深入浅出:手把手教你实现单链表
一、什么是链表
链表是一种链状数据结构。简单来说,要存储的数据在内存中分别独立存放,它们之间通过某种方式相互关联。
如果我们使用C语言来实现链表,需要声明一个结构体作为链表的结点,结点之间使用指针关联。
二、单向链表的结构
单向链表的每个结点内都有一个指针指向下一个结点,从而把所有结点串联起来。由于只有指向下一个结点的指针,这种结构是单向的,也就是前面的结点能找到后面的,但后面的结点找不到前面的,这就存在一定的问题。最后一个结点的指针是空指针,标识链表的尾结点。我们只需要获取链表头部的结点的地址,也就是指向链表头结点的指针,就能依次找到后面的每一个结点,从而管理整个链表。
说了这么多,链表的每个结点应该如何定义呢?很简单,每个结点应该有存储数据的变量(数据域)和指向下一个结点的指针(指针域)。我们假设存储的数据类型是int。
struct SListNode
{int data;struct SListNode* next;
};如果要存储其他类型的数据,为了修改方便,可以使用typedef,把int类型typedef成SLTDataType,从而方便修改存储类型。
typedef int SLTDataType;为了结构体使用方便,也typedef一下。
typedef struct SListNode
{int data;struct SListNode* next;
}SLTNode;三、打印、查找、销毁
这三个动作都要涉及一个知识点:如何遍历单链表?为了遍历单链表,我们需要获取指向链表头结点的指针(以下简称头指针)。假设我们已经获取了这个指针phead,每次我们都可以通过结点内的next指针找到下一个结点,直到找到尾结点,即next指针为NULL的结点。为此可以使用for循环遍历。
for (SLTNode* cur = phead; cur; cur = cur->next)
{// ...
}打印每个结点的数据就简单了。
for (SLTNode* cur = phead; cur; cur = cur->next)
{printf("%d->", cur->data);
}
printf("NULL\n");查找链表中的数据,也是依次遍历即可。
for (SLTNode* cur = phead; cur; cur = cur->next)
{if (cur->data == x)return cur;
}return NULL; // 找不到如果要销毁链表,由于我们一般把结点都存储在栈上,所以使用free函数来释放空间。注意,如果结点的空间被释放,nextz指针就成为了野指针,就找不到下一个结点了。所以遍历时应该保存要释放的结点,先让cur指向next,再free掉保存的结点。
for (SLTNode* cur = phead; cur; )
{SLTNode* del = cur;cur = cur->next;free(del);
}四、尾插、头插
如果要插入一个结点,我们需要先获取一个结点,前面说了,一般在堆上管理结点,所以使用malloc函数开辟结点。
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
if (newnode == NULL)
{perror("malloc申请空间失败");exit(-1);
}
newnode->data = x;
newnode->next = NULL;有了newnode之后,需要把newnode和原链表关联起来。
先说尾插,我们需要找到尾结点,再让尾结点的next指向newnode。找尾结点非常简单,遍历链表即可,只不过当cur->next为NULL时就找到了。
SLTNode* tail = phead;
for (; tail->next; tail = tail->next)
{;
}
tail->next = newnode;但是!上面的代码有一个严重的问题,你看出来了吗?代码中有tail->next的操作,也就是要对tail指针解引用,然而万一tail为NULL呢?tail为NULL说明phead为空,我们称链表phead为空的情况为空链表!也就是说一上来链表为空时尾插,就不能采取上面的方法。
该怎么办呢?你想想,此时链表里啥都没有,空空如也,只需要让phead指向newnode不就行了吗!
if (phead == NULL)phead = newnode;一般来说了解到这就足够了。但是在实现数据结构的时候,我们一般把插入、删除数据等接口封装成函数,也就是说,我们要用一个函数实现尾插。函数的声明如下:
void SListPushBack(SLTNode* phead, int x);以上实现的完整代码如下:
void SListPushBack(SLTNode* phead, int x)
{SLTNode* newnode = BuySListNode(x); // 假设已经把前面讲解的获取新结点的代码封装成函数if (phead){// 链表非空// 找尾结点SLTNode* tail = phead;for (; tail->next; tail = tail->next){;}tail->next = newnode;}else{// 空链表phead = newnode;}
}看出问题出在哪了吗?phead是函数的形参,对于phead=newnode这行代码,我们只是改变了形参,会影响外面的实参吗?不会!换句话说,我们把链表的头结点phead传给PushBack函数,函数内部对形参phead的修改不会影响外面的实参,而当PushBack函数调用结束后,函数内的形参phead会被销毁,这并没有完成尾插的任务!
为了完成任务,我们需要PushBack函数拿到phead的地址pphead,才能在函数内部通过解引用pphead的方式访问函数外的phead,从而修改phead。由于pphead是phead的地址,不可能为NULL,所以使用前都需要断言。
void SListPushBack(SLTNode** pphead, int x)
{assert(pphead);SLTNode* newnode = BuySListNode(x);if (*pphead){// 链表非空// 找尾结点SLTNode* tail = *pphead;for (; tail->next; tail = tail->next){;}tail->next = newnode;}else{// 空链表*pphead = newnode;}
}理解了尾插后,头插也就简单了。由于头插无论如何都会改变头结点,也就是无论如何都会改变phead,如果要在函数内部实现,就必须传二级指针pphead。
插入前的结构是:phead->头结点。插入后的结构是:phead->newnode ->原来的头结点。所以只需phead=newnode,并且newnode->next=原来的头结点(即phead)。但是两句话的顺序必须注意了,如果先把phead改了,就找不到原来的头结点了。你可以先思考一下两句顺序应该如何写呢?如果拿到的是phead的地址pphead,又应该如何写呢?
newnode->next = *pphead;
*pphead = newnode;思考一下,需不需要考虑链表为空的特殊情况?其实不用考虑,因为上述操作只对newnode解引用,而newnode不可能是NULL。如果还不放心,简单思考一下此时代码做的事情就明白了。*pphead为NULL,第一行代码使newnode的next指向了NULL,第二行代码使头指针指向了newnode。
五、尾删、头删
有了前面的铺垫,我们也很容易理解,如果要在函数内部实现删除操作,一定要传二级指针。这是因为,如果删除前只有一个结点,那么phead一定不为空,但删除之后链表为空,也就是phead为NULL,此时一定要改变phead,所以传参时需要传递phead的地址,即pphead。
删除前,必须要有一个准备工作,那就是断言一下链表非空。也就是phead不为NULL,即*pphead不为NULL。
assert(*pphead);先说头删,因为比较简单。只需要干掉头结点,然后让phead指向新的头结点即可。注意代码的先后顺序,如果头结点被释放,就找不到新的头结点了(即原头结点的next)。所以需要保存要释放的结点,让phead指向新的头结点后,再释放保存的结点。
SLTNode* del = *pphead;
*pphead = (*pphead)->next;
free(del);思考一下:需不需要考虑删除前链表只有1个结点的特殊情况?其实不需要,在该情况下以上代码仍然成立,只不过执行完后phead指向了NULL。
再来考虑下尾删。这是有一点挑战性的,如果你第一次学习链表,建议先自己实现一下,再来听我讲解。
我假设你已经尝试写了。思路还是那样,找到尾结点,再干掉它。就完了吗?No!你想想,新的尾结点是谁?是不是原来尾结点的前一个?那这个新的尾结点的next指针原来指向的结点被你干掉了,不就成野指针了吗?所以还要把这个指针置成NULL。也就是说,我们不仅需要找到尾结点并且把它干掉,还要找到尾结点的前一个结点,把这个结点的next置成NULL。
如果你一开始没想到这一点,现在再想想,如何找到尾结点的前一个结点呢?
由于单向链表每个结点只有next,没有prev(前驱指针,指向前一个结点的指针),所以只能向后找,不能向前找。找到尾结点的前一个结点tailPrev的代码如下,这个思路很巧妙,你能看懂吗?
SLTNode* tailPrev = *pphead;
for (; tailPrev->next->next; tailPrev = tailPrev->next)
{;
}其实很简单,只需要想想尾结点前一个结点有什么特征,在满足这个特征时跳出循环就行了。尾结点的特征时tail->next=NULL,那尾结点前一个结点就要走两步才能走到NULL,即tailPrev->next->next=NULL,所以就有了上面的代码。
但是这个代码忽视了一个特殊情况,那就是如果链表只有一个结点,也就是phead->next=NULL,由于一开始tailPrev=phead,此时tailPrev->next->next=phead->next->next=NULL->next,对空指针解引用了,程序会崩溃!所以要对这个特殊情况单独处理,你想想怎么处理?很简单嘛!只有一个结点了,只需要free掉这个结点,再把phead置成NULL就行了!
六、插入删除的一般化
如果我们想要在任意位置插入或者删除呢?有了前面的铺垫,这个问题就不难了,无非是链接一些结点,或者是干掉一些结点。由于总会有改变phead的情况,所以以下均需要使用二级指针pphead。
先说插入。插入分两种情况,一种是在pos前面插入,一种是在pos后面插入,你觉得哪种更简单?如果是在前面插入,你怎么找到pos前面的结点?那还要从头结点一个一个往后找,多麻烦!所以肯定是在后面插入简单。
前插的思路:找pos前面的结点,需要prev从phead开始一个一个往后找,直到prev->next=pos就找到了。找到后,使得prev->next=newnode,newnode->next=pos就行了。思考一下需不需要考虑先后顺序?其实不用,因为prev,newnode,pos是3个独立的结点,相互之间互不影响。
SLTNode* prev = *pphead;
for (; prev->next != pos; prev = prev->next)
{;
}newnode->next = pos;
prev->next = newnode;需要考虑一种特殊情况,头部的插入需要改变phead,由于头插前面讲过,这里就不重复了。
后插就简单了,有了前面这么多的铺垫,你应该也可以写出来。注意代码的先后顺序!
newnode->next = pos->next;pos->next = newnode;至于删除,也分为两种情况,分别是删除pos结点和删除pos之后的结点。想一想,哪种更简单?删除pos位置的结点,你还需要找到pos之前的结点,会更复杂一些。
删除pos位置的结点的思路:先找到pos之前的结点和pos之后的结点,连接这两个结点,干掉pos。注意代码的先后顺序!
SLTNode* prev = *pphead;
for (; prev->next != pos; prev = prev->next)
{;
}prev->next = pos->next;
free(pos);这里提一句,如果你不想总要考虑代码的先后顺序,可以先保存prev和next=pos->next,再让prev->next=next。
这里需要考虑一种特殊情况,如果phead=pos,即头删的情况,prev找到的就不是pos前面的结点了,此时需要单独处理,由于头删的情况前面已经讲解过,这里不再重复。
最后,删除pos之后结点就非常简单了。你可以自己写一下,然后对照后面的代码。
assert(pos->next); // pos后至少有1个结点SLTNode* del = pos->next;pos->next = del->next;free(del);你是否考虑了对pos->next的断言呢?如果没考虑到,请好好反省一下。删除pos后面的结点,就说明了pos后面必须有结点!也就是pos->next不为NULL!
七、总结
单向链表虽然结构很简单,但使用起来可真麻烦啊。所以这种结构是有一定缺陷的。事实上,这种链表结构的全称是单向+不循环+不带头链表,具有一定的局限性。
相关文章:

深入浅出:手把手教你实现单链表
一、什么是链表 链表是一种链状数据结构。简单来说,要存储的数据在内存中分别独立存放,它们之间通过某种方式相互关联。 如果我们使用C语言来实现链表,需要声明一个结构体作为链表的结点,结点之间使用指针关联。 二、单向链表的结…...

vite 打包项目后访问显示空白页的问题,开发环境正常,生产环境无报错。
有没有可能, 你跟我遇到同样的问题 白屏的写法 const routes [{path: /,component: import(../views/index.vue),} ]正确的写法 const routes [{path: /,component: () > import(../views/index.vue),} ]有时候方向很重要,当在错误的方向上无脑冲…...
打造成功的砍价营销大解析,销量飙升
砍价活动是吸引顾客的一种有效方式,可以帮助提高销量和提升品牌知名度。在乔拓云平台上,我们提供了一套简单易用的工具,让您能够轻松地制作一个成功的砍价活动。下面,我将详细介绍具体步骤,让您能够轻松上手。 第一步&…...

【Flink进阶】- Flink kubernetes operator 常用的命令
目录 1、应用程序管理 (1)提交 Flink 应用程序 (2)查看 Flink 应用程序列表...

ASP.NET Core 的日志系统
ASP.NET Core 提供了丰富日志系统。 可以通过多种途径输出日志,以满足不同的场景,内置的几个日志系统包括: Console,输出到控制台,用于调试,在产品环境可能会影响性能。Debug,输出到 System.Di…...
 以太网设置工具类)
android13(T) 以太网设置工具类
13 版本的以太网设置和以前版本有所变动,在 AS 中就能直接调用对应 API 将 build.gradle 版本修改 compileSdkVersion 31, 即可直接调用 EthernetManager 相关, 设置静态等方法可以通过反射调用设置。 以下是核心设置静态和动态参数工具类,…...

电脑报错提示xinput1_3.dll缺失怎么办?xinput1_3.dll丢失的简单恢复方案
今天,我将为大家分享一个与我们日常工作息息相关的话题——xinput1_3.dll丢失的4种解决方法。在我们的日常工作和生活中,电脑出现问题是常有的事,而xinput1_3.dll丢失则是其中较为常见的一种问题。那么,什么是xinput1_3.dll?它为…...

unity 之参数类型之引用类型
文章目录 引用类型引用类型与值类型的差异 引用类型 在Unity中,引用类型是指那些在内存中存储对象引用的数据类型。以下是在Unity中常见的引用类型的介绍: 节点(GameObject): 在Unity中,游戏对象ÿ…...
SpringBoot自定义工具类—基于定时器完成文件清理功能
直接复制粘贴既可!! import org.springframework.scheduling.annotation.Scheduled; import org.springframework.stereotype.Component; import java.io.File; import java.time.LocalDate; import java.time.LocalDateTime; import java.time.ZoneOff…...

安卓设置混淆后,gson报错解决方法
一,设置开启混淆release {minifyEnabled truezipAlignEnabled trueshrinkResources trueproguardFiles getDefaultProguardFile(proguard-android-optimize.txt), proguard-rules.pro } 二,混淆的文件中,对gson相关类不进行混淆,否…...
WPF实战项目十四(API篇):登录注册接口
1、新建UserDto.cs public class UserDto : BaseDto{private string userName;/// <summary>/// 用户名/// </summary>public string UserName{get { return userName; }set { userName value;OnPropertyChanged(); }}private string account;/// <summary>…...
10个免费PPT下载资源网站分享
PPT超级市场https://pptsupermarket.com/ PPT超级市场是一个完全免费的PPT模板下载网站,不需要注册登录,点击下载就能直接使用。 叮当设计https://www.dingdangsheji.com/ 叮当设计是一个完全免费的PPT模板下载网站,每一套PPT的质量都很高。除…...
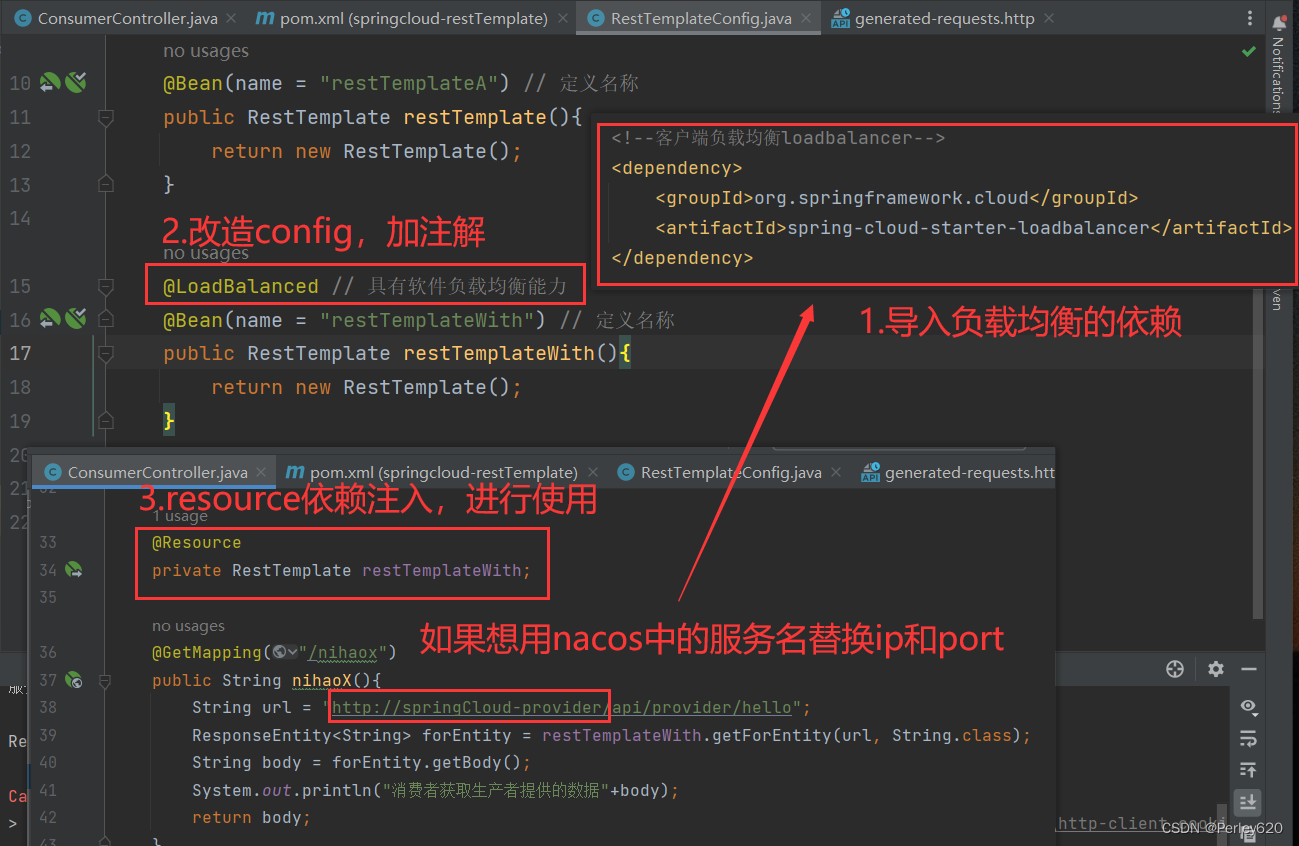
SpringCloud入门——微服务调用的方式 RestTemplate的使用 使用nacos的服务名初步(Ribbon负载均衡)
目录 引出微服务之间的调用几种调用方法spring提供的组件 RestTemplate的使用导入依赖生产者模块单个配置的情况多个配置的情况没加.yaml的报错【报错】两个同名配置【细节】 完整代码config配置主启动类controller层 消费者模块进行配置restTemplate配置类controller层 使用na…...
:python中__new__方法)
Python基础篇(16):python中__new__方法
一、__new__方法的定义 __new__() 方法是一种负责创建 类实例 的 静态方法 二、__new__方法的作用 在内存中为对象分配空间返回对象的引用 三、__new__方法的使用 创建对象时自动调用__new__方法,并且是在__init__初始化方法之前被调用Python解释器获得对象的引…...

linux并发服务器 —— 文件IO相关函数(三)
文件IO 以内存为主体,看待输入输出; 标准C库IO函数带有缓冲区,效率较高; 虚拟地址空间 虚拟地址空间是不存在的,一个应用程序运行期间对应一个虚拟地址空间; 虚拟地址空间的大小由CPU决定,位…...
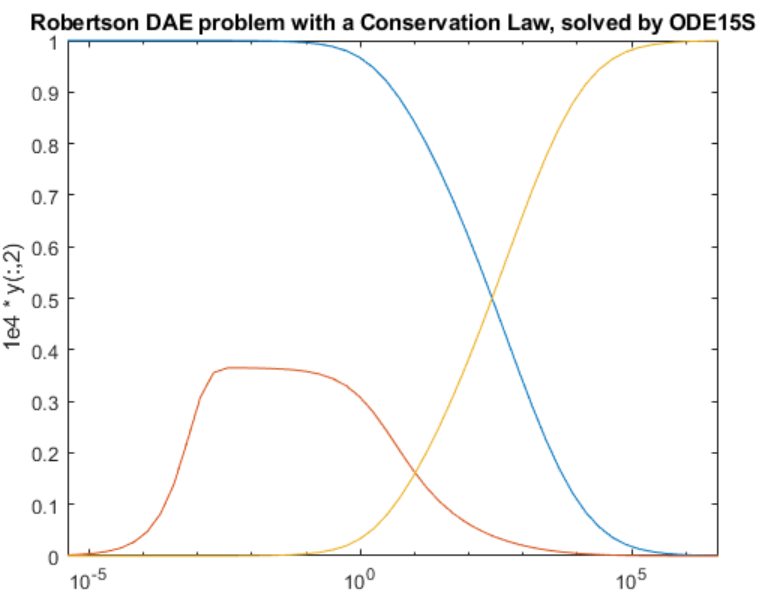
matlab使用教程(27)—微分代数方程(DAE)求解
1.什么是微分代数方程? 微分代数方程是一类微分方程,其中一个或多个因变量导数未出现在方程中。方程中出现的未包含其导数的变量称为代数变量,代数变量的存在意味着您不能将这些方程记为显式形式 y ′ f t , y 。相反,您可以…...

vue3组合式api <script setup> props 父子组件的写法
父组件传入子组个的变量, 子组件是无法直接修改的, 只能通过 emit的方式, 让父组件修改, 之后子组件更新 <template><div class"parent">我是父组件<son :msg"msg" :obj"obj" chan…...

Compose - 自定义作用域限制函数
一、概念 在 Compose 中对于作用域的应用特别多。比如 weight 修饰符只能用在 RowScope 或者 ColumnScope 作用域中,item 组件只能用在 LazyListScope 作用域中。 标准库中的作用域函数如 apply()、let() 会以不同方式持有和返回上下文对象,调用它们时 L…...
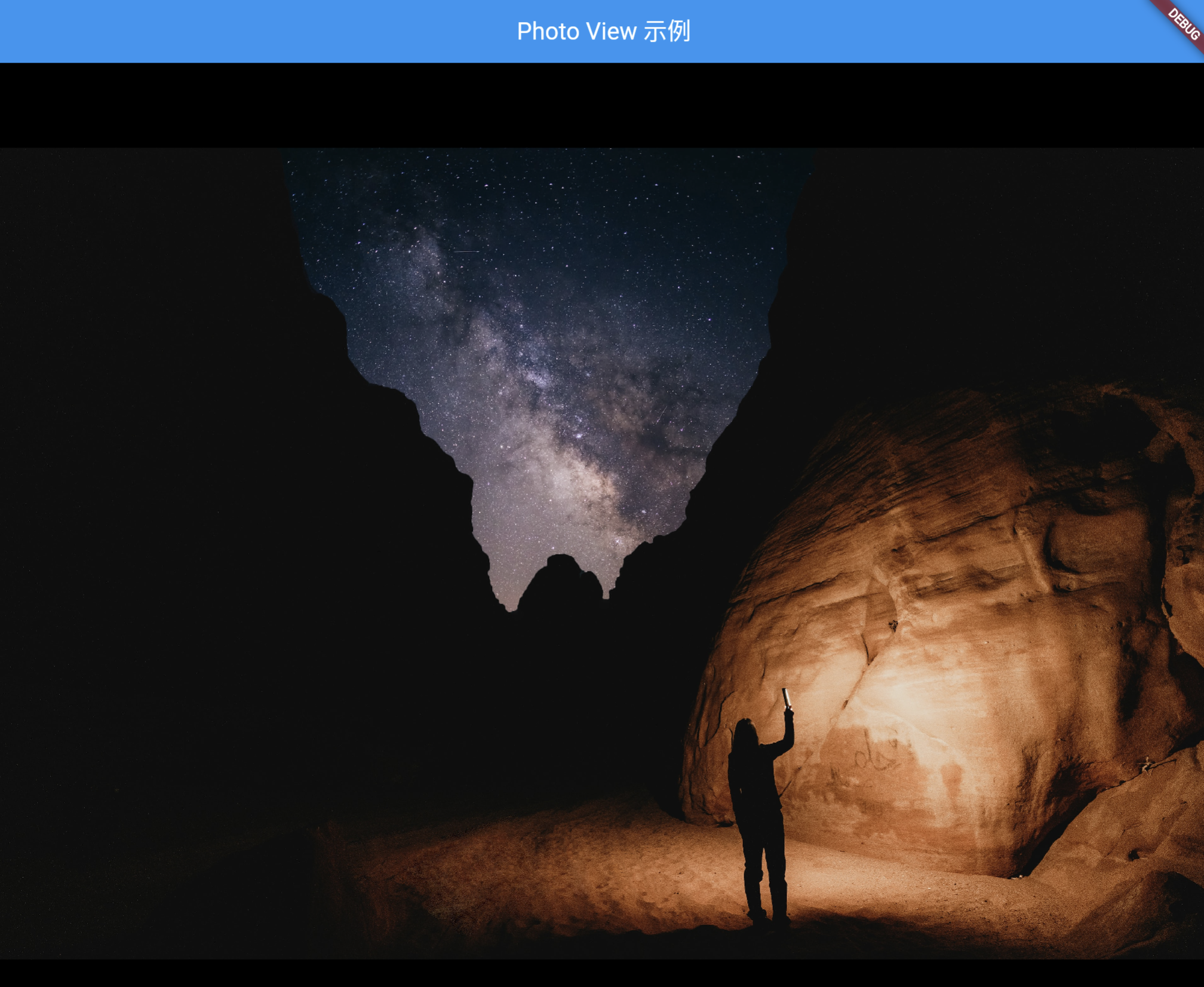
【Flutter】Flutter 使用 photo_view 实现图片查看器
【Flutter】Flutter 使用 photo_view 实现图片查看器 文章目录 一、前言二、photo_view 简介三、安装与基本使用四、使用 PhotoViewGallery 展示多张图片五、完整示例六、总结 一、前言 大家好,我是小雨青年,今天我要给大家介绍一个在 Flutter 中非常实…...

电脑组装教程分享!
案例:如何自己组装电脑? 【看到身边的小伙伴组装一台自己的电脑,我也想试试。但是我对电脑并不是很熟悉,不太了解具体的电脑组装步骤,求一份详细的教程!】 电脑已经成为我们日常生活中不可或缺的一部分&a…...

ContentBranch+CFBranch混合电影推荐模型|全网独家复现,深度学习实战篇 引入双分支融合架构,兼顾内容特征与协同信号、助力冷启动缓解、数据稀疏性优化、推荐精度有效涨点
目录 一、前言:混合推荐模型的核心价值与行业痛点 二、模型核心原理(全网独家拆解,通俗易懂) 2.1 整体架构逻辑 2.2 ContentBranch(内容分支)原理详解 2.3 CFBranch(协同过滤分支)原理详解 2.4 特征融合与预测层原理 2.5 模型优势总结 三、环境搭建(全平台适配…...

终极AMD Ryzen性能调优指南:SMUDebugTool完全掌握手册
终极AMD Ryzen性能调优指南:SMUDebugTool完全掌握手册 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gi…...

从低空协议劫持实战看 MAVLink 二进制审计在飞控发布环节的必要性
攻防实测复盘:协议劫持漏洞成因解析无人机接管攻击的本质不是高危漏洞,而是协议与生俱来的默认信任逻辑。近期多项低空攻防实测中,攻击者依托通用射频采集设备,即可持续捕获空口无线交互数据,实现对飞行设备的非正常控…...

企业AI合规:数据安全生死线
企业大模型应用中的数据安全合规体系建设 前言:数据安全合规——企业AI落地的必答题 一、合规风险识别与关键挑战 二、技术架构设计与安全合规方案 针对上述四大风险挑战,企业需要从技术架构层面构建纵深防御体系。以下从数据脱敏、访问控制、日志审计、…...

Mainframer与IntelliJ IDEA完美集成:提升开发体验的7个技巧
Mainframer与IntelliJ IDEA完美集成:提升开发体验的7个技巧 【免费下载链接】mainframer Tool for remote builds. Sync project to remote machine, execute command, sync back. 项目地址: https://gitcode.com/gh_mirrors/ma/mainframer Mainframer是一款…...

鸿蒙备考题库页面构建:今日计划与题目预览模块的详细解析
鸿蒙备考题库页面构建:今日计划与题目预览模块的详细解析 前言 在 HarmonyOS 6.0 应用开发中,在线教育类页面的学习计划展示和题目练习模块是用户停留时间最长的核心区域。本文将以“备考题库”应用中的“今日学习计划”任务列表和“题目预览”答题卡片为…...
 面向中小学数学教学的自动出题工具,覆盖从小学一年级到高中三年级共 7 个学段、33 种题型)
[工具] 数学题库生成器(小学,初中,高中全包括) 面向中小学数学教学的自动出题工具,覆盖从小学一年级到高中三年级共 7 个学段、33 种题型
数学题库生成器(小学,初中,高中全包括) 基本覆盖各个年级的重点题型生成,并导出为word,可以显示解题步骤。# 数学题库生成器 MathMaster 数学题库生成器(MathMaster)是一款面向中小学…...

鸿蒙中的自由流转
鸿蒙自由流转是 HarmonyOS(鸿蒙系统) 实现多设备协同的核心能力之一,旨在打破设备边界,让应用和服务在不同终端间无缝流转,提升用户体验。什么是鸿蒙自由流转?鸿蒙自由流转是指用户在多个搭载 Harm…...

蒙古语AI语音落地难?ElevenLabs最新v3.2模型支持率提升至98.7%,但90%开发者忽略这5个编码陷阱
更多请点击: https://intelliparadigm.com 第一章:蒙古语AI语音落地的现实困境与技术拐点 蒙古语作为中国少数民族语言中使用人口较多、语法高度黏着、音系复杂的阿尔泰语系代表,其AI语音技术长期受限于低资源特性——标准语音数据集不足50小…...

抖音获客失效?拆解本地商家流量困局的底层逻辑与破局路径
一、一个反直觉的数据先看两组数据,它们指向同一个方向。第一组:2025年,抖音本地生活服务GMV突破8500亿元。同期,入驻商家达到1519.8万家动销门店,399万新商家在一年内涌入。第二组:2026年Q1,抖…...