Windows NUMA编程实践 – 处理器组、组亲和性、处理器亲和性及版本变化
Windows在设计之初没有考虑过对大数量的多CPU和NUMA架构的设备的支持,大部分关于CPU的设计按照64个为上限来设计。核心数越来越多的多核处理器的进入市场使得微软不得不做较大的改动来进行支持,因此Windows 的进程、线程和NUMA API在各个版本中行为不一样,新版本逐步引入了新的API,微软官方文档中的介绍较为分散。本文旨在梳理和对比API的变动情况,同时考虑到对主流用户的兼容性,重点介绍使用Win7 API进行开发,并附带介绍Win 10 20385中的行为变化。
注1:以下正文中使用“处理器”、“cpu”、”核”的概念时,如没有特别说明,均是指“逻辑处理器”,即包括超线程核在内的不可再划分的处理器单元。
注2:以下正文中使用“节点”、“node”的概念时,如没有特别说明,均是指“逻辑node”,即包括由于单个物理node上cpu个数超过64而被Windows进一步划分成多个虚拟node的节点。
一、处理器组的概念
逻辑处理器与处理器组的关系
从Windows 7开始,当cpu数超过64时windows会将cpu分成处理器组(processor group),一个group最大能有64个cpu(由MAXIMUM_PROCESSORS宏定义),一般会将node内的所有cpu分到同一个group中,一个group也可以包括多个cpu较少的node,但cpu较多的node会被拆成多个虚拟node分别分配给不同group(会导致获取到的最大node数比实际的物理node数多!)。
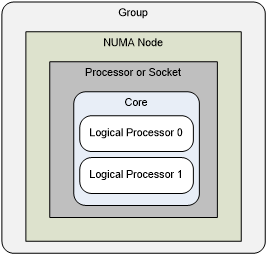
逻辑处理器由其组号及其组内编号标识,使用PROCESSOR_NUMBER 结构体表示,处理器亲和性则使用GROUP_AFFINITY结构体表示。例如,对于一个128核,划分为2个group的系统,全局编号为0的逻辑处理器,在组编号下Group = 0, Number = 0;全局编号为65的逻辑处理器,在组编号下为Group = 1, Number = 1。
typedef struct _PROCESSOR_NUMBER {WORD Group;BYTE Number;BYTE Reserved;
} PROCESSOR_NUMBER, *PPROCESSOR_NUMBER;typedef struct _GROUP_AFFINITY {KAFFINITY Mask;WORD Group;WORD Reserved[3];
} GROUP_AFFINITY, *PGROUP_AFFINITY;微软官方提供了一个命令行工具用于查看系统中拓扑和Group信息,
https://learn.microsoft.com/en-us/sysinternals/downloads/coreinfo,在任务管理器-详细信息-设置相关性中也可以看到Group信息。
NUMA节点与处理器组的关系
- + 一个(逻辑)node必定映射到某个group上
- + 一个group内可以有一或多个(逻辑)node
- + 一个(物理)node可能映射到一或多个group上
进程、线程与处理器组的关系
一个线程只能属于一个group,但由于进程内的不同线程可以处于不同group中,所以一个进程可以属于多个group。默认情况下,windows使用轮询算法为新的进程分配一个group,新创建的线程则继承创建它的线程的group,除非显式地指定线程的group亲和性。也就是说,如果程序代码不对设备上的group做识别,只是创建新的线程和使用旧的接口设置处理器亲和性的话,则最大能利用的cpu数只有group内的64个。
二、NUMA API
按照函数名排序
| 函数 | 描述 | 最低支持版本 |
|---|---|---|
| AllocateUserPhysicalPagesNuma | 分配要映射和取消映射的任何 地址窗口扩展 (指定进程的 AWE) 区域中的物理内存页,并为物理内存指定 NUMA 节点。 | WinVista |
| CreateFileMappingNuma | 为指定文件创建或打开命名或未命名的文件映射对象,并为物理内存指定 NUMA 节点。 | WinVista |
| GetLogicalProcessorInformation | 检索有关逻辑处理器和相关硬件的信息。 | WinXP(SP3) |
| GetLogicalProcessorInformationEx | 检索有关逻辑处理器和相关硬件关系的信息。 | Win7 |
| GetNumaAvailableMemoryNode | 检索指定UCHAR节点中的可用内存量。 | WinXP(SP2) |
| GetNumaAvailableMemoryNodeEx | 检索指定USHORT节点中的可用内存量。 | Win7 |
| GetNumaHighestNodeNumber | 检索当前具有的最大数目的节点。 | WinXP(SP2) |
| GetNumaNodeProcessorMask | 检索指定UCHAR节点的处理器掩码。 | WinXP(SP2) |
| GetNumaNodeProcessorMask2 | 检索指定节点的多组处理器掩码。 | Win10 20348 |
| GetNumaNodeProcessorMaskEx | 检索指定为USHORT值的节点的处理器掩码及其所在的group。 | Win7 |
| GetNumaProcessorNode | 检索指定处理器的UCHAR节点号。 | WinXP(SP2) |
| GetNumaProcessorNodeEx | 检索指定处理器的USHORT 节点号。 | Win7 |
| GetNumaProximityNode | 检索指定邻近度标识符的UCHAR节点号。 | WinVista |
| GetNumaProximityNodeEx | 检索节点号作为指定邻近标识符的USHORT值。 | Win7 |
| GetProcessDefaultCpuSetMasks | 检索由 SetProcessDefaultCpuSetMasks 或 SetProcessDefaultCpuSets 设置的进程默认集中 CPU 集的列表。 | Win10 20348 |
| GetThreadSelectedCpuSetMasks | 设置指定线程的所选 CPU 集分配。 如果设置了此分配,则此分配将替代进程默认分配。 | Win10 20348 |
| MapViewOfFileExNuma | 将映射的文件视图映射到调用进程的地址空间,并指定物理内存的 NUMA 节点。 | WinVista |
| SetProcessDefaultCpuSetMasks | 为指定进程中的线程设置默认的 CPU 集分配。 | Win10 20348 |
| SetThreadSelectedCpuSetMasks | 设置指定线程的所选 CPU 集分配。 如果设置了此分配,则此分配将替代进程默认分配。 | Win10 20348 |
| VirtualAllocExNuma | 在指定进程的虚拟地址空间中保留或提交内存区域,并为物理内存指定 NUMA 节点。 | WinVista |
可以发现,和NumaNode有关的函数,在Win7中添加的Ex版本都将Node的类型由UCHAR改为了USHORT以支持更大的node数。
按照最低版本排序
| 函数 | 描述 | 最低支持版本 |
|---|---|---|
| GetNumaAvailableMemoryNode | 检索指定UCHAR节点中的可用内存量。 | WinXP(SP2) |
| GetNumaHighestNodeNumber | 检索当前具有的最大数目的节点。 | WinXP(SP2) |
| GetNumaNodeProcessorMask | 检索指定UCHAR节点的处理器掩码。 | WinXP(SP2) |
| GetNumaProcessorNode | 检索指定处理器的UCHAR节点号。 | WinXP(SP2) |
| GetLogicalProcessorInformation | 检索有关逻辑处理器和相关硬件的信息。 | WinXP(SP3) |
| GetNumaProximityNode | 检索指定邻近度标识符的UCHAR节点号。 | WinVista |
| AllocateUserPhysicalPagesNuma | 分配要映射和取消映射的任何 地址窗口扩展 (指定进程的 AWE) 区域中的物理内存页,并为物理内存指定 NUMA 节点。 | WinVista |
| CreateFileMappingNuma | 为指定文件创建或打开命名或未命名的文件映射对象,并为物理内存指定 NUMA 节点。 | WinVista |
| MapViewOfFileExNuma | 将映射的文件视图映射到调用进程的地址空间,并指定物理内存的 NUMA 节点。 | WinVista |
| VirtualAllocExNuma | 在指定进程的虚拟地址空间中保留或提交内存区域,并为物理内存指定 NUMA 节点。 | WinVista |
| GetLogicalProcessorInformationEx | 检索有关逻辑处理器和相关硬件关系的信息。 | Win7 |
| GetNumaAvailableMemoryNodeEx | 检索指定USHORT节点中的可用内存量。 | Win7 |
| GetNumaNodeProcessorMaskEx | 检索指定为USHORT值的节点的处理器掩码及其所在的group。 | Win7 |
| GetNumaProcessorNodeEx | 检索指定处理器的USHORT 节点号。 | Win7 |
| GetNumaProximityNodeEx | 检索节点号作为指定邻近标识符的USHORT值。 | Win7 |
| GetProcessDefaultCpuSetMasks | 检索由 SetProcessDefaultCpuSetMasks 或 SetProcessDefaultCpuSets 设置的进程默认集中 CPU 集的列表。 | Win10 20348 |
| GetThreadSelectedCpuSetMasks | 设置指定线程的所选 CPU 集分配。 如果设置了此分配,则此分配将替代进程默认分配。 | Win10 20348 |
| SetProcessDefaultCpuSetMasks | 为指定进程中的线程设置默认的 CPU 集分配。 | Win10 20348 |
| SetThreadSelectedCpuSetMasks | 设置指定线程的所选 CPU 集分配。 如果设置了此分配,则此分配将替代进程默认分配。 | Win10 20348 |
| GetNumaNodeProcessorMask2 | 检索指定节点的多组处理器掩码。 | Win10 20348 |
三、进程、线程API
| 函数 | 描述 | 最低版本 |
|---|---|---|
| GetProcessAffinityMask | 检索指定进程的进程关联掩码和系统的系统关联掩码。 | WinXP |
| SetProcessAffinityMask | 为指定进程的线程设置处理器关联掩码。 | WinXP |
| SetThreadAffinityMask | 为指定线程设置处理器关联掩码。 | WinXP |
| GetProcessGroupAffinity | 检索指定进程的处理器组相关性。 | Win7 |
| GetThreadGroupAffinity | 检索指定线程的处理器组相关性。 | Win7 |
| SetThreadGroupAffinity | 设置指定线程的处理器组相关性。 | Win7 |
| SetThreadIdealProcessor | 设置线程的首选处理器。 系统尽可能在其首选处理器上计划线程。 | WinXP |
| SetThreadIdealProcessorEx | 设置指定线程的首选处理器,并选择性地检索上一个首选处理器。 | Win7 |
| CreateRemoteThreadEx | 创建线程。 | Win7 |
| GetActiveProcessorCount | 返回处理器组或系统中的活动处理器数。 | Win7 |
| GetActiveProcessorGroupCount | 返回系统中活动处理器组的数目。 | Win7 |
| GetCurrentProcessorNumber | 检索调用此函数时当前线程运行所在的处理器号。 | WinVista |
| GetCurrentProcessorNumberEx | 检索调用此函数时当前线程运行所在的处理器组和编号。 | Win7 |
Win7 引入的另一个变化是,SetThreadAffinityMask 和 SetThreadGroupAffinity 现在允许传入的Mask参数为0,代表使用组内的所有CPU。
四、受处理器分组影响的API
只有在系统中处理器数大于64时才会发生分组,否则系统中只有一个group 0,现有的函数在行为上没有变化。
| 函数 | 描述 | 影响 |
|---|---|---|
| GetLogicalProcessorInformation | 检索有关逻辑处理器和相关硬件的信息。 | 改动较多,参阅官方文档。主要变化是只能获取当前group中的处理器信息。 |
| GetLogicalProcessorInformationEx | 检索有关逻辑处理器和相关硬件关系的信息。 | Win7新增。参阅官方文档。能够获取所有组的处理器信息。 |
| GetNumaHighestNodeNumber | 检索当前具有的最大数目的节点。 | 返回的node数可能大于真实的物理node数。 |
| GetNumaNodeProcessorMask | 检索指定UCHAR节点的处理器掩码。 | 如果调用线程与指定的node不在同一group内,返回的处理器掩码为0。 |
| GetNumaNodeProcessorMaskEx | 检索指定为USHORT值的节点的处理器掩码及其所在的group。 | Win7新增。可以不考虑线程所在group,检索任意node。 |
| GetNumaProcessorNode | 检索指定处理器的UCHAR节点号。 | 传入的Processor参数变成组内编号。 |
| GetNumaProcessorNodeEx | 检索指定处理器的USHORT 节点号。 | Win7新增。传入的Processor参数类型为PPROCESSOR_NUMBER。 |
| GetProcessAffinityMask | 检索指定进程的进程关联掩码和系统的系统关联掩码。 | 返回的是组内掩码,如果进程处于多个group,则返回的掩码都为0。 |
| SetProcessAffinityMask | 为指定进程的线程设置处理器关联掩码。 | 传入的参数变为组内掩码;如果进程处于多个group,则返回值为0。 |
| SetThreadAffinityMask | 为指定线程设置处理器关联掩码。 | 传入的参数变为组内掩码。 |
| GetProcessGroupAffinity | 检索指定进程的处理器组相关性。 | Win7新增。 |
| GetThreadGroupAffinity | 检索指定线程的处理器组相关性。 | Win7新增。 |
| SetThreadGroupAffinity | 设置指定线程的处理器组相关性。 | Win7新增。 |
| SetThreadIdealProcessor | 设置线程的首选处理器。 系统尽可能在其首选处理器上计划线程。 | 传入参数变为组内编号。 |
| SetThreadIdealProcessorEx | 设置指定线程的首选处理器,并选择性地检索上一个首选处理器。 | Win7新增。传入的参数类型为PPROCESSOR_NUMBER。 |
| CreateRemoteThreadEx | 创建线程。 | Win7新增。允许用户在创建时指定线程的组亲和性。 |
| GetCurrentProcessorNumber | 检索调用此函数时当前线程运行所在的处理器号。 | 返回值变为组内编号。 |
| GetCurrentProcessorNumberEx | 检索调用此函数时当前线程运行所在的处理器组和编号。 | Win7新增。返回的参数类型为PPROCESSOR_NUMBER。 |
| GetSystemInfo | 检索有关当前系统的信息。 | 返回的 NumberOfProcessors 和 ActiveProcessorsAffinityMask 变为组内处理器信息。 |
总结一下,对于不识别group的现有函数,在引入group后其使用的处理器编号参数的含义变为组内编号,返回的处理器信息只有组内处理器信息。
五、内存绑定策略
Linux下的libnuma提供了独立的线程绑定策略和内存绑定策略,这给予了开发者将线程固定在某个cpu/node上运行的同时却能够在任意node上进行内存分配的灵活性。很可惜,Windows不提供这样的灵活性,没有独立的内存绑定策略,其默认的NUMA内存策略只有一种:在当前执行线程所在的node上进行内存分配,内存不足时到临近节点上分配。意味着我们在做NUMA内存管理时,只能在进行内存分配前,将当前线程切换到指定的cpu/node上运行。
虽然没有提供内存绑定策略这样灵活的机制,但是使用VirtualAllocExNuma函数依然可以在不改变处理器亲和性的情况下在任意的node上进行内存分配,但不方便的地方就是需要自己做内存页管理。具体请参考官方示例:从 NUMA 节点分配内存 - Win32 apps | Microsoft Learn
六、NUMA开发实例
如文章开头提到的,我们重点使用Win7提供的API,以下实例旨在提供一种类似于Linux上的全局逻辑处理器号的开发体验,让实际开发中不需要使用到group号+组内编号这样别扭的形式。
#include <iostream>
#include <string>
#include <windows.h>int max_group = 0;
int max_node = 0;
int max_cpu = 0;// 初始化
void NumaInitMaxCounts() {WORD group;ULONG node;// 获取最大的NUMA节点号GetNumaHighestNodeNumber(&node); // start from 0max_node = node + 1;// 获取系统中的processor group和总的cpu个数max_group = GetActiveProcessorGroupCount();for (group = 0; group < max_group; group++) {max_cpu += GetActiveProcessorCount(group); // 将所有group的cpu个数累加}
}// 将全局cpu号转换为组内编号
int NumaGetProcessorGroup(int cpu, _Out_ PROCESSOR_NUMBER *proc_num) {WORD group;int count;if (cpu < 0 || cpu >= max_cpu) {printf("NumaGetProcessorGroup: Invalid cpu %d", cpu);return -1;}for (group = 0; group < max_group; group++) {count = GetActiveProcessorCount(group);if (count - cpu - 1 >= 0) {proc_num->Group = group;proc_num->Number = cpu;return 0;}elsecpu -= count;}// should not reach herereturn -2;
}// 获取全局cpu号所在的node号
int NumaGetProcessorNode(int cpu) {BOOL bret;USHORT node;PROCESSOR_NUMBER proc_num = {};if (cpu < 0 || cpu >= max_cpu) {printf("NumaGetProcessorNode: Invalid cpu %d", cpu);return -1;}// 首先获取cpu组内编号if (NumaGetProcessorGroup(cpu, &proc_num) != 0)return -2;// 获取node号bret = GetNumaProcessorNodeEx(&proc_num, &node);if (!bret)return -2;return node;
}// 绑定线程到node上运行、分配内存
int NumaBindNode(USHORT node) {GROUP_AFFINITY gaffinity;GROUP_AFFINITY prev_gaffinity;BOOL bret;if (node >= max_node) {printf("NumaBindNode: Invalid node %u", node);return -1;}// 获取node下的所有cpu maskbret = GetNumaNodeProcessorMaskEx(node, &gaffinity);if (!bret)return -2;// 设置当前线程组CPU亲和性bret = SetThreadGroupAffinity(GetCurrentThread(), &gaffinity, &prev_gaffinity);if (!bret)return -2;return 0;
}// 绑定线程到cpu(全局cpu号)上运行、分配内存
int NumaBindProcessor(int cpu) {BOOL bret;int ret;PROCESSOR_NUMBER proc_num = {};GROUP_AFFINITY gaffinity = {};GROUP_AFFINITY prev_gaffinity = {};if (cpu < 0 || cpu >= max_cpu) {printf("NumaBindProcessor: Invalid cpu %d", cpu);return -1;}// 首先获取cpu组内编号ret = NumaGetProcessorGroup(cpu, &proc_num);if (ret < 0)return ret;gaffinity.Group = proc_num.Group;gaffinity.Mask = 1LL << proc_num.Number;// 设置当前线程组CPU亲和性bret = SetThreadGroupAffinity(GetCurrentThread(), &gaffinity, &prev_gaffinity);if (!bret)return -2;return 0;
}上述实例中提供了两种使用方式,一种是基于全局逻辑处理器号NumaBindProcessor(),以及基于node号的NumaBindNode()。
尽管(逻辑)node和group不是一种从属的关系,而是一种单映射关系(一个node对应于一个group,反之不然),但是node下的cpu是从属于某个group下的,这一点从GetNumaNodeProcessorMaskEx()返回的Mask中带有Group号可以看到,因此我们还是应当使用识别group的API来设置进程、线程亲和性。
七、从 Windows 10 内部版本 20348 开始的行为
没错,又变了!(-_-||)但幸好影响到的现有API只有4个。
Win 10 Build 20348,这个版本并没有发布给普通的Win 10用户,它与Windows Server 2022发布版本的版本号一致,在Windows SDK页面上也注明了该版本主要用于Server开发的用途,新增的API函数参考页面则直接注明最低支持版本为Win 11。所以,如果使用该API开发的话,基本上等同于目标群体为Win 11/Win Server 2022用户。
从 Windows 10 内部版本 20348 (部分文档中称为Iron Build)开始,为更好地支持包含 64 个以上处理器的NUMA系统,部分NUMA及相关函数的行为发生了变动。
创建“假”节点以适应组和节点之间的 1:1 映射的关系会导致出现混淆行为,即报告的 NUMA 节点数与物理节点数不符,因此,从 Windows 10 Build 20348 开始,OS 行为已做更改,停止创建"假"节点并允许多个组与一个node相关联,因此现在可以报告系统的真实 NUMA 拓扑。
作为 OS 的这些更改的一部分,许多 NUMA API 已更改,以支持报告node上的多个组。同时为兼容旧API,系统默认为每个节点分配一个主组。
由于删除节点拆分可能会影响现有应用程序,因此允许使用注册表值来选择重新启用旧的节点拆分行为。 可以通过在HKEY_LOCAL_MACHINE\System\CurrentControlSet\Control\NUMA下创建名为“SplitLargeNodes”的 REG_DWORD 值来重新启用节点拆分。 对此设置的更改需要重启才会生效。
reg add "HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\NUMA" /v SplitLargeNodes /t REG_DWORD /d 1从 Windows 11 和 Windows Server 2022 开始,在具有 64 个以上的处理器的设备上,进程和线程的相关性默认情况下将包括所有处理器组中的所有处理器。
新增及改动的API
| 函数 | 描述 | 影响 |
|---|---|---|
| GetLogicalProcessorInformation | 检索有关逻辑处理器和相关硬件的信息。 | RelationNumaNode 返回的是调用线程所在group的信息。 |
| GetLogicalProcessorInformationEx | 检索有关逻辑处理器和相关硬件关系的信息。 | RelationNumaNode 返回的是node所对应主group的信息,GroupCount的值为1。新增RelationNumaNodeEx。 |
| GetNumaNodeProcessorMask | 检索指定UCHAR节点的处理器掩码。 | 只返回node所对应主group的信息,并且仅在调用线程属于该group时返回。 |
| GetNumaNodeProcessorMaskEx | 检索指定为USHORT值的节点的处理器掩码及其所在的group。 | 只返回node所对应主group的信息。 |
| GetProcessDefaultCpuSetMasks | 检索由 SetProcessDefaultCpuSetMasks 或 SetProcessDefaultCpuSets 设置的进程默认集中 CPU 集的列表。 | 新增。 |
| GetThreadSelectedCpuSetMasks | 设置指定线程的所选 CPU 集分配。 如果设置了此分配,则此分配将替代进程默认分配。 | 新增。 |
| SetProcessDefaultCpuSetMasks | 为指定进程中的线程设置默认的 CPU 集分配。 | 新增。 |
| SetThreadSelectedCpuSetMasks | 设置指定线程的所选 CPU 集分配。 如果设置了此分配,则此分配将替代进程默认分配。 | 新增。 |
| GetNumaNodeProcessorMask2 | 检索指定节点的多组处理器掩码。 | 新增。 |
为了适应新的行为,建议新的代码都使用GetNumaNodeProcessorMask2。
八、进程、线程对亲和性的继承
Linux下将线程作为调度的单元,不区分进程和线程,新的线程/进程直接继承创建它的线程的处理器亲和性和内存策略。但是Windows下区分进程和线程,Mask和Group又拥有不同的继承策略:
| 进程 | 线程 | |
| Mask | 新进程默认继承父进程的掩码 | 新线程默认继承进程(process)的掩码 |
| Group | 新进程由OS以轮转方式分配一个Group | 新线程默认继承创建它的线程(thread)的Group |
如果需要在创建时指定亲和性,可以使用:
CreateRemoteThreadEx() + PROC_THREAD_ATTRIBUTE_GROUP_AFFINITY
CreateProcess() + INHERIT_PARENT_AFFINITY,注意如果父进程属于多个group,则从中随机选取一个分配给新进程。
参考:
> Process Creation Flags (WinBase.h) - Win32 apps | Microsoft Learn
> MoreThan64proc.docx "Group, Process, and Thread Affinity" 小节
验证线程对Mask的继承:
#include <iostream>
#include <string>
#include <windows.h>DWORD __stdcall func2(LPVOID arg) {BOOL bret;GROUP_AFFINITY gaffinity = {};GROUP_AFFINITY prev_gaffinity = {};PROCESSOR_NUMBER proc_num = {};bret = GetThreadGroupAffinity(GetCurrentThread(), &gaffinity);printf("ret = %d, Thread 2 ThreadGroupAffinity Group = %u, Mask = %llu\n", bret, gaffinity.Group, gaffinity.Mask);GetCurrentProcessorNumberEx(&proc_num);printf("Thread 2 CurrentProcessorGroup = %u, CurrentProcessorNum = %u\n", proc_num.Group, proc_num.Number);Sleep(100);return 0;
}DWORD __stdcall func1(LPVOID arg) {BOOL bret;GROUP_AFFINITY gaffinity = {};GROUP_AFFINITY prev_gaffinity = {};gaffinity.Group = 0;gaffinity.Mask = 1; // 设置线程1 使用 CPU 0bret = SetThreadGroupAffinity(GetCurrentThread(), &gaffinity, &prev_gaffinity);printf("ret = %d, Thread 1 prev ThreadGroupAffinity Group = %u, Mask = %llu\n", bret, prev_gaffinity.Group, prev_gaffinity.Mask);bret = GetThreadGroupAffinity(GetCurrentThread(), &gaffinity);printf("ret = %d, Thread 1 new ThreadGroupAffinity Group = %u, Mask = %llu\n", bret, gaffinity.Group, gaffinity.Mask);// 创建线程2CreateThread(NULL, 4096, func2, NULL, 0, NULL);Sleep(500);return 0;
}int main() {BOOL bret;PROCESSOR_NUMBER proc_num = {};GROUP_AFFINITY gaffinity = {};DWORD_PTR mask;DWORD_PTR sysmask;// 设置process Mask为 CPU 0~3mask = pow(2, 4) - 1;SetProcessAffinityMask(GetCurrentProcess(), mask);bret = GetProcessAffinityMask(GetCurrentProcess(), &mask, &sysmask);printf("ret = %d, ProcessAffinityMask = %llu, SystemMask = %llu\n", bret, mask, sysmask);// 设置process Mask为 CPU 0 + CPU 1gaffinity.Group = 0;gaffinity.Mask = mask = pow(2, 2) - 1;bret = SetThreadGroupAffinity(GetCurrentThread(), &gaffinity, nullptr);bret = GetThreadGroupAffinity(GetCurrentThread(), &gaffinity);printf("ret = %d, Main ThreadGroupAffinity Group = %u, Mask = %llu\n", bret, gaffinity.Group, gaffinity.Mask);CreateThread(NULL, 4096, func1, NULL, 0, NULL);Sleep(1000);return 0;
}在我的有4个处理器设备上运行的结果如下:
ret = 1, ProcessAffinityMask = 15, SystemMask = 15
ret = 1, Main ThreadGroupAffinity Group = 0, Mask = 3
ret = 1, Thread 1 prev ThreadGroupAffinity Group = 0, Mask = 15
ret = 1, Thread 1 new ThreadGroupAffinity Group = 0, Mask = 1
ret = 1, Thread 2 ThreadGroupAffinity Group = 0, Mask = 15
Thread 2 CurrentProcessorGroup = 0, CurrentProcessorNum = 1
九、总结
1. 自Win7引入处理器组开始,原有的不识别group的函数,参数和返回值都变成组内编号/信息。
2. 自Win10 20348 由于node可以关联多个group,引入“主组”之后,原有的node相关不支持多个group的函数,参数和返回值都变成主组信息。
参考资料
NUMA 支持 - Win32 apps | Microsoft Learn
处理器组 - Win32 apps | Microsoft Learn
What's New in Processes and Threads - Win32 apps | Microsoft Learn
download.microsoft.com/download/a/d/f/adf1347d-08dc-41a4-9084-623b1194d4b2/
MoreThan64proc.docx
White Paper "Supporting Systems That Have More Than 64 Processors" 介绍处理器组最全面的文档!
从 NUMA 节点分配内存 - Win32 apps | Microsoft Learn
Windows SDK and emulator archive | Microsoft Developer
Windows Server 2022 Now Generally Available - Microsoft Community Hub
Coreinfo - Sysinternals | Microsoft Learnhhansh
相关文章:
Windows NUMA编程实践 – 处理器组、组亲和性、处理器亲和性及版本变化
Windows在设计之初没有考虑过对大数量的多CPU和NUMA架构的设备的支持,大部分关于CPU的设计按照64个为上限来设计。核心数越来越多的多核处理器的进入市场使得微软不得不做较大的改动来进行支持,因此Windows 的进程、线程和NUMA API在各个版本中行为不一样…...
MATLAB中编译器中的变量联系到Simulink
MATLAB中编译器中的变量联系到Simulink 现在编译器中创建变量,进行编译,使其生成在工作区。 然后在Simulink中国使用变量即可。...

开展自动化方案时,需要考虑哪些内容,开展实施前需要做哪些准备呢?
在开展软件自动化测试方案时,需要考虑以下方面: 选择合适的自动化测试工具:根据项目的需求和技术栈选择适合的自动化测试工具,如Selenium、Appium、Jenkins等。确定自动化测试范围:明确需要自动化的功能模块和业务场景…...

进程、线程、内存管理
目录 进程和线程区别 进程和线程切换的区别 系统调用流程 系统调用是否会引起线程切换 为什么需要使用虚拟内存 进程和线程区别 本质区别: 进程是资源分配的基本单元。 线程是操作系统调度的基本单元。 地址空间: 进程具有独立的虚拟地址空间。 线程…...
设计模式系列-创建者模式
一、上篇回顾 上篇我们主要讲述了抽象工厂模式和工厂模式。并且分析了该模式的应用场景和一些优缺点,并且给出了一些实现的思路和方案,我们现在来回顾一下: 抽象工厂模式:一个工厂负责所有类型对象的创建,支持无缝的新增新的类型对…...

加工生产调度
题目描述 某工厂收到了 n 个产品的订单,这 n 个产品分别在 A、B 两个车间加工,并且必须先在 A 车间加工后才可以到 B 车间加工。 某个产品 在 A,B 两车间加工的时间分别为 。怎样安排这 n 个产品的加工顺序,才能使总的加工时间…...
Hadoop 集群小文件归档 HAR、小文件优化 Uber 模式
文章目录 小文件归档 HAR小文件优化 Uber 模式 小文件归档 HAR 小文件归档是指将大量小文件合并成较大的文件,从而减少存储开销、元数据管理的开销以及处理时的任务调度开销。 这里我们通过 Hadoop Archive (HAR) 来进行实现,它是一种归档格式…...

Android OkHttp源码阅读详解一
博主前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住也分享一下给大家 👉点击跳转到教程 前言:源码阅读基于okhttp:3.10.0 Android中OkHttp源码阅读二(责任链模式) implementation com.squareup.o…...

UG\NX CAM二次开发 查询工序所在的方法组TAG UF_OPER_ask_method_group
文章作者:代工 来源网站:NX CAM二次开发专栏 简介: UG\NX CAM二次开发 查询工序所在的方法组TAG UF_OPER_ask_method_group 效果: 代码: void MyClass::do_it() { int count=0;tag_t * objects;UF_UI_ONT_ask_selected_nodes(&count, &objects);for (i…...

npm获取函数名称和测试js脚本
这边遇到一个类似于测试的需求,需要从一个js文件里获取函数名,然后尝试执行这些函数和创建实例。这边首先遇到了一个问题是如何动态获取js里的函数名和类名,我这边暂时没找到特别好的方法,已有的方法都是类似于提取语法树那种提取…...

ISO/IEC/ITU标准如何快速查找(三十九)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 人生格言: 人生从来没有捷径,只有行动才是治疗恐惧和懒惰的唯一良药. 更多原创,欢迎关注:Android…...
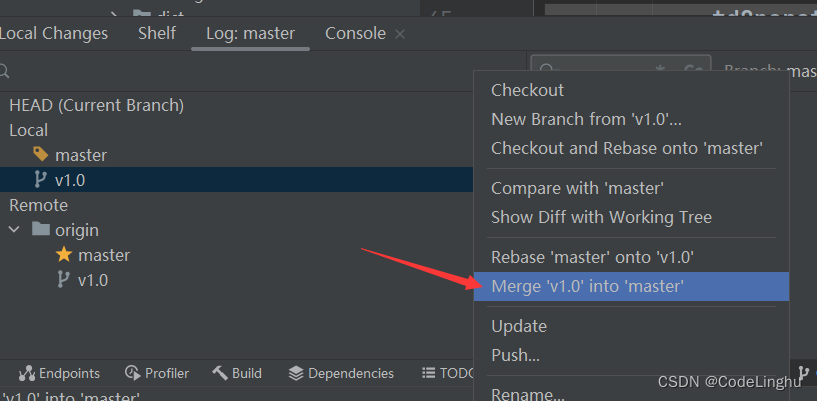
git私房菜
文章目录 1、公司项目开发Git协作流程2、合并相关的操作3、Git常用命令总结 公司中如何使用Git协同开发的?本文将具体介绍开发模式,以及一些常用命令。 1、公司项目开发Git协作流程 公司一个完整的项目出来,项目的推进是在主分支master上进行…...
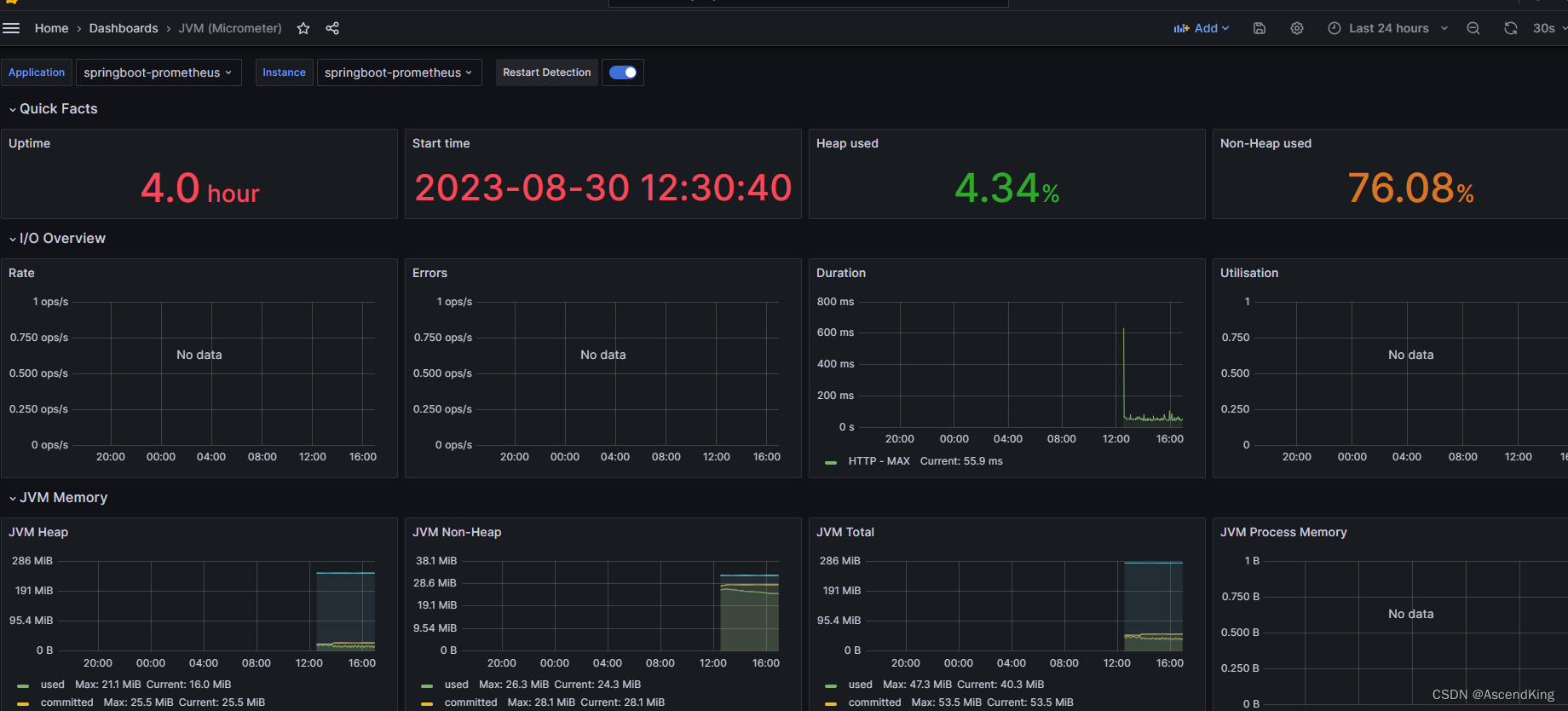
docker安装grafana,prometheus,exporter以及springboot整合详细教程(GPE)
springboot项目ip:192.168.168.1 测试服务器ip:192.168.168.81 文章来自互联网,自己略微整理下,更容易上手,方便自己,方便大家 最终效果: node springboot 1.下载镜像 docker pull prom/node-exporter docker pull prom/mysqld-exporter docker pull google/cadvisor dock…...

cka/ckad应试指南 从docker到kubernetes完全攻略
《cka/ckad应试指南 从docker到kubernetes完全攻略》 段超飞 docker 1-安装并配置docker,yum源,docker下载慢 2-基本命令:镜像管理,基本命令,创建容器 3-网络,存储卷,镜像仓库, 4-do…...

js中如何使用可选函数参数
js是网络的核心技术之一。大多数网站都使用它,并且所有现代网络浏览器都支持它,而不需要插件。在本文中,我们将讨论不同的提示和技巧,它们将帮助您进行日常 JavaScript 开发。 在 JavaScript 编码中,您经常需要将函数…...

基于Open3D的点云处理17-Open3d的C++版本
参考: http://www.open3d.org/docs/latest/cpp_api.htmlhttp://www.open3d.org/docs/latest/getting_started.html#chttp://www.open3d.org/docs/release/cpp_project.html#cplusplus-example-projecthttps://github.com/isl-org/open3d-cmake-find-packagehttps:/…...

GIT相关内容总结
Git相关内容总结 Git的功能Git常见命令 Git的功能 Git是版本控制工具。版本控制就是记录你对文件做的所有改动的一个系统,包括改动的内容,改动的时间,改动的备注等,便于你恢复特定的版本。 版本控制系统分为本地版本控制系统&…...

golang清空数组的方法
在Go语言中,数组是固定长度的数据结构,无法直接清空。但是,你可以通过以下两种方法来模拟清空数组的效果: 使用切片(Slicing): 切片是动态长度的,可以用来清空数组。你可以创建一个…...

postgresql并行查询(高级特性)
######################## 并行查询 postgresql和Oracle一样支持并行查询的,比如select、update、delete大事无开启并行功能后,能够利用多核cpu,从而充分发挥硬件性能,提升大事物的处理效率。 pg在9.6的版本之前是不支持的并行查询的,从9.6开始支持并行查询,但是功能非常…...
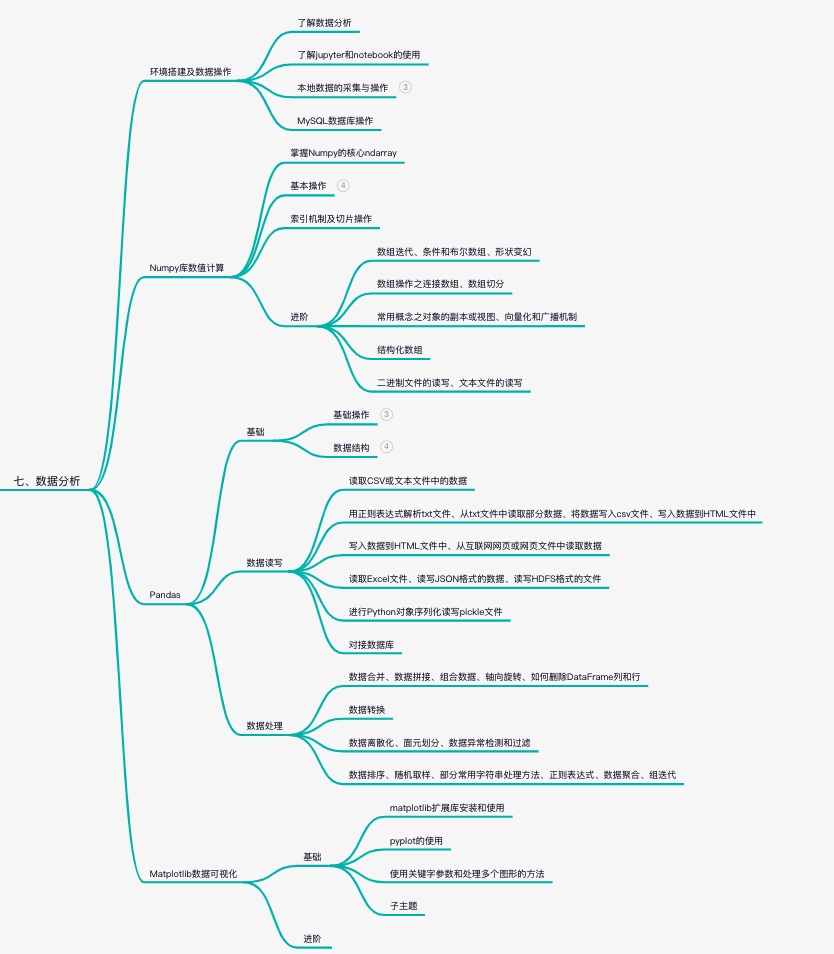
Python所有方向的学习路线图!!
学习路线图上面写的是某个方向建议学习和掌握的知识点汇总,举个例子,如果你要学习爬虫,那么你就去学Python爬虫学习路线图上面的知识点,这样学下来之后,你的知识体系是比较全面的,比起在网上找到什么就学什…...

eNSP安装避坑指南:WinPcap/Wireshark/VirtualBox依赖关系解析
eNSP安装避坑指南:WinPcap/Wireshark/VirtualBox依赖关系解析 当你第一次打开eNSP安装包时,可能会疑惑为什么需要同时安装WinPcap、Wireshark和VirtualBox这三个看似不相关的软件。这就像组装一台精密仪器——少了任何一个螺丝,整台机器都无法…...

3步实现BERT模型轻量化部署与性能优化:基于Torch-Pruning的结构化剪枝指南
3步实现BERT模型轻量化部署与性能优化:基于Torch-Pruning的结构化剪枝指南 【免费下载链接】Torch-Pruning [CVPR 2023] Towards Any Structural Pruning; LLMs / Diffusion / Transformers / YOLOv8 / CNNs 项目地址: https://gitcode.com/gh_mirrors/to/Torch-P…...

3步解锁音乐自由:NCMDump帮你破解网易云音乐NCM格式
3步解锁音乐自由:NCMDump帮你破解网易云音乐NCM格式 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为下载的网易云音乐只能在特定App里播放而烦恼吗?当你精心挑选的歌单无法在车载音响、运动手表或家庭音…...

显卡驱动深度清理指南:用DDU解决驱动残留难题
显卡驱动深度清理指南:用DDU解决驱动残留难题 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirrors/di/display-drivers-uninstaller 你是…...
)
【Mojo-Python互操作黄金标准】:基于CPython 3.12+Mojo 0.5.2的ABI兼容性白皮书(仅限首批200名开发者获取)
第一章:Mojo-Python互操作的ABI兼容性基石Mojo 语言设计之初即明确将 Python 生态无缝集成作为核心目标,其 ABI(Application Binary Interface)兼容性并非运行时桥接或胶水层模拟,而是通过底层统一的 CPython 对象模型…...
)
Vivado 2019.2实战:手把手教你封装自己的UART串口IP核(含参数化配置避坑指南)
Vivado 2019.2实战:从零构建可配置UART IP核的完整指南 在FPGA开发中,UART通信是最基础也最常用的功能之一。每次新项目都重新编写UART驱动不仅效率低下,还容易引入错误。本文将带你完整经历将一个经过验证的UART发送模块封装成可配置IP核的全…...

从零开始:用Chipyard和FireSim在云端FPGA上仿真你的第一个RISC-V SoC
从零开始:用Chipyard和FireSim在云端FPGA上仿真你的第一个RISC-V SoC 在数字时代,RISC-V架构以其开放性和灵活性正在重塑计算领域。对于渴望探索SoC设计的开发者而言,云端FPGA资源与开源工具链的结合,彻底打破了硬件开发的高门槛。…...

从卡顿到流畅:Win11Debloat开源工具3步解决Windows系统优化难题
从卡顿到流畅:Win11Debloat开源工具3步解决Windows系统优化难题 【免费下载链接】Win11Debloat 一个简单的PowerShell脚本,用于从Windows中移除预装的无用软件,禁用遥测,从Windows搜索中移除Bing,以及执行各种其他更改…...

【限时开源】FastAPI 2.0 AI流式SDK v1.0:内置token计数、流控限速、断点续传、前端SSE自动重连——仅开放首批200个GitHub Star领取资格
第一章:FastAPI 2.0 异步 AI 流式响应的核心演进与架构定位FastAPI 2.0 将原生异步流式响应能力从实验性支持升级为一级公民,彻底重构了 AI 应用服务端的实时交互范式。其核心演进体现在对 StreamingResponse 的深度重写、对 ASGI 3.0 协议的精准适配&am…...
)
三极管实战指南:从NPN到PNP,手把手教你识别与使用(附常见误区解析)
三极管实战指南:从NPN到PNP,手把手教你识别与使用(附常见误区解析) 在电子设计的世界里,三极管就像电路中的"水龙头",控制着电流的流动。无论是简单的LED驱动电路,还是复杂的音频放大…...