零碎的C++
构造函数和析构函数
构造函数不能是虚函数,而析构函数可以是虚函数。原因如下:
- 构造函数不能是虚函数,因为在执行构造函数时,对象还没有完全创建,还没有分配内存空间,也没有初始化虚函数表指针。如果构造函数是虚函数,就需要通过虚函数表来调用,但是此时虚函数表还不存在,无法找到正确的构造函数。
- 构造函数也不需要是虚函数,因为虚函数的作用是实现多态性,即通过父类的指针或引用来调用子类的成员函数。而构造函数是在创建对象时自动调用的,不可能通过父类的指针或引用去调用,因此也就没有多态性的需求。
- 析构函数可以是虚函数,而且当要使用基类指针或引用删除子类对象时,最好将基类的析构函数声明为虚函数,否则会存在内存泄漏的问题。 这是因为如果不使用多态性,那么编译器总是根据指针的类型来调用类成员函数。如果一个基类指针指向一个子类对象,那么删除这个指针时,只会调用基类的析构函数而不会调用子类的析构函数。这样就会导致子类对象中分配的资源没有被释放,造成内存泄漏。
- 如果将基类的析构函数声明为虚函数,那么在删除基类指针时,就会根据指针实际指向的对象类型来调用相应的析构函数。这样就可以保证子类对象中的资源也被正确地释放,避免内存泄漏。
智能指针
智能指针是一种封装了原始指针的类对象,可以自动管理指针所指向的资源的生命周期,避免内存泄漏和空悬指针等问题。C++ 标准库提供了三种智能指针:std::unique_ptr,std::shared_ptr 和 std::weak_ptr。另外,C++98 中还有一种智能指针 std::auto_ptr,但是在 C++11 中已经被废弃,不建议使用。
- std::unique_ptr 是一种独占所有权的智能指针,它保证同一时间只有一个 unique_ptr 指向某个资源,当 unique_ptr 超出作用域或被销毁时,它会自动释放所指向的资源。 unique_ptr 不支持拷贝和赋值操作,但是可以通过 std::move 转移所有权给另一个 unique_ptr。 unique_ptr 可以指向单个对象或者数组,并且可以自定义删除器来释放资源。
- std::shared_ptr 是一种共享所有权的智能指针,它允许多个 shared_ptr 指向同一个资源,并且维护一个引用计数来记录有多少个 shared_ptr 共享该资源。 当最后一个 shared_ptr 超出作用域或被销毁时,它会自动释放所指向的资源。shared_ptr 支持拷贝和赋值操作,每次拷贝或赋值都会增加引用计数。shared_ptr 也可以自定义删除器来释放资源。
- std::weak_ptr 是一种弱引用的智能指针,它不会增加所指向资源的引用计数,也不会影响资源的生命周期。weak_ptr 只能通过 shared_ptr 来构造,它可以观察 shared_ptr 所管理的资源,但是不能直接访问。为了访问资源,需要先调用 lock 方法将 weak_ptr 转换为 shared_ptr。 weak_ptr 的作用是防止 shared_ptr 之间的循环引用导致内存泄漏的问题。
指针和引用
指针和引用都是 C++ 中表示内存地址的概念,但是它们有很多不同的特点和用法。
- 定义和性质:指针是一个变量,它存储的是一个地址,指向内存中的一个存储单元;引用是一个变量的别名,它和原变量实质上是同一个东西,占用同一个存储单元。
例如:
int a = 10; // 定义一个整型变量 a
int *p = &a; // 定义一个指针 p,它的值是 a 的地址
int &r = a; // 定义一个引用 r,它是 a 的别名
- 初始化:指针可以在定义时不初始化,或者初始化为 NULL;引用必须在定义时初始化,并且不能为 NULL。例如:
int *p; // 合法,p 是一个未初始化的指针
int &r; // 不合法,r 必须初始化
int *q = NULL; // 合法,q 是一个空指针
int &s = NULL; // 不合法,s 不能为 NULL
- 修改:指针可以在初始化后改变它所指向的对象;引用一旦初始化后就不能再改变它所引用的对象。 例如:
int a = 10;
int b = 20;
int *p = &a; // p 指向 a
int &r = a; // r 引用 a
p = &b; // 合法,p 改变为指向 b
r = b; // 不合法,r 不能改变为引用 b,这里相当于给 a 赋值为 b
- 操作:指针需要通过解引用操作符(*)来访问或者修改所指对象的值;引用可以直接访问或者修改所引用对象的值。 例如:
int a = 10;
int *p = &a;
int &r = a;
*p = 20; // 合法,通过解引用修改 p 所指对象的值为 20
r = 30; // 合法,直接修改 r 所引用对象的值为 30
- 多级:指针可以有多级,即指向指针的指针;引用只能有一级,即不能有引用的引用。¹² 例如:
int a = 10;
int *p = &a;
int **q = &p; // 合法,q 是一个二级指针,指向 p
int &r = a;
int &&s = r; // 不合法,s 不能是 r 的引用
- sizeof:指针的 sizeof 结果是指针本身所占的字节数,与所指对象的类型无关;引用的 sizeof 结果是所引用对象所占的字节数,与引用本身无关。 例如:
int a = 10;
double b = 3.14;
char c = 'A';
int *p1 = &a;
double *p2 = &b;
char *p3 = &c;
int &r1 = a;
double &r2 = b;
char &r3 = c;
cout << sizeof(p1) << endl; // 输出 8(在64位机器上),表示 p1 占8个字节
cout << sizeof(p2) << endl; // 输出 8(在64位机器上),表示 p2 占8个字节
cout << sizeof(p3) << endl; // 输出 8(在64位机器上),表示 p3 占8个字节
cout << sizeof(r1) << endl; // 输出 4,表示 r1 所引用的对象 a 占4个字节
cout << sizeof(r2) << endl; // 输出 8,表示 r2 所引用的对象 b 占8个字节
cout << sizeof(r3) << endl; // 输出 1,表示 r3 所引用的对象 c 占1个字节
- 自增:指针的自增操作会根据所指对象的类型来移动指针的位置;引用的自增操作相当于对所引用对象进行自增操作。 例如:
int a[3] = {10, 20, 30};
int *p = a; // p 指向数组的第一个元素
int &r = a[0]; // r 引用数组的第一个元素
p++; // 合法,p 移动到数组的第二个元素
r++; // 合法,r 所引用的元素值增加 1,即 a[0] 变为 11
- 函数参数:指针和引用都可以作为函数的参数,从而实现对实参的修改;但是指针作为参数时需要检查是否为空,而引用不需要。例如:
void swap1(int *a, int *b) { // 使用指针作为参数if (a == NULL || b == NULL) return; // 需要检查指针是否为空int temp = *a;*a = *b;*b = temp;
}void swap2(int &a, int &b) { // 使用引用作为参数// 不需要检查引用是否为空,因为引用不能为空int temp = a;a = b;b = temp;
}
一些常见STL
- vector:vector 是一个动态数组,它可以在运行时改变大小,支持随机访问,也就是可以通过下标来访问任意位置的元素。 vector 的头文件是
<vector>,它的定义如下:
template <class T, class Allocator = allocator<T> >
class vector;
其中,T 是元素的类型,Allocator 是分配器的类型,默认为 std::allocator。
vector 的特性有:
- vector 会在内存中连续存储元素,因此可以高效地访问和遍历元素。
- vector 可以在尾部快速地插入和删除元素,但是在中间或者头部插入或删除元素会导致后面的元素移动,效率较低。
- vector 会根据需要自动调整容量,当容量不足时,会重新分配更大的内存空间,并复制原来的元素。
- vector 支持拷贝、赋值、移动等操作,可以方便地复制或转移数据。
vector 的用法有:
- 可以使用构造函数来创建一个 vector 对象,并指定初始大小、值、容量等参数。
vector<int> v1; // 创建一个空的 vector
vector<int> v2(10); // 创建一个包含 10 个 int 类型元素的 vector,默认值为 0
vector<int> v3(10, 1); // 创建一个包含 10 个 int 类型元素的 vector,初始值为 1
vector<int> v4(v3); // 创建一个和 v3 相同的 vector
vector<int> v5(v3.begin(), v3.end()); // 创建一个包含 v3 中所有元素的 vector
vector<int> v6{1, 2, 3, 4, 5}; // 创建一个包含初始化列表中元素的 vector
- 可以使用
push_back和pop_back方法在尾部插入或删除元素。
v1.push_back(10); // 在 v1 的尾部插入一个值为 10 的元素
v1.pop_back(); // 删除 v1 的尾部元素
- 可以使用
insert和erase方法在任意位置插入或删除一个或多个元素。
v1.insert(v1.begin(), 20); // 在 v1 的头部插入一个值为 20 的元素
v1.insert(v1.begin() + 2, 3, 30); // 在 v1 的第三个位置插入三个值为 30 的元素
v1.erase(v1.begin()); // 删除 v1 的头部元素
v1.erase(v1.begin(), v1.begin() + 3); // 删除 v1 的前三个元素
- 可以使用
resize和reserve方法来改变 vector 的大小或容量。
v1.resize(5); // 改变 v1 的大小为 5,如果原来小于 5,则在尾部添加默认值;如果原来大于 5,则删除多余的元素
v1.resize(10, -1); // 改变 v1 的大小为 10,如果原来小于 10,则在尾部添加值为 -1 的元素;如果原来大于 10,则删除多余的元素
v1.reserve(20); // 改变 v1 的容量为 20,如果原来小于 20,则分配更大的内存空间,但不改变大小;如果原来大于等于 20,则不做任何操作
- 可以使用
[]或at方法来访问或修改 vector 中的元素。
cout << v1[0] << endl; // 输出 v1 的第一个元素,不检查越界
cout << v1.at(0) << endl; // 输出 v1 的第一个元素,如果越界则抛出异常
v1[0] = 100; // 修改 v1 的第一个元素为 100,不检查越界
v1.at(0) = 200; // 修改 v1 的第一个元素为 200,如果越界则抛出异常
- 可以使用
front和back方法来访问或修改 vector 的头部或尾部元素。
cout << v1.front() << endl; // 输出 v1 的头部元素
cout << v1.back() << endl; // 输出 v1 的尾部元素
v1.front() = 300; // 修改 v1 的头部元素为 300
v1.back() = 400; // 修改 v1 的尾部元素为 400
- 可以使用
begin和end方法来获取 vector 的迭代器,用于遍历或操作 vector 中的元素。¹²
vector<int>::iterator it; // 定义一个迭代器
for (it = v1.begin(); it != v1.end(); it++) { // 遍历 v1 中的所有元素cout << *it << " "; // 输出当前元素的值*it += 10; // 将当前元素的值增加 10
}
cout << endl;
- 可以使用
empty和size方法来判断 vector 是否为空或获取 vector 中的元素个数。¹²
if (v1.empty()) { // 判断 v1 是否为空cout << "v1 is empty" << endl;
} else {cout << "v1 is not empty" << endl;
}
cout << "v1 size: " << v1.size() << endl; // 输出 v1 中的元素个数
- 可以使用
clear方法来清空 vector 中的所有元素。
v1.clear(); // 清空 v1 中的所有元素
- set:set 是一个有序的容器,其中的元素按照一定的规则进行排序。它不允许重复的元素,并且可以快速地插入、删除和查找元素。 set 的头文件是
<set>,它的定义如下:
template <class T, class Compare = less<T>, class Allocator = allocator<T> >
class set;
其中,T 是元素的类型,Compare 是比较函数对象的类型,默认为 std::less,表示按照升序排序;Allocator 是分配器的类型,默认为 std::allocator。
set 的特性有:
- set 底层是用红黑树实现的,因此可以保证插入、删除和查找操作的时间复杂度都是 O(log n)。
- set 中的元素是只读的,不能通过迭代器来修改它们的值,否则会破坏 set 的有序性。
- set 中不存在重复的元素,如果插入一个已经存在的元素,则会被忽略。
- set 支持拷贝、赋值、移动等操作,可以方便地复制或转移数据。
set 的用法有:
- 可以使用构造函数来创建一个 set 对象,并指定初始元素、比较函数等参数。
set<int> s1; // 创建一个空的 set
set<int> s2{1, 2, 3, 4, 5}; // 创建一个包含初始化列表中元素的 set
set<int> s3(s2); // 创建一个和 s2 相同的 set
set<int> s4(s2.begin(), s2.end()); // 创建一个包含 s2 中所有元素的 set
set<int, greater<int>> s5; // 创建一个按照降序排序的 set
- 可以使用
insert方法在 set 中插入一个或多个元素。
s1.insert(10); // 在 s1 中插入一个值为 10 的元素
s1.insert({20, 30, 40}); // 在 s1 中插入多个值为 20, 30, 40 的元素
s1.insert(s2.begin(), s2.end()); // 在 s1 中插入 s2 中的所有元素
- 可以使用
erase方法在 set 中删除一个或多个元素。
s1.erase(10); // 在 s1 中删除值为 10 的元素
s1.erase(s1.begin()); // 在 s1 中删除第一个元素
s1.erase(s1.begin(), s1.end()); // 在 s1 中删除所有元素
- 可以使用
find方法在 set 中查找一个元素,返回一个指向该元素的迭代器,如果没有找到则返回 end()。
auto it = s1.find(10); // 在 s1 中查找值为 10 的元素
if (it != s1.end()) {cout << "Found " << *it << endl; // 输出 Found 10
} else {cout << "Not found" << endl;
}
- 可以使用
count方法在 set 中统计一个元素出现的次数,返回一个整数值,由于 set 不允许重复元素,所以结果只能是 0 或 1。
int n = s1.count(10); // 在 s1 中统计值为 10 的元素出现的次数
cout << n << endl; // 输出 0 或 1
- 可以使用
lower_bound和upper_bound方法在有序的 set 中查找第一个大于等于或大于目标值的元素的位置,返回一个迭代器。
auto it1 = s1.lower_bound(15); // 在 s1 中查找第一个大于等于 15 的元素的位置
auto it2 = s1.upper_bound(15); // 在 s1 中查找第一个大于 15 的元素的位置
if (it1 != s1.end()) {cout << *it1 << endl; // 输出找到的元素的值
} else {cout << "Not found" << endl;
}
if (it2 != s1.end()) {cout << *it2 << endl; // 输出找到的元素的值
} else {cout << "Not found" << endl;
}
- 可以使用
begin和end方法来获取 set 的迭代器,用于遍历或操作 set 中的元素。
set<int>::iterator it; // 定义一个迭代器
for (it = s1.begin(); it != s1.end(); it++) { // 遍历 s1 中的所有元素cout << *it << " "; // 输出当前元素的值
}
cout << endl;
- 可以使用
empty和size方法来判断 set 是否为空或获取 set 中的元素个数。
if (s1.empty()) { // 判断 s1 是否为空cout << "s1 is empty" << endl;
} else {cout << "s1 is not empty" << endl;
}
cout << "s1 size: " << s1.size() << endl; // 输出 s1 中的元素个数
- 可以使用
clear方法来清空 set 中的所有元素。
s1.clear(); // 清空 s1 中的所有元素
- map:map 是一个关联容器,它存储了键值对(key-value pair)类型的元素,其中键是唯一的,值可以重复。它可以根据键快速地插入、删除和查找对应的值。 map 的头文件是
<map>,它的定义如下:
template <class Key, class T, class Compare = less<Key>, class Allocator = allocator<pair<const Key, T> > >
class map;
其中,Key 是键的类型,T 是值的类型,Compare 是比较函数对象的类型,默认为 std::less,表示按照升序排序;Allocator 是分配器的类型,默认为 std::allocator<pair<const Key, T>>。
map 的特性有:
- map 底层是用红黑树实现的,因此可以保证插入、删除和查找操作的时间复杂度都是 O(log n)。
- map 中的键是只读的,不能通过迭代器来修改它们的值,否则会破坏 map 的有序性。
- map 中不存在重复的键,如果插入一个已经存在的键,则会覆盖原来的值。
- map 支持拷贝、赋值、移动等操作,可以方便地复制或转移数据。
map 的用法有:
- 可以使用构造函数来创建一个 map 对象,并指定初始元素、比较函数等参数。
map<int, string> m1; // 创建一个空的 map
map<int, string> m2{{1, "one"}, {2, "two"}, {3, "three"}}; // 创建一个包含初始化列表中元素的 map
map<int, string> m3(m2); // 创建一个和 m2 相同的 map
map<int, string> m4(m2.begin(), m2.end()); // 创建一个包含 m2 中所有元素的 map
map<int, string, greater<int>> m5; // 创建一个按照降序排序的 map
- 可以使用
insert方法在 map 中插入一个或多个键值对。
m1.insert({10, "ten"}); // 在 m1 中插入一个键值对 {10, "ten"}
m1.insert({{20, "twenty"}, {30, "thirty"}}); // 在 m1 中插入多个键值对 {{20, "twenty"}, {30, "thirty"}}
m1.insert(m2.begin(), m2.end()); // 在 m1 中插入 m2 中的所有键值对
- 可以使用
erase方法在 map 中删除一个或多个键值对。
m1.erase(10); // 在 m1 中删除键为 10 的键值对
m1.erase(m1.begin()); // 在 m1 中删除第一个键值对
m1.erase(m1.begin(), m1.end()); // 在 m1 中删除所有键值对
- 可以使用
find方法在 map 中查找一个键对应的值,返回一个指向该键值对的迭代器,如果没有找到则返回 end()。
auto it = m1.find(10); // 在 m1 中查找键为 10 的键值对
if (it != m1.end()) {cout << "Found " << it->first << ": " << it->second << endl; // 输出 Found 10: ten
} else {cout << "Not found" << endl;
}
- 可以使用
count方法在 map 中统计一个键出现的次数,返回一个整数值,由于 map 不允许重复键,所以结果只能是 0 或 1。
int n = m1.count(10); // 在 m1 中统计键为 10 的键值对出现的次数
cout << n << endl; // 输出 0 或 1
- 可以使用
lower_bound和upper_bound方法在有序的 map 中查找第一个大于等于或大于目标键的键值对的位置,返回一个迭代器。
auto it1 = m1.lower_bound(15); // 在 m1 中查找第一个大于等于 15 的键值对的位置
auto it2 = m1.upper_bound(15); // 在 m1 中查找第一个大于 15 的键值对的位置
if (it1 != m1.end()) {cout << it1->first << ": " << it1->second << endl; // 输出找到的键值对
} else {cout << "Not found" << endl;
}
if (it2 != m1.end()) {cout << it2->first << ": " << it2->second << endl; // 输出找到的键值对
} else {cout << "Not found" << endl;
}
- 可以使用
begin和end方法来获取 map 的迭代器,用于遍历或操作 map 中的键值对。
map<int, string>::iterator it; // 定义一个迭代器
for (it = m1.begin(); it != m1.end(); it++) { // 遍历 m1 中的所有键值对cout << it->first << ": " << it->second << " "; // 输出当前键值对
}
cout << endl;
- 可以使用
empty和size方法来判断 map 是否为空或获取 map 中的键值对个数。
if (m1.empty()) { // 判断 m1 是否为空cout << "m1 is empty" << endl;
} else {cout << "m1 is not empty" << endl;
}
cout << "m1 size: " << m1.size() << endl; // 输出 m1 中的键值对个数
- 可以使用
clear方法来清空 map 中的所有键值对。
m1.clear(); // 清空 m1 中的所有键值对
- deque:deque 是一个双端队列,它可以在头部和尾部快速地插入和删除元素,也支持随机访问,但是相比 vector,它的随机访问效率较低。 deque 的头文件是
<deque>,它的定义如下:
template <class T, class Allocator = allocator<T> >
class deque;
其中,T 是元素的类型,Allocator 是分配器的类型,默认为 std::allocator。
deque 的特性有:
- deque 不是在内存中连续存储元素,而是分成多个块,每个块连续存储一部分元素,然后用一个索引表来记录每个块的位置。
- deque 可以在头部和尾部快速地插入和删除元素,不会影响其他元素的位置,但是在中间插入或删除元素会导致后面的元素移动,效率较低。
- deque 支持随机访问,可以通过下标来访问任意位置的元素,但是由于需要先查找块的位置再访问元素,所以效率不如 vector 高。
- deque 不会自动调整容量,当容量不足时,会在头部或尾部分配新的块,并更新索引表。
- deque 支持拷贝、赋值、移动等操作,可以方便地复制或转移数据。
deque 的用法有:
- 可以使用构造函数来创建一个 deque 对象,并指定初始大小、值等参数。
deque<int> d1; // 创建一个空的 deque
deque<int> d2(10); // 创建一个包含 10 个 int 类型元素的 deque,默认值为 0
deque<int> d3(10, 1); // 创建一个包含 10 个 int 类型元素的 deque,初始值为 1
deque<int> d4(d3); // 创建一个和 d3 相同的 deque
deque<int> d5(d3.begin(), d3.end()); // 创建一个包含 d3 中所有元素的 deque
deque<int> d6{1, 2, 3, 4, 5}; // 创建一个包含初始化列表中元素的 deque
- 可以使用
push_front和push_back方法在 deque 的头部或尾部插入元素。
d1.push_front(10); // 在 d1 的头部插入一个值为 10 的元素
d1.push_back(20); // 在 d1 的尾部插入一个值为 20 的元素
- 可以使用
pop_front和pop_back方法在 deque 的头部或尾部删除元素。
d1.pop_front(); // 删除 d1 的头部元素
d1.pop_back(); // 删除 d1 的尾部元素
- 可以使用
insert和erase方法在任意位置插入或删除一个或多个元素。
d1.insert(d1.begin(), 30); // 在 d1 的头部插入一个值为 30 的元素
d1.insert(d1.begin() + 2, 3, 40); // 在 d1 的第三个位置插入三个值为 40 的元素
d1.erase(d1.begin()); // 删除 d1 的头部元素
d1.erase(d1.begin(), d1.begin() + 3); // 删除 d1 的前三个元素
- 可以使用
resize方法来改变 deque 的大小。
d1.resize(5); // 改变 d1 的大小为 5,如果原来小于 5,则在尾部添加默认值;如果原来大于 5,则删除多余的元素
d1.resize(10, -1); // 改变 d1 的大小为 10,如果原来小于 10,则在尾部添加值为 -1 的元素;如果原来大于 10,则删除多余的元素
- 可以使用
[]或at方法来访问或修改 deque 中的元素。
cout << d1[0] << endl; // 输出 d1 的第一个元素,不检查越界
cout << d1.at(0) << endl; // 输出 d1 的第一个元素,如果越界则抛出异常
d1[0] = 100; // 修改 d1 的第一个元素为 100,不检查越界
d1.at(0) = 200; // 修改 d1 的第一个元素为 200,如果越界则抛出异常
- 可以使用
front和back方法来访问或修改 deque 的头部或尾部元素。
cout << d1.front() << endl; // 输出 d1 的头部元素
cout << d1.back() << endl; // 输出 d1 的尾部元素
d1.front() = 300; // 修改 d1 的头部元素为 300
d1.back() = 400; // 修改 d1 的尾部元素为 400
- 可以使用
begin和end方法来获取 deque 的迭代器,用于遍历或操作 deque 中的元素。
deque<int>::iterator it; // 定义一个迭代器
for (it = d1.begin(); it != d1.end(); it++) { // 遍历 d1 中的所有元素cout << *it << " "; // 输出当前元素的值*it += 10; // 将当前元素的值增加 10
}
cout << endl;
- 可以使用
empty和size方法来判断 deque 是否为空或获取 deque 中的元素个数。
if (d1.empty()) { // 判断 d1 是否为空cout << "d1 is empty" << endl;
} else {cout << "d1 is not empty" << endl;
}
cout << "d1 size: " << d1.size() << endl; // 输出 d1 中的元素个数
- 可以使用
clear方法来清空 deque 中的所有元素。
d1.clear(); // 清空 d1 中的所有元素
- queue:queue 是一个先进先出(FIFO)的队列,它只允许在尾部插入元素,在头部删除元素。 queue 的头文件是
<queue>,它的定义如下:
template <class T, class Container = deque<T> >
class queue;
其中,T 是元素的类型,Container 是底层容器的类型,默认为 std::deque。
queue 的特性有:
- queue 是一个适配器,它不是直接实现数据结构和算法,而是利用另一个容器(如 deque)来提供基本功能,并在此基础上添加一些限制和接口。
- queue 只提供了有限的操作,只能在尾部插入元素,在头部删除或访问元素,不能随机访问或修改其他位置的元素。
- queue 支持拷贝、赋值、移动等操作,可以方便地复制或转移数据。
queue 的用法有:
- 可以使用构造函数来创建一个 queue 对象,并指定初始容器等参数。
queue<int> q1; // 创建一个空的 queue
deque<int> d{1, 2, 3, 4, 5}; // 创建一个 deque 对象
queue<int> q2(d); // 创建一个包含 deque 中所有元素的 queue
- 可以使用
push方法在 queue 的尾部插入一个元素。
q1.push(10); // 在 q1 的尾部插入一个值为 10 的元素
- 可以使用
pop方法在 queue 的头部删除一个元素。
q1.pop(); // 删除 q1 的头部元素
- 可以使用
front和back方法来访问 queue 的头部或尾部元素。
cout << q1.front() << endl; // 输出 q1 的头部元素
cout << q1.back() << endl; // 输出 q1 的尾部元素
- 可以使用
empty和size方法来判断 queue 是否为空或获取 queue 中的元素个数。
if (q1.empty()) { // 判断 q1 是否为空cout << "q1 is empty" << endl;
} else {cout << "q1 is not empty" << endl;
}
cout << "q1 size: " << q1.size() << endl; // 输出 q1 中的元素个数
- unordered_set:unordered_set 是一个无序的容器,它存储了不重复的元素,并且可以快速地插入、删除和查找元素。 unordered_set 的头文件是
<unordered_set>,它的定义如下:
template <class T, class Hash = hash<T>, class KeyEqual = equal_to<T>, class Allocator = allocator<T> >
class unordered_set;
其中,T 是元素的类型,Hash 是哈希函数对象的类型,默认为 std::hash;KeyEqual 是判断两个元素是否相等的函数对象的类型,默认为 std::equal_to;Allocator 是分配器的类型,默认为 std::allocator。
unordered_set 的特性有:
- unordered_set 底层是用哈希表实现的,因此可以保证插入、删除和查找操作的平均时间复杂度都是 O(1)。
- unordered_set 中的元素是无序的,不能通过下标或迭代器来访问或修改它们的顺序。
- unordered_set 中不存在重复的元素,如果插入一个已经存在的元素,则会被忽略。
- unordered_set 支持拷贝、赋值、移动等操作,可以方便地复制或转移数据。
unordered_set 的用法有:
- 可以使用构造函数来创建一个 unordered_set 对象,并指定初始元素、哈希函数、相等函数等参数。
unordered_set<int> s1; // 创建一个空的 unordered_set
unordered_set<int> s2{1, 2, 3, 4, 5}; // 创建一个包含初始化列表中元素的 unordered_set
unordered_set<int> s3(s2); // 创建一个和 s2 相同的 unordered_set
unordered_set<int> s4(s2.begin(), s2.end()); // 创建一个包含 s2 中所有元素的 unordered_set
- 可以使用
insert方法在 unordered_set 中插入一个或多个元素。
s1.insert(10); // 在 s1 中插入一个值为 10 的元素
s1.insert({20, 30, 40}); // 在 s1 中插入多个值为 20, 30, 40 的元素
s1.insert(s2.begin(), s2.end()); // 在 s1 中插入 s2 中的所有元素
- 可以使用
erase方法在 unordered_set 中删除一个或多个元素。
s1.erase(10); // 在 s1 中删除值为 10 的元素
s1.erase(s1.begin()); // 在 s1 中删除第一个元素
s1.erase(s1.begin(), s1.end()); // 在 s1 中删除所有元素
- 可以使用
find方法在 unordered_set 中查找一个元素,返回一个指向该元素的迭代器,如果没有找到则返回 end()。
auto it = s1.find(10); // 在 s1 中查找值为 10 的元素
if (it != s1.end()) {cout << "Found " << *it << endl; // 输出 Found 10
} else {cout << "Not found" << endl;
}
- 可以使用
count方法在 unordered_set 中统计一个元素出现的次数,返回一个整数值,由于 unordered_set 不允许重复元素,所以结果只能是 0 或 1。
int n = s1.count(10); // 在 s1 中统计值为 10 的元素出现的次数
cout << n << endl; // 输出 0 或 1
- 可以使用
begin和end方法来获取 unordered_set 的迭代器,用于遍历或操作 unordered_set 中的元素。
unordered_set<int>::iterator it; // 定义一个迭代器
for (it = s1.begin(); it != s1.end(); it++) { // 遍历 s1 中的所有元素cout << *it << " "; // 输出当前元素的值
}
cout << endl;
- 可以使用
empty和size方法来判断 unordered_set 是否为空或获取 unordered_set 中的元素个数。
if (s1.empty()) { // 判断 s1 是否为空cout << "s1 is empty" << endl;
} else {cout << "s1 is not empty" << endl;
}
cout << "s1 size: " << s1.size() << endl; // 输出 s1 中的元素个数
- 可以使用
clear方法来清空 unordered_set 中的所有元素。
s1.clear(); // 清空 s1 中的所有元素
- unordered_map:unordered_map 是一个关联容器,它存储了键值对(key-value pair)类型的元素,其中键是唯一的,值可以重复。它可以根据键快速地插入、删除和查找对应的值。 unordered_map 的头文件是
<unordered_map>,它的定义如下:
template <class Key, class T, class Hash = hash<Key>, class KeyEqual = equal_to<Key>, class Allocator = allocator<pair<const Key, T> > >
class unordered_map;
其中,Key 是键的类型,T 是值的类型,Hash 是哈希函数对象的类型,默认为 std::hash;KeyEqual 是判断两个键是否相等的函数对象的类型,默认为 std::equal_to;Allocator 是分配器的类型,默认为 std::allocator<pair<const Key, T>>。
unordered_map 的特性有:
- unordered_map 底层是用哈希表实现的,因此可以保证插入、删除和查找操作的平均时间复杂度都是 O(1)。
- unordered_map 中的键是无序的,不能通过下标或迭代器来访问或修改它们的顺序。
- unordered_map 中不存在重复的键,如果插入一个已经存在的键,则会覆盖原来的值。
- unordered_map 支持拷贝、赋值、移动等操作,可以方便地复制或转移数据。
unordered_map 的用法有:
- 可以使用构造函数来创建一个 unordered_map 对象,并指定初始元素、哈希函数、相等函数等参数。
unordered_map<int, string> m1; // 创建一个空的 unordered_map
unordered_map<int, string> m2{{1, "one"}, {2, "two"}, {3, "three"}}; // 创建一个包含初始化列表中元素的 unordered_map
unordered_map<int, string> m3(m2); // 创建一个和 m2 相同的 unordered_map
unordered_map<int, string> m4(m2.begin(), m2.end()); // 创建一个包含 m2 中所有元素的 unordered_map
- 可以使用
insert方法在 unordered_map 中插入一个或多个键值对。
m1.insert({10, "ten"}); // 在 m1 中插入一个键值对 {10, "ten"}
m1.insert({{20, "twenty"}, {30, "thirty"}}); // 在 m1 中插入多个键值对 {{20, "twenty"}, {30, "thirty"}}
m1.insert(m2.begin(), m2.end()); // 在 m1 中插入 m2 中的所有键值对
- 可以使用
erase方法在 unordered_map 中删除一个或多个键值对。
m1.erase(10); // 在 m1 中删除键为 10 的键值对
m1.erase(m1.begin()); // 在 m1 中删除第一个键值对
m1.erase(m1.begin(), m1.end()); // 在 m1 中删除所有键值对
- 可以使用
find方法在 unordered_map 中查找一个键对应的值,返回一个指向该键值对的迭代器,如果没有找到则返回 end()。
auto it = m1.find(10); // 在 m1 中查找键为 10 的键值对
if (it != m1.end()) {cout << "Found " << it->first << ": " << it->second << endl; // 输出 Found 10: ten
} else {cout << "Not found" << endl;
}
- 可以使用
count方法在 unordered_map 中统计一个键出现的次数,返回一个整数值,由于 unordered_map 不允许重复键,所以结果只能是 0 或 1。
int n = m1.count(10); // 在 m1 中统计键为 10 的键值对出现的次数
cout << n << endl; // 输出 0 或 1
- 可以使用
begin和end方法来获取 unordered_map 的迭代器,用于遍历或操作 unordered_map 中的键值对。
unordered_map<int, string>::iterator it; // 定义一个迭代器
for (it = m1.begin(); it != m1.end(); it++) { // 遍历 m1 中的所有键值对cout << it->first << ": " << it->second << " "; // 输出当前键值对
}
cout << endl;
- 可以使用
empty和size方法来判断 unordered_map 是否为空或获取 unordered_map 中的键值对个数。
if (m1.empty()) { // 判断 m1 是否为空cout << "m1 is empty" << endl;
} else {cout << "m1 is not empty" << endl;
}
cout << "m1 size: " << m1.size() << endl; // 输出 m1 中的键值对个数
- 可以使用
clear方法来清空 unordered_map 中的所有键值对。
m1.clear(); // 清空 m1 中的所有键值对
- stack:stack 是一个后进先出(LIFO)的栈,它只允许在顶部插入和删除元素。 stack 的头文件是
<stack>,它的定义如下:
template <class T, class Container = deque<T> >
class stack;
其中,T 是元素的类型,Container 是底层容器的类型,默认为 std::deque。
stack 的特性有:
- stack 是一个适配器,它不是直接实现数据结构和算法,而是利用另一个容器(如 deque)来提供基本功能,并在此基础上添加一些限制和接口。
- stack 只提供了有限的操作,只能在顶部插入、删除或访问元素,不能随机访问或修改其他位置的元素。
- stack 支持拷贝、赋值、移动等操作,可以方便地复制或转移数据。
stack 的用法有:
- 可以使用构造函数来创建一个 stack 对象,并指定初始容器等参数。
stack<int> s1; // 创建一个空的 stack
deque<int> d{1, 2, 3, 4, 5}; // 创建一个 deque 对象
stack<int> s2(d); // 创建一个包含 deque 中所有元素的 stack
- 可以使用
push方法在 stack 的顶部插入一个元素。
s1.push(10); // 在 s1 的顶部插入一个值为 10 的元素
- 可以使用
pop方法在 stack 的顶部删除一个元素。
s1.pop(); // 删除 s1 的顶部元素
- 可以使用
top方法来访问或修改 stack 的顶部元素。
cout << s1.top() << endl; // 输出 s1 的顶部元素
s1.top() = 20; // 修改 s1 的顶部元素为 20
- 可以使用
empty和size方法来判断 stack 是否为空或获取 stack 中的元素个数。
if (s1.empty()) { // 判断 s1 是否为空cout << "s1 is empty" << endl;
} else {cout << "s1 is not empty" << endl;
}
cout << "s1 size: " << s1.size() << endl; // 输出 s1 中的元素个数
- 多态:多态是指同一个接口,可以有不同的实现方式,从而实现不同的功能。多态是面向对象编程的核心概念,它可以提高代码的复用性和扩展性。
- 静态多态:静态多态是指在编译期就确定了调用的函数,它是通过重载和模板技术实现的。静态多态不需要虚函数,也不需要继承关系,只需要各个具体类的实现中要求相同的接口声明,这里的接口称之为隐式接口。静态多态的优点是效率高,缺点是灵活性低。
- 动态多态:动态多态是指在运行期才确定调用的函数,它是通过虚函数和继承关系来实现的。动态多态需要抽象出相关类之间共同的功能集合,在基类中将共同的功能声明为多个公共虚函数接口,子类通过重写这些虚函数,实现各自对应的功能。在调用时,通过基类的指针或引用来操作这些子类对象,所需执行的虚函数会自动绑定到对应的子类对象上去。动态多态的优点是灵活性高,缺点是效率低。
动态多态的实现原理如下:
- 当一个类中有虚函数时,编译器会为该类生成一个虚函数表(vtable),存储该类中所有虚函数的地址。同时,编译器会为该类的每个对象添加一个虚指针(vptr),指向该类的虚函数表。
- 当一个子类继承了一个基类时,子类也会继承基类的虚函数表,并且如果子类重写了某个虚函数,那么子类的虚函数表中对应位置的地址会被替换为子类自己的虚函数地址。
- 当通过基类指针或引用调用一个虚函数时,编译器会根据该指针或引用所指向的对象的类型,找到对应的虚函数表,并根据虚函数在表中的偏移量,找到正确的虚函数地址,并调用之。
下面是一个简单的例子:
// 基类
class Animal {
public:// 虚析构函数virtual ~Animal() {}// 虚函数virtual void speak() {cout << "Animal speak" << endl;}
};// 子类
class Dog : public Animal {
public:// 重写虚函数virtual void speak() {cout << "Dog speak" << endl;}
};// 子类
class Cat : public Animal {
public:// 重写虚函数virtual void speak() {cout << "Cat speak" << endl;}
};// 测试代码
int main() {// 基类指针Animal* p = nullptr;// 指向子类对象p = new Dog();// 调用虚函数p->speak(); // 输出 Dog speak// 释放内存delete p;// 指向另一个子类对象p = new Cat();// 调用虚函数p->speak(); // 输出 Cat speak// 释放内存delete p;return 0;
}
不能是虚函数的函数
-
虚函数:虚函数是一种特殊的成员函数,它可以在基类中声明为 virtual,并在派生类中重写,从而实现动态多态。虚函数的调用是通过虚函数表(vtable)和虚指针(vptr)来实现的,每个有虚函数的类都有一个虚函数表,存储该类的所有虚函数的地址,每个有虚函数的对象都有一个虚指针,指向该对象所属类的虚函数表。当通过基类指针或引用调用一个虚函数时,会根据该指针或引用所指向的对象的类型,找到对应的虚函数表,并根据虚函数在表中的偏移量,找到正确的虚函数地址,并调用之。
-
不能是虚函数的函数:C++ 中有一些特殊的成员函数,它们不能被声明为虚函数,主要有以下几种:
-
构造函数:构造函数是用于创建对象并初始化对象状态的成员函数,它不能被声明为虚函数,因为在创建对象时,还没有分配内存空间,也没有生成虚指针和虚函数表,因此无法调用虚函数。如果将构造函数声明为虚函数,编译器会报错。但是,构造函数可以调用其他的虚函数,只是这时候调用的是自己类中定义或继承的版本,而不是子类重写的版本。
-
析构函数:析构函数是用于销毁对象并释放资源的成员函数,它可以被声明为虚函数,以实现多态的析构。如果一个基类指针或引用指向一个派生类对象,并且通过该指针或引用来删除该对象,那么如果基类的析构函数不是虚函数,就只会调用基类的析构函数,而不会调用派生类的析构函数,从而导致资源泄漏或其他错误。但是,析构函数不能被声明为纯虚函数(pure virtual function),也就是在声明时后面加上
= 0的那种。因为纯虚函数表示没有实现,需要子类来提供实现,而每个类都需要有自己的析构函数来执行清理工作。如果将析构函数声明为纯虚函数,编译器会报错。 -
静态成员函数:静态成员函数是属于类本身而不属于对象的成员函数,它可以通过类名或对象来调用,但是它不包含 this 指针,也不受访问控制符的限制。静态成员函数不能被声明为虚函数,因为静态成员函数不依赖于对象的存在,也就无法使用虚指针和虚函数表来实现多态。如果将静态成员函数声明为虚函数,编译器会报错。
-
友元函数:友元函数是一种特殊的非成员函数,它可以访问某个类或对象的私有或保护成员,但是它不属于该类或对象。友元关系不能被继承或传递。友元函数不能被声明为虚函数。
-
内联(inline)成员函数:内联成员函数是一种优化技术,它可以在编译期将内联成员函数的代码直接嵌入到调用处,从而避免了普通成员函数调用时产生的额外开销(如参数传递、栈帧分配等)。内联成员函数可以在定义时加上 inline 关键字来显式声明,也可以在类内部定义时隐式声明。内联成员函数不能被声明为虚函数,因为虚函数的调用是通过虚函数表和虚指针来实现的,这与内联成员函数的优化目的相矛盾。如果将内联成员函数声明为虚函数,编译器会忽略 inline 关键字,将其当作普通的虚函数处理。
-
vector 和 list
- vector:vector 是一种顺序容器,它使用连续的内存空间来存储元素,类似于数组,但是它可以动态地调整大小。vector 的头文件是
<vector>,它的定义如下:
template <class T, class Allocator = allocator<T> >
class vector;
其中,T 是元素的类型,Allocator 是分配器的类型,默认为 std::allocator。
vector 的特性有:
-
vector 支持随机访问,可以通过下标运算符 [] 或 at 方法来访问或修改任意位置的元素,时间复杂度为 O(1)。
-
vector 支持在尾部插入或删除元素,可以使用 push_back 或 pop_back 方法来实现,时间复杂度为 O(1)(摊还)。
-
vector 不支持在头部或中间插入或删除元素,如果要实现,可以使用 insert 或 erase 方法,但是时间复杂度为 O(n),因为需要移动后面的元素。
-
vector 有一个容量(capacity)和一个大小(size)的概念,容量表示已经分配的内存空间能够容纳的元素个数,大小表示实际存储的元素个数。当大小超过容量时,vector 会重新分配一块更大的内存空间,并将原来的元素复制过去,这会导致效率降低和迭代器失效。可以使用 reserve 方法来预先分配足够的内存空间,避免频繁的重新分配。
-
list:list 是一种顺序容器,它使用双向链表来存储元素,每个节点包含一个元素和两个指针,分别指向前一个节点和后一个节点。list 的头文件是
<list>,它的定义如下:
template <class T, class Allocator = allocator<T> >
class list;
其中,T 是元素的类型,Allocator 是分配器的类型,默认为 std::allocator。
list 的特性有:
-
list 不支持随机访问,只能通过迭代器或指针来访问或修改任意位置的元素,时间复杂度为 O(n)。
-
list 支持在头部或尾部插入或删除元素,可以使用 push_front, pop_front, push_back 或 pop_back 方法来实现,时间复杂度为 O(1)。
-
list 支持在中间插入或删除元素,可以使用 insert 或 erase 方法来实现,时间复杂度为 O(1),因为不需要移动其他元素。
-
list 没有容量和大小的概念,它只有一个大小(size)的概念,表示实际存储的元素个数。list 不需要重新分配内存空间,因为它是动态地分配每个节点的内存空间。
-
区别和适用场景:vector 和 list 容器的区别主要在于它们使用的数据结构和内存管理方式不同,这导致了它们在性能和功能上有各自的优缺点。一般来说:
- 如果需要频繁地访问或修改任意位置的元素,或者需要高效地利用内存空间,那么可以选择 vector 容器。
- 如果需要频繁地在头部或中间插入或删除元素,或者需要灵活地调整容器大小,那么可以选择 list 容器。
虚指针
虚指针(Virtual Pointer)是一种特殊的指针,它存在于含有虚函数的类的对象中,用于指向一个虚函数表(Virtual Function Table)。虚函数表是一个存储了该类所有虚函数地址的数组,它在编译时就被创建好了。¹²
当一个类被继承时,如果子类重写了父类的虚函数,那么子类就会有自己的虚函数表,其中包含了子类自己的虚函数地址。如果子类没有重写父类的虚函数,那么子类就会共用父类的虚函数表。²³
虚指针和虚函数表的作用是实现多态性,也就是让基类指针可以根据所指向的对象的不同,动态地调用相应的虚函数。这个过程发生在运行时,也叫做动态绑定(Dynamic Binding)。¹⁴
下面是一个简单的例子,演示了虚指针和虚函数表的使用:
#include <iostream>
using namespace std;class A { // 基类A
public:virtual void f() { // 虚函数fcout << "A::f()" << endl;}
};class B : public A { // 子类B
public:void f() override { // 重写虚函数fcout << "B::f()" << endl;}
};int main() {A a; // 基类对象aB b; // 子类对象bA* p = &a; // 基类指针p指向ap->f(); // 调用A::f()p = &b; // 基类指针p指向bp->f(); // 调用B::f()return 0;
}
输出结果为:
A::f()
B::f()
在这个例子中,基类A和子类B都有一个虚指针,分别指向各自的虚函数表。基类A的虚函数表中只有一个元素,就是A::f()的地址。子类B的虚函数表中也只有一个元素,就是B::f()的地址。当基类指针p指向不同的对象时,它会通过对象中的虚指针找到对应的虚函数表,并从中取出正确的虚函数地址来调用。
相关文章:

零碎的C++
构造函数和析构函数 构造函数不能是虚函数,而析构函数可以是虚函数。原因如下: 构造函数不能是虚函数,因为在执行构造函数时,对象还没有完全创建,还没有分配内存空间,也没有初始化虚函数表指针。如果构造…...
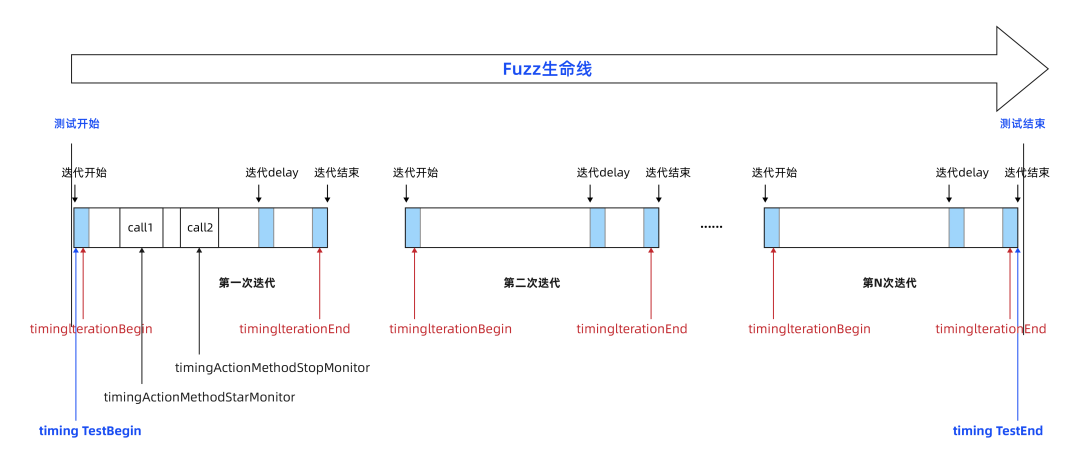
模糊测试面面观 | 模糊测试是如何发现异常情况的?
协议模糊测试是一种用于评估通信协议、文件格式和API实现系统安全性和稳定性的关键技术。在模糊测试过程中,监视器扮演着关键角色,它们能够捕获异常情况、错误响应、资源利用等,为测试人员提供有价值的信息,有助于发现潜在漏洞和问…...
C#备份数据库文件
c#备份数据库文件完整代码 sqlServer 存储过程: USE [PSIDBase] GO /****** Object: StoredProcedure [dbo].[sp_BackupDB] Script Date: 2023/8/31 16:49:02 ******/ SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GOALTER procedure [dbo].[sp_BackupDB]…...

行军遇到各种复杂地形怎么处理?
行军遇到各种复杂地形怎么处理? 【安志强趣讲《孙子兵法》第30讲】 【原文】 凡军好高而恶下,贵阳而贱阴,养生而处实,军无百疾,是谓必胜。 【注释】 阳,太阳能照到的地方。阴,太阳照不到的地方。…...
.............................................)
Python Number(数字).............................................
Python Number 数据类型用于存储数值。 数据类型是不允许改变的,这就意味着如果改变 Number 数据类型的值,将重新分配内存空间。 以下实例在变量赋值时 Number 对象将被创建: var1 1 var2 10您也可以使用del语句删除一些 Number 对象引用。 del语句…...

设置 Hue Server 与 Hue Web 界面之间的会话超时时间
设置 Hue Server 与 Hue Web 界面之间的会话超时时间 在 CDH 的 Hue 中,Auto Logout Timeout 参数表示用户在不活动一段时间后将自动注销(登出)的超时时间。当用户在 Hue 中处于不活动状态超过该设定时间时,系统将自动注销用户&am…...

openGauss学习笔记-57 openGauss 高级特性-并行查询
文章目录 openGauss学习笔记-57 openGauss 高级特性-并行查询57.1 适用场景与限制57.2 资源对SMP性能的影响57.3 其他因素对SMP性能的影响57.4 配置步骤 openGauss学习笔记-57 openGauss 高级特性-并行查询 openGauss的SMP并行技术是一种利用计算机多核CPU架构来实现多线程并行…...
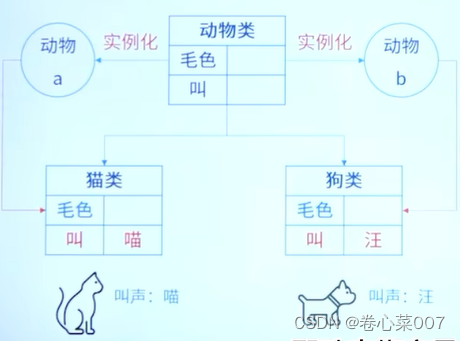
软考(1)-面向对象的概念
目录 一. 软考基本信息 1. 软考时间: 2. 软考科目: 3.专业知识介绍 -- 综合知识考点分布 4. 专业介绍 -- 软件设计考点分布 二. 面向对象概念 1. 封装 考点一:对象 考点二:封装private 2. 继承 考点三:类 考…...

深度学习推荐系统(四)WideDeep模型及其在Criteo数据集上的应用
深度学习推荐系统(四)Wide&Deep模型及其在Criteo数据集上的应用 在2016年, 随着微软的Deep Crossing, 谷歌的Wide&Deep以及FNN、PNN等一大批优秀的深度学习模型被提出, 推荐系统全面进入了深度学习时代, 时至今日&#x…...
)
第十二章 YOLO的部署实战篇(中篇)
cuda教程目录 第一章 指针篇 第二章 CUDA原理篇 第三章 CUDA编译器环境配置篇 第四章 kernel函数基础篇 第五章 kernel索引(index)篇 第六章 kenel矩阵计算实战篇 第七章 kenel实战强化篇 第八章 CUDA内存应用与性能优化篇 第九章 CUDA原子(atomic)实战篇 第十章 CUDA流(strea…...

面试题查漏补缺 i++和 ++ i哪个效率更高
i 和 i 哪个效率更高? 在这里声明,简单地比较前缀自增运算符和后缀自增运算符的效率是片面的,因为存在很多因素影响这个问题的答案。首先考虑内建数据类型的情况:如果自增运算表达式的结果没有被使用,而是仅仅简单地用于增加一员…...
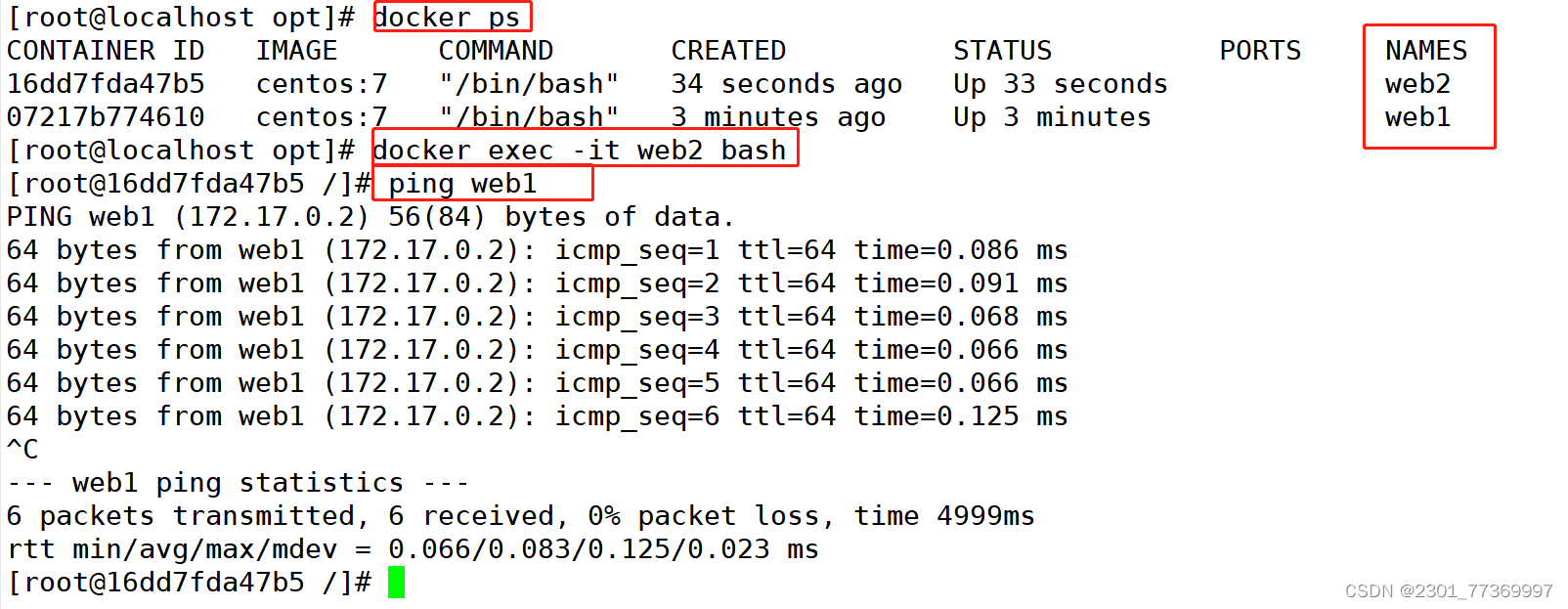
Docker的数据管理(持久化存储)
文章目录 一、概述二、数据卷三、数据卷容器四、端口映射五、容器互联(使用centos镜像)总结 一、概述 管理 Docker 容器中数据主要有两种方式:数据卷(Data Volumes)和数据卷容器(DataVolumes Containers&a…...

定时脚本自动自动将文件push到git
写脚本 绝对路径 环境注意 写python,bash脚本执行调用 py程序 定制crontab -e 日志要指定输入文件中 项目地址 https://gitee.com/stdev_1/sshpi10/ bash脚本 #!/bin/bash 设置要监控的仓库路径 #path~/github/ #watch_dir“/home/pi/gittest/ipset/sshpi10” p…...

025: vue父子组件中传递方法控制:$emit,$refs,$parent,$children
第025个 查看专栏目录: VUE ------ element UI 专栏目标 在vue和element UI联合技术栈的操控下,本专栏提供行之有效的源代码示例和信息点介绍,做到灵活运用。 (1)提供vue2的一些基本操作:安装、引用,模板使…...

使用js搭建简易的WebRTC实现视频直播
首先需要一个信令服务器,我们使用nodejs来搭建。两个端:发送端和接收端。我的目录结构如下图:流程 创建一个文件夹 WebRTC-Test。进入文件夹中,新建一个node的文件夹。使用终端并进入node的目录下,使用 npm init 创建p…...

LeetCode 2707. Extra Characters in a String【动态规划,记忆化搜索,Trie】1735
本文属于「征服LeetCode」系列文章之一,这一系列正式开始于2021/08/12。由于LeetCode上部分题目有锁,本系列将至少持续到刷完所有无锁题之日为止;由于LeetCode还在不断地创建新题,本系列的终止日期可能是永远。在这一系列刷题文章…...
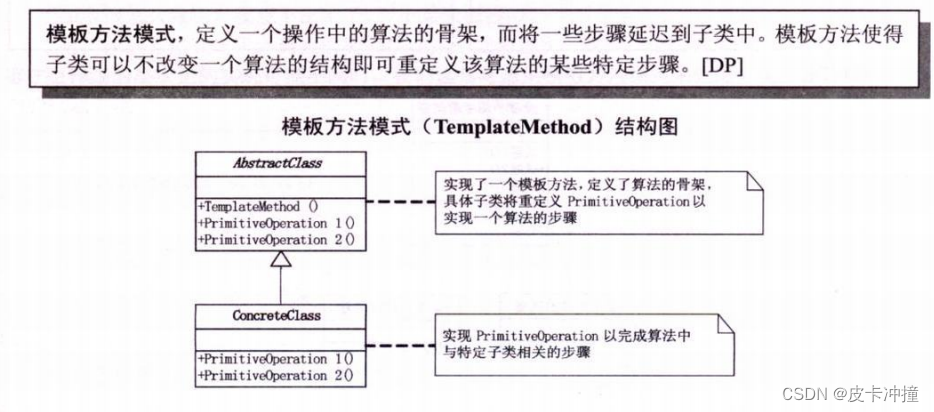
设计模式行为型-模板模式
文章目录 一:模板方法设计模式概述1.1 简介1.2 定义和目的1.3 关键特点1.4 适用场景 二:模板方法设计模式基本原理2.1 抽象类2.1.1 定义和作用2.1.2 模板方法2.1.3 具体方法 2.2 具体类2.2.1 定义和作用2.2.2 实现抽象类中的抽象方法2.2.3 覆盖钩子方法 …...

9.3.tensorRT高级(4)封装系列-自动驾驶案例项目self-driving-车道线检测
目录 前言1. 车道线检测总结 前言 杜老师推出的 tensorRT从零起步高性能部署 课程,之前有看过一遍,但是没有做笔记,很多东西也忘了。这次重新撸一遍,顺便记记笔记。 本次课程学习 tensorRT 高级-自动驾驶案例项目self-driving-车道…...
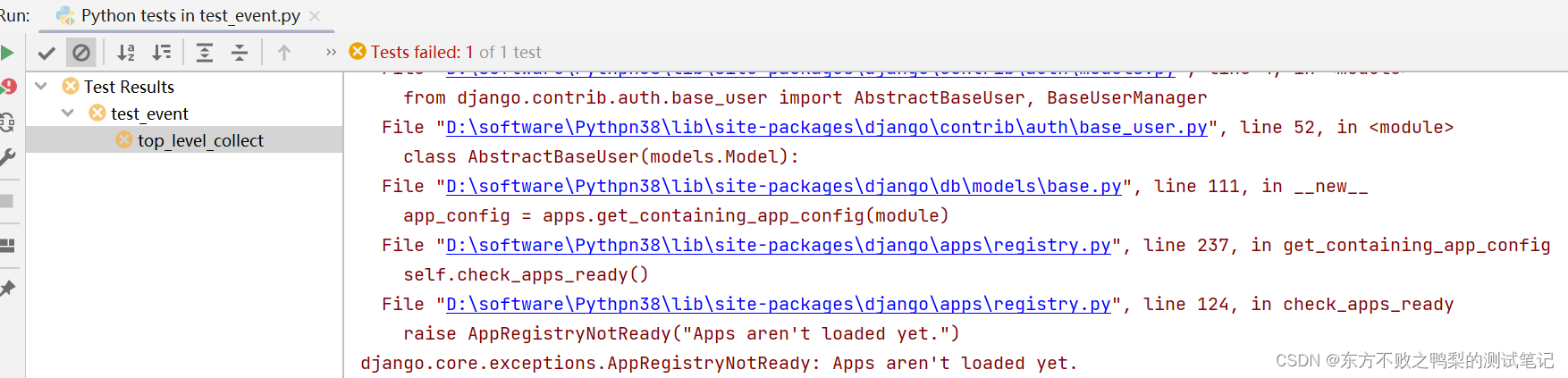
django.core.exceptions.AppRegistryNotReady: Apps aren‘t loaded yet.
运行django测试用例报错django.core.exceptions.AppRegistryNotReady: Apps arent loaded yet. 解决:在测试文件上方加上 django.setup() django.setup()是Django框架中的一个函数。它用于在非Django环境下使用Django的各种功能、模型和设置。 在常规的Django应用…...
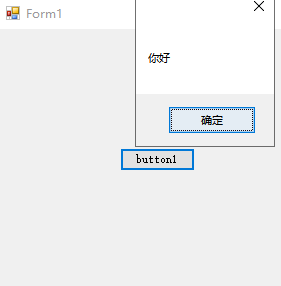
【C#】C#调用进程打开一个exe程序
文章目录 一、过程二、效果总结 一、过程 新建WinForm程序,并写入代码,明确要调用的程序的绝对路径(或相对路径)下的exe文件。 调用代码: 这里我调用的另一个程序的路径是: F:\WindowsFormsApplication2…...

SWAT建模效率翻倍:利用ArcGIS模型构建器自动化处理HWSD土壤数据全流程
SWAT建模效率革命:ArcGIS模型构建器全自动处理HWSD土壤数据实战指南 当你在凌晨三点盯着屏幕上第七次重复运行的"Extract by Mask"工具,看着进度条缓慢爬升时,是否想过这些机械化的操作本可以一键完成?本文将为中高级SW…...

初次使用 Taotoken 控制台的快速浏览与核心功能导引
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初次使用 Taotoken 控制台的快速浏览与核心功能导引 当你注册并登录 Taotoken 平台后,首先进入的就是用户控制台。这个…...

ARM中断机制深度解析:从硬件原理到实战调试与RTOS应用
1. 项目概述:从一行代码到硬件响应“ARM体系架构处理器的中断程序分析”这个标题,对于很多嵌入式开发者和系统软件工程师来说,就像一把钥匙。它指向了连接软件逻辑与硬件实时响应的核心枢纽。我处理过太多因为中断没玩明白而导致的系统“玄学…...
)
py之paho mqtt客户端代码示例(亲测可用)
from paho.mqtt import client as mqtt_clientdef on_connect(client, userdata, flags, reasonCode, properties):"""连接成功回调reasonCode: 0 表示成功,其他值表示失败"""print...

2026 酒店无人直播服务商推荐:警惕一次性收费陷阱,用心服务才是核心
"一次购买,无任何后续费用!"—— 这样的宣传语让不少酒店经营者心动不已,以为找到了低成本获客的捷径。然而,现实往往事与愿违:软件使用不到1个月,算力耗尽无法开播;直播间频繁卡顿、…...

IDEA里Git冲突别慌!手把手教你用Rebase和Merge搞定,附代码消失急救指南
IDEA中Git冲突与代码消失的终极解决方案:Rebase与Merge实战指南 在团队协作开发中,Git冲突如同程序员日常的"必修课",而IDEA作为Java开发者最信赖的IDE,其内置的Git工具链却常被低估。当你在深夜赶进度时突然遭遇冲突警…...

自适应滤波器提取胎儿心电信号的MATLAB及FPGA实现
自适应滤波器提取胎儿心电信号的MATLAB及FPGA实现 【下载地址】自适应滤波器提取胎儿心电信号的MATLAB及FPGA实现 本项目提供了一个完整的工程代码,用于实现自适应滤波器提取胎儿心电信号的MATLAB及FPGA实现。自适应滤波器是一种能够根据环境变化自动调整滤波器参数…...

NoFences:彻底告别桌面混乱的免费开源分区管理工具
NoFences:彻底告别桌面混乱的免费开源分区管理工具 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 你是否经常在杂乱无章的Windows桌面上花费大量时间寻找需要的文…...

2025最权威的AI写作方案横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 当人工智能技术于当下迅猛发展之际,对于企业来讲,核心挑战其中之一便…...

告别编译烦恼:在Windows上用vcpkg一键搞定libcurl+OpenSSL环境
现代C开发者的救星:vcpkg一键部署libcurl全攻略 在Windows平台进行C网络开发时,配置libcurl及其依赖项(如OpenSSL)往往是令人头疼的第一步。传统的手动编译方式不仅耗时费力,还容易因版本兼容性问题导致各种难以排查的…...