深度刨析数据在内存中的存储

✨博客主页:小钱编程成长记
🎈博客专栏:进阶C语言
深度刨析数据在内存中的存储
- 1.数据类型介绍
- 1.1 类型的基本归类
- 2.整形在内存中的存储
- 2.1 原码、反码、补码
- 2.2 大小端介绍
- 3.浮点型在内存中的存储
- 3.1 一个例子
- 3.2 浮点数的存储规则
- 3.3指数E从内存中取出的三种情况:
- 3.3一个例子的解释
- 4.总结
1.数据类型介绍
char ------------ 字符数据类型
short int ------- 短整型
int --------------- 整型
long int -------- 长整型
long long int – 更长整型
float ------------ 单精度浮点型
double --------- 双精度浮点型
short, long, long long后的int可省略。
有些小伙伴可能会有疑问,在C语言中有字符串类型吗? 答案是没有。
类型的意义:
1.使用这个类型开辟内存空间的大小(大小决定了使用范围)。
2.提供了看待内存空间的视角。
1.1 类型的基本归类
整型家族:
charunsigned charsigned char
shortunsigned short [int]signed short [int]
intunsigned intsigned int
longunsigned long [int]signed long [int]
long longunsigned long long [int]signed long long [int]
- C语言规定:short == signed short, int、long、long long也一样,
但char是否是signed char ,C语言标准中并没有规定,取决于编译器。- unsigned是无符号型,signed是有符号型,这两种类型的区别是数据的二进制的最高位是否为符号位。
[int]是什么意思呢?
意思是这里的int可以省略。
字符类型为什么会被归类到整型家族呢?
因为字符在内存中存储的是字符的ASCII码值,ASCII码值是整型,所以字符类型归类到整型家族。
浮点型家族:
float
double
long double
构造类型(自定义类型):
> 数组类型
> 结构体类型 struct
> 枚举类型 enum
> 联合类型 union
数组类型为什么也是自定义类型呢?
如:int arr[10] ; arr的类型是int [10] ,数组的大小改变了,数组类型也就改变了,又因为数组的大小是我们自己设置的,所以数组类型也是自定义类型。
指针类型:
int* pi;
char* pc;
float* pf;
void* pv;//无具体类型的指针
空类型:
void 表示空类型(无类型)
通常应用于函数的返回类型、函数的参数、指针类型。
如:void test(void) { },void* pv;
2.整形在内存中的存储
一个变量的创建是要在内存中开辟空间的。空间的大小是根据不同的类型而决定的。
那接下来我们谈谈数据在所开辟内存中到底是如何存储的?
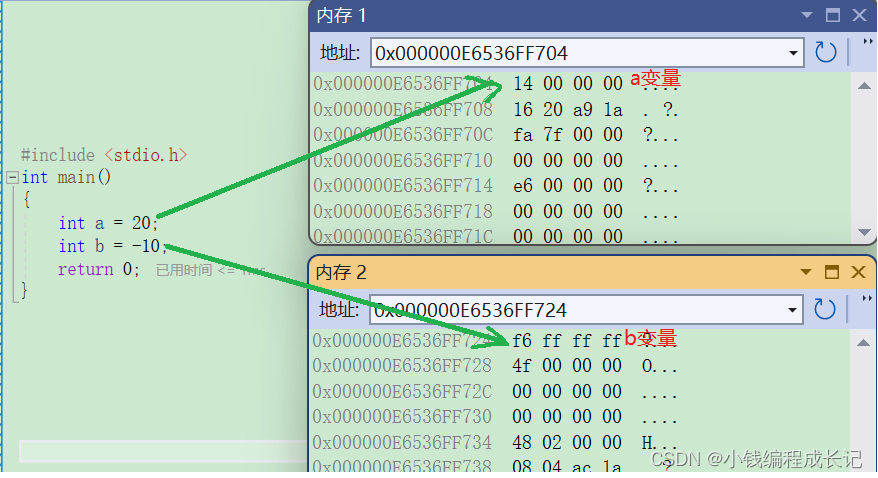
比如:
int a = 20;
int b = -10;
我们知道编译器为 a 分配四个字节的空间。
那到底如何存储?
接下来我们一起来了解下面的概念:
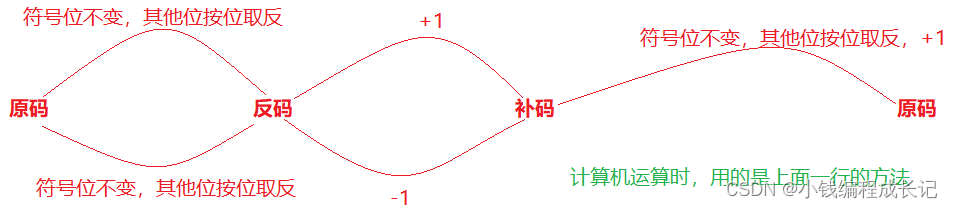
2.1 原码、反码、补码
计算机中的整数有三种2进制表示方法,即原码、反码和补码。
三种表示方法均有 符号位 和 数值位 两部分,符号位都是用0表示“正”,用1表示“负”。
正数的原、反、补码都相同。
负整数的三种表示方法各不相同。 区别如下:
原码 :
直接将数值按照正负数的形式翻译成二进制就可以得到原码。
反码 :
将原码的符号位不变,其他位依次按位取反就可以得到反码。
补码:
反码+1就得到补码。
对于整形来说:数据存放内存中其实存放的是补码。
那是为什么呢?
在计算机系统中,数值一律用补码来表示和存储。原因在于,使用补码,可以将符号位和数值域统一处理;
例如:
//1-1 -> 1+(-1)
00000000000000000000000000000001//1的补码
10000000000000000000000000000001//-1的原码
11111111111111111111111111111110//-1的反码
11111111111111111111111111111111//-1的补码
//1和-1的补码相加得
100000000000000000000000000000000
//共33位
//因为整型只有4字节,32位,所以最高位溢出丢失,结果得到 0,结果正确。//若用原码来计算,则结果为
10000000000000000000000000000010
//相加得-2,则结果错误。同时,加法和减法也可以统一处理(CPU只有加法器)此外,补码与原码相互转换,其运算过程是相同的,不需要额外的硬件电路。
我们来看看在内存中的存储:
小知识
0 1 2 3 4 5 6 7 8 9 a b c d e f (0 ~ 15)
15 -> 1111 所以十六进制中的1位等于二进制中的4位,
十六进制中的2位 == 二进制中的8位 == 一字节
例如:
int a = 10;
因为整型是4字节,32bit, 所以10在内存中是这样存储的:00000000000000000000000000001010
又因为二进制太长了,为了方便我们查看,编译器显示的的是十六进制0x0000000a我们看上面的图片,图片中在内存中的数据的顺序为什么是反的呢?
那就要学习下面的知识了。
2.2 大小端介绍
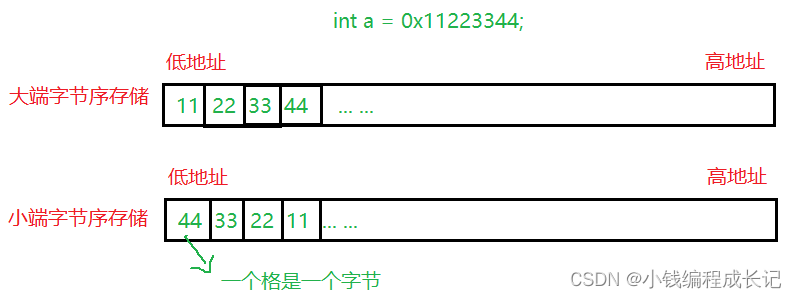
什么是大端小端:
大端(存储)模式:全称大端字节序存储模式,是指数据的低位字节处的数据保存在内存的高地址中,而数据的高位,保存在内存的低地址中;
小端(存储)模式:全称小端字节序存储模式,是指数据的低位字节处的数据保存在内存的低地址中,而数据的高位,保存在内存的高地址中。
如图:
为什么讨论顺序是以字节为单位?
因为内存的基本单位是一字节,一个地址管理一个内存单元(一字节),只有大于一字节才有顺序这一说。
为什么有大端和小端:
为什么会有大小端模式之分呢?这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为8bit。但是在C语言中除了8 bit的char之外,还有16 bit的short 型,32bit的long型(要看具体的编译器),另外,对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如何将多个字节安排的问题。因此就导致了大端存储模式和小端存储模式。
例如:一个16bit 的 short 型 x ,在内存中的地址为 0x0010 , x 的值为 0x1122 ,那么 0x11 为 高字节, 0x22为低字节。对于大端模式,就将 0x11 放在低地址中,即 0x0010 中, 0x22 放在高 地址中,即 0x0011中。小端模式,刚好相反。我们常用的 X86 结构是小端模式,而 KEIL C51 则为大端模式。很多的ARM,DSP都为小端模式。有些ARM处理器还可以由硬件来选择是大端模式 还是小端模式。
3.浮点型在内存中的存储
常见的浮点数:
3.14
1E10 == 1.0 * 10^10(科学计数法)
浮点数家族包括:float、double、long double 类型。
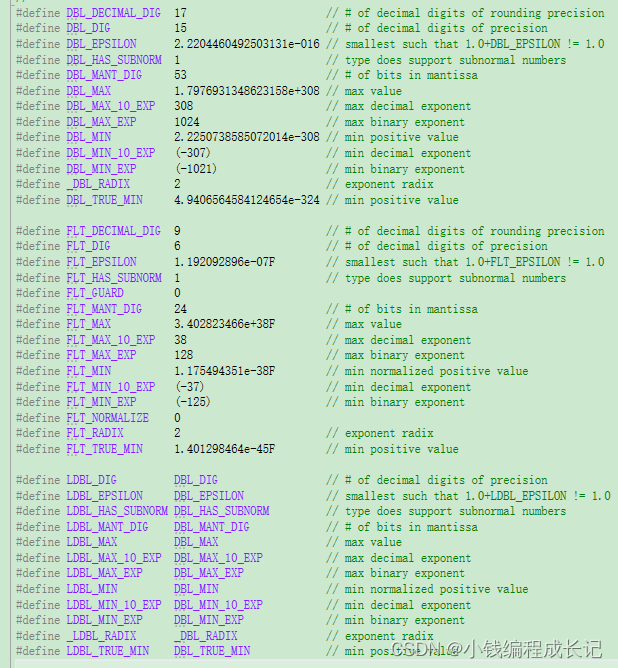
浮点数表示的范围:在float.h中定义,可以找到这个头文件查看, 如下所示:
3.1 一个例子
浮点数存储的例子:
int main()
{int n = 9;float *pFloat = (float *)&n;printf("n的值为:%d\n",n);printf("*pFloat的值为:%f\n",*pFloat);*pFloat = 9.0;printf("num的值为:%d\n",n);printf("*pFloat的值为:%f\n",*pFloat);return 0;
}

3.2 浮点数的存储规则
num 和 *pFloat 在内存中明明是同一个数,为什么浮点数和整数的解读结果会差别这么大?
要理解这个结果,一定要搞懂浮点数在计算机内部的表示方法。
详细解读:
根据国际标准IEEE(电气和电子工程协会)754,任意一个二进制浮点数V可以表示成下面的形式:
- (-1)^S * M * 2^E
- (-1)^S表示符号位,当S=0,V为正数;当S=1,V为负数。
- M表示有效数字,大于等于1,小于2。
- 2^E表示指数位。
举例来说:
十进制的5.0,写成二进制是 101.0 ,相当于 1.01×2^2 。 那么,按照上面V的格式,可以得出S=0,M=1.01,E=2。
十进制的-5.0,写成二进制是 -101.0 ,相当于 -1.01×2^2 。那么,S=1,M=1.01,E=2。
IEEE 754规定:
对于32位的浮点数(float),最高的1位是符号位S,接着的8位是指数E,剩下的32位为有效数字M。
对于64位的浮点数(double),最高的1位是符号位S,接着的11位是指数E,剩下的52位为有效数字M。
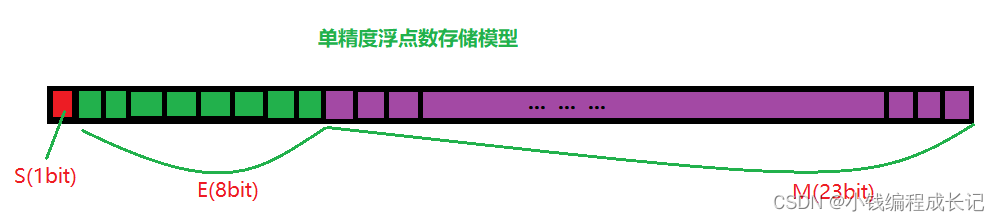
注意:1. 浮点数没有原码、反码、补码。只有整型有原码、反码、补码。
------ 2. 有几位有效数字,这种类型的精度就到几。
IEEE 754对有效数字M有一些特别规定
前面说过1≤M<2, 就是说,M可以写成1.xxxxxx 的形式,其中xxxxxx表示小数部分。
IEEE 754规定,在计算机内部保存M时,默认这个数的第一位总是1,因此可以被舍去,只保存后面的 xxxxxx部分。
比如保存1.01的时候,只保存01,等到读取的时候,再把第一位的1加上去。这样做的目的,是节省1位有效数字。
以32位浮点数为例,留给M只有23位,将第一位的1舍去以后,就可以保存23位小数,就等于可以保存24位有效数字。
至于指数E,情况就比较复杂
首先,E为一个无符号整数(unsigned int)
这意味着,如果E为8位,它的取值范围为0 ~ 255;
如果E为11位,它的取值范围为0 ~ 2047。
但是,我们知道,科学计数法中的E是可以出现负数的,所以IEEE 754规定,存入内存时E的真实值必须再加上一个中间数,这样就用无符号整型表示出了负数,对于8位的E,这个中间数是127;对于11位的E,这个中间数是1023。
比如,2^10的E是10,所以保存成32位浮点数时,必须保存成10+127=137,即10001001。
有些小伙伴可能会有疑问,如果一个一个数的指数E是负数,并且加上中间数仍为负数怎么办?
出现了这种情况,那就说明这个数的范围超出了当前这个数的浮点型范围,这个数需要更大的浮点型。
3.3指数E从内存中取出的三种情况:
E不全为0或不全为1
这时,浮点数就采用下面的规则表示,即指数E的计算值减去127(或1023),得到真实值,再将有效数字M前加上第一位的1。
E全为0
这时,浮点数的指数E等于1-127(或者1-1023)即为真实值,
有效数字M不再加上第一位的1,而是还原为0.xxxxxx的小数。这样做是为了表示 ±0,以及接近于0的很小的数字。
E全为1
这时,如果有效数字M全为0,表示 ±无穷大(正负取决于符号位S);好了,关于浮点数的表示规则,就说到这里。
注意:对于一些浮点数,它不能通过二进制准确的表示出来。比如:0.14,0.2,0.3等就无法用二进制数字来精确地表示出来,这就导致了部分浮点数在内存中很难被精确保存。
3.3一个例子的解释
int main()
{int n = 9;float *pFloat = (float *)&n;printf("n的值为:%d\n",n);printf("*pFloat的值为:%f\n",*pFloat);*pFloat = 9.0;printf("num的值为:%d\n",n);printf("*pFloat的值为:%f\n",*pFloat);return 0;
取出浮点数:
让我们回到一开始的问题:为什么以单精度浮点型指针pFloat的视角打印9;得到的结果却是0.000000?
首先先将整型9拆分,因为在内存中存储的都是二进制,所以拆分的是9的二进制。
9 —> 0 00000000 00000000000000000001001
我们是站在pFloat的视角打印的9,在pFloat的视角下地址都是float*,地址在内存中管理的空间上的数据是float类型的。我们要取出打印这个单精度浮点数,就要找到第1位符号位S,后面的8位指数E,最后的23位有效数字M。
由上面的二进制可知:S = 0,E = 00000000,M = 00000000000000000001001
因为E为全0,所以指数E应该为1 - 127 = -126,有效数字M不在是1.xxxxx…的小数,而是还原为0.xxxx…的小数。
因此,浮点数V就写成了:
V = (-1)^0 * 0.00000000000000000001001 * 2^(-126)
很显然,V是一个很小的接近于0的正数,所以用十进制小数表示就是0.000000
存储浮点数:
我们再看例题的第二部分,pFloat指向的数据(n的地址所管理的空间上的数据)已经被改为了float类型数据9.0。
但在int 类型的n的视角下,还把float类型的9.0当作整型,以整型的形式打印9.0。
我们先来思考一下9.0在内存中的32位二进制是什么样的?
9.0 -->1001.0 --> (-1)^0 * 1.001 * 2^3 --> S = 0, M = 1.001, E(十进制) = 3 + 127 = 130
所以,二进制中第一位符号位S = 0,有效数字位为001后面补0,凑满23位,
指数E为130的二进制 = 10000010 。
9.0的二进制即为:0 10000010 00100000000000000000000
转换成十进制正是 1091567616 。
4.总结
好啦,这就是本篇文章的所有内容了,本篇文章主要详细讲述了整型和浮点型数据在内存中的存储,两者有很大差异。最后,感谢大家的阅读,点赞收藏加关注,C语言学习不迷路!
相关文章:

深度刨析数据在内存中的存储
✨博客主页:小钱编程成长记 🎈博客专栏:进阶C语言 深度刨析数据在内存中的存储 1.数据类型介绍1.1 类型的基本归类 2.整形在内存中的存储2.1 原码、反码、补码2.2 大小端介绍 3.浮点型在内存中的存储3.1 一个例子3.2 浮点数的存储规则3.3指数…...
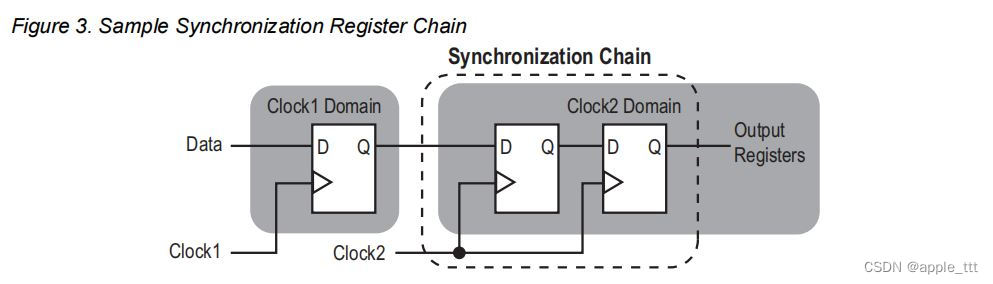
理解FPGA中的亚稳态
一、前言 大家应该经常能听说到亚稳态这个词,亚稳态主要是指触发器的输出在一段时间内不能达到一个确定的状态,过了这段时间触发器的输出随机选择输出0/1,这是我们在设计时需要避免的。本文主要讲述了FPGA中的亚稳态问题,可以帮助…...

Leetcode86. 分隔链表
给你一个链表的头节点 head 和一个特定值 x ,请你对链表进行分隔,使得所有 小于 x 的节点都出现在 大于或等于 x 的节点之前。 你应当 保留 两个分区中每个节点的初始相对位置。 力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台…...

如何处理 Flink 作业中的数据倾斜问题?
分析&回答 什么是数据倾斜? 由于数据分布不均匀,造成数据大量的集中到一点,造成数据热点。 举例:一个 Flink 作业包含 200 个 Task 节点,其中有 199 个节点可以在很短的时间内完成计算。但是有一个节点执行时间…...
cobbler自动化安装CentOS、windows和ubuntu
环境介绍 同时玩cobbler3.3和cobbler2.8.5 cobbler3.3 系统CentOS8.3 VMware虚拟机 桥接到物理网络 IP: 192.168.1.33 cobbler2.8.5 系统CentOS7.9 VMWare虚拟机 桥接到物理网络 IP:192.168.1.33 安装cobbler3.3 yum源修改 cat /etc/yum.repo.d/Cento…...

springcloud3 GateWay章节-Nacos+gateway动态路由负载均衡4
一 工程结构 1.1 工程 1.2 搭建gatewayapi工程 1.pom文件 <dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.13</version><scope>test</scope></dependency><!--gateway--&g…...

RESTful API 面试必问
RESTful API是一种基于 HTTP 协议的 API 设计风格,它提供了一组规范和约束,使得客户端(如 Web 应用程序、移动应用等)和服务端之间的通信更加清晰、简洁和易于理解。 RESTful API 的设计原则 使用 HTTP 协议:RESTful …...

软件机器人助力行政审批局优化网约车业务流程,推动审批业务数字化转型
随着社会的进步和发展,行政审批业务逐渐趋向于智能化和自动化。近日,某市行政审批局在市场准入窗口引入博为小帮软件机器人大幅度提升了网约车办理业务的效率,创新了原有的业务模式。 软件机器人以其自动化、智能化的特性,优化了网…...
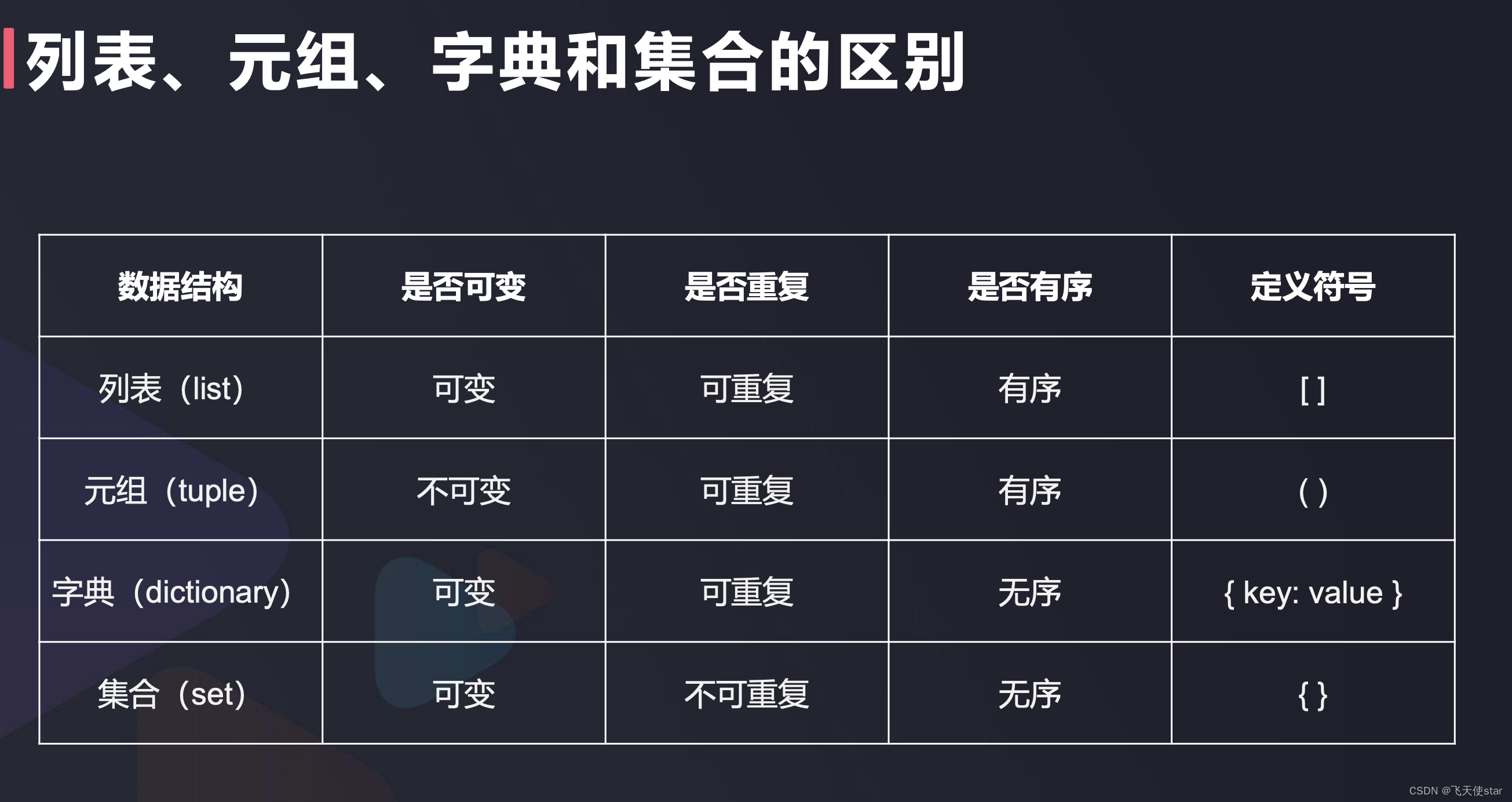
飞天使-python的字符串转义字符元组字典等
文章目录 基础语法数据类型python的字符串运算符输入和输出 数据结构列表与元组字典与集合 参考文档 基础语法 数据类型 数值型 ,整数 浮点型 布尔型, 真假, 假范围 字符型 类型转换python的字符串 了解转义字符一些基本的运算 \ 比如一行…...

stm32 uart dma方式接收不定长度字符
一般处理: stm32 uart使用dma接收时,会有自己的数据流中断,数据流中断会调用HAL_UART_RxCpltCallback。但是数据流中断只会在HAL_UART_Receive_DMA函数指定的buffer满时才会触发。 接收不定长度字符,需要和uart的UART_IT_IDLE结…...

SciencePub学术 | Elsevier出版社SCIEEI征稿中
SciencePub学术刊源推荐:Elsevier出版社SCIE&EI征稿中!信息如下,录满为止: 一、期刊概况: 计算机科学类SCI-01 【期刊简介】6.5-7.0,JCR1区,中科院2区; 【检索情况】正刊,SC…...
PHP小白搭建Kafka环境以及初步使用rdkafka
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、安装java(Kafka必须安装java,因为kafka依赖java核心)二、安装以及配置Kafka、zookeeper1.下载Kafka(无需下载…...

【Java Web】敏感词过滤
一、前缀树 假设有敏感词:b,abc,abd,bcd,abcd,efg,hii 那么前缀树可以构造为: 二、敏感词过滤器 package com.nowcoder.community.util;import org.apache.commons.lang3.CharUt…...
stable diffusion实践操作-提示词
本文专门开一节写提示词相关的内容,在看之前,可以同步关注: stable diffusion实践操作 正文 提示词是SD中非常重要,你生成的图片质量,基本就取决于提示词的好坏,提示词分为正向提示词和反向提示词。 模板…...

leetcode8.字符串转整数-Java
题目 请你来实现一个 myAtoi(string s) 函数,使其能将字符串转换成一个 32 位有符号整数(类似 C/C 中的 atoi 函数)。 函数 myAtoi(string s) 的算法如下: 读入字符串并丢弃无用的前导空格 检查下一个字符(假设还未到字…...

从零开始的Hadoop学习(四)| SSH无密登录配置、集群配置
1. SSH 无密登录配置 1.1 配置 ssh (1)基本语法 ssh 另一台电脑的IP地址 (2)ssh 连接时出现 Host key verification failed 的解决方法 [atguiguhadoop102 ~]$ ssh hadoop103(3)回退到 hadoop102 [at…...

微信小程序活动报名管理系统设计与实现
摘 要 随着当下的移动互联网技术的不断发展壮大,现在人们对于手机的应用已经非常的成熟,当下的时代基本上达到了人手一部手机,数字化、信息化已经成为了人们的主流生活。有数据统计,截止到2020年末我国的手机网民人数已经接近10亿…...

用Kubernetes(k8s)的ingress部署https应用
用Kubernetes的ingress部署https应用 环境准备Ingress安装域名证书准备 部署应用通过ingress暴露应用根据ssl证书生成对应的secret创建ingress暴露部署的应用确认自己安装了ingress创建ingress 访问你暴露的应用 环境准备 Ingress安装 我之前有一片文章写的是用ingress暴露应…...
【附安装包】MyEclipse2020安装教程
软件下载 软件:MyEclipse版本:2020语言:简体中文大小:1.61G安装环境:Win11/Win10/Win8/Win7硬件要求:CPU2.5GHz 内存4G(或更高)下载通道①百度网盘丨下载链接:https://pan.baidu.co…...
软件与软件工程
软件 软件的概念以及特点: 软件是计算机系统中不可或缺的一部分,与硬件共同构成特定的系统功能。 人们通常把各种不同功能的程序,包括系统程序、应用程序、用户自己编写的程序等称为软件 软件的概念: 软件不仅包括程序,还包括程序…...

让Windows 11任务栏唱歌:Taskbar-Lyrics插件如何改变你的音乐体验
让Windows 11任务栏唱歌:Taskbar-Lyrics插件如何改变你的音乐体验 【免费下载链接】Taskbar-Lyrics BetterNCM插件,在任务栏上嵌入歌词,目前仅建议Windows 11 项目地址: https://gitcode.com/gh_mirrors/ta/Taskbar-Lyrics 还在为切换…...
)
飞机在甲板上着陆--动基线RTK深度解析:定义、应用场景和基本原理(二)
飞机在甲板上着陆–动基线RTK深度解析:定义、应用场景和基本原理(二)接上文3.3 时序图:静态模式 vs 动基线模式的对比图2:动基线RTK时间对齐与外推机制详解#mermaid-svg-ImdeLLU9IW88fmy6{font-family:"trebuchet…...

终极热键冲突解决方案:Hotkey Detective专业指南
终极热键冲突解决方案:Hotkey Detective专业指南 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是否曾经在W…...
)
Sora 2批量视频生成工作流深度拆解(企业级高并发视频生产系统架构图首次公开)
更多请点击: https://codechina.net 第一章:Sora 2批量视频生成工作流全景概览 Sora 2作为新一代大规模视频生成模型,其批量处理能力已深度集成于可编程工作流中,支持从提示工程、参数调度、分片渲染到后处理导出的端到端自动化…...

后端架构:事件驱动架构设计与实现
后端架构:事件驱动架构设计与实现 大家好,我是欧阳瑞(Rich Own)。今天想和大家聊聊事件驱动架构这个重要话题。作为一个全栈开发者,事件驱动架构已经成为现代后端系统的重要设计模式。今天就来分享一下事件驱动架构的设…...

代码质量与代码审查
代码质量与代码审查 1. 技术分析 1.1 代码质量概述 代码质量是软件维护的关键: 代码质量维度可读性: 易于理解可维护性: 易于修改可测试性: 易于测试性能: 运行效率质量指标:圈复杂度代码覆盖率代码重复率1.2 代码审查流程 审查流程提交代码: PR/MR自动检查: CI/CD人…...

单物体最优抓取轨迹生成
基于 3D 位姿规划直线平滑抓取轨迹,包含趋近 - 抓取 - 复位三段最优运动路径,适配机械臂点位运动核心规划逻辑基准位:机械臂初始安全待机点趋近段:直线匀速靠近物体上方预备抓取点抓取段:垂直下落至物体抓取中心位姿抬…...

北航毕业论文LaTeX模板:3天掌握专业排版,告别格式焦虑
北航毕业论文LaTeX模板:3天掌握专业排版,告别格式焦虑 【免费下载链接】BUAAthesis 北航毕设论文LaTeX模板 项目地址: https://gitcode.com/gh_mirrors/bu/BUAAthesis 还在为毕业论文格式反复修改而焦虑吗?每年毕业季,无数…...
)
MySQL 性能监控实战:从零搭建 Prometheus + Grafana 监控告警体系(附排查 SOP)
📌 今日关键词:性能监控、PMM、Prometheus、Grafana、慢查询、告警、指标体系 大家好,我是数据库小学妹 👋 前面我们学习了锁机制、MVCC、慢查询诊断这些"事后分析"的技术。但你知道“数据库目前处于什么状态࿱…...

SNK施努卡铜箔包装线:从拔轴到入库,全流程自动化怎么实现?
在锂电铜箔生产中,生箔机产出的铜箔卷需要经过裁切、拔轴、包装、入库等多个环节。传统方式下,拔轴依靠人力或简易机械,包装过程需要多人配合搬运、开箱、投干燥剂、合盖捆扎,不仅效率低,而且容易损伤铜箔边缘…...