YOLOv5算法改进(11)— 替换主干网络之EfficientNetv2

前言:Hello大家好,我是小哥谈。EfficientNetV2是一个网络模型,旨在提供更小的模型和更快的训练速度。它是EfficientNetV1的改进版本。EfficientNetV2通过使用更小的模型参数和采用一种称为Progressive Learning的渐进学习策略来实现这一目标。🌈
![]() 前期回顾:
前期回顾:
YOLOv5算法改进(1)— 如何去改进YOLOv5算法
YOLOv5算法改进(2)— 添加SE注意力机制
YOLOv5算法改进(3)— 添加CBAM注意力机制
YOLOv5算法改进(4)— 添加CA注意力机制
YOLOv5算法改进(5)— 添加ECA注意力机制
YOLOv5算法改进(6)— 添加SOCA注意力机制
YOLOv5算法改进(7)— 添加SimAM注意力机制
YOLOv5算法改进(8)— 替换主干网络之MobileNetV3
YOLOv5算法改进(9)— 替换主干网络之ShuffleNetV2
YOLOv5算法改进(10)— 替换主干网络之GhostNet
目录
🚀1.论文
🚀2.EfficientNetV2详细解析
🚀3.YOLOv5结合EfficientNetV2
💥💥步骤1:在common.py中添加EfficientNetV2模块
💥💥步骤2:在yolo.py文件中加入类名
💥💥步骤3:创建自定义yaml文件
💥💥步骤4:验证是否加入成功
💥💥步骤5:修改train.py中的'--cfg'默认参数

🚀1.论文
EfficientNetV2是一种由Google AI开发的深度学习网络架构,它是在EfficientNet之上的一个改进版本,于2021年4月发表于 CVPR 。EfficientNetV2在保持与其他网络结构相同的准确率的情况下,可以显著减少网络的参数量和计算量,这使得EfficientNetV2在移动设备和嵌入式设备上更加高效。EfficientNetV2使用了一种叫做“模型缩放”的技术来自动调整网络的深度、宽度和分辨率,从而在保持准确率的同时最大限度地减少参数和计算量。EfficientNetV2在多个领域的图像分类任务中都取得了出色的结果。🌴
论文中给出的EfficientNetV2的性能参数如下图所示:

通过上图很明显能够看出EfficientNetV2网络不仅Accuracy达到了当前的SOTA(State-Of-The-Art)水平,而且训练速度更快参数数量更少(比当前火热的Vision Transformer还要强)。在EfficientNetV1中作者关注的是准确率、参数数量以及FLOPs(理论计算量小不代表推理速度快),在EfficientNetV2中作者进一步关注模型的训练速度。🌱

论文题目:《EfficientNetV2: Smaller Models and Faster Training》
论文地址: https://arxiv.org/abs/2104.00298
代码实现: https://github.com/google/automl/tree/master/efficientnetv2
🚀2.EfficientNetV2详细解析
作者系统性的研究了EfficientNet的训练过程,并总结出了三个问题:
🍀(1)训练图像的尺寸很大时,训练速度非常慢。 这确实是个槽点,在之前使用EfficientNet时发现当使用到B3(img_size=300)- B7(img_size=600)时基本训练不动,而且非常吃显存。通过下表可以看到,在Tesla V100上当训练的图像尺寸为380x380时,batch_size=24还能跑起来,当训练的图像尺寸为512x512时,batch_size=24时就报OOM(显存不够)了。针对这个问题一个比较好想到的办法就是降低训练图像的尺寸,之前也有一些文章这么干过。降低训练图像的尺寸不仅能够加快训练速度,还能使用更大的batch_size。🐳

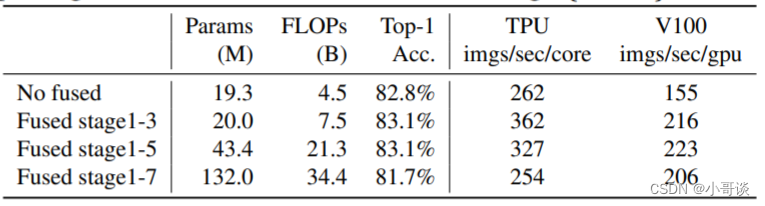
🍀(2)在网络浅层中使用Depthwise convolutions速度会很慢。 虽然Depthwise convolutions结构相比普通卷积拥有更少的参数以及更小的FLOPs,但通常无法充分利用现有的一些加速器(虽然理论上计算量很小,但实际使用起来并没有想象中那么快)。在近些年的研究中,有人提出了Fused-MBConv结构去更好的利用移动端或服务端的加速器。Fused-MBConv结构也非常简单,即将原来的MBConv结构主分支中的expansion conv1x1和depthwise conv3x3替换成一个普通的conv3x3。作者也在EfficientNet-B4上做了一些测试,发现将浅层MBConv结构替换成Fused-MBConv结构能够明显提升训练速度,将stage2,3,4都替换成Fused-MBConv结构后,在Tesla V100上从每秒训练155张图片提升到216张。但如果将所有stage都替换成Fused-MBConv结构会明显增加参数数量以及FLOPs,训练速度也会降低。所以作者使用NAS技术去搜索MBConv和Fused-MBConv的最佳组合。🐳
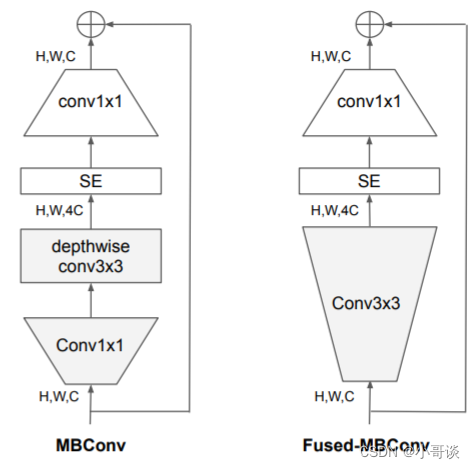
🍀(3)同等的放大每个stage是次优的。 在EfficientNetV1中,每个stage的深度和宽度都是同等放大的。但每个stage对网络的训练速度以及参数数量的贡献并不相同,所以直接使用同等缩放的策略并不合理。在这篇文章中,作者采用了非均匀的缩放策略来缩放模型。🐳
通过论文可知,作者首先通过NAS搜索得到模型EfficientNetV2-S的架构。与EfficientNet的主干相比,EfficientNetV2主要有以下几个区别:
💞(1)EfficientNetV2在早期阶段使用上面新加的Fused-MBConv结构,在后期阶段使用MBConv结构。
💞(2)EfficientNetV2在MBConv结构中更喜欢使用较小的扩展率,因为较小的扩展率往往具有更小的内存访问开销。
💞(3)EfficientNetV2更喜欢使用较小的3*3尺寸的内核,但EfficientNetV2增加更多层来补偿较小内核导致的感受野的减少。
💞(4)EfficientNetV2完全删除了原始EfficientNet中的最后一个有MBConv结构的阶段,可能因为该阶段较大的参数大小和内存访问开销。
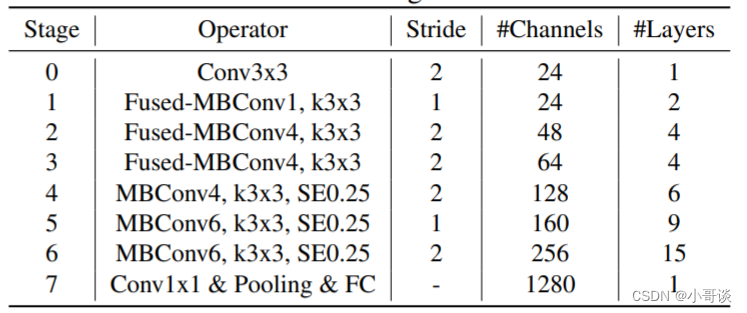
作者采用与EfficientNet相似的复合扩展策略来扩展EfficientNetV2-S来获得EfficientNetV2-M/L,并进行了一些额外的优化。
💞(1)将最大的推理图像大小限制为480,上面已经讲过非常大的图像通常会导致昂贵的内存和训练速度开销。
💞(2)在网络的后期阶段添加更多的层,以在不增加太多运算时开销的情况下增加网络容量。
本文主要贡献:
🍀(1)本文提出了EfficientNet V2,一个更小更快的模型,基于training-aware NAS和scaling,EfficientNetV2在训练速度和参数效率方面都优于之前的模型。
🍀(2)本文提出了一种改进的渐进式训练方法,它自适应的调整正则化和输入大小,通过实验证明该方法既加快了训练速度,同时也提高了准确性。
🍀(3)EfficientNetV2结合改进的渐进式训练方法,在ImageNet、CIFAR、Cars、Flowers数据集上,比之前的模型训练速度最高提升了11倍,参数效率最高提升了6.8倍。
🚀3.YOLOv5结合EfficientNetV2
💥💥步骤1:在common.py中添加EfficientNetV2模块
将下面EfficientNetV2模块的代码复制粘贴到common.py文件的末尾。
#EfficientNetV2class stem(nn.Module):def __init__(self, c1, c2, kernel_size=3, stride=1, groups=1):super().__init__()# kernel_size为3时,padding 为1,kernel为1时,padding为0padding = (kernel_size - 1) // 2# 由于要加bn层,所以不加偏置self.conv = nn.Conv2d(c1, c2, kernel_size, stride, padding=padding, groups=groups, bias=False)self.bn = nn.BatchNorm2d(c2, eps=1e-3, momentum=0.1)self.act = nn.SiLU(inplace=True)def forward(self, x):# print(x.shape)x = self.conv(x)x = self.bn(x)x = self.act(x)return xdef drop_path(x, drop_prob: float = 0., training: bool = False):if drop_prob == 0. or not training:return xkeep_prob = 1 - drop_probshape = (x.shape[0],) + (1,) * (x.ndim - 1)random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)random_tensor.floor_() # binarizeoutput = x.div(keep_prob) * random_tensorreturn outputclass DropPath(nn.Module):def __init__(self, drop_prob=None):super(DropPath, self).__init__()self.drop_prob = drop_probdef forward(self, x):return drop_path(x, self.drop_prob, self.training)class SqueezeExcite_efficientv2(nn.Module):def __init__(self, c1, c2, se_ratio=0.25, act_layer=nn.ReLU):super().__init__()self.gate_fn = nn.Sigmoid()reduced_chs = int(c1 * se_ratio)self.avg_pool = nn.AdaptiveAvgPool2d(1)self.conv_reduce = nn.Conv2d(c1, reduced_chs, 1, bias=True)self.act1 = act_layer(inplace=True)self.conv_expand = nn.Conv2d(reduced_chs, c2, 1, bias=True)def forward(self, x):# 先全局平均池化x_se = self.avg_pool(x)# 再全连接(这里是用的1x1卷积,效果与全连接一样,但速度快)x_se = self.conv_reduce(x_se)# ReLU激活x_se = self.act1(x_se)# 再全连接x_se = self.conv_expand(x_se)# sigmoid激活x_se = self.gate_fn(x_se)# 将x_se 维度扩展为和x一样的维度x = x * (x_se.expand_as(x))return x# Fused-MBConv 将 MBConv 中的 depthwise conv3×3 和扩展 conv1×1 替换为单个常规 conv3×3。
class FusedMBConv(nn.Module):def __init__(self, c1, c2, k=3, s=1, expansion=1, se_ration=0, dropout_rate=0.2, drop_connect_rate=0.2):super().__init__()# shorcut 是指到残差结构 expansion是为了先升维,再卷积,再降维,再残差self.has_shortcut = (s == 1 and c1 == c2) # 只要是步长为1并且输入输出特征图大小相等,就是True 就可以使用到残差结构连接self.has_expansion = expansion != 1 # expansion==1 为false expansion不为1时,输出特征图维度就为expansion*c1,k倍的c1,扩展维度expanded_c = c1 * expansionif self.has_expansion:self.expansion_conv = stem(c1, expanded_c, kernel_size=k, stride=s)self.project_conv = stem(expanded_c, c2, kernel_size=1, stride=1)else:self.project_conv = stem(c1, c2, kernel_size=k, stride=s)self.drop_connect_rate = drop_connect_rateif self.has_shortcut and drop_connect_rate > 0:self.dropout = DropPath(drop_connect_rate)def forward(self, x):if self.has_expansion:result = self.expansion_conv(x)result = self.project_conv(result)else:result = self.project_conv(x)if self.has_shortcut:if self.drop_connect_rate > 0:result = self.dropout(result)result += xreturn resultclass MBConv(nn.Module):def __init__(self, c1, c2, k=3, s=1, expansion=1, se_ration=0, dropout_rate=0.2, drop_connect_rate=0.2):super().__init__()self.has_shortcut = (s == 1 and c1 == c2)expanded_c = c1 * expansionself.expansion_conv = stem(c1, expanded_c, kernel_size=1, stride=1)self.dw_conv = stem(expanded_c, expanded_c, kernel_size=k, stride=s, groups=expanded_c)self.se = SqueezeExcite_efficientv2(expanded_c, expanded_c, se_ration) if se_ration > 0 else nn.Identity()self.project_conv = stem(expanded_c, c2, kernel_size=1, stride=1)self.drop_connect_rate = drop_connect_rateif self.has_shortcut and drop_connect_rate > 0:self.dropout = DropPath(drop_connect_rate)def forward(self, x):# 先用1x1的卷积增加升维result = self.expansion_conv(x)# 再用一般的卷积特征提取result = self.dw_conv(result)# 添加se模块result = self.se(result)# 再用1x1的卷积降维result = self.project_conv(result)# 如果使用shortcut连接,则加入dropout操作if self.has_shortcut:if self.drop_connect_rate > 0:result = self.dropout(result)# shortcut就是到残差结构,输入输入的channel大小相等,这样就能相加了result += xreturn result具体如下图所示:
💥💥步骤2:在yolo.py文件中加入类名
首先在yolo.py文件中找到parse_model函数这一行,加入stem、FusedMBConv、MBConv三个模块。
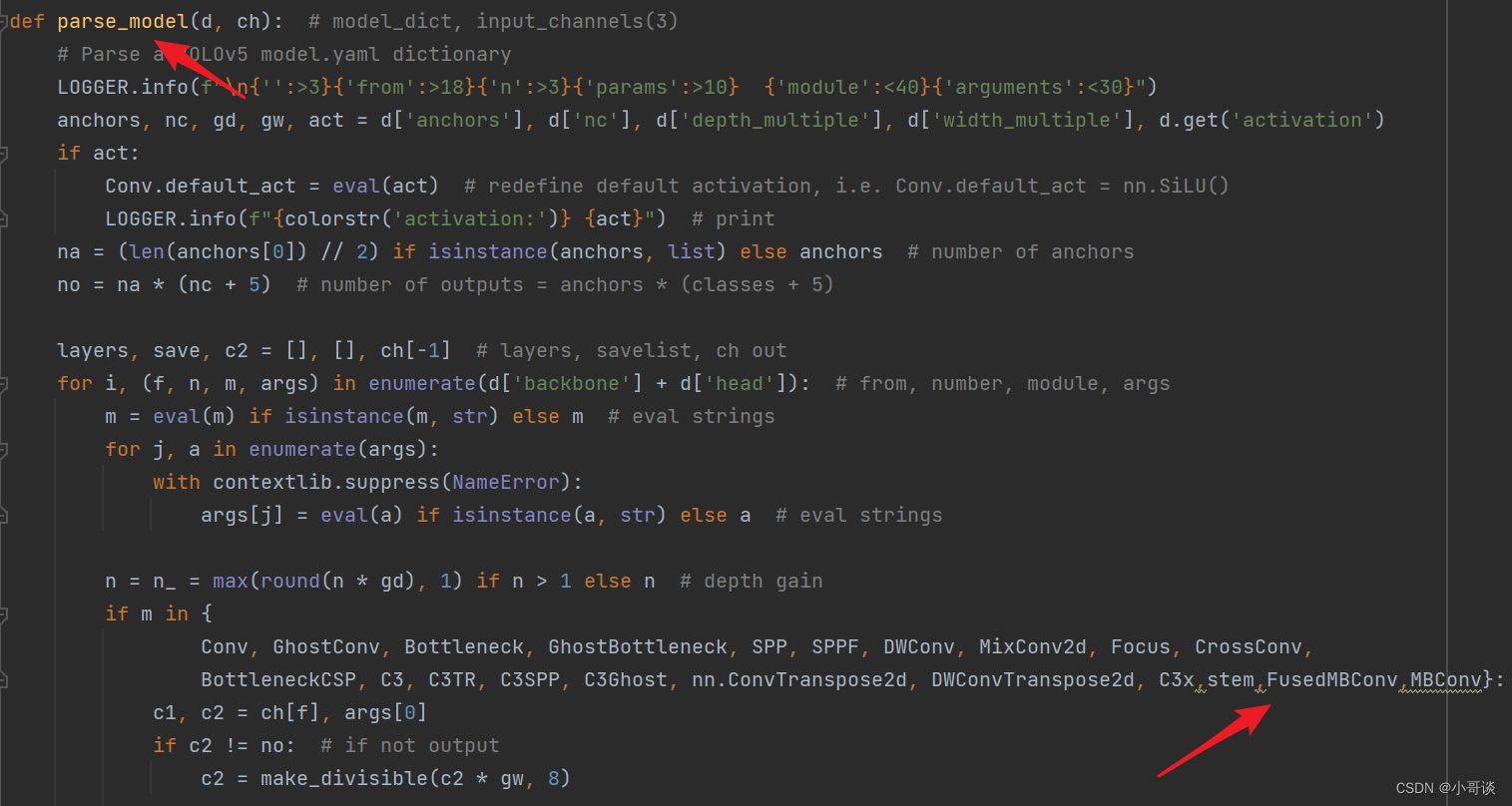
💥💥步骤3:创建自定义yaml文件
在models文件夹中复制yolov5s.yaml,粘贴并重命名为yolov5s_EfficientNetV2.yaml。
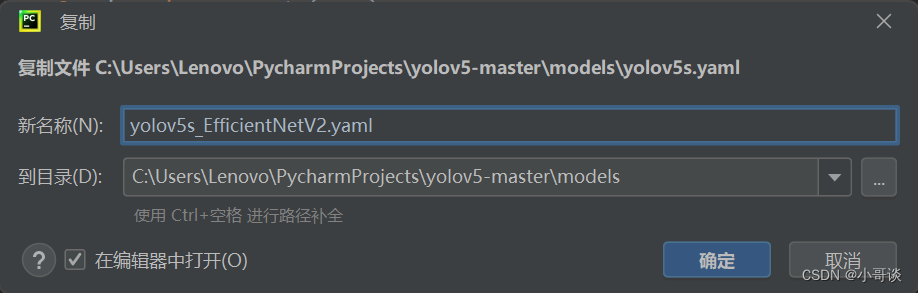
然后根据EfficientNetV2的网络架构来修改配置文件。

yaml文件修改后的完整代码如下:
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbonebackbone:# [from, number, module, args][[-1, 1, stem, [24, 3, 2]], #0 p1/2[-1, 2, FusedMBConv, [24, 3, 1, 1, 0]], # 1- last is use SE[-1, 1, FusedMBConv, [48, 3, 2, 4, 0]], # 2-p2/4[-1, 3, FusedMBConv, [48, 3, 1, 4, 0]], # 3[-1, 1, FusedMBConv, [64, 3, 2, 4, 0]], # 4-p3/8[-1, 3, FusedMBConv, [64, 3, 1, 4, 0]], # 5[-1, 1, MBConv, [128, 3, 2, 4, 0.25]], # 6-p4/16 last is use SE and ratio[-1, 5, MBConv, [128, 3, 1, 4, 0.25]], # 7[-1, 1, MBConv, [160, 3, 2, 6, 0.25]], # 8[-1, 8, MBConv, [160, 3, 1, 6, 0.25]], # 9[-1, 1, MBConv, [272, 3, 2, 4, 0.25]], # 10-p5/64[-1, 14, MBConv, [272, 3, 1, 4, 0.25]], # 11[-1, 1, SPPF, [1024, 5]], #12
# [-1, 1, SPP, [1024, [5, 9, 13]]],]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]], # 13[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 14[[-1, 9], 1, Concat, [1]], # 15 cat backbone P4[-1, 3, C3, [512, False]], # 16[-1, 1, Conv, [256, 1, 1]], # 17[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 18[[-1, 7], 1, Concat, [1]], # 19 cat backbone P3[-1, 3, C3, [256, False]], # 20 (P3/8-small)[-1, 1, Conv, [256, 3, 2]], # 21[[-1, 17], 1, Concat, [1]], # 22 cat head P4[-1, 3, C3, [512, False]], # 23 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]], # 24[[-1, 13], 1, Concat, [1]], # 25 cat head P5[-1, 3, C3, [1024, False]], # 26 (P5/32-large)[[20, 23, 26], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]💥💥步骤4:验证是否加入成功
在yolo.py文件里,配置我们刚才自定义的yolov5s_EfficientNetV2.yaml。
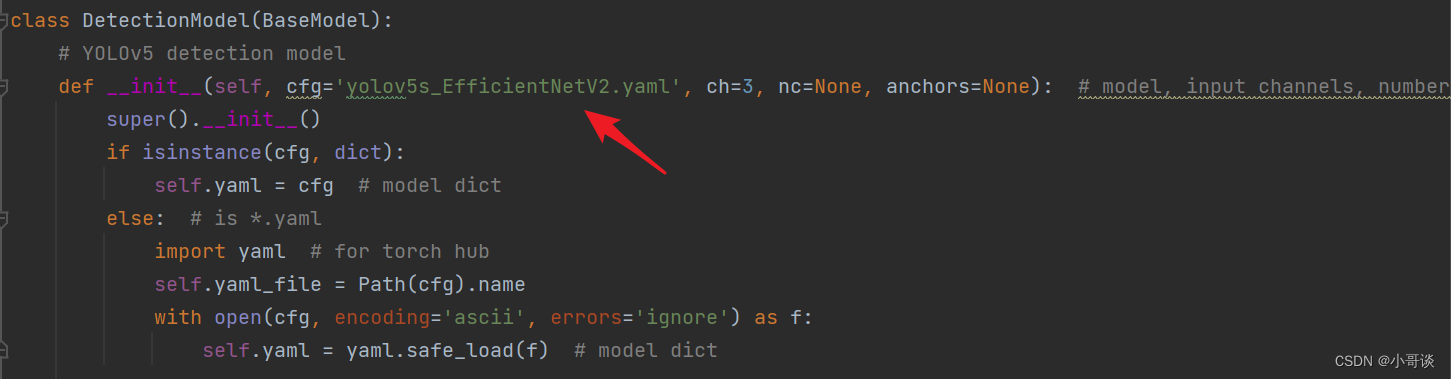
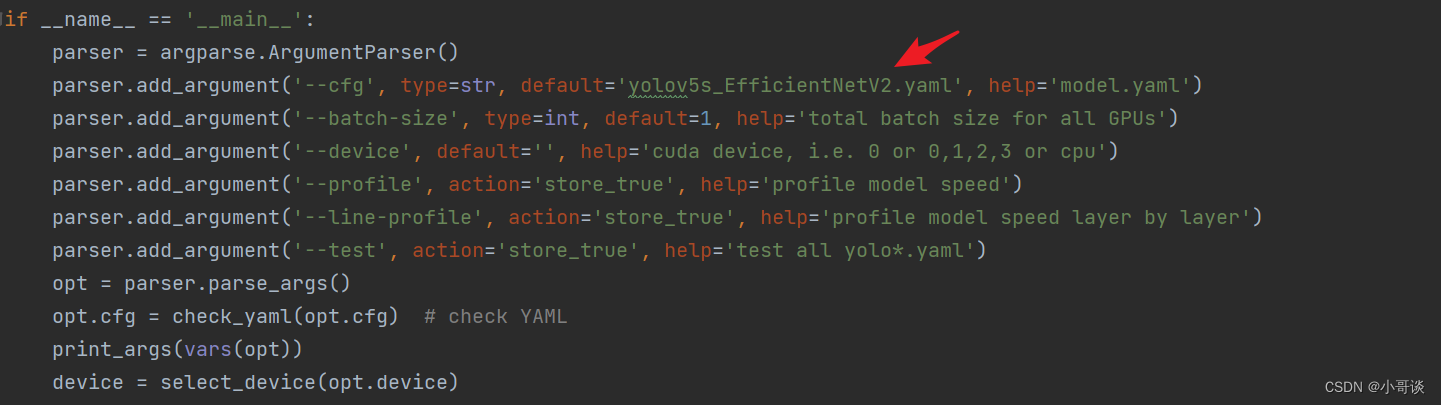
然后运行yolo.py,得到结果。

这样就算添加成功了。🎉🎉🎉
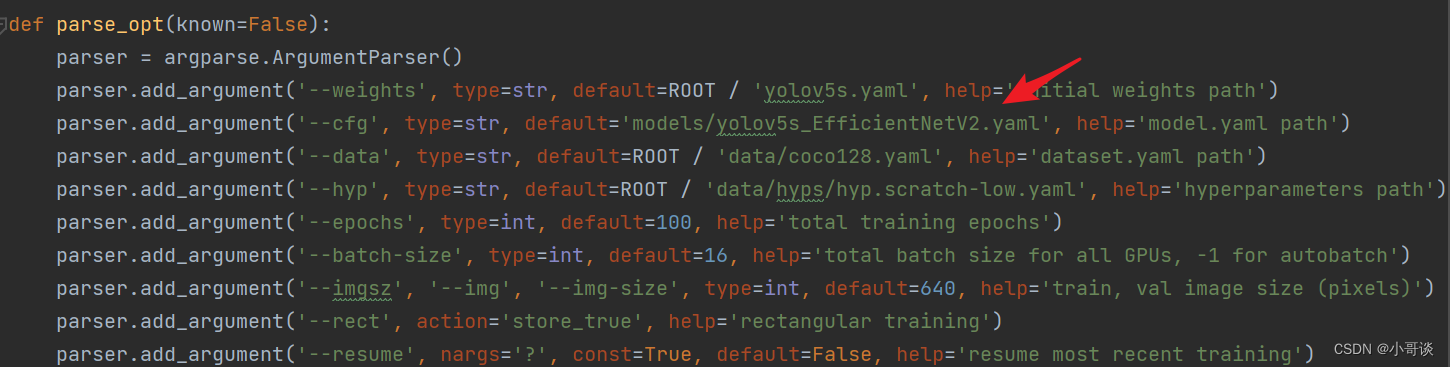
💥💥步骤5:修改train.py中的'--cfg'默认参数
在train.py文件中找到 parse_opt函数,然后将第二行 '--cfg' 的default改为 'models/yolov5s_EfficientNetV2.yaml ',然后就可以开始进行训练了。🎈🎈🎈

相关文章:
YOLOv5算法改进(11)— 替换主干网络之EfficientNetv2
前言:Hello大家好,我是小哥谈。EfficientNetV2是一个网络模型,旨在提供更小的模型和更快的训练速度。它是EfficientNetV1的改进版本。EfficientNetV2通过使用更小的模型参数和采用一种称为Progressive Learning的渐进学习策略来实现这一目标。…...

Lombok讲解
Lombok是一个可以通过简单的注解形式来帮助我们简化消除一些必须有但显得很臃肿的Java代码的工具,如:getter、setter、equals、hashCode、toString等。 Lombok的常用注解有: Data:这是一个自定义注解,它相当于Getter…...

【Android】功能丰富的dumpsys activity
在Android中,要查看客户端Binder的连接数,可以通过dumpsys命令结合service参数来获取相关信息。请按照以下步骤进行操作: 连接到设备的计算机上,打开命令行终端。 使用adb shell命令进入设备的Shell环境。 执行以下命令来查看服…...
亚马逊云科技 云技能孵化营——我的云技能之旅
文章目录 每日一句正能量前言活动流程后记 每日一句正能量 不能在已经获得足够多的成功时,还对自己的能力保持怀疑,露出自信的微笑,走出自信的步伐,做一个自信的人! 前言 亚马逊云科技 (Amazon Web Services) 是全球云…...
)
南大通用数据库-Gbase-8a-学习-38-常规日志(general log)
目录 一、环境信息 二、general log的用途 三、general log相关参数介绍 四、LInux环境模拟实验 1、查看参数配置 2、开启general log 3、输入测试SQL 4、查看文件级别general log 5、改为表级别general log 6、再次输入测试SQL 7、查看gbase.general_log 一、环境信…...

汽车信息安全导图
尊敬的读者们,欢迎来到我的信息安全专栏。在这个专栏中,我将结合我在信息安全领域的开发经验,为大家深入浅出地讲解信息安全的重要性和相关知识点。 在数字化时代,信息成为了我们生活中不可或缺的一部分。我们的个人信息、交易数据、社交网络、公司机密等都以电子形式存储…...

【元宇宙】区块链,元宇宙最大化的驱动力
如今,一些观察者认为区块链是在结构上实现元宇宙的必要条件,而其他人则认为这种说法是荒谬的。人们对于区块链技术本身仍然有很多困惑,所以根本谈不上清楚地了解込块链技术与元宇宙的关系。所以,我们可以从区块链的定义开始介绍。…...

$ref属性的介绍与使用
在Vue.js中,$ref是一个特殊的属性,用于访问Vue组件中的DOM元素或子组件实例。它允许你直接访问组件内部的DOM元素或子组件,并且可以在需要时进行操作或修改。以下是有关$ref的详细介绍和示例演示,给大家做一个简单的介绍和概念区分…...

Holistic Evaluation of Language Models
本文是LLM系列文章,针对《Holistic Evaluation of Language Models》的翻译。 语言模型的整体评价 摘要1 引言2 前言3 核心场景4 一般指标5 有针对性的评估6 模型7 通过提示进行调整8 实验和结果9 相关工作和讨论10 缺失11 不足和未来工作12 结论 摘要 语言模型&a…...

android 布局 横屏 android横屏适配
一、刘海屏适配 1、layoutInDisplayCutoutMode属性 Android 9.0系统中提供了3种layoutInDisplayCutoutMode属性来允许应用自主决定该如何对刘海屏设备进行适配。 LAYOUT_IN_DISPLAY_CUTOUT_MODE_DEFAULT 这是一种默认的属性,在不进行明确指定的情况下,系…...

北京已收录2023开学了《乡村振兴战略下传统村落文化旅游设计》中国建筑出版传媒许少辉八一新书
北京已收录2023开学了《乡村振兴战略下传统村落文化旅游设计》中国建筑出版传媒许少辉八一新书...
【Linux】Ubuntu20.04版本配置pytorch环境2023.09.05【教程】
【Linux】Ubuntu20.04版本配置pytorch环境2023.09.05【教程】 文章目录 【Linux】Ubuntu20.04版本配置pytorch环境2023.09.05【教程】一、安装Anaconda虚拟环境管理器二、创建虚拟环境并激活三、安装Pytorch四、测试pytorchReference 一、安装Anaconda虚拟环境管理器 首先进入…...

11 Python的正则表达式
概述 在上一节,我们介绍了Python的文件操作,包括:打开文件、读取文件、写入文件、关闭文件、文件指针移动、获取目录列表等内容。在这一节中,我们将介绍Python的正则表达式。正则表达式是一种强大的工具,用于在文本中进…...
关于工信部发布的app备案以及小程序备案流程
一、相关政策 通知:https://beian.miit.gov.cn/#/Integrated/lawStatute 腾讯备案:网站备案 首次备案-网站备案-文档中心-腾讯云 阿里备案:网站备案_ICP备案_备案迁移_备案-阿里云 二、遇到的问题 APP备案 安卓获取平台公钥方法…...
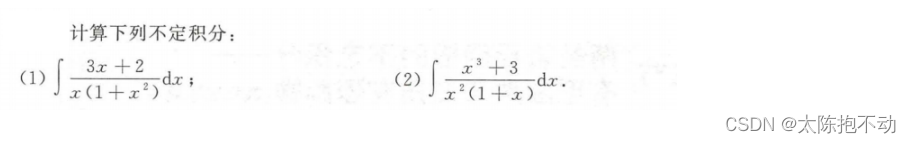
【高等数学基础知识篇】——不定积分
文章目录 一、不定积分的概念与基本性质1.1 原函数与不定积分的基本概念1.2 不定积分的基本性质 二、不定积分基本公式与积分法2.1 不定积分基本公式2.2 不定积分的积分法2.2.1 换元积分法2.2.2 分部积分法 三、两类重要函数的不定积分——有理函数与三角有理函数3.1 有理函数的…...

python使用鼠标在图片上画框
python rect.py 图片文件夹先左击左上角,再右击右下角,画出一个框结果保存在res文件夹rect.py import cv2, sys, ospathsys.argv[1] imcv2.imread(path) alos.listdir(path) al.sort() if not os.path.exists(res): os.makedirs(res)def getInfo(event,…...

算法通关村第十五关:青铜-用4KB内存寻找重复元素
青铜挑战-用4KB内存寻找重复元素 位运算在查找元素中的妙用 题目要求: 给定一个数组,包含从1到N的整数,N最大为32000,数组可能还有重复值,且N的取值不定,若只有4KB的内存可用,该如何打印数组中…...
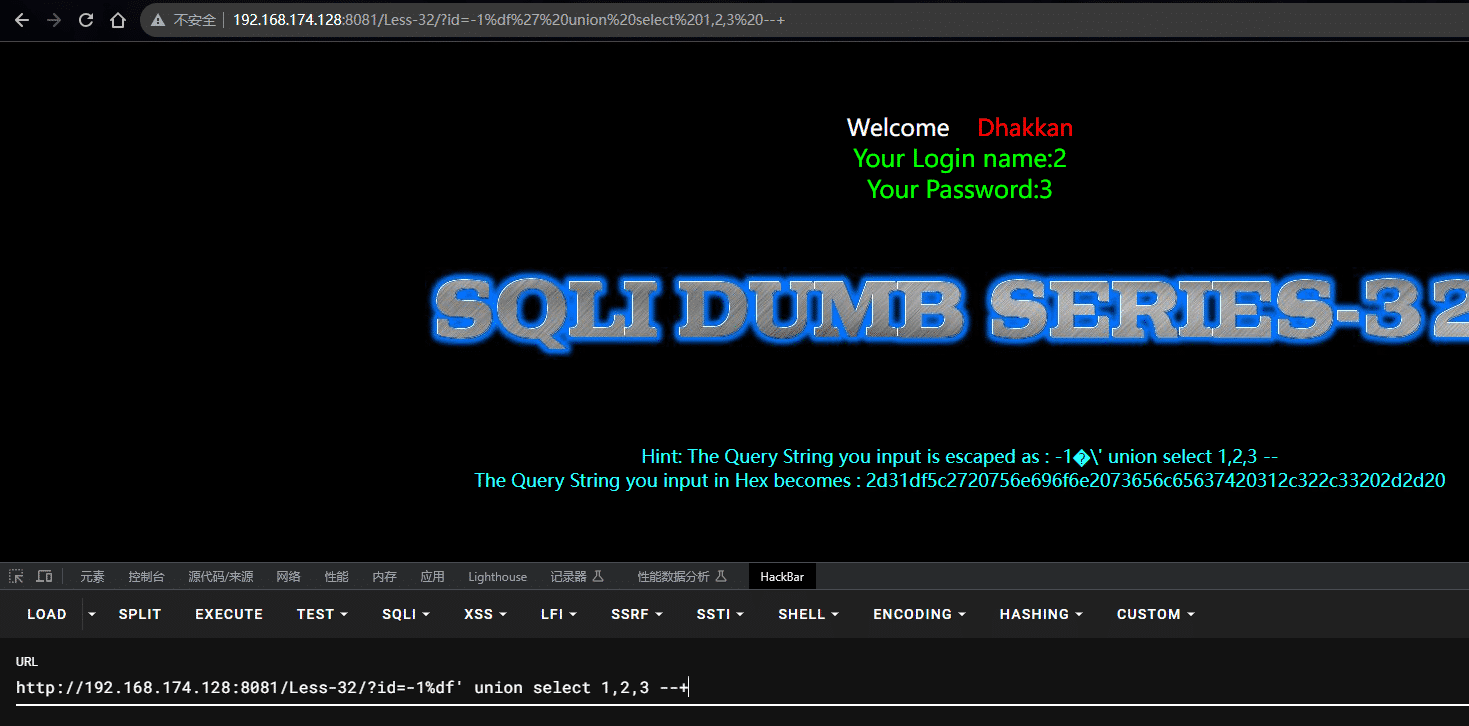
SQL注入 - 宽字节注入
文章目录 SQL注入 - 宽字节注入宽字节注入前置知识宽字节靶场实战判断是否存在SQL注入判断位数判显错位判库名判表名判列名 SQL注入 - 宽字节注入 靶场 sqli - labs less-32 宽字节注入主要是绕过魔术引号的,数据库解析中除了UTF-8编码外的所有编码如:G…...
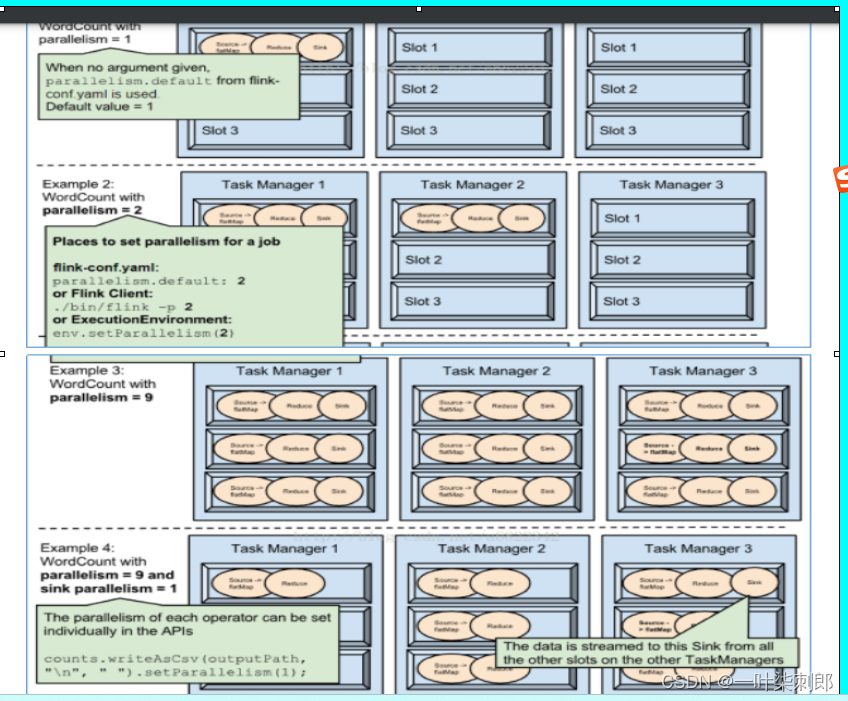
Flink基础
Flink architecture job manager is master task managers are workers task slot is a unit of resource in cluster, number of slot is equal to number of cores(超线程则slot2*cores), slot一组内存一些线程共享CPU when starting a cluster,job manager will allocate a …...
javaee spring aop 注解实现
切面类 package com.test.advice;import org.aspectj.lang.ProceedingJoinPoint; import org.aspectj.lang.annotation.*;//切面类 Aspect public class MyAdvice {//定义切点表达式Pointcut("execution(* com.test.service.impl.*.add(..))")public void pc(){}//B…...

OSINT自动化平台ClawShield:模块化架构与安全运营实战解析
1. 项目概述:一个面向安全运营的公开情报收集与分析平台最近在整理自己的开源项目收藏夹,发现一个挺有意思的仓库,叫SleuthCo/clawshield-public。乍一看这个名字,“ClawShield”,爪子与盾牌,就透着一股子攻…...

进化算法驱动机械爪设计优化:从原理到EvoClaw项目实践
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“EvoClaw”。光看这个名字,可能有点摸不着头脑,但点进去一看,发现这是一个关于“进化算法驱动的机械爪设计优化”的开源项目。简单来说,就是利用计算机…...

ADXL335模拟传感器读数不稳?手把手教你用Arduino进行软件滤波与校准
ADXL335模拟传感器读数不稳?手把手教你用Arduino进行软件滤波与校准 当你把ADXL335加速度计接入Arduino,兴奋地跑起第一个测试程序时,那些跳动的数字可能很快会浇灭你的热情。原始读数像得了疟疾般颤抖,静止时本该稳定的1g重力加速…...

Path of Building:3个步骤从Build小白到规划大师的完整指南
Path of Building:3个步骤从Build小白到规划大师的完整指南 【免费下载链接】PathOfBuilding Offline build planner for Path of Exile. 项目地址: https://gitcode.com/GitHub_Trending/pa/PathOfBuilding Path of Building作为流放之路玩家最信赖的Build规…...

AI智能体GUI交互实战:从原理到实现,让AI玩转桌面应用
1. 项目概述:一个能“玩”游戏的AI智能体最近在AI智能体(Agent)的圈子里,一个名为“ChattyPlay-Agent”的开源项目引起了我的注意。乍一看名字,你可能会觉得它又是一个基于大语言模型(LLM)的聊天…...

OCT-X算法:早期胃癌AI检测的技术突破与应用
1. OCT-X算法:早期胃癌AI检测的技术突破在医疗影像分析领域,胃癌早期检测一直面临着巨大挑战。传统内窥镜检查依赖医生经验判断,存在主观性强、漏诊率高等问题。我们团队开发的OCT-X(One Class Twin Cross Learning)算…...

Arduino驱动128x64 VFD显示屏:SPI像素回读与图形应用实战
1. 项目概述:为什么选择128x64图形VFD?如果你玩过各种OLED、LCD或者TFT屏幕,可能会觉得显示技术已经足够成熟,亮度、对比度似乎都够用。但当你第一次点亮一块真空荧光显示屏时,那种独特的、带着一丝复古科技感的蓝色辉…...
在Multi-Agent系统中的应用(图编排、动态DAG、Dynamic DAG)动态Agent Graph)
有向无环图(DAG)在Multi-Agent系统中的应用(图编排、动态DAG、Dynamic DAG)动态Agent Graph
文章目录有向无环图(DAG)在 Multi-Agent 系统中的应用一、什么是 DAG(有向无环图)二、为什么 Multi-Agent 需要 DAG三、Multi-Agent 的本质:任务图四、DAG 在 Multi-Agent 中的核心作用五、一个典型 Multi-Agent DAG六…...

基于容器技术的在线代码沙盒:架构设计与安全实践
1. 项目概述:一个开箱即用的在线代码运行沙盒最近在折腾一些需要快速验证代码片段、或者给团队做技术分享的场景,我发现一个痛点:环境配置太麻烦了。你想让新人跑个Python脚本,他可能得先装Python、配环境变量、装依赖库ÿ…...

2025-2026年国内PCB厂家:五大产品专业评测 解决散热不均致焊点脱落痛点
摘要 当企业将PCB选型从通用需求转向高精尖领域适配,决策者面临如何在技术复杂度与成本可控间取得平衡的现实挑战:是追求极致性能,还是优先保障供应链稳定?根据Prismark Partners发布的2024年全球PCB产业报告,全球PCB…...