pytorch深度学习实践
B站-刘二大人
参考-PyTorch 深度学习实践_错错莫的博客-CSDN博客
线性模型
import numpy as np
import matplotlib.pyplot as pltx_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]def forward(x):return x * wdef loss(x, y):y_pred = forward(x)return (y_pred - y) ** 2# 穷举法
w_list = []
mse_list = []
for w in np.arange(0.0, 4.1, 0.1):print("w=", w)l_sum = 0for x_val, y_val in zip(x_data, y_data):y_pred_val = forward(x_val)loss_val = loss(x_val, y_val)l_sum += loss_valprint('\t', x_val, y_val, y_pred_val, loss_val)print('MSE=', l_sum / 3)w_list.append(w)mse_list.append(l_sum / 3)plt.plot(w_list, mse_list)
plt.ylabel('Loss')
plt.xlabel('w')
plt.show() 线性模型作业
import numpy as np
import matplotlib.pyplot as pltx_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]def forward(x):return x * wdef loss(x, y):y_pred = forward(x)return (y_pred - y) ** 2# 穷举法
w_list = []
mse_list = []
for w in np.arange(0.0, 4.1, 0.1):print("w=", w)l_sum = 0for x_val, y_val in zip(x_data, y_data):y_pred_val = forward(x_val)loss_val = loss(x_val, y_val)l_sum += loss_valprint('\t', x_val, y_val, y_pred_val, loss_val)print('MSE=', l_sum / 3)w_list.append(w)mse_list.append(l_sum / 3)plt.plot(w_list, mse_list)
plt.ylabel('Loss')
plt.xlabel('w')
plt.show() 梯度下降
import matplotlib.pyplot as plt# prepare the training set
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]# initial guess of weight
w = 1.0# define the model linear model y = w*x
def forward(x):return x * w# define the cost function MSE
def cost(xs, ys):cost = 0for x, y in zip(xs, ys):y_pred = forward(x)cost += (y_pred - y) ** 2return cost / len(xs)# define the gradient function gd
def gradient(xs, ys):grad = 0for x, y in zip(xs, ys):grad += 2 * x * (x * w - y)return grad / len(xs)epoch_list = []
cost_list = []
print('predict (before training)', 4, forward(4))
for epoch in range(100):cost_val = cost(x_data, y_data)grad_val = gradient(x_data, y_data)w -= 0.01 * grad_val # 0.01 learning rateprint('epoch:', epoch, 'w=', w, 'loss=', cost_val)epoch_list.append(epoch)cost_list.append(cost_val)print('predict (after training)', 4, forward(4))plt.plot(epoch_list, cost_list)
plt.ylabel('cost')
plt.xlabel('epoch')
plt.show()随机梯度下降
import matplotlib.pyplot as pltx_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]w = 1.0def forward(x):return x * w# calculate loss function
def loss(x, y):y_pred = forward(x)return (y_pred - y) ** 2# define the gradient function sgd
def gradient(x, y):return 2 * x * (x * w - y)epoch_list = []
loss_list = []
print('predict (before training)', 4, forward(4))
for epoch in range(100):for x, y in zip(x_data, y_data):grad = gradient(x, y)w = w - 0.01 * grad # update weight by every grad of sample of training setprint("\tgrad:", x, y, grad)l = loss(x, y)print("progress:", epoch, "w=", w, "loss=", l)epoch_list.append(epoch)loss_list.append(l)print('predict (after training)', 4, forward(4))
plt.plot(epoch_list, loss_list)
plt.ylabel('loss')
plt.xlabel('epoch')
plt.show()pytorch线性回归
import torch
import matplotlib.pyplot as plt
import numpy as np# prepare dataset
# x,y是矩阵,3行1列 也就是说总共有3个数据,每个数据只有1个特征
x_data = torch.tensor([[1.0], [2.0], [3.0]])
y_data = torch.tensor([[2.0], [4.0], [6.0]])# design model using class
"""
our model class should be inherit from nn.Module, which is base class for all neural network modules.
member methods __init__() and forward() have to be implemented
class nn.linear contain two member Tensors: weight and bias
class nn.Linear has implemented the magic method __call__(),which enable the instance of the class can
be called just like a function.Normally the forward() will be called
"""class LinearModel(torch.nn.Module):def __init__(self):super(LinearModel, self).__init__()# (1,1)是指输入x和输出y的特征维度,这里数据集中的x和y的特征都是1维的# 该线性层需要学习的参数是w和b 获取w/b的方式分别是~linear.weight/linear.biasself.linear = torch.nn.Linear(1, 1)def forward(self, x):y_pred = self.linear(x)return y_predmodel = LinearModel()# construct loss and optimizer
# criterion = torch.nn.MSELoss(size_average = False)
criterion = torch.nn.MSELoss(reduction='sum')
optimizer = torch.optim.SGD(model.parameters(), lr=0.01) # model.parameters()自动完成参数的初始化操作,这个地方我可能理解错了# training cycle forward, backward, update
for epoch in range(1000):y_pred = model(x_data) # forward:predictloss = criterion(y_pred, y_data) # forward: lossprint(epoch, loss.item())optimizer.zero_grad() # the grad computer by .backward() will be accumulated. so before backward, remember set the grad to zeroloss.backward() # backward: autograd,自动计算梯度optimizer.step() # update 参数,即更新w和b的值print('w = ', model.linear.weight.item())
print('b = ', model.linear.bias.item())x_test = torch.tensor([[4.0]])
y_test = model(x_test)
print('y_pred = ', y_test.data)logistic回归
import torch# import torch.nn.functional as F# prepare dataset
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[0], [0], [1]])# design model using class
class LogisticRegressionModel(torch.nn.Module):def __init__(self):super(LogisticRegressionModel, self).__init__()self.linear = torch.nn.Linear(1, 1)def forward(self, x):# y_pred = F.sigmoid(self.linear(x))y_pred = torch.sigmoid(self.linear(x))return y_predmodel = LogisticRegressionModel()# construct loss and optimizer
# 默认情况下,loss会基于element平均,如果size_average=False的话,loss会被累加。
criterion = torch.nn.BCELoss(size_average=False)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)# training cycle forward, backward, update
for epoch in range(1000):y_pred = model(x_data)loss = criterion(y_pred, y_data)print(epoch, loss.item())optimizer.zero_grad()loss.backward()optimizer.step()print('w = ', model.linear.weight.item())
print('b = ', model.linear.bias.item())x_test = torch.Tensor([[4.0]])
y_test = model(x_test)
print('y_pred = ', y_test.data)多特征输入
import numpy as np
import torch
import matplotlib.pyplot as plt# prepare dataset
xy = np.loadtxt('diabetes.csv.gz', delimiter=',', dtype=np.float32)
x_data = torch.from_numpy(xy[:, :-1]) # 第一个‘:’是指读取所有行,第二个‘:’是指从第一列开始,最后一列不要
y_data = torch.from_numpy(xy[:, [-1]]) # [-1] 最后得到的是个矩阵# design model using classclass Model(torch.nn.Module):def __init__(self):super(Model, self).__init__()self.linear1 = torch.nn.Linear(8, 6) # 输入数据x的特征是8维,x有8个特征self.linear2 = torch.nn.Linear(6, 4)self.linear3 = torch.nn.Linear(4, 1)self.sigmoid = torch.nn.Sigmoid() # 将其看作是网络的一层,而不是简单的函数使用def forward(self, x):x = self.sigmoid(self.linear1(x))x = self.sigmoid(self.linear2(x))x = self.sigmoid(self.linear3(x)) # y hatreturn xmodel = Model()# construct loss and optimizer
# criterion = torch.nn.BCELoss(size_average = True)
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)epoch_list = []
loss_list = []
# training cycle forward, backward, update
for epoch in range(100):y_pred = model(x_data)loss = criterion(y_pred, y_data)print(epoch, loss.item())epoch_list.append(epoch)loss_list.append(loss.item())optimizer.zero_grad()loss.backward()optimizer.step()plt.plot(epoch_list, loss_list)
plt.ylabel('loss')
plt.xlabel('epoch')
plt.show()加载数据
import torch
import numpy as np
from torch.utils.data import Dataset
from torch.utils.data import DataLoader# prepare datasetclass DiabetesDataset(Dataset):def __init__(self, filepath):xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32)self.len = xy.shape[0] # shape(多少行,多少列)self.x_data = torch.from_numpy(xy[:, :-1])self.y_data = torch.from_numpy(xy[:, [-1]])def __getitem__(self, index):return self.x_data[index], self.y_data[index]def __len__(self):return self.lendataset = DiabetesDataset('diabetes.csv.gz')
train_loader = DataLoader(dataset=dataset, batch_size=32, shuffle=True, num_workers=0) # num_workers 多线程# design model using classclass Model(torch.nn.Module):def __init__(self):super(Model, self).__init__()self.linear1 = torch.nn.Linear(8, 6)self.linear2 = torch.nn.Linear(6, 4)self.linear3 = torch.nn.Linear(4, 1)self.sigmoid = torch.nn.Sigmoid()def forward(self, x):x = self.sigmoid(self.linear1(x))x = self.sigmoid(self.linear2(x))x = self.sigmoid(self.linear3(x))return xmodel = Model()# construct loss and optimizer
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)# training cycle forward, backward, update
if __name__ == '__main__':for epoch in range(100):for i, data in enumerate(train_loader, 0): # train_loader 是先shuffle后mini_batchinputs, labels = datay_pred = model(inputs)loss = criterion(y_pred, labels)print(epoch, i, loss.item())optimizer.zero_grad()loss.backward()optimizer.step()加载数据划分数据集
import torch
import numpy as np
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
from sklearn.model_selection import train_test_split# 读取原始数据,并划分训练集和测试集
raw_data = np.loadtxt('diabetes.csv.gz', delimiter=',', dtype=np.float32)
X = raw_data[:, :-1]
y = raw_data[:, [-1]]
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X, y, test_size=0.3)
Xtest = torch.from_numpy(Xtest)
Ytest = torch.from_numpy(Ytest)# 将训练数据集进行批量处理
# prepare datasetclass DiabetesDataset(Dataset):def __init__(self, data, label):self.len = data.shape[0] # shape(多少行,多少列)self.x_data = torch.from_numpy(data)self.y_data = torch.from_numpy(label)def __getitem__(self, index):return self.x_data[index], self.y_data[index]def __len__(self):return self.lentrain_dataset = DiabetesDataset(Xtrain, Ytrain)
train_loader = DataLoader(dataset=train_dataset, batch_size=32, shuffle=True, num_workers=0) # num_workers 多线程# design model using classclass Model(torch.nn.Module):def __init__(self):super(Model, self).__init__()self.linear1 = torch.nn.Linear(8, 6)self.linear2 = torch.nn.Linear(6, 4)self.linear3 = torch.nn.Linear(4, 2)self.linear4 = torch.nn.Linear(2, 1)self.sigmoid = torch.nn.Sigmoid()def forward(self, x):x = self.sigmoid(self.linear1(x))x = self.sigmoid(self.linear2(x))x = self.sigmoid(self.linear3(x))x = self.sigmoid(self.linear4(x))return xmodel = Model()# construct loss and optimizer
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)# training cycle forward, backward, updatedef train(epoch):train_loss = 0.0count = 0for i, data in enumerate(train_loader, 0):inputs, labels = datay_pred = model(inputs)loss = criterion(y_pred, labels)optimizer.zero_grad()loss.backward()optimizer.step()train_loss += loss.item()count = iif epoch % 2000 == 1999:print("train loss:", train_loss / count, end=',')def test():with torch.no_grad():y_pred = model(Xtest)y_pred_label = torch.where(y_pred >= 0.5, torch.tensor([1.0]), torch.tensor([0.0]))acc = torch.eq(y_pred_label, Ytest).sum().item() / Ytest.size(0)print("test acc:", acc)if __name__ == '__main__':for epoch in range(10000):train(epoch)if epoch % 2000 == 1999:test()
多分类问题(softmax)
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim# prepare datasetbatch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]) # 归一化,均值和方差train_dataset = datasets.MNIST(root='./dataset/mnist/', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='./dataset/mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)# design model using classclass Net(torch.nn.Module):def __init__(self):super(Net, self).__init__()self.l1 = torch.nn.Linear(784, 512)self.l2 = torch.nn.Linear(512, 256)self.l3 = torch.nn.Linear(256, 128)self.l4 = torch.nn.Linear(128, 64)self.l5 = torch.nn.Linear(64, 10)def forward(self, x):x = x.view(-1, 784) # -1其实就是自动获取mini_batchx = F.relu(self.l1(x))x = F.relu(self.l2(x))x = F.relu(self.l3(x))x = F.relu(self.l4(x))return self.l5(x) # 最后一层不做激活,不进行非线性变换model = Net()# construct loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)# training cycle forward, backward, updatedef train(epoch):running_loss = 0.0for batch_idx, data in enumerate(train_loader, 0):# 获得一个批次的数据和标签inputs, target = dataoptimizer.zero_grad()# 获得模型预测结果(64, 10)outputs = model(inputs)# 交叉熵代价函数outputs(64,10),target(64)loss = criterion(outputs, target)loss.backward()optimizer.step()running_loss += loss.item()if batch_idx % 300 == 299:print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))running_loss = 0.0def test():correct = 0total = 0with torch.no_grad():for data in test_loader:images, labels = dataoutputs = model(images)_, predicted = torch.max(outputs.data, dim=1) # dim = 1 列是第0个维度,行是第1个维度total += labels.size(0)correct += (predicted == labels).sum().item() # 张量之间的比较运算print('accuracy on test set: %d %% ' % (100 * correct / total))if __name__ == '__main__':for epoch in range(10):train(epoch)test()卷积神经网络
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim# prepare datasetbatch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])train_dataset = datasets.MNIST(root='./dataset/mnist/', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='./dataset/mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)# design model using classclass Net(torch.nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5)self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=5)self.pooling = torch.nn.MaxPool2d(2)self.fc = torch.nn.Linear(320, 10)def forward(self, x):# flatten data from (n,1,28,28) to (n, 784)batch_size = x.size(0)x = F.relu(self.pooling(self.conv1(x)))x = F.relu(self.pooling(self.conv2(x)))x = x.view(batch_size, -1) # -1 此处自动算出的是320x = self.fc(x)return xmodel = Net()# construct loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)# training cycle forward, backward, updatedef train(epoch):running_loss = 0.0for batch_idx, data in enumerate(train_loader, 0):inputs, target = dataoptimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, target)loss.backward()optimizer.step()running_loss += loss.item()if batch_idx % 300 == 299:print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))running_loss = 0.0def test():correct = 0total = 0with torch.no_grad():for data in test_loader:images, labels = dataoutputs = model(images)_, predicted = torch.max(outputs.data, dim=1)total += labels.size(0)correct += (predicted == labels).sum().item()print('accuracy on test set: %d %% ' % (100 * correct / total))if __name__ == '__main__':for epoch in range(10):train(epoch)test()卷积神经网络-GPU
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
import matplotlib.pyplot as plt# prepare datasetbatch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])train_dataset = datasets.MNIST(root='./dataset/mnist/', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='./dataset/mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)# design model using classclass Net(torch.nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5)self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=5)self.pooling = torch.nn.MaxPool2d(2)self.fc = torch.nn.Linear(320, 10)def forward(self, x):# flatten data from (n,1,28,28) to (n, 784)batch_size = x.size(0)x = F.relu(self.pooling(self.conv1(x)))x = F.relu(self.pooling(self.conv2(x)))x = x.view(batch_size, -1) # -1 此处自动算出的是320# print("x.shape",x.shape)x = self.fc(x)return xmodel = Net()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)# construct loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)# training cycle forward, backward, updatedef train(epoch):running_loss = 0.0for batch_idx, data in enumerate(train_loader, 0):inputs, target = datainputs, target = inputs.to(device), target.to(device)optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, target)loss.backward()optimizer.step()running_loss += loss.item()if batch_idx % 300 == 299:print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))running_loss = 0.0def test():correct = 0total = 0with torch.no_grad():for data in test_loader:images, labels = dataimages, labels = images.to(device), labels.to(device)outputs = model(images)_, predicted = torch.max(outputs.data, dim=1)total += labels.size(0)correct += (predicted == labels).sum().item()print('accuracy on test set: %d %% ' % (100 * correct / total))return correct / totalif __name__ == '__main__':epoch_list = []acc_list = []for epoch in range(10):train(epoch)acc = test()epoch_list.append(epoch)acc_list.append(acc)plt.plot(epoch_list, acc_list)plt.ylabel('accuracy')plt.xlabel('epoch')plt.show()Inception Moudel
import torch
import torch.nn as nn
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim# prepare datasetbatch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]) # 归一化,均值和方差train_dataset = datasets.MNIST(root='./dataset/mnist/', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='./dataset/mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)# design model using class
class InceptionA(nn.Module):def __init__(self, in_channels):super(InceptionA, self).__init__()self.branch1x1 = nn.Conv2d(in_channels, 16, kernel_size=1)self.branch5x5_1 = nn.Conv2d(in_channels, 16, kernel_size=1)self.branch5x5_2 = nn.Conv2d(16, 24, kernel_size=5, padding=2)self.branch3x3_1 = nn.Conv2d(in_channels, 16, kernel_size=1)self.branch3x3_2 = nn.Conv2d(16, 24, kernel_size=3, padding=1)self.branch3x3_3 = nn.Conv2d(24, 24, kernel_size=3, padding=1)self.branch_pool = nn.Conv2d(in_channels, 24, kernel_size=1)def forward(self, x):branch1x1 = self.branch1x1(x)branch5x5 = self.branch5x5_1(x)branch5x5 = self.branch5x5_2(branch5x5)branch3x3 = self.branch3x3_1(x)branch3x3 = self.branch3x3_2(branch3x3)branch3x3 = self.branch3x3_3(branch3x3)branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)branch_pool = self.branch_pool(branch_pool)outputs = [branch1x1, branch5x5, branch3x3, branch_pool]return torch.cat(outputs, dim=1) # b,c,w,h c对应的是dim=1class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(1, 10, kernel_size=5)self.conv2 = nn.Conv2d(88, 20, kernel_size=5) # 88 = 24x3 + 16self.incep1 = InceptionA(in_channels=10) # 与conv1 中的10对应self.incep2 = InceptionA(in_channels=20) # 与conv2 中的20对应self.mp = nn.MaxPool2d(2)self.fc = nn.Linear(1408, 10)def forward(self, x):in_size = x.size(0)x = F.relu(self.mp(self.conv1(x)))x = self.incep1(x)x = F.relu(self.mp(self.conv2(x)))x = self.incep2(x)x = x.view(in_size, -1)x = self.fc(x)return xmodel = Net()# construct loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)# training cycle forward, backward, updatedef train(epoch):running_loss = 0.0for batch_idx, data in enumerate(train_loader, 0):inputs, target = dataoptimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, target)loss.backward()optimizer.step()running_loss += loss.item()if batch_idx % 300 == 299:print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))running_loss = 0.0def test():correct = 0total = 0with torch.no_grad():for data in test_loader:images, labels = dataoutputs = model(images)_, predicted = torch.max(outputs.data, dim=1)total += labels.size(0)correct += (predicted == labels).sum().item()print('accuracy on test set: %d %% ' % (100 * correct / total))if __name__ == '__main__':for epoch in range(10):train(epoch)test()ResidualBlock
import torch
import torch.nn as nn
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim# prepare datasetbatch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]) # 归一化,均值和方差train_dataset = datasets.MNIST(root='../dataset/mnist/', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)# design model using class
class ResidualBlock(nn.Module):def __init__(self, channels):super(ResidualBlock, self).__init__()self.channels = channelsself.conv1 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)self.conv2 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)def forward(self, x):y = F.relu(self.conv1(x))y = self.conv2(y)return F.relu(x + y)class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(1, 16, kernel_size=5)self.conv2 = nn.Conv2d(16, 32, kernel_size=5) # 88 = 24x3 + 16self.rblock1 = ResidualBlock(16)self.rblock2 = ResidualBlock(32)self.mp = nn.MaxPool2d(2)self.fc = nn.Linear(512, 10) # 暂时不知道1408咋能自动出来的def forward(self, x):in_size = x.size(0)x = self.mp(F.relu(self.conv1(x)))x = self.rblock1(x)x = self.mp(F.relu(self.conv2(x)))x = self.rblock2(x)x = x.view(in_size, -1)x = self.fc(x)return xmodel = Net()# construct loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)# training cycle forward, backward, updatedef train(epoch):running_loss = 0.0for batch_idx, data in enumerate(train_loader, 0):inputs, target = dataoptimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, target)loss.backward()optimizer.step()running_loss += loss.item()if batch_idx % 300 == 299:print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))running_loss = 0.0def test():correct = 0total = 0with torch.no_grad():for data in test_loader:images, labels = dataoutputs = model(images)_, predicted = torch.max(outputs.data, dim=1)total += labels.size(0)correct += (predicted == labels).sum().item()print('accuracy on test set: %d %% ' % (100 * correct / total))if __name__ == '__main__':for epoch in range(10):train(epoch)test()相关文章:

pytorch深度学习实践
B站-刘二大人 参考-PyTorch 深度学习实践_错错莫的博客-CSDN博客 线性模型 import numpy as np import matplotlib.pyplot as pltx_data [1.0, 2.0, 3.0] y_data [2.0, 4.0, 6.0]def forward(x):return x * wdef loss(x, y):y_pred forward(x)return (y_pred - y) ** 2# …...
)
直方图反向投影(Histogram Backprojection)
直方图反向投影(Histogram Backprojection)是一种在计算机视觉中用于对象检测和图像分割的技术。它的原理基于图像的颜色分布,允许我们在一幅图像中找到与给定对象颜色分布相匹配的区域。这个技术常常用于图像中的目标跟踪、物体识别和图像分…...

day32 泛型 数据结构 List
一、泛型 概述 JDK1.5同时推出了两个和集合相关的特性:增强for循环,泛型 泛型可以修饰泛型类中的属性,方法返回值,方法参数, 构造函数的参数 Java提供的泛型类/接口 Collection, List, Set,Iterator 等 …...

DW-AHB Central DMAC
文章目录 AHB Central DMAC —— Design Ware AHB Central DMAC —— Design Ware AHB(Adavenced High-performace BUS) Central DMAC(Direct Memory Access Controller) : 一个高性能总线系统。 作用:在嵌入式系统种连接高速设备,如处理器内存&#x…...

JavaScript设计模式(四)——策略模式、代理模式、观察者模式
个人简介 👀个人主页: 前端杂货铺 🙋♂️学习方向: 主攻前端方向,正逐渐往全干发展 📃个人状态: 研发工程师,现效力于中国工业软件事业 🚀人生格言: 积跬步…...

JS画布的基本使用
直线 <!DOCTYPE html> <html> <head> <meta charset"utf-8"> <title></title> <style> #myname{ border: 1px solid red; /* background: linear-gradient(to righ…...

c++ set/multiset
set/multiset 集合,一个单个,一个多个(multi)。两个库都是"set"。 https://blog.csdn.net/fckbb/article/details/130917681 对象创建 set(const Pred& compPred(),const A& alA()):创建空集合。set(const set& x):…...
)
多线程与高并发——并发编程(4)
文章目录 四、阻塞队列1 基础概念1.1 生产者消费者概念1.2 JUC阻塞队列的存取方法2 ArrayBlockingQueue2.1 ArrayBlockingQueue的基本使用2.2 生产者方法实现原理2.2.1 ArrayBlockingQueue的常见属性2.2.2 add方法2.2.3 offer方法2.2.4 offer(time,unit)方法2.2.5 put方法2.3 消…...
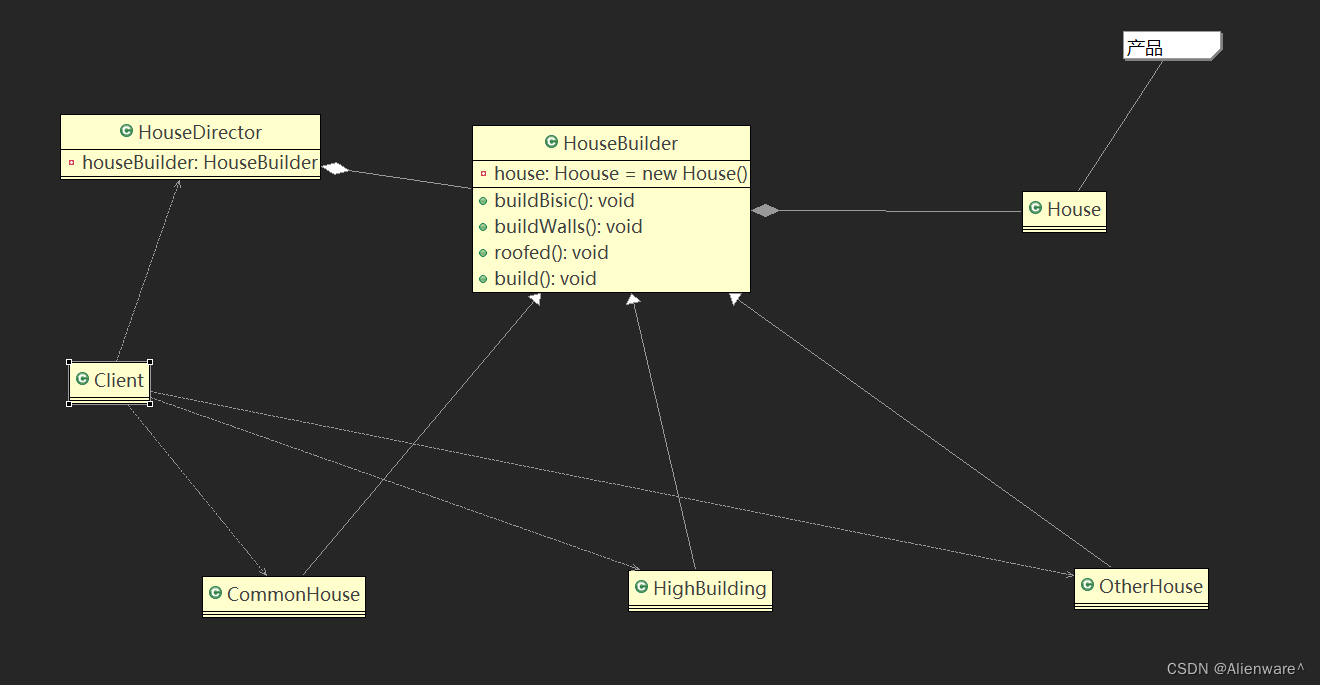
设计模式之建造者模式
文章目录 盖房项目需求传统方式解决盖房需求传统方式的问题分析建造者模式概述是建造者模式的四个角色建造者模式原理类图建造者模式的注意事项和细节 盖房项目需求 需要建房子:这一过程为打桩、砌墙、封顶房子有各种各样的,比如普通房,高楼…...

源码编译安装opencv4.6.0,别的版本也行
1.下载opencv4.6.0 系统: ubuntu 1804 64位点我下载opencv 4.6.0 https://codeload.github.com/opencv/opencv/zip/refs/tags/4.6.0 指令下载 推荐: wget -O opencv.zip https://github.com/opencv/opencv/archive/4.6.0.zip wget -O opencv_contrib.zip https://github.com/…...

【MongoDB】Springboot中MongoDB简单使用
1. docker安装MongoDB 拉取镜像 docker pull mongo创建容器 docker run -di --name mongo-service --restartalways -p 27017:27017 -v ~/data/mongodata:/data mongo2. 导入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactI…...

Python 面试:单元测试unit testing 使用pytest
1. 对于函数进行单元测试 calc.py def add(x, y):"""Add Function"""return x ydef subtract(x, y):"""Subtract Function"""return x - ydef multiply(x, y):"""Multiply Function""…...

螺旋矩阵、旋转矩阵、矩阵Z字打印
螺旋矩阵 #include <iostream> #include <vector> void display(std::vector<std::vector<int>>&nums){for(int i 0; i < nums.size(); i){for(int j 0; j < nums[0].size(); j){std::cout<<nums[i][j]<< ;}std::cout<<…...
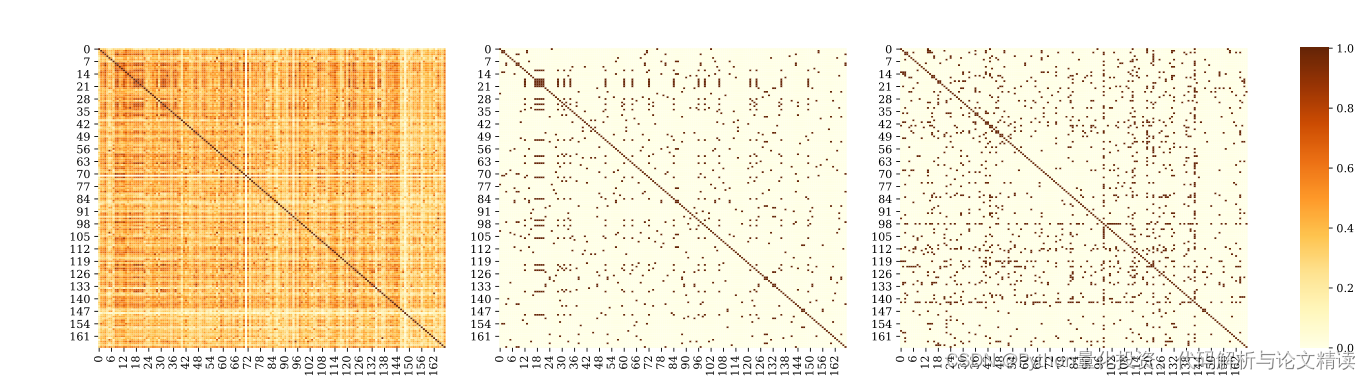
Seaborn绘制热力图的子图
Seaborn绘制热力图的子图 提示:如何绘制三张子图 绘制的时候,会出现如下问题 (1)如何绘制1*3的子图 (2)三个显示条,如何只显示最后一个 提示:下面就展示详细步骤 Seaborn绘制热力…...

C++二级题目4
小白鼠再排队 不会 多余的数 #include<iostream> #include<string.h> #include<stdio.h> #include<iomanip> #include<cmath> #include<bits/stdc.h> int a[2000][2000]; int b[2000]; char c[2000]; long long n; using namespace std; i…...
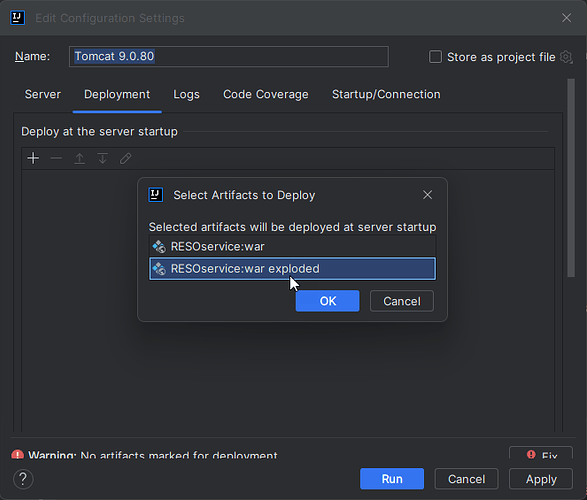
Tomcat 部署时 war 和 war exploded区别
在 Tomcat 调试部署的时候,我们通常会看到有下面 2 个选项。 是选择war还是war exploded 这里首先看一下他们两个的区别: war 模式:将WEB工程以包的形式上传到服务器 ;war exploded 模式:将WEB工程以当前文件夹的位置…...

Delphi IdTcpServer IdTcpClient 传输简单文本
Delphi IdTcpServer IdTcpClient 传输简单文本 已经很久敲代码了,想找一段直接Delphi11 TCP简单文本传输,费劲!FStringStream 、FStrStream : FStringStream:TStringStream.Create(,TEncoding.UTF8); 已经很久敲代码了,…...
界面控件Telerik UI for WPF——Windows 11主题精简模式提升应用体验
Telerik UI for WPF拥有超过100个控件来创建美观、高性能的桌面应用程序,同时还能快速构建企业级办公WPF应用程序。Telerik UI for WPF支持MVVM、触摸等,创建的应用程序可靠且结构良好,非常容易维护,其直观的API将无缝地集成Visua…...

PoseC3D 基于人体姿态的动作识别新范式
摘要1. Introduction2. Related Work动作识别 3D-CNN基于骨架的动作识别 GCN基于骨骼的动作识别 2D-CNN3. Framework3.1. Good Practice for Pose Extraction3.2. From 2D Poses to 3D Heatmap Volumes3.3 基于骨骼的动作识别 3D-CNNPose-SlowOnlyRGBPose-SlowFast4. Experimen…...

html2canvas 截图空白 或出现toDataURL‘ on ‘HTMLCanvasElement或img标签没截下来 的所有解决办法
1.如果截图空白: 1.1以下的参数是必须要有的。 width: shareContent.offsetWidth, //设置canvas尺寸与所截图尺寸相同,防止白边height: shareContent.offsetHeight, //防止白边logging: true,useCORS: true,x:0,y:0,2,如果出现了报错 toData…...

MySQL高手第三章
从磁盘读取数据页到Buffer Pool的时候,free链表有什么用?我们怎么知道那些缓存是空闲的?当我们数据库运行起来的时候,肯定会不断的做增删改查,将磁盘上读取一个一个数据页放入Buffer Pool中对应的缓存页里去但是从磁盘…...

Excel办公必备4个技巧:格式转换、隔列插入、限制编辑、文本数字分离
在日常办公中,Excel是我们使用频率最高的软件之一,但很多人只掌握了最基础的录入和简单计算功能,遇到一些“卡脖子”的小问题就束手无策,不得不手动折腾半天。其实,Excel中隐藏着不少实用的小技巧,能帮你轻…...

打造手游PC级操控:QtScrcpy键鼠映射完全指南
打造手游PC级操控:QtScrcpy键鼠映射完全指南 【免费下载链接】QtScrcpy Android实时投屏软件,此应用程序提供USB(或通过TCP/IP)连接的Android设备的显示和控制。它不需要任何root访问权限 项目地址: https://gitcode.com/barry-ran/QtScrcpy 手机…...

Spring PetClinic实战解析:从单体应用到云原生部署的5大架构亮点
Spring PetClinic实战解析:从单体应用到云原生部署的5大架构亮点 【免费下载链接】spring-petclinic A sample Spring-based application 项目地址: https://gitcode.com/gh_mirrors/sp/spring-petclinic 你是否遇到过这样的困境:在学习Spring框架…...

从GigE Vision到千兆UDP:FPGA图像采集系统的灵活升级与10G MAC预留设计
从GigE Vision到千兆UDP:FPGA图像采集系统的灵活升级与10G MAC预留设计 在工业视觉和机器视觉领域,图像采集系统的带宽需求正以惊人的速度增长。随着4K、8K高分辨率相机的普及,以及多相机同步采集场景的增多,传统的千兆以太网接口…...

Chrome密码提取终极指南:ChromePass工具完整使用教程
Chrome密码提取终极指南:ChromePass工具完整使用教程 【免费下载链接】chromepass Get all passwords stored by Chrome on WINDOWS. 项目地址: https://gitcode.com/gh_mirrors/chr/chromepass 你是否曾经因为忘记某个重要网站的登录密码而感到困扰…...
)
K230目标检测实战:手把手教你用Labelme标注数据并一键转成VOC格式(附避坑指南)
K230目标检测实战:高效数据标注与VOC格式转换全攻略 当你第一次接触K230开发板进行目标检测项目时,数据准备往往是最大的拦路虎。特别是从原始图片到符合AI_Cube要求的VOC格式数据集,这个过程充满了各种"坑"。本文将分享一套经过实…...

六边形地理索引的终极指南:H3算法如何革新空间数据分析
六边形地理索引的终极指南:H3算法如何革新空间数据分析 【免费下载链接】h3 Hexagonal hierarchical geospatial indexing system 项目地址: https://gitcode.com/gh_mirrors/h3/h3 你是否曾为处理大规模地理空间数据而头疼?传统的地理索引系统在…...

目前专业的LED数码管屏厂商哪家好
在现代显示技术领域,LED数码管屏因其高亮度、低功耗和长寿命等特点,广泛应用于各种电子设备中。选择一家专业的LED数码管屏厂商至关重要。本文将为您推荐几家市场上表现突出的厂商,并进行详细对比。1. 杭州斡能电子有限公司公司简介ÿ…...

WarcraftHelper:魔兽争霸3现代兼容性解决方案,让你的经典游戏焕发新生
WarcraftHelper:魔兽争霸3现代兼容性解决方案,让你的经典游戏焕发新生 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 魔兽争霸…...