使用perf_analyzer和model-analyzer测试tritonserver的模型性能超详细完整版
导读
当我们在使用tritonserver部署模型之后,通常需要测试一下模型的服务QPS的能力,也就是1s我们的模型能处理多少的请求,也被称为吞吐量。
测试tritonserver模型服务的QPS通常有两种方法,一种是使用perf_analyzer 来测试,另一种是通过model-analyzer来获取更为详细的模型服务启动的参数,使得模型的QPS达到最大,下面我们将分别来介绍如何通过这两种工具来测试tritonserver模型服务的吞吐量。
环境准备
使用docker镜像来进行测试非常的方便,一般对应版本的tritonserver都会有一个tritonserver-sdk的版本,例如21.10需要准备的镜像如下
nvcr.io/nvidia/tritonserver:21.10-py3
nvcr.io/nvidia/tritonserver:21.10-py3-sdk
nvcr.io/nvidia/tensorrt:21.10-py3
- tritonserver:tritonserver模型启动服务所需要的镜像
- tritonserver-py3-sdk:包含
perf_analyzer和model-analyzer可以用于做性能测试的镜像 - tensorrt:包含与tritonserver镜像中一样的
tensorrt版本,该镜像主要用来将onnx模型转换为engine用于tritonserver启动模型服务时所需要的模型文件
注:不同版本的版本的镜像所需要的nvidia-driver的版本不一样,21.10所需要的nvida-driver版本为>=470.82(cuda11.4),如果低于该版本时,在启动镜像的时候会提示不兼容。在准备上面镜像的时候tritonserver和tensorrt版本一定要一致,因为不同的版本依赖库以及tensorrt的版本可能会不一样,导致模型可能无法通用
perf_analyzer
- 启动tritonserver模型服务
docker run --gpus all --rm -p8000:8000 -p8001:8001 -p8002:8002 -v triton_models:/models nvcr.io/nvidia/tritonserver:21.10-py3 tritonserver --model-repository=/models
- –gpus:表示启动tritonserver服务是否使用gpu
- –rm:当退出容器的时候会自动删除容器
- -p:用于容器内和宿主机之间的端口映射
- –model-repository:指定tritonserver运行的时候所需要的模型文件

启动之后输出上面的信息就表示tritonserver模型服务启动成功
- 运行
tritonserver-sdk镜像
docker run -it --rm --net=host nvcr.io/nvidia/tritonserver:21.10-py3-sdk
因为这里我们只是使用了perf_analyzer性能测试工具,所以其他的启动参数可以不用管
3. 性能测试
perf_analyzer -m resnet34 --percentile=95 --concurrency-range 100
- -m:指定测试的模型
- –percentile:以百分位数表示置信度值用于确定测量结果是否稳定
- –concurrency-range:指定并发量参数,还可以使用,100:120:10表示并发量在100到120之间以10作为间隔测试所有并发量情况下的吞吐量
- -b:指定请求的batch-size,默认为1
- -i:指定请求所使用的协议,参数可以为
http或grpc
其他更多的参数可以通过perf_analyzer -h查看
执行成功之后会输出模型所能承受的吞吐量以及时延
*** Measurement Settings ***
Batch size: 1
Using “time_windows” mode for stabilization
Measurement window: 5000 msec
Using synchronous calls for inference
Stabilizing using p95 latency
Request concurrency: 100
Client:
Request count: 11155
Throughput: 2231 infer/sec
p50 latency: 43684 usec
p90 latency: 61824 usec
p95 latency: 67900 usec
p99 latency: 76275 usec
Avg HTTP time: 45183 usec (send/recv 161 usec + response wait 45022 usec)
Server:
Inference count: 13235
Execution count: 722
Successful request count: 722
Avg request latency: 29032 usec (overhead 629 usec + queue 11130 usec + compute input 7317 usec + compute infer 9889 usec + compute output 67 usec)
Inferences/Second vs. Client p95 Batch Latency
Concurrency: 100, throughput: 2231 infer/sec, latency 67900 usec
在使用http协议进行测试的时候,可能会存在比较大的波动,小伙伴们可以多测试几组来取平均值,grpc协议相对来说更加稳定一些。
我们最重要的是关注最后一行的输出信息,表示在100并发的请求下,tritonserver的吞吐量可以达到2231请求/s,时延是67900微秒。可以看出tritonserver模型服务的推理能力还是很强的,显卡是RTX3090,在只使用了一个count的情况下ResNet34可以达到2200FPS
model-analyzer
- 启动
tritonserver-sdk
docker run --gpus 1 --shm-size=1g --ulimit memlock=-1 --ulimit stack=67108864 -ti -v /var/run/docker.sock:/var/run/docker.sock --net host --privileged --rm -v /home/***/triton_models:/models -v /data/reports:/data/reports nvcr.io/nvidia/tritonserver:21.10-py3-sdk bash
这里需要注意的是,我们在这里不需要再去启动tritonserver模型服务了,但是启动的参数多了很多,上面这些参数都是必要的
- v指定docker.sock是让容器能够启动tritonser模型服务容器
- /data/reports:/data/reports:指定模型测试报告存储的路径,这里容器内外的路径需要保持一致,否则后面再使用model-analyzer的时候会报错
- 创建tritonserver可执行文件
touch /opt/tritonserver
chmod +x /opt/tritonserver
- 启动model-analyzer测试
model-analyzer profile --model-repository /models --profile-models resnet34 --run-config-search-max-concurrency 2 --run-config-search-max-instance-count 2 --gpus '0' --triton-launch-mode=docker --output-model-repository=/data/reports/resnet34 --triton-server-path=/opt/tritonserver --override-output-model-repository
- profile:
- model-repository:指定模型保存的目录,这里可以是包含多个模型的目录
- profile-models :指定测试模型的名字
- run-config-search-max-concurrency:最大的并发数
- run-config-search-max-instance-count:最大的count也就是模型实例数
- triton-launch-mode:docker或local,如果是local的时候需要容器内安装tritonserver,这里使用的是docker
- output-model-repository:测试报告保存的目录
- override-output-model-repository:每次测试的时候都会覆盖之前的测试报告
为了加快测试的速度,这里我将count设置为2,concurrency 也设置为2,在实际使用的过程中小伙伴们可以设置一个范围,使用min和max来进行控制,而不要直接固定住这些参数。因为我们最终需要的是得到count、concurrency、batch-size这些参数的最优值。
注:需要注意triton-model-analyzer的版本,不同的版本指定的参数会不一样,这里triton-model-analyzer==1.9.0,小伙伴们可以通过model-analyzer -h来查看参数。
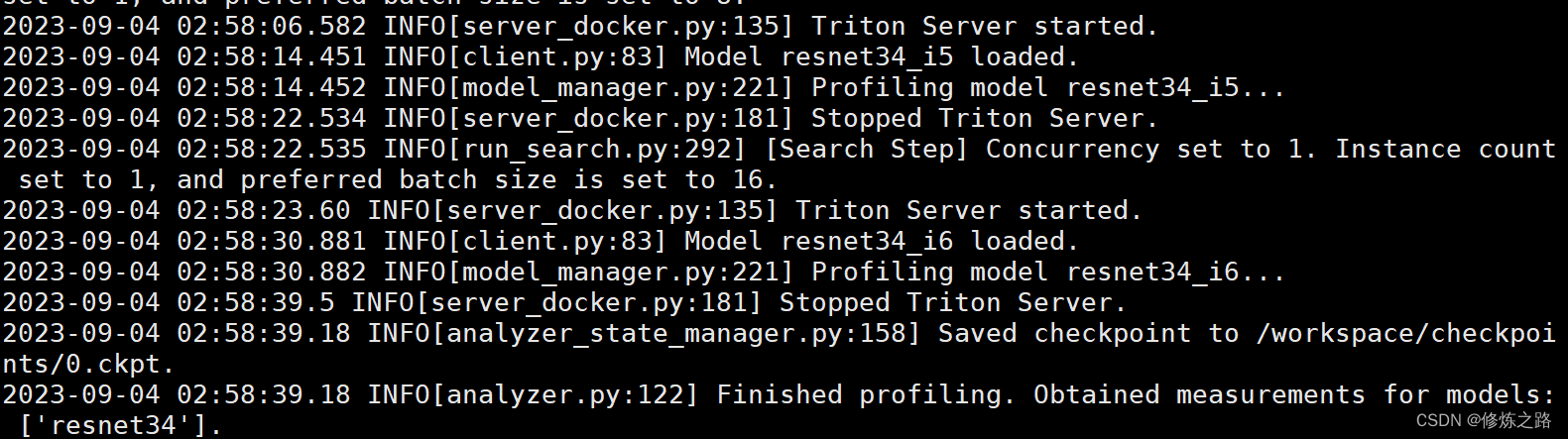
执行成功之后我们会得到一个ckpt的文件
- 导出模型的性能报告
mkdir analysis_results
model-analyzer analyze --analysis-models resnet34 -e analysis_results
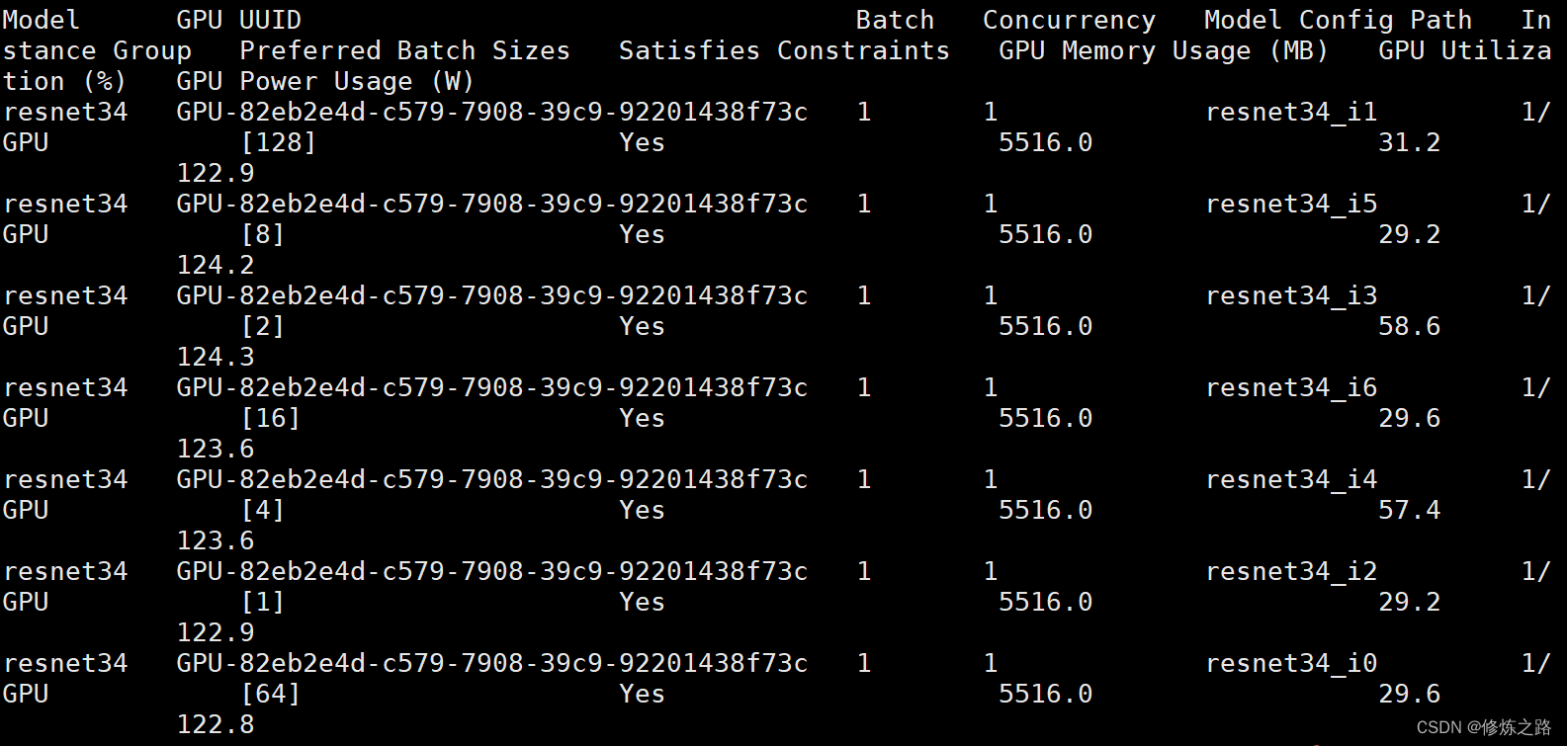
5. 查看结果
拷贝报告,将容器内的报告拷贝到宿主机上,通过docker ps -a来查看容器的id
docker cp 5610298c2c93:/workspace/analysis_results ./
在/analysis_results/reports/summaries/resnet34目录下有一个result_summary.pdf文件里面记录了模型的性能参数
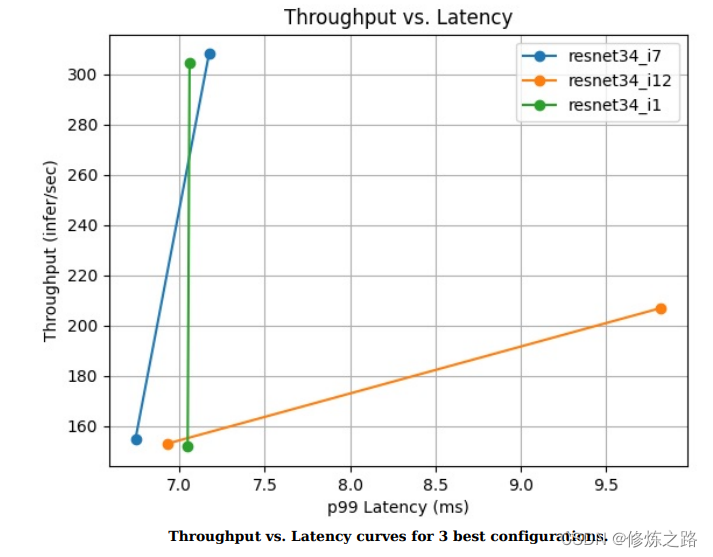
这里吞吐量低的主要原因是因为我们把最大的并发数设置为2了,大家在使用的时候可以设置大一点,参数搜索的范围越大所需要的时间就会越长
相关错误以及解决办法
- 启动
tritonserver服务失败
I0903 13:53:33.877351 1 server.cc:233] Waiting for in-flight requests to complete.
I0903 13:53:33.877375 1 server.cc:248] Timeout 30: Found 0 live models and 0 in-flight non-inference requests
error: creating server: Internal - failed to load all models
模型服务启动失败时,注意看前面的错误信息,前面会有显示每个模型的加载状态以及加载失败的原因

上面错误的原因是因为在转换启动模型文件的时候,所使用的tensorrt版本与容器内tensorrt的版本不一致导致加载失败,通过使用与tritonserver版本一致的tensorrt进行将onnx模型重新转换一下即可。
2. Failed to set the value for field “triton_server_path”
2023-09-03 14:45:35.892 ERROR[entrypoint.py:214] Model Analyzer encountered an error: Failed to set the value for field “triton_server_path”. Error: Either the binary ‘tritonserver’ is not on the PATH, or Model Analyzer does not have permissions to execute os.stat on this path.
touch /opt/tritonserver
chmod +x /opt/tritonserver
- OSError: [Errno 16] Device or resource busy: ‘/data/reports’
在执行model-analyzer的时候提示resource busy,详细错误信息如下
2023-09-04 02:52:07.192 ERROR[entrypoint.py:214] Model Analyzer encountered an error: Failed to set the value for field “triton_server_path”. Error: Either the binary ‘/opt/tritonserver’ is not on the PATH, or Model Analyzer does not have permissions to execute os.stat on this path.
root@zhouwen3090:/workspace# touch /opt/tritonserver
root@zhouwen3090:/workspace# chmod +x /opt/tritonserver
root@zhouwen3090:/workspace# model-analyzer profile --model-repository /models --profile-models resnet34 --run-config-search-max-concurrency 1 --run-config-search-max-instance-count 1 --gpus ‘0’ --triton-launch-mode=docker --output-model-repository=/data/models/reports --triton-server-path=/opt/tritonserver --override-output-model-repository
2023-09-04 02:52:22.668 INFO[gpu_device_factory.py:50] Initiliazing GPUDevice handles…
2023-09-04 02:52:23.764 INFO[gpu_device_factory.py:246] Using GPU 0 NVIDIA GeForce RTX 3090 with UUID GPU-82eb2e4d-c579-7908-39c9-92201438f73c
Traceback (most recent call last):
File “/usr/local/bin/model-analyzer”, line 8, in
sys.exit(main())
File “/usr/local/lib/python3.8/dist-packages/model_analyzer/entrypoint.py”, line 289, in main
create_output_model_repository(config)
File “/usr/local/lib/python3.8/dist-packages/model_analyzer/entrypoint.py”, line 249, in create_output_model_repository
os.mkdir(config.output_model_repository_path)
FileNotFoundError: [Errno 2] No such file or directory: ‘/data/models/reports’
root@zhouwen3090:/workspace# model-analyzer profile --model-repository /models --profile-models resnet34 --run-config-search-max-concurrency 1 --run-config-search-max-instance-count 1 --gpus ‘0’ --triton-launch-mode=docker --output-model-repository=/data/reports --triton-server-path=/opt/tritonserver --override-output-model-repository
2023-09-04 02:53:38.665 INFO[gpu_device_factory.py:50] Initiliazing GPUDevice handles…
2023-09-04 02:53:39.750 INFO[gpu_device_factory.py:246] Using GPU 0 NVIDIA GeForce RTX 3090 with UUID GPU-82eb2e4d-c579-7908-39c9-92201438f73c
Traceback (most recent call last):
File “/usr/local/lib/python3.8/dist-packages/model_analyzer/entrypoint.py”, line 249, in create_output_model_repository
os.mkdir(config.output_model_repository_path)
FileExistsError: [Errno 17] File exists: ‘/data/reports’
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File “/usr/local/bin/model-analyzer”, line 8, in
sys.exit(main())
File “/usr/local/lib/python3.8/dist-packages/model_analyzer/entrypoint.py”, line 289, in main
create_output_model_repository(config)
File “/usr/local/lib/python3.8/dist-packages/model_analyzer/entrypoint.py”, line 258, in create_output_model_repository
shutil.rmtree(config.output_model_repository_path)
File “/usr/lib/python3.8/shutil.py”, line 722, in rmtree
onerror(os.rmdir, path, sys.exc_info())
File “/usr/lib/python3.8/shutil.py”, line 720, in rmtree
os.rmdir(path)
OSError: [Errno 16] Device or resource busy: ‘/data/reports’
只需要修改一下--output-model-repository=/data/reports指定的路径即可,在后面增加一个模型的名称修改为--output-model-repository=/data/reports/resnet34
4. /usr/bin/wkhtmltopdf: error while loading shared libraries: libQt5Core.so.5: cannot open shared object file: No such file or directory
strip --remove-section=.note.ABI-tag /usr/lib/x86_64-linux-gnu/libQt5Core.so.5
参考
- https://github.com/triton-inference-server/client/blob/main/src/c%2B%2B/perf_analyzer/docs/cli.md
- https://github.com/triton-inference-server/model_analyzer/tree/main/docs
- https://github.com/triton-inference-server/model_analyzer/blob/main/docs/quick_start.md
- https://github.com/triton-inference-server/model_analyzer/blob/main/docs/install.md
- https://github.com/triton-inference-server/model_analyzer/issues/120
相关文章:
使用perf_analyzer和model-analyzer测试tritonserver的模型性能超详细完整版
导读 当我们在使用tritonserver部署模型之后,通常需要测试一下模型的服务QPS的能力,也就是1s我们的模型能处理多少的请求,也被称为吞吐量。 测试tritonserver模型服务的QPS通常有两种方法,一种是使用perf_analyzer 来测试&#…...
docker 部署springboot(成功、截图)
1.新建sringboot工程并打包 2.编写Dockerfile文件 # 基础镜像使用java FROM openjdk:8 # 作者 MAINTAINER feng # VOLUME 指定了临时文件目录为/tmp。 # 其效果是在主机 /var/lib/docker 目录下创建了一个临时文件,并链接到容器的/tmp VOLUME /tmp # 将jar包添加…...
VMware ubuntu空间越用越大
前言 用Ubuntu 1604编译了RK3399的SDK,之后删了一些多余的文件,df - h 已用21G,但window硬盘上还总用了185GB,采用了碎片整理,压缩无法解决 1 启动Ubuntu后, 安装 VMware Tools(T) 、 2 打开ubuntu终端,压…...
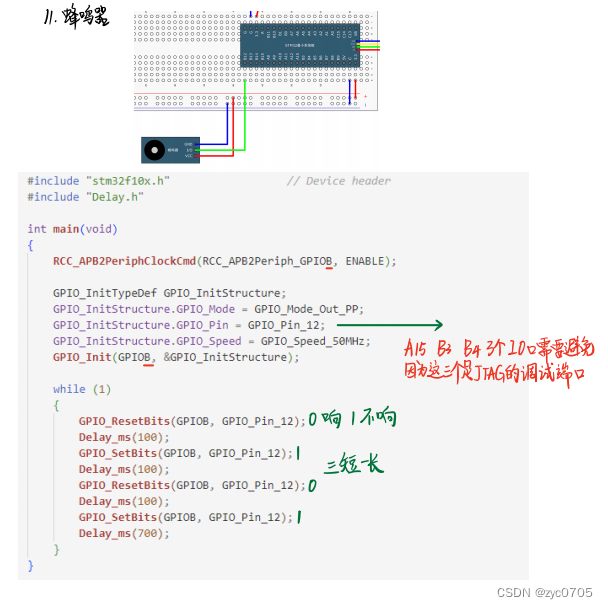
stm32 学习笔记:GPIO输出
一、GPIO简介 引脚电平 0-3.3V,部分可容忍5V,对输出而言最大只能输出3.3V, 只要可以用高低电平来控制的地方,都可以用GPIO来完成,如果控制的功率比较大的设备,只需加入驱动电路即可 GPIO 通用输入输出口,可配置为 8种 …...

css换行
强制显示一行,超出... .box{white-space: nowrap; /* 强制显示一行 */overflow: hidden;text-overflow: ellipsis; /* 超出... */ } 自动换行 一般默认制动换行 .box1{word-wrap:break-word; } 显示2行,超出... .box2 {overflow: hidden;display: -…...
面试算法-常用数据结构
文章目录 数据结构数组链表 栈队列双端队列树 1)算法和数据结构 2)判断候选人的标准 算法能力能够准确辨别一个程序员的功底是否扎实 数据结构 数组 链表 优点: 1)O(1)时间删除或者添加 灵活分配内存空间 缺点: 2&…...
【动态规划刷题 10】等差数列划分 最长湍流子数组
413. 等差数列划分 链接: 413. 等差数列划分 如果一个数列 至少有三个元素 ,并且任意两个相邻元素之差相同,则称该数列为等差数列。 例如,[1,3,5,7,9]、[7,7,7,7] 和 [3,-1,-5,-9] 都是等差数列。 给你一个整数数组 nums ,返回…...

redis 配置与优化
目录 一、关系数据库和非关系型数据库 二、关系型数据库和非关系型数据库区别 三、非关系型数据库产生背景 四、redis 1、概念 2、redis的优点 3、redis为什么这么快 五、redis安装与配置 一、关系数据库和非关系型数据库 关系型数据库:关系型数据库是一个结…...

数据结构例题代码及其讲解-递归与树
树 树的很多题目中都包含递归的思想 递归 递归包括递归边界以及递归式 即:往下递,往上归 递归写法的特点:写起来代码较短,但是时间复杂度较高 01 利用递归求解 n 的阶乘。 int Func(int n) {if (n 0) {return 1;}else …...

Jenkins | 流水线构建使用expect免密交互时卡住,直接退出
注意: expect 脚本必须以 interact 或 expect eof 结束。 原因: interact:使用interact会保持在终端而不会退回到原终端,所以就卡在这里。 expect eof:expect脚本默认的是等待10s,当执行完命令后,自动切回…...

git修改默认分支
git checkout 分支 切换到当前分支 git branch --set-upstream-toorigin/complete(远程分支名) 设置当前分支的上游分支为远程分支complete git branch --unset-upstream master 取消master上游分支的身份 现在,使用git commit,git push 命令可以直接…...
Android Studio开发入门教程:如何更改APP的图标?
更改APP的图标(安卓系统) 环境:Windows10、Android Studio版本如下图、雷电模拟器。 推荐图标库 默认APP图标 将新图标拉进src/main/res/mipmap-hdpi文件夹(一般app的icon图标是存放在mipmap打头的文件夹下的) 更改sr…...

MATLAB/Python的编程教程: 匹配滤波器的实现
MATLAB/Python的编程教程: 匹配滤波器的实现 注1:本文系“MATLAB/Python的编程教程”系列之一,致力于使用Python和Matlab实现特定的功能。本次要实现的功能是:匹配滤波器的实现。 匹配滤波器,这是一个在信号处理领域常见的主题,主要用于增强特定信号的检测性能,特别是在噪…...
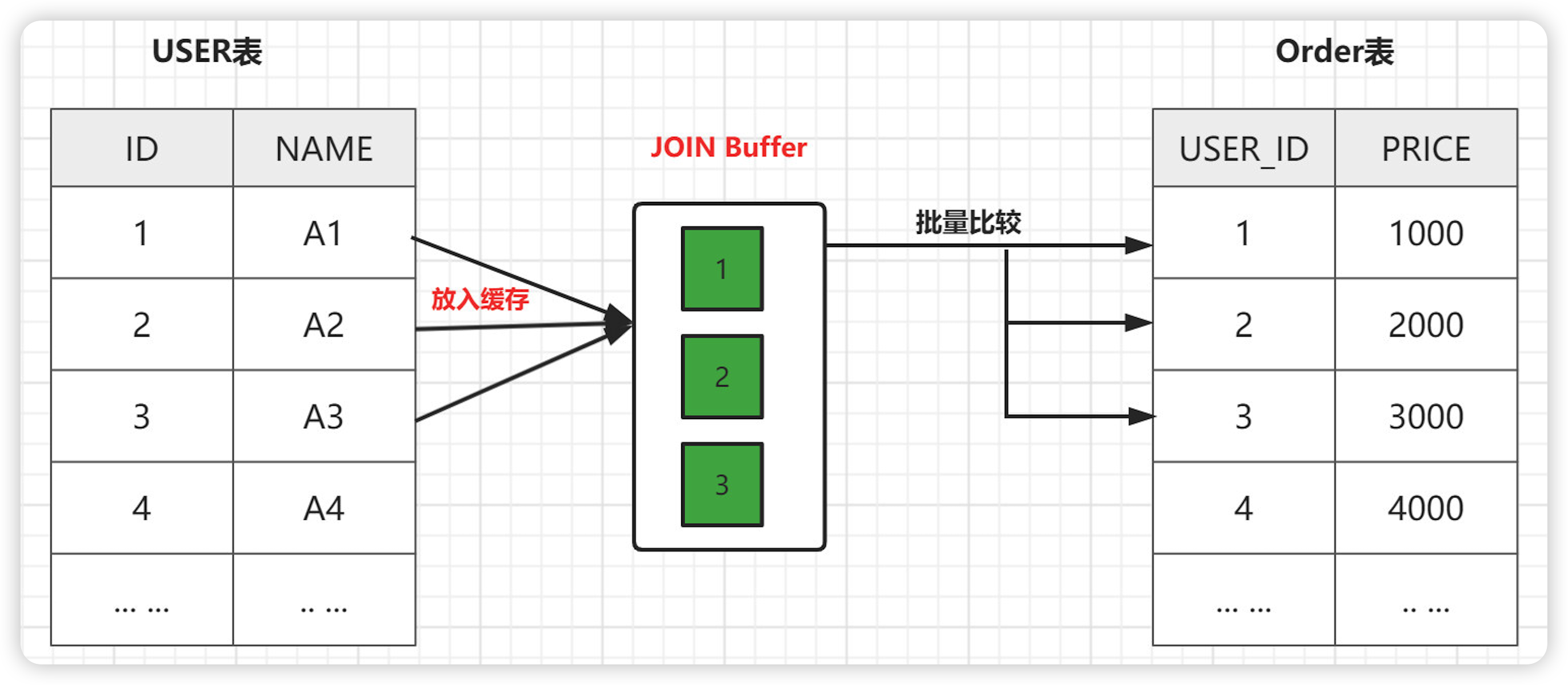
java八股文面试[数据库]——JOIN优化
JOIN 是 MySQL 用来进行联表操作的,用来匹配两个表的数据,筛选并合并出符合我们要求的结果集。 JOIN 操作有多种方式,取决于最终数据的合并效果。常用连接方式的有以下几种: 什么是驱动表 ? 多表关联查询时,第一个被处理的表就是驱动表,使用…...
Java语法中一些需要注意的点(仅用于个人学习)
1.当字符串和其他类型相加时,基本都是字符串,这与运算顺序有关。 2.Java中用ctrl d 来结束循环输入。 3.nextLine() 遇到空格不会结束。 4.方法重载 4.1. 方法名必须相同 4.2. 参数列表必须不同(参数的个数不同、参数的类型不同、类型的次序必须不…...

golang 线程 定时器 --chatGPT
问:线程函数write(ch,timer),功能为启动一个线程,循环执行打印,打印条件为触发ch chane 或 timer定时器每隔一段时间会触发 GPT:以下是一个示例Golang代码,其中有一个名为 write 的线程函数,它会在触发ch通道或每隔一…...

java 编程 7个简单的调优技巧
你的Java性能调优有救了!分享7个简单实用的Java性能调优技巧 一、以编程方式连接字符串 在Java中有很多不同的连接字符串的选项。比如,可以使用简单的或、良好的旧StringBuffer或StringBuilder。 那么,应该选择哪种方法? 答案取…...

03-Dockerfile
Dockerfile简介 Dockerfile是什么? Dockerfile是用来构建Docker镜像的文本文件,是由一条条构建镜像所需的指令和参数构成的脚本 Dockerfile官网 https://docs.docker.com/engine/reference/builder/ Dockerfile构建三步曲 编写Dockerfile文件docke…...

【AI】机器学习——朴素贝叶斯
文章目录 2.1 贝叶斯定理2.1.1 贝叶斯公式推导条件概率变式 贝叶斯公式 2.1.2 贝叶斯定理2.1.3 贝叶斯决策基本思想 2.2 朴素贝叶斯2.2.1 朴素贝叶斯分类器思想2.2.2 条件独立性对似然概率计算的影响2.2.3 基本方法2.2.4 模型后验概率最大化损失函数期望风险最小化策略 2.2.5 朴…...

数学建模:模糊综合评价分析
🔆 文章首发于我的个人博客:欢迎大佬们来逛逛 数学建模:模糊综合评价分析 文章目录 数学建模:模糊综合评价分析综合评价分析常用评价方法一级模糊综合评价综合代码 多级模糊综合评价总结 综合评价分析 构成综合评价类问题的五个…...
安装与中文环境配置实战)
Halcon深度学习工具(DLT)安装与中文环境配置实战
1. Halcon DLT安装前的准备工作 第一次接触Halcon深度学习工具(DLT)时,我完全被各种专业术语搞晕了。后来才发现,只要做好前期准备,安装过程其实比想象中简单得多。首先需要确认的是你的Windows系统版本,DLT目前支持Windows 10和1…...

开源技能库构建指南:Git+Markdown+Docsify打造个人技术知识体系
1. 项目概述:一个开源技能库的诞生与价值在技术领域,尤其是软件开发、运维和数据分析等方向,我们每天都在与海量的工具、框架和命令打交道。时间一长,一个很现实的问题就摆在了面前:那些曾经花了好几个小时才调通的复杂…...

DownKyi技术架构解析:构建高性能B站视频下载引擎的工程实践
DownKyi技术架构解析:构建高性能B站视频下载引擎的工程实践 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等&…...

从零构建Go Web框架:解析the0极简框架的设计原理与实现
1. 项目概述:一个极简主义Web框架的诞生在Web开发的世界里,我们常常面临一个选择:是拥抱功能齐全但略显臃肿的“巨无霸”框架,还是追求极致轻量与灵活的自定义方案?对于许多追求性能、热爱掌控感,或是需要构…...

Midjourney像素艺术提示词工程:98%新手忽略的4个隐藏权重指令,实测提升风格还原度320%
更多请点击: https://intelliparadigm.com 第一章:Midjourney像素艺术提示词工程的底层逻辑重构 像素艺术在 Midjourney 中并非天然适配的生成模态,其高精度、低分辨率、强风格约束的特性与扩散模型默认的连续性渲染范式存在根本张力。要实现…...

CircuitPython硬件交互实战:引脚命名、模块管理与内存优化
1. 项目概述:CircuitPython硬件交互的基石 如果你刚开始接触CircuitPython,或者从Arduino转过来,可能会对如何控制板子上的某个引脚感到困惑。板子上明明印着“A0”、“D13”,但在代码里到底该怎么写? board.A0 和 …...

树莓派+Kali Linux+PiTFT打造便携式安全测试平台全攻略
1. 项目概述如果你和我一样,对网络安全和嵌入式硬件都抱有浓厚的兴趣,那么将Kali Linux与树莓派结合,再配上一块小巧的触摸屏,绝对是一个能让你兴奋起来的项目。这不仅仅是把两个热门技术拼在一起,更是打造一个真正便携…...

基于Vanilla JS与IndexedDB构建本地化Markdown笔记工具
1. 项目概述:从零开始构建一个轻量级笔记工具最近在整理个人知识库时,发现市面上的笔记软件要么功能过于臃肿,要么云端同步存在隐私顾虑,要么就是定制化程度不够。作为一个有十多年开发经验的从业者,我决定自己动手&am…...

CC2530与ESP8266物联网网关:ZigBee转Wi-Fi通信协议转换实战
1. 项目概述:当ZigBee遇上Wi-Fi最近在折腾一个智能家居的传感器节点,核心是TI的CC2530 ZigBee芯片。这玩意儿功耗低、组网方便,是很多低功耗传感网络的绝佳选择。但问题来了,ZigBee网络的数据最终怎么方便地送到我们手机上去看呢&…...

AI智能体开发实战:从Devin现象到代码辅助智能体构建
1. 项目概述:当开发者遇上AI智能体最近在GitHub上闲逛,发现一个叫“awesome-devins”的仓库热度飙升。点进去一看,好家伙,这简直是一个关于“AI智能体”的宝藏目录。这个由e2b-dev团队维护的项目,本质上是一个精心整理…...