安装logstash
五、logstash日志收集文件格式(默认存储在/etc/logstash/conf.d)
六、node1节点安装kibana
一、为什么要使用ELK
日志对于分析系统、应用的状态十分重要,但一般日志的量会比较大,并且比较分散。
如果管理的服务器或者程序比较少的情况我们还可以逐一登录到各个服务器去查看、分析。但如果服务器或者程序的数量比较多了之后这种方法就显得力不从心。基于此,一些集中式的日志系统也就应用而生。目前比较有名成熟的有,Splunk(商业)、FaceBook 的Scribe、Apache的Chukwa Cloudera的Fluentd、还有ELK等等。
二、ELK作用
日志收集
日志分析
日志可视化
二、组件
一、elasticsearch
日志分析 开源的日志收集、分析、存储程序
特点
分布式
零配置
自动发现
索引自动分片
索引副本机制
Restful风格接口
多数据源
自动搜索负载
二、logstash
日志收集 搜集、分析、过滤日志的工具
工作过程
一般工作方式为c/s架构,Client端安装在需要收集日志的服务器上,Server端负责将收到的各节点日志进行过滤、修改等操作,再一并发往Elasticsearch上去
Inputs → Filters → Outputs
输入-->过滤-->输出
INPUT(输入)
File: 从文件系统的文件中读取,类似于tail -f命令
Syslog: 在514端口上监听系统日志消息,并根据RFC3164标准进行解析
Redis: 从redis service中读取
Beats: 从filebeat中读取
FILETER(过滤)
Grok: 解析任意文本数据,Grok 是 Logstash 最重要的插件。它的主要作用就是将文本格式的字符串,转换成为具体的结构化的数据,配合正则表达式使用。
官方提供的grok表达式: logstash-patterns-core/patterns at main · logstash-plugins/logstash-patterns-core · GitHub
Grok在线调试: Grok Debugger
Mutate: 对字段进行转换。例如对字段进行删除、替换、修改、重命名等。
Drop: 丢弃一部分Events不进行处理。
Clone: 拷贝Event,这个过程中也可以添加或移除字段。
Geoip: 添加地理信息(为前台kibana图形化展示使用)
OUTPUTS(输出)
Elasticsearch: 可以高效的保存数据,并且能够方便和简单的进行查询。
File: 将Event数据保存到文件中。
Graphite: 将Event数据发送到图形化组件中,踏实一个当前较流行的开源存储图形化展示的组件。
三、kibana
日志可视化
为Logstash和ElasticSearch在收集、存储的日志基础上进行分析时友好的Web界面,可以帮助汇总、分析和搜索重要数据日志。
三、架构类型
ELK
es
logstash
kibana
ELKK
es
logstash
kafka
kibana
ELFK
es
logstash 重量级 占用系统资源较多
filebeat 轻量级 占用系统资源较少
kibana
ELFKK
es
logstash
filebeat
kafka
kibana
EFK
es
logstash
fluentd
kafka
kibana
四、构建ELk集群
基于Java环境yum install -y java-1.8.0-OpenJDK)
虚拟机 内存4G 四核
已经下载好的 tar包
一、环境配置
关闭防火墙,selinux
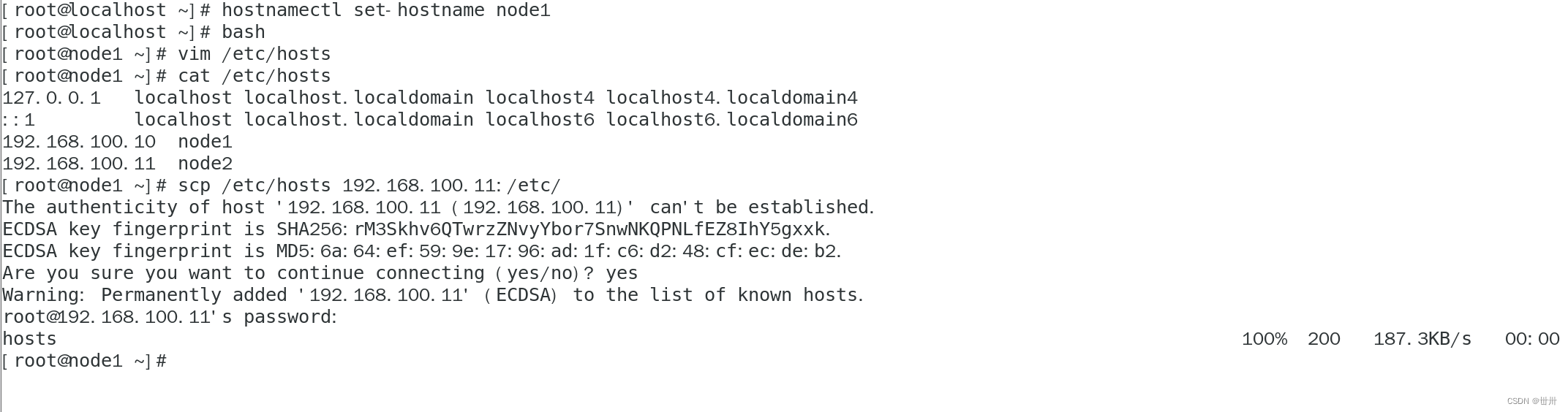
设置各个主机的IP地址为静态IP,两个节点中修改主机名为node1和node2并设置hosts文件
node1:192.168.100.10/24
hostnamectl set-hostname node1
vim /etc/hosts
192.168.1.1 node1
192.168.1.2 node2
node2:192.168.100.11/24
hostnamectl set-hostname node2
vim /etc/hosts
192.168.1.1 node1
192.168.1.2 node2

二、安装node1与node2节点的elasticsearch
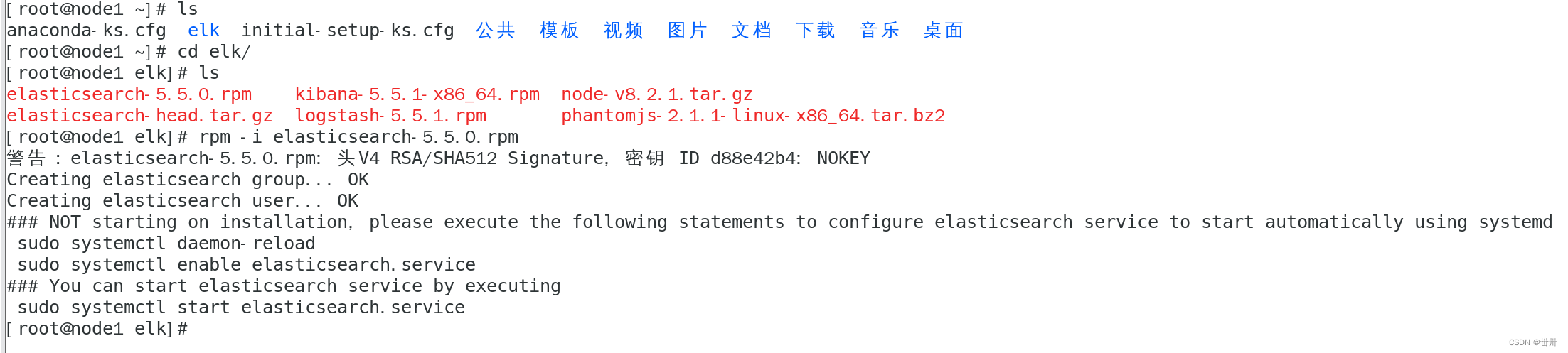
安装 rpm -ivh elasticsearch-5.5.0.rpm
配置 vim /etc/elasticsearch/elasticsearch.yml
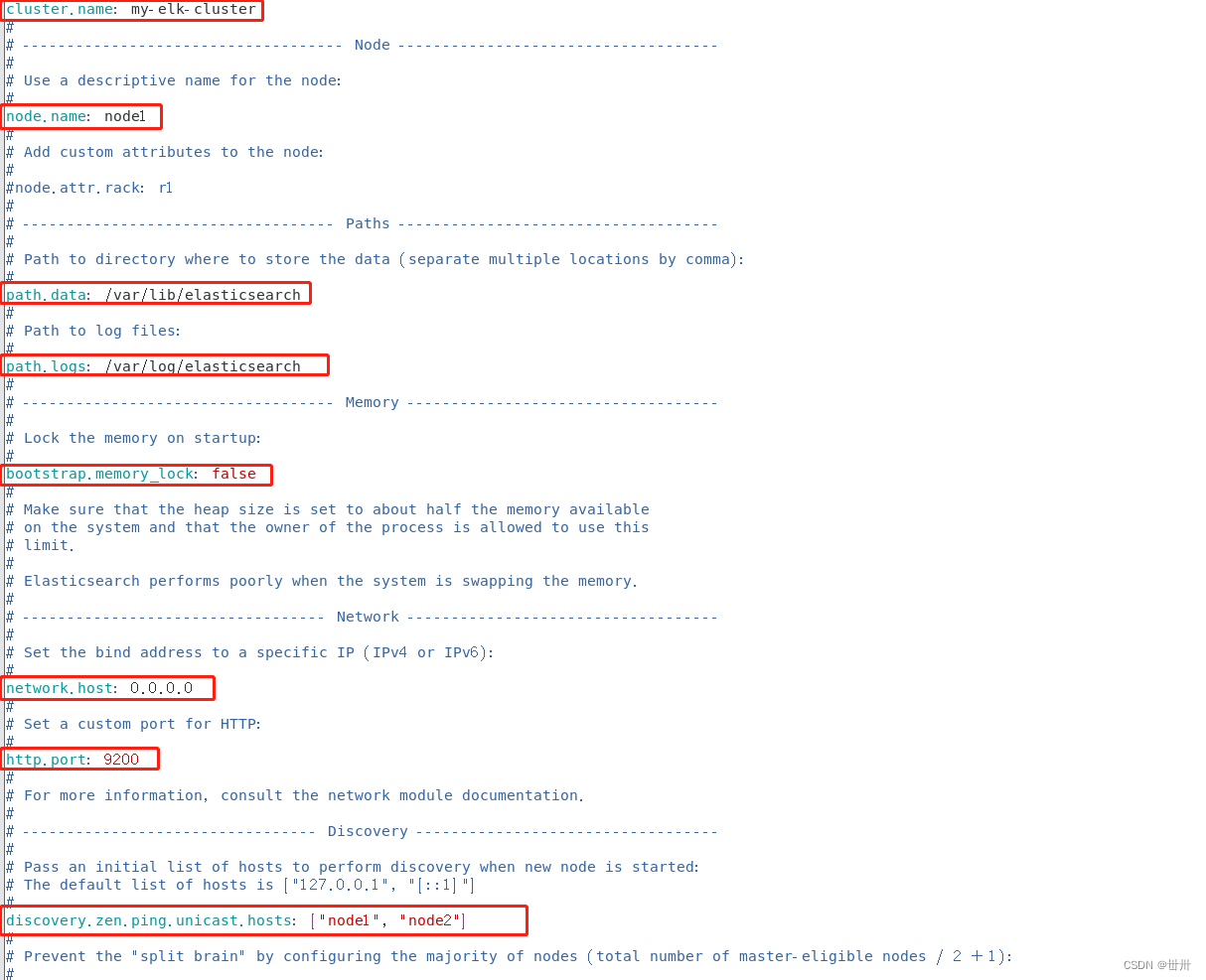
cluster.name:my-elk-cluster //集群名称
node.name:node1 //节点名字
path.data:/var/lib/elasticsearch //数据存放路径
path.logs: /var/log/elasticsearch/ //日志存放路径
bootstrap.memory_lock:false //在启动的时候不锁定内存
network.host:0.0.0.0 //提供服务绑定的IP地址,0.0.0.0代表所有地址
http.port:9200 //侦听端口为9200
discovery.zen.ping.unicast.hosts:【"node1","node2"】 //群集发现通过单播实现
node2:
vim /etc/elasticsearch/elasticsearch.yml
cluster.name:my-elk-cluster //集群名称
node.name:node2 //节点名字
path.data:/var/lib/elasticsearch //数据存放路径
path.logs: /var/log/elasticsearch/ //日志存放路径
bootstrap.memory_lock:false //在启动的时候不锁定内存
network.host:0.0.0.0 //提供服务绑定的IP地址,0.0.0.0代表所有地址
http.port:9200 //侦听端口为9200
discovery.zen.ping.unicast.hosts:【"node1","node2"】 //群集发现通过单播实现
启动elasticsearch服务
node1和node2
systemctl start elasticsearch

查看节点信息
192.168.100.10:9200
192.168.100.11:9200


三、在node1安装elasticsearch-head插件
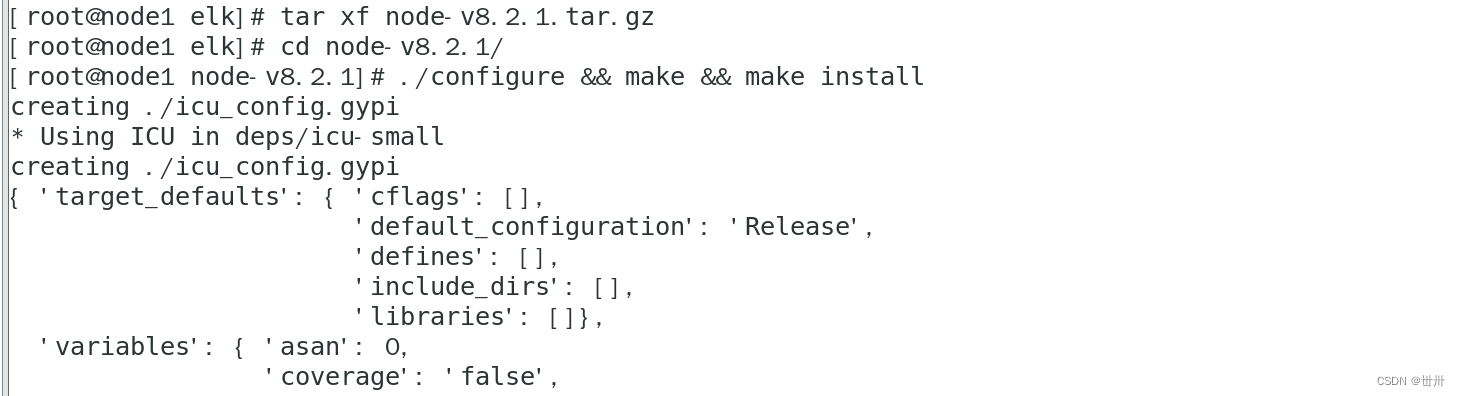
安装node
cd elk
tar xf node-v8.2.1.tar.gz
cd node-v8.2.1
./configure && make -j4&& make install
拷贝命令
cd elk
tar xf phantomjs-2.1.1-linux-x86_64.tar.bz2
cd phantomjs-2.1.1-linux-x86_64/bin
cp phantomjs /usr/local/bin

安装elasticsearch-head
cd elk
tar xf elasticsearch-head.tar.gz
cd elasticsearch-head
npm install(npm 由node包生成)

修改elasticsearch配置文件
vim /etc/elasticsearch/elasticsearch.yml
#action.destructive_requires_name:true
http.cors.enabled: true //开启跨域访问支持,默认为false
http.cors.allow-origin:"*" //跨域访问允许的域名地址
重启服务: systemctl restart elasticsearch

启动elasticsearch-head
cd /root/elk/elasticsearch-head
npm run start &
查看监听: netstat -anput | grep :9100

访问: 192.168.100.10:9100
测试
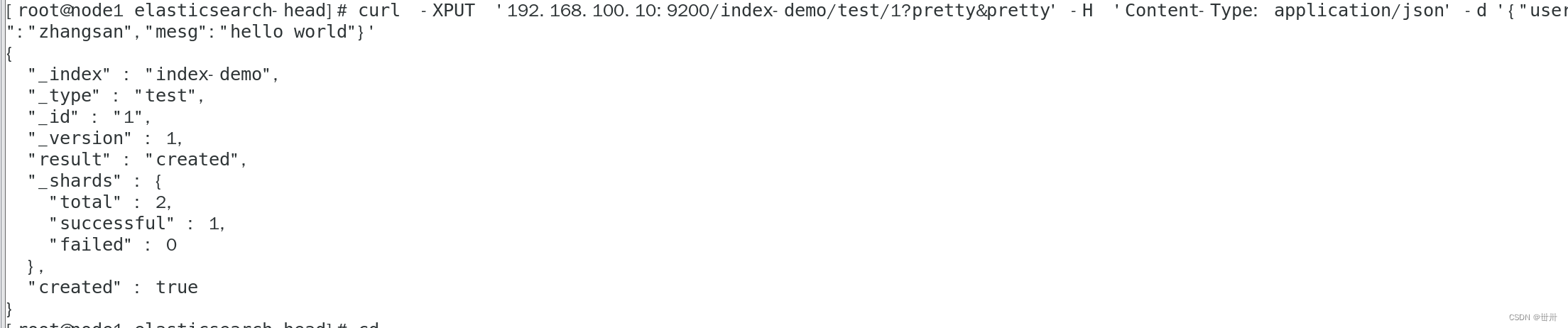
在node1的终端中输入:
curl -XPUT 'localhost:9200/index-demo/test/1?pretty&pretty' -H 'Content-Type: application/json' -d '{"user":"zhangsan","mesg":"hello world"}'
刷新浏览器可以看到对应信息即可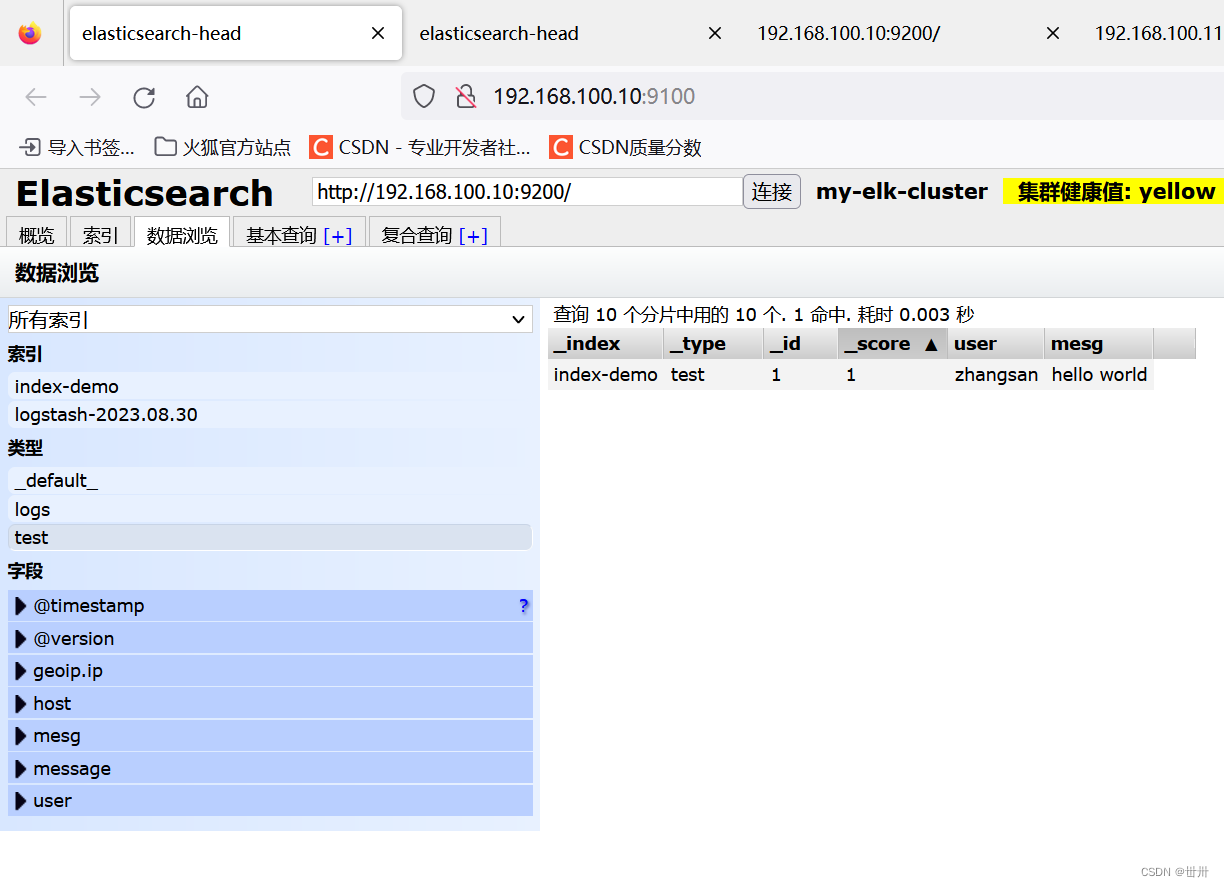
四、node1服务器安装logstash
cd elk
rpm -ivh logstash-5.5.1.rpm
systemctl start logstash.service
In -s /usr/share/logstash/bin/logstash /usr/local/bin/

测试1: 标准输入与输出
logstash -e 'input{ stdin{} }output { stdout{} }'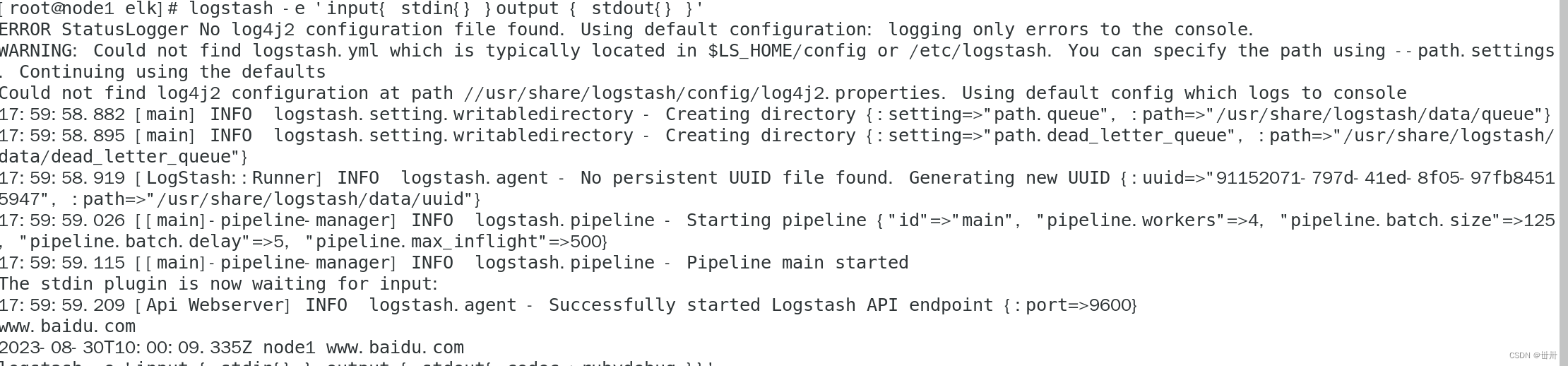
测试2: 使用rubydebug解码
logstash -e 'input { stdin{} } output { stdout{ codec=>rubydebug }}'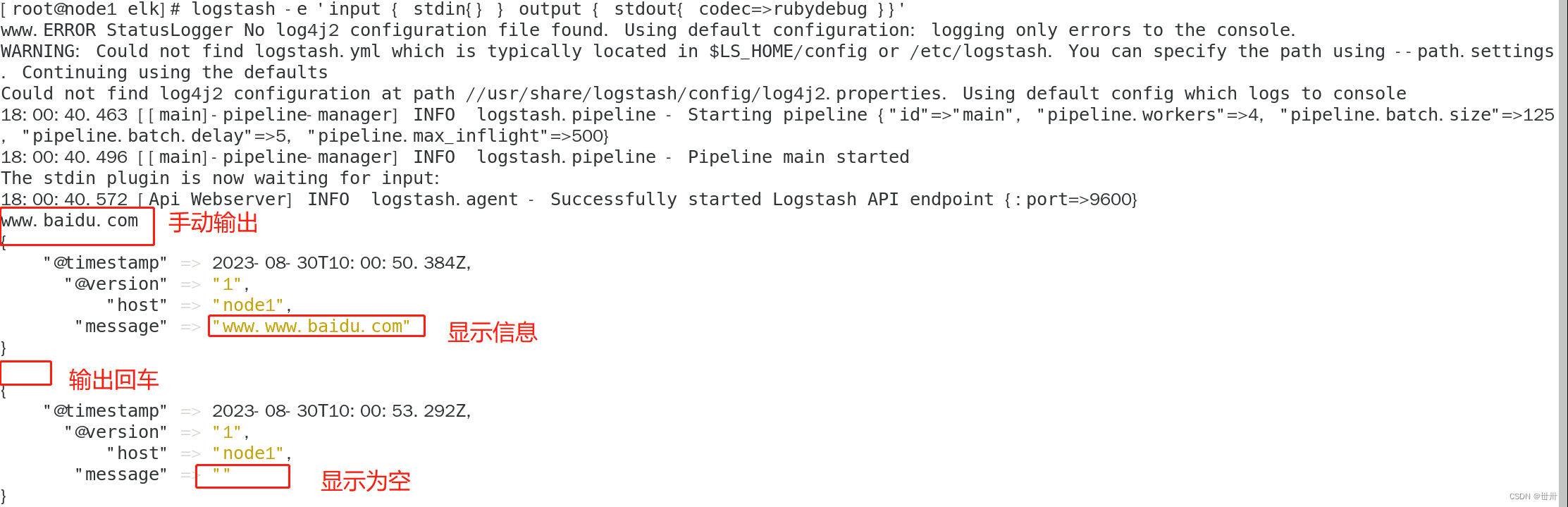
测试3:输出到elasticsearch
logstash -e 'input { stdin{} } output { elasticsearch{ hosts=>["192.168.1.1:9200"]} }'
查看结果:192.168.100.10:9100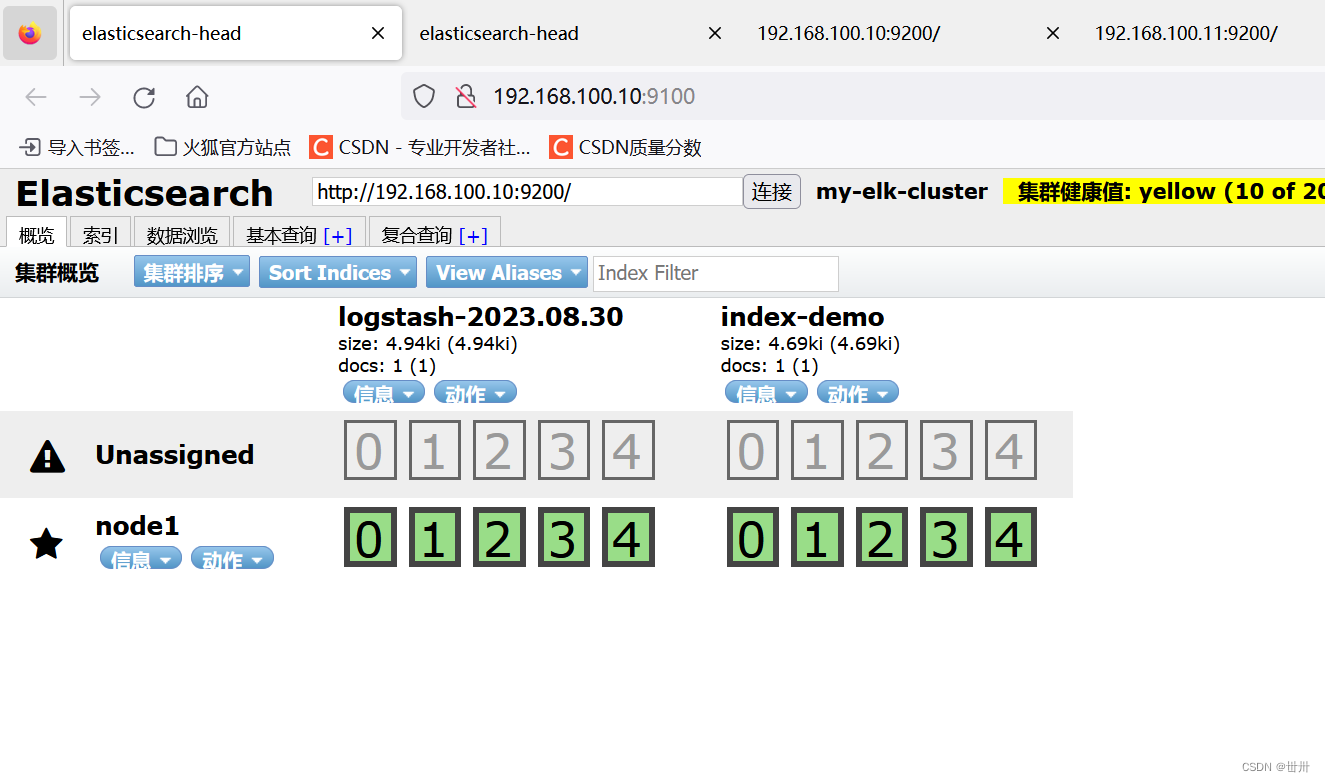
五、logstash日志收集文件格式(默认存储在/etc/logstash/conf.d)
Logstash配置文件基本由三部分组成:input、output以及 filter(根据需要)。标准的配置文件格式如下:
input (...) 输入
filter {...} 过滤
output {...} 输出
在每个部分中,也可以指定多个访问方式。例如,若要指定两个日志来源文件,则格式如下:
input {
file{path =>"/var/log/messages" type =>"syslog"}
file { path =>"/var/log/apache/access.log" type =>"apache"}
}
通过logstash收集系统信息日志
chmod o+r /var/log/messages
vim /etc/logstash/conf.d/system.conf
input {
file{
path =>"/var/log/messages"
type => "system"
start_position => "beginning"
}
}
output {
elasticsearch{
hosts =>["192.168.100.10:9200"]
index => "system-%{+YYYY.MM.dd}"
}
}
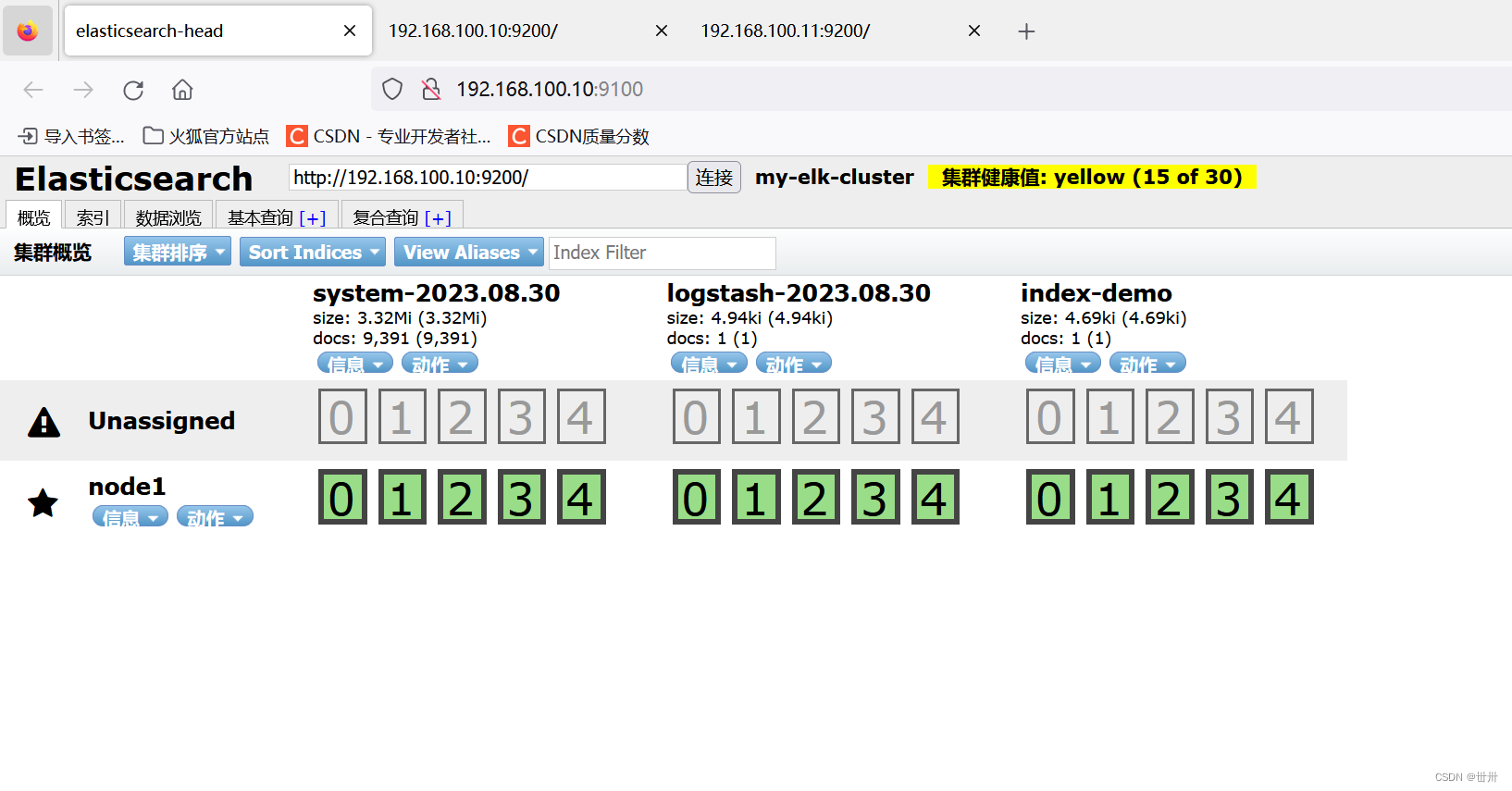
重启日志服务: systemctl restart logstash
查看日志: 192.168.100.10:9100

六、node1节点安装kibana
cd elk
rpm -ivh kibana-5.5.1-x86_64.rpm
配置kibana
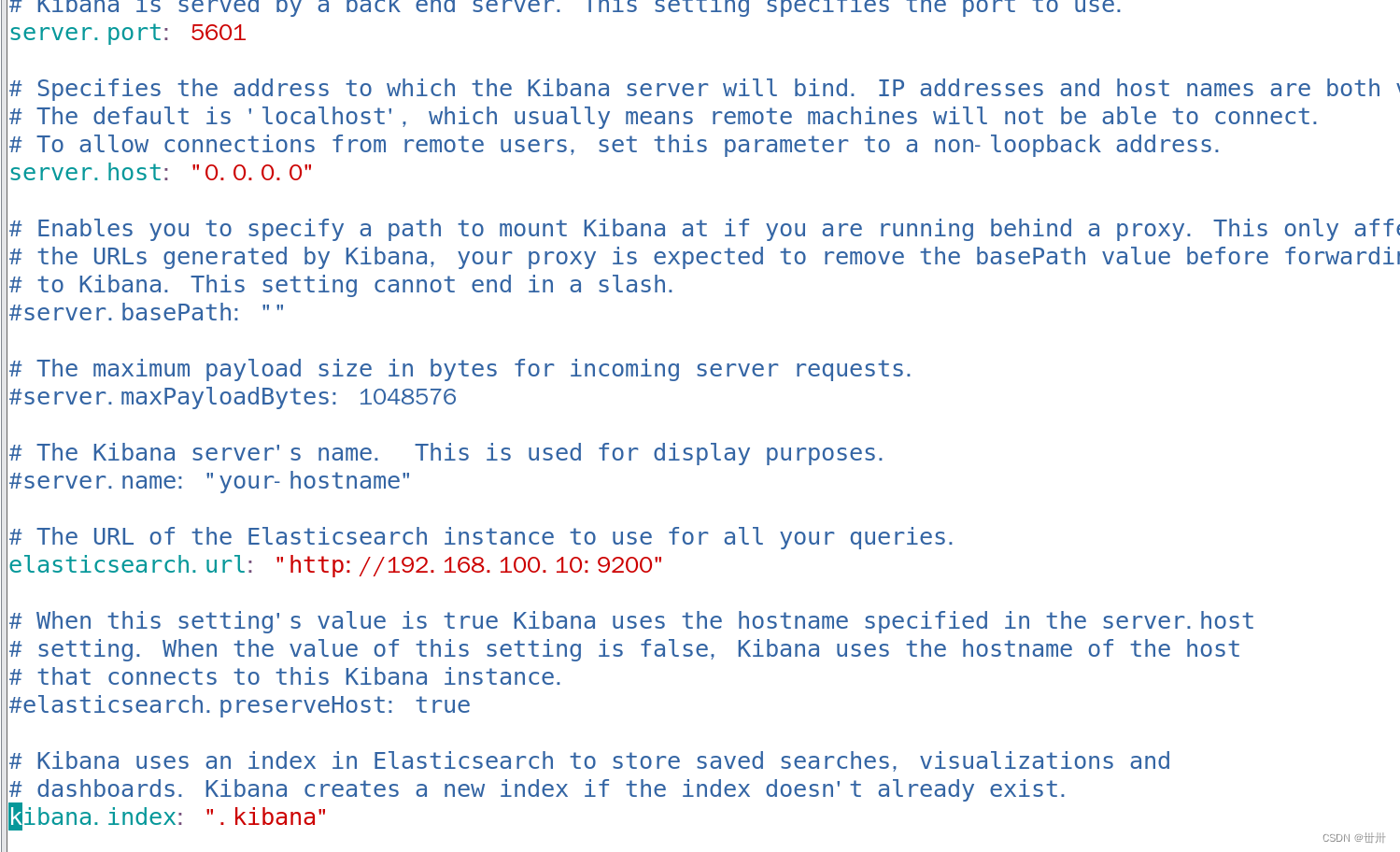
vim /etc/kibana/kibana.yml
server.port:5601 //Kibana打开的端口
server.host:"0.0.0.0" //Kibana侦听的地址
elasticsearch.url: "http://192.168.8.134:9200"
//和Elasticsearch 建立连接
kibana.index:".kibana" //在Elasticsearch中添加.kibana索引
启动kibana
systemctl start kibana

访问kibana : 192.168.100.10:5601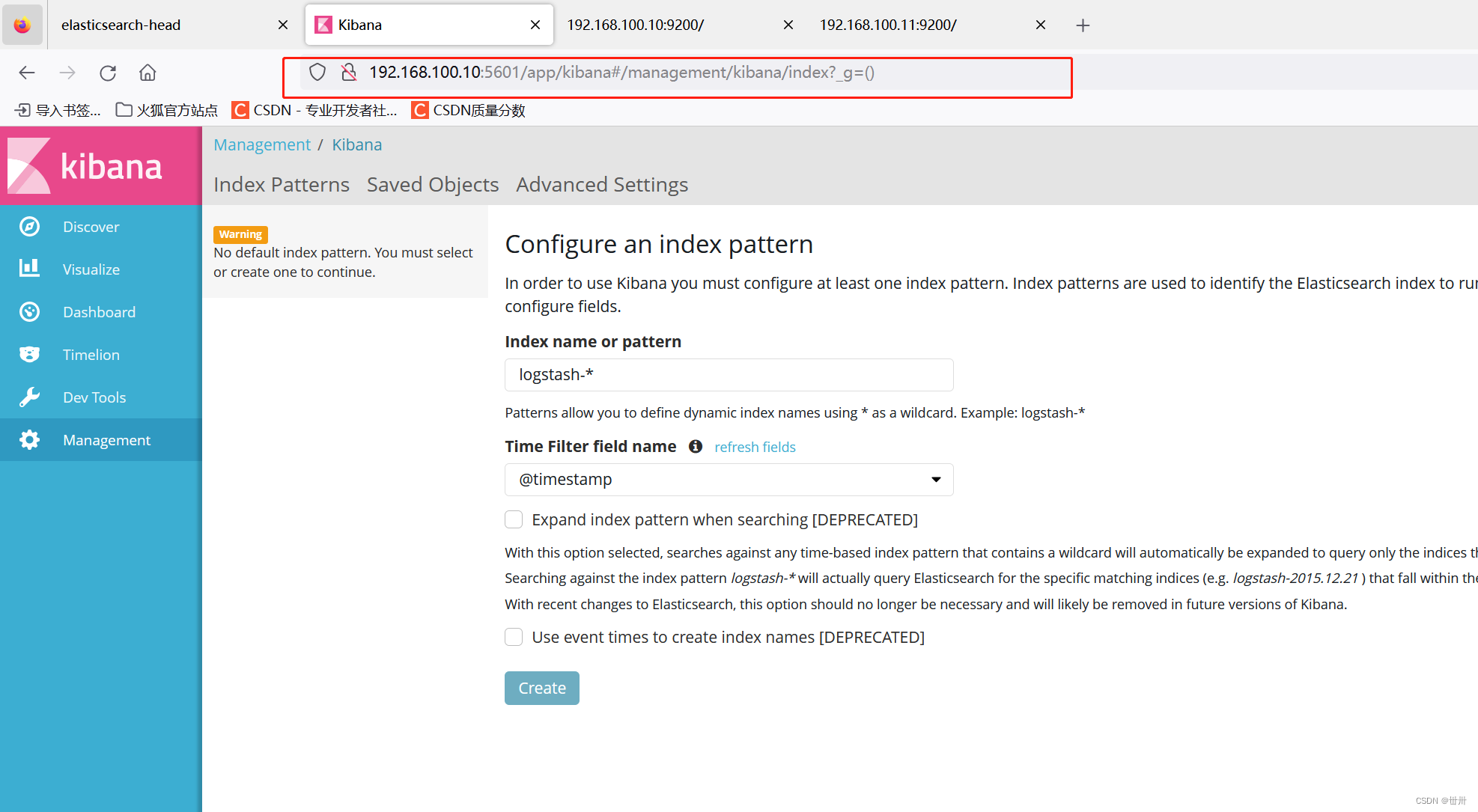
首次访问需要添加索引,我们添加前面已经添加过的索引:system-*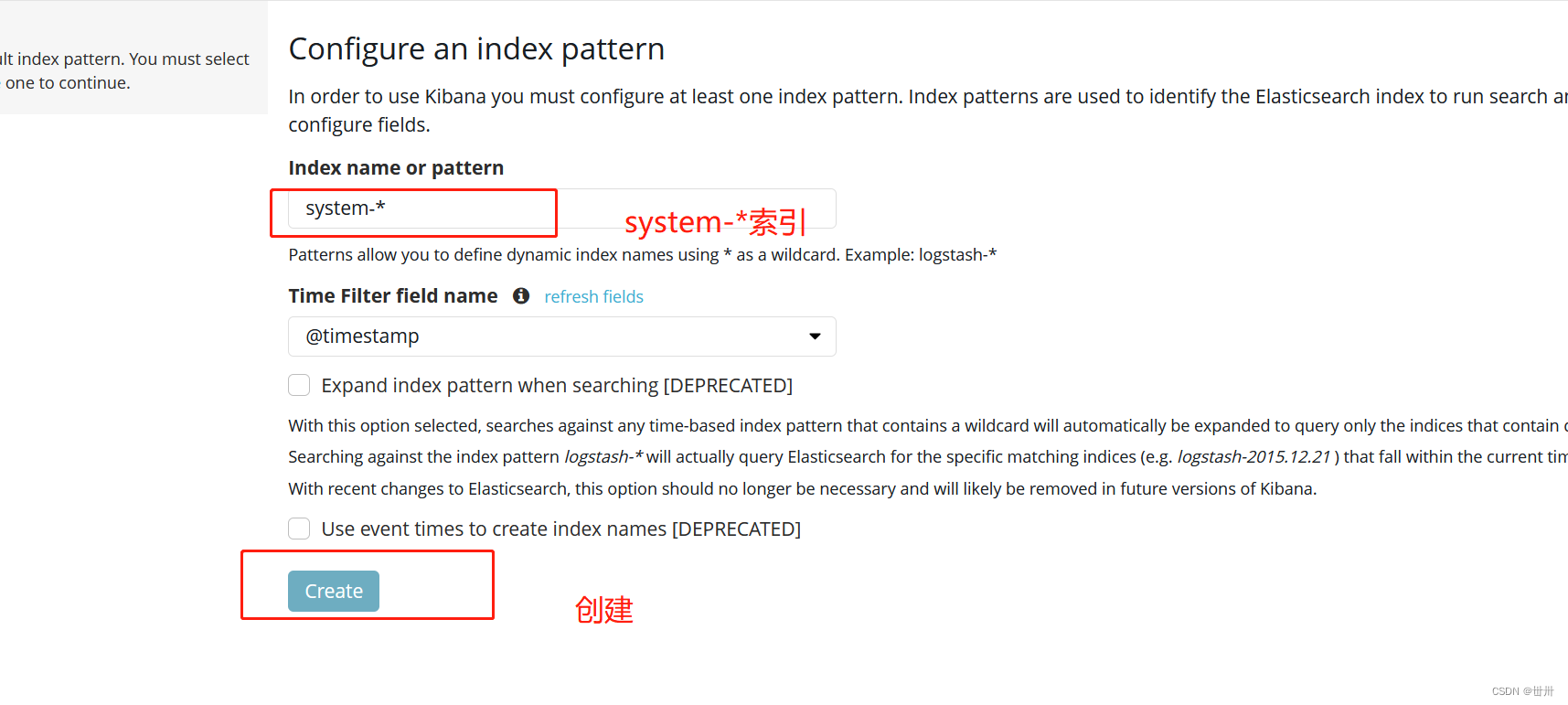
相关文章:
linux————ELK(日志收集系统集群)
目录 一、为什么要使用ELK 二、ELK作用 二、组件 一、elasticsearch 特点 二、logstash 工作过程 INPUT(输入) FILETER(过滤) OUTPUTS(输出) 三、kibana 三、架构类型 ELK ELKK ELFK ELFKK EFK 四、构建ELk集群…...

Leetcode213 打劫家舍2
思路:既然头尾不能同时取,那就分别算只取头或者只取尾,不考虑特殊情况的话是一个简单的动态规划 class Solution:def rob(self, nums: list[int]) -> int:if len(nums) < 3:return max(nums)max_sum [nums[0], max(nums[1], nums[0])…...
Redis全局命令
"那篝火在银河尽头~" Redis-cli命令启动 现如今,我们已经启动了Redis服务,下⾯将介绍如何使⽤redis-cli连接、操作Redis服务。客户端与服务端交互的方式有两种: ● 第⼀种是交互式⽅式: 后续所有的操作都是通过交互式的⽅式实现,…...

Xml转json
利用fastjson转换,pom文件依赖: <dependency><groupId>dom4j</groupId><artifactId>dom4j</artifactId><version>1.6.1</version> </dependency> <dependency><groupId>com.alibaba</groupId><artifa…...
Spring框架知识点汇总
01.Spring框架的基本理解 关键字:核心思想IOC/AOP,作用(解耦,简化),简单描述框架组成; Spring框架是一款轻量级的开发框架,核心思想是IOC(反转控制)和AOP&a…...

JavaScript Web APIs - 06 正则表达式
Web APIs - 06 文章目录 Web APIs - 06正则表达式正则基本使用元字符边界符量词范围字符类 替换和修饰符正则插件change 事件判断是否有类 目标:能够利用正则表达式完成小兔鲜注册页面的表单验证,具备常见的表单验证能力 正则表达式综合案例阶段案例 正…...
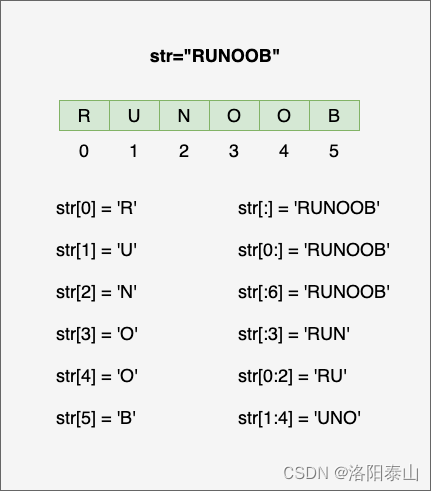
Python入门教程 | Python3 字符串
字符串是 Python 中最常用的数据类型。我们可以使用引号( ’ 或 " )来创建字符串。 创建字符串很简单,只要为变量分配一个值即可。例如: var1 Hello World! var2 "Tarzan"Python 访问字符串中的值 Python 不支持单字符类型ÿ…...
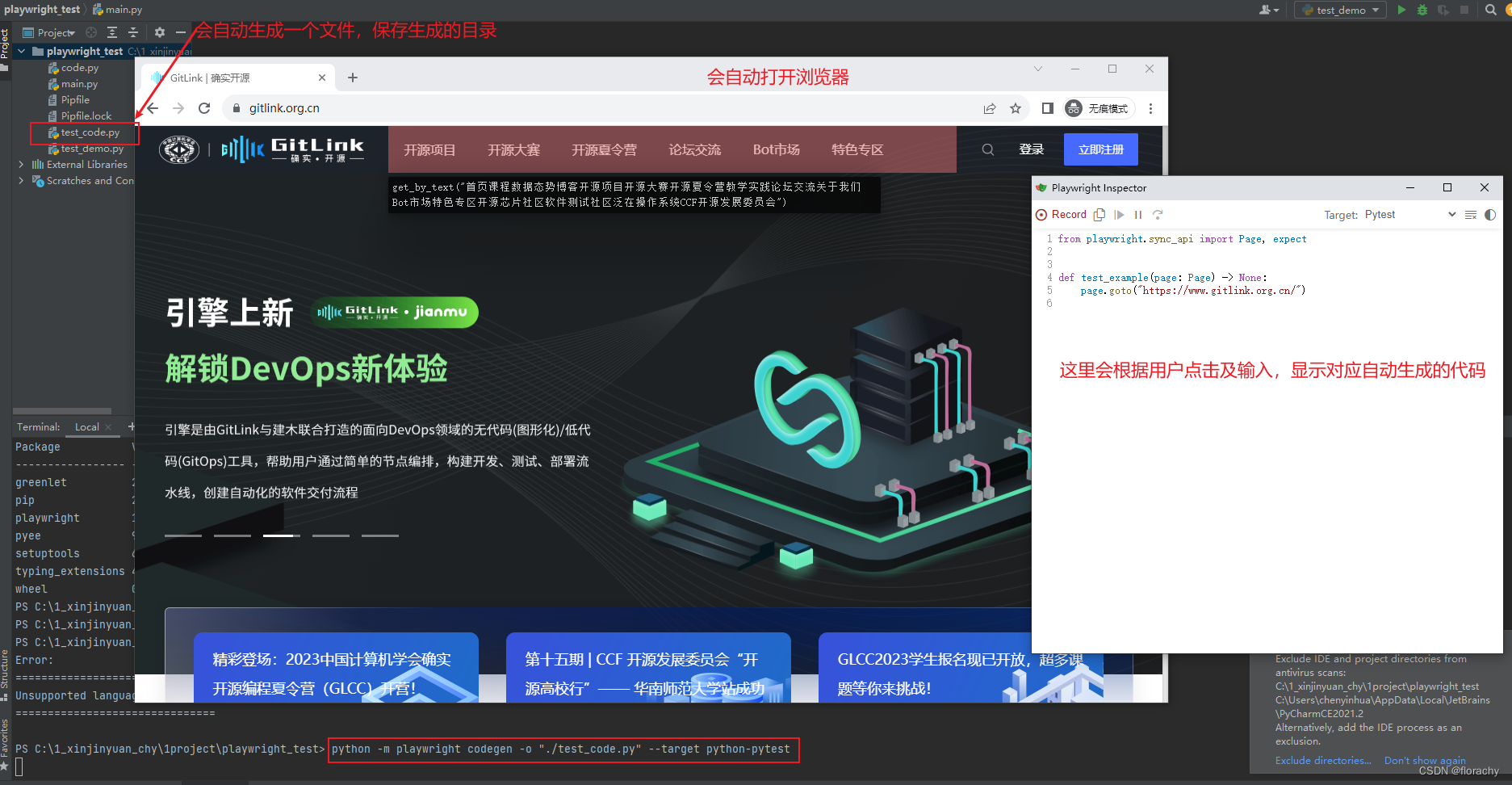
Playwright for Python:安装及初步使用
文章目录 一、Playwright介绍1.1 简单介绍1.2 支持的平台1.3 支持语言1.4 官方文档(python) 二、开始2.1 安装要求2.2 安装2.3 脚本录制2.4 代码示例 一、Playwright介绍 1.1 简单介绍 Playwright是微软推出来的一款自动化测试工具,是专门为…...
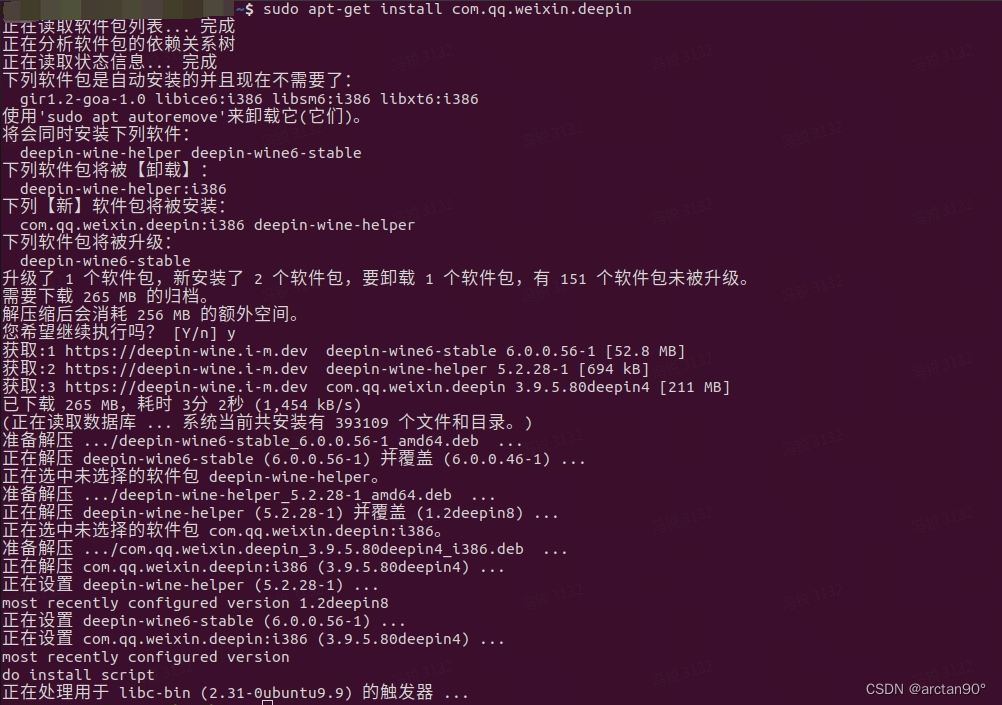
Ubuntu 20.04.5 怎么安装微信
这是我的ubutun版本号 在这个系统装桌面版微信很多功能不健全。搜索了很多方法,这个算是不错的一个法子。 1.添加仓库 首次使用时,你需要运行如下一条命令将移植仓库添加到系统中。 wget -O- https://deepin-wine.i-m.dev/setup.sh | sh 2.应用安装 …...

HummerRisk V1.4.0发布
大家好,HummerRisk 1.4.0和大家见面了,在这个版本中我们变更了多云检测的底层逻辑,增加了每次检测的project概念,更好的去支持检测历史和检索需要,增加阿里云最佳实践中资源监控检测规则,增加资源态势中的细…...

C语言每日一练----Day(12)
本专栏为c语言练习专栏,适合刚刚学完c语言的初学者。本专栏每天会不定时更新,通过每天练习,进一步对c语言的重难点知识进行更深入的学习。 今日练习题关键字:最大连续1的个数 完全数计算 💓博主csdn个人主页࿱…...
)
【Tkinter系列11/15】小部件 (Text)
24. 小部件Text 文本小部件是一种更通用的方法 处理比小部件多行文本。文本小部件几乎是一个完整的文本 窗口中的编辑器:Label 您可以将文本与不同的字体、颜色和 背景。 您可以用文本穿插嵌入的图像。一 图像被视为单个字符。请参见第 24.3 节 “文本小部件图像”…...
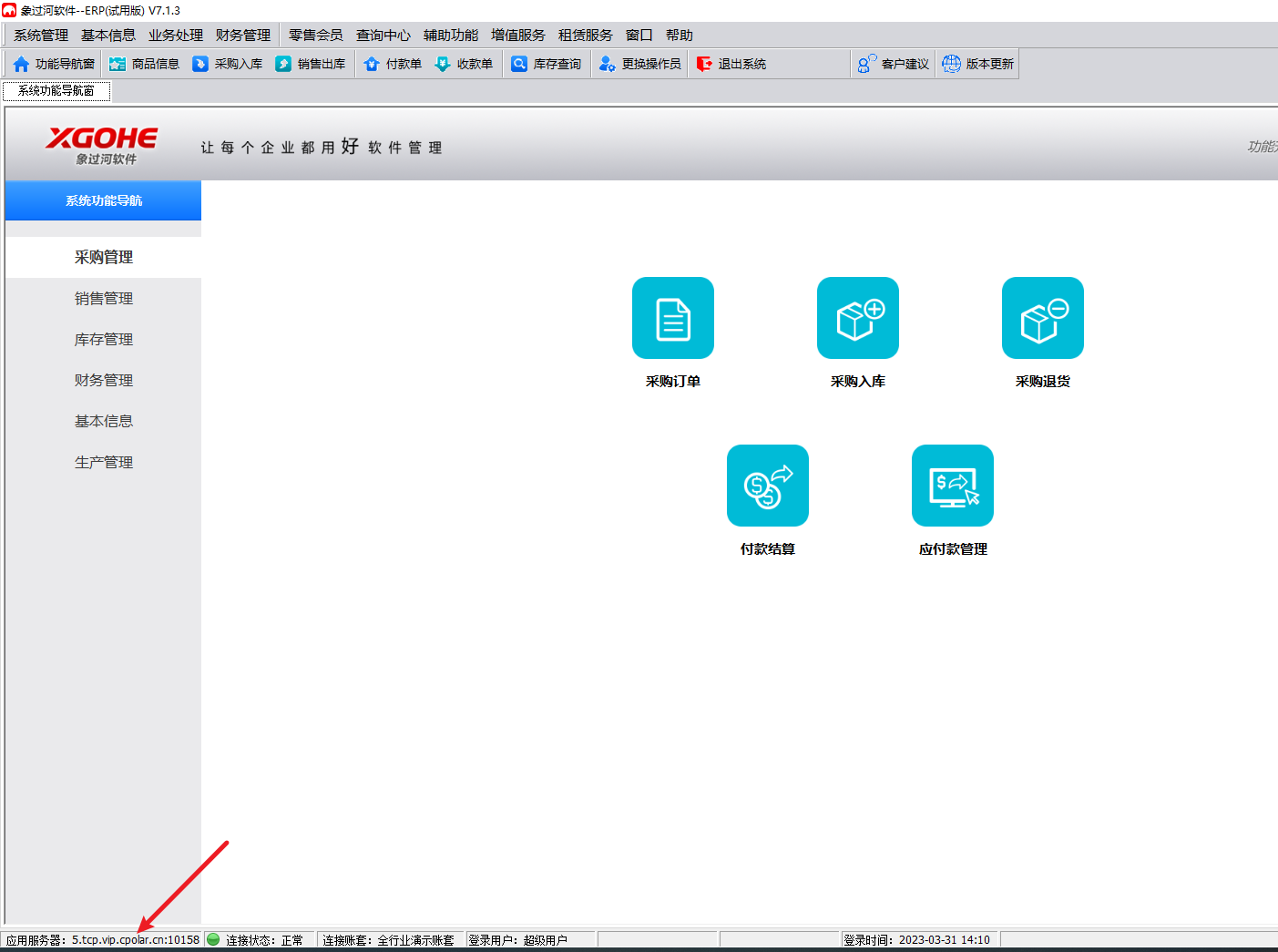
通过「内网穿透」技术,实现出差期间远程访问企业局域网中的象过河ERP系统
文章目录 概述1.查看象过河服务端端口2.内网穿透3. 异地公网连接4. 固定公网地址4.1 保留一个固定TCP地址4.2 配置固定TCP地址 5. 使用固定地址连接 概述 ERP系统对于企业来说重要性不言而喻,不管是财务、生产、销售还是采购,都需要用到ERP系统来协助。…...
是什么关系?)
ChatGPT和大型语言模型(LLM)是什么关系?
参考:https://zhuanlan.zhihu.com/p/615203178 # ChatGPT和大型语言模型(LLM)是什么关系? 参考:https://zhuanlan.zhihu.com/p/622518771 # 什么是LLM大语言模型?Large Language Model,从量变到质变 https://zhuanla…...

list(介绍与实现)
目录 1. list的介绍及使用 1.1 list的介绍 1.2 list的使用 1.2.1 list的构造 1.2.2 list iterator的使用 1.2.3 list capacity 1.2.4 list element access 1.2.5 list modififiers 1.2.6 list的迭代器失效 2. list的模拟实现 2.1 模拟实现list 2.2 list的反向迭代器 1.…...
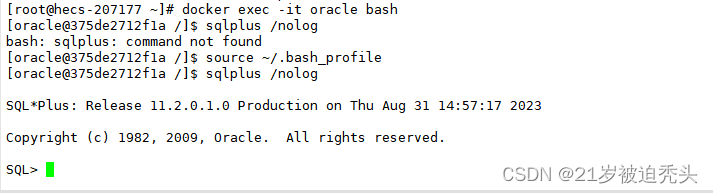
Centos7 使用docker安装oracle数据库(超详细)
在linux中采用解压安装包的方式安装oracle非常麻烦,并且稍微不注意就会出现问题,因此采用docker来安装,下面为详细的步骤: 若不知道是否安装docker可查看这篇文章:docker安装 1、拉取oracle镜像 docker pull registr…...

昨天面试的时候被提问到的问题集合(答案)
1、vue的双向绑定原理是什么?里面的关键点在哪里? Vue的双向绑定原理是基于Object.defineProperty或者Proxy来实现的,其关键点在于数据劫持,即对数据的读取和修改进行拦截,在数据发生变化时自动更新视图 2、实现水平垂…...

PYTHON用户流失数据挖掘:建立逻辑回归、XGBOOST、随机森林、决策树、支持向量机、朴素贝叶斯和KMEANS聚类用户画像...
原文链接:http://tecdat.cn/?p24346 在今天产品高度同质化的品牌营销阶段,企业与企业之间的竞争集中地体现在对客户的争夺上(点击文末“阅读原文”获取完整代码数据)。 “用户就是上帝”促使众多的企业不惜代价去争夺尽可能多的客…...

详解IP协议
在介绍IP协议之前,先抛出一个概念:IP地址的作用——定位主机,具有将数据从主机A跨网络传输到主机B的能力,有了TCP提供的策略,例如滑动窗口、拥塞控制等,IP去执行它,所以我们通常叫TCP/IP协议&am…...

Stream流式编程用例
Stream流式编程用例: filter, map, flatmap, limit, skip, sort, distinct, collect, reduce, summary statistics public class StreamTest {public static void main(String[] args) {//filterStream<Integer> stream Stream.of(1, 2, 3, 4, 5);Stream&l…...

Agent Runtime 正在 commoditize:从 session-as-event-log 看 AI 基础设施分层
1. 这不是新赛道,而是 runtime 层的“操作系统时刻”正在重演你打开手机看到新闻标题《Anthropic Just Shipped the Layer That’s Already Going to Zero》,第一反应可能是:又一个大模型公司搞出了什么黑科技?但如果你真花十分钟…...

CANN/PyPTO hypot函数API文档
pypto.hypot 【免费下载链接】pypto PyPTO(发音: pai p-t-o):Parallel Tensor/Tile Operation编程范式。 项目地址: https://gitcode.com/cann/pypto 产品支持情况 产品是否支持Ascend 950PR/Ascend 950DT√Atlas A3 训练系列产品/At…...

Sub-Zero字幕格式转换:从SRT到VTT的完整处理流程
Sub-Zero字幕格式转换:从SRT到VTT的完整处理流程 【免费下载链接】Sub-Zero.bundle Subtitles for Plex, as good you would expect them to be. 项目地址: https://gitcode.com/gh_mirrors/su/Sub-Zero.bundle Sub-Zero是一款为Plex媒体服务器提供高质量字幕…...

Spec-Kit + Superpowers 实战:Go语言博客论坛系统的规范驱动开发
从“凭感觉写代码”到“按规范做工程”,一套完整的AI驱动开发方法论落地 一、引言:AI编程的“效率陷阱” 2024年Google DORA报告揭示了一个令人困惑的数据:AI编码助手采用率每提升25%,软件交付稳定性反而下降7.2%。问题出在哪?研究表明,当上下文从1K Token扩展到32K Tok…...

AI犯了错没人追责,工程师犯了错丢饭碗?
芯片公司开始大量引入AI辅助设计工具,生成RTL代码、跑仿真、做时序分析。与此同时,公司对工程师的容错空间越来越小,考核越来越严,出了bug第一反应是找人背锅。这两件事放在一起,细想一下,其实挺荒诞的。AI…...

YOLOv11公共场所人群年龄目标检测数据集-280张-pedestrian-1_5
YOLOv11公共场所人群年龄目标检测数据集 📊 数据集基本信息 目标类别: [‘adult’, ‘child’, ‘elder’]中文类别:[‘成人’, ‘儿童’, ‘老人’]训练集:196 张验证集:56 张测试集:28 张总计:…...

模型加速全景图:从“瘦身”到“飞驰”的知识图谱
文章目录知识图谱:模型加速的三大维度维度一:模型自身优化(让模型更“瘦”)维度二:计算过程优化(让计算更“顺”)维度三:硬件与系统优化(让硬件更“忙”)如何…...

Onekey Steam清单下载工具:3步搞定游戏清单管理的终极指南
Onekey Steam清单下载工具:3步搞定游戏清单管理的终极指南 【免费下载链接】Onekey Onekey Steam Depot Manifest Downloader 项目地址: https://gitcode.com/gh_mirrors/one/Onekey 在Steam游戏生态中,清单文件是连接游戏客户端与服务器资源的关…...

3C产品功能太多15秒讲不完?用爆款复刻Agent做2分钟完整演示,用户看完直接下单
3C数码产品做千川素材,最容易遇到一个问题:功能很多,15秒根本讲不清。蓝牙耳机要讲降噪、音质、续航、佩戴舒适度;智能手表要讲运动监测、健康功能、续航、防水和系统兼容;小家电要讲使用场景、操作步骤、参数差异和售…...

Unity游戏配置管线实战:Luban Schema与Data分离设计
1. 为什么表格配置不是“偷懒”,而是Unity项目规模化生存的刚需在Unity游戏开发里,我见过太多团队把角色属性、武器参数、任务对话全写死在C#脚本里——刚上线时改个血量要改三处代码,策划提个新武器需求得等程序员下班后加字段,版…...