Pytorch-以数字识别更好地入门深度学习
目录
一、数据介绍
二、下载数据
三、可视化数据
四、模型构建
五、模型训练
六、模型预测
一、数据介绍
MNIST数据集是深度学习入门的经典案例,因为它具有以下优点:
1. 数据量小,计算速度快。MNIST数据集包含60000个训练样本和10000个测试样本,每张图像的大小为28x28像素,这样的数据量非常适合在GPU上进行并行计算。
2. 标签简单,易于理解。MNIST数据集的标签只有0-9这10个数字,相比其他图像分类数据集如CIFAR-10等更加简单易懂。
3. 数据集已标准化。MNIST数据集中的图像已经被归一化到0-1之间,这使得模型可以更快地收敛并提高准确率。
4. 适合初学者练习。MNIST数据集是深度学习入门的最佳选择之一,因为它既不需要复杂的数据预处理,也不需要大量的计算资源,可以帮助初学者快速上手深度学习。
综上所述,MNIST数据集是深度学习入门的经典案例,它具有数据量小、计算速度快、标签简单、数据集已标准化、适合初学者练习等优点,因此被广泛应用于深度学习的教学和实践中。
手写数字识别技术的应用非常广泛,例如在金融、保险、医疗、教育等领域中,都有很多应用场景。手写数字识别技术可以帮助人们更方便地进行数字化处理,提高工作效率和准确性。此外,手写数字识别技术还可以用于机器人控制、智能家居等方面 。
使用torch.datasets.MNIST下载到指定目录下:./data,当download=True时,如果已经下载了不会再重复下载,同train选择下载训练数据还是测试数据
官方提供的类:
class MNIST(root: str,train: bool = True,transform: ((...) -> Any) | None = None,target_transform: ((...) -> Any) | None = None,download: bool = False
)
Args:root (string): Root directory of dataset where MNIST/raw/train-images-idx3-ubyteand MNIST/raw/t10k-images-idx3-ubyte exist.train (bool, optional): If True, creates dataset from train-images-idx3-ubyte,otherwise from t10k-images-idx3-ubyte.download (bool, optional): If True, downloads the dataset from the internet andputs it in root directory. If dataset is already downloaded, it is not downloaded again.transform (callable, optional): A function/transform that takes in an PIL imageand returns a transformed version. E.g, transforms.RandomCroptarget_transform (callable, optional): A function/transform that takes in thetarget and transforms it.二、下载数据
# 导入数据集
# 训练集
import torch
from torchvision import datasets,transforms
from torch.utils.data import Dataset
train_loader = torch.utils.data.DataLoader(datasets.MNIST(root="./data",train=True,download=True,transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,),(0.3081,))])),batch_size=64,shuffle=True)# 测试集
test_loader = torch.utils.data.DataLoader(datasets.MNIST("./data",train=False,transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,),(0.3081,))])),batch_size=64,shuffle=True
)pytorch也提供了自定义数据的方法,根据自己数据进行处理
使用PyTorch提供的Dataset和DataLoader类来定制自己的数据集。如果想个性化自己的数据集或者数据传递方式,也可以自己重写子类。
以下是一个简单的例子,展示如何创建一个自定义的数据集并将其传递给模型进行训练:
import torch
from torch.utils.data import Dataset, DataLoaderclass MyDataset(Dataset):def __init__(self, data, labels):self.data = dataself.labels = labelsdef __len__(self):return len(self.data)def __getitem__(self, index):x = self.data[index]y = self.labels[index]return x, ydata = torch.randn(100, 3, 32, 32)
labels = torch.randint(0, 10, (100,))my_dataset = MyDataset(data, labels)
my_dataloader = DataLoader(my_dataset, batch_size=4, shuffle=True)
详细完整流程可参考: Pytorch快速搭建并训练CNN模型?
三、可视化数据
mport matplotlib.pyplot as plt
import numpy as np
import torchvision
def imshow(img):img = img / 2 + 0.5 # 逆归一化npimg = img.numpy()plt.imshow(np.transpose(npimg,(1,2,0)))plt.title("Label")plt.show()# 得到batch中的数据
dataiter = iter(train_loader)
images,labels = next(dataiter)
# 展示图片
imshow(torchvision.utils.make_grid(images))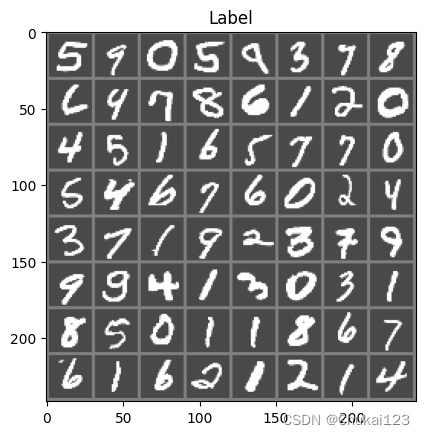
四、模型构建
定义模型类并继承nn.Module基类
# 构建模型
import torch.nn as nn
import torch
import torch.nn.functional as F
class MyNet(nn.Module):def __init__(self):super(MyNet,self).__init__()# 输入图像为单通道,输出为六通道,卷积核大小为5×5self.conv1 = nn.Conv2d(1,6,5)self.conv2 = nn.Conv2d(6,16,5)# 将16×4×4的Tensor转换为一个120维的Tensor,因为后面需要通过全连接层self.fc1 = nn.Linear(16*4*4,120)self.fc2 = nn.Linear(120,84)self.fc3 = nn.Linear(84,10)def forward(self,x):# 在(2,2)的窗口上进行池化x = F.max_pool2d(F.relu(self.conv1(x)),2)x = F.max_pool2d(F.relu(self.conv2(x)),2)# 将维度转换成以batch为第一维,剩余维数相乘为第二维x = x.view(-1,self.num_flat_features(x))x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return xdef num_flat_features(self,x):size = x.size()[1:]num_features = 1for s in size:num_features *= sreturn num_featuresnet = MyNet()
print(net)输出:
MyNet((conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))(fc1): Linear(in_features=256, out_features=120, bias=True)(fc2): Linear(in_features=120, out_features=84, bias=True)(fc3): Linear(in_features=84, out_features=10, bias=True)
)简单的前向传播
# 前向传播
print(len(images))
image = images[:2]
label = labels[:2]
print(image.shape)
print(image.size())
print(label)
out = net(image)
print(out)输出:
16
torch.Size([2, 1, 28, 28])
torch.Size([2, 1, 28, 28])
tensor([6, 0])
tensor([[ 1.5441e+00, -1.2524e+00, 5.7165e-01, -3.6299e+00, 3.4144e+00,2.7756e+00, 1.1974e+01, -6.6951e+00, -1.2850e+00, -3.5383e+00],[ 6.7947e+00, -7.1824e+00, 8.8787e-01, -5.2218e-01, -4.1045e+00,4.6080e-01, -1.9258e+00, 1.8958e-01, -7.7214e-01, -6.3265e-03]],grad_fn=<AddmmBackward0>)计算损失:
# 计算损失
# 因为是多分类,所有采用CrossEntropyLoss函数,二分类用BCELoss
image = images[:2]
label = labels[:2]
out = net(image)
criterion = nn.CrossEntropyLoss()
loss = criterion(out,label)
print(loss)输出:
tensor(2.2938, grad_fn=<NllLossBackward0>)五、模型训练
# 开始训练
model = MyNet()
# device = torch.device("cuda:0")
# model = model.to(device)
import torch.optim as optim
optimizer = optim.SGD(model.parameters(),lr=0.01) # lr表示学习率
criterion = nn.CrossEntropyLoss()
def train(epoch):# 设置为训练模式:某些层的行为会发生变化(dropout和batchnorm:会根据当前批次的数据计算均值和方差,加速模型的泛化能力)model.train()running_loss = 0.0for i,data in enumerate(train_loader):# 得到输入和标签inputs,labels = data# 消除梯度optimizer.zero_grad()# 前向传播、计算损失、反向传播、更新参数outputs = model(inputs)loss = criterion(outputs,labels)loss.backward()optimizer.step()# 打印日志running_loss += loss.item()if i % 100 == 0:print("[%d,%5d] loss: %.3f"%(epoch+1,i+1,running_loss/100))running_loss = 0train(10)输出:
[11, 1] loss: 0.023
[11, 101] loss: 2.302
[11, 201] loss: 2.294
[11, 301] loss: 2.278
[11, 401] loss: 2.231
[11, 501] loss: 1.931
[11, 601] loss: 0.947
[11, 701] loss: 0.601
[11, 801] loss: 0.466
[11, 901] loss: 0.399六、模型预测
# 模型预测结果
correct = 0
total = 0
with torch.no_grad():for data in test_loader:images,labels = dataoutputs = model(images)# 最大的数值及最大值对应的索引value,predicted = torch.max(outputs.data,1)total += labels.size(0)# 对bool型的张量进行求和操作,得到所有预测正确的样本数,采用item将整数类型的张量转换为python中的整型对象correct += (predicted == labels).sum().item()print("predicted:{}".format(predicted[:10].tolist()))print("label:{}".format(labels[:10].tolist()))print("Accuracy of the network on the 10 test images: %d %%"% (100*correct/total))imshow(torchvision.utils.make_grid(images[:10],nrow=len(images[:10])))
输出:
predicted:[1, 0, 7, 6, 5, 2, 4, 3, 2, 6]
label:[1, 0, 7, 6, 5, 2, 4, 8, 2, 6]
Accuracy of the network on the 10 test images: 91 %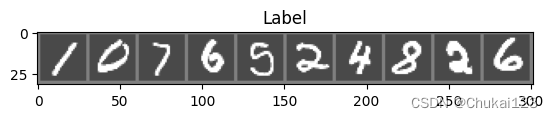
对应类别的准确率:
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
classes = [i for i in range(10)]with torch.no_grad():# model.eval()for data in test_loader:images,labels = dataoutputs = model(images)value,predicted = torch.max(outputs,1)c = (predicted == labels).squeeze()# 对所有labels逐个进行判断for i in range(len(labels)):label = labels[i]class_correct[label] += c[i].item()class_total[label] += 1print("class_correct:{}".format(class_correct))print("class_total:{}".format(class_total))# 每个类别的指标
for i in range(10):print('Accuracy of -> class %d : %2d %%'%(classes[i],100*class_correct[i]/class_total[i]))输出:
class_correct:[958.0, 1119.0, 948.0, 938.0, 901.0, 682.0, 913.0, 918.0, 748.0, 902.0]
class_total:[980.0, 1135.0, 1032.0, 1010.0, 982.0, 892.0, 958.0, 1028.0, 974.0, 1009.0]
Accuracy of -> class 0 : 97 %
Accuracy of -> class 1 : 98 %
Accuracy of -> class 2 : 91 %
Accuracy of -> class 3 : 92 %
Accuracy of -> class 4 : 91 %
Accuracy of -> class 5 : 76 %
Accuracy of -> class 6 : 95 %
Accuracy of -> class 7 : 89 %
Accuracy of -> class 8 : 76 %
Accuracy of -> class 9 : 89 %相关文章:
Pytorch-以数字识别更好地入门深度学习
目录 一、数据介绍 二、下载数据 三、可视化数据 四、模型构建 五、模型训练 六、模型预测 一、数据介绍 MNIST数据集是深度学习入门的经典案例,因为它具有以下优点: 1. 数据量小,计算速度快。MNIST数据集包含60000个训练样本和1000…...
微服务--服务介绍
Spring Cloud实现对比 Spring Cloud 作为一套标准,实现不一样 Spring Cloud AlibabaSpring Cloud NetflixSpring Cloud 官方Spring Cloud Zookeeper分布式配置Nacos ConficArchaiusSpring Cloud ConfigZookeeper服务注册/发现Nacos DiscoveryEureka--Zookeeper服务…...

自定义线程池-初识
自定义线程池-初步了解 创建一个固定大小的线程池 在Java中,你可以通过自定义线程池并指定线程的名称来实现你的需求。下面是一个简单的示例,展示了如何创建一个固定大小的线程池,并给每个线程指定一个名称: import java.util.…...
低代码平台:IVX 重新定义编程
目录 🍬一、写在前面 🍬二、低代码平台是什么 🍬三、为什么程序员和技术管理者不太可能接受“低代码”平台? 🍭1、不安全(锁定特性) 🍭2、不信任 🍬四、IVX低代码平台 &a…...

Android之自定义时间选择弹框
文章目录 前言一、效果图二、实现步骤1.自定义Dialog2.xml布局3.背景白色转角drawable4.取消按钮背景drawable5.确定按钮背景drawable6.NumberPicker样式和弹框样式7.弹框动画8.Activity使用 总结 前言 随着产品人员不断变态下,总是会要求我们的界面高大上…...

异地容灾系统和数据仓库系统设计和体系结构
( 1)生产系统数据同步到异地容灾系统 生产系统与异地容灾系统之间是通过百兆网连接的;生产系统的数据库是 Oracle 9i RAC,总的数据量大约为 3 TB,涉及五千多张表。对这些表进行分析归 类,发现容灾系统真正…...

【pytest】tep环境变量、fixtures、用例三者之间的关系
tep是一款测试工具,在pytest测试框架基础上集成了第三方包,提供项目脚手架,帮助以写Python代码方式,快速实现自动化项目落地。 在tep项目中,自动化测试用例都是放到tests目录下的,每个.py文件相互独立&…...
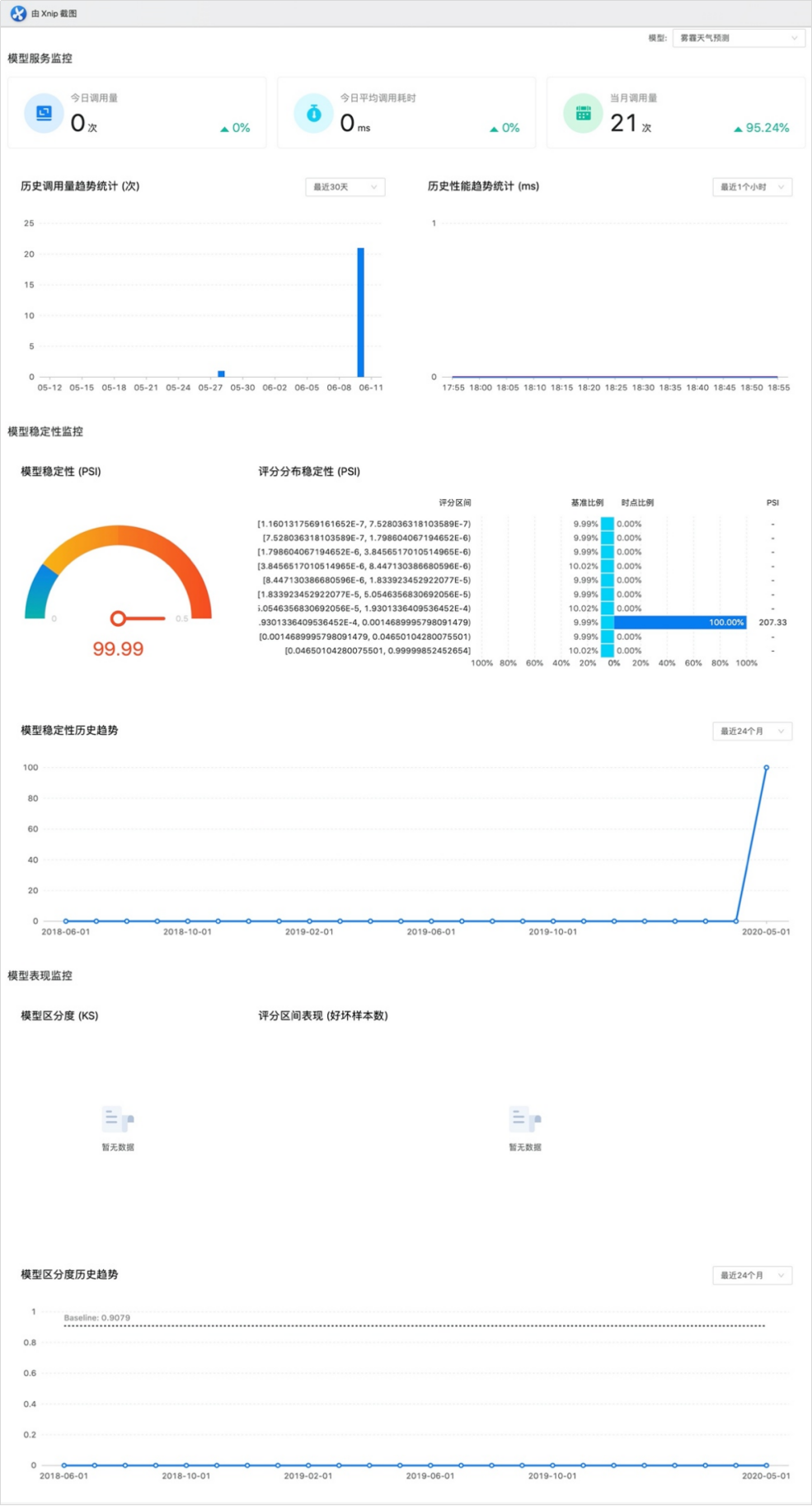
风控引擎如何快速添加模型,并实时了解运行状态?
目录 风控模型的主要类型 风控引擎如何管理模型? 模型就是基于目标群体的大规模采样数据,挖掘出某个实际问题或客观事物的现象本质及运行规律,利用抽象的概念分析存在问题或风险,计算推演出减轻、防范问题或风险的对策过程&…...

一文读懂|内核顺序锁
Linux 内核有非常多的锁机制,如:自旋锁、读写锁、信号量和 RCU 锁等。本文介绍一种和读写锁比较相似的锁机制:顺序锁(seqlock)。 顺序锁与读写锁一样,都是针对多读少写且快速处理的锁机制。而顺序锁和读写…...

openproject在docker下的安装
官方指引:https://www.openproject.org/docs/installation-and-operations/installation/docker/ 网友指引:https://blog.csdn.net/joefive/article/details/119409550 建个自己的数据文件夹: sudo mkdir -p /var/lib/openproject/{mydata…...
React【React是什么?、创建项目 、React组件化、 JSX语法、条件渲染、列表渲染、事件处理】(一)
文章目录 React是什么? 为什么要学习React React开发前准备 创建React项目 React项目结构简介 React组件化 初识JSX 渲染JSX描述的页面 JSX语法 JSX的Class与Style属性 JSX生成的React元素 条件渲染(一) 条件渲染 ࿰…...
Ubuntu系统下配置 Qt Creator 输入中文、配置软件源的服务器地址、修改Ubuntu系统时间
上篇介绍了Ubuntu系统下搭建QtCreator开发环境。我们可以发现安装好的QtCreator不能输入中文,也没有中文输入法供选择,这里需要进行设置。 文章目录 1. 配置软件源的服务器地址2. 先配置Ubuntu系统语言,设置为中文3. 安装Fcitx插件ÿ…...

Ab3d.PowerToys 11.0.8614 Crack
版本 11.0.8614 修补程序 使用 MouseCameraController 移动相机时防止旋转 FreeCamera。 版本 11.0.8585 重大更改:由于专利问题删除了 ViewCubeCameraController - 请联系支持人员以获取更多信息以及如果您想继续使用此控件。添加了 CameraNavigationCircles 控件…...
汽车3D HMI图形引擎选型指南【2023】
推荐:用 NSDT编辑器 快速搭建可编程3D场景 2002年,电影《少数派报告》让观众深入了解未来。 除了情节的核心道德困境之外,大多数人都对它的技术着迷。 我们看到了自动驾驶汽车、个性化广告和用户可以无缝交互的 3D 计算机界面。 令人惊讶的是…...
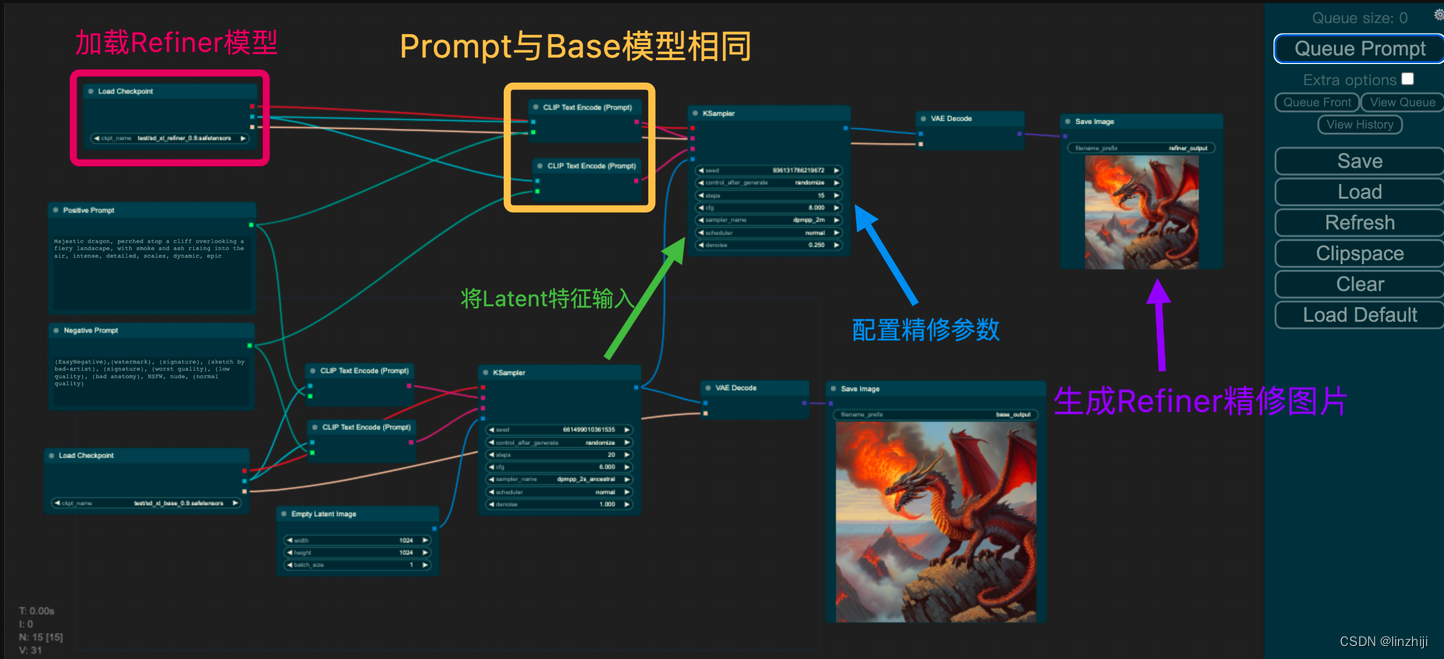
Stable Diffusion stable-diffusion-webui开发笔记
https://lexica.art/ lexica.art 该网站拥有数百万Stable Diffusion案例的文字描述和图片,可以为大家提供足够的创作灵感。可以提供promt灵感 https://civitai.com/ Civitai是一个聚集AI绘图爱好者的社区,在此网站上有许多定制化的模型,特…...
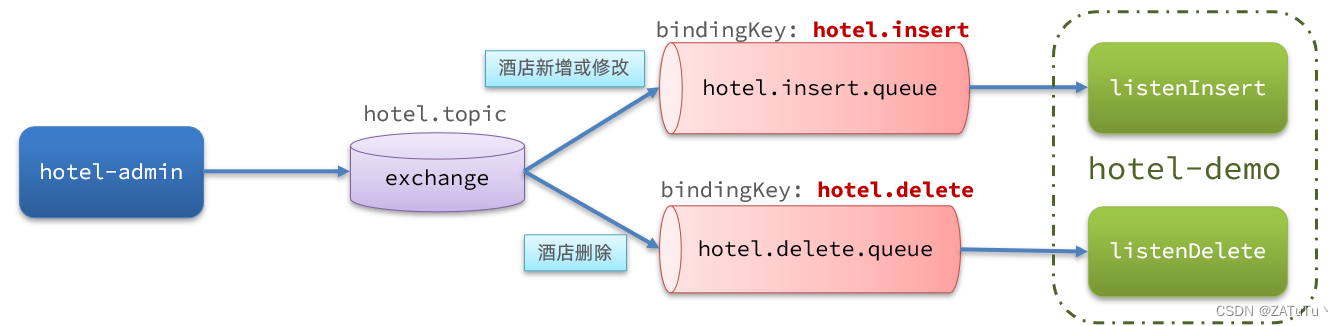
利用MQ实现mysql与elasticsearch数据同步
流程 1.声明exchange、queue、RoutingKey 2. 在hotel-admin中进行增删改(SQL),完成消息发送 3. 在hotel-demo中完成消息监听,并更新elasticsearch数据 4. 测试同步 1.引入依赖 <!--amqp--> <dependency><groupId&…...
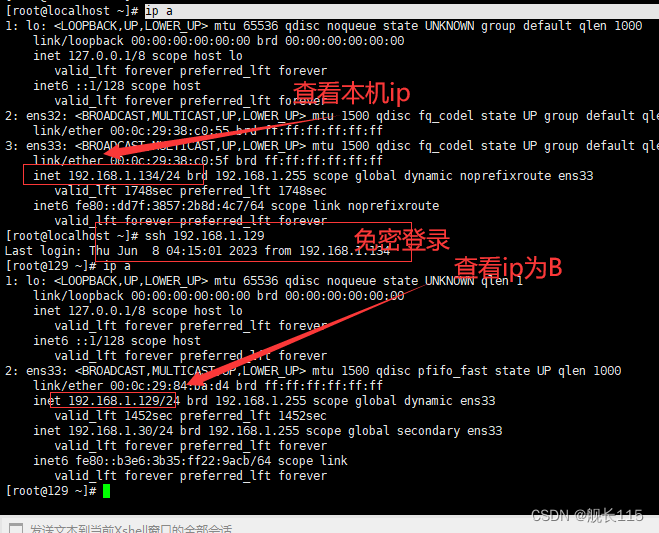
linux免密登录最简单--图文详解
最简单的免密登录 1.A电脑生成秘钥 ssh-keygen -t rsa 2.A电脑将秘钥传给B电脑 ssh-copy-id root192.168.1.129 #将秘钥直接传给B电脑 需要输入B电脑的密码,可以看到成功。 3.测试 同理:如果B->A也需要免密登录,统一的操作。 大功告…...

HTTP/1.1协议中的请求报文
2023年8月30日,周三上午 目录 概述请求报文示例详述 概述 HTTP/1.1协议的请求报文由以下几个部分组成: 请求行(Request Line)请求头部(Request Headers)空行(Blank Line)请求体&a…...

攻防世界-Hear-with-your-Eyes
原题 解题思路 是一个没有后缀的文件,题目提示要用眼睛看这段音频,notepad打开文件,没什么东西。 加后缀zip再解压看看。 使用Audacity打开音频文件...

ZED相机获取图像python
import pyzed.sl as sl import cv2 import numpy as np import osclass CameraZed2:def __init__(self,resolutionNone,fps30,depthMode None):self.zed sl.Camera()self.input_type sl.InputType()self.init_params sl.InitParameters(input_tself.input_type)# 设置分辨率…...

2026年AI文字做海报工具横评:6款实测对比,设计小白也能5分钟出图
摘要 2026年,AI做海报已经不是新鲜事,但"输入文字就能出海报"和"出一张能用的海报"之间,差距大得离谱。 我测了6款主流的可以AI文字做海报的工具,有的生成速度很快但排版像模板套娃,有的效果惊艳…...

标签系统的底层同步拓扑:大批量客户标签异步更新的一致性方案
标签(Tag)是私域精细化运营的灵魂。在进行大规模广告投放、或者老客清洗时,企业系统经常需要同时为上万个外部客户批量追加或清空标签。 1. 标签同步的复杂性在哪里? 原生设计中,企业微信的标签是以“企业标签组&#…...

从Hive Metastore到HiveServer2:手把手教你配置生产级远程访问服务
从Hive Metastore到HiveServer2:生产级远程访问服务架构与实践 在大数据生态系统中,Hive作为数据仓库工具扮演着至关重要的角色。随着企业数据规模的增长,单机部署模式已无法满足多用户并发访问的需求。本文将深入探讨如何构建一个高可用、安…...

CSDN博客批量下载器重构实战:MVC架构下的智能爬虫解决方案
CSDN博客批量下载器重构实战:MVC架构下的智能爬虫解决方案 【免费下载链接】CSDNBlogDownloader 项目地址: https://gitcode.com/gh_mirrors/cs/CSDNBlogDownloader 在技术博客内容日益成为开发者知识体系核心的时代,网络内容的不稳定性与知识管…...

vue-pdf踩坑实录:从‘Cannot read properties of undefined’到完美预览的避坑指南
Vue-PDF实战避坑指南:从版本冲突到性能优化的全链路解决方案 1. 当控制台抛出"undefined catch"错误时 那个令人窒息的红色报错框突然出现在控制台——"Cannot read properties of undefined (reading catch)"。作为经历过三次类似场景的老手&a…...

Cadence Allegro实战:除了Shape Keepout,还有哪些方法能精准控制铺铜区域?
Cadence Allegro实战:5种精准控制铺铜区域的进阶技巧 在复杂PCB设计中,铺铜区域的控制往往决定了信号完整性和EMC性能。Shape Keepout虽然是设计师最熟悉的工具,但Allegro其实提供了更丰富的"Areas"类命令集。本文将深入解析Route …...

Google关键词能带来多少流量?大词和长尾词的真实流量比例
一家销售软件的公司耗费六个月将“CRM”排至谷歌首页第五名。该词每月产生50万次搜索。网页获得2100次点击。跳出率高达89%。停留时间仅12秒。投入资金4万美元。获得零份询盘。做“外贸企业定制管理软件”排名首页第一。此词汇每月搜索量150次。每月收获62次点击。停留时间4分3…...

FPGA硬解 vs 软件模拟:实测MiSTer在延迟和画质上到底强在哪?
FPGA硬解 vs 软件模拟:实测MiSTer在延迟和画质上到底强在哪? 在复古游戏的世界里,每一帧的延迟都可能决定《拳皇97》中一个连招的成败,每一像素的偏差都会影响《魂斗罗》子弹轨迹的判断。当硬核玩家们争论FPGA方案与软件模拟孰优孰…...

网易云音乐API深度解析:模块化接口开发与实战应用指南
网易云音乐API深度解析:模块化接口开发与实战应用指南 【免费下载链接】NeteaseCloudMusicApiBackup 项目地址: https://gitcode.com/gh_mirrors/ne/NeteaseCloudMusicApiBackup 在当今音乐应用开发领域,后端服务的稳定性和可扩展性至关重要。网…...
)
仅限专业影像团队内部流通的Perplexity摄影搜索矩阵(含ISO/快门/色温等8维结构化Prompt库)
更多请点击: https://codechina.net 第一章:Perplexity摄影技巧搜索的底层逻辑与架构设计 Perplexity 并非专为摄影设计的工具,但其搜索系统在处理“摄影技巧”类长尾、意图模糊、多模态关联的问题时,展现出独特的推理架构特征。…...