chatGPT训练过程
强化学习基础
强化学习是指智能体在不确定环境中最大化其获得的奖励从而达到自主决策的目的。其执行过程为:智能体依据策略决策从而执行动作,然后感知环境获取环境的状态,进而得到奖励(以便下次再到相同状态时能采取更优的动作),然后再继续按此流程“依据策略执行动作-感知状态–得到奖励”循环进行。

【强化学习是一种无监督学习】强化学习没有标签告诉它在某种情况下应该做出什么样的行为,只有一个做出一系列行为后最终反馈回来的reward,然后判断当前选择的行为是好是坏。某一状态的价值函数等于即时奖励+折扣因子×后续一系列状态的奖励。
基于值函数的方法
通过求解一个状态或者状态下某个动作的估值为手段,从而寻找最佳的价值函数,找到价值函数后,再提取最佳策略。【总结】通过做出动作后,找最佳的价值函数,提取最佳策略。
基于策略的方法
一般先进行策略评估,即对当前已经搜索到的策略函数进行估值,得到估值后,进行策略改进,不断重复这两步直至策略收敛。【总结】对策略进行估值,优化使策略估值最大化。
马尔科夫
当且仅当某时刻的状态只取决于上一时刻的状态时,一个随机过程被称为具有马尔可夫性质。具备马尔科夫性质的随机过程称为马尔科夫过程。
马尔科夫奖励
在马尔科夫过程的基础上加入奖励函数和折扣因子就变为了马尔科夫奖励过程。
【奖励函数】某个状态s的奖励是指转移到该状态s时可以获得的奖励期望。
【回报】其实某一状态获得的奖励是持久的,因为当前状态导致下一状态获得的奖励乘以折扣因子就是持久奖励。回报=当前奖励+持久奖励。
【状态价值】某一状态可以获得回报的期望。

马尔科夫决策过程
在马尔科夫奖励过程中加入来自外界的刺激如智能体的动作,就得到了马尔科夫决策过程。
【状态价值函数】某一状态可以获得奖励的期望乘以该状态的价值。
【动作价值函数】在某一状态下采取某一动作所获得奖励的期望。—Q函数
强化学习的分类
基于模型的强化学习
可以简单的使用动态规划求解,任务可定义为预测和控制,预测的目的是评估当前策略的好坏,即求解状态价值函数。
无模型的强化学习
基于价值的强化学习,其会学习并贪婪的选择奖励值最大的动作。
基于策略的强化学习,其对策略进行建模和优化。
重要性采样
假设有一个函数,x需要从分布p中采样数据;但是当不能从分布p中采样数据而只能从另一个分布q中采用数据时,需要做一些变换。

如此便可以从分布q中采样x,再进行计算。
而异策略就是基于重要性采样的原理实现的。
策略学习
【策略梯度更新的思想】参数为θ的策略πθ接受状态s,输出动作概率分布,在动作概率分布中采样动作,执行动作(形成运动轨迹),得到奖励r,跳到下一个状态。在这样的步骤下,可以使用策略π收集一批样本,然后使用梯度下降算法学习这些样本,不过当策略π的参数更新后,这些样本不能继续被使用,还要重新使用策略π与环境互动收集数据。
TRPO:加进KL散度解决两个分布相差大的问题
在目标函数里面加入了约束。TRPO的问题在于把 KL 散度约束当作一个额外的约束,没有放在目标里面,导致TRPO很难计算
PPO(相对TRPO减少了计算量)
通过KL散度(相对熵)加入惩罚项、截断的方式使得更新的策略不与原策略相差太大。
RLHF:基于人类偏好的强化学习
1.首先,智能体的一对1-2秒的行为片段定期地回馈给人类操作员,人类基于偏好对智能体的行为作出某种偏好性的选择评判。
2.接着,人类这种基于偏好的选择评判被预测器来预测奖励函数。
3.智能体通过预测器预测出的奖励函数作出更优的行为。
ChatGPT的训练过程
第一阶段:利用人类的问答数据对GPT3微调进行有监督训练出SFT模型(作为baseline)。
1.一共进行了16个epochs的训练。
2.采用了余弦学习率衰减策略。
3.残差丢弃率。
第二阶段:通过RLHF的思路训练一个奖励模型RM。
首先使用第一阶段训练的SFT模型初始化第二阶段的RM模型。针对每个问题收集4-9个不同的回答,人工对这些回答的好坏进行标注且排序,排序的结果来训练一个RM模型,使模型从排序数据中理解人类的偏好。
不同回答两两组合,计算奖励差值。
第三阶段:通过最大化奖励函数的目标下,通过PPO算法继续微调GPT4模型。
首先使用第一阶段训练的SFT模型初始化一个PPO模型,使用不带任何人工标注的数据集训练,使用第二阶段训练的RM奖励模型去给PPO模型的预测结果进行打分和排序。之后通过奖励最大化优化PPO模型的策略参数,PPO算法限制策略更新范围。
总目标函数

第一部分是使奖励最大化,利用重采样的思想展开如下所示:

第二部分是惩罚项,目的是不让新学习到的策略函数偏离baseline策略SFT太多。
第三部分是偏置项,防止训练出的模型过于讨好人类偏好,而不根据问题回答答案。(个人理解可以是防止数据集中的噪声带来干扰)
从GPT1到GPT2
虽然GPT1的预训练加微调的范式仅需要少量的微调和些许的架构改动,但能不能有一种模型完全不需要对下游任务进行适配就可以表现优异?GPT2便是在往这个方向努力:不微调但给模型一定的参考样例以帮助模型推断如何根据任务输入生成相应的任务输出。
针对【小样本/零样本】分为三种:零样本学习(是指在没有任何样本/示例情况下,让预训练语言模型完成特定任务)、单样本学习(是指在只有一个样本/示例的情况下,预训练语言模型完成特定任务)、少样本学习(是指在只有少量样本/示例的情况下,预训练语言模型完成特定任务)。【注】零样本、单样本、少样本并没有被模型去学习和微调,模型学习了样本输入输出的分布。
prompt learning
让模型逐步学会人类的各种自然指令,而不用根据下游任务去微调模型或更改模型的参数,直接根据指令去干活,这个指令就叫做prompt。
指令微调技术(IFT)
IFT的数据通常是由人工手写指令和语言模型引导的指令实例的集合,这些指令数据由三个主要组成部分组成:指令、输入和输出,对于给定的指令,可以有多个输入和输出实例。
关于「prompt learning」最简单粗暴的理解,其实就是让模型逐步学会人类的各种自然指令或人话,而不用根据下游任务去微调模型或更改模型的参数,直接根据人类的指令直接干活,这个指令就是prompt,而设计好的prompt很关键也需要很多技巧,是一个不算特别小的工程,所以叫prompt engineering。
基于思维链(Cot)技术的prompt
为了让大模型进一步具备解决数学推理问题的能力,推出了最新的prompting机制–chain of thought,其给模型推理步骤的prompt,让其学习如何一步一步的推理,从而让模型具备推理能力,最终可以求解一些简单甚至相对复杂的数学问题。
instructGPT
InstructGPT=GPT3+指令学习+RLHF
【训练三阶段】①有监督微调“经过自监督预训练好的GPT3”。②然后基于人类偏好排序的数据训练一个奖励模型。③最终在最大化奖励的目标下通过PPO算法来优化策略。
chatGPT与InstructGPT的区别在于:chatGPT是基于GPT3.5做微调,instructGPT是基于GPT3.0做微调。
基于GPT4的chatGPT的改进版:增加了多模态的技术能力。
基于GPT4的ChatGPT改进版
新增了多模态技术能力。
相关文章:
chatGPT训练过程
强化学习基础 强化学习是指智能体在不确定环境中最大化其获得的奖励从而达到自主决策的目的。其执行过程为:智能体依据策略决策从而执行动作,然后感知环境获取环境的状态,进而得到奖励(以便下次再到相同状态时能采取更优的动作),…...

原神角色数据分析项目说明文档
---项目涉及--- 前端html语言,flask框架,excel,MySQL,DataFrame数组,numpy,pyecharts ---实现方式--- 将所有角色数据存储在excel表格中,在需要时读取,当用户想要查看某一项时&…...
property)
【Qt】QML-04:自定义变量(属性)property
1、property 1.1 介绍 property用来自定义属性。 什么是属性?面向对象中,类由方法和属性构成。对于从C语言的过来人,更喜欢称之为变量。 之所以说“自定义”,是因为QML语言本身已有默认定义好的属性,这些属性不可以…...
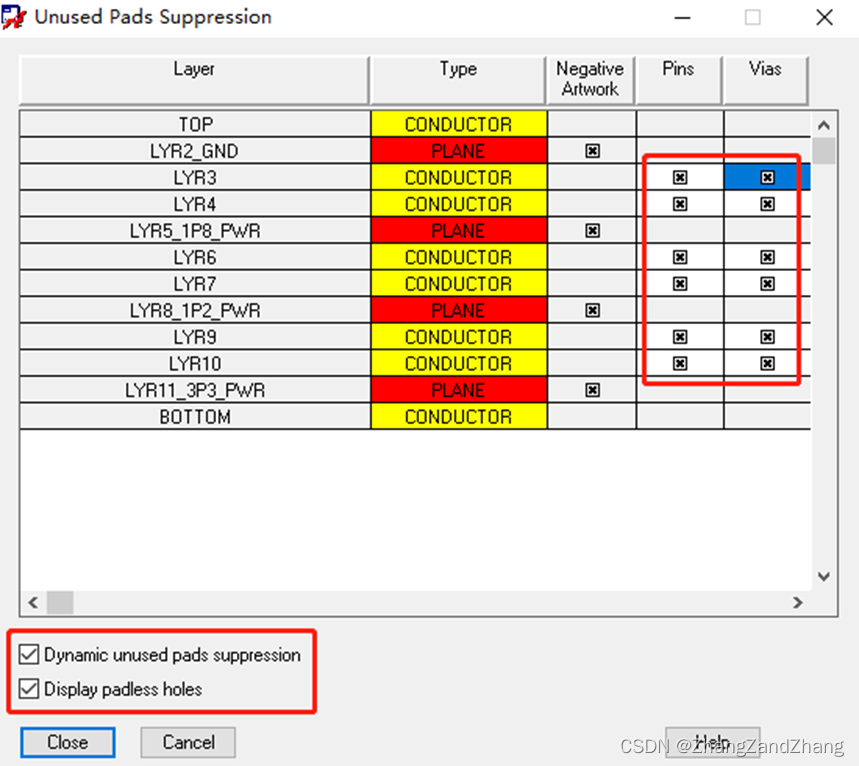
基于Cadence Allegro无盘设计操作流程
无盘设计 1.因为过孔具有电容效应,无盘设计能最大限度保证阻抗连续性,从而减小反射与插损; 2.减缓走线压力,降低产品成本与风险; SetupConstraintsModelSpacing Models勾选Hole to line SetupUnused Pads Su…...
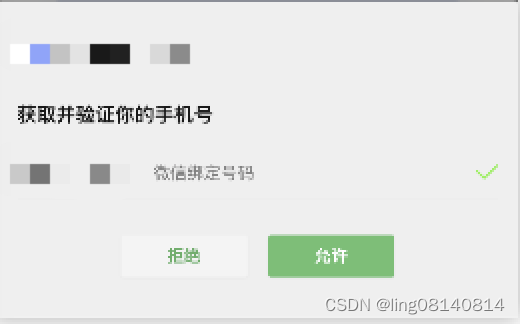
微信小程序 - 2023年最新版手机号快捷登录详细教程
前言 最近开发公司手机快捷登录的功能,花费了不少时间,这里附上详细教程。 这里以海底捞小程序的图片为例,如有侵权请联系小编删除。 代码如下 <button open-type"getPhoneNumber" getphonenumber"getPhoneNumber"…...

Spring_Bean的自动装配
目录 三种配置机制 测试搭建 byName byType 使用注解 Autowire Qualifer Resource Autowire和Resource的不同 自动装配是使用spring满足bean依赖的一种条件 三种配置机制 在xml中显式配置;在java中显式配置;隐式的bean发现机制和自动装配。 …...
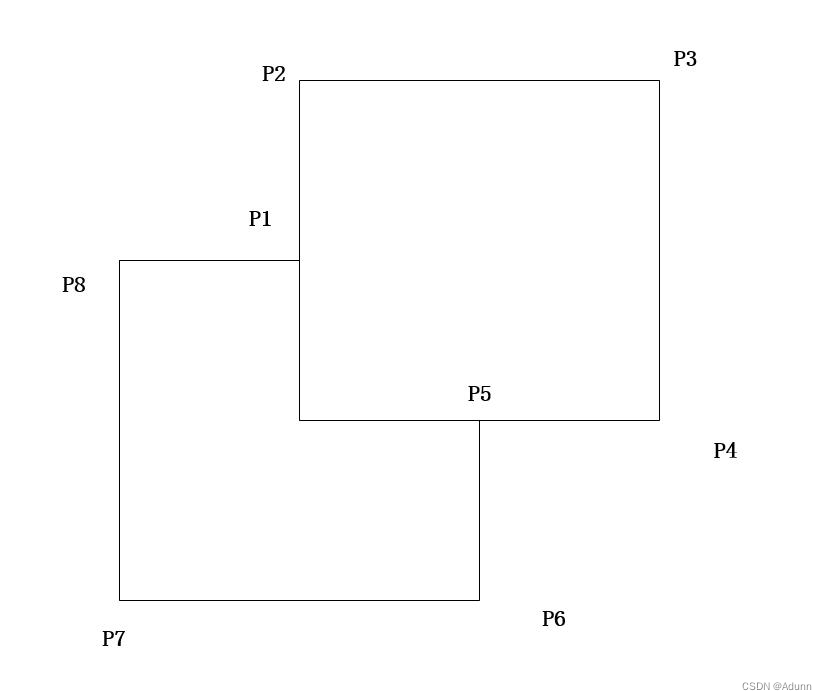
使用boost::geometry::union_ 合并边界(内、外)- 方案一
使用boost::geometry::union_ 合并边界(内、外):方案一 结合 boost::geometry::read_wkt() 函数 #include <iostream> #include <vector>#include <boost/geometry.hpp> #include <boost/geometry/geometries/point_x…...

面向高速公路车辆切入场景的自动驾驶测试用例生成方法
1 前言 自动驾驶汽车为解决“交通事故、交通拥堵、环境污染、能源短缺”等问题提供了新的途径[1]。科学完善的测试验证评价体系对提高自动驾驶汽车的研发效率、健全相关法律法规、推进智能交通发展至关重要[2]。自2009年起,谷歌自动驾驶汽车已经进行了超过560万km公…...
实现后端主动向前端推送数据)
Java:SpringBoot整合SSE(Server-Sent Events)实现后端主动向前端推送数据
SpringBoot整合SSE(Server-Sent Events)可以实现后端主动向前端推送数据 目录 核心代码完整代码参考文章 核心代码 依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</a…...

cmd命令行设置 windows 设置环境变量
cmd命令行设置 windows 设置环境变量 参考 51CTO博客 设置用户级别的环境变量 :: 设置新参数 JAVA_HOME1 setx JAVA_HOME1 "c:\test"; exit; echo "%JAVA_HOME1%";:: 追加参数内容 JAVA_HOME1 setx JAVA_HOME1 "%JAVA_HOME1%;c:\test2\;"; exi…...
基于负载均衡的在线OJ实战项目
前言: 该篇讲述了实现基于负载均衡式的在线oj,即类似在线编程做题网站一样,文章尽可能详细讲述细节即实现,便于大家了解学习。 文章将采用单篇不分段形式(ps:切着麻烦),附图文&#…...
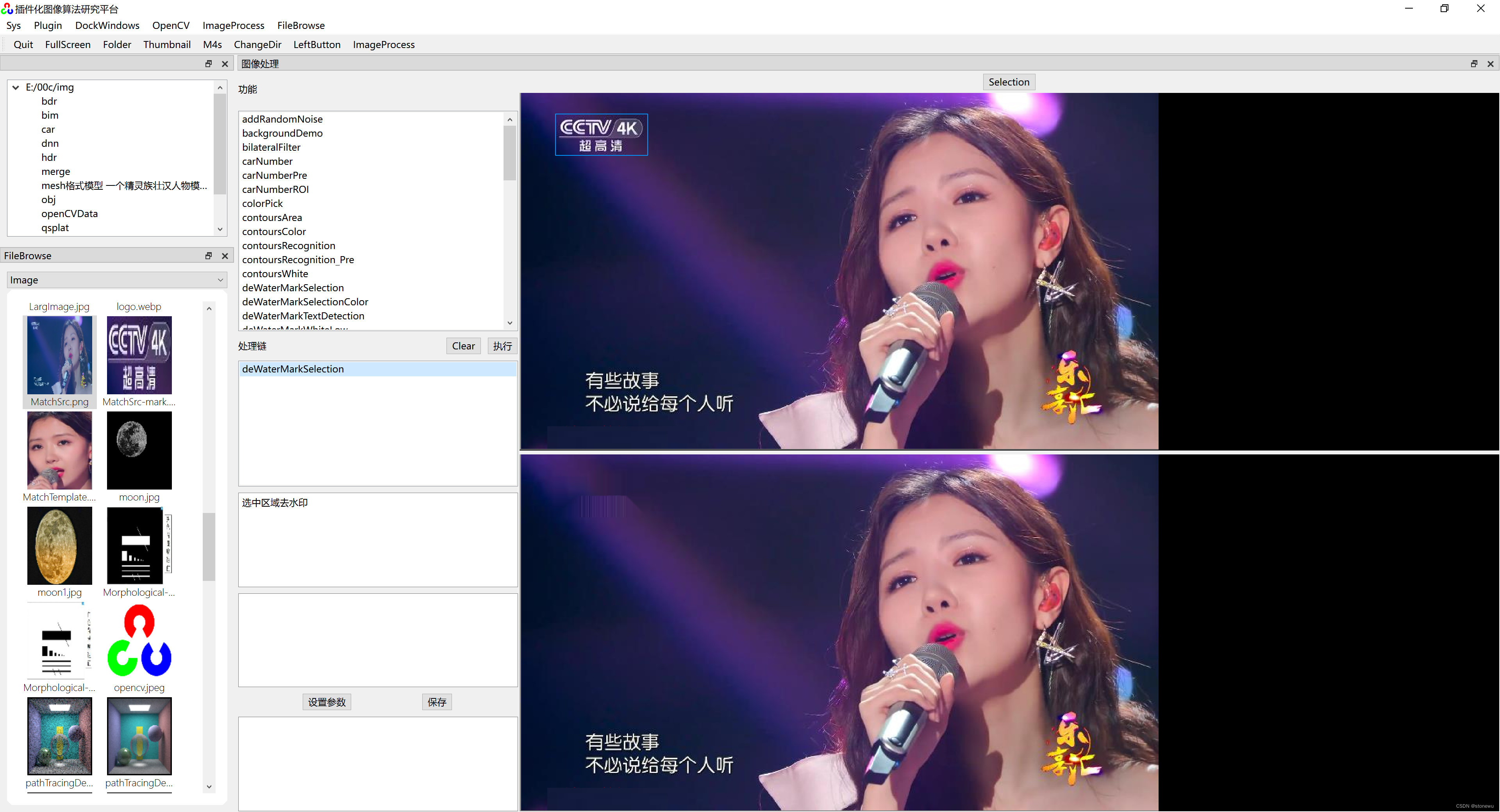
Opencv手工选择图片区域去水印
QT 插件化图像算法研究平台的功能在持续完善,补充了一个人工选择图片区域的功能。 其中,图片选择功能主要代码如下: QRect GLImageWidget::getSeleted() {QRect ajust(0,0,0,0);if(image.isNull() || !hasSelection)return ajust;double w1…...
《向量数据库》——向量数据库跟大模型是什么关系呢?
在人工智能领域,最近的一个重要趋势是大模型的兴起。在大模型的世界里,我们面临着处理和管理大规模向量数据的挑战,而向量数据库,就是为了满足这个需求而不断发展着。 那么,向量数据库跟大模型是什么关系呢?…...

通过这 5 项 ChatGPT 创新增强您的见解
为什么绝大多数的人还不会使用chatGPT来提高工作效能?根本原因就在还不会循序渐进的发问与chatGPT互动。本文总结了5个独特的chatGPT提示,可以帮助您更好地与Chat GPT进行交流,以获得更清晰的信息、额外的信息和见解。 澄清假设和限制 用5种提…...
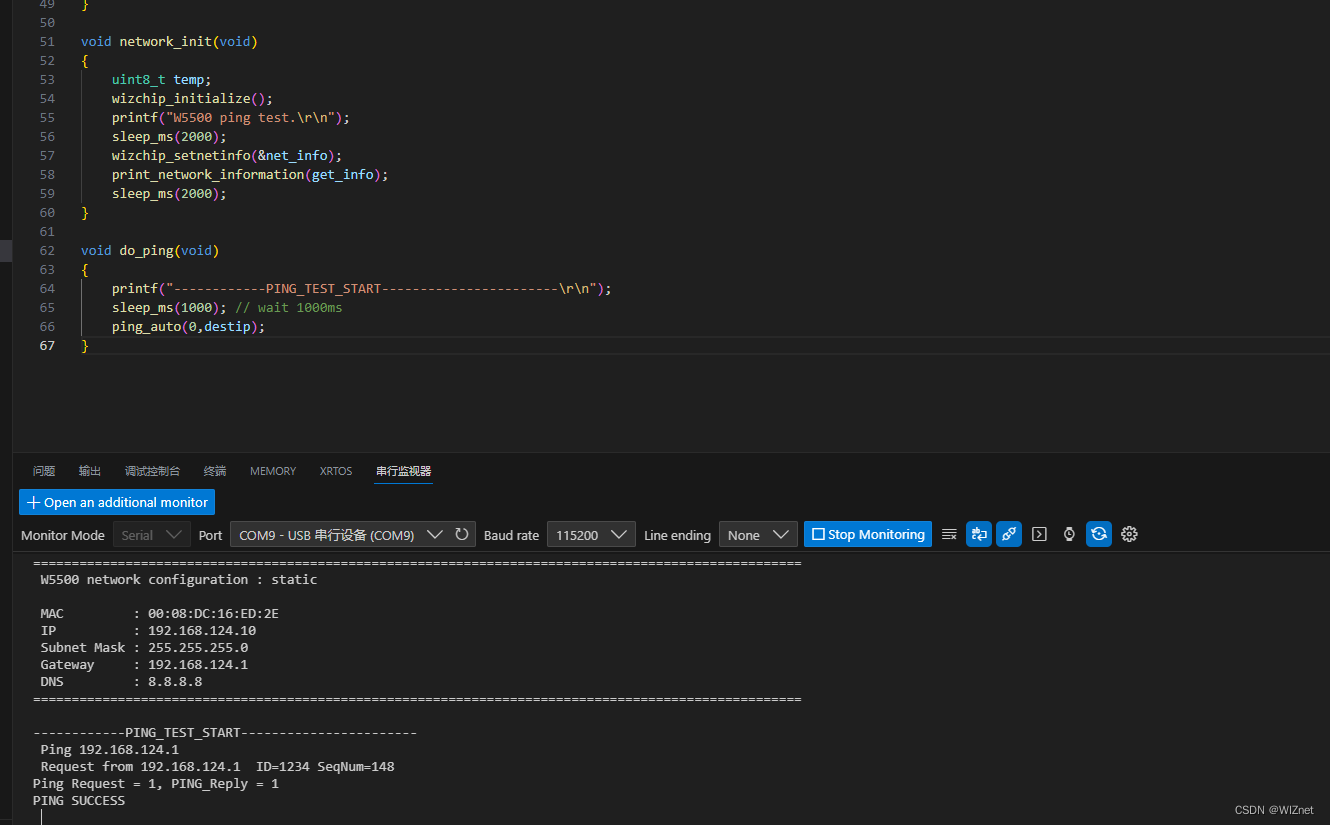
W5500-EVB-PICO主动PING主机IP检测连通性(十)
前言 上一章我们用W5500_EVB_PICO 开发板做UDP组播数据回环测试,那么本章我们进行W5500_EVB_PICO Ping的测试。 什么是PING? Ping (Packet Internet Groper)是一种因特网包探索器,用于测试网络连接量的程序 。Ping是…...

解释基本的3D理论
推荐:使用 NSDT场景编辑器 快速搭建3D应用场景 坐标系 3D 本质上是关于 3D 空间中形状的表示,并使用坐标系来计算它们的位置。 WebGL 使用右侧坐标系 — 轴指向右侧,轴指向上方,轴指向屏幕外,如上图所示。xyz 对象 …...

C# 练习题
26. Enum(枚举) /*枚举是一组命名整型常量。枚举类型是使用 enum 关键字声明的。C# 枚举是值类型。换句话说,枚举包含自己的值,且不能继承或传递继承。 */using System;public class EnumTest {enum Day { Sun, Mon, Tue, Wed, Thu, Fri, Sat };static…...

解决Linux报错:Swap file “xxxxxx.swp“ already exists
出现问题 Swap file “.models_conf.yaml.swp” already exists! 在 Linux 下 vim 编辑过程中,由于某种原因异常退出正在编辑的文件,再次编辑该文件时,会出现如下提示: 一个文件出现了带有.swp的副本文件的时候,会出现…...

基于飞桨图学习框架的空间异配性感知图神经网络
本期文章将为大家分享飞桨社区开发者肖淙曦、周景博发表于数据挖掘顶会KDD2023的论文《Spatial Heterophily Aware Graph Neural Networks》。 肖淙曦 肖淙曦,百度研究院商业智能实验室研究实习生,中国科学技术大学在读博士生,主要从事时空…...

Springboot整合JWT
1. 应用场景 前后端分离项目保持登录状态。 问题:ajax请求如何跨域,将无法携带jsessionid,这样会导致服务器端的session不可用。如何解决? 后端: 登录接口在验证过用户密码后,将用户的身份信息转换成…...

windows下vs 2015 libtorrent库的配置,vs2015下-boost-openssl-libtorrent的配置
libtorrent依赖OpenSSL和boost库,首先要编译Openssl和boost库。 1、安装ActivePerl,下载地址:网上找。 安装完后配置环境变量(一般安装成功后,环境变量就已经配置好了,如果没有配置自己配置环境变量): …...

2026脑机接口:技术突破与产业爆发
2026年脑机接口技术的发展现况 2026年,脑机接口技术已从实验室前沿研究加速迈向产业化与规模化应用的关键节点,其发展现况呈现出“技术突破、场景深化、生态初成”的鲜明特征。 一、 技术路线:侵入式与非侵入式并行突破,性能边界…...

PaperXie 期刊论文写作全解析|从选题到成稿,一键适配普通 / 核心 / SCI 期刊
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/期刊论文https://www.paperxie.cn/ai/journalArticleshttps://www.paperxie.cn/ai/journalArticles 一、前言:期刊论文写作的痛点,你中了几个? 在学术圈,期刊…...

渗透测试授权书:法律效力与技术执行的耦合设计
1. 这份授权书不是“走个形式”,而是渗透测试合法性的生死线很多人第一次接触渗透测试,看到《渗透测试授权书》模板,第一反应是:“不就是签个字的事?网上随便找个PDF填上名字就行。”我2015年刚入行时也这么想…...

区块链与计算机视觉融合:构建可信机器感知系统的架构与实践
1. 项目概述:当计算机视觉遇见区块链在人工智能的浪潮中,计算机视觉(CV)无疑是那颗最耀眼的明星之一。它让机器拥有了“看”和理解世界的能力,从医疗影像中精准定位病灶,到自动驾驶汽车识别路况,…...

终极指南:Commit Message Emoji 让每次提交都充满仪式感
终极指南:Commit Message Emoji 让每次提交都充满仪式感 【免费下载链接】commit-message-emoji Every commit is important. So lets celebrate each and every commit with a corresponding emoji! :smile: 项目地址: https://gitcode.com/gh_mirrors/co/commit…...

LSTM比特币价格预测:特征工程驱动的交易信号生成器
1. 项目概述:为什么用RNN/LSTM做比特币价格预测,而不是随便套个模型?我从2018年开始接触加密资产量化分析,最早用的是ARIMA和随机森林——前者对趋势拐点完全失灵,后者在训练集上准确率92%,一到实盘就跌破6…...

Pydantic序列化避坑指南:model_dump vs dict、exclude/include高级用法与SerializeAsAny解析
Pydantic序列化避坑指南:model_dump vs dict、exclude/include高级用法与SerializeAsAny解析 在Python生态中,Pydantic已经成为数据验证和序列化的标杆工具。但许多开发者在实际使用中,常常会遇到一些看似简单却容易踩坑的序列化问题。本文将…...

2026年研究生开题报告降AI攻略:开题报告AIGC超标4.8元一次过知网完整处理指南
2026年研究生开题报告降AI攻略:开题报告AIGC超标4.8元一次过知网完整处理指南 从AI率71%到5.9%,我用了一个晚上。研究生开题报告降AI完整经历。 核心工具:嘎嘎降AI(www.aigcleaner.com),4.8元,…...
)
机器学习---监督学习入门实验全攻略(小白友好版)
新晋码农一枚,小编会定期整理一些写的比较好的代码和知识点,作为自己的学习笔记,试着做一下批注和补充,转载或者参考他人文献会标明出处,非商用,如有侵权会删改!欢迎大家斧正和讨论!…...