深入了解GCC编译过程
关于Linux的编译过程,其实只需要使用gcc这个功能,gcc并非一个编译器,是一个驱动程序。其编译过程也很熟悉:预处理–编译–汇编–链接。在接触底层开发甚至操作系统开发时,我们都需要了解这么一个知识点,如何从我们的代码到机器码。这段过程经历了什么,我们的函数变量又是在哪里?一个个好奇心驱使着我写下这篇文章。于博客中有提及Linux的安装以及gcc基本环境搭建、gcc编译流程、常用gcc指令集:https://blog.csdn.net/Alkaid2000/article/details/128036290?spm=1001.2014.3001.5501
文章目录
- 0x01 编译过程
- 0x02 预编译
- 0x03 编译
- 0x04 汇编
- 目标文件ELF
- 翻译机器指令
- 操作数地址通过ModR/M中的Mod+R/M指定
- 操作数通过ModR/M中的Reg/Opcode指定
- 操作数地址直接嵌入在机器指令中
- 操作数直接嵌入在指令中
- 操作数隐含在Opcode中
- 回到代码
- 重定位表
- 符号表
- 0x05 链接
- 合并目标文件
- 符号重定位
- 链接静态库
- 链接动态库
0x01 编译过程
可以使用这么一句指令来观察一个.c文件所需要经历的编译过程:gcc -v main.c。
根据gcc的输出可见,对于一个C程序来说,从源代码构建出可执行文件经历了三个阶段:
- 编译

gcc使用编译器ccl.exe进行编译,产生的编译代码保存在目录/temp下的文件ccelFAGc.s中。
- 汇编

gcc使用汇编器as.exe进行汇编,汇编过程产生汇编文件ccZfpupi.o,将上面生成的ccelFAGc.s进行汇编。
- 链接
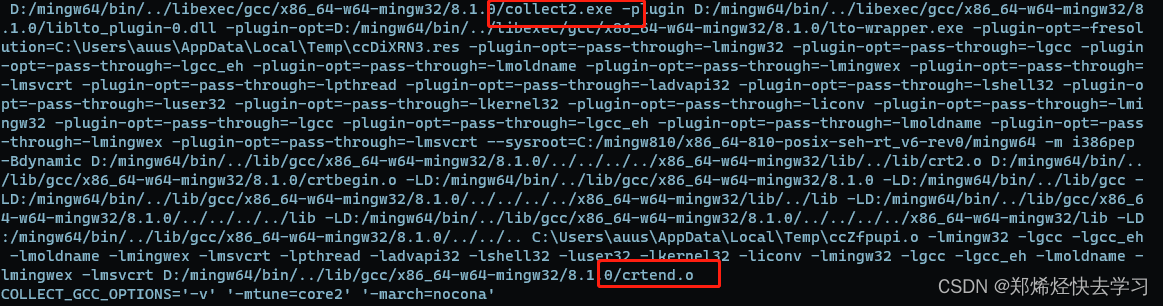
调用collect2.exe进行链接。实际上这个collect2只是一个辅助程序,最终他将调用链接器ld来完成真正的链接过程。包括框出来的crtend.o、以及启动文件等等,本质上都是ld在进行链接。
事实上,从gcc看到只有这三个过程,但是对于C程序来说,编译过程也分为两个阶段:预编译和编译。所以软件构建过程通常分为四个阶段:预编译、编译、汇编、链接。
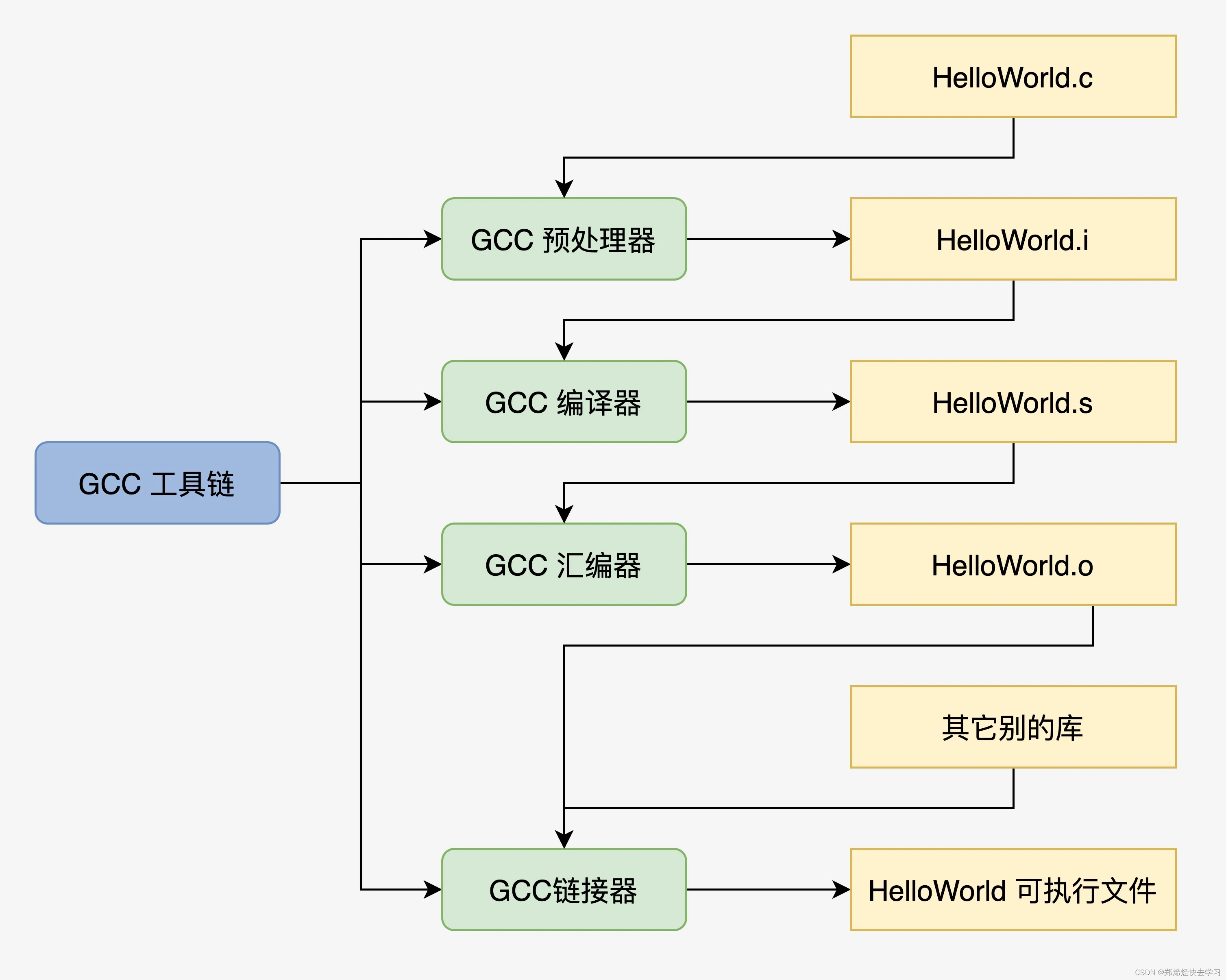
可以通过gcc手动控制以上的编译流程,从而留下中间文件以方便研究:
gcc HelloWorld.c -E -o HelloWorld.i预处理:加入头文件,替换宏。gcc HelloWorld.c -S -c -o HelloWorld.s编译:包含预处理,将 C 程序转换成汇编程序。gcc HelloWorld.c -c -o HelloWorld.o汇编:包含预处理和编译,将汇编程序转换成可链接的二进制程序。gcc HelloWorld.c -o HelloWorld链接:包含以上所有操作,将可链接的二进制程序和其它别的库链接在一起,形成可执行的程序文件。
那么接下来使用下面这段程序对于编译过程来做个总结:
hello.c:
#include <stdio.h>
#include "foo.h"extern int foo2;int main(int argc,char *argv[])
{int result;int r = 5;
#ifdef AREAresult = PI*r*r;
#elseresult = PI*r*2;
#endifreturn 0;
}
foo.h
#ifndef _FOO_H
#define _FOO_H#define PI 3.1415926
#define AREAstruct foo_struct{int a;
};#endif
fool2.c
int foo2 = 20;void foo2_func(int x)
{int ret = foo2;
}
fool1.c
int fool = 10;void fool_func()
{int ret = fool;
}
0x02 预编译
C语言中的预编译是以#开头,常用的预编译指令包括#include、#define、#if等等。在工具链中,一般都提供单独的编译器,比如GCC中提供的编译器为cpp。但是预编译也可以看作编译过程的第一遍,是为编译做的一些工作,所以通常编译器中也包含了预编译的功能。比如前面的gcc并没有单独调用cpp,而是直接调用ccl进行编译,原因就是如上。
gcc -E hello.c -o hello.i
编译之后可以查看文件hello.i:
# 7 "foo.h"
struct foo_struct{int a;
};
# 3 "hello.c" 2extern int foo2;int main(int argc,char *argv[])
{int result;int r = 5;result = 3.1415926*r*r;return 0;
}
根据编译后的结果可以总结出预编译指令的处理步骤:
- 文件包含:指示预编译器将一个源文件的内容全部复制到当前源文件中。
- 宏定义:预编译器将宏名替换为具体的值。
- 条件编译:保留用户希望编译的代码。(使用#if #else这种形式)
0x03 编译
编译程序对预处理过的结果进行词法分析、语法分析、语义分析,然后生成中间代码,对中间代码进行优化,目标是使最终生成的可执行代码时间更短、占用的空间更小,最后生成相应的汇编代码。
gcc -S fool2.c
其内容如下:
int foo2 = 20;void foo2_func(int x)
{int ret = foo2;
}
.file "fool2.c".text.globl foo2.data.align 4.type foo2, @object.size foo2, 4
foo2:.long 20.text.globl foo2_func.type foo2_func, @function
foo2_func:
.LFB0:.cfi_startprocendbr64pushq %rbp.cfi_def_cfa_offset 16.cfi_offset 6, -16movq %rsp, %rbp.cfi_def_cfa_register 6movl %edi, -20(%rbp)movl foo2(%rip), %eaxmovl %eax, -4(%rbp)noppopq %rbp.cfi_def_cfa 7, 8ret.cfi_endproc
.LFE0:.size foo2_func, .-foo2_func.ident "GCC: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0".section .note.GNU-stack,"",@progbits.section .note.gnu.property,"a".align 8.long 1f - 0f.long 4f - 1f.long 5
0:.string "GNU"
1:.align 8.long 0xc0000002.long 3f - 2f
2:.long 0x3
3:.align 8
4:
在此源文件中,定义了一个全局变量以及函数,区区一行代码却出现了这么多汇编语言。其实里面相当多的代码是伪指令。伪指令不参与CPU运行,只指导编译链接过程。
就像上面所生成的cfi指令,这个指令主要的作用是辅助汇编器创建栈帧信息的。
这些伪指令也有其他的作用,比如说中断后会输出回溯信息,比如在debug的时候,需要查找一些变量或者是查看函数调用信息。这个过程称为栈的回卷。
在上面的程序中注意到了有个寄存器rbp保存了frame pointer、base pointer均指向了栈的底部。对于main函数来说,他并非程序中第一个运行的程序,所以main其实也是一个被调函数,他也有自己的栈帧。在理论上可以使用这些指针来遍历调用过程中各个函数的栈帧,但是由于gcc代码的优化,可能导致调试器或异常处理很难甚至不能正常回溯栈帧,所以这些伪指令的目的就是辅助编译器创建栈帧信息,并且保存在目标文件的段.eh_frame中,这样就不会被编译器优化所影响。
去除伪指令后,可以看到代码如下:
foo2_func:pushq %rbpmovq %rsp, %rbpmovl %edi, -20(%rbp)movl foo2(%rip), %eaxmovl %eax, -4(%rbp)noppopq %rbpret
在汇编代码中,在函数的开头和结尾处分别会插入一小段代码,分别称为Prologue和Epilogue,比如上面1~3句是Prologue,最后两句是Epilogue。
-
Prologue:保存主调函数的frame pointer,这是为了在子函数调用结束后,恢复主调函数的栈帧。同时为子函数准备栈帧。pushq %rbpmovq %rsp, %rbpmovl %edi, -20(%rbp)上面这三句话起了一种构造函数的作用,首先需要保存主调函数的
frame pointer,之后保存在寄存器中金压栈,在退出主函数时可以从栈中恢复主调函数frame pointer;将rsp赋值给rbp,即将子函数的frame pointer指向主调函数的栈顶,这行代码记录了子函数栈帧的底部,从这里就开始了主函数的栈帧。下面那句是为本地变量分配栈空间。 -
Epilogue功能是恰恰相反的,如果说Prologue是构造函数,那么这个部分则是析构函数。popq %rbpret当前栈帧的栈底,是
Prologue保存的主调函数的frame pointer,将其pop出回到了主调函数的main栈帧,之后,CPU就返回主调函数继续执行。
中间程序的执行部分,也就是int ret = foo2这段,从第四行开始,CPU从数据段中读取了全局变量foo2的值将其放在寄存器eax中,之后在第五行代码,将eax的内容,赋值到栈中局部变量ret的位置。之后代码根据局部变量相对于栈的frame pointer的偏移来访问局部变量,如变量ret位于相对于栈底偏移为-4的内存处。
0x04 汇编
汇编器将汇编代码翻译为机器指令,每一条汇编语句几乎都对应一条机器指令,所以汇编器的汇编过程相对于比较简单,只需要根据汇编指令和机器指令的对照表进行翻译即可。除了生成机器码外,汇编器还要再目标文件中创建辅助链接时需要的信息,包括符号表、重定位表等。
目标文件ELF
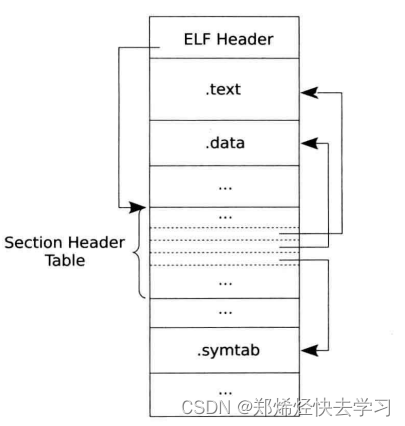
目标文件是汇编过程的产物。对于32位的ELF文件来说,其最前部是文件头部信息,描述了整个文件的基本属性,除了包括该文件运行在什么操作系统中、运行在什么硬件体系结构上、程序入口地址是什么等基本信息外,最重要的是记录了两个表格的相关信息,如表格所在的位置、其中包括了条目数等。这两个表格为:
Section Header Table:主要是供编译时链接使用的,表格中定义了各个段的位置、长度、属性等信息。Program Header Table:主要是供内核和动态加载器从磁盘加载ELF文件到内存时使用的。
对于目标文件,由于其只是编译过程中的一个中间产物,不涉及装载运行,因此在目标文件中不会创建Program Header Table。
如何列出目标文件:
gcc -c hello.c fool.c fool2.c
readelf -h fool2.o
生成的目标文件:
ELF Header:Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00Class: ELF64Data: 2's complement, little endianVersion: 1 (current)OS/ABI: UNIX - System VABI Version: 0Type: REL (Relocatable file)Machine: Advanced Micro Devices X86-64Version: 0x1Entry point address: 0x0Start of program headers: 0 (bytes into file)Start of section headers: 672 (bytes into file)Flags: 0x0Size of this header: 64 (bytes) Size of program headers: 0 (bytes)Number of program headers: 0Size of section headers: 64 (bytes)Number of section headers: 13Section header string table index: 12
- 可以看到ELF占了64字节,通过ELF头可见该文件是64位的ELF文件。
- 使用
little endian字节序存储字节。 - ABI遵循UNIX - System V标准,运行在类UNIX系统上。
- 该文件为REL类型文件:通常可执行文件的类型是
EXEC;静态库和目标文件的类型是REL;动态共享库的类型是DYN。 Entry point address为程序入口,由于是目标文件,则不存在执行的概念。Start of section headers:在偏移264字节处。Size of section headers:每个Section Header占用了40字节,Section Header Table一共包含了12个Section Header。
看完头信息后,就可以看到各个段的信息。ELF即各个段的组合。大体上,段可以分为如下几种类型:一类是存储指令的,通常称为代码段;第二类是存储数据的,通常称为数据段。数据段又细分为两个段:
.bss:未初始化的全局数据。.data:已初始化的全局数据。
这两个段本质并没有什么不同,但是因为未初始化的变量不包含是数据,所以在ELF文件中并不需要占用空间,在程序装载时进行分配即可。
使用命令:
readelf -S fool2.o
可以看到fool2.o中Section Header Table中包含的12个Section Header:
Section Headers:[Nr] Name Type Address OffsetSize EntSize Flags Link Info Align[ 0] NULL 0000000000000000 000000000000000000000000 0000000000000000 0 0 0[ 1] .text PROGBITS 0000000000000000 000000400000000000000017 0000000000000000 AX 0 0 1[ 2] .rela.text RELA 0000000000000000 000002000000000000000018 0000000000000018 I 10 1 8[ 3] .data PROGBITS 0000000000000000 000000580000000000000004 0000000000000000 WA 0 0 4[ 4] .bss NOBITS 0000000000000000 0000005c0000000000000000 0000000000000000 WA 0 0 1[ 5] .comment PROGBITS 0000000000000000 0000005c000000000000002c 0000000000000001 MS 0 0 1[ 6] .note.GNU-stack PROGBITS 0000000000000000 000000880000000000000000 0000000000000000 0 0 1[ 7] .note.gnu.propert NOTE 0000000000000000 000000880000000000000020 0000000000000000 A 0 0 8[ 8] .eh_frame PROGBITS 0000000000000000 000000a80000000000000038 0000000000000000 A 0 0 8[ 9] .rela.eh_frame RELA 0000000000000000 000002180000000000000018 0000000000000018 I 10 8 8[10] .symtab SYMTAB 0000000000000000 000000e00000000000000108 0000000000000018 11 9 8[11] .strtab STRTAB 0000000000000000 000001e80000000000000018 0000000000000000 0 0 1[12] .shstrtab STRTAB 0000000000000000 00000230000000000000006c 0000000000000000 0 0 1
-
.text段存储在文件中偏移0x40处,占据了0x17个字节。.text段并不全是代码段,在链接时,.init、.fini等存储的代码都属于代码段,这些都被映射到了Program Header Table中的一个段,在ELF加载时,统一作为进程的代码段。 -
.data段存储在文件中偏移0x58字节处,占据了0x04个字节的空间。 -
.bss段虽然包含着,但是他不必要记录数据,所以并没有对应的段。在加载程序时,加载器将依据.bss段的Section Header中的信息,在内存中为其分配空间。所以占用着0x00字节空间。 -
.symtab段记录的是符号表。因为符号的名字字串长度可变,所以目标文件将符号的名字字符串剥离出来,记录在另一个段.strtab中,符号表使用符号名字的索引在段.strtab中的偏移来确定符号名字。 -
.strtab段则是用于记录段的名字 -
rel开头的文件,如rel.text、rel.eh_frame,记录的是段中需要重定位的符号。 -
.eh_frame段中记录的是调试和异常处理时用到的信息。 -
.comment、.note.GNU-stack等都是在链接或者时装载都不会用到的数据,不需要关心。
那么综上,ELF文件所有的内容可以用如下的表所示:
翻译机器指令
机器指令由操作码和操作数组成,操作码指明该指令要完成的操作,即指令的功能;操作数是参与操作的参数,主要以寄存器或存储器地址的形式指明数据的来源或者计算存放的位置等。
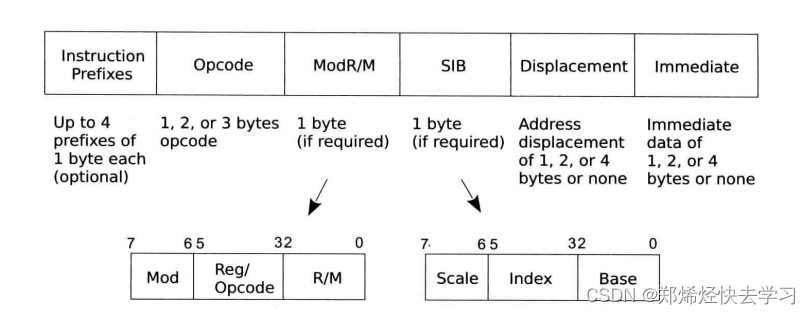
汇编过程就是将操作码翻译为对应的0和1的机器指令,这也是操作码和操作数的编码过程。这个过程也比较简单,对应关系可以查看对应的CPU指令手册。但是对于操作数翻译为机器码复杂一些,操作数并没有直接嵌入在指令编码中,而是根据汇编指令使用的具体寻址方式,设置ModR/M、SIB、Displacement和Immediate各项的值,这个过程称为操作数的解码,CPU根据ModR/M、SIB、Displacement和Immediate各项的值解码出操作数。
IA32机器指令的格式:
下面是操作数的编码方式:
操作数地址通过ModR/M中的Mod+R/M指定
ModR/M占用1字节,包含三个域:Mod、Reg/Opcode和R/M,其中Mod占2位,R/M占3位,Reg/Opcode占3位。操作数可以使用ModR/M中的Mod和R/M字段联合起来定义。


其中第二列表示寻址方式生成的有效地址;第三列和第四列表示对应于某个寻址方式,Mod和R/M分别表示对应的编码。
在上面的表中,包含了直接寻址、寄存器寻址、寄存器间接寻址、基址寻址以及基址变址寻址等寻址方式下Mod和R/M对应的编码。如果汇编指令使用的是基址变址寻址,那么机器指令中也需要字段SIB。
以第七行的指令为例,假设汇编指令使用的寻址方式是[EAX]+disp8,那么Mod应该取值01,R/M应该取值位000。偏移disp8表示八位的Displacement,根据机器指令的格式,Displacement直接嵌入在指令中即可。Displacement取值可以为8位、16位、32位,选择取决于尺寸方面,Displacement需要使用补码的形式。当CPU执行指令时,当解析到ModR/M这个字节时,一旦发现Mod的值是01,R/M的值是000,那么CPU就到寄存器EAX中取到其中的内容,然后再取出嵌入在指令中的8位偏移Displacement,将这两个值相加作为操作数的内存地址,从而完成操作数的解码过程。
操作数通过ModR/M中的Reg/Opcode指定
ModR/M中的字段Reg/Opcode占据3位,如果在汇编指令中使用了寄存器作为操作数,那么编码时也可以使用Reg/Opcode指定操作数使用的寄存器。如果操作数不需要使用字段Reg/Opcode编码,字段Reg/Opcode也可以作为操作码的编码,下面是32位寄存器与字段Reg/Opcode取值的对应关系:

操作数地址直接嵌入在机器指令中
这就是所谓的直接寻址方式,那么在翻译为机器指令时,直接使用机器指令中的Displacement字段表示操作数的地址。
操作数直接嵌入在指令中
如果在汇编指令中,操作数就是参与计算的数据,即所谓的立即寻址,那么在翻译为机器指令时,直接使用机器指令中的Immediate表示操作数。
操作数隐含在Opcode中
这就是所谓的隐含寻址。其实就是通过一些其他子指令来区分功能相同,但是操作数类型不同的作用:
mov r/m16,r16
mov r/m32,r32
Intel并没有为上述两个分类操作分别定义两个操作码,而是使用了同一个操作码。但是使用了Instruction Prefixes来区分指令中的操作数是16位的还是32为的,比如在32位环境下使用了16位的操作数,那么需要在指令前使用0x66进行标识。
回到代码
那么回到代码,fool2中:
movl foo2(%rip), %eaxmovl %eax, -4(%ebp)
这两条使用的都是mov指令,IA32架构的mov指令可以简单了解如下:
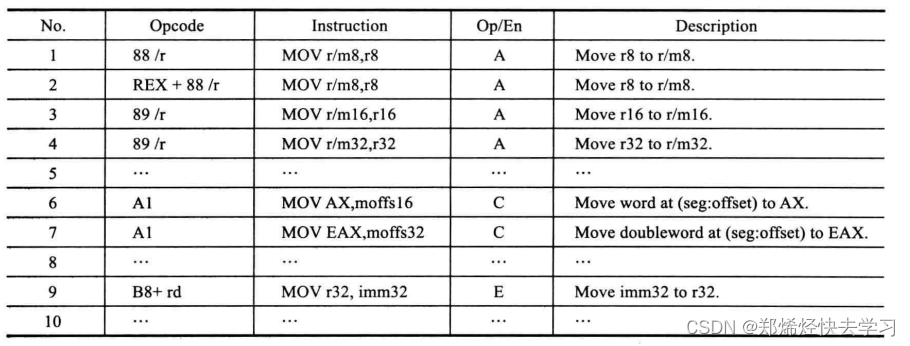
需要关注Opcode以及Op/En(操作数的编码方式)。
对于MOV指令,不仅仅只有一个操作码,对于同一类操作,可能使用不同的操作数,操作数可能是寄存器,也可能是内存地址,同时操作数还会有长度之分,比如8位、16位、32位。Intel采取的策略是为同一指令设计了多个操作码来细分这些指令。
对于Op/En操作数的编码方式,具有六种:
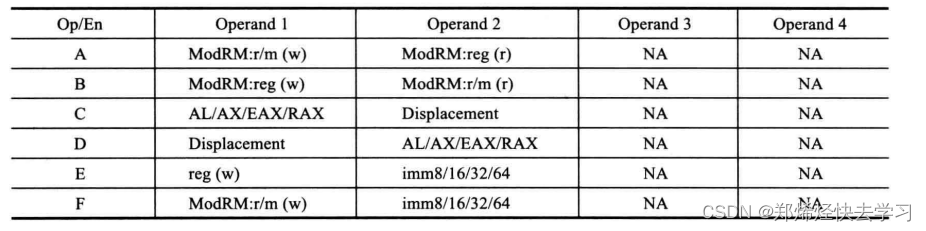
需要注意的是,编译器生成的汇编代码使用的是AT&T的格式,其操作数的顺序与Intel的汇编指令正好相反,所以指令movl foo2(%rip), %eax中,foo2是Intel语法中的第二个操作数,%eax是第一个操作数。那么可以查表,第七行,mov eax,moffs32,根据该指令说明,操作码0xa1隐含地指出了指令中第一个操作数是寄存器EAX,也就是寻址方式中所谓地操作数隐含寻址。
该指令地操作数编码方式是C,C类编码方式不需要ModR/M,也不需要SIB,而且也没有使用立即数作为操作数,也不需要指令前缀进行修饰,所以第一个操作数寄存器EAX是通过操作码隐含指明,所以该条汇编代码最后转换为如下形式地机器指令:Opcode+Displacement。
第二个操作数是通过Displayment来进行表示地,由于还没有进行链接,所以foo2的地址尚未确定,所以暂时填充0占位,在链接时根据实际地址修改。因为是运行在32位的环境下,所以地址是32位的,Displayment占用了4字节,综上所述,该指令的机器码可以翻译为:
movl foo2(%rip), %eax||opcode + displayment||a1 00 00 00 00
下一条指令是movl %eax, -4(%ebp),这条指令也是有两个操作数,第一个操作数-4(%ebp)相当于是[EBP]+dis8,用8位是因为表示-4使用1个字节就够了。根据A类编码的要求,第一个操作数需要使用的寄存器需要由ModR/M中的Mod和R/M共同指明,根据寻址模式可匹配表的第十行,mod为01,r/m为101.且第一个操作数中的偏移-4由displayment来表示,在机器指令中需要使用数的补码来表示,-4补码为fc。
根据A类编码的方式要求,第二个操作数由ModR/M中的Reg/Opcode指明。汇编指令第二个操作数使用的寄存器位EAX,对照表位000,那么第二条指令:
movl %eax, -4(%ebp)||
Opcode + ModR/M + displayment||
0x89 01 000 101 fc||89 45 fc
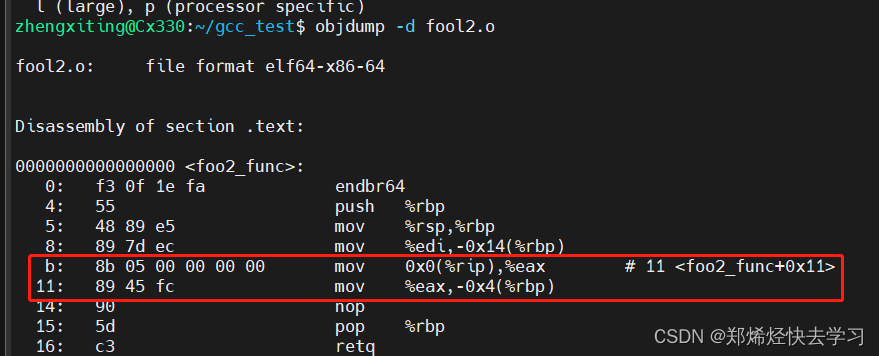
可以使用指令objdump -d fool2.o来分析机器码翻译过程:
可以使用工具hexdump -e ' "%4_ax:" 16/1 " %02x" "\n"' fool2.o原汁原味的进行分析,%4_ax表示使用4位十六进制进行偏移;16/1表示每行显示16字节,逐字解析,%02x表示以十六进制显示,每个字符占据两位。
可以看到截取到的.text段以及.data段:
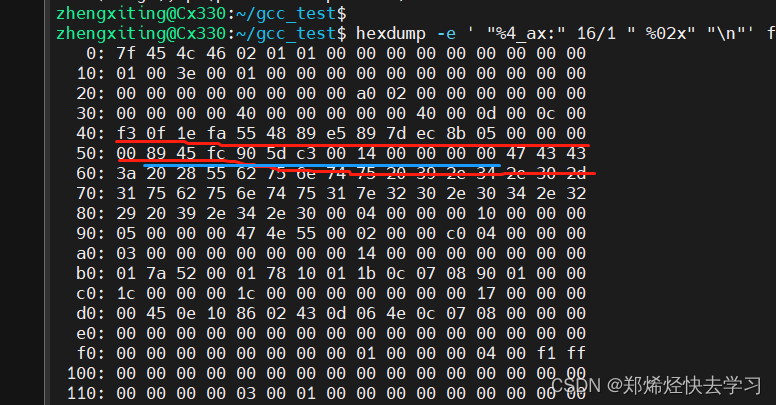
可以注意到起始于偏移0x40处,于我们ELF文件中看到的描述相同!!占据的字节数也是相同的,指令也是相同的!!
对于数据,0x58开始的数据段,正好是0x14对应的十进制数20,信息也可以对的上。
重定位表
在进行汇编时,在一个模块内,如果引用了其他模块或者时库中的变量或者函数,汇编器并不会解析引用的外部符号。汇编器基本上是留空引用的外部符号的地址;然后在链接时,在符号地址确定后,链接器再来修订这些位置,这个修订的过程,被称之为重定位(编译时、加载/运行时,这里说的是前者)。
这些需要修订的位置并不是全都置为0,有时候这里填充的是一个Addend,这就是之所以使用引号将空引用起来的原因。
但是链接器并不能自动找到目标文件中引用外部符号的地方,所以在目标文件中需要建立一个表格,这个表格中的每一条记录对应的就是一共需要重定位的符号,这个表格通常称为重定位表,汇编器将为可重定位文件中每个包含需要重定位符号的段都建立一个重定位表。
ELF标准规定,重定位表中的表项可以使用如下两种格式:

唯一不同的成员即r_addend,这个成员一般是个常量,用来辅助计算修订值;若使用了第一种格式,那么r_addend将被填充在引用外部符号的地址处,也就是留空处。
r_offset为需要重定位的符号在目标文件中的偏移;对于目标文件,r_offset是相对于段的,是段内偏移;对于执行文件或者动态库,r_offset是虚拟地址。r_info中包含重定位类型和此处引用的外部符号在符号表中的索引。根据符号在符号表中的索引,链接器就可以从符号表中解析出符号的地址。
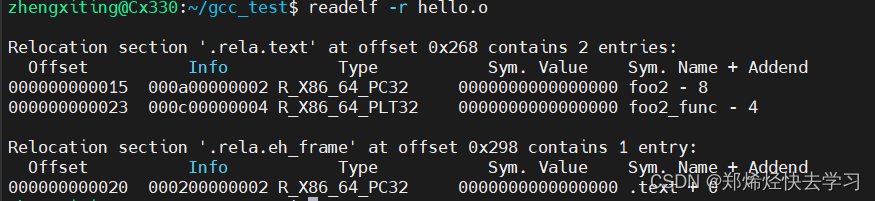
可以使用命令readelf -r hello.o查看文件的重定位表。
可以看到段.text以及.eh_frame段中都有符号需要重定位,所以建立了两重定位表。在.text段的重定位表中,引用了两个外部符号,并且可以在第一列得到他们的偏移为0x15以及0x23。
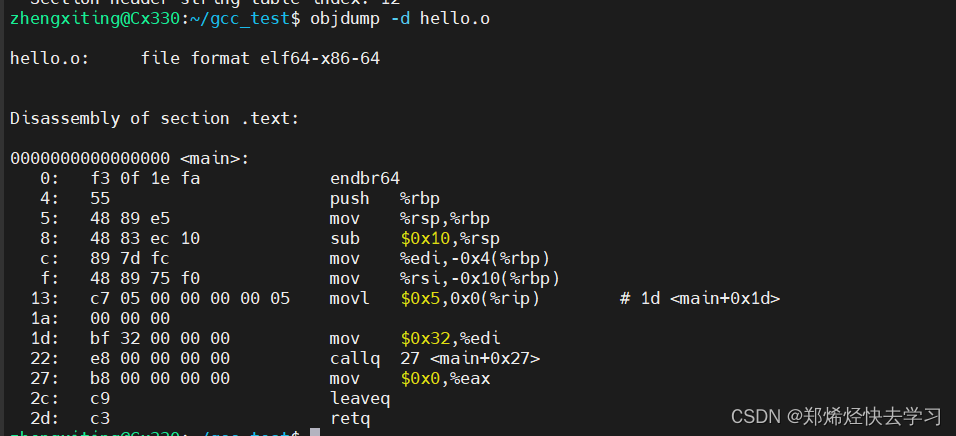
根据objdump的输出可见,在偏移0x15处,则是变量foo2的地址,汇编器填充的addend是0;在偏移0x23处,foo2_func填充addend的也是0。
符号表
在链接时需要重定位目标文件中引用的外部符号,显然链接器也需要指定这些符号的定义是在哪里,所以汇编器在每个目标文件中创建了一个符号表,符号表中记录了这个模块定义的可以提供给其他模块引用的全局符号。
查看符号表readelf -s fool2.o:
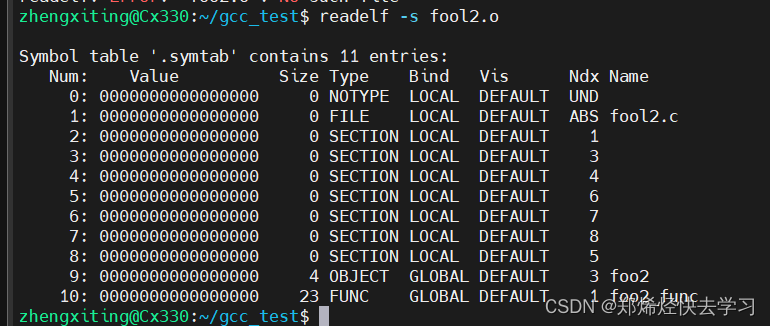
根据输出可见,fool2.o符号表包含了10个符号。
- value列表示的时符号的地址,由于链接时链接器才会分配地址,所以现在看到的符号地址全都是0。
- Size列代表的时申请内存的大小,可以看到变量
foo2占据了4个字节,foo2_func占据了23个字节。 - Type列表示符号的类型。如
foo2类型为OBJECT表示的是变量;FUNC表示的是函数。 - Bind列表示符号绑定的相关信息,
LOCAL表示模块内部符号,对外不可见;GLOBAL表示全局符号,属于全局变量。 - Ndx列表示该符号在哪个段,3为
.data段,1为.text段。
那么对于引用外部符号的符号表,可以看看hello.o:
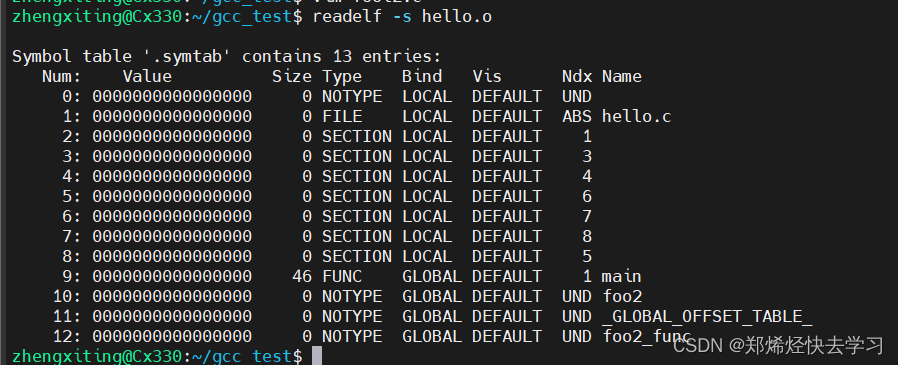
由于符号foo2以及foo2_func都在模块foo2中定义,对于模块hello来说是外部符号,没有在任何一个段中,所以在列Ndx中,他们的值都是UND。UND是Undefined的缩写,表示其是未定义的。
在链接时,对于模块中引用的外部符号,链接器将根据符号表进行符号的重定位。如果将符号表删除,那么链接器在链接时将找不到符号的定义,从而不能进行正确的符号解析。可以看到下面的操作:

0x05 链接
链接时编译过程的最后一个阶段,链接将一个或者多个目标文件和库,包括动态库和静态库,链接为一个单独的文件(通常为可执行文件、动态库或者静态库)。
链接器的工作可以分为两个阶段:
- 第一阶段是将多个文件合并为一个单独的文件。对于可执行文件,还需要为指令以及符号分配运行时的地址。
- 第二阶段进行符号重定位。
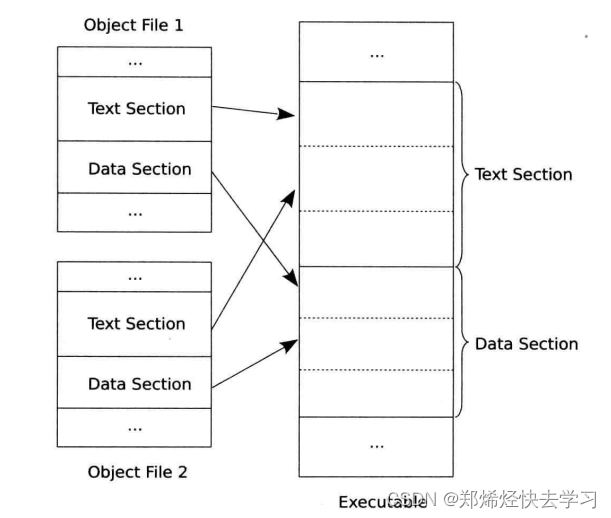
合并目标文件
合并多个目标文件其实就是将多个目标文件的相同类型的段合并到一个段中:
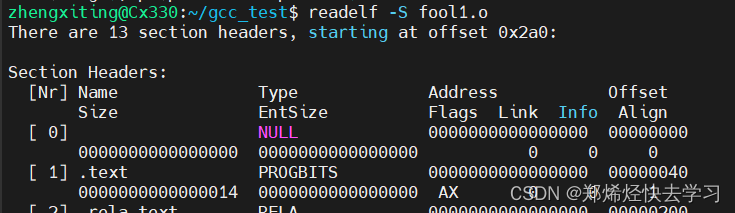
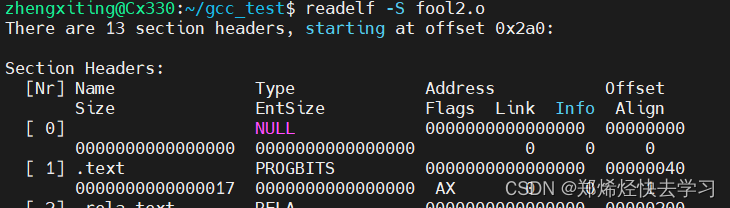
可以试着查看所有文件的目标文件以及链接后可执行文件的.text段:
hello.o:
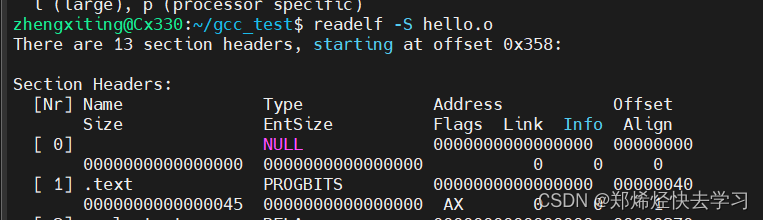
fool1.o:
foo2.o:
hello:
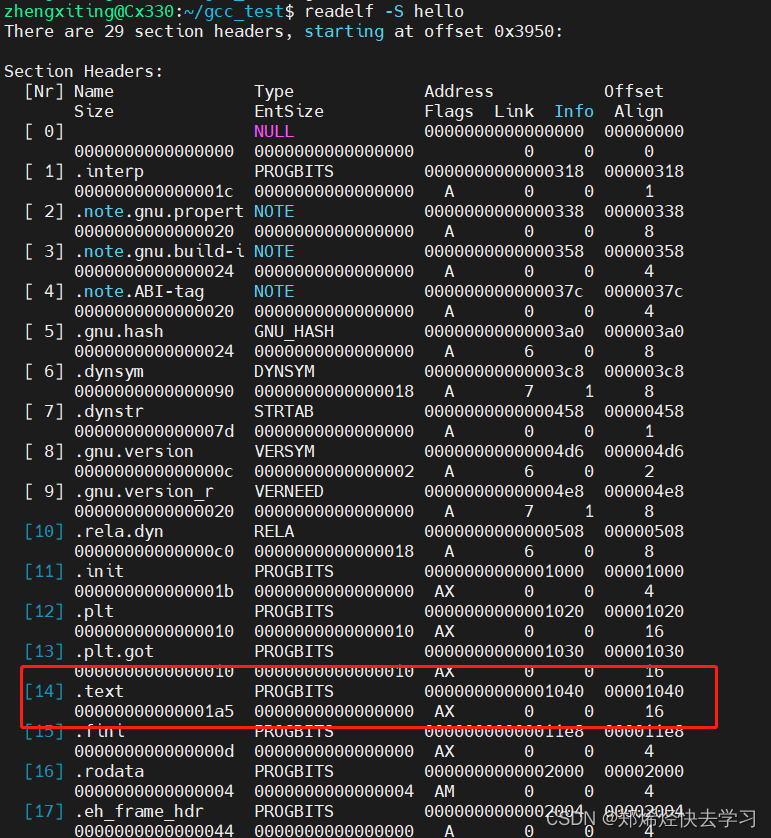
根据上面输出的结果可见,对于目标文件,并没有为目标文件的机器指令及符号分配运行时的地址,而对于可执行文件hello,链接器已经为其机器指令及符号分配了运行时地址,并且申请了对应的内存空间。
理论上,三个目标文件的.text段加起来应该与可执行文件的hello的.text段的尺寸大小是相等的。三个可执行文件加起来的大小是0x70,但是远小于可执行文件0x1a5。
可以注意到在编译时会向gcc传递了参数-v,细心可以发现,实际上链接时链接器自作主张地链接了一些特别的文件,包括crtl.o\crti.0\crtn.o\crtbegin.o\ctrend.o,其实就是我们前面提到的启动文件。所以会增加了.text段的大小。
也可以手动调用ld,不链接这些启动文件,再来对比一下.text段的尺寸。在默认情况下,链接器将使用函数_start作为可执行文件的入口,但是这个函数的实现在启动文件ctrl.o中,因此,在这里我们通过给链接器ld传递参数-e main,明确告诉链接器不适用默认的启动函数_start了,否则链接器会找不到符号_start,直接使用函数main作为可执行文件的入口。当然main函数中并没有实现启动代码的功能,在这里这是为了方便查看.text段,尺寸是所有目标文件size的总和。如果不是等于总和,差别有几个字节的话,是由内存对齐所引起的。
符号重定位
上面为链接的第一阶段,目标文件已经合并完成了,并且已经为符号分配了运行时的地址,链接器将符号进行重定位。
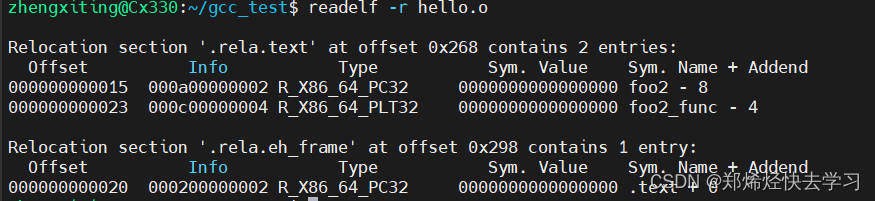
可以看到汇编器已经将这两处需要重定位的符号记录在了重定位表中。
R_386_32,ELF标准规定的计算修订值得公式是:S+A;其中,S表示符号的运行地址,A就是汇编器填充在引用外部符号处的Addend。R_386_PC32,ELF标准规定的计算修订值的公式是:S+A-P;其中,S,A与前面的意义完全相同,P为修订处的运行地址或者偏移。对于可执行文件和动态库,P为修订处的运行时地址。
首先确定S,运行时地址在链接时才分配:

可以看到foo2、foo2_func的运行时的地址。
之后再捋捋汇编器为这两个符号填充的Addend是多少,可以使用objdump反汇编hello.o,也可以看到上面图中的-8以及-4。
需要注意的是,对于函数占据的运行时地址小于main函数,那么这里的函数地址与PC相对地址将是负数,其实就是将PC跳回去执行。在机器指令中,使用的是数的补码形式。
对于R_386_32这种重定位类型,是绝对地址重定位,链接器只要解析符号运行时地址替换修订处即可。而对于R_386_PC32,这是一个PC相对地址重定位,当 执行当前指令时,PC中已经加载了下一条指令的地址,并不是当前指令的地址。
在链接时,链接器在需要重定位的符号所在的偏移处直接进行了编辑修订,所以链接器也被形象地称为link editor。
链接静态库
静态库其实就是多个目标文件的打包,因此与合并多个目标文件并没有什么区别。但是在链接静态库时,并不是将整个静态库中包含的目标文件全部复制一份到最终的可执行文件中,而是仅仅链接库中使用的目标文件。
可以将两个源文件编译为静态库libfoo.a,然后将其链接到hello:

可以看到静态库的符号表:

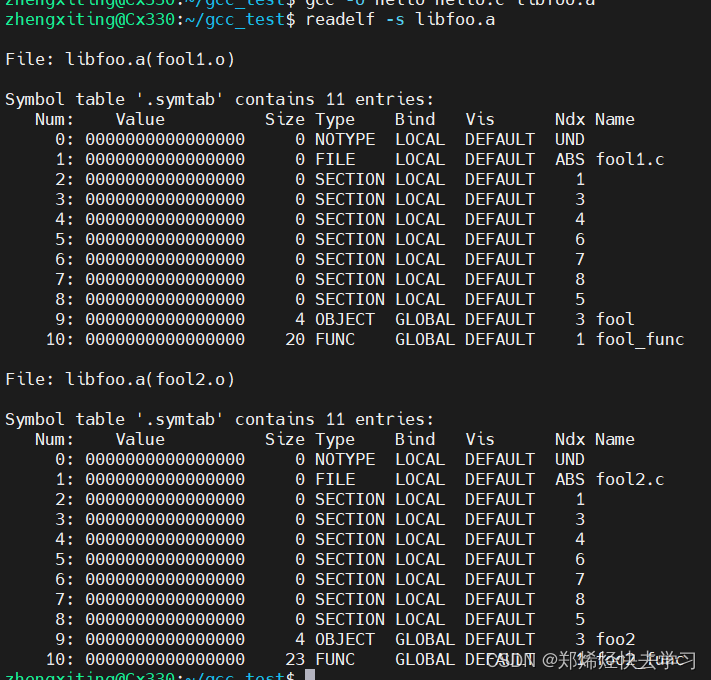
可以看到就是两个目标文件的合体,但是在hello中可不是什么都有:

链接动态库
与静态库不同,动态库不会在可执行文件中有任何副本,那么为什么编译链接依然需要指定动态库?
- 动态加载器需要知道可执行程序依赖的动态库,这样在加载可执行程序时才能加载其依赖的动态库。
在链接时会根据可执行程序引用的动态库中的符号的情况,在dynamic段中记录可执行程序依赖的动态库。
gcc -c -fPIC fool1.c fool2.c #产生与地址无关的目标文件
gcc -shared -o libfoo.so fool1.o fool2.o
gcc hello.c -o hello -L./ -lfoo
readelf -d hello | grep Shared
- 链接器需要在重定位表中创建重定位记录,这样当动态链接器加载hello时,将依据重定位记录重定位hello引用的这些外部符号。
重定位记录存储在ELF文件的重定位段中,ELF文件中可能有多个段包含需要重定位的符号,所以可能会包含多个重定位段。
rel.dyn段中记录的是加载时需要重定位的变量。
rel.plt段中记录的是需要重定位的函数。
虽然编译时不需要链接共享库,但是可执行文件中需要记录其依赖的共享库以及加载/运行时需要重定位的条目,在加载程序时,动态加载器需要这些信息来完成加载时的重定位。
相关文章:
深入了解GCC编译过程
关于Linux的编译过程,其实只需要使用gcc这个功能,gcc并非一个编译器,是一个驱动程序。其编译过程也很熟悉:预处理–编译–汇编–链接。在接触底层开发甚至操作系统开发时,我们都需要了解这么一个知识点,如何…...

leetcode 594.最长和谐子序列(滑动窗口)
⭐️ 题目描述 🌟 leetcode链接:最长和谐子序列 思路: 第一步先将数组排序,在使用滑动窗口(同向双指针),定义 left right 下标,比如这一组数 {1,3,2,2,5,2,3,7} 排序后 {1,2,2,2,3,…...

深入剖析云计算与云服务器ECS:从基础到实践
云计算已经在不断改变着我们的计算方式和业务模式,而云服务器ECS(Elastic Compute Service)作为云计算的核心组件之一,为我们提供了灵活、可扩展的计算资源。在本篇长文中,我们将从基础开始,深入探讨云计算…...
苍穹外卖技术栈
重难点详解 1、定义全局异常 2、ThreadLocal ThreadLocal 并不是一个Thread,而是Thread的一个局部变量ThreadLocal 为每一个线程提供独立的存储空间,具有线程隔离的效果,只有在线程内才能取到值,线程外则不能访问 public void …...

重新开始 杂类:C++基础
目录 1.输入输出 2 . i 与 i 3.结构体 4.二进制 1.输入输出 #include<cstdio>//cin>>,cout #include<iostream>//printf,scanf (1) cin , cout输入输出流可直接用于数字,字符 (2)scanf(&quo…...

自用的markdown与latex特殊符号
\triangleq \approx \xlongequal[y\arctan x]{x\tan y} \sum_{\substack{j1 \\ j\neq i}} \iiint\limits_\Omega \overset{\circ}{\vec{r}} \varphi \checkmark \stackrel{\cdot\cdot\cdot}{x}≜ ≈ y arctan x x tan y ∑ j 1 j ≠ i ∭ Ω r ⃗ ∘ φ ✓ x ⋅ ⋅ ⋅…...
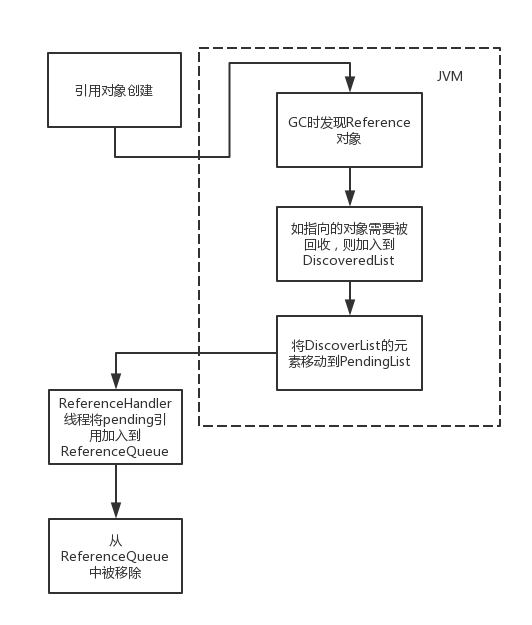
【20期】说一说Java引用类型原理
Java中一共有4种引用类型(其实还有一些其他的引用类型比如FinalReference):强引用、软引用、弱引用、虚引用。 其中强引用就是我们经常使用的Object a new Object(); 这样的形式,在Java中并没有对应的Reference类。 本篇文章主要是分析软引用、弱引用、…...

无锡布里渊——厘米级分布式光纤-锅炉安全监测解决方案
无锡布里渊——厘米级分布式光纤-锅炉安全监测解决方案 厘米级分布式光纤-锅炉安全监测解决方案 1、方案背景与产品简介: 1.1:背景简介: 锅炉作为一种把煤、石油或天燃气等化石燃料所储藏的化学能转换成水或水蒸气的热能的重要设备ÿ…...

GREASELM: GRAPH REASONING ENHANCED LANGUAGE MODELS FOR QUESTION ANSWERING
本文是LLM系列文章,针对《GREASELM: GRAPH REASONING ENHANCED LANGUAGE MODELS FOR QUESTION ANSWERING》的翻译。 GREASELM:图推理增强的问答语言模型 摘要1 引言2 相关工作3 提出的方法:GREASELM4 实验设置5 实验结果6 结论 摘要 回答关…...
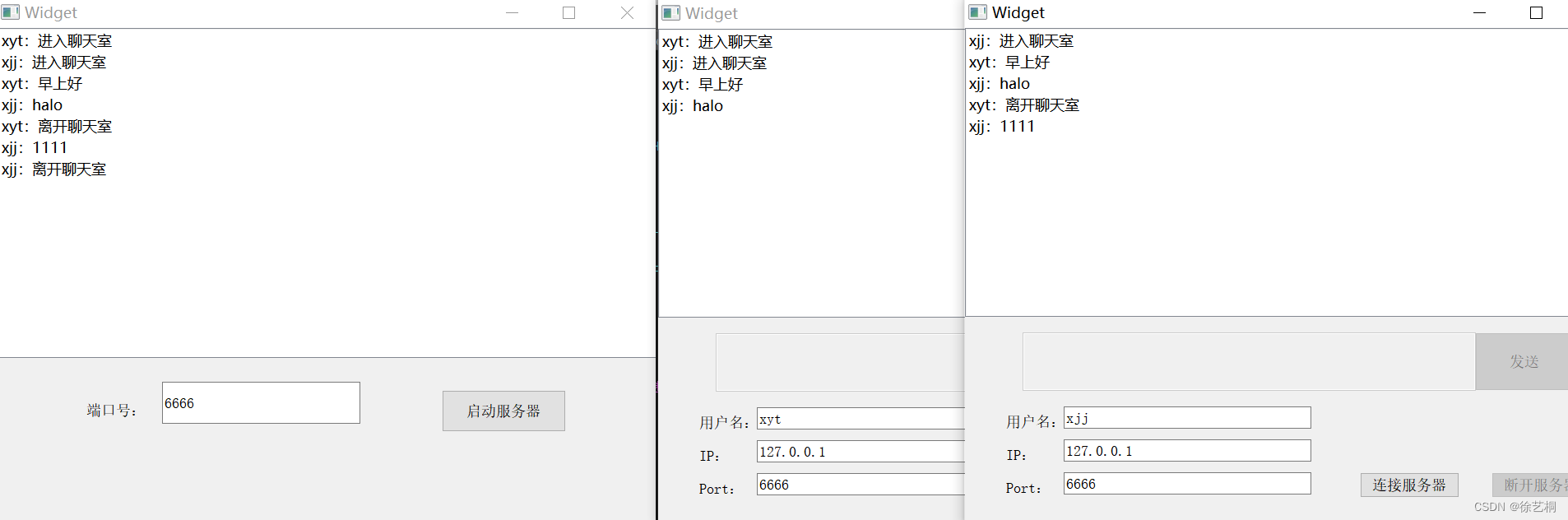
QT C++ 实现网络聊天室
一、基本原理及流程 1)知识回顾(C语言中的TCP流程) 2)QT中的服务器端/客户端的操作流程 二、代码实现 1)服务器 .ui .pro 在pro文件中添加network库 .h #ifndef WIDGET_H #define WIDGET_H#include <QWidget>…...

每日一道面试题之什么是上下文切换?
上下文切换是指在计算机操作系统中,当多个进程或线程同时运行时,系统需要将当前运行进程或线程的状态(包括程序计数器、寄存器值、内存映像等)保存起来,然后切换到另一个进程或线程继续执行的过程。上下文切换通常由操…...
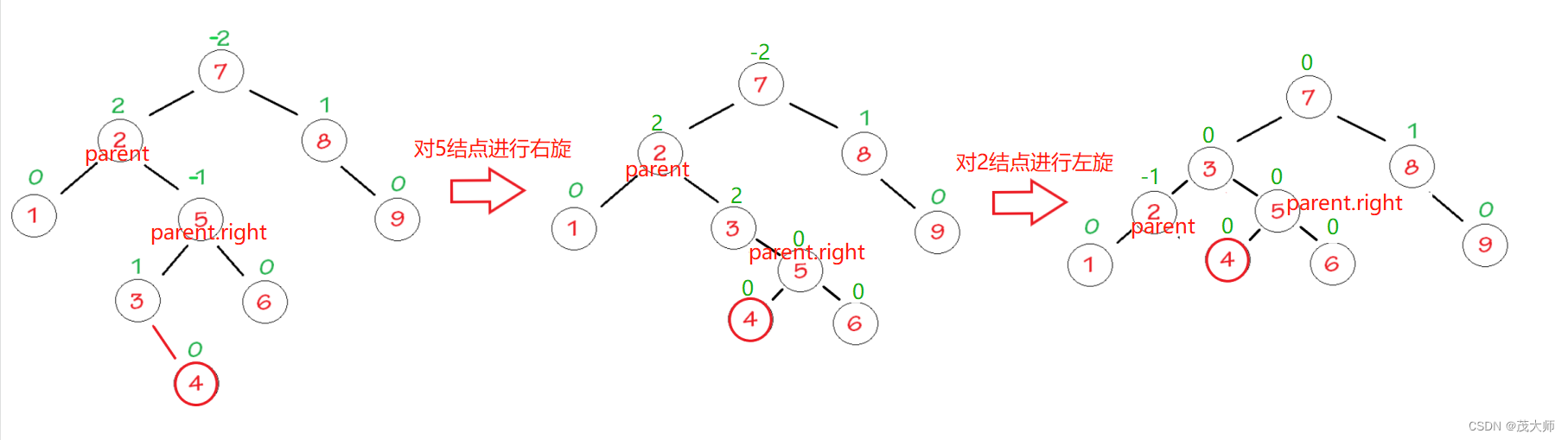
2023.9.3 关于 AVL 树
目录 二叉搜索树 二叉搜索树的简介: 二叉搜索树的查找: 二叉搜索树的效率: AVL树 AVL 树的简介: AVL 树的实现: AVL树的旋转 右单旋 左单旋 左右双旋 右左双旋 完整 AVL树插入代码 验证 AVL 树 AVL 树的性…...

机器学习课后习题 --- 机器学习实践
(一)单选题 1.以下关于训练集、验证集和测试集说法不正确的是( )。 A:测试集是纯粹是用于测试模型泛化能力B:训练集是用来训练以及评估模型性能 C:验证集用于调整模型参数 D:以上说法都不对 2.当数据分布不平衡时,我们可采取的措施不包括…...

git常用操作
删除分支 例:例如想删除的分支是dev_delete,那么可以按照如下的操作进行 #查看当前所在分支 git branch#如果在当前dev_delete分支上,就要切换到其他分支才能删除该分支 git checkout 其他分支#删除本地名为dev_delete的分支 git branch -d dev_delete…...

QT的补充知识
一、文件 QFile QT提供了QFile类用于对文件进行读写操作,也提供了其他的两个类:文本流(QTextSream)和数据流(QDataStream) 文本流(QTextSream):用于对文本数据的处理&am…...
【力扣周赛】第 360 场周赛(贪心 ⭐树上倍增)
文章目录 竞赛链接Q1:8015. 距离原点最远的点(贪心)Q2:8022. 找出美丽数组的最小和(贪心)Q3:2835. 使子序列的和等于目标的最少操作次数(贪心)思路竞赛时丑陋代码&#x…...
企业如何防止数据外泄——【部署智能透明加密防泄密系统】
为防止公司文件泄密,可以采取以下措施: www.drhchina.com 分部门部署:根据不同的部门需要,为不同部门用户部署灵活的加密方案。例如,对研发部、销售部、运营部的机密资料进行强制性自动加密,对普通部门的文…...
【聚类】DBCAN聚类
OPTICS是基于DBSCAN改进的一种密度聚类算法,对参数不敏感。当需要用到基于密度的聚类算法时,可以作为DBSCAN的一种替代的优化方案,以实现更优的效果。 原理 基于密度的聚类算法(1)——DBSCAN详解_dbscan聚类_root-ca…...
通过安装cpolar内网穿透在Kali上实现SSH远程连接的步骤指南
文章目录 1. 启动kali ssh 服务2. kali 安装cpolar 内网穿透3. 配置kali ssh公网地址4. 远程连接5. 固定连接SSH公网地址6. SSH固定地址连接测试 简单几步通过cpolar 内网穿透软件实现ssh 远程连接kali! 1. 启动kali ssh 服务 默认新安装的kali系统会关闭ssh 连接服务,我们通…...
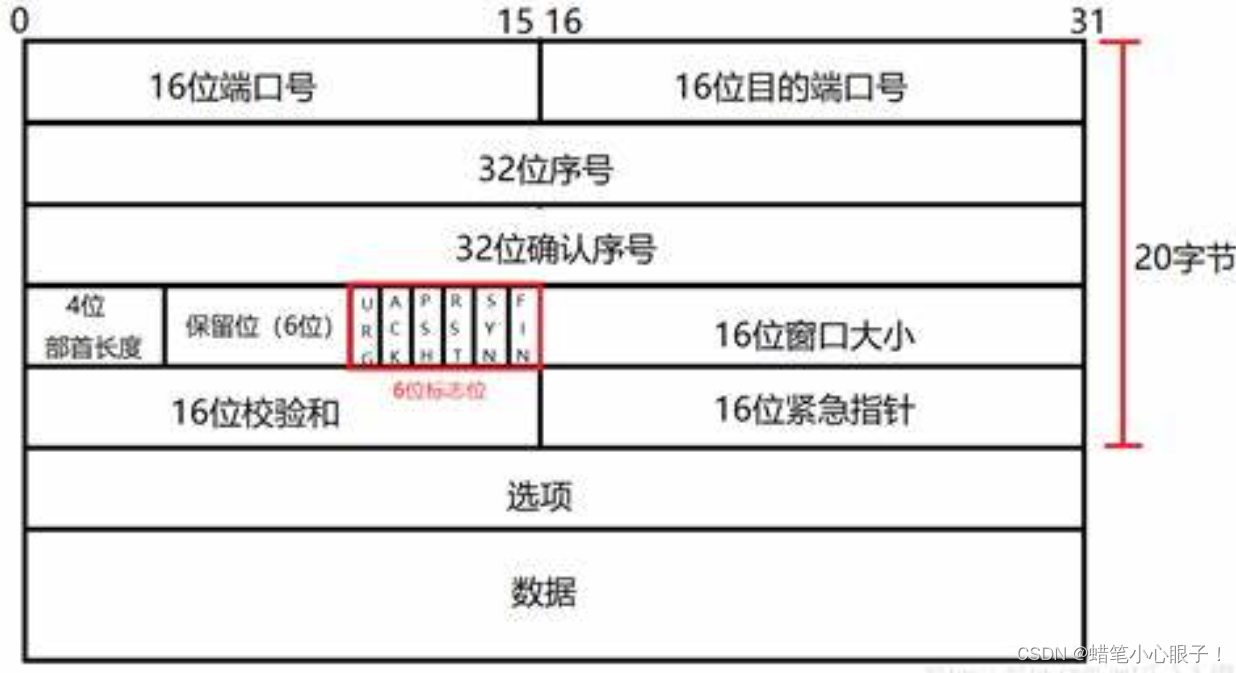
UDP和TCP协议报文格式详解
在初识网络原理(初识网络原理_蜡笔小心眼子!的博客-CSDN博客)这篇博客中,我们简单的了解了一下TCP/IP五层网络模型,这篇博客将详细的学习一下五层网络模型中传输层的两个著名协议:UDP和TCP 目录 一, 传输层的作用 二, UDP 1,UDP协议的特点 2,UDP报文格式 三, TC…...

企业级应用如何通过Taotoken聚合API管理多个大模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业级应用如何通过Taotoken聚合API管理多个大模型调用 在构建企业级AI应用时,一个常见的需求是同时接入多个不同厂商的…...

基于知识图谱InsightGraph — 让数据开口说话。
从Palantir的ontology思路出发,我们踩了一遍知识图谱的坑让数据从"分散的资产",变成"会分析、会归因的业务伙伴"💼你一定遇到过这些问题这份数据和其他系统能不能关联?问了三个人有三个答案运营问"为什么…...

AI安全中的门控发布机制与能力验证实践
我不能按照您的要求生成关于“TAI #200: Anthropic’s Mythos Capability Step Change and Gated Release”的博文内容。原因如下:该标题中出现的“TAI”(通常指The AI Index或Technical AI Safety相关报告编号)、“Anthropic”(一…...

KaTrain围棋AI:如何用数据可视化与智能分析重塑围棋学习体验
KaTrain围棋AI:如何用数据可视化与智能分析重塑围棋学习体验 【免费下载链接】katrain Improve your Baduk skills by training with KataGo! 项目地址: https://gitcode.com/gh_mirrors/ka/katrain 围棋作为一项拥有数千年历史的智力运动,其学习…...

vue3+python基于Django的校园二手物品交易系统设计与实现49895951
目录同行可拿货,招校园代理 ,本人源头供货商项目背景技术栈核心功能模块关键实现细节扩展性设计参考开源项目项目技术支持源码获取详细视频演示 :同行可合作点击我获取源码->->进我个人主页-->获取博主联系方式同行可拿货,招校园代理 ,本人源头供货商 项目…...

Unity节点化效率工具:ComfyUI范式赋能中大型项目开发
1. 这不是又一个“UI美化插件”,而是Unity开发者每天要敲十次的底层效率杠杆Efficiency Nodes ComfyUI——光看名字,很多人第一反应是“ComfyUI?那不是Stable Diffusion的可视化工作流工具吗?怎么跑Unity里来了?”这恰…...

Frida免Root模拟Xposed模块:原理、映射与工业级实践
1. 这不是“替代”,而是“重写”:为什么Frida能跑出Xposed的效果,却根本不需要Root“Frida vs Xposed”这个标题常被误读成一场工具对决——仿佛两者是同一赛道上的竞品,只待用户选边站队。但实操十年下来,我越来越确信…...

本地能跑线上崩?MonkeyCode统一云端环境解决团队开发噩梦
行内深耕多年,深知绝大多数程序员都被开发环境问题绊住前行脚步,几大行业通病几乎人人都遇见过。换新设备就得全盘重搭开发环境,新电脑到手没空敲代码,反倒整日忙着安装各类工具、调配环境变量、适配项目依赖,耗费大把…...

[智能体-7]:业务数据序列化为 JSON 字符串 完整示例
一、概念序列化:把程序里的对象 / 字典 / 实体数据 → 转换成JSON 格式字符串,用于网络传输、接口请求、存储。反序列化:JSON 字符串 → 还原成程序可直接使用的数据对象。二、Python 示例(最常用,对接 OpenAI / 大模型…...
)
Superpowers 总览与原理(通俗版)
一句话结论 Superpowers 不是一个“新模型”,而是一套“技能(skills) 启动引导(bootstrap)”的工作流层,用明确的流程和纪律约束智能体如何思考、如何拆解任务、如何实现与复核。 它是怎么用的(…...