EXPLAIN概述与字段剖析
6. 分析查询语句:EXPLAIN(重点)
6.1 概述
定位了查询慢的sQL之后,我们就可以使用EXPLAIN或DESCRIBE 工具做针对性的分析查询语句。DESCRIBE语句的使用方法与EXPLAIN语句是一样的,并且分析结果也是一样的。
MySQL中有专门负责优化SELECT语句的优化器模块,主要功能:通过计算分析系统中收集到的统计信息,为客户端请求的Query提供它认为最优的执行计划(他认为最优的数据检索方式,但不见得是DBA认为是最优的,这部分最耗费时间)。
这个执行计划展示了接下来具体执行查询的方式,比如多表连接的顺序是什么,对于每个表采用什么访问方法来具体执行查询等等。MySQL为我们提供了EXPLAIN语句来帮助我们查看某个查询语句的具体执行计划,大家看懂EXPLAIN语句的各个输出项,可以有针对性的提升我们查询语句的性能。
1.能做什么?
●表的读取顺序
●数据读取操作的操作类型
●哪些索引可以使用
●哪些索引被实际使用
●表之间的引用
●每张表有多少行被优化器查询
2. 版本情况
1. MySQL 5.6.3以前只能 EXPLAIN SELECT ;MYSQL 5.6.3以后就可以 EXPLAIN SELECT,UPDATE,DELETE
2. 在5.7以前的版本中,想要显示 partitions 需要使用 explain partitions 命令;想要显示
filtered 需要使用 explain extended 命令。在5.7版本后,默认explain直接显示partitions和
filtered中的信息。
6.2 基本语法
如果我们想看看某个查询的执行计划的话,可以在具体的查询语句前边加一个 EXPLAIN ,就像这样:
mysql> EXPLAIN SELECT 1;
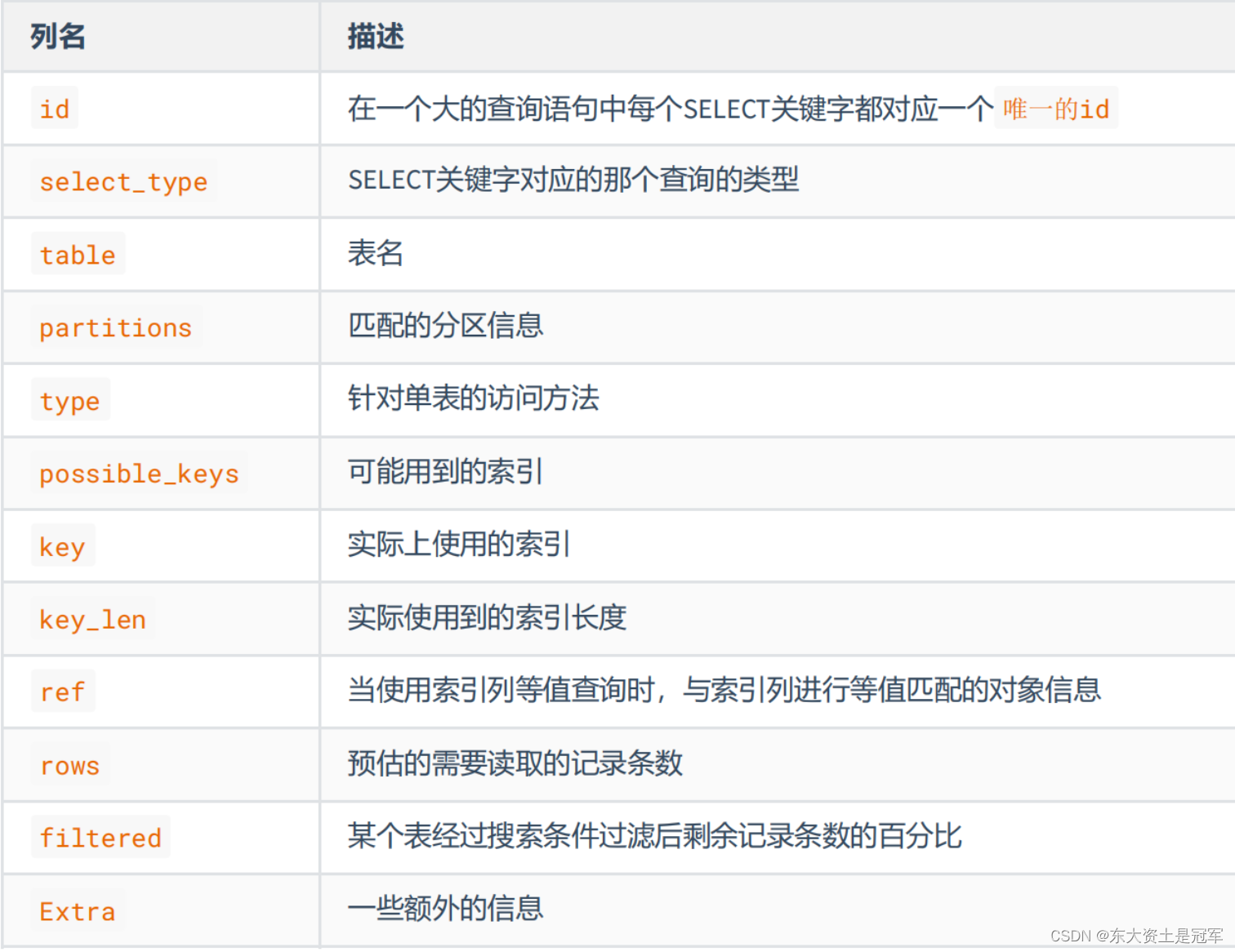
EXPLAIN 语句输出的各个列的作用如下:
6.3 数据准备
1. 建表
表s1首先将id设为主键, 对key1 , key3 建立普通索引, 对key2建立唯一索引, 对key_part1, key_part2, key_part3按顺序建立联合索引
普通字段 common_field
CREATE TABLE s1 (
id INT AUTO_INCREMENT,
key1 VARCHAR(100),
key2 INT,
key3 VARCHAR(100),
key_part1 VARCHAR(100),
key_part2 VARCHAR(100),
key_part3 VARCHAR(100),
common_field VARCHAR(100),
PRIMARY KEY (id),
INDEX idx_key1 (key1),
UNIQUE INDEX idx_key2 (key2),
INDEX idx_key3 (key3),
INDEX idx_key_part(key_part1, key_part2, key_part3)
) ENGINE=INNODB CHARSET=utf8;CREATE TABLE s2 (
id INT AUTO_INCREMENT,
key1 VARCHAR(100),
key2 INT,
key3 VARCHAR(100),
key_part1 VARCHAR(100),
key_part2 VARCHAR(100),
key_part3 VARCHAR(100),
common_field VARCHAR(100),
PRIMARY KEY (id),
INDEX idx_key1 (key1),
UNIQUE INDEX idx_key2 (key2),
INDEX idx_key3 (key3),
INDEX idx_key_part(key_part1, key_part2, key_part3)
) ENGINE=INNODB CHARSET=utf8;2. 设置参数 log_bin_trust_function_creators
创建函数,假如报错,需开启如下命令:允许创建函数设置:
set global log_bin_trust_function_creators=1; # 不加global只是当前窗口有效。
3. 创建函数
DELIMITER //
CREATE FUNCTION rand_string1(n INT)RETURNS VARCHAR(255) #该函数会返回一个字符串
BEGINDECLARE chars_str VARCHAR(100) DEFAULT
'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';DECLARE return_str VARCHAR(255) DEFAULT '';DECLARE i INT DEFAULT 0;WHILE i < n DOSET return_str =CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1));SET i = i + 1;END WHILE;RETURN return_str;
END //
DELIMITER ;4. 创建存储过程
创建往s1表中插入数据的存储过程:
DELIMITER //
CREATE PROCEDURE insert_s1 (IN min_num INT (10),IN max_num INT (10))
BEGINDECLARE i INT DEFAULT 0;SET autocommit = 0;REPEATSET i = i + 1;INSERT INTO s1 VALUES((min_num + i),rand_string1(6),(min_num + 30 * i + 5),rand_string1(6),rand_string1(10),rand_string1(5),rand_string1(10),rand_string1(10));UNTIL i = max_numEND REPEAT;COMMIT;
END //
DELIMITER ;创建往s2表中插入数据的存储过程:
DELIMITER //
CREATE PROCEDURE insert_s2 (IN min_num INT (10),IN max_num INT (10))
BEGINDECLARE i INT DEFAULT 0;SET autocommit = 0;REPEATSET i = i + 1;INSERT INTO s2 VALUES((min_num + i),rand_string1(6),(min_num + 30 * i + 5),rand_string1(6),rand_string1(10),rand_string1(5),rand_string1(10),rand_string1(10));UNTIL i = max_numEND REPEAT;COMMIT;
END //
DELIMITER ;5. 调用存储过程
s1表数据的添加:加入1万条记录:
CALL insert_s1(10001,10000);s2表数据的添加:加入1万条记录:
CALL insert_s2(10001,10000);6.4 EXPLAIN各列作用
为了让大家有比较好的体验,我们调整了下 EXPLAIN 输出列的顺序。
1. table
不论我们的查询语句有多复杂,里边儿 包含了多少个表 ,到最后也是需要对每个表进行 单表访问 的,所 以MySQL规定EXPLAIN语句输出的每条记录都对应着某个单表的访问方法,该条记录的table列代表着该表的表名(有时不是真实的表名字,可能是简称)。
2. id
我们写的查询语句一般都以 SELECT 关键字开头,比较简单的查询语句里只有一个 SELECT 关键字 (大多数情况下:出现几个select就有几个id)
特殊情况:
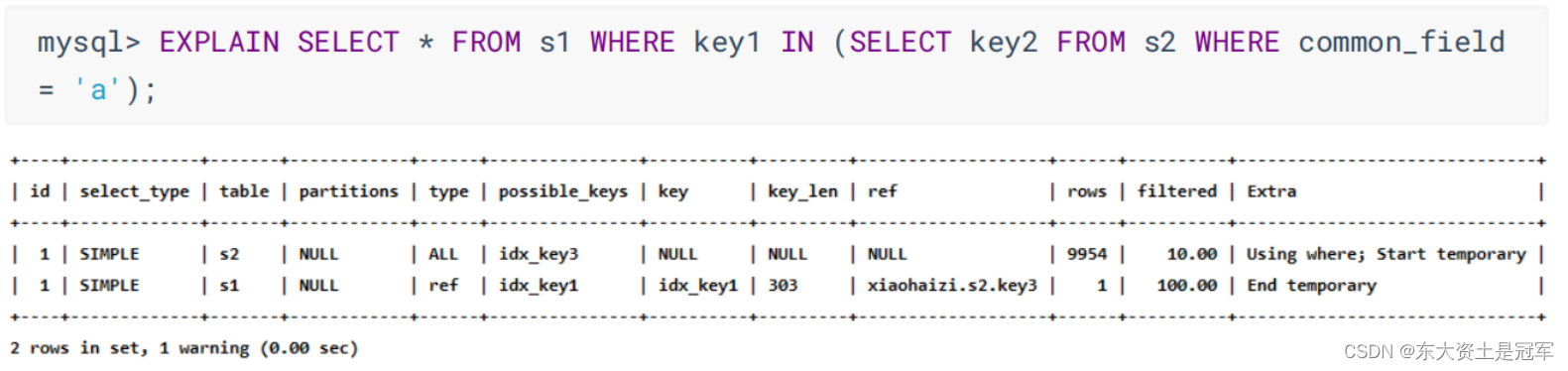
1. 查询优化器可能对涉及子查询的查询语句进行重写, 转变为多表查询的操作:
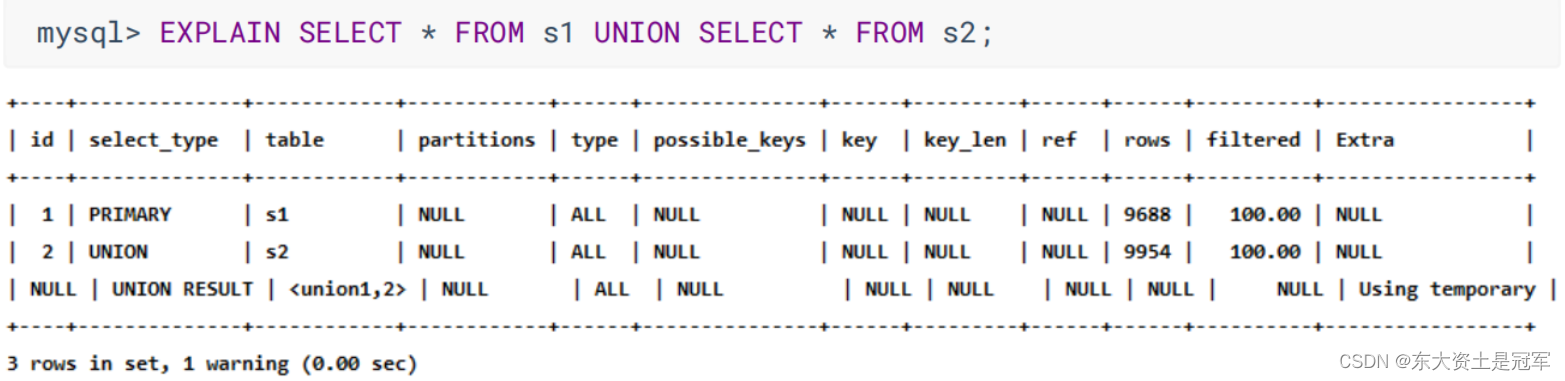
2. Union 去重, 需要创建临时表(第3行), 再在其中去重
Union All 不需要去重 所以不创建临时表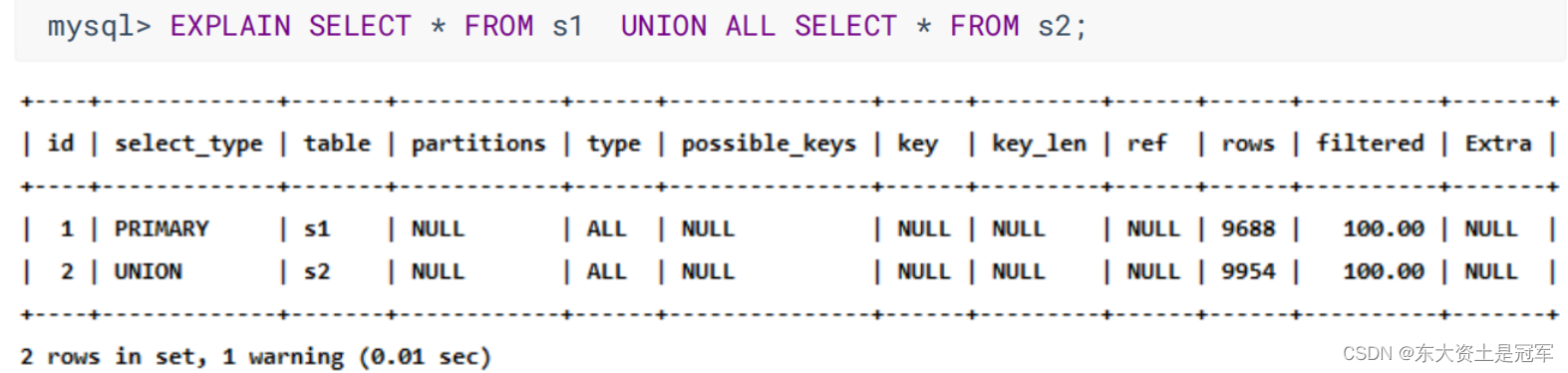
小结:
id如果相同,可以认为是一组,从上往下顺序执行
在所有组中,id值越大,优先级越高,越先执行
关注点:id号每个号码,表示一趟独立的查询, 一个sql的查询趟数越少越好
3. select_type
一条大的查询语句里边可以包含若干个SELECT关键字,每个SELECT关键字代表着一个小的查询语句,而每个SELECT关键字的FROM子句中都可以包含若干张表(这些表用来做连接查询),每一张表都对应着执行计划输出中的一条记录,对于在同一个SELECT关键字中的表来说,它们的id值是相同的。
MySQL为每一个SELECT关键字代表的小查询都定义了一个称之为select_type的属性,意思是我们只要知道了某个小查询的select_type属性,就知道了这个小查询在整个大查询中扮演了一个什么角色,我们看一下select_type都能取哪些值,请看官方文档:
SIMPLE:
查询语句不包含'UNION'或者子查询的查询都算是'SIMPLE'类型

PRIMARY:
对于包含'UNION'或者'UNION ALL' 的大查询来说,, 他是有几个小查询组成的, 其中最左边select_typee'值就是'PRIMARY'
UNION
对于包含'UNION' 或者'UNION ALL'的大查询来说, 除了最左边的查询外, 其余的小查询的'select_type' 值就是'UNION'
UNION RESULT
MysQL 选择使用临时表来完成'UNION'查询的去重工作, 针对该临时表的查询的select_type就是UNION RESULT
mysql> EXPLAIN SELECT * FROM s1 UNION SELECT * FROM s2; SUBQUERY
SUBQUERY
包含子查询的查询语句不能转为对应的semi-join 形式, 并且该子查询是不相关子查询,则该子查询的第一个select关键字代表的那个查询select_type 就是SUBQUERY
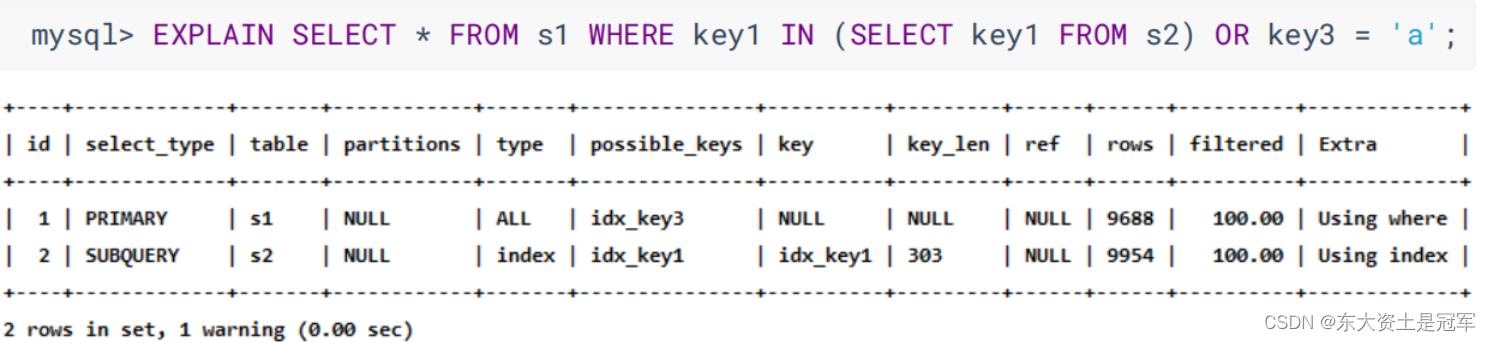
包含子查询的查询语句不能转为对应的semi-join 形式, 并且该子查询是相关子查询,则该子查询的第一个select关键字代表的那个查询select_type 就是DEPENDENT SUBQUERY
 DEPENDENT UNION
DEPENDENT UNION
在包含UINON或者UNION ALL的大查询中, 如果各个小查询都是依赖外层查询的话, 那除了最左边的那个小查询外, 其余的小查询select_type 都是 DEPENDENT UNION

DERIVED
派生表
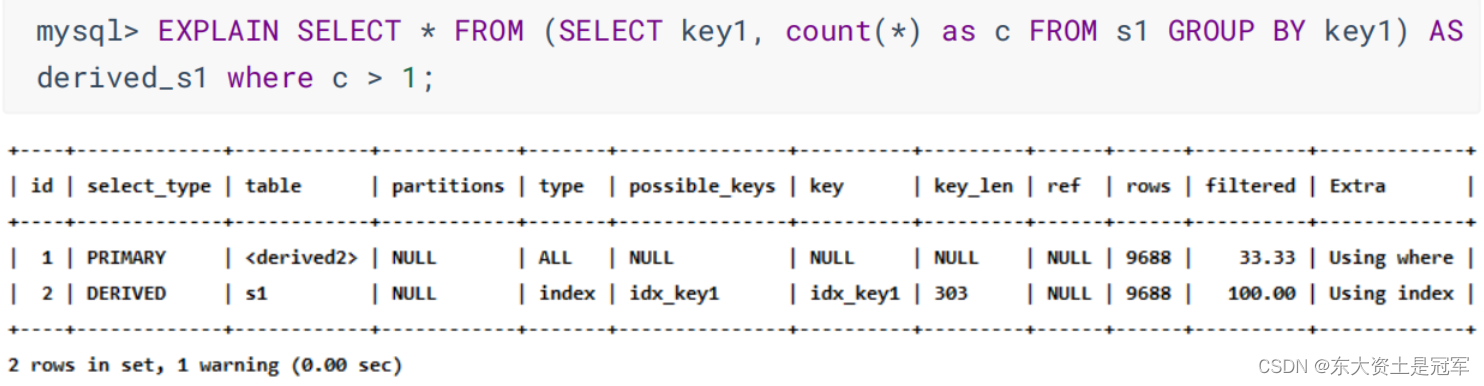
MATERIALIZED
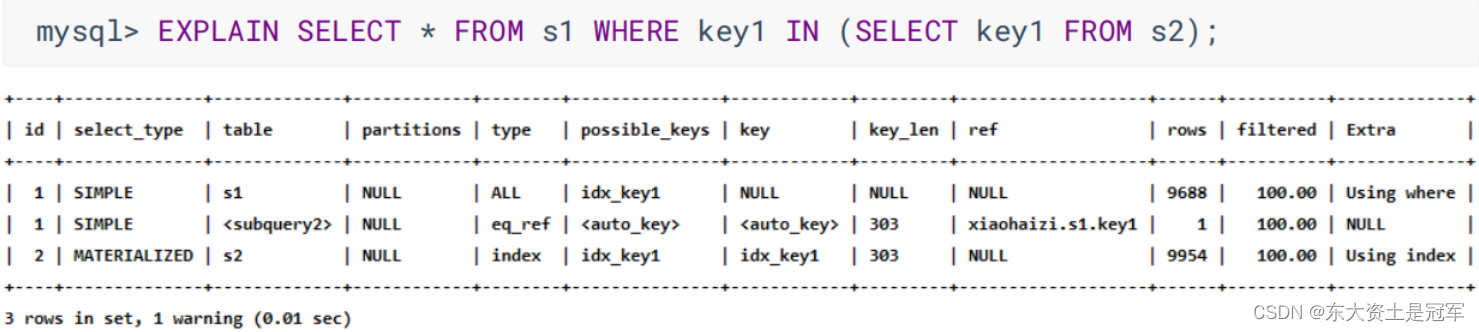
4. type ☆
mysql> CREATE TABLE t(i int) Engine=MyISAM;
Query OK, 0 rows affected (0.05 sec)
mysql> INSERT INTO t VALUES(1);
Query OK, 1 row affected (0.01 sec)mysql> EXPLAIN SELECT * FROM t;
mysql> EXPLAIN SELECT * FROM s1 WHERE id = 10005 ;
 eq_ref
eq_ref
在连接查询时, 如果被驱动表是通过主键或者唯一二级索引等值匹配的方式进行访问的
(如果该主键或者唯一二级索引是联合索引的话, 所有的索引列都必须进行等值比较), 则对该被驱动表的访问方法就是eq_ref
mysql> EXPLAIN SELECT * FROM s1 INNER JOIN s2 ON s1 .id = s2 .id ;
 从执行计划的结果中可以看出,MySQL打算将s2作为驱动表,s1作为被驱动表,重点关注s1的访问方法是 eq_ref ,表明在访问s1表的时候可以 通过主键的等值匹配 来进行访问。
从执行计划的结果中可以看出,MySQL打算将s2作为驱动表,s1作为被驱动表,重点关注s1的访问方法是 eq_ref ,表明在访问s1表的时候可以 通过主键的等值匹配 来进行访问。
mysql> EXPLAIN SELECT * FROM s1 WHERE key1 = 'a' ;

range
使用索引获取某些范围区间的记录 
index
mysql> EXPLAIN SELECT key_part2 FROM s1 WHERE key_part3 = 'a' ;
当我们可以使用索引覆盖
mysql> EXPLAIN SELECT key_part2 FROM s1 WHERE key_part3 = 'a';

5. possible_keys和key
可能用到的索引和 实际上使用的索引
6. key_len ☆
实际使用到的索引长度(即:字节数)
![]()

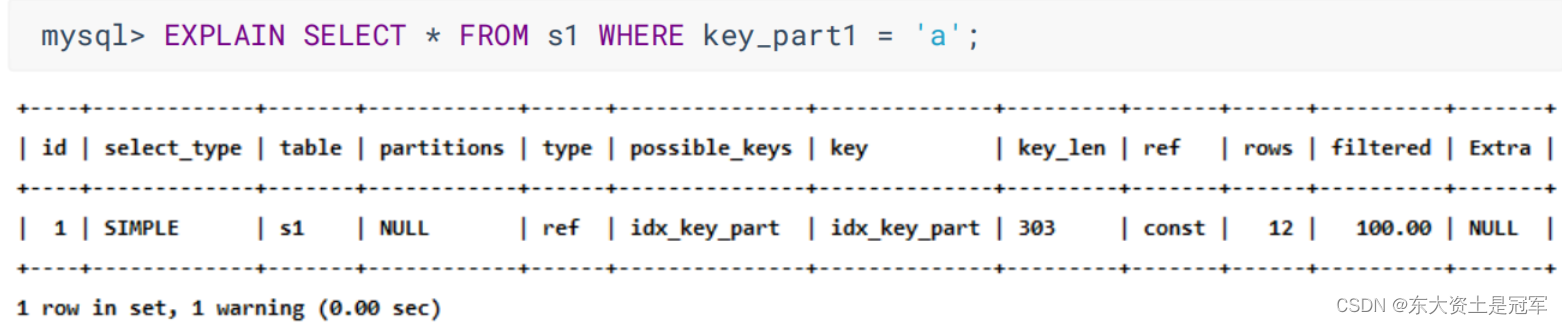
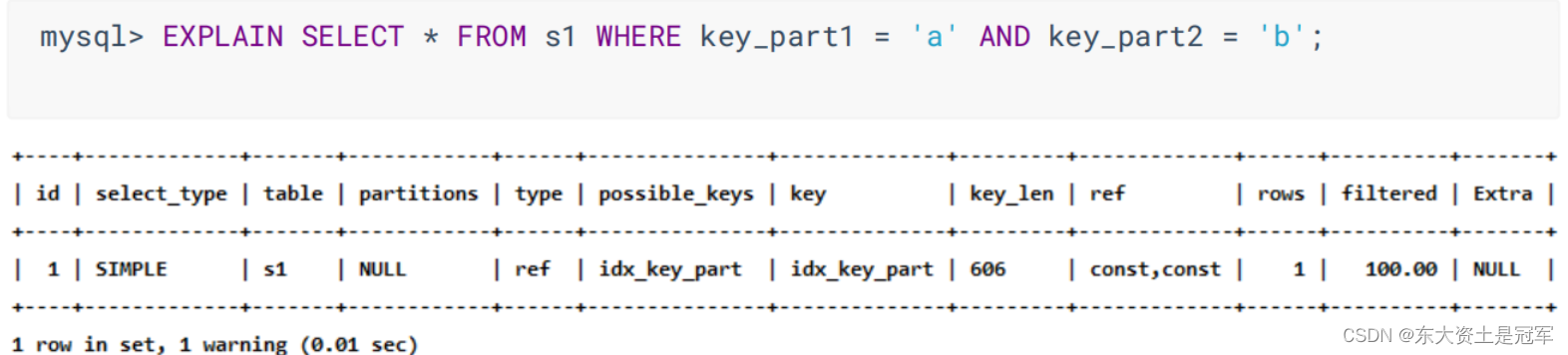
可以看到606 会比303 更好
utf8一个字符占3个字节
303 = 允许长度100 * 3 + 一个字节(null) + 两个字节变长字段
 7. Extra ☆
7. Extra ☆
太多了 不抄了 见书260
相关文章:
EXPLAIN概述与字段剖析
6. 分析查询语句:EXPLAIN(重点) 6.1 概述 定位了查询慢的sQL之后,我们就可以使用EXPLAIN或DESCRIBE 工具做针对性的分析查询语句。DESCRIBE语句的使用方法与EXPLAIN语句是一样的,并且分析结果也是一样的。 MySQL中有专门负责优化SELECT语句…...

基于Java IO 序列化方案的memcached-session-manager多memcached节点配置
session的序列化方案官方推荐的有4种 java serializationmsm-kryo-serializermsm-javolution-serializermsm-xstream-serializer 关于这几种,官方也给出了比较: Java serialization is very robust and a proven technology. The biggest disadvantage IMHO is th…...
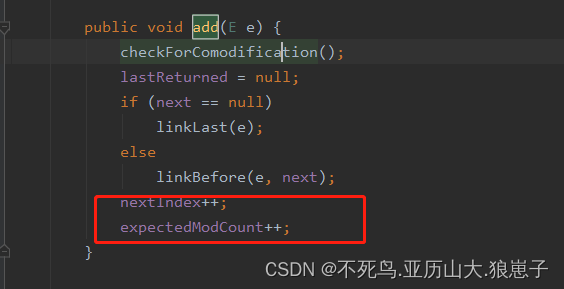
LinkedList(3):并发异常
1 LinkedList并发异常 package com.example.demo;import java.util.Iterator; import java.util.LinkedList;public class TestLinkedList {public static void main(String[] args) {LinkedList linkedList new LinkedList(); //双向链表linkedList.add(11);linkedList.add(…...

vue里el-form+el-table实现验证规则的写法
vue里el-formel-table实现验证规则的写法 vue里el-formel-table实现验证规则的写法 vue里el-formel-table实现验证规则的写法 重点是因为使用el-form el-table与单独使用el-form时数据不同,前者是对象json数组,后者是对象,导致了el-form-ite…...
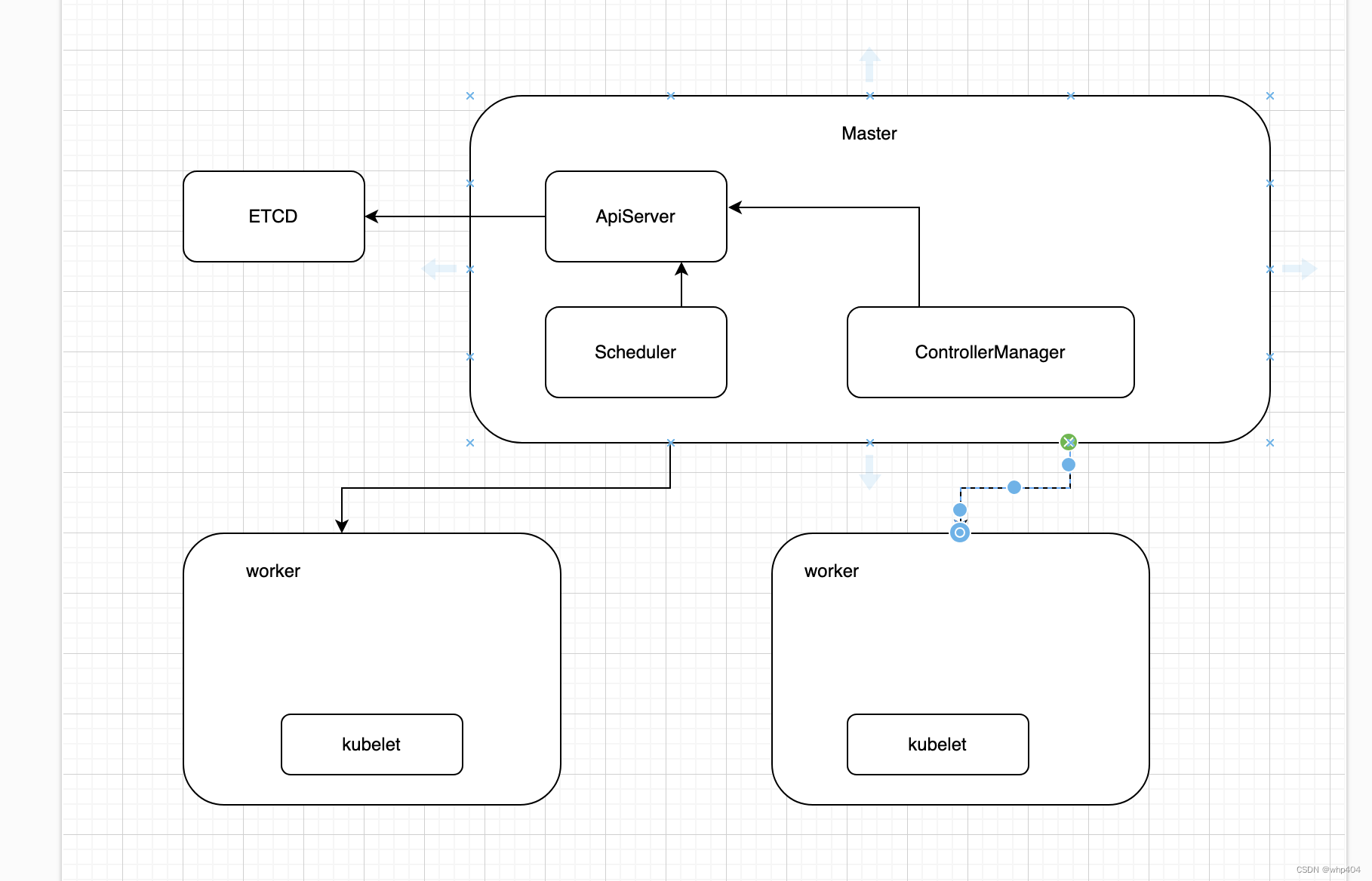
K8S 基础概念学习
1.K8S 通过Deployment 实现滚动发布,比如左边的ReplicatSet 的 pod 中 是V1版本的镜像,Deployment通过 再启动一个 ReplicatSet 中启动 pod中 镜像就是V2 2.每个pod 中都有一个pause 容器,他会连接本pod中的其他容器,实现互通。p…...

Java之正则表达式的详细解析
正则表达式 1.1 正则表达式的概念及演示 在Java中,我们经常需要验证一些字符串,例如:年龄必须是2位的数字、用户名必须是8位长度而且只能包含大小写字母、数字等。正则表达式就是用来验证各种字符串的规则。它内部描述了一些规则,…...
是两回事儿)
移动端的屏幕分辨率与浏览器的视口宽度(视口大小)是两回事儿
问:在移动端的Web设计中,屏幕的分辨率和视口大小是不是是两回事儿? 答: 是的,屏幕的分辨率和视口大小在移动端的Web设计中是两个不同的概念。 屏幕分辨率(Screen Resolution):这指的…...
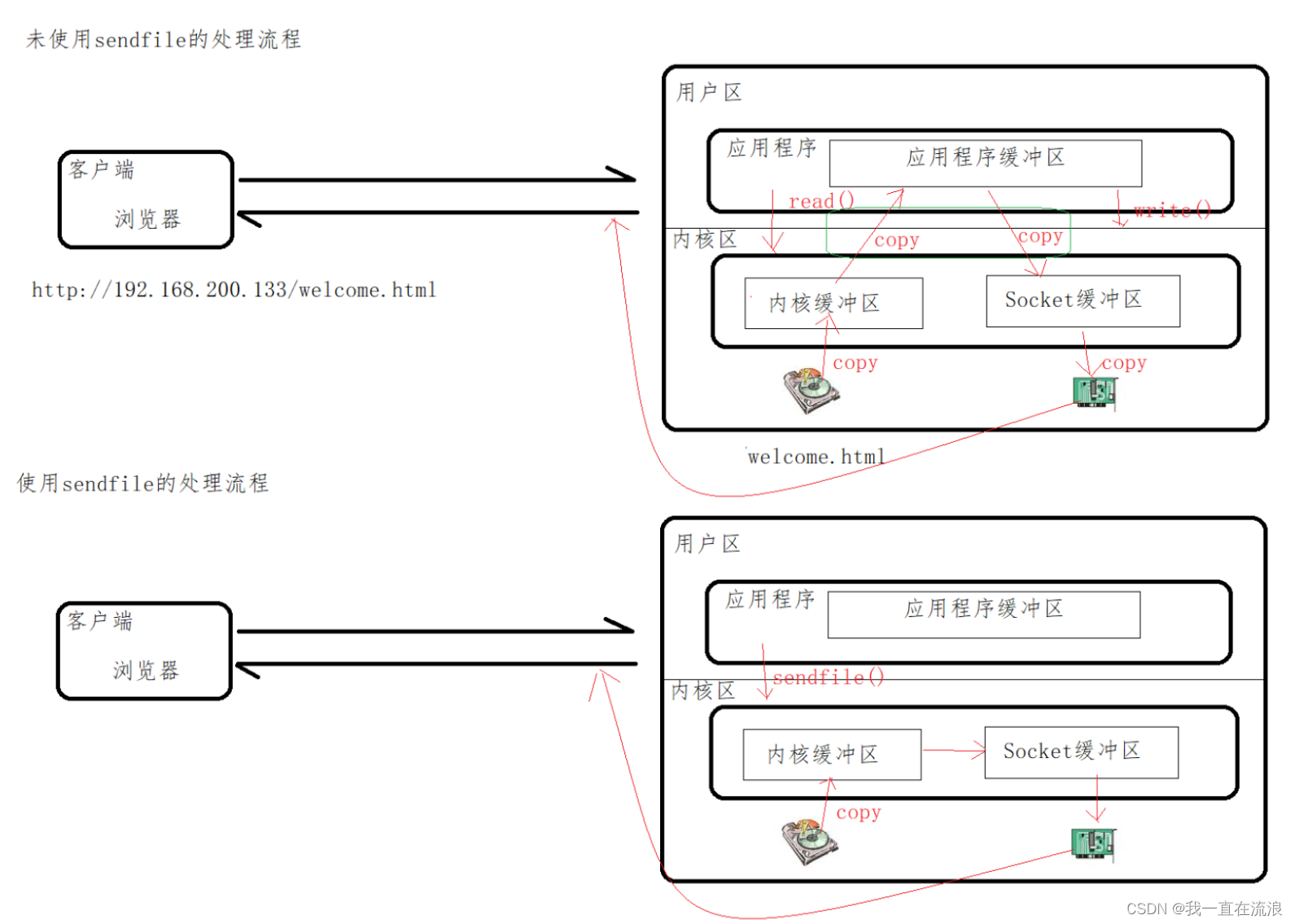
分布式 - 服务器Nginx:基础系列之Nginx静态资源优化配置指令sendfile | tcp_nopush | tcp_nodelay
文章目录 1. sendfile 指令2. tcp_nopush 指令3. tcp_nodelay 指令 1. sendfile 指令 请求静态资源的过程:客户端通过网络接口向服务端发送请求,操作系统将这些客户端的请求传递给服务器端应用程序,服务器端应用程序会处理这些请求ÿ…...

Sentinel配置的blockHandler方法不生效
①首先配置流控的资源名跟SentinelResource中的Value配置的一定要一直且唯一 ②其次blockhandler后面的方法一定要跟下面指定的方法名称是一样的 ③也就是我犯下的错误,一定要注意是上面那个才是Sentinel的,下面的是sun公司的…我说呢,一直…...

Mybatis的三种映射关系以及联表查询
目录 一、概念 二、一对一 1、配置generatorConfig.xml 2、Vo包的编写 3、xml的sql编写 4、编写对应接口及实现类 5、测试 三、一对多 1、Vo包类的编写 2、xml的sql编写 3、编写对应接口及实现类 4、测试 四、多对多 1、Vo类 2、xml的sql配置 3、接口及接口实现…...
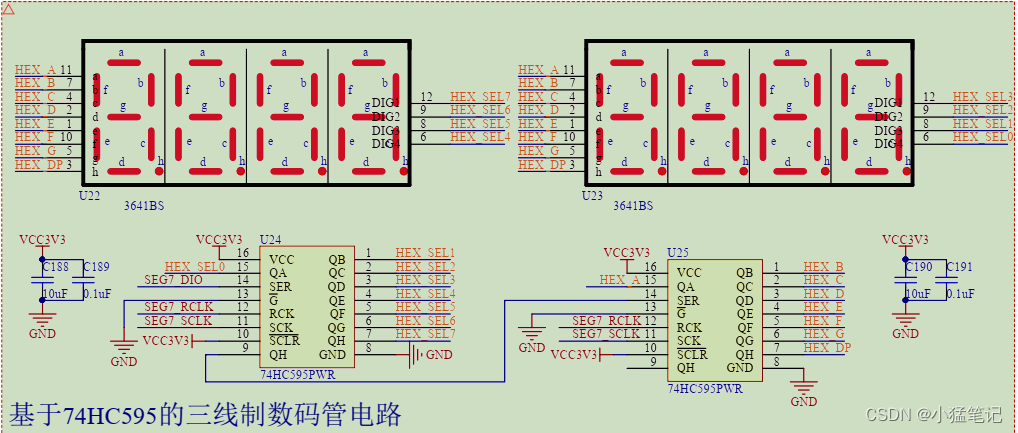
基于串口校时的数字钟设计
文章目录 设计目标硬件设计数码管串口 软件设计顶层模块串口接收模块数据处理模块时钟模块串口发送模块 总结 设计目标 环境:ACX720开发板 实现功能: 数码管能够显示时分秒能够接收串口数据修改时间能够将当前时间以1s一次速率发送到电脑 硬件设计 数…...
)
支持向量机(二)
文章目录 前言具体内容 前言 总算要对稍微有点难度的地方动手了,前面介绍的线性可分或者线性不可分的情况,都是使用平面作为分割面的,现在我们采用另一种分割面的设计方法,也就是核方法。 核方法涉及的分割面不再是 w x b 0 wx…...
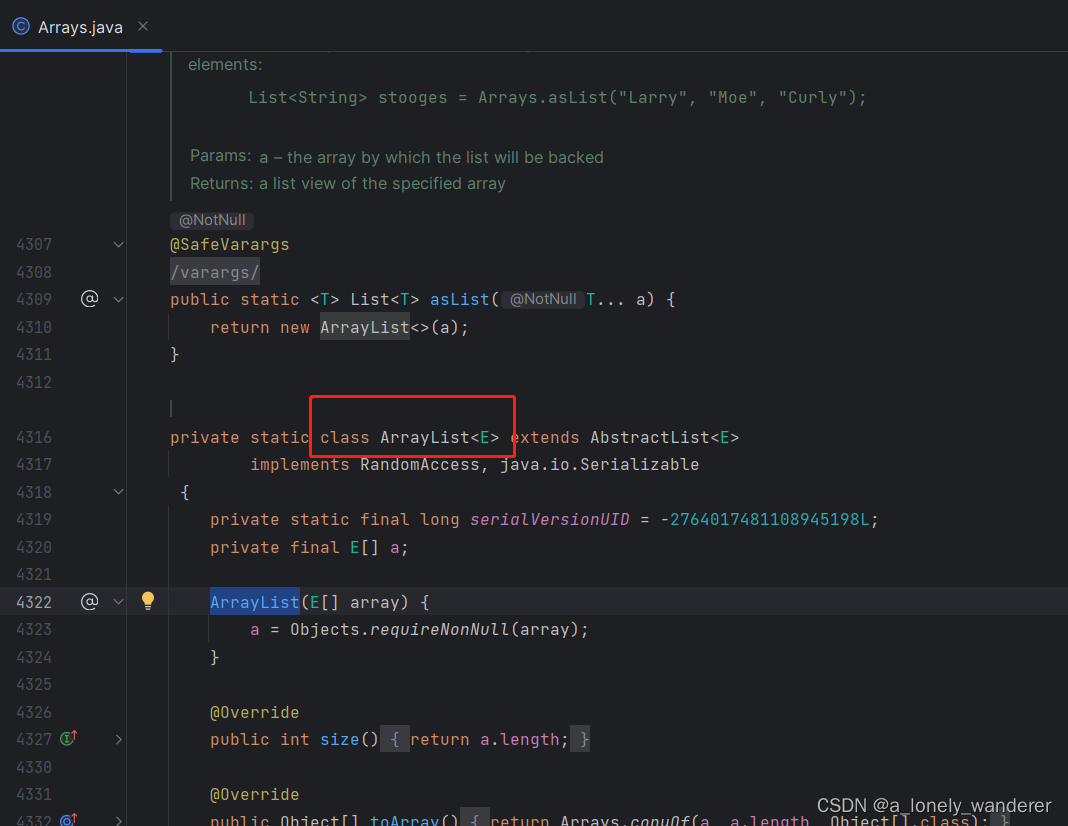
Arrays.asList 和 null 类型
一、Arrays.asList 类型简析 Arrays.asList() 返回的List 是它的内部类,不能使用 retainAll() 取交集,导致元素的删除,会报错。 List<String> list Arrays.asList(value.split(",")); 替换为> List<String> list…...

《论文阅读》用提示和释义模拟对话情绪识别的思维过程 IJCAI 2023
《论文阅读》用提示和复述模拟对话情绪识别的思维过程 IJCAI 2023 前言简介相关知识prompt engineeringparaphrasing模型架构第一阶段第二阶段History-oriented promptExperience-oriented Prompt ConstructionLabel Paraphrasing损失函数前言 你是否也对于理解论文存在困惑?…...
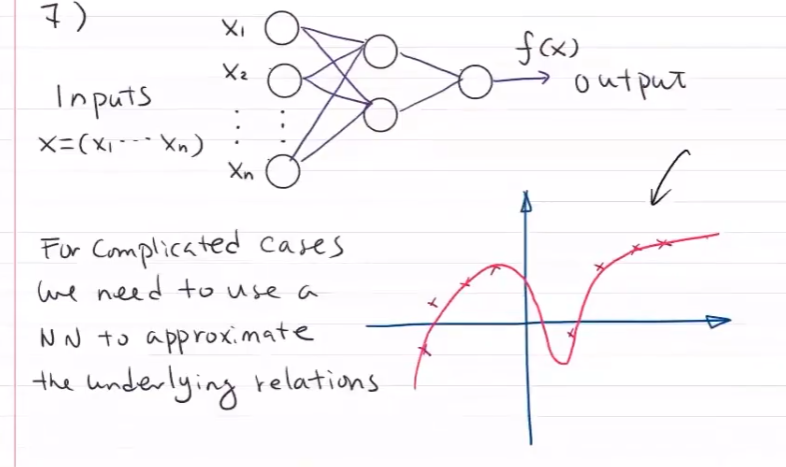
【AI】机器学习——绪论
文章目录 1.1 机器学习概念1.1.1 定义统计机器学习与数据挖掘区别机器学习前提 1.1.2 术语1.1.3 特点以数据为研究对象目标方法——基于数据构建模型SML三要素SML步骤 1.2 分类1.2.1 参数化/非参数化方法1.2.2 按算法分类1.2.3 按模型分类概率模型非概率模型逻辑斯蒂回归 1.2.4…...

linux 查看端口占用
查看端口占用 使用lsof 可以使用lsof -i:端口号 来查看端口占用情况 lsof -i:8010COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAMEnginx 35653 zhanghe 10u IPv4 0xcac2e413ddf9c5b9 0t0 TCP *:8010 (LISTEN)nginx 35654 zhanghe 10u…...

modernC++手撸任意层神经网络22前向传播反向传播梯度下降等23代码补全的例子0901b
以下神经网络代码,请添加输入:{{1,0},{1,1}},输出{1,0};添加反向传播,梯度下降等训练! 以下神经网络代码,请添加输入:{{1,0},{1,1}},输出{1,0};添加反向传播,梯度下降等训练! #include <iostream> #include<vector> #include<Eigen/Dense> #include<rando…...
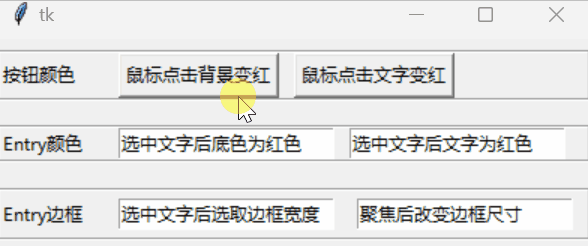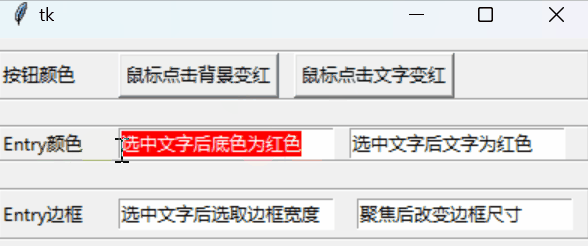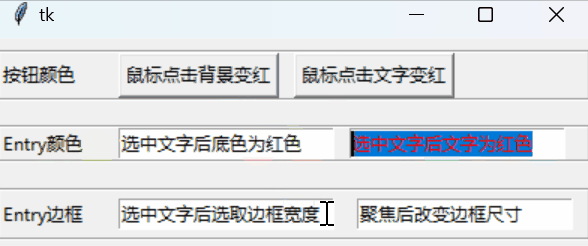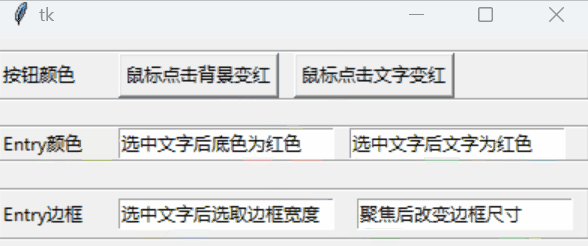
tkinter控件样式
文章目录 以按钮为例共有参数动态属性 tkinter系列: GUI初步💎布局💎绑定变量💎绑定事件💎消息框💎文件对话框💎控件样式扫雷小游戏💎强行表白神器 以按钮为例 tkinter对控件的诸…...

【linux命令讲解大全】042. 深入了解 which 命令:查找和显示命令的绝对路径
文章目录 which补充说明语法选项参数实例 从零学 python which 查找并显示给定命令的绝对路径 补充说明 which 命令用于查找并显示给定命令的绝对路径,环境变量 PATH 中保存了查找命令时需要遍历的目录。which 指令会在环境变量 $PATH 设置的目录里查找符合条件的…...
实战项目 在线学院之集成springsecurity的配置以及执行流程
一 后端操作配置 1.0 工程结构 1.1 在common下创建spring_security模块 1.2 pom文件中依赖的注入 1.3 在service_acl模块服务中引入spring-security权限认证模块 1.3.1 service_acl引入spring-security 1.3.2 在service_acl编写查询数据库信息 定义userDetailServiceImpl 查…...

4步实现代码块专业化管理:技术文档效率提升指南
4步实现代码块专业化管理:技术文档效率提升指南 【免费下载链接】obsidian-better-codeblock Add title, line number to Obsidian code block 项目地址: https://gitcode.com/gh_mirrors/ob/obsidian-better-codeblock 在技术文档创作过程中,代码…...

阿姆智创15.6寸触摸工控一体机,工业智造终端解决方案,源头工厂ODM定制赋能自动化升级
在工业自动化与智能制造深度融合的当下,稳定可靠、适配性强、可定制化的工控终端,已成为SMT产线、MES/ESOP系统等场景高效运行的关键支撑。阿姆智创15.6寸触摸工控一体机,以硬核工业性能、丰富系统接口、灵活ODM定制服务,打造一站…...

Qwen3-14B Function Calling功能详解:让AI不仅能说,更能实干
Qwen3-14B Function Calling功能详解:让AI不仅能说,更能实干 你有没有想过,让AI不仅能和你聊天,还能帮你查天气、订机票、甚至处理工作流程?这听起来像是科幻电影里的场景,但现在,通过Qwen3-14…...

LM339比较器:从基础参数到典型应用场景解析
1. LM339比较器基础解析 第一次接触LM339时,我完全被它"四合一"的设计惊艳到了——这个比指甲盖还小的芯片里,竟然藏着四个独立工作的电压比较器。简单来说,它就像四个并排摆放的天平,能同时比较八路电压信号的高低。实…...
)
【人工智能基础-机器学习】- 线性归回知识点(有个人理解)
机器学习:线性回归 一、线性回归基础 1.1 数据准备 将x0置为1,与xn组合得到nn的矩阵 1.2 理论基础 正态分布: 基于中心极限定理,误差(预测值-实际值)服从正态分布 最大似然估计(MLE)…...

告别重复劳动:用快马平台智能整合opencode,打造专属效率工具库
作为一名经常需要处理各种数据格式和工具函数的开发者,我最近发现了一个能显著提升开发效率的方法——利用InsCode(快马)平台快速生成可复用的工具库。今天就来分享下如何用这个平台智能整合opencode资源,打造自己的JavaScript效率工具库。 为什么需要工…...
)
Win11+Ubuntu22.04双系统避坑指南:如何正确分配分区空间(含CUDA安装建议)
Win11Ubuntu 22.04双系统分区策略与CUDA开发环境配置实战 作为一名长期在深度学习领域工作的开发者,我经历过无数次双系统安装的"血泪史"。特别是当项目 deadline 临近,却因为分区不当导致 CUDA 无法安装时,那种绝望感至今难忘。本…...

别再只用Speedtest了!自建LibreSpeed测速站,监控家庭宽带/公司内网真实表现
自建网络测速站:用LibreSpeed打造精准带宽监控系统 每次看到运营商宣传的"千兆宽带",你是否怀疑过实际使用中根本达不到承诺速度?公共测速网站的结果总让人将信将疑——它们可能被ISP特殊优化,或是受限于服务器位置。更…...

python pyoxidizer
# 关于PyOxidizer的一些思考 最近在Python打包工具领域,有个工具引起了不小的讨论,那就是PyOxidizer。如果你经常需要将Python代码打包成可执行文件,或者部署到没有Python环境的机器上,可能会对这个工具感兴趣。 它到底是什么 PyO…...

OpenClaw+千问3.5-9B学术助手:自动整理参考文献与生成综述
OpenClaw千问3.5-9B学术助手:自动整理参考文献与生成综述 1. 为什么需要自动化文献处理 去年冬天,当我面对堆积如山的PDF文献时,突然意识到传统文献管理方式已经跟不上现代研究的节奏。手动标注重点、复制粘贴引用、反复切换不同文献工具—…...