MPI内置类型与自定义类型
内置类型
MPI_CHAR: 字符型
- MPI_UNSIGNED_CHAR: 无符号字符型
- MPI_BYTE: 字节型
- MPI_SHORT: 短整型
- MPI_UNSIGNED_SHORT: 无符号短整型
- MPI_INT: 整型
- MPI_UNSIGNED: 无符号整型
- MPI_LONG: 长整型
- MPI_UNSIGNED_LONG: 无符号长整型
- MPI_FLOAT: 单精度浮点型
- MPI_DOUBLE: 双精度浮点型
- MPI_LONG_DOUBLE: 长双精度浮点型
自定义类型
MPI_Type_contiguous: 创建一个由相同大小的元素组成的类型
函数原型
int MPI_Type_contiguous(int count, MPI_Datatype oldtype,
MPI_Datatype *newtype)
参数详解
- count:新类型中元素的数量。
- oldtype:待复制元素的类型。
- newtype:返回一个新类型。
MPI_Type_vector: 创建一个由相同大小、位于相隔固定间距的元素组成的类型
函数原型
int MPI_Type_vector(int count,
int blocklength, int stride, MPI_Datatype oldtype,
MPI_Datatype *newtype)
参数详解
- count:向量中连续元素的数量。
- blocklength:向量中相邻元素之间的间距。
- stride:元素之间的间距(读取到该元素后,要跳过多少个元素才能读取下一个元素)。
- oldtype:待复制元素的类型。
- newtype:返回一个新类型。
MPI_Type_create_struct: 创建一个由不同类型的元素组成的类型
函数原型
int MPI_Type_create_struct(int count, const int* array_of_blocklengths,
const MPI_Aint* array_of_displacements,
const MPI_Datatype* array_of_types, MPI_Datatype* newtype)
参数详解
- count:新类型中元素的数量。
- array_of_blocklengths:指定每个元素的长度。
- array_of_displacements:指定每个元素的偏移量。需要注意的是,对于数组类型,偏移量必须是 MPI_Aint 类型。
- array_of_types:指定每个元素的类型。
- newtype:返回一个新类型。
代码实例
#include <stdio.h>
#include <mpi.h>typedef struct {int x, y;
} Vector2D;int main(int argc, char** argv) {int size, rank;MPI_Init(&argc, &argv);MPI_Comm_size(MPI_COMM_WORLD, &size);MPI_Comm_rank(MPI_COMM_WORLD, &rank);MPI_Datatype Vector2D_type;MPI_Type_vector(1, 2, 3, MPI_INT, &Vector2D_type);const MPI_Aint displacements[] = {0, offsetof(Vector2D, y)};const int blocklengths[] = {1, 1};MPI_Datatype types[] = {MPI_INT, MPI_INT};MPI_Type_create_struct(2, blocklengths, displacements, types, &Vector2D_type);MPI_Type_commit(&Vector2D_type);if (rank == 0) {Vector2D v = {1, 2};MPI_Send(&v, 1, Vector2D_type, 1, 0, MPI_COMM_WORLD);printf("Process 0 sent vector [%d, %d] to process 1\n", v.x, v.y);} else if (rank == 1) {Vector2D v_recv;MPI_Recv(&v_recv, 1, Vector2D_type, 0, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);printf("Process 1 received vector [%d, %d] from process 0\n", v_recv.x, v_recv.y);}MPI_Type_free(&Vector2D_type);MPI_Finalize();return 0;
}
MPI_Type_indexed函数创建一个由相同大小的元素组成的类型,但这些元素并不连续,而是位于一个数组的不同位置
函数原型
int MPI_Type_indexed(int count, const int* array_of_blocklengths,
const int* array_of_displacements,MPI_Datatype oldtype, MPI_Datatype* newtype)
参数详解
- count:新类型中元素的数量。
- array_of_blocklengths:一个整数数组,指定每个块中连续元素的数量。
- array_of_displacements:一个整数数组,指定每个块的起始位置。
- oldtype:待复制元素的类型。
- newtype:返回一个新类型。
代码实例
#include <stdio.h>
#include <mpi.h>int main(int argc, char** argv) {int size, rank;MPI_Init(&argc, &argv);MPI_Comm_size(MPI_COMM_WORLD, &size);MPI_Comm_rank(MPI_COMM_WORLD, &rank);int block_lengths[3] = {2, 3, 2};int displacements[3] = {0, 4, 12};int data[7] = {1, 2, 3, 4, 5, 6, 7};MPI_Datatype Complex_type;MPI_Type_indexed(3, block_lengths, displacements, MPI_INT, &Complex_type);MPI_Type_commit(&Complex_type);if (rank == 0) {printf("Sending complex data...\n");MPI_Send(data, 1, Complex_type, 1, 0, MPI_COMM_WORLD);} else if (rank == 1) {int recv_data[7];MPI_Recv(recv_data, 7, MPI_INT, 0, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);printf("Received complex data: [");for (int i = 0; i < 7; i++) {printf("%d ", recv_data[i]);}printf("]\n");}MPI_Type_free(&Complex_type);MPI_Finalize();return 0;
}
MPI_Type_hvector 创建一个向量数据类型,但与 MPI_Type_vector 不同的是,所有的数据元素不需要具有相同的大小和类型。具体来说,MPI_Type_hvector 允许用户按照任意的字节长距离来描述向量的结构
函数原型
int MPI_Type_hvector(int count, int blocklength,
MPI_Aint stride, MPI_Datatype oldtype, MPI_Datatype *newtype)
参数详解
- count:向量中元素的数量。
- blocklength:向量中每个元素的个数。
- stride:相邻元素之间的偏移(以字节为单位)。
- oldtype:要重复的原始数据类型。
- newtype:输出的新数据类型。
代码实例
假设有一个数组 a,它的每个元素的大小是 4 字节,我们想要创建一个新的 MPI 类型,每 2 个元素组合在一起,组成一个长度为 8 字节的结构体。在这种情况下,我们可以使用 MPI_Type_hvector 来创建新的数据类型:
MPI_Datatype struct_type, temp_type;
MPI_Type_contiguous(2, MPI_INT, &temp_type);
MPI_Type_create_resized(temp_type, 0, 8, &struct_type);
MPI_Type_commit(&struct_type);
MPI_Type_free(&temp_type);MPI_Datatype vector_type;
MPI_Type_hvector(4, 1, 8, struct_type, &vector_type);
MPI_Type_commit(&vector_type);
相关文章:

MPI内置类型与自定义类型
内置类型 MPI_CHAR: 字符型 MPI_UNSIGNED_CHAR: 无符号字符型MPI_BYTE: 字节型MPI_SHORT: 短整型MPI_UNSIGNED_SHORT: 无符号短整型MPI_INT: 整型MPI_UNSIGNED: 无符号整型MPI_LONG: 长整型MPI_UNSIGNED_LONG: 无符号长整型MPI_FLOAT: 单精度浮点型MPI_DOUBLE: 双精度浮点型M…...

【ES新特性三】Object 原型、原型链相关方法
一、Object 原型、原型链相关方法 1.1 静态方法(Object 调用): Object.setPrototypeOf(obj,prototype) 方法用于设置某个实例对象的原型(可以是null,也可以是一个对象) Object.getPrototypeOf(obj) …...

学习大数据应该掌握哪些基础语言
大数据技术的体系庞大且复杂,每年都会涌现出大量新的技术,目前大数据行业所涉及到的核心技术主要就是:数据采集、数据存储、数据清洗、数据查询分析和数据可视化。 学习大数据需要掌握什么语言基础? 1、Java基础 大数据框架90%以…...

Kubernetes技术--k8s核心技术 ingress
1.引入 我们之前在部署应用(如nginx)的时候,如果你需要外部进行访问,使用的是service中的nodePort方式进行对外的暴露。然后外部就可以使用ip + 端口号来进行访问部署应用。 其实这一种方式是存在着较为明显的缺陷,每一个端口你只能够使用一次,一个端口对应一个应用,而且访…...
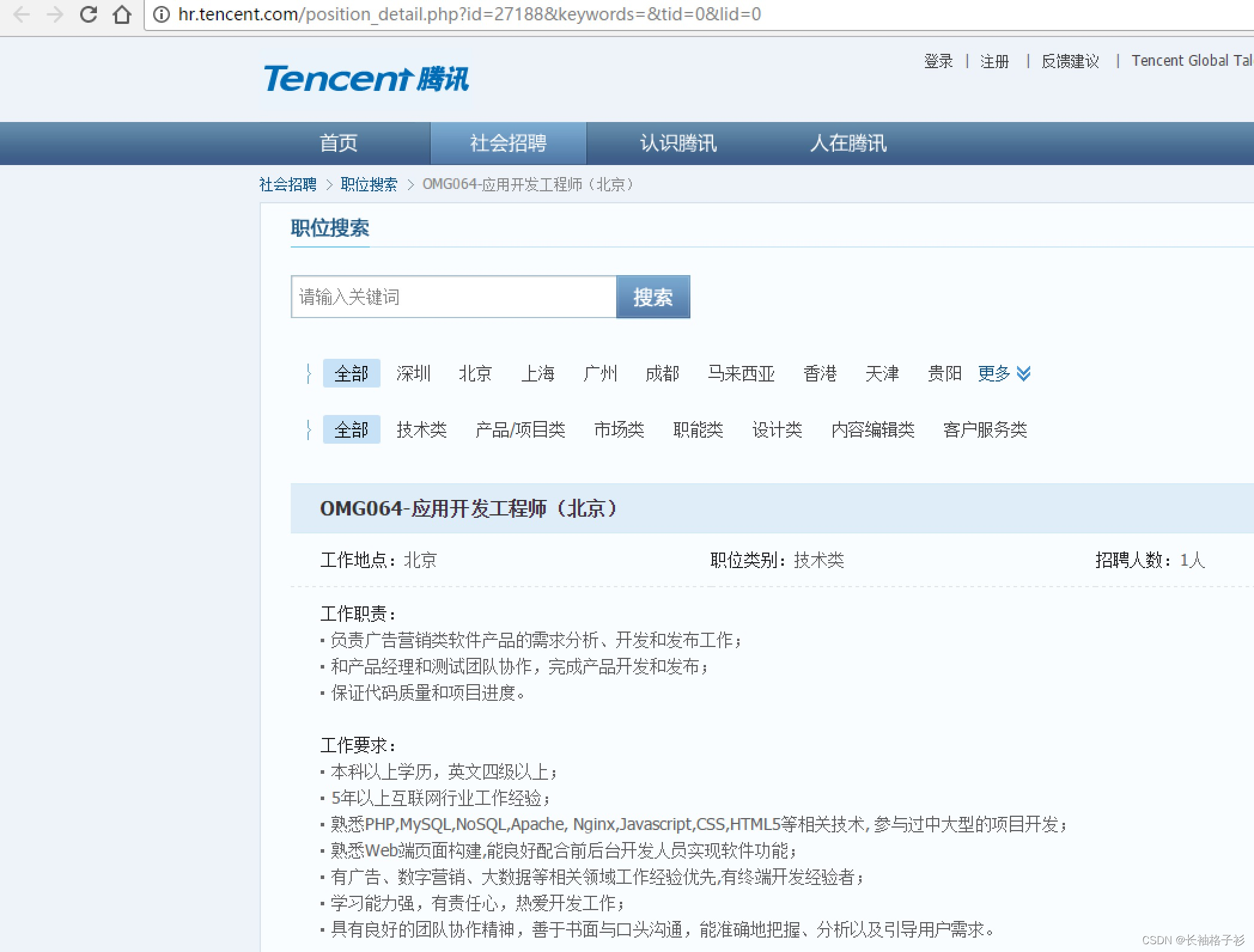
中级深入--day15
案例:使用BeautifuSoup4的爬虫 我们以腾讯社招页面来做演示:搜索 | 腾讯招聘 使用BeautifuSoup4解析器,将招聘网页上的职位名称、职位类别、招聘人数、工作地点、发布时间,以及每个职位详情的点击链接存储出来。 # bs4_tencent.p…...

内存四区(个人学习笔记黑马学习)
1、内存分区模型 C程序在执行时,将内存大方向划分为4个区域: 代码区:存放函数体的二进制代码,由操作系统进行管理的全局区:存放全局变量和静态变量以及常量栈区:编译器自动分配释放,存放函数的参数值,局部变量等 堆区:由程序员分配和释放,若程…...

如何使用RPA + ChatGPT自动化提高自己的工作效率
使用RPA(Robotic Process Automation)和ChatGPT可以结合来自动化提高自己的工作效率。下面是一些步骤: (1)确定自动化任务 首先,需要确定哪些任务或工作流程可以通过自动化来提高效率。这些任务应该是重复…...

uni-app之android项目配置和打包
1,项目根目录,找到mainfest.json,如果appid是空的,需要生成一个appid 2,点击重新获取appid,这个时候需要登录,那就输入账号密码登录下 3,登陆后可以看到获取appid成功 4,…...
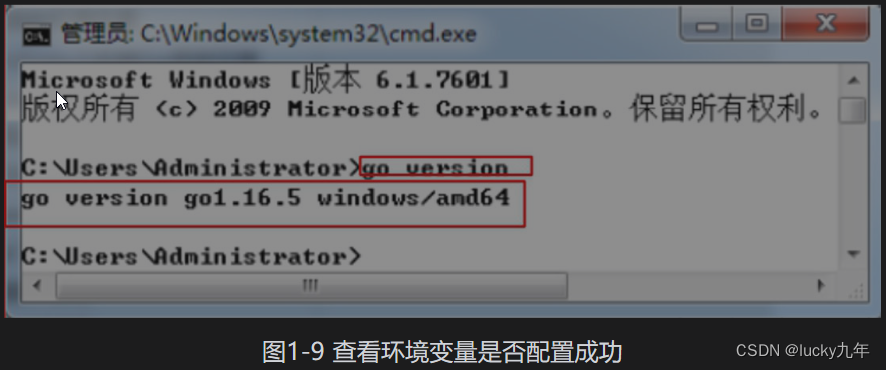
go语言配置
1、Go语言的环境变量 与Java等编程语言一样,安装Go语言开发环境需要设置全局的操作系统环境变量(除非是用包管理工具直接安装) 主要的系统级别的环境变量有两个: (1)GOROOT:表示Go语言环境在计算机上的安…...
【深度学习】ChatGPT
本文基于Andrej Karpathy(OpenAI 联合创始人,曾担任特斯拉的人工智能和自动驾驶视觉主管)在Microsoft Build 2023上的演讲整理而成(完整的视频在文末,直接拖到文章底部),主要分为2大部分: 1.如何训练GPT(可…...
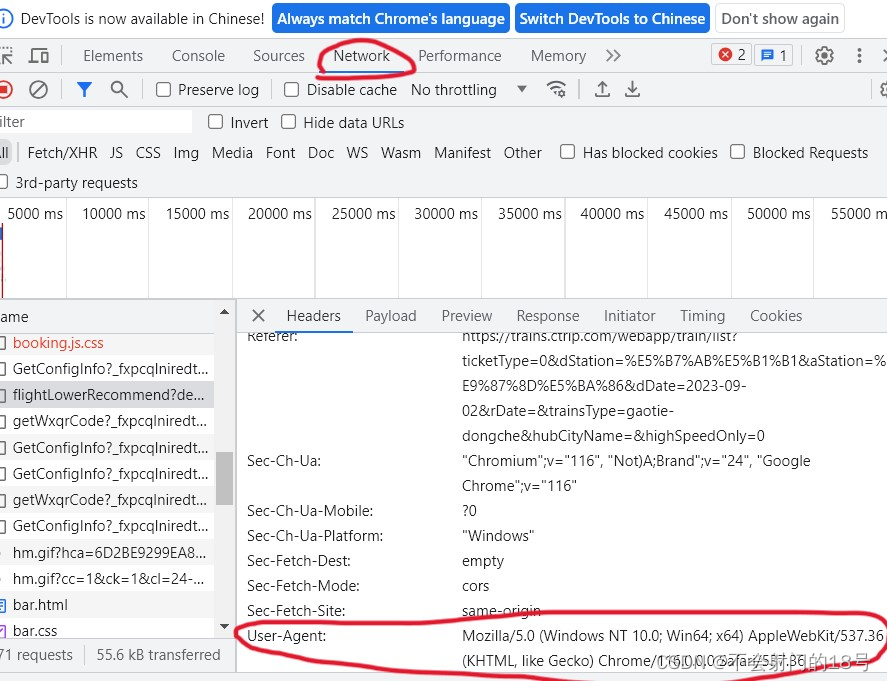
爬虫--爬取自己想去的目的的车票信息
前言: 本篇文章主要作为一个爬虫项目的小练习,来给大家进行一下爬虫的大致分析过程以及来帮助大家在以后的爬虫编写中有一个更加清晰的认识。 一:环境配置 Python版本:3.7 IDE:PyCharm 所需库:requests࿰…...
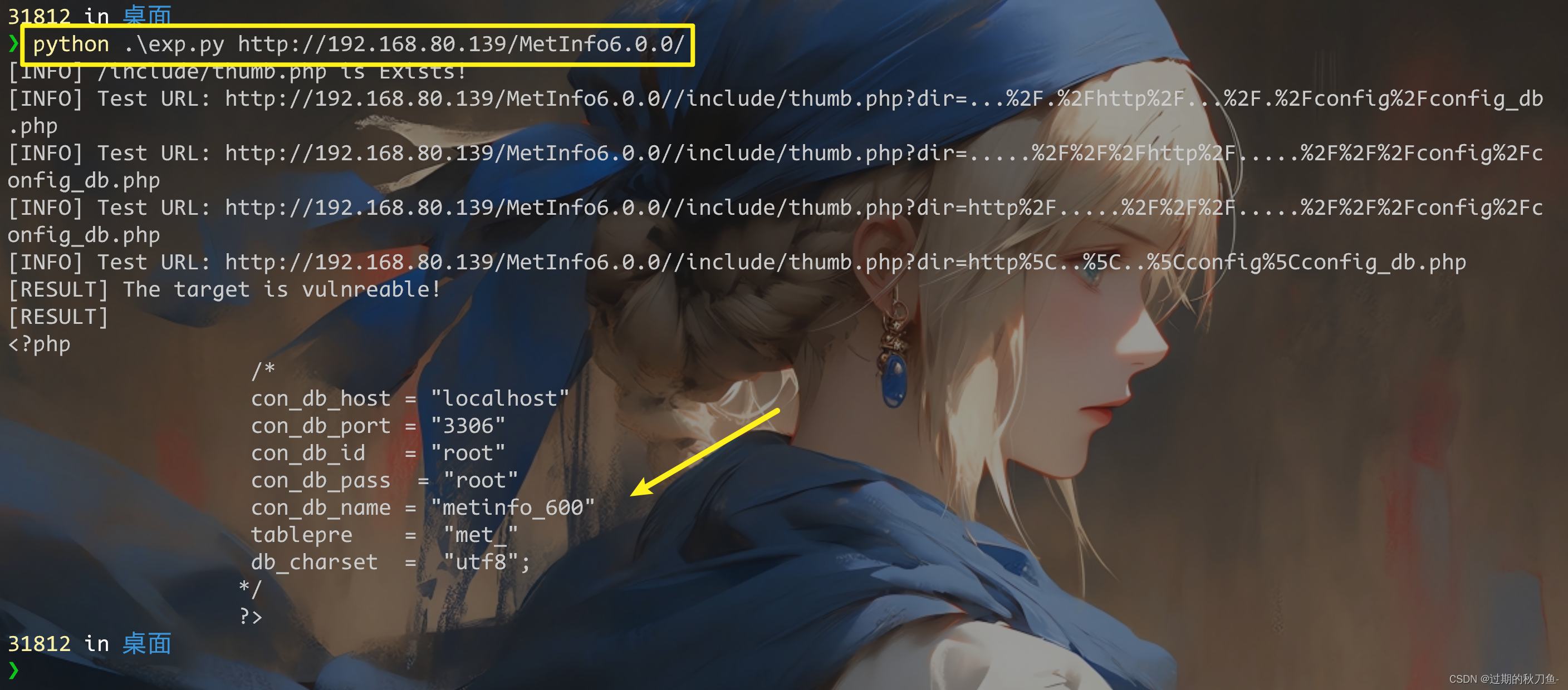
Metinfo6.0.0任意文件读取【漏洞复现】
文章目录 1.1、漏洞描述1.2、漏洞等级1.3、影响版本1.4、漏洞复现代码审计漏洞点 1.5、深度利用EXP编写 1.6、漏洞挖掘1.7修复建议 1.1、漏洞描述 漏洞名称:MetInfo任意文件读取 漏洞简介:MetInfo是一套使用PHP和MySQL开发的内容管理系统,其…...
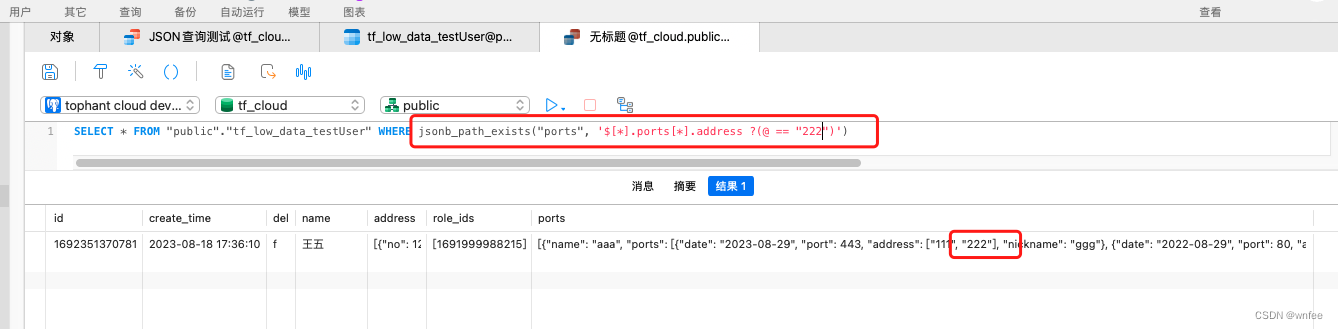
Postgresql JSON对象和数组查询
文章目录 一. Postgresql 9.5以下版本1.1 简单查询(缺陷:数组必须指定下标,不推荐)1.1.1 模糊查询1.1.2 等值匹配1.1.3 时间搜索1.1.4 在列表1.1.5 包含 1.2 多层级JSONArray(推荐)1.2.1 模糊查询1.2.2 模糊查询 NOT1.2.3 等值匹配…...

搭配购买——并查集+01背包
Joe觉得云朵很美,决定去山上的商店买一些云朵。 商店里有 n 朵云,云朵被编号为 1,2,…,n,并且每朵云都有一个价值。但是商店老板跟他说,一些云朵要搭配来买才好,所以买一朵云则与这朵云有搭配的云都要买。但是Joe的钱有…...
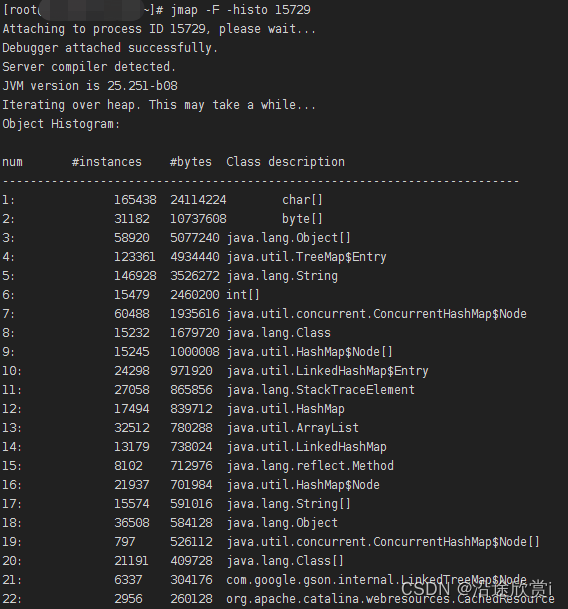
JVM调优指令参数
常用命令查找文档站点:https://docs.oracle.com/javase/8/docs/technotes/tools/unix/index.html -XX:PrintFlagsInitial 输出所有参数的名称和默认值,默认不包括Diagnostic和Experimental的参数。可以配合 -XX:UnlockDiagnosticVMOptions和-XX:UnlockEx…...

数据结构入门 — 队列
本文属于数据结构专栏文章,适合数据结构入门者学习,涵盖数据结构基础的知识和内容体系,文章在介绍数据结构时会配合上动图演示,方便初学者在学习数据结构时理解和学习,了解数据结构系列专栏点击下方链接。 博客主页&am…...
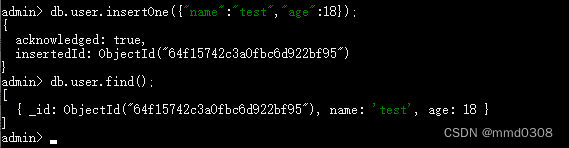
MongoDB - 安装
一、Docker安装MongoDB 1. 安装 安装版本: 7.0.0 docker run -itd --name mongodb -v C:\\data\\mongodb\\data:/data/db -p 27017:27017 mongo:7.0.0 --auth-v: 将容器目录/data/db映射到本地C:\\data\\mongodb\\data目录,防止容器删除数据丢失-p: 端口映射--aut…...
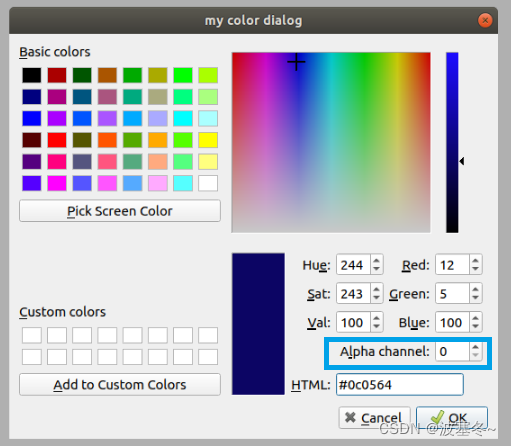
Qt应用开发(基础篇)——颜色选择器 QColorDialog
一、前言 QColorDialog类继承于QDialog,是一个设计用来选择颜色的对话框部件。 对话框窗口 QDialog QColorDialog颜色选择器一般用来让用户选择颜色,比如画图工具中选择画笔的颜色、刷子的颜色等。你可以使用静态函数QColorDialog::getColor()直接显示对…...
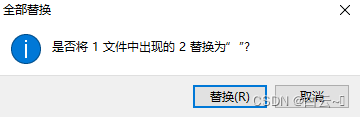
vscode 清除全部的console.log
在放页面的大文件夹view上面右键点击在文件夹中查找 console.log.*$ 注意:要选择使用正则匹配 替换为 " " (空字符串)...

UG\NX CAM二次开发 插入工序 UF_OPER_create
文章作者:代工 来源网站:NX CAM二次开发专栏 简介: UG\NX CAM二次开发 插入工序 UF_OPER_create 效果: 代码: void MyClass::do_it() {tag_t setup_tag=NULL_TAG;UF_SETUP_ask_setup(&setup_tag);if (setup_tag==NULL_TAG){uc1601("请先初始化加工环境…...
)
从‘看不见’到‘毁不掉’:深入聊聊数字水印的鲁棒性到底怎么测(附常见攻击模拟方法)
数字水印鲁棒性测试实战指南:从理论到攻击模拟 数字水印技术已经从单纯的学术研究走向了广泛的商业应用,成为版权保护领域不可或缺的一环。但真正决定一个水印系统实用价值的,是其抵抗各种攻击的鲁棒性——这项指标直接关系到水印能否在现实…...

如何用SMUDebugTool完全掌控AMD Ryzen处理器性能
如何用SMUDebugTool完全掌控AMD Ryzen处理器性能 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gitcode.com/gh_mir…...

对比直接使用官方API,通过Taotoken接入在成本控制上的实际感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用官方API,通过Taotoken接入在成本控制上的实际感受 1. 引言:从单一渠道到聚合平台 对于个人开…...

蘑菇博客MoguBlog:微服务架构的前后端分离博客系统完整指南 [特殊字符]
蘑菇博客MoguBlog:微服务架构的前后端分离博客系统完整指南 🚀 【免费下载链接】mogu_blog_v2 蘑菇博客(MoguBlog),一个基于微服务架构的前后端分离博客系统。Web端使用Vue Element , 移动端使用uniapp和ColorUI。后端使用Spring cloud Spr…...

SegFormer凭什么不用位置编码?深入拆解Mix-FFN与重叠Patch Merging的设计哲学
SegFormer革命性设计:为何抛弃位置编码仍能称霸语义分割? 在视觉Transformer的浪潮中,SegFormer以其独特的设计哲学脱颖而出——它大胆摒弃了传统Transformer中视为标配的位置编码(Positional Encoding),却…...

如何在5分钟内解锁所有Steam成就:Steam Achievement Manager完整使用指南
如何在5分钟内解锁所有Steam成就:Steam Achievement Manager完整使用指南 【免费下载链接】SteamAchievementManager A manager for game achievements in Steam. 项目地址: https://gitcode.com/gh_mirrors/st/SteamAchievementManager 还在为Steam游戏中那…...

专业解密QQ音乐加密格式:QMCDecode让音乐文件重获自由播放权
专业解密QQ音乐加密格式:QMCDecode让音乐文件重获自由播放权 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录,…...

服务器电源、电机驱动、UPS:IRLR3636TRPBF的60V功率MOSFET应用版图
IRLR3636TRPBF:DPAK封装60V/50A N沟道功率MOSFET的大电流开关应用解析在大功率开关电源、不间断电源以及直流电机驱动等领域,功率MOSFET的导通损耗直接影响系统的温升和能效等级。当设计需要在60V电压平台上处理50A级别的大电流时,导通电阻和…...

PCB直流电阻精确估算:从基础公式到工程实践的全解析
1. 项目概述:为什么需要精确估算PCB直流电阻? 在硬件设计,尤其是电源完整性、信号完整性和热管理的世界里,PCB走线的直流电阻常常是一个被低估的关键参数。很多工程师在设计初期,注意力都集中在阻抗匹配、串扰和EMI上&…...

Inter字体终极指南:从零开始掌握现代界面设计的免费开源字体方案
Inter字体终极指南:从零开始掌握现代界面设计的免费开源字体方案 【免费下载链接】inter The Inter font family 项目地址: https://gitcode.com/gh_mirrors/in/inter Inter字体是一款专为计算机屏幕精心设计的开源无衬线字体系统,凭借其卓越的可…...