使用Python进行健身手表数据分析
健身手表(Fitness Watch)数据分析涉及分析健身可穿戴设备或智能手表收集的数据,以深入了解用户的健康和活动模式。这些设备可以跟踪所走的步数、消耗的能量、步行速度等指标。本文将带您完成使用Python进行Fitness Watch数据分析的任务。
Fitness Watch数据分析是健康和保健领域企业的重要工具。通过分析健身可穿戴设备的用户数据,公司可以了解用户行为,提供个性化的解决方案,并有助于改善用户的整体健康和福祉。
下面是我们在处理健身手表数据分析问题时可以遵循的过程:
-
从健身手表收集数据,确保数据准确可靠。
-
执行EDA以获得对数据的初步了解。
-
从原始数据中创建可能提供更有意义的见解的新功能。
-
创建数据的可视化表示,以有效地传达见解。
-
根据时间间隔或健身指标水平对用户的活动进行分段,并分析其表现。
因此,该过程始于从健身手表收集数据。每款健身手表都可与智能手机上的应用程序配合使用。您可以从智能手机上的该应用程序收集数据。例如,这里用的是从苹果的健康应用程序收集了的一个健身手表的数据。
使用Python进行分析
现在,让我们通过导入必要的Python库和数据集来开始Fitness Watch数据分析的任务:
1import pandas as pd
2import plotly.io as pio
3import plotly.graph_objects as go
4pio.templates.default = "plotly_white"
5import plotly.express as px
6
7data = pd.read_csv("Apple-Fitness-Data.csv")
8print(data.head()) 输出
1 Date Time Step Count Distance Energy Burned \ 20 2023-03-21 16:01:23 46 0.02543 14.620 31 2023-03-21 16:18:37 645 0.40041 14.722 42 2023-03-21 16:31:38 14 0.00996 14.603 53 2023-03-21 16:45:37 13 0.00901 14.811 64 2023-03-21 17:10:30 17 0.00904 15.153 7 8 Flights Climbed Walking Double Support Percentage Walking Speed 90 3 0.304 3.060
101 3 0.309 3.852
112 4 0.278 3.996
123 3 0.278 5.040
134 3 0.281 5.184
让我们看看这个数据是否包含任何null值:
1print(data.isnull().sum()) 输出
1Date 0
2Time 0
3Step Count 0
4Distance 0
5Energy Burned 0
6Flights Climbed 0
7Walking Double Support Percentage 0
8Walking Speed 0
9dtype: int64 因此,数据没有任何空值。让我们进一步分析步数随时间的变化:
1# Step Count Over Time
2fig1 = px.line(data, x="Time",
3 y="Step Count",
4 title="Step Count Over Time")
5fig1.show() 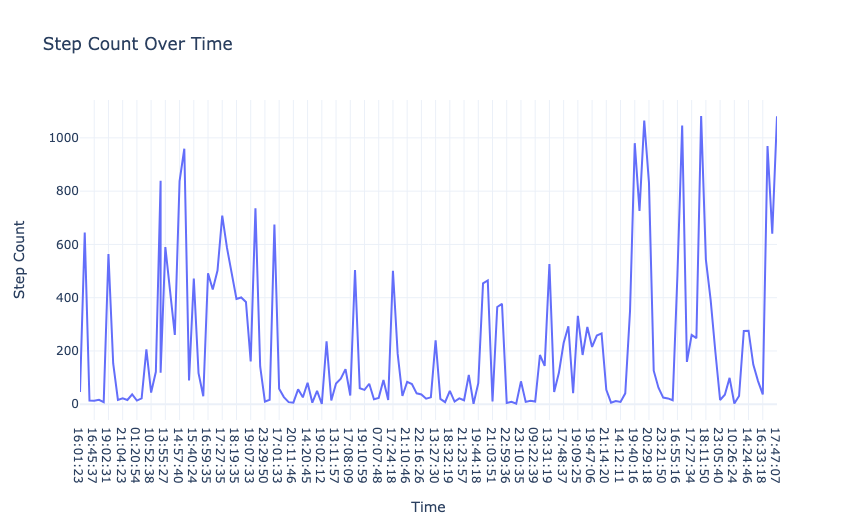
现在,让我们来看看随着时间的推移所覆盖的距离:
1# Distance Covered Over Time
2fig2 = px.line(data, x="Time",
3 y="Distance",
4 title="Distance Covered Over Time")
5fig2.show() 
现在,让我们来看看能量随着时间推移的消耗:
1# Energy Burned Over Time
2fig3 = px.line(data, x="Time",
3 y="Energy Burned",
4 title="Energy Burned Over Time")
5fig3.show() 现在,让我们来看看步行速度随着时间的推移:
1# Walking Speed Over Time
2fig4 = px.line(data, x="Time",
3 y="Walking Speed",
4 title="Walking Speed Over Time")
5fig4.show() 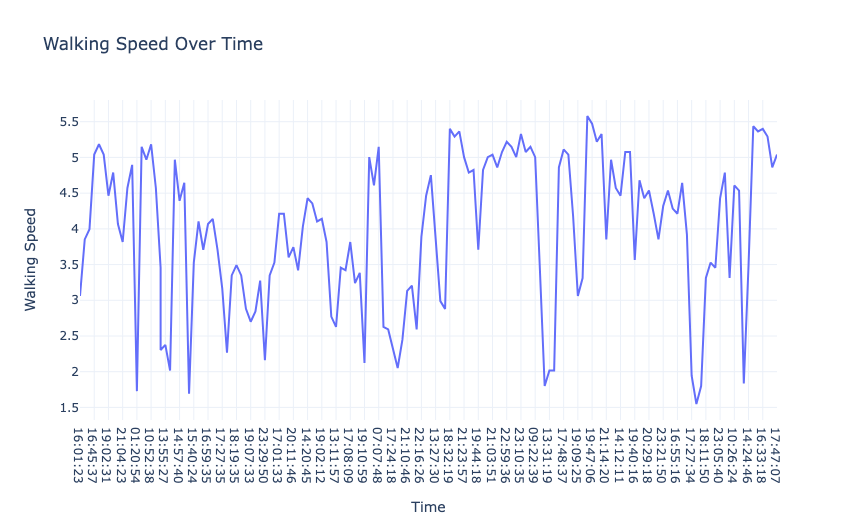
现在,让我们计算并查看每天的平均步数:
1# Calculate Average Step Count per Day
2average_step_count_per_day = data.groupby("Date")["Step Count"].mean().reset_index()
3
4fig5 = px.bar(average_step_count_per_day, x="Date",
5 y="Step Count",
6 title="Average Step Count per Day")
7fig5.update_xaxes(type='category')
8fig5.show() 输出
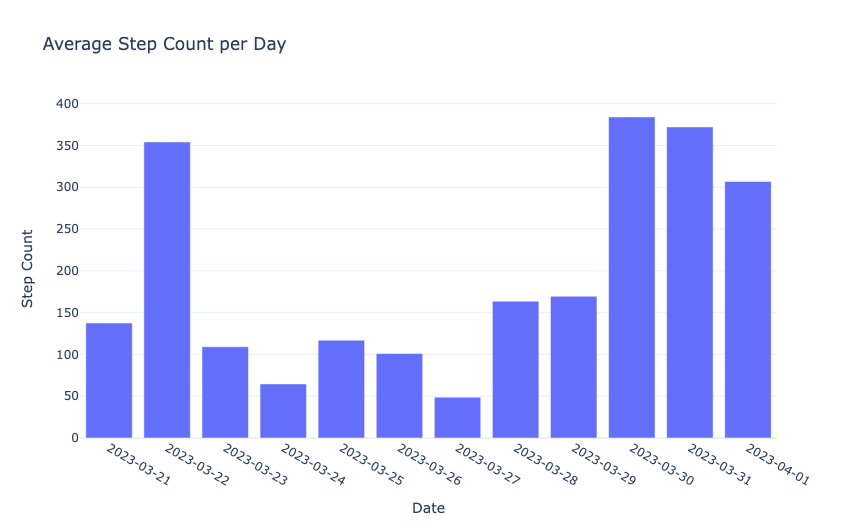
现在,让我们来看看步行效率:
1# Calculate Walking Efficiency
2data["Walking Efficiency"] = data["Distance"] / data["Step Count"]
3
4fig6 = px.line(data, x="Time",
5 y="Walking Efficiency",
6 title="Walking Efficiency Over Time")
7fig6.show() 
现在,让我们来看看步数和步行速度随时间间隔的变化:
1# Create Time Intervals 2time_intervals = pd.cut(pd.to_datetime(data["Time"]).dt.hour, 3 bins=[0, 12, 18, 24], 4 labels=["Morning", "Afternoon", "Evening"], 5 right=False) 6 7data["Time Interval"] = time_intervals 8 9# Variations in Step Count and Walking Speed by Time Interval
10fig7 = px.scatter(data, x="Step Count",
11 y="Walking Speed",
12 color="Time Interval",
13 title="Step Count and Walking Speed Variations by Time Interval",
14 trendline='ols')
15fig7.show()

现在,让我们比较所有健康和健身指标的日平均值:
1# Reshape data for treemap 2daily_avg_metrics = data.groupby("Date").mean().reset_index() 3 4daily_avg_metrics_melted = daily_avg_metrics.melt(id_vars=["Date"], 5 value_vars=["Step Count", "Distance", 6 "Energy Burned", "Flights Climbed", 7 "Walking Double Support Percentage", 8 "Walking Speed"]) 9
10# Treemap of Daily Averages for Different Metrics Over Several Weeks
11fig = px.treemap(daily_avg_metrics_melted,
12 path=["variable"],
13 values="value",
14 color="variable",
15 hover_data=["value"],
16 title="Daily Averages for Different Metrics")
17fig.show()

上图将每个健康和健身指标表示为矩形图块。每个图块的大小对应于度量的值,并且图块的颜色表示度量本身。悬停数据在与可视化交互时显示每个指标的精确平均值。
步骤计数度量由于其与其他度量相比通常更高的数值而主导可视化,使得难以有效地可视化其他度量中的变化。由于步数的值高于所有其他指标的值,让我们再次查看此可视化,但不包含步数:
1# Select metrics excluding Step Count 2metrics_to_visualize = ["Distance", "Energy Burned", "Flights Climbed", 3 "Walking Double Support Percentage", "Walking Speed"] 4 5# Reshape data for treemap 6daily_avg_metrics_melted = daily_avg_metrics.melt(id_vars=["Date"], value_vars=metrics_to_visualize) 7 8fig = px.treemap(daily_avg_metrics_melted, 9 path=["variable"],
10 values="value",
11 color="variable",
12 hover_data=["value"],
13 title="Daily Averages for Different Metrics (Excluding Step Count)")
14fig.show()
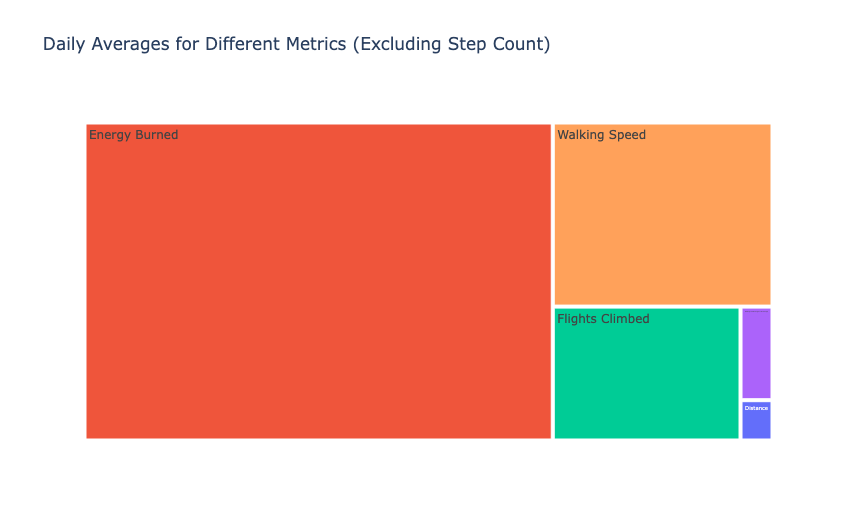
总结
这就是如何使用Python进行健身数据分析。Fitness Watch数据分析是健康和保健领域企业的重要工具。通过分析健身可穿戴设备的用户数据,公司可以了解用户行为,提供个性化的解决方案,并有助于改善用户的整体健康和福祉。
题外话

感兴趣的小伙伴,赠送全套Python学习资料,包含面试题、简历资料等具体看下方。
👉CSDN大礼包🎁:全网最全《Python学习资料》免费赠送🆓!(安全链接,放心点击)
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

六、面试宝典


简历模板
👉CSDN大礼包🎁:全网最全《Python学习资料》免费赠送🆓!(安全链接,放心点击)
若有侵权,请联系删除
相关文章:
使用Python进行健身手表数据分析
健身手表(Fitness Watch)数据分析涉及分析健身可穿戴设备或智能手表收集的数据,以深入了解用户的健康和活动模式。这些设备可以跟踪所走的步数、消耗的能量、步行速度等指标。本文将带您完成使用Python进行Fitness Watch数据分析的任务。 Fitness Watch数据分析是健…...
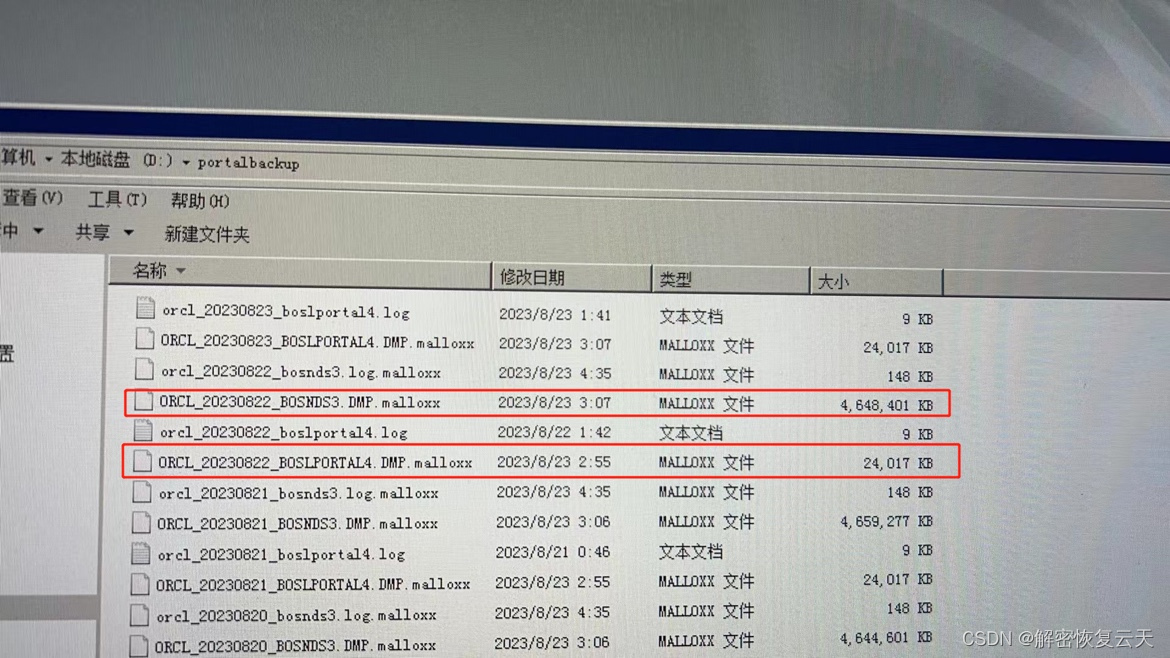
什么是malloxx勒索病毒,服务器中malloxx勒索病毒了怎么办?
Malloxx勒索病毒是一种新型的电脑病毒,它通过加密用户电脑中的重要文件数据来威胁用户,并以此勒索钱财。这种病毒并不是让用户的电脑瘫痪,而是以非常独特的方式进行攻击。在感染了Malloxx勒索病毒后,它会加密用户服务器中的数据&a…...
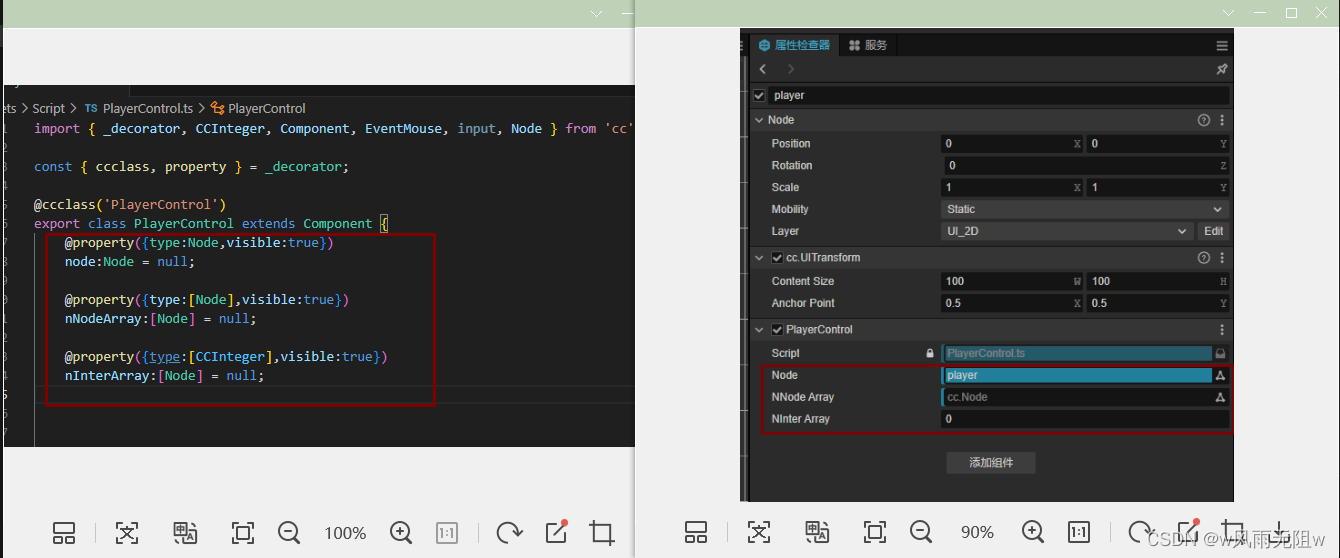
CocosCreator3.8研究笔记(六)CocosCreator 脚本装饰器的理解
一、什么是装饰器? 装饰器是TypeScript脚本语言中的概念。 TypeScript的解释:在一些场景下,我们需要额外的特性来支持标注或修改类及其成员。装饰器(Decorators)为我们在类的声明及成员上通过元编程语法添加标注提供了…...

docker login harbor http login登录
前言 搭建的 harbor 仓库为 http 协议,在本地登录时出现如下报错: docker login http://192.168.xx.xx Username: admin Password: Error response from daemon: Get "https://192.168.xx.xx/v2/": dialing 192.168.xx.xx:443 matches static …...
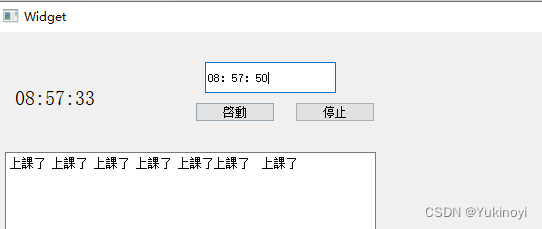
day5 qt
#include "widget.h" #include "ui_widget.h"Widget::Widget(QWidget *parent): QWidget(parent), ui(new Ui::Widget) {ui->setupUi(this);timer_idthis->startTimer(100);//啓動一個定時器 每100ms發送一次信號ui->Edit1->setPlaceholderTex…...
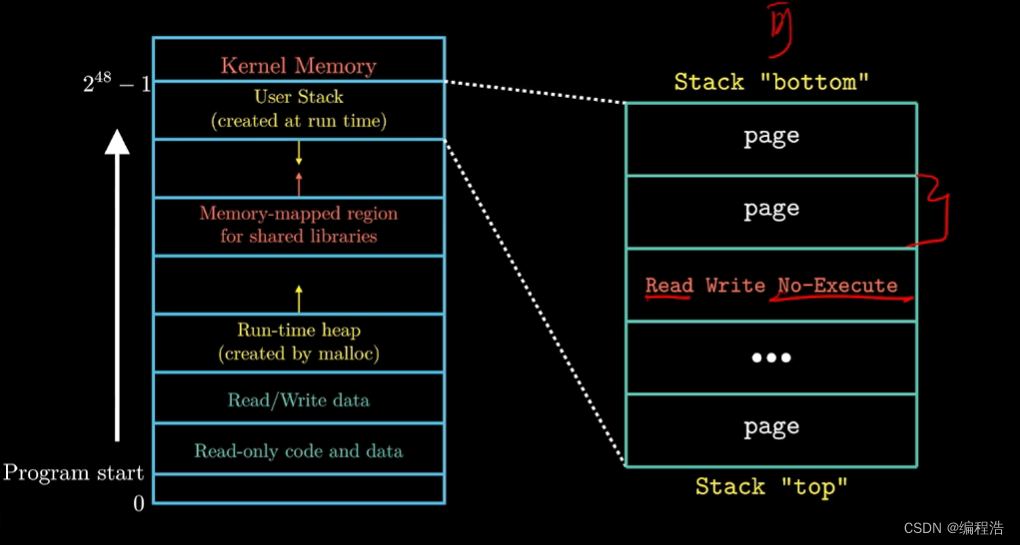
【80天学习完《深入理解计算机系统》】第十三天 3.7 缓冲区溢出 attack lab
3.7 缓冲区溢出 && attack lab...

Hadoop生态之hive
一 概述与特点 之所以把Hive放在Hadoop生态里面去写,是因为它本身依赖Hadoop。Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类 SQL 查询功能。 其本质是将 SQL 转换为 MapReduce/Spark 的任务进行运算,底层由 HDFS 来提供…...

AWS DynamoDB浅析
AWS DynamoDB是一个NOSQL数据库。 可以通过IAM直接控制权限,和AWS其他服务连用非常方便。 DynamoDB的几个概念 Partition Key:分区键。如果没有Sort key,那么Partition Key必须唯一,如有Sort key,Partition Key可以重…...

Linux安装ffmpeg
1 下载yasm wget http://www.tortall.net/projects/yasm/releases/yasm-1.3.0.tar.gz tar -zxvf yasm-1.3.0.tar.gz cd yasm-1.3.0 ./configure make && make install2 下载ffmpeg wget http://ffmpeg.org/releases/ffmpeg-3.1.3.tar.bz2 tar jxvf ffmpeg-3.1.3.tar.…...
不重启服务动态停止、启动RabbitMQ消费者)
(18)不重启服务动态停止、启动RabbitMQ消费者
我们在消费RabbitMQ消息的过程中,有时候可能会想先暂停消费一段时间,然后过段时间再启动消费者,这个需求怎么实现呢?我们可以借助RabbitListenerEndpointRegistry这个类来实现,它的全类名是org.springframework.amqp.r…...

数据仓库的流程
数据仓库完全用统计分析框架实现:Spark,MR 但是因为实际生产环境中,需求量非常大, 如果每个需求都采用独立c代码开发方式,重复计算会很多. 提高性能的方法: 1.减少数据量 2. 减少重复计算 例如RDD cache 可以减少重复计算,但是不安全,都在缓存中, persist 都放内存中,但是慢 而…...

MyBatis-Plus深入 —— 条件构造器与插件管理
前言 在前面的文章中,荔枝梳理了一个MyBatis-Plus的基本使用、配置和通用Service接口,我们发现在MyBatis-Plus的辅助增强下我们不再需要通过配置xml文件中的sql语句来实现基本的sql操作了,不愧是最佳搭档!在这篇文章中,…...

C语言结构体的初始化方式
逐个初始化字段:这是最直接的方式,你可以逐个为结构体的每个字段进行初始化。 struct Student { char name[50]; int age; float marks; }; struct Student student1 {"Alice", 20, 89.5}; 2.使用结构体字面值初始化:这种方…...

Vue生成多文件pdf准考证
这是渲染的数据 这是生成的pdf文件,直接可以打印 需要安装和npm依赖和引入封装的pdf.js文件 npm install --save html2canvas // 页面转图片 npm install jspdf --save // 图片转pdfpdf.js文件 import html2canvas from "html2canvas"; import jsPDF …...

Rust的derive思考
这几天在Yew的学习实践中,发现derive中的参数中包含了yew自己的东西,比如yew::Properties。习惯使用#[derive(Clone, Debug, PartialEq)]之后,发现还有新的成员,这让我好奇起来。 首先让我们来回顾一下derive是什么。 #[derive(…...

Python常用模块
文章目录 1. time:时间2. calendar:日历3. datetime:可以运算的时间4. sys:系统5. os:操作系统6. random:随机数7. json:序列化8. pickle:序列化9. logging 模块9.1 什么是logging模…...
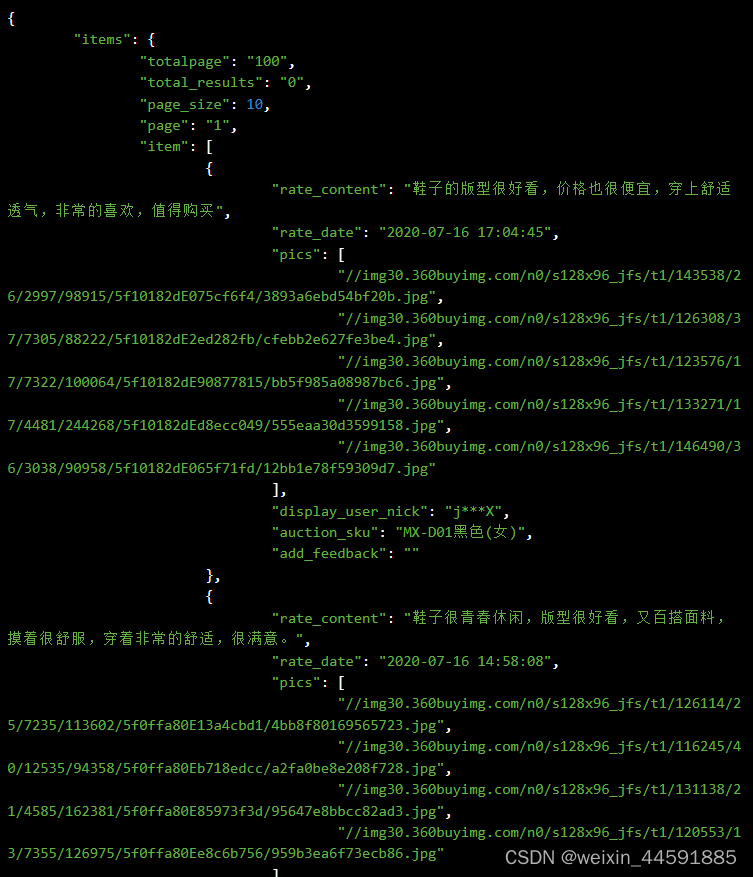
Java“牵手”京东商品评论数据接口方法,京东商品评论接口,京东商品评价接口,行业数据监测,京东API实现批量商品评论内容数据抓取示例
京东平台商品评论数据接口是开放平台提供的一种API接口,通过调用API接口,开发者可以获取京东商品的标题、价格、库存、月销量、总销量、库存、详情描述、图片、评论内容、评论日期、评论图片、追评内容等详细信息 。 获取商品评论接口API是一种用于获取…...
)
算法leetcode|75. 颜色分类(rust重拳出击)
文章目录 75. 颜色分类:样例 1:样例 2:提示: 分析:题解:rust:go:c:python:java: 75. 颜色分类: 给定一个包含红色、白色和蓝色、共 n…...

网络安全(黑客)自学笔记学习路线
谈起黑客,可能各位都会想到:盗号,其实不尽然;黑客是一群喜爱研究技术的群体,在黑客圈中,一般分为三大圈:娱乐圈 技术圈 职业圈。 娱乐圈:主要是初中生和高中生较多,玩网恋…...

NoSQL:非关系型数据库分类
NoSQL,全称 Not Only SQL,意为不仅仅是 SQL,泛指非关系型数据库。NoSQL 是基于键值对的,而且不需要经过 SQL 层的解析,数据之间没有耦合性,性能非常高。 非关系型数据库又可细分如下: 键值存储…...

避开Arduino PID编程的3个常见坑:为什么你的控制总是不稳?
Arduino PID控制实战:避开3个致命陷阱实现精准调节 当你在深夜盯着反复震荡的电机转速曲线,或是加热棒温度始终无法稳定的数据时,是否怀疑过自己复制的PID代码有问题?这不是你的错觉——大多数Arduino PID控制问题都源于三个容易被…...

百川2-13B量化模型提示工程:降低OpenClaw操作失误率
百川2-13B量化模型提示工程:降低OpenClaw操作失误率 1. 问题背景与挑战 去年冬天,当我第一次尝试用OpenClaw自动化整理电脑上积压的半年项目文档时,遭遇了令人崩溃的"AI灾难现场"——这个本该帮我分类归档的助手,把财…...

IDToolsPico:Pico平台轻量级UUID与MAC生成库
1. IDToolsPico 库深度解析:面向嵌入式系统的 UUID 与 MAC 地址生成器 1.1 库定位与工程价值 IDToolsPico 是专为 Raspberry Pi Pico 平台设计的轻量级标识符生成库,核心目标是为资源受限的微控制器提供符合标准的、可重复使用的唯一设备标识能力。在物…...

一文详解RPC,深入浅出从原理到主流框架
什么是RPC? RPC 全称 Remote Procedure Call,即远程过程调用。它的核心目标非常简单:让开发者调用远程机器上的函数/方法,就像调用本地函数一样简单,无需关注底层的网络连接、数据传输、序列化与反序列化等繁琐细节[1]…...

OpenClaw多模型切换:Qwen2.5-VL-7B与文本模型协同工作
OpenClaw多模型切换:Qwen2.5-VL-7B与文本模型协同工作 1. 为什么需要多模型协同 去年夏天,当我第一次尝试用OpenClaw自动化处理团队的知识库文档时,遇到了一个棘手的问题:有些文档包含大量截图和图表说明,而纯文本模…...

C语言核心特性与工程实践详解
1. C语言核心特性解析C语言作为一门经典的编程语言,其核心特性决定了它在系统编程和嵌入式开发中的不可替代地位。让我们从底层机制开始剖析:1.1 静态类型与编译执行C语言采用静态类型系统,这意味着所有变量必须在编译前明确声明其类型。这种…...

三线制SPI通信原理与ZYNQ实现方案
1. 三线制SPI通信的背景与应用场景 在嵌入式系统设计中,SPI(Serial Peripheral Interface)总线是最常用的通信接口之一。传统四线制SPI包含SCLK(时钟)、MOSI(主机输出从机输入)、MISO(主机输入从机输出)和SS(片选)四条信号线。但在某些特定应用场景下,为…...

C语言三大控制结构:零基础学循环与选择
C语言编程里,控制结构用以构架程序逻辑,是新手入门的关键要点,掌握顺序、选择、循环这三大基本控制结构,可使你脱离单纯顺序代码编写,达成更复杂、更灵活的程序逻辑,本文会将C语言控制结构的核心知识点讲解…...

工资条生成器:财务人员的高效办公利器
在企业财务管理工作中,工资条的制作与发放是一项既繁琐又重要的任务。 传统的手工制作方式不仅耗时耗力,还容易出现数据错误和格式不统一的问题。 工资条生成器的出现,为财务人员带来了全新的解决方案。 这款软件专门针对财务工作场景设计…...

use Yii;的本质的庖丁解牛
use Yii; 这行代码,常被误解为“引入了一个类”或者“为了少打几个字”。 但本质上,它是 Yii 框架(尤其是 Yii2)架构哲学的“图腾”。 它标志着 Yii 选择了一条与 Laravel、Symfony 截然不同的道路:将核心功能暴露为一…...