大数据组件-Flume集群环境搭建
🥇🥇【大数据学习记录篇】-持续更新中~🥇🥇
个人主页:beixi@
本文章收录于专栏(点击传送):【大数据学习】
💓💓持续更新中,感谢各位前辈朋友们支持学习~💓💓
文章目录
- 1.Flume集群环境介绍
- 2.搭建环境介绍
- 3.启动HDFS集群环境
- 4.Flume集群环境搭建
1.Flume集群环境介绍
Flume是一个分布式、可靠和高可用性的数据采集工具,用于将大量数据从各种源采集到Hadoop生态系统中进行处理。在大型互联网企业的数据处理任务中,Flume被广泛应用。
Flume集群环境介绍:
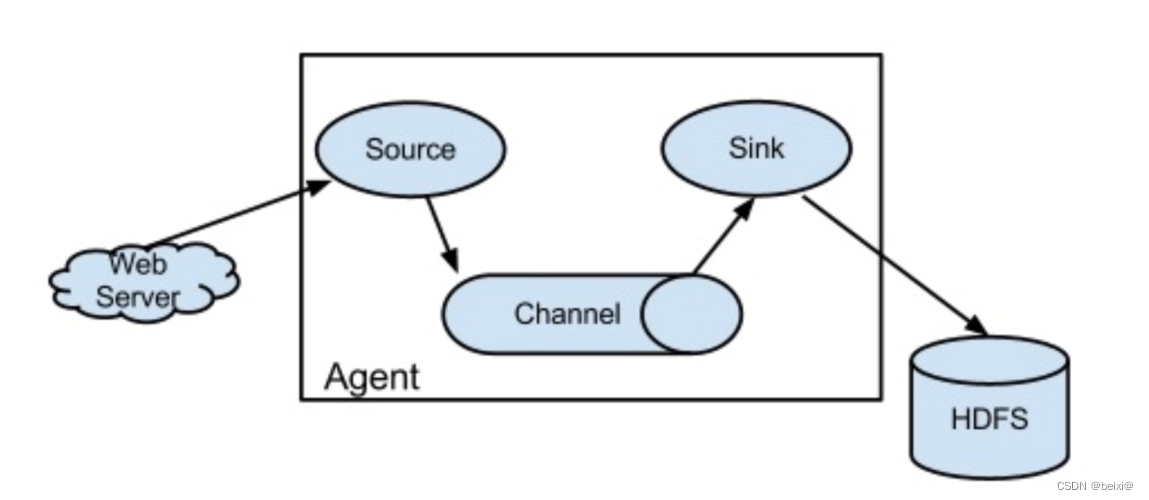
Agent:Flume的基本组成单元是Agent,用于在不同的节点之间传输数据。Agent可以是单节点或分布式部署。
Source:Source是Flume数据采集的起点,用于从数据源(如日志文件、网络流、消息队列等)中获取数据并将其发送到Channel中。Flume支持多种Source类型,如Avro、Netcat、Exec等。
Channel:Channel是Flume的缓存区,用于暂存从Source获取的数据。Flume支持多种Channel类型,如Memory、File、Kafka等,可以根据数据量和数据传输速率选择合适的Channel类型。
Sink:Sink是Flume的目标,用于将数据输出到指定的目标位置。Flume支持多种Sink类型,如HDFS、HBase、Elasticsearch等。
Event:Event是Flume传输的基本单元,表示采集到的数据。一个Event包含Header和Body两个部分,其中Header用于描述Event的属性(如时间戳、数据类型等),Body是实际的数据内容。
Collector:Collector用于收集Flume的监控信息,如Agent的启停状态、数据采集速率等。Flume提供了Web界面和API接口来实现监控和管理。
Flume逻辑上分三层架构:agent,collector,storage。agent用于采集数据,agent是Flume中产生数据流的地方,同时,agent会将产生的数据流传输到collector。collector的作用是将多个agent的数据汇总后,加载到storage中。storage是存储系统,可以是一个普通file,也可以是HDFS,HIVE,HBase等。
2.搭建环境介绍
本次搭建的环境有:
Oracle Linux 7.4,三台虚拟机,分别为master,slave1,slave2
JDK1.8.0_144
Hadoop2.7.4集群环境
Flume1.6.0
3.启动HDFS集群环境
1.打开master命令窗口,启动HDFS平台。
start-dfs.sh

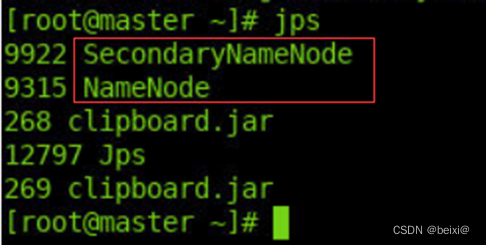
2.查看”主节点”上HDFS守护进程
jps
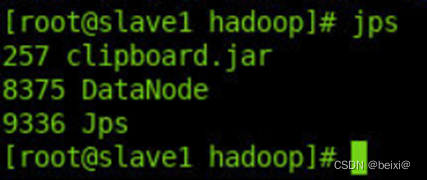
3.打开slave1从机命令窗口,查看HDFS守护进程。
jps
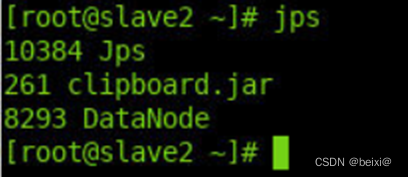
4.打开slave2从机命令窗口,查看HDFS守护进程。
jps
4.Flume集群环境搭建
1.打开master命令窗口。
2.解压Flume压缩文件至/opt目录。
tar -zxvf experiment/file/apache-flume-1.6.0-bin.tar.gz -C /opt

3.修改解压后文件夹的名字为flume。
mv /opt/apache-flume-1.6.0-bin /opt/flume

4.查看Flume配置文件目录conf
ll /opt/flume/conf/

5.复制Flume配置文件flume-env.sh.template名为flume-env.sh
cp /opt/flume/conf/flume-env.sh.template /opt/flume/conf/flume-env.sh

6.查找Java安装路径
echo $JAVA_HOME

7.配置flume-env.sh文件
vim /opt/flume/conf/flume-env.sh
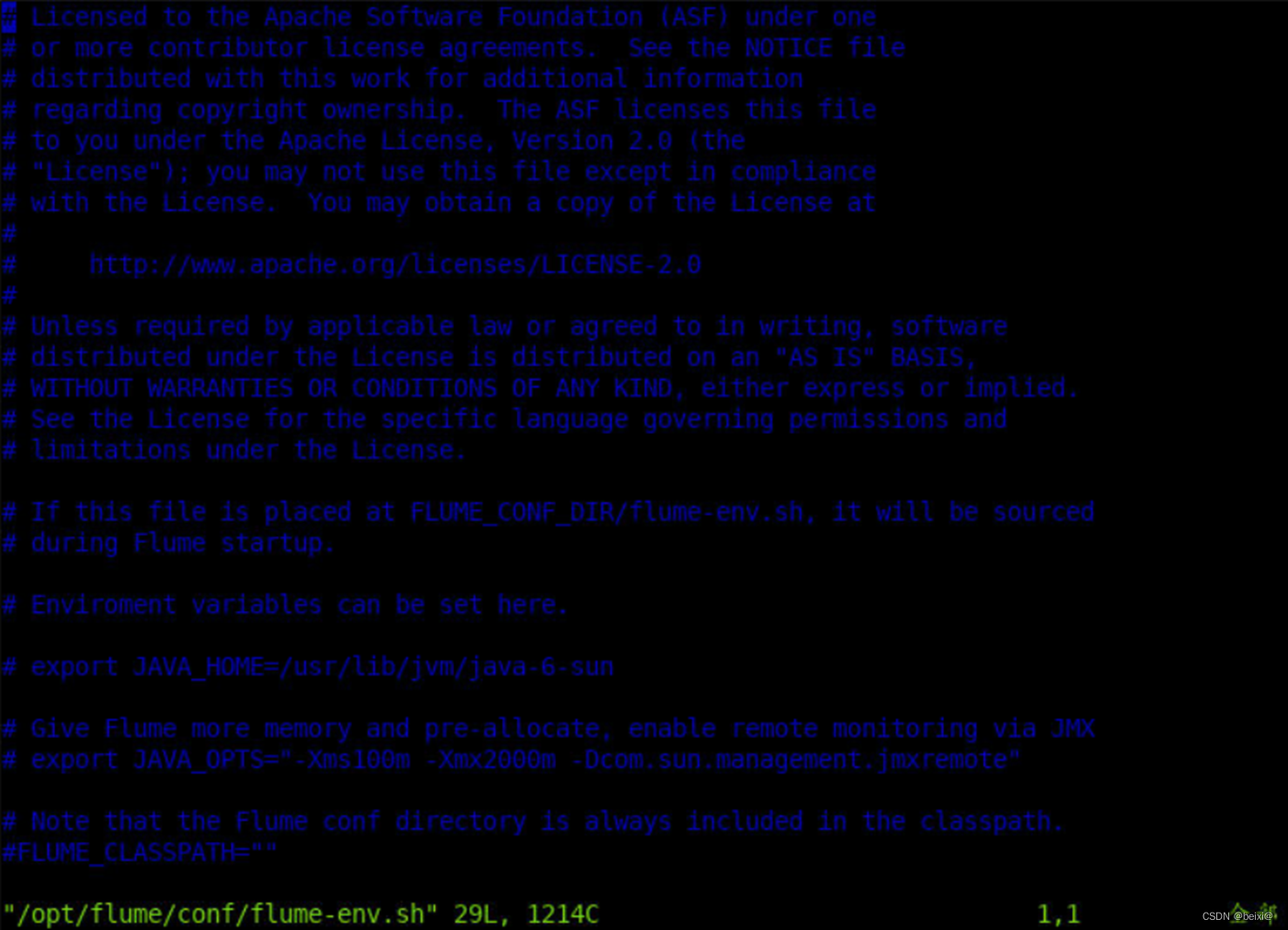
8.按键 i ,更改代码如下:
export JAVA_HOME=/usr/lib/java-1.8
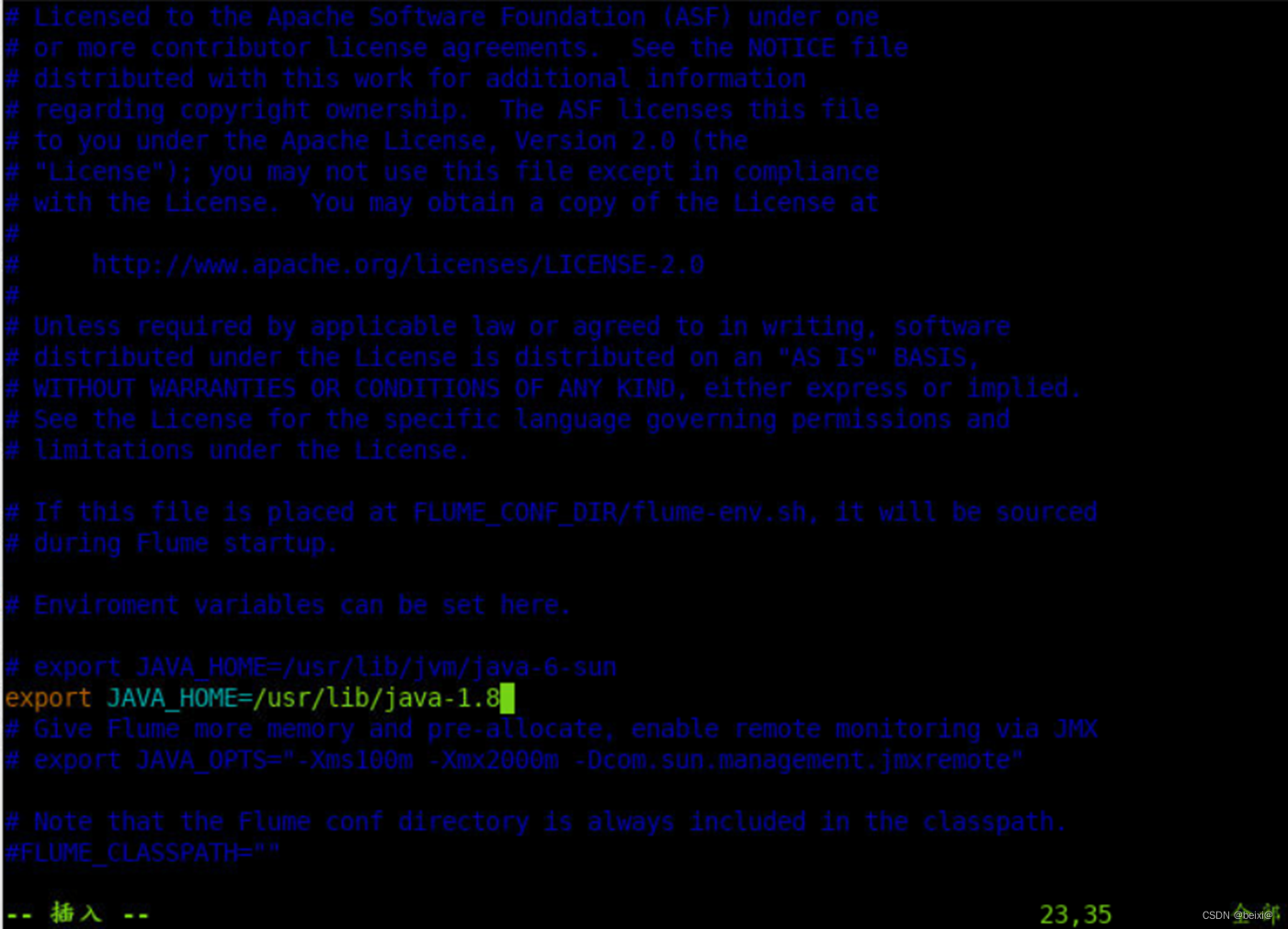
9.按键Esc,按键”:wq!”保存退出。
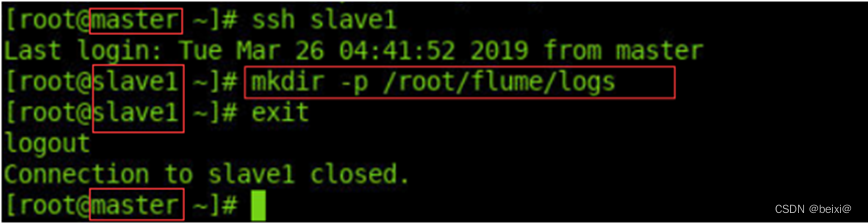
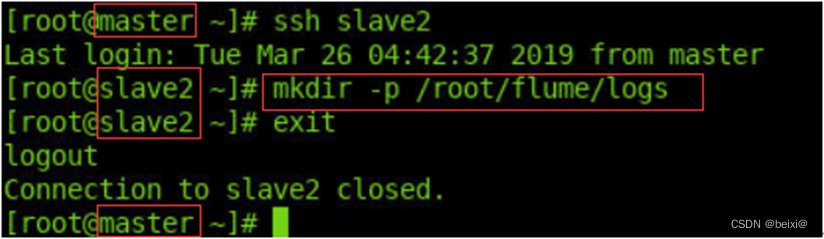
10.通过ssh命令,跳转至slave1机器命令窗口创建日志文件夹,再退回到master命令窗口。
ssh slave1
mkdir -p /root/flume/logs
exit
11.通过ssh命令,跳转至slave2机器命令窗口创建日志文件夹,再退回到master命令窗口。
ssh slave2
mkdir -p /root/flume/logs
exit
12.在当前“主节点”命令窗口中,配置slave.conf文件,进行配置。
vim /opt/flume/conf/slave.conf

13.按键 i ,更改代码如下:
# 主要作用是监听目录中的新增数据,采集到数据之后,输出到avro (输出到agent)
# 注意:Flume agent的运行,主要就是配置source channel sink
# 下面的a1就是agent的代号,source叫r1 channel叫c1 sink叫k1
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#具体定义source
a1.sources.r1.type = spooldir
#先创建此目录,保证里面空的
a1.sources.r1.spoolDir = /root/flume/logs
#对于sink的配置描述 使用avro日志做数据的消费
a1.sinks.k1.type = avro
# hostname是最终传给的主机名称或者ip地址
a1.sinks.k1.hostname = master
a1.sinks.k1.port = 44444
#对于channel的配置描述 使用文件做数据的临时缓存 这种的安全性要高
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /root/flume/checkpoint
a1.channels.c1.dataDirs = /root/flume/data
#通过channel c1将source r1和sink k1关联起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
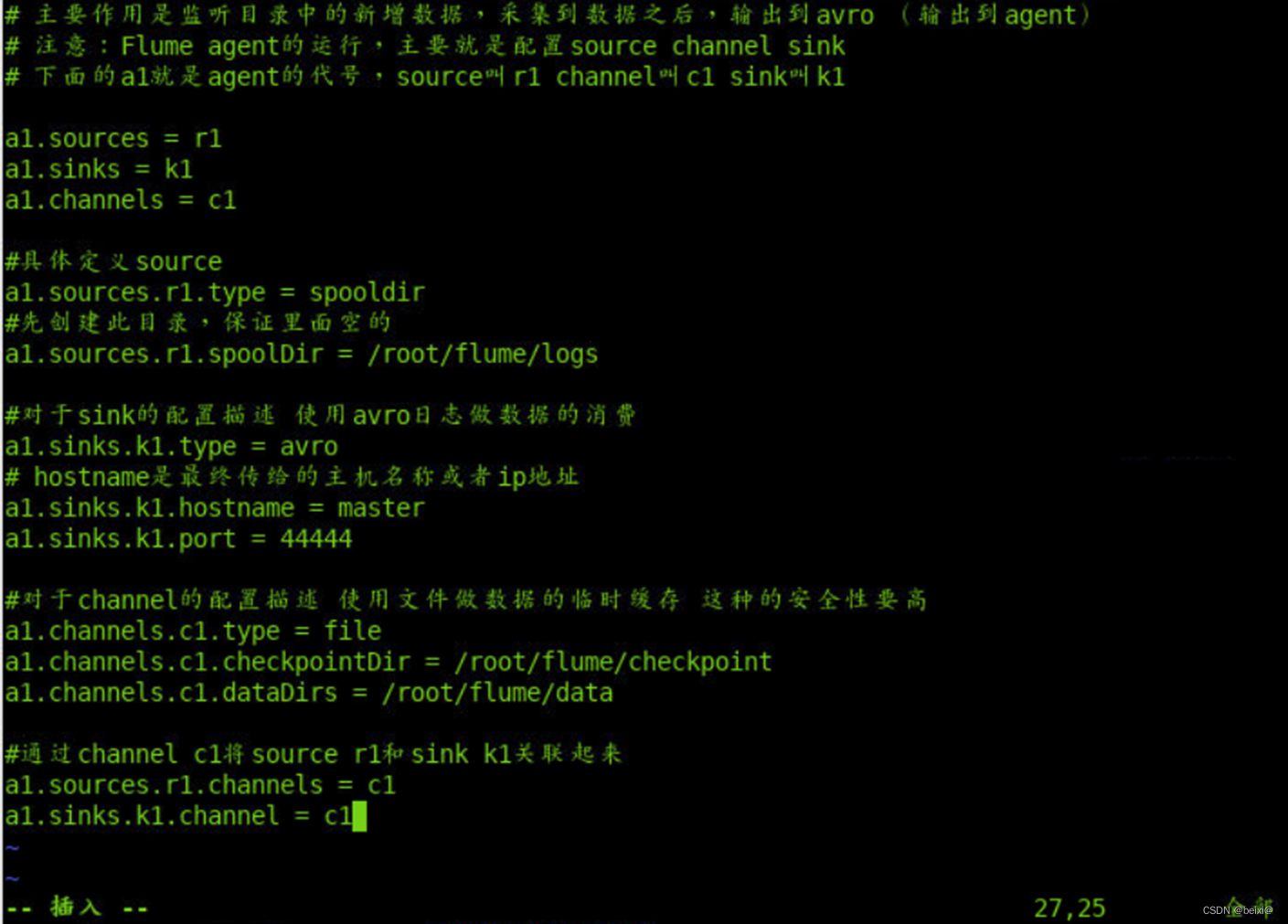
14.按键Esc,按键”:wq!”保存退出。
15.将flume分发至slave1、slave2机器。
scp -r /opt/flume slave1:/opt

scp -r /opt/flume slave2:/opt

16.配置master.conf文件
vim /opt/flume/conf/master.conf

17.按键 i ,更改代码如下:
# 获取slave1,2上的数据,聚合起来,传到hdfs上面
# 注意:Flume agent的运行,主要就是配置source channel sink
# 下面的a1就是agent的代号,source叫r1 channel叫c1 sink叫k1a1.sources = r1
a1.sinks = k1
a1.channels = c1#对于source的配置描述 监听avro
a1.sources.r1.type = avro
# hostname是最终传给的主机名称或者ip地址
a1.sources.r1.bind = master
a1.sources.r1.port = 44444#定义拦截器,为消息添加时间戳
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = org.apache.flume.interceptor.TimestampInterceptor$Builder#对于sink的配置描述 传递到hdfs上面
a1.sinks.k1.type = hdfs
#集群的nameservers名字
#单节点的直接写:hdfs://主机名(ip):9000/xxx
#ns是hadoop集群名称
# a1.sinks.k1.hdfs.path = hdfs://ns/flume/%Y%m%d
a1.sinks.k1.hdfs.path = /flume/events/root
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.fileType = DataStream
#不按照条数生成文件
a1.sinks.k1.hdfs.rollCount = 0
#HDFS上的文件达到128M时生成一个文件
a1.sinks.k1.hdfs.rollSize = 134217728
#HDFS上的文件达到60秒生成一个文件
a1.sinks.k1.hdfs.rollInterval = 60 #对于channel的配置描述 使用内存缓冲区域做数据的临时缓存
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100#通过channel c1将source r1和sink k1关联起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
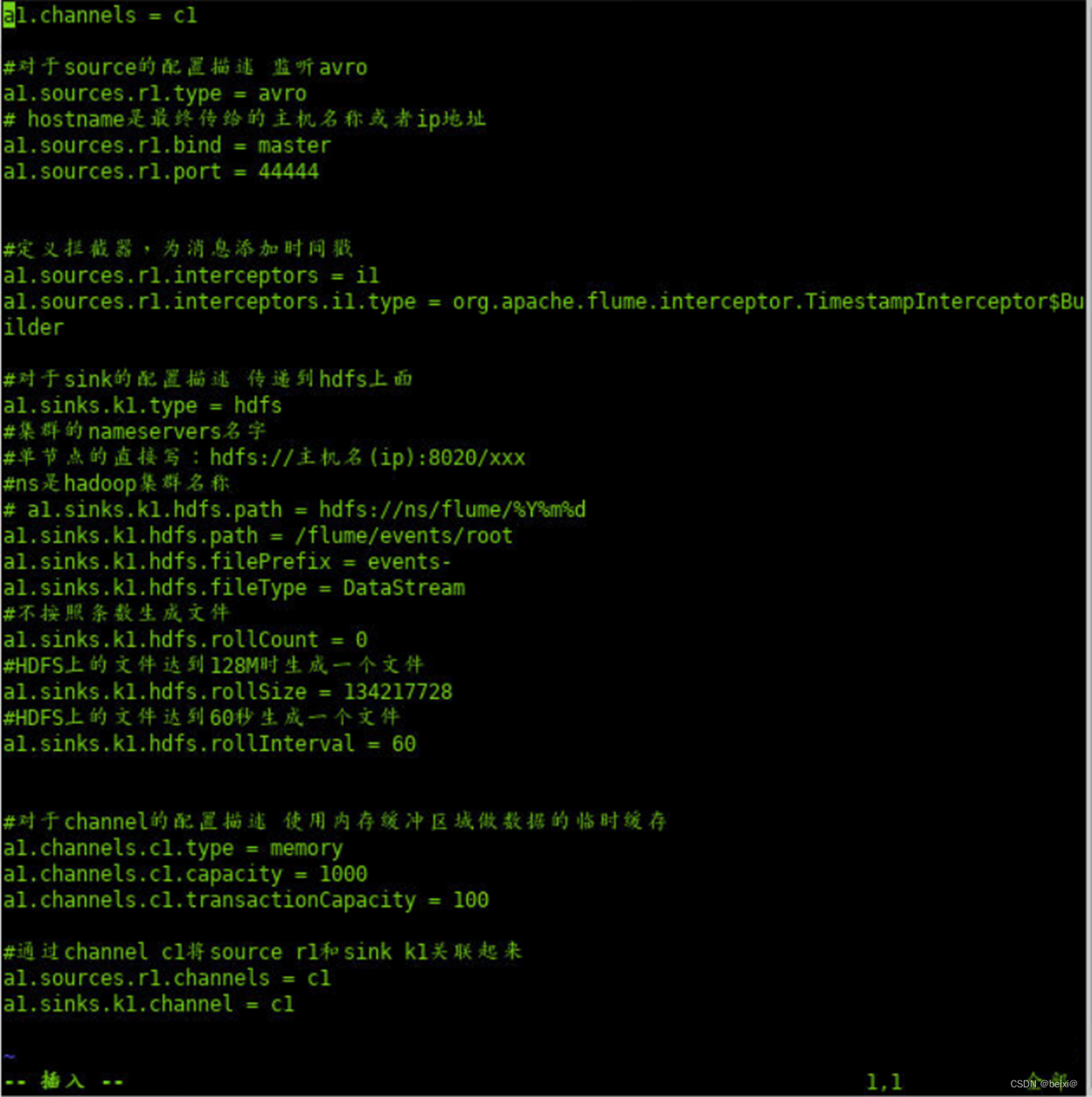
18.按键Esc,按键”:wq!”保存退出。
至此,Flume集群环境搭建就到此结束了,如果本篇文章对你有帮助记得点赞收藏+关注~
相关文章:
大数据组件-Flume集群环境搭建
🥇🥇【大数据学习记录篇】-持续更新中~🥇🥇 个人主页:beixi 本文章收录于专栏(点击传送):【大数据学习】 💓💓持续更新中,感谢各位前辈朋友们支持…...

想系列服务迁移专有云效实操
想系列服务迁移专有云效实操 1注册应用 查看jenkins脚本是否需要修改代码编译路径 gemdale_jenkins/maven3-service/k8s-image/maven3-service-deploy.sh Jenkins上的打包路径 service_tgt_path s e r v i c e w s / t a r g e t / service_ws/target/ servicews/target/ser…...
)
2020 牛客多校第三场 C Operation Love (叉积判断顺逆时针)
2020 牛客多校第三场 (叉积判断顺逆时针) Operation Love 大意: 给出一个手型 , 每个手型都有 20 个点 ,手型有可能旋转后给出 , 但不会放大和缩小 . 手型点集有可能顺时针给出也可能逆时针给出 , 判断给出的是左手还…...

基于OFDM的水下图像传输通信系统matlab仿真
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 5.算法完整程序工程 1.算法运行效果图预览 2.算法运行软件版本 matlab2022a 3.部分核心程序 function [rx_img] func_TR(tx_img, num_path, pathdelays, pathgains, snr) rng(default); …...
Docsify + Gitalk详细配置过程讲解
💖 作者简介:大家好,我是Zeeland,开源建设者与全栈领域优质创作者。📝 CSDN主页:Zeeland🔥📣 我的博客:Zeeland📚 Github主页: Undertone0809 (Zeeland)&…...

React中的setState的执行机制
文章目录 前言setState是什么?更新类型批量更新后言 前言 在 React 中,setState 是用于更新组件状态的方法。它是一个异步操作 值得注意的是,由于 setState 是异步的,所以在调用 setState 后立即访问 this.state 可能得到的还是旧的状态值。…...
2023最新任务悬赏平台源码uniapp+Thinkphp新款悬赏任务地推拉新充场游戏试玩源码众人帮威客兼职任务帮任务发布分销机
新款悬赏任务地推拉新充场游戏试玩源码众人帮威客兼职任务帮任务发布分销机制 后端是:thinkphpFastAdmin 前端是:uniapp 1.优化首页推荐店铺模块如有则会显示此模块没有则隐藏。 2修复首页公告,更改首页公告逻辑。(后台添加有公…...
微服务事务管理(Dubbo)
Seata 是什么 Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。Seata 将为用户提供了 AT、TCC、SAGA 和 XA 事务模式,为用户打造一站式的分布式解决方案。 一、示例架构说明 可在此查看本示例完整代码地址&#x…...

Springboot整合ClickHouse
一、快速开始 1、添加依赖 <dependency><groupId>ru.yandex.clickhouse</groupId><artifactId>clickhouse-jdbc</artifactId><version>0.3.1-patch</version> </dependency> <dependency><groupId>com.alibaba&…...
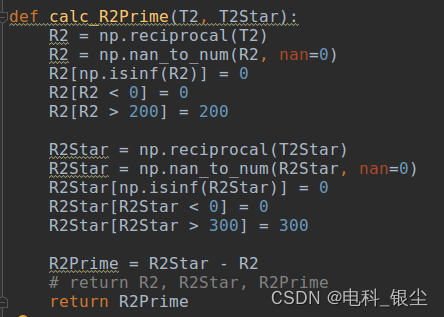
【材料整理】-- Python、Matlab中常用调试代码,持续更新!
文章目录 Python、Matlab中常用调试代码,持续更新!一、Python常用调试代码:二、Matlab常用调试代码: Python、Matlab中常用调试代码,持续更新! 一、Python常用调试代码: 1、保存.mat文件 from…...

什么是同源策略(same-origin policy)?它对AJAX有什么影响?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ 同源策略(Same-Origin Policy)与 AJAX 影响⭐ 同源策略的限制⭐ AJAX 请求受同源策略影响⭐ 跨域资源共享(CORS)⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 记…...

视频汇聚/视频云存储/视频监控管理平台EasyCVR接入海康SDK协议后无法播放该如何解决?
开源EasyDarwin视频监控/安防监控/视频汇聚EasyCVR能在复杂的网络环境中,将分散的各类视频资源进行统一汇聚、整合、集中管理,在视频监控播放上,视频安防监控汇聚平台可支持1、4、9、16个画面窗口播放,可同时播放多路视频流&#…...
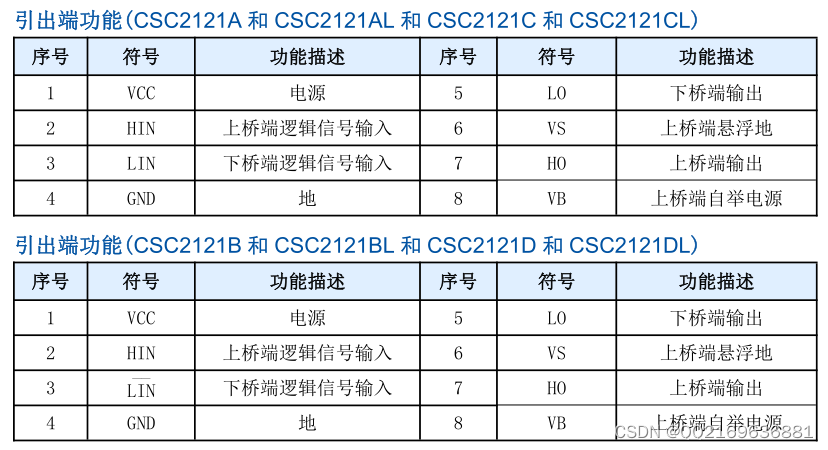
CSC2121A
半桥架构的栅极驱动电路CSC2121A CSC2121系列是一款高性价比的半桥架构的栅极驱动专用电路,用于大功率MOS管、IGBT管栅极驱动。IC内部集成了逻辑信号处理电路、死区时间控制电路、欠压保护电路、电平位移电路、脉冲滤波电路及输出驱动电路,专用于无刷电…...

高级进程编程-系统调用-创建守护进程
系统调用 API 参考:用时现查 如何在Linux下的进行多进程编程(初步) - 知乎 (zhihu.com)。 Linux 下系统调用的三种方法_海风林影的博客-CSDN博客。 linux系统调用(持续更新....)_tiramisu_L的博客-CSDN博客。 通过 glibc 提供的库函数、…...

Redis之发布订阅
一、Redis的发布订阅 Redis的发布与订阅功能由PUBLISH、SUBSCRIBE、PSUBSCRIBE等命令组成。通过执行SUBSCRIBE命令,客户端可以订阅一个或多个频道,从而成为这些频道的订阅者(subscriber):每当有其他客户端向被订阅的频…...

交换机 路由器的常见指令
常用的指令 交换机和路由器是网络中最常见的设备之一,它们都有一些常用的指令。下面是它们的常用指令和解释: 交换机常用指令 show interfaces:显示交换机上的所有接口信息,包括状态、速率、错误信息等。show mac-address-tabl…...

Matlab 基本教程
1 清空环境变量及命令 clear all % 清除Workspace 中的所有变量 clc % 清除Command Windows 中的所有命令 2 变量命令规则 (1)变量名长度不超过63位 (2)变量名以字母开头, 可以由字母、数字和下划线…...

现浇钢筋混泥土楼板施工岗前安全VR实训更安全高效
建筑行业天天与钢筋混凝土砼在,安全施工便成了企业发展的头等大事。 当今社会,人人都奉行生命无价,安全至上。可工地安全事故频繁发生,吞噬掉多少宝贵生命。破坏了多小个家庭?痛定死痛,为了提高施工人员的安全意识。 …...
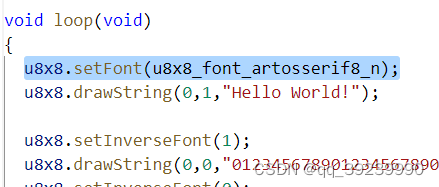
ARDUINO STM32 SSD1306
STM32F103XX系列SPI接口位置 在ARUDINO 下,(不需要设置引脚功能,不需要开启时钟设置,ARDUINO已经帮我们处理了) stm32f103c6t6 flash不足,不足以运行U8G2,产生错误 改用U8X8,后将字体改为u8x8_…...

临时抱佛脚
马上就要面试了,心里面比较紧张~ 交换型数据结构 在进行网络消息处理的时候,经常会对发送过来的消息进行读写操作。采用普通的方法,需要将读到消息频繁的进行copy操作,这样无疑会降低系统的效率。交换型数据机构指的…...

Intel X710/X722网卡在ESXi下的‘隐形杀手’:从一次诡异的VM网络中断谈驱动固件升级
Intel X710/X722网卡在ESXi环境下的深度故障排查与固件升级指南 虚拟化平台运维工程师们经常遇到一种令人头疼的问题——毫无征兆的虚拟机网络中断。这种故障往往像幽灵一样难以捉摸,特别是在使用Intel X710/X722系列网卡搭配ESXi环境时。本文将带您深入探究这一&qu…...

如何5分钟实现桌面股票实时监控:TrafficMonitor股票插件完全指南
如何5分钟实现桌面股票实时监控:TrafficMonitor股票插件完全指南 【免费下载链接】TrafficMonitorPlugins 用于TrafficMonitor的插件 项目地址: https://gitcode.com/gh_mirrors/tr/TrafficMonitorPlugins 还在为错过重要行情而烦恼吗?想在工作时…...

5分钟极速上手:通达信缠论插件ChanlunX让技术分析智能化
5分钟极速上手:通达信缠论插件ChanlunX让技术分析智能化 【免费下载链接】ChanlunX 缠中说禅炒股缠论可视化插件 项目地址: https://gitcode.com/gh_mirrors/ch/ChanlunX 还在为复杂的缠论分析而头疼吗?面对K线图中的顶底分型、笔段划分、中枢识别…...
PixelFlasher:5分钟掌握Pixel设备刷机与Root管理的终极指南
PixelFlasher:5分钟掌握Pixel设备刷机与Root管理的终极指南 【免费下载链接】PixelFlasher Pixel™ phone flashing GUI utility with features. 项目地址: https://gitcode.com/gh_mirrors/pi/PixelFlasher PixelFlasher是一款专为Google Pixel设备设计的图…...
:技术栈选择与工具集成)
AI智能体开发(二):技术栈选择与工具集成
主流开发框架深度对比 在上一篇中我们了解了Agent的核心架构,现在让我们看看如何用代码实现这些架构组件。目前市面上有多个成熟的Agent开发框架,每个都有其独特的优势和适用场景。 LangChain 定位:最全面的LLM应用开发框架 核心优势: 生态系统最完善 - 支持100+ LLM提…...

在珠宝首饰加工中,遨博协作机器人配合微力控技术,实现宝石的自动化镶嵌
在珠宝首饰的高端制造领域,宝石镶嵌是决定产品最终价值与艺术表现力的灵魂工序。这一过程要求近乎苛刻的精度、无可挑剔的稳定性,以及对脆性材料的极致呵护。长期以来,这依赖于镶嵌师多年练就的“手感”与专注力,属于劳动力高度密…...

PPTist免费在线演示文稿制作完全指南:从零到专业演示的终极教程
PPTist免费在线演示文稿制作完全指南:从零到专业演示的终极教程 【免费下载链接】PPTist PowerPoint-ist(/pauəpɔintist/), An online presentation application that replicates most of the commonly used features of MS PowerPoint, al…...

Unity 2019格斗游戏开发:帧同步、输入缓冲与Hitbox/Hurtbox实现
1. 为什么2019版Unity仍是横板格斗开发的“黄金锚点”我带过三届游戏开发训练营,每次开课前都会问学员:“你最想用哪个版本做格斗游戏?”——超过七成的人脱口而出“最新版”。但当我把他们拉进一个用Unity 2019.4.40f1跑通的《街霸》风格连招…...

Python爬虫实战:Python + curl_cffi 穿透 Adidas 新品榜:TLS 指纹伪装实战!
㊗️本期内容已收录至专栏《Python爬虫实战》,持续完善知识体系与项目实战,建议先订阅收藏,后续查阅更方便~ ㊙️本期爬虫难度指数:⭐⭐ 🉐福利: 一次订阅后,专栏内的所有文章可永久…...

终极量化数据获取指南:3步掌握pywencai高效获取同花顺问财数据
终极量化数据获取指南:3步掌握pywencai高效获取同花顺问财数据 【免费下载链接】pywencai 获取同花顺问财数据 项目地址: https://gitcode.com/gh_mirrors/py/pywencai 在量化投资和金融数据分析领域,获取精准、实时的A股市场数据一直是技术开发者…...