PyTorch 模型性能分析和优化 - 第 3 部分
这[1]是关于使用 PyTorch Profiler 和 TensorBoard 分析和优化 PyTorch 模型主题的系列文章的第三部分。我们的目的是强调基于 GPU 的训练工作负载的性能分析和优化的好处及其对训练速度和成本的潜在影响。特别是,我们希望向所有机器学习开发人员展示 PyTorch Profiler 和 TensorBoard 等分析工具的可访问性。您无需成为 CUDA 专家即可通过应用我们在帖子中讨论的技术获得有意义的性能提升。
在我们的第一篇文章中,我们演示了如何使用 PyTorch Profiler TensorBoard 插件的不同视图来识别性能问题,并回顾了一些用于加速训练的流行技术。在第二篇文章中,我们展示了如何使用 TensorBoard 插件 Trace View 来识别张量何时从 CPU 复制到 GPU 以及返回。这种数据移动——可能会导致同步点并大大降低训练速度——通常是无意的,有时很容易避免。这篇文章的主题是我们遇到 GPU 和 CPU 之间与张量副本无关的同步点的情况。与张量副本的情况一样,这些可能会导致训练步骤停滞并大大减慢训练的整体时间。我们将演示此类事件的存在、如何使用 PyTorch Profiler 和 PyTorch Profiler TensorBoard 插件 Trace View 来识别它们,以及以最小化此类同步事件的方式构建模型的潜在性能优势。
与我们之前的文章一样,我们将定义一个玩具 PyTorch 模型,然后迭代地分析其性能、识别瓶颈并尝试修复它们。我们将在 Amazon EC2 g5.2xlarge 实例(包含 NVIDIA A10G GPU 和 8 个 vCPU)上运行实验,并使用官方 AWS PyTorch 2.0 Docker 映像。请记住,我们描述的某些行为可能因 PyTorch 版本而异。
玩具示例
在下面的块中,我们介绍了一个玩具 PyTorch 模型,它对 256x256 输入图像执行语义分割,即,它采用 256x256 RGB 图像,并输出来自十个语义类别的“每像素”标签的 256x256 映射。
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim
import torch.profiler
import torch.utils.data
from torch import Tensor
class Net(nn.Module):
def __init__(self, num_hidden=10, num_classes=10):
super().__init__()
self.conv_in = nn.Conv2d(3, 10, 3, padding='same')
hidden = []
for i in range(num_hidden):
hidden.append(nn.Conv2d(10, 10, 3, padding='same'))
hidden.append(nn.ReLU())
self.hidden = nn.Sequential(*hidden)
self.conv_out = nn.Conv2d(10, num_classes, 3, padding='same')
def forward(self, x):
x = F.relu(self.conv_in(x))
x = self.hidden(x)
x = self.conv_out(x)
return x
为了训练我们的模型,我们将使用标准交叉熵损失并进行一些修改:
-
我们假设目标标签包含一个忽略值,指示我们想要从损失计算中排除的像素。 -
我们假设语义标签之一将某些像素识别为属于图像的“背景”。我们定义损失函数来将它们视为忽略标签。 -
仅当我们遇到目标张量至少包含两个唯一值的批次时,我们才会更新模型权重。
虽然我们出于演示目的选择了这些修改,但这些类型的操作并不罕见,并且可以在许多“标准”PyTorch 模型中找到。由于我们已经是性能分析方面的“专家”,因此我们已经使用 torch.profiler.record_function 上下文管理器将每个操作包装在损失函数中(如我们的第二篇文章中所述)。
class MaskedLoss(nn.Module):
def __init__(self, ignore_val=-1, num_classes=10):
super().__init__()
self.ignore_val = ignore_val
self.num_classes = num_classes
self.loss = torch.nn.CrossEntropyLoss()
def cross_entropy(self, pred: Tensor, target: Tensor) -> Tensor:
# create a boolean mask of valid labels
with torch.profiler.record_function('create mask'):
mask = target != self.ignore_val
# permute the logits in preparation for masking
with torch.profiler.record_function('permute'):
permuted_pred = torch.permute(pred, [0, 2, 3, 1])
# apply the boolean mask to the targets and logits
with torch.profiler.record_function('mask'):
masked_target = target[mask]
masked_pred = permuted_pred[mask.unsqueeze(-1).expand(-1, -1, -1,
self.num_classes)]
masked_pred = masked_pred.reshape(-1, self.num_classes)
# calculate the cross-entropy loss
with torch.profiler.record_function('calc loss'):
loss = self.loss(masked_pred, masked_target)
return loss
def ignore_background(self, target: Tensor) -> Tensor:
# discover all indices where target label is "background"
with torch.profiler.record_function('non_zero'):
inds = torch.nonzero(target == self.num_classes - 1, as_tuple=True)
# reset all "background" labels to the ignore index
with torch.profiler.record_function('index assignment'):
target[inds] = self.ignore_val
return target
def forward(self, pred: Tensor, target: Tensor) -> Tensor:
# ignore background labels
target = self.ignore_background(target)
# retrieve a list of unique elements in target
with torch.profiler.record_function('unique'):
unique = torch.unique(target)
# check if the number of unique items pass the threshold
with torch.profiler.record_function('numel'):
ignore_loss = torch.numel(unique) < 2
# calculate the cross-entropy loss
loss = self.cross_entropy(pred, target)
# zero the loss in the case that the number of unique elements
# is below the threshold
if ignore_loss:
loss = 0. * loss
return loss
我们的损失函数看起来很简单,对吧?错误的!正如我们将在下面看到的,损失函数包括许多触发主机设备同步事件的操作,这些操作会大大降低训练速度 - 这些操作都不涉及将张量复制到 GPU 中或从 GPU 中复制出来。正如我们在上一篇文章中一样,我们要求您在继续阅读之前尝试找出三个性能优化的机会。
为了演示的目的,我们使用随机生成的图像和每像素标签图,如下定义。
from torch.utils.data import Dataset
# A dataset with random images and label maps
class FakeDataset(Dataset):
def __init__(self, num_classes=10):
super().__init__()
self.num_classes = num_classes
self.img_size = [256, 256]
def __len__(self):
return 1000000
def __getitem__(self, index):
rand_image = torch.randn([3]+self.img_size, dtype=torch.float32)
rand_label = torch.randint(low=-1, high=self.num_classes,
size=self.img_size)
return rand_image, rand_label
train_set = FakeDataset()
train_loader = torch.utils.data.DataLoader(train_set, batch_size=256,
shuffle=True, num_workers=8, pin_memory=True)
最后,我们使用根据我们的需求配置的 PyTorch Profiler 定义训练步骤:
device = torch.device("cuda:0")
model = Net().cuda(device)
criterion = MaskedLoss().cuda(device)
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
model.train()
# training loop wrapped with profiler object
with torch.profiler.profile(
schedule=torch.profiler.schedule(wait=1, warmup=4, active=3, repeat=1),
on_trace_ready=torch.profiler.tensorboard_trace_handler('/tmp/prof'),
record_shapes=True,
profile_memory=True,
with_stack=True
) as prof:
for step, data in enumerate(train_loader):
inputs = data[0].to(device=device, non_blocking=True)
labels = data[1].to(device=device, non_blocking=True)
if step >= (1 + 4 + 3) * 1:
break
outputs = model(inputs)
loss = criterion(outputs, labels)
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
prof.step()
如果您天真地运行这个训练脚本,您可能会看到 GPU 利用率很高(~90%),但不知道它有什么问题。只有通过分析,我们才能识别潜在的性能瓶颈和训练加速的潜在机会。那么,话不多说,让我们看看我们的模型的表现如何。
初始性能结果
在这篇文章中,我们将重点介绍 PyTorch Profiler TensorBoard 插件的跟踪视图。请参阅我们之前的文章,了解有关如何使用该插件支持的其他一些视图的提示。
在下图中,我们显示了玩具模型单个训练步骤的跟踪视图。
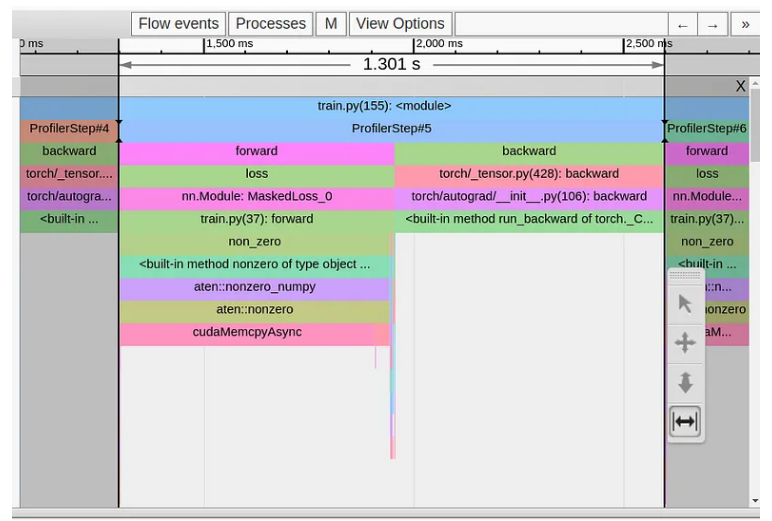
我们可以清楚地看到,我们的 1.3 秒长训练步骤完全由损失函数第一行中的 torch.nonzero 运算符主导。所有其他操作都聚集在巨大的 cudaMemcpyAsyn 事件的两侧。到底是怎么回事??!!为何如此看似平淡无奇的行动,却会引起如此大的眼花缭乱呢?
也许我们不应该如此惊讶,因为 torch.nonzero 文档确实包含以下注释:“当输入位于 CUDA 上时,torch.nonzero() 会导致主机设备同步。”与其他常见的 PyTorch 操作相反,torch.nonzero 返回的张量的大小不是预先确定的,因此需要同步。 CPU提前不知道输入张量中有多少个非零元素。它需要等待来自 GPU 的同步事件,以便执行适当的 GPU 内存分配并适当地准备后续的 PyTorch 操作。
请注意,cudaMempyAsync 的长度并不表示 torch.nonzero 操作的复杂性,而是反映了 CPU 需要等待 GPU 完成 CPU 启动的所有先前内核的时间量。例如,如果我们在第一个调用之后立即进行额外的 torch.nonzero 调用,那么我们的第二个 cudaMempyAsync 事件将比第一个事件显着短,因为 CPU 和 GPU 已经或多或少“同步”。 (请记住,这个解释来自非 CUDA 专家,所以请随意理解……)
优化 #1:减少 torch.nonzero 操作的使用
现在我们了解了瓶颈的根源,挑战就变成了寻找执行相同逻辑但不会触发主机设备同步事件的替代操作序列。对于我们的损失函数,我们可以使用 torch.where 运算符轻松完成此操作,如下面的代码块所示:
def ignore_background(self, target: Tensor) -> Tensor:
with torch.profiler.record_function('update background'):
target = torch.where(target==self.num_classes-1,
-1*torch.ones_like(target),target)
return target
在下图中,我们显示了此更改后的跟踪视图。
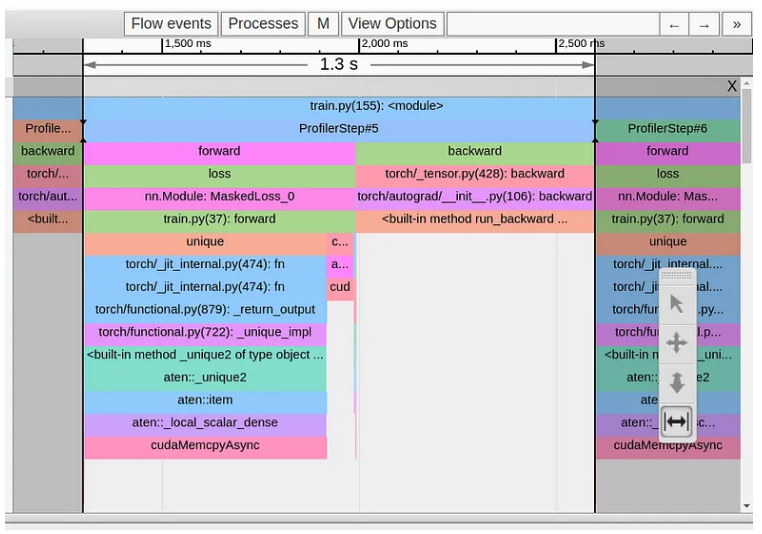
虽然我们成功删除了来自 torch.nonzero 操作的 cudaMempyAsync,但它已立即被来自 torch.unique 操作的 cudaMempyAsync 替换,并且我们的步骤时间没有变化。这里的 PyTorch 文档不太友好,但根据我们之前的经验,我们可以假设,由于我们使用了大小不确定的张量,我们再次遭受主机设备同步事件的困扰。
优化 #2:减少 torch.unique 操作的使用
用等效的替代方案替换 torch.unique 运算符并不总是可行的。然而,在我们的例子中,我们实际上不需要知道唯一标签的值,我们只需要知道唯一标签的数量。这可以通过在展平的目标张量上应用 torch.sort 操作并计算所得步骤函数中的步骤数来计算。
def forward(self, pred: Tensor, target: Tensor) -> Tensor:
# ignore background labels
target = self.ignore_background(target)
# sort the list of labels
with torch.profiler.record_function('sort'):
sorted,_ = torch.sort(target.flatten())
# indentify the steps of the resultant step function
with torch.profiler.record_function('deriv'):
deriv = sorted[1:]-sorted[:-1]
# count the number of steps
with torch.profiler.record_function('count_nonzero'):
num_unique = torch.count_nonzero(deriv)+1
# calculate the cross-entropy loss
loss = self.cross_entropy(pred, target)
# zero the loss in the case that the number of unique elements
# is below the threshold
with torch.profiler.record_function('where'):
loss = torch.where(num_unique<2, 0.*loss, loss)
return loss
在下图中,我们捕获了第二次优化后的跟踪视图:

我们再次解决了一个瓶颈,但又面临一个新的瓶颈,这次来自布尔掩码例程。
布尔掩码是我们常用的例程,用于减少所需的机器操作总数。在我们的例子中,我们的目的是通过删除“忽略”像素并将交叉熵计算限制为感兴趣的像素来减少计算量。显然,这适得其反。和以前一样,应用布尔掩码会导致大小不确定的张量,并且它触发的 cudaMempyAsync 大大掩盖了排除“忽略”像素所节省的任何费用。
优化 #3:注意布尔掩码操作
在我们的例子中,解决这个问题相当简单,因为 PyTorch CrossEntropyLoss 有一个用于设置ignore_index的内置选项。
class MaskedLoss(nn.Module):
def __init__(self, ignore_val=-1, num_classes=10):
super().__init__()
self.ignore_val = ignore_val
self.num_classes = num_classes
self.loss = torch.nn.CrossEntropyLoss(ignore_index=-1)
def cross_entropy(self, pred: Tensor, target: Tensor) -> Tensor:
with torch.profiler.record_function('calc loss'):
loss = self.loss(pred, target)
return loss
在下图中,我们显示了生成的跟踪视图:
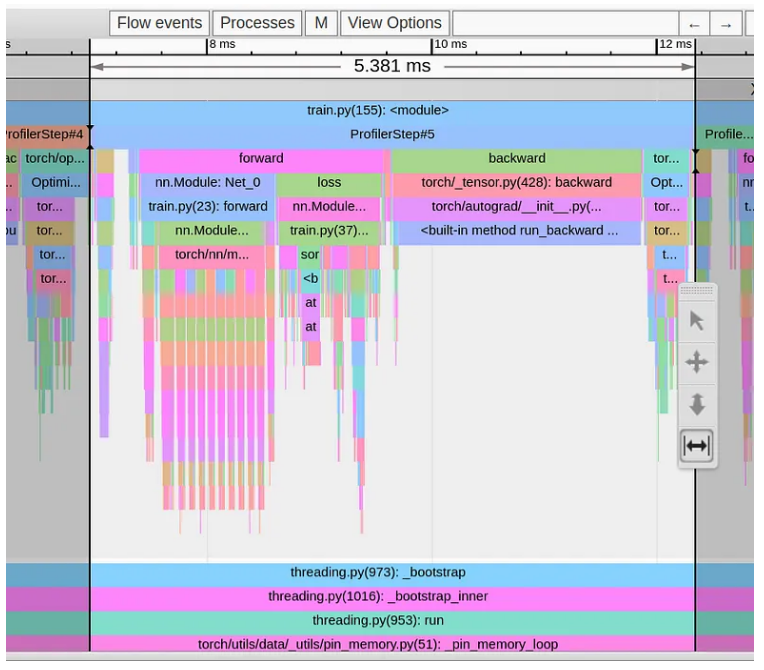
天啊!!我们的步数时间已一路下降至 5.4 毫秒。这比我们开始时快了 240 (!!) 倍。通过简单地改变一些函数调用并且不对损失函数逻辑进行任何修改,我们能够显着优化训练步骤的性能。
重要提示:在我们选择的玩具示例中,我们为减少 cudaMempyAsync 事件数量而采取的步骤对训练步骤时间有明显影响。然而,在某些情况下,相同类型的更改可能会损害而不是提高性能。例如,在布尔掩码的情况下,如果我们的掩码非常稀疏并且原始张量非常大,那么应用掩码所节省的计算量可能会超过主机设备同步的成本。重要的是,应根据具体情况评估每次优化的影响。
总结
在这篇文章中,我们重点关注由主机设备同步事件引起的训练应用程序中的性能问题。我们看到了触发此类事件的 PyTorch 运算符的几个示例 - 所有这些运算符的共同属性是它们输出的张量的大小取决于输入。您可能还会遇到来自其他操作员的同步事件,本文未介绍。我们演示了如何使用 PyTorch Profiler 等性能分析器及其关联的 TensorBoard 插件来识别此类事件。
在我们的玩具示例中,我们能够找到有问题的运算符的等效替代方案,这些运算符使用固定大小的张量并避免需要同步事件。这些导致训练时间显着缩短。然而,在实践中,您可能会发现解决此类瓶颈要困难得多,甚至是不可能的。有时,克服它们可能需要重新设计模型的某些部分。
Reference
Source: https://towardsdatascience.com/pytorch-model-performance-analysis-and-optimization-part-3-1c5876d78fe2
本文由 mdnice 多平台发布
相关文章:
PyTorch 模型性能分析和优化 - 第 3 部分
这[1]是关于使用 PyTorch Profiler 和 TensorBoard 分析和优化 PyTorch 模型主题的系列文章的第三部分。我们的目的是强调基于 GPU 的训练工作负载的性能分析和优化的好处及其对训练速度和成本的潜在影响。特别是,我们希望向所有机器学习开发人员展示 PyTorch Profi…...

【力扣每日一题】2023.9.1 买钢笔和铅笔的方案数
目录 题目: 示例: 分析: 代码: 题目: 示例: 分析: 题目给我们三个数,一个是我们拥有的钱,一个是钢笔的价格,另一个是铅笔的价格。 问我们一共有几种买笔…...
实现不同局域网间的文件共享和端口映射,使用Python自带的HTTP服务
文章目录 1. 前言2. 本地文件服务器搭建2.1 python的安装和设置2.2 cpolar的安装和注册 3. 本地文件服务器的发布3.1 Cpolar云端设置3.2 Cpolar本地设置 4. 公网访问测试5. 结语 1. 前言 数据共享作为和连接作为互联网的基础应用,不仅在商业和办公场景有广泛的应用…...

Kubernetes技术--k8s核心技术Pod
(1).概述 Pod 是 k8s 系统中可以创建和管理的最小单元,是资源对象模型中由用户创建或部署的最小资源对象模型。 k8s不会直接处理容器,而是 Pod,Pod 是由一个或多个 container 组成。 一个pod中的容器共享网络命名空间。 Pod是一个短暂存在的。 (2).为什么k8s中最小单元是…...
基于Springboot实现的Echarts图表
概述 ECharts是百度开源的一个前端组件。它是一个使用 JavaScript 实现的开源可视化库,可以流畅的运行在 PC 和移动设备上,兼容当前绝大部分浏览器(IE8/9/10/11,Chrome,Firefox,Safari等)&…...
 doesn‘t match this client (39))
adb server version (41) doesn‘t match this client (39)
异常: adb server version (41) doesnt match this client (39); killing... ADB server didnt ACK安装ADB后:查看版本 $ adb version Android Debug Bridge version 1.0.39 Version 1:8.1.1-1r23-5.4-1eagle Installed as /usr/lib/android-sdk/platf…...
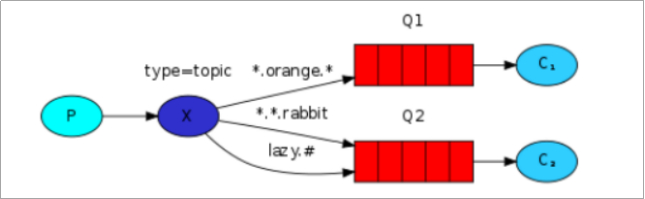
B080-RabbitMQ
目录 RabbitMQ认识概念使用场景优点AMQP协议JMS RabbitMQ安装安装elang安装RabbitMQ安装管理插件登录RabbitMQ消息队列的工作流程 RabbitMQ常用模型HelloWorld-基本消息模型生产者发送消息导包获取链接工具类消息的生产者 消费者消费消息模拟消费者手动签收消息 Work QueuesSen…...
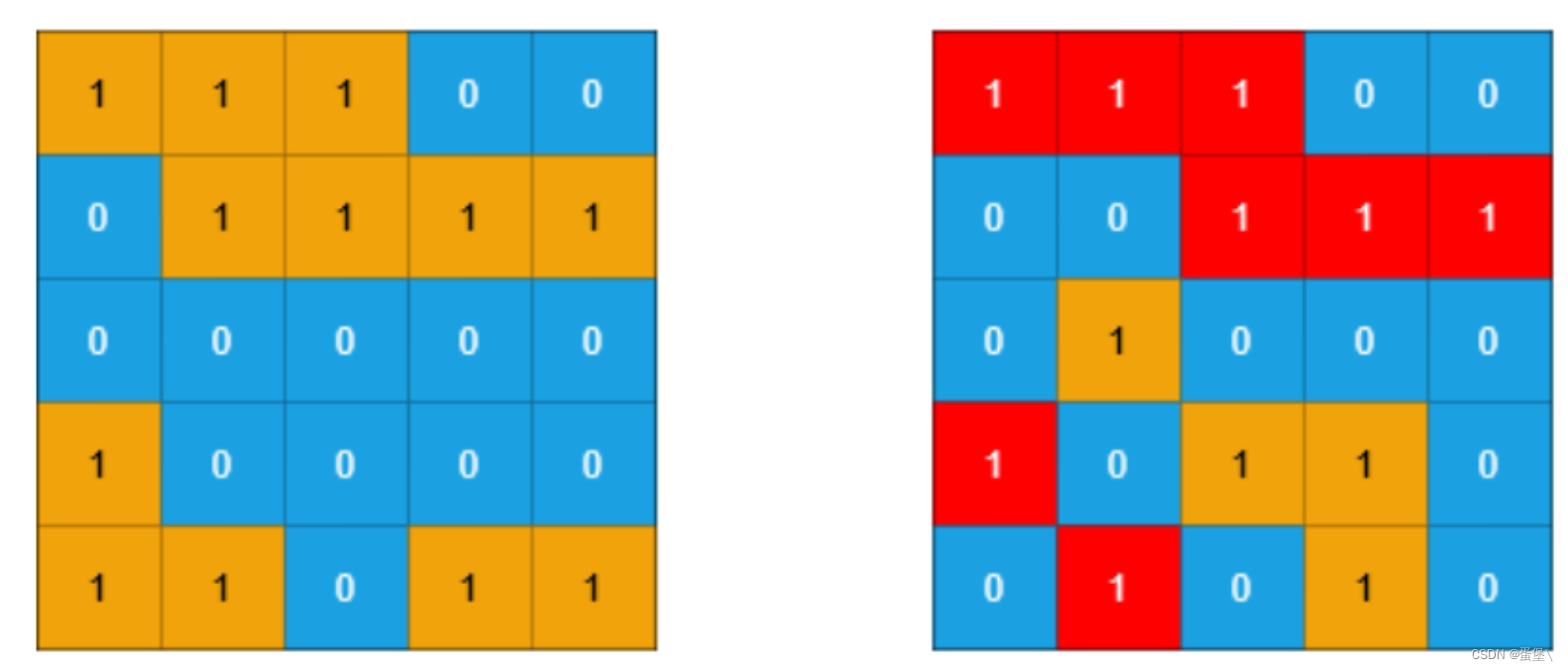
关于岛屿的三道leetcode原题:岛屿周长、岛屿数量、统计子岛屿
题1:岛屿周长 给定一个 row x col 的二维网格地图 grid ,其中:gridi 1 表示陆地, gridi 0 表示水域。 网格中的格子 水平和垂直 方向相连(对角线方向不相连)。整个网格被水完全包围,但其中恰…...

lintcode 1081 · 贴纸拼单词【hard 递归+记忆化搜索才能通过】
题目 https://www.lintcode.com/problem/1081/ 给出N种不同类型的贴纸。 每个贴纸上都写有一个小写英文单词。 通过裁剪贴纸上的所有字母并重排序来拼出字符串target。 每种贴纸可以使用多次,假定每种贴纸数量无限。 拼出target最少需要多少张贴纸?如果…...
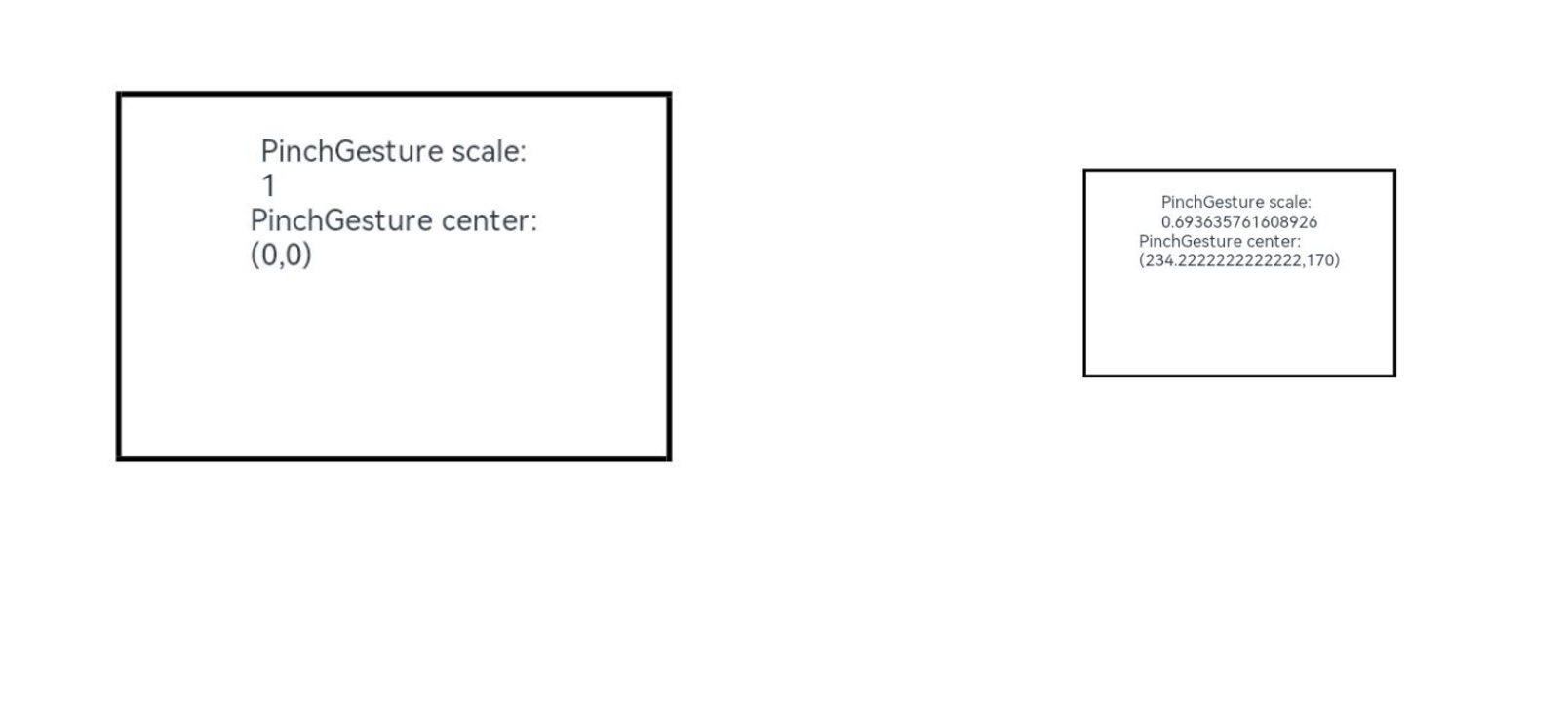
HarmonyOS/OpenHarmony(Stage模型)应用开发单一手势(二)
三、拖动手势(PanGesture) .PanGestureOptions(value?:{ fingers?:number; direction?:PanDirection; distance?:number}) 拖动手势用于触发拖动手势事件,滑动达到最小滑动距离(默认值为5vp)时拖动手势识别成功&am…...
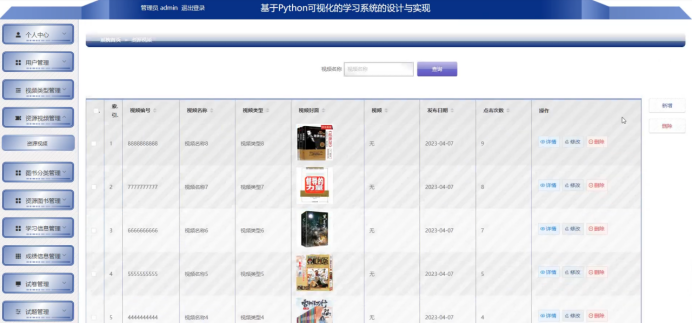
计算机毕设之基于Python+django+MySQL可视化的学习系统的设计与实现
系统阐述的是使用可视化的学习系统的设计与实现,对于Python、B/S结构、MySql进行了较为深入的学习与应用。主要针对系统的设计,描述,实现和分析与测试方面来表明开发的过程。开发中使用了 django框架和MySql数据库技术搭建系统的整体架构。利…...

Kotlin inline、noinline、crossinline 深入解析
主要内容: inline 高价函数的原理分析Non-local returns noinlinecrossinline inline 如果有C语言基础的,inline 修饰一个函数表示该函数是一个内联函数。编译时,编译器会将内联函数的函数体拷贝到调用的地方。我们先看下在一个普通的 kot…...

在 CentOS 7 / RHEL 7 上安装 Python 3.11
原文链接:https://computingforgeeks.com/install-python-3-on-centos-rhel-7/ Python 是一种高级解释性编程语言,已被用于各种应用程序开发,并在近年来获得了巨大的流行。Python 可用于编写广泛的应用程序,包括 Web 开发、数据分…...

SVN基本使用笔记——广州云科
简介 SVN是什么? 代码版本管理工具 它能记住你每次的修改 查看所有的修改记录 恢复到任何历史版本 恢复己经删除的文件 SVN跟Git比,有什么优势 使用简单,上手快 目录级权限控制,企业安全必备 子目录Checkout,减少不必要的文件检出…...

python爬虫-Selenium
一、Selenium简介 Selenium是一个用于Web应用程序测试的工具,Selenium 测试直接运行在浏览器中,就像真正的用户在操作一样。模拟浏览器功能,自动执行网页中的js代码,实现动态加载。 二、环境配置 1、查看本机电脑谷歌浏览器的版…...
flutter plugins插件【一】【FlutterJsonBeanFactory】
1、FlutterJsonBeanFactory 在Setting->Tools->FlutterJsonBeanFactory里边自定义实体类的后缀,默认是entity 复制json到粘贴板,右键自己要存放实体的目录,可以看到JsonToDartBeanAction Class Name是实体名字,会默认加上…...
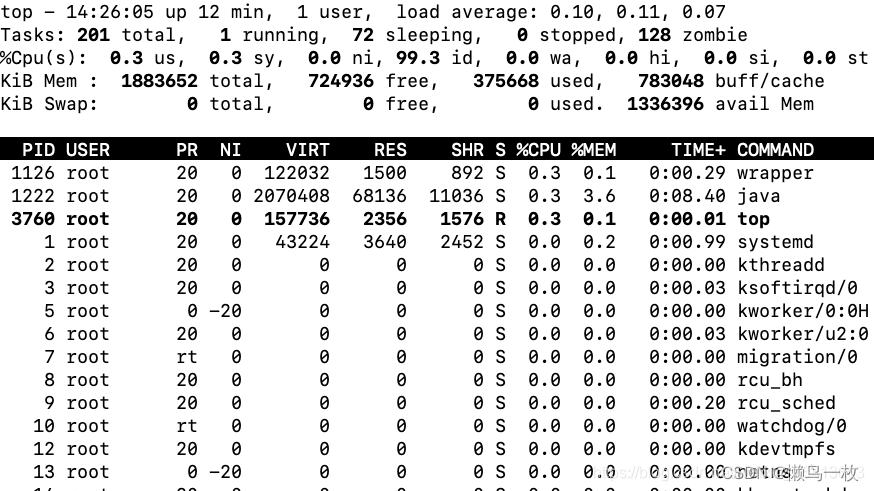
系统中出现大量不可中断进程和僵尸进程(理论)
一 进程状态 当 iowait 升高时,进程很可能因为得不到硬件的响应,而长时间处于不可中断状态。从 ps 或者 top 命令的输出中,你可以发现它们都处于 D 状态,也就是不可中断状态(Uninterruptible Sleep)。 R …...
 测试点全过)
L1-012 计算指数(Python实现) 测试点全过
前言: {\color{Blue}前言:} 前言:本系列题使用的是“PTA中的团体程序设计天梯赛——练习集”的题库,难度有L1、L2、L3三个等级,分别对应团体程序设计天梯赛的三个难度,如有需要可以直接查看对应专栏。发布个…...

String、StringBuffer、StringBuilder的区别
String、StringBuffer、StringBuilder的区别 String的内容不可修改,StringBuffer与StringBuilder的内容可以修改.StringBuffer与StringBuilder(更快)大部分功能是相似的StringBuffer采用同步处理,属于线程安全操作;而S…...

.net基础概念
1. .NET Framework .NET Framework开发平台包含公共语言运行库(CLR)和基类库(BCL),前者负载管理代码的执行,后者提供了丰富的类库来构建应用程序。.NET Framework仅支持Windows平台 2. Mono 由于.NET Framework支支持windows环境,因此社区…...

避坑指南:在Xilinx ZYNQ上调试Linux DMA驱动时常见的5个问题与解决方法
避坑指南:在Xilinx ZYNQ上调试Linux DMA驱动时常见的5个问题与解决方法 当工程师在Xilinx ZYNQ平台上开发Linux DMA驱动时,往往会遇到一些看似简单却极具迷惑性的问题。这些问题轻则导致数据传输失败,重则引发系统崩溃。本文将聚焦五个最具代…...

DownGit终极指南:3分钟掌握GitHub精准下载技巧
DownGit终极指南:3分钟掌握GitHub精准下载技巧 【免费下载链接】DownGit github 资源打包下载工具 项目地址: https://gitcode.com/gh_mirrors/dow/DownGit 你是否曾经在GitHub上找到心仪的代码片段,却不得不下载整个庞大的项目仓库?或…...

如何在JavaScript中精确计算太阳位置和月亮相位:SunCalc终极指南
如何在JavaScript中精确计算太阳位置和月亮相位:SunCalc终极指南 【免费下载链接】suncalc A tiny JavaScript library for calculating sun/moon positions and phases. 项目地址: https://gitcode.com/gh_mirrors/su/suncalc 你是否曾想过,如何…...

从账单明细看Taotoken按Token计费模式如何帮助用户精确定位高消耗场景
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从账单明细看Taotoken按Token计费模式如何帮助用户精确定位高消耗场景 在构建基于大模型的应用时,成本控制是一个持续性…...

GRETNA脑网络分析工具包:MATLAB中的图论网络分析终极指南
GRETNA脑网络分析工具包:MATLAB中的图论网络分析终极指南 【免费下载链接】GRETNA A Graph-theoretical Network Analysis Toolkit in MATLAB 项目地址: https://gitcode.com/gh_mirrors/gr/GRETNA GRETNA(Graph-theoretical Network Analysis To…...

Unity Package Manager缓存失效排错指南
1. 这不是“删库跑路”,而是Unity包管理器的静默失效现场 刚接手一个老项目,打开Unity编辑器就弹出红色报错: Library/PackageCache/com.unity.xxxxxx not found 。点开Project窗口,原本该显示的Package图标全灰了,I…...

华硕笔记本性能优化终极指南:G-Helper轻量控制工具全面解析
华硕笔记本性能优化终极指南:G-Helper轻量控制工具全面解析 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenboo…...
:文件操作、终端执行与 PDF 生成工具)
AI Agent 项目学习笔记(十):文件操作、终端执行与 PDF 生成工具
1. 本期目标 上一篇文章分析了 ai_agent 项目中的三个联网工具: WebSearchTool WebScrapingTool ResourceDownloadTool它们主要解决的是: 智能体如何从外部网络获取信息?这一期继续分析工具模块中的另一类能力: 本地执行与结果…...

锂电 / 光伏工业相机选型:5 大品牌核心参数与适用场景解析
2026 年锂电与光伏行业工业相机选型,早已不再是单纯比拼分辨率数值。行业竞争焦点已转向高速传输下的运行稳定性、与 AI 智能检测的融合深度,以及复杂生产场景下的专属定制能力。像锂电极片高速涂布、光伏硅片隐裂筛查这类核心生产环节,对工业…...

抖音批量下载完整指南:3步实现无水印视频高效获取
抖音批量下载完整指南:3步实现无水印视频高效获取 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. …...