Pytorch并行计算(三): 梯度累加
梯度累加
梯度累加(Gradient Accmulation)是一种增大训练时batch size的技巧。当batch size在一张卡放不下时,可以将很大的batch size分解为一个个小的mini batch,分别计算每一个mini batch的梯度,然后将其累加起来优化
正常的pytorch训练流程如下(来自知乎)
for i, (image, label) in enumerate(train_loader):pred = model(image) # 1loss = criterion(pred, label) # 2optimizer.zero_grad() # 3loss.backward() # 4optimizer.step() # 5
- 神经网络forward过程
- 获取loss,通过pred和label计算你损失函数
- 清空网络中参数的梯度
- 反向传播,计算当前梯度
- 根据梯度更新网络参数
使用梯度累加的方法如下
for i,(image, label) in enumerate(train_loader):# 1. input outputpred = model(image)loss = criterion(pred, label)# 2.1 loss regularizationloss = loss / accumulation_steps # 2.2 back propagationloss.backward()# 3. update parameters of netif (i+1) % accumulation_steps == 0:# optimizer the netoptimizer.step() # update parameters of netoptimizer.zero_grad() # reset gradient
- 神经网络forward过程,同时计算损失函数
- 反向传播计算当前梯度(在backward时,计算的loss要除batch的大小得到均值)
- 不断重复1、2步骤,重复获取梯度
- 梯度累加到一定次数后,先optimizer.step()更新网络参数,随后zero_grad()清除梯度,为下一次梯度累加做准备
DDP中的梯度累加
问题:在DDP中所有卡的梯度all_reduce阶段发生在loss.bachward()阶段,也就是说执行loss.backward()之后,所有卡的梯度会进行一次汇总,但是如果我们如果使用梯度累加策略,假设梯度累加K=2,就需要all_reduce汇总两次,会带来额外的计算错误和时间开销
解决方案:知乎写的很好,这里参考其解决方案,只需要在前K-1次取消梯度同步即可,DDP提供了一个暂时取消梯度同步的context函数no_sync(),在这个函数下,DDP不会进行梯度同步
model = DDP(model)for 每次梯度累加循环optimizer.zero_grad()# 前accumulation_step-1个step,不进行梯度同步,每张卡分别累积梯度。for _ in range(K-1)::with model.no_sync():prediction = model(data)loss = loss_fn(prediction, label) / Kloss.backward() # 积累梯度,但是多卡之间不进行同步# 第K个stepprediction = model(data)loss = loss_fn(prediction, label) / Kloss.backward() # 进行多卡之间的梯度同步optimizer.step()
优雅写法
from contextlib import nullcontext
# 如果你的python版本小于3.7,请注释掉上面一行,使用下面这个:
# from contextlib import suppress as nullcontextif local_rank != -1:model = DDP(model)optimizer.zero_grad()
for i, (data, label) in enumerate(dataloader):# 只在DDP模式下,轮数不是K整数倍的时候使用no_syncmy_context = model.no_sync if local_rank != -1 and i % K != 0 else nullcontextwith my_context():prediction = model(data)loss = loss_fn(prediction, label) / Kloss.backward() # 积累梯度,不应用梯度改变if i % K == 0:optimizer.step()optimizer.zero_grad()
梯度累加的影响
BN的影响
相关文章:
: 梯度累加)
Pytorch并行计算(三): 梯度累加
梯度累加 梯度累加(Gradient Accmulation)是一种增大训练时batch size的技巧。当batch size在一张卡放不下时,可以将很大的batch size分解为一个个小的mini batch,分别计算每一个mini batch的梯度,然后将其累加起来优…...
最小覆盖子串(滑动窗口解法))
蓝桥杯入门即劝退(十八)最小覆盖子串(滑动窗口解法)
欢迎关注点赞评论,共同学习,共同进步! ------持续更新蓝桥杯入门系列算法实例-------- 如果你也喜欢Java和算法,欢迎订阅专栏共同学习交流! 你的点赞、关注、评论、是我创作的动力! -------希望我的文章…...

Android一~
进程和线程的区别https://zhuanlan.zhihu.com/p/60375108https://zhuanlan.zhihu.com/p/138689342线程池的用法和原理tcp三次握手和四次挥手、tcp基础http请求报文格式二叉树中序遍历(算法)activity启动模式OKhttp源码讲解Java修饰符Java线程同步的方法s…...

一月券商金工精选
✦研报目录✦ ✦简述✦ 按发布时间排序 国盛证券 “薪火”量化分析系列研究(二)-票据逾期数据中的选股信息 发布日期:2023-01-04 关键词:股票、票据、票据预期 主要内容:本文深入探讨了“票据持续逾期名单”这一…...
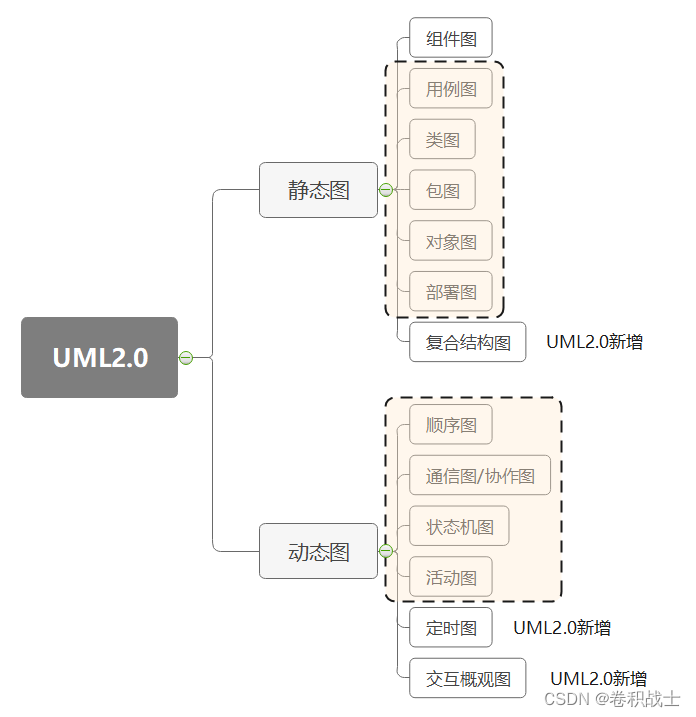
UML中常见的9种图
UML是Unified Model Language的缩写,中文是统一建模语言,是由一整套图表组成的标准化建模语言。UML用于帮助系统开发人员阐明,展示,构建和记录软件系统的产出。通过使用UML使得在软件开发之前, 对整个软件设计有更好的…...
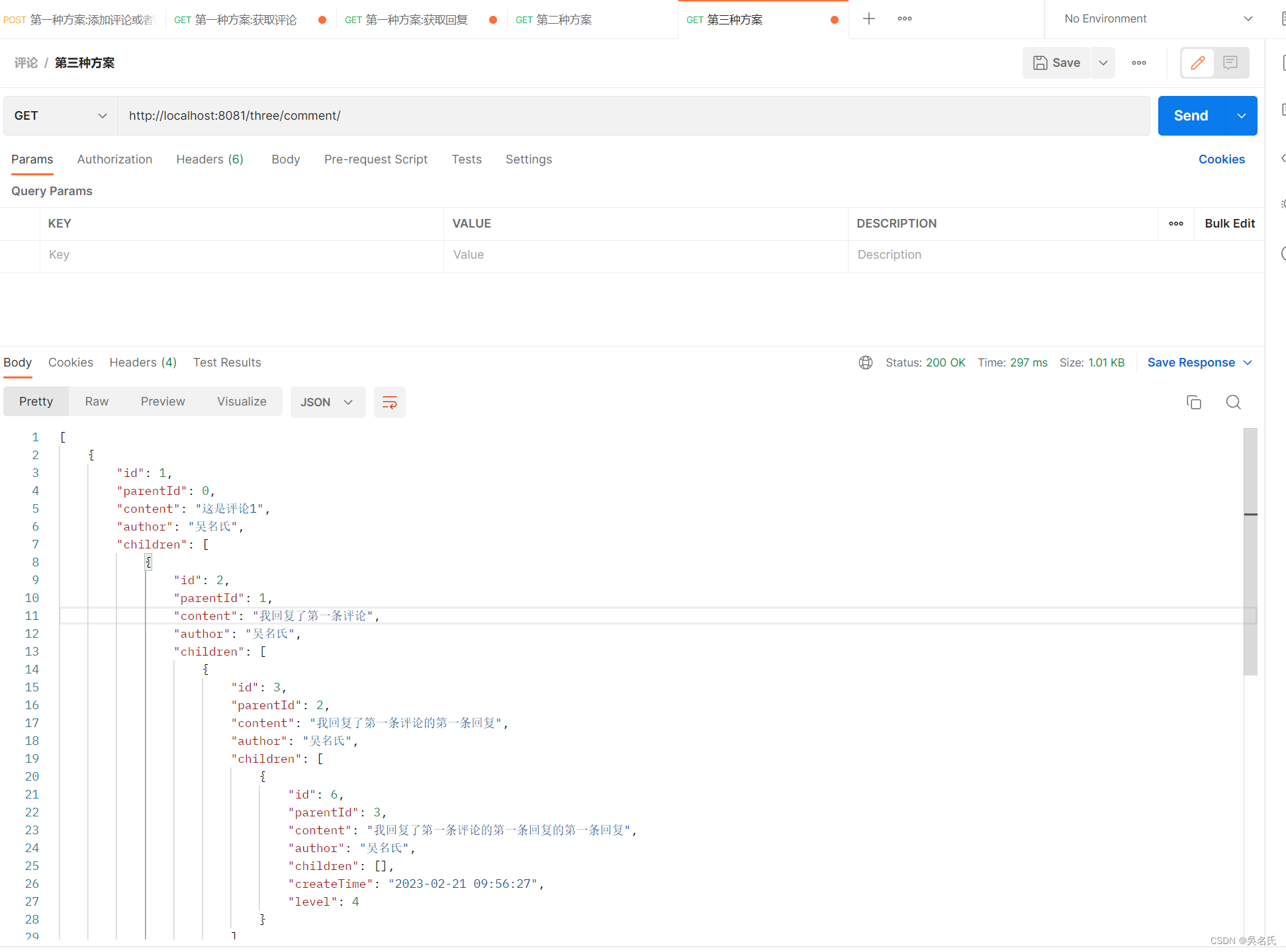
使用SpringBoot实现无限级评论回复功能
评论功能已经成为APP和网站开发中的必备功能。本文采用springbootmybatis-plus框架,通过代码主要介绍评论功能的数据库设计和接口数据返回。我们返回的格式可以分三种方案,第一种方案是先返回评论,再根据评论id返回回复信息,第二种方案是将评论回复直接封装成一个类似于树的数据…...
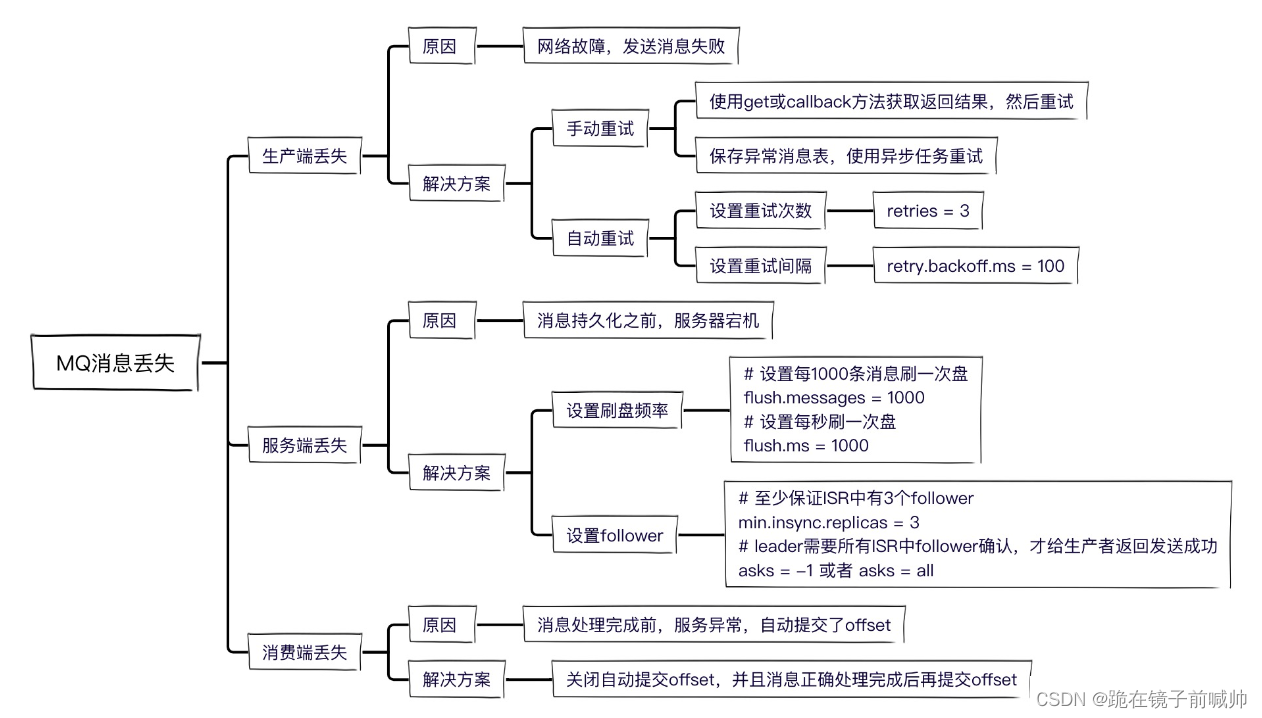
Kafka 介绍和使用
文章目录前言1、Kafka 系统架构1.1、Producer 生产者1.2、Consumer 消费者1.3、Consumer Group 消费者群组1.4、Topic 主题1.5、Partition 分区1.6、Log 日志存储1.7、Broker 服务器1.8、Offset 偏移量1.9、Replication 副本1.10、Zookeeper2、Kafka 环境搭建2.1、下载 Kafka2.…...
[学习笔记]Rocket.Chat业务数据备份
Rocket.Chat 的业务数据主要存储于mongodb数据库的rocketchat库中,聊天中通过发送文件功能产生的文件储存于/app/uploads中(文件方式设置为"FileSystem"),因此在对Rocket.Chat做数据移动或备份主要分为两步,…...
)
【ZOJ 1090】The Circumference of the Circle 题解(海伦公式+正弦定理推论)
计算圆的周长似乎是一项简单的任务——只要你知道它的直径。但如果你没有呢? 我们给出了平面中三个非共线点的笛卡尔坐标。 您的工作是计算与所有三个点相交的唯一圆的周长。 输入规范 输入文件将包含一个或多个测试用例。每个测试用例由一条包含六个实数x1、y1、x…...

【go】slice原理
slice包含3个部分: 1.内存的起始位置 2.切片的大小(已经存放的元素数量) 3.容量(可以存放的元素数量) 使用make初始化切片会开辟底层内存,并初始化元素值为默认值,如数字为0,字符串为空 使用New初始化切片不会开辟底层数组&…...
,真的很详细,一篇文章你就会了)
【数据库】MySQL概念知识语法-基础篇(DQL),真的很详细,一篇文章你就会了
目录通用语法及分类DQL(数据查询语言)基础查询条件查询聚合查询(聚合函数)分组查询排序查询分页查询内连接查询外连接查询自连接查询联合查询子查询列子查询行子查询表子查询总结通用语法及分类 ● DDL: 数据定义语言,…...
博客界的至高神:属于自己的WordPress网站,你值得拥有!
【如果暂时没时间安装,可以直接跳转到最后先看展示效果】 很多朋友都想有一个对外展示的窗口,在那里放一些个人的作品或者其他想对外分享的东西。大部分人选择了在微博、公众号等平台,毕竟这些平台流量大,我们可以很轻易地把自己…...
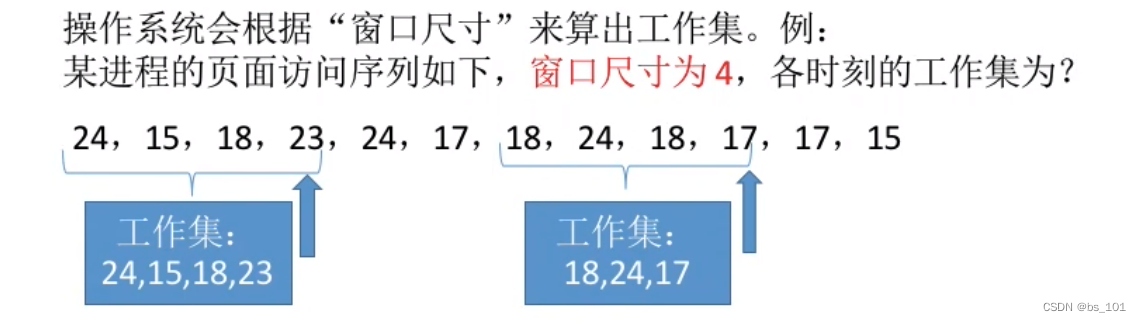
操作系统(day13)-- 虚拟内存;页面分配策略
虚拟内存管理 虚拟内存的基本概念 传统存储管理方式的特征、缺点 一次性: 作业必须一次性全部装入内存后才能开始运行。驻留性:作业一旦被装入内存,就会一直驻留在内存中,直至作业运行结束。事实上,在一个时间段内&…...
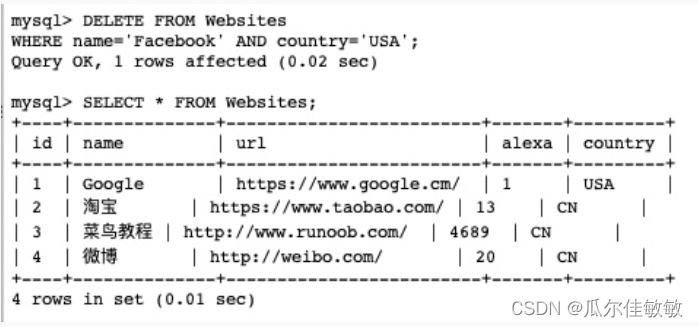
SQL零基础入门学习(四)
SQL零基础入门学习(三) SQL INSERT INTO 语句 INSERT INTO 语句用于向表中插入新记录。 SQL INSERT INTO 语法 INSERT INTO 语句可以有两种编写形式。 第一种形式无需指定要插入数据的列名,只需提供被插入的值即可: INSERT …...
19岁就患老年痴呆!这些前兆别忽视!
在大部分人的印象中,阿尔兹海默症好像是专属于老年人的疾病,而且它的另一个名字就是老年痴呆症。然而,前不久,一位19岁的男生患上了阿尔兹海默症,是迄今为止最年轻的患者。这个男生从17岁开始,就出现了注意…...
【C++】thread|mutex|atomic|condition_variable
本篇博客,让我们来认识一下C中的线程操作 所用编译器:vs2019 阅读本文前,建议先了解线程的概念 👉 线程概念 1.基本介绍 在不同的操作系统,windows、linux、mac上,都会对多线程操作提供自己的系统调用接口…...
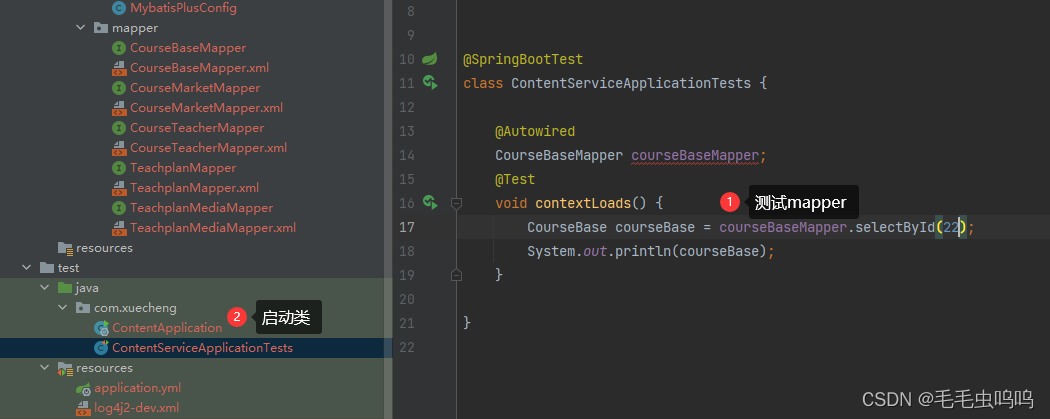
学成在线项目笔记
业务层开发 DAO开发示例 生成实体类对应的mapper和xml文件 定义MybatisPlusConfig,用于扫描mapper和配置分页拦截器 MapperScan("com.xuecheng.content.mapper") Configuration public class MybatisPlusConfig {Beanpublic MybatisPlusInterceptor myb…...

FreeRTOS队列
队列简介队列是一种任务到任务,任务到中断,中断到任务数据交流得一种机制。在队列中可以存储数量有限,大小固定得多个数据,队列中的每一个数据叫做队列项目,队列能够存储队列项目的最大数量称为队列的长度,…...
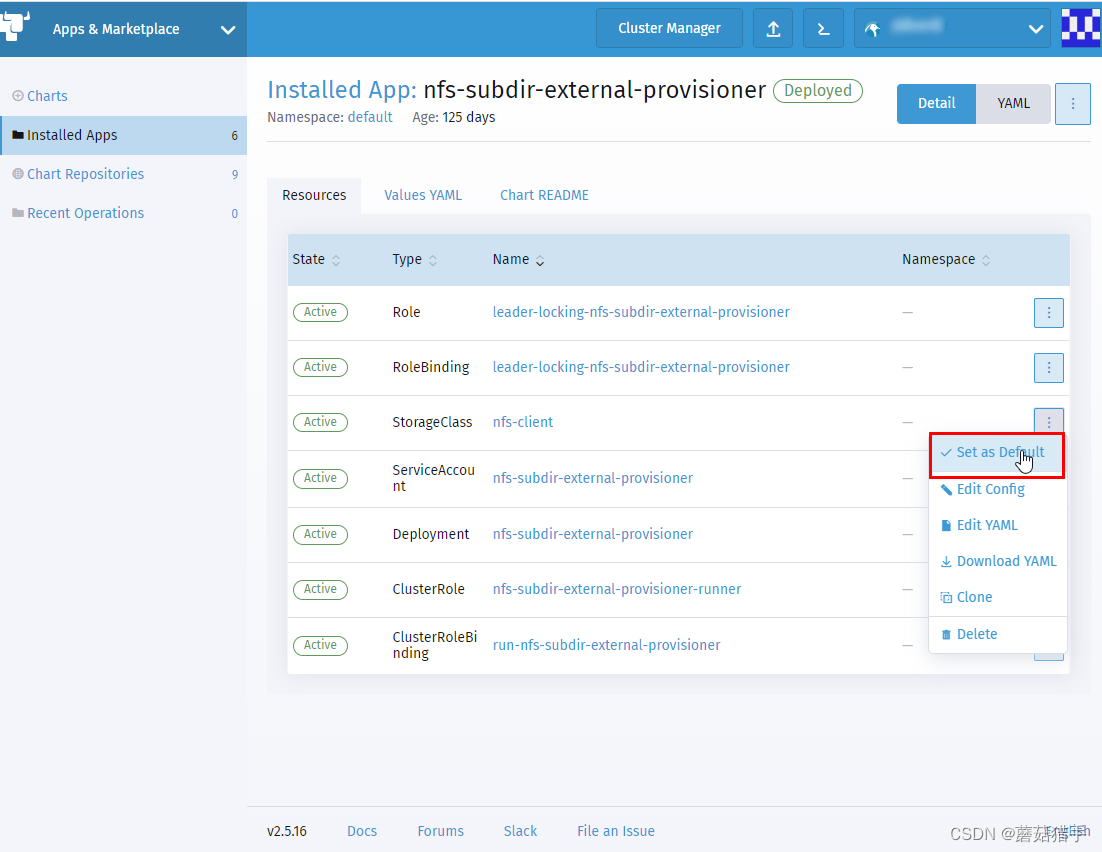
rancher2安装nfs-subdir-external-provisioner为PVC/PV动态提供存储空间(动态分配卷)
接上一篇《centos7部署rancher2.5详细图文教程》 一、 安装nfs服务 1. 所有节点都需要操作 $ # 下载 nfs 相关软件 $ sudo yum -y install nfs-utils rpcbind$ # 启动服务并加入开机自启 $ sudo systemctl start nfs && systemctl enable nfs $ sudo systemctl star…...

1.JAVA-JDK安装
前言:工具下载地址阿里云盘:Java-Jdk:https://www.aliyundrive.com/s/JpV55xhVq2A提取码: j53y一、jdk下载:前往Oracle官网可免费下载地址:https://www.oracle.com/java/technologies/downloads/ 此处我下载的是jdk8&a…...

深度学习从心电信号中解码呼吸频率:原理、实现与临床价值
1. 项目概述:从心电信号中“听”到呼吸声呼吸频率,这个我们每分钟都在进行却很少被精确量化的生命体征,在临床医学中扮演着至关重要的角色。它不仅是评估呼吸系统功能的直接指标,更是反映全身代谢、循环乃至神经系统状态的“窗口”…...

别再乱算相似度了!用Python实战二元变量聚类:从Jaccard系数到病人分组
医疗数据分析实战:用Python实现基于Jaccard系数的病人症状聚类在医疗数据分析领域,如何从海量病人症状数据中发现潜在规律一直是临床研究的难点。传统方法往往依赖医生经验或简单统计,而现代数据挖掘技术为我们提供了更科学的解决方案。本文将…...

BLE四大广播模式详解:可连接/不可连接/定向/周期广播
一、前言在低功耗蓝牙(BLE)开发中,广播(Advertising)是设备发现、连接建立、数据广播、设备重连的核心基石,所有BLE交互流程均始于广播报文的收发。不同于传统经典蓝牙,BLE所有广播行为标准化、…...

SSH工具对比:新手用户和熟练运维,选型逻辑有什么不同
结论 新手用户和熟练运维在选择 SSH 工具时,关注点往往完全不同。 新手更在意的是:能不能顺利连接、界面是否直观、文件和配置是否容易找到、网站出问题时能不能快速定位。 而熟练运维更在意的是:连接效率、命令自由度、多服务器管理能力、原…...
)
Python基础语法:生成器 generator(yield)
一、简介根据指定的规则循环生成数据,当条件不成立时则生成数据结束。数据不是一次性全部生成出来,而是使用一个,再生成一个,好处是可以节约大量的内存。就像设计模式中的懒汉式。适合处理大数据或流数。生成器是一种特殊的迭代器…...

荣耀出征官方网站下载正版手游 翅膀养成细节玩法全方位讲解
玩荣耀出征的玩家都清楚,翅膀不仅是角色的颜值象征,更是提升整体战力的核心途径。很多新手玩家只顾着升级、刷装备,完全忽略翅膀养成,导致等级很高但战力始终上不去。还有不少玩家胡乱合成、盲目进阶,浪费了大量稀有翅…...
)
Postgresql基础实践教程(八)
⭐️⭐️⭐️⭐️⭐️ 完整数据详见 练习数据免费 ⭐️⭐️⭐️⭐️⭐️ 六十九、查找会员ID 27的向上推荐链 问题 查找会员ID 27的向上推荐链:即推荐该会员的人,以及推荐那个人的人,依此类推。返回会员ID、名字和姓氏。按会员ID降序排列。…...

AI圈内火热的Agent、MCP、Skill、CLI是啥?用装修房子讲透,看完秒懂
本文用装修房子的比喻,详细解释了AI领域的四个核心概念:Agent如同会自主规划任务的私人助理;MCP是AI与外部工具数据的统一接口,类似USB-C;Skill是指导AI按标准操作执行的手册;CLI则是不依赖图形界面的命令行…...

武汉国电华美16875kVA串联谐振试验装置,这手活儿细
在超高压变电站和长距离电缆的现场,交流耐压试验是检验设备绝缘的“最后一关”。这位老师傅经手过不少大工程,他说,面对GIS、大型变压器这些“大块头”电容性试品,能不能顺利“过关”,往往就看串联谐振装置顶不顶得住。…...

别再只用递归了!用C语言栈实现非递归快速排序,内存效率提升实战
从递归到迭代:C语言栈实现非递归快速排序的工程实践 在嵌入式开发和大规模数据处理场景中,递归实现的快速排序常常面临栈溢出风险。当排序10万个元素的数组时,递归深度可能达到log₂100000≈17层,在仅有2KB栈空间的STM32F103上极易…...