使用kafka还在依赖Zookeeper,kraft模式了解下
Kafka的Kraft模式
概述
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。其核心组件包含Producer、Broker、Consumer,以及依赖的Zookeeper集群。其中Zookeeper集群是Kafka用来负责集群元数据的管理、控制器的选举等。
用过kafka的开发者应该知道,每次启动kafka服务时,都是需要先把Zookeeper启动,然后启动kafka,步骤相当繁琐。
Kafka在使用的过程当中,会出现一些问题。由于重度依赖Zookeeper集群,当Zookeeper集群性能发生抖动时,Kafka的性能也会收到很大的影响。因此,在Kafka发展的过程当中,为了解决这个问题,提供KRaft模式3.0+版本,来取消Kafka对Zookeeper的依赖。
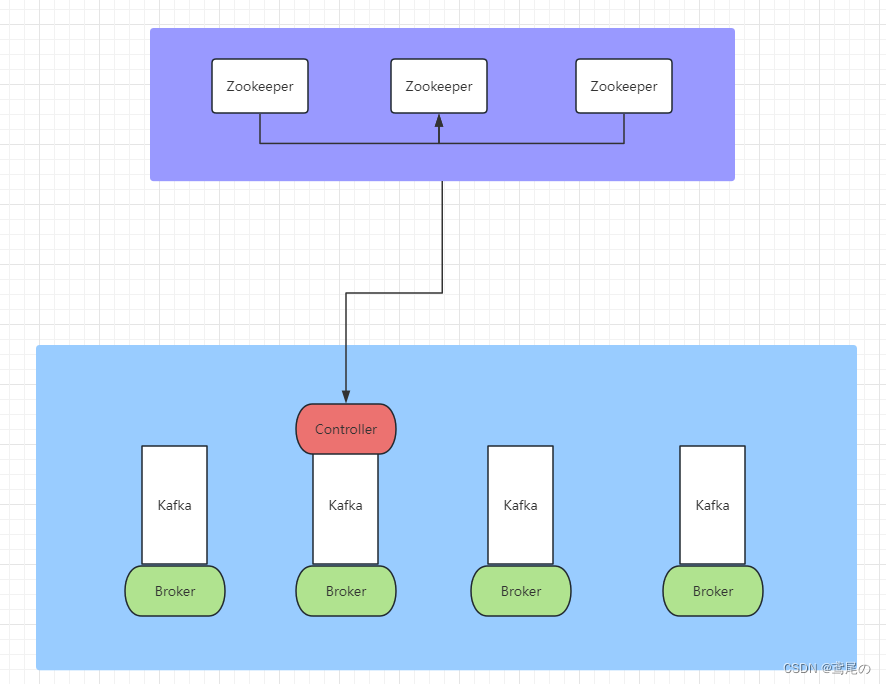
上图是未使用kraft模式时,依赖Zookeeper集群的一个架构图,做元数据管理、Controller的选举都需要依赖Zookeeper集群。
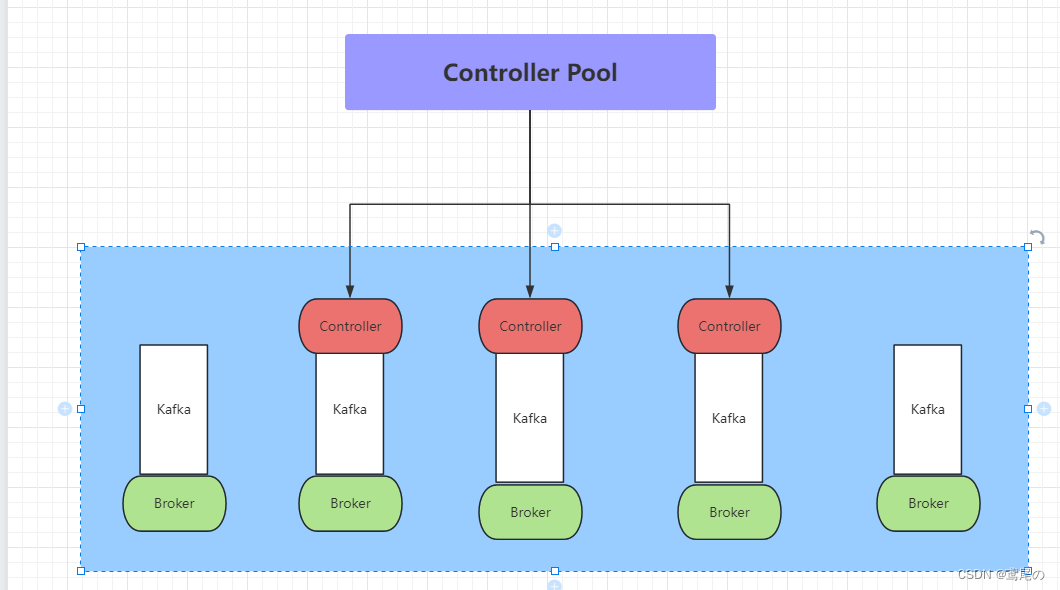
在Kafka引入Kraft新内部功能后,对Zookeeper的依赖将会被取消。在 Kraft中,一部分 broker 被指定为控制器,这些控制器提供过去由 ZooKeeper 提供的共识服务。所有集群元数据都将存储在 Kafka 主题中并在内部进行管理。
优势
- 更简单的部署和管理:通过只安装和管理一个应用程序,Kafka 现在的运营足迹要小得多。这也使得在边缘的小型设备中更容易利用 Kafka;
- 提高可扩展性:KRaft 的恢复时间比 ZooKeeper 快一个数量级。这使我们能够有效地扩展到单个集群中的数百万个分区。ZooKeeper 的有效限制是数万;
- 更有效的元数据传播:基于日志、事件驱动的元数据传播可以提高 Kafka 的许多核心功能的性能
Kraft集群节点角色
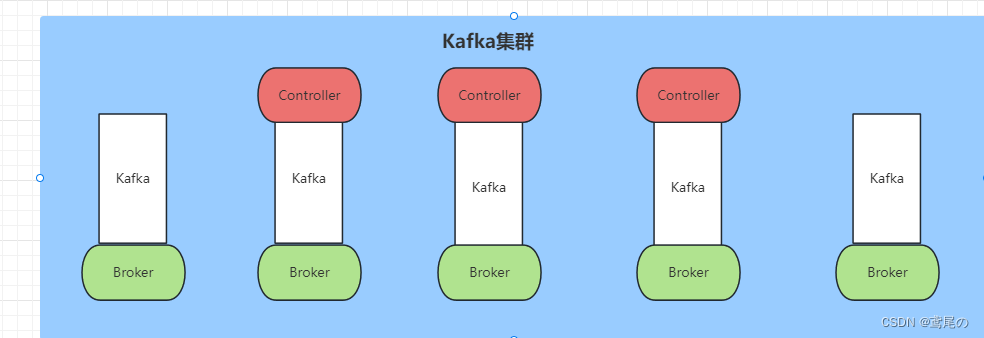
在 Kraft 模式下,Kafka 集群可以走专用模式或共享模式运行。
在专用模式下,一些节点将其process.roles配置设置为controller,而其余节点将其设置为broker。
对于共享模式,一些节点将process.roles设置为controller, broker并且这些节点将执行双重任务。采用哪种方式取决于集群的大小。
controller
在KRaft模式下,只有一小部分特别指定的服务器可以作为控制器,在server.properties的process.roles 参数里面配置。不像基于ZooKeeper的模式,任何服务器都可以成为控制器
Process Roles
每个Kafka服务器现在都有一个新的配置项,叫做process.roles, 这个参数可以有以下值:
- 如果process.roles = broker, 服务器在KRaft模式中充当 broker。
- 如果process.roles = controller, 服务器在KRaft模式下充当 controller。
- 如果process.roles = broker,controller,服务器在KRaft模式中同时充当 broker 和controller。
- 如果process.roles 没有设置。那么集群就假定是运行在ZooKeeper模式下。
Quorum Voters
系统中的所有节点都必须设置 controller.quorum.voters 配置。这个配置标识有哪些节点是 Quorum 的投票者节点。所有想成为控制器的节点都需要包含在这个配置里面。
controller.quorum.voters 配置需要包含每个节点的id。格式为: id1@host1:port1,id2@host2:port2
那么假如有7个broker和3个controller,分别是controller1、controller2、controller3,那么在controller1中的server.properties中会有如下配置:
process.roles=controller
node.id=1
listeners=CONTROLLER://controller1.example.com:9093
controller.quorum.voters=1@controller1:9093,2@controller2:9093,3@controller3:9093
每个broker和每个controller 都必须设置 controller.quorum.voters。需要注意的是,controller.quorum.voters 配置中提供的节点ID必须与提供给服务器的节点ID匹配。
Kraft单机模式
Kafka是依赖于JDK的,需要先把java环境配置一下
到kafka官方地址下载需要的kafka版本即可。下载地址
# 下载
wget https://archive.apache.org/dist/kafka/3.2.3/kafka_2.12-3.2.3.tgz# 解压
tar -zxvf kafka_2.12-3.2.3.tgz
解压完毕后,到里面看下目录结构
可以配置一下hosts域名解析(不配置也可以,后面需要用到的配置中直接写localhost就行)
hostnamectl set-hostname kafka1
然后去修改config/kraft/server.properties
# 表示此节点,既是broker又可以当controller
process.roles=broker,controller
# 节点id,不重名即可
node.id=1
# controller竞争者,也就是controller将从它们之中诞生(这里的kafka1是刚刚设置的本机的域名解析,或者直接写localhost也行)
controller.quorum.voters=1@kafka1:9093
listeners=PLAINTEXT://:9092,CONTROLLER://:9093
# 监听地址(也就是客户端连接时访问的地址)
advertised.listeners=PLAINTEXT://192.168.1.38:9092
controller.listener.names=CONTROLLER
# kafka数据存放地址
log.dirs=/wlh/kafka/data
整理完毕后,初始化一下数据存储目录
# 生成一个uuid,后面需要用
./bin/kafka-storage.sh random-uuid
# 示例如下:
NxAPV0sdTtSDsMN2IwDgPA# 格式化存储
./bin/kafka-storage.sh format -t xtzWWN4bTjitpL3kfd9s5g -c ./config/kraft/server.properties
格式化完毕后,可以启动节点了(守护进程启动加-daemon 参数)。
./bin/kafka-server-start.sh -daemon ./config/kraft/server.properties
启动完毕后,可以进行连接访问kafka服务器了。记得把防火墙关了,或者只开放9092端口即可。
systemctl stop firewalld
若跨机器访问,如使用windows连接,可以先tcping一下,看看kafka服务器的状态是否正常。
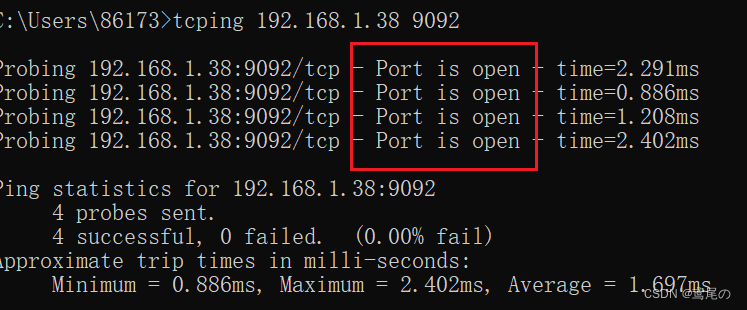
可以看到,没有问题。kafka可视化管理页面https://gitee.com/dushixiang/kafka-map/,有兴趣可以自行搭建。
这里用cmd命令行测试下。
-
服务器创建topic–
kafka-testbin/kafka-topics.sh --create --topic kafka-test --partitions 1 --replication-factor 1 --bootstrap-server kafka1:9092 -
创建生产者、消费者
# 生产者 kafka-console-producer.bat --broker-list 192.168.1.38:9092 --topic kafka-test# 消费者 kafka-console-consumer.bat --bootstrap-server 192.168.1.38:9092 --topic kafka-test
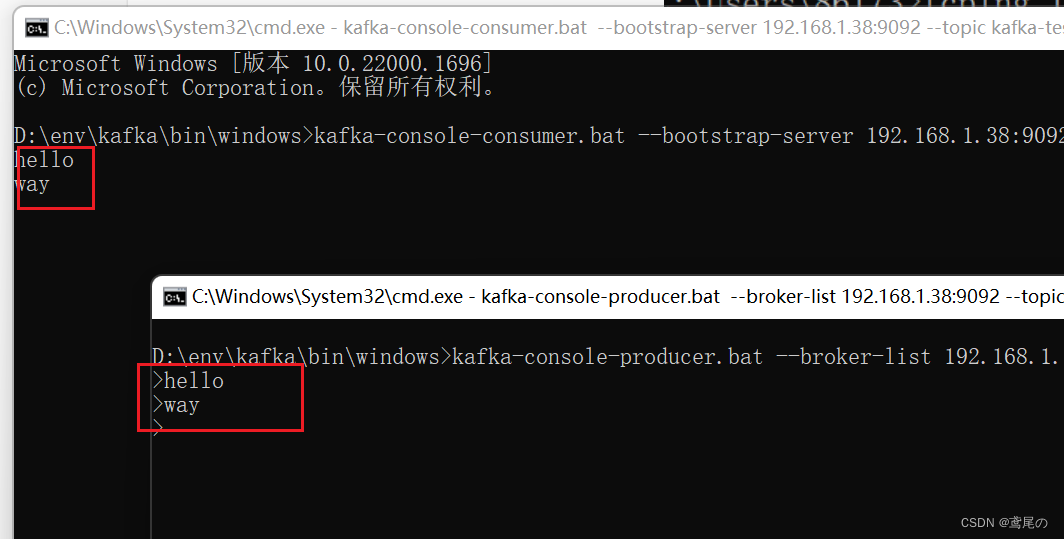
完事儿收工。
kraft集群模式
集群模式和单机模式大差不差,就是配置文件多了的问题。由于机器数量有限,这里就不展示多台服务器的了,看下单台机器部署集群。
准备好3个kafka,分别是kafka01、kafka02、kafka03,分别到它们的config/kraft/server.properties中做配置
kafka01
process.roles=broker,controller
node.id=1
controller.quorum.voters=1@localhost:19093,2@localhost:29093,3@localhost:39093
listeners=PLAINTEXT://:19092,CONTROLLER://:19093
advertised.listeners=PLAINTEXT://192.168.1.38:19092
controller.listener.names=CONTROLLER
log.dirs=/wlh/kafka01/data
kafka02
process.roles=broker,controller
node.id=2
controller.quorum.voters=1@localhost:19093,2@localhost:29093,3@localhost:39093
listeners=PLAINTEXT://:29092,CONTROLLER://:29093
advertised.listeners=PLAINTEXT://192.168.1.38:29092
controller.listener.names=CONTROLLER
log.dirs=/wlh/kafka02/data
kafka03
process.roles=broker,controller
node.id=3
controller.quorum.voters=1@localhost:19093,2@localhost:29093,3@localhost:39093
listeners=PLAINTEXT://:39092,CONTROLLER://:39093
advertised.listeners=PLAINTEXT://192.168.1.38:39092
controller.listener.names=CONTROLLER
log.dirs=/wlh/kafka03/data
配置做完后,生成uuid且格式化它们的存储目录
# 生成一个uuid,后面需要用
/wlh/kafka01/bin/kafka-storage.sh random-uuid
# 示例如下:
NxAPV0sdTtSDsMN2IwDgPA# 格式化存储
/wlh/kafka01/bin/kafka-storage.sh format -t xtzWWN4bTjitpL3kfd9s5g -c /wlh/kafka01/config/kraft/server.properties
/wlh/kafka02/bin/kafka-storage.sh format -t xtzWWN4bTjitpL3kfd9s5g -c /wlh/kafka02/config/kraft/server.properties
/wlh/kafka03/bin/kafka-storage.sh format -t xtzWWN4bTjitpL3kfd9s5g -c /wlh/kafka03/config/kraft/server.properties# 分别启动它们
/wlh/kafka01/bin/kafka-server-start.sh -daemon /wlh/kafka01/config/kraft/server.properties
/wlh/kafka02/bin/kafka-server-start.sh -daemon /wlh/kafka01/config/kraft/server.properties
/wlh/kafka03/bin/kafka-server-start.sh -daemon /wlh/kafka01/config/kraft/server.properties
命令测试一下kafka集群。
kafka1/bin/kafka-topics.sh --create --topic kafka-test --partitions 1 --replication-factor 1 --bootstrap-server 192.168.1.38:19092
# 生产者
kafka-console-producer.bat --broker-list 192.168.1.38:19092,192.168.1.38:29092,192.168.1.38:39092 --topic kafka-test# 消费者
kafka-console-consumer.bat --bootstrap-server 192.168.1.38:19092,192.168.1.38:29092,192.168.1.38:39092 --topic kafka-test
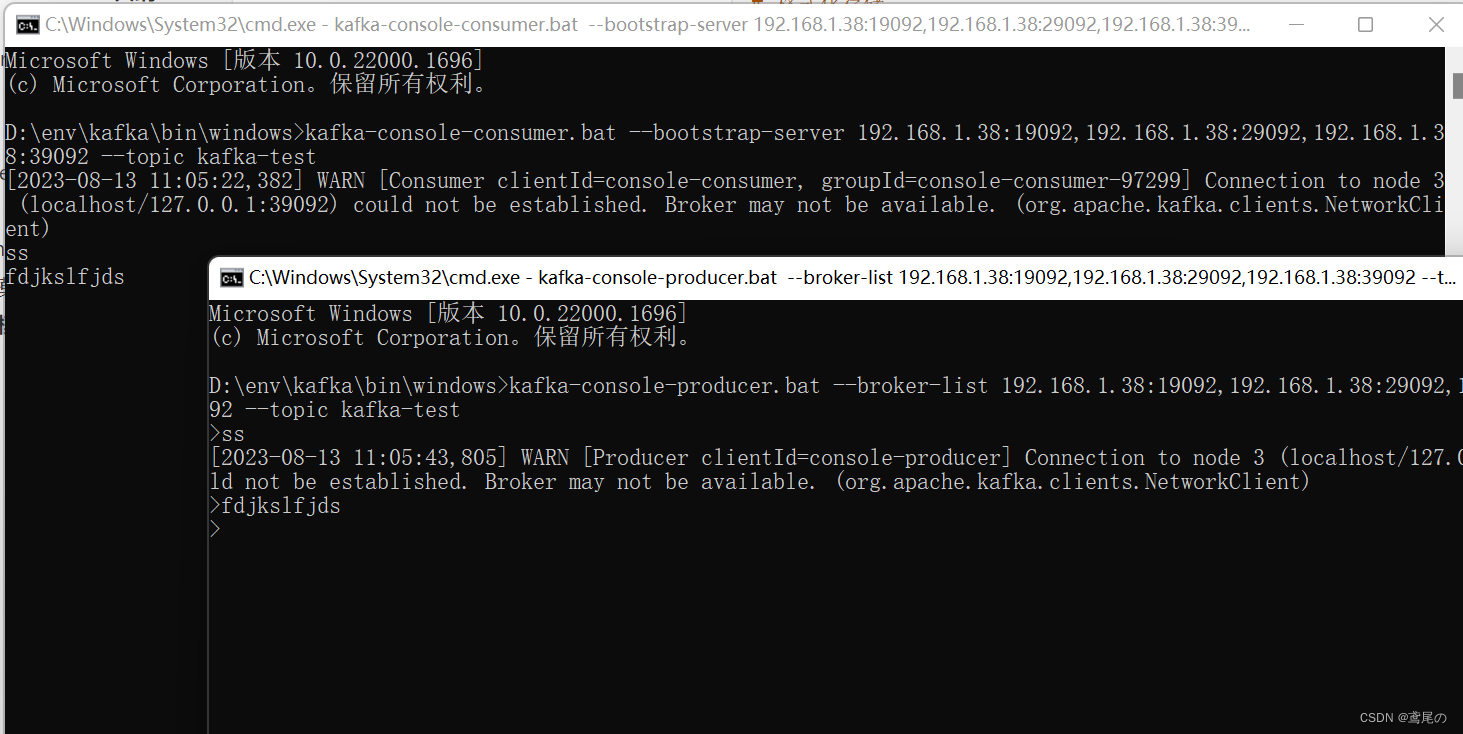
完事儿,大功告成!!
相关文章:
使用kafka还在依赖Zookeeper,kraft模式了解下
Kafka的Kraft模式 概述 Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。其核心组件包含Producer、Broker、Consumer,以及依赖的Zookeeper集群。其中Zookeeper集群是Kafka用来负责集群元数据的管理、控制器…...
【100天精通Python】Day52:Python 数据分析_Numpy入门基础与数组操作
目录 1 NumPy 基础概述 1.1 NumPy的主要特点和功能 1.2 NumPy 安装和导入 2 Numpy 数组 2.1 创建NumPy数组 2.2 数组的形状和维度 2.3 数组的数据类型 2.4 访问和修改数组元素 3 数组操作 3.1 数组运算 3.2 数学函数 3.3 统计函数 4 数组形状操作 4.1 重塑数组形…...

Day01-Java基础语法
目录 1. 人机交互 1.1 什么是cmd? 1.2 如何打开CMD窗口? 1.3 常用CMD命令 1.4 CMD练习 1.5 环境变量 2. Java概述 1.1 Java是什么? 1.2下载和安装 1.2.1 下载 1.2.2 安装 1.2.3 JDK的安装目录介绍 1.3 HelloWorld小案例 2.3.1 …...

代码随想录二刷day06
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、力扣242. 有效的字母异位词二、力扣349. 两个数组的交集三、力扣202. 快乐数四、力扣1两数之和 前言 一、力扣242. 有效的字母异位词 class Solution {pub…...
可扩展的Blender插件开发汇总
成熟的 Blender 3D 插件是令人惊奇的事情。作为 Python 和 Blender 的新手,我经常发现自己被社区中的人们创造的强大的东西弄得目瞪口呆。坦率地说,其中一些包看起来有点神奇,当自我怀疑或冒名顶替综合症的唠叨声音被打破时,很容易想到“如果有人能做出可以做xxx的东西就好…...
2023_Spark_实验二:IDEA安装及配置
一、下载安装包 链接:百度网盘 请输入提取码 所在文件夹:大数据必备工具--》开发工具(前端后端)--》后端 下载文件名称:ideaIU-2019.2.3.exe (喜欢新版本也可安装新版本,新旧版本会存在部分差异) IDEA …...

小赢科技,寻找金融科技核心价
如果说金融是经济的晴雨表,是通过改善供给质量以提高经济质量的切入口,那么金融科技公司,就是这一切行动的推手。上半年,社会经济活跃程度提高背后,金融科技公司既是奉献者,也是受益者。 8月29日࿰…...
NAT与代理服务器
1.DNS Domain Name System 是一整套从域名映射到IP的系统(把域名转化为IP地址) 2.域名简介 3.周鸿祎 傅盛 4.ICMP协议 用来网络故障排查原因 草图理解“位置” ping ICMP 是绕过TCP UDP传输协议的,没有端口号 traceroute 5.NAT技术 N…...
24.排序,插入排序,交换排序
目录 一. 插入排序 (1)直接插入排序 (2)折半插入排序 (3)希尔排序 二. 交换排序 (1)冒泡排序 (2)快速排序 排序:将一组杂乱无章的数据按一…...

Navicat16安装教程
注:因版权原因,本文已去除破解相关的文件和内容 1、在本站下载解压后即可获得Navicat16安装包和破解补丁,如图所示 2、双击“navicat160_premium_cs_x64.exe”程序,即可进入安装界面, 3、点击下一步 4、如图所示勾选“…...

【看表情包学Linux】初识文件描述符 | 虚拟文件系统 (VFS) 初探 | 系统传递标记位 | O_TRUNC | O_APPEND
爆笑教程《看表情包学Linux》👈 猛戳订阅! 💭 写在前面:通过上一章节的讲解,想必大家已对文件系统基本的接口有一个简单的了解,本章我们将继续深入讲解,继续学习系统传递标志位&…...
ssm+vue“魅力”繁峙宣传网站源码和论文
ssmvue“魅力”繁峙宣传网站源码和论文102 开发工具:idea 数据库mysql5.7 数据库链接工具:navcat,小海豚等 技术:ssm 摘 要 随着科学技术的飞速发展,各行各业都在努力与现代先进技术接轨,通过科技手段提高自身…...
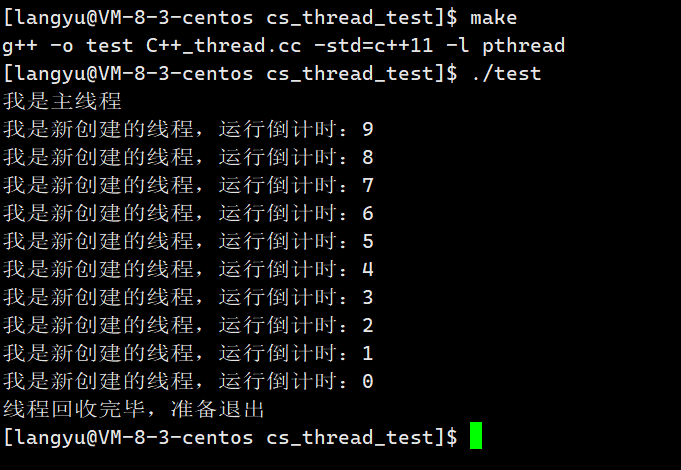
Linux系统编程5(线程概念详解)
线程同进程一样都是OS中非常重要的部分,线程的应用场景非常的广泛,试想我们使用的视频软件,在网络不是很好的情况下,通常会采取下载的方式,现在你很想立即观看,又想下载,于是你点击了下载并且在…...

leetcode645. 错误的集合(java)
错误的集合 题目描述优化空间代码演示 题目描述 难度 - 简单 LC645 - 错误的集合 集合 s 包含从 1 到 n 的整数。不幸的是,因为数据错误,导致集合里面某一个数字复制了成了集合里面的另外一个数字的值,导致集合 丢失了一个数字 并且 有一个数…...

Pytest参数详解 — 基于命令行模式
1、--collect-only 查看在给定的配置下哪些测试用例会被执行 2、-k 使用表达式来指定希望运行的测试用例。如果测试名是唯一的或者多个测试名的前缀或者后缀相同,可以使用表达式来快速定位,例如: 命令行-k参数.png 3、-m 标记࿰…...

【python爬虫】3.爬虫初体验(BeautifulSoup解析)
文章目录 前言BeautifulSoup是什么BeautifulSoup怎么用解析数据提取数据 对象的变化过程总结 前言 上一关,我们学习了HTML基础知识,知道了HTML是一种用来描述网页的语言,又了解了HTML的基本结构。 认识了HTML中的常见标签和常见属性&#x…...
【Three.js + Vue 构建三维地球-Part One】
Three.js Vue 构建三维地球-Part One Vue 初始化部分Vue-cli 安装初始化 Vue 项目调整目录结构 Three.js 简介Three.js 安装与开始使用 实习的第一个任务是完成一个三维地球的首屏搭建,看了很多的案例,也尝试了用 Echarts 3D地球的模型进行构建…...
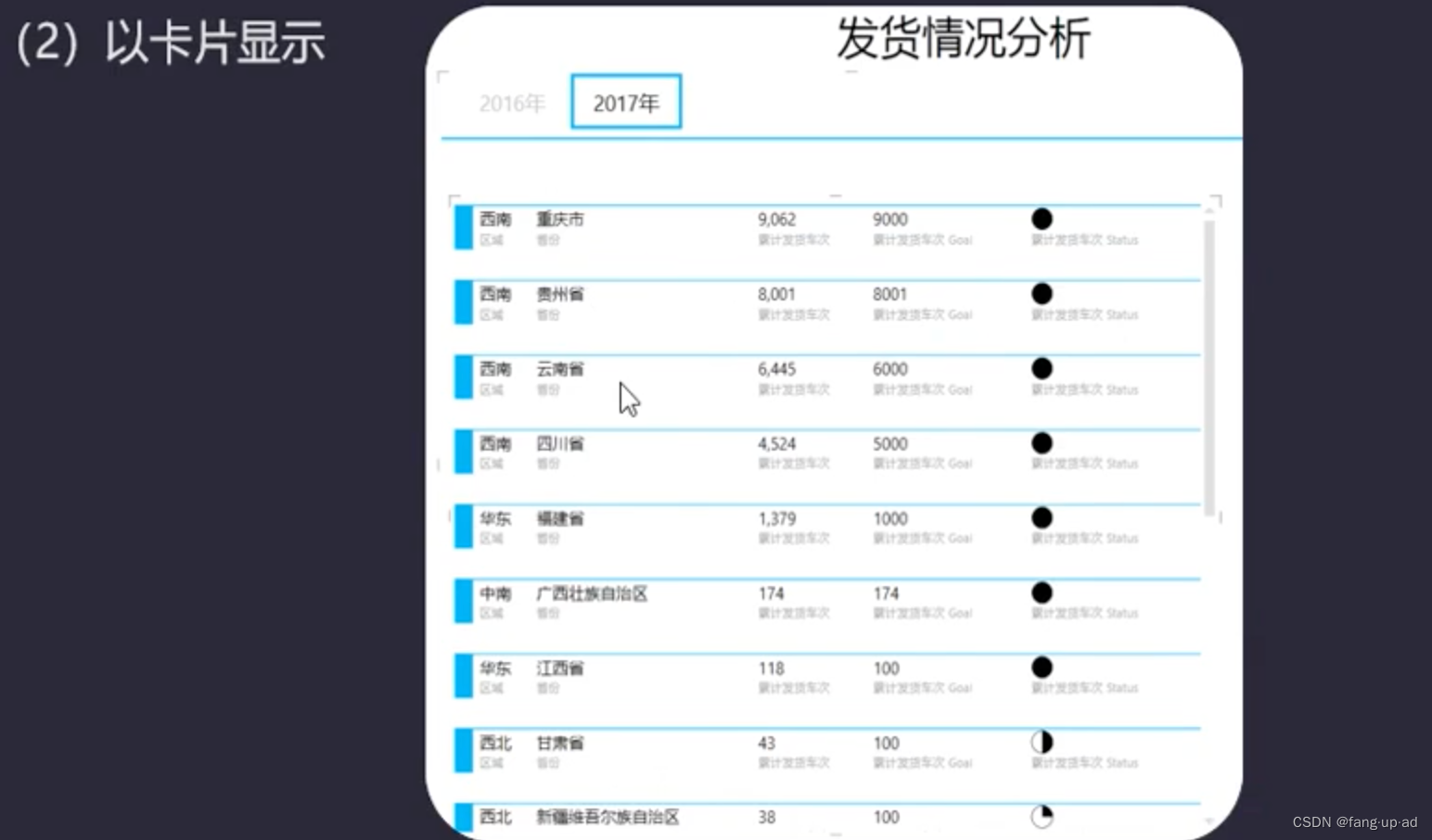
Power View
界面 切换可视化效果 对于已经上传到透视表的数据,选择power view,形成表格后。...

SQL查询本年每月的数据
--一、以一行数据的形式,显示本年的12月的数据,本示例以2017年为例,根据统计日期字段判断,计算总和,查询语句如下:selectsum(case when datepart(month,统计日期)1 then 支付金额 else 0 end) as 1月, sum…...

C++之struct和union对比介绍
C之struct和union对比介绍 在C中,struct和union都是用来定义自定义数据类型的关键字,但它们的作用略有不同。 首先了解一下它们的基本概念: struct(结构体):struct 是一个用户自定义的数据类型ÿ…...

对称与负电源测试:动态直流电子负载的设计、原理与应用
1. 项目概述:对称与负电源的静态与动态直流负载在电子实验室里,测试一个电源的性能,尤其是它的动态响应能力,是件既基础又关键的事。我们常说的“直流电子负载”就是这个领域的核心工具。我之前设计并分享过一个用于正电源测试的静…...

DeepSeek基准测试避坑手册:92%开发者忽略的4大陷阱——硬件配置偏差、tokenizer不一致、batch size幻觉、温度值污染
更多请点击: https://codechina.net 第一章:DeepSeek基准测试避坑手册:92%开发者忽略的4大陷阱——硬件配置偏差、tokenizer不一致、batch size幻觉、温度值污染 硬件配置偏差:GPU显存与计算精度的隐性干扰 在A100(8…...

AI写的论文双率如何压到20%以下?这几款工具实测有效
毕业季、投稿季用AI写论文已经成为不少人的高效选择,但查重率飘红、AIGC疑似率超标两大问题,让很多人犯了难。2026年学术检测标准持续收紧,知网、维普及主流AIGC检测系统同步上线双检规则,两项指标均控制在20%以下才符合基本提交要…...

别再死记硬背了!用5个生活化比喻彻底搞懂Linux进程的fork、exec和wait
别再死记硬背了!用5个生活化比喻彻底搞懂Linux进程的fork、exec和wait想象你正在厨房准备一顿大餐。菜谱上写着"切菜"、"炒菜"、"装盘"等步骤,但突然发现需要同时处理多道菜品——这时候,你会本能地让家人分工…...

Windows Cleaner深度解析:5大核心模块彻底解决系统空间不足问题
Windows Cleaner深度解析:5大核心模块彻底解决系统空间不足问题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner Windows Cleaner是一款完全免费开源的…...

收藏干货|2026 版企业 AI 落地实操指南,程序员小白入门避坑必备
如今人工智能早已脱离概念炒作阶段,全面扎根企业实际业务场景,成为技术从业者与企业管理者无法回避的发展课题。各行各业都加速布局AI赛道,行业心态也从初期观望试探,彻底转变为实打实的落地攻坚。 不少企业高层主动牵头统筹AI规划…...

告别Postman!用APIfox搞定接口测试+自动化,这份保姆级教程带你从环境配置到报告生成
从Postman到APIfox:接口测试自动化的高效迁移指南如果你还在为接口测试中的重复劳动和多环境切换头疼,是时候考虑从Postman迁移到APIfox了。作为一名经历过这个转型过程的开发者,我想分享一些实战经验,帮助你平滑过渡并最大化利用…...

机器学习与深度学习在社交媒体心理健康检测中的权衡与选择
1. 项目概述:当AI遇见心灵,社交媒体心理健康检测的技术十字路口在社交媒体成为我们数字生活延伸的今天,海量的文本数据无意中记录着用户的情感波动与心理状态。作为一名长期混迹于数据科学和自然语言处理(NLP)一线的从…...

JMeter实现RSA签名验签全流程实战
1. 为什么RSA加密接口测试总卡在“连通但失败”这一步? 你有没有遇到过这种情况:接口文档写得清清楚楚,Postman里填好URL、Header、Body,一发请求——返回 {"code":4001,"msg":"签名验证失败"} …...

告别繁琐审核!实测AI Agent如何重塑复杂非结构化票据与合同处理流程?
摘要:在企业数字化转型步入深水区的2026年,处理复杂非结构化票据与合同已成为横亘在财务、法务部门面前的“最后一公里”难题。传统RPA因UI变动易崩溃、主流智能体因缺乏API适配而无法落地,导致大量业务仍依赖低效的人工操作。本文由「企服AI…...