【100天精通Python】Day55:Python 数据分析_Pandas数据选取和常用操作
目录
Pandas数据选择和操作
1 选择列和行
2 过滤数据
3 添加、删除和修改数据
4 数据排序
 Pandas数据选择和操作
Pandas数据选择和操作
Pandas是一个Python库,用于数据分析和操作,提供了丰富的功能来选择、过滤、添加、删除和修改数据。
1 选择列和行
Pandas 提供了多种方式来选择行和列,这取决于您希望获取的数据的类型和结构。
1.1 选择列
(1)使用列标签
使用列标签来选择一个或多个列。您可以将列标签传递给 DataFrame 的索引器,例如
[]。(2)使用
.loc[]方法
.loc[]方法可以根据标签名称选择行和列。对于列选择,可以使用:选择所有行。
1.2 选择行
(1)使用行索引
使用行索引来选择一个或多个行。您可以使用
.loc[]方法或.iloc[]方法。(2)使用
.iloc[]方法
.iloc[]方法使用整数位置来选择行和列。它与.loc[]方法的不同之处在于,它使用整数索引而不是标签。
示例代码:
import pandas as pddata = {'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]}
df = pd.DataFrame(data)# 选择单个列
column_A = df['A']
print("单个列 'A':\n", column_A)
# 结果:
# 单个列 'A':
# 0 1
# 1 2
# 2 3
# Name: A, dtype: int64# 选择多个列
columns_AB = df[['A', 'B']]
print("多个列 'A' 和 'B':\n", columns_AB)
# 结果:
# 多个列 'A' 和 'B':
# A B
# 0 1 4
# 1 2 5
# 2 3 6# 使用 .loc[] 选择列
column_A_loc = df.loc[:, 'A']
print("使用 .loc[] 选择列 'A':\n", column_A_loc)
# 结果:
# 使用 .loc[] 选择列 'A':
# 0 1
# 1 2
# 2 3
# Name: A, dtype: int64# 选择多个列
columns_AB_loc = df.loc[:, ['A', 'B']]
print("使用 .loc[] 选择多个列 'A' 和 'B':\n", columns_AB_loc)
# 结果:
# 使用 .loc[] 选择多个列 'A' 和 'B':
# A B
# 0 1 4
# 1 2 5
# 2 3 6# 使用 .loc[] 选择单个行
row_0_loc = df.loc[0]
print("使用 .loc[] 选择单个行 (索引 0):\n", row_0_loc)
# 结果:
# 使用 .loc[] 选择单个行 (索引 0):
# A 1
# B 4
# C 7
# Name: 0, dtype: int64# 使用 .loc[] 选择多个行
rows_01_loc = df.loc[0:1]
print("使用 .loc[] 选择多个行 (索引 0 到 1):\n", rows_01_loc)
# 结果:
# 使用 .loc[] 选择多个行 (索引 0 到 1):
# A B C
# 0 1 4 7
# 1 2 5 8# 使用 .iloc[] 选择单个行
row_0_iloc = df.iloc[0]
print("使用 .iloc[] 选择单个行 (整数位置 0):\n", row_0_iloc)
# 结果:
# 使用 .iloc[] 选择单个行 (整数位置 0):
# A 1
# B 4
# C 7
# Name: 0, dtype: int64# 使用 .iloc[] 选择多个行
rows_01_iloc = df.iloc[0:2]
print("使用 .iloc[] 选择多个行 (整数位置 0 到 1):\n", rows_01_iloc)
# 结果:
# 使用 .iloc[] 选择多个行 (整数位置 0 到 1):
# A B C
# 0 1 4 7
# 1 2 5 8# 混合选择行和列
subset = df.loc[0:1, ['A', 'B']]
print("选择特定的行和列:\n", subset)
# 结果:
# 选择特定的行和列:
# A B
# 0 1 4
# 1 2 5
2 过滤数据
在Pandas中,您可以使用不同的方法来过滤数据,根据特定条件筛选出满足条件的数据。以下是一些过滤数据的示例和方法:
2.1 基于条件的过滤
通过创建一个条件表达式,您可以选择DataFrame中满足条件的行。
import pandas as pddata = {'A': [1, 2, 3, 4, 5],'B': [10, 20, 30, 40, 50]}
df = pd.DataFrame(data)# 选择满足条件的行,例如 'A' 列大于 3 的行
filtered_data = df[df['A'] > 3]
print(filtered_data)
输出结果:
A B
3 4 40
4 5 50
2.2 使用多个条件
您可以组合多个条件,使用 &(与)和 |(或)等逻辑运算符。
# 选择同时满足多个条件的行,例如 'A' 列大于 2 且 'B' 列小于 30 的行
filtered_data = df[(df['A'] > 2) & (df['B'] < 30)]
print(filtered_data)
输出结果:
A B
2 3 30
2.3 使用 isin() 进行筛选
您可以使用 isin() 方法来筛选出匹配指定值的行。
# 选择 'A' 列中匹配特定值的行
filtered_data = df[df['A'].isin([2, 4])]
print(filtered_data)
输出结果:
A B
1 2 20
3 4 40
2.4 使用字符串方法
如果您的数据包含字符串列,您可以使用字符串方法进行过滤。
data = {'Name': ['Alice', 'Bob', 'Charlie', 'David'],'Age': [25, 30, 35, 40]}
df = pd.DataFrame(data)# 选择包含特定字符串的行
filtered_data = df[df['Name'].str.contains('b', case=False)]
print(filtered_data)
输出结果:
Name Age
1 Bob 30
3 添加、删除和修改数据
3.1 添加数据
(1)添加行
要向 DataFrame 添加新行,通常可以创建一个新的数据项,然后将其附加到 DataFrame。这可以使用
append方法来完成。确保设置ignore_index=True来重置索引。(2)添加列
要添加新列,只需分配一个新的列名并提供相应的数据。这样可以在 DataFrame 中增加新的列,以便存储额外的信息。
3.2 删除数据
(1)删除行
使用
drop方法可以删除指定的行。您可以指定要删除的行的索引或标签,并使用axis=0参数来表示删除行。(2)删除列
要删除列,使用
drop方法并设置axis=1参数,然后指定要删除的列名。这将允许您从 DataFrame 中移除不需要的列。
3.3 修改数据
(1)修改特定单元格的值
要修改 DataFrame 中特定单元格的值,您可以使用
.loc[]方法,通过指定行和列的标签或索引,来更新该单元格的值。(2)更新多个值
要批量更新数据,通常可以使用条件来选择要更新的行,然后赋予新的值。这可以帮助您一次性更新多个数据点,而不必一个一个手动修改。
3.4 代码示例
import pandas as pd# 创建一个示例 DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie'],'Age': [25, 30, 35]}
df = pd.DataFrame(data)# 添加新行
new_row = pd.Series({'Name': 'David', 'Age': 40})
df = df.append(new_row, ignore_index=True)
# 结果:
# Name Age
# 0 Alice 25
# 1 Bob 30
# 2 Charlie 35
# 3 David 40# 添加新列
df['City'] = ['New York', 'Los Angeles', 'Chicago', 'Houston']
# 结果:
# Name Age City
# 0 Alice 25 New York
# 1 Bob 30 Los Angeles
# 2 Charlie 35 Chicago
# 3 David 40 Houston# 删除行
df = df.drop(2) # 删除索引为2的行
# 结果:
# Name Age City
# 0 Alice 25 New York
# 1 Bob 30 Los Angeles
# 3 David 40 Houston# 删除列
df = df.drop('City', axis=1) # 删除名为 'City' 的列
# 结果:
# Name Age
# 0 Alice 25
# 1 Bob 30
# 3 David 40# 修改特定单元格的值
df.loc[1, 'Age'] = 31
# 结果:
# Name Age
# 0 Alice 25
# 1 Bob 31
# 3 David 40# 更新多个值
df.loc[df['Age'] > 30, 'Age'] = 32 # 更新年龄大于30的行的年龄为32
# 结果:
# Name Age
# 0 Alice 25
# 1 Bob 32
# 3 David 32# 输出最终结果
print(df)
4 数据排序
在 Pandas 中,您可以使用 sort_values() 方法对 DataFrame 中的数据进行排序。以下是有关如何进行列排序、包括升序和降序排序,以及如何按多列进行排序。
4.1 按列排序:
要按列对数据进行排序,首先选择要排序的列名称,并使用 sort_values() 方法进行操作。默认情况下,数据将按升序排序。
升序排序:使用
sort_values(by='列名'),其中 '列名' 是您要排序的列的名称。例如,df.sort_values(by='Age')将按 'Age' 列的升序进行排序。降序排序:要按降序排序,可以使用
sort_values(by='列名', ascending=False),其中 '列名' 是您要排序的列的名称。例如,df.sort_values(by='Age', ascending=False)将按 'Age' 列的降序进行排序。
4.2 按多列排序:
如果需要按多列进行排序,您可以通过提供列名称的列表来实现。首先,按列表中的第一个列名进行排序,然后按照列表中的下一个列名进行排序。
例如,要按 'City' 列升序排序,然后按 'Age' 列升序排序,您可以使用
sort_values(by=['City', 'Age'])。
4.3 重置索引:
请注意,排序后的 DataFrame 可能会保留之前的索引顺序。如果希望重新设置索引以匹配新的排序顺序,可以使用
reset_index(drop=True)方法来删除旧的索引并创建一个新的整数索引。
4.4 代码示例
import pandas as pd# 创建一个示例 DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie', 'David'],'Age': [25, 30, 35, 40],'City': ['New York', 'Los Angeles', 'Chicago', 'Houston']}
df = pd.DataFrame(data)# 按列排序
# 默认按升序排序
df_sorted = df.sort_values(by='Age')
# 按照 'Age' 列的升序排序
print("按 'Age' 列的升序排序:\n", df_sorted)# 按照 'Age' 列的降序排序
df_sorted_desc = df.sort_values(by='Age', ascending=False)
print("\n按 'Age' 列的降序排序:\n", df_sorted_desc)# 按多列排序
# 先按 'City' 列升序排序,再按 'Age' 列升序排序
df_multi_sorted = df.sort_values(by=['City', 'Age'])
print("\n按 'City' 列和 'Age' 列的升序排序:\n", df_multi_sorted)# 恢复索引
df_multi_sorted = df_multi_sorted.reset_index(drop=True)
print("\n重置索引后的 DataFrame:\n", df_multi_sorted)
这个示例演示了如何在 Pandas 中按列对数据进行排序,包括升序和降序排序以及按多列排序。您还可以使用
reset_index()方法来重置排序后的 DataFrame 的索引。
相关文章:
【100天精通Python】Day55:Python 数据分析_Pandas数据选取和常用操作
目录 Pandas数据选择和操作 1 选择列和行 2 过滤数据 3 添加、删除和修改数据 4 数据排序 Pandas数据选择和操作 Pandas是一个Python库,用于数据分析和操作,提供了丰富的功能来选择、过滤、添加、删除和修改数据。 1 选择列和行 Pandas 提供了多种…...

f12工具
抓包工具 elements查看器: 可用于自动化脚本的元素定位,前端页面-html页面 Selenium提供了八种定位元素方式 1、id 2、name 3、class_name 4、tag_name 5、link_text 6、partial_link_text 7、XPath(倾向于用相对路径://input【name“phone”】…...

Spring MVC实现RESTful
在 Spring MVC 中,我们可以通过 RequestMapping PathVariable 注解的方式,来实现 RESTful 风格的请求。 1. 通过RequestMapping 注解的路径设置 当请求中携带的参数是通过请求路径传递到服务器中时,我们就可以在 RequestMapping 注解的 val…...

ClickHouse配置Hdfs存储数据
文章目录 背景配置单机配置HA高可用Hdfs集群性能测试统计trait最多的10个trait term统计性状xxx minValue > 500 0000的数量结论 参考文档 背景 由于公司初始使用Hadoop这一套,所以希望ClickHouse也能使用Hdfs作为存储 看了下ClickHouse的文档,拿Hdf…...
zabbix监控网络设备和zabbix proxy
监控linux主机 [rootrocky8 conf]# yum -y install net-snmp vim /etc/snmp/snmpd.conf com2sec notConfigUser default 123456##修改此行,设置团体密码,默认为public,此处 改为123456 view systemview included .1. ##添加此行,自定义授权,否则 zabbix 无法获取数据 [rootr…...

halcon双目标定双相机标定
halcon双目标定 *取消更新 dev_update_off () *获取窗体句柄 dev_get_window (WindowHandle) *设置窗体字体样式 set_display_font (WindowHandle, 16, mono, true, false) *设置线条粗细 dev_set_line_width (3) *创建空对象 gen_empty_obj (ImageL) *读取指定文件内子集 li…...
Vue框架学习记录之环境安装与第一个Vue项目
Node.js的安装与配置 首先是Node.js的安装,安装十分简单,只需要去官网下载安装包后,一路next即可。 Node.js是一个开源的、跨平台的 JavaScript 运行时环境 下载地址,有两个版本,一个是推荐的,一个是最新…...
【DockerCE】Docker-CE 24.0.6正式版发布
官网下载地址(For RHEL/CentOS 7.9): https://download.docker.com/linux/centos/7/x86_64/stable/Packages/ 相对于24.0.5版本,本次24.0.6版本更新的rpm包有 5 个,使用目录对比软件对比的结果如下: 在Lin…...

【管理运筹学】第 7 章 | 图与网络分析(1,图论背景以及基本概念、术语、矩阵表示)
文章目录 引言一、图与网络的基本知识1.1 图与网络的基本概念1.1.1 图的定义1.1.2 图中相关术语1.1.3 一些特殊图类1.1.4 图的运算 1.2 图的矩阵表示1.2.1 邻接矩阵1.2.2 可达矩阵1.2.3 关联矩阵1.2.4 权矩阵 写在最后 引言 按照正常进度应该学习动态规划了,但我想…...

支持CAN FD的Kvaser PCIEcan 4xCAN v2编码: 73-30130-01414-5如何应用?
这里是引用 Kvaser PCIEcan 4xCAN v2(编码: 73-30130-01414-5)是一款小巧而先进的多通道实时CAN接口,可发送和接收CAN总线上的标准和扩展CAN消息,时间戳精度高。其与所有使用Kvaser CANlib的应用程序兼容。 主要特性 PCI Express…...

经济2023---风口
改革开放以来,中国共有12次比较好的阶级跃迁的机会: 包括80年代选部委院校、办乡镇企业、倒卖商品;90年代下海、选外语外贸、炒股;00年代从事资源品行业、选金融、炒房;10年代选计算机、搞互联网、买比特币。 从这里…...

JWFD开源工作流-矩阵引擎设计-高维向量空间分析法
JWFD开源工作流-矩阵引擎设计-高维向量空间分析法 在把已知的流程节点查找到之后,输出下标,但是我们发现,还有一些节点并未被 探测到,遍历并没有完全的完成,仍然有泄露的节点在其中,这个问题…...

WIN10访问Ubuntu的Samba
WIN10访问Ubuntu的Samba 在Ubuntu中安装好Samba后,如果无法在Win10里访问共享目录或者无法进行写操作,可以进行如下检查: 检查用户是否添加到共享和共享组 $ sudo adduser yourname sambashare 可以编辑:,查看文件/etc…...

AbstractExecutorService 抽象类
java.util.concurrent.AbstractExecutorService 是 Java 并发编程中的一个抽象类,它定义了 ExecutorService 接口的基本行为。ExecutorService 是一个接口,它提供了一种以异步方式执行任务的方法。 AbstractExecutorService 类包含以下一些重要的方法: void execute(Runnab…...

Android12 ethernet和wifi共存
1.修改网络优先走wifi packages/modules/Connectivity/service/src/com/android/server/connectivity/NetworkRanker.java -44,7 44,7 import java.util.Arrays;import java.util.Collection;import java.util.List;import java.util.function.Predicate; - import andro…...
记录使用layui弹窗实现签名、签字
一、前言 本来项目使用的是OCX方式做签字的,因为项目需要转到国产化,不在支持OCX方式,需要使用前端进行签字操作 注:有啥问题看看文档,或者换着思路来,本文仅供参考! 二、使用组件 获取jSign…...
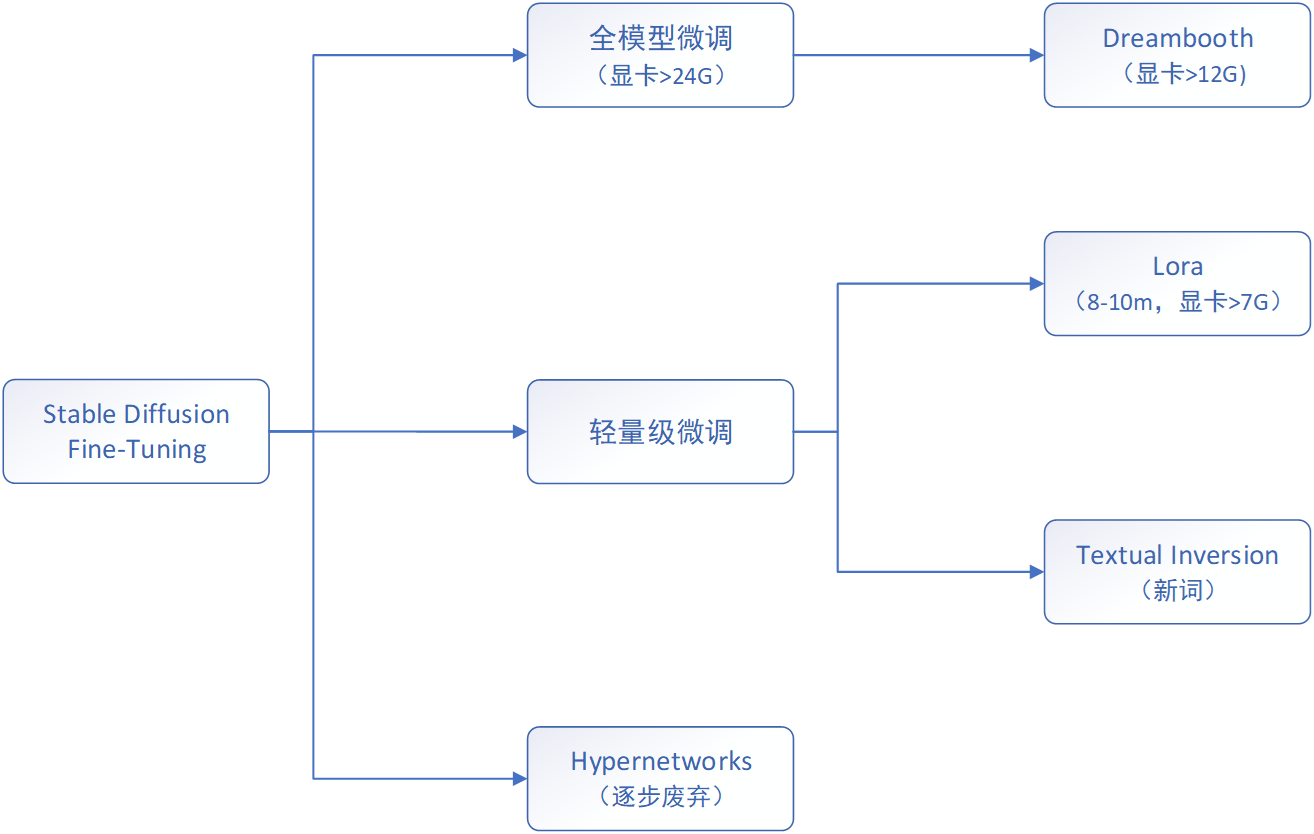
【AIGC系列】Stable Diffusion 小白快速入门课程大纲
一、前言 本文是《Stable Diffusion 从入门到企业级应用实战》系列课程的前置学习引导部分,《Stable Diffusion新手完整学习地图课程》的课程大纲。该课程主要的培训对象是: 没有人工智能背景,想快速上手Stable Diffusion的初学者;想掌握St…...
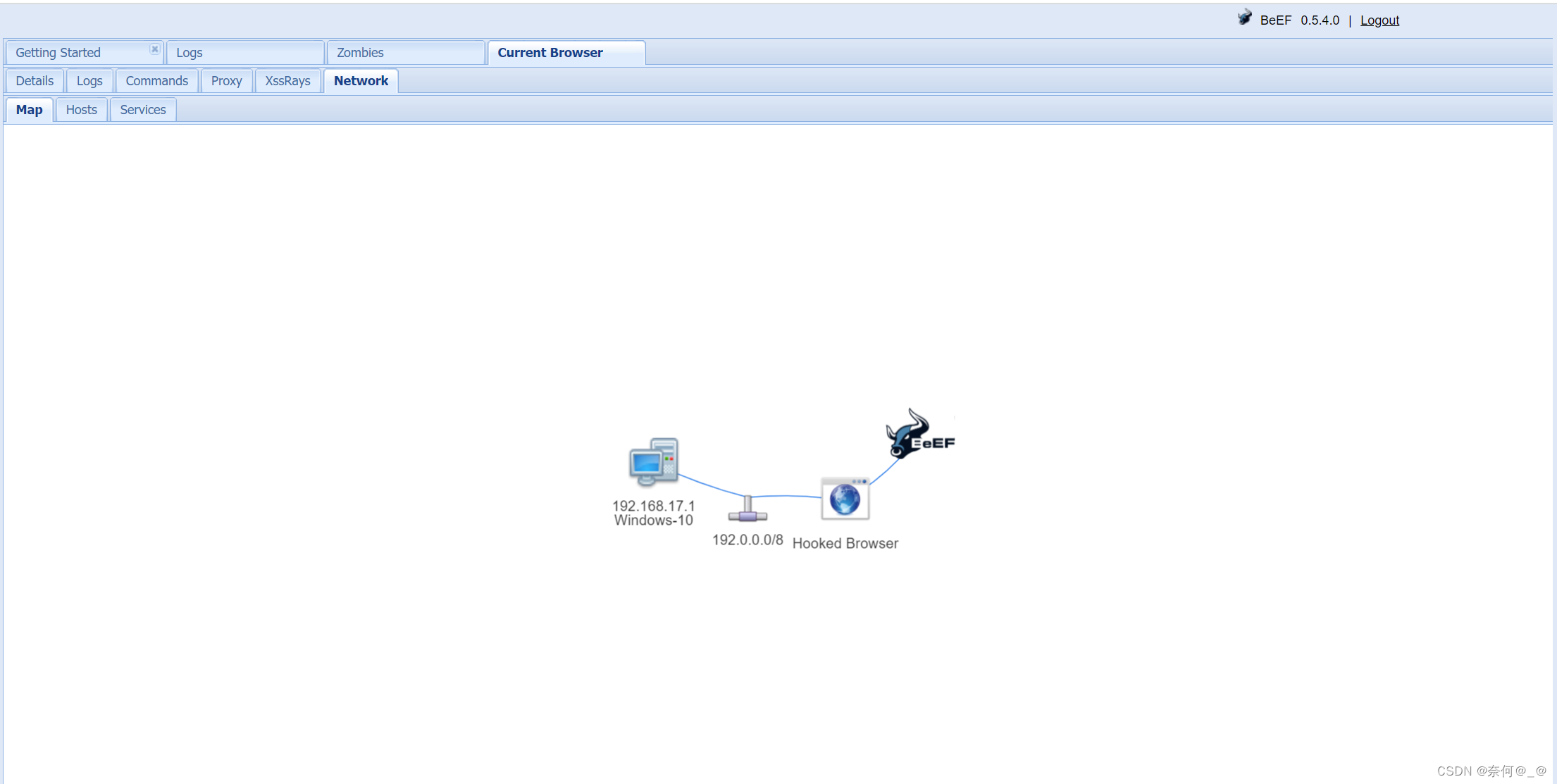
在kali环境下安装Beef-Xss靶场搭建
目录 一、更新安装包 二、安装beef-xss 三、启动Beef-Xss工具 1、查看hook.js 2、查看后台登录地址 3、查看用户名和登录密码 4、登录页面 5、点击 Hook me:将配置的页面导入BEEF中 一、更新安装包 ┌──(root㉿kali)-[/home/kali] └─# apt-get update 二、安装be…...

【Apollo】自动驾驶技术的介绍
阿波罗是百度发布的名为“Apollo(阿波罗)”的向汽车行业及自动驾驶领域的合作伙伴提供的软件平台。 帮助汽车行业及自动驾驶领域的合作伙伴结合车辆和硬件系统,快速搭建一套属于自己的自动驾驶系统。 百度开放此项计划旨在建立一个以合作为中…...
HTML emoji整理 表情符号
<!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8" /><title>测试</title></head><body><div style"font-size: 50px;">🔔</div><script>let count 0d…...

CentOS8实战:ZeroTier构建安全异地虚拟局域网
1. 为什么选择ZeroTier替代传统内网穿透方案 最近在帮朋友搭建远程办公环境时,遇到了一个典型问题:分布在三个不同物理位置的服务器需要像在同一个办公室内网那样互相访问。最初考虑使用FRP方案,但实测下来发现几个痛点:首先是带宽…...

AI量化交易框架解析:从架构设计到实战部署
1. 项目概述:一个AI驱动的加密资产对冲基金框架最近在GitHub上看到一个挺有意思的项目,叫“ai-hedge-fund-crypto”。光看名字,就能感受到一股浓浓的“量化AI加密”的混合气息。这其实是一个开源框架,旨在帮助开发者或量化研究员&…...

HS2-HF_Patch终极指南:一键为Honey Select 2安装完整增强补丁
HS2-HF_Patch终极指南:一键为Honey Select 2安装完整增强补丁 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch HS2-HF_Patch是专为《Honey Select 2》…...

Docker化OpenOffice部署:文档自动化转换服务实战指南
1. 项目概述与核心价值最近在折腾一个老项目,需要处理一批.odt格式的文档,这让我想起了那个曾经在开源办公软件领域与微软Office分庭抗礼的“老将”——OpenOffice。虽然现在LibreOffice的风头更盛,但OpenOffice依然有其独特的生态位和用户群…...

构建个人代码仓库:提升开发效率的实践指南
1. 项目概述:一个面向21世纪开发者的代码仓库最近在GitHub上看到一个挺有意思的项目,叫“21st-dev/1code”。光看这个名字,你可能觉得有点抽象,但点进去之后,我发现它其实是一个挺有想法的代码仓库。这个项目没有复杂的…...

C# AI开发实战:BotSharp框架构建企业级NLP应用指南
1. 项目概述:当C#开发者遇上AI应用开发如果你是一名长期深耕.NET生态的开发者,最近看着Python在AI领域风生水起,心里是不是有点痒,又有点不甘?总觉得为了跑个模型、搭个智能对话,就得切到另一个完全不同的技…...

如何为深信服超融合平台上的应用快速接入大模型能力
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何为深信服超融合平台上的应用快速接入大模型能力 对于在深信服超融合平台上部署业务应用的企业开发团队而言,集成智…...
)
Midjourney Ash印相参数白皮书(含Adobe RGB/ProPhoto RGB双色域适配矩阵及ICC Profile嵌入规范)
更多请点击: https://intelliparadigm.com 第一章:Midjourney Ash印相技术演进与核心定位 Midjourney Ash印相(Ash Toning)并非传统暗房化学工艺的简单复刻,而是基于生成式AI图像合成模型的一套语义化风格映射机制。它…...

Camera Graph™相机拓扑图谱引擎技术白皮书
前言在数字孪生、全域感知、智能安防等领域快速发展的今天,多镜头协同感知已成为实现全域覆盖、精准识别、连续追踪的核心基础。然而,传统多相机部署模式下,各镜头始终处于“孤立工作”状态,数据互通存在壁垒、时空对齐精度不足、…...

多机驱动振动系统同步控制理论【附模型】
✨ 长期致力于振动机械、自同步、控制同步、GA-BP PID、定速比研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)GA-BP神经网络PID控制器设计及其参数自…...