DocEE:一种用于文档级事件抽取的大规模细粒度基准 论文解读
DocEE: A Large-Scale and Fine-grained Benchmark for Document-level Event Extraction

论文:NAACL2022.pdf (tongmeihan1995.github.io)
代码:tongmeihan1995/DocEE: DocEE: A Large-Scale and Fine-grained Benchmark for Document-level Event Extraction (github.com)
期刊/会议:NAACL 2022
摘要
事件抽取旨在识别一个事件,然后抽取参与该事件的论元。尽管在句子级事件抽取方面取得了巨大的成功,但事件更自然地以文档的形式呈现,事件论元分散在多个句子中。然而,推动文档级事件抽取的一个主要障碍是缺乏大规模和实用的训练和评估数据集。在本文中,我们提出了DocEE,一个新的文档级事件抽取数据集,包括27,000多个事件,180,000多个论元。我们重点介绍了三个特性:大规模手动标注、细粒度论元类型和面向应用程序的设置。实验表明,最先进的模型与人类之间仍然存在很大的差距(F1分数41% Vs 85%),说明DocEE是一个开放的问题。
1、简介
事件抽取(EE)旨在从文本中检测事件,包括事件分类和事件论元抽取。EE是文本挖掘的基本任务之一(Feldman和Sanger, 2006),有很多应用。例如,它可以监测政治或军事危机,以生成实时通知和警报(Dragos, 2013),并挖掘显要人物之间的联系和联系(例如,谁见过谁和什么时候见过谁),以进行肖像分析(Zhan等人,2020)。
大多数现有数据集(例如,ACE2005和KBP2017)专注于句子级事件抽取,而事件通常在文档级描述,事件论元通常分散在不同的句子中(Hamborg et al, 2019)。图1显示了一个Air Crash事件。为了抽取论元Date,我们需要阅读句子[1],而为了抽取论元Cause of the Accident,我们需要整合句子[6]和[7]中的信息。显然,这需要对多个句子进行推理,并对长距离依赖进行建模,直观上超出了句子级EE的范围。因此,有必要将EE从句子级推进到文档级。

只有少数数据集是针对文档级EE的。MUC-4(griishman and Sundheim, 1996)提供了1700篇新闻文章,标注了4种事件类型和5种论元类型。这5个论元在不同的事件类型之间共享,无需进一步细化。WikiEvents(Li et al, 2021)仅由246个文档组成,其中很少(占总数的22%)跨句论元标注。RAMS(Ebner et al, 2020)将5句话窗口中的论元的范围限制在其事件触发词周围,这与实际应用不符合,RAMS中的论元类型数量只有65个,非常有限。Doc2EDAG, TDJEE和GIT (Zheng等,2019;Wang等,2021;Xu et al, 2021)在金融领域中只包含5种事件类型和35种论元类型。综上所述,现有的文档级EE数据集在以下方面存在不足:数据规模小,域覆盖有限,论元类型细化不足。因此,迫切需要开发一个人工标记的大规模数据集来加速文档级EE的研究。
在本文中,我们提出了DocEE,一个大规模的人工标注文档级EE数据集。图1展示了DocEE的一个示例。DocEE侧重于主事件的抽取,即每个文档一个事件。我们将新闻标题作为主要事件的触发词,并着重于整篇文章的主要事件论元抽取。我们强调了DocEE在这一领域的三个贡献:1)大规模手动标注。DocEE包含27,485个文档级事件和180,528个论元,远远超过现有文档级EE数据集的规模。DocEE的大规模标注可以提供足够的训练和测试数据,公平地评估EE模型。2)细粒度论元类型。DocEE共有356种论元类型,远远超过现有数据集中的论元类型数量(MUC-5中有5种,RAMS中有65种)。除了一般论元,如时间和位置,我们还为每种事件类型设计了更多个性化的事件论元,如洪水事件的水位和地震事件的震级。这些细粒度的角色可以带来更详细的语义,对现有模型的语义消歧能力提出了更高的挑战。3)面向应用的设置。在实际应用中,事件抽取经常面临如何从资源丰富的领域快速适应到新的领域的问题。因此,我们添加了一个跨域设置来更好地测试EE模型的传输能力。此外,DocEE还取消了论元范围应在RAMS中的某个窗口内的限制,以更好地应对文章长度特别长、事件的论元可能出现在文章的任何角落的现实场景。由于事件论元更加分散(参见表1),DocEE对现有模型的长文本处理能力提出了更高的挑战。
为了评估DocEE的挑战,我们在DocEE上实现了9个最新的最先进的EE模型,并进行了人工评估。实验证明了DocEE的高质量,即使是SOTA模型的性能也远低于人类的性能,说明现有技术在处理文档级EE方面的薄弱。
2、相关的数据集
句子级时间抽取数据集:ACE2005、TAC-KBP、Chinese Emergency Corpus(CEC)、RED(https://catalog.ldc.upenn.edu/LDC2016T23)、MAVEN、LSEE。
文档级事件抽取:20news(https://archive.ics.uci.edu/ml/datasets/Twenty+Newsgroups)、THUCNews(http://thuctc.thunlp.org)、MUC-4、WikiEvents、RAMS、financial domain、biological domain。
开放领域事件抽取:要在开放领域中收集EE数据集,一种方法是利用半结构化资源(Wikipedia)或现有知识库(Freebase)。代表性作品有EventKG (Gottschalk and Demidova, 2018)、Event Wiki (Ge et al, 2018)和Historical Wiki (Hienert and Luciano, 2012)。
3、构建DocEE
我们的主要目标是收集大规模数据集,以促进事件抽取从句子级到文档级的发展。在接下来的部分中,我们将首先介绍如何构建事件模式,然后介绍如何收集候选数据以及如何通过众包对它们进行标记。
3.1 事件模式构建
新闻是热点事件的第一手来源,所以我们注重从新闻中提炼事件。之前的事件模式,如FrameNet (Baker, 2014)和HowNet (Dong and Dong, 2003),更多地关注吃饭(eating)和睡觉(sleeping)等琐碎的动作,因此不适合文档级的新闻事件抽取。
为了构建事件图式,我们从新闻学中获得了洞察力。新闻业通常将事件分为硬新闻和软新闻(Reinemann等人,2012;Tuchman, 1973)。硬新闻是指必须立即报道的社会紧急事件,如地震、交通事故和武装冲突。软新闻指的是与人类生活相关的有趣事件,如名人事迹、体育赛事和其他以娱乐为中心的报道。基于硬/软新闻理论和(Lehman-Wilzig and Seletzky, 2010)中的类别框架,我们一共定义了59种事件类型,其中硬新闻事件类型31种,软新闻事件类型28种。具体情况见附录表1。我们的模式涵盖了人类关注的有影响力的事件,如地震、洪水和外交峰会,这些事件无法在句子层面上抽取,需要多个句子来描述。


为了构建论证模式,我们利用维基百科中的信息框。如图3(a)所示,Wikipedia页面描述了一个事件,框中的关键信息,如时间(Time)和总的死亡人数(Total fatalities),可以看作是事件的原型论元。基于这种观察,我们为每种事件类型手动收集了20个wiki页面,并在信息框中使用它们的共享键作为我们的基本论元类型集。在此之后,我们进一步扩展基本集。具体来说,对于eee类事件,我们首先从纽约时报收集了20篇新闻报道,然后邀请了5名学生(英语为母语,新闻专业)来总结公众希望从eee类新闻中了解到的关键事实。例如,在洪水事件新闻中,水位是一个关键事实,因为它是洪水成因分析和救灾决策的重要事实依据,可以引起广泛关注。最后,通过合并5个学生的关键事实,我们完成了论元类型的展开。为了保证质量,我们进一步邀请了上述5位同学对收集到的新闻进行试贴标签,过滤文章中出现频率较低的参论元类型。
我们总共为59种事件类型定义了356种事件论元类型。平均来说,每个类有6.0个事件论元。图2显示了我们定义的事件论元类型的一些示例。完整的模式和相应的示例可以在事件模式的补充材料中。
3.2 候选数据集收集
在本节中,我们将介绍如何收集候选文档级事件。我们选择wiki作为数据源。Wiki包含两种事件:历史事件和时间轴事件(Hienert and Luciano, 2012)。历史事件指的是那些有自己维基页面的事件,比如1922年皮卡迪号的空中相撞事件。时间轴事件是指按时间顺序组织的新闻事件,例如wiki页面Portal:Current_events/June_2010.7中的热浪袭击印度和南亚。图3显示了两个事件的示例。我们采用这两种事件作为我们的候选数据,因为仅使用历史事件将导致在我们的事件模式下数据分布不均匀,而时间轴事件可以作为一个很好的补充。对于一个历史事件,我们采用它的维基百科文章作为事件论元1的文档进行标注。对于时间轴事件,我们使用URL下载原始新闻文章,作为要标注的事件论元的文档。因为22%的时间轴事件没有URL(维基百科编辑在编辑条目时不提供URL),所以我们使用Scale SERP来查找新闻文章并手动确认其真实性。对于历史事件,我们采用模板+事件类型作为查询关键词来检索候选事件。模板包括“列表”+事件类型,事件类型+“在”+年份,类别:“+事件类型+“在”+国家,等等。更多模板见附录表7。对于时间轴事件,我们选择1980年到2021年之间的事件作为候选事件,因为1980年之前的事件很少。
为了平衡文章的长度,我们过滤掉了少于5句话的文章,也截断了过长的文章(超过50句话)。最后,我们从维基百科中选择了44000个候选事件。
3.3 众包标注
给定候选事件和预定义的事件模式,我们现在介绍如何通过众包对它们进行标注。为保证标注质量,标注人员均为英语母语者或托福成绩在100以上或雅思成绩在7.5以上的英语专业学生。众包标注过程包括两个阶段。
3.3.1 阶段一:事件分类
在此阶段,需要标注这将候选事件分类为预定义的事件类型。以下(Hamborg et al, 2018;Hsi, 2018),我们专注于主事件分类,因此阶段1是单标签分类任务。具体来说,主事件是指标题中反映的、文章中主要描述的事件。形式上,假定候选事件e=<t,a>e =< t, a >e=<t,a>,其中ttt表示标题,aaa表示文章,阶段1的目的是为每个eee获取标签yAyAyA,其中yyy属于3.1小节中定义的59种事件类型。
我们总共邀请了大约60名标注人员参与第一阶段的标注。在线标注页面如图5所示。我们首先手动将100篇文章作为标准答案标注给预测标注者,剔除准确率低于70%的标注者,剩下48个有效标注者。然后,我们请两个独立的标注者对每个候选事件进行标注。如果两个标注者的结果不一致(在本案例中占32.8%),第三个标注者将是最终的裁判。由于实际事件类型的多样性,候选事件可能不属于任何预定义的类。我们将此类事件归为另一类,占总数据的23.6%。
3.3.2 阶段二:事件论元抽取
在此阶段,需要标注者从整篇文章中抽取事件论元。形式上,给定候选事件e=<t,a>e =< t, a >e=<t,a>,它的事件类型y和y和y和预定义的论元类型R(y)R(y)R(y),阶段2的目标是找到文章aaa中的所有论元。
由于第二阶段工作繁重,我们邀请了90多名标注员。附录图6显示了在线标注页面的一个示例。我们使用初步标注-多轮检查方法进行标注。在初步标注步骤中,每个文章都将由标注者标记。在此步骤中,我们将不超过两种事件类型分配给每个标注者,以使标注者更加集中。然后,在多轮检查的步骤中,我们首先根据批注人之间的协议,选择高精度的批注人组成审稿人团队(占总数的44.4%),然后每篇文章由审稿人团队中三位独立的标注者进行三轮纠错。在每一轮之后,我们将把标注问题反馈给评审员,以便他们在下一轮标注中纠正这些问题。每轮标记的准确率从56.24%、76.83%稳步提高到85.96%,说明了我们的标记方法的有效性。我们以第三轮的结果作为最终的标注结果。
我们在这里澄清一些标注细节。我们的标注中不包括冠词、介词。例如,我们在“damaged car”、“damaged car belonging to the victim”和“the damaged car”中选择“damaged car”。对于文档中多次提到的事件论元,例如,图1中的Cause of the Accident有两次提到,我们将标记所有提到,以确保抽取的完整性。对于提及同一实体的重复提及,我们只标记一次。
3.3.3 标注质量与报酬
遵循(Artstein and Poesio, 2008;McHugh, 2012),我们使用Cohen 's kappa系数来衡量标注者者间协议(IAA)。状态1事件分类和阶段2事件论元抽取的IAA得分分别为94%和81%,属于较高水平。在阶段1中,标注人员平均花0.5分钟标记一条数据,因此我们为每条数据支付他们0.1美元。在第二阶段,标记一个数据大约需要5分钟,所以我们为每个数据支付0.8美元。
4、DocEE的数据分析

![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pA5mGQPa-1676958180022)(DocEE: A Large-Scale and Fine-grained Benchmark for Document-level Event Extraction.assets/image-20230220095857847.png)]](https://img-blog.csdnimg.cn/ffc240f2fe2b4a93ad9da2f2192b3319.png#pic_center)

5、DocEE上的实验
两种基准设置:普通设置和跨领域设置。

5.1 事件分类

四个结论:(1)基于Transformer的预训练语言模型表现效果好,原因在于在大规模无监督预料中进行预训练,有更多的背景知识。(2)人类标注的分数最高,数据标注质量很好。(3)现有的SOTA模型和人类的水平还是存在较大的差异。(4)领域迁移还是巨大的挑战,在迁移学习上。
5.2 事件论元抽取
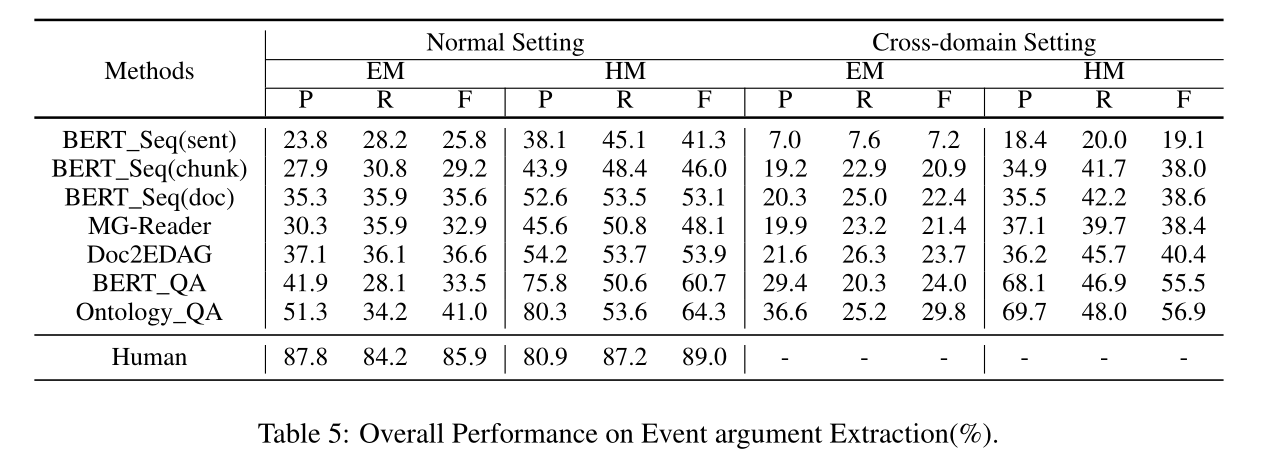
如表5所示,SOTA模型的性能与人类性能之间存在很大差距(F score 41.0% Vs 85.9%),这表明文档级事件论元抽取仍然是一项具有挑战性的任务。
现有基线的失败可能是由于两个原因。一个可能的原因是神经网络中的灾难性遗忘。与NER和句子级EE相比,文档级EE(我们的任务)突出了模型处理长文本的能力:在确定span的论元类型之前,模型必须读取整个文本。虽然已经提出了一些模型来提高预训练模型的长文本能力(如longformer),并取得了良好的效果,(longformer的性能(BERT_Seq(doc))优于BERT_Seq(sent)和BERT_Seq(chunk)如表5所示),但这些模型与人类相比仍有较大的性能差距。
另一个原因是现有的基线在语义理解方面能力较差,这体现在两个方面:1)EE模型不能区分相似事件的参数。例如,文章主要描述了2021年的美国阿拉斯加半岛大地震,也简要提及2008年汶川大地震。在询问主要事件的日期时,EE模型很容易混淆正确答案2021和错误答案2008。2) EE模型经常将不相关的实体误认为事件论元。例如,在911恐怖袭击五角大楼事件中抽取事件论元Attack Target时,除了正确答案是纽约五角大楼外,EE模型经常将文章中其他不相关的位置实体(如Mount Sinai Hospital)误认为答案之一。
我们认为以下研究方向值得关注:1)探索具有较强长文本处理能力的预训练模型。2)利用本体和常识知识,提高对EE模型的语义理解。在未来,我们将专注于将事件抽取提升到更高的级别,例如跨文档级别。
6、总结
在本文中,我们提出了DocEE,一个大型文档级EE数据集,以促进从句子级到文档级的事件抽取。与现有数据集相比,DocEE极大地扩展了数据规模,拥有超过27,000+个事件和180,000+个论元,并包含更精细的事件论元。实验表明,DocEE仍然是一个悬而未决的问题。
相关文章:
DocEE:一种用于文档级事件抽取的大规模细粒度基准 论文解读
DocEE: A Large-Scale and Fine-grained Benchmark for Document-level Event Extraction 论文:NAACL2022.pdf (tongmeihan1995.github.io) 代码:tongmeihan1995/DocEE: DocEE: A Large-Scale and Fine-grained Benchmark for Document-level Event Ext…...
ImageCombiner设计源码详解
前言在前面的博客中介绍了一款Java的海报生成器ImageCombiner,原文地址:拿来就用的Java海报生成器ImageCombiner(一),在博文中简单介绍了一下代码以及一个真实的生成案例。但是对源码的介绍不多,本文就针对源码进行深入…...

python基础 | python基础语法
文章目录📚基础语法🐇输入和输出🥕print()输出🥕input()输入🐇 变量的命名🐇条件判断🥕单向判断🥕双向判断🥕多向判断🥕if嵌套🥕三元表达式&#…...
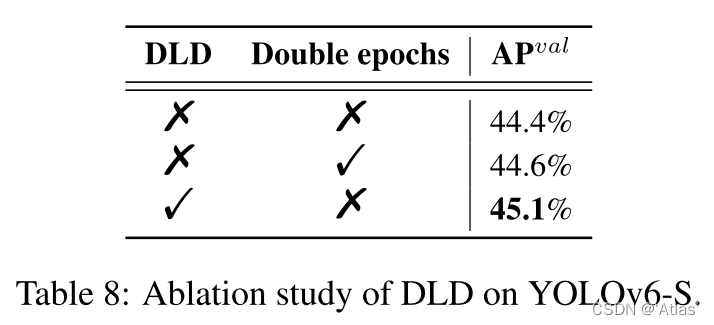
YOLOv6-3.0-目标检测论文解读
文章目录摘要算法2.1网络设计2.2Anchor辅助训练2.3自蒸馏实验消融实验结论论文: 《YOLOv6 v3.0: A Full-Scale Reloading 》github: https://github.com/meituan/YOLOv6上版本参考 YOLOv6摘要 YOLOv6 v3.0中YOLOv6-N达到37.5AP,1187FPS&…...

JAVA集合之Map >>HashMap/Hashtable/TreeMap/LinkedHashMap结构
Map 是一种键-值对(key-value)集合,键不可以重复,值可以重复。常见的实现类有:HashMap、Hashtable、TreeMap、LinkedHashMap等。 HashMap&Hashtable HashMap:数据结构为哈希表,允许使用 n…...
JavaScript从零开始 学习记录(一)
前言 选择视频课程之前,不仅查阅了资料,还询问了网友,最终敲定了学习黑马前端的视频教程,学了5小节,发现挺对自己口味的且从反响来看,还是相当不错的,便打算利用这个寒假学完 笔记范围 从这节…...
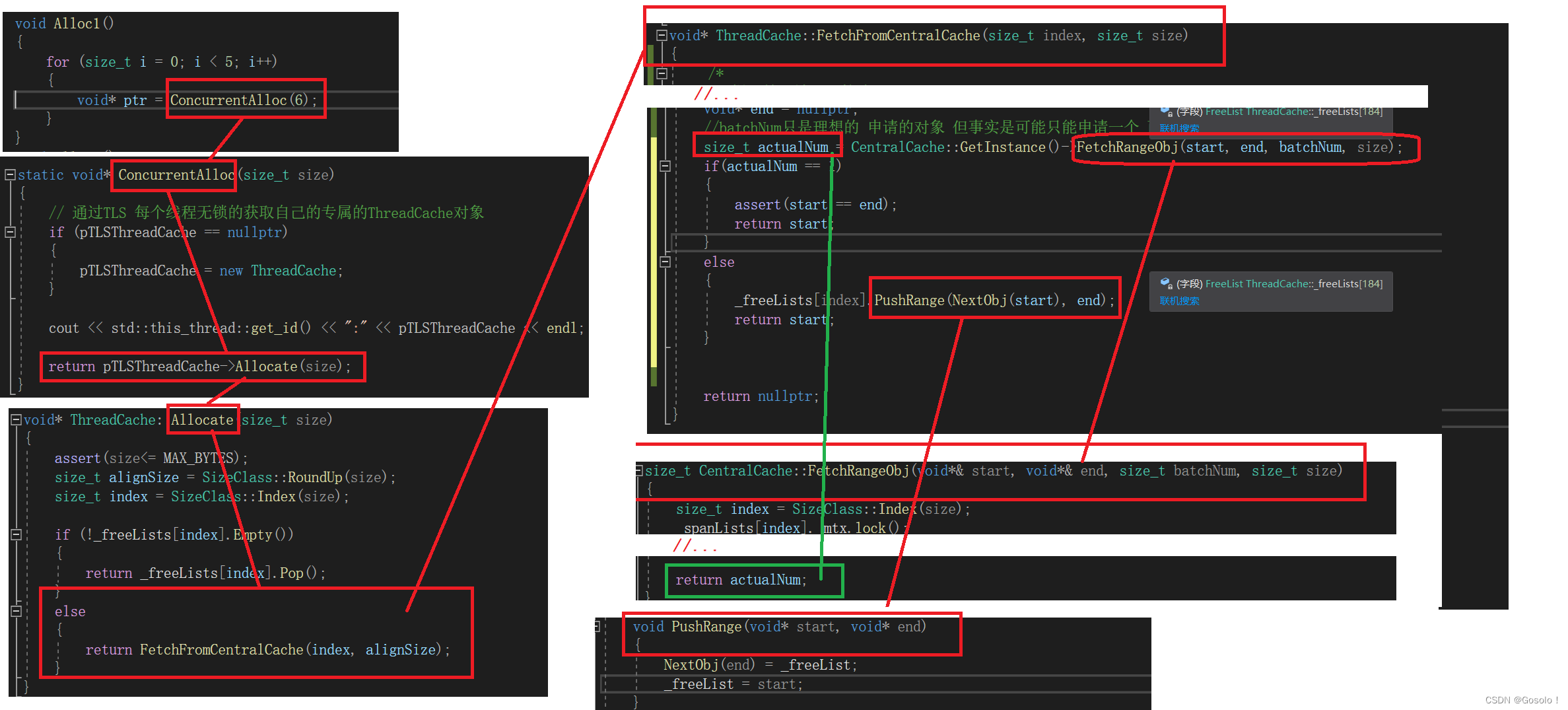
C++项目——高并发内存池(3)--central cache整体设计
1.central cache的介绍 1.1框架思想 1.1.1哈希映射 centralcache其实也是哈希桶结构的,并且central cache和thread cacha的哈希映射关系是一致的。目的为了,当thread cache某一个哈希桶下没有内存块时,可以利用之前编写的SizeClass::Index…...

Spring Boot 整合 MyBatis 配置等案例教程
运行环境:JDK 7 或 8、Maven 3.0 技术栈:SpringBoot 1.5、SpringBoot Mybatis Starter 1.2 、MyBatis 3.4 前言 距离第一篇 Spring Boot 系列的博文 3 个月了。《Springboot 整合 Mybatis 的完整 Web 案例》第一篇出来是 XML 配置 SQL 的形式。虽然 XM…...
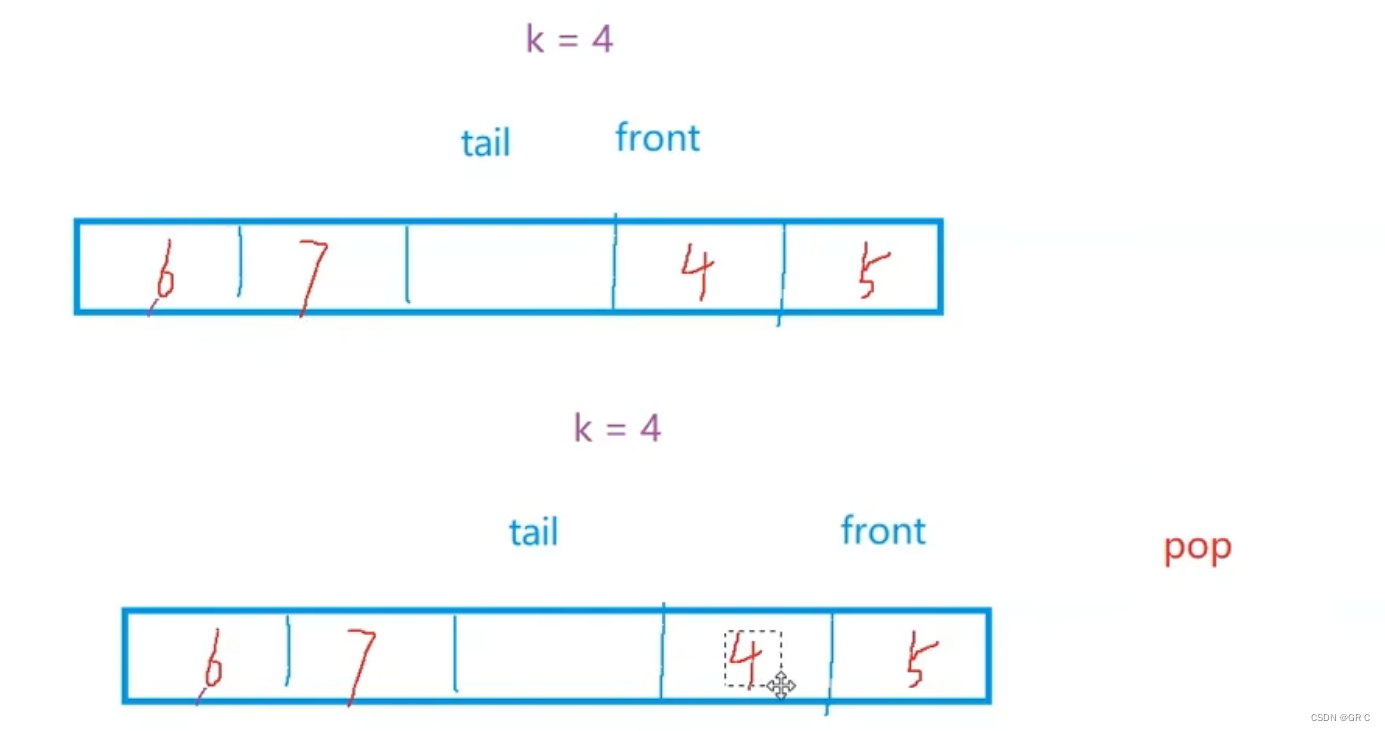
比特数据结构与算法(第三章_下)队列的概念和实现(力扣:225+232+622)
一、队列(Queue)队列的概念:① 队列只允许在一端进行插入数据操作,在另一端进行删除数据操作的特殊线性表。② 入队列,进行插入操作的一端称为 队尾。出队列,进行删除操作的一端称为 队头。③ 队列中的元素…...

c++提高篇——STL容器实现打分系统
一、案例说明 有5名选手:选手ABCDE,10个评委分别对每一名选手打分,去除最高分,去除评委中最低分,取平均分。 二、案例实现 在实现这个系统时,我们规划一下实现的步骤以及细节: 1、创建一个选手类&#x…...
)
【图片上传记录三】element-ui组件详解与封装(自定义上传、限制文件大小、格式以及图片尺寸)
业务上有需求是前端上传 jpg/png/gif 格式, 并且 尺寸为 150px * 150px,300px*300px,428*428px 的图片 同时在上传的同时需要携带用户的个人信息以及其他额外信息 因此在 element-upload 基础之上 实现这个需求需要在上传前检查图片的大小,格式以及尺寸如何上传也成…...

一个golang版本管理工具
GitHub - moqsien/gvc: GVC is a productive tool to manage your dev environment for multi platforms and machines. | GVC 是一个用于快速配置和管理多机器跨平台的开发环境的生产力工具。 目前,gvc拥有以下功能或特点: go编译器自动安装和添加环…...
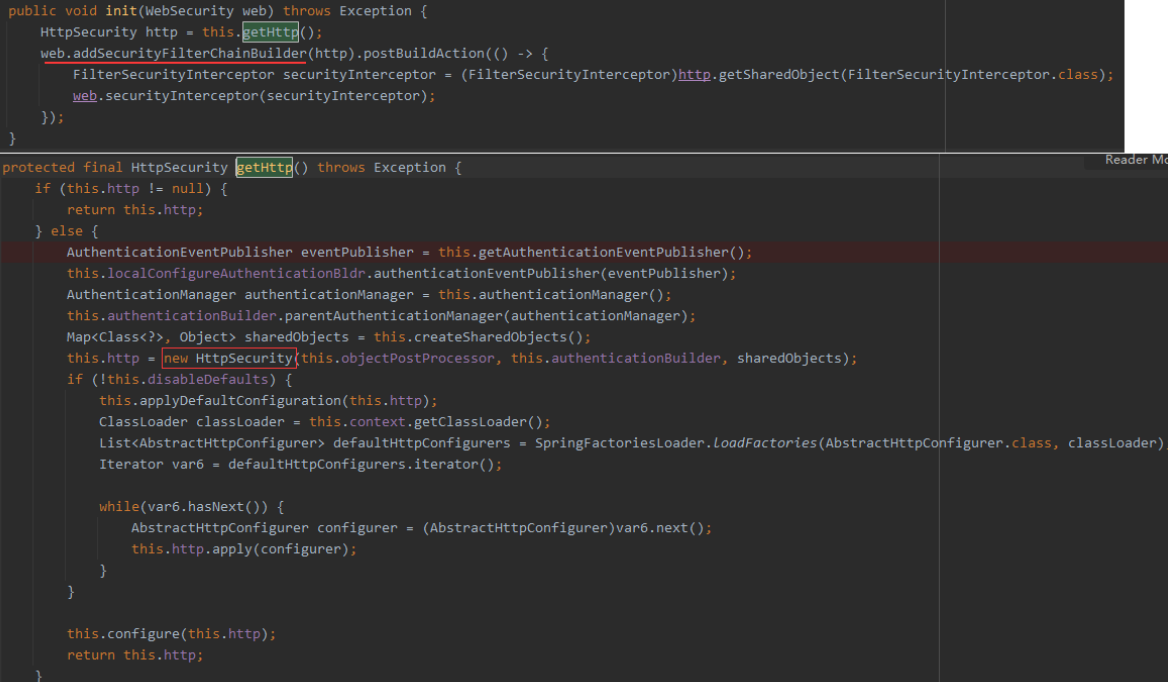
SpringBoot整合Spring Security过滤器链加载执行流程源码分析
文章目录1.引言2.Spring Security过滤器链加载1.2.注册名为 springSecurityFilterChain的过滤器2、查看 DelegatingFilterProxy类3.查看 FilterChainProxy类3.1 查看 doFilterInternal方法。3.2 查看 getFilters方法。4 查看 SecurityFilterChain接口5 查看 SpringBootWebSecur…...
Jest使用
一、测试到底测什么 提到测试的时候,即使是最简单的一个代码块可能都让初学者不知所措。最常问的问题的是“我怎么知道要测试什么?”。如果你正在写一个 Web 应用,那么你每个页面每个页面的测试用户交互的方式,就是一个很好的开端…...
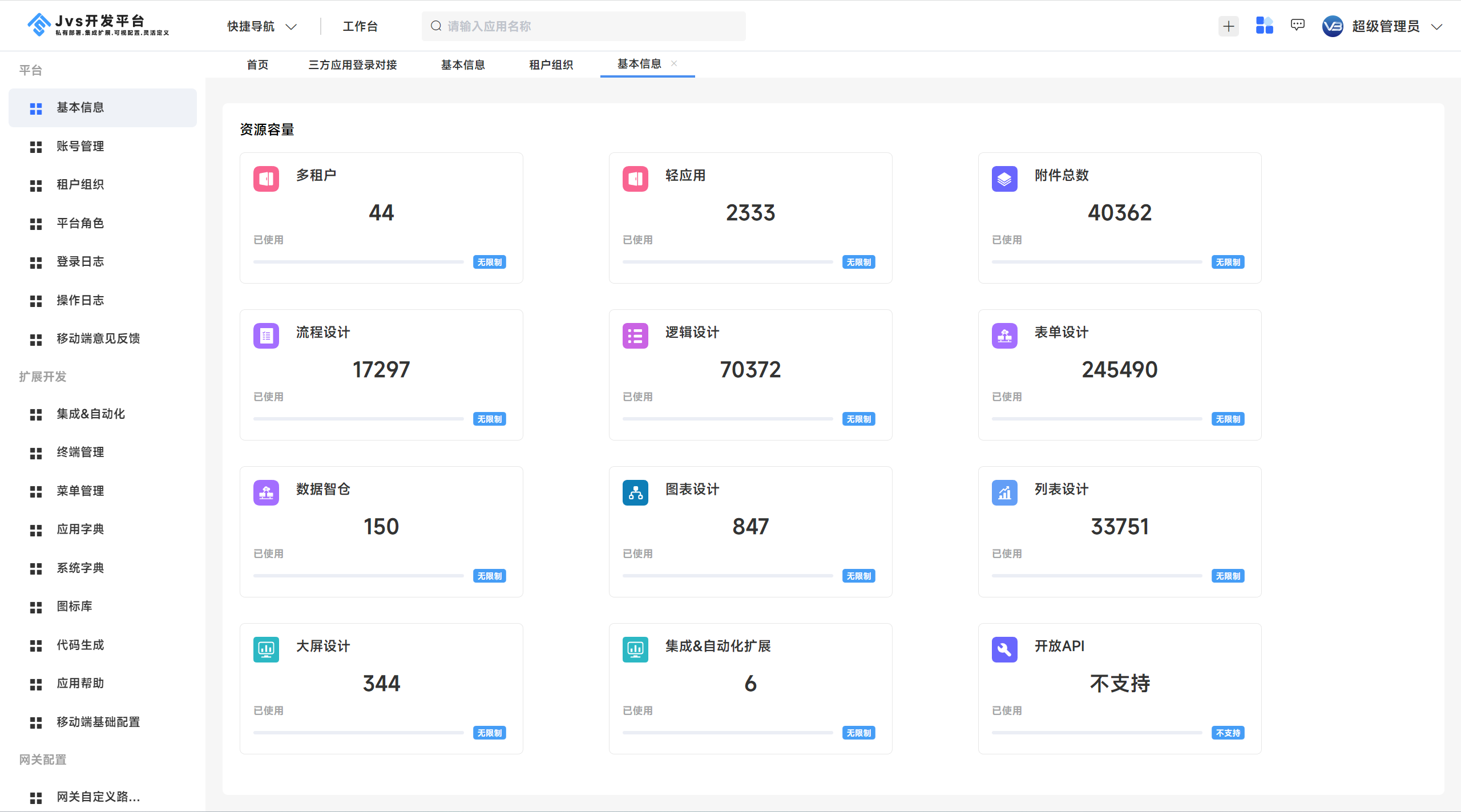
定位于企业数字化底座,开箱可用(spring cloud+Vue)基础框架,赶紧收藏!
项目介绍:JVS是什么?JVS是企业级应用构建的基础脚手架,提供开箱即用的基础功能集成,其中集成了账户管理、租户管理、用户权限体系、三方登录、环境配置、各种业务日志等功能,还提供了对接低代码、数据中台的能力。JVS能…...

java字符统计
问题描述 给定一个只包含大写字母的字符串 � S, 请你输出其中出现次数最多的字符。 如果有多个字母均出现了最多次, 按字母表顺序依次输出所有这些字母。 输入格式 一个只包含大写字母的字符串 � S. 输出格式 若干个大写字母,代表答案。 …...
C#:Krypton控件使用方法详解(第八讲) ——kryptonBreadCrumb
今天介绍的Krypton控件中的kryptonBreadCrumb,下面开始介绍这个控件的属性:首先要介绍的是RootItem属性和外观属性:RootItem属性组中包含属性如下:image属性:代表在文字对象的前方插入一个图片,属性值如下图…...

2023从0开始学性能(1) —— 性能测试基础【持续更新】
背景 不知道各位大佬有没遇到上面的情况,性能这个东西到底是什么,还是以前的358原则吗?明显并不是适用于现在了。多次想踏入性能测试门槛都以失败告终,这次就以系列的方式来督促自己真正踏进性能测试的门槛。 什么是性能测试 通…...
如何通过一台 iPhone 申请一个 icloud 邮箱账号 后缀为 @icloud.com
总目录 iOS开发笔记目录 从一无所知到入门 文章目录需求关键步骤步骤后续需求 在 iPhone 自带的邮箱软件中添加账号,排第一位的是 iCloud 邮箱: 选 iCloud 之后: 提示信息是exampleicloud.com,也就是说是有icloud.com为域的邮箱…...

SQL89 计算总和
描述OrderItems表代表订单信息,包括字段:订单号order_num和item_price商品售出价格、quantity商品数量。order_numitem_pricequantitya110105a211100a21200a421121a5510a2119a775【问题】编写 SQL 语句,根据订单号聚合,返回订单总…...

AI开始替人办事后,最危险的不是模型不够强,而是它把旧资料当真了
AI开始替人办事后,最危险的不是模型不够强,而是它把旧资料当真了2026年真正值得重视的AI底层能力,是让模型知道该信谁 你有没有发现一个很扎心的变化。 以前我们用AI,最怕它不会。 现在我们用AI,最怕它太会了。 它能写…...

从“DOC/PDF”到“WPS”:细看GJB438C-2021文档格式要求背后的国产化信号与落地指南
从“DOC/PDF”到“WPS”:GJB438C-2021文档格式变革的深度解读与实施策略 当一份国家军用标准在文档格式描述中刻意删除"DOC/PDF"字样,转而明确标注"(WPS)文档处理器"时,这绝非简单的技术参数调整。…...
)
告别混乱绑定!在UE5 GAS中优雅管理技能输入(基于GameplayTag)
告别混乱绑定!在UE5 GAS中优雅管理技能输入(基于GameplayTag)当你的UE5 RPG项目发展到中期,技能数量从十几个膨胀到几十个时,最痛苦的莫过于发现InputAction绑定已经变成一团乱麻。每次新增技能都要修改输入绑定逻辑&a…...

WarcraftHelper终极指南:深度解析魔兽争霸III现代化兼容性解决方案
WarcraftHelper终极指南:深度解析魔兽争霸III现代化兼容性解决方案 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper WarcraftHelper是一款专…...

【审计专栏】【财务领域】 第四十九篇 人在企业中的核心资产和核心利益01
编号 类型 企业 (行业/企业产品/企业利益链/生态位与层级) 业务领域 企业性质 企业中人的角色/岗位/利益矩阵 人在企业中的核心资产/附属资产 资产的业务-财务数学模型及数字/数值 关联知识 1 核心经营性资产(如IP、数据、品牌) 行业:人工智能 产品:工业视觉检…...

【C语言】C 语言为什么叫 C 语言呢?
【C语言】C 语言为什么叫 C 语言呢?笔记改自于王道训练营资料 其实是因为先有高级语言ALGOL 60,简称 A 语言,后来经过简化,变为 BCPL 语言,简称 B 语言,而 C 语言是在 B 语言的基础之上发展而来的ÿ…...

【RT-DETR实战】070、模型分析工具:PyTorch Profiler性能分析
上周在部署RT-DETR到边缘设备时遇到一个诡异现象:模型推理时延波动极大,有时30ms,偶尔突然跳到200ms。 盯着代码看了半天没发现逻辑问题,数据流也正常。这种时候,靠猜是没用的,必须上性能分析工具——PyTorch Profiler。 今天我们就来聊聊怎么用它揪出那些藏在细节里的…...

GEP协议深度解读:AI智能体自我进化的基因工程
OpenAI 官宣全面支持MCP协议,标志着AI应用架构的"连接标准"已定。如果说MCP是AI时代的USB-C,解决了模型与工具的连接问题,那么GEP(Genome Evolution Protocol,基因组进化协议)则正在解决另一个更本质的问题——智能体的自我进化与生命周期管理。 作为下一代AI基…...

基于Arduino UNO的真随机数生成与数据持久化在Tambola游戏机中的应用
1. 项目概述:用Arduino UNO打造一台全自动Tambola游戏机如果你玩过或者听说过Tambola(在印度非常流行的游戏,在欧美也叫Bingo或Housie),就知道它的核心玩法是主持人从一个装有数字球的容器中随机抽取号码,玩…...

ROS机器人仿真架构解析:基于wpr_simulation的移动操作机器人技术实现
ROS机器人仿真架构解析:基于wpr_simulation的移动操作机器人技术实现 【免费下载链接】wpr_simulation 项目地址: https://gitcode.com/gh_mirrors/wp/wpr_simulation 在机器人操作系统(ROS)开发领域,硬件依赖和测试成本一直是制约算法迭代效率的…...