C++-list实现相关细节和问题
前言:C++中的最后一个容器就是list,list是可以在常数范围内在任意位置进行插入和删除的序列式容器,并且该容器可以前后双向迭代。list的底层是双向链表结构,双向链表中每个元素存储在互不相关的独立节点中,在节点中通过指针指向其前一个元素和后一个元素。与其他的序列式容器相比(array,vector,deque),list通常在任意位置进行插入、移除元素的执行效率更好。下面我们就来模仿官方库中的list,自行实现一个list,并从中总结实现细节和经验。

目录
1.基本节点类和链表类的框架
数据节点类
list节点类
尾插函数
2.迭代器类的实现
迭代器的分类及实现
为什么不用析构函数和深拷贝?
为什么能使用前置++就不用后置++?
怪异的" -> "?地址解引用重载
如何在list类中使用迭代器
3.插入删除函数
4.const迭代器和拷贝赋值函数
const iterator和const_iterator?......有区别吗?
实现const_iterator
模板参数列表泛式编程
迭代器类终极版
拷贝构造和赋值函数
5.必须采用typename格式的场景
6.源码看这里
list.h
test.cpp
1.基本节点类和链表类的框架
数据节点类
list的实现不同于其他的容器,比如vector等,list的底层是一个双向链表结构,每一个节点都由三部分组成,分别是数据,上一个节点和下一个节点,所以,对于list所存储的数据成员,我们需要单独开一个结构体来表示链表中的每一个数据成员,
template<class T>struct list_node //链表的数据成员结构{T _data;list_node<T>* _next;list_node<T>* _prev;list_node(const T& x = T())//给一个匿名对象:_data(x), _next(nullptr), _prev(nullptr){}};list节点类
接着就是list类的创建,我们知道,双线链表大致的结构如下所示,我们list的设计也基本遵循这个框架,
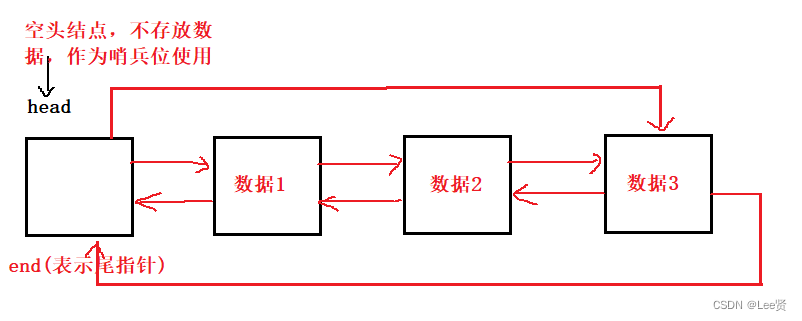
template<class T>class list {typedef list_node<T> Node;public:void empty_init()//空list初始化{_head = new Node;_head->_next = _head;_head->_prev = _head;_size = 0;}list(){empty_init();}size_t size(){return _size;}private:Node* _head;//虚拟的头结点,实际上第一个节点在该节点的下一个位置上,而尾结点end就是头结点的位置,这样,方便我们构成双向链表size_t _size;//链表长度,因为遍历一遍链表需要花费大量的时间,所以建议当做数据成员存储};尾插函数
在上面功能的基础上,我们就可以实现简易的push_back函数了,这里就不再赘述,
void push_back(const T& x){//此时我们的最后一个元素是头结点的上一个元素,因为我们是一个双向循环链表,现在head和end都指向哨兵节点Node* tail = _head->_prev;Node* newnode = new Node(x);tail->_next = newnode;newnode->_prev = tail;newnode->_next = _head;_head->_prev = newnode;}2.迭代器类的实现
迭代器的分类及实现

list官方库中对迭代器的要求:
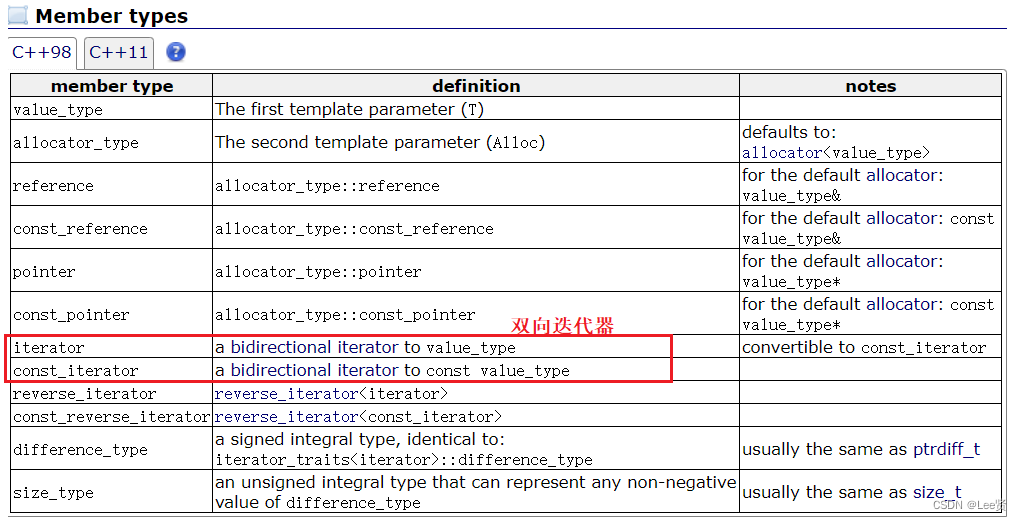
对于我们的list中的迭代器来说,我们常见的迭代器的使用需要满足,比如取数据,修改数据等,但是我们的list存储的实际上是一个个结构体,对结构体解引用编译器不认识,并且我们的链表存储并不是顺序表的顺序结构,而是随机存储结构,简单的对于迭代器地址增加并不能找到下一个数据,而且还涉及多种迭代器类型的使用,比如反向迭代器等,所以,list的迭代器需要具备取数据,++或者--自动到目标节点等等的功能,涉及重载函数等功能,因此,为了方便我们的使用,我们便让迭代器自成一个类,采用封装加重载的方式,这样我们就可以创建迭代器对象来更加方便地访问数据成员和其他操作。
为什么不用析构函数和深拷贝?
迭代器本身作为一个链表的访问工具,但是如果写析构函数,在迭代器对象析构时,因为迭代器本身是指向链表节点的一个指针,释放指针必然会导致节点被影响,这是我们不允许的,所以不能写析构函数,采用默认的空操作的析构函数即可。
而对于迭代器的深浅拷贝问题,迭代器本质上是节点的指针,但是并不是迭代器所指向的资源就归迭代器管理,我们只是把迭代器作为遍历和修改的工具,本质上就是让迭代器移动遍历,因此只需要浅拷贝链表节点即可。
为什么能使用前置++就不用后置++?
我们看见上面的前置和后置++的区别在于一个返回本对象,另一个则返回本对象的拷贝,返回对象的拷贝的后置++在返回时返回的是临时对象tmp的拷贝,也就需要再次调用我们自定义的拷贝构造函数,在时间上不如前置++效率高。
怪异的" -> "?地址解引用重载
我们在上面的函数中有这样一个函数重载:

当数据存在自定义对象时,比如我们的数据成员就是一个结构体,我们链表的节点保存的是结构体指针,那么我们如何取获得结构体中的数据成员的值呢,我们需要对迭代器进行解引用操作才能获取具体的元素的值,除了直接用(*it).xx来访问,我们还经常采用一种方式,就是it->xx的方式,上面这个函数就是我们需要采用该解引用方法时所需要重载的->运算符,重载完后即可正常使用地址解引用操作。

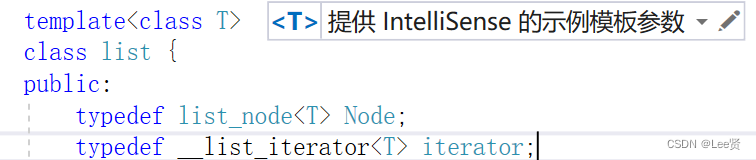
如何在list类中使用迭代器
现在我们的迭代器自成一个类,但是我们需要在list类中使用它,我们就可以将迭代器定义在我们的类域内即可调用:

3.插入删除函数
在官方库的inert和erase函数中,更加推荐使用迭代器作为返回值,在容器中,我们选择元素一般都会以迭代器的位置为基准,对于insert函数,因为不会涉及扩容问题,也就不存在迭代器失效问题,所以,我们可以返回插入元素位置的迭代器,方便对迭代器的再使用,同时对于erase函数,删除迭代器位置上的元素,节点删除必然会导致节点空间的释放,将必然导致迭代器失效,所以我们根据官方的文档中的解决方法,索性直接返回被删除元素的下一个位置的迭代器即可。
iterator insert(iterator pos,const T&x)//我们和官方文档的函数保持一致,返回新插入元素的迭代器(在pos位置之前插入){Node* newnode = new Node(x);//因为不存在扩容,所以不存在迭代器失效问题Node* prev = (pos._node)->_prev;prev->_next = newnode;newnode->_prev = prev;newnode->_next = pos._node;(pos._node)->_prev = newnode;++_size;return iterator(newnode);//类型转换}iterator erase(iterator pos)//返回删除元素的下一个位置{Node* cur = pos._node;Node* prev = cur->_prev;Node* next = cur->_next;delete cur;//释放掉后迭代器失效prev->_next = next;next->_prev = prev;--_size;return iterator(next);}因为迭代器的使用,我们就可以顺势写出一下的常用函数接口:
~list()
{clear();//不释放头结点delete _head;_head = nullptr;
}void clear()
{iterator it = begin();while (it != end()){it = erase(it);}
}
void push_back(const T& x)
{insert(end(), x);//优化
}void push_front(const T& x)
{insert(begin(), x);
}void pop_front()
{erase(begin());
}void pop_back()
{erase(--end());
}4.const迭代器和拷贝赋值函数
const iterator和const_iterator?......有区别吗?
首先,我们要知道,const迭代器是修饰迭代器所指向的元素本身不能被改变而不是修饰迭代器本身的指向不能被改变,const迭代器的类型相当于const T*而不是T*const,而const iterator相当于直接修饰了迭代器,相当于定死了迭代器就是指向某一个元素,这违背了我们使用迭代器作为遍历工具的原则,const迭代器产生就是为了遍历只读元素使用,而const_iterator就是这样一种特定的迭代器类型,这一点要做好区分。
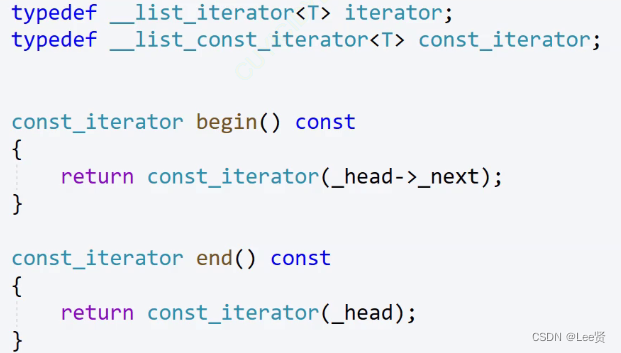
实现const_iterator
要实现const迭代器,我们就要知道,在原迭代器类中,哪些函数时能够影响到修改数据成员的,显然,只有对迭代器进行解引用才会影响数据修改,所以,我们只需要在原来的迭代器类的基础上,限定重载的解引用运算符即可,

当然,我们需要在list类中引入const迭代器类到类域中去:
模板参数列表泛式编程
上面的const迭代器虽然实现了,但是我们要写两个迭代器类,而且两个迭代器类只有重载解引用操作时才会有不同的行为,而我们为了这个要多些一个类,实在是太麻烦了,我们就来看一看C++祖师爷是如何解决的吧,
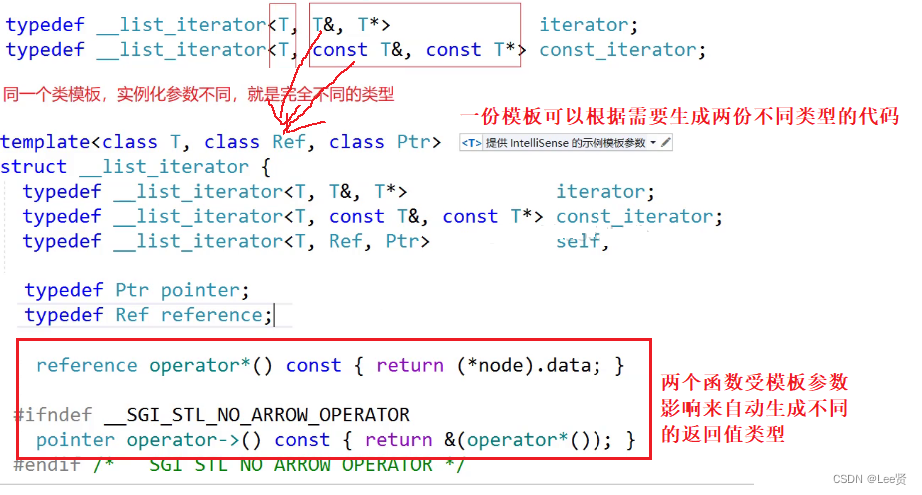

这也太香了,相当于模板参数列表里增加了两个模板参数,返回值根据参数来影响重载运算符的返回值类型,不愧是祖师爷,这也是泛式编程的思想,封装屏蔽了底层的实现细节,提供统一的访问方式。
不多说了,拿来吧你~~

迭代器类终极版
template<class T,class Ref,class Ptr>struct __list_iterator //我们尽量与官方文档的保持一致{typedef list_node<T> Node;typedef __list_iterator<T,Ref,Ptr> self;//迭代器对象起别名Node* _node;__list_iterator(Node* node)//节点的指针可以隐式类型转换成迭代器:_node(node){}//对迭代器需要进行++和解引用操作,注意,迭代器的解引用应该是得到数据本身,所以我们的解引用也需要重载self operator++()//前置++{_node = _node->_next;return *this;}self& operator--()//前置--{_node = _node->_prev;return *this;}self& operator++(int)//后置++{self temp(*this);_node = _node->_next;return temp;}self& operator--(int)//后置++{self temp(*this);_node = _node->_prev;return temp;}//对于影响const迭代器调用的功能的函数传不同的返回值类型时使用Ref operator*(){return _node->_data;}Ptr operator->(){return &(_node->_data);}bool operator!=(const self& s)//迭代器比较结束条件判断{return _node != s._node;}bool operator==(const self& s){return _node == s._node;}};拷贝构造和赋值函数
之所以把这一个知识放在迭代器实现完全之后再将,是因为我们在拷贝和赋值时经常需要传递const对象,而我们前面的迭代器是非const版本,无法对const对象进行解引用操作,也就导致了无法拷贝const对象,所以放在这里进行讲解,但是此时这两个函数用我们自己提供的接口完全可以实现,这里也不涉及深浅拷贝的问题,就直接给出了,
//拷贝构造list(const list<T>& lt){empty_init();for (auto e : lt)//迭代器重载后取得是数据元素,故可以使用push_back(e);}//赋值操作list& operator=(const list<T>& lt)//返回值也可以写list类型,类内均正确,但是为规范不建议{if (this != <){clear();//先清空原来的链表,但头结点还在for (auto e : lt)push_back(e);}return *this;}5.必须采用typename格式的场景
基于以上的代码,我们来运行下面的测试样例:
template<class T>void print_list(const list<T>& lt){list<T>::const_iterator it = lt.begin();while (it != lt.end()){cout << *it << " ";it++;}cout << endl;}void test_list4(){list<int> lt;lt.push_back(1);lt.push_back(2);lt.push_back(3);lt.push_back(4);lt.push_back(5);print_list(lt);list<string> lt2;lt2.push_back("1111111111111");lt2.push_back("1111111111111");lt2.push_back("1111111111111");lt2.push_back("1111111111111");lt2.push_back("1111111111111");print_list(lt2);}看上去没什么问题吧,我们也用了类模板,应该是能跑起来的,但是实际上,
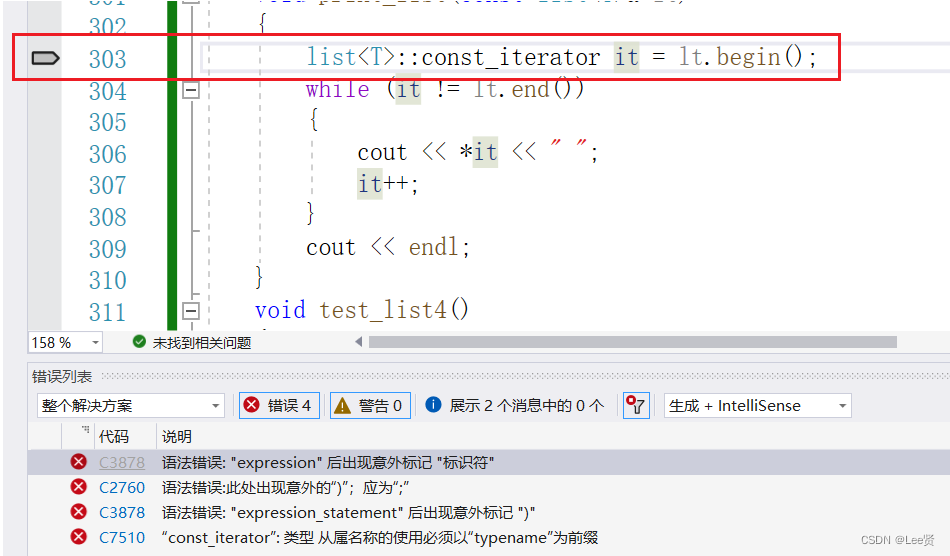
这上面说,让我们在迭代器类型前面加一个typename,这是为什么呢?
在编译阶段,编译器只能看到我们的list是list<T>类型的,模板还没有被实例化,导致编译器无法在对应的类中找到类域下的成员,向上面的const_iterator,编译器因为list<T>是未实例化的模板,所以也无法在确定的类域内找到const_iterator相应的实现和功能,所以编译器不认识这个变量是什么,也就导致了出错,前面加一个typename是告诉编译器,这里是一个类型,等list<T>实例化再去类里面去取。

void test_list4(){list<int> lt;lt.push_back(1);lt.push_back(2);lt.push_back(3);lt.push_back(4);lt.push_back(5);print_container(lt);list<string> lt2;lt2.push_back("1111111111111");lt2.push_back("1111111111111");lt2.push_back("1111111111111");lt2.push_back("1111111111111");lt2.push_back("1111111111111");print_container(lt2);vector<string> v;v.push_back("222222222222");v.push_back("222222222222");v.push_back("222222222222");v.push_back("222222222222");v.push_back("222222222222");print_container(v);}
6.源码看这里
list.h
#pragma once
#include <vector>
namespace my_std
{template<class T>struct list_node //链表的数据成员结构{T _data;list_node<T>* _next;list_node<T>* _prev;list_node(const T& x = T())//给一个匿名对象:_data(x), _next(nullptr), _prev(nullptr){} };template<class T,class Ref,class Ptr>struct __list_iterator //我们尽量与官方文档的保持一致{typedef list_node<T> Node;typedef __list_iterator<T,Ref,Ptr> self;//迭代器对象起别名Node* _node;__list_iterator(Node* node)//节点的指针可以隐式类型转换成迭代器:_node(node){}//对迭代器需要进行++和解引用操作,注意,迭代器的解引用应该是得到数据本身,所以我们的解引用也需要重载self operator++()//前置++{_node = _node->_next;return *this;}self& operator--()//前置--{_node = _node->_prev;return *this;}self& operator++(int)//后置++{self temp(*this);_node = _node->_next;return temp;}self& operator--(int)//后置++{self temp(*this);_node = _node->_prev;return temp;}//对于影响const迭代器调用的功能的函数传不同的返回值类型时使用Ref operator*(){return _node->_data;}Ptr operator->(){return &(_node->_data);}bool operator!=(const self& s)//迭代器比较结束条件判断{return _node != s._node;}bool operator==(const self& s){return _node == s._node;}};template<class T>class list {public:typedef list_node<T> Node;typedef __list_iterator<T,T&,T*> iterator;typedef __list_iterator<T, const T&,const T*> const_iterator;iterator begin(){return _head->_next;}iterator end(){return _head;}const_iterator begin()const {return const_iterator(_head->_next);//含隐式类型转换,自己写转不转换都行}const_iterator end()const{return _head;}void empty_init()//空list初始化{_head = new Node;_head->_next = _head;_head->_prev = _head;_size = 0;}list(){empty_init();}//拷贝构造list(const list<T>& lt){empty_init();for (auto e : lt)//迭代器取得是数据元素,故可以使用push_back(e);}//赋值操作list& operator=(const list<T>& lt)//返回值也可以写list类型,类内均正确,但是为规范不建议{if (this != <){clear();//先清空原来的链表,但头结点还在for (auto e : lt)push_back(e);}return *this;}~list(){clear();//不释放头结点delete _head;_head = nullptr;}void clear(){iterator it = begin();while (it != end()){it = erase(it);}}void push_back(const T& x){//此时我们的最后一个元素是头结点的上一个元素,因为我们是一个双向循环链表,现在head和end都指向哨兵节点/*Node* tail = _head->_prev;Node* newnode = new Node(x);tail->_next = newnode;newnode->_prev = tail;newnode->_next = _head;_head->_prev = newnode;*/insert(end(), x);}void push_front(const T& x){insert(begin(), x);}void pop_front(){erase(begin());}void pop_back(){erase(--end());}iterator insert(iterator pos,const T&x)//我们和官方文档的函数保持一致,返回新插入元素的迭代器(在pos位置之前插入){Node* newnode = new Node(x);//因为不存在扩容,所以不存在迭代器失效问题Node* prev = (pos._node)->_prev;prev->_next = newnode;newnode->_prev = prev;newnode->_next = pos._node;(pos._node)->_prev = newnode;++_size;return iterator(newnode);//类型转换}iterator erase(iterator pos)//返回删除元素的下一个位置{Node* cur = pos._node;Node* prev = cur->_prev;Node* next = cur->_next;delete cur;//释放掉后迭代器失效prev->_next = next;next->_prev = prev;--_size;return iterator(next);}size_t size(){return _size;}private:Node* _head;//虚拟的头结点,实际上第一个节点在该节点的下一个位置上,而尾结点end就是头结点的位置,这样,方便我们构成双向循环链表size_t _size;//链表长度,因为遍历一遍链表需要花费大量的时间,所以建议当做数据成员存储};void test_list1(){list<int> lt;lt.push_back(1);lt.push_back(2);lt.push_back(3);lt.push_back(4);lt.push_back(5);// 封装屏蔽底层差异和实现细节// 提供统一的访问修改遍历方式list<int>::iterator it = lt.begin();//迭代器需要单独编写迭代器类,以供应需求,说清楚为什么需要编写(迭代器的种类),重载哪些运算符等while (it != lt.end()){*it += 20;cout << *it << " ";it++;}cout << endl;for (auto e : lt){cout << e << " ";}cout << endl;}void test_list2(){list<int> lt;lt.push_back(1);lt.push_back(2);lt.push_back(3);lt.push_back(4);lt.push_back(5);list<int> lt1(lt);for (auto e : lt){cout << e << " ";}cout << endl;for (auto e : lt1){cout << e << " ";}cout << endl;list<int> lt2;lt2.push_back(10);lt2.push_back(20);lt2.push_back(30);lt2.push_back(40);lt2.push_back(50);lt1 = lt2;for (auto e : lt1){cout << e << " ";}cout << endl;for (auto e : lt2){cout << e << " ";}cout << endl;}struct AA{AA(int a1 = 0, int a2 = 0):_a1(a1), _a2(a2){}int _a1;int _a2;};void test_list3(){list<AA> lt;lt.push_back(AA(1, 1));lt.push_back(AA(2, 2));lt.push_back(AA(3, 3));list<AA>::iterator it = lt.begin();while (it != lt.end()){//cout << (*it)._a1<<" "<<(*it)._a2 << endl;cout << it->_a1 << " " << it->_a2 << endl;//本来应该是it->->_a1,编译器特殊处理,省略了一个->cout << it.operator->()->_a1 << " " << it.operator->()->_a1 << endl;//显式调用运算符重载函数++it;}cout << endl;}//typename场景template<class T>void print_list(const list<T>& lt){typename list<T>::const_iterator it = lt.begin();while (it != lt.end()){cout << *it << " ";it++;}cout << endl;}//再抽象,我们可以将类型再抽象为容器,这样就可以打印list之外的容器的元素template<typename Container>void print_container(const Container& lt){typename Container::const_iterator it = lt.begin();while (it != lt.end()){cout << *it << " ";it++;}cout << endl;}void test_list4(){list<int> lt;lt.push_back(1);lt.push_back(2);lt.push_back(3);lt.push_back(4);lt.push_back(5);print_container(lt);list<string> lt2;lt2.push_back("1111111111111");lt2.push_back("1111111111111");lt2.push_back("1111111111111");lt2.push_back("1111111111111");lt2.push_back("1111111111111");print_container(lt2);vector<string> v;v.push_back("222222222222");v.push_back("222222222222");v.push_back("222222222222");v.push_back("222222222222");v.push_back("222222222222");print_container(v);}
}
test.cpp
#include<iostream>
using namespace std;
#include"list.h"int main()
{my_std::test_list4();return 0;
}当你越来越专注,越来越自律,顺其自然得社交,随时随地地启程,开始爱惜自己,不在意他人的议论揣测,拿得起放得下,你就成为了很棒的自己。

相关文章:
C++-list实现相关细节和问题
前言:C中的最后一个容器就是list,list是可以在常数范围内在任意位置进行插入和删除的序列式容器,并且该容器可以前后双向迭代。list的底层是双向链表结构,双向链表中每个元素存储在互不相关的独立节点中,在节点中通过指…...

hadoop学习:mapreduce的wordcount时候,继承mapper没有对应的mapreduce的包
踩坑描述:在学习 hadoop 的时候使用hadoop 下的 mapreduce,却发现没有 mapreduce。 第一反应就是去看看 maven 的路径对不对 settings——》搜索框搜索 maven 检查一下 Maven 路径对不对 OK 这里是对的 那么是不是依赖下载失败导致 mapreduce 没下下…...
windows10上搭建caffe以及踩到的坑
对动作捕捉的几篇论文感兴趣,想复现一下,需要caffe环境就折腾了下!转模型需要python 2.7环境,我顺便也弄了!!! 1. 环境 Windows10 RTX2080TI 11G Anaconda Python2.7 visual studio 2013 cuda…...

大数据Flink(七十):SQL 动态表 连续查询
文章目录 SQL 动态表 & 连续查询 一、SQL 应用于流处理的思路...

「MySQL-04」Linux环境下使用C/C++连接并操纵MySQL
目录 一、准备mysql库:Connector/C 1. 查看是否有mysql相关的库和头文件 2. 安装devel(开发库) 3.到官网下载开发包,并上传到Linux 3.0 须知 3.1 到官网下载开发包 3.2 上传安装包至Linux 二、mysql库:Connector/C 的使用 1. 创建并初始化mys…...
)
【力扣】两数相除(c/c++)
目录 题目 注意: 示例 1: 示例 2: 提示: 题目解析 题目思路 代码思路 数据处理 注意 减法函数 第一次使用的函数 问题 第二次改良后的代码 处理i的值并且返回 总代码 力扣的代码 注意 题目 给你两个整数,被除数 dividend 和…...
《Kubernetes部署篇:Ubuntu20.04基于二进制安装安装kubeadm、kubelet和kubectl》
一、背景 由于客户网络处于专网环境下, 使用kubeadm工具安装K8S集群,由于无法连通互联网,所有无法使用apt工具安装kubeadm、kubelet、kubectl,当然你也可以使用apt-get工具在一台能够连通互联网环境的服务器上下载kubeadm、kubele…...
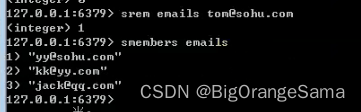
go学习part21 Redis
300_尚硅谷_Redis的基本介绍和原理示意_哔哩哔哩_bilibili Redis 命令 | 菜鸟教程 (runoob.com) 1.基本介绍 2.基本操作 Redis的基本使用: 说明:Redis安装好后,默认有16个数据库,初始默认使用0号库,编号是0...15 1.添加key-val [set] 2.查看当前redi…...
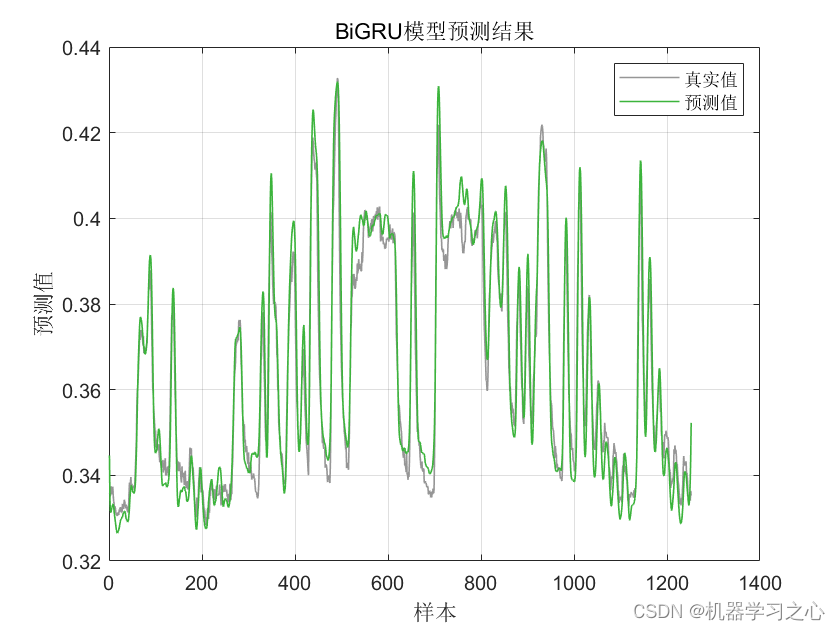
时序预测 | MATLAB实现基于PSO-BiGRU、BiGRU时间序列预测对比
时序预测 | MATLAB实现基于PSO-BiGRU、BiGRU时间序列预测对比 目录 时序预测 | MATLAB实现基于PSO-BiGRU、BiGRU时间序列预测对比效果一览基本描述程序设计参考资料 效果一览 基本描述 1.时序预测 | MATLAB实现基于PSO-BiGRU、BiGRU时间序列预测; 2.单变量时间序列数…...
Unity3D下如何采集camera场景数据并推送RTMP服务?
Unity3D使用场景 Unity3D是非常流行的游戏开发引擎,可以创建各种类型的3D和2D游戏或其他互动应用程序。常见使用场景如下: 游戏开发:Unity3D是一个广泛用于游戏开发的环境,适用于创建各种类型的游戏,包括动作游戏、角…...

黑客可利用 Windows 容器隔离框架绕过端点安全系统
新的研究结果表明,攻击者可以利用一种隐匿的恶意软件检测规避技术,并通过操纵 Windows 容器隔离框架来绕过端点安全的解决方案。 Deep Instinct安全研究员丹尼尔-阿维诺姆(Daniel Avinoam)在本月初举行的DEF CON安全大会上公布了…...

STM32注入通道
什么是注入通道? 注入通道是ADC的一种采样方式,主要用于在规则通道转换期间并行处理快速变化信号的采样。注入通道的转换可以在规则通道转换时强行插入,相当于一个“中断通道”。当有注入通道需要转换时,规则通道的转换会停止,优先执行注入通道的转换,当注入通道的转换执…...

WebVR — 网络虚拟现实
推荐:使用 NSDT编辑器 快速搭建3D应用场景 虚拟现实设备 随着Oculus Rift和许多其他生产设备即将上市,未来看起来很光明——我们已经有足够的技术来使VR体验“足够好”,可以玩游戏。有许多设备可供选择:像Oculus Rift或HTC Vive这…...

ASP.NET Core 的 Routing
ASP.NET Core 的 Routing ASP.NET Core 的 controllers 使用Routing 中间件匹配客户端的 url 请求,然后映射到对应的 controller 的处理方法(Action)上。 Actions 可以是 常规路由 或 属性路由 的映射。 MVC App一般使用常规路由。 REST API…...
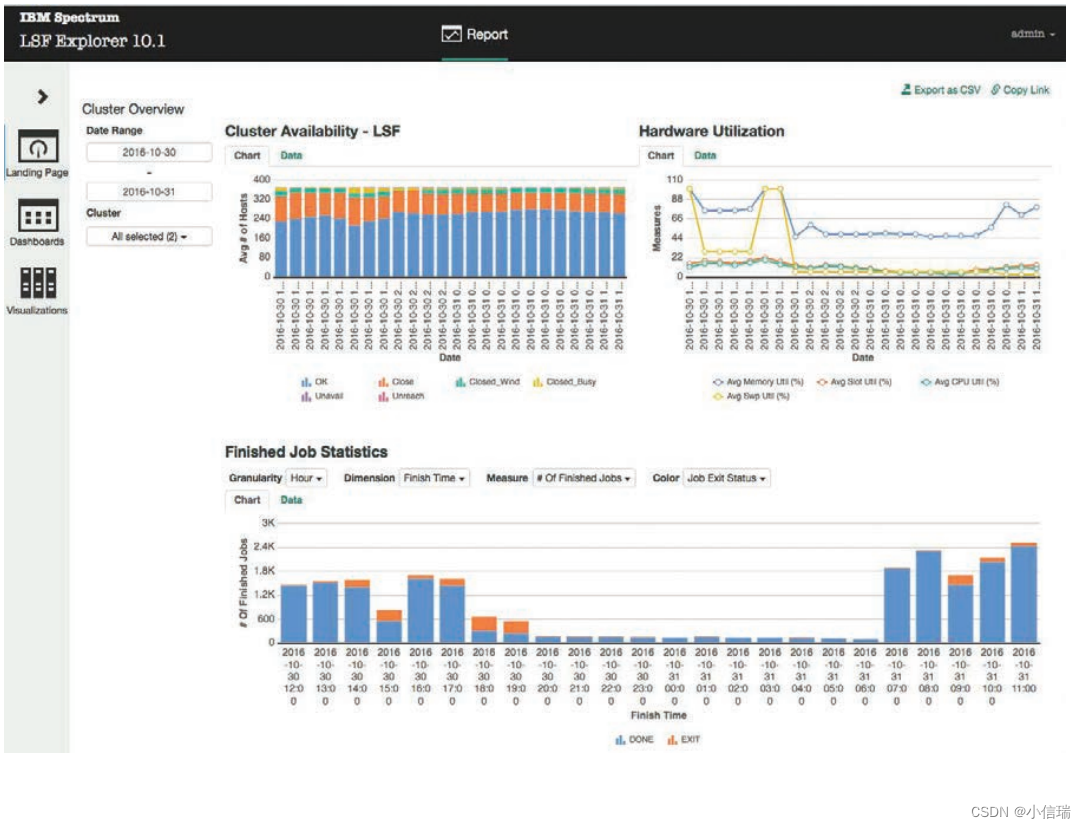
IBM Spectrum LSF Explorer 为要求苛刻的分布式和任务关键型高性能技术计算环境提供强大的工作负载管理
IBM Spectrum LSF Explorer 适用于 IBM Spectrum LSF 集群的强大、轻量级报告解决方案 亮点 ● 允许不同的业务和技术用户使用单一解决方案快速创建和查看报表和仪表板 ● 利用可扩展的库提供预构建的报告 ● 自定义并生成性能、工作负载和资源使用情况的报…...
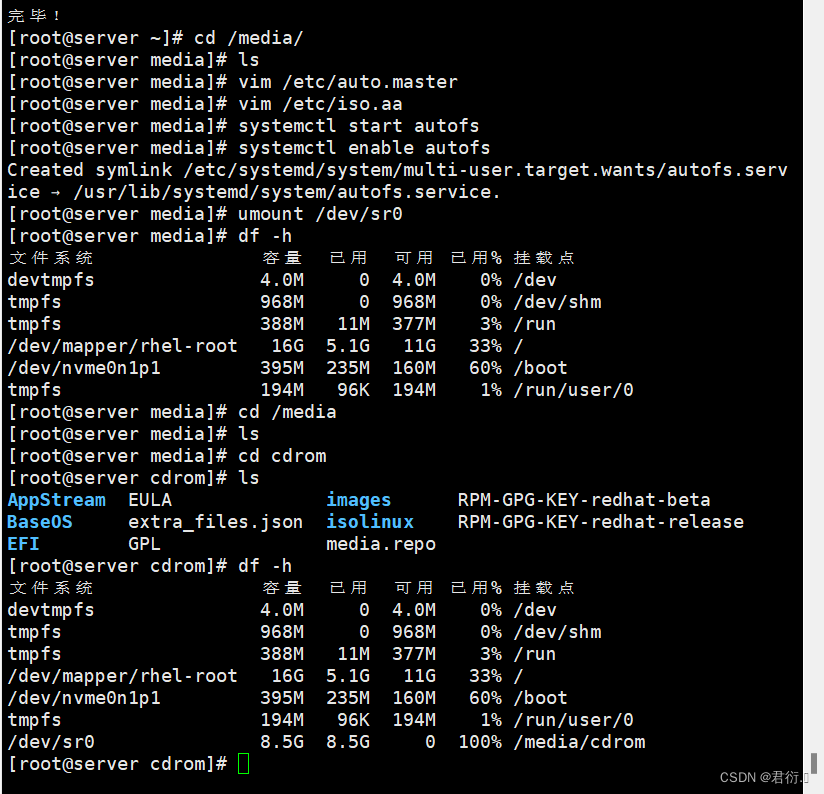
RHCE——十一、NFS服务器
NFS服务器 一、简介1、NFS背景介绍2、生产应用场景 二、NFS工作原理1、示例图2、流程 三、NFS的使用1、安装2、配置文件3、主配置文件分析3.1 实验1 4、NFS账户映射4.1 实验24.2 实验3 四、autofs自动挂载服务1、产生原因2、安装3、配置文件分析4、实验45、实验5 一、简介 1、…...

Python编程练习与解答 练习100:随机密码
编写一个生成最忌密码的函数,密码的长度应该在7-10个字符之间。每个字符应该从ASCII表的第33位到126位中随机选择。函数不接受任何参数,返回随机生成的密码作为位移结果。在文件的main程序中显示随机生成的密码。main程序只在解答没有被导入另一个文件时…...
华为云云服务器评测 | 从零开始:云耀云服务器L实例的全面使用解析指南
文章目录 一、前言二、云耀云服务器L实例要点介绍2.1 什么是云耀云服务器L实例2.1.1 浅析云耀云服务器L实例 2.2 云耀云服务器L实例的产品定位2.3 云耀云服务器L实例优势2.4 云耀云服务器L实例支持的镜像与应用场景2.5 云耀云服务器L实例与弹性云服务器(ECS…...
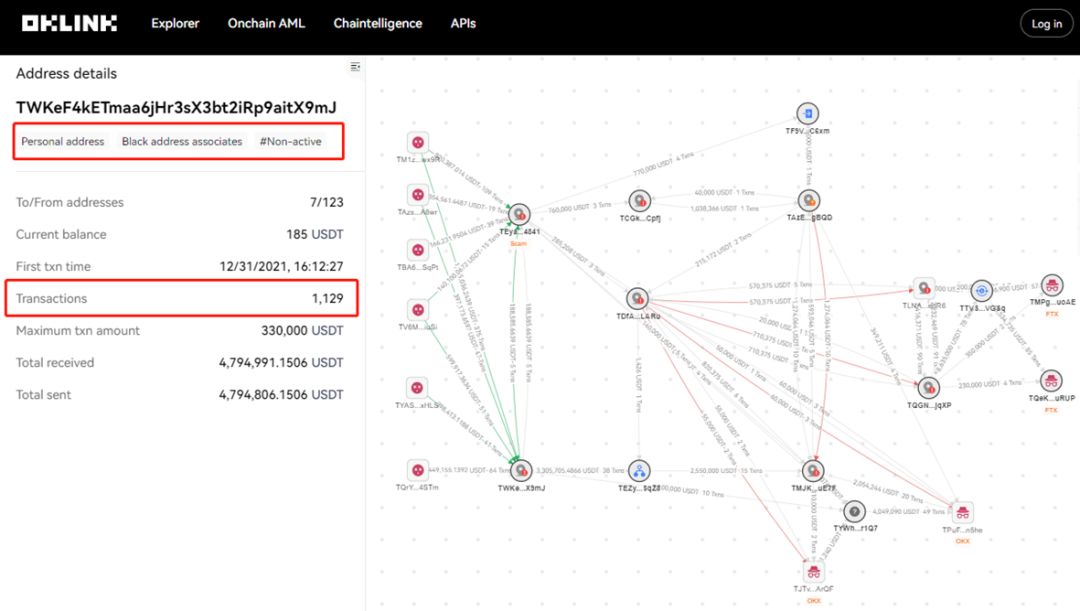
欧科云链研究院探析Facebook稳定币发行经历会不会在PayPal重演
引言 作者最近的报告-探析PayPal发行稳定币是否会重蹈Facebook覆辙-近期被英国的金融时报(中文版)刊登。由于该报告在欧科云链研究院内部反响较好,下面就带大家简单的剖析这篇报告的主要内容。 *这篇文章主要由对比分析(已删减&a…...

docker 容器pip、git安装异常;容器内web对外端口ping不通
1、docker 容器pip、git安装异常 错误信息: git clone https://github.com/vllm-project/vllm.git Cloning into ‘vllm’… fatal: unable to access ‘https://github.com/vllm-project/vllm.git/’: Failed to connect to 127.0.0.1 port 10808: Connection ref…...

SigmaStudio和A2B软件安装避坑大全:Win10/Win11系统关联DLL与插件配置一步到位
SigmaStudio与A2B开发环境配置全指南:从DLL配置到音频总线调试实战 在汽车音频系统开发领域,ADI的SigmaStudio和A2B软件组合已成为行业标配工具链。这套工具链能够帮助开发者快速搭建从主机到节点的完整音频总线架构,但在实际环境配置过程中&…...
到底怎么选?实战对比与避坑指南)
从ChatGPT到Llama:主流大模型的分词器(Tokenizer)到底怎么选?实战对比与避坑指南
从ChatGPT到Llama:主流大模型的分词器实战指南 当你在ChatGPT中输入"深度学习"四个字时,系统实际处理的可能是["深","度","学","习"]四个token——这个看似简单的切分过程,直接影响着大模…...

港科大沈劭劼、谭平团队最新成果:开源280万全景数据集,实现零样本立体匹配
「一举攻克全景3D视觉两大瓶颈」 目录 01 行业痛点:数据匮乏与畸变失效的双重桎梏 1. 数据集稀缺,泛化能力受限 2. 球面畸变破坏单目先验一致性 02 核心突破:超大数据与航向对齐先验双驱动 1. 280万级合成数据集,打破数据壁…...

用Sunshine搭建私人游戏串流服务器:从零到畅玩的完整指南
用Sunshine搭建私人游戏串流服务器:从零到畅玩的完整指南 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 你是否想过将高性能游戏电脑变成随时可用的云游戏服务器&…...

数科OFD阅读历史清理全攻略:统信UOS/麒麟KYLINOS下图形界面与命令行两种方法实测
数科OFD阅读历史清理全攻略:统信UOS/麒麟KYLINOS下图形界面与命令行两种方法实测 在国产化办公环境中,数科OFD作为主流的版式文档阅读工具,其使用痕迹管理常被忽视却至关重要。无论是个人用户希望保护阅读隐私,还是企业IT管理员需…...

小白程序员必备:从零基础到大模型实战,这份学习路线图请收藏!
本文结合530名开发者的经验,为AI初学者提供从零基础到项目实战的完整学习路线。核心内容包括:Python编程、数学基础、机器学习、深度学习框架(PyTorch)、科学计算库(NumPy)等关键技能,并避开了常…...

论文重复率过低该怎么办?
很多人第一次看到“论文重复率过低”会慌,觉得是不是“太低反而有问题”。先说结论:单纯“重复率低”本身通常不是问题,关键看你低到什么程度,以及你的论文内容是否合理。常见情况分这几种:1. 10%以下:很正…...

PPTXjs终极指南:3分钟学会在浏览器中完美预览PPTX文件
PPTXjs终极指南:3分钟学会在浏览器中完美预览PPTX文件 【免费下载链接】PPTXjs jquery plugin for convertation pptx to html 项目地址: https://gitcode.com/gh_mirrors/pp/PPTXjs 还在为PPT文件兼容性问题烦恼吗?当精心制作的演示文稿在不同设…...

收藏必备!VSCode 超详细入门教程 从安装到精通
系统下载 1、KALI安装版 https://pan.quark.cn/s/483c664db4fb 2、KALI免安装版 https://pan.quark.cn/s/23d4540a800b 3、下载所有Kali系统 https://pan.quark.cn/s/7d8b9982012f 4、KALI软件源 https://pan.quark.cn/s/33781a6f346d 5、所有Linux系统 https://pan.…...

W5500 TCP客户端开发避坑指南:从寄存器配置到稳定通信的5个关键步骤
W5500 TCP客户端开发避坑指南:从寄存器配置到稳定通信的5个关键步骤 在嵌入式网络通信领域,W5500作为一款硬件集成TCP/IP协议栈的以太网控制器,因其易用性和稳定性备受开发者青睐。然而,当项目从实验室demo转向实际部署时…...