大数据之MapReduce
MapReduce概述
是一个分布式的编程框架,MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。
- 优点:
- 易于编程,简单的实现一些接口,就可以完成一个分布式程序。
- 良好的扩展性,可以增加机器来扩展计算能力。
- 高容错性,子任务失败后可以重试4次。
- 缺点:
- 不擅长实时计算
- 不能进行流式计算,MapReduce的输入数据集是静态的,不能动态变化。
- 不擅长DAG有向无环图:下一段计算的起始数据取决于上一个阶段的结果。
MapReduce核心思想
- Map: 读单词,进行分区
- Shuffle:排序是框架内固定的代码,必须排序。进行快排
- Reduce:对区间有序的内容进行归并排序,累加单词
- 在MapReduce过程中只能有一个Map和一个Reduce
- MapReduce进程
- MrAppMaster:负责整个程序的过程调度及状态协调。
- MapTask:负责Map阶段的整个数据处理流程。
- ReduceTask:负责Reduce阶段的整个数据处理流程。
- 序列化
- 变量类型后面加上Writable,转换成可以序列化的类型
- String类型有点特别,相应的序列化类型为Text
- java类型转hadoop类型
private IntWritable key = new IntWritable();key.set(java_value);- 构造器转换
new intWritable(1);
- hadoop类型转java类型
int value = key.get();
WordCount案例
Driver类的8个步骤
该类中的步骤是使用hadoop框架的核心,这8个步骤是写死的,无法更改,具体为:
- 获取配置信息,获取job对象实例
- 指定本程序的jar包所在的本地路径
- 关联Mapper/Reducer业务类
- 指定Mapper输出数据的kv类型
- 指定最终输出数据的kv类型,部分案例不需要reduce这个步骤
- 指定job的输入原始文件所在目录
- 指定job的输出结果所在目录
- 提交作业
WordCountMapper类的实现
- 继承mapper类,选择mapreduce包,新版本,老版本的叫mapred包
- 根据业务需求设定泛型的具体类型,输入的kv类型,输出的kv类型。
- 输入类型
- keyIn:起始偏移量,是字节偏移量。一般不参与计算,类型为longwritable
- valueIn:每一行数据,类型为Text
- 输出类型
- keyOut: 每个单词
- valueOut:数字1
- 输入类型
- 重写map方法,ctrl + o 快捷键重写方法
@Overrideprotected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {//1.获取一行// atguigu atguiguString line = value.toString();//2.切割//atguigu//atguiguString[] words = line.split(" ");//3.循环写出for (String word : words) {//封装outKeycontext.write(new Text(word),new IntWritable(1));}}
WordCountReducer类的实现
- 继承Reduce类
- 设置输入输出类型
- 输入: 跟Map的输出类型对应即可
- 输出:
- keyInt, 单词,类型为Text
- keyOut, 次数,类型为IntWritable
- 重写reduce方法
@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {int sum = 0;//atguigu(1,1)//累加for (IntWritable value : values) {sum += value.get();}//写出context.write(key, new IntWritable(sum);//注意}
在处理大数据时,不要在循环中new对象,创建对象是很消耗资源的。可以使用ctrl + alt + F将这两个变量提升为全局变量,作为Reducer类的属性值。但其实还有更好的方法,可以使用Mapper类中的setup()方法来实现该需求。该方法是框架里面原本就设定好的方法,在map阶段前只会执行1次。
private Text outKey;private IntWritable outValue;@Overrideprotected void setup(Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {outKey = new Text();outValue = new IntWritable(1);}
Driver类的实现
该类的写法基本上是固定的,不同需求只需要在此基础上修改一下map和reduce业务类即可。
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {//1.获取JobConfiguration conf = new Configuration();Job job = Job.getInstance();//2.设置jar包路径,绑定driver类job.setJarByClass(WordCountDriver.class);//3.关联mapper和reducerjob.setMapperClass(WordCountMapper.class);job.setReducerClass(WordCountReducer.class);//4.设置map的kv类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);//5.设置最终输出的kv类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);//6.设置输入路径和输出路径FileInputFormat.setInputPaths(job, new Path("D:\\inputOutput\\input\\wordcount"));FileOutputFormat.setOutputPath(job, new Path("D:\\inputOutput\\output\\output666"));//7.提交jobjob.waitForCompletion(true);}
打包本地程序到集群中运行
- 修改本地程序Driver类中的输入输出路径
//6.设置输入路径和输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
- 使用maven的package命令打包本地程序成.jar文件,生成的jar包在target目录下
- 使用jar命令解压运行
jar 包名 数据输入路径 数据输出路径
可以直接在window中的IDEA中发送任务到Linux集群中,但配置方式较为烦琐,生产环境中使用该方法的人较少。
序列化
java序列化
序列化目的是将内存的对象放进磁盘中进行保存,序列化实际上是为了传输对象中的属性值,而不是方法。序列化本质上是一种数据传输技术,IO流。
- ObjectOutputStream 序列化流 writeObject()
- ObjectInputStream 反序列化流 readObject(Object obj)
- 序列化前提条件:
- 实现Serializable接口
- 空参构造器
- 私有的属性
- 准备get和set方法
总结:java序列化是一个比较重的序列化,序列化的内容很多,比如属性+校验+血缘关系+元数据。
hadoop序列化
特点: 轻量化,只有属性值和校验
hadoop中自定义bean对象步骤:
- 实现writable接口
- 空参构造器
- 私有的属性
- get和set方法
- 重写
write方法和readFields方法(write方法出现的属性顺序必须和readFields的读取顺序一致) - 如果自定义的bean对象要作为reduce的输出结果,需要重写
toString方法,否则存入磁盘的是地址值 - 如果自定义的bean对象要作为map输出结果中的key进行输出,并进行reduce操作,必须实现
comparable接口。
MapReduce框架原理
- 粗略流程:
mapreduce = map + reduce - 大体流程:
mapreduce = inputFormat --> map --> shuffle(排序) --> reduce -->outputFormat - 源码流程:
- inputformat
- map
- map
- sort: 按照字典序进行快排
- reduce
- copy:拉取map的处理结果
- sort:由于结果是局部有序,不是整体有序,进行归并排序
- reduce:之后再进行数据合并规约
InputFormat/OutputFormat基类
实现类有TextInputFormat和TextOutputFormat, 其中重点是切片逻辑和读写逻辑,读写部分的代码框架已经写死了,主要关注如何切片即可。
切片与MapTask并行度决定机制
数据块:Block是物理上真的分开存储了。
数据切片:只是逻辑上进行分片处理,每个数据切片对应一个MapTask。
正常来说,如果数据有300M,我们按照常理来说会平均划分成3 x 100 M,但是物理上每个物理块是128M,每个MapTask进行计算时需要从另外那个主机读取数据,跨越主机读取数据需要进行网络IO,这是很慢的。

所有MR选择的是按照128M来进行切分,尽管这样会导致划分的数据块并不是十分均匀,但是对于网络IO的延迟来说,还是可以接受的。
Hadoop提交流程源码和切片源码
提交源码主要debug节点
- job.waitForCompletion()
- JobState枚举类,DEFINE、RUNING
- submit()
- connect()
- 匿名内部类、new方法 无法进入,打好断点,点击快速运行进入
- ctrl + alt + 左方向键,可以返回原先的位置
- initProviderList(): 添加了本地客户端协议和Yarn客户端协议
- create(conf): 根据配置文件来决定代码的运行环境(Yarn分布式环境/本地单机环境)
- submitter 根据运行环境获取相应的提交器
- checkSpecs(job):检查输出路径是否正确
- jobStagingArea: job的临时运行区域,给定一个绝对路径的目录D:\tmp\hadoop\mapred\staging,里面存放了:
- local: 切片结果+8个配置文件总和
- yarn:切片结果+8个配置文件总和+jar包
- copyAndConfigureFiles(): 读取任务需要的支持文件读取到job的临时运行环境中,在Yarn环境中,会上传jar包到该路径中
- writeSplits():给数据添加切片标记,实际还未切分,会生成切片文件到临时区域中
- writeConf(): 写配置文件到目录中
提交源码总结:
- mapreduce.framework.name这个参数决定了运行环境
- 切片个数决定了MapTask个数
相关文章:
大数据之MapReduce
MapReduce概述 是一个分布式的编程框架,MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。 优点: 易于编程,简单的实现一些接口,就可以完成一…...

《机器人学一(Robotics(1))》_台大林沛群 第 5 周【机械手臂 轨迹规划】 Quiz 5
我又行了!🤣 求解的 位置 可能会有 变动,根据求得的A填写相应值即可。注意看题目。 coursera链接 文章目录 第1题 Cartesian space求解 题1-3 的 Python 代码 第2题第3题第4题 Joint space求解 题4-6 的 Python 代码 第5题第6题其它可参考代…...
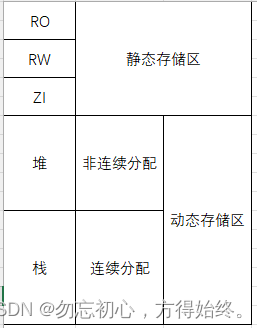
嵌入式面试/笔试C相关总结
1、存储 单片机端编译后分为code ro rw zi几个区域,其中code是执行文件,ro(read only)只读区域,存放const修饰常量、字符串。rw(read write)存放已初始化变量。zi存放未初始化变量。编译完成后bin大小为coderorw。运行时所需内存为rwzi。 在电…...

支付宝使用OceanBase的历史库实践分享
为解决因业务增长引发的数据库存储空间问题,支付宝基于 OceanBase 数据库启动了历史库项目,通过历史数据归档、过期数据清理、异常数据回滚,实现了总成本降低 80%。 历史数据归档:将在线库(SSD 磁盘)数据归…...
)
accelerate 分布式技巧(一)
accelerate分布式技巧 简单使用 Accelerate是一个来自Hugging Face的库,它简化了将单个GPU的PyTorch代码转换为单个或多台机器上的多个GPU的代码。 Accelerate精确地抽象了与多GPU/TPU/fp16相关的模板代码,并保持Pytorch其余代码不变。 import torchim…...
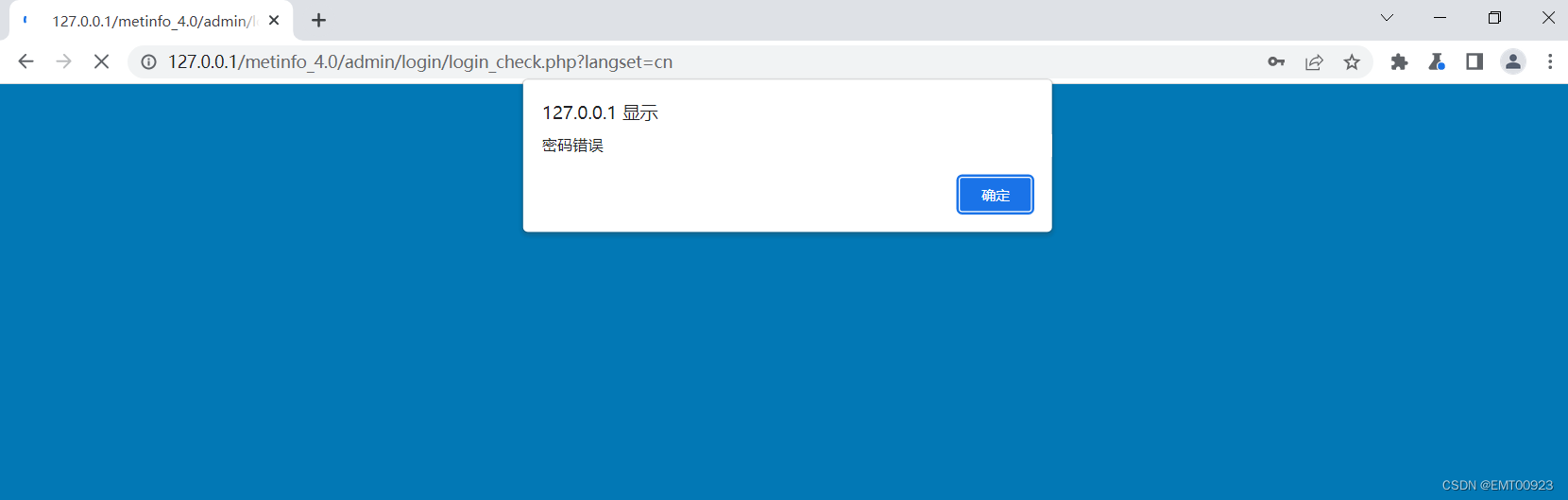
密码找回安全
文章目录 密码找回安全任意秘密重置 密码找回安全 用户提交修改密码请求;账号认证:服务器发送唯一ID (例如信验证码)只有账户所有者才能看的地方,完成身份验证;身份验证:用户提交验证码完成身份验证;修改密码:用户修改密码。 任意秘密重置 登录metinfo4…...

Spring Boot + Vue的网上商城之商品管理
Spring Boot Vue的网上商城之商品管理 在网上商城中,商品管理是一个非常重要的功能。它涉及到商品的添加、编辑、删除和展示等操作。本文将介绍如何使用Spring Boot和Vue来实现一个简单的商品管理系统。 下面是一个实现Spring Boot Vue的网上商城之商品管理的思路…...

B站:提高你的词汇量:如何用英语谈论驾驶
视频链接:提高你的词汇量:如何用英语谈论驾驶_哔哩哔哩_bilibili 英文音标中文hood/hʊd/n. 汽车的引擎盖go over仔细检查;认真讨论;用心思考There are plenty of videos go over this.有很多关于这个的视频unlockvt. 发现;揭开&…...

大前端面试注意要点
前端面试:从IT专家角度全面解析 在数字时代,前端开发工程师的角色变得越来越重要。随着网站和应用程序的复杂性和交互性越来越高,对具有专业技能的前端开发人员的需求也在不断增长。对于正在寻找前端开发职位的开发者,或者正在寻…...
)
稻盛和夫-如是说(读书笔记)
本书解答的核心问题: “今天,我们需要的不是短期有效的处方。作为人,何谓正确?作为人,应该如何度过人生?这才是一切问题的根源。 有几个要点和认知比较深的地方谈一谈。 1、利他 类似于阳明心学࿰…...

Jmeter是用来做什么的?
JMeter是一个开源的Java应用,主要用于性能测试和功能测试。它最初由Apache软件基金会设计用于测试Web应用程序,但现在已经扩展到其他测试功能。JMeter的主要功能如下: 性能测试:性能测试是JMeter的核心功能,主要分为两…...

Docker基础教程
Docker基础教程 Docker简介 Docker基本操作 Docker应用 Docker自定义镜像 Docker compose 为什么使用DockerDocker简介安装DockerDocker的中央仓库Docker镜像操作Docker容器操作准备一个web项目创建MySQL容器创建Tomcat容器将项目部署到TomcatDocker数据卷DockerfileDock…...

Linux命令200例:who用于显示当前登录到系统的用户信息
🏆作者简介,黑夜开发者,CSDN领军人物,全栈领域优质创作者✌。CSDN专家博主,阿里云社区专家博主,2023年6月csdn上海赛道top4。 🏆数年电商行业从业经验,历任核心研发工程师࿰…...
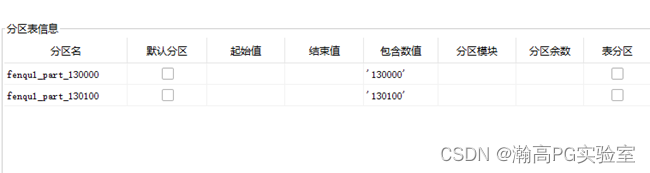
HGDB-修改分区表名称及键值
瀚高数据库 目录 环境 文档用途 详细信息 环境 系统平台:N/A 版本:4.5.7 文档用途 使用存储过程拼接SQL,修改分区名称、分区键值、并重新加入主表,适用于分区表较多场景。 详细信息 说明:本文档为测试过程࿱…...

1分钟了解音频、语音数据和自然语言处理的关系
机器学习在日常场景中的应用 音频、语音数据和自然语言处理这三者正在不断促进人工智能技术的发展,人机交互也逐渐渗透进生活的每个角落。在各行各业包括零售业、银行、食品配送服务商)的多样互动中,我们都能通过与某种形式的AI(…...
线性代数的学习和整理20,关于向量/矩阵和正交相关,相似矩阵等
目录 1 什么是正交 1.1 正交相关名词 1.2 正交的定义 1.3 正交向量 1.4 正交基 1.5 正交矩阵的特点 1.6 正交矩阵的用处 1 什么是正交 1.1 正交相关名词 orthogonal set 正交向量组正交变换orthogonal matrix 正交矩阵orthogonal basis 正交基orthogonal decompositio…...
OpenCV之ellipse函数
ellipse函数用来在图片中绘制椭圆、扇形,有两个重载函数。 函数原型1: void cv::ellipse( InputOutputArray img,Point center,Size axes,double angle,double startAngle,double …...
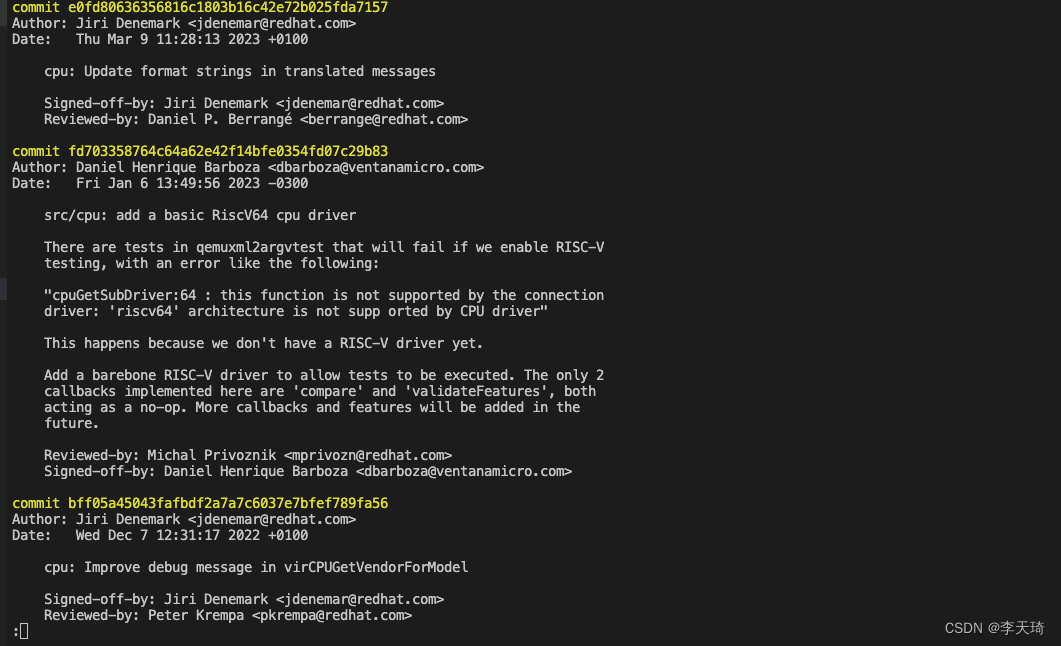
git快速查看某个文件修改的所有commit
1. git blame file git blame 可以显示历史修改的每一行记录,有时候我们只想了解某个文件一共提交几次commit,只显示commit列表,这种方式显然不满足要求。 2.git log常规使用 (1)显示整个project的所有commit (2)显示某个文件的所有commit 这是git log不添加参数的常规…...
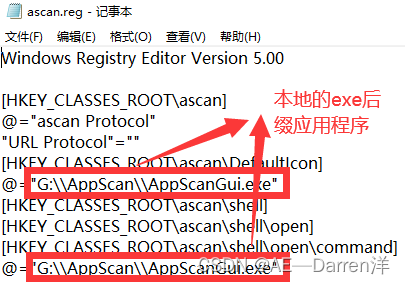
加强版python连接飞书通知——本地电脑PC端通过网页链接打开本地已安装软件(调用注册表形式,以漏洞扫描工具AppScan为例)
前言 如果你想要通过超链接来打开本地应用,那么你首先你需要将你的应用添入windows注册表中(这样网页就可以通过指定代号来调用程序),由于安全性的原因所以网页无法直接通过输入绝对路径来调用本地文件。 一、通过创建reg文件自动配置注册表 创建文本文档,使用记事本打开…...
Jmeter进阶使用指南-使用断言
Apache JMeter是一个流行的开源负载和性能测试工具。在JMeter中,断言(Assertions)是用来验证响应数据是否符合预期的一个重要组件。它是对请求响应的一种检查,如果响应不符合预期,那么断言会标记为失败。 以下是如何在…...

终极指南:10分钟掌握SPT-AKI存档编辑器完整使用教程
终极指南:10分钟掌握SPT-AKI存档编辑器完整使用教程 【免费下载链接】SPT-AKI-Profile-Editor Программа для редактирования профиля игрока на сервере SPT-AKI 项目地址: https://gitcode.com/gh_mirrors/sp/…...

终极macOS清理神器:Pearcleaner 3步彻底卸载应用不留痕迹
终极macOS清理神器:Pearcleaner 3步彻底卸载应用不留痕迹 【免费下载链接】Pearcleaner A free, source-available and fair-code licensed mac app cleaner 项目地址: https://gitcode.com/gh_mirrors/pe/Pearcleaner 你是否曾将macOS应用拖入废纸篓后&…...

Go语言开源漏洞扫描器Abyss-Scanner:架构解析与CI/CD集成实践
1. 项目概述:一个为安全而生的开源漏洞扫描器最近在整理自己的开源项目工具箱,发现一个挺有意思的工具,叫 Abyss-Scanner。这名字起得挺有深意,“深渊扫描器”,听起来就有点探索未知、发现潜在风险的味道。简单来说&am…...

Ruby中文分词利器Rurima:纯Ruby实现的高性能分词引擎详解
1. 项目概述:一个为Ruby打造的现代中文分词引擎在Ruby社区里,处理中文文本一直是个有点“硌脚”的活儿。如果你做过中文搜索、内容分析或者简单的词频统计,肯定遇到过这个经典难题:怎么把一串连续的中文字符,准确地切割…...

5分钟快速上手:使用res-downloader实现视频号批量下载的终极指南
5分钟快速上手:使用res-downloader实现视频号批量下载的终极指南 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader …...

轻量级HTTP代理monica-proxy:精准流量转发与多场景部署指南
1. 项目概述与核心价值最近在折腾一些需要跨网络环境访问特定服务的项目,发现一个挺有意思的工具叫ycvk/monica-proxy。这本质上是一个基于 Go 语言开发的轻量级 HTTP/HTTPS 代理服务器,但它和我们常见的那些“全能型”代理不太一样。它的设计初衷非常聚…...

基于树莓派与QT Py的本地化物联网红外遥控器DIY指南
1. 项目概述与核心价值想没想过,把家里那堆遥控器——电视的、机顶盒的、空调的、音响的——统统集成到一个你手机能打开的网页里?而且这个控制中心完全在你家局域网里运行,不依赖任何云服务,不用担心厂商倒闭后设备变砖。今天分享…...

如何用Wedecode实现微信小程序源代码的完美还原:从加密包到可读代码的完整指南
如何用Wedecode实现微信小程序源代码的完美还原:从加密包到可读代码的完整指南 【免费下载链接】wedecode 全自动化,微信小程序 wxapkg 包 源代码还原工具, 线上代码安全审计,支持 Windows, Macos, Linux 项目地址: https://gitcode.com/gh…...

FastAPI+AI应用脚手架:模块化架构与生产级实践指南
1. 项目概述:一个为AI应用量身定制的FastAPI脚手架如果你正在寻找一个能快速启动、结构清晰且功能强大的AI应用后端框架,那么fastapi-genai-boilerplate这个项目绝对值得你花时间研究。它不是一个简单的“Hello World”示例,而是一个面向生产…...

从理论到ONNX:手把手带你拆解pytorch_quantization量化YOLOv7的每一个Tensor变化
从理论到ONNX:手把手拆解YOLOv7量化中的Tensor演变 量化技术正在重塑计算机视觉模型的部署格局。当我们将YOLOv7这样的复杂检测模型从FP32压缩到INT8时,每一个卷积核、每一层激活值的细微变化都可能影响最终检测框的坐标精度。本文将以手术刀般的精确度&…...