是否在业务中使用大语言模型?
ChatGPT取得了巨大的成功,在短短一个月内就获得了1亿用户,并激发了企业和专业人士对如何在他们的组织中利用这一工具的兴趣和好奇心。
但LLM究竟是什么,它们如何使你的企业受益?它只是一种炒作,还是会长期存在?
在这篇文章中我们将讨论上面这个问题并尝试解答为什么LLM对企业来说是一项伟大的投资,或者不是。是大炮打蚊子 还是 物尽其用?这就要看何时以及如何有效和高效地使用这个大模型了。

训练
LLM的训练是非常昂贵……但是这并不意味着每次要使用LLM完成特定任务时都要训练它,也不意味着你根本就不需要训练它。有很多方法可以利用LLM的现有知识和技能,无需从头开始训练。
LLM能够根据单词和短语相互跟随的概率生成文本。也可以通过让它“根据上下文阅读”来“模仿”这种行为。这就好比给某人一本书,然后让他们在书中找到他们认为可能有X问题答案的那一章。一旦读者找到这一章,他们就会阅读,然后试图向你解释他们刚刚读到的内容。
这需要某种程度上对他进行提示,这也就是我们常说的prompt。网上有很多关于关于提示教程,提示工程以及如何为LLM生成良好的提示。所以当你试图得到上下文答案时,LLM可以很好的工作。但不要指望机器知道一切,因为它们擅长的是放置文字,而不是阐述事实。
只有当你想让机器像专业人士一样说话时,你才需要重新训练它。
业务专业术语
所有组织和企业都有自己的行话和特定于其领域的技术术语。例如,Jam可以指甜甜的Smucker草莓果冻,但也可以指非正式播放的音乐。
这意味着不是每个人都能很容易地理解特定业务使用的语言,除非他们熟悉其词汇和概念。所以对于不熟悉该领域的潜在客户或合作伙伴来说可能是一个障碍。使用llm可以将技术语言翻译成更自然和可访问的语言。
LLM可以根据所需的风格和细节水平,使用提更简单的单词或示例来帮助解释复杂术语或概念的含义,这可以使信息对任何人都更具吸引力和可理解性。
知识图谱是在图结构中组织信息的一种方式,其中实体及其关系表示为节点和边。这使得存储和访问信息比使用传统文本格式更容易。知识图谱可以独立于任何大型语言模型(llm)构建,并且知识图谱也可以从llm的功能中受益。
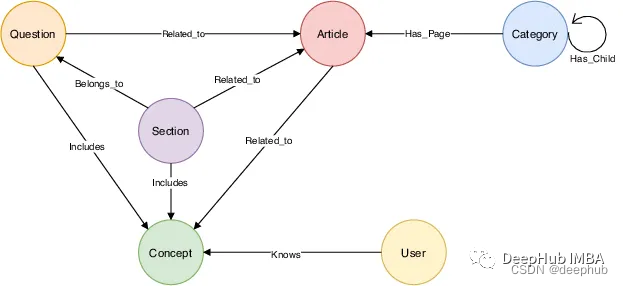
要创建知识图谱,需要从数据源(如pdf)中提取实体和关系,并将它们插入图数据库中。llm可以帮助完成这项任务,通过生成代码将数据插入到数据库中。
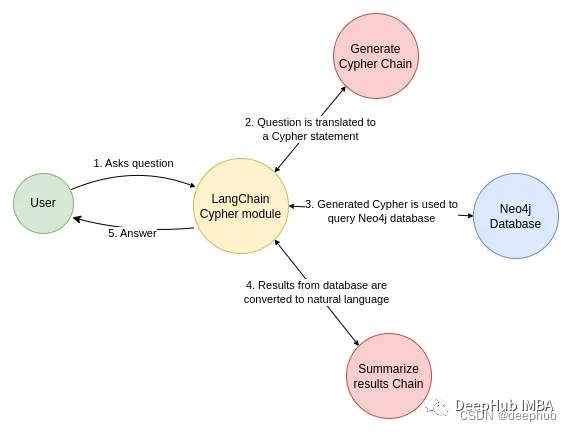
llm还可以帮助使用自然语言查询知识图谱,以简单易懂的方式解释结果。通过这种方式,用户可以使用文本与数据进行交互,并从知识图中获得事实和相关的答案。
LLM可以从提供的上下文中使用更简单的单词或示例来帮助解释复杂术语或概念的含义
敏感数据
还记得三星的问题吧,工程师的一些机密源代码被意外上传到ChatGPT,
你一直觉得,这种风险仅适用于使用OpenAI网站上的免费ChatGPT界面。其实任何被称为“免费”的东西都可能以某种方式获得投资回报。比如使用你的信息来改进模型。一个稍微好一些的选择是通过API使用付费LLM服务,该服务不会使用任何敏感数据进行再训练。
显示现在就好很多了,有许多替代ChatGPT的方法。比如Falcon、Llama、Palm或其他性能与ChatGPT相似甚至更好的模型。我们还可以根据自己的具体需求定制自己的模型或解决方案。
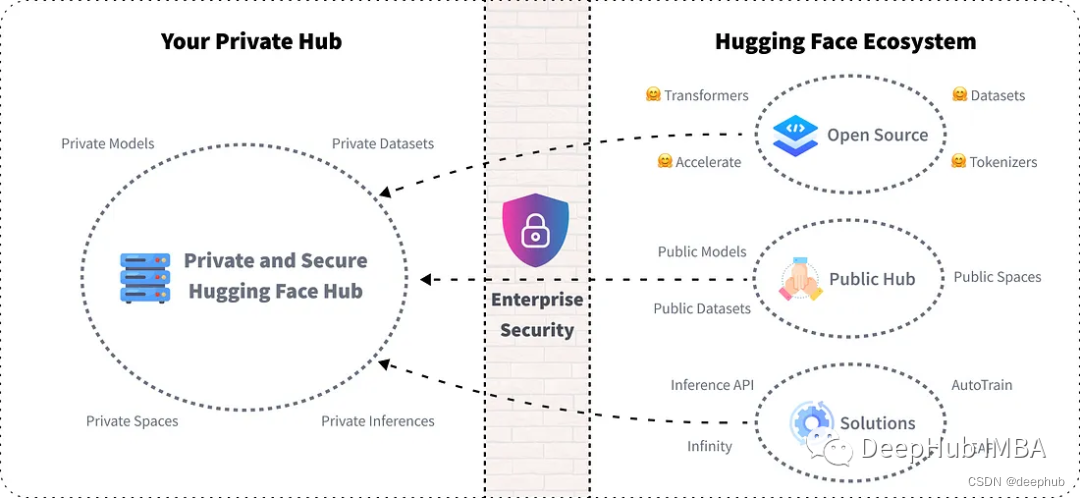
通过托管自己的LLM,可以确保它仅用于预期目的,并且可以在将来需要时对其进行重新训练。还可以探索通过使用这些模型生成的数据,以改进您的业务。例如,查看向模型提出的最重要的问题,可以创建更好的业务解决方案并从中获利。
有了开源的基础模型,我们可以搭建自己的LLM,并且随时调整训练。
部分还是全部
这里我们以推荐系统为例:
推荐系统是一种基于某些标准推荐项目或操作的系统。例如,Spotify使用你的收听历史和偏好来为你创建个性化的播放列表。你可以把它想象成根据其他人的喜好推荐音乐,这可能与你的喜好相匹配。
LLM也可以做到这一点,通过嵌入来衡量两个信息片段之间的相似性或差异性,比如一个问题和一个答案。但是如果我们只把LLM简化到这个程度(只生成嵌入),那么推荐系统不是要更简单吗,而且推荐系统能够得到更准确的结果,需要的资源还更少。
那我们为什么要用LLM来做这个呢?
找到对任何给定问题的最准确的回答,然后解释为什么它是一个好的匹配,这是推荐引擎无法做到的。嵌入不仅可以对文本做同样的事情,还可以对任何来源做同样的事情;从音频到图像。推荐系统需要额外的组件来处理和标记这些类型的信息。
所以这是一种种特殊情况,我们的推荐需要音频你和图像吗?所以在使用前需要评估要解决的问题否需要LLM所能提供的所有功能,或者是否可以用更传统的方式解决问题。(其实上面的音频和图像只要增加几个模型就可以了,投入远远要比使用LLM低很多)
如果只用了LLM的一少部分功能,那么肯定有比他更好的更传统的解决方案
总结
LLM不仅仅是一种炒作,它们其实是一种强大而通用的技术,可以实现业务目标并提高客户满意度。但是LLM并不是灵丹妙药,使用时尤其需要需要仔细规划、评估和优化,以确保其有效性和效率。
如果你打算以正确的方式将llm整合到业务中,记住:
专业的人做专业的事
https://avoid.overfit.cn/post/6280016cc99749aa827c8841e6e83da2
相关文章:
是否在业务中使用大语言模型?
ChatGPT取得了巨大的成功,在短短一个月内就获得了1亿用户,并激发了企业和专业人士对如何在他们的组织中利用这一工具的兴趣和好奇心。 但LLM究竟是什么,它们如何使你的企业受益?它只是一种炒作,还是会长期存在? 在这篇文章中我…...

37. 交换字符(第三期模拟笔试)
题目: 给定一个01串(仅由字符0和字符1构成的字符串)。每次操作可以交换两个相邻的字符。 例如:对于字符串"001110"来说, 可以交换第二个字符0和第三个字符1,交换之后的字符串变成了"0101…...

git 查看当前分支最近一次提交的commit SHA
获取当前分支最近一次commit SHA (长度为40个16进制数字的字符)命令如下: git rev-parse HEAD 获取简写(短) commit SHA git rev-parse --short HEAD...
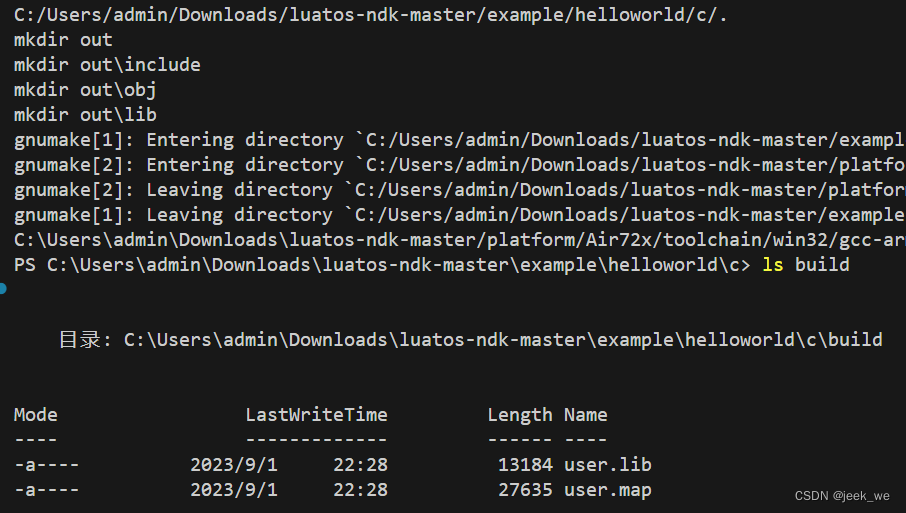
LuatOS 开发指南
NDK 开发 官方教程 官方例程 API 下载软件 下载官方NDK例程压缩包到本地,并解压。可以看到目录如下: doc: 文档教程 env: 编译环境 example: NDK示例 platform: 需要编译的平台(air72x/air8xx) tools: 其他辅助软件 VSCode 使…...
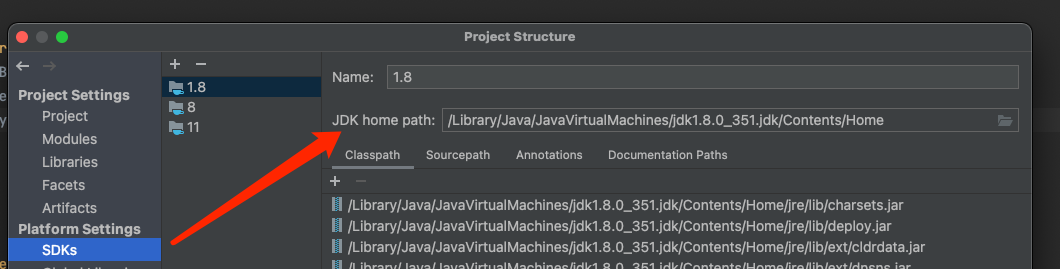
maven推包The environment variable JAVA_HOME is not correctly set
解决办法: 打开idea查看jdk安装位置 1.在/etc下面创建(如果存在就是更新)launchd.conf。里面添加一行: setenv JAVA_HOME /Library/Java/JavaVirtualMachines/jdk1.8.0_351.jdk/Contents/Home #JAVA_HOME后面是我的java安装路径…...
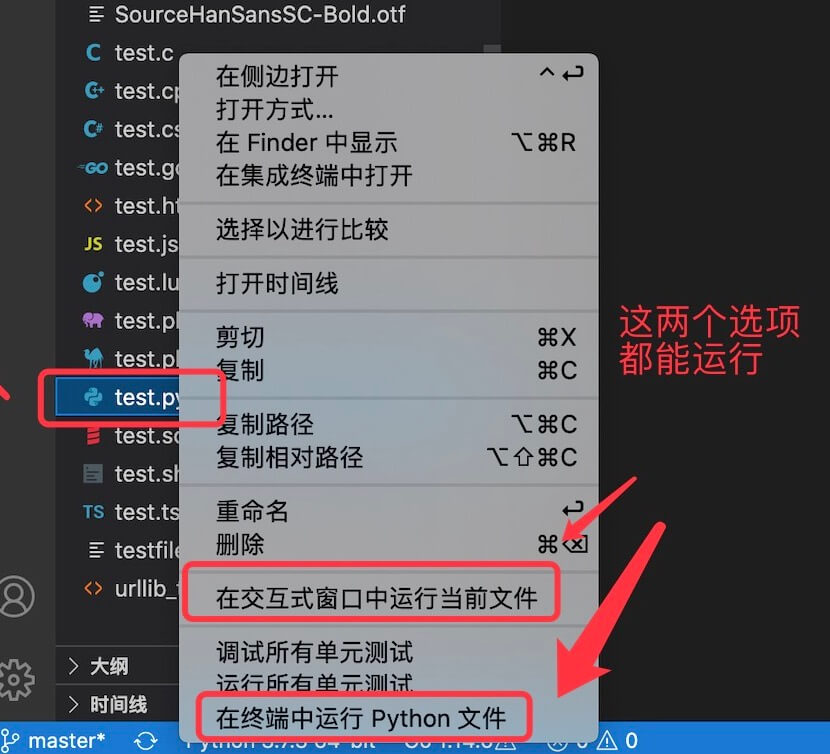
Python VScode 配置
在上一章节中我们已经安装了 Python 的环境,本章节我们将介绍 Python VScode 的配置。 准备工作: 安装 VS Code安装 VS Code Python 扩展安装 Python 3 安装 VS Code VSCode(全称:Visual Studio Code)是一款由微软…...

【vue2第九章】组件化开发和根组件以及style上的scoped作用
组件化开发和根组件 什么是组件化开发? 一个页面可以拆分为多个组件,每个组件有自己的样式,结构,行为,组件化开发的好处就是,便于维护,利于重复利用,提升开发的效率。 便于维护&…...

从零开始的Hadoop学习(五)| HDFS概述、shell操作、API操作
1. HDFS 概述 1.1 HDFS 产出背景及定义 1)HDFS 产生背景 随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切 需要一种系统来管理多台机器上的…...
【spark】序列化和反序列化,transient关键字的使用
序列化 Spark是基于JVM运行的进行,其序列化必然遵守Java的序列化规则。 序列化就是指将一个对象转化为二进制的byte流(注意,不是bit流),然后以文件的方式进行保存或通过网络传输,等待被反序列化读取出来。…...
)
2.4 Vector<T> 动态数组(随机访问迭代器)
C自学精简教程 目录(必读) 该 Vector 版本特点 这里的版本主要是使用模板实现、支持随机访问迭代器,支持std::sort等所有STL算法。(本文对随机迭代器的支持参考了 复旦大学 大一公共基础课C语言的一次作业) 随机访问迭代器的实现主要是继承std::iterator<std:…...

Ubuntu下运行QEMU模拟riscv64跑Debian
1.安装QEMU 下载地址: https://www.qemu.org/download/ 建议选择稳定版本,下载后解压,然后make wget https://download.qemu.org/qemu-8.0.3.tar.xz tar xjvf qemu-8.0.3.tar.xz cd qemu-8.0.3 ./configure --enable-kvm --enable-virtfs …...

移动基站ip的工作原理
原理介绍 Basic Principle 先说一下概念,大家在不使用 WIFI 网络的时候,使用手机通过运营商提供的网络进行上网的时候,目前都是在用户端使用私有IP,然后对外做 NAT 转换,这样的情况就导致大家统一使用一些 IP 段进行访…...

Kubernetes技术--使用kubeadm搭建高可用的K8s集群(贴近实际环境)
1.高可用k8s集群架构(多master) 2.安装硬件要求 一台或多台机器,操作系统 CentOS7.x-86_x64 硬件配置:2GB或更多RAM,2个CPU或更多CPU,硬盘30GB或更多 注: 这里属于教学环境,所以使用三台虚拟机模拟实现。 3.部署规划 4.部署前准备 (1).关闭防火墙 systemctl stop fi…...

【Linux】文件
Linux 文件 什么叫文件C语言视角下文件的操作文件的打开与关闭文件的写操作文件的读操作 & cat命令模拟实现 文件操作的系统接口open & closewriteread 文件描述符进程与文件的关系重定向问题Linux下一切皆文件的认识文件缓冲区缓冲区的刷新策略 stuout & stderr 什…...

Android OTA 相关工具(六) 使用 lpmake 打包生成 super.img
我在 《Android 动态分区详解(二) 核心模块和相关工具介绍》 介绍过 lpmake 工具,这款工具用于将多个分区镜像打包生成一个 Android 专用的动态分区镜像,一般称为 super.img。Android 编译时,系统会自动调用 lpmake 并传入相关参数来生成 sup…...

信创环境 Phytium S2500 虚拟机最大内存规格测试
在 ARM 架构中,"IPA" 通常指的是 "Instruction Set Architecture"(指令集架构),arm环境的虚拟机支持的最大内存规格与母机上内存多少无关,由arm本身的ipa size决定,ipa size 可以理解为虚拟机的物理地址空间,kernel5.4.32中ipa默认是44bits(16T si…...

新建工程——第一个S32DS工程
之前的"测试开发板"章节 测试开发板——第一个AutoSAR程序,使用了一个 demo 工程,不管是裸机程序还是 AutoSAR 程序,那都是别人已经创建好的工程。本节来介绍如何来创建自己的工程,本节介绍如何创建一个 S32DS 的工程,点亮开发板上的 LED 我们从官方提供的例程…...

基于Open3D的点云处理16-特征点匹配
点云配准 将点云数据统一到一个世界坐标系的过程称之为点云配准或者点云拼接。(registration/align) 点云配准的过程其实就是找到同名点对;即找到在点云中处在真实世界同一位置的点。 常见的点云配准算法: ICP、Color ICP、Trimed-ICP 算法…...
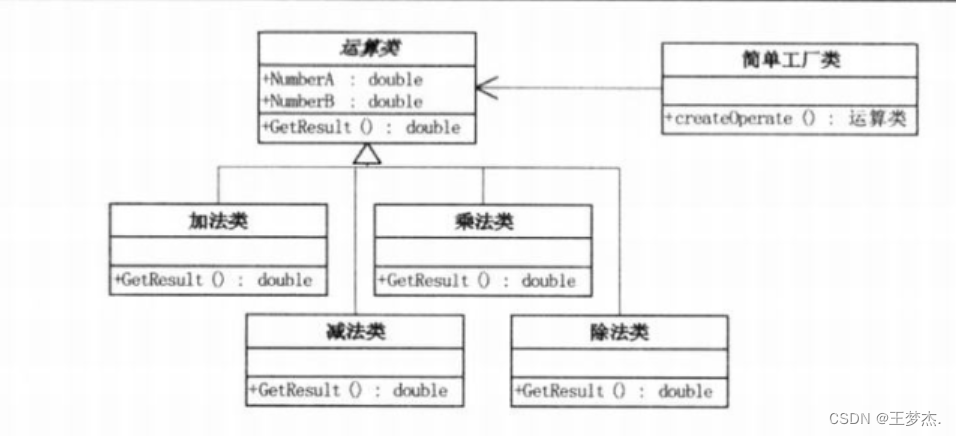
设计模式—简单工厂
目录 一、前言 二、简单工厂模式 1、计算器例子 2、优化后版本 3、结合面向对象进行优化(封装) 3.1、Operation运算类 3.2、客户端 4、利用面向对象三大特性(继承和多态) 4.1、Operation类 4.2、加法类 4.3、减法类 4…...
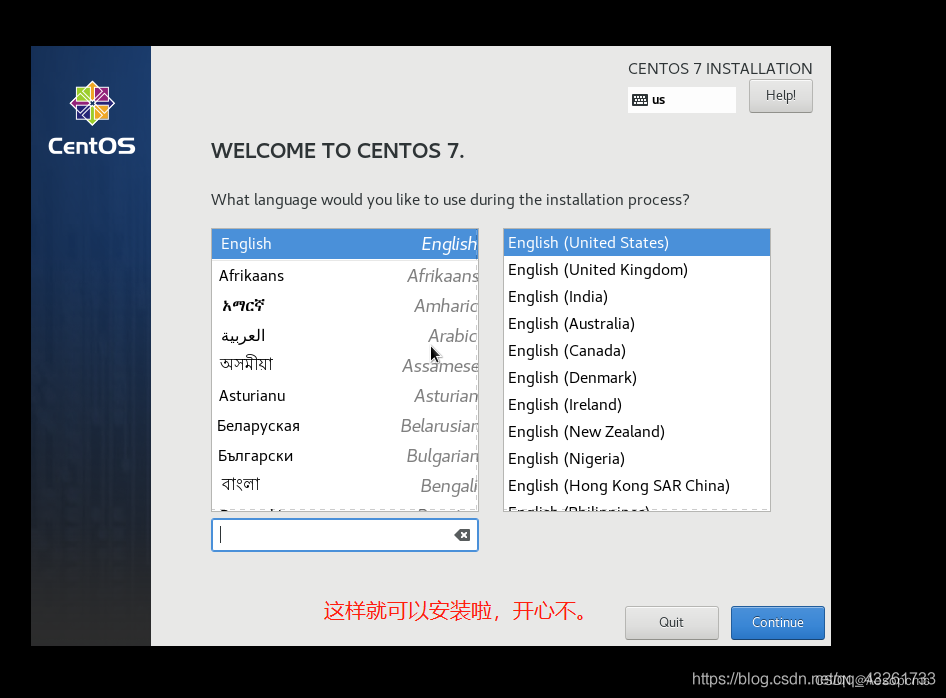
真机安装Linux Centos7
准备工具: 8G左右U盘最新版UltraISOCentOS7光盘镜像 操作步骤 下载镜像 地址:http://isoredirect.centos.org/centos/7/isos/x86_64/ 安装刻录工具UltraISO,刻录镜像到U盘 ① 选择ISO镜像文件 ② 写入磁盘镜像,在这里选择你的U盘…...

汽车零部件企业 ERP 推荐清单:聚焦智能制造与供应链协同方案
汽车零部件制造业作为汽车产业的核心支撑,正经历着前所未有的变革压力。新能源汽车渗透率突破50%、主机厂JIT(准时制)交付要求日益严苛、全球化供应链波动加剧,这些趋势共同推动行业进入智能制造与供应链深度协同的新阶段。在此背…...
)
别再手动忽略.git和.svn了!WinMerge过滤器保姆级配置指南(附常用正则模板)
WinMerge高效过滤指南:彻底告别版本控制与构建文件干扰 接手新项目时,你是否曾被满屏的.git、.svn和.class文件对比结果淹没?WinMerge的过滤器功能正是解决这一痛点的利器。本文将带你从零开始配置专属过滤规则,让文件对比回归核心…...

MCP39F501电能计量芯片:高精度单相计量方案与工程实践详解
1. 项目概述:为什么我们需要一颗专用的电能计量芯片?在智能家居、工业物联网和新能源领域,精确测量交流电(AC)的用电参数——比如电压、电流、功率、电能——是底层最核心的需求之一。你可能觉得,用个高精度…...

告别mmWaveStudio卡顿:手把手教你用DCA1000EVM CLI命令行录制IWR1642雷达数据
告别mmWaveStudio卡顿:手把手教你用DCA1000EVM CLI命令行录制IWR1642雷达数据 在雷达信号处理领域,数据采集的稳定性和效率直接影响后续算法开发的效果。传统图形界面工具mmWaveStudio虽然功能全面,但在长时间连续采集时容易出现卡顿、崩溃等…...

如何用Lano Visualizer打造智能音频可视化桌面:从音乐爱好者到专业用户的完整指南
如何用Lano Visualizer打造智能音频可视化桌面:从音乐爱好者到专业用户的完整指南 【免费下载链接】Lano-Visualizer A simple but highly configurable visualizer with rounded bars. 项目地址: https://gitcode.com/gh_mirrors/la/Lano-Visualizer 你是否…...

AArch64虚拟内存系统架构与地址转换详解
1. AArch64虚拟内存系统架构概述虚拟内存是现代计算机系统的核心机制,它通过地址转换技术将程序使用的虚拟地址(VA)映射到实际的物理地址(PA)。AArch64作为ARMv8-A和ARMv9-A架构的64位执行状态,其虚拟内存系统在设计上兼顾了灵活性和性能需求。在AArch64…...

科研抢发期必看:Perplexity图书推荐查询速效组合技——3分钟生成带引用格式的跨学科书单
更多请点击: https://codechina.net 第一章:科研抢发期必看:Perplexity图书推荐查询速效组合技——3分钟生成带引用格式的跨学科书单 在论文投稿前的关键窗口期,快速定位权威参考文献是提升学术严谨性与跨学科说服力的核心能力。…...

从堆叠到双线性:手把手图解注意力机制的‘进化史’与PyTorch实现对比
从堆叠到双线性:手把手图解注意力机制的‘进化史’与PyTorch实现对比 在计算机视觉与自然语言处理的交叉领域,注意力机制早已从最初的简单加权求和发展为具有复杂交互能力的计算范式。本文将带您穿越注意力机制的进化长廊,通过PyTorch实战演示…...

ArcGIS新手避坑指南:批量拼接栅格时,Mosaic和Mosaic To New Raster到底该选哪个?
ArcGIS栅格拼接工具深度对比:Mosaic与Mosaic To New Raster实战解析 当你第一次在ArcGIS的ArcToolbox中搜索栅格拼接工具时,很可能会被两个名称相似的工具搞得一头雾水——Mosaic和Mosaic To New Raster。这两个工具都位于Data Management Tools下的Rast…...

STM32 SPI驱动W25Q128避坑指南:CubeMX配置、时序模式与读写超时那些事儿
STM32 SPI驱动W25Q128实战避坑指南:从时序陷阱到性能调优 1. 当SPI遇上Flash:硬件工程师的暗礁地带 在嵌入式存储解决方案中,W25Q128系列SPI Flash凭借其紧凑封装和简单接口,已成为众多STM32项目的标配外设。但看似简单的四线接口…...