ClickHouse进阶(五):副本与分片-1-副本与分片

进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容!
🏡个人主页:含各种IT体系技术,IT贫道_Apache Doris,大数据OLAP体系技术栈,Kerberos安全认证-CSDN博客
📌订阅:拥抱独家专题,你的订阅将点燃我的创作热情!
👍点赞:赞同优秀创作,你的点赞是对我创作最大的认可!
⭐️ 收藏:收藏原创博文,让我们一起打造IT界的荣耀与辉煌!
✏️评论:留下心声墨迹,你的评论将是我努力改进的方向!
目录
1. 数据副本
2. 数据分片
clickhouse数据存储时支持副本和分片,副本指的就是一份数据可以在不同的节点上存储,这些节点上存储的每份数据相同,数据副本是增加数据存储冗余来防止数据丢失。分片指的是clickhouse一张表的数据可以横向切分为多份,每份中的数据不相同且存储在不同的节点上,分片的目的主要是实现数据的水平切分,方便多线程和分布式查询数据。
这里以由3台clickhouse节点组成的clickhouse集群对应的几张图来描述clickhouse中的副本与分片,方便大家理解:
- 表temp只有一个分片,1个副本(数据本身可看成1个副本)
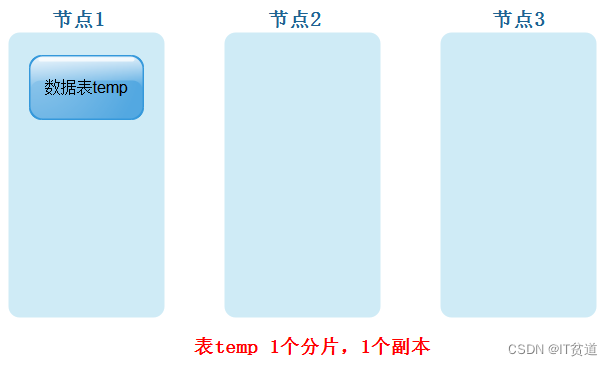
- 表temp只有一个分片,每个分片有1个副本
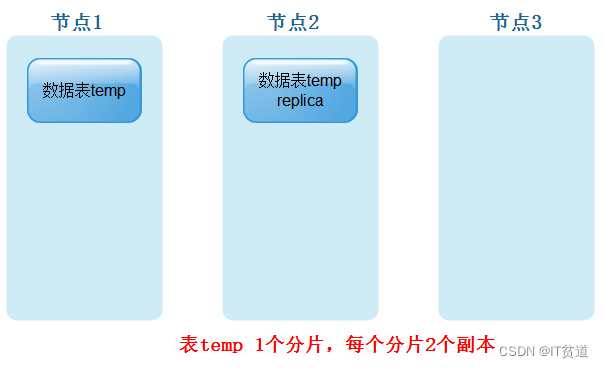
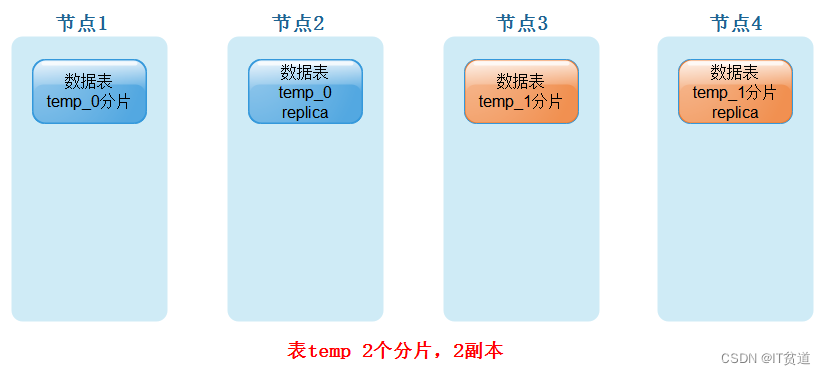
- 表temp有2个分片,每个分片有1个副本
1. 数据副本
存储在clickhouse中的数据想要有副本,创建表时需要在对应的表引擎前面加上“Replicated”前缀组成一种新的变种引擎,并且目前只有MergeTree系列表引擎才支持副本,如下图所示:

下面我们以ReplicatedMergeTree引擎来举例讲解clickhouse中的数据副本。
创建副本表语法:
Engine = ReplicatedMergeTree('zk_path','replica_name')在上述创建语法中,有zk_path和replica_name两项配置,代表意思如下:
- zk_path:
在zookeeper中创建的数据表的路径,路径名称可以自定义,用户可以自己定义成希望的任何路径。clickhouse提供了一些约定俗成的配置模板:/clickhouse/tables/{shard}/table_name ,其中“/clickhouse/tables”是约定俗成的路径固定前缀,表示存放数据表的根路径;“{shard}”表示分片编号,通常使用数值代替,例如:01,02,03,一张数据表可以有多个分片,而每个分片都拥有自己的副本;“table_name”表示数据表的名称,通常与物理表的名字相同。
- replica_name:
定义在zookeeper中创建的副本名称,该名称是区分不同副本实例的唯一标识,一种约定俗成的命名方式是使用所在服务器的域名称。
创建副本表举例,我们在node1节点进入clickhouse,执行如下建表语句:
Create table person_info(id UInt32,name String,age UInt32,gender String,loc String) engine = ReplicatedMergeTree('/clickhouse/tables/01/person_info','node1')partition by locorder by id;在node2节点进入clickhouse,执行如下建表语句:
Create table person_info(id UInt32,name String,age UInt32,gender String,loc String) engine = ReplicatedMergeTree('/clickhouse/tables/01/person_info','node2')partition by locorder by id;以上两张表创建完成之后,在zookeeper中会看到创建“/clickhouse/tables/01/person_info”路径,对此路径下的部分重要目录解释如下:
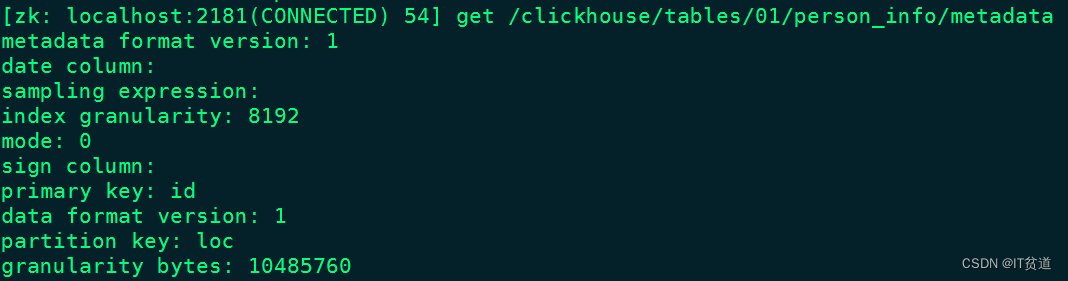
- /metadata:
保存元数据信息,包括主键、分区键、采样表达式。
- /columns:
保存列字段信息,包括列名称和数据类型。
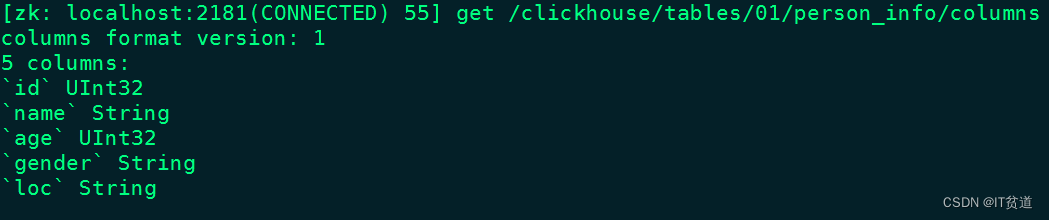
- /replicas:
保存副本名称,对应设置参数中的replica_name。


- /leader_election:
用于主副本的选举工作,主副本主要负责merge、Alter delte 、alter update操作。



在node1向表“person_info”中插入以下数据:
insert into person_info values (1,'zs',18,'m','beijing'),(2,'ls',19,'f','shanghai'),(3,'ww',20,'m','beijing'),(4,'ml',21,'m','shanghai')插入数据之后,我们在node1上进行查询:
select * from person_info;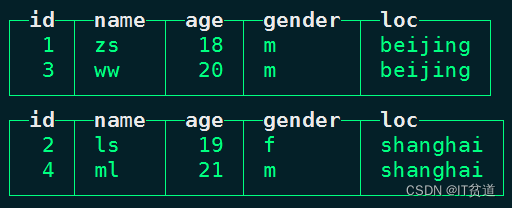
由于有副本作用,在node2节点上我们同样也可以查询到表person_info中的数据:
select * from person_info;
以上在node1节点或者node2节点上表“person_info”中插入数据时,都会通过zookeeper的监听,立即同步到另外节点,可以在node1,node2节点“/var/lib/clickhouse/data/default/person_info”路径下发现相同的一份数据。


2. 数据分片
通过数据副本我们可以降低数据丢失的风险,到现在为止每个副本上都有表全量数据,当业务量十分庞大的场景下,依靠副本并不能解决单表的新能瓶颈,我们可以对一张表水平分为多个分片,这些分片分别存储在不同的clickhouse集群节点中。例如一个clickhouse集群有3台节点,我们在创建表temp时可以分成3个分片,这3个分片内的数据不相同,分别存储在不同的clickhouse节点上,当然为了保证数据的高可用也可以给每个分片设置副本。
特别注意:在clickhouse中,每个节点只能配置在一个<shard>标签下的<replica>中,不能与其他的<shard>标签下的<replica>节点名称相同。例如:配置一个clickhouse集群拥有3个分片,且每个分片有2个副本,那么metrika.xml配置文件配置如下:
<remote_servers><clickhouse_cluster_3shards_2replicas><shard><internal_replication>true</internal_replication><replica><host>node1</host><port>9000</port></replica><replica><host>node2</host><port>9000</port></replica></shard><shard><internal_replication>true</internal_replication><replica><host>node3</host><port>9000</port></replica><replica><host>node4</host><port>9000</port></replica></shard><shard><internal_replication>true</internal_replication><replica><host>node5</host><port>9000</port></replica><replica><host>node6</host><port>9000</port></replica></shard></clickhouse_cluster_3shards_1replicas></remote_servers>以上完成配置拥有3个分片,2个副本的clickhouse集群需要6台节点。
在介绍副本时,为了创建多张表我们需要分别登录到不同的clickhouse节点,在各自的clickhouse节点上执行create建表命令,创建的表名称都是一样的,这是因为Create、Drop、Rename、Alter等DDL语句并不支持分布式执行,而在分布式的clickhouse集群中我们可以使用新的语法实现分布式DDL,其语法格式为:
CREATE/DROP/RENAME/ALTER TABLE xxx ON CLUSTER cluste_name其中以上“xxx”代表创建的表名称,“cluster_name”对应前面集群配置文件metrika.xml中的集群名称,根据配置文件,clickhouse会根据集群的配置信息,找到每个节点执行DDL语句,“xxx”表也会在各个节点上被创建。
创建具有3分片和1副本的表“person_score”,建表语句如下:
Create table person_score on cluster clickhouse_cluster_3shards_1replicas (id UInt32,name String,age UInt32,gender String,score Decimal(9,2))engine = ReplicatedMergeTree('/clickhouse/tables/{shard}/person_score','{replica}')order by id;注意:
- 以上“clickhouse_cluster_3shards_1replicas”是在“/etc/clickhouse-server/config.d/metrika.xml”配置文件中配置的clickhouse集群的名称
- {shard}与{replica}两个变量是在metrika.xml中<macros>宏变量标签中配置的对应值,这样当在clickhouse集群中的某台节点执行以上建表语句时,clickhouse会自动在各个节点创建此表,这里每台clickhouse节点上的表person_socre是本地表。
可以在zookeeper中找到查看对应的分片信息:
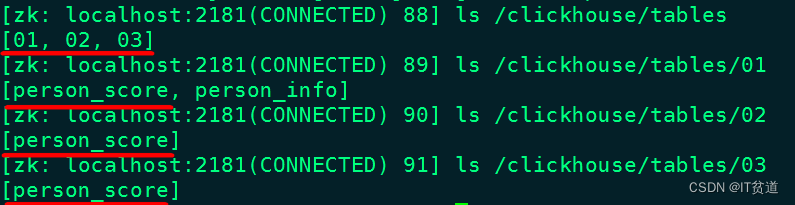
向表person_score中插入数据,在哪台clickhouse节点向本地表person_score中插入数据,那么数据就存入当前本地表对应的分片中。
#在node1向node1本地表person_score中插入以下数据:
insert into person_score values (1,'zs',18,'m',100),(2,'ls',19,'f',200);#在node1上查询本地表 person_score数据:
node1 :) select * from person_score;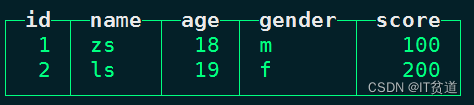
#在node2向node2本地表person_score中插入以下数据:
insert into person_score values (3,'ww',20,'m',300),(4,'ml',21,'m',400);#在node2上查询本地表 person_score数据:
node2 :) select * from person_score;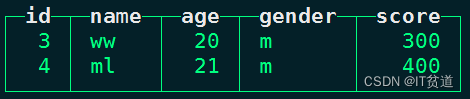
#在node3向node3本地表person_score中插入以下数据:
insert into person_score values (5,'ml',22,'f',500),(6,'tq',23,'f',600);#在node3上查询本地表 person_score数据:
node3 :) select * from person_score;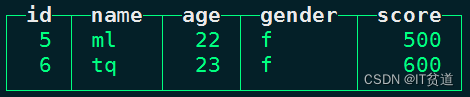
以上我们创建的person_score表在clickhouse集群节点node1、node2、node3上都是本地表,插入数据时插入到了对应节点的分片上,查询时也只能查询对应节点上的分片数据,如果我们想要通过一张表将各个clickhouse节点上的person_score表进行查询,这时就需要使用Distribute表引擎,所以在实际工作中clickhouse的数据分片需要结合Distriubute表引擎一同使用。
👨💻如需博文中的资料请私信博主。
相关文章:
ClickHouse进阶(五):副本与分片-1-副本与分片
进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容! 🏡个人主页:含各种IT体系技术,IT贫道_Apache Doris,大数据OLAP体系技术栈,Kerberos安全认证-CSDN博客 📌订阅…...

Android 华为手机荣耀8X调用系统裁剪工具不能裁剪方形图片,裁剪后程序就奔溃,裁剪后获取不到bitmap的问题
买了个华为荣耀8X,安装自己写的App后,调用系统裁剪工具发现裁剪是圆形的,解决办法: //专门针对华为手机解决华为手机裁剪图片是圆形图片的问题 if (Build.MANUFACTURER.equals("HUAWEI")) {intent.putExtra("aspectX", 9998);intent.putExtra("a…...
《Flink学习笔记》——第十二章 Flink CEP
12.1 基本概念 12.1.1 CEP是什么 1.什么是CEP? 答:所谓 CEP,其实就是“复杂事件处理(Complex Event Processing)”的缩写;而 Flink CEP,就是 Flink 实现的一个用于复杂事件处理的库(…...

谷歌IndexedDB客户端存储数据
IndexedDB 具有以下主要特点: 1.存储大量数据:IndexedDB 可以存储大量的数据,比如存储离线应用程序的本地缓存或存储在线应用程序的大量数据。 2.结构化数据:IndexedDB 使用对象存储空间(Object Stores)来…...

天气数据的宝库:解锁天气预报API的无限可能性
前言 天气预报一直是我们日常生活中的重要组成部分。我们依赖天气预报来决定穿什么衣服、何时出行、规划户外活动以及做出关于农业、交通和能源管理等方面的重要决策。然而,要提供准确的天气预报,需要庞大的数据集和复杂的计算模型。这就是天气预报API的…...
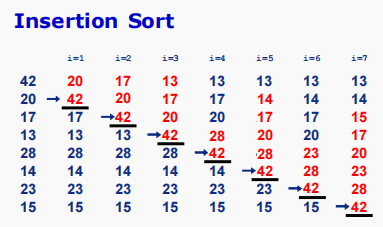
插入排序(Insertion Sort)
C自学精简教程 目录(必读) 插入排序 每次选择未排序子数组中的第一个元素,从后往前,插入放到已排序子数组中,保持子数组有序。 打扑克牌,起牌。 输入数据 42 20 17 13 28 14 23 15 执行过程 完整代码 #include <iostream…...
2023蓝帽杯初赛
最近打完蓝帽杯 现在进行复盘 re 签到题 直接查看源代码 输出的内容就是 变量s 变量 number 而这都是已经设定好了的 所以flag就出来了 WhatisYourStory34982733 取证 案件介绍 取证案情介绍: 2021年5月,公安机关侦破了一起投资理财诈骗类案件&a…...
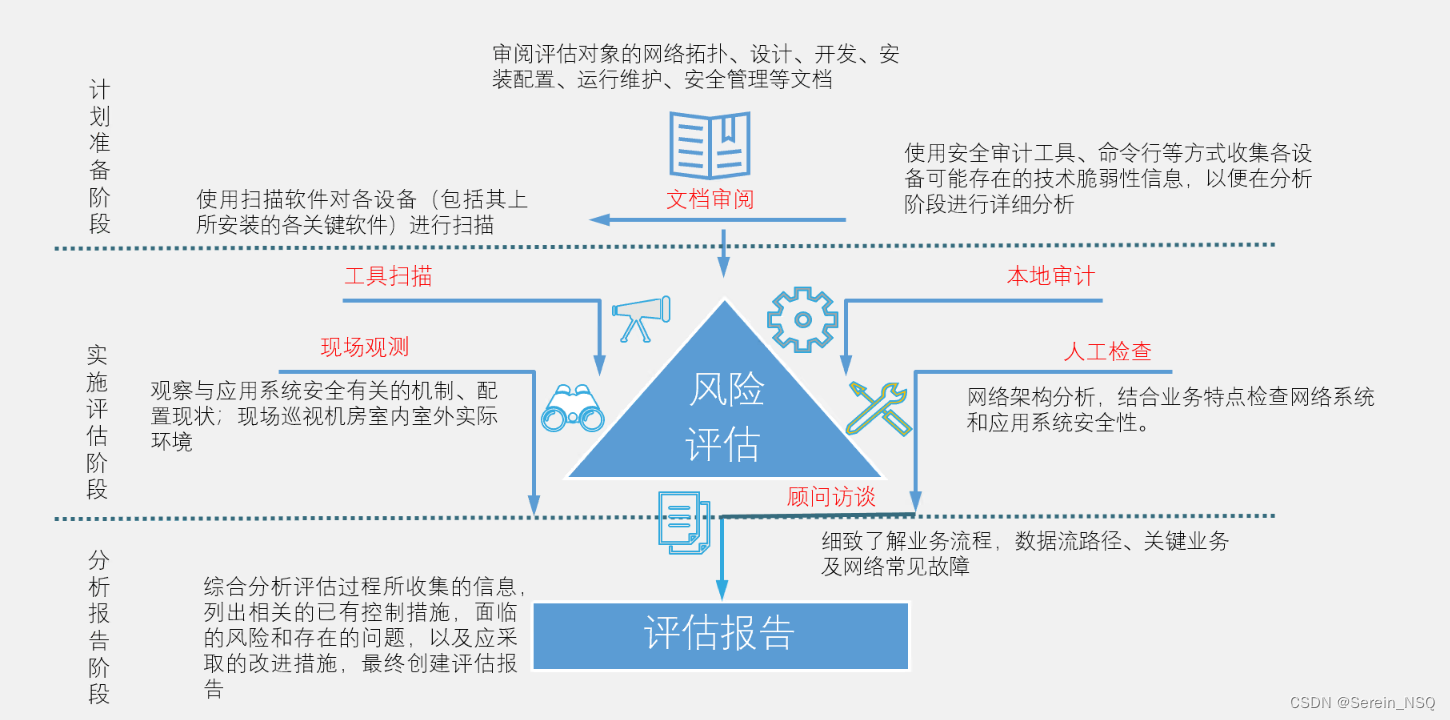
风险评估
风险评估概念 风险评估是一种系统性的方法,用于识别、评估和量化潜在的风险和威胁,以便组织或个人能够采取适当的措施来管理和减轻这些风险。 风险评估的目的 风险评估要素关系 技术评估和管理评估 风险评估分析原理 风险评估服务 风险评估实施流程...

直播软件app开发中的AI应用及前景展望
在当今数字化时代,直播市场蓬勃发展,而直播软件App成为人们获取实时信息和娱乐的重要渠道。随着人工智能(AI)技术的迅猛发展,直播软件App开发正逐渐融入AI的应用,为用户带来更智能、更个性化的直播体验。 …...

vscode html使用less和快速获取标签less结构
扩展插件里面搜索 css tree 插件 下载 使用方法 选择你要生成的标签结构然后按CTRLshiftp 第一次需要在输入框输入 get 然后选择 Generate CSS tree less结构就出现在这个里面直接复制到自己的less文件里面就可以使用了 在html里面使用less 下载 Easy LESS 插件 自己创建…...
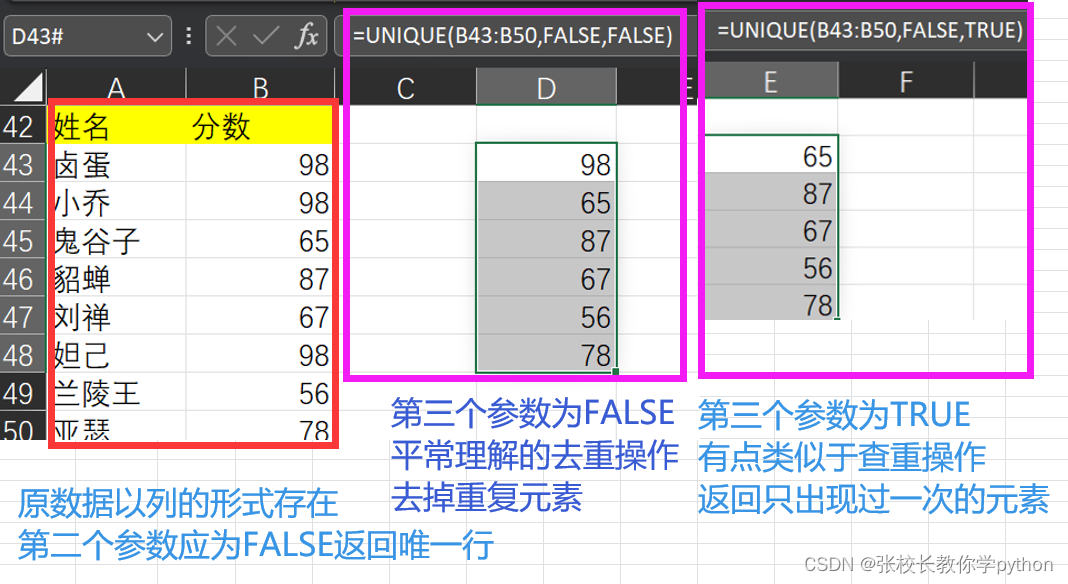
excel中的引用与查找函数篇1
1、COLUMN(reference):返回与列号对应的数字 2、ROW(reference):返回与行号对应的数字 参数reference表示引用/参考单元格,输入后引用单元格后colimn()和row()会返回这个单元格对应的列号和行号。若参数reference没有引用单元格,…...
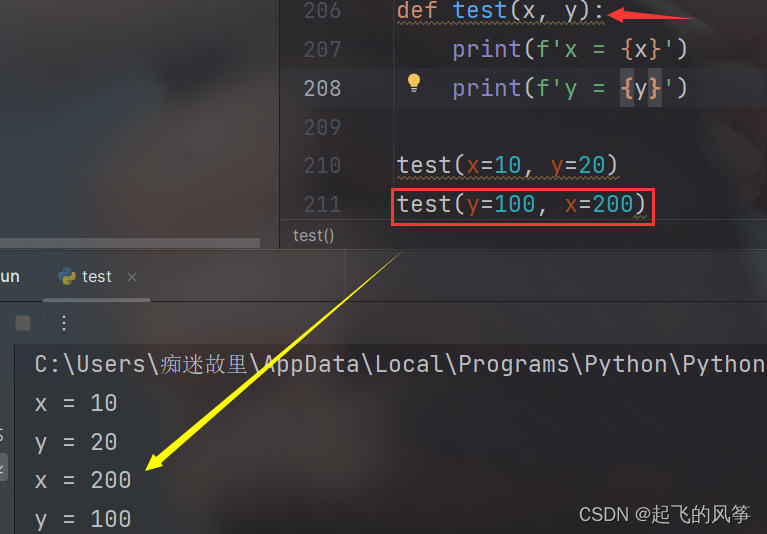
【python】—— 函数详解
前言: 本期,我们将要讲解的是有关python中函数的相关知识!!! 目录 (一)函数是什么 (二)语法格式 (三)函数参数 (四)函…...
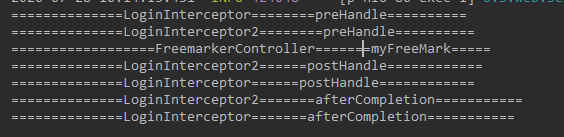
springboot web开发登录拦截器
在SpringBoot中我们可以使用HandlerInterceptorAdapter这个适配器来实现自己的拦截器。这样就可以拦截所有的请求并做相应的处理。 应用场景 日志记录,可以记录请求信息的日志,以便进行信息监控、信息统计等。权限检查:如登陆检测ÿ…...
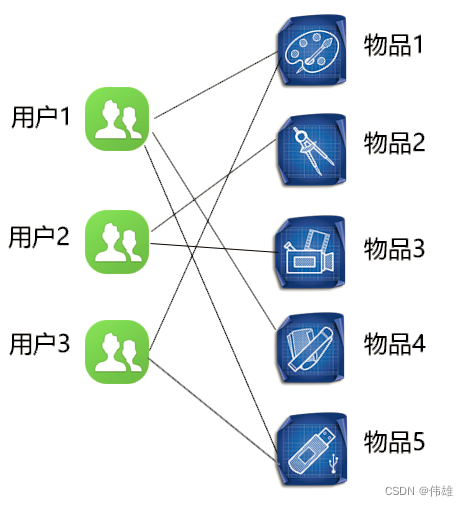
大数据课程K17——Spark的协同过滤法
文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州 ▲ 本章节目的 ⚪ 了解Spark的协同过滤概念; 一、协同过滤概念 1. 概念 协同过滤是一种借助众包智慧的途径。它利用大量已有的用户偏好来估计用户对其未接触过的物品的喜好程度。其内在思想是相似度的定义…...

【力扣】1588. 所有奇数长度子数组的和 <前缀和>
【力扣】1588. 所有奇数长度子数组的和 给你一个正整数数组 arr ,请你计算所有可能的奇数长度子数组的和。子数组 定义为原数组中的一个连续子序列。请你返回 arr 中 所有奇数长度子数组的和 。 示例 1: 输入:arr [1,4,2,5,3] 输出&#x…...

socket,tcp,http三者之间的原理和区别
目录 1、TCP/IP连接 2、HTTP连接 3、SOCKET原理 4、SOCKET连接与TCP/IP连接 5、Socket连接与HTTP连接 socket,tcp,http三者之间的区别和原理 http、TCP/IP协议与socket之间的区别 下面的图表试图显示不同的TCP/IP和其他的协议在最初OSI模型中的位置…...

【FPGA零基础学习之旅#11】数码管动态扫描
🎉欢迎来到FPGA专栏~数码管动态扫描 ☆* o(≧▽≦)o *☆嗨~我是小夏与酒🍹 ✨博客主页:小夏与酒的博客 🎈该系列文章专栏:FPGA学习之旅 文章作者技术和水平有限,如果文中出现错误,希望大家能指正…...
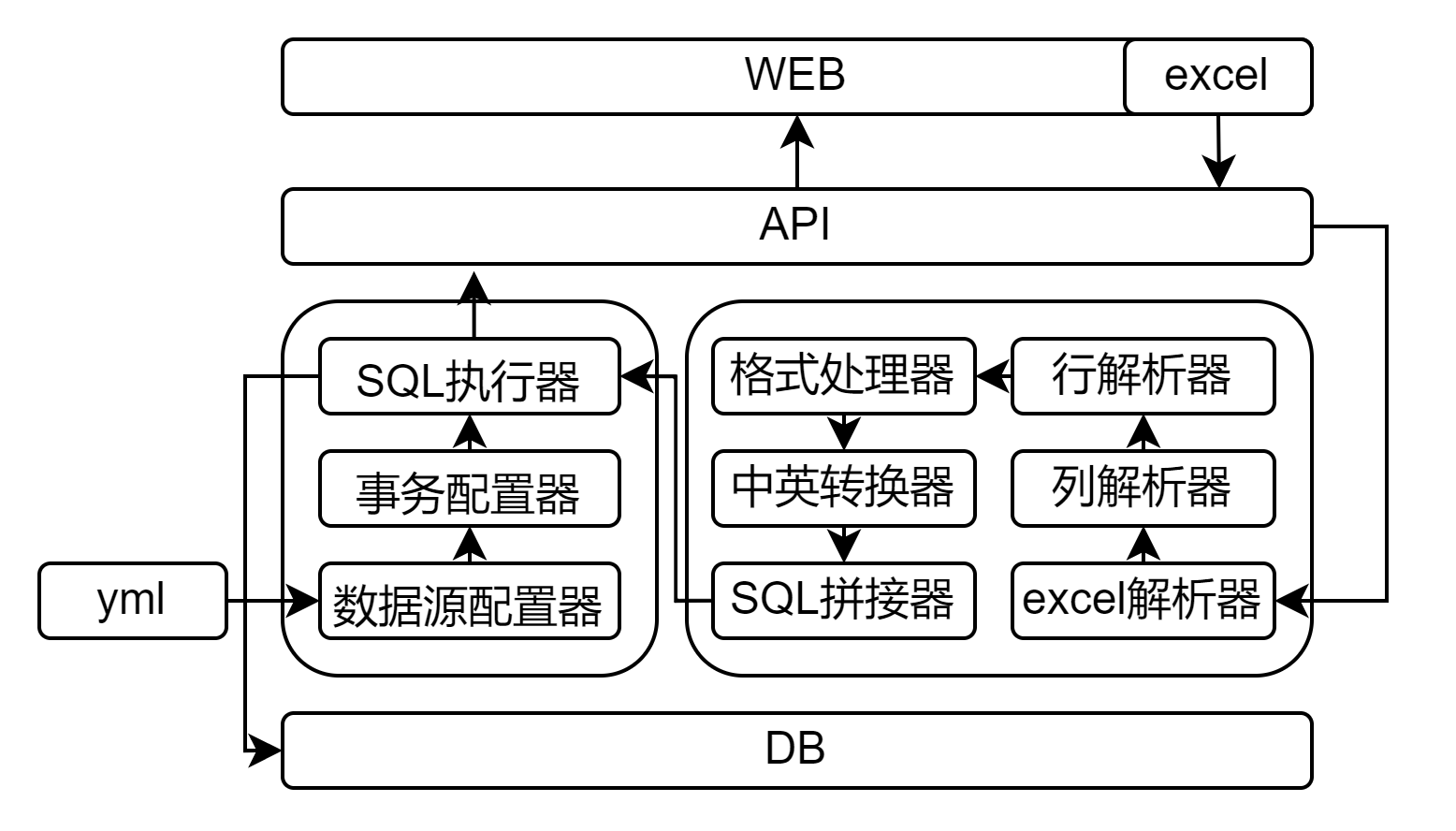
JavaExcel:自动生成数据表并插入数据
故事背景 出于好奇,当下扫描excel读取数据进数据库 or 导出数据库数据组成excel的功能层出不穷,代码也是前篇一律,poi或者easy excel两种SDK的二次利用带来了各种封装方法。 那么为何不能直接扫描excel后根据列的属性名与行数据的属性建立S…...
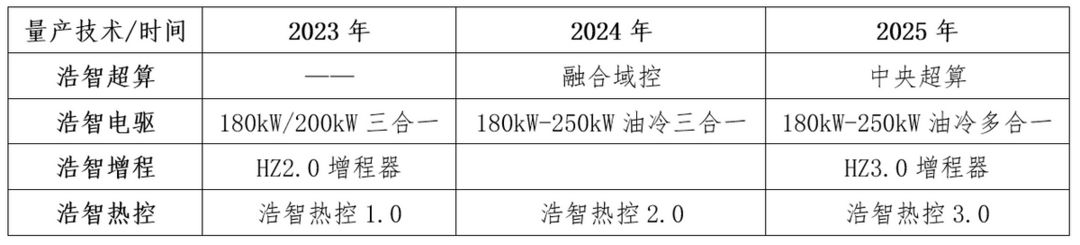
哪吒汽车“三头六臂”之「浩智电驱」
撰文 / 翟悦 编审 / 吴晰 8月21日,在哪吒汽车科技日上,哪吒汽车发布“浩智战略2025”以及浩智技术品牌2.0。根据公开信息,主编梳理了以下几点:◎浩智滑板底盘支持400V/800V双平台◎浩智电驱包括180kW 400V电驱系统和250kW 800…...

补码的反码加1为什么是原码?
搞了半个小时,终于弄懂了。 168421原码10011反码01100补码01101 学到这里了,我们肯定知道,原码补码 0,在这里也就是 19 13 32,溢出来的一位正好舍去了; 所以说,对啊,只要保证…...
)
人工智能-现代方法(一)
2026.05.12 这几天开始看《人工智能-现代方法》,做一些知识记录。 1、学习的概念:归纳和演绎。(19章) 演绎靠逻辑推理,归纳靠经验总结。所以在前提正确的情况下,演绎的结论必然正确。归纳的结论则有可能出现…...

VS2019编译OpenSceneGraph 3.6.5踩坑全记录:从CMake配置到解决第三方库缺失
VS2019编译OpenSceneGraph 3.6.5实战避坑指南 第一次在Windows平台用VS2019编译OpenSceneGraph 3.6.5时,我原以为按照官方文档就能轻松搞定。直到CMake报出一连串第三方库缺失的红色警告,才意识到这趟编译之旅远没有想象中简单。如果你也正对着Could NOT…...

Windows XP图标主题完整指南:如何为现代Linux系统注入经典怀旧风格
Windows XP图标主题完整指南:如何为现代Linux系统注入经典怀旧风格 【免费下载链接】Windows-XP Remake of classic YlmfOS theme with some mods for icons to scale right 项目地址: https://gitcode.com/gh_mirrors/win/Windows-XP 还在为现代Linux桌面环…...

【目录】运筹优化
运筹学篇章已全部更新完毕......运筹学开篇搜索理论基础线性规划之单纯形法线性规划的对偶理论线性规划之内点法单纯形法的补充与代码实现最短路与动态规划(一)最短路与动态规划(二)最短路与动态规划(三)网…...

3个关键策略:qmcdump如何高效解密QQ音乐加密音频文件
3个关键策略:qmcdump如何高效解密QQ音乐加密音频文件 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump 你是否…...

repo2txt:Git仓库转纯文本工具,为AI分析、代码归档与审查提供完整上下文
1. 项目概述:从代码仓库到纯文本的自动化提取最近在整理个人技术笔记和项目文档时,我遇到了一个挺普遍但有点烦人的问题:如何把一个完整的Git代码仓库,包括它的目录结构、所有源代码文件以及提交历史,以一种清晰、可读…...

如何在Dev-C++中配置TDM-GCC编译器
在Dev-C中配置TDM-GCC编译器的步骤如下: 步骤1:下载TDM-GCC编译器 访问 TDM-GCC官网下载适用于Windows的安装包(推荐选择64位版本:tdm-gcc-xxx.exe) 步骤2:安装TDM-GCC 运行安装程序,选择默认…...

图解UART串口通信:从电平标准到数据帧的完整解析
1. UART串口通信基础:从物理层到协议层 第一次接触嵌入式开发时,我被UART这个名字唬住了——Universal Asynchronous Receiver/Transmitter(通用异步收发器),听起来像是某种高端设备。直到用USB转TTL模块点亮了第一个L…...

2026出海技术观察:云API接口迭代的能力边界与业务增量空间
摘要:2026年AI出海告别粗放扩张,底层技术适配能力成为竞争核心。云API接口迭代持续优化跨境对接、算力调度与合规适配体系,补齐传统出海技术短板,为企业全球化精细化运营提供坚实支撑。一、2026 AI出海新格局:底层接口…...

ISSCC传感器设计启示:从高精度温度测量到低功耗系统优化
1. 从ISSCC看传感器设计的巅峰与启示每年二月的国际固态电路会议,对于像我这样泡在实验室和产线里的硬件工程师来说,就像一场技术界的“春晚”。它不发布概念,不空谈趋势,只展示过去一年里,全球顶尖研究团队在硅片上实…...