自然语言处理(四):全局向量的词嵌入(GloVe)
全局向量的词嵌入(GloVe)
全局向量的词嵌入(Global Vectors for Word Representation),通常简称为GloVe,是一种用于将词语映射到连续向量空间的词嵌入方法。它旨在捕捉词语之间的语义关系和语法关系,以便在自然语言处理任务中能够更好地表示词语的语义信息。
GloVe的设计基于两个观察结果:共现矩阵(co-occurrence matrix)和词向量的线性关系。共现矩阵记录了词语之间在上下文中的共现频率,即它们在一定窗口大小内同时出现的次数。GloVe利用这个共现矩阵来计算词语之间的相似性,并通过优化目标函数来得到词向量。
GloVe的核心思想是将词语的向量表示表示为两个词向量的差异,这两个词向量分别表示词语在共现矩阵中的位置信息和语义信息。通过对这两个向量的点积操作,可以得到词语之间的共现概率。GloVe的优化目标是最小化预测共现概率和实际共现概率之间的误差。
与其他词嵌入方法(如Word2Vec)相比,GloVe具有一些优势。它在语义和语法任务上表现良好,并且能够更好地捕捉到词语之间的线性关系。此外,GloVe的训练过程相对简单,并且能够在大规模语料库上进行高效训练。
上下文窗口内的词共现可以携带丰富的语义信息。例如,在一个大型语料库中,“固体”比“气体”更有可能与“冰”共现,但“气体”一词与“蒸汽”的共现频率可能比与“冰”的共现频率更高。此外,可以预先计算此类共现的全局语料库统计数据:这可以提高训练效率。为了利用整个语料库中的统计信息进行词嵌入,让我们首先回顾上一节中的跳元模型,但是使用全局语料库统计(如共现计数)来解释它。
文章内容来自李沐大神的《动手学深度学习》并加以我的理解,感兴趣可以去https://zh-v2.d2l.ai/查看完整书籍
文章目录
- 全局向量的词嵌入(GloVe)
- 带全局语料统计的跳元模型
- GloVe模型
- 从条件概率比值理解GloVe模型
- GloVe和word2vec的区别
带全局语料统计的跳元模型
用 q i j q_{ij} qij表示词 w j w_j wj的条件概率P(w_j|w_i),在跳元模型中给定词 w i w_i wi,我们有:
q i j = e x p ( u j T v i ) ∑ k ∈ V e x p ( u k T v i ) q_{ij}=\frac{exp(u_j^Tv_i)}{\sum_{k\in V}exp(u_k^{T}v_i)} qij=∑k∈Vexp(ukTvi)exp(ujTvi)
其中,对于任意索引 i i i,向量 v i v_i vi和 u i u_i ui分别表示词 w i w_i wi作为中心词和上下文词,且 V = { 0 , 1 , . . . , ∣ V ∣ − 1 } V=\{0,1,...,|V|-1\} V={0,1,...,∣V∣−1}是词表的索引集。
考虑词 w i w_i wi可能在语料库中出现多次。在整个语料库中,所有以 w i w_i wi为中心词的上下文词形成一个词索引的多重集 C i C_i Ci,该索引允许同一元素的多个实例。对于任何元素,其实例数称为其重数。举例说明,假设词 w i w_i wi在语料库中出现两次,并且在两个上下文窗口中以 w i w_i wi为其中心词的上下文词索引是 k , j , m , k k,j,m,k k,j,m,k和 k , l , k . j k,l,k.j k,l,k.j。因此,多重集 C i = { j , j , k , k , k , k , l , m } C_i=\{j,j,k,k,k,k,l,m\} Ci={j,j,k,k,k,k,l,m},其中元素 j , k , l , m j,k,l,m j,k,l,m的重数分别为2、4、1、1。
现在,让我们将多重集 C i C_i Ci中的元素 j j j的重数表示为 x i j x_{ij} xij。这是词 w j w_j wj(作为上下文词)和词 w i w_i wi(作为中心词)在整个语料库的同一上下文窗口中的全局共现计数。使用这样的全局语料库统计,跳元模型的损失函数等价于:
− ∑ i ∈ V ∑ j ∈ V x i j l o g q i j -\sum_{i\in V}\sum_{j\in V}x_{ij}logq_{ij} −i∈V∑j∈V∑xijlogqij
我们用 x i x_i xi表示上下文窗口中的所有上下文词的数量,其中 w i w_i wi作为它们的中心词出现,这相当于 ∣ C i ∣ |C_i| ∣Ci∣。设 p i j p_{ij} pij为用于生成上下文词 w j w_j wj的条件概率 x i j / x i x_{ij}/x_i xij/xi。给定中心词 w i w_i wi, 上式可以重写为:
− ∑ i ∈ V x i ∑ j ∈ V p i j l o g q i j -\sum_{i\in V}x_{i}\sum_{j\in V}p_{ij}log\ q_{ij} −i∈V∑xij∈V∑pijlog qij
在上式中, − ∑ j ∈ V x i j l o g q i j -\sum_{j\in V}x_{ij}log\ q_{ij} −∑j∈Vxijlog qij计算全局语料统计的条件分布 p i j p_{ij} pij和模型预测的条件分布 q i j q_{ij} qij的交叉熵。如上所述,这一损失也按 x i x_i xi加权。在式中最小化损失函数将使预测的条件分布接近全局语料库统计中的条件分布。
虽然交叉熵损失函数通常用于测量概率分布之间的距离,但在这里可能不是一个好的选择。一方面,规范化 q i j q_{ij} qij的代价在于整个词表的求和,这在计算上可能非常昂贵。另一方面,来自大型语料库的大量罕见事件往往被交叉熵损失建模,从而赋予过多的权重。
GloVe模型
有鉴于此,GloVe模型基于平方损失 (Pennington et al., 2014)对跳元模型做了三个修改:
- 使用 p i j ′ = x i j p'_{ij}=x_{ij} pij′=xij和 q i j ′ = e x p ( u j T v i ) q'_{ij}=exp(u_j^Tv_i) qij′=exp(ujTvi)而非概率分布,并取两者的对数,所以平方损失项是
( l o g p i j ′ − l o g q i j ′ ) 2 = ( u j T v i + b i + c j − l o g x i j ) 2 (log\ p'_{ij}-log\ q_{ij}')^2=(u_j^Tv_i+b_i+c_j-log \ x_{ij})^2 (log pij′−log qij′)2=(ujTvi+bi+cj−log xij)2 - 为每个词 w i w_i wi添加两个标量模型参数:中心词偏置 b i b_i bi和上下文词偏置 c i c_i ci
- 用权重函数 h ( x i j ) h(x_{ij}) h(xij)替换每个损失项的权重,其中 h ( x ) h(x) h(x)在 [ 0 , 1 ] [0,1] [0,1]的间隔内递增。
整合代码,训练GloVe是为了尽量降低以下损失函数:
∑ i ∈ V ∑ j ∈ V h ( x i j ) ( u j T v i + b i + c j − l o g x i j ) 2 \sum_{i\in V}\sum_{j\in V}h(x_{ij})(u_j^Tv_i+b_i+c_j-log\ x_{ij})^2 i∈V∑j∈V∑h(xij)(ujTvi+bi+cj−log xij)2
对于权重函数,建议的选择是:当 x < c x<c x<c(例如, c = 100 c=100 c=100)时, h ( x ) = ( x / c ) α h(x)=(x/c)^\alpha h(x)=(x/c)α(例如 α = 0.75 \alpha=0.75 α=0.75);否则 h ( x ) = 1 h(x)=1 h(x)=1。在这种情况下,由于 h ( x ) = 1 h(x)=1 h(x)=1,为了提高计算效率,可以省略任意 x i j = 0 x_{ij}=0 xij=0的平方损失项。例如,当使用小批量随机梯度下降进行训练时,在每次迭代中,我们随机抽样一小批量非零的 x i j x_{ij} xij来计算梯度并更新模型参数。注意,这些非零的 x i j x_{ij} xij是预先计算的全局语料库统计数据;因此,该模型GloVe被称为全局向量。
该强调的是,当词 w i w_i wi出现在词 w j w_j wj的上下文窗口时,词 w j w_j wj也出现在词 w i w_i wi的上下文窗口。因此, x i j = x j i x_{ij}=x_{ji} xij=xji。与拟合非对称条件概率 p i j p_{ij} pij的word2vec不同,GloVe拟合对称概率 l o g x i j log\ x_{ij} log xij。因此,在GloVe模型中,任意词的中心词向量和上下文词向量在数学上是等价的。但在实际应用中,由于初始值不同,同一个词经过训练后,在这两个向量中可能得到不同的值:GloVe将它们相加作为输出向量。
从条件概率比值理解GloVe模型
我们也可以从另一个角度来理解GloVe模型。设 p i j = P ( w j ∣ w i ) p_{ij}=P(w_j|w_i) pij=P(wj∣wi)为生成上下文词 w j w_j wj的条件概率,给定
作为语料库中的中心词。 tab_glove根据大量语料库的统计数据,列出了给定单词“ice”和“steam”的共现概率及其比值。
大型语料库中的词-词共现概率及其比值(根据 (Pennington et al., 2014)中的表1改编)
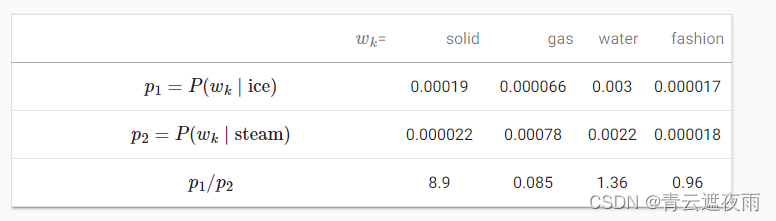
从 tab_glove中,我们可以观察到以下几点:
- 对于与“ice”相关但与“steam”无关的单词 w k w_k wk,例如 w k = s o l i d w_k=solid wk=solid,我们预计会有更大的共现概率比值,例如8.9。
- 对于与“steam”相关但与“ice”无关的单词 w k w_k wk,例如 w k = g a s w_k=gas wk=gas,我们预计较小的共现概率比值,例如0.085。
- 对于同时与“ice”和“steam”相关的单词 w k w_k wk,例如 w k = w a t e r w_k=water wk=water,我们预计其共现概率的比值接近1,例如1.36。
- 对于与“ice”和“steam”都不相关的单词,例如 w k = f a s h i o n w_k=fashion wk=fashion,我们预计共现概率的比值接近1,例如0.96.
由此可见,共现概率的比值能够直观地表达词与词之间的关系。因此,我们可以设计三个词向量的函数来拟合这个比值。对于共现概率 p i j / p i k p_{ij}/p_{ik} pij/pik的比值,其中 w i w_i wi是中心词, w j w_j wj和 w k w_k wk是上下文词,我们希望使用某个函数 f f f来拟合该比值:
f ( u j , u k , v i ) ≈ p i j p i k f(u_j,u_k,v_i)\approx \frac{p_{ij}}{p_{ik}} f(uj,uk,vi)≈pikpij
在 f f f的许多可能的设计中,我们只在以下几点中选择了一个合理的选择。因为共现概率的比值是标量,所以我们要求 f f f是标量函数,例如 f ( u j , u k , v i ) = f ( ( u j − u k ) T v i ) f(u_j,u_k,v_i)=f((u_j-u_k)^Tv_i) f(uj,uk,vi)=f((uj−uk)Tvi)。在 上述式中交换词索引 j j j和 k k k,它必须保持 f ( x ) f ( − x ) = 1 f(x)f(-x)=1 f(x)f(−x)=1,所以一种可能性是 f ( x ) = e x p ( x ) f(x)=exp(x) f(x)=exp(x),即:

现在让我们选择 e x p ( u j T v i ) ≈ α p i j exp(u_j^Tv_i)\approx\alpha p_{ij} exp(ujTvi)≈αpij,其中 α \alpha α是常数。从 p i j = x i j p_{ij}=x_{ij} pij=xij开始,取两边的对数得到 u i T v i ≈ l o g α + l o g x i j − l o g x i u_i^Tv_i\approx log\alpha+logx_{ij}-logx_{i} uiTvi≈logα+logxij−logxi。我们可以使用附加的偏置项来拟合 − l o g α + l o g x i -log\ \alpha+log x_i −log α+logxi,如中心词偏置 b i b_i bi和上下文词偏置 c j c_j cj,得到:

此时我们便得到了全局向量的词嵌入的损失函数
GloVe和word2vec的区别
GloVe(Global Vectors for Word Representation)和word2vec都是用于自然语言处理中的词向量表示方法,它们之间有一些区别:
-
构建方式:GloVe是基于全局词频统计的方法,它使用了全局的统计信息来学习词向量。而word2vec是基于局部上下文窗口的方法,它通过预测上下文词来学习词向量。
-
训练效果:GloVe在一些语义和语法任务上表现较好,尤其是在类比推理任务上。它能够捕捉到词之间的线性关系。而word2vec在一些语法任务上表现较好,尤其是在词类比和词性推断任务上。它能够捕捉到词之间的局部上下文信息。
-
算法原理:GloVe使用了共现矩阵来建模词之间的关系,通过最小化词向量之间的欧氏距离和词频之间的关系来训练词向量。word2vec使用了两种不同的算法:Skip-gram和CBOW(Continuous Bag-of-Words)。Skip-gram模型通过目标词预测上下文词,而CBOW模型通过上下文词预测目标词。
-
训练速度:一般情况下,GloVe的训练速度比word2vec要快,因为它使用了全局信息进行训练,可以并行处理。
选择使用GloVe还是word2vec取决于具体的任务和需求。它们在不同的语义和语法任务上可能表现不同,因此在应用中需要根据实际情况进行选择。
相关文章:
自然语言处理(四):全局向量的词嵌入(GloVe)
全局向量的词嵌入(GloVe) 全局向量的词嵌入(Global Vectors for Word Representation),通常简称为GloVe,是一种用于将词语映射到连续向量空间的词嵌入方法。它旨在捕捉词语之间的语义关系和语法关系&#…...
Flink中RPC实现原理简介
前提知识 Akka是一套可扩展、弹性和快速的系统,为此Flink基于Akka实现了一套内部的RPC通信框架;为此先对Akka进行了解 Akka Akka是使用Scala语言编写的库,基于Actor模型提供一个用于构建可扩展、弹性、快速响应的系统;并被应用…...
ELK安装、部署、调试(五)filebeat的安装与配置
1.介绍 logstash 也可以收集日志,但是数据量大时太消耗系统新能。而filebeat是轻量级的,占用系统资源极少。 Filebeat 由两个主要组件组成:harvester 和 prospector。 采集器 harvester 的主要职责是读取单个文件的内容。读取每个文件&…...

Python数据分析案例30——中国高票房电影分析(爬虫获取数据及分析可视化全流程)
案例背景 最近总看到《消失的她》票房多少多少,《孤注一掷》票房又破了多少多少..... 于是我就想自己爬虫一下获取中国高票房的电影数据,然后分析一下。 数据来源于淘票票:影片总票房排行榜 (maoyan.com) 爬它就行。 代码实现 首先爬虫获…...

科技资讯|苹果Vision Pro头显申请游戏手柄专利和商标
苹果集虚拟现实和增强现实于一体的头戴式设备 Vision Pro 推出一个月后,美国专利局公布了两项苹果公司申请的游戏手柄专利,其中一项的专利图如下图所示。据 PatentlyApple 报道,虽然专利本身并不能保证苹果公司会推出游戏手柄,但是…...

Compose学习 - remember、mutableStateOf的使用
一、需求 在显示界面中,数据变动,界面刷新是非常常见的操作,所以使用compose该如何实现呢? 二、remember、mutableStateOf的使用 我们可以借助标题的两个概念 remember、mutableStateOf来完成。这里先不写定义,定义…...
字符串哈希
字符串前缀哈希法 str "ABCABCDEHGJK" 预处理每一个前缀的哈希值,如 : h[0] 0; h[1] "A"的哈希值 h[2] "AB"的哈希值 h[3] "ABC"的哈希值 h[4] "ABCA"的哈希值 问题 : 如何定义一个前缀的哈希值 : 将字符串看…...

【python】【centos】使用python杀死进程后自身也会退出
问题 使用python杀死进程后自身程序也会退出,无法执行后边的代码 这样不行: # cmd " ps -ef | grep -v grep | grep -E task_pull_and_submit.py$|upgrade_system.py$| awk {print $2}"# pids os.popen(cmd).read().strip(\n).split(\n)# p…...
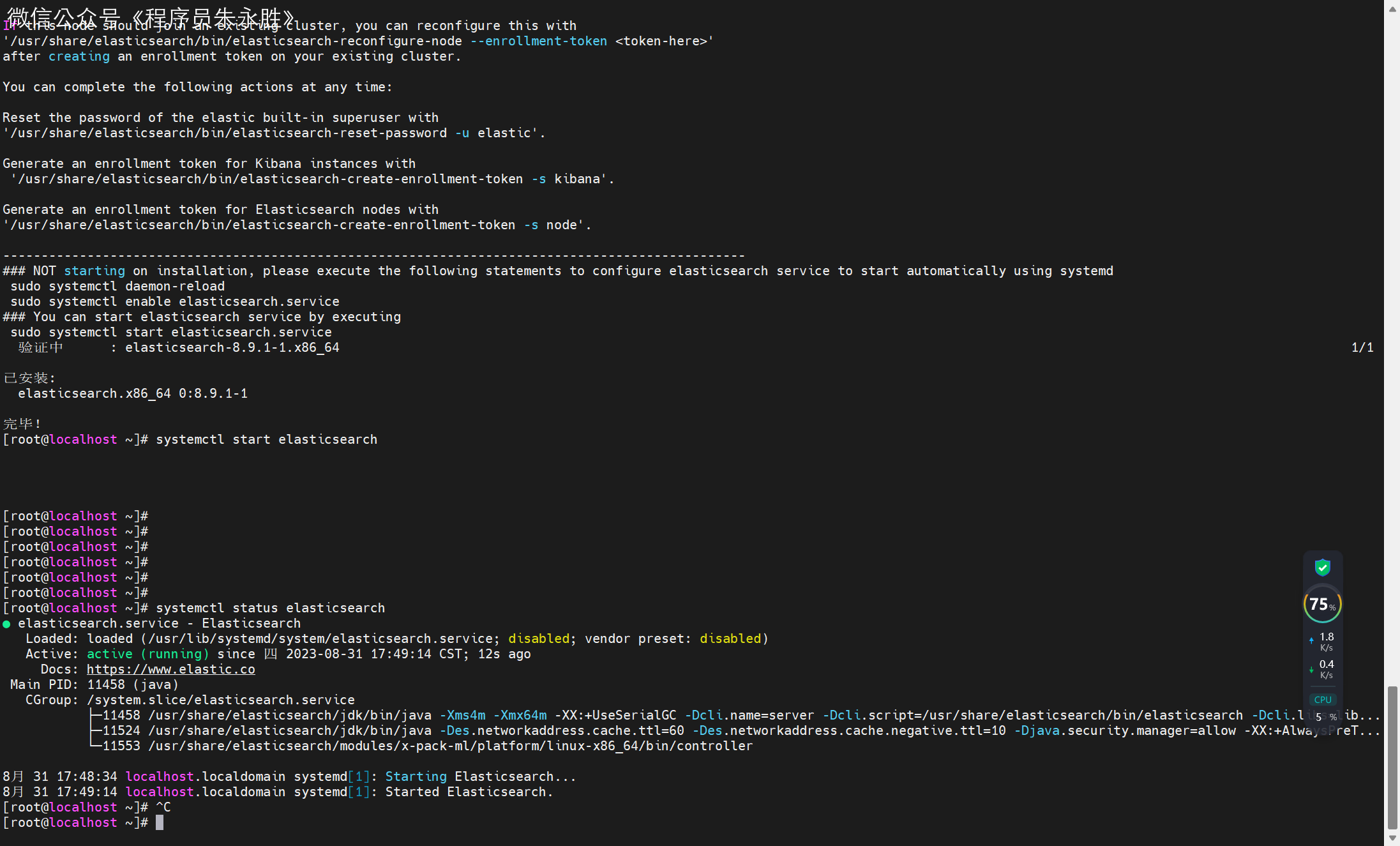
【ES系列】(一)简介与安装
首发博客地址 首发博客地址[1] 系列文章地址[2] 教学视频[3] 为什么要学习 ES? 强大的全文搜索和检索功能:Elasticsearch 是一个开源的分布式搜索和分析引擎,使用倒排索引和分布式计算等技术,提供了强大的全文搜索和检索功能。学习 ES 可以掌…...

opencv案例06-基于opencv图像匹配的消防通道障碍物检测与深度yolo检测的对比
基于图像匹配的消防通道障碍物检测 技术背景 消防通道是指在各种险情发生时,用于消防人员实施营救和被困人员疏散的通道。消防法规定任何单位和个人不得占用、堵塞、封闭消防通道。事实上,由于消防通道通常缺乏管理,导致各种垃圾࿰…...

练习2:88. 合并两个有序数组
这里写自定义目录标题 题目解体思路代码 题目 给你两个按非递减顺序排列的整数数组 nums1 和 nums2,另有两个整数 m和 n ,分别表示 nums1 和 nums2中的元素数目。 请你合并nums2 到 nums1 中,使合并后的数组同样按非递减顺序排列。 注意&a…...
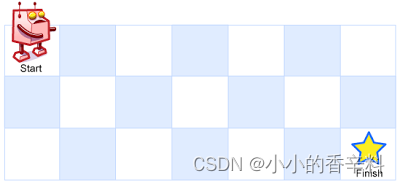
【代码随想录day23】不同路径
题目 一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。 机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish” )。 问总共有多少条不同的路径? 示…...
SpringBoot 博客网站
SpringBoot 博客网站 系统功能 登录注册 博客列表展示 搜索 分类 个人中心 文章分类管理 我的文章管理 发布文章 开发环境和技术 开发语言:Java 使用框架: SpringBoot jpa H2 Spring Boot是一个用于构建Java应用程序的开源框架,它是Spring框架的一…...
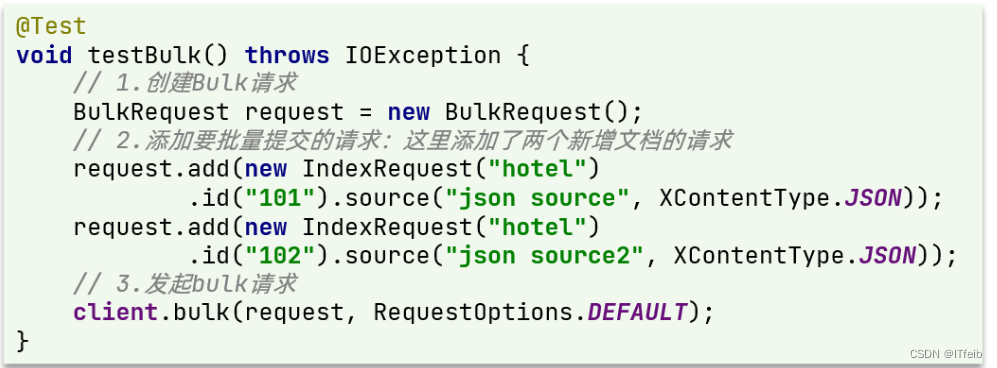
【分布式搜索引擎elasticsearch】
文章目录 1.elasticsearch基础索引和映射索引库操作索引库操作总结 文档操作文档操作总结 RestAPIRestClient操作文档 1.elasticsearch基础 什么是elasticsearch? 一个开源的分布式搜索引擎,可以用来实现搜索、日志统计、分析、系统监控等功能 什么是…...
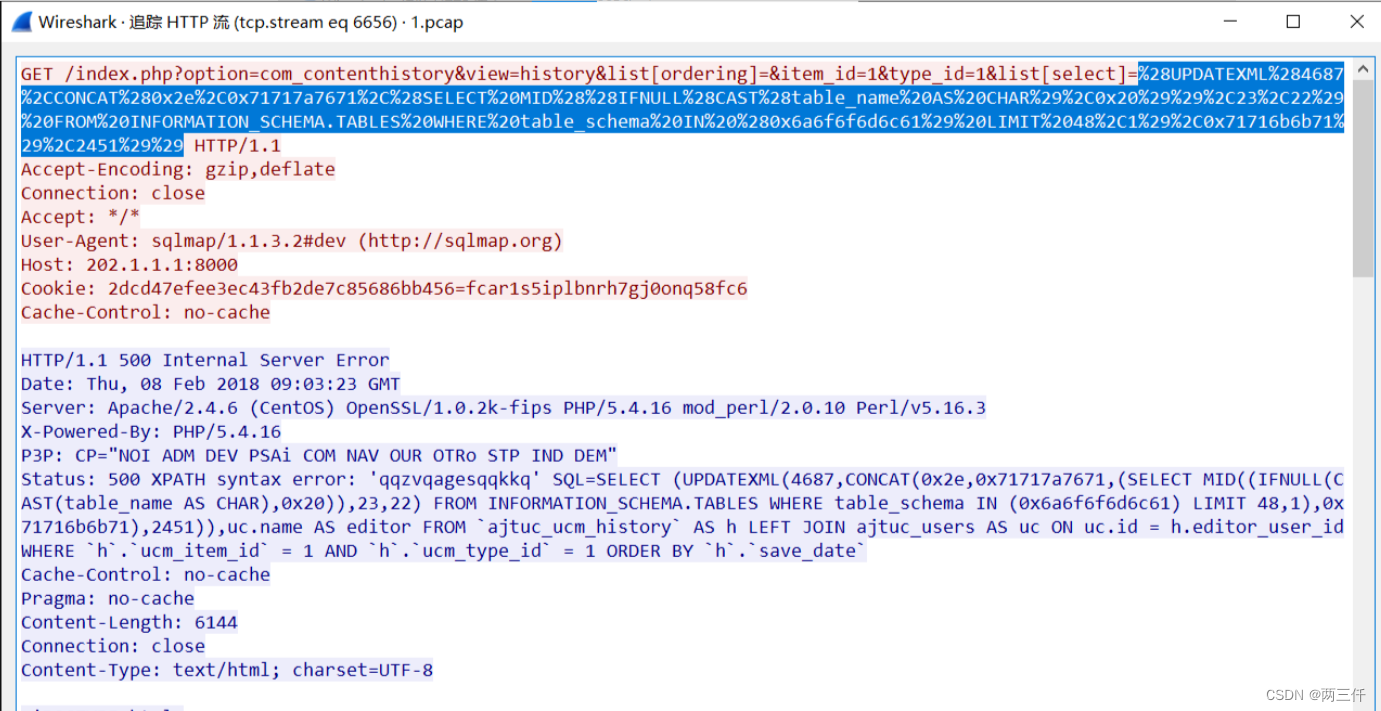
wireshark 流量抓包例题
一、题目一(1.pcap) 题目要求: 1.黑客攻击的第一个受害主机的网卡IP地址 2.黑客对URL的哪一个参数实施了SQL注入 3.第一个受害主机网站数据库的表前缀(加上下划线例如abc) 4.第一个受害主机网站数据库的名字 看到题目SQL注入,…...

【Axure视频教程】表格编号函数
今天教大家在Axure里如何使用表格编号函数,包括表格编号函数的基本原理、在需要翻页的中继器表格里如何正确使用该函数、函数作为条件的应用,包括让指定第几行的元件默认变色效果以及更新对应第几行内容的效果。该教程主要讲解表格编号函数,不…...

大数据-玩转数据-Flink定时器
一、说明 基于处理时间或者事件时间处理过一个元素之后, 注册一个定时器, 然后指定的时间执行. Context和OnTimerContext所持有的TimerService对象拥有以下方法: currentProcessingTime(): Long 返回当前处理时间 currentWatermark(): Long 返回当前watermark的时间戳 registe…...

Linux 操作系统实战视频课 - GPIO 基础介绍
文章目录 一、GPIO 概念说明二、视频讲解沉淀、分享、成长,让自己和他人都能有所收获!😄 📢本篇我们将讲解 GPIO 。 一、GPIO 概念说明 ARM 平台中的 GPIO(通用输入/输出)是用于与外部设备进行数字输入和输出通信的重要硬件接口。ARM 平台的 GPIO 特性可以根据具体的芯…...

ChatGPT在医疗保健信息管理和电子病历中的应用前景如何?
ChatGPT在医疗保健信息管理和电子病历中有着广阔的应用前景,可以提高医疗保健行业的效率、准确性和可访问性。本文将详细讨论ChatGPT在医疗保健信息管理和电子病历中的应用前景,以及相关的益处和挑战。 ### 1. ChatGPT在医疗保健信息管理中的应用前景 …...

安防监控/视频存储/视频汇聚平台EasyCVR接入海康Ehome车载设备出现收流超时的原因排查
安防视频监控/视频集中存储/云存储/磁盘阵列EasyCVR平台可拓展性强、视频能力灵活、部署轻快,可支持的主流标准协议有国标GB28181、RTSP/Onvif、RTMP等,以及支持厂家私有协议与SDK接入,包括海康Ehome、海大宇等设备的SDK等。视频汇聚平台既具…...

终极网页资源下载神器:ResourcesSaverExt完整操作指南
终极网页资源下载神器:ResourcesSaverExt完整操作指南 【免费下载链接】ResourcesSaverExt Chrome Extension for one click downloading all resources files and keeping folder structures. 项目地址: https://gitcode.com/gh_mirrors/re/ResourcesSaverExt …...

诚邀您参加 2026 Google Cloud Startup Day
以下文章来源于谷歌云服务,作者 Google Cloud...

向量化映射框架优化图着色问题的FPGA实现
1. 问题背景与核心挑战图着色问题作为组合优化领域的经典NP难问题,在集成电路布局分解、寄存器分配、逻辑最小化等场景中具有广泛应用。传统Ising机采用独热编码(one-hot encoding)方案,将每个节点的q种颜色状态映射为q个物理比特…...

私有化 IM vs 公有云 IM:3 个维度告诉你该怎么选
企业在选择即时通讯工具时,常常陷入 “功能越多越好” 的误区。实际上,IM 选型的本质是一次数据治理策略的决策。私有化 IM 和公有云 IM 没有绝对的好坏,只有适合不适合。今天我们从三个核心维度,帮你做出正确的选择。第一个维度&…...

三亚高端小区实景落地选哪家
在三亚,高端小区对居住品质的要求近乎苛刻——不仅要有气派的视觉呈现,更要经得起台风、高湿、海风盐雾的考验。如果您正在寻找一家能真正实现“所见即所得”的实景落地服务商,三亚秦鼎科技有限公司就是您不容错过的选择。为什么是秦鼎科技&a…...

深入解析TI C6474多核DSP架构:从硬件设计到并行编程实战
1. 项目概述:从单核到多核的必然演进在嵌入式信号处理领域,德州仪器(TI)的TMS320系列DSP一直是高性能、高可靠性的代名词。我接触TI DSP超过十年,从早期的C5000系列到后来的C6000系列,亲眼见证了其从单核、…...
)
Linux】2026 年 13 款最强视频播放器(含安装命令 + 优缺点)
Linux视频播放器选择多样,如榛名、MPlayer、VLC等,功能强大、支持多格式,满足各类用户需求 一、榛名视频播放器 榛名视频播放器是一款基于Qt的开源视频播放器,提供了许多基本功能。其特点包括支持Youtube-dl、控制播放速度、丰富…...

王炸!史上最强的智慧园区管理系统,java最新技术栈,支持信创!
一、项目简介本软件是一款面向智慧园区与智慧楼宇的综合管理系统,采用先进的微服务架构(SpringCloud)、JDK 17、Spring Boot 3.2、MySQL、Vue3、Vite 和 UniApp 技术栈,支持小程序、H5、公众号、App 多端适配,前后端分…...

这些坑我已经帮你踩过了,Vue3+TS 实战开发必看!
这些坑我已经帮你踩过了,Vue3TS 实战开发必看! 上周五临下班,产品突然甩过来一个“紧急需求”:把核心的数据看板模块用 Vue3 TypeScript 重构,周一早会直接给老板演示。我当时的内心是极度自信的:“Vue3 组…...
:状态管理选型)
React 从入门到生产(五):状态管理选型
创作者: Yardon | GitHub: github.com/YardonYan | 版本: v1.0 什么时候需要状态管理 先泼一盆冷水:大多数 React 应用不需要 Redux。 这句话不是我说的,是 Redux 的作者 Dan Abramov 本人说的。他在 2020 年就公…...