SQL高阶语句
目录
1、概念
1.1、概述
1.2、常见的MySQL高阶语句的概念:
1.3、 SQL高阶语句的作用
2、常用查询
2.1、按关键字排序
2.1.1、概述和作用
2.1.2、 (1)语法
2.1.3、模板表:ky30
编辑2.1.4、分数按降序排列
2.1.5、ORDER BY 语句
编辑2.1.6、查询学生信息先按兴趣id降序排列,相同分数的,id按升序排列
2.1.7、 区间判断及查询不重复记录
2.1.7.1、AND/OR ——且/或
2.1.7.2、嵌套/多条件
2.1.7.3、distinct 查询不重复记录 语法:
2.2、对结果进行分组
2.1、语法
2.2、结合where语句,筛选分数大于等于80的分组,计算学生个数
2.3、结合order by把计算出的学生个数按升序排列
3、限制结果条目(limit)
3.1、语法
3.2、查询所有信息显示前4行记录
3.3、从第4行开始,往后显示3行内容
3.4、 结合order by语句,按id的大小升序排列显示前三行
3.5、基础select 小的升阶 怎么输出最后三行
4、设置别名(alias ——》as)
4.1、语法
4.2、列别名设置示例:
4.3、 表的长度较长设置别名
4.4、查询info表的字段数量,以number显示
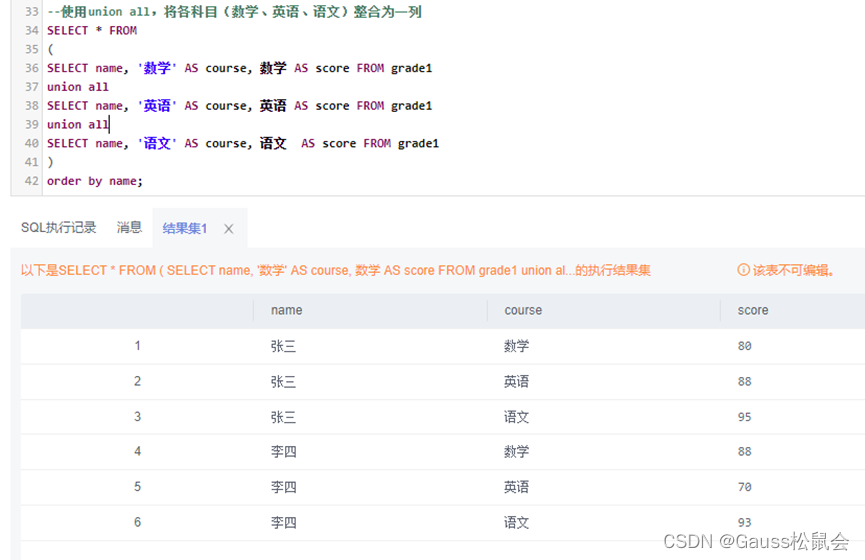
4.5、 适用场景:
4.6、创建表的连接
4.7、as 的作用:
4.8、 克隆、复制表结构
5、通配符
5.1、查询名字是c开头的记录
5.2、 查询名字里是l和i中间有两个字符的记录
5.3、 查询名字中间有l的记录
编辑 5.4、查询l后面3个字符的名字记录
6、子查询
6.1、概述
6.2、主语句与子语句
6.3、不同表/多表示例
6.4、in与not in
6.5 子查询与insert
6.6、UPDATE 语句
6.7、DELETE 也适用于子查询
6.8、EXISTS
7、MySQL视图
7.1、作用范围:
7.2、功能:
7.3、区别
7.4、联系:
7.5、实例:
7.5.1、创建ky30的视图
7.5.2、 查看视图
编辑7.5.3、查看视图与源表结构
7.5.4、修改原表数值
7.5.5、 视图与源的结构
7.6、多表创建视图
1、概念
1.1、概述
在MySQL中,高阶语句是指一些复杂、高级的查询语句或操作,用于满足更特定和复杂的数据需求。这些高阶语句通常涉及更多的SQL功能和技巧,以扩展MySQL的功能和性能。
在MySQL中,它们扩展了基本的SELECT、INSERT、UPDATE和DELETE等常见操作,提供了更强大和灵活的数据库查询、处理和管理能力
1.2、常见的MySQL高阶语句的概念:
1. 子查询(Subqueries):子查询是嵌套在其他查询中的查询语句。它可以在主查询中使用子查询的结果来动态生成查询条件,实现更复杂的数据检索和筛选。
2. 联合查询(Joins):通过连接多个相关联的表,从中检索相关的数据。MySQL支持多种连接类型(如INNER JOIN、LEFT JOIN、RIGHT JOIN等),以满足不同的数据关联需求。
3. 窗口函数(Window Functions):窗口函数是一种在查询结果集上执行聚合、排序和排名等操作的高级函数。它可以在查询结果中定义窗口,并对窗口内的数据进行计算和处理。
4. 分组集(GROUPING SETS):分组集允许在单个查询中指定多个分组依据,以得到不同维度的聚合结果。它可以简化复杂的GROUP BY操作,提供更灵活的聚合查询能力。
5. WITH语句(Common Table Expressions):WITH语句允许创建临时命名的查询块,类似于子查询,但可重复使用。它可以提高查询的可读性和可维护性,尤其在复杂查询中。
6. UNION操作符:UNION操作符用于合并多个SELECT语句的结果集,并消除重复行。UNION ALL则包含所有的查询结果,不进行去重。
7. 正则表达式(Regular Expressions):MySQL支持使用正则表达式进行模式匹配和搜索。REGEXP和RLIKE是两个常用的正则表达式操作符,用于在字符串字段中进行高级模式匹配。
8. 分页查询(Pagination):分页查询用于限制查询结果的数量,实现分页展示。使用LIMIT和OFFSET子句可以指定返回的行数和起始位置,实现分页功能。
9. 自定义函数(User-defined Functions):MySQL允许开发者创建自定义函数,扩展SQL的功能。自定义函数可以根据业务需求编写,提供更灵活和个性化的数据处理能力。
这些高阶语句为MySQL查询和操作提供了更丰富、灵活的功能和技巧。通过运用这些高级语句,可以满足复杂业务需求,提高查询性能,实现更精确和高效的数据操作和分析。
1.3、 SQL高阶语句的作用
MySQL的高阶语句提供了更强大和灵活的功能,:
1. 复杂查询:高阶语句使得进行复杂的数据查询变得更加容易。例如,使用子查询可以在查询结果的基础上动态生成查询条件,实现更精确和特定的数据检索。
2. 关联查询:通过联合查询,可以连接多个相关联的表,从中检索出满足特定条件的相关数据。这对于处理多个表之间的关系非常有用,如查询订单与顾客的关联信息。
3. 聚合操作:通过高级聚合函数和分组集,可以对查询结果进行更复杂的聚合操作。例如,在分组查询中可以计算每个组的总数、平均值等统计信息,并得到相应的汇总结果。
4. 分页查询:高阶语句中的LIMIT和OFFSET子句可用于实现分页查询。这对于在Web应用程序中展示大量数据时非常有用,可以根据需要返回指定数量的结果。
5. 数据分析:窗口函数提供了在查询结果上进行排序、排名和分析的能力。通过窗口函数,可以计算累积和、移动平均值等复杂的数据分析指标。
6. 动态SQL:动态SQL允许根据不同的运行时条件和变量构建和修改SQL语句。这在需要根据用户输入或其他动态情况来生成不同查询的场景下非常有用。
7. 存储过程和触发器:存储过程和触发器是一些预定义的SQL代码块,可以实现复杂的业务逻辑和数据处理操作。它们提供了更高级的数据库控制和自动化能力。
通过使用MySQL的高阶语句,可以更灵活地处理和管理数据,满足复杂的查询需求,并进行更高级和精细化的数据操作和分析。这些功能对于开发复杂应用、进行数据挖掘和业务分析等领域非常有帮助。
2、常用查询
增、删、改、查
对 MySQL 数据库的查询,除了基本的查询外,有时候需要对查询的结果集进行处理。 例如只取 10 条数据、对查询结果进行排序或分组等等
2.1、按关键字排序
2.1.1、概述和作用
使用 SELECT 语句可以将需要的数据从 MySQL 数据库中查询出来,如果对查询的结果进行排序,可以使用 ORDER BY 语句来对语句实现排序,并最终将排序后的结果返回给用户。这个语句的排序不光可以针对某一个字段,也可以针对多个字段
先创建好数据
2.1.2、 (1)语法
SELECT column1, column2, ... FROM table_name ORDER BY column1, column2, ... ASC与DESC区别
ASC 是按照升序进行排序的,是默认的排序方式,即 ASC 可以省略。SELECT 语句中如果没有指定具体的排序方式,则默认按 ASC方式进行排序。 DESC 是按降序方式进 行排列。当然 ORDER BY 前面也可以使用 WHERE 子句对查询结果进一步过滤。
2.1.3、模板表:ky30
数据库有一张ky30表,记录了学生的id,姓名,分数,地址和爱好
Databascreate table ky30(id int(5) not null,name varchar(20) primary key not null,score decimal(5,2),address varchar(20),hobbid int(5));mysql> insert into ky30 values(1,'liuyi',80,'beijing',2);
mysql> insert into ky30 values(2,'wangwu',90,'shenzhen',2);
mysql> insert into ky30 values(3,'lisi',60,'shanghai',4);
mysql> insert into ky30 values(4,'tianqi',99,'hangzhou',5);
Query OK, 1 row affected (0.00 sec)
mysql> insert into ky29 values(5,'jiaoshou',98,'laowo',3);mysql> insert into ky30 values(5,'jiaoshou',98,'laowo',3);
Query OK, 1 row affected (0.01 sec)mysql> insert into ky30 values(6,'hanmeimei',10,'nanjing',3);
Query OK, 1 row affected (0.01 sec)mysql> insert into ky30 values(7,'lilei',11,'nanjing',5);
Query OK, 1 row affected (0.01 sec)
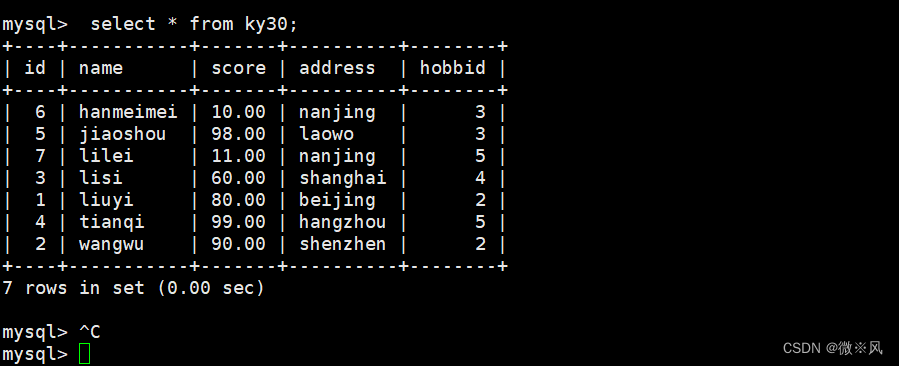
按分数排序,默认不指定是升序排列
mysql> select id,name,score from ky30 order by score; 2.1.4、分数按降序排列
2.1.4、分数按降序排列
mysql> select id,name,score from ky30 order by score desc;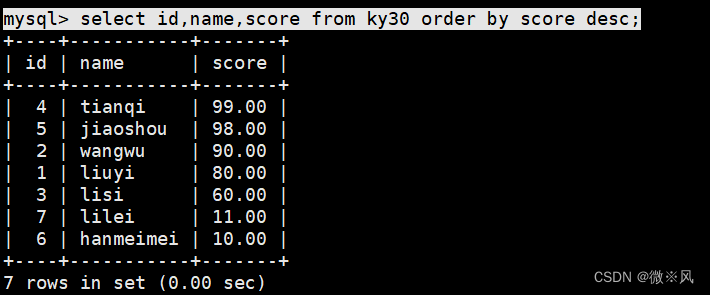
order by还可以结合where进行条件过滤,筛选地址是杭州的学生按分数降序排列
mysql> select name,score from ky30 where address='hangzhou'order by score desc;

2.1.5、ORDER BY 语句
可以使用多个字段来进行排序,当排序的第一个字段相同的记录有多条的情况下,这些多条的记录再按照第二个字段进行排序,ORDER BY 后面跟多个字段时,字段之间使用英文逗号隔开,优先级是按先后顺序而定
但order by 之后的第一个参数只有在出现相同值时,第二个字段才有意义
mysql> select id,name,hobbid from ky30 order by hobbid desc,id desc;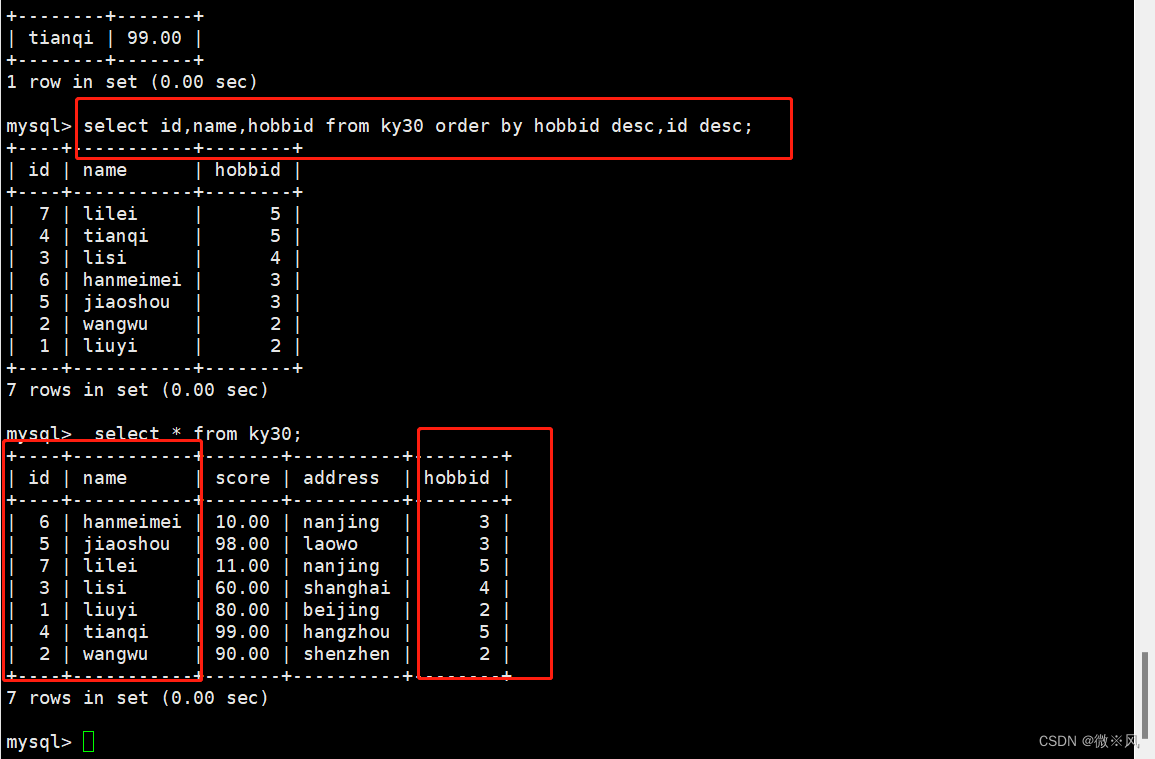 2.1.6、查询学生信息先按兴趣id降序排列,相同分数的,id按升序排列
2.1.6、查询学生信息先按兴趣id降序排列,相同分数的,id按升序排列
mysql> select id,name,hobbid from ky30 order by hobbid desc,id;
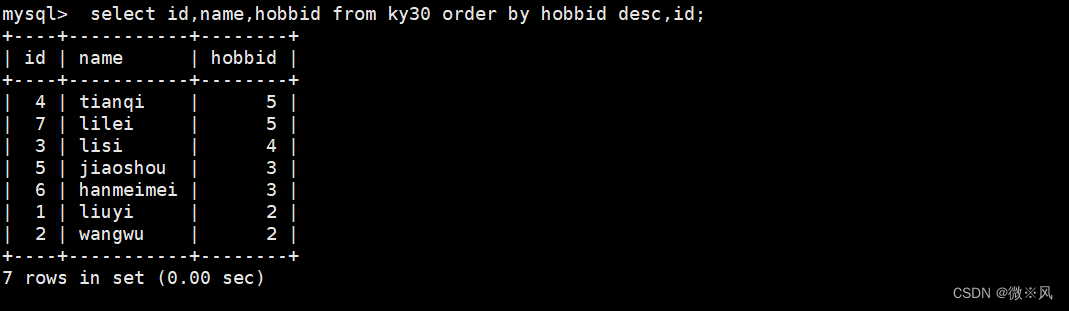
2.1.7、 区间判断及查询不重复记录
2.1.7.1、AND/OR ——且/或
mysql> select * from ky30 where score >70 and score <=90;
mysql> select * from ky30 where score >70 or score <=90;2.1.7.2、嵌套/多条件
mysql> select * from ky30 where score >70 or (score >75 and score <90);

2.1.7.3、distinct 查询不重复记录 语法:
mysql> select distinct hobbid from ky30;
2.2、对结果进行分组
通过 SQL 查询出来的结果,还可以对其进行分组,使用 GROUP BY 语句来实现 ,GROUP BY 通常都是结合聚合函数一起使用的,常用的聚合函数包括:计数(COUNT)、 求和(SUM)、求平均数(AVG)、最大值(MAX)、最小值(MIN),GROUP BY 分组的时候可以按一个或多个字段对结果进行分组处理。
2.1、语法
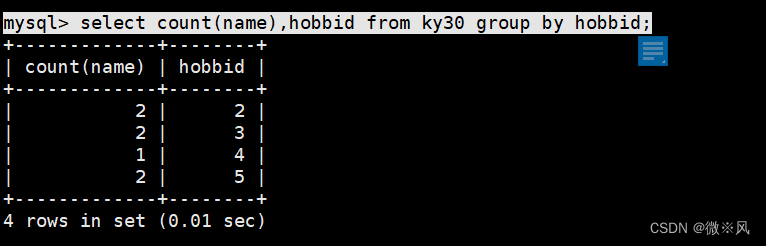
SELECT column_name, aggregate_function(column_name)FROM table_name WHERE column_name operator value GROUP BY column_name;按hobbid相同的分组,计算相同分数的学生个数(基于name个数进行计数)
mysql> select count(name),hobbid from ky30 group by hobbid;
2.2、结合where语句,筛选分数大于等于80的分组,计算学生个数
mysql> select count(name),hobbid from ky30 where score>=80 group by hobbid;
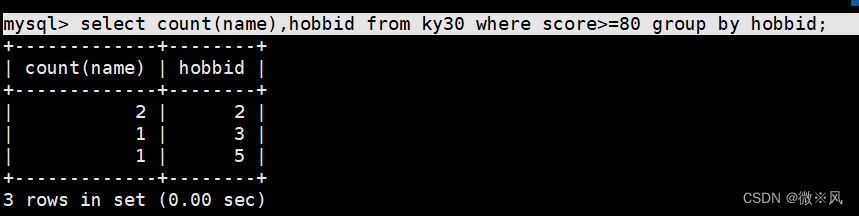
全班同学成绩表
count(name):计数
score 分数 :
score>=80 :优秀
score >=60 and score <80 :优-
2.3、结合order by把计算出的学生个数按升序排列
mysql> select count(name),score,hobbid from ky30 where score>=80 group by hobbid order by count(name) asc;

3、限制结果条目(limit)
limit 限制输出的结果记录
在使用 MySQL SELECT 语句进行查询时,结果集返回的是所有匹配的记录(行)。有时候仅 需要返回第一行或者前几行,这时候就需要用到 LIMIT 子句
3.1、语法
SELECT column1, column2, ... FROM table_name LIMIT [offset,] numberLIMIT 的第一个参数是位置偏移量(可选参数),是设置 MySQL 从哪一行开始显示。 如果不设定第一个参数,将会从表中的第一条记录开始显示。需要注意的是,第一条记录的 位置偏移量是 0,第二条是 1,以此类推。第二个参数是设置返回记录行的最大数目。
3.2、查询所有信息显示前4行记录
mysql> select * from ky30 limit 3;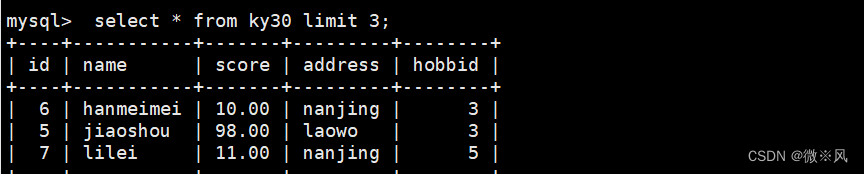
我的虚拟机通过这个命令查询的顺序就是乱的,所以有所不同(每个人情况不同)
3.3、从第4行开始,往后显示3行内容
mysql> select * from ky30 limit 3,3;
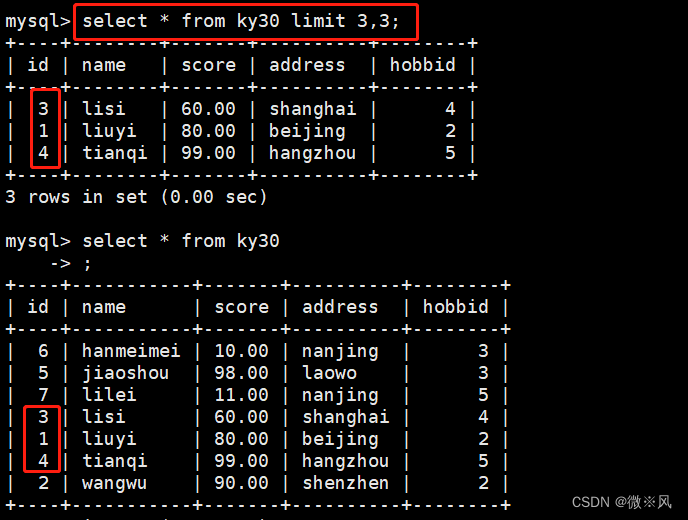
3.4、 结合order by语句,按id的大小升序排列显示前三行
mysql> select id,name from ky30 order by id limit 3;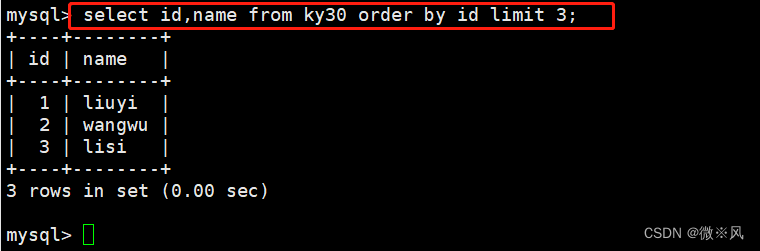
3.5、基础select 小的升阶 怎么输出最后三行
mysql> select id,name from ky30 order by id desc limit 3;

输出前三行,怎么输出 : limit 3 limit 2 您说的是前三行,limit 是做为位置偏移量的定义,他的起始是从0开始,而0表示的是字段
4、设置别名(alias ——》as)
在 MySQL 查询时,当表的名字比较长或者表内某些字段比较长时,为了方便书写或者 多次使用相同的表,可以给字段列或表设置别名。使用的时候直接使用别名,简洁明了,增强可读性
4.1、语法
对于列的别名:SELECT column_name AS alias_name FROM table_name;
对于表的别名:SELECT column_name(s) FROM table_name AS alias_name;在使用 AS 后,可以用 alias_name 代替 table_name,其中 AS 语句是可选的。AS 之后的别名,主要是为表内的列或者表提供临时的名称,在查询过程中使用,库内实际的表名 或字段名是不会被改变的
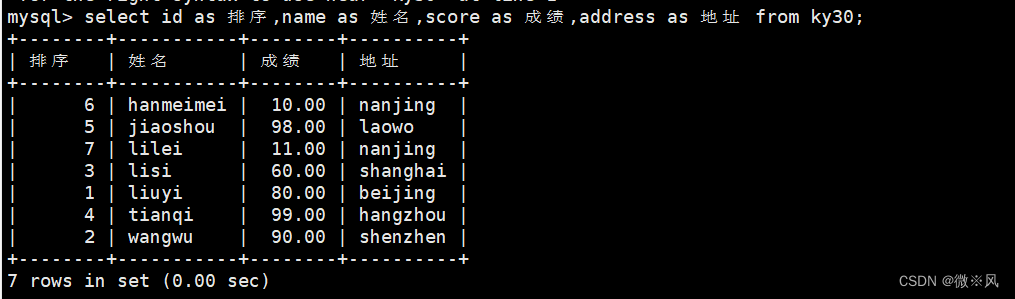
4.2、列别名设置示例:
mysql> select id as 排序,name as 姓名,score as 成绩,address as 地址 from ky30;

4.3、 表的长度较长设置别名
如果表的长度比较长,可以使用 AS 给表设置别名,在查询的过程中直接使用别名 临时设置info的别名为i
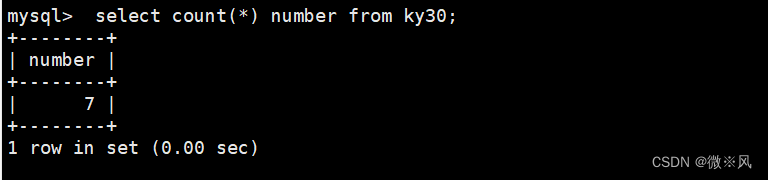
select i.name as 姓名,i.score as 成绩 from info as i;4.4、查询info表的字段数量,以number显示
mysql> select count(*) as number from ky30;
不用as也可以显示
4.5、 适用场景:
- 对复杂的表进行查询的时候,别名可以缩短查询语句的长度
- 多表相连查询的时候(通俗易懂、减短sql语句)
4.6、创建表的连接
此外,AS 还可以作为连接语句的操作符。
创建da表,将ky30表的查询记录全部插入da表
mysql> create table da as select * from ky30;
Query OK, 7 rows affected (0.02 sec)
Records: 7 Duplicates: 0 Warnings: 0mysql> select * from ky30;
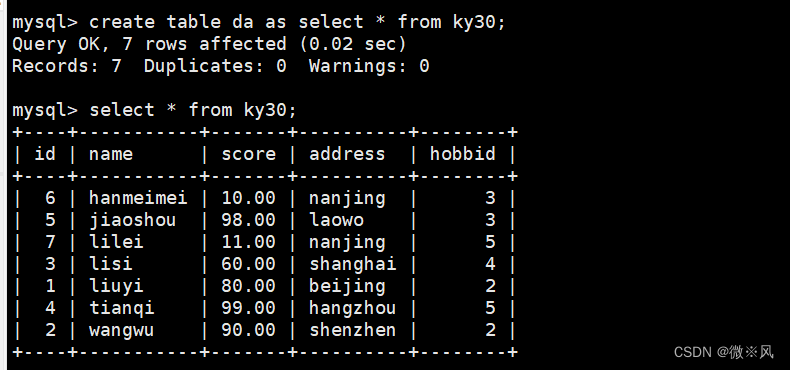
需要注意的是:连接不会复制原表的主键
4.7、as 的作用:
- 创建了一个新表t1 并定义表结构,插入表数据(与info表相同)
- 但是”约束“没有被完全”复制“过来 #但是如果原表设置了主键,那么附表的:default字段会默认设置一个0
4.8、 克隆、复制表结构
create table t1 (select * from info);
可以加入where 语句判断
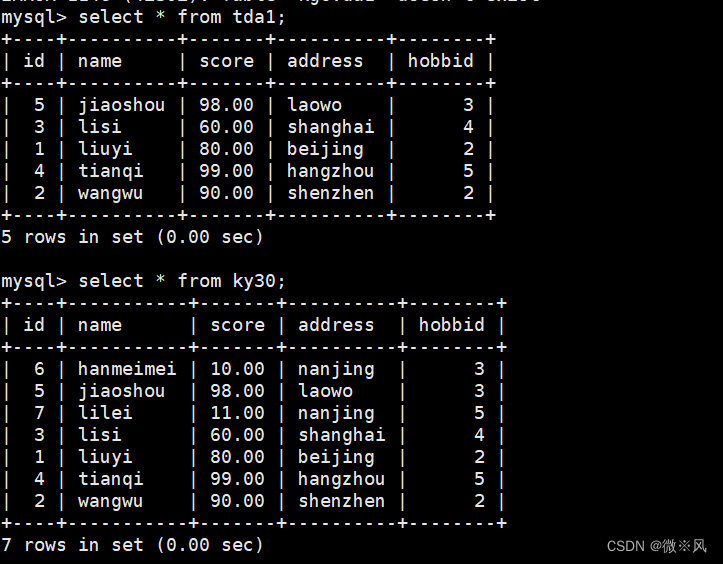
mysql> create table tda1 as mysql> * from ky30 where score >=60;
在为表设置别名时,要保证别名不能与数据库中的其他表的名称冲突。 列的别名是在结果中有显示的,而表的别名在结果中没有显示,只在执行查询时使用。
5、通配符
通配符主要用于替换字符串中的部分字符,通过部分字符的匹配将相关结果查询出来。
通常通配符都是跟 LIKE 一起使用的,并协同 WHERE 子句共同来完成查询任务。常用的通配符有两个,分别是:
%:百分号表示零个、一个或多个字符
_:下划线表示单个字符
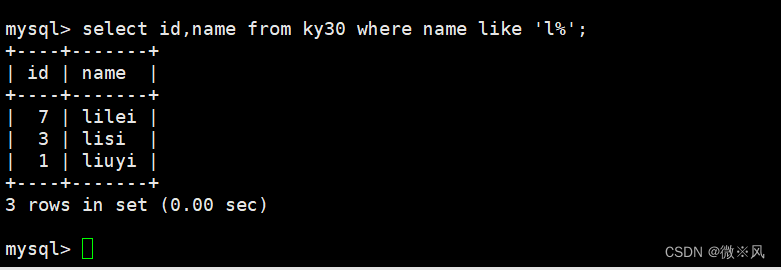
5.1、查询名字是c开头的记录
mysql> select id,name from ky30 where name like 'l%';
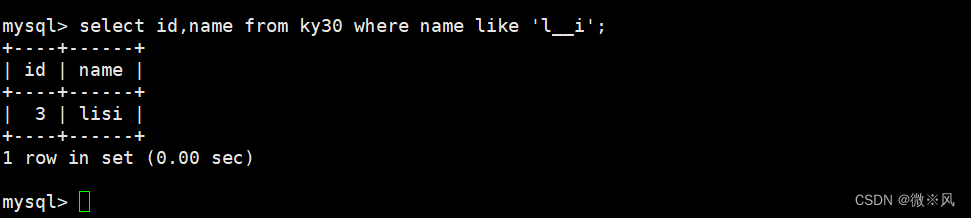
5.2、 查询名字里是l和i中间有两个字符的记录
mysql> select id,name from ky30 where name like 'l__i';
5.3、 查询名字中间有l的记录
mysql> select id,name from ky30 where name like '%l%';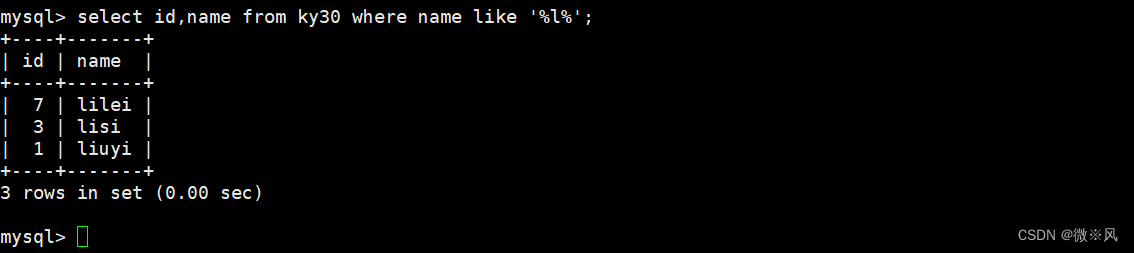 5.4、查询l后面3个字符的名字记录
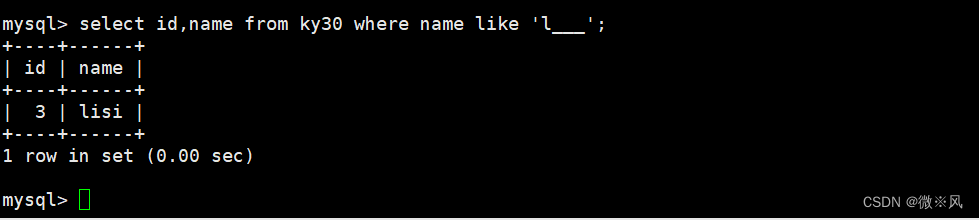
5.4、查询l后面3个字符的名字记录
mysql> select id,name from ky30 where name like 'l___';
通配符“%”和“_”不仅可以单独使用,也可以组合使用 查询名字以w开头的记录
mysql> select id,name from ky30 where name like 'w%__';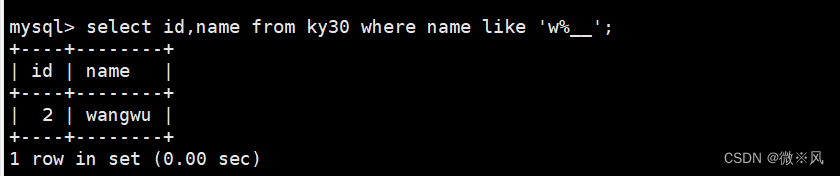
6、子查询
6.1、概述
子查询也被称作内查询或者嵌套查询,是指在一个查询语句里面还嵌套着另一个查询语 句。子查询语句是先于主查询语句被执行的,其结果作为外层的条件返回给主查询进行下一 步的查询过滤。
6.2、主语句与子语句
子语句可以与主语句所查询的表相同,也可以是不同表
mysql> select name,score from ky30 where id in (select id from ky30 where score>60);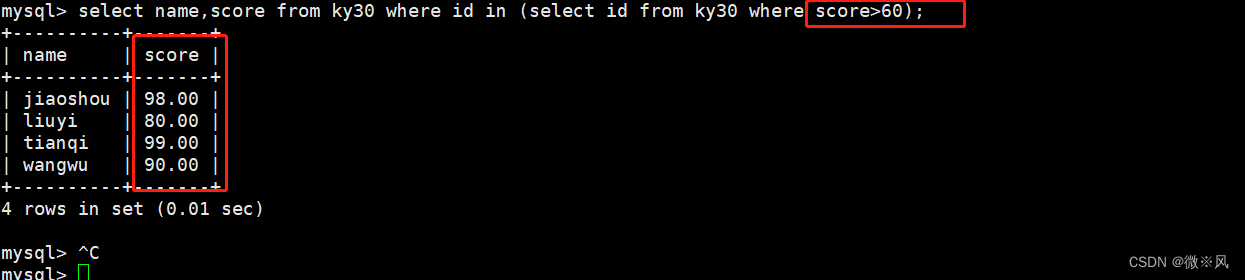 主语句: select name,score from ky30 where id in
主语句: select name,score from ky30 where id in
子语句(集合): (select id from ky30 where score>60);
子语句中的sql语句是为了,最后过滤出一个结果集,用于主语句的判断条件
将主表和子表关联/连接的语法
6.3、不同表/多表示例
mysql> create table ky30_da(id int);
Query OK, 0 rows affected (0.01 sec)mysql> insert into ky30_da values(1),(2),(3);
Query OK, 3 rows affected (0.01 sec)
Records: 3 Duplicates: 0 Warnings: 0mysql> select id,name,score from ky30 where id in (select id from ky30_da);
子查询不仅可以在 SELECT 语句中使用,在 INERT、UPDATE、DELETE 中也同样适用。在嵌套的时候,子查询内部还可以再次嵌套新的子查询,也就是说可以多层嵌套。
6.4、in与not in
语法
IN 用来判断某个值是否在给定的结果集中,通常结合子查询来使用
语法:
.<表达式> [NOT] IN <子查询>
当表达式与子查询返回的结果集中的某个值相等时,返回 TRUE,否则返回 FALSE。 若启用了 NOT 关键字,则返回值相反。需要注意的是,子查询只能返回一列数据,如果需 求比较复杂,一列解决不了问题,可以使用多层嵌套的方式来应对。 多数情况下,子查询都是与 SELECT 语句一起使用的
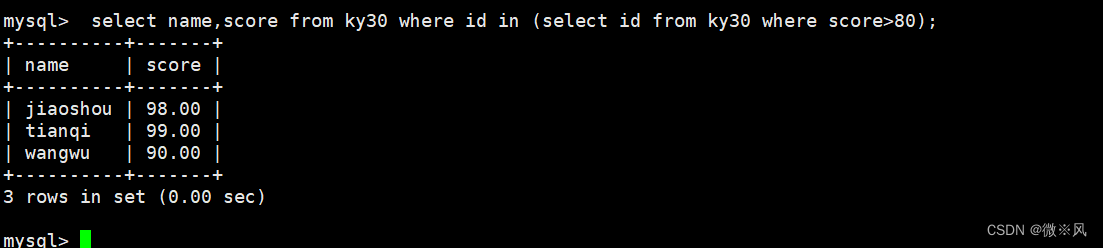
查询分数大于80的记录
mysql> select name,score from ky30 where id in (select id from ky30 where score>80);
6.5 子查询与insert
子查询还可以用在 INSERT 语句中。子查询的结果集可以通过 INSERT 语句插入到其 他的表中
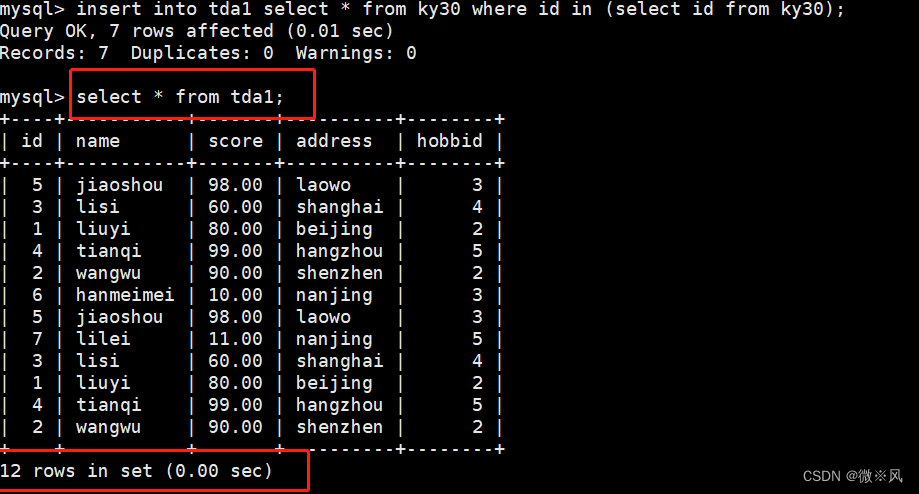
将t1里的记录全部删除,重新插入info表的记录
mysql> insert into tda1 select * from ky30 where id in (select id from ky30);
mysql> select * from tda1;
6.6、UPDATE 语句
可以使用子查询。UPDATE 内的子查询,在 set 更新内容时,可以是单独的一列,也可以是多列。
mysql> update da set score=80 where id in (select id from ky30 where id=2);

mysql> update da set score=100 where id not in (select id from ky30 where id >3);

6.7、DELETE 也适用于子查询
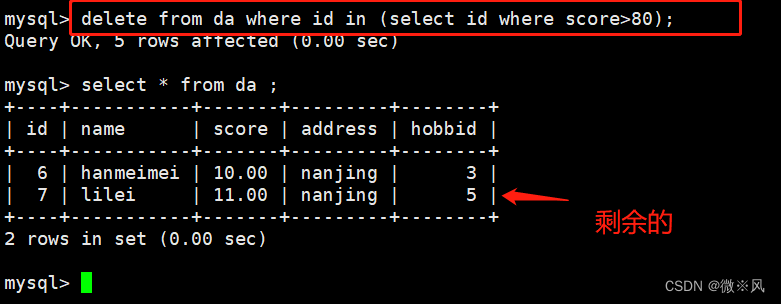
删除分数大于80的记录
mysql> delete from da where id in (select id where score>80);
Query OK, 5 rows affected (0.00 sec)
在 IN 前面还可以添加 NOT,其作用与IN相反,表示否定(即不在子查询的结果集里面) 删除分数不是大于等于80的记录
删除小于80的
mysql> delete from tda1 where id not in (select id where score>=80);

6.8、EXISTS
这个关键字在子查询时,主要用于判断子查询的结果集是否为空。如果不为空, 则返回 TRUE;反之,则返回 FALSE
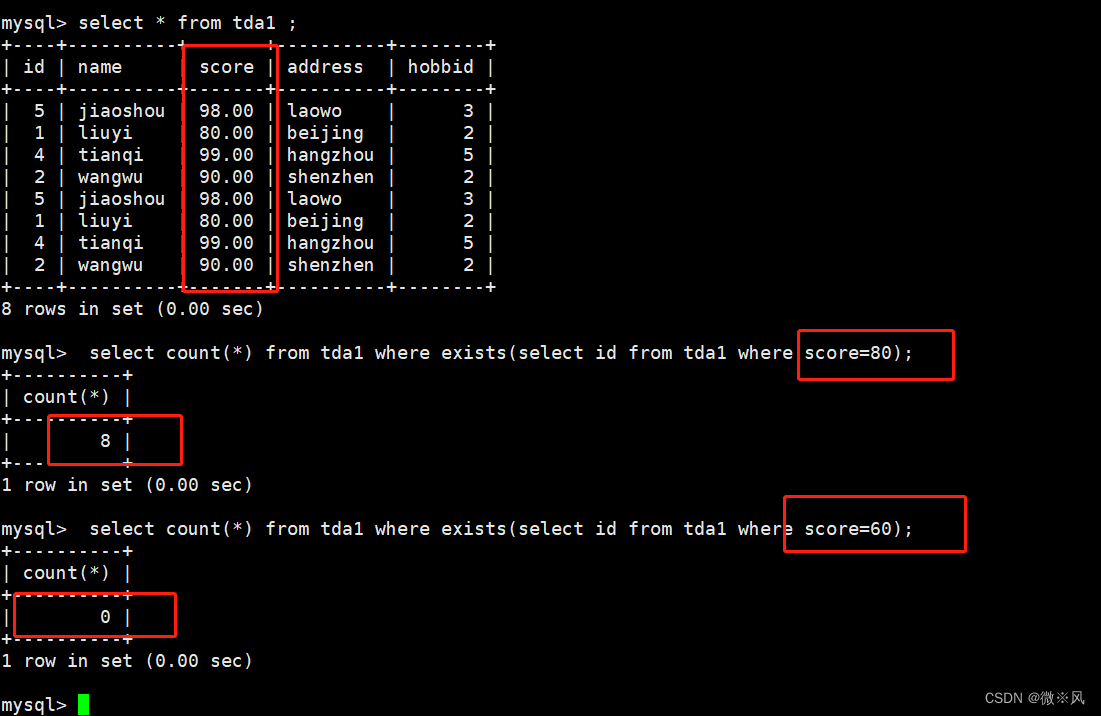
mysql> select count(*) from tda1 where exists(select id from tda1 where score=80);
mysql> select count(*) from tda1 where exists(select id from tda1 where score=60)查询如果存在分数等于80的记录则计算tda1的字段数
查询如果存在分数没有等于60的不记录则计算tda1的字段数
子查询,别名as
将结果集做为一张表进行查询的时候,我们也需要用到别名,
mysql> select a.id from (select id,name from tda1) a;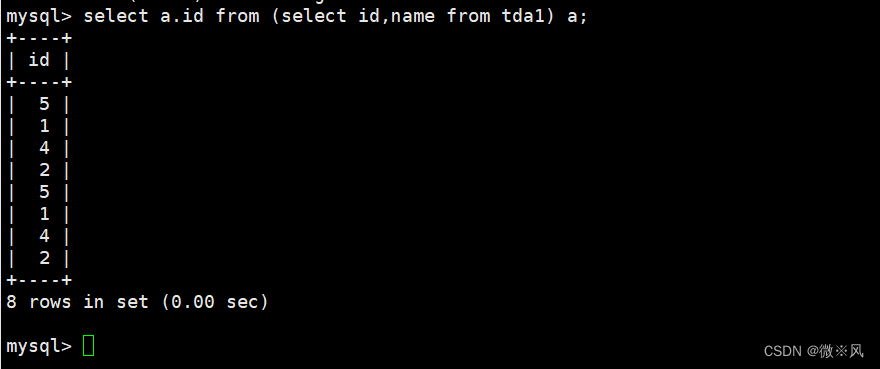
7、MySQL视图
视图:优化操作+安全方案
数据库中的虚拟表,这张虚拟表中不包含真实数据,只是做了真实数据的映射
视图可以理解为镜花水月/倒影,动态保存结果集(数据)
基础表info (7行记录) ——》映射(投影)--视图
作用场景
针对不同的人(权限身份),提供不同结果集的“表”(以表格的形式展示)
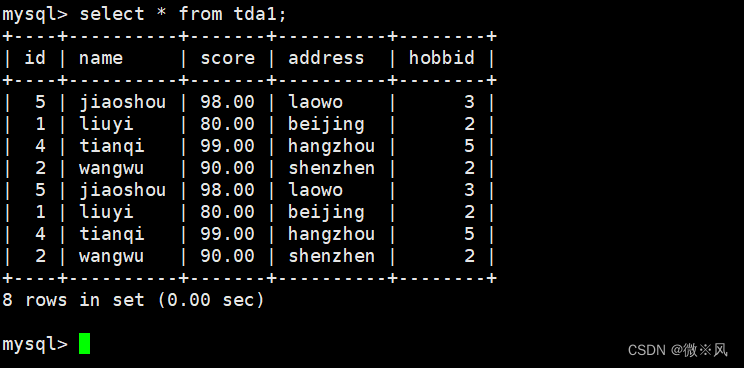
7.1、作用范围:
select * from info; #展示的部分是info表
select * from view_name; #展示的一张或多张表
7.2、功能:
简化查询结果集、灵活查询、可以针对不同用户呈现不同结果集、相对有更高的安全性 本质而言视图是一种select(结果集的呈现)
视图适合于多表连接浏览时使用!不适合增、删、改
而存储过程适合于使用较频繁的SQL语句,这样可以提高执行效率!
视图和表的区别和联系
7.3、区别
①、视图是已经编译好的sql语句。而表不是
②、视图没有实际的物理记录。而表有。 show table status\G
③、表只用物理空间而视图不占用物理空间,视图只是逻辑概念的存在,表可以及时对它进行修改,但视图只能有创建的语句来修改
④、视图是查看数据表的一种方法,可以查询数据表中某些字段构成的数据,只是一些SQL语句的集合。从安全的角度说,视图可以不给用户接触数据表,从而不知道表结构。
⑤、表属于全局模式中的表,是实表;视图属于局部模式的表,是虚表。
⑥、视图的建立和删除只影响视图本身,不影响对应的基本表。(但是更新视图数据,是会影响到基本表的)
7.4、联系:
视图(view)是在基本表之上建立的表,它的结构(即所定义的列)和内容(即所有数据行)都来自基本表,它依据基本表存在而存在。一个视图可以对应一个基本表,也可以对应多个基本表。视图是基本表的抽象和在逻辑意义上建立的新关系。
7.5、实例:
满足80分的学生展示在视图中
这个结果会动态变化,同时可以给不同的人群(例如权限范围)展示不同的视图
7.5.1、创建ky30的视图
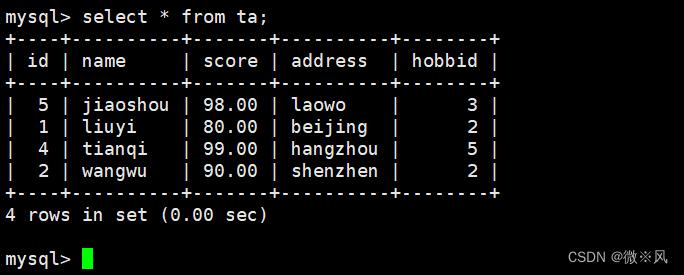
mysql> create view ta as select * from ky30 where score>=80;
7.5.2、 查看视图
 7.5.3、查看视图与源表结构
7.5.3、查看视图与源表结构
7.5.4、修改原表数值
当达到视图表要求的范围,则视图表也随之改变
mysql> update ky30 set score=88 where id=3;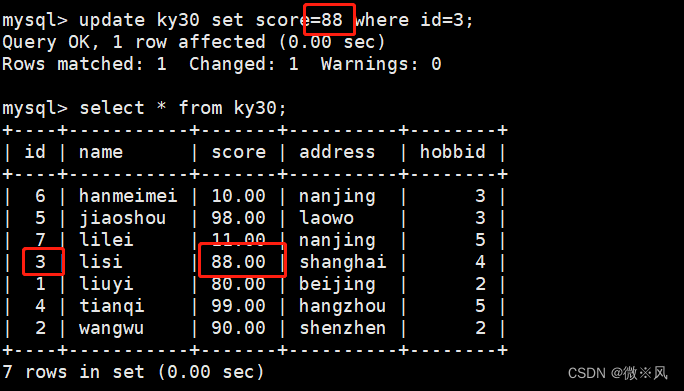
视图的数据

7.5.5、 视图与源的结构
视图结构
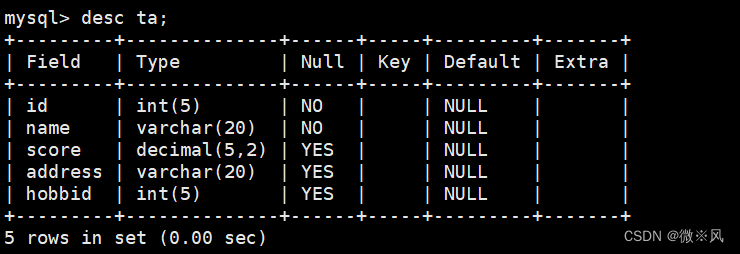 源的结构
源的结构

7.6、多表创建视图
mysql> create table ky10 (id int,name varchar(10),age char(10));
mysql> insert into ky10 values(1,'zhangsan',20);
mysql> insert into ky10 values(2,'lisi',30);
mysql> insert into ky10 values(3,'wangwu',29);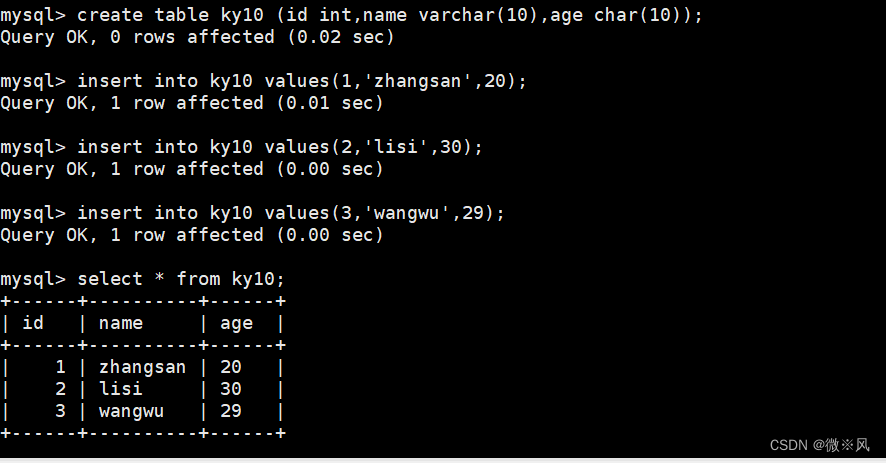
null值
概述
在 SOL 语句使用过程中,经常会碰到 NULL 这几个字符。通常使用 NULL 来表示缺失的值,也就是在表中该字段是没有值的。如果在创建表时,限制某些字段不为空,则可以使用 NOT NULI关键字,不使用则默认可以为空。在向表内插入记录或者更新记录时,如果该字段没有 NOT NULL并且没有值,这时候新记录的该字段将被保存为 NULL。需要注意 的是,NULL 值与数字 0或者空白 (spaces)的字段是不同的,值为 NULI 的字段是没有 值的。在 SOL 语句中,使用 IS NULL可以判断表内的某个字段是不是 NULL 值,相反的用 IS NOT NULL 可以判断不是 NULL 值。
查询info表结构,name字段是不允许空值的
nu11值与空值的区别(空气与真空)
空值长度为0,不占空间,NULL值的长度为nul1,占用空间is null无法判断空值空值使用"="或者"<>"来处理 (!=)
count () 计算时,NULL会忽略,空值会加入计算
在计算机编程中,"null"值和"空"值(Empty value)是两个不同的概念。
1. "null"值:它表示一个变量或表达式没有有效的值或未被赋值。通常用于指示缺少数据、未知或无效的情况。在许多编程语言中,"null"是一个特殊的关键字或保留字,用于表示空引用或空对象。
2. "空"值:它表示一个变量或数据结构中没有任何数据或内容。与"null"不同,"空"值仍然被认为是一个有效的值,只是它表示没有具体的数据内容。
简而言之,"null"值表示缺少或无效的数据,而"空"值表示存在但没有具体内容。在某些编程语言中,"null"可以作为特殊的值进行处理,而"空"值则是一种数据状态或占位符。需要根据所使用的编程语言和上下文来理解和使用这两个概念。
常见的应用场景:
- 变量初始化:在声明变量时,可以将其初始值设置为"null",表示该变量暂时没有有效的值。
- 解除引用:将一个对象或变量的引用置为"null",可以释放对该对象的引用,从而帮助垃圾回收器回收内存。
- 条件检查:可以使用"null"值来检查变量是否存在有效的值,避免出现空指针异常等错误。
需要注意的是,每种编程语言对于"null"值的处理方式可能不同。某些语言可能会提供更丰富的空值处理机制,如"Optional"类型或"Maybe"类型,以更好地处理空值的情况。因此,在具体的编程环境中,建议查阅相关文档或参考相应的语言规范以了解准确的行为。
8、内连接 左连接 右链接
左连接:将两张表的内容及逆行匹配,按照SQL查询的顺序(左——>右)输出坐标的全部内容和右表共同的数据内容
内连接: 输出匹配共同数据/字段的数据内容
8.1、区别
左连接(Left Join):
左连接是关系型数据库中的一种连接操作,它将两个表按照指定的条件(通常是两表之间的某个字段的值相等)进行连接,并返回左表中所有的记录以及与右表匹配的记录。如果右表中没有匹配的记录,则返回NULL值。

右连接(Right Join):
右连接也是关系型数据库中的一种连接操作,它与左连接的原理类似,只是返回的结果集包括右表中所有的记录以及与左表匹配的记录。如果左表中没有匹配的记录,则返回NULL值。
右连接和左连接相反
内连接(Inner Join):
内连接是关系型数据库中最常用的连接操作之一。它仅返回两个表中满足连接条件的记录。也就是说,只有在左表和右表之间存在匹配的记录时,才会将这些记录返回。

三者之间的区别在于返回结果的不同:
- 左连接返回左表的全部记录以及与右表匹配的记录。
- 右连接返回右表的全部记录以及与左表匹配的记录。
- 内连接只返回符合连接条件的记录。
需要注意的是,连接操作需要指定连接条件,即表之间关联的字段。根据实际需求选择正确的连接类型可以帮助我们获取所需的数据结果。
8.2、内连接
8.2.1、概述:
MySQL 中的内连接就是两张或多张表中同时符合某种条件的数据记录的组合。通常在 FROM 子句中使用关键字 INNER JOIN 来连接多张表,并使用 ON 子句设置连接条件,内连接是系统默认的表连接,所以在 FROM 子句后可以省略 INNER 关键字,只使用 关键字 JOIN。同时有多个表时,也可以连续使用 INNER JOIN 来实现多表的内连接,不过为了更好的性能,建议最好不要超过三个表
8.2.2、语法:
SELECT column_name(s)FROM table1 INNER JOIN table2 ON table1.column_name = table2.column_name;8.2.3、实例
创建表
mysql> create table ky10(name varchar(40),score decimal((4,2),address varchar(40));
添加数据
insert into ky10 values('wangwu',80,'beijing'),('zhangsan',99,'shanghai'),('lisi',99.99,'nanjing');
mysql> select * from ky10;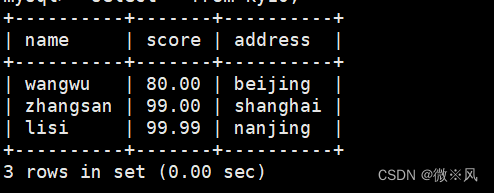
创建第二张表
mysql> create table ky20(name varchar(40),score decimal((4,2),address varchar(40));
Query OK, 0 rows affected (0.01 sec)mysql> insert into ky10 values('wangwu',80,'beijing'),('zs',99,'shanghai'),('lisi',99.99,'nanjing');
Query OK, 3 rows affected (0.00 sec)
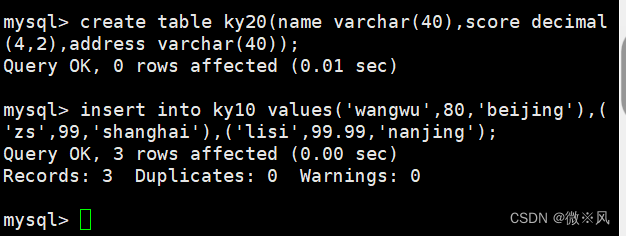
mysql> select ky20.name from ky20 inner join ky10 on ky20.name=ky10.name;
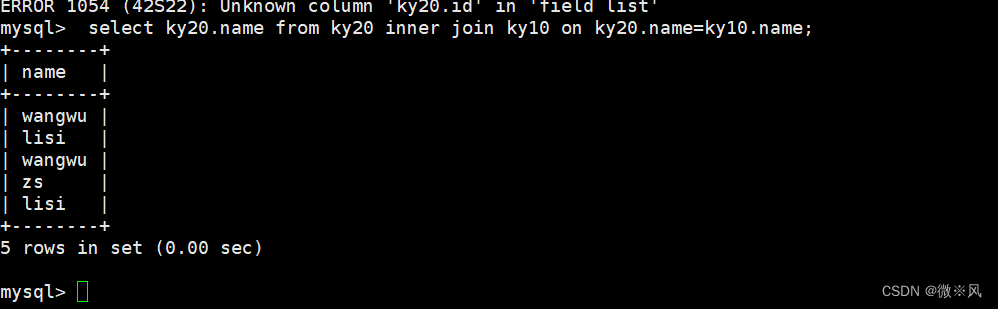
内连查询:通过inner join 的方式将两张表指定的相同字段的记录行输出出来
内连查询:面试,直接了当的说 用inner join 就可以
8.3、左连接:
8.3.1、概述:
.左连接也可以被称为左外连接,在 FROM 子句中使用 LEFT JOIN 或者 LEFT OUTER JOIN 关键字来表示。左连接以左侧表为基础表,接收左表的所有行,并用这些行与右侧参 考表中的记录进行匹配,也就是说匹配左表中的所有行以及右表中符合条件的行。
mysql> select * from info left join infos on info.name=infos.name;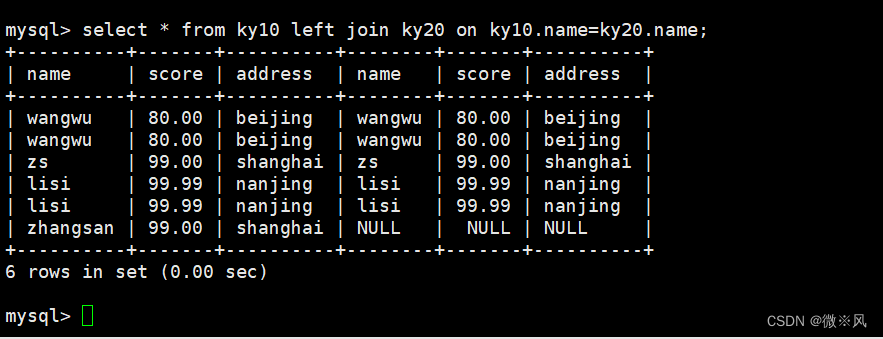 左连接中左表的记录将会全部表示出来,而右表只会显示符合搜索条件的记录,右表记录不足的地方均为 NULL。
左连接中左表的记录将会全部表示出来,而右表只会显示符合搜索条件的记录,右表记录不足的地方均为 NULL。
8.4、右连接
右连接也被称为右外连接,在 FROM 子句中使用 RIGHT JOIN 或者 RIGHT OUTER JOIN 关键字来表示。右连接跟左连接正好相反,它是以右表为基础表,用于接收右表中的所有行,并用这些记录与左表中的行进行匹配
mysql> select * from ky20 right join ky10 on ky20.name=ky10.name;
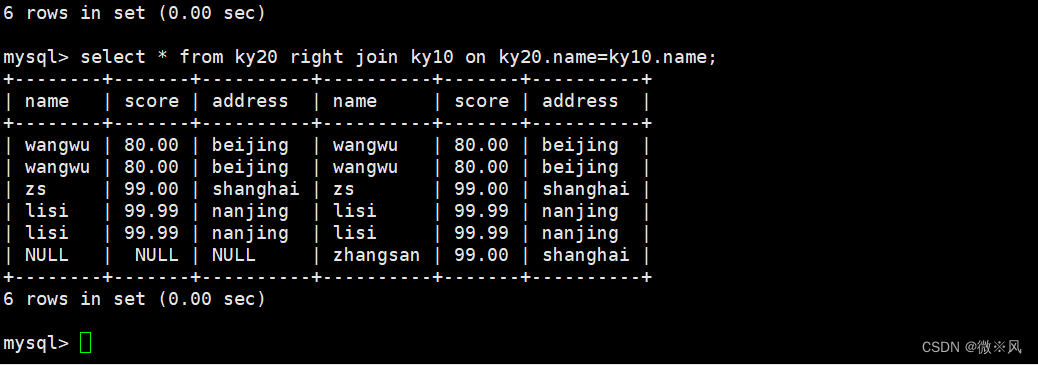 在右连接的查询结果集中,除了符合匹配规则的行外,还包括右表中有但是左表中不匹 配的行,这些记录在左表中以 NULL 补足
在右连接的查询结果集中,除了符合匹配规则的行外,还包括右表中有但是左表中不匹 配的行,这些记录在左表中以 NULL 补足
9、存储过程
9.1、概述
前面学习的 MySQL 相关知识都是针对一个表或几个表的单条 SQL 语句,使用这样的SQL 语句虽然可以完成用户的需求,但在实际的数据库应用中,有些数据库操作可能会非常复杂,可能会需要多条 SQL 语句一起去处理才能够完成,这时候就可以使用存储过程, 轻松而高效的去完成这个需求,有点类似shell脚本里的函数
9.2、、简介-
- 存储过程是一组为了完成特定功能的SQL语句集合。 两个点 第一 触发器(定时任务) 第二个判断
- 存储过程这个功能是从5.0版本才开始支持的,它可以加快数据库的处理速度,增强数据库在实际应用中的灵活性。存储过程在使用过程中是将常用或者复杂的工作预先使用SQL语句写好并用一个指定的名称存储起来,这个过程经编译和优化后存储在数据库服务器中。当需要使用该存储过程时,只需要调用它即可。操作数据库的传统 SQL 语句在执行时需要先编译,然后再去执行,跟存储过程一对比,明显存储过程在执行上速度更快,效率更高
存储过程在数据库中L 创建并保存,它不仅仅是 SQ语句的集合,还可以加入一些特殊的控制结构,也可以控制数据的访问方式。存储过程的应用范围很广,例如封装特定的功能、 在不同的应用程序或平台上执行相同的函数等等。
9.3、存储过程的优点:
- 执行一次后,会将生成的二进制代码驻留缓冲区,提高执行效率
- SQL语句加上控制语句的集合,灵活性高
- 在服务器端存储,客户端调用时,降低网络负载
- 可多次重复被调用,可随时修改,不影响客户端调用
- 可完成所有的数据库操作,也可控制数据库的信息访问权限
9.4、 语法
CREATE PROCEDURE <过程名> ( [过程参数[,…] ] ) <过程体>
[过程参数[,…] ] 格式
<过程名>:尽量避免与内置的函数或字段重名
<过程体>:语句
[ IN | OUT | INOUT ] <参数名><类型>实例
##创建存储过程##
DELIMITER $$ #将语句的结束符号从分号;临时改为两个$$(可以自定义)
CREATE PROCEDURE Proc() #创建存储过程,过程名为Proc,不带参数
-> BEGIN #过程体以关键字 BEGIN 开始
-> create table mk (id int (10), name char(10),score int (10));
-> insert into mk values (1, 'wang',13);
-> select * from mk; #过程体语句
-> END $$ #过程体以关键字 END 结束
DELIMITER ; #将语句的结束符号恢复为分号9.5、调用存储过程
CALL Proc();
I 存储过程的主体都分,被称为过程体
II 以BEGIN开始,以END结束,若只有一条sQL语句,则可以省略BEGIN-END
III 以DELIMITER开始和结束 mysgl>DEL工M工TER $$ $$是用户自定义的结束符 省略存储过程其他步骤
mysql>DELIMITER ; 分号前有空格
9.6、查看存储过程
格式:
mysql> show create procedure proc\GSHOW CREATE PROCEDURE [数据库.]存储过程名; #查看某个存储过程的具体信息后缀加“G”与不加 显示的方式
9.7、查看存储过程
SHOW PROCEDURE STATUS 9.8、查看指定存储过程
mysql> SHOW PROCEDURE STATUS like '%proc%'\G9.9存储过程的参数
IN 输入参数:表示调用者向过程传入值(传入值可以是字面量或变量)
OUT 输出参数:表示过程向调用者传出值(可以返回多个值)(传出值只能是变量)
INOUT 输入输出参数:既表示调用者向过程传入值,又表示过程向调用者传出值(值只能是变量)
即表示调用者向过程传入值,又表示过程向调用者传出值(只能是变量)
mysql> delimiter @@
mysql> create procedure proc (in inname varchar(40)) #行参-> begin-> select * from info where name=inname;-> end @@
mysql> delimiter @@
mysql> call proc2('wangwu'); #实参修改存储过程
ALTER PROCEDURE <过程名>[<特征>... ]
ALTER PROCEDURE GetRole MODIFIES SQL DATA SQL SECURITY INVOKER;
MODIFIES sQLDATA:表明子程序包含写数据的语句
SECURITY:安全等级
invoker:当定义为INVOKER时,只要执行者有执行权限,就可以成功执行删除存储过程
存储过程内容的修改方法是通过删除原有存储过程,之后再以相同的名称创建新的存储过程。DROP PROCEDURE IF EXISTS Proc;
相关文章:
SQL高阶语句
目录 1、概念 1.1、概述 1.2、常见的MySQL高阶语句的概念: 1.3、 SQL高阶语句的作用 2、常用查询 2.1、按关键字排序 2.1.1、概述和作用 2.1.2、 (1)语法 2.1.3、模板表:ky30 编辑2.1.4、分数按降序排列 2.1.5、ORDER…...

【交换机】如何通过Web方式登陆交换机
一、华为交换机web登陆配置 Web网管是一种对交换机的管理方式,它利用交换机内置的Web服务器,为用户提供图形化的操作界面。用户可以从终端通过HTTPS登录到Web网管,对交换机进行管理和维护,同时也非常方便。 一、配置思路ÿ…...
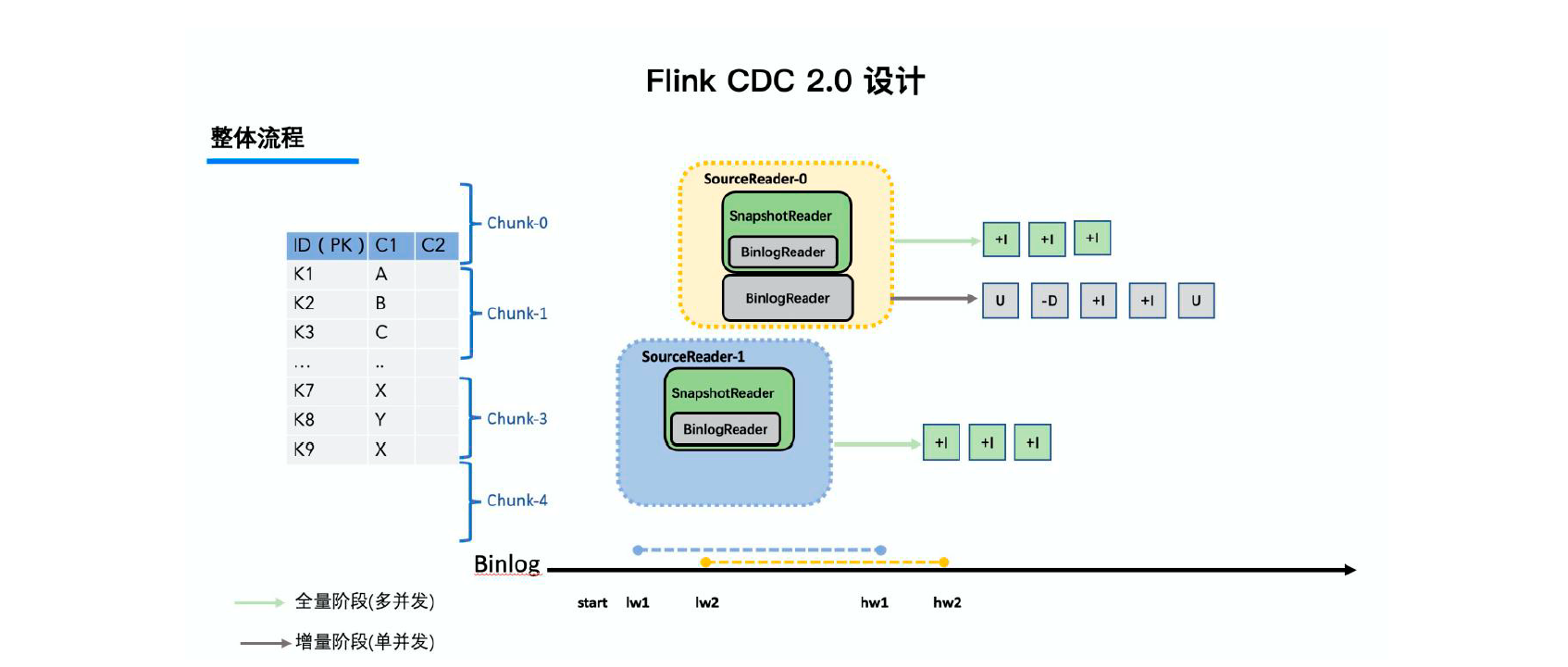
Flink CDC学习笔记
第一章 CDC简介 1.1 什么是CDC CDC (Change Data Capture 变更数据获取)的简称。核心思想就是,检测并获取数据库的变动(增删查改),将这些变更按发生的顺序记录下来,写入到消息中间件以供其它服务进行订…...

NEOVIM学习笔记
GitHub - blogercn/nvim-config: A pretty epic NeoVim setup 一直使用vim,每次到了新公司都要配置半天,而且常常配置失败,很多插件过期不好用。偶然看到别人的NEO VIM,就试着用了一下,感觉还不错。 用来开发和阅读C代…...

Docker三剑客之docker-compose
docker-compose 是 Docker 生态系统中的一个重要成员,它允许开发人员使用一个简单的配置文件来定义和运行多个 Docker 容器。通过 docker-compose,你可以定义应用程序的各个组件、容器之间的依赖关系以及网络配置,从而实现在一个命令中启动、…...

单调队列
目录 一,单调队列 二,模板实现 三,OJ实战 剑指 Offer 59 - I. 滑动窗口的最大值 一,单调队列 单调队列是双端队列的拓展,支持尾部插入,双端删除,其中的数据始终维持单调性,从而…...

effective c++ 笔记
TODO:还没看太懂的篇章 item25 item35 模板相关内容 文章目录 基础视C为一个语言联邦以const, enum, inline替换#define尽可能使用constconst成员函数 确定对象使用前已被初始化 构造、析构和赋值内含引用或常量成员的类的赋值操作需要自己重写不想使用自动生成的函…...

【送书活动】深入浅出SSD:固态存储核心技术、原理与实战
前言 「作者主页」:雪碧有白泡泡 「个人网站」:雪碧的个人网站 「推荐专栏」: ★java一站式服务 ★ ★ React从入门到精通★ ★前端炫酷代码分享 ★ ★ 从0到英雄,vue成神之路★ ★ uniapp-从构建到提升★ ★ 从0到英雄ÿ…...
GaussDB数据库SQL系列-行列转换
一、前言 二、简述 1、行转列概念 2、列转行概念 三、GaussDB数据库的行列转行实验示例 1、行转列示例 1)创建实验表(行存表) 2)静态行转列 3)行转列(结果值:拼接式) 4&…...

美国陆军网络司令部利用人工智能增强网络攻防和作战决策能力
源自: 奇安网情局 声明:公众号转载的文章及图片出于非商业性的教育和科研目的供大家参考和探讨,并不意味着支持其观点或证实其内容的真实性。版权归原作者所有,如转载稿涉及版权等问题,请立即联系我们删除。 “人工智能技术与咨询…...

Notion团队协作魔法:如何玩转数字工作空间?
Notion简介 Notion已经成为现代团队协作的首选工具之一。它不仅仅是一个笔记应用,更是一个强大的团队协作平台,能够满足多种工作场景的需求。 Notion的核心功能 Notion提供了丰富的功能,如文档、数据库、看板、日历等,满足团队的…...

视频云存储/安防监控/AI视频智能分析平台新功能:人员倒地检测详解
人工智能技术已经越来越多地融入到视频监控领域中,近期我们也发布了基于AI智能视频云存储/安防监控视频智能分析平台的众多新功能,该平台内置多种AI算法,可对实时视频中的人脸、人体、物体等进行检测、跟踪与抓拍,支持口罩佩戴检测…...

解决RabbitMQ报错Stats in management UI are disabled on this node
文章目录 问题描述:解决步骤:进入容器后,cd到以下路径修改 management_agent.disable_metrics_collector false退出容器重启rabbitmq容器 问题描述: linux 部署 rabbitmq后,打开rabbitmq管理界面。点击channels&#…...

【重点】【NAND】聊聊固态硬盘SSD的寿命及其影响因素
固态硬盘是由主控芯片、存储颗粒芯片组成的闪存设备,固体硬盘的英文简称是SSD,如果是移动用的固态硬盘,则其英文简称为PSSD。 固态硬盘SSD分工业级和消费级等,目前,工业级固态硬盘SSD通常采用MLC闪存,而消…...

数据库约束
文章目录 1. 简介2. 代码演示3. 外键约束4. 外键删除和更新行为 1. 简介 概念:约束时作用于表中子段上的规则,用于限制存储在表中的shuju目的:保证数据库中数据的正确、有效性和完整性分类: 约束描述关键字非空约束限制该字段不…...

Unity实现MQTT服务器
首先下载MqttNet:MqttNet下载地址 解压好后使用vs打开,并生成.dll文件(我这里下载的是4.1.2.350版本) 然后再/Source/MQTTnet/bin/Debug/net452 文件夹中找到生成的文件 新建unity工程,创建Plugins文件夹࿰…...

Linux(centos) 下 Mysql 环境安装
linux 下进行环境安装相对比较简单,可还是会遇到各种奇奇怪怪的问题,我们来梳理一波 安装 mysql 我们会用到下地址: Mysql 官方文档的地址,可以参考,不要全部使用 https://dev.mysql.com/doc/refman/8.0/en/linux-i…...
决策树(Decision Tree)
决策树的定义: 分类决策树模型是一种描述对实例进行分类的树形结构。决策树由结点(node)和有向边(directed edge)组成。结点有两种类型: 内部结点(internal node)和叶结点(leaf node࿰…...

解决 PaddleClas 下载预训练模型报错 ModuleNotFoundError No module named ‘ppcls‘ 的问题
当我们在使用 PaddleClas 进行预训练模型下载时,可能会遇到一个报错,报错信息为 ModuleNotFoundError: No module named ppcls。这个错误通常是因为 Python 解释器无法找到名为 ppcls 的模块,而我们的代码中正尝试导入它。让我们一起来解决这…...
视觉化洞察:为什么我们需要数据可视化?
为什么我们需要数据可视化?这个问题在信息时代变得愈发重要。数据,如今已成为生活的一部分,我们每天都在产生大量的数据,从社交媒体到购物记录,从健康数据到工作表现,数据无处不在。然而,数据本…...

大学生零基础打CTF比赛全攻略:要学啥、怎么学,看完就能参赛
大学生零基础打CTF比赛全攻略:要学啥、怎么学,看完就能参赛(干货版) 摘要:对大学生来说,CTF(Capture The Flag,夺旗赛)不仅是网络安全领域最具实战性的竞赛,…...

使用Taotoken CLI工具一键为团队所有网站项目配置统一API接入点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken CLI工具一键为团队所有网站项目配置统一API接入点 在团队协作开发中,确保所有成员使用统一的大模型API接…...

AI设计泳装,能颠覆今夏潮流?
AI设计泳装,能颠覆今夏潮流? 夏日临近,泳装市场硝烟再起。然而,海量款式与消费者挑剔审美的矛盾日益尖锐——设计周期长、打版成本高、爆款命中率低,让无数商家深陷库存泥潭。如何破局?北京先智先行科技有限…...

十大榜单全覆盖,价值兑现引领:联想定义中国AI企业新高度
当前,全球 AI 产业已正式迈入规模化商业落地的关键周期,“技术炫技”让位于“价值兑现”,“算力筑基—技术创新—场景落地”的协同闭环成为高质量发展的核心逻辑。据《全球首席信息官(CIO)报告:企业级 AI 竞…...
)
告别高斯模糊!用OpenCV+Python手把手实现引导滤波,保留图像边缘细节(附完整代码)
边缘保持滤波新选择:OpenCV与Python实现引导滤波实战指南 在数字图像处理领域,平滑滤波与边缘保持一直是一对难以调和的矛盾。传统的高斯滤波虽然能有效去除噪声,却常常以牺牲图像细节为代价;双边滤波虽然在一定程度上解决了边缘保…...

XXMI启动器:一站式二次元游戏模组管理终极指南,轻松管理热门游戏模组
XXMI启动器:一站式二次元游戏模组管理终极指南,轻松管理热门游戏模组 【免费下载链接】XXMI-Launcher Modding platform for GI, HSR, WW and ZZZ 项目地址: https://gitcode.com/gh_mirrors/xx/XXMI-Launcher XXMI启动器是一款功能强大的开源游戏…...

三分钟完成Taotoken的API Key配置与curl调用测试
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 三分钟完成Taotoken的API Key配置与curl调用测试 基础教程类,面向刚注册Taotoken并获取了API Key的开发者,…...

终极LuaJIT反编译指南:如何快速恢复丢失的Lua源代码
终极LuaJIT反编译指南:如何快速恢复丢失的Lua源代码 【免费下载链接】luajit-decompiler https://gitlab.com/znixian/luajit-decompiler 项目地址: https://gitcode.com/gh_mirrors/lu/luajit-decompiler 你是否曾面对编译后的LuaJIT字节码文件束手无策&…...

Vue+ElementUI构建蘑菇博客管理后台:前端架构与最佳实践
VueElementUI构建蘑菇博客管理后台:前端架构与最佳实践 【免费下载链接】mogu_blog_v2 蘑菇博客(MoguBlog),一个基于微服务架构的前后端分离博客系统。Web端使用Vue Element , 移动端使用uniapp和ColorUI。后端使用Spring cloud Spring boot mybatis-…...

利用Taotoken模型广场为AIGC应用选择性价比最优的文本生成模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken模型广场为AIGC应用选择性价比最优的文本生成模型 对于AIGC应用开发者而言,文本生成模型的选择直接影响着…...