【深度学习实验】数据可视化
目录
一、实验介绍
二、实验环境
三、实验内容
0. 导入库
1. 归一化处理
归一化
实验内容
2. 绘制归一化数据折线图
报错
解决
3. 计算移动平均值SMA
移动平均值
实验内容
4. 绘制移动平均值折线图
5 .同时绘制两图
6. array转换为tensor张量
7. 打印张量
一、实验介绍
Visualizing the Trend of Random Data Changes可视化随机数据变化的趋势
二、实验环境
conda create -n DL python=3.7 conda activate DLpip install torch==1.8.1+cu102 torchvision==0.9.1+cu102 torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
conda install matplotlib
三、实验内容
0. 导入库
According to the usual convention, import numpy, matplotlib.pyplot, and torch.按照通常的惯例,导入 numpy、matplotlib.pyplot 和 torch。
import numpy as np
import matplotlib.pyplot as plt
import torch1. 归一化处理
归一化
归一化处理是一种常用的数据预处理技术,用于将数据缩放到特定的范围内,通常是[0,1]或[-1,1]。这个过程可以确保不同特征或指标具有相似的数值范围,避免某些特征对模型训练的影响过大。
在机器学习和数据分析中,归一化可以帮助改善模型的收敛速度和性能,减少由于特征尺度差异导致的问题。例如,某些机器学习算法(如梯度下降)对特征的尺度敏感,如果不进行归一化处理,可能会导致模型难以收敛或产生不准确的结果。
常用的归一化方法包括最小-最大归一化(Min-Max normalization)和Z-score归一化(标准化)。
- 最小-最大归一化将数据线性地缩放到指定的范围内。
- Z-score归一化通过计算数据的均值和标准差,将数据转换为均值为0,标准差为1的分布。
实验内容
Read the file named `data.txt` containing 100 integers using NumPy, normalize all values to the range [0, 1], and store the normalized array with two decimal places.
使用 NumPy 读取包含 100 个整数的名为“data.txt”的文件,将所有值规范化为范围 [0, 1],并存储具有两个小数位的规范化数组。
data = np.loadtxt('data.txt')
# 归一化处理
normalized_array = (data - np.min(data)) / (np.max(data) - np.min(data))
# 保留两位小数
normalized_data = np.round(normalized_array, 2)
# 打印归一化后的数组
print(normalized_array)
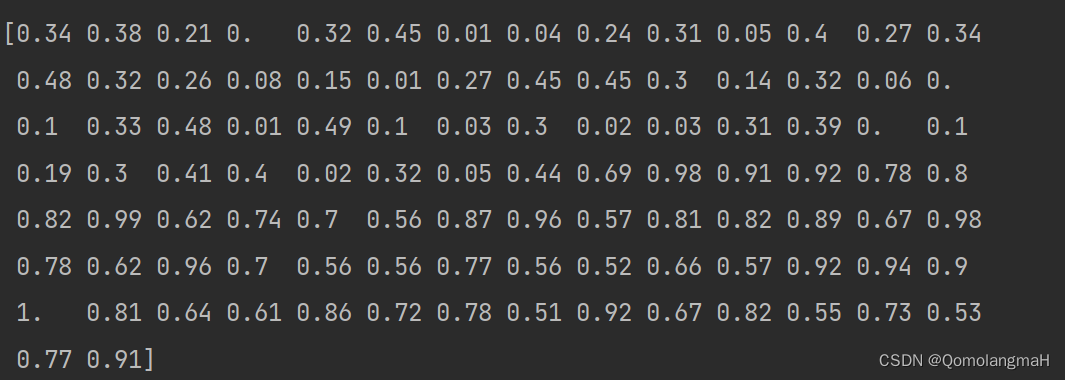
2. 绘制归一化数据折线图
Create a line plot using Matplotlib where the x-axis represents the indices of the normalized array ranging from 1 to 100, and the y-axis represents the values of the normalized array ranging from 0 to 1.
使用 Matplotlib 创建一个折线图,其中 x 轴表示规范化数组的索引,范围从1到100,y 轴表示规范化数组的值,范围从0到1。
# 创建x轴数据
x = np.arange(1, 101)
# 绘制折线图
plt.plot(x, normalized_array)# 设置x轴和y轴的范围
plt.xlim(1, 100)
plt.ylim(0, 1)
plt.title("Normalized Data")
plt.xlabel("Index")
plt.ylabel("Normalized Array")
plt.show()
报错
OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.
OMP: Hint This means that multiple copies of the OpenMP runtime have been linked into the program. That is dangerous, since it can degrade performance or cause incorrect results. The best thing to do is to ensure that only a single OpenMP runtime is linked into the process, e.g. by avoiding static linking of the OpenMP runtime in any library. As an unsafe, unsupported, undocumented workaround you can set the environment variable KMP_DUPLICATE_LIB_OK=TRUE to allow the program to continue to execute, but that may cause crashes or silently produce incorrect results. For more information, please see http://www.intel.com/software/products/support/.
解决
conda install nomkl
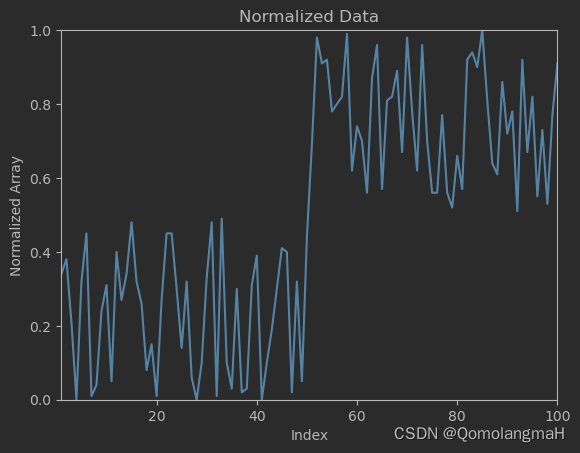
3. 计算移动平均值SMA
移动平均值
移动平均值(Moving Average)是一种数据平滑处理的方法,可以在一段时间内计算数据序列的平均值。这种方法通过不断更新计算的平均值,使得输出的数据更加平滑,减少噪声和突变的影响。
移动平均值有多种类型,其中最常见的是简单移动平均值(Simple Moving Average,SMA)和指数移动平均值(Exponential Moving Average,EMA)。这两种方法的计算方式略有不同。
-
简单移动平均值(SMA):
简单移动平均值是对指定时间段内的数据进行平均处理的方法,计算公式如下:SMA = (X1 + X2 + X3 + ... + Xn) / n其中,X1, X2, ..., Xn 是指定时间段内的数据,n 是时间段的长度。
例如,要计算最近5天的简单移动平均值,可以将这5天的数据相加,再除以5。
-
指数移动平均值(EMA):
指数移动平均值是对数据进行加权平均处理的方法,计算公式如下:EMA = (X * (2/(n+1))) + (EMA_previous * (1 - (2/(n+1))))其中,X 是当前数据点的值,n 是时间段的长度,EMA_previous 是上一个时间段的指数移动平均值。
指数移动平均值使用了指数衰减的加权系数,更加重视最近的数据点。
使用移动平均值可以平滑数据序列,使得数据更具可读性,减少随机波动的影响。这在时间序列分析、技术分析和数据预测等领域经常被使用。
实验内容
Calculate the moving average of the normalized results using NumPy with a window size of 5. Store the calculated moving average values in a new one-dimensional NumPy array, referred to as the "average values array."
使用窗口大小为 5 的 NumPy 计算归一化结果的移动平均值。将计算出的移动平均值存储在新的一维 NumPy 数组(称为“平均值数组”)中。
# 计算移动平均值
average_values_array = np.convolve(normalized_array, np.ones(5)/5, mode='valid')
print(average_values_array)
4. 绘制移动平均值折线图
Create another line plot using Matplotlib where the x-axis represents the indices of the average values array ranging from 5 to 100, and the y-axis represents the values of the average values array ranging from 0 to 1.
使用 Matplotlib 创建另一个线图,其中 x 轴表示平均值数组的索引,范围从 5 到 100,y 轴表示从 0 到 1 的平均值数组的值。
x_axis = range(5, 101)# 绘制折线图
plt.plot(x_axis, average_values_array)plt.xlim(5, 100)
plt.ylim(0, 1)
plt.title('Moving Average Line')
plt.xlabel('Index')
plt.ylabel('Average Values Array.')
plt.show()
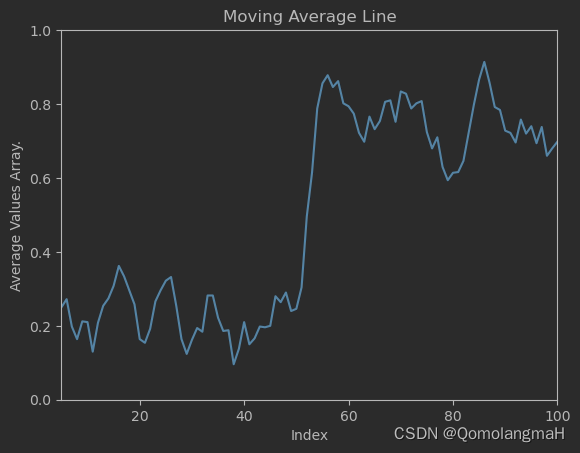
5 .同时绘制两图
Combine the line plots of the normalized array and the average values array in the same figure using different colors for each line.
将归一化数组的线图和平均值数组组合在同一图中,每条线使用不同的颜色。
plt.plot(x, normalized_array, color='r', label='Normalized Array Line')
plt.plot(x_axis, average_values_array, color='b', label='Moving Average Line')
plt.legend()
plt.xlim(1, 100)
plt.ylim(0, 1)
plt.xlabel('Index')
plt.ylabel('Value')
plt.show()
6. array转换为tensor张量
Transform the normalized array into a 2x50 Tensor by reshaping the data.
通过重塑数据将归一化数组转换为 2x50 张量。
normalized_tensor = torch.tensor(normalized_array).reshape(2, 50)
7. 打印张量
Print the resulting Tensor.
print(normalized_tensor)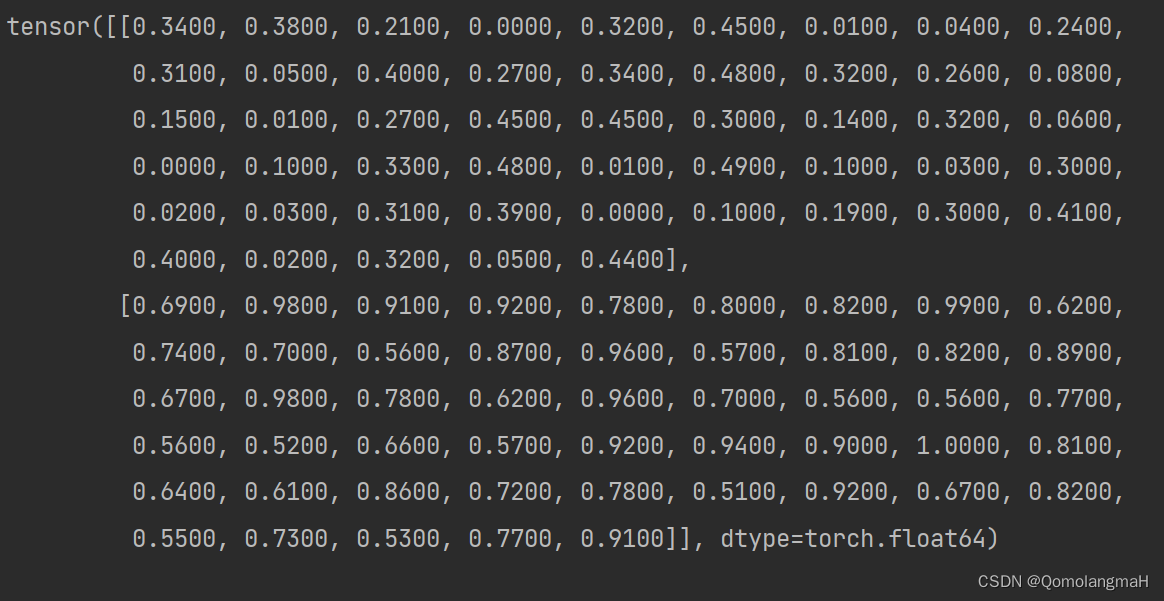
相关文章:
【深度学习实验】数据可视化
目录 一、实验介绍 二、实验环境 三、实验内容 0. 导入库 1. 归一化处理 归一化 实验内容 2. 绘制归一化数据折线图 报错 解决 3. 计算移动平均值SMA 移动平均值 实验内容 4. 绘制移动平均值折线图 5 .同时绘制两图 6. array转换为tensor张量 7. 打印张量 一、…...

【Golang】函数篇
1、golang函数基本定义与使用 func 函数名 (形参列表) (返回值类型列表) {函数体return 返回值列表 }其中func用于表明这是一个函数,剩下的东西与其他语言的函数基本一致,在定义与使用的时候注意函数名、参数、返回值书写的位置即可。下面使用一个例子…...
在ubuntu上安装ns2和nam(ubuntu16.04)
在ubuntu上安装ns2和nam 版本选择安装ns2安装nam 版本选择 首先,版本的合理选择可以让我们避免很多麻烦 经过测试,ubuntu的版本选择为ubuntu16.04,ns2的版本选择为ns-2.35,nam包含于ns2 资源链接(百度网盘) 链接:https://pan.bai…...

SpringCloudAlibaba之Sentinel介绍
文章目录 1 Sentinel1.1 Sentinel简介1.2 核心概念1.2.1 资源1.2.2 规则 1.3 入门Demo1.3.1 引入依赖1.3.2 集成Spring1.3.3 Spring中资源规则 1.4 Sentinel控制台1.5 核心原理1.5.1 NodeSelectorSlot1.5.2 ClusterBuilderSlot1.5.3 LogSlot1.5.4 StatisticSlot1.5.5 Authority…...
苹果微信聊天记录删除了怎么恢复?果粉原来是这样恢复的
粗心大意删除了微信聊天记录?有时候,一些小伙伴可能只是想要删除一部分聊天记录,但是在进行批量删除时,不小心勾选到了很重要的对话,从而导致记录丢失。 如果这时想找回聊天记录该怎么办?微信聊天记录删除…...
JVM的故事——虚拟机字节码执行引擎
虚拟机字节码执行引擎 文章目录 虚拟机字节码执行引擎一、概述二、运行时栈帧结构三、方法调用 一、概述 执行引擎Java虚拟机的核心组成之一,它是由软件自行实现的,能够执行那些不被硬件直接支持的指令集格式。 对于不同的虚拟机实现,执行引…...
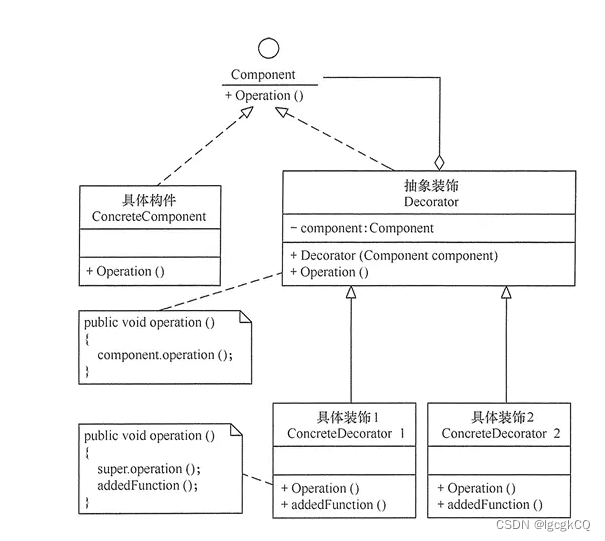
设计模式之适配器与装饰器
目录 适配器模式 简介 角色 使用 优缺点 使用场景 装饰器模式 简介 优缺点 模式结构 使用 使用场景 适配器模式 简介 允许将不兼容的对象包装成一个适配器类,使得其他类可以通过适配器类与原始对象进行交互,从而提高兼容性 角色 目标角色…...
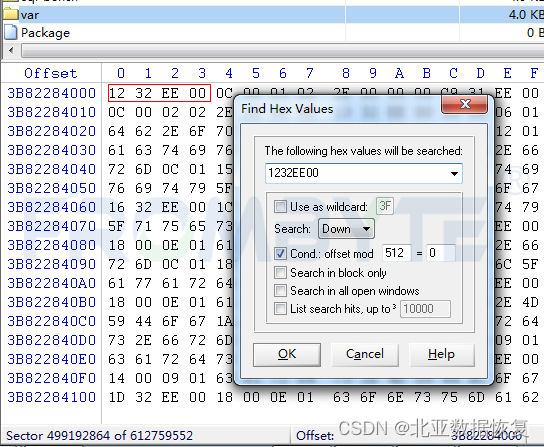
服务器数据恢复- Ext4文件系统分区挂载报错的数据恢复案例
Ext4文件系统相关概念: 块组:Ext4文件系统的空间被划分为若干个块组,每个块组内的结构大致相同。 块组描述符表:每个块组都对应一个块组描述符,这些块组描述符统一放在文件系统的前部,称为块组描述符表。每…...

19-springcloud(上)
一 微服务架构进化论 单体应用阶段 (夫妻摊位) 在互联网发展的初期,用户数量少,一般网站的流量也很少,但硬件成本较高。因此,一般的企业会将所有的功能都集成在一起开发一个单体应用,然后将该单体应用部署到一台服务器…...
前端基础---HTML笔记汇总一
HTML定义 HTML超文本标记语言——HyperText Markup Language。 超文本是什么? 链接标记是什么? 标记也叫标签,带尖括号的文本 标签分类 单标签:只有开始标签,没有结束标签(<br>换行 <hr>水平线 <img> 图像标…...

智汇云舟亮相中国安防工程商集成商大会
智汇云舟亮相中国安防工程商集成商大会,以视频孪生驱动安防行业数字化转型 近日,由中国安全防范产品行业协会指导,永泰传媒主办的中国安防工程商(系统集成商)大会暨第69届中国安防新产品、新技术成果展示在石家庄圆满…...

使用 Sealos 在离线环境中光速安装 K8s 集群
作者:尹珉。Sealos 开源社区 Ambassador,云原生爱好者。 当容器化交付遇上离线环境 在当今快节奏的软件交付环境中,容器化交付已经成为许多企业选择的首选技术手段。在可以访问公网的环境下,容器化交付不仅能够提高软件开发和交付…...

算法-模拟
1、旋转数组 public class Solution {/*** 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可** 旋转数组* param n int整型 数组长度* param m int整型 右移距离* param a int整型一维数组 给定数组* return int整型一维数组*/…...
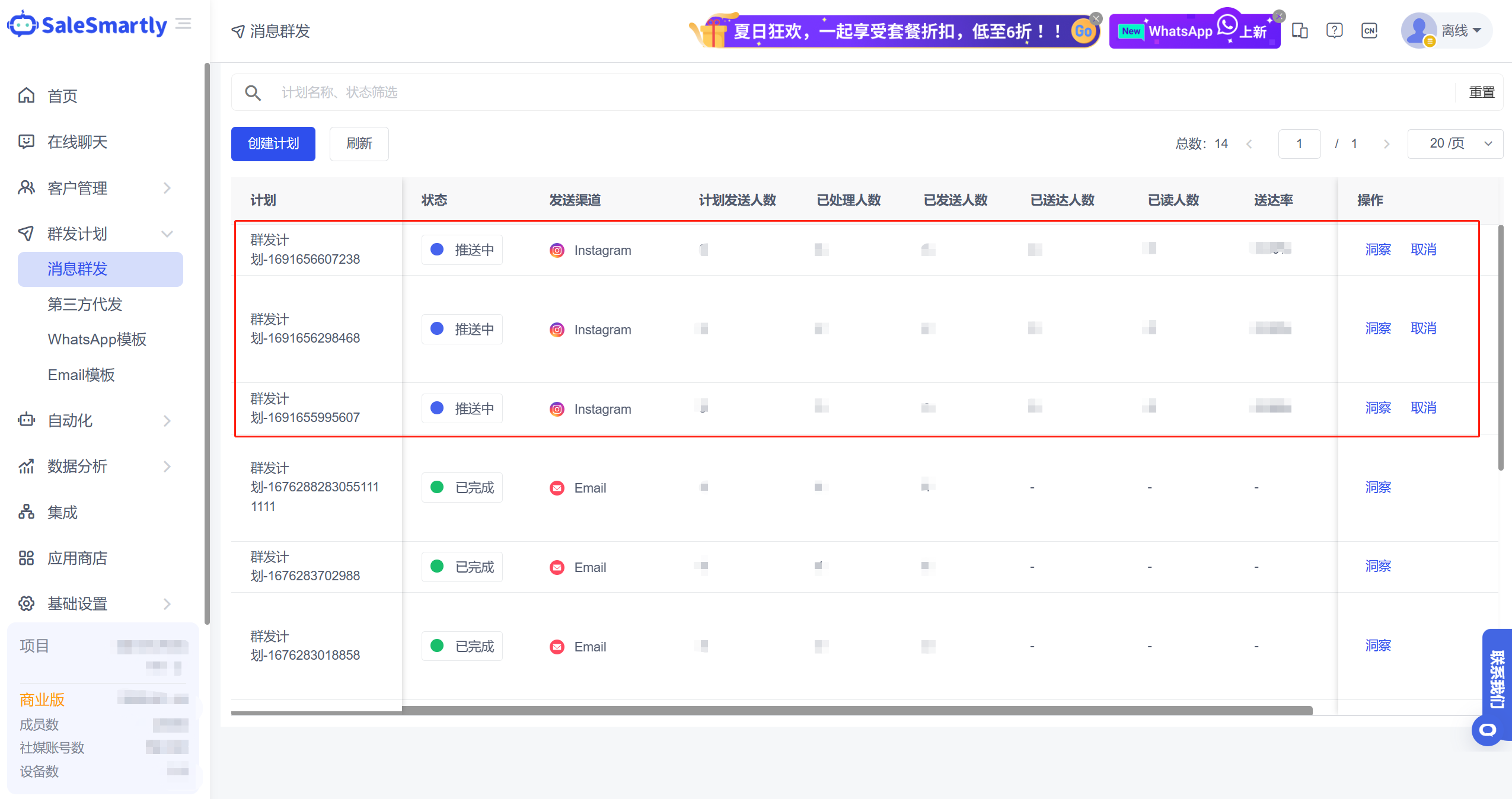
如何通过Instagram群发消息高效拓展客户?
之前小S有跟大家说过关于独立站+Instagram如何高效引流,发现大家都对Instagram的话题挺关注的。Instagram作为全球最受欢迎的社交媒体之一,对于许多商家和营销人员来说,Instagram是一个不可忽视的营销平台,他们可以通过…...

基于springboot实现多线程抢锁的demo
1、本代码基于定时调度和异步执行同时处理,如果只加异步处理,会导致当前任务未执行完,下个任务到点也不会触发执行 Scheduled(fixedRate 50_000)Asyncpublic void testThread() throws Exception{ZkLock lock new ZkLock(zkJob.getZK(), &q…...
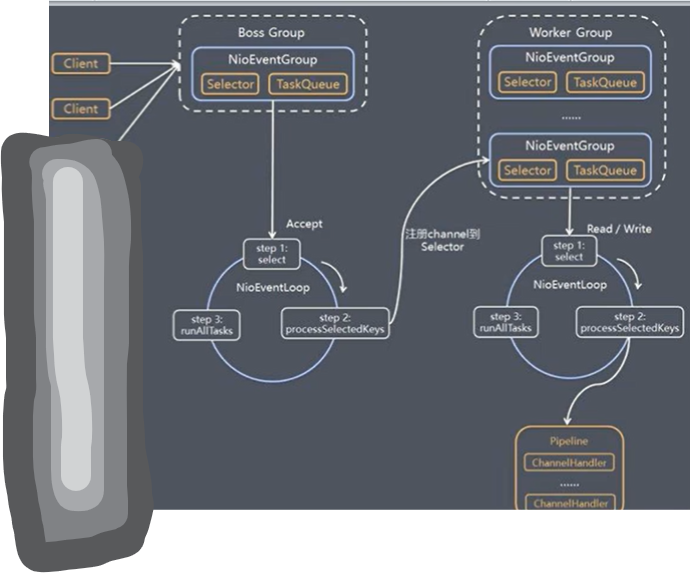
Java I/O模型发展以及Netty网络模型的设计思想
Java I/O模型发展以及Netty网络模型的设计思想 I/O模型Java BIOJava NIOJava AIO NIO Reactor网络模型单Reactor单线程模型单Reactor多线程模型主从Reactor多线程模型 Netty通信框架 前言: BIO、NIO的代码实践参考:Java分别用BIO、NIO实现简单的客户端服…...

智能电网时代:数字孪生的崭露头角
随着科技的不断进步,数字孪生已经开始在电力行业崭露头角,为这个关键的行业带来了前所未有的机遇和潜力。本文就带大家了解一下数字孪生在哪些方面为电力行业做出改变,以及未来的创新应用。 首先,数字孪生可以提高电力系统运营效率…...
每日一题 501二叉搜素树中的众数(中序遍历)
题目 给你一个含重复值的二叉搜索树(BST)的根节点 root ,找出并返回 BST 中的所有 众数(即,出现频率最高的元素)。 如果树中有不止一个众数,可以按 任意顺序 返回。 假定 BST 满足如下定义&a…...
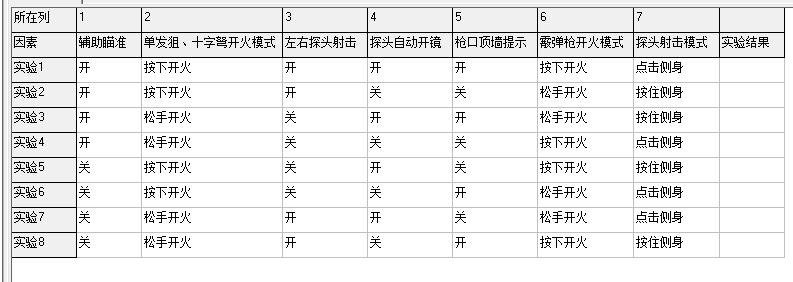
测试理论与方法----测试流程第三个环节:设计测试用例
测试流程第三个环节:设计测试用例:怎么测<——>测试需求的提取:测什么 ### 5、测试用例 描述:测试用例(TestCase):是一份关于【具体测试步骤】的文档,是为了达到最佳的测试效果或高效揭露软件中潜藏的…...
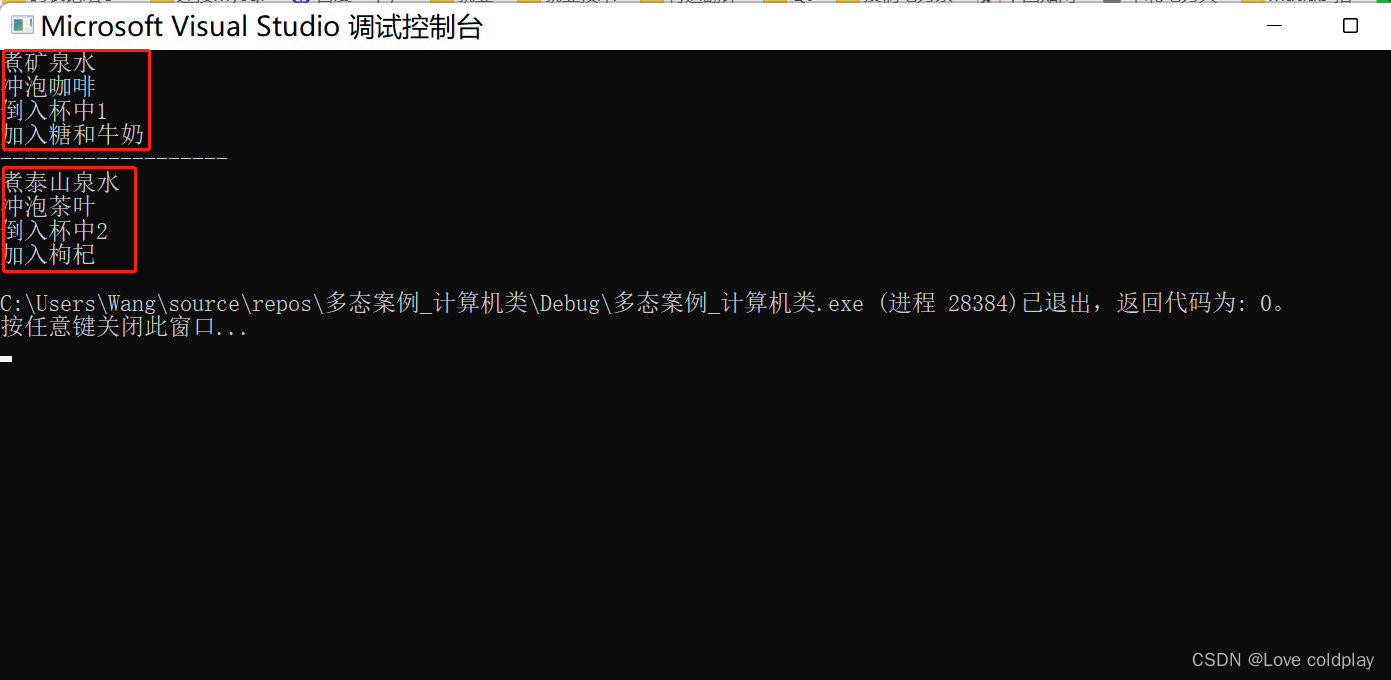
C++多态案例2----制作饮品
#include<iostream> using namespace std;//制作饮品的大致流程都为: //煮水-----冲泡-----倒入杯中----加入辅料//本案例利用多态技术,提供抽象类制作饮品基类,提供子类制作茶叶和咖啡class AbstractDrinking {public://煮水//冲水//倒…...

C# 环境:深入解析与应用
C# 环境:深入解析与应用 引言 C#(读作“C Sharp”)是一种由微软开发的高级编程语言,广泛应用于Windows平台的应用程序开发。自从2002年推出以来,C#已经成为了全球开发者喜爱的编程语言之一。本文将深入解析C#环境,包括其特点、应用场景以及开发环境搭建等。 C#环境概述…...

如何让老旧游戏手柄重获新生:XOutput输入转换器完整指南
如何让老旧游戏手柄重获新生:XOutput输入转换器完整指南 【免费下载链接】XOutput DirectInput to XInput wrapper 项目地址: https://gitcode.com/gh_mirrors/xo/XOutput 你是否拥有一些老旧但质量优秀的游戏手柄、摇杆或方向盘,却发现在现代游戏…...

STM32F103 + TM1628实战:如何用31个LED做一个可调亮度的简易仪表盘?
STM32F103 TM1628实战:如何用31个LED打造智能动态仪表盘 在嵌入式开发领域,将基础硬件模块转化为实用创意项目的能力,往往是区分普通开发者和资深工程师的关键。STM32F103作为经典的ARM Cortex-M3内核微控制器,以其出色的性价比和…...

从信号放大器到协议感知:深入解析Retimer与Redriver在高速链路中的角色演进
1. 高速链路中的信号完整性挑战 当你把手机靠近路由器时,网速会突然变快;用Type-C线连接移动硬盘传输大文件时,偶尔会出现卡顿——这些现象背后都隐藏着信号完整性这个关键问题。在AI服务器、数据中心互连、高端显卡这些需要高速数据传输的场…...
 逃逸/LP模式 传输详解和波形图)
MIPI CSI-2(3) 逃逸/LP模式 传输详解和波形图
专栏目录 MIPI CSI-2(1) D-PHY详细解析 MIPI CSI-2(2) HS模式 传输详解和波形图 MIPI CSI-2(3) 逃逸/LP模式 传输详解和波形图 逃逸模式时序 逃逸模式下lane始终通过LP-TX驱动,不要求有时钟&…...

PostgreSQL列式存储革命:cstore_fdw完整指南与10个性能优化技巧
PostgreSQL列式存储革命:cstore_fdw完整指南与10个性能优化技巧 【免费下载链接】cstore_fdw Columnar storage extension for Postgres built as a foreign data wrapper. Check out https://github.com/citusdata/citus for a modernized columnar storage implem…...

FanControl风扇控制软件:5分钟快速上手指南,轻松解决电脑噪音与散热难题
FanControl风扇控制软件:5分钟快速上手指南,轻松解决电脑噪音与散热难题 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gi…...

人类的自然关系与AI的形式化关系
“人类的自然关系”与“AI的形式化关系”是理解下一代人机环境系统智能的两个核心哲学维度。它们分别代表了智能系统在物理世界中的生存根基与在数字世界中的运行逻辑。我们可以从以下三个层面来深度解析这两者的区别与融合:人类的自然关系:从“征服掠夺…...

2026年支持人民币计价的金价追踪APP有哪些
家人们谁懂啊!上周我发小蹲了3个月的50克古法金镯子终于下手,结账的时候才傻了眼:她之前用来盯金价的APP默认是美元离岸价,自己换算的时候忘了算汇率差和国内基础金价的浮动,预估的总价和实际付款差了快1800࿰…...

从“会响”到“可靠”:给这个经典12V降5V电路加个二极管和电容,稳定性提升不止一点点
从“会响”到“可靠”:经典12V降5V电路的稳定性优化实战 当你在面包板上搭建好那个经典的稳压管NPN降压电路,看着万用表显示稳定的5V输出时,或许会感到一丝成就感。但当你接上负载,发现电压开始波动,或者在电源反接时闻…...