elasticsearch的搜索补全提示
当用户在搜索框输入字符时,我们应该提示出与该字符有关的搜索项
拼音分词器
下载
要实现根据字母做补全,就必须对文档按照拼音分词,GitHub上有拼音分词插件
GitHub - medcl/elasticsearch-analysis-pinyin: This Pinyin Analysis plugin is used to do conversion between Chinese characters and Pinyin.
解压
解压到一个文件夹中去
上传
上传到服务器中,elasticsearch的plugin目录

重启
重启elasticsearch
docker restart es
测试
POST /_analyze
{"text": "如家酒店还不错","analyzer": "pinyin"
}返回拼音

自定义分词器
默认的拼音分词器会将每个汉字单独分为拼音,而我们希望的是每个词条形成一组拼音,需要对拼音分词器做个性化定制,形成自定义分词器。
elasticsearch中分词器(analyzer)的组成包含三部分:
character filters:在tokenizer之前对文本进行处理。例如删除字符、替换字符
tokenizer:将文本按照一定的规则切割成词条(term)。例如keyword,就是不分词;还有ik_smart
tokenizer filter:将tokenizer输出的词条做进一步处理。例如大小写转换、同义词处理、拼音处理等

自定义分词器
PUT /myanalyzer
{"settings": {"analysis": {"analyzer": { "my_analyzer": { "tokenizer": "ik_max_word","filter": "py"}},"filter": { "py": { "type": "pinyin", "keep_full_pinyin": false,"keep_joined_full_pinyin": true,"keep_original": true,"limit_first_letter_length": 16,"remove_duplicated_term": true,"none_chinese_pinyin_tokenize": false}}}},"mappings": {"properties": {"name": {"type": "text","analyzer": "my_analyzer","search_analyzer": "ik_smart"}}}
}- analyzer自定义分词器
- my_analyzer分词器名称
- filter自定义tokenizer filter
- py过滤器名称
- filter.type过滤器类型,这里是pinyin
- name分词的字段
测试
POST /myanalyzer/_analyze
{"text": ["华美达酒店还不错"],"analyzer": "my_analyzer"
}结果

自动补全查询
创建索引库
PUT /hotel
{"settings": {"analysis": {"analyzer": {"text_anlyzer": {"tokenizer": "ik_max_word","filter": "py"},"completion_analyzer": {"tokenizer": "keyword","filter": "py"}},"filter": {"py": {"type": "pinyin","keep_full_pinyin": false,"keep_joined_full_pinyin": true,"keep_original": true,"limit_first_letter_length": 16,"remove_duplicated_term": true,"none_chinese_pinyin_tokenize": false}}}},"mappings": {"properties": {"id":{"type": "keyword"},"name":{"type": "text","analyzer": "text_anlyzer","search_analyzer": "ik_smart","copy_to": "all"},"address":{"type": "keyword","index": false},"price":{"type": "integer"},"score":{"type": "integer"},"brand":{"type": "keyword","copy_to": "all"},"city":{"type": "keyword"},"starName":{"type": "keyword"},"business":{"type": "keyword","copy_to": "all"},"location":{"type": "geo_point"},"pic":{"type": "keyword","index": false},"all":{"type": "text","analyzer": "text_anlyzer","search_analyzer": "ik_smart"},"suggestion":{"type": "completion","analyzer": "completion_analyzer"}}}
}HotelDoc实体
import lombok.Data;
import lombok.NoArgsConstructor;import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;@Data
@NoArgsConstructor
public class HotelDoc {private Long id;private String name;private String address;private Integer price;private Integer score;private String brand;private String city;private String starName;private String business;private String location;private String pic;private Object distance;private Boolean isAD;private List<String> suggestion;public HotelDoc(Hotel hotel) {this.id = hotel.getId();this.name = hotel.getName();this.address = hotel.getAddress();this.price = hotel.getPrice();this.score = hotel.getScore();this.brand = hotel.getBrand();this.city = hotel.getCity();this.starName = hotel.getStarName();this.business = hotel.getBusiness();this.location = hotel.getLatitude() + ", " + hotel.getLongitude();this.pic = hotel.getPic();// 组装suggestionif(this.business.contains("/")){// business有多个值,需要切割String[] arr = this.business.split("/");// 添加元素this.suggestion = new ArrayList<>();this.suggestion.add(this.brand);Collections.addAll(this.suggestion, arr);}else {this.suggestion = Arrays.asList(this.brand, this.business);}}
}导入数据
@Testvoid testBulkRequest() throws IOException {// 批量查询酒店数据List<Hotel> hotels = hotelService.list();// 1.创建RequestBulkRequest request = new BulkRequest();// 2.准备参数,添加多个新增的Requestfor (Hotel hotel : hotels) {// 2.1.转换为文档类型HotelDocHotelDoc hotelDoc = new HotelDoc(hotel);// 2.2.创建新增文档的Request对象request.add(new IndexRequest("hotel").id(hotelDoc.getId().toString()).source(JSON.toJSONString(hotelDoc), XContentType.JSON));}// 3.发送请求client.bulk(request, RequestOptions.DEFAULT);}
controller类
import cn.itcast.hotel.pojo.PageResult;
import cn.itcast.hotel.pojo.RequestParams;
import cn.itcast.hotel.service.IHotelService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;import java.util.List;
import java.util.Map;@RestController
@RequestMapping("/hotel")
public class HotelController {@Autowiredprivate IHotelService hotelService;// 搜索酒店数据@GetMapping("suggestion")public List<String> getSuggestions(@RequestParam("key") String prefix) {return hotelService.getSuggestions(prefix);}
}service类
import cn.itcast.hotel.mapper.HotelMapper;
import cn.itcast.hotel.pojo.Hotel;
import cn.itcast.hotel.pojo.HotelDoc;
import cn.itcast.hotel.pojo.PageResult;
import cn.itcast.hotel.pojo.RequestParams;
import cn.itcast.hotel.service.IHotelService;
import com.alibaba.fastjson.JSON;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.geo.GeoPoint;
import org.elasticsearch.common.unit.DistanceUnit;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.functionscore.FunctionScoreQueryBuilder;
import org.elasticsearch.index.query.functionscore.ScoreFunctionBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.aggregations.Aggregations;
import org.elasticsearch.search.aggregations.bucket.terms.Terms;
import org.elasticsearch.search.sort.SortBuilders;
import org.elasticsearch.search.sort.SortOrder;
import org.elasticsearch.search.suggest.Suggest;
import org.elasticsearch.search.suggest.SuggestBuilder;
import org.elasticsearch.search.suggest.SuggestBuilders;
import org.elasticsearch.search.suggest.completion.CompletionSuggestion;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;@Service
public class HotelService extends ServiceImpl<HotelMapper, Hotel> implements IHotelService {@Autowiredprivate RestHighLevelClient client;@Overridepublic List<String> getSuggestions(String prefix) {try {// 1.准备RequestSearchRequest request = new SearchRequest("hotel");// 2.准备DSLrequest.source().suggest(new SuggestBuilder().addSuggestion("suggestions",SuggestBuilders.completionSuggestion("suggestion").prefix(prefix).skipDuplicates(true).size(10)));// 3.发起请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析结果Suggest suggest = response.getSuggest();// 4.1.根据补全查询名称,获取补全结果CompletionSuggestion suggestions = suggest.getSuggestion("suggestions");// 4.2.获取optionsList<CompletionSuggestion.Entry.Option> options = suggestions.getOptions();// 4.3.遍历List<String> list = new ArrayList<>(options.size());for (CompletionSuggestion.Entry.Option option : options) {String text = option.getText().toString();list.add(text);}return list;} catch (IOException e) {throw new RuntimeException(e);}}}
测试
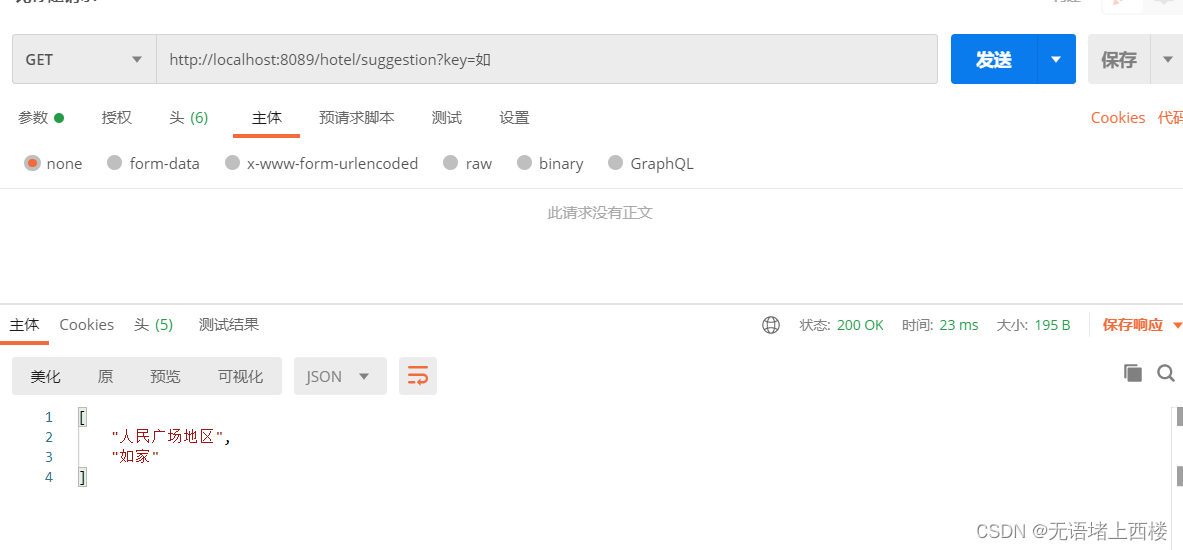
相关文章:
elasticsearch的搜索补全提示
当用户在搜索框输入字符时,我们应该提示出与该字符有关的搜索项 拼音分词器 下载 要实现根据字母做补全,就必须对文档按照拼音分词,GitHub上有拼音分词插件 GitHub - medcl/elasticsearch-analysis-pinyin: This Pinyin Analysis plugin…...
AJAX学习笔记7 AJAX实现省市联动
需求:网页上选择对应省份之后,动态的关联出该省份对应的市.选择对应的市之后,动态的关联出该市对应的区 关于省市区全国三级Mysql数据:全国省市区三级地区MySQL数据_biubiubiu0706的博客-CSDN博客 页面加载完毕显示所有省份 <!DOCTYPE html> <html lang&…...

国商佳美合作火山引擎数智平台 助推深圳餐博会及美博会数字化升级
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群 近日,深圳市国商佳美展览有限公司(以下简称“深圳国商佳美”)与火山引擎数智平台VeDI达成合作,双方将聚焦于2023年11…...

数据结构与算法学习(day4)——解决实际问题
前言 在本章的学习此前,需要复习前三章的内容,每个算法都动手敲一遍解题。宁愿学慢一点,也要对每个算法掌握基本的理解! 前面我们学习了简化版桶排序、冒泡排序和快速排序三种算法,今天我们来实践一下前面的三种算法。…...

PG库列类型转换
首先自定义两个函数,其中try_cast_numeric函数是将字符类型转成数字类型,try_cast_timestamp函数是将字符类型转成时间戳类型。 create or replace function try_cast_numeric(p_in text, p_default numeric default null)returns numeric as $$ beginb…...

vue3中的reactive赋值问题
问题 当通过方法对reactive变量修改的时候,发现页面上的值没有及时更新? 解决方法 具体原因: 上面这样赋值检测不到,因为响应式的是它的属性,而不是它自身. 方法1: 单个赋值 如下: let obj reactive({name: zha…...

thinkphp 操作远程oracle遇到的相关坑
坑一:没有内置oracle 解决方法: 1,下载think-oracle 扩展,资源很多,百度即可下载,分别放置于db下的connector 和 builder 文件夹下 2,安装oracle本地客户端,一搜一大把,核…...

流媒体之推流和拉流
推流:将直播内容推送至服务器的过程 拉流:为服务器已有直播内容,用指定地址进行拉取的过程 什么是推流? 推流,指的是把采集阶段封包好的内容传输到服务器的过程。其实就是将现场的视频信号传到网络的过程。“推流”…...
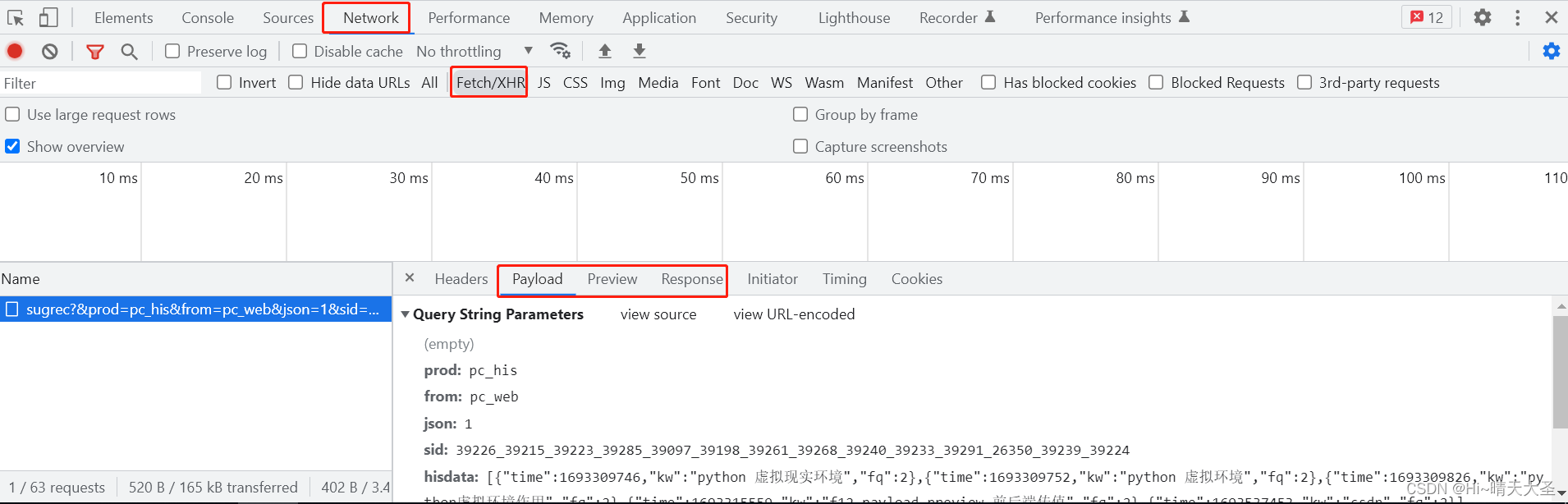
浏览器中怎样查看前后端传值
路径:F12–>Network -->Fetch/XHR,选择一个接口地址。 在payload里面是前端发送给后端的参数。也即客户端发送给服务端的请求数据,即接口地址入参。 Preview和Response里都是后端返回给前端的。Preview是格式化过的,比较容易看。Resp…...
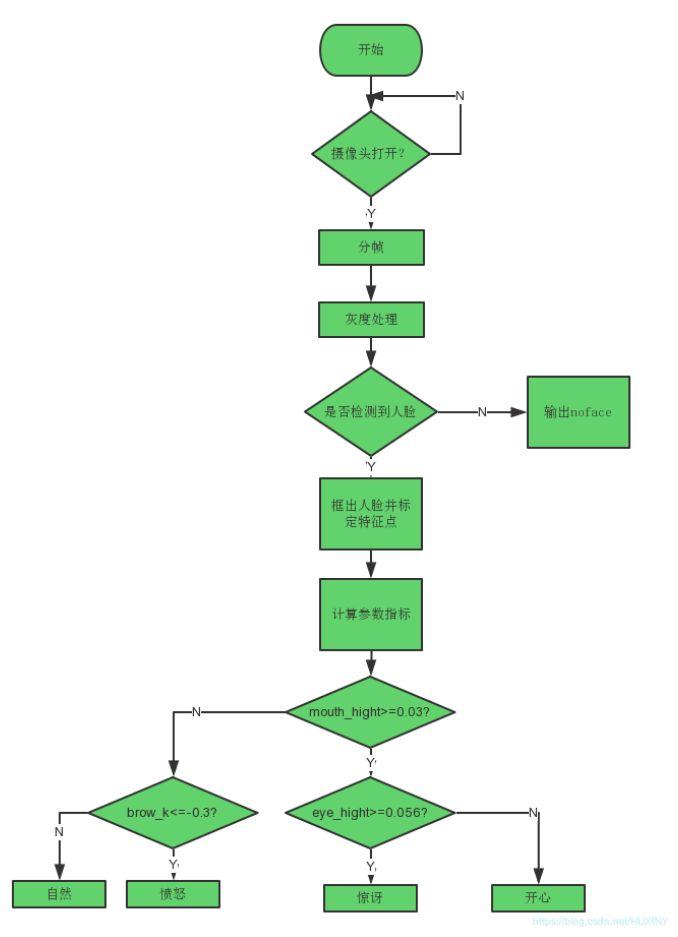
计算机竞赛 基于深度学习的人脸表情识别
文章目录 0 前言1 技术介绍1.1 技术概括1.2 目前表情识别实现技术 2 实现效果3 深度学习表情识别实现过程3.1 网络架构3.2 数据3.3 实现流程3.4 部分实现代码 4 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 基于深度学习的人脸表情识别 该项目较…...

虹科分享 | MKA:基于先进车载网络安全解决方案的密钥协议
MKA作为MACsec的密钥协议,具有安全、高效、针对性强的特点,为您的汽车ECU通讯创建了一个安全的通信平台,可以助力您的各种汽车创新项目! 虹科方案 | 什么是基于MACsec的汽车MKA 一、MACsec在汽车行业的应用 在以往的文章中&#…...
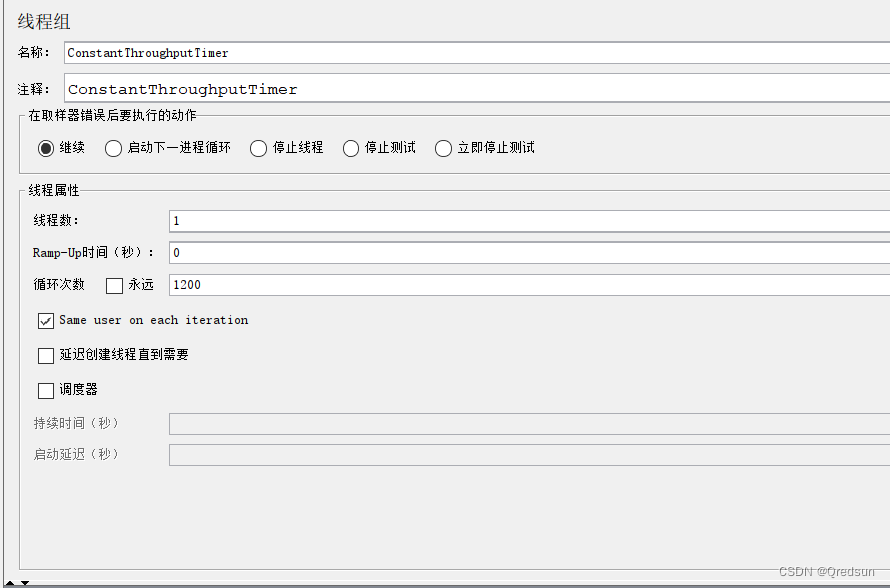
jmeter 常数吞吐量定时器
模拟固定吞吐量的定时器。它可以控制测试计划中各个请求之间的时间间隔,以达到预期的吞吐量。 参数包括: Target Throughput:目标吞吐量(每分钟请求数)Calculate Throughput based on:吞吐量计算基准&…...
【大数据Hive】hive 加载数据常用方案使用详解
目录 一、前言 二、load 命令使用 2.1 load 概述 2.1.1 load 语法规则 2.1.2 load语法规则重要参数说明 2.2 load 数据加载操作演示 2.2.1 前置准备 2.2.2 加载本地数据 2.2.3 HDFS加载数据 2.2.4 从HDFS加载数据到分区表中并指定分区 2.3 hive3.0 load 命令新特性 …...
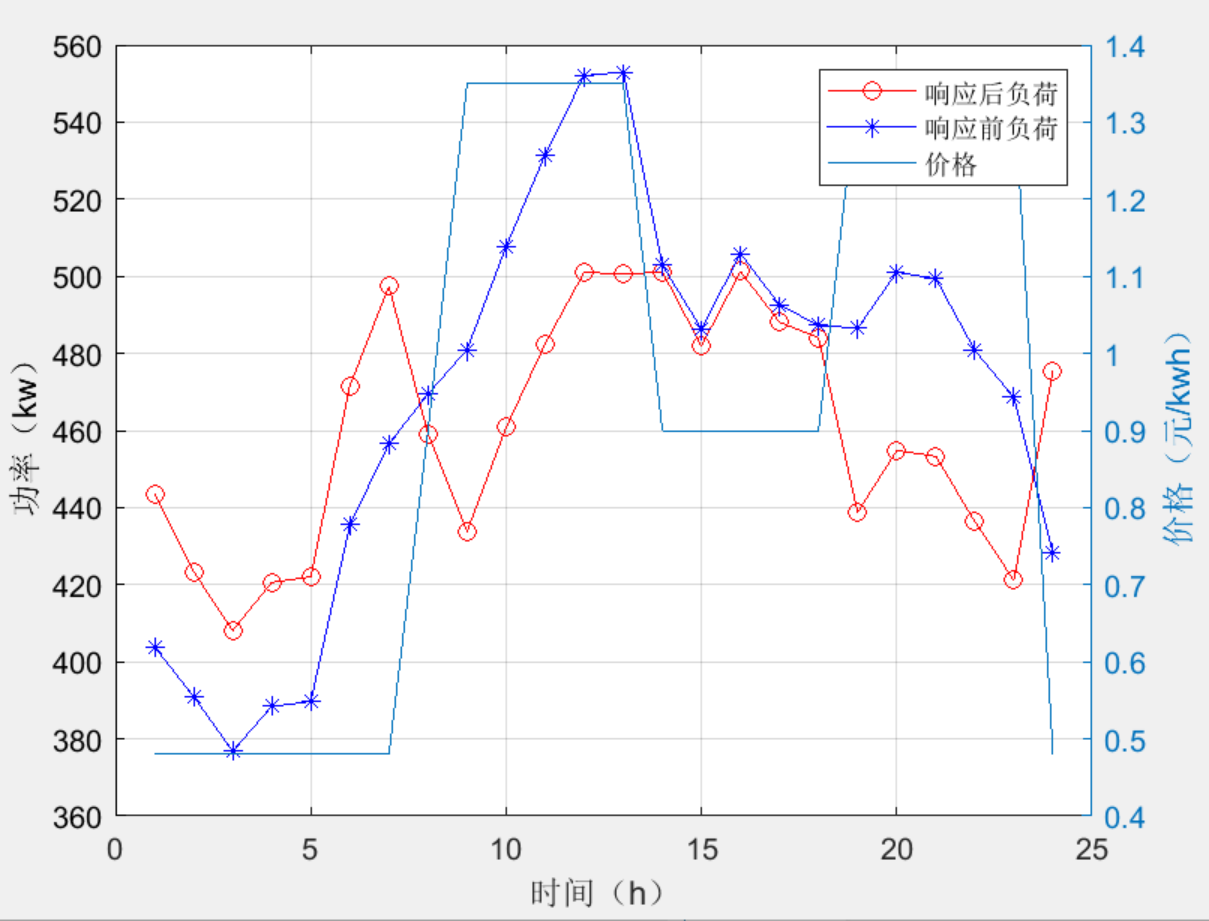
计及电池储能寿命损耗的微电网经济调度(matlab代码)
目录 1 主要内容 2 部分代码 3 程序结果 4 下载链接 1 主要内容 该程序参考文献《考虑寿命损耗的微网电池储能容量优化配置》模型,以购售电成本、燃料成本和储能寿命损耗成本三者之和为目标函数,创新考虑储能寿命损耗约束、放电深度约束和储能循环次…...
DP读书:鲲鹏处理器 架构与编程(十四)ACPI与软件架构具体调优
一分钟速通ACPI和鲲鹏软件移植 操作系统内核鲲鹏软件移植鲲鹏软件移植流程 编译工具选择编译参数移植案例源码修改案例鲲鹏分析扫描工具 Dependency Advisor鲲鹏代码迁移工具 Porting Advisor 鲲鹏软件性能调优鲲鹏软件性能调优流程CPU与内存子系统性能调优网络子系统性能调优磁…...
4.正则提取html中的img标签的src内容
我们以百度贴吧的1吧举例 目录 1 把网页搞下来 2 收集url 3 处理url 4 空的src 5 容错 6 不使用数字作为文件名 7 并不是所有的图片都用img标签表示 8 img标签中src请求下来不一定正确 9 分页 1 把网页搞下来 搞下来之后,双击打开是这样的 2 收…...

安装对应版本pytorch和torchvision
遇见报错: ERROR: Could not find a version that satisfies the requirement torch (from versions: none) ERROR: No matching distribution found for torch 解决方法: 1、网站找到对应torch和torchvision版本,cp对应python版本ÿ…...

酷克数据与华为合作更进一步 携手推出云数仓联合解决方案
在一起,共迎新机遇!8月25-26日,2023华为数据存储用户精英论坛在西宁召开。酷克数据作为国内云原生数据仓库的代表企业,也是华为重要的生态合作伙伴,受邀参与本次论坛,并展示了云数仓领域最新前沿技术以及联…...
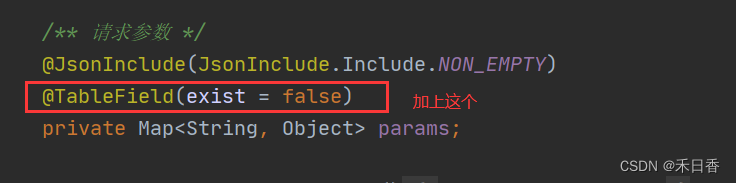
若依 MyBatis改为MyBatis-Plus
主要内容:升级成mybatis-plus,代码生成也是mybatis-plus版本 跟着我一步一步来,就可完成升级! 检查:启动程序,先保证若依能启动 第一步:添加依赖 这里需要在两个地方添加,一个是最…...

docker-ubuntu
docker ps docker images 拉取ubuntu镜像 docker pull ubuntu 启动 docker start podid docker run -itd -e TZAsia/Shanghai --name ubuntu-test -v /share:/shared -d ubuntu:latest 进入bash界面 docker exec -it podid /bin/bash 安装sudo apt-get install sudo …...

Simple Runtime Window Editor:突破游戏窗口限制的终极解决方案
Simple Runtime Window Editor:突破游戏窗口限制的终极解决方案 【免费下载链接】SRWE Simple Runtime Window Editor 项目地址: https://gitcode.com/gh_mirrors/sr/SRWE 你是否曾为游戏内置分辨率选项太少而烦恼?是否想在窗口模式下获得全屏游戏…...

Solidworks PDM二次开发实战:文件夹权限与数据卡配置详解
1. Solidworks PDM二次开发入门指南 如果你正在使用Solidworks PDM管理产品数据,可能会遇到需要批量创建文件夹并设置权限的场景。比如新项目启动时,需要为不同部门创建标准化的文件夹结构,同时设置工程师只读、管理员完全控制的权限规则。手…...

网盘下载新革命:九大平台一键直链,告别客户端束缚
网盘下载新革命:九大平台一键直链,告别客户端束缚 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘…...

GD32F103C8T6烧录方式全解析:串口ISP、ST-Link Utility、Keil在线,哪种最适合你?
GD32F103C8T6烧录方案深度评测:从原型开发到量产部署的全场景指南 在嵌入式开发领域,选择正确的程序烧录方式往往决定着开发效率和生产成本。作为STM32F103的国产替代方案,GD32F103C8T6凭借其出色的性价比赢得了广泛关注。但许多开发者在迁移…...

STM32F407通过SPI接口高效读写SD卡:CubeMX配置与底层驱动实战
1. SD卡基础与SPI通信原理 SD卡作为嵌入式系统中最常用的存储介质之一,其SPI模式因其接线简单、协议清晰而广受欢迎。先说说我实际项目中遇到的坑:曾经因为没理解清楚SPI模式下SD卡的初始化时序,导致整整两天卡在设备无法识别的困境里。 SD卡…...

DownKyi完全指南:三步解锁B站8K视频下载的终极方案
DownKyi完全指南:三步解锁B站8K视频下载的终极方案 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等ÿ…...

如何通过Jellyfin Android TV客户端打造家庭影院级媒体体验?
如何通过Jellyfin Android TV客户端打造家庭影院级媒体体验? 【免费下载链接】jellyfin-androidtv Android TV Client for Jellyfin 项目地址: https://gitcode.com/gh_mirrors/je/jellyfin-androidtv 想要在智能电视上享受专业的媒体管理体验吗?…...

VHD2VL终极指南:5分钟快速将VHDL转换为Verilog的免费工具
VHD2VL终极指南:5分钟快速将VHDL转换为Verilog的免费工具 【免费下载链接】vhd2vl 项目地址: https://gitcode.com/gh_mirrors/vh/vhd2vl 在FPGA和ASIC设计领域,VHDL转Verilog是许多工程师面临的共同挑战。手动转换不仅耗时费力,还容…...

手把手教你用三菱FX3U PLC的RS指令和RS2指令与电脑串口调试助手‘对话’
三菱FX3U PLC串口通信实战:从零搭建RS485数据收发系统 第一次接触工业控制系统的串口通信时,我被那些密密麻麻的接线和晦涩的协议参数弄得晕头转向。直到在自动化生产线上亲眼看到PLC通过两根电线与十几台设备稳定通信,才意识到串口技术的精妙…...

芯片老化座的工作温度范围?
在芯片测试领域,老化座(Burn-in Socket)是保障半导体器件长期可靠性的关键设备。它不仅要在极端温度下稳定工作,还要确保测试数据的精准度。今天,我们以HMILU(深圳市鸿怡电子有限公司)为例&…...