数据结构——哈希表
哈希表
这里没有讲哈希表底层的概念,什么转红黑树,什么链表的,这篇文章主要讲的是如何用C实现哈希表,以及哈希表的基本概念。后面我会出一篇文章来讲C++中hashmap中的底层逻辑的知识。
哈希表的概念
哈希表是一种数据结构,类似于数组,但它的主要优势在于快速查找和检索数据。在数组中,每个位置可以存储值,查找或删除特定位置的值的效率是O(1),只需将相应的索引提供给数组即可直接访问。然而,如果您只有值,想要在数组中查找这个值时,时间复杂度会变成O(n),因为您需要遍历整个数组来找到匹配的值。
哈希表通过使用哈希函数来改善这种情况,将查找操作的平均时间复杂度降低到O(1)。哈希函数将键(key)映射到数组的特定位置,这个位置通常称为“桶”。通过哈希函数,我们可以快速确定要查找或删除的数据所在的桶,从而显著减少了查找的时间。
然而,哈希表的优化是基于空间换时间的原则。它需要使用额外的内存空间来存储哈希表本身,而且在某些情况下,不同的键可能会映射到相同的桶,导致哈希冲突。解决哈希冲突需要额外的处理,例如链地址法或开放寻址法。尽管如此,总体而言,哈希表仍然提供了一种高效的数据存储和检索方式,特别适用于需要快速查找数据的应用场景。
它的数据结构:
结构定义:
物理结构:
数据域:存储数据的位置,也就是概念中所说的桶,每个桶用于存储一个数据项或多个数据项的链表(或其他数据结构)。数组的大小通常是一个固定的值,但在一些实现中也可以动态调整。
哈希函数:哈希函数接受键(Key)作为输入,并生成一个整数值,这个值通常被称为索引。哈希函数的作用是将键映射到数组(桶)中的一个特定位置,然后就可以通过Key值获得索引,看当前位置是否有Key值。
冲突处理机制:由于不同的键可能映射到相同的桶位置,因此哈希表需要一种方法来处理这种冲突。常见的冲突处理方法包括链地址法,在同一个位置,也就是同一个通中形成一个链表讲不同的Key值像链表一样串起来;开放寻址法(在冲突的情况下寻找下一个可用的桶),或者再哈希法(讲带入过哈希函数的返回的值,再次带入哈希函数)。
typedef struct Node {//结点void key;//这里就是存储的key值,可以是任何类型,字符串,数值,字符等等struct Node *next;//链表,肯定需要记录下一个结点的地址嘛 } Node;typedef struct Hash{int size;//哈希表的长度Node **data;//数据域,这里用到了链表,也就是链式地址法,俗称拉链法//假如哈希冲突了,不同的key值,找到了同一个位置,然后就直接接到这个链表的后面,然后进行对比该条链表的结点的key值,如果找到了说明存在key值,如果没找到就说不不纯在key值 } Hash;int Hashfunchtion(void key) {//哈希函数return ;//这里就需要看key是对应的什么类型来定义哈希函数 }逻辑结构:
键-值对:哈希表的逻辑结构由键-值对组成。键是用户提供的数据,而值是与键关联的实际数据。哈希表使用键来计算索引,并将值存储在对应的桶中。
索引:索引是通过哈希函数计算得到的整数值,它用于确定数据项在数组中的位置。索引是键的逻辑表示,在查找、插入和删除数据时都用到。
结构操作:
哈希表主要就是插入和查找操作,其他的操作只要学会了前面两个操作,基本都能自己实现,下面我就讲述插入和查找操作:
插入操作:
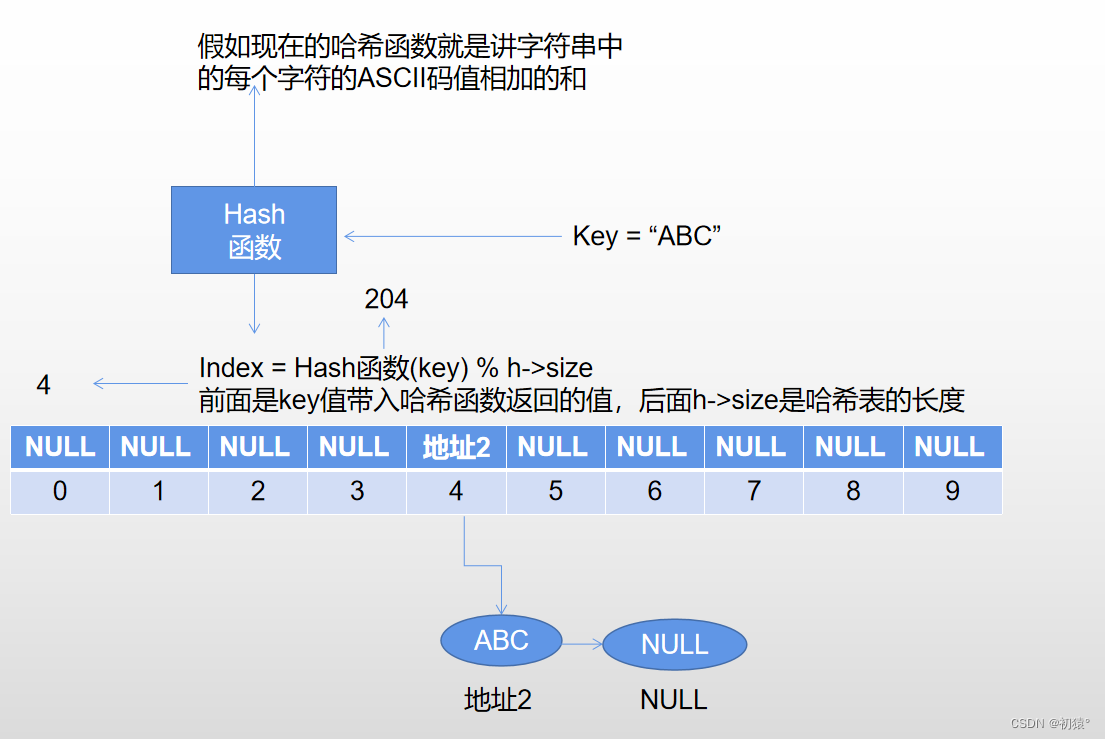
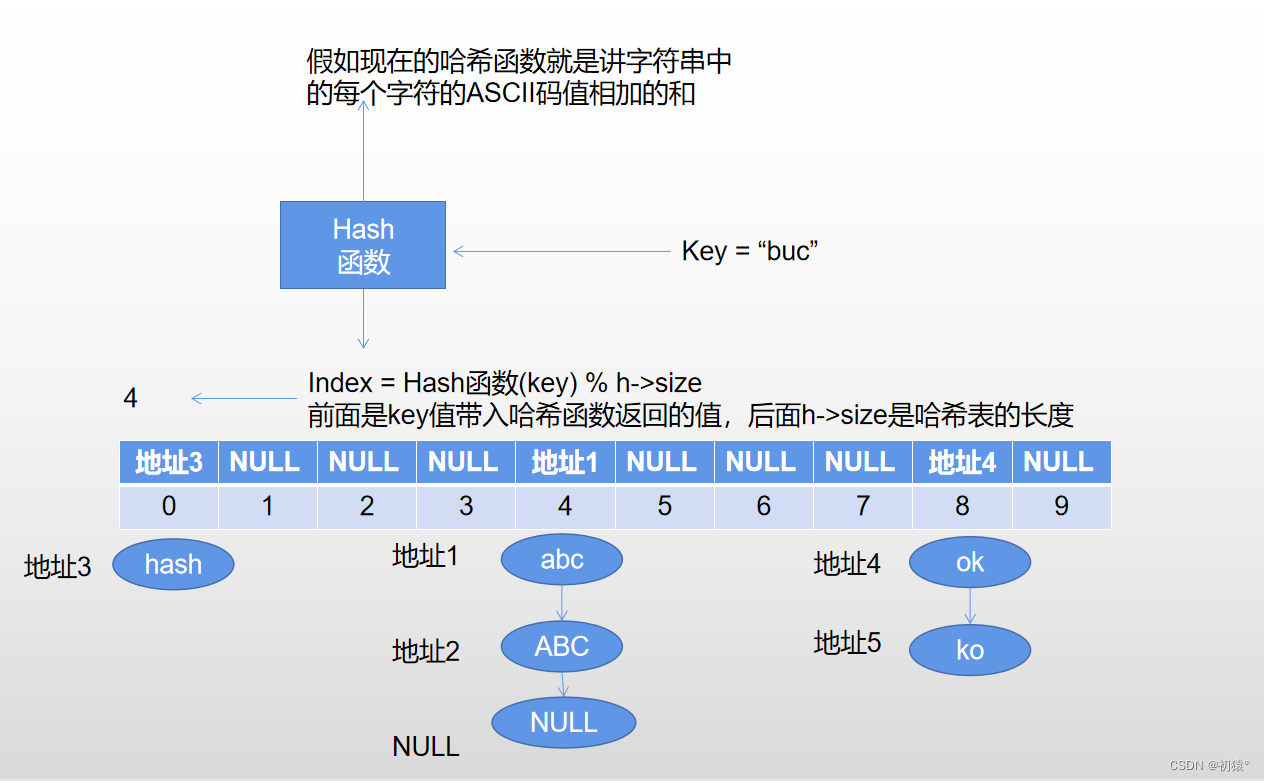
如图:插入操作,这里的key值用的是字符串,将字符串ABC添加入哈希表中:
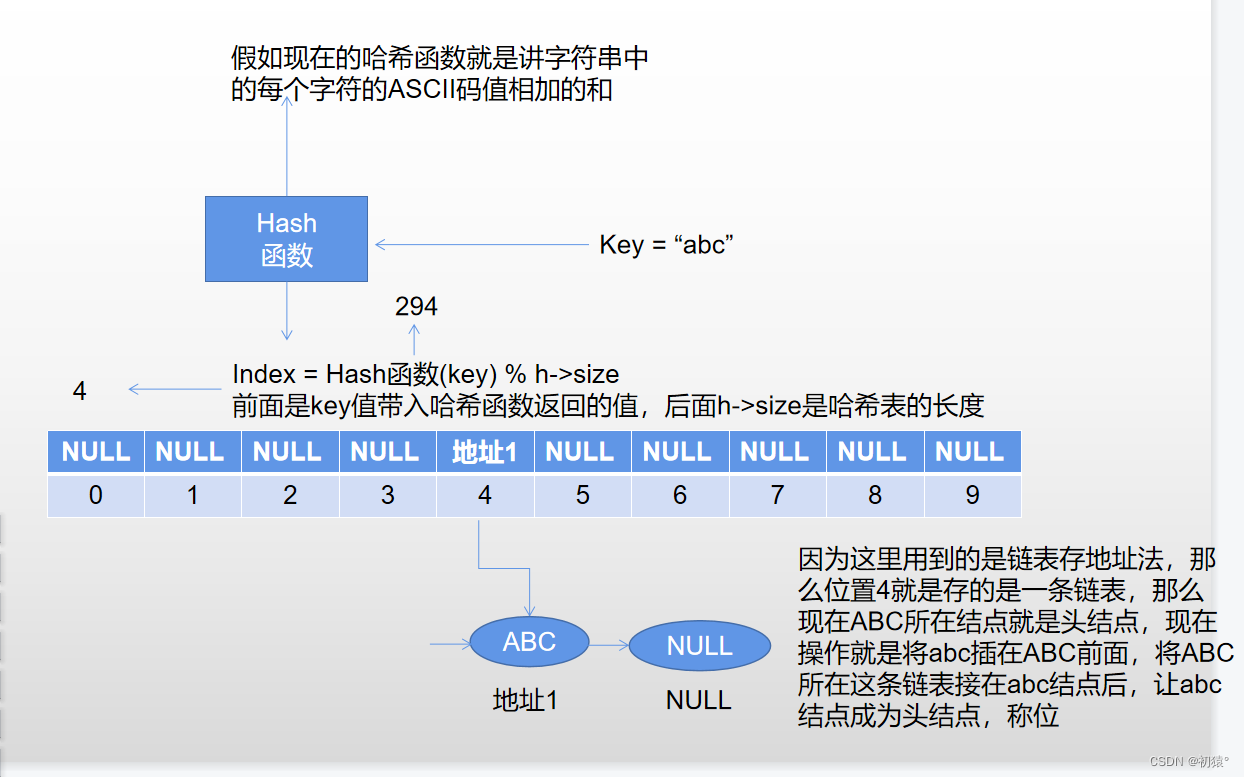
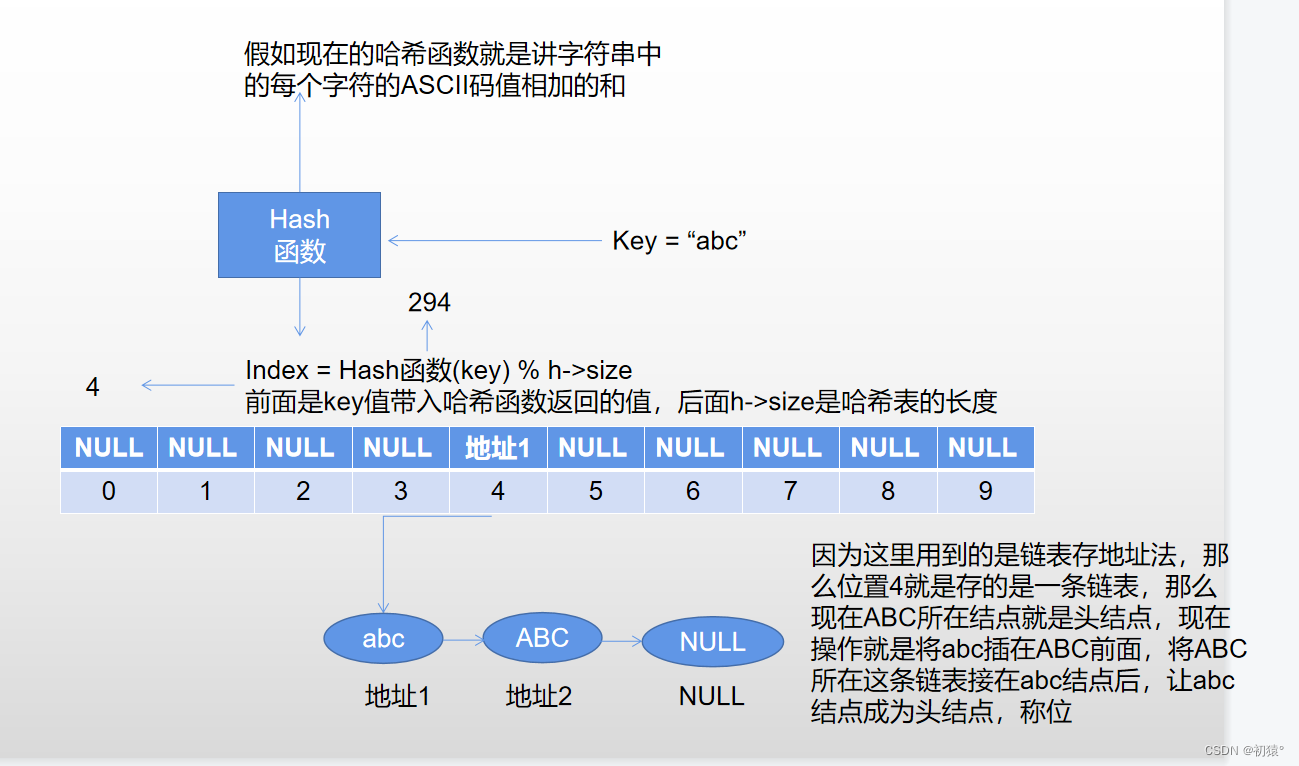
假如key值换了,然后获得的下标也是4,下面就是防冲突机制处理,这里添加的字符串是abc:
然后完成了冲突操作的插入;
片段代码实现:
int Hashfunchtion(char *key) {//哈希函数,这里用到的和图中的不一样,这样可以更高效的防冲突int seed = 18, hash = 0;for (int i = 0; key[i]; i++) hash = hash * seed + key[i];//这里可能会变为负数return hash & 0x7fffffff;//0x7fffffff这是16进制你转换为二进制就是除了符号位都是1//正数与上它不变,负数与上就变为整数 }Node *getNewNode(char *key, Node *head) {Node *p = (Node *)malloc(sizeof(Node));p->key = strdup(key);p->next = head;//这里用到的是头插法,从头部直接插入,接上后面的结点,如果是第一次插入这个位置,那么head就是NULL;return p; }int insert(Hash *h, char *key) {//插入元素int ind = Hashfunchtion(key) % h->size;//先将key带入哈希函数转为整数,然后模上哈希表的长度,使他的值不会超出哈希表的范围,最后获得索引h->data[ind] = getNewNode(key, h->data[ind]);return 1; }查找操作:
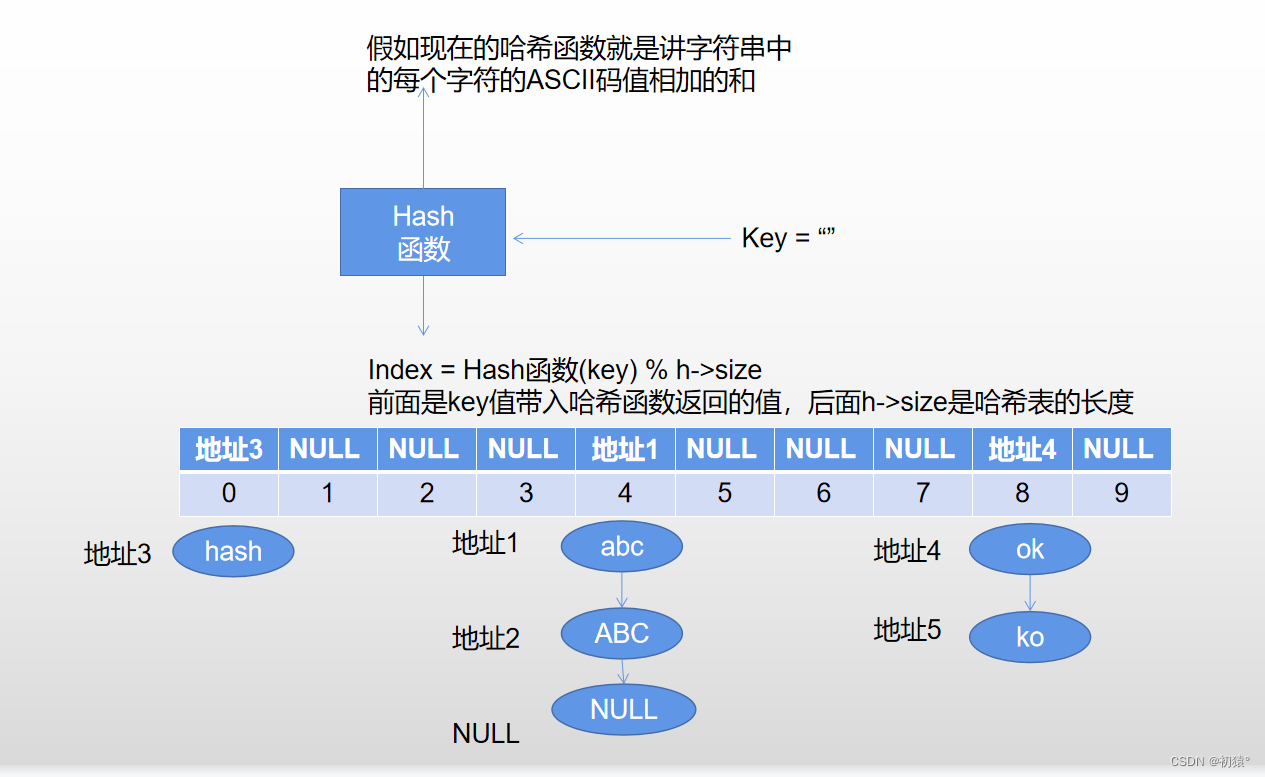
现在我添加了几个元素进这个哈希表中如图:
现在在这个哈希表中查找Key = good,
在哈希表中查询,该位置的地址为空,那么就说明在哈希表中没有该元素,返回0;
现在查询Key = buc
索引为4,对应地址不为空,那么就,创建一个指针进行对链表遍历,进行对链表中每个结点中的对应的Key值进行对比,最后发现没有,遍历完链表,现在指针应该指向空,一样返回0;
现在查询Key = ABC;
索引为4,对应地址不为空,那么就,创建一个指针进行对链表遍历,进行对链表中每个结点中的对应的Key值进行对比,然后指针指到地址2时匹配成功,最后返回该指针是否为空,为空就返回0,不为空返回1,那么现在返回的就是1,查找成功;
ok集中查询情况了解了,来看一下代码片段是如何实现的:
int Hashfunchtion(char *key) {//哈希函数int seed = 18, hash = 0;for (int i = 0; key[i]; i++) hash = hash * seed + key[i];//这里可能会变为负数return hash & 0x7fffffff;//0x7fffffff这是16进制你转换为二进制就是除了符号位都是1//正数与上它不变,负数与上就变为整数 }int search(Hash *h, char *key) {//查找key是否在哈希表中int ind = Hashfunchtion(key) % h->size; //先获取key值对应索引Node *p = h->data[ind];while (p && strcmp(p->key, key)) p = p->next;//比较当前索引的结点链表中的key,因为这里key是字符串需要用到strcmp函数进行对比return p != NULL;//如果p==NULL,返回0说明没有找到,如果p不为空那说明找到 }最终代码:
#include <stdio.h> #include <string.h> #include <stdlib.h>typedef struct Node {//结点char *key;//这里就是存储的key值,可以是任何类型,字符串,数值,字符等等struct Node *next;//链表,肯定需要记录下一个结点的地址嘛 } Node;typedef struct Hash{int size;//哈希表的长度Node **data;//数据域,这里用到了链表,也就是链式地址法,俗称拉链法//假如哈希冲突了,不同的key值,找到了同一个位置,然后就直接接到这个链表的后面,然后进行对比该条链表的结点的key值,如果找到了说明存在key值,如果没找到就说不不纯在key值 } Hash;Hash *getNewHash(int n) {Hash *h = (Hash *)malloc(sizeof(Hash)); h->size = n << 1;//为了防止以外开两倍h->data = (Node **)calloc(sizeof(Node *), h->size);return h; }int Hashfunchtion(char *key) {//哈希函数int seed = 18, hash = 0;for (int i = 0; key[i]; i++) hash = hash * seed + key[i];//这里可能会变为负数return hash & 0x7fffffff;//0x7fffffff这是16进制你转换为二进制就是除了符号位都是1//正数与上它不变,负数与上就变为整数 }Node *getNewNode(char *key, Node *head) {Node *p = (Node *)malloc(sizeof(Node));p->key = strdup(key);p->next = head;//这里用到的是头插法,从头部直接插入,接上后面的结点,如果是第一次插入这个位置,那么head就是NULL;return p; }int insert(Hash *h, char *key) {//插入元素int ind = Hashfunchtion(key) % h->size;//先将key带入哈希函数转为整数,然后模上哈希表的长度,使他的值不会超出哈希表的范围,最后获得索引h->data[ind] = getNewNode(key, h->data[ind]);return 1; }int search(Hash *h, char *key) {//查找key是否在哈希表中int ind = Hashfunchtion(key) % h->size; //先获取key值对应索引Node *p = h->data[ind];while (p && strcmp(p->key, key)) p = p->next;//比较当前索引的结点链表中的key,因为这里key是字符串需要用到strcmp函数进行对比return p != NULL;//如果p==NULL,返回0说明没有找到,如果p不为空那说明找到 }void clearNode(Node *root) {if (!root) return ;Node *p = root, *q;while (p) {q = p->next;free(p->key);free(p);p = q;}free(q);return ; }void clearHash(Hash *h) {if (!h) return ;for (int i = 0; i < h->size; i++) clearNode(h->data[i]);free(h->data);free(h);return ; }int main() {int op;char key[105] = {0};Hash *h = getNewHash(100);while (~scanf("%d%s", &op, key)) {switch (op) {case 0: {printf("insert %s from Hash is success\n", key);insert(h, key);} break;case 1: {printf("search %s from Hash is %d\n", key, search(h, key)); } break;default:{clearHash(h);return 0;}}}return 0; }

这里我只是实现了一种放冲突方法,其实还有很多优秀的防冲突方法,比如这个链表存地址的方法,如果一个位置冲突多了,链表的长度也变长了,查找效率也变低了,然后在c++中的hashmap中转换为一个红黑树的结构,这样插入和查找效率稳定在O(logn);
相关文章:

数据结构——哈希表
哈希表 这里没有讲哈希表底层的概念,什么转红黑树,什么链表的,这篇文章主要讲的是如何用C实现哈希表,以及哈希表的基本概念。后面我会出一篇文章来讲C中hashmap中的底层逻辑的知识。 哈希表的概念 哈希表是一种数据结构࿰…...

Kafka3.0.0版本——手动调整分区副本示例
目录 一、服务器信息二、启动zookeeper和kafka集群2.1、先启动zookeeper集群2.2、再启动kafka集群 三、手动调整分区副本3.1、手动调整分区副本的前提条件3.2、手动调整分区副本的示例需求3.3、手动调整分区副本的示例 一、服务器信息 四台服务器 原始服务器名称原始服务器ip节…...

玩客云 线刷Armbian 搭配Alist 阿里云盘 Jellyfin NovaVideoPlayer搞电视墙
啰嗦的背景 喜欢看电影,买了个投影仪,是这一切折腾的开端。 投影仪虽然有当贝系统,但是想看的电影总是需要**电视会员,那我肯定是不用的。因为有爱腾优的会员,最开始都是使用手机投屏,当呗的投影仪好就好…...

9月1日,每日信息差
1、华大智造:已实现海外基因测序仪和测序试剂的量产,实现了海外基因测序仪和测序试剂的量产 2、邮储银行下调定存利率。价格表显示,整存整取,一年期存款年利率为1.58%,二年期年利率为1.85%,三年期年利率为…...

【大数据】Flink 详解(六):源码篇 Ⅰ
Flink 详解(六):源码篇 Ⅰ 55、Flink 作业的提交流程?56、Flink 作业提交分为几种方式?57、Flink JobGraph 是在什么时候生成的?58、那在 JobGraph 提交集群之前都经历哪些过程?59、看你提到 Pi…...
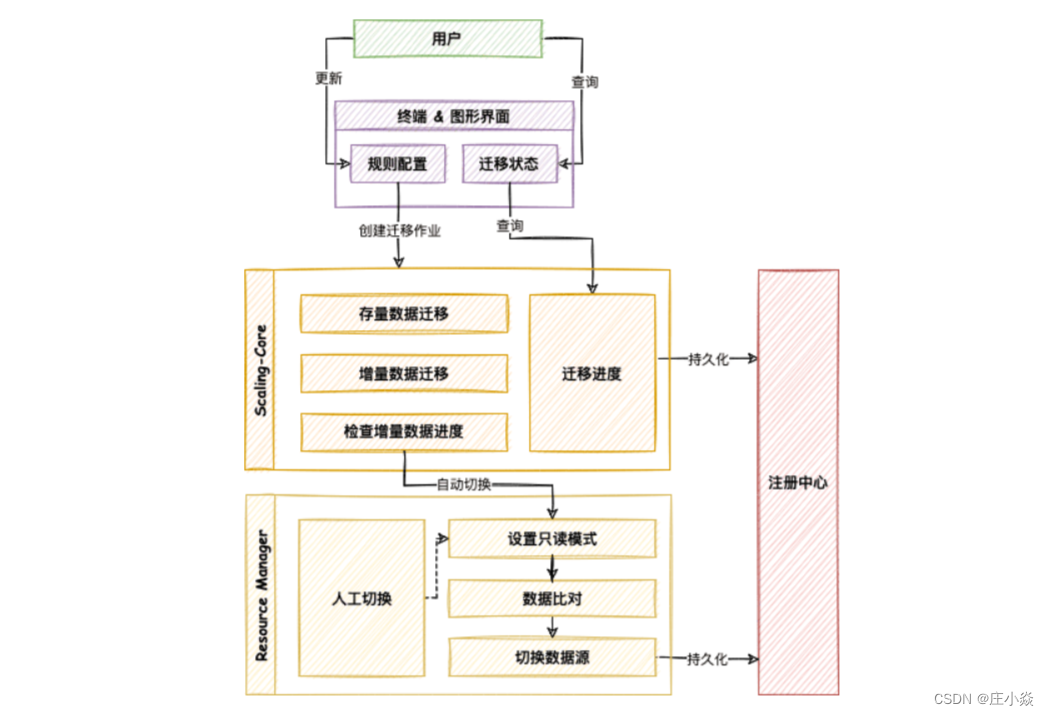
ShardingSphere——弹性伸缩原理
摘要 支持自定义分片算法,减少数据伸缩及迁移时的业务影响,提供一站式的通用弹性伸缩解决方案,是 Apache ShardingSphere 弹性伸缩的主要设计目标。对于使用单数据库运行的系统来说,如何安全简单地将数据迁移至水平分片的数据库上…...

Linux项目自动化构建工具-make/Makefile
一、什么是make和makefile make是一条指令 Makefile是当前目录下的一个文件 二、makefile文件编写 依赖关系::前为要目标文件,后为其依赖的文件 依赖方法:用依赖文件生成目标文件的具体指令 简便写法: $:表示目标文件 $^:表示…...

Python爬虫实战:自动化数据采集与分析
在大数据时代,数据采集与分析已经成为了许多行业的核心竞争力。Python作为一门广泛应用的编程语言,拥有丰富的爬虫库,使得我们能够轻松实现自动化数据采集与分析。本文将通过一个简单的示例,带您了解如何使用Python进行爬虫实战。…...
视频智能分析平台EasyCVR安防视频汇聚平台助力森林公园防火安全的应用方案
一、研发背景 随着经济的发展和人们生活水平的提高,越来越多的人喜欢在周末去周边的森林公园旅游,享受大自然的美景,并进行野炊和烧烤等娱乐活动。然而,近年来由于烟蒂和烧烤碳渣等人为因素,森林公园火灾频繁发生。森…...

跨境做独立站,如何低成本引流?
大家都知道,海外的消费习惯与国内不同,独立站一向是海外消费者的最喜欢的购物方式之一,这也吸引了许多跨境商家开设独立站。 独立站不同于其他的第三方平台,其他平台可以靠平台自身流量来获得转化,而独立站本身没有流…...
leetcode55.跳跃游戏 【贪心】
题目: 给你一个非负整数数组 nums ,你最初位于数组的 第一个下标 。数组中的每个元素代表你在该位置可以跳跃的最大长度。 判断你是否能够到达最后一个下标,如果可以,返回 true ;否则,返回 false 。 示例…...
探秘C语言扫雷游戏实现技巧
本篇博客会讲解,如何使用C语言实现扫雷小游戏。 0.思路及准备工作 使用2个二维数组mine和show,分别来存储雷的位置信息和排查出来的雷的信息,前者隐藏,后者展示给玩家。假设盘面大小是99,这2个二维数组都要开大一圈…...

Leetcode112. 路径总和
力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 给你二叉树的根节点 root 和一个表示目标和的整数 targetSum 。判断该树中是否存在 根节点到叶子节点 的路径,这条路径上所有节点值相加等于目标和 targetSum 。如果存在,返回 t…...

生成12位短id,自增且不连续,永不重复,不依赖数据库
基本思路: 设计模式:单例模式 是否加锁:是 synchronized 获取最后一次生成的时间戳值T0 限定初始时间为2023-08-01 00:00:00,获取当前时间时间戳T1,T1与初始时间的毫秒差值T2,转为16进制,转为字符串为r1,获取该字符串的长度L1…...

Zip压缩文件夹php打包函数代码
Zip压缩文件夹php打包函数代码,Zip相关函数是PHP的扩展功能,此函数可以直接复制使用。 以下是代码: <?php # 将文件夹的文件压缩到文件里 class Zip {/*** 将目标文件夹下的内容压缩到zip中(zip包含文件夹目录)* @param $sourcePath *文件夹路径 例: /home/test* @p…...

RISC-V交叉工具链riscv-gnu-toolchain编译
文章目录 1、下载2、编译1. 依赖安装2. 编译 3、运行 1、下载 $ sudo apt-get install git wget build-essential $ git clone https://github.com/riscv-collab/riscv-gnu-toolchain $ git checkout 2023.06.02注意上面 clone 的仓库,我们称其为构建脚本仓库&…...

我能“C“——指针进阶(上)
目录 指针的概念 1. 字符指针 2. 指针数组 3. 数组指针 3.1 数组指针的定义 3.2 &数组名VS数组名 3.3 数组指针的使用 4. 数组参数、指针参数 4.1 一维数组传参 4.2 二维数组传参 4.3 一级指针传参 4.4 二级指针传参 5. 函数指针 阅读两段有趣的代码&…...

SQLServer2008数据库还原失败 恢复失败
源地址:http://www.taodudu.cc/news/show-1609349.html?actiononClick 还原数据库问题解决方案 在还原数据库“Dsideal_school_db”时,有时会遇见上图中的问题“因为数据库正在使用,所以无法获得对数据库的独占访问权”,此时我们…...

【微服务部署】04-ForwardedHeaders
文章目录 1. ForwardedHeaders1.1 场景1.2 关键的HTTP头1.3 核心处理要点 1. ForwardedHeaders 1.1 场景 获取用户IP获取用户请求的原始URL 1.2 关键的HTTP头 X-Forwarded-ForX-Forwarded-ProtoX-Forwarded-Host 1.3 核心处理要点 设置PathBase设置ForwardedHeaders中间件…...
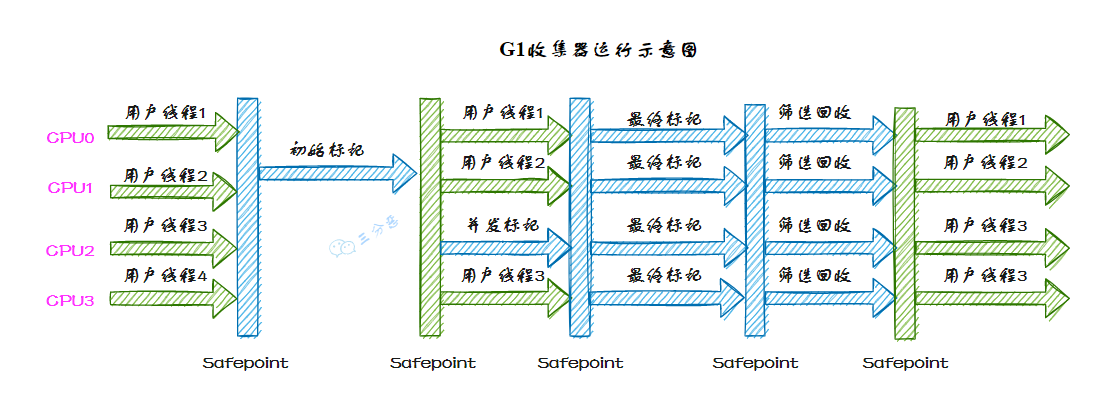
JVM 垃圾收集器
重点:CMS,G1,ZGC 主要垃圾收集器如下,图中标出了它们的工作区域、垃圾收集算法,以及配合关系。 Serial 收集器 Serial 收集器是最基础、历史最悠久的收集器。 如同它的名字(串行),…...

Apache APISIX Dashboard:现代化API网关管理的架构演进与实践方案
Apache APISIX Dashboard:现代化API网关管理的架构演进与实践方案 【免费下载链接】apisix-dashboard Dashboard for Apache APISIX 项目地址: https://gitcode.com/gh_mirrors/ap/apisix-dashboard 在微服务架构日益普及的今天,API网关已成为连接…...

为什么angular-dragdrop是AngularJS开发者的必备工具?
为什么angular-dragdrop是AngularJS开发者的必备工具? 【免费下载链接】angular-dragdrop Implementing jQueryUI Drag and Drop functionality in AngularJS (with Animation) is easier than ever 项目地址: https://gitcode.com/gh_mirrors/an/angular-dragdro…...

LiveSplit终极指南:速度跑者的专业计时解决方案
LiveSplit终极指南:速度跑者的专业计时解决方案 【免费下载链接】LiveSplit A sleek, highly customizable timer for speedrunners. 项目地址: https://gitcode.com/gh_mirrors/li/LiveSplit LiveSplit是一款专为速度跑者设计的专业计时软件,通过…...

终极指南:如何用OpenHTMLtoPDF轻松生成专业级PDF文档
终极指南:如何用OpenHTMLtoPDF轻松生成专业级PDF文档 【免费下载链接】openhtmltopdf An HTML to PDF library for the JVM. Based on Flying Saucer and Apache PDF-BOX 2. With SVG image support. Now also with accessible PDF support (WCAG, Section 508, PDF…...

早上好呀
早上好...
)
占坑uvm之stop_sequence()
最近遇到个仿真报错:parent sequence * should not finish before all items from itself and items from descendent sequences are peocessed.观察log发现,目前已进去reset区间,各sequencer正在进行stop_sequences。结合仿真log错误信息提示…...
)
从暗房到云端:一位古籍修复师用Midjourney蓝晒法重制《天工开物》插图的72小时实录(含失败21次原始日志)
更多请点击: https://intelliparadigm.com 第一章:从暗房到云端:一场古籍图像的跨时空显影 在胶片时代,古籍修复师需在幽暗的暗房中,借助红光灯与显影液,一帧一帧唤醒沉睡于纸背的墨痕;而今&am…...
)
中药实验管理系统|基于springboot+vue的中药实验管理系统(源码+数据库+文档)
中药实验管理系统 目录 基于springbootvue的中药实验管理系统 一、前言 二、系统设计 三、系统功能设计 四、数据库设计 五、核心代码 六、论文参考 七、最新计算机毕设选题推荐 八、源码获取: 博主介绍:✌️大厂码农|毕设布道师,…...

抖音批量下载终极指南:免费高效获取视频、图集、合集和音乐
抖音批量下载终极指南:免费高效获取视频、图集、合集和音乐 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback …...
)
在树莓派4B上实战:用Electron-builder打包Linux ARM应用(含Wayland配置)
树莓派4B实战:Electron应用打包与Wayland适配全指南 树莓派4B作为一款性价比极高的ARM开发板,已经成为许多开发者和爱好者的首选平台。随着Electron框架的普及,越来越多的开发者希望将自己的桌面应用移植到树莓派上运行。本文将带你从零开始&…...