docker 笔记5:redis 集群分布式存储案例
尚硅谷Docker实战教程(docker教程天花板)_哔哩哔哩_bilibili
目录
1.cluster(集群)模式-docker版哈希槽分区进行亿级数据存储
1.1面试题
1.1.1 方案1 哈希取余分区
1.1.2 方案2 一致性哈希算法分区
原理
优点
一致性哈希算法的容错性
一致性哈希算法的扩展性
缺点
一致性哈希算法的数据倾斜问题
总结
1.1.3 方案3 哈希槽分区
3 多少个hash槽
哈希槽计算
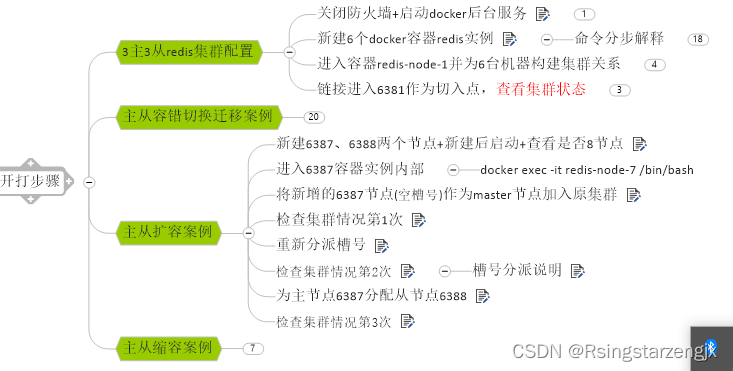
2.3主3从redis集群扩缩容配置案例架构说明
关闭防火墙+启动docker后台服务
3.主从容错切换迁移案例
3.1大纲 :
3.2 数据读写存储
4.主从扩容案例
编辑 4.1新建6387、6388两个节点+新建后启动+查看是否8节点
4.2 进入6387容器实例内部
4.3 将新增的6387节点(空槽号)作为master节点加入原集群
4.4检查集群情况第1次
redis-cli --cluster check 真实ip地址:6381
4.5 重新分派槽号
4.6 检查集群情况第2次
4.7 为主节点6387分配从节点6388
4.8检查集群情况第3次
5.主从缩容案例
5.1检查集群情况1获得6388的节点ID
编辑5.2将6387的槽号清空,重新分配,本例将清出来的槽号都给6381
5.3检查集群情况第二次
5.4将6387删除
5.5检查集群情况第三次

1.cluster(集群)模式-docker版
哈希槽分区进行亿级数据存储
1.1面试题
1~2亿条数据需要缓存,请问如何设计这个存储案例
单机单台100%不可能,肯定是分布式存储,用redis如何落地?
上述问题阿里P6~P7工程案例和场景设计类必考题目,
一般业界有3种解决方案
1.1.1 方案1 哈希取余分区
2亿条记录就是2亿个k,v,我们单机不行必须要分布式多机,假设有3台机器构成一个集群,用户每次读写操作都是根据公式:
hash(key) % N个机器台数,计算出哈希值,用来决定数据映射到哪一个节点上。
优点:
简单粗暴,直接有效,只需要预估好数据规划好节点,例如3台、8台、10台,就能保证一段时间的数据支撑。使用Hash算法让固定的一部分请求落到同一台服务器上,这样每台服务器固定处理一部分请求(并维护这些请求的信息),起到负载均衡+分而治之的作用。
缺点:
原来规划好的节点,进行扩容或者缩容就比较麻烦了额,不管扩缩,每次数据变动导致节点有变动,映射关系需要重新进行计算,在服务器个数固定不变时没有问题,如果需要弹性扩容或故障停机的情况下,原来的取模公式就会发生变化:Hash(key)/3会变成Hash(key) /?。此时地址经过取余运算的结果将发生很大变化,根据公式获取的服务器也会变得不可控。
某个redis机器宕机了,由于台数数量变化,会导致hash取余全部数据重新洗牌。
1.1.2 方案2 一致性哈希算法分区
原理
致性Hash算法背景(是什么?)
一致性哈希算法在1997年由麻省理工学院中提出的,设计目标是为了解决
分布式缓存数据变动和映射问题,某个机器宕机了,分母数量改变了,自然取余数不OK了。
提出一致性Hash解决方案。(能做什么?)
目的是当服务器个数发生变动时,
尽量减少影响客户端到服务器的映射关系
3大步骤
算法构建一致性哈希环
一致性哈希环
一致性哈希算法必然有个hash函数并按照算法产生hash值,这个算法的所有可能哈希值会构成一个全量集,这个集合可以成为一个hash空间[0,2^32-1],这个是一个线性空间,但是在算法中,我们通过适当的逻辑控制将它首尾相连(0 = 2^32),这样让它逻辑上形成了一个环形空间。
它也是按照使用取模的方法,前面笔记介绍的节点取模法是对节点(服务器)的数量进行取模。而一致性Hash算法是对2^32取模,简单来说,一致性Hash算法将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0-2^32-1(即哈希值是一个32位无符号整形),整个哈希环如下图:整个空间按顺时针方向组织,圆环的正上方的点代表0,0点右侧的第一个点代表1,以此类推,2、3、4、……直到2^32-1,也就是说0点左侧的第一个点代表2^32-1, 0和2^32-1在零点中方向重合,我们把这个由2^32个点组成的圆环称为Hash环。

服务器IP节点映射
将集群中各个IP节点映射到环上的某一个位置。
将各个服务器使用Hash进行一个哈希,具体可以选择服务器的IP或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置。假如4个节点NodeA、B、C、D,经过IP地址的哈希函数计算(hash(ip)),使用IP地址哈希后在环空间的位置如下:
key落到服务器的落键规则
当我们需要存储一个kv键值对时,首先计算key的hash值,hash(key),将这个key使用相同的函数Hash计算出哈希值并确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器,并将该键值对存储在该节点上。
如我们有Object A、Object B、Object C、Object D四个数据对象,经过哈希计算后,在环空间上的位置如下:根据一致性Hash算法,数据A会被定为到Node A上,B被定为到Node B上,C被定为到Node C上,D被定为到Node D上。
优点
一致性哈希算法的容错性 一致性哈希算法的扩展性
一致性哈希算法的容错性
假设Node C宕机,可以看到此时对象A、B、D不会受到影响,只有C对象被重定位到Node D。一般的,在一致性Hash算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响。简单说,就是C挂了,受到影响的只是B、C之间的数据,并且这些数据会转移到D进行存储。
一致性哈希算法的扩展性
数据量增加了,需要增加一台节点NodeX,X的位置在A和B之间,那受到影响的也就是A到X之间的数据,重新把A到X的数据录入到X上即可,
不会导致hash取余全部数据重新洗牌。

缺点
一致性哈希算法的数据倾斜问题
Hash环的数据倾斜问题
一致性Hash算法在服务节点太少时,容易因为节点分布不均匀而造成数据倾斜(被缓存的对象大部分集中缓存在某一台服务器上)问题,
例如系统中只有两台服务器:
总结
为了在节点数目发生改变时尽可能少的迁移数据
将所有的存储节点排列在收尾相接的Hash环上,每个key在计算Hash后会顺时针找到临近的存储节点存放。
而当有节点加入或退出时仅影响该节点在Hash环上顺时针相邻的后续节点。
优点
加入和删除节点只影响哈希环中顺时针方向的相邻的节点,对其他节点无影响。
缺点
数据的分布和节点的位置有关,因为这些节点不是均匀的分布在哈希环上的,所以数据在进行存储时达不到均匀分布的效果。
1.1.3 方案3 哈希槽分区
1 为什么出现?
一致性哈希的数据倾斜问题
哈希槽实质就是一个数组,数组[0,2^14 -1]形成hash slot空间。
解决均匀分配的问题,在数据和节点之间又加入了一层,把这层称为哈希槽(slot),用于管理数据和节点之间的关系,现在就相当于节点上放的是槽,槽里放的是数据。
解决均匀分配的问题,在数据和节点之间又加入了一层,把这层称为哈希槽(slot),用于管理数据和节点之间的关系,现在就相当于节点上放的是槽,槽里放的是数据。
3 多少个hash槽
哈希槽计算
一个集群只能有16384个槽,编号0-16383(0-2^14-1)。这些槽会分配给集群中的所有主节点,分配策略没有要求。可以指定哪些编号的槽分配给哪个主节点。集群会记录节点和槽的对应关系。解决了节点和槽的关系后,接下来就需要对key求哈希值,然后对16384取余,余数是几key就落入对应的槽里。slot = CRC16(key) % 16384。以槽为单位移动数据,因为槽的数目是固定的,处理起来比较容易,这样数据移动问题就解决了。
Redis 集群中内置了 16384 个哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点。当需要在 Redis 集群中放置一个 key-value时,redis 先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,也就是映射到某个节点上。如下代码,key之A 、B在Node2, key之C落在Node3上

2.3主3从redis集群扩缩容配置案例架构说明
关闭防火墙+启动docker后台服务
![]()
systemctl start docker
新建6个docker容器redis实例
docker run -d --name redis-node-1 --net host --privileged=true -v /data/redis/share/redis-node-1:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6381docker run -d --name redis-node-2 --net host --privileged=true -v /data/redis/share/redis-node-2:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6382docker run -d --name redis-node-3 --net host --privileged=true -v /data/redis/share/redis-node-3:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6383docker run -d --name redis-node-4 --net host --privileged=true -v /data/redis/share/redis-node-4:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6384docker run -d --name redis-node-5 --net host --privileged=true -v /data/redis/share/redis-node-5:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6385docker run -d --name redis-node-6 --net host --privileged=true -v /data/redis/share/redis-node-6:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6386 如果运行成功,效果如下:
命令分步解释

进入容器redis-node-1并为6台机器构建集群关系
进入容器
docker exec -it redis-node-1 /bin/bash
构建主从关系
//注意,进入docker容器后才能执行一下命令,且注意自己的真实IP地址
redis-cli --cluster create 192.168.111.147:6381 192.168.111.147:6382 192.168.111.147:6383 192.168.111.147:6384 192.168.111.147:6385 192.168.111.147:6386 --cluster-replicas 1redis-cli --cluster create 192.168.111.147:6381 192.168.111.147:6382 192.168.111.147:6383 192.168.111.147:6384 192.168.111.147:6385 192.168.111.147:6386 --cluster-replicas 1
--cluster-replicas 1 表示为每个master创建一个slave节点

一切OK的话,3主3从搞定
链接进入6381作为切入点,查看集群状态

cluster info cluster nodes
3.主从容错切换迁移案例
3.1大纲 :
3.2 数据读写存储
启动6机构成的集群并通过exec进入
对6381新增两个key
防止路由失效加参数-c并新增两个key

查看集群信息
redis-cli --cluster check 192.168.111.147:6381

容错切换迁移
主6381和从机切换,先停止主机6381

6381宕机了,6385上位成为了新的master。
备注:本次脑图笔记6381为主下面挂从6385。
每次案例下面挂的从机以实际情况为准,具体是几号机器就是几号
先还原之前的3主3从

中间需要等待一会儿,docker集群重新响应。

先启动6381 :docker start redis-node-1
再停6385 :docker stop redis-node-5

再启6385 :docker start redis-node-5

主从机器分配情况以实际情况为准
查看集群状态
redis-cli --cluster check 自己IP:6381
4.主从扩容案例
 4.1新建6387、6388两个节点+新建后启动+查看是否8节点
4.1新建6387、6388两个节点+新建后启动+查看是否8节点
docker run -d --name redis-node-7 --net host --privileged=true -v /data/redis/share/redis-node-
docker run -d --name redis-node-7 --net host --privileged=true -v /data/redis/share/redis-node-7:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6387docker run -d --name redis-node-8 --net host --privileged=true -v /data/redis/share/redis-node-8:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6388docker ps4.2 进入6387容器实例内部
docker exec -it redis-node-7 /bin/bash4.3 将新增的6387节点(空槽号)作为master节点加入原集群
将新增的6387作为master节点加入集群
redis-cli --cluster add-node 自己实际IP地址:6387 自己实际IP地址:6381
6387 就是将要作为master新增节点
6381 就是原来集群节点里面的领路人,相当于6387拜拜6381的码头从而找到组织加入集群
4.4检查集群情况第1次
redis-cli --cluster check 真实ip地址:6381
4.5 重新分派槽号
重新分派槽号
命令:redis-cli --cluster reshard IP地址:端口号
redis-cli --cluster reshard 192.168.111.147:6381
4.6 检查集群情况第2次
槽号分派说明
为什么6387是3个新的区间,以前的还是连续?
重新分配成本太高,所以前3家各自匀出来一部分,从6381/6382/6383三个旧节点分别匀出1364个坑位给新节点6387
4.7 为主节点6387分配从节点6388
命令:redis-cli --cluster add-node ip:新slave端口 ip:新master端口 --cluster-slave --cluster-master-id 新主机节点ID
redis-cli --cluster add-node 192.168.111.147:6388 192.168.111.147:6387 --cluster-slave --cluster-master-id e4781f644d4a4e4d4b4d107157b9ba8144631451-------这个是6387的编号,按照自己实际情况
4.8检查集群情况第3次
redis-cli --cluster check 192.168.111.147:6382
5.主从缩容案例

5.1检查集群情况1获得6388的节点ID
redis-cli --cluster check 192.168.111.147:6382
5.2将6388删除
从集群中将4号从节点6388删除
命令:redis-cli --cluster del-node ip:从机端口 从机6388节点ID
redis-cli --cluster del-node 192.168.111.147:6388 5d149074b7e57b802287d1797a874ed7a1a284a8

5.2将6387的槽号清空,重新分配,本例将清出来的槽号都给6381
redis-cli --cluster reshard 192.168.111.147:6381

5.3检查集群情况第二次
redis-cli --cluster check 192.168.111.147:6381
4096个槽位都指给6381,它变成了8192个槽位,相当于全部都给6381了,不然要输入3次,一锅端
5.4将6387删除
命令:redis-cli --cluster del-node ip:端口 6387节点ID
redis-cli --cluster del-node 192.168.111.147:6387 e4781f644d4a4e4d4b4d107157b9ba8144631451

5.5检查集群情况第三次
redis-cli --cluster check 192.168.111.147:6381
相关文章:
docker 笔记5:redis 集群分布式存储案例
尚硅谷Docker实战教程(docker教程天花板)_哔哩哔哩_bilibili 目录 1.cluster(集群)模式-docker版哈希槽分区进行亿级数据存储 1.1面试题 1.1.1 方案1 哈希取余分区 1.1.2 方案2 一致性哈希算法分区 原理 优点 一致性哈希算法的容错性 一致性…...
【Vue2】 axios库
网络请求库-axios库 认识Axios库为什么选择Axios库安装Axios axios发送请求常见的配置选项简单请求可以给Axios设置公共的基础配置发送多个请求 axios创建实例为什么要创建axios的实例 axios的拦截器请求拦截器响应拦截器 axios请求封装 认识Axios库 为什么选择Axios库 在游览…...
云计算 - 百度AIStudio使用小结
云计算 - 百度AIStudio使用小结 前言 本文以ffmpeg处理视频为例,小结一下AI Studio的使用体验及一些避坑技巧。 算力获得 免费的算力获得方式为:每日登录后运行一个项目(只需要点击运行,不需要真正运行)即可获得8小…...
刷新你对Redis持久化的认知
认识持久化 redis是一个内存数据库,数据存储到内存中。而内存的数据是不持久的,要想做到持久化,就需要让redis把数据存储到硬盘上。因此redis既要在内存上存储一份数据,还要在硬盘上存储一份数据。这样这两份数据在理论上是完全相…...

Greenplum-最佳实践小结
注:本文翻译自https://docs.vmware.com/en/VMware-Greenplum/7/greenplum-database/best_practices-logfiles.html 数据模型 Greenplum数据库是一个分析型MPP无共享数据库。该模型与高度规范化/事务性的SMP数据库明显不同。Greenplum数据库使用适合MPP分析处理的非…...
从Gamma空间改为Linear空间会导致性能下降吗
1)从Gamma空间改为Linear空间会导致性能下降吗 2)如何处理没有使用Unity Ads却收到了GooglePlay平台的警告 3)C#端如何处理xLua在执行DoString时候死循环 4)Texture2DArray相关 这是第350篇UWA技术知识分享的推送,精选…...

双轨制的发展,弊端和前景
双轨制是一种经济体制,指两种不同的规则或机制并行运行,以适应不同的市场或客户需求。双轨制最早出现在中国的改革开放中,是从计划经济向市场经济过渡的一种渐进式改革方式。 双轨制的发展可以分为三个阶段: 第一阶段(…...

生成对抗网络(GAN):在图像生成和修复中的应用
文章目录 什么是生成对抗网络(GAN)?GAN在图像生成中的应用图像生成风格迁移 GAN在图像修复中的应用图像修复 拓展应用领域总结 🎉欢迎来到AIGC人工智能专栏~生成对抗网络(GAN):在图像生成和修复…...
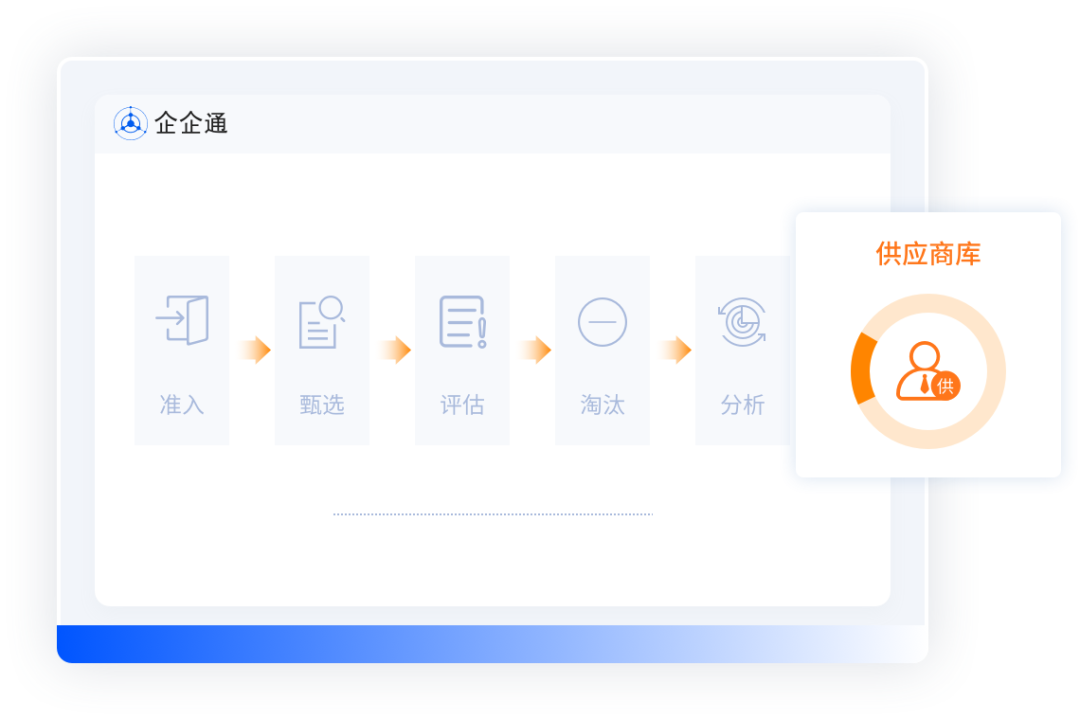
扬杰科技携手企企通,召开SRM采购供应链协同系统项目启动会
近日,中国功率半导体领先企业扬州扬杰电子科技股份有限公司(以下简称“扬杰科技”)与企企通召开SRM采购供应链协同系统项目启动会,双方项目团队成员一同出席本次会议。 会上,双方就扬杰科技采购供应链管理平台项目的目…...
AtCoder Beginner Contest 318
目录 A - Full Moon B - Overlapping sheets C - Blue Spring D - General Weighted Max Matching E - Sandwiches F - Octopus A - Full Moon #include<bits/stdc.h> using namespace std; const int N1e65; typedef long long ll ; const int maxv4e65; typedef …...

《Python魔法大冒险》003 两个神奇的魔法工具
魔法师:小鱼,要开始编写魔法般的Python程序,我们首先需要两个神奇的工具:Python解释器和代码编辑器。 小鱼:这两个工具是做什么的? 魔法师:你可以把Python解释器看作是一个魔法棒,只要你向它说出正确的咒语,它就会为你施展魔法。 小鱼:那这个解释器和我之前用的电…...
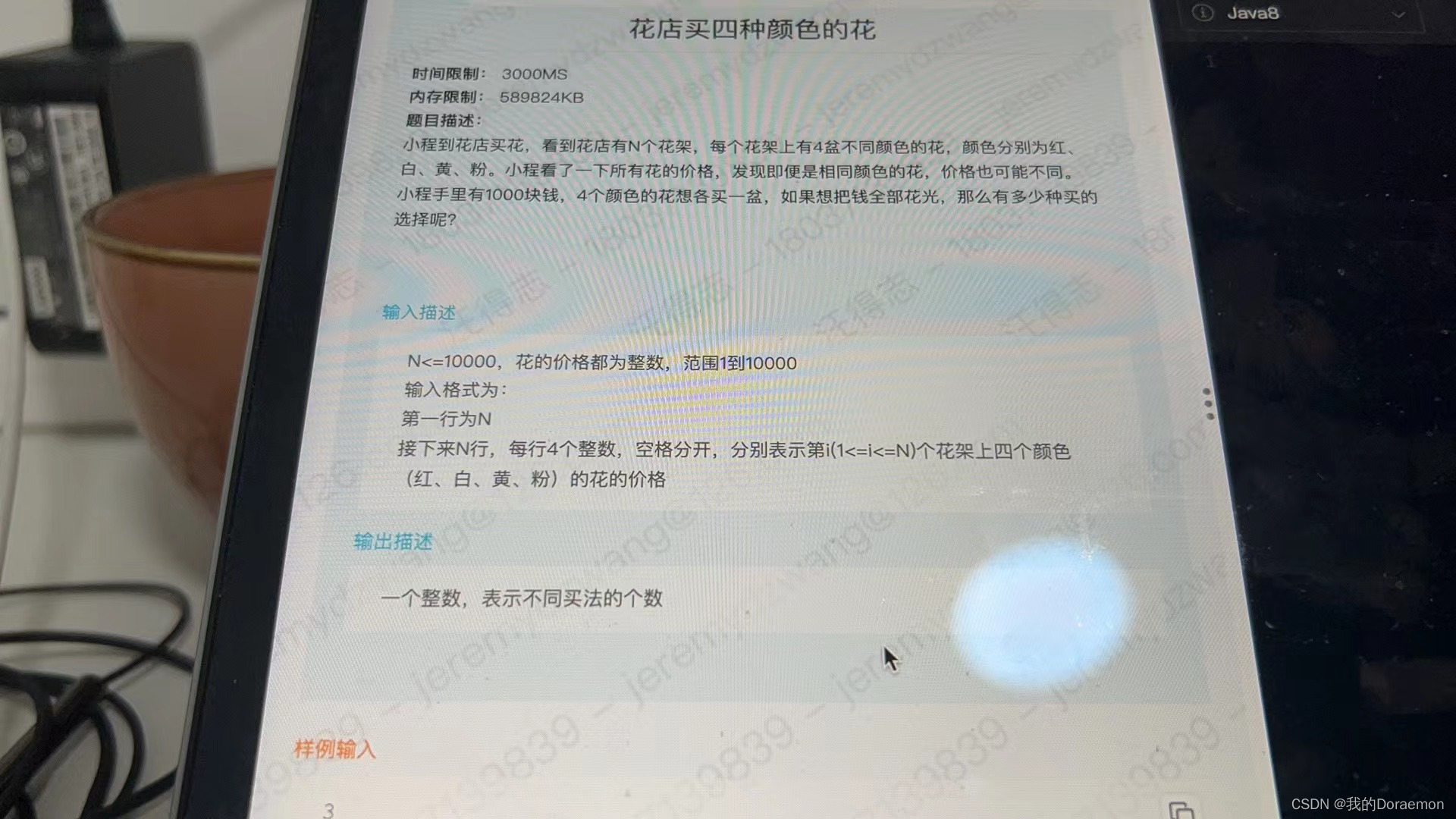
每日一题-动态规划(从不同类型的物品中各挑选一个,使得最后花费总和等于1000)
四种类型的物品,每一种类型物品数量都是n,先要从每种类型的物品中挑选一件,使得最后花费总和等于1000 暴力做法10000^4 看到花费总和是1000,很小且固定的数字,肯定有玄机,从这里想应该是用dp,不…...
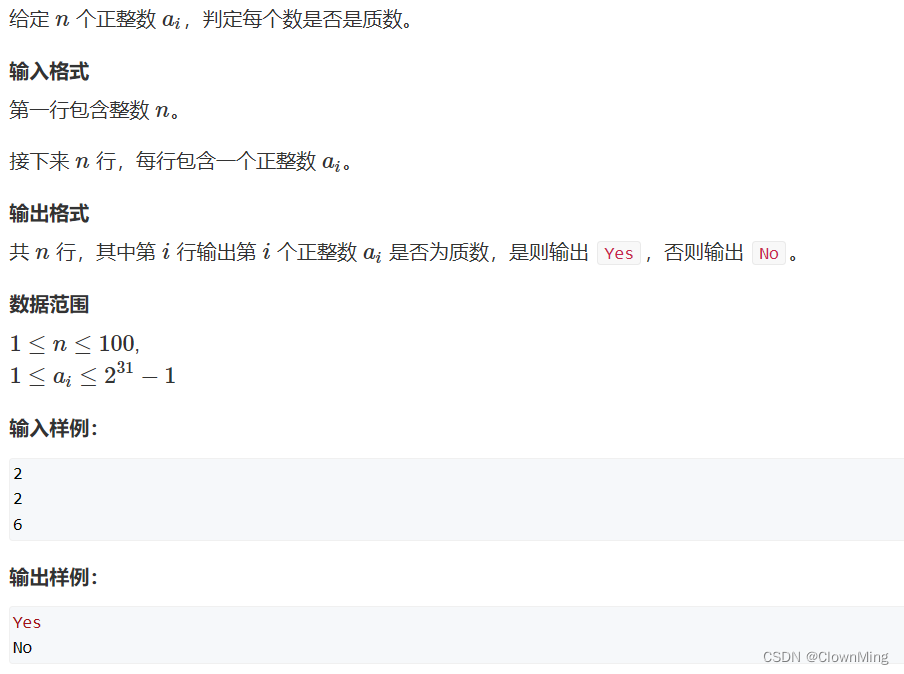
2023-9-3 试除法判定质数
题目链接:试除法判定质数 #include <iostream>using namespace std;bool is_prime(int n) {if(n < 2) return false;for(int i 2; i < n / i; i){if(n % i 0) return false;}return true; }int main() {int n;cin >> n;while(n--){int x;cin &g…...

【Apollo学习笔记】——规划模块TASK之RULE_BASED_STOP_DECIDER
文章目录 前言RULE_BASED_STOP_DECIDER相关配置RULE_BASED_STOP_DECIDER总体流程StopOnSidePassCheckClearDoneCheckSidePassStopIsPerceptionBlockedIsClearToChangeLaneCheckSidePassStopBuildStopDecisionELSE:涉及到的一些其他函数NormalizeAngleSelfRotate CheckLaneChang…...
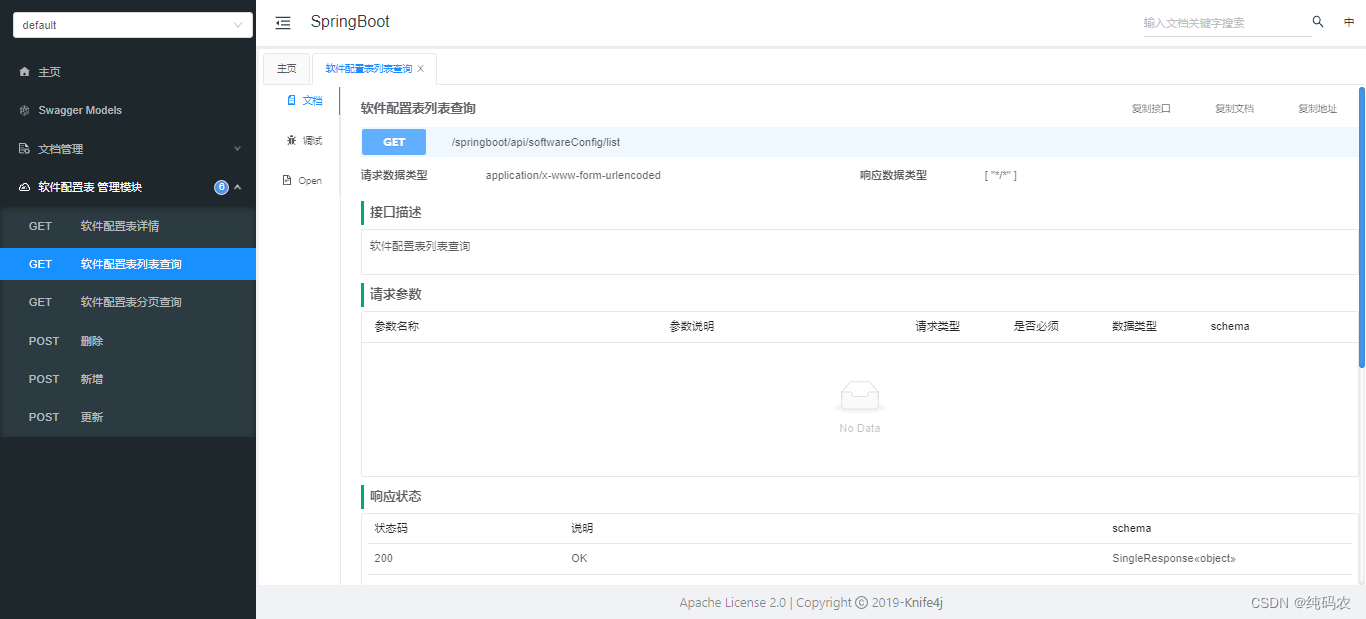
【SpringBoot】最基础的项目架构(SpringBoot+Mybatis-plus+lombok+knife4j+hutool)
汝之观览,吾之幸也! 从本文开始讲下项目中用到的一些框架和技术,最基本的框架使用的是SpringBoot(2.5.10)Mybatis-plus(3.5.3.2)lombok(1.18.28)knife4j(3.0.3)hutool(5.8.21),可以做到代码自动生成,满足最基本的增删查改。 一、新…...
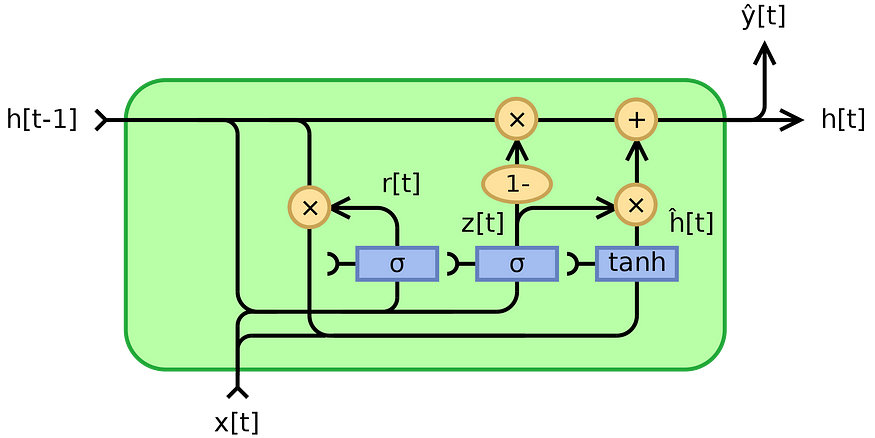
RNN 单元:分析 GRU 方程与 LSTM,以及何时选择 RNN 而不是变压器
一、说明 深度学习往往感觉像是在雪山上找到自己的道路。拥有坚实的原则会让你对做出决定更有信心。我们都去过那里 在上一篇文章中,我们彻底介绍并检查了 LSTM 单元的各个方面。有人可能会争辩说,RNN方法已经过时了,研究它们是没有意义的。的…...
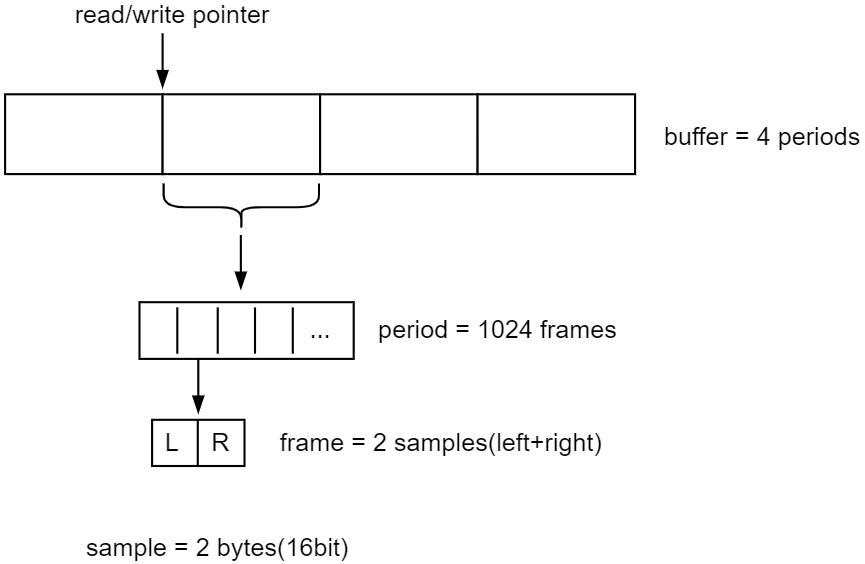
Linux音频了解
ALPHA I.MX6U 开发板支持音频,板上搭载了音频编解码芯片 WM8960,支持播放以及录音功能! 本章将会讨论如下主题内容。 ⚫ Linux 下 ALSA 框架概述; ⚫ alsa-lib 库介绍; ⚫ alsa-lib 库移植; ⚫ alsa-l…...
精心整理了优秀的GitHub开源项目,包含前端、后端、AI人工智能、游戏、黑客工具、网络工具、AI医疗等等,空闲的时候方便看看提高自己的视野
精心整理了优秀的GitHub开源项目,包含前端、后端、AI人工智能、游戏、黑客工具、网络工具、AI医疗等等,空闲的时候方便看看提高自己的视野。 刚开源就变成新星的 igl,不仅获得了 2k star,也能提高你开发游戏的效率,摆…...
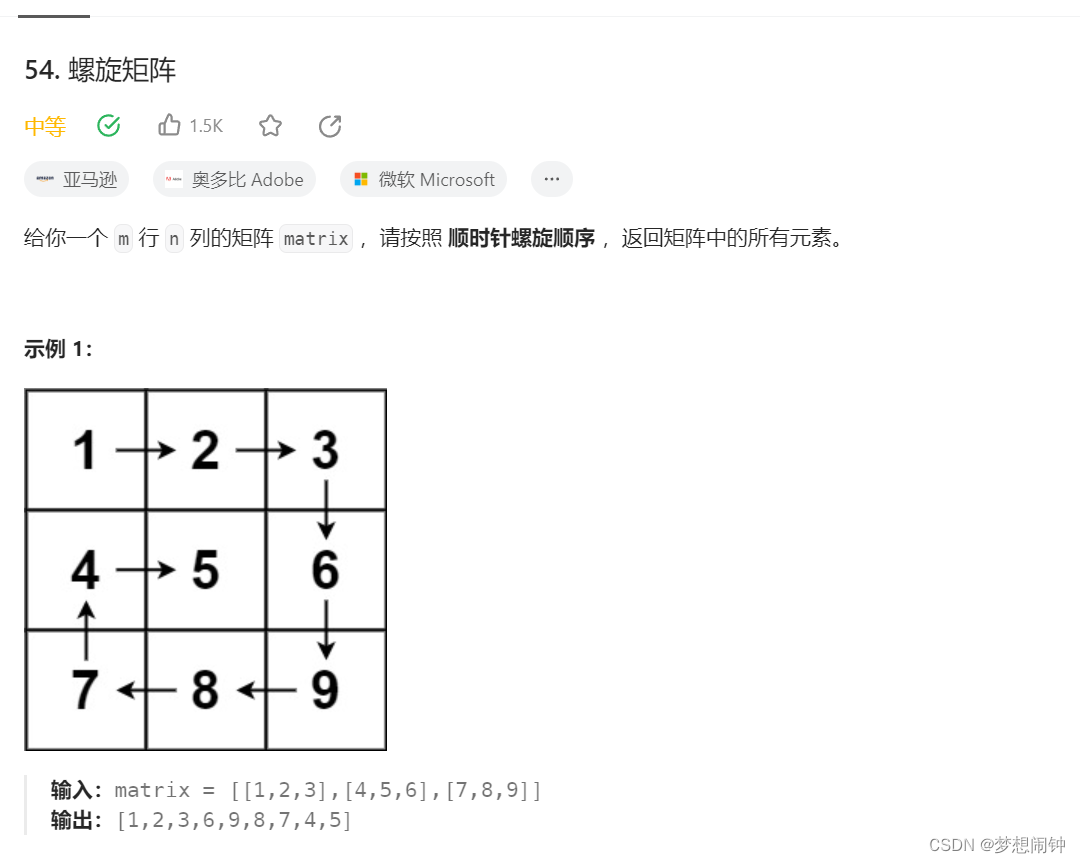
Leetcode54螺旋矩阵
思路:用set记录走过的地方,记下走的方向,根据方向碰壁变换 class Solution:def spiralOrder(self, matrix: list[list[int]]) -> list[int]:max_rows len(matrix)max_cols len(matrix[0])block_nums max_cols * max_rowscount 1i 0j…...

element-plus 表格-方法、事件、属性的使用
记录element-plus 表格的使用。方法、事件、属性的使用。因为是vue3的方式用到了const install getCurrentInstance();才能获取表格的相关信息 没解决怎么获取选中的行的行号,采用自己记的方式实习的。 利用row-class-name"setRowClass"实现样式的简单…...

App无辜躺枪?手把手教你搞定腾讯手机管家误报导致的应用商店下架
当合规应用遭遇误报下架:开发者系统性应对指南运动健康类应用被标记为金融诈骗软件?社交工具因"病毒风险"被各大商店紧急下架?这类看似荒谬的误报事件,正在成为中小开发团队的"无妄之灾"。某知名运动App开发团…...

【DeepSeek灰度发布黄金法则】:20年SRE亲授7步零故障上线实战框架
更多请点击: https://intelliparadigm.com 第一章:DeepSeek灰度发布策略全景图 DeepSeek模型服务的灰度发布并非简单的流量切分,而是一套融合可观测性、渐进式验证与多维熔断机制的工程化闭环体系。其核心目标是在保障线上推理稳定性的同时&…...
)
【Veo 2提示词SOP白皮书】:从模糊意图到像素级输出的8步标准化工作流(附NASA级测试用例库)
更多请点击: https://intelliparadigm.com 第一章:Veo 2提示词工程的本质与范式跃迁 Veo 2并非单纯升级的视频生成模型,而是一次提示词工程范式的根本性重构——它将传统“指令式提示”(prompt-as-command)转向“意图…...

抖音内容批量下载实战:从零开始构建个人视频资料库
抖音内容批量下载实战:从零开始构建个人视频资料库 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support.…...

Arduino ADC自检:用RC电路诊断模数转换器故障
1. 项目概述:当你的体重秤开始“说谎”你有没有遇到过这样的情况:站上家里的电子体重秤,屏幕上跳出来的数字让你瞬间怀疑人生?要么是轻得离谱,要么是重得吓人,更诡异的是,它可能只在两个固定的、…...

AutoWall终极指南:如何在Windows上轻松设置炫酷动态壁纸
AutoWall终极指南:如何在Windows上轻松设置炫酷动态壁纸 【免费下载链接】AutoWall 🌌 Live wallpapers on Windows 7/8/10/11 using open-source wallpaper engine 项目地址: https://gitcode.com/gh_mirrors/au/AutoWall 厌倦了千篇一律的静态桌…...

开源三角洲机器人Delta-Robot One:从入门到精通的创客实践指南
1. 项目概述:一个为学习而生的开源三角洲机器人如果你对机器人感兴趣,但又觉得它高深莫测、无从下手,那么Delta-Robot One(我们亲切地称它为“One”)可能就是为你量身打造的入门项目。这不是一个遥不可及的工业设备&am…...

如何快速实现U盘文件自动备份:USBCopyer终极指南
如何快速实现U盘文件自动备份:USBCopyer终极指南 【免费下载链接】USBCopyer 😉 用于在插上U盘后自动按需复制该U盘的文件。”备份&偷U盘文件的神器”(写作USBCopyer,读作USBCopier) 项目地址: https://gitcode.…...

ncmdumpGUI终极指南:深度解析网易云音乐NCM加密文件转换技术
ncmdumpGUI终极指南:深度解析网易云音乐NCM加密文件转换技术 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI ncmdumpGUI是一款专为Windows平台设计…...

NsEmuTools:10分钟搞定NS模拟器配置,让你专注游戏乐趣
NsEmuTools:10分钟搞定NS模拟器配置,让你专注游戏乐趣 【免费下载链接】ns-emu-tools 一个用于安装/更新 NS 模拟器的工具 项目地址: https://gitcode.com/gh_mirrors/ns/ns-emu-tools 还在为NS模拟器的复杂配置而头疼吗?每次想玩Swit…...