详解排序算法(附带Java/Python/Js源码)
冒泡算法
依次比较两个相邻的子元素,如果他们的顺序错误就把他们交换过来,重复地进行此过程直到没有相邻元素需要交换,即完成整个冒泡,时间复杂度。
- 比较相邻的元素。如果第一个比第二个大,就交换它们两个;
- 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对,这样在最后的元素应该会是最大的数;
- 针对所有的元素重复以上的步骤,除了最后一个;
- 重复步骤1~3,直到排序完成。
Java
/*** 冒泡排序* @param array* @return*/public static int[] bubbleSort(int[] array){if(array.length > 0){for(int i = 0;i<array.length;i++){for(int j = 0;j<array.length - 1 - i;j++){if(array[j] > array[j+1]){int temp = array[j];array[j] = array[j+1];array[j+1] = temp;}}}}return array;}优化后,可减少循环次数
//定义标志位,用于判定最外层每一轮是否进行了交换boolean flag = false;for (int i = 0; i < arr.length - 1; i++) {for (int j = 0; j < arr.length - 1 - i; j++) {if (arr[j] > arr[j + 1]) {//进入这个if分支里边,则说明有元素进行了交换//所以将flag=trueflag = true;int temp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = temp;}}//在进行一轮的排序后,判断是否发生了元素是否交换;if (!flag) {// 没有交换,数组已是有序,则结束排序;break;} else {//如果发生交换,将flag再次置为false,进行下一轮排序flag = false;}}Python
from typing import List# 冒泡排序
def bubble_sort(arr: List[int]):"""冒泡排序(Bubble sort):param arr: 待排序的List,此处限制了排序类型为int:return: 冒泡排序是就地排序(in-place)"""length = len(arr)if length <= 1:returnfor i in range(length):'''设置标志位,若本身已经有序,则直接break'''is_made_swap = Falsefor j in range(length - i - 1):if arr[j] > arr[j + 1]:arr[j], arr[j + 1] = arr[j + 1], arr[j]is_made_swap = Trueif not is_made_swap:breakreturn arrif __name__ == '__main__':arr = bubble_sort([55, 34, 55, 33, 13, 45, 67])print(arr)
Js
for(var i=0;i<arr.length-1;i++){//确定轮数for(var j=0;j<arr.length-i-1;j++){//确定每次比较的次数if(arr[j]>arr[j+1]){tem = arr[j];arr[j] = arr[j+1];arr[j+1] = tem;}}}
选择排序
每一趟从待排序数组中选出最小的数字,按顺序放在已经排好序的数组的后面,直到全部排完。 时间复杂度: 空间复杂度:
(常规)
- 初始状态:无序区为R[1..n],有序区为空;
- 第i趟排序(i=1,2,3…n-1)开始时,当前有序区和无序区分别为R[1..i-1]和R(i..n)。该趟排序从当前无序区中-选出关键字最小的记录 R[k],将它与无序区的第1个记录R交换,使R[1..i]和R[i+1..n)分别变为记录个数增加1个的新有序区和记录个数减少1个的新无序区;
- n-1趟结束,数组有序化了
Java
private static Integer[] selectSort(Integer[] arr) {/*初始化左端、右端元素索引*/int left = 0;int right = arr.length - 1;while (left < right) {/*初始化最小值、最大值元素的索引*/int min = left;int max = right;for (int i = left; i <= right; i++) {/*标记每趟比较中最大值和最小值的元素对应的索引min、max*/if (arr[i] < arr[min])min = i;if (arr[i] > arr[max])max = i;}/*最大值放在最右端*/int temp = arr[max];arr[max] = arr[right];arr[right] = temp;/*此处是先排最大值的位置,所以得考虑最小值(arr[min])在最大位置(right)的情况*/if (min == right)min = max;/*最小值放在最左端*/temp = arr[min];arr[min] = arr[left];arr[left] = temp;/*每趟遍历,元素总个数减少2,左右端各减少1,left和right索引分别向内移动1*/left++;right--;}return arr;}// 测试public static void main(String[] args) {Integer[] arr = new Integer[]{77, 22, 3, 4, 1, 44, 34, 41};Integer[] arrs = selectSort(arr);for (Integer integer : arrs) {System.out.println(integer);}}Python
def selectionSort(A):le = len(A)for i in range(le): # 遍历次数for j in range(i + 1, le): # 查找待排序序列中的最小元素并交换if A[i] > A[j]:A[i], A[j] = A[j], A[i]print(A)tes = [22, 41, 55, 46, 4, 5, 3, 32, 454]
selectionSort(tes) # [3, 4, 5, 22, 32, 41, 46, 55, 454]
Js
var arr = [2, 8, 6, 2, 9, 7, 3, 11, 6]//从第0次开始for (var j = 0; j < arr.length - 1; j++) {var minIndex = jfor (var i = j + 1; i < arr.length; i++) {if (arr[i] < arr[minIndex]) minIndex = i}if (minIndex != j) {var tmp = arr[j]arr[j] = arr[minIndex]arr[minIndex] = tmp}
}console.log(arr)
插入排序
将一个记录插入到已经排序好的有序表中,从而得到一个新的、记录增加1的有序表。在实现过程中使用双层循环,外层循环对除了第一个元素之外的所有元素,内层循环对当前元素前面有序表进行待插入位置查找,进行移动。时间复杂度: 空间复杂度:
(常规)
- 从第一个元素开始,该元素可以认为已经被排序;
- 取出下一个元素,在已经排序的元素序列中从后向前扫描;
- 如果该元素(已排序)大于新元素,将该元素移到下一位置;
- 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置;
- 将新元素插入到该位置后;
- 重复步骤2~5。
Java
直接插入排序
public static void insertSort2 (int[] numbers) {//控制循环轮数for (int i = 1; i < numbers.length; i++) {int temp = numbers[i]; //定义待交换元素int j; //定义待插入的位置for (j = i; j > 0 && temp < numbers[j - 1]; j --) {numbers[j] = numbers[j - 1];}numbers[j] = temp;System.out.println("第" + i + "轮的排序结果为:" + Arrays.toString(numbers));}System.out.println("排序后的结果为:" + Arrays.toString(numbers));}折半插入排序
在直接插入排序的基础上,将查找方法从顺序查找改为折半查找,就是在将 将要插入到现有 有序序列的数字寻找适当插入位置的比较次数减少了。
private static void bInsertSort(int[] s){for(int i=1;i<s.length;i++){int temp=s[i];//保存要插入的数的数值int low=0;//设置查找区间初始值 下区间值int high=i-1;//上区间值while(low<=high){//查找结束条件int mid=(high+low)/2;//折半,中间值if(s[mid]>temp){//待插入值小于中间值high=mid-1;//上区间值变为中间值-1}else {//待插入值大于中间值low=mid+1;//下区间值变为中间值+1}}for (int j=i-1;j>=low;j--){s[j+1]=s[j];//将low及low之前的数向前移动一位}s[low]=temp;//low就是待插入值的适当插入点}System.out.println(Arrays.toString(s));//输出排好序的数组}
Python
import pandas as pd
import random
import timeimport seaborn as sns
import matplotlib.pyplot as plt# 解决win 系统中文不显示问题
from pylab import mpl
mpl.rcParams['font.sans-serif']=['SimHei']def insert_sort(tg_list):''' 排序算法:插入排序 '''for i in range(1,len(tg_list)):for j in range(i,0,-1):if tg_list[j] < tg_list[j-1]:tg_list[j-1], tg_list[j] = tg_list[j], tg_list[j-1]else:breakdef get_runtime(n):''' 获取排序耗时 '''time_start = time.clock() # 记录开始时间list_ = [random.randint(1,n) for i in range(n)]insert_sort(list_)time_end = time.clock() # 记录结束时间time_sum = time_end - time_start # 计算的时间差为程序的执行时间,单位为秒/sreturn [n,time_sum]def plot(df):''' 绘制折线图 '''pd.options.display.notebook_repr_html=False # 表格显示plt.rcParams['figure.dpi'] = 75 # 图形分辨率sns.set_style(style='darkgrid') # 图形主题plt.figure(figsize=(4,3),dpi=150)sns.lineplot(data=df,x='数量',y='耗时(s)')if __name__ == "__main__":nums = range(100,10000,100)res = list(map(get_runtime,nums))res_df = pd.DataFrame(res,columns=['数量','耗时(s)'])plot(res_df)
Js
function insertSort(arr) {var len =arr.length;for (var i=1;i<len; i++) {var temp=arr[i];var j=i-1;//默认已排序的元素while (j>=0 && arr[j]>temp) { //在已排序好的队列中从后向前扫描arr[j+1]=arr[j]; //已排序的元素大于新元素,将该元素移到一下个位置j--;}arr[j+1]=temp;}return arr}二分插入排序
function binaryInsertSort(arr) {var len =arr.length;for (var i=1;i<len; i++) {var key=arr[i],left=0,right=i-1;while(left<=right){ //在已排序的元素中二分查找第一个比它大的值var mid= parseInt((left+right)/2); //二分查找的中间值if(key<arr[mid]){ //当前值比中间值小 则在左边的子数组中继续寻找 right = mid-1;}else{left=mid+1;//当前值比中间值大 在右边的子数组继续寻找}} for(var j=i-1;j>=left;j--){arr[j+1]=arr[j];}arr[left]=key;}return arr;} 快速排序
每趟排序时选出一个基准值,然后将所有元素与该基准值比较,并按大小分成左右两堆,然后递归执行该过程,直到所有元素都完成排序。
- 从数列中挑出一个元素,称为 “基准”(pivot);
- 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
- 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序

Java
##--------------------------第一版----------------------------------------public static void quickSort1(int[] arr) {if (arr == null || arr.length < 2) {return;}process1(arr, 0, arr.length - 1);}//第一版快排,这一版的时间复杂度为O(n2)public static void process1(int[] arr, int L, int R) {if (L >= R) {return;}//在[L,R]范围上,根据arr[R],模仿netherlandsFlag方法,//将数组分为三个部分:<=arr[R]的部分,arr[R]本身,>=//arr[R]的部分,这样确定了在最终的数组中arr[R]的位置,//并返回这个位置int M = partition(arr, L, R);//接下来只要在左右两侧重复这个过程就行process1(arr, L, M - 1);process1(arr, M + 1, R);}public static int partition(int[] arr, int L, int R) {if (L > R) {return -1;}if (L == R) {return L;}int lessEqual = L - 1;int index = L;while (index < R) {if (arr[index] <= arr[R]) {swap(arr, index, ++lessEqual);}index++;}swap(arr, ++lessEqual, R);return lessEqual;}##--------------------------第二版----------------------------------------public static void quickSort2(int[] arr) {if (arr == null || arr.length < 2) {return;}process2(arr, 0, arr.length - 1);}//第二版快排:相比第一版的区别/优势:在于一次可以确定//相等基准值的一个区域,而不再只是一个值//第二版的时间复杂度为O(n2)public static void process2(int[] arr, int L, int R) {if (L >= R) {return;}int[] equalArea = netherlandsFlag(arr, L, R);process2(arr, L, equalArea[0] - 1);process2(arr, equalArea[1] + 1, R);}//这个方法的目的是按arr[R]为基准值,将arr数组划分为小于基准值、//等于基准值、大于基准值三个区域//在arr[L...R]上,以arr[R]做基准值,在[L...R]范围内,<arr[R]的数//都放在左侧,=arr[R]的数放在中间,>arr[R]的数放在右边//返回的值为和arr[R]相等的范围的数组public static int[] netherlandsFlag(int[] arr, int L, int R) {if (L > R) {return new int[] { -1, -1 };}if (L == R) {return new int[] { L, R };}//小于基准值的区域的右边界int less = L - 1;//大于基准值的区域的左边界int more = R;int index = L;while (index < more) {//等于基准值,不做处理,判断下一个数据if (arr[index] == arr[R]) {index++;//当前数小于基准值} else if (arr[index] < arr[R]) {//将当前值和小于区域右边的一个值交换:swap//判断下一个数据:index++//小于区域右移:++less(先++是为了完成swap)swap(arr, index++, ++less);} else {//将当前值和大于区域左边的一个值交换:swap//大于区域左移:--more(先--是为了完成swap)swap(arr, index, --more);}}//因为最开始是把arr[R]作为基准值的,所以在进行接下来的一步之前,//arr[R]实际是在大于区域的最右侧的,所以还需要进行一步交换,这样//整个数组就成了小于区域、等于区域、大于区域的样子swap(arr, more, R);//less + 1是等于区域的起始位置,more经过上一步的和arr[R]交换后,//就成了等于区域的结束位置return new int[] { less + 1, more };}##--------------------------第三版----------------------------------------public static void quickSort3(int[] arr) {if (arr == null || arr.length < 2) {return;}process3(arr, 0, arr.length - 1);}//第三版快排:不再固定去arr[R],改为去随机位置的值,然后//和arr[R]进行交换,接下来的过程就和第二版一样//第三版的复杂度变化了,是O(nlogn),该事件复杂度是最终求//的是数学上的一个平均期望值public static void process3(int[] arr, int L, int R) {if (L >= R) {return;}swap(arr, L + (int) (Math.random() * (R - L + 1)), R);int[] equalArea = netherlandsFlag(arr, L, R);process3(arr, L, equalArea[0] - 1);process3(arr, equalArea[1] + 1, R);}public static void swap(int[] arr, int i, int j) {int tmp = arr[i];arr[i] = arr[j];arr[j] = tmp;}
Python
# coding=utf-8
def quick_sort(array, start, end):if start >= end:returnmid_data, left, right = array[start], start, endwhile left < right:while array[right] >= mid_data and left < right:right -= 1array[left] = array[right]while array[left] < mid_data and left < right:left += 1array[right] = array[left]array[left] = mid_dataquick_sort(array, start, left-1)quick_sort(array, left+1, end)if __name__ == '__main__':array = [11, 14, 34, 7, 30, 14, 27, 45, 25, 5, 66, 11]quick_sort(array, 0, len(array)-1)print(array)
Js
function quickSort( arr ) {if(arr.length <= 1) return arr;const num = arr[0];let left = [], right = [];for(let i = 1;i < arr.length; i++) {if(arr[i]<=num) left.push(arr[i]);else right.push(arr[i]);}return quickSort(left).concat([num],quickSort(right));
}
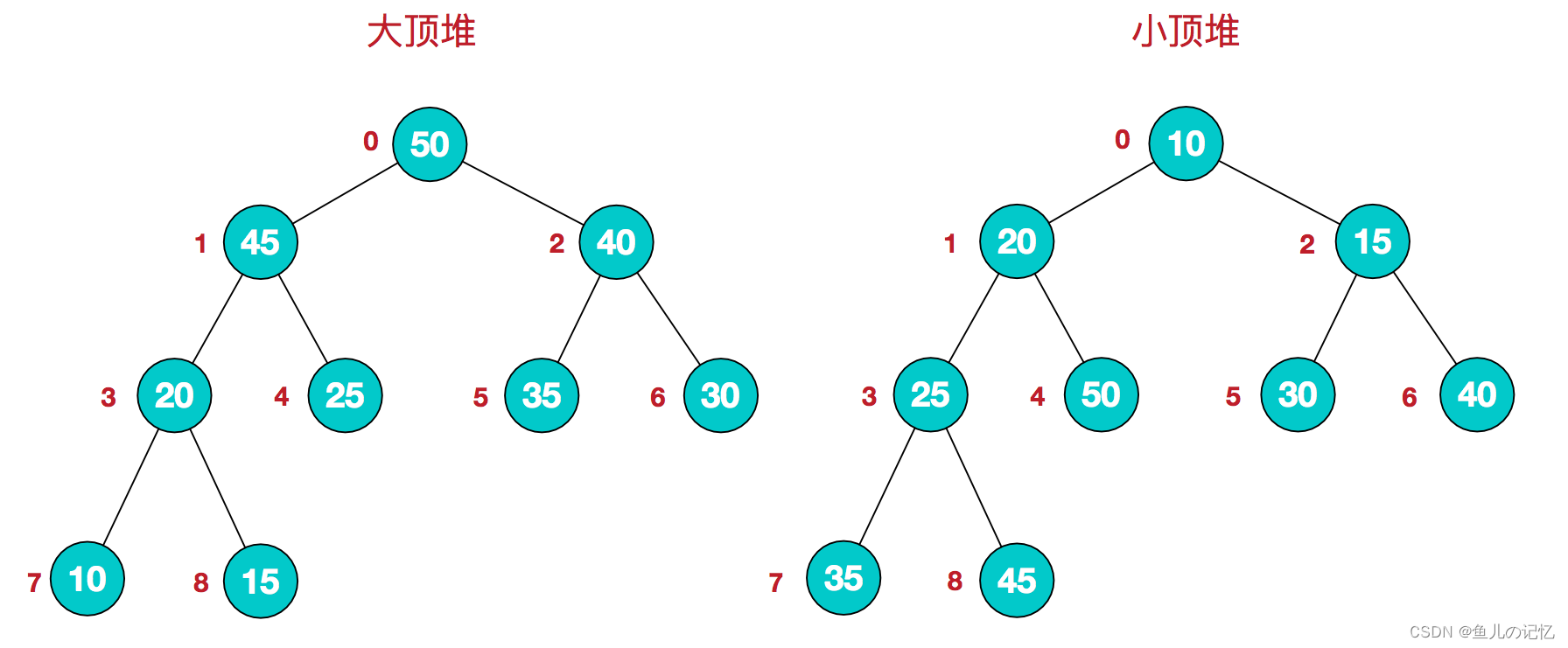
堆排序
利用堆这种数据结构而设计的一种排序算法,堆排序是一种选择排序,它的最坏,最好,平均时间复杂度均为0(nlogn),它也是不稳定排序。
- 将初始待排序关键字序列(R1,R2….Rn)构建成大顶堆,此堆为初始的无序区;
- 将堆顶元素R[1]与最后一个元素R[n]交换,此时得到新的无序区(R1,R2,……Rn-1)和新的有序区(Rn),且满足R[1,2…n-1]<=R[n];
- 由于交换后新的堆顶R[1]可能违反堆的性质,因此需要对当前无序区(R1,R2,……Rn-1)调整为新堆,然后再次将R[1]与无序区最后一个元素交换,得到新的无序区(R1,R2….Rn-2)和新的有序区(Rn-1,Rn)。不断重复此过程直到有序区的元素个数为n-1,则整个排序过程完成。

Java
public static void sort(int []arr){//1.构建大顶堆for(int i=arr.length/2-1;i>=0;i--){//从第一个非叶子结点从下至上,从右至左调整结构adjustHeap(arr,i,arr.length);}//2.调整堆结构+交换堆顶元素与末尾元素for(int j=arr.length-1;j>0;j--){swap(arr,0,j);//将堆顶元素与末尾元素进行交换adjustHeap(arr,0,j);//重新对堆进行调整}}/*** 调整大顶堆(仅是调整过程,建立在大顶堆已构建的基础上)* @param arr* @param i* @param length*/public static void adjustHeap(int []arr,int i,int length){int temp = arr[i];//先取出当前元素ifor(int k=i*2+1;k<length;k=k*2+1){//从i结点的左子结点开始,也就是2i+1处开始if(k+1<length && arr[k]<arr[k+1]){//如果左子结点小于右子结点,k指向右子结点k++;}if(arr[k] >temp){//如果子节点大于父节点,将子节点值赋给父节点(不用进行交换)arr[i] = arr[k];i = k;}else{break;}}arr[i] = temp;//将temp值放到最终的位置}/*** 交换元素* @param arr* @param a* @param b*/public static void swap(int []arr,int a ,int b){int temp=arr[a];arr[a] = arr[b];arr[b] = temp;}
Python
建堆-调堆-排序
def heapify(unsorted, index, heap_size):largest = indexleft_index = 2 * index + 1right_index = 2 * index + 2if left_index < heap_size and unsorted[left_index] > unsorted[largest]:largest = left_indexif right_index < heap_size and unsorted[right_index] > unsorted[largest]:largest = right_indexif largest != index:unsorted[largest], unsorted[index] = unsorted[index], unsorted[largest]heapify(unsorted, largest, heap_size)
def heap_sort(unsorted):n = len(unsorted)for i in range(n // 2 - 1, -1, -1):heapify(unsorted, i, n)for i in range(n - 1, 0, -1):unsorted[0], unsorted[i] = unsorted[i], unsorted[0]heapify(unsorted, 0, i)return unsortedif __name__ == '__main__':test = [4,3,2,1]print(heap_sort(test))Js
/*调整函数@param arr 待排序的数组@param i 表示等待调整的那个非叶子节点的索引@param length 待调整长度
*/
function adjustHeap(arr,i,length){var notLeafNodeVal = arr[i]; //非叶子节点的值//for循环,k的初始值为当前非叶子节点的左孩子节点的索引//k = 2*k+1表示再往左子节点找for(var k=i*2+1;k<length;k=2*k+1){//如果k+1还在待调整的长度内,且右子树的值大于等于左子树的值//将k++,此时为当前节点的右孩子节点的索引if(k+1<length && arr[k]<arr[k+1]){k++;}//如果孩子节点大于当前非叶子节点if(arr[k]>notLeafNodeVal){arr[i] = arr[k]; //将当前节点赋值为孩子节点的值i = k;//将i赋值为孩子的值,再看其孩子节点是否有比它大的}else{break; //能够break的保证是:从左到右、从上到下进行调整//只要上面的不大于,下面的必不大于}}//循环结束后,将i索引处的节点赋值为之前存的那个非叶子节点的值arr[i] = notLeafNodeVal;
}//堆排序函数
function heapSort(arr){//进行第一次调整for(var i=parseInt(arr.length/2)-1;i>=0;i--){adjustHeap(arr,i,arr.length);}for(var j=arr.length-1;j>0;j--){/*进行交换:第一次调整的时候从左到右、从上到下的;交换时只是变动了堆顶元素和末尾元素,末尾元素不用去管,因为已经是之前长度最大的了,只需要把当前堆顶元素找到合适的位置即可*/var temp = arr[j];arr[j] = arr[0];arr[0] = temp;adjustHeap(arr,0,j);}
}var arr = [0,2,4,1,5];
console.log("排序前的数组:",arr);
heapSort(arr);
console.log("排序后的数组:",arr);希尔排序
插入排序的一种算法,先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,待整个序列中的记录"基本有序"时,再对全体记录进行依次直接插入排序。时间复杂度O(N^1.3)
- 选择一个增量序列t1,t2,…,tk,其中ti>tj,tk=1;
- 按增量序列个数k,对序列进行k 趟排序;
- 每趟排序,根据对应的增量ti,将待排序列分割成若干长度为m 的子序列,分别对各子表进行直接插入排序。仅增量因子为1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
Java
/*初始化划分增量*/int increment = len; int j,temp,low,mid,high;/*每次减小增量,直到increment = 1*/while (increment > 1){ /*增量的取法之一:除三向下取整+1*/increment = increment/3 + 1;/*对每个按增量划分后的逻辑分组,进行直接插入排序*/for (int i = increment; i < len; ++i) { low = 0;high = i-1;temp = arr[i];while(low <= high){mid = (low+high)/2;if(arr[mid]>temp){high = mid-1;}else{low = mid+1;}}j = i-increment;/*移动元素并寻找位置*/while(j >= high+1){ arr[j+increment] = arr[j];j -= increment;} /*插入元素*/arr[j+increment] = temp; }}
Python
# 希尔排序
def shell_sort(input_list):# 希尔排序:三重循环,依次插入,直接插入法的优化版l = input_list # 简化参数名gaps = [701, 301, 132, 57, 23, 10, 4, 1] # Marcin Ciura's gap sequencefor gap in gaps:for i in range(gap, len(l)):insert_value = l[i] # 终止条件j = iwhile j >= gap and l[j - gap] > insert_value:l[j] = l[j - gap]j -= gapif j != i:l[j] = insert_value # 循环终止,插入值return l
'''# 另外一种写法
def shell_sort(input_list):# 希尔排序:三重循环,依次插入,直接插入法的优化版l = input_list # 简化参数名gap = len(l) // 2 # 长度取半while gap > 0:for i in range(gap, len(l)):insert_value = l[i] # 终止条件j = iwhile j >= gap and l[j - gap] > insert_value:l[j] = l[j - gap]j -= gapif j != i:l[j] = insert_value # 循环终止,插入值gap //= 2return l
'''if __name__ == '__main__':test = [4,3,2,1]print(shell_sort(test))Js
function shellSort(arr) {let len = arr.length;for (let gap = Math.floor(len / 2); gap > 0; gap = Math.floor(gap / 2)) {for (let i = gap; i < len; i++) {let j = i;let current = arr[i];while (j - gap >= 0 && arr[j - gap] > current) {arr[j] = arr[j - gap];j = j - gap;}arr[j] = current;}}return arr;
}
归并排序
归并排序是建立在归并操作上的一种有效的排序算法,该算法是采用分治法的一个非常典型的应用。将已有序的子 序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序 表,称为二路归并。时间复杂度为O(nlogn)
- 把长度为n的输入序列分成两个长度为n/2的子序列;
- 对这两个子序列分别采用归并排序;
- 将两个排序好的子序列合并成一个最终的排序序列。
Java
public class Merge02 {private static Comparable[] assist;public void sort(Comparable[] arr) {assist = new Comparable[arr.length];sort(arr, 0, arr.length - 1);}public void sort(Comparable[] arr, int lo, int hi) {if (lo >= hi) {return;}int mid = lo + (hi - lo) / 2;sort(arr, lo, mid);sort(arr, mid + 1, hi);merge(arr, lo, mid, hi);}public void merge(Comparable[] arr, int lo, int mid, int hi) {int i = lo;int p1 = lo;int p2 = mid + 1;while (p1 <= mid && p2 <= hi) {if (arr[p1].compareTo(arr[p2]) > 0) {assist[i++] = arr[p2++];} else {assist[i++] = arr[p1++];}}while (p1 <= mid) {assist[i++] = arr[p1++];}while (p2 <= hi) {assist[i++] = arr[p2++];}for (int index = lo; index <= hi; index++) {arr[index] = assist[index];}}
}
Python
#merge的功能是将前后相邻的两个有序表归并为一个有序表的算法。
def merge(left, right):ll, rr = 0, 0result = []while ll < len(left) and rr < len(right):if left[ll] < right[rr]:result.append(left[ll])ll += 1else:result.append(right[rr])rr += 1result+=left[ll:]result+=right[rr:]return resultdef merge_sort(alist):if len(alist) <= 1:return alistnum = len(alist) // 2 # 从中间划分两个子序列left = merge_sort(alist[:num]) # 对左侧子序列进行递归排序right = merge_sort(alist[num:]) # 对右侧子序列进行递归排序return merge(left, right) #归并tesl=[1,3,45,23,23,12,43,45,33,21]
print(merge_sort(tesl))
#[1, 3, 12, 21, 23, 23, 33, 43, 45, 45]
Js
// 合并做分支数组和右分支数组,左分支和右分支在自己数组里面已经是有序的。所以就方便很多。
function merge(left, right){// 剪枝优化if(left[left.length -1] <= right[0]){return left.concat(right)}if(right[right.length-1] <= left[0]){return right.concat(left)}let tmp = [];let leftIndex =0, rightIndex = 0;while(leftIndex < left.length && rightIndex < right.length) {if(left[leftIndex] <= right[rightIndex]) {tmp.push(left[leftIndex]);leftIndex ++;}else{tmp.push(right[rightIndex]);rightIndex ++;}}// 最后,检查一下是否有数组内容没有拷贝完if(leftIndex < left.length){tmp = tmp.concat(left.slice(leftIndex))}if(rightIndex < right.length){tmp = tmp.concat(right.slice(rightIndex))}return tmp;
}function mergeSort(arr){// 拆到只有一个元素的时候,就不用再拆了。if(arr.length <2){return arr;}const mid = arr.length/2;const left = arr.slice(0, mid);const right = arr.slice(mid);const leftSplited = mergeSort(left);const rightSplited = mergeSort(right);return merge(leftSplited, rightSplited);
}基数排序(Radix Sort)
基数排序是按照低位先排序,然后收集;再按照高位排序,然后再收集;依次类推,直到最高位。有时候有些属性是有优先级顺序的,先按低优先级排序,再按高优先级排序。最后的次序就是高优先级高的在前,高优先级相同的低优先级高的在前。基数排序基于分别排序,分别收集,所以是稳定的。 基数排序的平均时间复杂度为 O(nk),k 为最大元素的长度,最坏时间复杂度为 O(nk),空间复杂度为 O(n) ,是稳定排序。
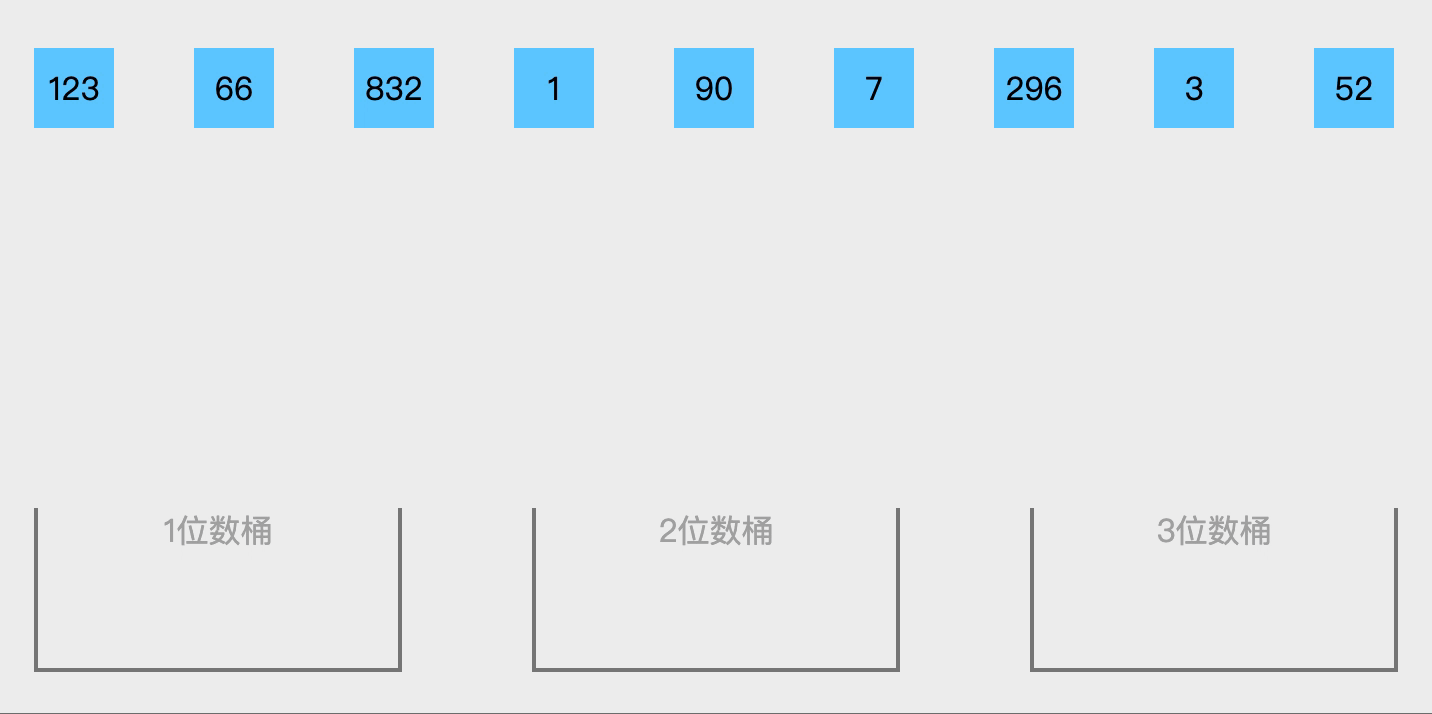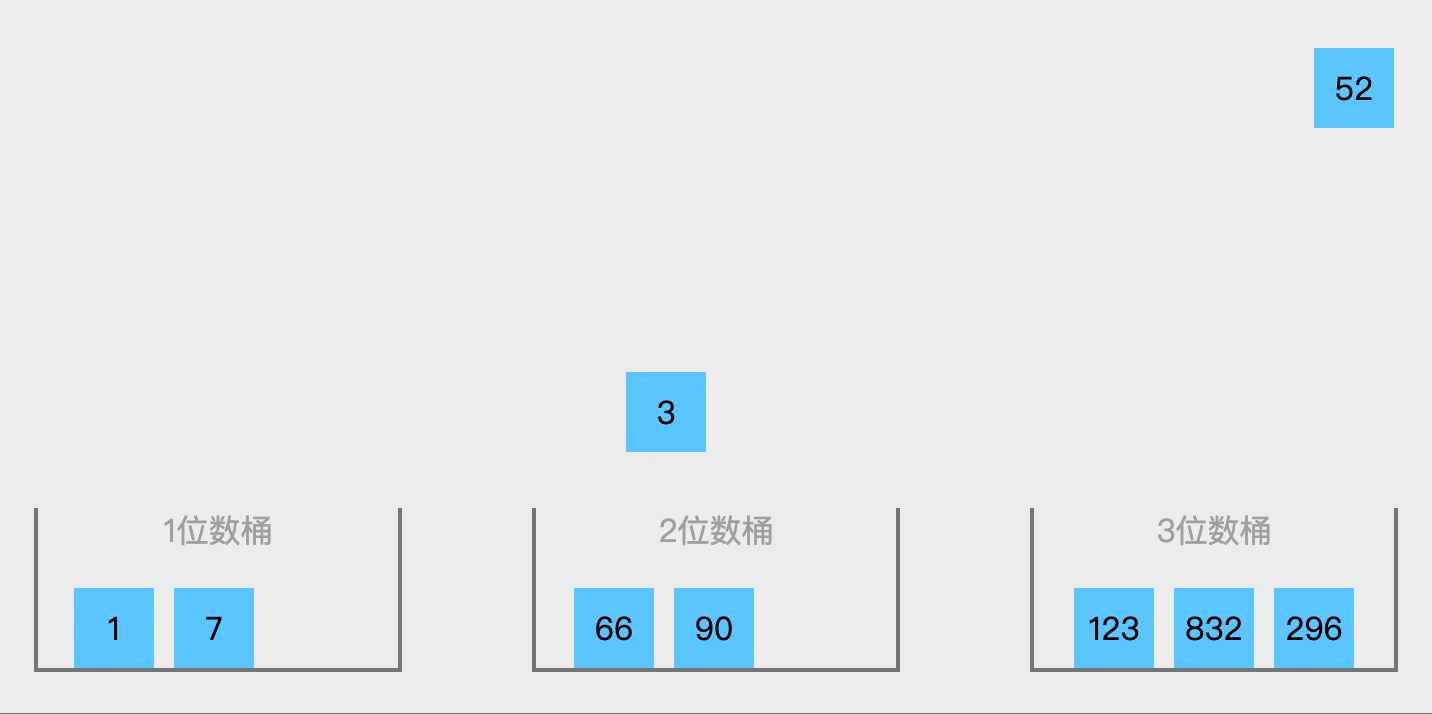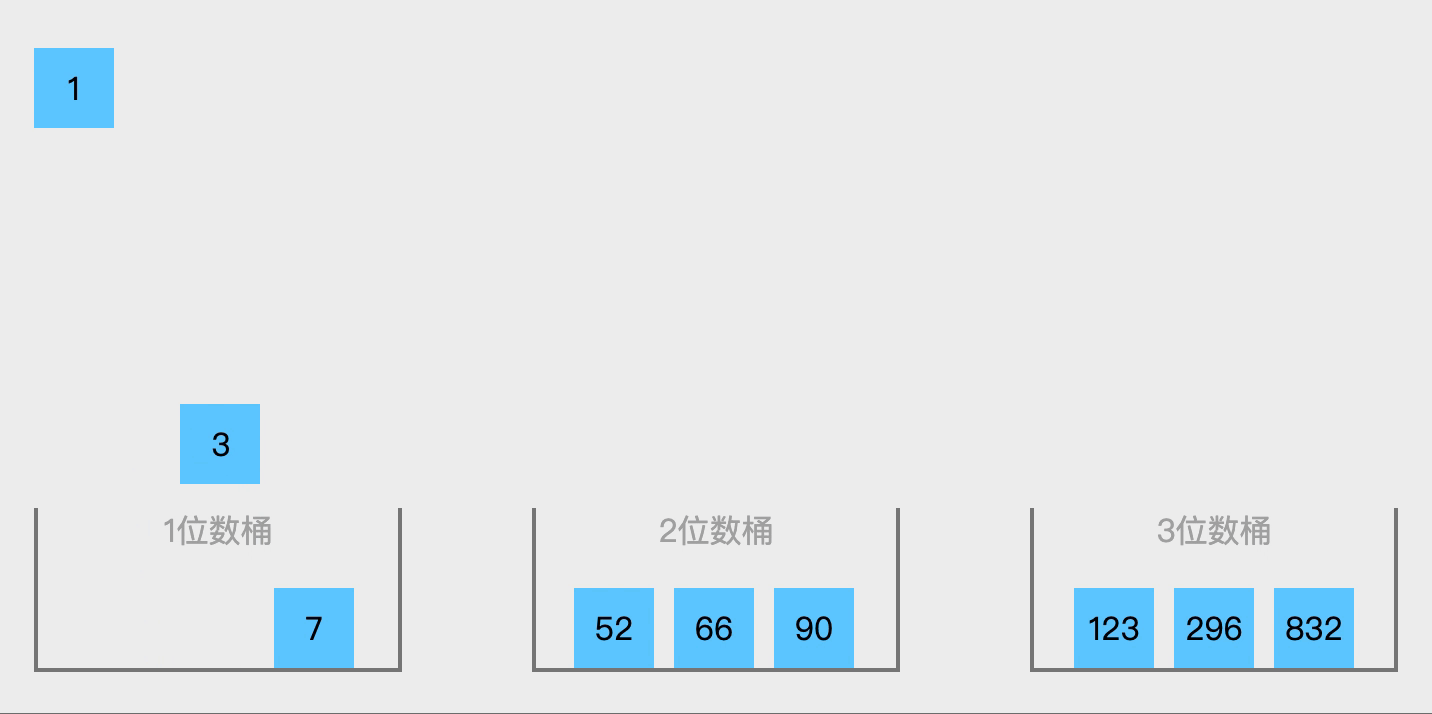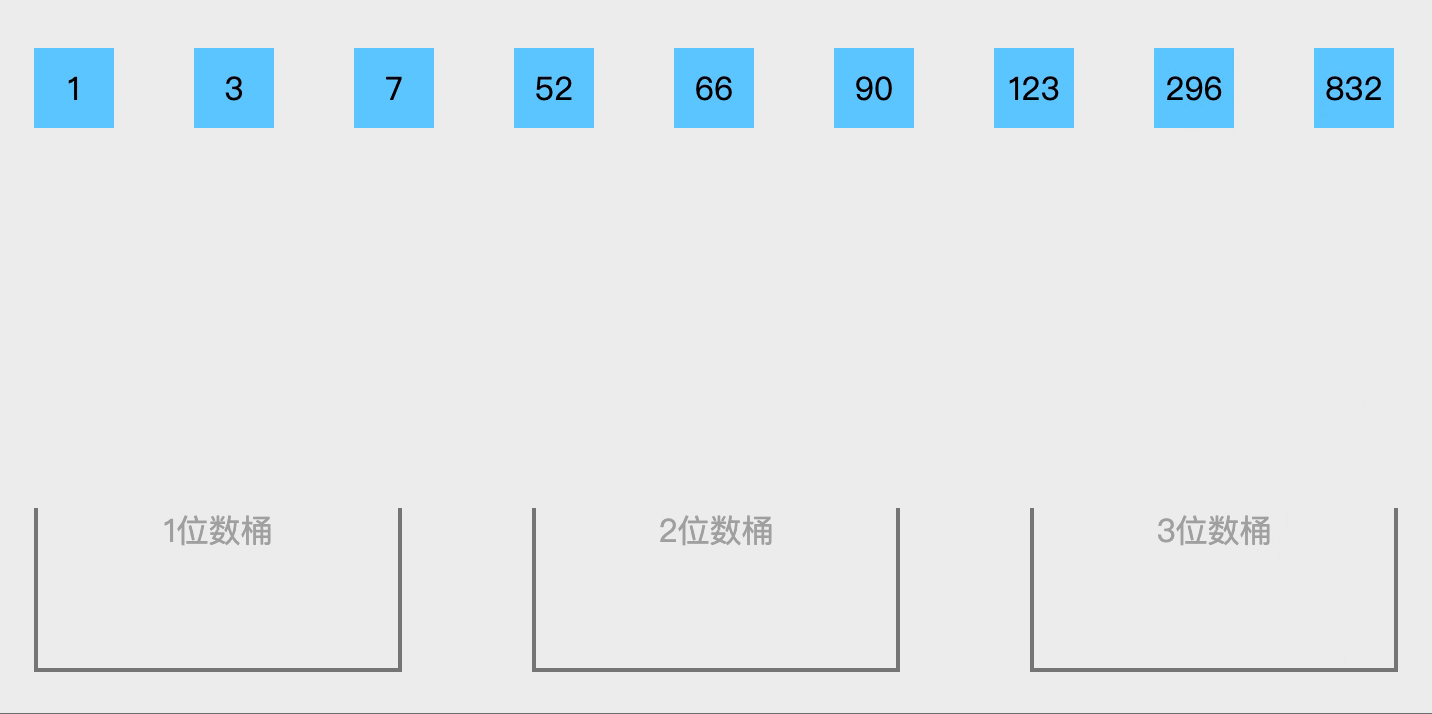
- 取得数组中的最大数,并取得位数,即为迭代次数n(例如:数组中最大数为123,则 n=3);
- arr为原始数组,从最低位(或最高位)开始根据每位的数字组成radix数组(radix数组是个二维数组,其中一维长度为10),例如123在第一轮时存放在下标为3的radix数组中;
- 将radix数组中的数据从0下标开始依次赋值给原数组;
- 重复2~3步骤n次即可。

Java
public static void radixSort(int[] arr) {if (arr.length < 2) return;int maxVal = arr[0];//求出最大值for (int a : arr) {if (maxVal < a) {maxVal = a;}}int n = 1;while (maxVal / 10 != 0) {//求出最大值位数maxVal /= 10;n++;}for (int i = 0; i < n; i++) {List<List<Integer>> radix = new ArrayList<>();for (int j = 0; j < 10; j++) {radix.add(new ArrayList<>());}int index;for (int a : arr) {index = (a / (int) Math.pow(10, i)) % 10;radix.get(index).add(a);}index = 0;for (List<Integer> list : radix) {for (int a : list) {arr[index++] = a;}}}}
Python
def radix_sort(input_list):RADIX = 10placement = 1max_digit = max(input_list)while placement <= max_digit:buckets: list[list] = [list() for _ in range(RADIX)]for i in input_list:tmp = int((i / placement) % RADIX)buckets[tmp].append(i)a = 0for b in range(RADIX):for i in buckets[b]:input_list[a] = ia += 1# move to nextplacement *= RADIXreturn input_listif __name__ == '__main__':test = [4,3,2,1]print(radix_sort(test))Js
function radixSort(array) {let length = array.length;// 如果不是数组或者数组长度小于等于1,直接返回,不需要排序if (!Array.isArray(array) || length <= 1) return;let bucket = [],max = array[0],loop;// 确定排序数组中的最大值for (let i = 1; i < length; i++) {if (array[i] > max) {max = array[i];}}// 确定最大值的位数loop = (max + '').length;// 初始化桶for (let i = 0; i < 10; i++) {bucket[i] = [];}for (let i = 0; i < loop; i++) {for (let j = 0; j < length; j++) {let str = array[j] + '';if (str.length >= i + 1) {let k = parseInt(str[str.length - 1 - i]); // 获取当前位的值,作为插入的索引bucket[k].push(array[j]);} else {// 处理位数不够的情况,高位默认为 0bucket[0].push(array[j]);}}array.splice(0, length); // 清空旧的数组// 使用桶重新初始化数组for (let i = 0; i < 10; i++) {let t = bucket[i].length;for (let j = 0; j < t; j++) {array.push(bucket[i][j]);}bucket[i] = [];}}return array;
}桶排序(Bucket Sort)
计数排序的升级版。在额外空间充足的情况下,尽量增大桶的数量。使用的映射函数能够将输入的 N 个数据均匀的分配到 K 个桶中。
设置一个bucketSize(该数值的选择对性能至关重要,性能最好时每个桶都均匀放置所有数值,反之最差),表示每个桶最多能放置多少个数值;
遍历输入数据,并且把数据依次放到到对应的桶里去;
对每个非空的桶进行排序,可以使用其它排序方法(这里递归使用桶排序);
从非空桶里把排好序的数据拼接起来即可。
Java
private static List<Integer> bucketSort(List<Integer> arr, int bucketSize) {int len = arr.size();if (len < 2 || bucketSize == 0) {return arr;}int minVal = arr.get(0), maxVal = arr.get(0);for (int i = 1; i < len; i++) {if (arr.get(i) < minVal) {minVal = arr.get(i);} else if (arr.get(i) > maxVal) {maxVal = arr.get(i);}}int bucketNum = (maxVal - minVal) / bucketSize + 1;List<List<Integer>> bucket = new ArrayList<>();for (int i = 0; i < bucketNum; i++) {bucket.add(new ArrayList<>());}for (int val : arr) {int idx = (val - minVal) / bucketSize;bucket.get(idx).add(val);}for (int i = 0; i < bucketNum; i++) {if (bucket.get(i).size() > 1) {bucket.set(i, bucketSort(bucket.get(i), bucketSize / 2));}}List<Integer> result = new ArrayList<>();for (List<Integer> val : bucket) {result.addAll(val);}return result;}Python
def bucket_sort(input_list):l = input_listif not l:return []l_max, l_min = max(l), min(l)bucket_len = int(l_max - l_min) + 1buckets: list[list] = [[] for _ in range(bucket_len)]for i in l:buckets[int(i - l_min)].append(i)return [i for bucket in buckets for i in sorted(bucket)]if __name__ == '__main__':test = [4,3,2,1]print(bucket_sort(test))Js
function bucketSort(arr, bucketSize) {if (arr.length === 0) {return arr;}var i;var minValue = arr[0];var maxValue = arr[0];//求出最大值和最小值,这里有两种方式,两种方式只用其一,这里采用方式二。方式一://for (i = 1; i < arr.length; i++) {// if (arr[i] < minValue) {// minValue = arr[i]; // 输入数据的最小值// } else if (arr[i] > maxValue) {// maxValue = arr[i]; // 输入数据的最大值// }// }//方式二:maxValue = Math.max(...arr);minValue = Math.min(...arr);//桶的初始化var DEFAULT_BUCKET_SIZE = 5; // 设置桶的默认数量为5bucketSize = bucketSize || DEFAULT_BUCKET_SIZE;var bucketCount = Math.floor((maxValue - minValue) / bucketSize) + 1; var buckets = new Array(bucketCount);for (i = 0; i < buckets.length; i++) {buckets[i] = [];}//利用映射函数将数据分配到各个桶中for (i = 0; i < arr.length; i++) {buckets[Math.floor((arr[i] - minValue) / bucketSize)].push(arr[i]);}arr.length = 0;for (i = 0; i < buckets.length; i++) {insertionSort(buckets[i]); // 对每个桶进行排序,这里使用了插入排序,这里也可以直接用js的数组sort方法,很直接for (var j = 0; j < buckets[i].length; j++) {arr.push(buckets[i][j]); }}return arr;
}
计数排序
计数排序是一种非基于比较的排序算法,其空间复杂度和时间复杂度均为O(n+k),其中k是整数的范围。基于比较的排序算法时间复杂度最小是O(nlogn)的。
- 找出数组中的最大值maxVal和最小值minVal;
- 创建一个计数数组countArr,其长度是maxVal-minVal+1,元素默认值都为0;
- 遍历原数组arr中的元素arr[i],以arr[i]-minVal作为countArr数组的索引,以arr[i]的值在arr中元素出现次数作为countArr[a[i]-min]的值;
- 遍历countArr数组,只要该数组的某一下标的值不为0则循环将下标值+minVal输出返回到原数组即可。
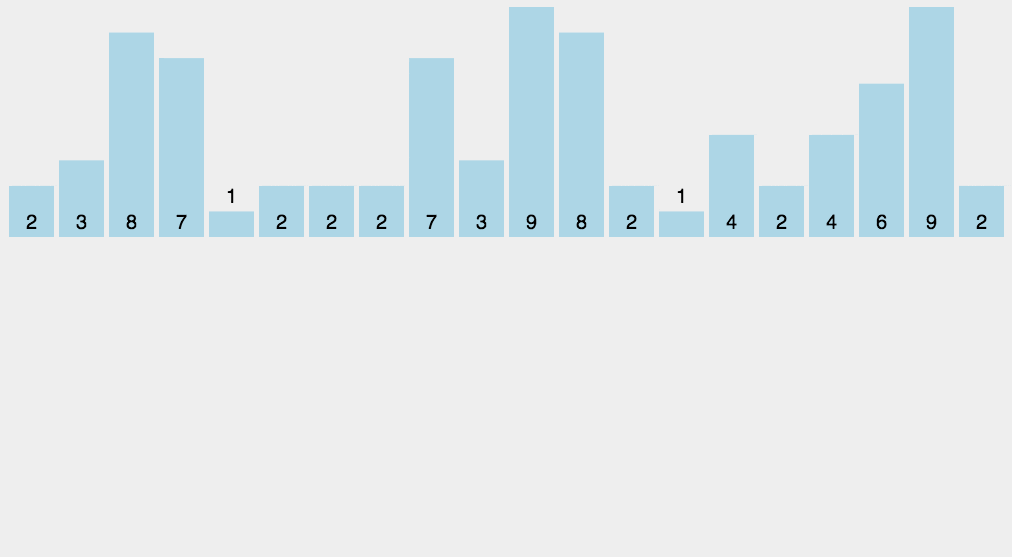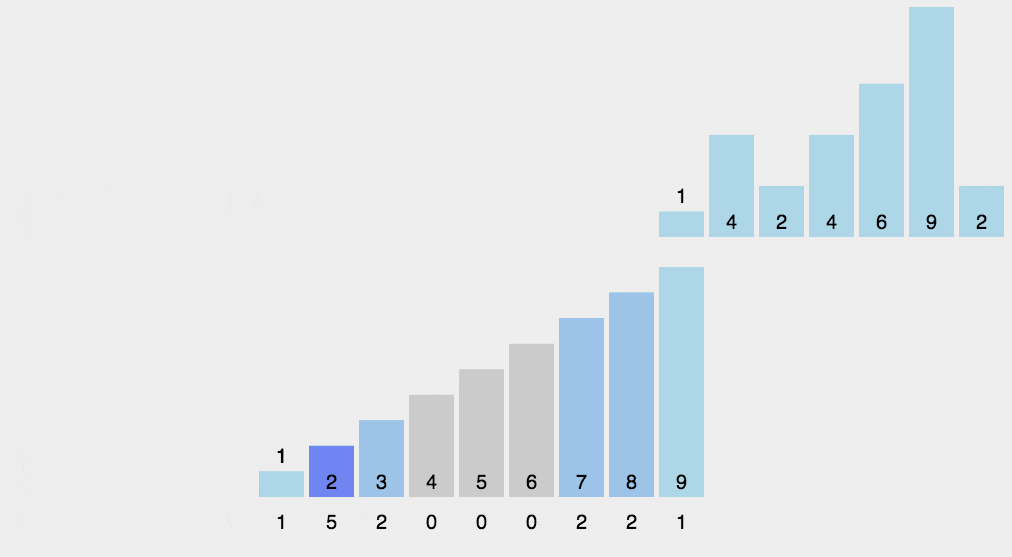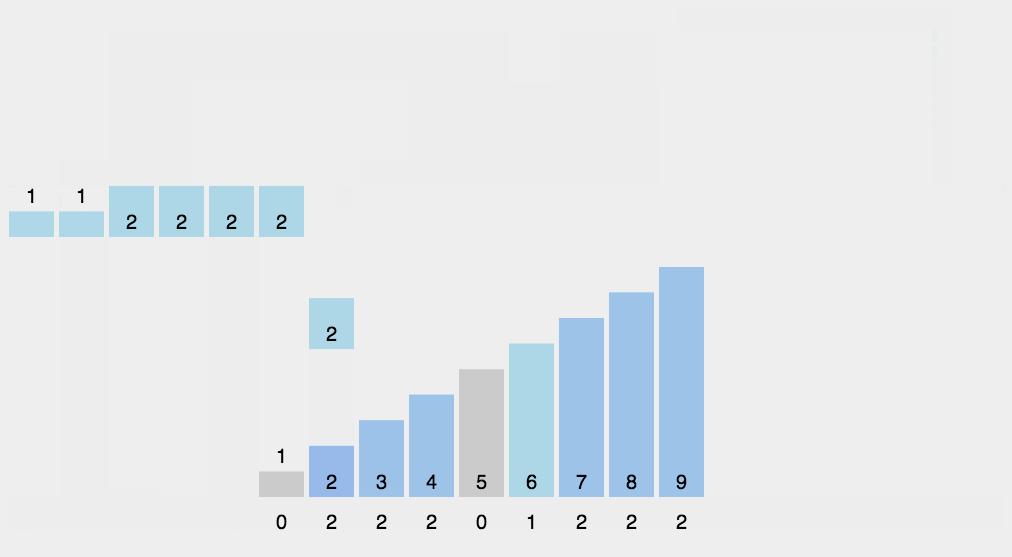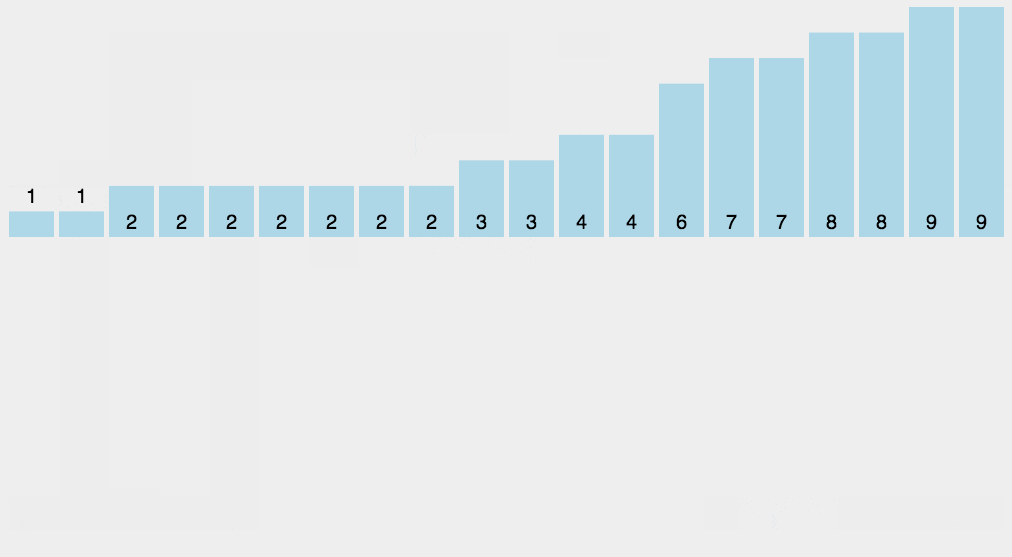
Java
public static void countingSort(int[] arr) {int len = arr.length;if (len < 2) return;int minVal = arr[0], maxVal = arr[0];for (int i = 1; i < len; i++) {if (arr[i] < minVal) {minVal = arr[i];} else if (arr[i] > maxVal) {maxVal = arr[i];}}int[] countArr = new int[maxVal - minVal + 1];for (int val : arr) {countArr[val - minVal]++;}for (int arrIdx = 0, countIdx = 0; countIdx < countArr.length; countIdx++) {while (countArr[countIdx]-- > 0) {arr[arrIdx++] = minVal + countIdx;}}}Python
def count_sort2(arr):maxi = max(arr)mini = min(arr)count_arr_length = maxi - mini + 1 # 计算待排序列表的数值区域长度,如4-9共9+1-4=6个数count_arr = [0 for _ in range(count_arr_length)] # 创建一个全为0的列表for value in arr:count_arr[value - mini] += 1 # 统计列表中每个值出现的次数# 使count_arr[i]存放<=i的元素个数,就是待排序列表中比某个值小的元素有多少个for i in range(1, count_arr_length):count_arr[i] = count_arr[i] + count_arr[i - 1]new_arr = [0 for _ in range(len(arr))] # 存放排序结果for i in range(len(arr)-1, -1, -1): # 从后往前循环是为了使排序稳定new_arr[count_arr[arr[i] - mini] - 1] = arr[i] # -1是因为下标是从0开始的count_arr[arr[i] - mini] -= 1 # 每归位一个元素,就少一个元素return new_arrif __name__ == '__main__':user_input = input('输入待排序的数,用\",\"分隔:\n').strip()#strip() 方法用于移除字符串头尾指定的字符(默认为空格)unsorted = [int(item) for item in user_input.split(',')]print(count_sort2(unsorted))Js
function countingSort(arr, maxValue) {var bucket = new Array(maxValue+1),sortedIndex = 0;arrLen = arr.length,bucketLen = maxValue + 1;for (var i = 0; i < arrLen; i++) {if (!bucket[arr[i]]) {bucket[arr[i]] = 0;}bucket[arr[i]]++;}for (var j = 0; j < bucketLen; j++) {while(bucket[j] > 0) {arr[sortedIndex++] = j;bucket[j]--;}}return arr;
}
var arr = [2, 3, 8, 7, 1, 2, 7, 3];
console.log(countingSort(arr,8));//1,2,2,3,3,7,7,8🌹 以上分享 10大常见排序算法,如有问题请指教写。🌹🌹 如你对技术也感兴趣,欢迎交流。🌹🌹🌹 如有需要,请👍点赞💖收藏🐱🏍分享 相关文章:
详解排序算法(附带Java/Python/Js源码)
冒泡算法 依次比较两个相邻的子元素,如果他们的顺序错误就把他们交换过来,重复地进行此过程直到没有相邻元素需要交换,即完成整个冒泡,时间复杂度。 比较相邻的元素。如果第一个比第二个大,就交换它们两个;…...
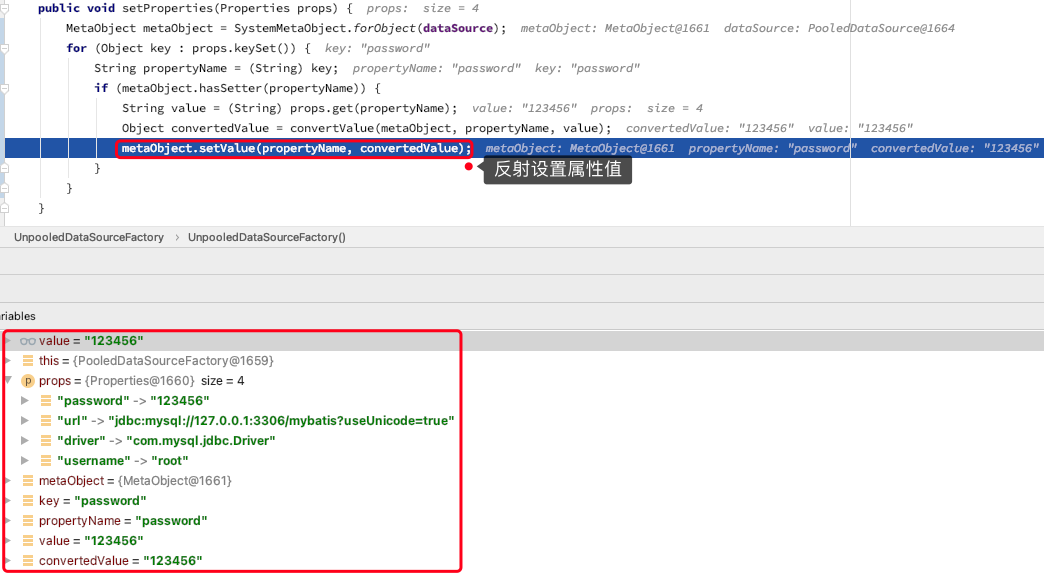
手写Mybatis:第8章-把反射用到出神入化
文章目录 一、目标:元对象反射类二、设计:元对象反射类三、实现:元对象反射类3.1 工程结构3.2 元对象反射类关系图3.3 反射调用者3.3.1 统一调用者接口3.3.2 方法调用者3.3.3 getter 调用者3.3.4 setter 调用者 3.4 属性命名和分解标记3.4.1 …...
基于AI智能分析网关EasyCVR视频汇聚平台关于能源行业一体化监控平台可实施应用方案
随着数字经济时代的到来,实体经济和数字技术深度融合已成为经济发展的主流思路。传统能源行业在运营管理方面也迎来了新的考验和机遇。许多大型能源企业已开始抓住机遇,逐步将视频监控、云计算、大数据和人工智能技术广泛应用于生产、维护、运输、配送等…...
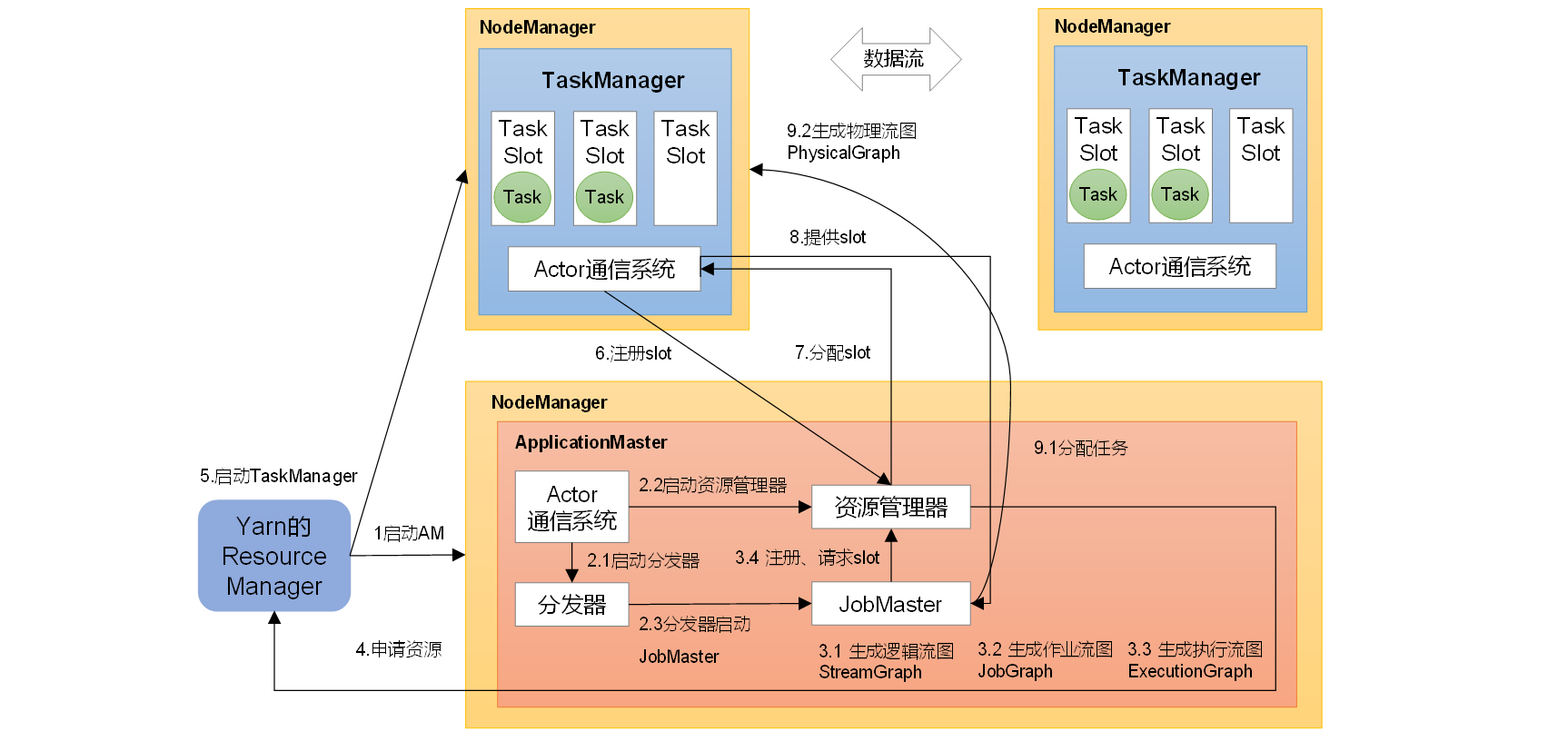
《Flink学习笔记》——第四章 Flink运行时架构
4.1 系统架构 Flink运行时架构 Flink 运行时由两种类型的进程组成:一个 JobManager 和一个或者多个 TaskManager。 1、作业管理器(JobManager) JobManager是一个Flink集群中任务管理和调度的核心,是控制应用执行的主进程。也就…...

vue3使用Elementplus 动态显示菜单icon不生效
1.问题描述 菜单icon由后端提供,直接用的字符串返回,前端使用遍历显示,发现icon不会显示 {id: 8, path:/userManagement, authName: "用户管理", icon: User, rights:[view]}, <el-menu-item :index"menu.path" v-f…...
升级iOS17后iPhone无法连接App Store怎么办?
最近很多用户反馈,升级最新iOS 17系统后打开App Store提示"无法连接",无法正常打开下载APP。 为什么升级后无法连接到App Store?可能是以下问题导致: 1.网络问题导致App Store无法正常打开 2.网络设置问题 3.App Sto…...
antd日期选择禁止
1、年月日——日期禁止当天之前的,不包括当天的(带有时间的除外) 2、年月日——日期禁用当天之前的(包括当天的) 部分代码如下:...
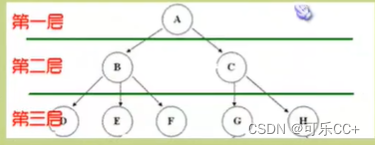
数据结构--树4.1
目录 一、树的定义 二、结点的分类 三、结点间的关系 四、结点的层次 五、树的存储结构 一、树的定义 树(Tree)是n(n>0)个结点的有限集。当n0时称为空树,在任意一个非空树中: ——有且仅有一个特定的…...
webpack介绍与基础配置)
webpack(二)webpack介绍与基础配置
什么是webpack webpack最初的目标是实现前端项目模块化,旨在更高效的管理和维护项目中的每一个资源。 可以看做是模块打包机,分析你的项目结构,找到javascript模块以及其它一些浏览器不能直接运行的拓展语言(Scss、TypeScript等&…...

RabbitMQ | 在ubuntu中使用apt-get安装高版本RabbitMQ
目录 一、官方脚本 二、彻底卸载 三、重新安装 1.安装高版本Erlang 2.安装RabbitMQ 一、官方脚本 直接使用apt安装的rabbitmq版本较低,甚至可能无法使用死信队列等插件。首先提供一个 官方 的安装脚本: #!/usr/bin/sh sudo apt-get install curl …...

springboot集成es 插入和查询的简单使用
第一步:引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId><version>2.2.5.RELEASE</version></dependency>第二步:…...
liunx下ubuntu基础知识学习记录
使用乌班图 命令安装使用安装网络相关工具安装dstat抓包工具需要在Ubuntu内安装openssh-server gcc安装vim安装hello word输出1. 首先安装gcc 安装这个就可以把gcc g一起安装2. 安装VIM3.编译运行代码 解决ubuntu与主机不能粘贴复制 命令安装使用 安装网络相关工具 使用ifconf…...
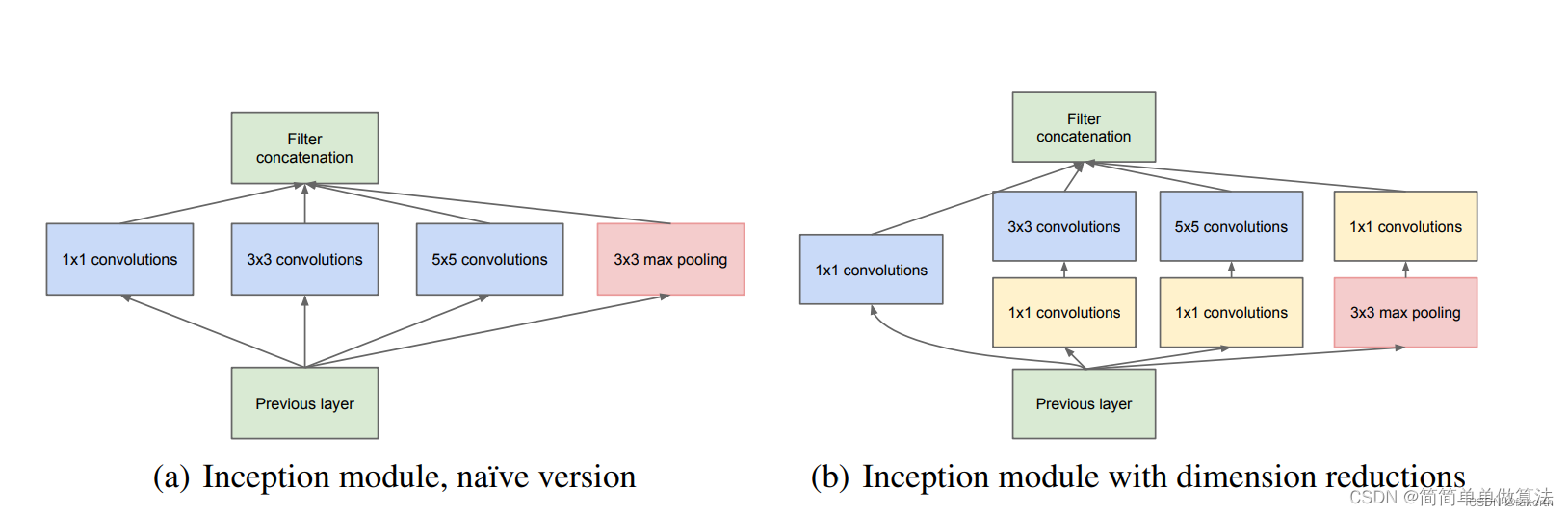
基于Googlenet深度学习网络的螺丝瑕疵检测matlab仿真
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 5.算法完整程序工程 1.算法运行效果图预览 2.算法运行软件版本 matlab2022a 3.部分核心程序 ....................................................................................% 获…...
keepalived + lvs (DR)
目录 一、概念 二、实验流程命令 三、实验的目的 四、实验步骤 一、概念 Keepalived和LVS(Linux Virtual Server)可以结合使用来实现双机热备和负载均衡。 Keepalived负责监控主备服务器的可用性,并在主服务器发生故障时,将…...

微服务框架 go-zero 快速实战
对于咱们快速了解和将 go-zero 使用起来,我们需要具备如下能力: 基本的环境安装和看文档的能力 Golang 的基本知识 Protobuf 的基本知识 web,rpc 的基本知识 基本的 mysql 知识 其实这些能力,很基础,不需要多么深入&a…...

mysql基础面经之三:事务
6 事务 6.1 说一下事务的ACID和隔离级别 1 讲解了AID三个特性都是为了C(一致性)服务的。一般数据库需要使用事务保证数据库的一致性。 正确情况下最好详细讲讲: ACID是用来描述数据库事务的四个关键特性的首字母缩写,具体包括&a…...
JavaScript基本数组操作
在JavaScript中,内置了很多函数让我们可以去对数组进行操作,本文我们就来学习这些函数吧 添加元素 push ● push可以让我们在数组后面再添加一个数据,例如 const friends ["张三", "李四", "王五"]; frie…...

C#---第21: partial修饰类的特性及应用
0.知识背景 局部类型适用于以下情况: 类型特别大,不宜放在一个文件中实现。一个类型中的一部分代码为自动化工具生成的代码,不宜与我们自己编写的代码混合在一起。需要多人合作编写一个类 局部类型的限制: 局部类型只适用于类、接口、结构&am…...
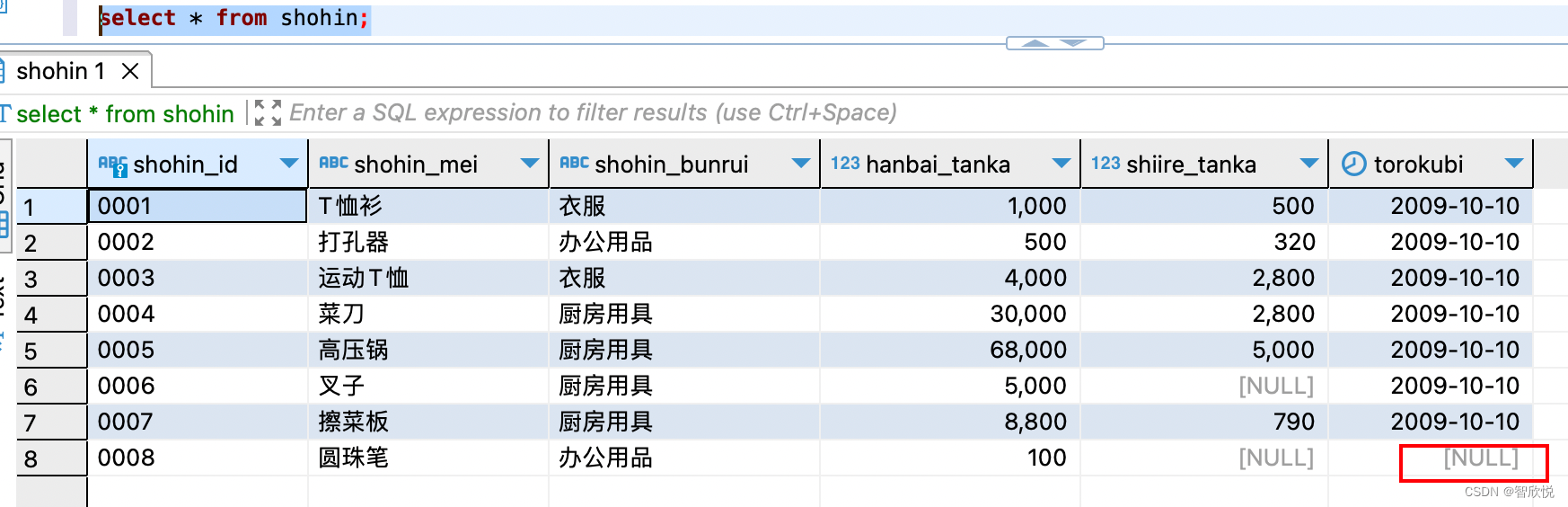
SQL 语句继续学习之记录三
一,数据的插入(insert 语句的使用方法) 使用insert语句可以向表中插入数据(行)。原则上,insert语句每次执行一行数据的插入。 列名和值用逗号隔开,分别扩在()内,这种形式称为清单。…...

Nexus仓库介绍以及maven deploy配置
一 、Nexus仓库介绍 首先介绍一下Nexus的四个仓库的结构: maven-central 代理仓库,代理了maven的中央仓库:https://repo1.maven.org/maven2/; maven-public 仓库组,另外三个仓库都归属于这个组,所以我们的…...
)
中性点不接地系统或中性点经消弧线圈接地系统的小电流接地故障仿真研究(Simulink仿真实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 🎁…...

ChatGPT API调用费用暴涨?揭秘token计费陷阱:5个被90%开发者忽略的隐性成本源
更多请点击: https://intelliparadigm.com 第一章:ChatGPT API调用费用暴涨?揭秘token计费陷阱:5个被90%开发者忽略的隐性成本源 ChatGPT API 的账单突增,往往并非源于请求量激增,而是被 token 计费机制中…...

大模型时代的技术人:要么驾驭AI,要么被AI驾驭——致软件测试从业者
测试者的新分水岭当ChatGPT在2022年底横空出世时,很多人还只是把它当作一个更会聊天的玩具。然而,仅仅数月之后,当GitHub Copilot 开始自动补全测试脚本,当AI能够在几秒钟内生成数十条高覆盖率的测试用例,当一张手绘草…...

Unity背包系统架构设计:数据驱动、事件总线与三层物品模型
1. 为什么“背包系统”不是功能模块,而是游戏体验的神经中枢 很多人第一次在Unity里拖一个Panel、加几个Image和Text,就以为背包做完了。我见过太多项目——美术资源堆得漂亮,UI动效拉满,结果点开背包,物品不能拖拽、堆…...

iOS自动化测试真机连接失败的五大根因与工程化解决方案
1. 为什么iOS自动化测试总卡在“连不上真机”这一步? Appium做iOS自动化,标题里写“全网最详细”,不是吹牛,是踩过太多坑之后的实话。我带过三支测试团队,从2018年用Xcode 9配Appium 1.8开始,到今天Xcode 1…...

用 Excel 手算一个 1-6-1 MLP:前向传播、损失、反向传播与参数更新
计算示例:本文用一个单输入、6 个隐藏神经元、单输出的多层感知机(MLP)作为例子,展示如何用 Excel 公式完整复现一次训练迭代。配套 Excel 文件中的“MLP计算过程”工作表已经把前向传播、损失计算、反向传播梯度和参数更新全部写…...

监区越界预警革命:UWB单点局限,无感定位全域穿透式风控
监区越界预警革命:UWB单点局限,无感定位全域穿透式风控一、行业现状:传统UWB定位管控的单点式致命短板当前国内绝大多数智慧监区、看守所、戒毒所的人员越界预警与区域管控体系,仍高度依赖UWB穿戴式定位技术,依托定位基…...

用达尔文进化论重构神经网络设计
1. 这不是科幻脑洞,而是一次严肃的思想实验 “What if Charles Darwin Built a Neural Network?”——这个标题乍看像咖啡馆里哲学系学生的即兴发问,但在我过去十年拆解过37个跨学科AI项目、亲手复现过12种生物启发式学习模型后,我敢说&…...

新手教程使用curl命令通过Taotoken测试大模型API连通性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 新手教程:使用curl命令通过Taotoken测试大模型API连通性 当你刚刚在Taotoken平台创建了API Key,最直接、最…...

C++类型推导与auto关键字
C类型推导与auto关键字 类型推导是C11引入的重要特性,通过auto和decltype关键字,编译器可以自动推导变量的类型,减少代码冗余并提高可维护性。 auto关键字让编译器根据初始化表达式推导变量类型。 #include #include #include #include v…...