开始MySQL之路——MySQL存储引擎概念
一、存储引擎概念
MySQL数据库和大多数的数据库不同, MySQL数据库中有一个存储引擎的概念, 针对不同的存储需求可以选择最优的存储引擎。
存储引擎就是存储数据,建立索引,更新查询数据等等技术的实现方式 。存储引擎是基于表的,而不是基于库的。所以存储引擎也可被称为表类型。
Oracle,SqlServer等数据库只有一种存储引擎。MySQL提供了插件式的存储引擎架构。所以MySQL存在多种存储引擎,可以根据需要使用相应引擎,或者编写存储引擎。
1.1存储引擎架构
MySQL的逻辑架构分为四层:
第一层:连接层,最上层是一些客户端和链接服务,包含本地sock 通信和大多数基于客户端/服务端工具实现的类似于 TCP/IP的通信。主要完成一些类似于连接处理、授权认证、及相关的安全方案。在该层上引入了线程池的概念,为通过认证安全接入的客户端提供线程。同样在该层上可以实现基于SSL的安全链接。服务器也会为安全接入的每个客户端验证它所具有的操作权限。它们都是服务于C/S程序或者是这些程序所需要的 :连接处理,身份验证,安全性等等。
第二层:服务层(值得关注)。这是MySQL的核心部分。通常叫做 SQL Layer。在 MySQL数据库系统处理底层数据之前的所有工作都是在这一层完成的,包括权限判断, sql解析,行计划优化, query cache 的处理以及所有内置的函数(如日期,时间,数学运算,加密)等等。各个存储引擎提供的功能都集中在这一层,如存储过程,触发器,视图等。
第三层:引擎层。通常叫做StorageEngine Layer ,也就是底层数据存取操作实现部分,由多种存储引擎共同组成。它们负责存储和获取所有存储在MySQL中的数据。就像Linux众多的文件系统 一样。每个存储引擎都有自己的优点和缺陷。服务器是通过存储引擎API来与它们交互的。这个接口隐藏 了各个存储引擎不同的地方。对于查询层尽可能的透明。这个API包含了很多底层的操作。如开始一个事物,或者取出有特定主键的行。存储引擎不能解析SQL,互相之间也不能通信。仅仅是简单的响应服务器 的请求。
第四层:存储层。主要是将数据存储在文件系统之上,并完成与存储引擎的交互。和其他数据库相比,MySQL有点与众不同,它的架构可以在多种不同场景中应用并发挥良好作用。主要体现在存储引擎上,插件式的存储引擎架构,将查询处理和其他的系统任务以及数据的存储提取分离。这种架构可以根据业务的需求和实际需要选择合适的存储引擎。
二、MySQL中查看与修改引擎
2.1查看mysql所支持的存储引擎,以及从中得到mysql默认的存储引擎。
show engines;创建新表时如果不指定存储引擎,那么系统就会使用默认的存储引擎,MySQL5.5之前的默认存储引擎是MyISAM,5.5之后就改为了InnoDB。
查看Mysql数据库默认的存储引擎 , 指令 :
show variables like '%storage_engine%' ;

可以看出,默认的数据库引擎是InnoDB。附上各个参数说明:
| 参数名称 | 解释说明 |
|---|---|
| Engine | 存储引擎名称 |
| Support | 是否支持该引擎以及该引擎是否为默认存储引擎,YES表示支持,NO表示不支持 |
| DEFAULT | DEFAULT表示为默认存储引擎 |
| Comment | 存储引擎的简单介绍 |
| Transactions | 表示该引擎是否支持事务 |
| XA | 说明该存储引擎是否支持分布事务 |
| Savepoints | 说明该存储引擎是否支持部分事务回滚 |
2.2如何更改默认存储引擎。
找到MySQL配置文件mysql.ini,首先将其备份。
cp mysql.ini mysql.ini.bak在[mysqld]后面添加default-storage-engine=引擎名字 ,保存,重启MySQL服务即可。
2.3如何在建表时设置引擎以及建表后修改引擎。
建表时设置引擎语法:
create table 表名(...) type=引擎名建表后更改表的引擎语法:
alter table 表名 type=引擎名;2.4如何查看修改和创建表的存储引擎。
语法一: show create table 表名;
show create table user;语法二: show table status like '表名'
show table status like 'user'2.5准确查看某个数据库中的某一表所使用的存储引擎。
语法: show table status from 数据库名 where name='表名'
show table status from xxkk where name='user';三、MySQL中存储引擎
下面重点介绍几种常用的存储引擎, 并对比各个存储引擎之间的区别, 如下表所示 :
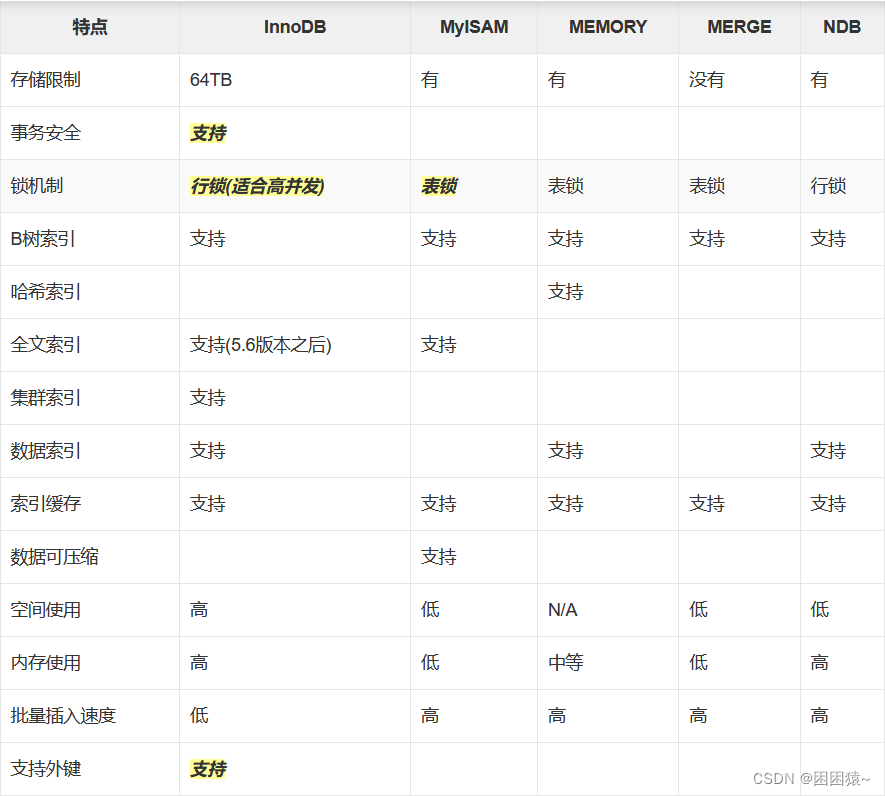 3.1InnoDB引擎
3.1InnoDB引擎
InnoDB是一个事务型存储引擎,提供了对数据库ACID事务的支持,并实现了SQL标准的四种隔离级别,具有行级锁定(这一点说明锁的粒度小,在写数据时,不需要锁住整个表,因此适用于高并发情形)及外键支持(所有数据库引擎中独一份,仅有它支持外键)
该引擎的设计目标便是处理大容量数据的数据库系统,MySQL在运行时InnoDB会在内存中建立缓冲池,用于缓存数据及索引。
优点:
- 支持自动增长列
- 支持外键约束
缺点:
- 该引擎不支持FULLTEXT类型的索引
- 没有保存表的行数,在执行select count(*) from 表名 查询单行时,需要遍历扫描全表
在以下场合下,使用InnoDB是最理想的选择:
- 更新密集的表。 InnoDB存储引擎特别适合处理多重并发的更新请求。
- 事务。 InnoDB存储引擎是支持事务的标准MySQL存储引擎。
- 自动灾难恢复。 与其它存储引擎不同,InnoDB表能够自动从灾难中恢复。
- 外键约束。 MySQL支持外键的存储引擎只有InnoDB。
- 支持自动增加列AUTO_INCREMENT属性。
- 从5.7开始innodb存储引擎成为默认的存储引擎。
一般来说,如果需要事务支持,并且有较高的并发读取频率,InnoDB是不错的选择。
3.2MyLSAM引擎
MyISAM存储引擎:不支持事务、也不支持外键,优势是访问速度快,对事务完整性没有 要求或者以select,insert为主的应用基本上可以用这个引擎来创建表
支持3种不同的存储格式,分别是:静态表;动态表;压缩表
- 静态表:表中的字段都是非变长字段,这样每个记录都是固定长度的,优点存储非常迅速,容易缓存,出现故障容易恢复;缺点是占用的空间通常比动态表多。
- 动态表:记录不是固定长度的,这样存储的优点是占用的空间相对较少;缺点:频繁的更新、删除数据容易产生碎片,需要定期执行OPTIMIZE TABLE或者myisamchk-r命令来改善性能
- 压缩表:因为每个记录是被单独压缩的,所以只有非常小的访问开支
MyISAM表是独立于操作系统的,这说明可以轻松地将其从Windows服务器移植到Linux服务器。
每当我们建立一个MyISAM引擎的表时,就会在本地磁盘上建立三个文件,文件名就是表名。
MyISAM表无法处理事务,这就意味着有事务处理需求的表,不能使用MyISAM存储引擎。
MyISAM存储引擎特别适合在以下几种情况下使用:
-
选择密集型的表。 MyISAM存储引擎在筛选大量数据时非常迅速,这是它最突出的优点。
-
插入密集型的表。 MyISAM的并发插入特性允许同时选择和插入数据。
由此看来,MyISAM存储引擎很适合管理服务器日志数据。
3.3Memory(Heap)引擎
Memory存储引擎将表的数据存放在内存中。每个MEMORY表实际对应一个磁盘文件,格式是.frm ,该文件中只存储表的结构,而其数据文件,都是存储在内存中,这样有利于数据的快速处理,提高整个表的效率。MEMORY 类型的表访问非常地快,因为他的数据是存放在内存中的,并且默认使用HASH索引 , 但是服务一旦关闭,表中的数据就会丢失。
Memory同时支持散列索引和B树索引,B树索引可以使用部分查询和通配查询,也可以使用<,>和>=等操作符方便数据挖掘,散列索引相等的比较快但是对于范围的比较慢很多
可能的缺点:
1. 要求存储的数据是数据长度不变的格式,Blob和Text类型数据不可用(长度不固定)
2. 用完表格后表格便被删除
适用场景:
- 那些内容变化不频繁的代码表,或者作为统计操作的中间结果表,便于高效地堆中间结果进行分析并得到最终的统计结果
- 目标数据比较小,而且非常频繁的进行访问,在内存中存放数据,如果太大的数据会造成内存溢出。可以通过参数max_heap_table_size控制Memory表的大小,限制Memory表的最大的大小
- 数据是临时的,而且必须立即能取出用到,于是可存放在内存中
- 存储在Memory表中的数据如果突然间丢失的话也没有太大的关系
3.4MRG_MyISAM引擎
MRG_MyISAM存储引擎是一组MyISAM表的组合,说白了,Merge表就是几个相同MyISAM表的聚合器;Merge表中并没有数据,对Merge类型的表可以进行查询、更新、删除操作,这些操作实际上是对内部的MyISAM表进行操作。
比如:我们可能会遇到这样的问题,同一种类的数据会根据数据的时间分为多个表,如果这时候进行查询的话,就会比较麻烦,Merge可以直接将多个表聚合成一个表统一查询,然后再删除Merge表(删除的是定义),原来的数据不会影响。
MRG_MyISAM引擎缺点如下:
- 使用表级锁,虽然内存访问快,但如果频繁的读写,表级锁会成为瓶颈。
- 只支持固定大小的行。Varchar类型的字段会存储为固定长度的Char类型,浪费空间。
- 不支持TEXT、BLOB字段。当有些查询需要使用到临时表(使用的也是MEMORY存储引擎)时,如果表中有TEXT、BLOB字段,那么会转换为基于磁盘的MyISAM表,严重降低性能。
- 由于内存资源成本昂贵,一般不建议设置过大的内存表,如果内存表满了,可通过清除数据或调整内存表参数来避免报错。
3.5Blackhole引擎
任何写入到此引擎的数据均会被丢弃掉, 不做实际存储;Select语句的内容永远是空。他会丢弃所有的插入的数据,服务器会记录下Blackhole表的日志,所以可以用于复制数据到备份数据库。
适用场景:
- 充当日志服务器
- 验证dump file语法正确性
- 以使用blackhole引擎来检测binlog功能所需要的额外负载
四、MyISAM与InnoDB如何选择
两种存储引擎的大致区别表现在:
- InnoDB支持事务,MyISAM不支持。事务是一种高级的处理方式,如在增删改中要是出错可以回滚还原数据,而MyISAM就不可以了,这是非常重要的。
- MyISAM适合查询以及插入为主的应用,InnoDB适合频繁修改以及涉及到安全性较高的应用。
- InnoDB支持外键,MyISAM不支持。
- InnoDB是默认引擎,MylSAM不是。
- InnoDB不支持FULLTEXT类型的索引。
- InnoDB中不保存表的行数,如在查询数据表时,InnoDB需要扫描一遍整个表来计算有多少行,但是MyISAM只要简单的读出保存好的行数即可。
- 对于自增长的字段,InnoDB中必须包含只有该字段的索引,但是在MyISAM表中可以和其他字段一起建立联合索引。
- 清空整个表时,InnoDB是一行一行的删除,效率非常慢。MyISAM则会重建表。
- InnoDB支持行锁。
如果数据量比较大,这是需要通过升级架构来解决,比如分表分库,读写分离,而不是单纯地依赖存储引擎。一般都是选用InnoDB了,主要是MyISAM的全表锁,读写串行问题,并发效率锁表,效率低,MyISAM对于读写密集型应用一般是不会去选用的。
相关文章:
开始MySQL之路——MySQL存储引擎概念
一、存储引擎概念 MySQL数据库和大多数的数据库不同, MySQL数据库中有一个存储引擎的概念, 针对不同的存储需求可以选择最优的存储引擎。 存储引擎就是存储数据,建立索引,更新查询数据等等技术的实现方式 。存储引擎是基于表的,而不是基…...

ant-design 设置Form.Item中的input框的值的方法
ant-design 设置Form.Item中的input中的value值是不知道什么原因是无效的,所以有以下两种方法设置: 1.可以通过 initialValues 属性来为表单设置默认值。具体使用方法如下: 在表单最外层的 Form 组件上加入 initialValues 属性,…...
CS420 课程笔记 P6 - 游戏逆向中的虚拟内存
文章目录 IntroVirtual memoryExample!Static example Intro 在上个视频中,我们知道有些地址在你重进游戏时就会无效,有的有时有效,我们需要了解称为虚拟内存的东西 记住这些信息:当你双击打开 Squally.exe 游戏时,系…...

公信力不是儿戏:政府与非营利组织如何利用爱校对提升信息质量
公信力是政府和非营利组织成功的基础,而这种公信力大多来源于对外发布的信息的准确性和可靠性。在这个方面,“爱校对”展现了它的强大能力和实用性。以下我们将具体探讨这两种组织如何通过使用爱校对来提升他们的信息质量。 政府:公开与透明&…...
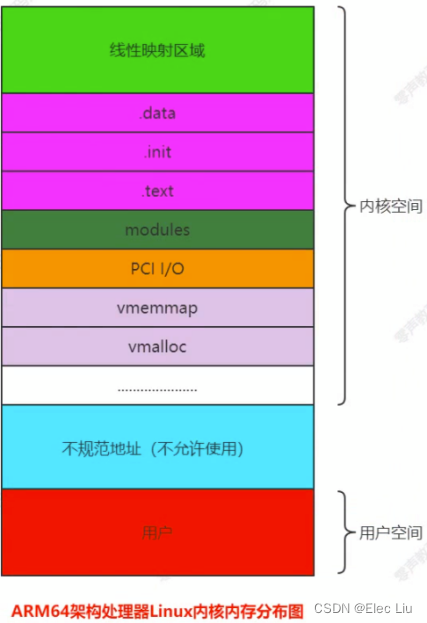
Linux内核源码分析 (B.1)内核内存布局和堆管理
Linux内核源码分析 (B.1)内核内存布局和堆管理 文章目录 Linux内核源码分析 (B.1)内核内存布局和堆管理一、Linux内核内存布局二、堆管理 一、Linux内核内存布局 64位Linux一般使用48位来表示虚拟地址空间,45位表示物理地址。通过命令:cat/proc/cpuinfo。…...

Python---函数
函数定义: """ def 函数名(传入参数):函数体return 返回值 """ 函数调用: """ 函数名(传入参数) """ 例子: # 不带参 def check():print("欢迎光临\n请进") che…...

Myvatis关联关系映射与表对象之间的关系
目录 一、关联关系映射 1.1 一对一 1.2 一对多 1.3 多对多 二、处理关联关系的方式 2.1 嵌套查询 2.2 嵌套结果 三、一对一关联映射 3.1 建表 编辑 3.2 配置文件 3.3 代码生成 3.4 编写测试 四、一对多关联映射 五、多对多关联映射 六、小结 一、关联关系映射 …...

算法通关村第十四关:黄金挑战-数据流的中位数
黄金挑战-数据流的中位数 1.数据流中中位数的问题 LeetCode295 https://leetcode.cn/problems/find-median-from-data-stream/ 思路分析 中位数的问题,我们一般都可以用 大顶堆小顶堆 来求解 小顶堆(minHeap):存储所有元素中…...
【2023集创赛】国家集创中心杯三等奖:不对称轻失配运算放大器
本文为2023年第七届全国大学生集成电路创新创业大赛(“集创赛”)国家集创中心杯三等奖作品分享,参加极术社区的【有奖征集】分享你的2023集创赛作品,秀出作品风采,分享2023集创赛作品扩大影响力,更有丰富电…...

手写Mybatis:第18章-一级缓存
文章目录 一、目标:一级缓存二、设计:一级缓存三、实现:一级缓存3.1 工程结构3.2 一级缓存类图3.3 一级缓存实现3.3.1 定义缓存接口3.3.2 实现缓存接口3.3.3 创建缓存KEY3.3.4 NULL值缓存key 3.4 定义缓存机制、占位符和修改配置文件3.4.1 定…...

哈夫曼编码实现文件的压缩和解压
程序示例精选 哈夫曼编码实现文件的压缩和解压 如需安装运行环境或远程调试,见文章底部个人QQ名片,由专业技术人员远程协助! 前言 这篇博客针对《哈夫曼编码实现文件的压缩和解压》编写代码,代码整洁,规则࿰…...

解决六大痛点促进企业更好使用生成式AI,亚马逊云科技顾凡采访分享可用方案
亚马逊云科技大中华区战略业务发展部总经理顾凡在接受21世纪经济报道记者专访时表示,生成式人工智能将从四个方面为企业带来机遇:第一是创造全新的客户体验;第二是提高企业内部员工的生产力;第三是帮助企业提升业务运营效率&#…...

Qt 定时器放在线程中执行,支持随时开始和停止定时器。
前言:因为项目需要定时检查网络中设备是否能连通,需要定时去做ping操作,若是网络不通,则ping花费时间比较久(局域网大概4秒钟才能结束,当然如果设置超时时间啥的,也能很快返回,就是会…...
验证入参,验签(sign) Demo)
java 过滤器 接口(API)验证入参,验签(sign) Demo
java 过滤器 接口(API)验证入参,验签(sign) Demo 一、思路 1、配置yml文件; 2、创建加载配置文件类; 3、继承 OncePerRequestFilter 重写方法 doFilterInternal; 4、注册自定义过滤器; 二、步骤 1、配置yml文件; ###系…...

独家!微信正在灰测一款全新消金产品
来源 | 镭射财经(leishecaijing) 「镭射财经」独家获悉,微信将推出一款名为“微信分期”的新消费信贷产品,目前该产品正处于小范围灰测阶段,还未正式上线。上线后,微信将运营微信分付和微信分期两款自营消…...

阿秀C++笔记-学习记录
81.C中的组合和继承相比的优缺点 在C中组合一对象系用描述对象包对象系组一个拥对象例其变合类的含的现。这的量类当有员被创建。 以下一个示例,展示了在C中如何实现组合关系: class Engine {// Engine class definition... };class Car {Engine engi…...

前端入门到入土?
文章目录 前言http和https的区别,https加密的原理是?区别https的加密原理 TCP为什么要三次握手?proxy代理的原理?内存泄漏?什么是内存泄漏?为什么会有内存泄漏?内存泄漏的情况?如何防…...
架构设计基础设施保障IaaS之网络
目录 1 DNS运用1.1 DNS功能作用1.2 DNS配置实践 2 DNS生产最佳实践方案2.1 全球加速功能2.2 不同运营商的加速方案2.3 全球业务高可用方案2.4 跨地域负载均衡 3 DNS域名劫持解决方案4 CDN剖析4.1 CDN原理4.2 缓存过期配置处理流程4.3 缓存配置规则 5 CDN运用6 CDN最佳实践方案6…...
zabbix安装部署
前期准备:安装mysql数据库和nginx 一、下载zabbix rpm -Uvh https://repo.zabbix.com/zabbix/4.4/rhel/7/x86_64/zabbix-release-4.4-1.el7.noarch.rpm yum-config-manager --enable rhel-7-server-optional-rpms yum install epel-release numactl yum install…...

零碎的C++
构造函数和析构函数 构造函数不能是虚函数,而析构函数可以是虚函数。原因如下: 构造函数不能是虚函数,因为在执行构造函数时,对象还没有完全创建,还没有分配内存空间,也没有初始化虚函数表指针。如果构造…...

别再只会调库了!用NumPy手搓SMOTE算法,从原理到代码保姆级拆解
从零实现SMOTE算法:用NumPy彻底掌握类别不平衡处理技术 在数据科学项目中,我们常常会遇到类别不平衡问题——某些类别的样本数量远少于其他类别。这种不平衡会导致模型过度关注多数类而忽略少数类。传统解决方案如随机过采样可能引发过拟合,而…...
 从零构建:基于GCC与VSCode的轻量级ARM开发工作流)
HC32L110(三) 从零构建:基于GCC与VSCode的轻量级ARM开发工作流
1. 为什么选择GCCVSCode开发HC32L110 第一次接触HC32L110这款MCU时,我像大多数嵌入式开发者一样,本能地打开了Keil和IAR这些传统IDE。但很快发现,这些"重量级选手"在资源受限的HC32L110开发中显得格外笨重——动辄几个GB的安装包、…...

6.滑动窗口和双指针
文章目录双指针对撞指针快慢指针滑动窗口双指针 双指针:指的是在遍历对象的过程中,不是普通的使用单个指针进行访问,而是使用两个相同方向(快慢指针)或者相反方向(对撞指针)的指针进行扫描&…...

NAS如何变身创作利器?基于绿联DX4600 Pro自建图床与Typora无缝协作
1. 为什么选择NAS自建图床? 作为一名长期使用Markdown写作的内容创作者,我深知图片管理的重要性。过去三年我先后尝试过七牛云、又拍云等第三方图床服务,虽然费用不高(每月约5-10元),但经常遇到两个致命问题…...

3分钟上手Awoo Installer:Switch游戏安装终极指南
3分钟上手Awoo Installer:Switch游戏安装终极指南 【免费下载链接】Awoo-Installer A No-Bullshit NSP, NSZ, XCI, and XCZ Installer for Nintendo Switch 项目地址: https://gitcode.com/gh_mirrors/aw/Awoo-Installer 还在为Switch游戏安装烦恼吗…...

B站视频转文字终极指南:如何快速将B站视频转换为可搜索文本
B站视频转文字终极指南:如何快速将B站视频转换为可搜索文本 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text Bili2Text是一款开源的B站视频转文字工…...

OpenClaw 2.7.5 Windows 一键部署教程|零配置开箱即用
前言 本地 AI 智能体技术持续迭代,私有化部署、数据安全可控、低门槛快速落地,已成为用户选型的核心考量。开源轻量化 AI 智能体 OpenClaw 2.7.5 版本完成全面优化升级,在环境适配性、服务稳定性与模型集成能力上均有显著提升,原…...
)
别再手动算矩阵了!COMSOL中矢量与矩阵变换的保姆级配置指南(附避坑点)
COMSOL中矢量与矩阵变换的高效配置与实战避坑指南 在COMSOL Multiphysics的建模过程中,矢量与矩阵操作是处理复杂物理场问题的核心技能之一。许多工程师和研究人员在初次接触COMSOL的变量定义系统时,往往会陷入一个误区——试图像常规编程语言那样直接定…...

如何用HTML5视频加速控制器提升学习效率:3步掌握时间管理新维度
如何用HTML5视频加速控制器提升学习效率:3步掌握时间管理新维度 【免费下载链接】videospeed HTML5 video speed controller (for Google Chrome) 项目地址: https://gitcode.com/gh_mirrors/vi/videospeed 在信息过载的数字时代,视频内容占据了网…...

给项目选YOLO模型别再纠结了:从参数量、训练曲线到mAP,手把手教你根据数据集做决策
YOLO模型选型实战指南:从参数解析到场景适配的决策方法论 在目标检测领域,YOLO系列模型凭借其出色的实时性能,已成为工业界和学术界的首选架构之一。然而,面对从YOLOv5到YOLOv9的多个版本迭代,以及每个版本中不同规模的…...