大数据知识图谱项目——基于知识图谱的医疗知识问答系统(详细讲解及源码)
基于知识图谱的医疗知识问答系统
一、项目概述
本项目基于医疗方面知识的问答,通过搭建一个医疗领域知识图谱,并以该知识图谱完成自动问答与分析服务。本项目以neo4j作为存储,基于传统规则的方式完成了知识问答,并最终以关键词执行cypher查询,并返回相应结果查询语句作为问答。
问答系统完全基于规则匹配实现,通过关键词匹配,对问句进行分类,医疗问题本身属于封闭域类场景,对领域问题进行穷举并分类,然后使用cypher的match去匹配查找neo4j,根据返回数据组装问句回答,最后返回结果。
二、实现知识图谱的医疗知识问答系统基本流程
1、Node4j软件的安装和使用。
2、数据预处理方法。
3、Python处理数据方法。
4、能够实现一个知识图谱问答系统。
三、项目工具所用的版本号
Node4j-4.4.5,Python,JDK1.8
四、Node4j实验环境的安装配置
(一)安装JAVA
1.下载java安装包:
官网下载链接:https://www.oracle.com/java/technologies/javase-downloads.html
本人下载的版本为JDK-1.8,JDK版本的选择一定要恰当,版本太高或者太低都可能导致后续的neo4j无法使用。
安装好JDK之后就要开始配置环境变量了。 配置环境变量的步骤如下:
右键单击此电脑—点击属性—点击高级系统设置—点击环境变量
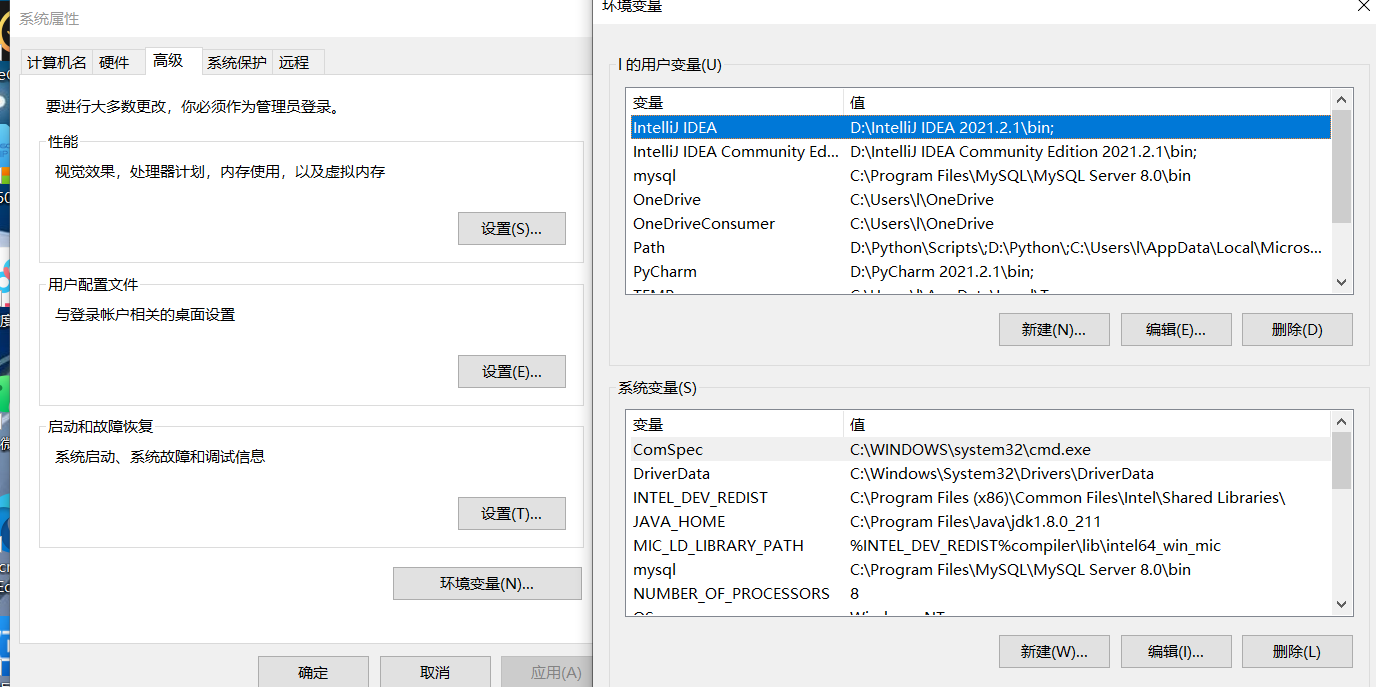
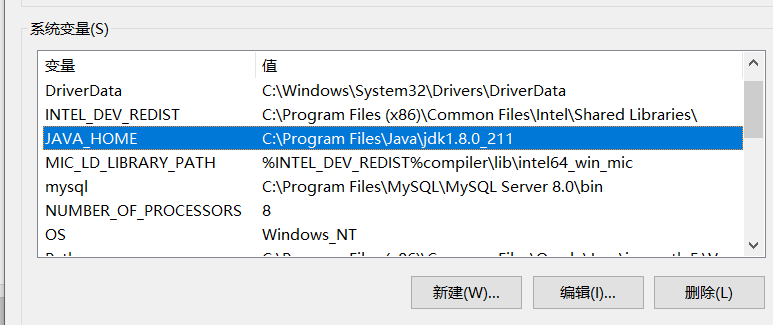
在下方的系统变量区域,新建环境变量,命名为JAVA_HOME,变量值设置为刚才JAVA的安装路径,我这里是C:\Program Files\Java\jdk1.8.0_211
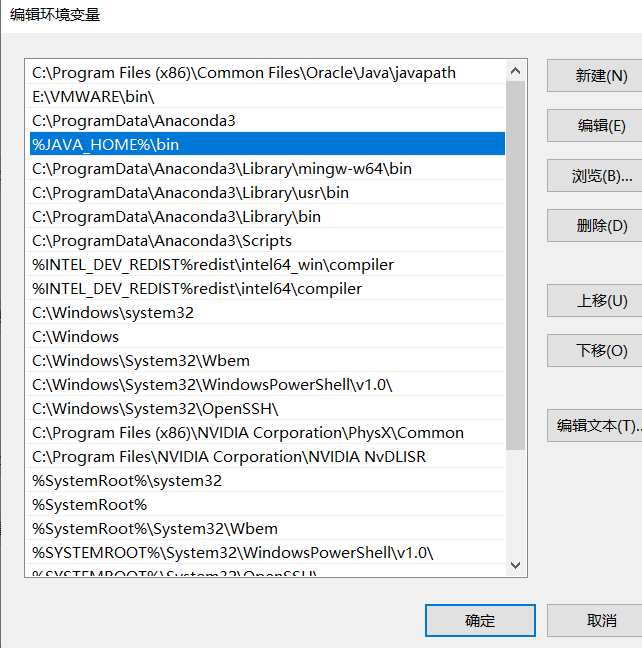
编辑系统变量区的Path,点击新建,然后输入 %JAVA_HOME%\bin
打开命令提示符CMD(WIN+R,输入cmd),输入 java -version,若提示Java的版本信息,则证明环境变量配置成功。
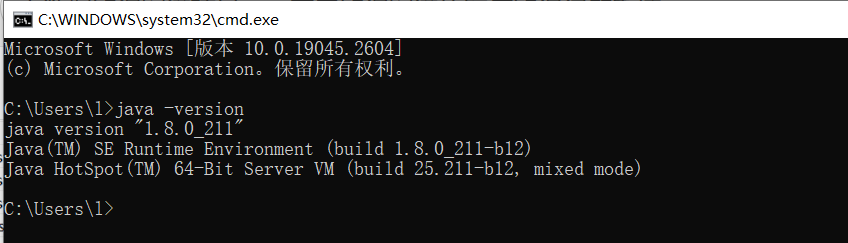
2.安装好JDK之后,就可以安装neo4j了
2.1 下载neo4j
官方下载链接:https://neo4j.com/download-center/#community
也可以直接下载我上传到云盘链接:
Neo4j Desktop Setup 1.4.15.exe
https://www.aliyundrive.com/s/huXS4HXMn9V
提取码: 36vf
打开之后会有一个自己设置默认路径,可以根据自己电脑情况自行设置,然后等待启动就行了
打开之后我们新建一个数据库,名字叫做:“基于医疗领域的问答系统”
详细信息看下图: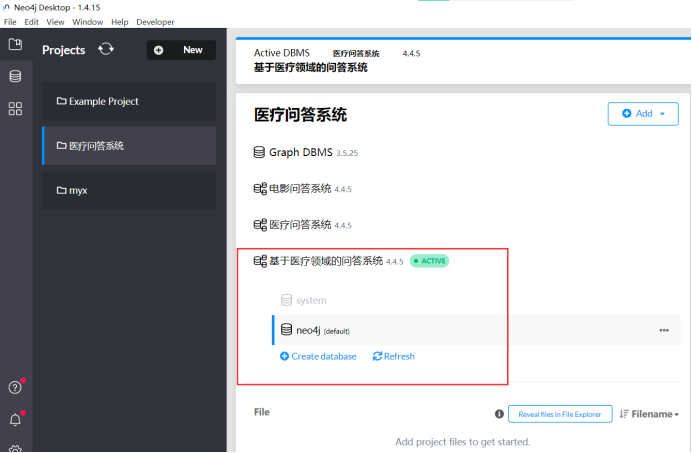
数据库所用的是4.4.5版本,其他数据库参数信息如下:

项目结构整体目录:
├── pycache \编译结果保存目录
│ ├── answer_search.cpython-39.pyc
│ ├── question_classifier.cpython-39.pyc
│ └── question_parser.cpython-39.pyc
├── answer_search.py
├── build_medicalgraph.py \知识图谱数据入库脚本
├── chatbot_graph.py \问答程序脚本
├── data
│ └── medical.json \本项目的数据,通过build_medicalgraph.py导neo4j
│ └── medical2.json\本项目的部分数据,通过build_medicalgraph.py导neo4j
├── dict
│ ├── check.txt \诊断检查项目实体库
│ ├── deny.txt \否定词词库
│ ├── department.txt \医疗科目实体库
│ ├── disease.txt \疾病实体库
│ ├── drug.txt \药品实体库
│ ├── food.txt \食物实体库
│ ├── producer.txt \在售药品库
│ └── symptom.txt \疾病症状实体库
├── prepare_data
│ ├──__pycache__
│ ├── build_data.py \数据库操作脚本
│ ├── data_spider.py \网络资讯采集脚本
│ └── max_cut.py \基于词典的最大向前/向后脚本
│ ├── 处理后的medical数据.xlsx
│ ├── MongoDB数据转为json格式数据文件.py
│ ├──从MongoDB导出的medical.csv
│ ├──data.json #从MongoDB导出的json格式数据
├── question_classifier.py \问句类型分类脚本
├── answer_search.py \基于问题答复脚本
├── build_medicalgraph.py \构建医疗图谱脚本
├── chatbot_graph.py \小艺问答系统机器人脚本
├── question_parser.py \基于问句解析脚本
├── 删除所有关系.py
├── 删除关系链.py
├── 两节点新加关系.py
├── 交互 匹配所有节点.py
├── 更新节点.py
这里chatbot_graph.py脚本首先从需要运行的chatbot_graph.py文件开始分析。
该脚本构造了一个问答类ChatBotGraph,定义了QuestionClassifier类型的成员变量classifier、QuestionPase类型的成员变量parser和AnswerSearcher类型的成员变量searcher。
question_classifier.py脚本构造了一个问题分类的类QuestionClassifier,定义了特征词路径、特征词、领域actree、词典、问句疑问词等成员变量。
question_parser.py问句分类后需要对问句进行解析。
该脚本创建一个QuestionPaser类,该类包含三个成员函数。
answer_search.py问句解析之后需要对解析后的结果进行查询。
该脚本创建了一个AnswerSearcher类。与build_medicalgraph.py类似,该类定义了Graph类的成员变量g和返回答案列举的最大个数num_list。
该类的成员函数有两个,一个查询主函数一个回复模块。
问答系统框架的构建是通过chatbot_graph.py、answer_search.py、question_classifier.py、question_parser.py等脚本实现。
五、系统实现具体步骤
1)数据来源,爬取数据来源。
安装MongoDB数据库:
MongoDB官方下载地址:
https://www.mongodb.com/try
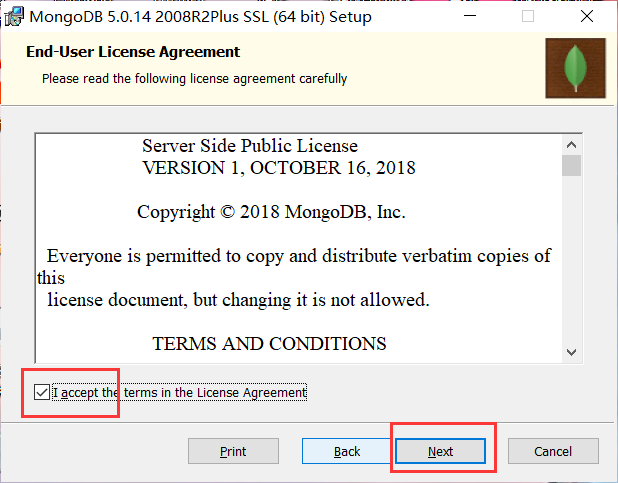
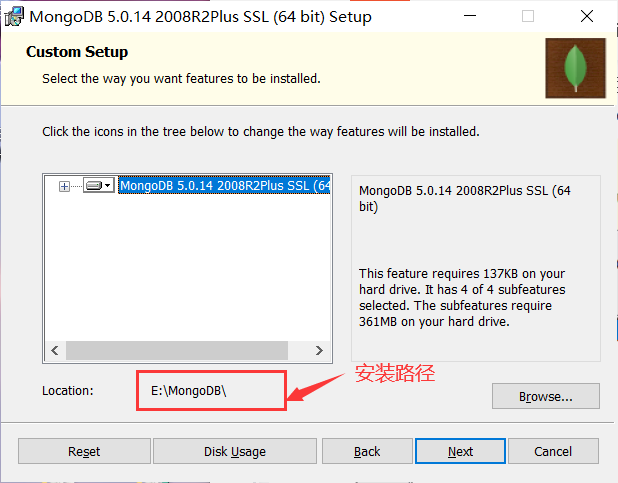
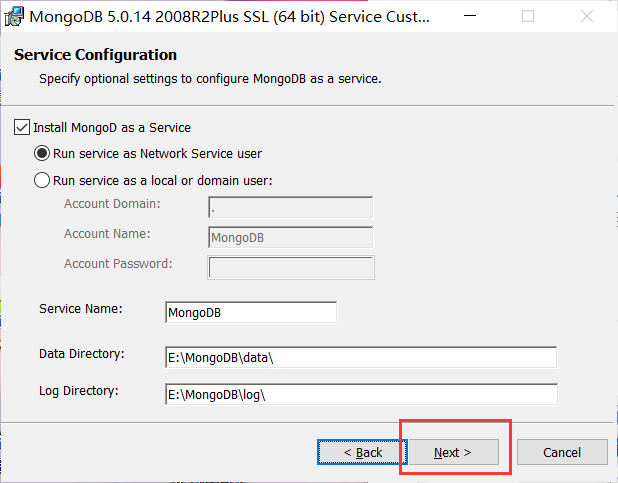
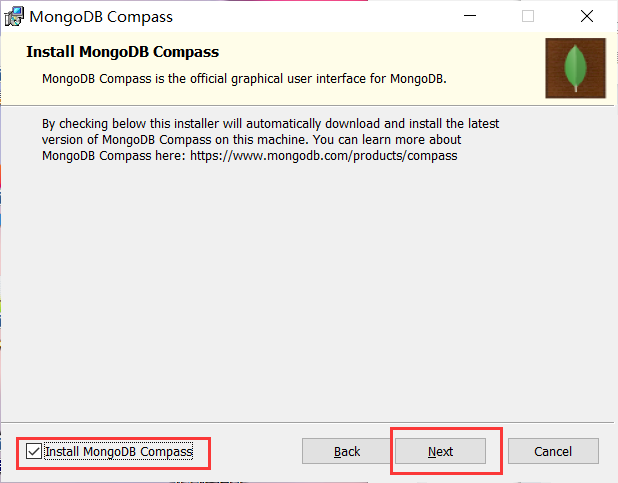
安装完成:
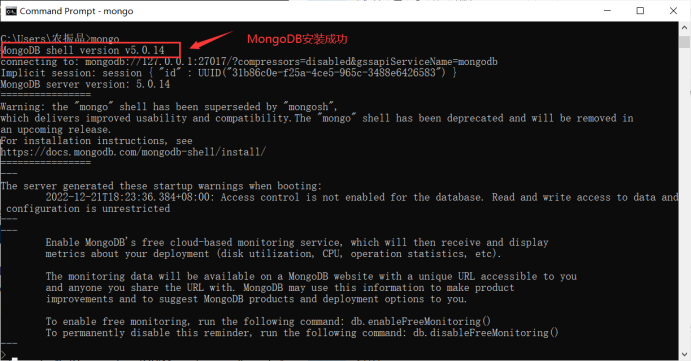
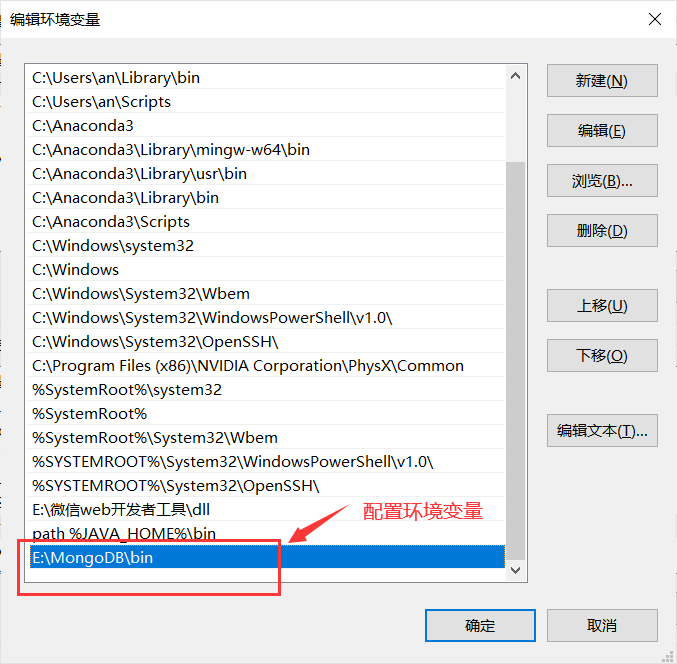
进行MongoDB环境配置:
在变量Path里加入E:\MongoDB\bin
打开终端(cmd)输入mongod --dbpath E:\MongoDB\data\db
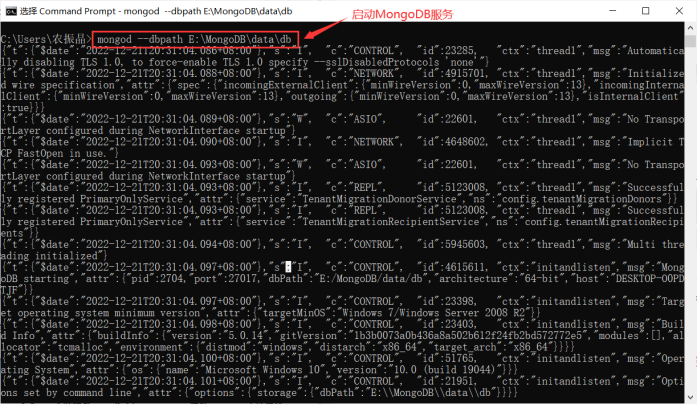
在浏览器输入
127.0.0.1:27017
查看MongoDB服务是否启动成功:
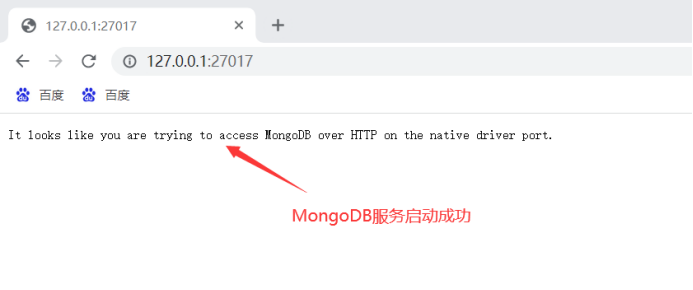
安装好MongoDB之后开始爬取数据:
数据来源于寻医问药网:http://jib.xywy.com/
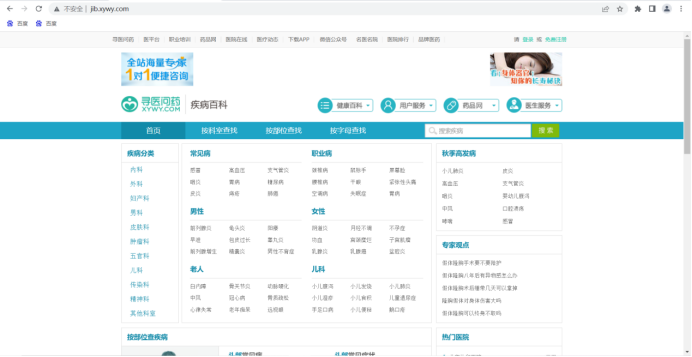
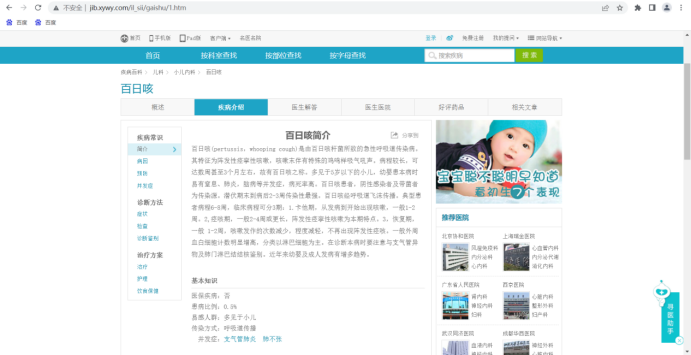
具体的疾病详情页面如下:
首先对网址上的疾病链接进行分析,以感冒为例:
感冒的链接:http://jib.xywy.com/il_sii_38.htm
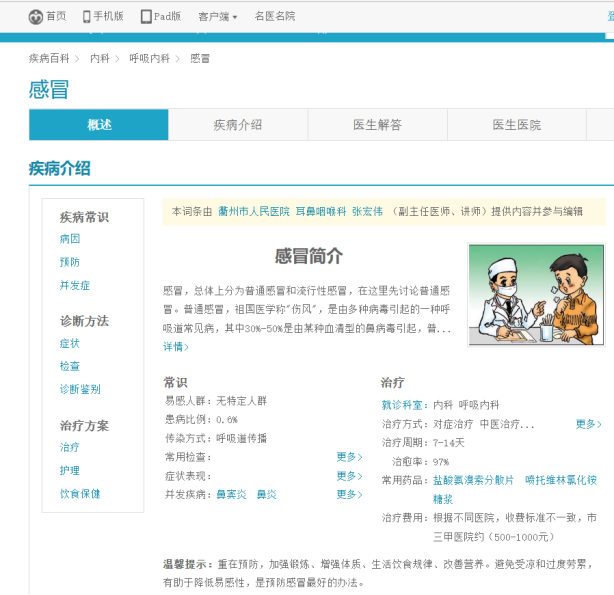
可以看到,上面包含了疾病的简介、病因、预防、症状、检查、治疗、并发症、饮食保健等详情页的内容。下面我们要使用爬虫把信息收集起来。
通过观察可以看出,链接部分 http://jib.xywy.com/il_sii_ 都是相同的,是通过数字的叠加来组成不同的病例。通过string类型的拼接进行循环后可以得到我们需要的内容。
数据收集模块放在/prepare_data文件夹下面。
要收集 url 下面对应的数据,具体爬虫代码如下: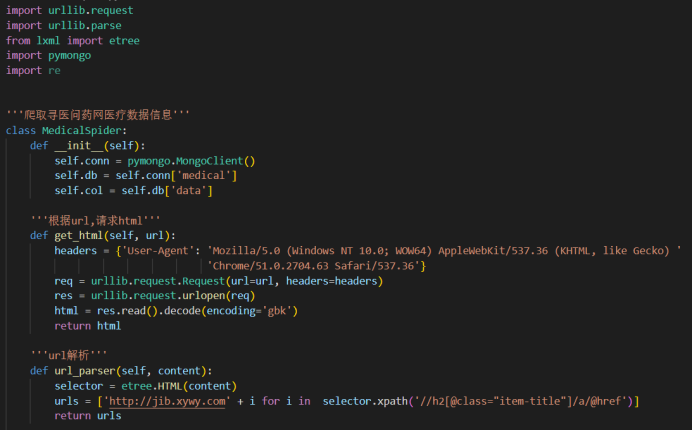
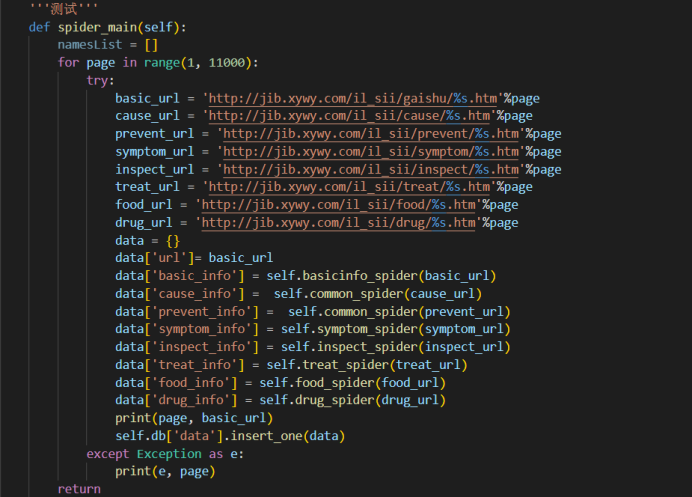
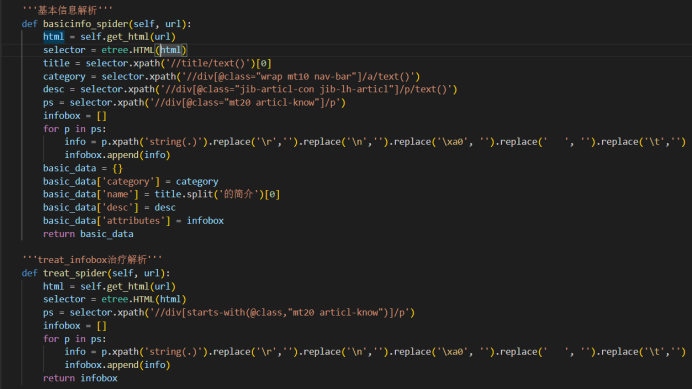
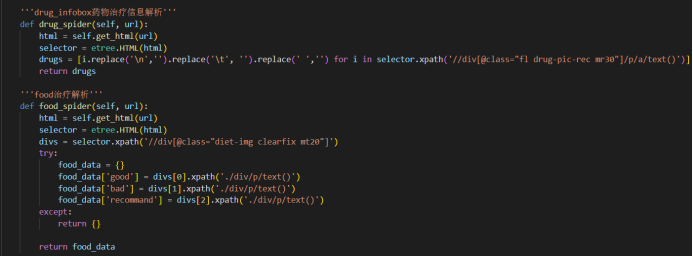
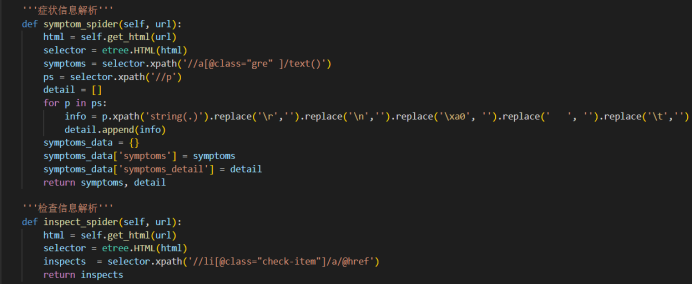
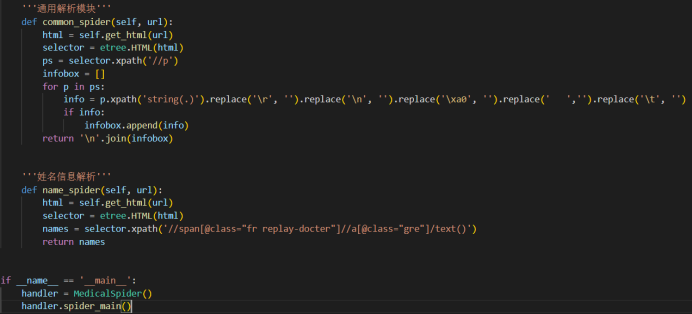
需要爬取的信息包括疾病名、所属目录、症状、治疗方案等等,都可以从页面上获取。
在MongoDB中查看爬取到的疾病链接和解析出的网页内容: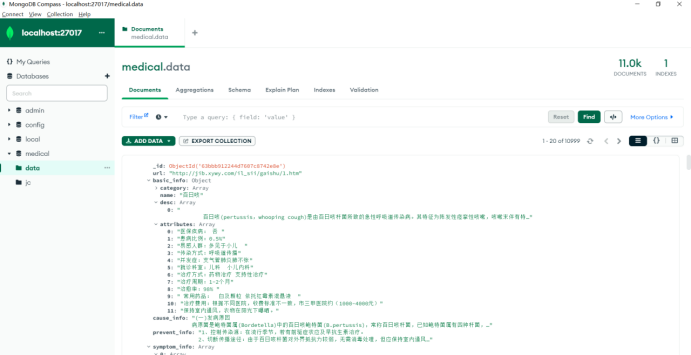

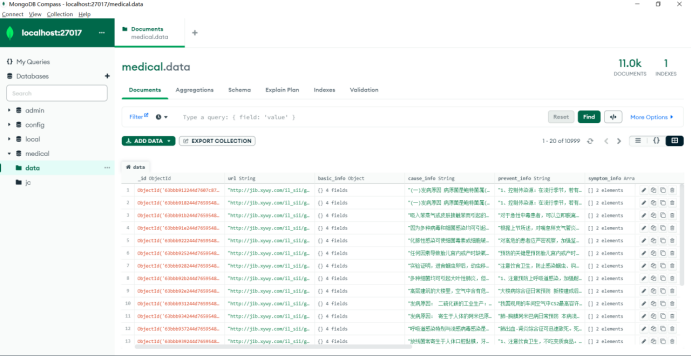
2)原始数据的处理。
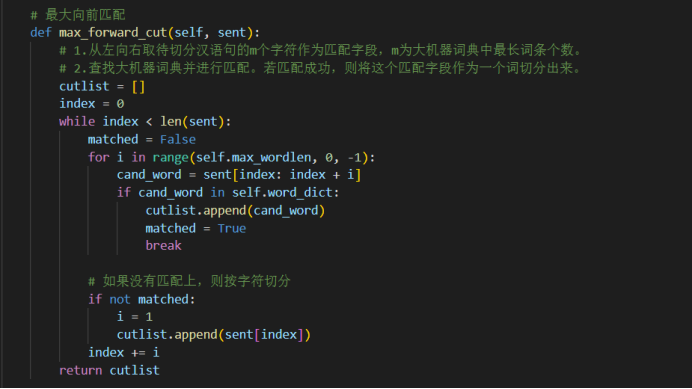
定义一个max_cut.py文件来进行词语的切分,其中包含了最大向前匹配,最大向后匹配,双向最大向前匹配。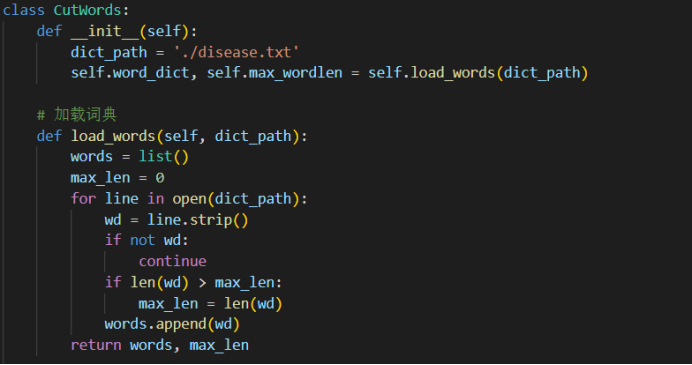
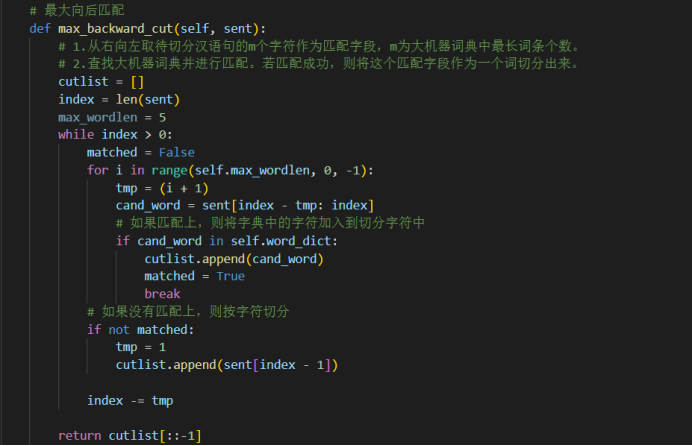
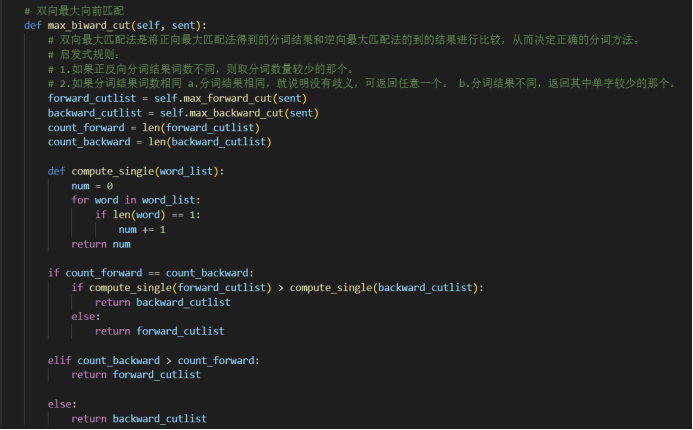
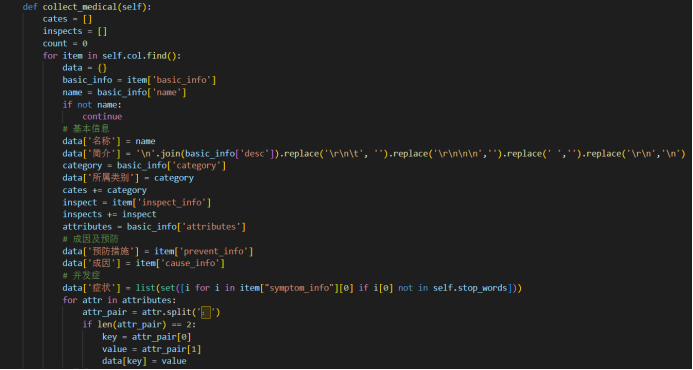
然后通过collect_medical函数完成数据的收集整理工作。
再将整理好的数据重新存入数据库中。
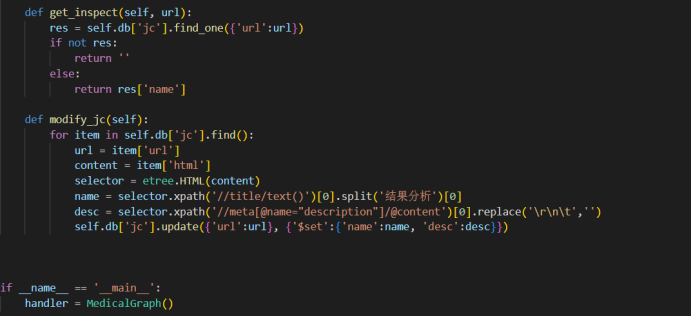
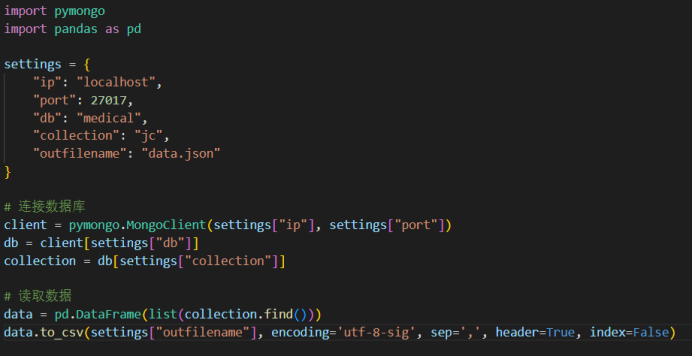
在init文件里配置数据库连接,找到当前文件所在的目录,指定连接的数据库及其下面的collection。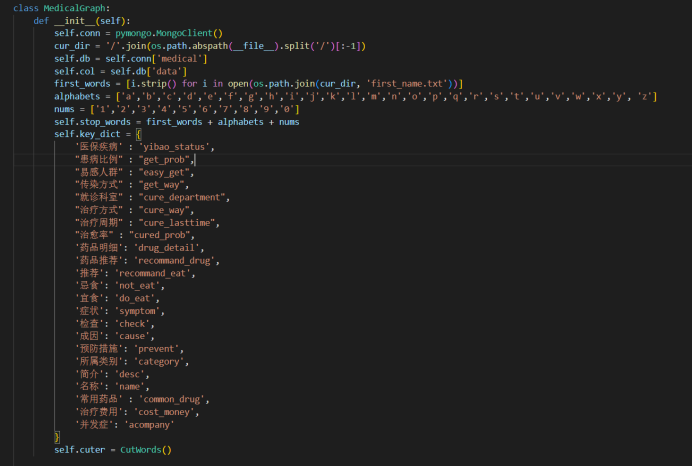
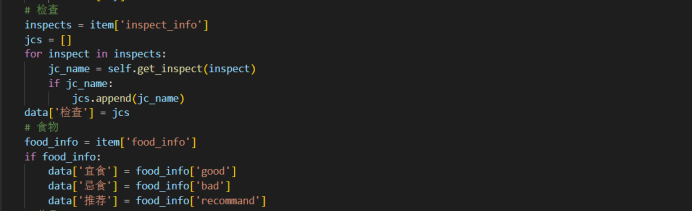
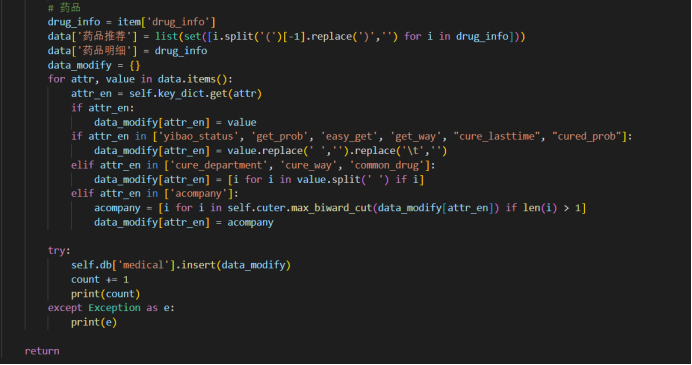
再利用python脚本导出爬出的医疗数据并设置格式为data.json格式文件:

处理数据后对应的图谱系统数据关键词:
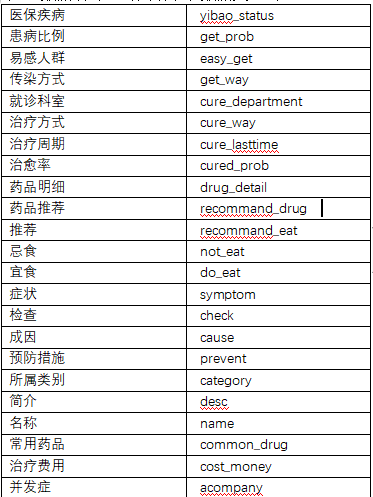
将从MongoDB导出的data.json数据格式处理之后保存为medical.json和medical2.json文件,其中medical2.json为medical.json中的部分数据。
考虑到构建全部知识图谱需要很久,所以取出一部分数据(medical2.json)先进行构建图谱。

处理后结构化的数据保存到excel文件:
3)所搭建的系统框架,包括知识图谱实体类型,实体关系类型,知识图谱属性类型等。
知识图谱实体类型: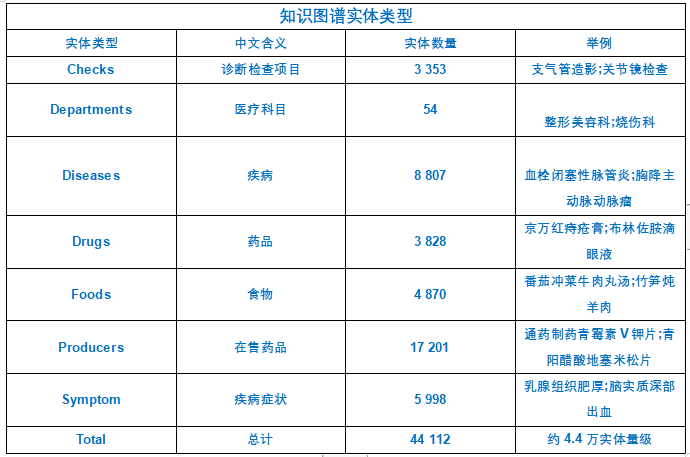
departments = [] #科室diseases = [] # 疾病drugs = [] # 药品foods = [] # 食物producers = [] #药品大类symptoms = []#症状

实体关系类型:
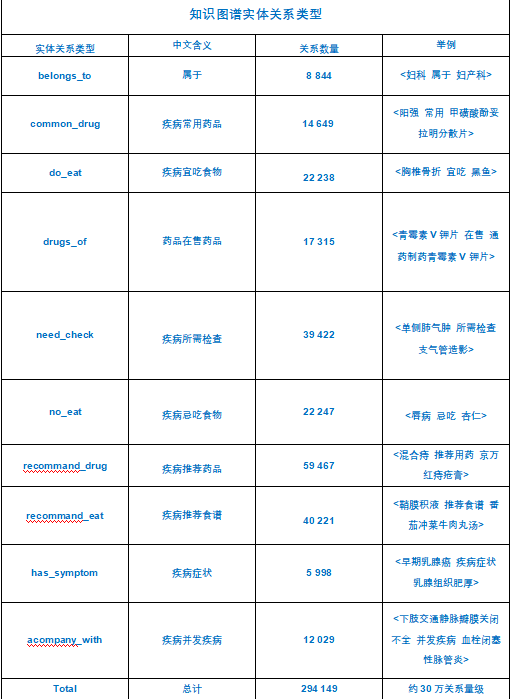
# 构建节点实体关系,共11类,medical2做出来的只有10类,因为数据量少rels_department = []rels_noteat = [] # 疾病-忌吃食物关系rels_doeat = [] # 疾病-宜吃食物关系rels_recommandeat = [] # 疾病-推荐吃食物关系rels_commonddrug = [] # 疾病-通用药品关系rels_recommanddrug = [] # 疾病-热门药品关系rels_check = [] # 疾病-检查关系rels_drug_producer = [] # 厂商-药物关系rels_symptom = [] #疾病症状关系rels_acompany = [] # 疾病并发关系rels_category = [] # 疾病与科室之间的关系
知识图谱属性类型:
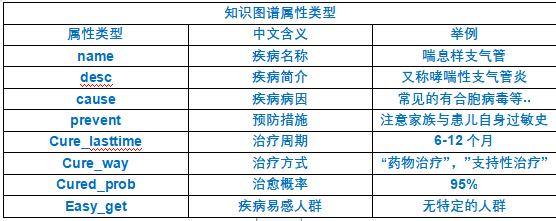
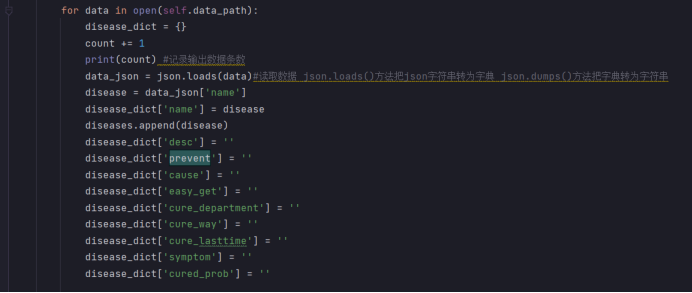
4)导入Neo4j数据库,生成图谱。
新建一个数据库:基于医疗领域的问答系统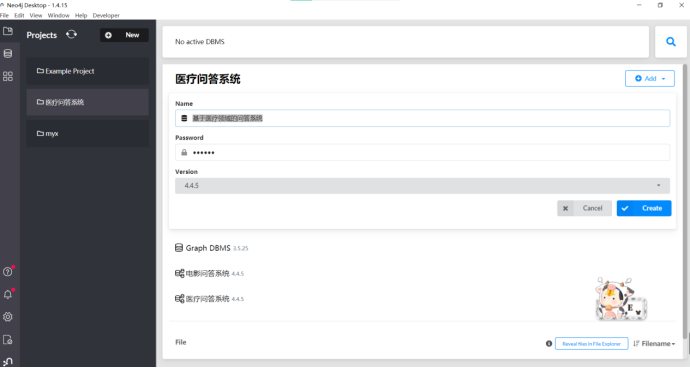
开启Node4j数据库: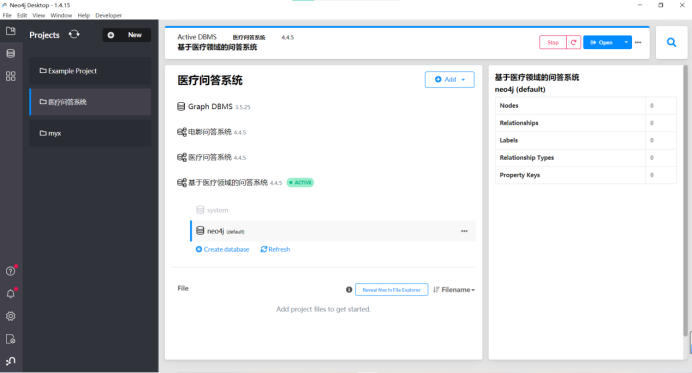
连接我们所建的neo4j数据库:
知识图谱数据入库:
根据字典形式的数据创建结点,以疾病为中心定义关系形成三元组表示的知识,将结点和关系导入neo4j数据库形成知识图谱,通过运行build_medicalgraph.py脚本构建图谱:
建立实体关系类型:
该脚本构建了一个MedicalGraph类,定义了Graph类的成员变量g和json数据路径成员变量data_path。
建立的图谱实体关系和属性类型数量有点多,需要等待一会。
脚本运行完之后查看neo4j数据库中构建的知识图谱:
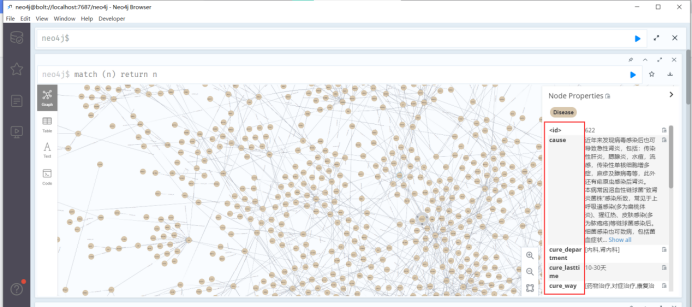
match (n) return n

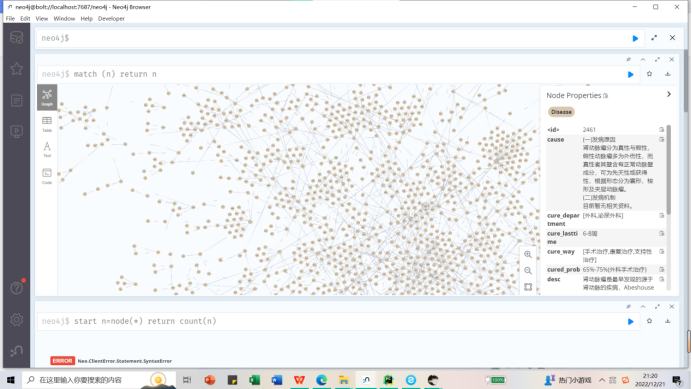
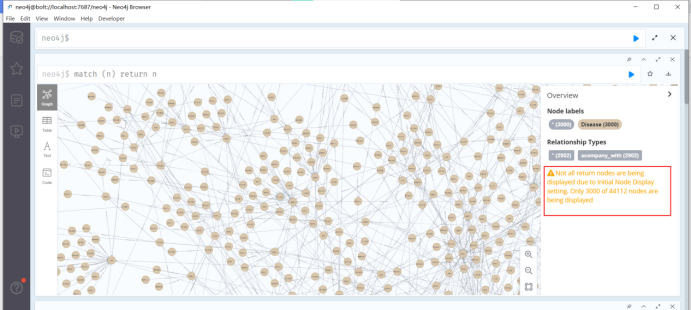
提示:Not all return nodes are being displayed due to Initial Node Display setting. Only 3000 of 44112 nodes are being displayed
由于“初始节点显示”设置,并非所有返回节点都显示。44112个节点中仅显示3000个
这里因为我设置的参数只显示前3000个,4万多个节点只显示了一部分。
对于单个节点分析是先建一个label为disease、name为疾病名称的node,property方面包括prevent、cure_way、cause等等,另外,对于症状、科室、检查方法等信息都建立单独的node,同时通过has_symptom、belongs_to、need_check等关联把它们和疾病名称关联起来,因为疾病之间存在并发关系,疾病之间也可以通过症状串联起来,所以最后我们利用大量的
医疗数据,就能构建一个大型的医疗知识图谱:
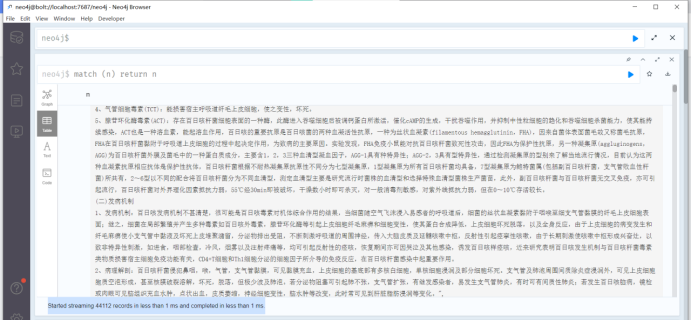
提示:Started streaming 44112 records in less than 1 ms and completed in less than 1 ms.
在不到1毫秒内开始流式传输44112条记录,并在不到1秒内完成。
5)Python 与Neo4j的交互实现。
连接Node4j数据库:
from py2neo import Graph
class AnswerSearcher:def __init__(self):#调用数据库进行查询# self.g = Graph("bolt://localhost:7687", username="neo4j", password="123456")#老版本neo4jself.g = Graph("bolt://localhost:7687", auth=("neo4j", "123456"))#输入自己修改的用户名,密码self.num_limit = 20#最多显示字符数量

创建图对象:
class MedicalGraph:def __init__(self):cur_dir = '/'.join(os.path.abspath(__file__).split('/')[:-1])self.data_path = os.path.join(cur_dir, 'data/medical.json')# self.g = Graph("http://localhost:7474", username="neo4j", password="123456")self.g = Graph("bolt://localhost:7687", auth=("neo4j", "123456"))
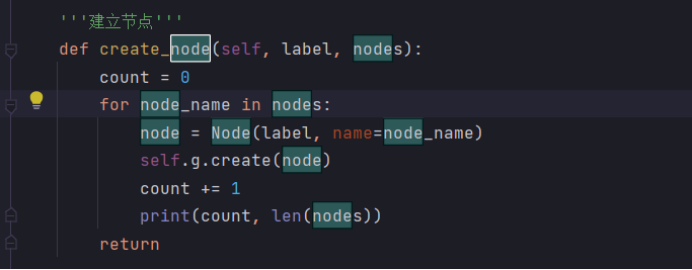
增加node节点:
def create_node(self, label, nodes):count = 0for node_name in nodes:node = Node(label, name=node_name)self.g.create(node)count += 1print(count, len(nodes))return
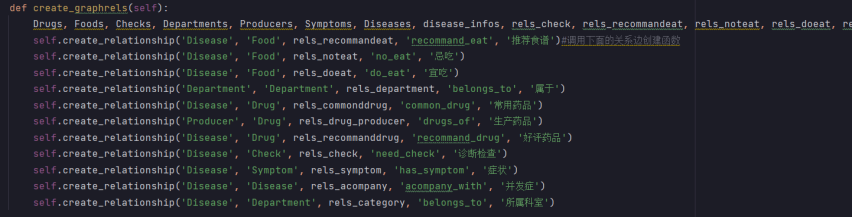
创建实体关系:
def create_graphrels(self):Drugs, Foods, Checks, Departments, Producers, Symptoms, Diseases, disease_infos, rels_check, rels_recommandeat, rels_noteat, rels_doeat, rels_department, rels_commonddrug, rels_drug_producer, rels_recommanddrug,rels_symptom, rels_acompany, rels_category = self.read_nodes()self.create_relationship('Disease', 'Food', rels_recommandeat, 'recommand_eat', '推荐食谱')#调用下面的关系边创建函数self.create_relationship('Disease', 'Food', rels_noteat, 'no_eat', '忌吃')self.create_relationship('Disease', 'Food', rels_doeat, 'do_eat', '宜吃')self.create_relationship('Department', 'Department', rels_department, 'belongs_to', '属于')self.create_relationship('Disease', 'Drug', rels_commonddrug, 'common_drug', '常用药品')self.create_relationship('Producer', 'Drug', rels_drug_producer, 'drugs_of', '生产药品')self.create_relationship('Disease', 'Drug', rels_recommanddrug, 'recommand_drug', '好评药品')self.create_relationship('Disease', 'Check', rels_check, 'need_check', '诊断检查')self.create_relationship('Disease', 'Symptom', rels_symptom, 'has_symptom', '症状')self.create_relationship('Disease', 'Disease', rels_acompany, 'acompany_with', '并发症')self.create_relationship('Disease', 'Department', rels_category, 'belongs_to', '所属科室')
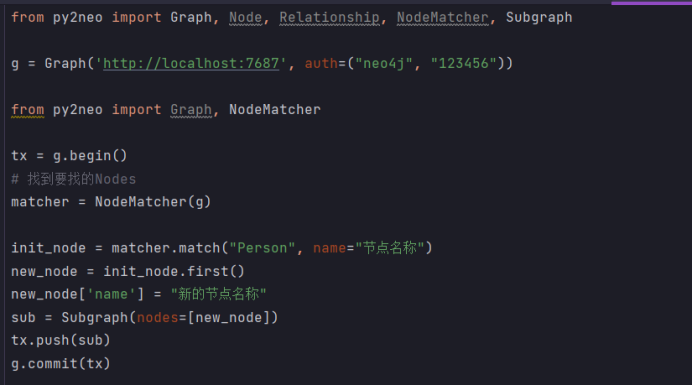
更新节点:
更新先要找出Nodes,再使用事务的push更新
from py2neo import Graph, Node, Relationship, NodeMatcher, Subgraphg = Graph('http://localhost:7687', auth=("neo4j", "123456"))from py2neo import Graph, NodeMatchertx = g.begin()# 找到要找的Nodes
matcher = NodeMatcher(g)init_node = matcher.match("Person", name="节点名称")
new_node = init_node.first()
new_node['name'] = "新的节点名称"
sub = Subgraph(nodes=[new_node])
tx.push(sub)
g.commit(tx)from py2neo import Graph, Node, Relationship, NodeMatcher, Subgraphg = Graph('http://localhost:7687', auth=("neo4j", "123456"))from py2neo import Graph, NodeMatchertx = g.begin() # 找到要找的Nodes
matcher = NodeMatcher(g)init_node = matcher.match("Person", name="节点名称")
new_node = init_node.first()
new_node['name'] = "新的节点名称"
sub = Subgraph(nodes=[new_node])
tx.push(sub)
g.commit(tx)
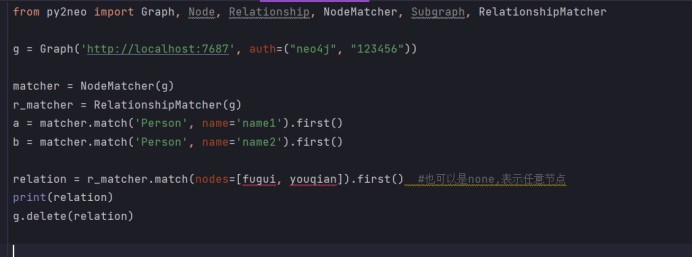
删除关系链(节点也会删除):
from py2neo import Graph, Node, Relationship, NodeMatcher, Subgraph, RelationshipMatcherg = Graph('http://localhost:7687', auth=("neo4j", "123456"))matcher = NodeMatcher(g)
r_matcher = RelationshipMatcher(g)
fugui = matcher.match('Person', name='name1').first()
youqian = matcher.match('Person', name='name2').first()relation = r_matcher.match(nodes=[fugui, youqian]).first() #也可以是none,表示任意节点
print(relation)
g.delete(relation)
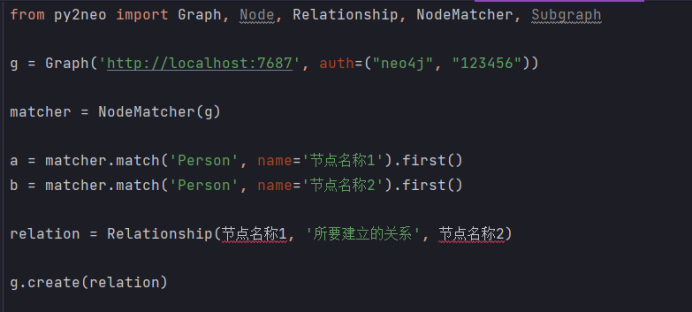
两个节点新加关系:
from py2neo import Graph, Node, Relationship, NodeMatcher, Subgraphg = Graph('http://localhost:7687', auth=("neo4j", "123456"))matcher = NodeMatcher(g)fugui = matcher.match('Person', name='节点名称1').first()
youqian = matcher.match('Person', name='节点名称2').first()relation = Relationship(节点名称1, '所要建立的关系', 节点名称2)g.create(relation)
6)问答系统的实现与测试,包括问答系统·支持的问答类型,实现方法与步骤。
本项目问答对话系统的分析思路,整体上接近一个基于规则的对话系统,首先我们需要对用户输入进行分类,其实就是分析用户输入涉及到的实体及问题类型,也就是Neo4j中的node、property、relationship,然后我们利用分析出的信息,转化成Neo4j的查询语句,最后再把查询的结果返回给用户,就完成了一次问答。
本项目问答系统支持的问答类型: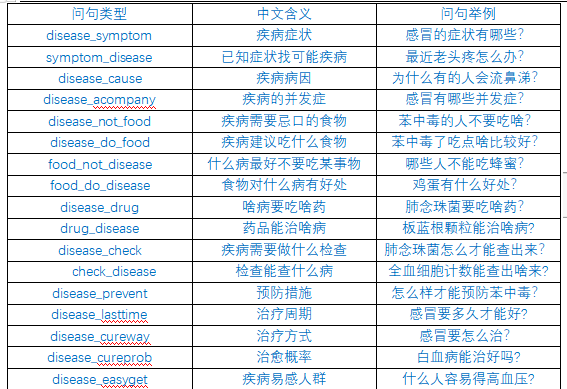
问答系统整体上涉及到三个模块,问题的分类、问题的解析以及回答的搜索。
对于property和relationship,我们先预设定一系列的问句疑问词,从而对问句的每个词进行对比分析,判断出问句的类型
然后,根据问句的类型和之前识别出来的实体,基于规则推断出property和relationship: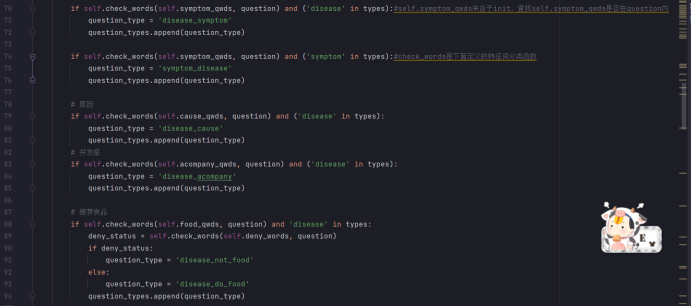
把问题转化为Neo4j的Cypher语句,其实也是预先写好Cypher语句的模板,根据实际的情况把之前分析得到的node、property、relationship填入Cypher语句中进行查询。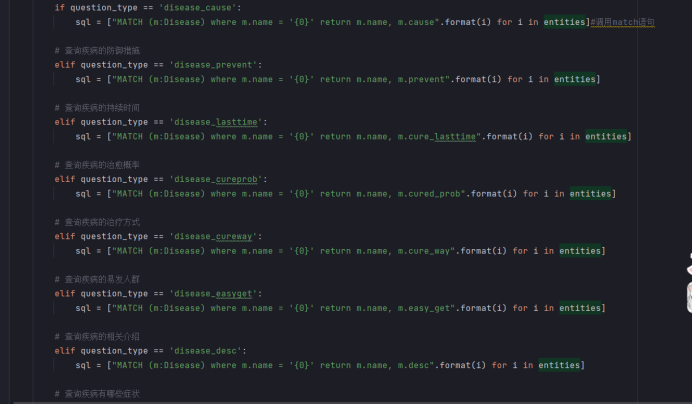
得到了Cypher语句,我们就能连接Neo4j数据库进行查询,得到结果之后,还需要对语句进行一点微调,根据对应的qustion_type,调用相应的回复模板: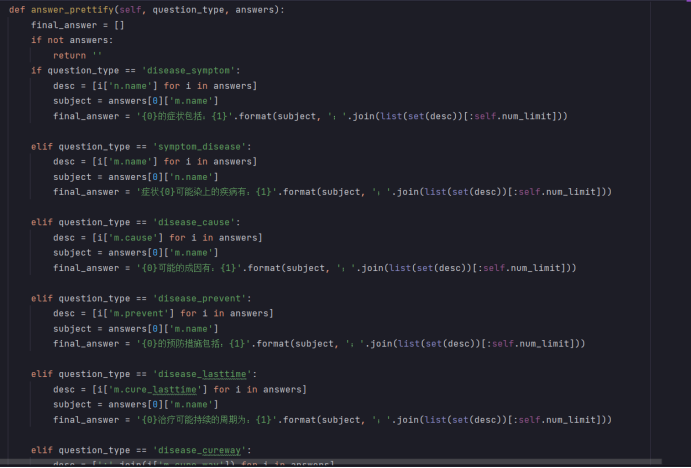
问答框架包含问句分类、问句解析、查询结果三个步骤,具体一步步分析。
首先是问句分类,是通过question_classifier.py脚本实现的。
再通过question_parser.py脚本进行问句分类后对问句进行解析。
然后通过answer_search.py脚本对解析后的结果进行查询
最后通过chatbot_graph.py脚本进行问答实测。
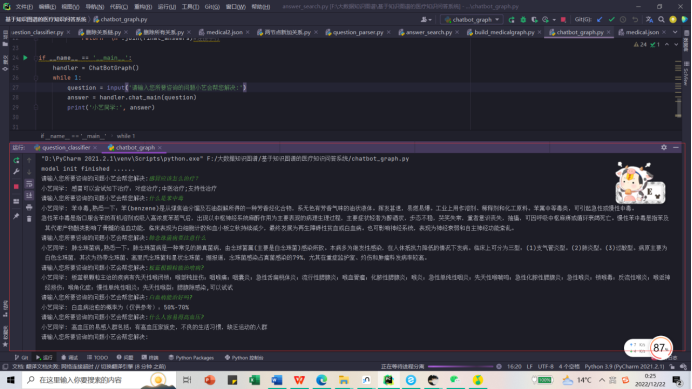
执行chatbot_graph.py脚本后出现:
“请输入您所要咨询的问题小艺会帮您解决:” 我们输入一个简单的问题:感冒应该怎么治疗?
我们输入一个简单的问题:感冒应该怎么治疗?
问答系统返回的结果如下:

再试试其它的问题:比如什么是苯中毒等等
问答系统返回结果如下: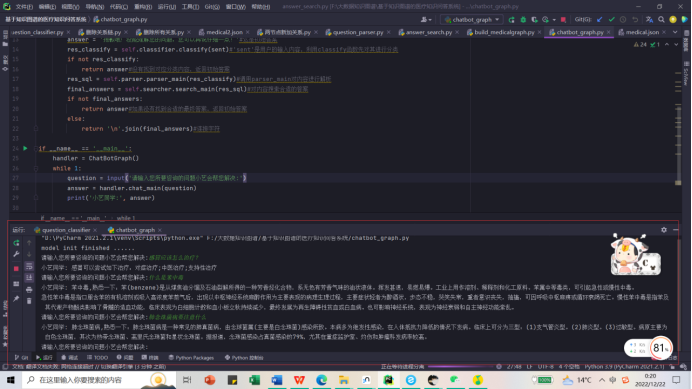
经过测试本问答系统能回答的问题有很多,基于问句中存在的关键词回答效果表现很好。做出来的基于知识图谱的医疗知识问答系统能够根据用户提出的问题很好的进行解答。
做出来的问答系统还是很Nice的。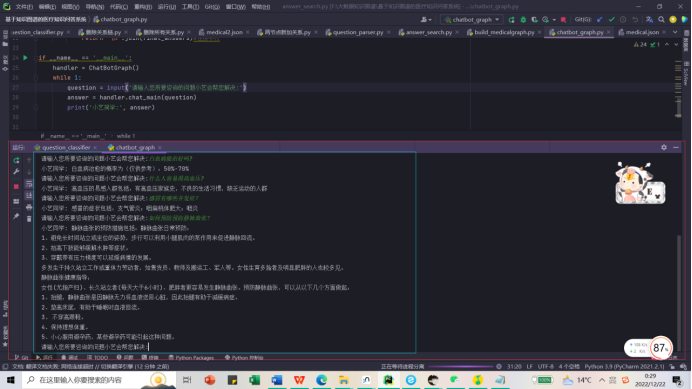 本项目问答系统的主要特征是知识图谱,系统依赖一个或多个领域的实体,并基于图谱进行推理或演绎,深度回答用户的问题,更擅长回答知识性问题,与基于模板的聊天机器人有所不同的是它更直接、直观的给用户答案。本项目问答系统没有复杂的算法,一般采用模板匹配的方式寻找匹配度最高的答案,可以直接给出答案。
本项目问答系统的主要特征是知识图谱,系统依赖一个或多个领域的实体,并基于图谱进行推理或演绎,深度回答用户的问题,更擅长回答知识性问题,与基于模板的聊天机器人有所不同的是它更直接、直观的给用户答案。本项目问答系统没有复杂的算法,一般采用模板匹配的方式寻找匹配度最高的答案,可以直接给出答案。
各位有兴趣的小伙伴可以私信我要详细的项目文档和项目完整系统源码,欢迎各位小伙伴的来访!
相关文章:
大数据知识图谱项目——基于知识图谱的医疗知识问答系统(详细讲解及源码)
基于知识图谱的医疗知识问答系统 一、项目概述 本项目基于医疗方面知识的问答,通过搭建一个医疗领域知识图谱,并以该知识图谱完成自动问答与分析服务。本项目以neo4j作为存储,基于传统规则的方式完成了知识问答,并最终以关键词执…...

威马汽车:跃马扬鞭未竟,鞍马劳顿难行?
“活下去,像牲口一样地活下去。” 威马汽车创始人、董事长兼CEO沈晖1月在社交媒体上分享的电影台词,已然成为威马近况的真实写照。 来源:新浪微博威马汽车沈晖Freeman 最近,网上出现了大量关于“威马汽车将实施全员停薪留职”的…...
【网络】网络基础
🥁作者: 华丞臧. 📕专栏:【网络】 各位读者老爷如果觉得博主写的不错,请诸位多多支持(点赞收藏关注)。如果有错误的地方,欢迎在评论区指出。 推荐一款刷题网站 👉 LeetCode刷题网站 文章…...

Linux系统之Uboot、Kernel、Busybox思考之三
目录 三 内核的运行 5-中断子系统 6 锁、延迟与原子上下文 7 内存管理子系统 8 驱动的两类框架 三 内核的运行 5-中断子系统 中断子系统的数据结构及设计思想。 中断子系统需要解决中断管理的问题。 如果系统中断较少的话,其管理就不用设计这样一个中断子系统这…...
FPGA 20个例程篇:20.USB2.0/RS232/LAN控制并行DAC输出任意频率正弦波、梯形波、三角波、方波(一)
在最后一个例程中笔者精挑细选了一个较为综合性的项目实战,其中覆盖了很多知识点,也是从一个转产产品中所提炼出来的,所以非常贴近实战项目。 整个工程实现了用户通过对上位机PC端人机界面的操作,即可达到控制豌豆开发并行DAC输出…...

性能测试学习和性能瓶颈分析路线
很多企业招聘都只写性能测试,会使用LR,jmeter工具。其实会使用jmeter和LR进行性能测试还只是性能测试的第一步,离真正的性能测试工程师还很远,笔者也还在路上 .。 性能测试,都是要求测试系统性能,系统自然…...
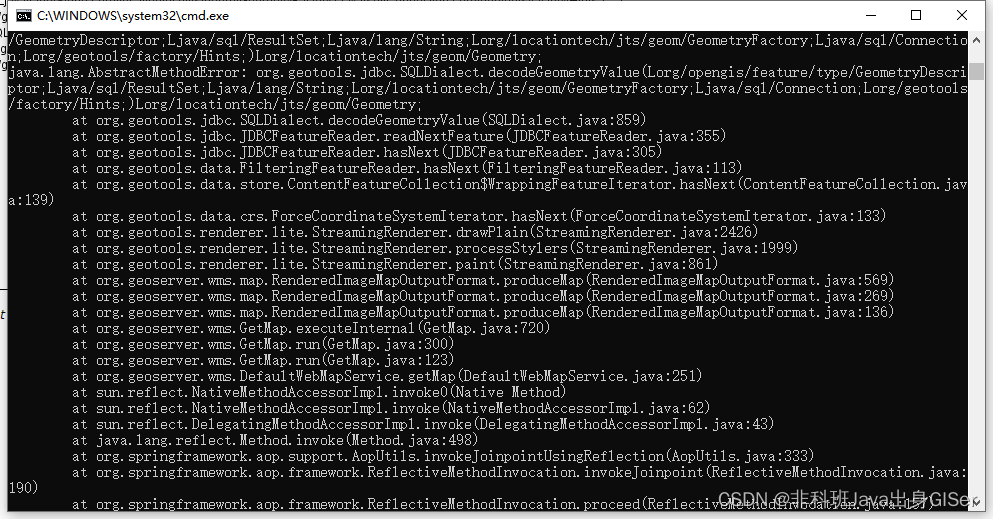
达梦数据库(DM8)集成使用 Geoserver(2.22.2) 以及其他对应版本详解
达梦数据库(DM8)集成使用 Geoserver(2.22.2) 以及其他对应版本详解系统环境版本Geoserver 驱动对应版本达梦 8 集成 Geoserver 过程试错过程问题总结项目需要国产化,选择使用达梦数据库,在技术测试阶段&…...
全开源无加密的RuleApp文章社区APP客户端源码
内容目录一、详细介绍二、效果展示1.部分代码2.效果图展示三、学习资料下载一、详细介绍 开源无加密的文章社区客户端源码分享 RuleApp文章社区,VIP会员,写作投稿积分商城,付费模块集成,多平台兼容这是一款开源免费,界…...

基于springboot校园二手市场平台
一、项目简介 本项目是一套基于springboot校园二手市场平台,主要针对计算机相关专业的正在做bishe的学生和需要项目实战练习的Java学习者。 包含:项目源码、数据库脚本等,该项目可以直接作为bishe使用。 项目都经过严格调试,确保…...
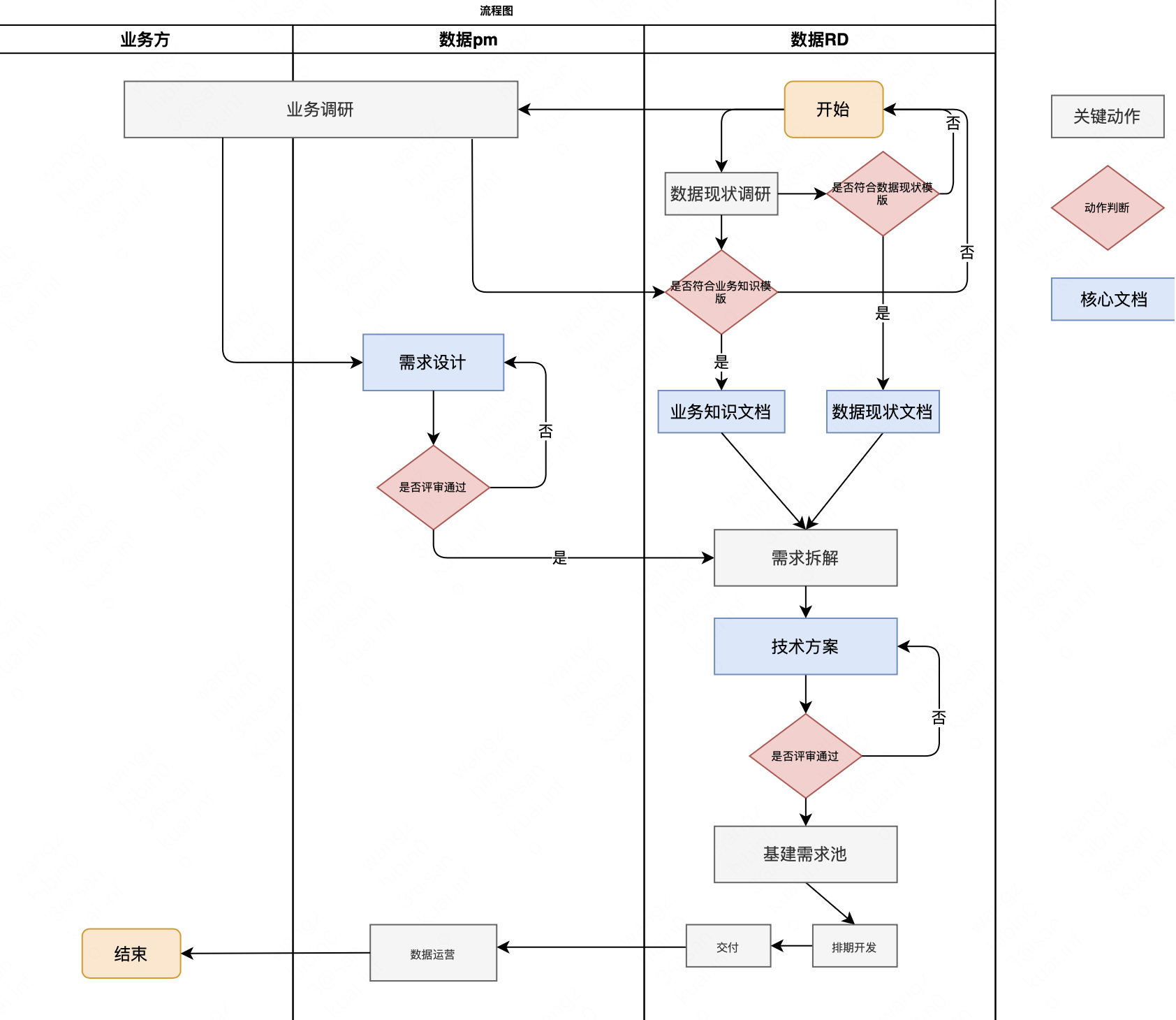
维度建模基本流程总结
一、维度建模基本流程图数据RD进行业务调研和数据现状调研,产出符合相关模版规范的业务知识文档和数据现状文档。数据PM也会调研相关业务产出需求设计文档,三方参与需求评审,评审通过后基建数据RD进行需求拆解,产出技术方案&#…...
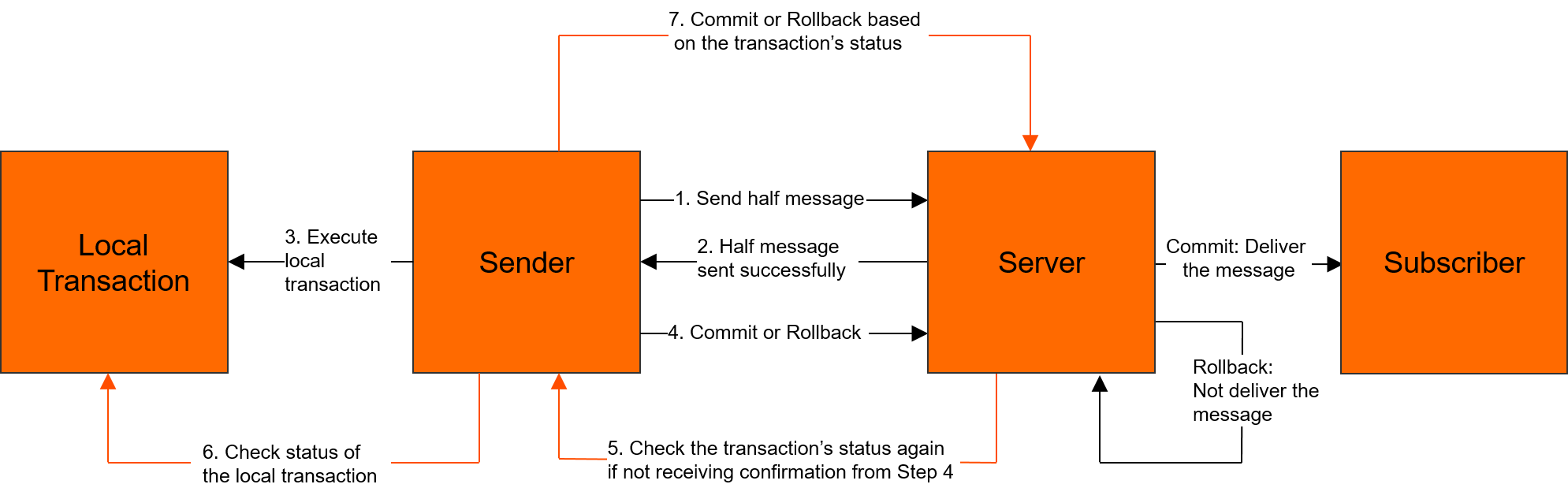
RocketMQ事务消息
RocketMQ事务消息 RocketMq提供的一种高级消息类型,支持在分布式场景下面保障消息生产和本地事务的一致性 生产者将消息发送到服务端服务端将消息持久化成功后,向生产者返回ACK确认消息发送成功,此时消息状态为待投递,这种状态下的消息称之为…...

大数据处理 - 双层桶划分
分桶法简介其实本质上还是分而治之的思想,重在“分”的技巧上!适用范围: 第k大,中位数,不重复或重复的数字基本原理及要点: 因为元素范围很大,不能利用直接寻址表,所以通过多次划分,逐步确定范围…...

NFC标签读写器隐私协议
【标签读写器】(以下简称“我们”)深知个人信息对您的重要性,并会尽全力保护您的个人信息安全可靠。我们致力于维持您对我们的信任,恪守以下原则,保护您的个人信息:权责一致原则、目的明确原则、选择同意原…...
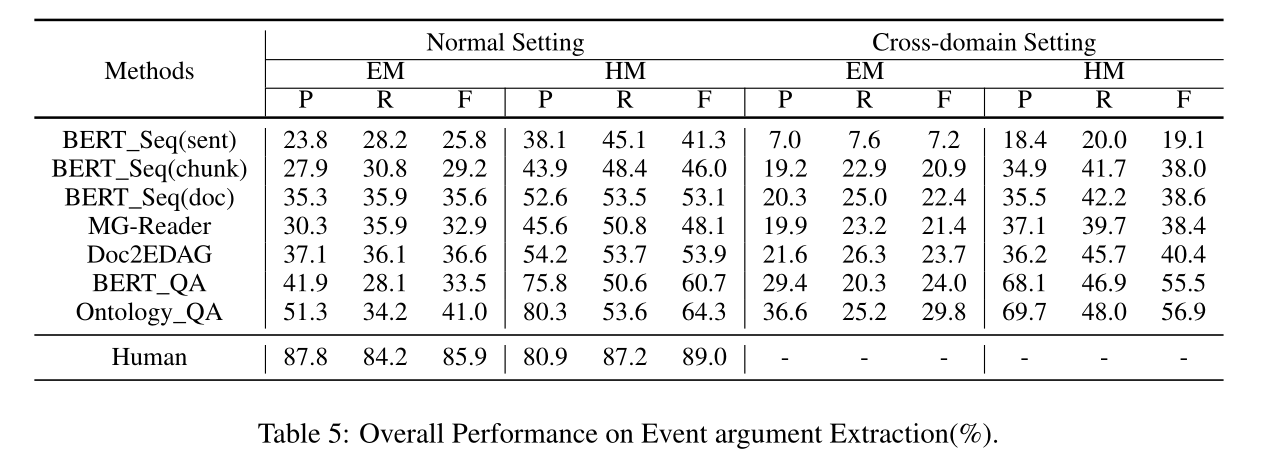
DocEE:一种用于文档级事件抽取的大规模细粒度基准 论文解读
DocEE: A Large-Scale and Fine-grained Benchmark for Document-level Event Extraction 论文:NAACL2022.pdf (tongmeihan1995.github.io) 代码:tongmeihan1995/DocEE: DocEE: A Large-Scale and Fine-grained Benchmark for Document-level Event Ext…...
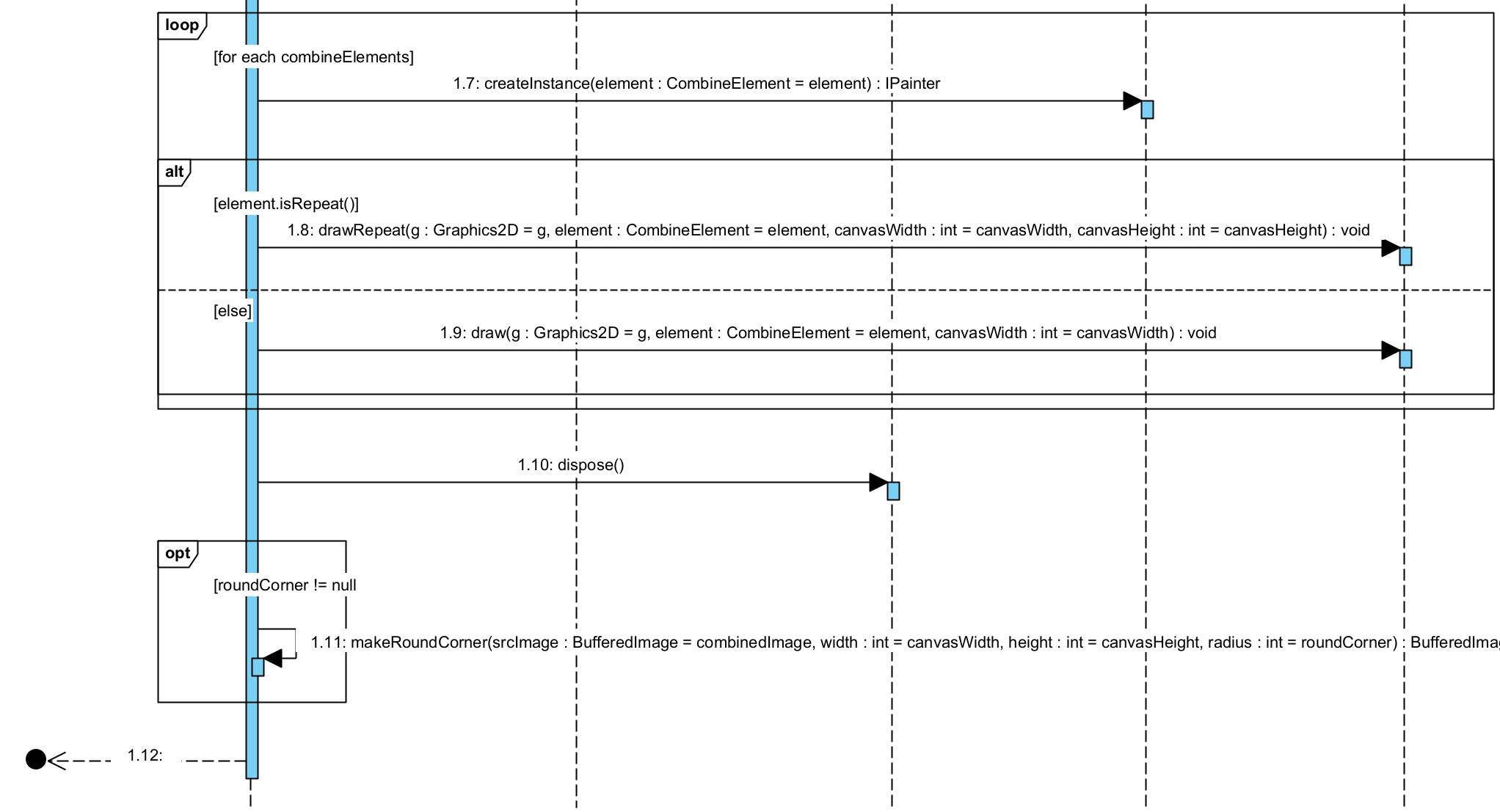
ImageCombiner设计源码详解
前言在前面的博客中介绍了一款Java的海报生成器ImageCombiner,原文地址:拿来就用的Java海报生成器ImageCombiner(一),在博文中简单介绍了一下代码以及一个真实的生成案例。但是对源码的介绍不多,本文就针对源码进行深入…...

python基础 | python基础语法
文章目录📚基础语法🐇输入和输出🥕print()输出🥕input()输入🐇 变量的命名🐇条件判断🥕单向判断🥕双向判断🥕多向判断🥕if嵌套🥕三元表达式&#…...
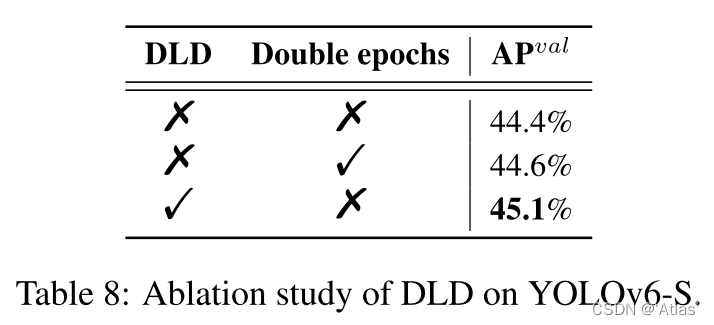
YOLOv6-3.0-目标检测论文解读
文章目录摘要算法2.1网络设计2.2Anchor辅助训练2.3自蒸馏实验消融实验结论论文: 《YOLOv6 v3.0: A Full-Scale Reloading 》github: https://github.com/meituan/YOLOv6上版本参考 YOLOv6摘要 YOLOv6 v3.0中YOLOv6-N达到37.5AP,1187FPS&…...

JAVA集合之Map >>HashMap/Hashtable/TreeMap/LinkedHashMap结构
Map 是一种键-值对(key-value)集合,键不可以重复,值可以重复。常见的实现类有:HashMap、Hashtable、TreeMap、LinkedHashMap等。 HashMap&Hashtable HashMap:数据结构为哈希表,允许使用 n…...
JavaScript从零开始 学习记录(一)
前言 选择视频课程之前,不仅查阅了资料,还询问了网友,最终敲定了学习黑马前端的视频教程,学了5小节,发现挺对自己口味的且从反响来看,还是相当不错的,便打算利用这个寒假学完 笔记范围 从这节…...
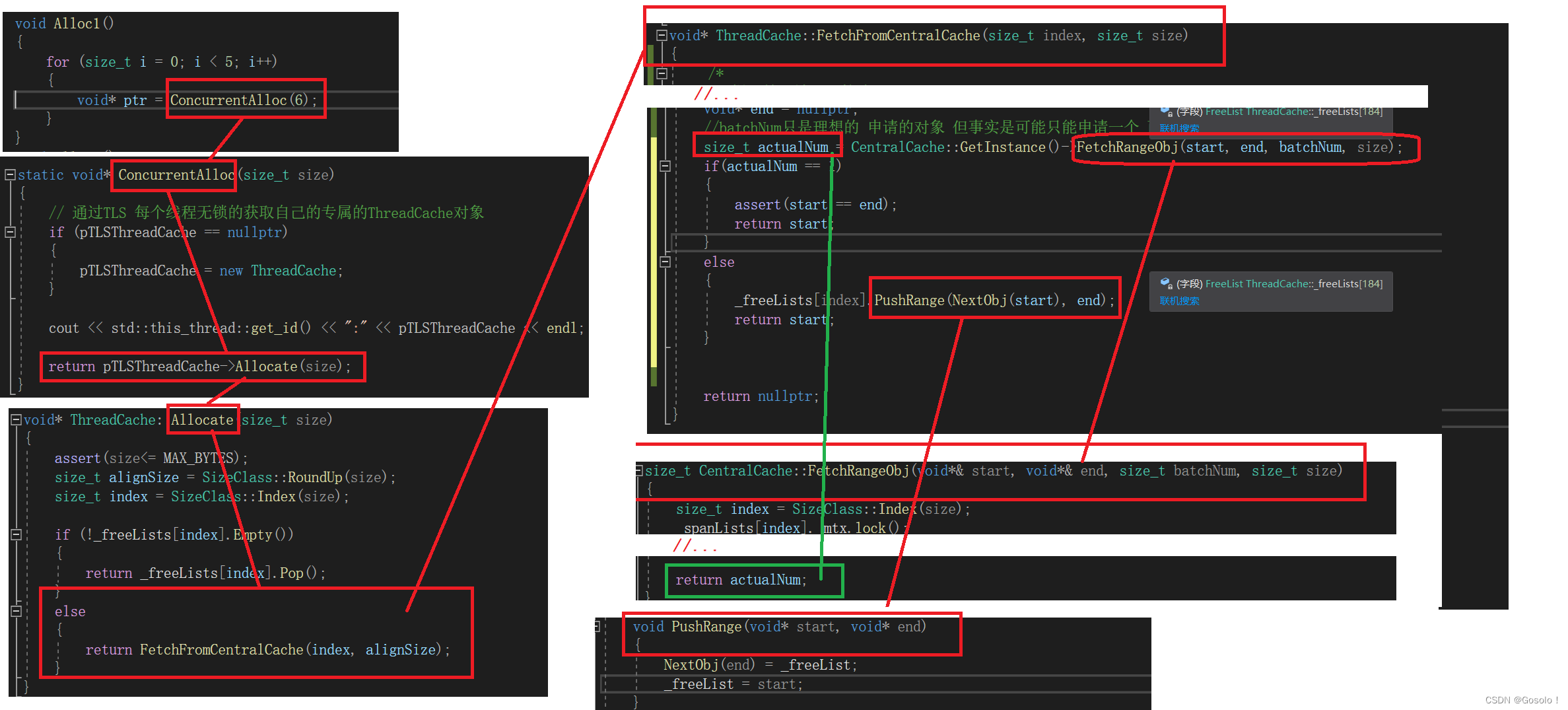
C++项目——高并发内存池(3)--central cache整体设计
1.central cache的介绍 1.1框架思想 1.1.1哈希映射 centralcache其实也是哈希桶结构的,并且central cache和thread cacha的哈希映射关系是一致的。目的为了,当thread cache某一个哈希桶下没有内存块时,可以利用之前编写的SizeClass::Index…...

AI Agent在智能风控中的实战:多智能体欺诈检测与预警
AI Agent在智能风控中的实战:多智能体欺诈检测与预警 你有没有过明明是正常交易却被银行冻结账户的糟糕体验?或是听说过某电商平台上线新活动首日就被黑产团伙薅走数千万补贴的新闻?随着黑产欺诈向团伙化、专业化、动态化演进,传统依赖规则引擎、单模型机器学习的风控体系已…...

Kerberos身份认证原理与实战排错指南
1. 为什么今天还要花时间搞懂 Kerberos?——一个被低估的“老协议”正在悄悄支撑着你的日常你每天登录公司内网查邮件、访问财务系统提交报销、用 Jenkins 构建代码、甚至在 Windows 域环境中打开一台同事的共享文件夹……这些看似顺滑的操作背后,大概率…...

别再只用Service了!ROS1 Action通信保姆级教程:从导航进度条到任务取消,手把手教你实现带反馈的机器人任务
别再只用Service了!ROS1 Action通信保姆级教程:从导航进度条到任务取消,手把手教你实现带反馈的机器人任务当你的机器人正在执行一个长达10分钟的导航任务时,突然发现目标点设置错误,这时候如果只能干等着任务完成或者…...
)
放弃编码器!纯靠MPU6050和PID算法,手把手教你用TT马达实现平衡小车稳定控制(STM32F103C8T6实战)
纯MPU6050STM32F103的TT马达平衡车实战:无编码器PID控制全解析当大多数平衡小车方案都在强调编码器对速度反馈的不可或缺性时,我们决定挑战一个更极简的配置:仅用5美元的TT马达、9轴的MPU6050和STM32F103C8T6最小系统板,完全舍弃编…...

HDI 高密度互连板阶数的深度理解
一、概述高密度互连板(High Density Interconnector, HDI)是通过激光微孔技术和逐层积层工艺实现高密度布线的印制电路板。其阶数划分是行业内统一的技术标准,核心依据为独立积层压合次数与配套激光盲孔制程次数,而非单面层数或钻…...

长期使用Token Plan套餐在项目开发中的成本观察
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Token Plan套餐在项目开发中的成本观察 在AI驱动的项目开发中,成本控制与预算管理是团队负责人必须面对的现实…...

高精度光照检测
光线检测仪,kotlin开发,调用手机感光模块检测室内外光照强度,用途多多,我主要用途孩子写作业检测光照保护视力。 食用方法∶打开即测,速度快,无广告,手机平视即可,无须直视光线。 买…...
)
【2025】AWVS安装保姆级教程(最新25.1.2可用)
【2025】AWVS安装保姆级教程(最新25.1.2可用) 文章目录 工具下载Host 重定向AWVS安装AWVS查看安装失败原因 工具下载 点击下载即可 下载完的工具后缀格式为.apk,需要将其改为.zip,然后将其解压得到以下工具后续安装使用 Host 重…...

机器学习的最佳实践:这7个原则让你的模型更稳定
对于软件测试从业者而言,机器学习技术正在快速融入测试流程:从自动化测试用例生成、缺陷预测到测试环境异常检测,机器学习模型的稳定性直接决定了测试结果的可靠性——如果模型在测试环境波动、输入数据变化时性能骤降,不仅无法提…...

为什么你的Midjourney雾效总像“水汽”而非“山岚”?——资深CG总监拆解大气散射物理模型在--v 6.1中的3层映射偏差
更多请点击: https://kaifayun.com 第一章:为什么你的Midjourney雾效总像“水汽”而非“山岚”? Midjourney 生成的雾气常呈现为均匀、半透明、边界模糊的“水汽感”——厚重、潮湿、缺乏层次与呼吸感。这并非模型能力不足,而是提…...