使用 BERT 进行文本分类 (03/3)

一、说明
在使用BERT(2)进行文本分类时,我们讨论了什么是PyTorch以及如何预处理我们的数据,以便可以使用BERT模型对其进行分析。在这篇文章中,我将向您展示如何训练分类器并对其进行评估。
二、准备数据的又一个步骤
上次,我们使用train_test_split将数据拆分为测试和验证数据。接下来需要的一个重要步骤是将数据转换为值列表,以便稍后可以在我们的训练器方法中调用它们。此步骤在其他教程中经常被忽略,当您无法微调模型时,这通常是问题所在。
# This is a continuation from the code written in Text Classification with BERT (2)
from sklearn.model_selection import train_test_split
X_train, X_val, y_train, y_val = train_test_split(df_balanced['Message'],df_balanced['Label'], stratify=df_balanced['Label'], test_size=.2)# Store everything in list of values
train_texts = X_train.to_list()
val_texts = X_val.to_list()
train_labels = y_train.to_list()
val_labels = y_val.to_list()2.1 标记化
现在我们已经准备好了我们的数据集,我们需要做一些标记化。我们将使用DistilBERT来实现这一点。引用拥抱脸的话:
DistilBERT是一种小型,快速,廉价和轻便的变压器模型,通过蒸馏Bert基础进行训练。它的参数比 bert-base-uncase 少 40%,运行速度快 60%,同时保留了 95% 以上的 Bert 性能,如 GLUE 语言理解基准测试所示。
导入模型后,我们将文本传递给分词器。如果您已经忘记了填充和截断,请检查使用 BERT 进行文本分类 (01/3) 的 文
from transformers import DistilBertTokenizerFast
tokenizer = DistilBertTokenizerFast.from_pretrained('distilbert-base-uncased')train_encodings = tokenizer(train_texts, truncation=True, padding=True)
val_encodings = tokenizer(val_texts, truncation=True, padding=True)2.2 格式化我们的数据集
在这里,我们需要将输入数据转换为可用于使用 PyTorch 训练深度学习模型的格式。
import torchclass SmapDataset(torch.utils.data.Dataset):def __init__(self, encodings, labels):self.encodings = encodingsself.labels = labelsdef __getitem__(self, idx):item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}item['labels'] = torch.tensor(self.labels[idx])return itemdef __len__(self):return len(self.labels)train_dataset = SmapDataset(train_encodings, train_labels)
val_dataset = SmapDataset(val_encodings, val_labels) 类的构造函数方法 () 通过将输入存储为 和 类属性来初始化数据集对象。__init__SmapDatasetencodingslabels
此类的方法用于从给定索引处的数据集中检索单个项目。它返回一个包含两个元素的字典对象:__getitem__idxitem
- 该元素是包含输入编码的字典对象,其中键是编码功能的名称,值是包含给定索引处的编码数据的 PyTorch 张量。
encodingsidx - 该元素是一个 PyTorch 张量,其中包含给定索引处的标签数据。
labelsidx
此类的方法返回数据集中的样本总数。__len__
最后,代码创建两个数据集对象,并使用类传入 、、 和 作为输入参数。这些数据集对象可用于在 PyTorch 模型中进行训练和验证。train_datasetval_datasetSmapDatasettrain_encodingstrain_labelsval_encodingsval_labels
2.3 使用培训师进行微调
我们以培训师预期的方式准备了数据。现在我们需要根据数据微调预训练模型。默认情况下,trainer.train 方法将仅报告训练损失。我将定义自己的指标函数并将其传递给培训师。
from sklearn.metrics import accuracy_score, precision_recall_fscore_supportdef compute_metrics(pred):labels = pred.label_idspreds = pred.predictions.argmax(-1)precision, recall, f1, _ = precision_recall_fscore_support(labels, preds, average='weighted', zero_division=0)acc = accuracy_score(labels, preds)return {'accuracy': acc,'f1': f1,'precision': precision,'recall': recall}- 准确性: 这是正确分类的样本占数据集中样本总数的比例。换句话说,它衡量模型正确预测数据集中所有样本的类标签的能力。虽然准确性是一个常用的指标,但在某些情况下可能会产生误导,尤其是在处理类分布不相等的不平衡数据集时。
- 精度:此指标度量真阳性预测(正确预测的正样本)在模型做出的所有正预测中的比例。换句话说,它衡量模型正确预测正样本的频率。当我们想要避免假阳性预测时,即当错误地将样本预测为阳性时,当样本实际上是负数时,精度非常有用。
- 召回:此指标衡量数据集中所有真阳性样本中真正预测的比例。换句话说,它衡量模型找到所有正样本的能力。当我们想要避免假阴性预测时,即当错误地将样本预测为阴性时,当样本实际上是阳性时,召回率很有用。
- F1比分:此指标是精度和召回率的调和平均值,并提供了一种平衡这两个指标的方法。它衡量精度和召回率之间的平衡,并且在假阳性和假阴性错误都有后果时很有用。
from transformers import DistilBertForSequenceClassification, Trainer, TrainingArgumentstraining_args = TrainingArguments(output_dir='./results', # output directorynum_train_epochs=3, # total number of training epochsper_device_train_batch_size=16, # batch size per device during trainingper_device_eval_batch_size=64, # batch size for evaluationwarmup_steps=500, # number of warmup steps for learning rate schedulerweight_decay=0.01, # strength of weight decaylogging_dir='./logs', # directory for storing logslogging_steps=10,evaluation_strategy="steps"
)model = DistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased")trainer = Trainer(model=model, # the instantiated 🤗 Transformers model to be trainedargs=training_args, # training arguments, defined abovetrain_dataset=train_dataset, # training dataseteval_dataset=val_dataset, # validation datasetcompute_metrics=compute_metrics
)trainer.train()2.4 结果
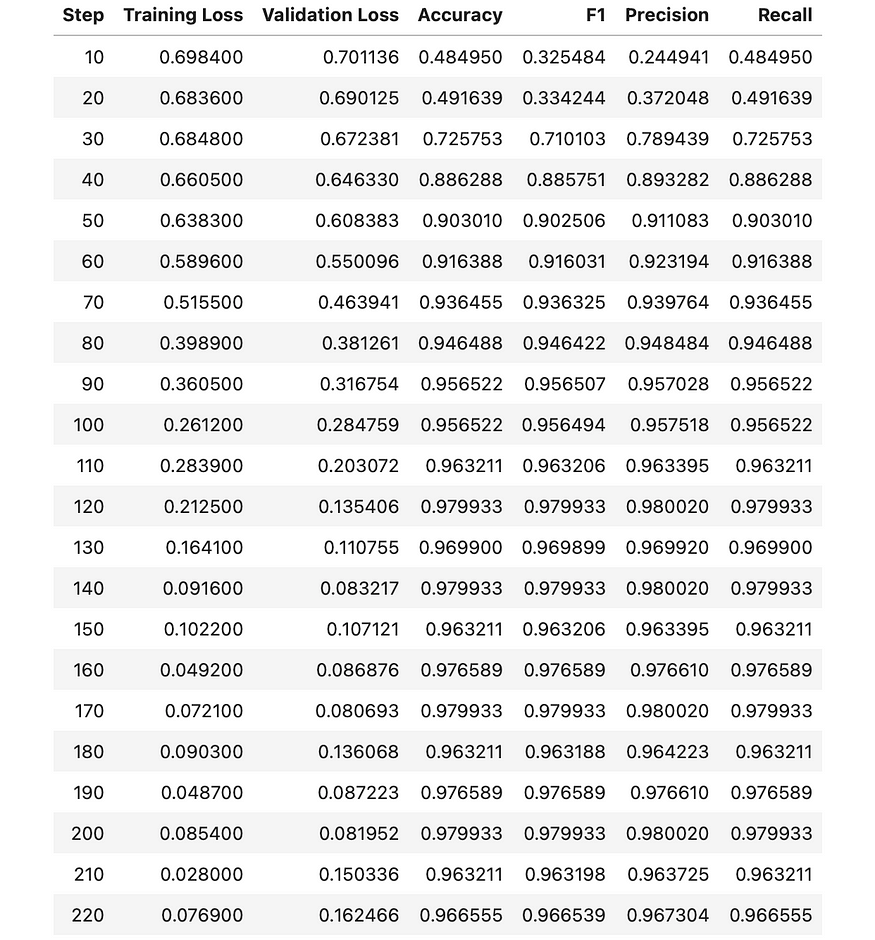
正如我们所看到的,我们的 F1 分数达到了 98% 左右,这表明我们的模型在判断邮件在我们的验证数据集中是垃圾邮件还是正常邮件方面表现良好。请记住,真正的测试数据集是野外未标记的消息。在本案例研究中,我们没有特权测试它在现实世界中的执行方式。
三、总结
在这篇文章中,我们学习了如何微调BERT模型以进行文本分类,并定义了自己的函数来评估我们的自定义模型。达门·
相关文章:
使用 BERT 进行文本分类 (03/3)
一、说明 在使用BERT(2)进行文本分类时,我们讨论了什么是PyTorch以及如何预处理我们的数据,以便可以使用BERT模型对其进行分析。在这篇文章中,我将向您展示如何训练分类器并对其进行评估。 二、准备数据的又一个步骤 …...
Leetcode Top 100 Liked Questions(序号236~347)
236. Lowest Common Ancestor of a Binary Tree 题意:二叉树,求最近公共祖先,All Node.val are unique. 我的思路 首先把每个节点的深度得到,之后不停向上,直到val相同,存深度就用map存吧 但是它没有向…...

MySQL数据库学习【基础篇】
📃基础篇 下方链接使用科学上网速度可能会更加快一点哦! 请点击查看数据库MySQL笔记大全 通用语法及分类 DDL: 数据定义语言,用来定义数据库对象(数据库、表、字段)DML: 数据操作语言,用来对数据库表中的…...
Kubernetes技术--k8s核心技术Service服务
1.service概述 Service 是 Kubernetes 最核心概念,通过创建 Service,可以为一组具有相同功能的容器应用提供一个统一的入口地址,并且将请求负载分发到后端的各个容器应用上。 2.service存在的意义 -1:防止pod失联(服务发现) 我们先说一下什么叫pod失联。 -2:...
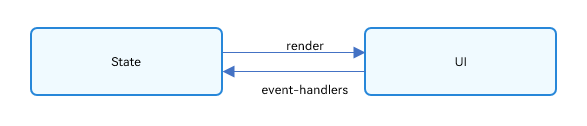
OpenHarmony 应用 ArkUI 状态管理开发范例
本文转载自《#2023 盲盒码 # OpenHarmony 应用 ArkUI 状态管理开发范例》,作者:zhushangyuan_ 本文根据橘子购物应用,实现 ArkUI 中的状态管理。 在声明式 UI 编程框架中,UI 是程序状态的运行结果,用户构建了一个 UI …...
二、QTableWidget 类 clear() 和 clearContents() 的区别及程序崩溃原因分析
问题描述:区分 QTableWidget 类的 clear() 和 clearContents() 的用法,以及可能由于这两个方法使用不当导致程序崩溃的原因分析 Qt 官方文档对 QTableWidget 类的 clear() 方法描述如下: [slot] void QTableWidget::clear() Removes all ite…...

spring boot 项目中搭建 ElasticSearch 中间件 一 postman 操作 es
postman 操作 es 1. 简介2. 环境3. postman操作索引3.1 创建索引3.2 查看索引3.3 查看所有索引3.4 删除索引 4. postman操作文档4.1 添加文档4.2 查询文档4.3 查询全部文档4.4 更新文档4.5 局部更新文档4.6 删除文档4.7 条件查询文档14.8 条件查询文档24.9 条件查询文档 limit4…...
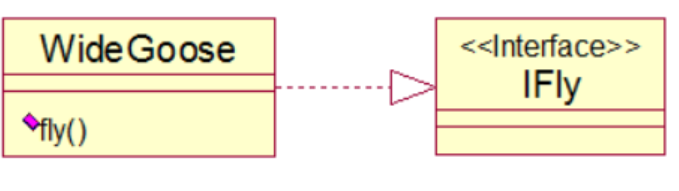
设计模式—观察者模式(Observer)
目录 思维导图 一、什么是观察者模式? 二、有什么优点吗? 三、有什么缺点吗? 四、什么时候使用观察者模式? 五、代码展示 ①、双向耦合的代码 ②、解耦实践一 ③、解耦实践二 ④、观察者模式 六、这个模式涉及到了哪些…...
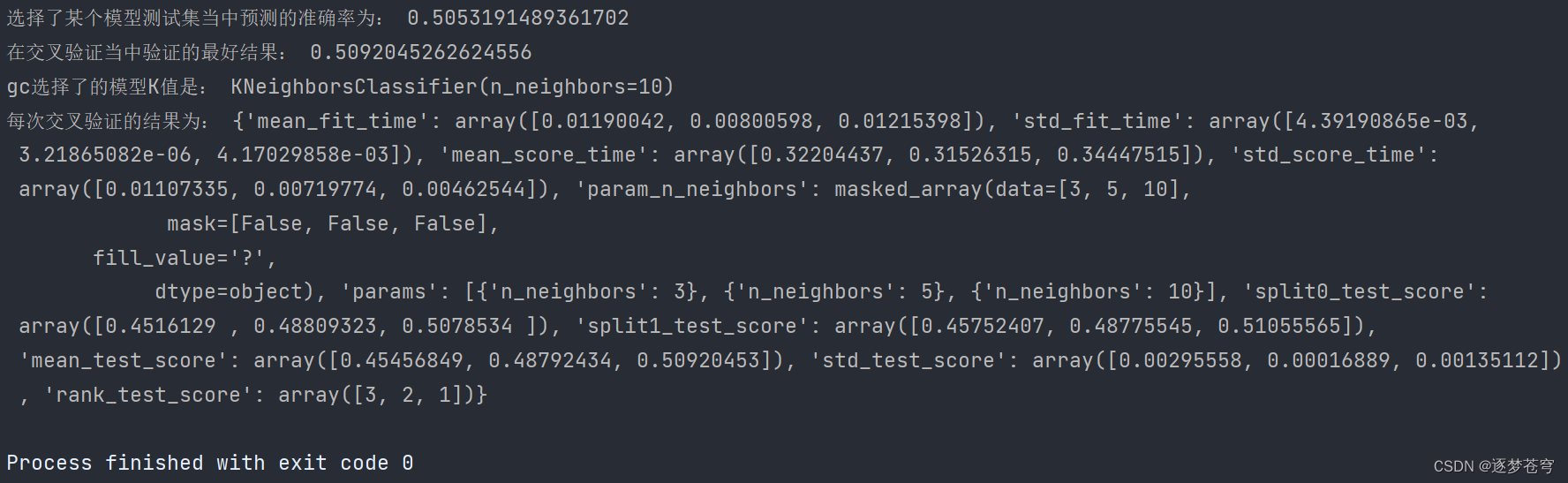
分类算法系列③:模型选择与调优 (Facebook签到位置预测)
目录 模型选择与调优 1、介绍 模型选择(Model Selection): 调优(Hyperparameter Tuning): 本章重点 2、交叉验证 介绍 为什么需要交叉验证 数据处理 3、⭐超参数搜索-网格搜索(Grid Search) 介绍…...

PCL RANSAC分割提取多个空间圆
目录 一、概述二、代码实现三、结果展示1、原始数据2、提取结果四、测试数据本文由CSDN点云侠原创,原文链接。如果你不是在点云侠的博客中看到该文章,那么此处便是不要脸的爬虫。 一、概述 使用PCL分割提取多个空间圆,其核心原理仍然是RANSAC拟合空间圆,这里只是做简单修改…...
Java八股文学习笔记day01
01.和equals区别 对于字符串变量来说,使用""和"equals"比较字符串时,其比较方法不同。""比较两个变量本身的值,即两个对象在内存中的首地址,"equals"比较字符串包含内容是否相同。 对于非…...

vant的NavBar导航栏可以自定义背景图片吗
可以的,Vant的NavBar导航栏提供了一个background-image属性,可以设置自定义背景图片。例 如: <van-nav-bar title"标题" left-text"返回" left-arrow background-image"url(https://example.com/image.jpg)&qu…...

深入浅出AXI协议(5)——数据读写结构读写响应结构
目录 一、前言 二、写选通(Write strobes) 三、窄传输(Narrow transfers) 1、示例1 2、示例2 四、字节不变性(Byte invariance) 五、未对齐的传输(Unaligned transfers) 六…...

IntelliJ Idea开发Vue遇到的几个问题
IntelliJ Idea开发Vue遇到的几个问题 确保 idea已安装插件【Vue.js】 问题1:ts方法错误 或 提示导入 import xxx.vue标红 解决办法:在 env.d.ts中添加以下代码(若无此文件,重新创建): /* eslint-disable */ declare module *.…...

sql查找最晚一天/日期最大的一条记录 两种方法
例:查找最晚入职员工的所有信息 建表: CREATE TABLE employees ( emp_no int(11) NOT NULL, birth_date date NOT NULL, first_name varchar(14) NOT NULL, last_name varchar(16) NOT NULL, gender char(1) NOT NULL, hire_date date NOT NULL, PRIMA…...

详解python的
详解& 在Python中,使用&符号可以求取两种数据类型的交集: 集合(Set):你可以使用&来计算两个集合的交集。例如: set1 {1, 2, 3, 4} set2 {3, 4, 5, 6} common_elements set1 & set2 pri…...

Modbus TCP通信笔记
目录 1 Modbus TCP 数据协议1.1 数据格式1.2 报文头(MBAP头)1.3 功能码1.4 Modbus 地址映射到 CPU 地址 2 Modbus TCP 通讯数据示例2.1 功能码01 读离散输出线圈2.2 功能码02 读离散输入线圈2.3 功能码03 读保持寄存器2.4 功能码04 读输入寄存器2.5 功能码05 写单个离散输出寄存…...
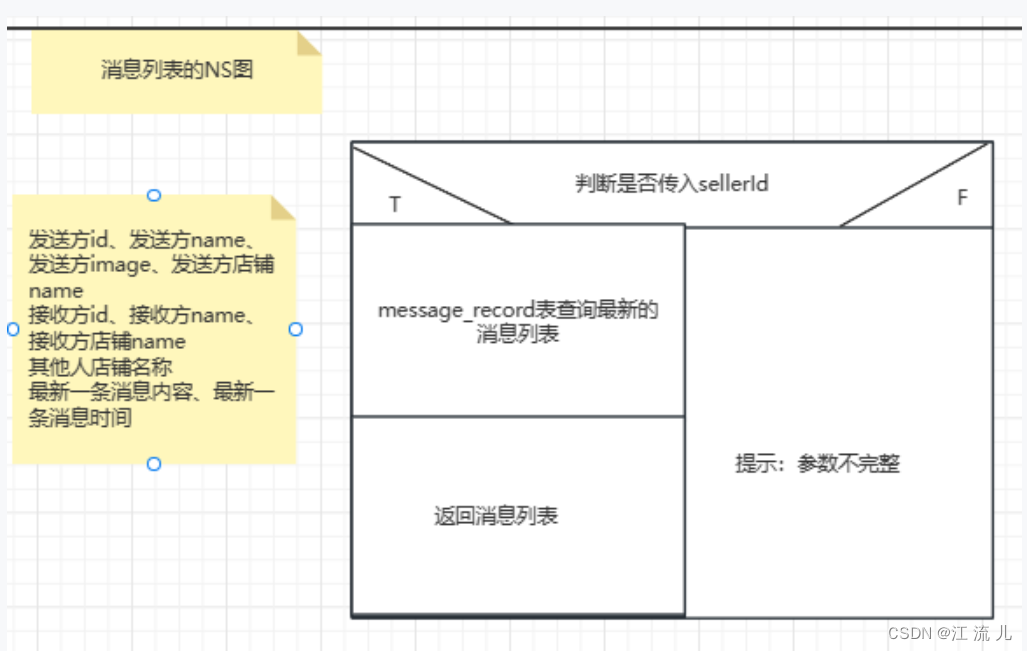
CIM和websockt-实现实时消息通信:双人聊天和消息列表展示
欢迎大佬的来访,给大佬奉茶 一、文章背景 有一个业务需求是:实现一个聊天室,我和对方可以聊天;以及有一个消息列表展示我和对方(多个人)的聊天信息和及时接收到对方发来的消息并展示在列表上。 项目框架概…...

useLayoutEffect和useEffect有什么作用?
useEffect 和 useLayoutEffect 都是 React 中的钩子函数,用于在组件渲染过程中执行副作用操作。它们的主要区别在于执行时机。 useEffect: useEffect 是异步执行的,它在浏览器渲染完成之后才执行。这意味着它不会阻塞浏览器的渲染过程,因此适合用于处理副作用,如数据获取、…...
django中配置使用websocket终极解决方案
django ASGI/Channels 启动和 ASGI/daphne的区别 Django ASGI/Channels 是 Django 框架的一个扩展,它提供了异步服务器网关接口(ASGI)协议的支持,以便处理实时应用程序的并发连接。ASGI 是一个用于构建异步 Web 服务器和应用程序…...

【AI】关于claude code长会话过程中逐渐遗忘给它提供的标准操作规范问题思考
问题 在使用claude code的时候,我发现,我提供了一系列的操作规范,比如代码编译,容器创建,资源初始化等标准化的操作规范,我让它按照规范执行操作。会话前期,它会严格执行,但是会话长…...
角色为何在创业公司成为最稀缺的竞争力?)
产品工程师(Product Engineer)角色为何在创业公司成为最稀缺的竞争力?
在科技招聘市场,一位能力顶尖的工程师投递了上百份简历,却始终卡在“技术面试过关、产品讨论却露怯”的阶段。团队明明需要能快速交付价值的人,可最终录用的往往是那些“既懂代码又能自己做产品决策”的少数派。大多数候选人把精力全放在刷 L…...
)
保姆级教程:在Windows上用Python连接CoppeliaSim远程API(附避坑指南)
从零开始掌握CoppeliaSim与Python的远程控制:Windows环境实战指南 在机器人仿真领域,CoppeliaSim(原V-REP)因其强大的功能和友好的用户界面而广受欢迎。对于希望将Python的灵活性与CoppeliaSim的仿真能力结合的研究者和工程师来说…...

从MVC到DDD:微服务架构下应对业务复杂性的实战演进
1. 从“造到飞起”到“稳如老狗”:一个老码农的架构心路干了十几年开发,带过不少团队,也趟过无数坑。要说这些年最大的感受是什么,那就是:变化是常态,混乱是必然,而架构的价值,就是在…...
)
K3s离线安装保姆级避坑指南:从镜像准备到集群验证(含Harbor私有仓库配置)
K3s离线安装全流程实战:从私有仓库搭建到集群高可用 在金融、军工、政务等对网络安全要求极高的领域,离线环境部署Kubernetes集群已成为刚需。作为轻量级Kubernetes发行版,K3s凭借其小于50MB的二进制体积和内置组件简化设计,成为隔…...

GB/T14710有源设备环境及运输经验总结及怎样避免被的发补
近期有朋友询问:有源设备在检验所做了GB/T 14710里面的振动、碰撞、实车跑提交注册的时候却被审核老师发补重做,14710和运输都要再来一遍,理由是要加上包装运输试验。在我看来是一个不太明智的决定,也是在赌运气,既然花…...

kagent支持的5大AI框架对比:ADK、CrewAI、LangGraph、OpenAI、技能框架
kagent支持的5大AI框架对比:ADK、CrewAI、LangGraph、OpenAI、技能框架 【免费下载链接】kagent Cloud Native Agentic AI | Discord: https://bit.ly/kagentdiscord 项目地址: https://gitcode.com/gh_mirrors/ka/kagent kagent作为一款云原生智能代理平台&…...
搭建AI大模型应用开发环境)
15天学会AI应用开发(一)搭建AI大模型应用开发环境
AI大模型时代来了,程序员们纷纷入坑AI应用开发,可是苦于AI教程良莠不齐,往往花费了大量时间精力和金钱,却仍然过其门而不入。 有鉴于此,博主开始连载AI应用开发教程《15天学会AI应用开发》,帮助大家快速掌…...

RT-Thread Studio开发RA2L1:从环境搭建到GPIO输入输出实战
1. 项目概述与核心价值最近在捣鼓瑞萨电子的RA2L1 MCU开发板,想基于RT-Thread Studio这个国产IDE快速上手。我发现很多朋友拿到一块新板子,第一步“点亮LED”或者“读取按键”这个看似简单的操作,往往就卡在了环境搭建上。网上的资料要么过于…...

阿里云服务器上fastText安装踩坑记:从C++11报错到模型量化压缩的完整避坑指南
阿里云ECS实战:fastText从编译报错到模型量化的全流程解决方案 当你在阿里云ECS上部署fastText模型时,是否遇到过那个令人头疼的"C11编译错误"?这仅仅是开始——内存占用过高、磁盘空间不足、推理速度慢等问题会接踵而至。本文将带…...