【深度学习】实验07 使用TensorFlow完成逻辑回归
文章目录
- 使用TensorFlow完成逻辑回归
- 1. 环境设定
- 2. 数据读取
- 3. 准备好placeholder
- 4. 准备好参数/权重
- 5. 计算多分类softmax的loss function
- 6. 准备好optimizer
- 7. 在session里执行graph里定义的运算
- 附:系列文章
使用TensorFlow完成逻辑回归
TensorFlow是一种开源的机器学习框架,由Google Brain团队于2015年开发。它被广泛应用于图像和语音识别、自然语言处理、推荐系统等领域。
TensorFlow的核心是用于计算的数据流图。在数据流图中,节点表示数学操作,边表示张量(多维数组)。将操作和数据组合在一起的数据流图可以使 TensorFlow 对复杂的数学模型进行优化,同时支持分布式计算。
TensorFlow提供了Python,C++,Java,Go等多种编程语言的接口,让开发者可以更便捷地使用TensorFlow构建和训练深度学习模型。此外,TensorFlow还具有丰富的工具和库,包括TensorBoard可视化工具、TensorFlow Serving用于生产环境的模型服务、Keras高层封装API等。
TensorFlow已经发展出了许多优秀的模型,如卷积神经网络、循环神经网络、生成对抗网络等。这些模型已经在许多领域取得了优秀的成果,如图像识别、语音识别、自然语言处理等。
除了开源的TensorFlow,Google还推出了基于TensorFlow的云端机器学习平台Google Cloud ML,为用户提供了更便捷的训练和部署机器学习模型的服务。
解决分类问题里最普遍的baseline model就是逻辑回归,简单同时可解释性好,使得它大受欢迎,我们来用tensorflow完成这个模型的搭建。
1. 环境设定
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'import warnings
warnings.filterwarnings("ignore")import numpy as np
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import time
2. 数据读取
#使用tensorflow自带的工具加载MNIST手写数字集合
mnist = input_data.read_data_sets('./data/mnist', one_hot=True)
Extracting ./data/mnist/train-images-idx3-ubyte.gz
Extracting ./data/mnist/train-labels-idx1-ubyte.gz
Extracting ./data/mnist/t10k-images-idx3-ubyte.gz
Extracting ./data/mnist/t10k-labels-idx1-ubyte.gz
#查看一下数据维度
mnist.train.images.shape
(55000, 784)
#查看target维度
mnist.train.labels.shape
(55000, 10)
3. 准备好placeholder
batch_size = 128
X = tf.placeholder(tf.float32, [batch_size, 784], name='X_placeholder')
Y = tf.placeholder(tf.int32, [batch_size, 10], name='Y_placeholder')
4. 准备好参数/权重
w = tf.Variable(tf.random_normal(shape=[784, 10], stddev=0.01), name='weights')
b = tf.Variable(tf.zeros([1, 10]), name="bias")
logits = tf.matmul(X, w) + b
5. 计算多分类softmax的loss function
# 求交叉熵损失
entropy = tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=Y, name='loss')
# 求平均
loss = tf.reduce_mean(entropy)
6. 准备好optimizer
这里的最优化用的是随机梯度下降,我们可以选择AdamOptimizer这样的优化器
learning_rate = 0.01
optimizer = tf.train.AdamOptimizer(learning_rate).minimize(loss)
7. 在session里执行graph里定义的运算
#迭代总轮次
n_epochs = 30with tf.Session() as sess:# 在Tensorboard里可以看到图的结构writer = tf.summary.FileWriter('../graphs/logistic_reg', sess.graph)start_time = time.time()sess.run(tf.global_variables_initializer()) n_batches = int(mnist.train.num_examples/batch_size)for i in range(n_epochs): # 迭代这么多轮total_loss = 0for _ in range(n_batches):X_batch, Y_batch = mnist.train.next_batch(batch_size)_, loss_batch = sess.run([optimizer, loss], feed_dict={X: X_batch, Y:Y_batch}) total_loss += loss_batchprint('Average loss epoch {0}: {1}'.format(i, total_loss/n_batches))print('Total time: {0} seconds'.format(time.time() - start_time))print('Optimization Finished!')# 测试模型preds = tf.nn.softmax(logits)correct_preds = tf.equal(tf.argmax(preds, 1), tf.argmax(Y, 1))accuracy = tf.reduce_sum(tf.cast(correct_preds, tf.float32))n_batches = int(mnist.test.num_examples/batch_size)total_correct_preds = 0for i in range(n_batches):X_batch, Y_batch = mnist.test.next_batch(batch_size)accuracy_batch = sess.run([accuracy], feed_dict={X: X_batch, Y:Y_batch}) total_correct_preds += accuracy_batch[0]print('Accuracy {0}'.format(total_correct_preds/mnist.test.num_examples))writer.close()
Average loss epoch 0: 0.36748782022571785 Average loss epoch 1: 0.2978815356126198 Average loss epoch 2: 0.27840628396797845 Average loss epoch 3: 0.2783186247437706 Average loss epoch 4: 0.2783641471138923 Average loss epoch 5: 0.2750668214473413 Average loss epoch 6: 0.2687560408126502 Average loss epoch 7: 0.2713795114126239 Average loss epoch 8: 0.2657588795522154 Average loss epoch 9: 0.26322007090686916 Average loss epoch 10: 0.26289192279735646 Average loss epoch 11: 0.26248606019989873 Average loss epoch 12: 0.2604622903056356 Average loss epoch 13: 0.26015280702939403 Average loss epoch 14: 0.2581879366319496 Average loss epoch 15: 0.2590309207117085 Average loss epoch 16: 0.2630510463581219 Average loss epoch 17: 0.25501730025578767 Average loss epoch 18: 0.2547102673000945 Average loss epoch 19: 0.258298404375851 Average loss epoch 20: 0.2549241428330784 Average loss epoch 21: 0.2546788509283866 Average loss epoch 22: 0.259556887067837 Average loss epoch 23: 0.25428259843365575 Average loss epoch 24: 0.25442713139565676 Average loss epoch 25: 0.2553852511383159 Average loss epoch 26: 0.2503043229415978 Average loss epoch 27: 0.25468004046828596 Average loss epoch 28: 0.2552785321479633 Average loss epoch 29: 0.2506257003663859 Total time: 28.603315353393555 seconds Optimization Finished! Accuracy 0.9187
附:系列文章
| 序号 | 文章目录 | 直达链接 |
|---|---|---|
| 1 | 波士顿房价预测 | https://want595.blog.csdn.net/article/details/132181950 |
| 2 | 鸢尾花数据集分析 | https://want595.blog.csdn.net/article/details/132182057 |
| 3 | 特征处理 | https://want595.blog.csdn.net/article/details/132182165 |
| 4 | 交叉验证 | https://want595.blog.csdn.net/article/details/132182238 |
| 5 | 构造神经网络示例 | https://want595.blog.csdn.net/article/details/132182341 |
| 6 | 使用TensorFlow完成线性回归 | https://want595.blog.csdn.net/article/details/132182417 |
| 7 | 使用TensorFlow完成逻辑回归 | https://want595.blog.csdn.net/article/details/132182496 |
| 8 | TensorBoard案例 | https://want595.blog.csdn.net/article/details/132182584 |
| 9 | 使用Keras完成线性回归 | https://want595.blog.csdn.net/article/details/132182723 |
| 10 | 使用Keras完成逻辑回归 | https://want595.blog.csdn.net/article/details/132182795 |
| 11 | 使用Keras预训练模型完成猫狗识别 | https://want595.blog.csdn.net/article/details/132243928 |
| 12 | 使用PyTorch训练模型 | https://want595.blog.csdn.net/article/details/132243989 |
| 13 | 使用Dropout抑制过拟合 | https://want595.blog.csdn.net/article/details/132244111 |
| 14 | 使用CNN完成MNIST手写体识别(TensorFlow) | https://want595.blog.csdn.net/article/details/132244499 |
| 15 | 使用CNN完成MNIST手写体识别(Keras) | https://want595.blog.csdn.net/article/details/132244552 |
| 16 | 使用CNN完成MNIST手写体识别(PyTorch) | https://want595.blog.csdn.net/article/details/132244641 |
| 17 | 使用GAN生成手写数字样本 | https://want595.blog.csdn.net/article/details/132244764 |
| 18 | 自然语言处理 | https://want595.blog.csdn.net/article/details/132276591 |
相关文章:

【深度学习】实验07 使用TensorFlow完成逻辑回归
文章目录 使用TensorFlow完成逻辑回归1. 环境设定2. 数据读取3. 准备好placeholder4. 准备好参数/权重5. 计算多分类softmax的loss function6. 准备好optimizer7. 在session里执行graph里定义的运算 附:系列文章 使用TensorFlow完成逻辑回归 TensorFlow是一种开源的…...

2023-09-04 Linux 让shell编译脚本里面设置的环境变量改变kernel里面驱动文件的宏定义值方法,我这里用来做修改固件版本
一、原生的读取版本接口是/proc/version,我这里需要提供获取固件版本号的api给app,因为版本号会经常需要修改,如果每次都到kernel下修改比较麻烦,我这里是想在编译脚本里面对版本号进行修改,这样方便一点。 二、主要修…...

Python操作Excel实战:Excel行转列
# 1、原始数据准备 样例数据准备 地区1m2-5m6-10m11-20m21-40m地区单价计费单位费用最小值费用最大值北京13012011010090 天津13012011010090 石家庄13012011010090 保定140130120110100 张家口170150130120110 邢台1401201101…...

java实现迭代器模式
迭代器模式(Iterator Pattern)是一种行为型设计模式,它提供一种方法来顺序访问一个聚合对象(如列表、集合、数组等)中的元素,而不暴露聚合对象的内部表示。迭代器模式通常包括以下角色:迭代器&a…...

C++day7模板、异常、auto关键字、lambda表达式、数据类型转换、STL、list、文件操作
作业 封装一个学生的类,定义一个学生这样类的vector容器, 里面存放学生对象(至少3个) 再把该容器中的对象,保存到文件中。 再把这些学生从文件中读取出来,放入另一个容器中并且遍历输出该容器里的学生。 #include …...

【校招VIP】产品分析之活动策划宣传
考点介绍: 产品的上线运营是非常重要的。应该来说好的产品都是运营出来的,在一运营过程中难免会依靠策划活动来提高产品知名度、用户数。用户粘度等等指标一,如何策划一个成功的活动就显得非常重要。 产品分析之活动策划宣传-相关题目及解析…...

node基础之一:fs 模块
概念:文件的创建、删除、重命名、移动、写入、读取等 const fs require("fs");// 写入 fs.writeFile("./demo.txt", "hello", (err) > {}); fs.writeFileSync();// 追加 fs.appendFile("./demo.txt", "hello&quo…...
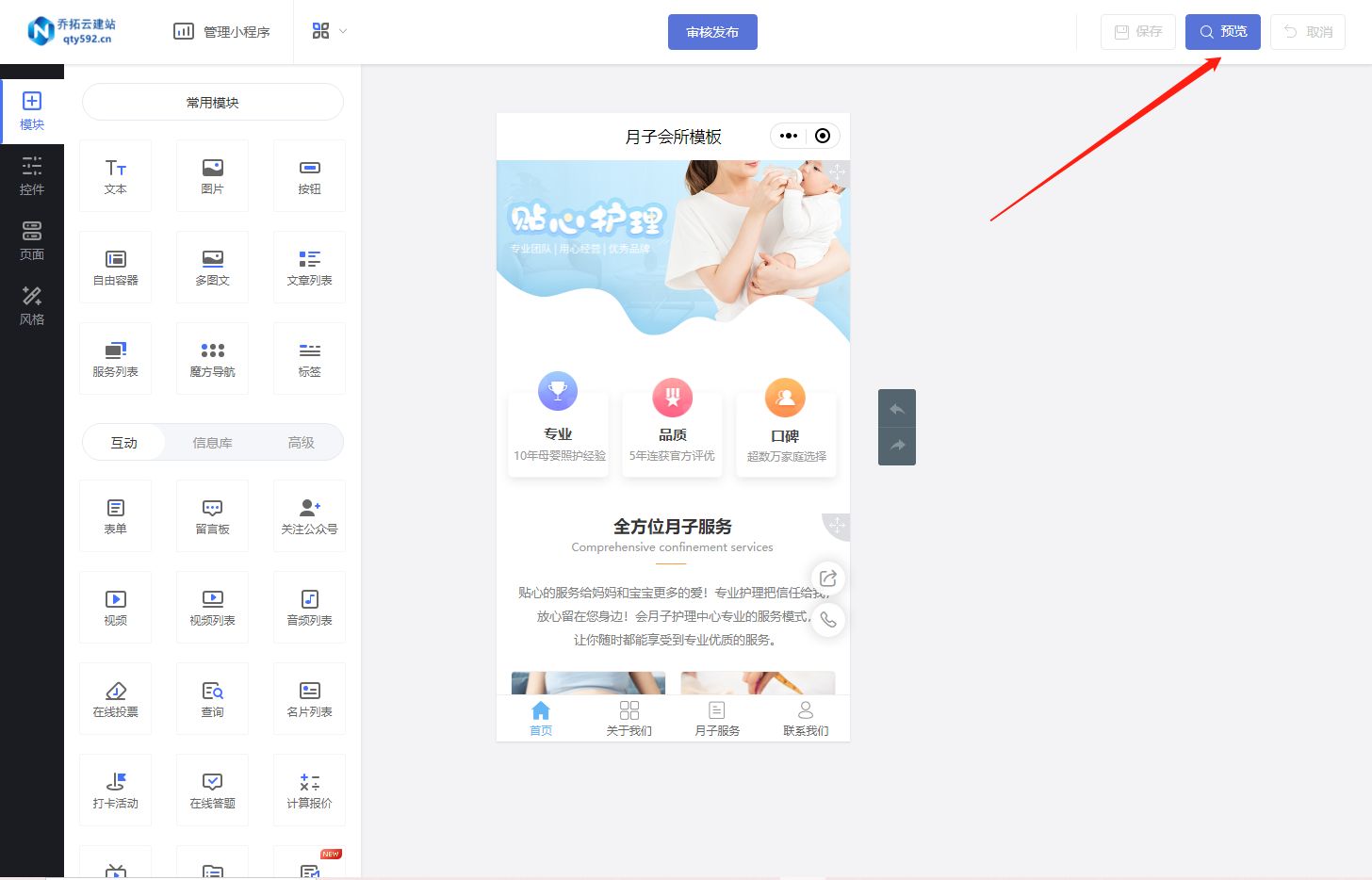
如何快速搭建母婴行业的微信小程序?
如果你想为你的母婴行业打造一个独特的小程序,但没有任何编程经验,别担心!现在有许多小程序制作平台提供了简单易用的工具,让你可以轻松地建立自己的小程序。接下来,我将为你详细介绍搭建母婴行业小程序的步骤。 首先&…...

【科普向】Jmeter 如何测试接口保姆式教程
现在对测试人员的要求越来越高,不仅仅要做好功能测试,对接口测试的需求也越来越多!所以也越来越多的同学问,怎样才能做好接口测试? 要真正的做好接口测试,并且弄懂如何测试接口,需要从如下几个…...
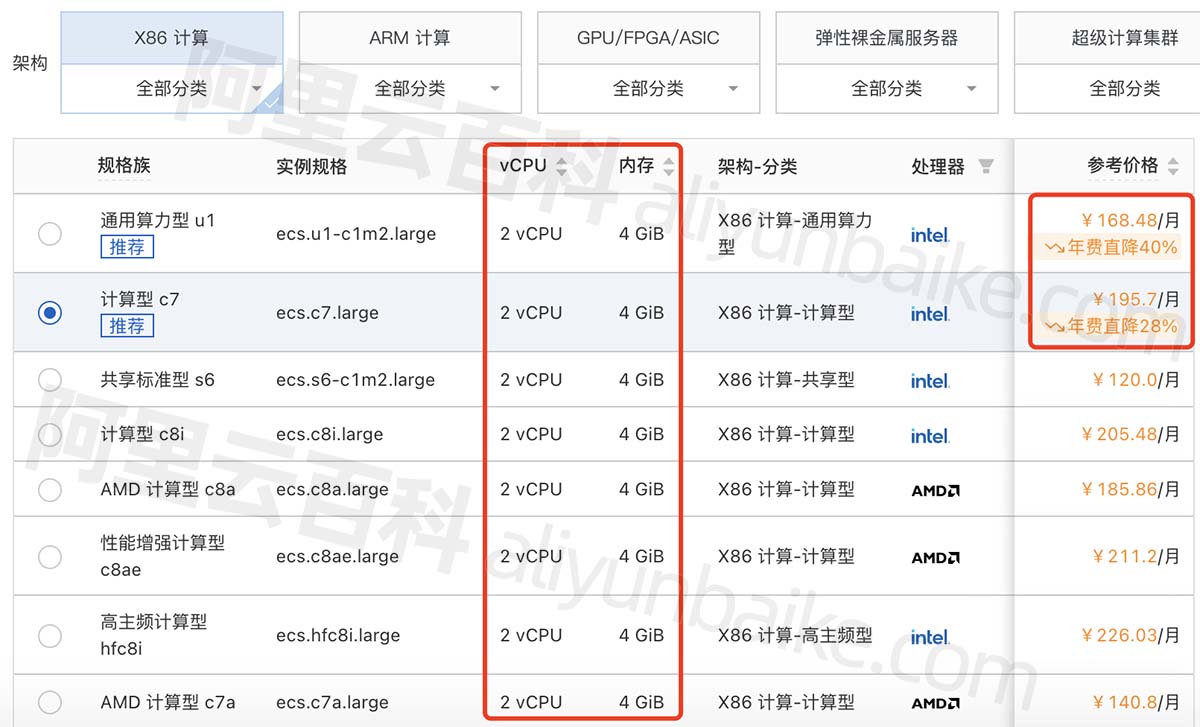
阿里云2核4G服务器5M带宽5年费用价格明细表
阿里云2核4G服务器5M带宽可以选择轻量应用服务器或云服务器ECS,轻量2核4G4M带宽服务器297元一年,2核4G云服务器ECS可以选择计算型c7、c6或通用算力型u1实例等,买5年可以享受3折优惠,阿腾云分享阿里云服务器2核4G5M带宽五年费用表&…...

【图解RabbitMQ-2】图解JMS规范与AMQP协议是什么
🧑💻作者名称:DaenCode 🎤作者简介:CSDN实力新星,后端开发两年经验,曾担任甲方技术代表,业余独自创办智源恩创网络科技工作室。会点点Java相关技术栈、帆软报表、低代码平台快速开…...

springboot整合mybatis实现增删改查(xml)--项目阶段1
目录 一、前言 二、创建项目 创建MySQL数据库和表 创建springboot项目 本文总体代码结构图预览 三、编写代码 (一)新建实体层属性类 (二)新建数据层mapper接口 (三)新建mapper的映射SQL(…...

springboot文件上传异步报错
因为迁移的生产环境,在新的服务器发生了之前没有遇到的问题,这种问题是在异步文件上传的时候才会出现 错误信息如下 16:17:50.009 ERROR c.w.einv.minio.service.impl.MinioFileServiceImpl - 文件上传错误! java.io.FileNotFoundException: /applicati…...

error: unable to unlink old ‘.gitlab-ci.yml‘: Permission denied
#gitlab-runner 执行代码git pull origin xxx 更新时候报 error: unable to unlink old ‘.gitlab-ci.yml’: Permission denied 问题环境:centos 部署gitlab-runner 执行脚本方式 选的shell 产生问题的原因:gitlab-runner程序进程占用锁定了.gitlab-ci…...
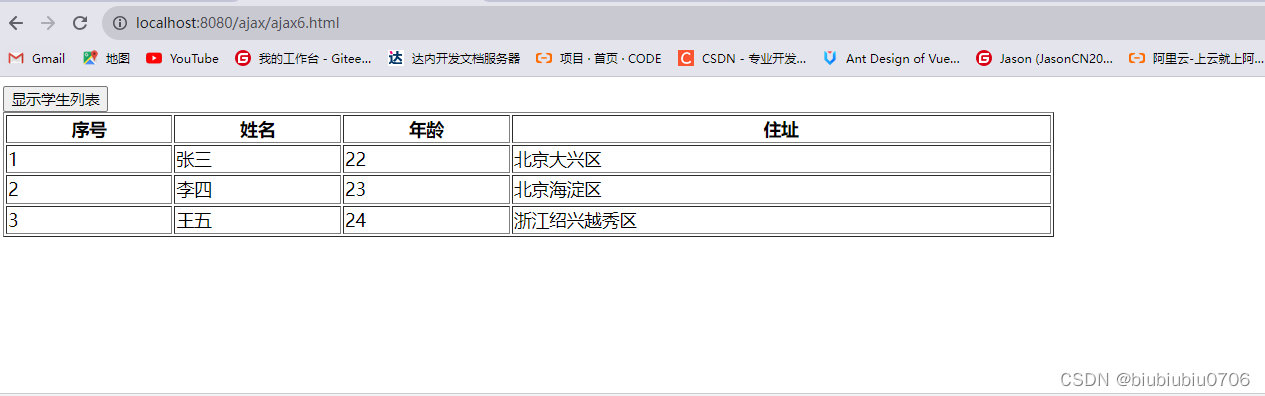
AJAX学习笔记3练习
AJAX学习笔记2发送Post请求_biubiubiu0706的博客-CSDN博客 1.验证用户名是否可用 需求,用户输入用户名,失去焦点-->onblur失去焦点事件,发送AJAX POST请求,验证用户名是否可用 新建表 前端页面 WEB-INF下新建lib包引入依赖,要用JDBC 后端代码 package com.web;import jav…...
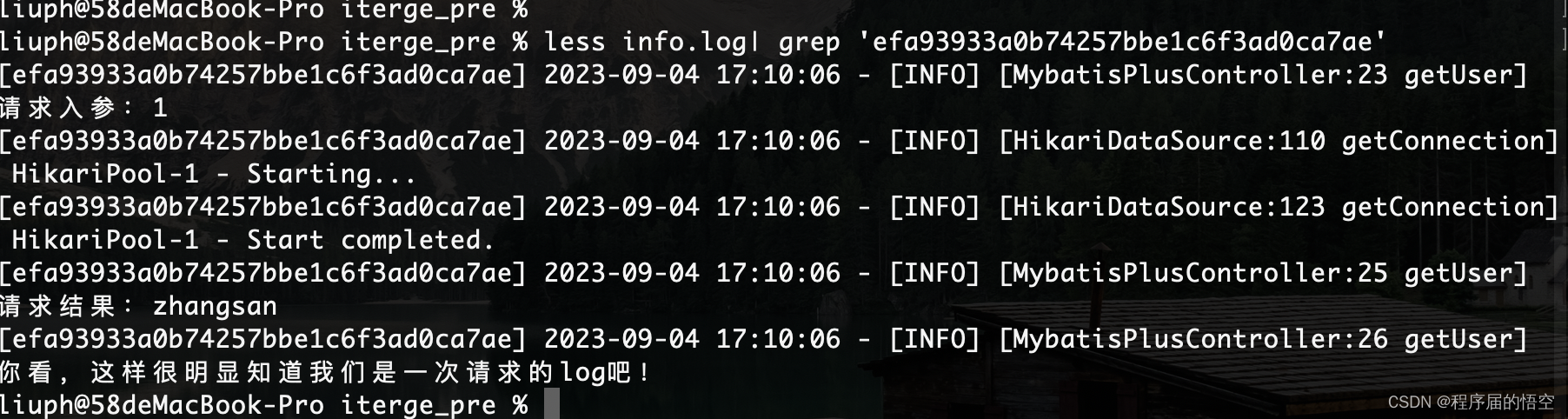
springboot实战(五)之sql业务日志输出,重要
目录 环境: 一、mybatis-plus之sql分析日志输出 1.配置 2.验证 3.高级输出方式 二、业务日志输出到文件 1.添加log4j2依赖 2.排除logback依赖 3.新增log4j2的配置文件 4.添加配置 5.启动测试 6.给日志请求加个id 6.1、过滤器filter实现 6.2、测试 6.3、…...

redis7.2.0 centos源码编译安装并设置开机自启动
下载源码包 wget https://github.com/redis/redis/archive/7.2.0.tar.gz tar -zxf 7.2.0.tar.gz 编译编码 编译编码 cd redis-7.2.0 make && make install 此时默认redis-server redis-cli等命令行安装到目录/usr/local/bin/目录中。 如果你想安装命令行到指定目录中你…...
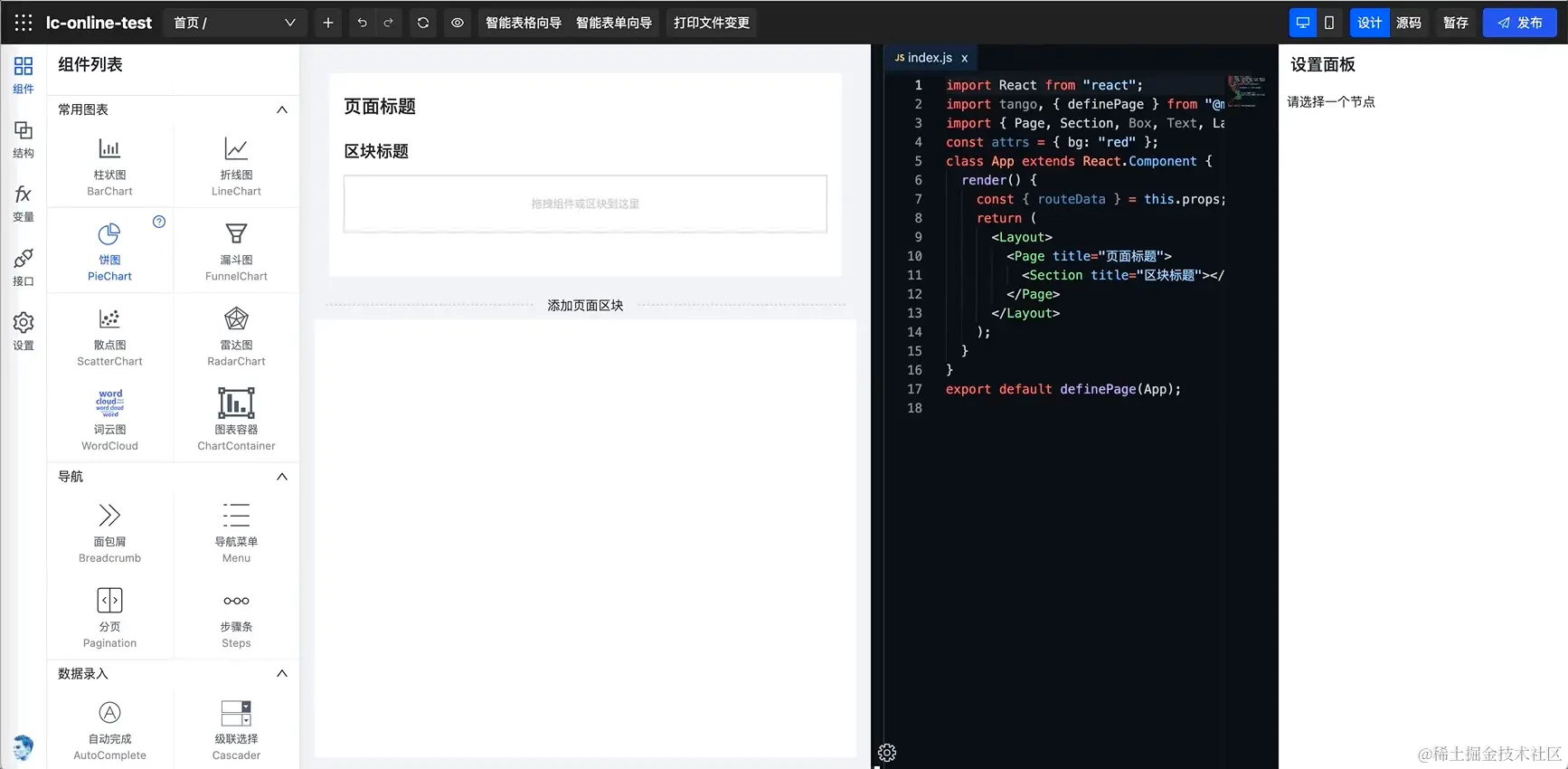
网易低代码引擎Tango正式开源
一、Tango简介 Tango 是一个用于快速构建低代码平台的低代码设计器框架,借助 Tango 只需要数行代码就可以完成一个基本的低代码平台前端系统的搭建。Tango 低代码设计器直接读取前端项目的源代码,并以源代码为中心,执行和渲染前端视图,并为用户提供低代码可视化搭建能力,…...
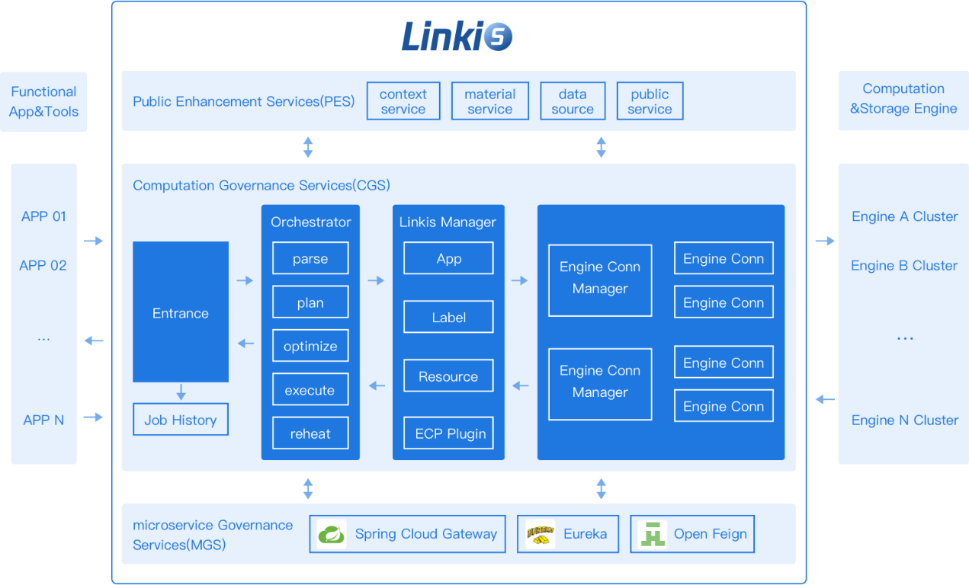
Apache Linkis 与 OceanBase 集成:实现数据分析速度提升
导语:恭喜 OceanBase 生态全景图中又添一员,Apache Linkis 构建了一个计算中间件层,以促进上层应用程序和底层数据引擎之间的连接、治理和编排。 近日,计算中间件 Apache Linkis 在其新版本中通过数据源功能,支持用户通…...

EXPLAIN概述与字段剖析
6. 分析查询语句:EXPLAIN(重点) 6.1 概述 定位了查询慢的sQL之后,我们就可以使用EXPLAIN或DESCRIBE 工具做针对性的分析查询语句。DESCRIBE语句的使用方法与EXPLAIN语句是一样的,并且分析结果也是一样的。 MySQL中有专门负责优化SELECT语句…...

seo关键词排名如何提升_seo关键词堆砌会不会被搜索引擎惩罚
SEO关键词排名如何提升_SEO关键词堆砌会不会被搜索引擎惩罚 在当前竞争激烈的网络环境中,提升SEO关键词排名已经成为网站运营者必须面对的重要课题。在追求高排名的过程中,如何避免关键词堆砌这一问题,成为了许多人关心的问题。本文将从问题…...

UI-TARS-desktop部署避坑指南:快速解决模型启动问题
UI-TARS-desktop部署避坑指南:快速解决模型启动问题 1. UI-TARS-desktop概述 1.1 核心功能与架构 UI-TARS-desktop是一款基于Qwen3-4B-Instruct-2507模型的多模态AI应用框架,采用vLLM推理引擎提供高效服务。该系统将大语言模型能力与桌面自动化操作相…...

崇左便宜的饭店本地人推荐
一、行业现象观察在崇左地区,尤其是德天瀑布、明仕田园等旅游核心区域,餐饮消费呈现明显的游客与本地人差异。本地食客更倾向于选择价格合理、口味地道、注重性价比的餐食;而游客则多关注用餐的视觉呈现、异国风情氛围及沉浸式体验。景区周边…...
)
告别手动操作!手把手教你用影刀RPA+钉钉机器人打造自动化工作流(附完整配置截图)
零代码革命:用影刀RPA钉钉机器人实现行政工作全自动化 行政部门的张琳每天早晨都要重复同样的工作:登录五个系统导出数据、整理成Excel报表、手动发送到十个钉钉群。这种机械性操作不仅消耗两小时黄金时间,还常因人为疏忽导致数据错误。直到她…...

C++的std--ranges视图转换函数异常安全与资源清理在惰性求值中的处理
C的std::ranges视图转换函数异常安全与资源清理在惰性求值中的处理 现代C引入的std::ranges库为序列操作提供了声明式编程支持,其中视图转换函数(如transform、filter等)通过惰性求值优化性能。惰性求值机制与异常安全、资源清理的交互可能引…...

Linux基础之目录结构
初学Linux,首先需要弄清Linux 标准目录结构 / root — 启动Linux时使用的一些核心文件。如操作系统内核、引导程序Grub等。home — 存储普通用户的个人文件 ftp — 用户所有服务httpdsambauser1user2 bin — 系统启动时需要的执行文件(二进制…...

第3课 神经网络基础
神经网络,本质上是模仿生物神经元网络构建的人工模型,由人工神经元(或节点)相互连接形成网络或电路。这些节点间的连接的方式与人类神经元网络相似,能够高效传递并处理输入信息,是深度学习领域的核心基础。 神经网络的核心结构由输入层、隐含层和输出层三部分组成:每个节…...

2026最权威的十大AI辅助写作平台横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 基于深度学习模型的论文一键生成技术,可快速整合文献资料,能提取核心…...

Amadeus的知识库 | 告别碎片化集成:深度解析 AI 时代的“USB 协议” —— MCP
一、引文在 LLM(大语言模型)飞速发展的今天,我们正从“对话框 AI”转向“智能体(Agent)”。然而,开发者在集成 AI 时一直面临一个巨大的痛点:数据孤岛。为了解决这个问题,Anthropic …...

无公网IP解决方案:OpenClaw+Phi-3-mini-128k-instruct内网穿透技巧
无公网IP解决方案:OpenClawPhi-3-mini-128k-instruct内网穿透技巧 1. 为什么需要内网穿透? 上周我遇到了一个棘手的问题:公司网络环境限制严格,没有公网IP,但需要在外网环境下触发本地的OpenClaw自动化任务。更麻烦的…...