【大数据Hive】hive 加载数据常用方案使用详解
目录
一、前言
二、load 命令使用
2.1 load 概述
2.1.1 load 语法规则
2.1.2 load语法规则重要参数说明
2.2 load 数据加载操作演示
2.2.1 前置准备
2.2.2 加载本地数据
2.2.3 HDFS加载数据
2.2.4 从HDFS加载数据到分区表中并指定分区
2.3 hive3.0+ load 命令新特性
2.3.1 操作演示
三、insert 命令使用
3.1 语法
3.2 insert + select 操作演示
3.2.1 创建一张源表
3.2.2 加载数据
3.2.3 创建一张目标表
3.2.4 使用insert+select插入数据到新表
3.3 multiple inserts
3.3.1 操作演示
3.4 insert 之动态分区插入
3.4.1 动态分区概述
3.4.2 操作演示
3.5 insert 之导出数据
3.5.1 标准语法
3.5.2 其他写法
3.5.3 导出数据操作演示1
3.5.4 导出数据操作演示2
3.5.5 导出数据操作演示3
四、写在文末
一、前言
使用hive对数据表加载数据时方式有很多,比如直接通过insert into插入数据,或者先创建表,然后在hdfs上面上传数据文件进行数据加载的方式等等,本篇将重点介绍如何对hive的table进行数据的导入导出。
二、load 命令使用
在正式开始之前,先来回顾下之前的文章中讲到的一种常用的数据加载方式,即使用load的方式进行数据映射;
总结来说,包括如下几点:
- 在Hive中建表成功之后,就会在HDFS上创建一个与之对应的文件夹,且文件夹名字就是表名;
- 文件夹父路径是由参数hive.metastore.warehouse.dir控制,默认值是/user/hive/warehouse;
- 也可以在建表的时候使用location语句指定任意路径;
默认情况下,当我们创建完成一个table之后,不管路径在哪里,只有把数据文件移动到对应的表文件夹下面,Hive才能映射解析成功,最原始的方式就是使用 hadoop fs –put|-mv 等方式直接将数据移动到表文件夹下,但是,Hive官方推荐使用Load命令将数据加载到表中;
2.1 load 概述
Load英文单词的含义为:加载、装载,所谓加载是指:将数据文件移动到与Hive表对应的位置,移动时是纯复制、移动操作;
纯复制、移动指在数据load加载到表中时,Hive不会对表中的数据内容进行任何转换,任何操作;
2.1.1 load 语法规则
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
或者
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)] [INPUTFORMAT 'inputformat' SERDE 'serde'] (3.0 or later)
2.1.2 load语法规则重要参数说明
语法规则之filepath
- filepath表示待移动数据的路径。可以指向文件(在这种情况下,Hive将文件移动到表中),也可以指向目录(在这种情况下,Hive将把该目录中的所有文件移动到表中);
- filepath文件路径支持下面三种形式,要结合LOCAL关键字一起考虑;
filepath可以使用绝对路径或者相对路径
1、相对路径,例如:project/data1;
2、绝对路径,例如:/user/hive/project/data1;
3、具有schema的完整URI,例如:hdfs://namenode:9000/user/hive/project/data1;
语法规则之 local
- 指定LOCAL, 将在本地文件系统中查找文件路径;
1、若指定相对路径,将相对于用户的当前工作目录进行解释;
2、用户也可以为本地文件指定完整的URI-例如:file:///user/hive/project/data1
如果没有指定 local 关键字
- 如果filepath指向的是一个完整的URI,会直接使用这个URI;
- 如果没有指定schema,Hive会使用在hadoop配置文件中参数fs.default.name指定的(不出意外,都是HDFS);
问题:LOCAL本地是哪里?
如果对HiveServer2服务运行此命令,本地文件系统指的是Hiveserver2服务所在机器的本地Linux文件系统,不是Hive客户端所在的本地文件系统
语法规则之 OVERWRITE
如果使用了OVERWRITE关键字,则目标表(或者分区)中的已经存在的数据会被删除,然后再将filepath指向的文件/目录中的内容添加到表/分区中。
2.2 load 数据加载操作演示
模拟从本地加载数据
2.2.1 前置准备
创建三张表,分别演示从本地以及hdfs上面加载数据
create table student_local(num int,name string,sex string,age int,dept string)
row format delimited fields terminated by ',';
再创建第二张表
create external table student_HDFS(num int,name string,sex string,age int,dept string)
row format delimited fields terminated by ',';
创建第三张分区表,用于演示从HDFS加载数据到分区表
create table student_HDFS_p(num int,name string,sex string,age int,dept string)
partitioned by(country string) row format delimited fields terminated by ',';
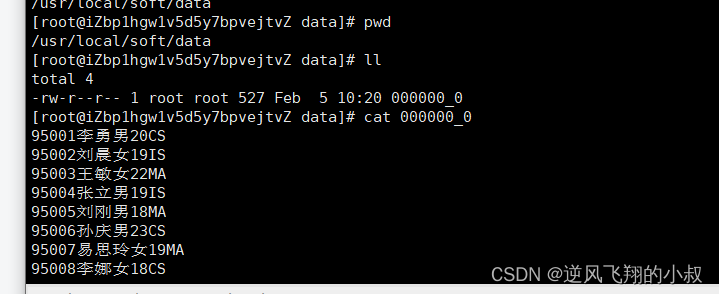
2.2.2 加载本地数据
从本地加载数据
LOAD DATA LOCAL INPATH '/usr/local/soft/hivedata/students.txt' INTO TABLE student_local;执行完成后查看表,可以看到数据就加载到表中了;

同时再去检查hdfs目录,可以看到数据也被加载到hdfs目录下了;
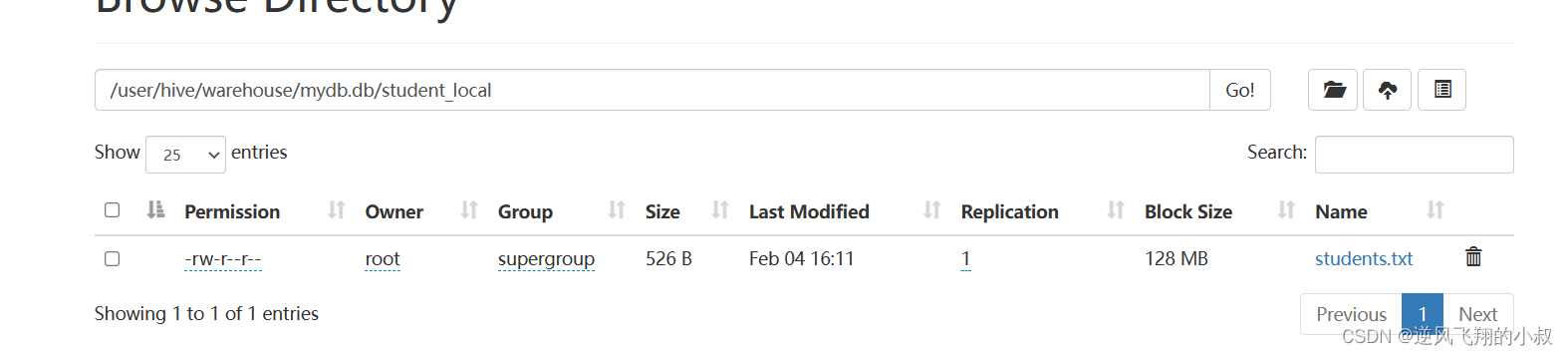
其实,这种操作其底层在执行时,本质上还是执行了是hadoop fs -put上传的操作
2.2.3 HDFS加载数据
将数据上传到hdfs
hdfs dfs -put /usr/local/soft/hivedata/students.txt /

上传成功后,在根目录下就可以看到这个文件了

将上述hdfs根目录下的数据移动到表中
LOAD DATA INPATH '/students.txt' INTO TABLE student_HDFS;

这时再去hdfs的根目录下检查,发现这个数据文件竟然不在了
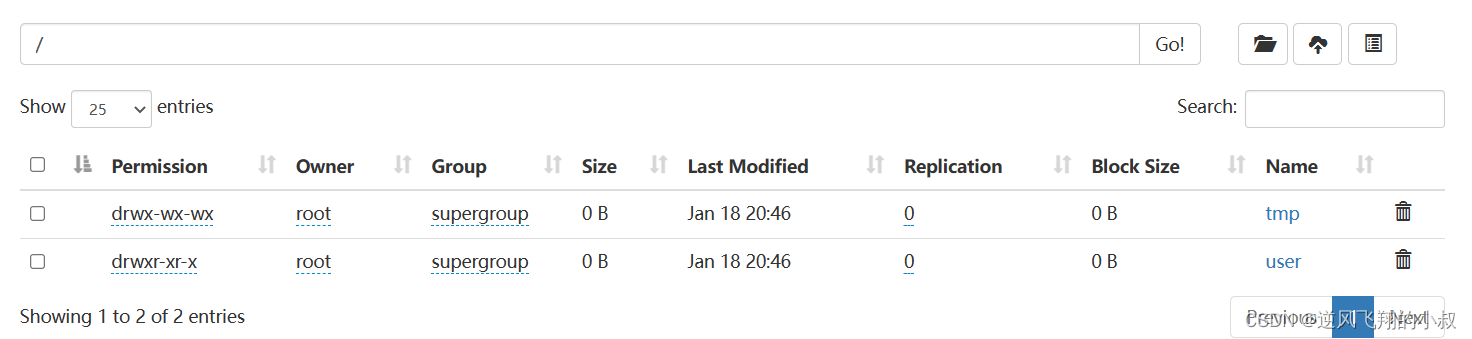
这种加载数据的方式,其本质是hadoop fs -mv 进行数据移动的操作
2.2.4 从HDFS加载数据到分区表中并指定分区
上传数据到根目录
hdfs dfs -put /usr/local/soft/hivedata/students.txt /

使用load命令将数据加载到分区表
LOAD DATA INPATH '/students.txt' INTO TABLE student_HDFS_p partition(country ="China");

2.3 hive3.0+ load 命令新特性
Hive3.0之后,load加载数据时除了移动、复制操作之外,在某些场合下还会将加载重写为INSERT AS SELECT,还支持使用inputformat、SerDe指定输入格式,例如Text,ORC等。
比如,如果表具有分区,则load命令没有指定分区,则将load转换为INSERT AS SELECT,并假定最后一组列为分区列,如果文件不符合预期,则报错。
2.3.1 操作演示
创建一张测试使用的分区表
CREATE TABLE if not exists tab1 (col1 int, col2 int)
PARTITIONED BY (col3 int)
row format delimited fields terminated by ',';创建一个数据文件,格式如下
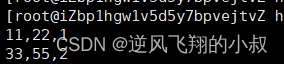
正常情况下的数据加载
LOAD DATA LOCAL INPATH '/usr/local/soft/hivedata/tab1.txt' INTO TABLE tab1 partition(col3="1");加载完成后可以看到数据已经加载到表中
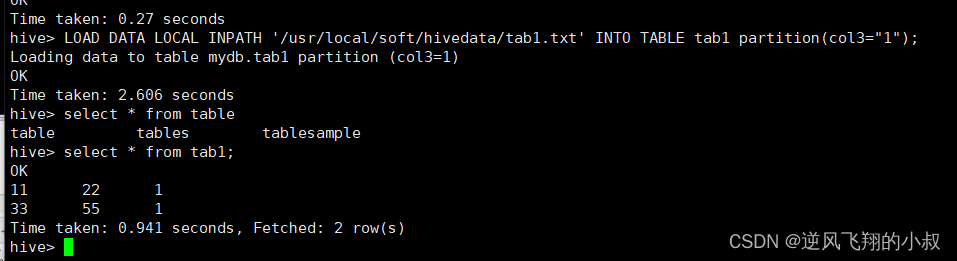
上面谈到hive3.0之后,load命令如果没有指定分区,则将load转换为INSERT AS SELECT,并假定最后一组列为分区列,接下来我们清空该表,使用下面的命令重新执行一次;
LOAD DATA LOCAL INPATH '/usr/local/soft/hivedata/tab1.txt' INTO TABLE tab1;

从hdfs上面可以发现,被成功映射为分区表了;
通过执行过程发现,这个时间有点长,因为底层要将这个操作转化为 INSERT AS SELECT 的操作;
三、insert 命令使用
MySQL这样的RDBMS中,通常使用insert+values的方式来向表插入数据,并且执行速度很快,假如把Hive当成RDBMS,用insert+values的方式插入数据,会如何?
不妨来做过简单的试验吧,创建一张表
create table t_test_insert(id int,name string,age int);
然后向表中插入一条数据
insert into table t_test_insert values(1,"allen",18);
尽管数据可以插入成功,但是执行过程比较漫长,原因在于底层是开启了了MapReduce任务,通过map-reduce任务把数据写入Hive表中;

试想一下,如果在Hive中使用insert+values,对于大数据环境一条条插入数据,用时难以想象,所以Hive官方推荐加载数据的方式:清洗数据成为结构化文件,再使用Load语法加载数据到表中。这样的效率更高。
但是并不意味insert语法在Hive中没有用武之地了,下面介绍hive中insert的其他用法;
insert + select
insert+select表示:将后面查询返回的结果作为内容插入到指定表中,注意OVERWRITE将覆盖已有数据;
3.1 语法
INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1 FROM from_statement;或
INSERT INTO TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement;
使用insert+select 需要注意:
- 需要保证查询结果列的数目和需要插入数据表格的列数目一致;
- 如果查询出来的数据类型和插入表格对应的列数据类型不一致,将会进行转换,但是不能保证转换一定成功,转换失败的数据将会为NULL;
3.2 insert + select 操作演示
3.2.1 创建一张源表
create table student(num int,name string,sex string,age int,dept string)
row format delimited
fields terminated by ',';

3.2.2 加载数据
load data local inpath '/usr/local/soft/hivedata/students.txt' into table student;
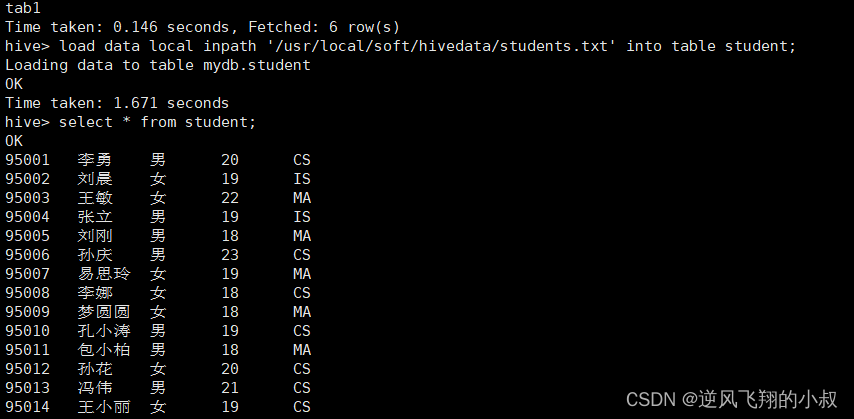
3.2.3 创建一张目标表
该表只有两个字段
create table student_from_insert(sno int,sname string);

3.2.4 使用insert+select插入数据到新表
不难理解,执行了这条sql之后,student表中的num,name两个字段数据将会填充到student_from_insert表中;
insert into table student_from_insert select num,name from student;
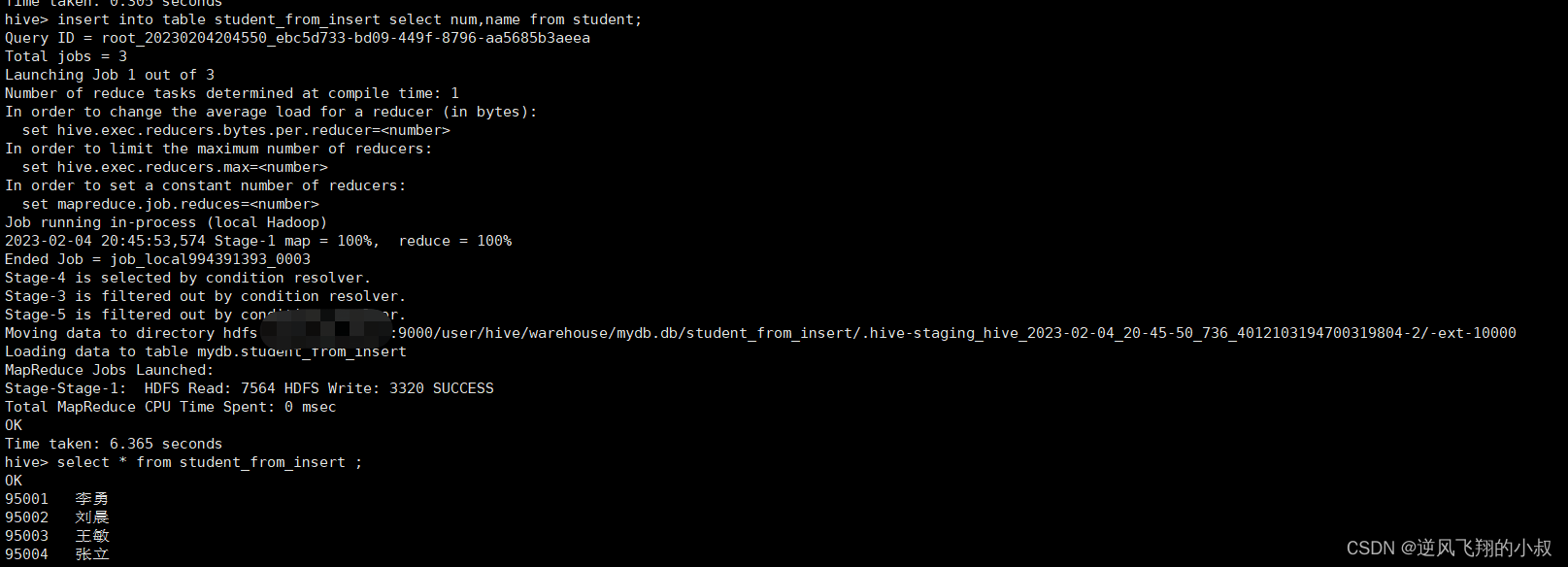
3.3 multiple inserts
顾名思义就是,多次插入,多重插入,其核心功能是:一次扫描,多次插入;
使用该语法的目的就是减少扫描的次数,在一次扫描中,完成多次insert操作;
3.3.1 操作演示
在上面的insert + select 中创建了一张student的表,再创建两张新表,各有一个字段;
create table student_insert1(sno int);
create table student_insert2(sname string);
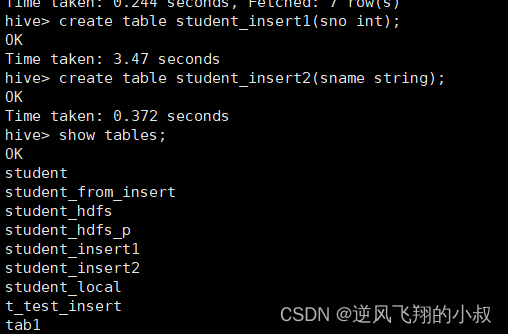
我们的需求是,从student中查询出sno放到第一个表,然后查询出sname放到另一个表中,如果按照大多数人直观的考虑,可能会像下面这么做:
insert into student_insert1 select num from student;
insert into student_insert2 select name from student;
如果使用多重插入来做的话,就可以使用下面的sql一次性完成;
from student
insert overwrite table student_insert1
select num
insert overwrite table student_insert2
select name;
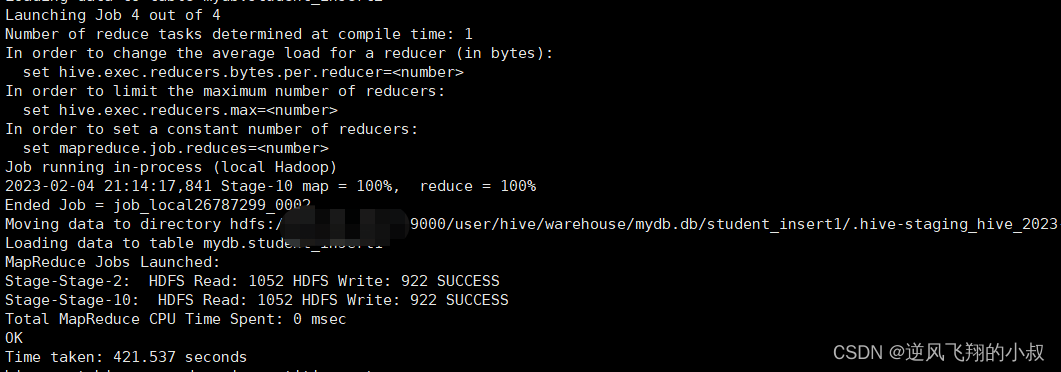
执行完成后,可以检查两个表的数据是否成功插入;
3.4 insert 之动态分区插入
背景说明
对于分区表的数据导入加载,最基础的是通过load命令加载数据,在load过程中,分区值是手动指定写死的,叫做静态分区。
假如说,现在有全球224个国家的人员名单(每个国家名单单独一个文件),导入到分区表中,不同国家不同分区,如何高效实现?如果使用load命令,岂不是要导入224次?这样的话效率就太低了。
3.4.1 动态分区概述
动态分区插入指的是:分区的值是由后续的select查询语句的结果来动态确定的,根据查询结果自动分区。
两个重要参数
| hive.exec.dynamic.partition | true | 需要设置true为启用动态分区插入 |
| hive.exec.dynamic.partition.mode | strict | 在strict模式下,用户必须至少指定一个静态分区,以防用户意外覆盖所有分区;在nonstrict模式下,允许所有分区都是动态的 |
3.4.2 操作演示
首先设置动态分区模式为非严格模式(默认已经开启了动态分区功能)
set hive.exec.dynamic.partition = true;
set hive.exec.dynamic.partition.mode = nonstrict;
在当前库下,已经有一张student表,创建分区表;
create table student_partition(Sno int,Sname string,Sex string,Sage int)
partitioned by(Sdept string);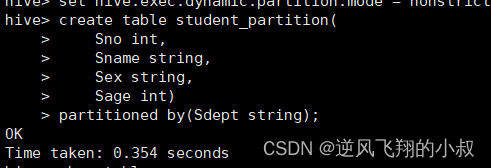
执行动态分区insert操作插入数据
insert into table student_partition partition(Sdept)
select num,name,sex,age,dept from student;
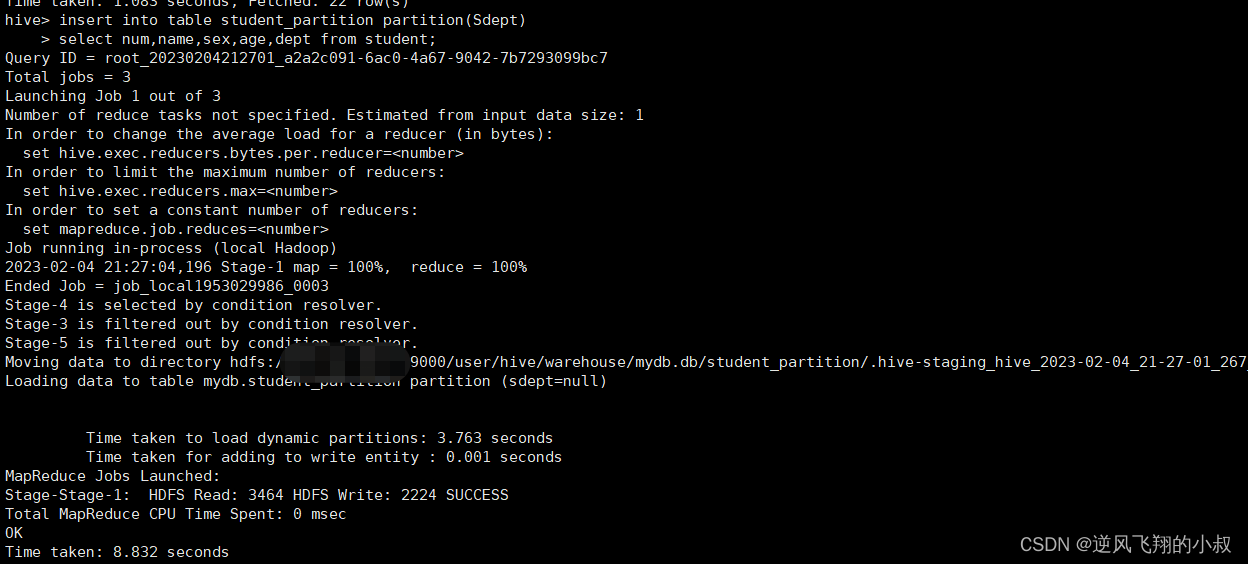
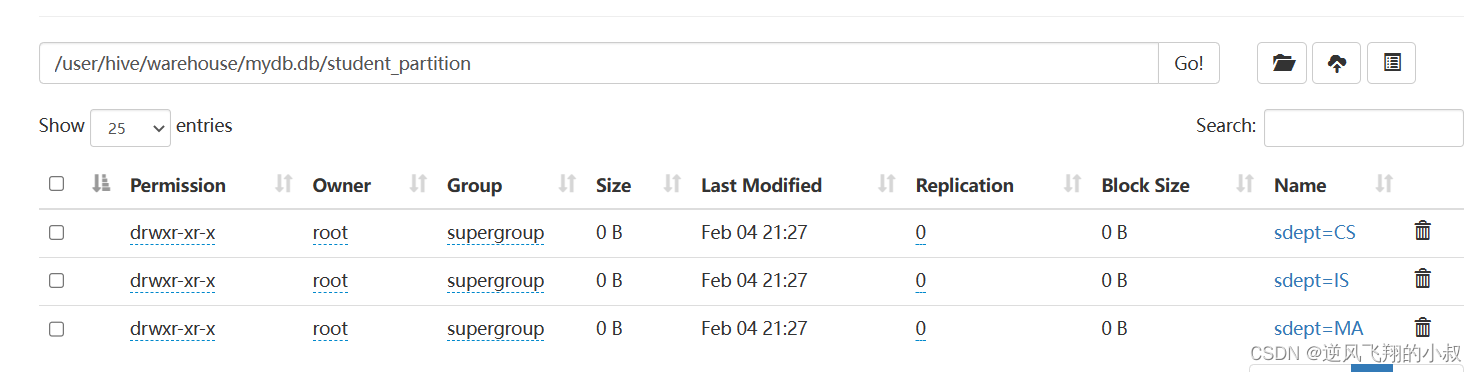
执行完成后,检查hdfs目录,可以发现数据已经按照分区保持了
3.5 insert 之导出数据
Hive支持将select查询的结果导出成文件存放在文件系统中,语法格式如下;
3.5.1 标准语法
INSERT OVERWRITE [LOCAL] DIRECTORY directory1
[ROW FORMAT row_format] [STORED AS file_format]
SELECT ... FROM ...
3.5.2 其他写法
FROM from_statement
INSERT OVERWRITE [LOCAL] DIRECTORY directory1 select_statement1
[INSERT OVERWRITE [LOCAL] DIRECTORY directory2 select_statement2] ...
关于语法补充说明
- 目录可以是完整的URI。如果未指定scheme,则Hive将使用hadoop配置变量fs.default.name来决定导出位置;
- 如果使用LOCAL关键字,则Hive会将数据写入本地文件系统上的目录;
- 写入文件系统的数据被序列化为文本,列之间用\001隔开,行之间用换行符隔开。如果列都不是原始数据类型,那么这些列将序列化为JSON格式。也可以在导出的时候指定分隔符换行符和文件格式;
3.5.3 导出数据操作演示1
在上文中演示时用到了一张student表
导出查询结果到HDFS指定目录下
insert overwrite directory '/data' select num,name,age from student;
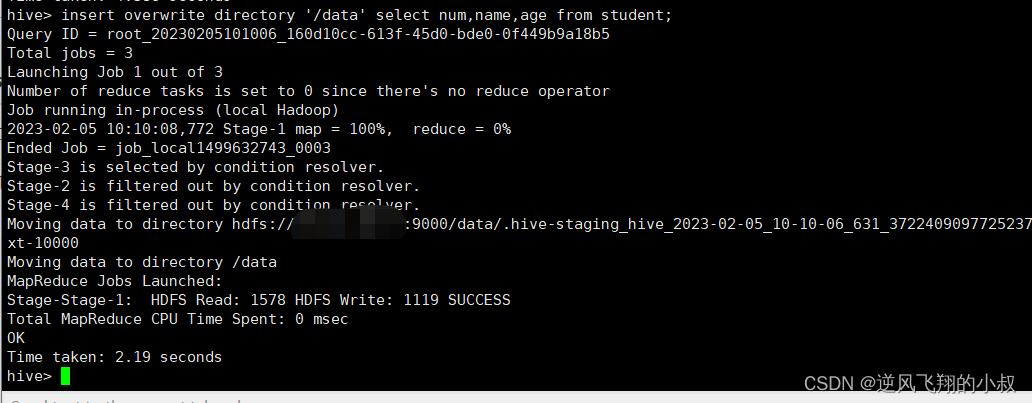
任务完成之后到hdfs目录下检查数据是否导出成功,也可以从hdfs将文件下载下来再次确认数据的正确性;

3.5.4 导出数据操作演示2
接下来我们在导出的时候指定一下分隔符和文件存储格式
insert overwrite directory '/data' row format delimited fields terminated by ','
stored as orc select * from student;
执行上面的导出sql

去hdfs上检查数据是否导出成功

3.5.5 导出数据操作演示3
导出数据到本地文件系统指定目录下
insert overwrite local directory '/usr/local/soft/data' select * from student;
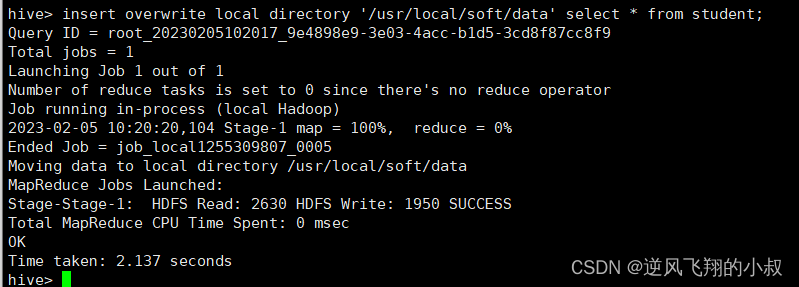
执行完成之后检查本地数据目录下已经有了导出的数据;
四、写在文末
hive的数据导入在日常开发、运维过程中运用的场景非常普遍,且频率非常高,选择合理的数据导入方式可以给开发提升很多效率,有必要深入掌握。
相关文章:
【大数据Hive】hive 加载数据常用方案使用详解
目录 一、前言 二、load 命令使用 2.1 load 概述 2.1.1 load 语法规则 2.1.2 load语法规则重要参数说明 2.2 load 数据加载操作演示 2.2.1 前置准备 2.2.2 加载本地数据 2.2.3 HDFS加载数据 2.2.4 从HDFS加载数据到分区表中并指定分区 2.3 hive3.0 load 命令新特性 …...
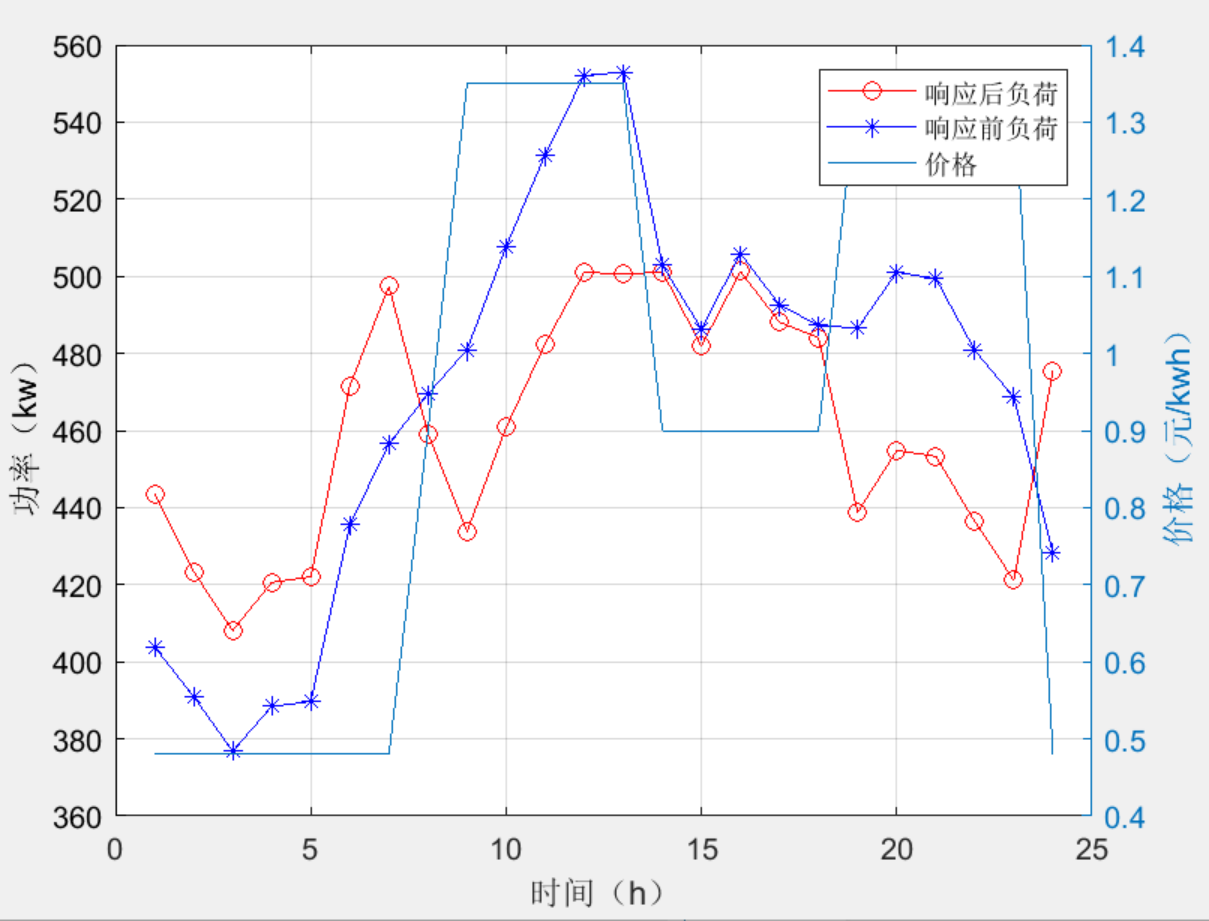
计及电池储能寿命损耗的微电网经济调度(matlab代码)
目录 1 主要内容 2 部分代码 3 程序结果 4 下载链接 1 主要内容 该程序参考文献《考虑寿命损耗的微网电池储能容量优化配置》模型,以购售电成本、燃料成本和储能寿命损耗成本三者之和为目标函数,创新考虑储能寿命损耗约束、放电深度约束和储能循环次…...
DP读书:鲲鹏处理器 架构与编程(十四)ACPI与软件架构具体调优
一分钟速通ACPI和鲲鹏软件移植 操作系统内核鲲鹏软件移植鲲鹏软件移植流程 编译工具选择编译参数移植案例源码修改案例鲲鹏分析扫描工具 Dependency Advisor鲲鹏代码迁移工具 Porting Advisor 鲲鹏软件性能调优鲲鹏软件性能调优流程CPU与内存子系统性能调优网络子系统性能调优磁…...
4.正则提取html中的img标签的src内容
我们以百度贴吧的1吧举例 目录 1 把网页搞下来 2 收集url 3 处理url 4 空的src 5 容错 6 不使用数字作为文件名 7 并不是所有的图片都用img标签表示 8 img标签中src请求下来不一定正确 9 分页 1 把网页搞下来 搞下来之后,双击打开是这样的 2 收…...

安装对应版本pytorch和torchvision
遇见报错: ERROR: Could not find a version that satisfies the requirement torch (from versions: none) ERROR: No matching distribution found for torch 解决方法: 1、网站找到对应torch和torchvision版本,cp对应python版本ÿ…...

酷克数据与华为合作更进一步 携手推出云数仓联合解决方案
在一起,共迎新机遇!8月25-26日,2023华为数据存储用户精英论坛在西宁召开。酷克数据作为国内云原生数据仓库的代表企业,也是华为重要的生态合作伙伴,受邀参与本次论坛,并展示了云数仓领域最新前沿技术以及联…...
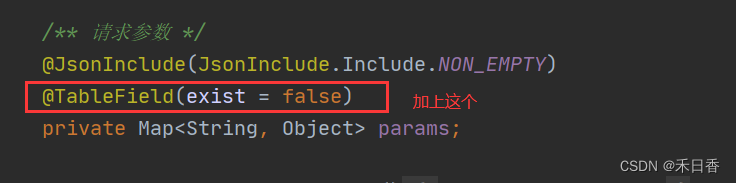
若依 MyBatis改为MyBatis-Plus
主要内容:升级成mybatis-plus,代码生成也是mybatis-plus版本 跟着我一步一步来,就可完成升级! 检查:启动程序,先保证若依能启动 第一步:添加依赖 这里需要在两个地方添加,一个是最…...

docker-ubuntu
docker ps docker images 拉取ubuntu镜像 docker pull ubuntu 启动 docker start podid docker run -itd -e TZAsia/Shanghai --name ubuntu-test -v /share:/shared -d ubuntu:latest 进入bash界面 docker exec -it podid /bin/bash 安装sudo apt-get install sudo …...
Mock 基本使用
mock解决的问题 开发时,后端还没完成数据输出,前端只好写静态模拟数据。数据太长了,将数据写在js文件里,完成后挨个改url。某些逻辑复杂的代码,加入或去除模拟数据时得小心翼翼。想要尽可能还原真实的数据,…...
MySql学习笔记08——事务介绍
事务 基本概念 事务是一个完整的业务逻辑,是一个最小的工作单元,不可再分。 一个完整的业务逻辑包括一系列的操作,这些操作是整个业务逻辑中的最小单元,这些操作要么同时成功,要么同时失败。 由于只有DML语句中才会…...

AMEYA360:思瑞浦推出汽车级超低静态功耗高压LDO—TPL8031Q
聚焦高性能模拟芯片和嵌入式处理器创新研发的半导体公司——思瑞浦3PEAK(股票代码:688536),推出全新一代汽车级超低静态功耗高压线性稳压器——TPL8031Q。 TPL8031Q拥有支持3V~42V宽输入电压范围、3μA超低静态功耗、多种封装可选等性能优势,…...

保留 N 条数据功能 实现方案
需求:用户浏览某信息后 就插入一条浏览记录,该浏览记录限制只保留 N 条。 实现方案: 1. 插入记录 2. 查询总记录 3. 判断:总记录 是否大于 阈值 3.1 如果大于:总记录 - 阈值 获取到超出数量,将对超出数…...
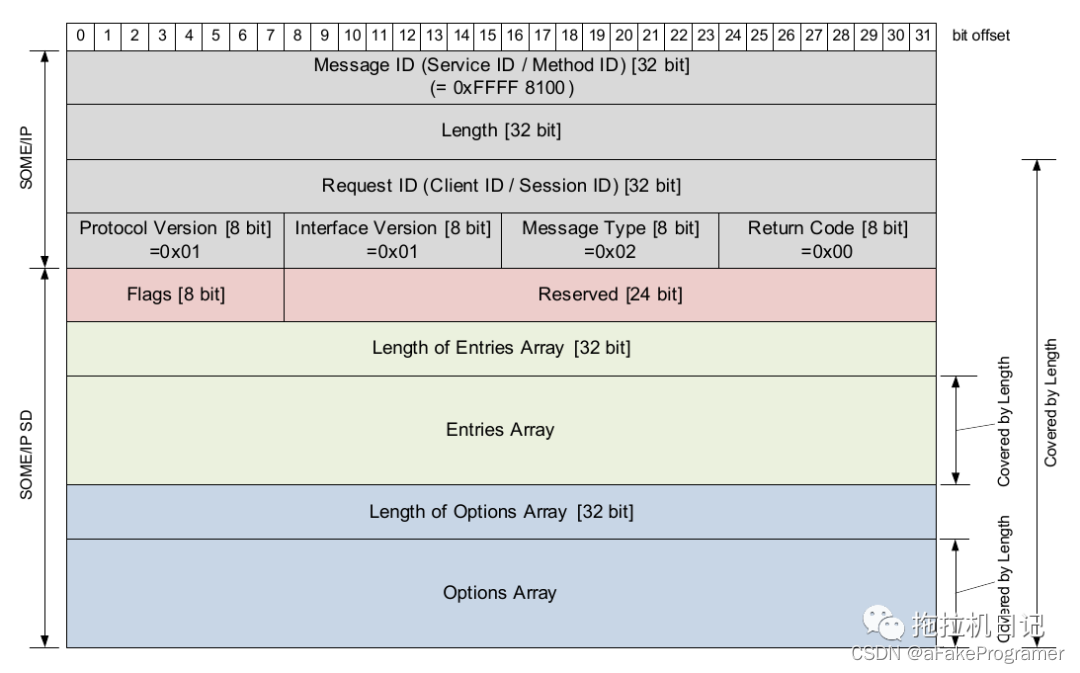
SOME/IP TTL 在各种Entry 中各是什么意思?有什么限制?
1 服务发现 SOME/IP SD 服务发现主要用于 定位服务实例检测服务实例状态是否在运行发布/订阅行为管理SOME/IP SD 也是 SOME/IP 消息,遵循 SOME/IP 消息格式,有固定的 Message ID、Request ID 以及 Message Type 等。并对 SOME/IP Payload 进行了详细的定义。 SOME/IP SD …...

CSS中如何实现元素的旋转和缩放效果?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ 元素的旋转和缩放效果⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 记得点击上方或者右侧链接订阅本专栏哦 几何带你启航前端之旅 欢迎来到前端入门之旅!这个专栏是为那些对Web开发感兴趣、刚刚踏…...

Unity通过偏移UV播放序列帧动画
大家好,我是阿赵。 在Unity引擎里面用shader播放序列图,估计很多人都有用到了,我自己而已写过好几个版本。这里大概介绍一下。 一、原理 先说目的,我现在有一张这样的图片: 这张图片上面,有9个格子&a…...

无涯教程-Android - List fragments函数
框架的ListFragment的静态库支持版本,用于编写在Android 3.0之前的平台上运行的应用程序,在Android 3.0或更高版本上运行时,仍使用此实现。 List fragment 的基本实现是用于创建fragment中的项目列表 List in Fragments 示例 本示例将向您说明如何基于…...

【图解RabbitMQ-3】消息队列RabbitMQ介绍及核心流程
🧑💻作者名称:DaenCode 🎤作者简介:CSDN实力新星,后端开发两年经验,曾担任甲方技术代表,业余独自创办智源恩创网络科技工作室。会点点Java相关技术栈、帆软报表、低代码平台快速开…...
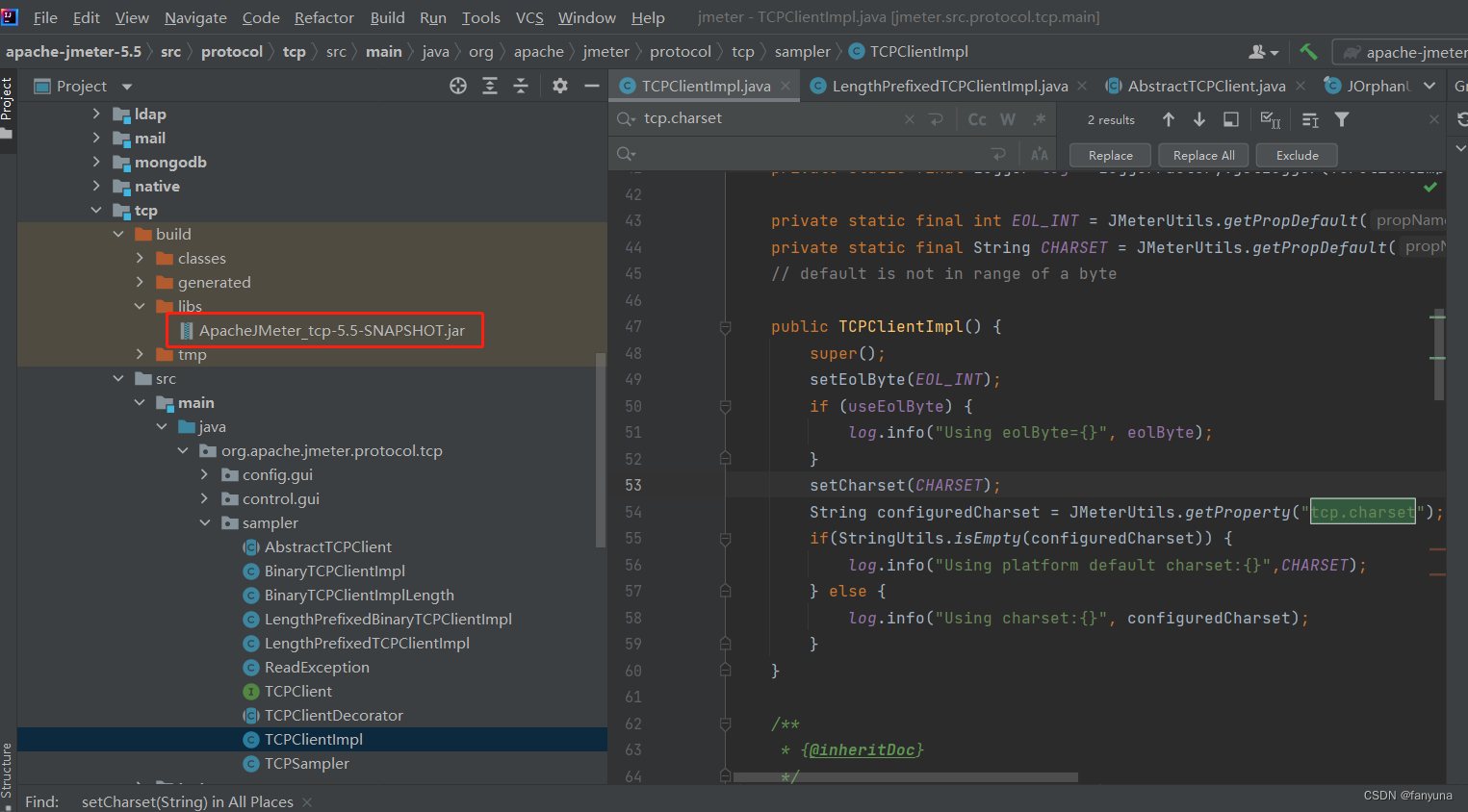
jmeter源码二次开发
本文以jmeter5.5为例,扩展“TCP Socket支持定长的返回字节流”功能。 一、 源码本地编译运行 1、在jmeter官网下载源码:jmeter各版本源码地址 2、在idea中用gradle导入jmeter源码,idea中要配置jdk,gradle,我用的是j…...

深入实现 MyBatis 底层机制的任务阶段4 - 开发 Mapper 接口和 Mapper.xml
😀前言 在我们的自定义 MyBatis 底层机制实现过程中,我们已经深入研究了多个任务阶段,包括配置文件的读取、数据库连接的建立、执行器的编写,以及 SqlSession 的封装。每个任务阶段都为我们揭示了 MyBatis 内部工作原理的一部分&a…...
分享一下在微信上有哪些微信活动可以做
微信营销活动是吸引更多用户和提高品牌知名度的有效策略。下面是一些微信营销活动的做法: 抽奖活动:通过设置奖品和参与条件,吸引用户参与抽奖活动。例如,可以设置关注公众号、转发活动页面等条件,吸引更多用户参与抽奖…...

美国不断自我革新的历史,为这个国家面对充满巨大机遇却又充满不确定性的未来提供了引人深思的经验教训
https://www.mckinsey.com/mgi/our-research/At-250-sustaining-Americas-competitive-edge 美国不断自我革新的历史,为这个国家面对充满巨大机遇却又充满不确定性的未来提供了引人深思的经验教训 这一切始于一场惊天动地的反抗行动。 1776年7月,来自13…...

Speechless:三步完成微博PDF备份的终极免费Chrome扩展
Speechless:三步完成微博PDF备份的终极免费Chrome扩展 【免费下载链接】Speechless 把新浪微博的内容,导出成 PDF 文件进行备份的 Chrome Extension。 项目地址: https://gitcode.com/gh_mirrors/sp/Speechless 在数字时代,我们的社交…...

深度学习图像风格迁移:从Gatys算法到PyTorch工程实践
1. 项目概述:一个基于深度学习的图像风格迁移应用最近在GitHub上闲逛,发现了一个名为“aristoapp/DDalkkak”的项目。单看这个名字,可能有点摸不着头脑,但点进去一看,发现这是一个关于图像风格迁移(Image S…...

Go语言实现跨平台系统更新检查器:自动化运维与安全监控实践
1. 项目概述:一个被低估的系统运维“哨兵”在服务器和桌面系统的日常运维中,有一个场景大家一定不陌生:某天,你管理的服务器突然因为一个已知漏洞被攻击,事后排查发现,相关的安全补丁其实在几周前就已经发布…...

开源办公套件自动化部署与集成实战:基于OpenOffice的服务化解决方案
1. 项目概述:为什么我们需要一个“开源”的办公套件?如果你在GitHub上搜索过办公软件相关的仓库,大概率会看到过longyangxi/OpenOffice这个项目。乍一看,你可能会以为这是一个Apache OpenOffice的镜像或者某个分支。但点进去仔细研…...

Windows上运行Swift代码的三种实战路径
1. 为什么Windows开发者需要Swift? Swift作为苹果生态的主力编程语言,近年来在服务端开发、机器学习等领域的应用越来越广泛。但很多刚接触Swift的Windows开发者会发现:官方文档里压根没提Windows支持!这其实是因为Swift最初就是…...

详解C++作用域与生命周期
Pascal之父Nicklaus Wirth曾经提出一个公式,展示出了程序的本质:程序算法数据结构。后人又给出一个公式与之遥相呼应:软件程序文档。这两个公式可以简洁明了的为我们展示程序和软件的组成。程序的运行过程可以理解为算法对数据的加工过程&…...

WarcraftHelper:魔兽争霸3终极增强插件5分钟快速上手指南
WarcraftHelper:魔兽争霸3终极增强插件5分钟快速上手指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper WarcraftHelper是一款专为魔兽争…...

从零构建天气预报Web应用:Vue.js与Node.js全栈实战指南
1. 项目概述:一个开源的天气预报应用 最近在GitHub上看到一个挺有意思的项目,叫 fsboy/weather-forecast 。光看名字就知道,这是一个天气预报应用。但如果你以为它只是个简单的天气查询工具,那就太小看它了。这个项目吸引我的地…...

基于Python与Playwright的招聘信息自动化聚合与智能筛选工具实践
1. 项目概述:一个面向求职者的自动化信息聚合与投递工具最近在和一些做开发的朋友聊天,发现大家普遍有个痛点:找工作太费时间了。每天要在几个招聘App之间来回切换,重复筛选岗位、刷新列表、投递简历,机械性的操作占据…...