数据结构例题代码及其讲解-递归与树
树
树的很多题目中都包含递归的思想
递归
递归包括递归边界以及递归式
即:往下递,往上归
递归写法的特点:写起来代码较短,但是时间复杂度较高
01 利用递归求解 n 的阶乘。
int Func(int n) {if (n == 0) {return 1;}else {return n * Func(n - 1);}
}
02 斐波那契数列是满足 F(0)=1,F(1)=1,F(n)=F(n-1)+F(n-2)(n≥2)的数列,数列的前几项为 1,1,2,3,5,8,13,21…。写出求解斐波那契数列第 n 项的程序。
int Fbnq(int n) {if (n == 0||n == 1) {return 1;}else {return Fbnq(n - 1) + Fbnq(n - 2);}
}
树
二叉树的链式存储结构体定义。
typedef struct BiTNode {int data;struct BiTNode* lchild, * rchild;
}BiTNode,*BiTree;
01 二叉树先序递归遍历算法
先序递归遍历:根左右
void PreOrder(BiTree T) {if (T == NULL) {//递归边界return;}else {printf("%d", T->data);//打印此结点数据域中的数据值PreOrder(T->lchild);//递归遍历左子树PreOrder(T->rchild);//递归遍历右子树}
}
简便写法如下:
//简便
void PreOrder(BiTree T) {if (T != NULL) {printf("%d", T->data);PreOrder(T->lchild);PreOrder(T->rchild);}
}
因此有些代码看着比较难懂,是因为它们把递归边界隐藏了,变得不容易轻易看懂。
02 二叉树中序递归遍历算法
中序递归遍历:左根右
void InOrder(BiTree T) {if (T != NULL) {//若所处理的结点不为空InOrder(T->lchild);//递归遍历左子树printf("%d", T->data);//打印此结点数据域中的数据值InOrder(T->rchild);//递归遍历右子树}
}
03 二叉树后序递归遍历算法
后序递归遍历:左右根
void PostOrder(BiTree T) {if (T != NULL) {PostOrder(T->lchild);PostOrder(T->rchild);printf("%d", T->data);}
}
04 在一棵以二叉链表为存储结构的二叉树中,查找数据域值等于 key 的结点是否存在,如果存在,则将指针 q 指向该结点,假设结点数据域为 int 型。(二叉树中结点值都不相同)
- 由于指针q可能会发生改变,因此需要加&;从变量标识符开始从右往左看,最靠近标识符的是变量的本质类型,而再往左即为对变量类型的进一步修饰,在C++中星号代表指针,而&代表引用,而*&代表指针引用;
- BiTNode*& q:标识符q左边紧邻的是&,说明q是一个引用变量,再往左是 *,所以q是一个指针变量的引用,在往左是BiTNode,可见q是一个指向BiTNode类型的指针的引用。
- 这里改写先序递归遍历。
void Search(BiTree T, BiTNode*& q, int key) {if(T!=NULL){if (T->data == key) {q = T;//若为 key 则指针 q 指向该结点}else {Search(T->lchild, q, key);Search(T->rchild, q, key);}}
}
05 假设二叉树采用二叉链表形式存储,设计一个算法,求先序遍历序列中第 k(1≤k≤二叉树中结点个数)个结点的值。
- 需要一个计数的变量,由于是递归,每次调用自己相当于重新开始调用函数,因此该计数变量需要是全局变量;
- 这题改写前序递归遍历,由于初始时n=0,因此进入if时先自加,然后判断;
int n = 0;//定义全局变量 n 进行计数
int Search_k(BiTree T, int k) {if (T != NULL) {//改写先序递归遍历n++;//更新变量 n,记录现在访问的是第几个结点if (n == k) {//若 n 等于 k 则直接打印访问结点的数据值并结束此次递归printf("%d", T->data);return T->data;}else {Search_k(T->lchild, k);Search_k(T->rchild, k);}}
}
06 利用递归计算二叉树中所有结点的个数。
法一
利用递归
int n = 0;
void calc(BiTree T) {if (T == NULL) {return;}else {n++;calc(T->lchild);calc(T->rchild);}
}
int n=0;//定义全局变量 n 用来计数
void calc(BiTree T){if(T!=NULL){//改写先序递归遍历n++;//将先序遍历中访问结点代码改写为计数代码calc(T->lchild);//递归遍历左子树calc(T->rchild);//递归遍历右子树}
}
法二
- 注意法二思想:如果计算以某一结点为根的这颗树的所有结点个数,可以先计算出该节点左结点为根的所有结点个数,然后计算出该节点右结点为根的所有个数,最后加上1(该结点本身),就得到了所有结点个数;然后继续拆分问题。
- 定义n1和n2变量,用来接收左子树和右子树的结点个数,该变量为局部变量,记录此次递归函数左子树和右子树的结点个数。
- 由于是递归,到达叶子结点时,继续往下递,左子树为空,返回0,所以n1=0,右子树为空,返回0,所以n2=0,因此叶子结点往上归的时候是n1 + n2 + 1=1。接着依次往上归得到了结点数。
int Count(BiTree T) {int n1, n2;//定义 n1 和 n2 分别用于接收左右子树结点个数if (T == NULL) {return 0;}else {n1 = Count(T->lchild);//递归求解左子树中结点个数,结果 n1 接收n2 = Count(T->rchild);return n1 + n2 + 1;//再加根结点}
}
法二的代码是求二叉树的高度、求叶子结点的个数、求单/双分支结点的个数的算法思想,递归时尽量把叶子结点的左右空子树也画出来。
07 利用递归计算二叉树中所有叶子结点的个数。
法一
- 改写先序递归遍历
//法一
int n = 0;
void Countleaves(BiTree T) {if (T != NULL) {//所处理结点是否为叶子结点if (T->lchild == NULL && T->rchild == NULL) {n++;//若遍历结点是叶子结点则计数}Countleaves(T->lchild);//递归遍历左子树Countleaves(T->rchild);}
}
法二
- 递归边界,树为空,说明没有叶子结点,结点是叶子结点,返回1
- 最后返回的是n1+n2
//法二
int Countl(BiTree T) {int n1, n2;//接受左右子树的叶子结点个数if (T == NULL) {return 0;}else if (T->lchild == NULL && T->rchild == NULL) {return 1;}else {n1 = Countl(T->lchild);//递归求解左子树中叶子结点的个数,结果 n1 接收n2 = Countl(T->rchild);return n1 + n2;}
}
08 (题一)利用递归计算二叉树中所有双分支结点个数。
- 双分支结点的分类及其处理
①双分支 n1+n2+1, 看左子树的双分支,右子树的双分支,加上本身;
②单分支 n1+n2, 看左子树的双分支,右子树的双分支;
③叶子结点 n1+n2, 看左子树的双分支,右子树的双分支;
④NULL 0(递归边界)
上面双分支的+1操作是加上本次的,所以需要+1
- 由于是双分支还是单分支,导致递归式的变化。
//(题一)利用递归计算二叉树中所有双分支结点个数。
int Count(BiTree T) {int n1, n2;if (T == NULL) {//递归边界return 0;}else if (T->lchild != NULL && T->rchild != NULL) {n1 = Count(T->lchild);//递归求解左子树双分支结点个数,结果用 n1 接收 n2 = Count(T->rchild);return n1 + n2 + 1;}else {若不为空树,根结点也不为双分支结点,也就是叶子结点和单分支结点的情况n1 = Count(T->lchild);n2 = Count(T->rchild);return n1 + n2;}
}
09 (题二)利用递归计算二叉树中所有单分支结点个数。
- 单分支结点的分类及其处理
①双分支 n1+n2 看左子树的单分支,右子树的单分支;
②单分支(有左孩子没有右孩子或者有右孩子没有左孩子) n1+n2+1 看左子树的单分支,右子树的单分支,加上本身;
③叶子结点 n1+n2 看左子树的单分支,右子树的单分支;
④NULL 0
- 将上面的①和③合并到else中。
int Count_Simple_Node(BiTree T) {int n1, n2;if (T == NULL) {return 0;}if ((T->lchild && T->rchild == NULL) || (T->lchild == NULL && T->rchild)) {n1 = Count_Simple_Node(T->lchild);//递归求解左子树单分支结点个数,结果用 n1 接收n2 = Count_Simple_Node(T->rchild);return n1 + n2 + 1;}else {n1 = Count_Simple_Node(T->lchild);//递归求解左子树单分支结点个数,结果用 n1 接收n2 = Count_Simple_Node(T->rchild);return n1 + n2;}
}10 利用递归计算二叉树的深度。
- 定义两个变量用来接收左右子树的深度;
判断左右子树哪个更深,若左子树更深则树总深度为左子树深度+1(根也算一层) ,若右子树更深则树总深度为右子树深度+1(根也算一层) , 两棵子树高相等,既可以左子树+1,也可以右子树+1,这里的1就是根所在的一层,所以+1,可以自己模拟一下。
int Depth(BiTree T) {int ldep;int rdep;if (T == NULL) {return 0;}ldep = Depth(T->lchild);//递归求解左子树深度,结果用 ldep 接收rdep = Depth(T->rchild);//判断左右子树哪个更高,高的树加上根节点那一层if (ldep > rdep) {return ldep + 1;}else {return rdep + 1;}
}
11 设树 B 是一棵采用二叉链表形式存储的二叉树,编写一个把树 B 中所有结点的左、右子树进行交换的函数。
- 采用递归,改写先序递归遍历,根左右,每次将其左右孩子交换。
void Swap(BiTree &B){if(B!=NULL){BiTNode *temp=B->lchild;//定义 temp 辅助指针,辅助 B 左右子树交换,交换(指针域变换)B->lchild=B->rchild;B->rchild=temp;Swap(B->lchild);//递归处理左子树Swap(B->rchild);//递归处理右子树}
}
12 假设二叉树采用二叉链表存储结构,设计一个算法,求二叉树 T 中值为 x 的结点的层次号。
- 查找结点,要遍历,这里用先序遍历,这里多传了一个level参数,代表这个根当前所在层数;
- 这题不太同常规。
void Search_x_level(BiTree T, int x, int level) {//level是当前根节点所在的层次if (T != NULL) {if (T->data == x) {printf("x所处的层数为%d", level);}Search_x_level(T->lchild, x, level + 1);Search_x_level(T->lchild, x, level + 1);}
}
void Func(BiTree T, int x) {Search_x_level(T, x, 1);//初始时根所在层次为 1
}
思路2:先把结点分层,如结点1在第一层,结点2、3在第二层,结点4、5、6、7在第三层,然后查找值为x所在的层次。该思路感觉有点麻烦
13 请写出二叉树层次遍历算法。
- 由于层次遍历是按层来遍历,会跳结点,需要辅助**队列**(先进先出)
①先将根结点入队;
②出队,打印;
③lchild入队;
④rchild入队;
②③④循环
void LevelOrder(BiTree T) {Queue Q;//定义一个队列 QInitQueue(Q);//初始化队列 QBiTNode* p = T;//定义一个遍历指针 p,初始时指向根结点EnQueue(Q, p);//将根结点入队while (!IsEmpty(Q)) {//队列不为空则继续循环DeQueue(Q, p);//出队,并让 p 指向出队结点printf("%d", p->data);//打印出队结点数据域中的数据if (p->lchild != NULL) {EnQueue(Q, p->lchild);//若出队结点有左孩子,则让其左孩子入队}if (p->rchild != NULL) {EnQueue(Q, p->rchild);//若出队结点有右孩子,则让其右孩子入队}}
}
14 试写出二叉树的自下而上、从右到左的层次遍历算法。
- 层序遍历是从上到下,从左到右,也就是反转层序遍历。—
栈,当然还是需要用到队列,只是说先入栈,等到最后依次出栈打印。 - 打印:对栈依次出栈,打印(笔者刚开始用for循环,说明还是对栈与队列的基本操作不熟悉)
- 本题中,层次遍历在队列中的排序是结点从上到下,从左到右,而题目要求相反,因此猜测中间还做了一步额外的操作使得顺序颠倒,而栈刚好输入和输出相反(先进后出、后进先出),因此可以将每次出队结点进行压栈,到最后遍历栈即可。
- 本题代码和上题类似,只不过出队后打印,而是将其压栈,到最后队列为空,处理完每层结点后,对栈遍历打印。
- 注意打印操作需要出队或者出栈后,然后打印。
void ReverseLevelOrder(BiTree T) {Queue Q;//定义队列 QStack S;//定义栈 SInitQueue(Q);//初始化队列 QInitStack(S);//初始化栈 SBiTNode* p = T;//定义遍历指针 p,初始时指向根结点EnQueue(Q, p);//根结点入队while (!IsEmpty(Q)) {DeQueue(Q, p);Push(S, p);//将出队结点压入栈 S 中if (p->lchild) {EnQueue(Q, p->lchild);}if (p->rchild) {EnQueue(Q, p->rchild);}}//打印操作while (!IsEmpty(S)) {//栈不为空则继续循环Pop(S, p);//出栈,并让 p 指向出栈结点printf("%d", p->data);}
}
15 二叉树按二叉链表形式存储,写一个判别给定二叉树是否是完全二叉树的算法。
⭐⭐⭐⭐⭐
- 首先要知道什么是完全二叉树,完全二叉树它除了最后一层外,其他层的节点都是满的,并且最后一层的节点都尽可能地靠左排列。简单来说,完全二叉树是一个结构紧凑且平衡的二叉树。
- 该算法思想和层序遍历一样,定义一个遍历指针,指向根结点,然后入队。若队列不为空,出队,有左孩子,将左孩子入队,有右孩子,将右孩子入队,重复;
- 判断完全二叉树时候,将NULL也入队,因为完全二叉树结点在队列中是连续的,中间没有NULL的存在,而不是完全二叉树的话,在队列中,NULL结点后面还会有带值的结点在,导致结点在队列中不连续。通过这个可以判断是否为完全二叉树,也就是当我们遍历到NULL结点时候,我们可以将队列中的结点全部出队,如果非空结点存在,说明不是完全二叉树。
- 大家可以画个树和队列模拟一下过程。
int IsComplete(BiTree T) {if (T == NULL) {//空树是完全二叉树return 1;}Queue Q;//定义队列InitQueue(Q);BiTNode* p = T;//定义遍历指针p初始时指向根结点EnQueue(Q, p);//让根结点入队while (!IsEmpty(Q)) {DeQueue(Q, p);//出队并让 p 指向出队结点if (p != NULL) {//若 p 不为空EnQueue(Q, p->lchild);//让其左孩子入队(左孩子为空则入队 NULL)EnQueue(Q, p->rchild);//让其右孩子入队(右孩子为空则入队 NULL)}else {//p是空结点,队列中其后面的所有结点均应该是空结点,否则不符合完全二叉树while (!IsEmpty(Q)) {//队列不为空则需继续循环DeQueue(Q, p);//出队并让 p 指向出队结点if (p != NULL) {return 0;//若后续还有结点则不是完全二叉树}}}}return 1;//若队列中剩余数据都为 NULL 则证明是完全二叉树
}
16 二叉树采用二叉链表形式存储,设计一个算法完成:对于树中每个元素值为 x 的结点,删去以它为根的子树,并释放相应的空间。
①查找到元素为x的结点②如何删除以它为根的树,从下往上删除结点,因为如果从上往下,把根节点删了,无法定位其左右孩子结点的位置;- 查找元素为x的结点后,要将x与其父亲结点的链路断链,这里采用层序遍历,一层一层查找;
- 树为空、树的根节点的值就是x这两种情况算是特别情况,需要单独写出来,
- 正常查找过程中,先定义一个队列,然后将树的根节点入队,然后进行(判断队列是否为空,不为空则出队,左孩子入队,右孩子入队)循环,在左孩子入队和右孩子入队过程中,如果其值为x,直接调用DeleteTree函数,最后将其指针域置空,详见代码;
从下往上删除以T为根节点的树
- 改写后序递归遍历 ,左右根,也就是先去找左子树,然后去找右子树,最后处理根,最后递归下来,根节点是最后删除的。
//从下往上删除以T为根节点的树
void DeleteTree(BiTree& T) {if (T != NULL) {DeleteTree(T->lchild);DeleteTree(T->rchild);free(T);//释放结点空间}
}
查找元素为x的结点
- 当树的根节点就是要查找的x时候,直接调用DeleteTree()函数,最后写个return,表示可以结束运行了。
- 普通的层序遍历是,如果左右子树不为空,将其左右子树入队,而这里需要的是,如果左右子树不为空,判断其值是否等于x,如果等于,说明查找到了,需要删除,调用DeleteTree()函数,且这时候需要将该节点的左右指针域置空;如果不等于x,没找到则和普通操作一样。
//查找元素为x的结点
void SearchX(BiTree& T, int x) {if (T == NULL) {return;}if (T->data == x) {//删除整棵树也是这里的特殊情况,因为不需要做任何遍历查找DeleteTree(T);return;//函数执行结束}Queue Q;InitQueue(Q);BiTNode* p = T;EnQueue(Q, p);//入队while (!IsEmpty(Q)) {DeQueue(Q, p);//出队并让 p 指向出队结点if (p->lchild != NULL) {//左孩子判断if (p->lchild->data == x) {//如果p的左孩子的值=x,说明查找到了,删除DeleteTree(p->lchild);p->lchild = NULL;//指针域置空,因为删除函数只是对结点的删除}else {EnQueue(Q, p->lchild);//如果p的左孩子的值不是x,正常进行层次遍历}}if (p->rchild != NULL) {//右孩子判断if (p->rchild->data == x) {//如果p的左孩子的值=x,说明查找到了,删除DeleteTree(p->rchild);p->rchild = NULL;//指针域置空,因为删除函数只是对结点的删除}else {EnQueue(Q, p->rchild);//如果p的左孩子的值不是x,正常进行层次遍历}}}
}
17 二叉树采用二叉链表存储结构,设计一个非递归算法求二叉树的高度。
-
由于非递归求二叉树的高度,因此需要层次遍历,定义一个变量h,每遍历一层,h相应变化;
-
如何判断某一层遍历完了:定义last变量:指向每一层最后一个结点,假如每层最后一个结点处理完了,这一层也就处理完了,h可以变化了;
-
之前的题目都是调用队列的基本操作,这次不行了,这次研究的更细一些,需要进行更改;之前初始化时候,front和rear都是0。
-
但是在这里如果采用上面的方式,会导致rear指向每次结点的后一个位置,相当于错开了,而求二叉树高度定义的last变量需要和rear一起使用,因此这里我们初始化时将front和rear均指向-1,入队时,先rear+1,然后赋值入队,此时rear和结点没有错开。
-
这里判断==
队列==是否为空是front<rear,判断是否为每层最后一个节点是front == last,这里初始时,last=0,因为根节点先入队列,其下标也为0,且根节点也是第一层的最后一个元素,这样就保证了第一次根节点入队后,进入循环,根节点出队,此时front也是0,last也是0,使得h++、更新last。
int Depth(BiTree T) {if (T == NULL) {return 0;}int h = 0;//变量 h 用来记录高度int last = 0;//变量 last 用来记录每一层最右边结点位置 BiTNode* Q[MaxSize];//定义队列 Qint front = -1, rear = -1;//定义队头指针和队尾指针BiTNode* p = T;//定义遍历指针p初始时指向根结点Q[++rear] = p;//根结点入队 while (front < rear) {//队列不为空则继续循环 p = Q[++front];//出队,p 指向出队结点 if (p->lchild) {//若此结点有左孩子则让其左孩子入队 Q[++rear] = p->lchild;}if (p->rchild){//若此结点有右孩子则让其右孩子入队 Q[++rear] = p->rchild;}if (front == last) {//若二叉树其中一层的最右边结点出队 h++;//让高度加一 last = rear;//更新 last,使其指向下一层最右边结点位置 }}return h;//返回二叉树的高度
}
18 假设二叉树采用二叉链表存储结构,设计一个算法,求给定的二叉树的宽度。(宽度即树中具有结点数最多那一层的结点个数)
-
层次遍历二叉树;
-
这里记录结点属于哪一层时,定义一个新的数组专门用来记录每个结点所在层数;
-
层次遍历完后,得到的数组就是包含每个结点所在层数的记录,只需要遍历这个数组,找到哪一层的数最多,这样也就找到宽度以及其对应的层数。
-
举个例子:假设结点元素为
1
3 4
5 8 9 4
6
则数组中为1 2 2 3 3 3 3 4,说明宽度是4,因为第三层的结点个数是4。
int Width(BiTree T) {if (T == NULL)//若为空树则宽度为 0 return 0;BiTNode* Q[MaxSize];//定义队列 Q int front = 0, rear = 0;//定义队头指针和队尾指针 int level[MaxSize];//定义存储结点层数的数组 BiTNode* p = T;//定义遍历指针 p,初始时指向根结点 int k = 1;//定义变量 k 记录指针 p 指向结点所在的层数 ,初始时有结点,说明有高度,k从1开始,Q[rear] = p;//根结点入队 level[rear] = k;//记录根结点所在层数为 1 rear++;//尾指针后移 //遍历二叉树,目的是得到结点所在层数的数组while (front < rear) {//若队列不为空则需继续循环 p = Q[front];//出队并让 p 指向出队结点 k = level[front];//更新 k 为出队结点所在层数 ,p变了k也要变front++;//头指针后移 if (p->lchild) {//若出队结点有左孩子 Q[rear] = p->lchild;//将该结点左孩子入队level[rear] = k + 1;//新入队结点所在层数为 k+1 rear++;//尾指针后移 }if (p->rchild) {//若出队结点有右孩子 Q[rear] = p->rchild;//将该结点右孩子入队 level[rear] = k + 1;//新入队结点所在层数为 k+1 rear++;//尾指针后移 }}//查找最大的宽度int max = 0, i = 0, n;//定义 max 记录宽度,i 作为遍历索引,n 记录每一层结点数 k = 1;//k 用来表示所计数的是第几层,初始时等于 1 表示计数第一层 while (i < rear) {//遍历记录结点层数的数组 n = 0;//对每一层结点计数时都需初始化变量 n while (i < rear && level[i] == k) {//对第 k 层结点进行计数 n++;i++;}k++;//本层计数结束,更新变量 k,准备对下一层结点计数 if (n > max)//判断此层结点数是否为当前遍历过的最大宽度max = n;}return max;//返回此树的宽度
}
代码中,首先将根节点对应的数组元素设为1,相当于根节点在第一层,
19 请写出先序非递归遍历二叉树的算法。
- 递归用递归工作栈,非递归就自己定义栈;
- 先序(根->左->右),定义遍历指针 p,初始时指向根结点,打印,将结点压入栈(因为需要从左子树跳转到右子树,不用栈实现不了从左子树回到根再到右子树),处理左子树,左子树处理完了,才出栈,去处理右子树,
- 具体的讲就是和代码一样,若p指针不为空或者栈不为空,一直循环,如果栈为空,p指针不为空(最开始就是这种情况),入栈,遍历左子树,遍历多次,后来p指针为空,说明左子树遍历完了,就要通过出栈,找到右子树进行遍历;如果栈不为空,但是p指针为空,说明多次压栈,到叶子结点的左右孩子结点处,因此需要通过出栈找到上一层的右子树;最后p为NULL栈为空,说明遍历结束了。
- 这类题目的循环条件注意刚开始的时候,到叶子结点的时候及其左右空子树的时候。
void PreOrder(BiTree T) {Stack S;//定义一个栈 S InitStack(S);//初始化栈 S BiTNode* p = T;//定义遍历指针 p,初始时指向根结点 while (p || !IsEmpty(S)) {//若 p 指针不为空或栈 S 不为空则继续循环 if (p != NULL) {//若 p 指针不为空 printf("%d", p->data);//打印此结点数据域中的数据值 Push(S, p);//将此结点压入栈 S 中 p = p->lchild;//遍历指针 p 继续遍历此结点的左子树 }else {Pop(S, p);//若 p 为空则出栈,并让 p 指向出栈结点 p = p->rchild;//p 继续遍历此结点的右子树 }}
}
20 请写出中序非递归遍历二叉树的算法。
- 中序(左->根->右),遍历左子树后回到根,需要栈帮助;
- 由于先左子树,然后根,因此先将结点入栈,等到左子树全部处理完,也就是p为NULL时候,,需要出栈,该元素就是根结点,然后打印,去到右子树那边去。
- 先一直处理左子树,当左子树结点为空时候,此时栈不为空,说明没有左子树了,返回到根,打印,处理右结点;到最后p为空、栈为空,结束。
- p到达叶子结点的左结点时候,p指向NULL,此时需要出栈,也就是中序中的左->根,并让 p 指向出栈结点,此时p指向的就是根节点。
void InOrder(BiTree T) {Stack S;InitStack(S);BiTNode* p = T;while (p || !IsEmpty(S)) {if (p != NULL) {Push(S, p);//将所处理结点压入栈中p = p->lchild;//p 继续遍历此结点左子树}else {Pop(S, p);//若 p 指针为空,则出栈,并让 p 指向出栈结点printf("%d", p->data);p = p->rchild;//遍历指针 p 继续遍历此结点的右子树}}
}
21 请写出后序非递归遍历二叉树的算法。
⭐⭐⭐⭐⭐
- 后序(左右根),左子树处理完需要处理右子树,这时候需要通过栈来实现,但是这又出现一个问题,左子树到右子树,需要到根,而右子树处理完,也要到根,这两个都可能需要到根结点处,需要区分(左子树处理完,需要通过根结点遍历访问到右子树;右子树处理完,需要到根,打印,这两个的原因不同,因此需要不同情况处理),因此定义一个r指针负责记录上一个打印的结点位置
- else分支的意思是,在p指向空的时候,其根结点有没有右孩子,以及根节点的这个右孩子有没有处理过,分情况处理。
- 此外,else处的意思:在p指向空时候,需要出栈,p指向出栈结点,使得此时p就是根节点,然后进行操作,但是这是前序和中序非递归的思想,对于后续非递归算法,由于左右子树均有到根结点的情况,需要分情况讨论,如果只是左子树需要通过根跳转到右子树的情况,我们就不用出栈,而是需要到右子树,等右子树处理完在打印根节点;而如果是右子树跳转到根了,说明需要打印,此时出栈打印,此时更新记录指针r,表示该节点是最近一次遍历打印过了。由上面是否出栈的情况,因此这里使用栈的GetTop()函数用来获取栈顶元素,方便判断该节点是否存在右孩子且右孩子是否被遍历访问过。
- 前序和中序非递归算法不用判断p->rchild是否为NULL,因为它们都是每次循环的最后一步,到下一次循环时候,循环条件会判断p是否为NULL,而后续非递归涉及到右子树是否被遍历过,因此需要判断是否存在右子树。
void PostOrder(BiTree T) {Stack S;InitStack(S);BiTNode* p = T;BiTNode* r = NULL;while (p || !IsEmpty(S)) {if (p != NULL) {Push(S, p);//先压栈,然后去到左子树那里p = p->lchild;}else {GetTop(S, p); if ((p->rchild != NULL)&&(p->rchild!=r)) {//有右孩子且右孩子没有被访问过,左->右p = p->rchild;}else {//若结点没有右子树或者右子树已被遍历过,右->根Pop(S, p);printf("%d", p->data);r = p;//更新记录指针 }}}
}
模拟一下,发现有问题,左下角的叶子结点处理后会陷入死循环,其原因是p到达左下角叶子结点时候,p!=NULL,此时p去到叶子结点的左孩子那,此时p=NULL,进入else中,p回到叶子结点处,且若没有右子树,会出栈,打印,然后更新记录指针,此时都没有变化p,使得p!=NULL,从而陷入循环了,下面代码在每次更新记录指针后,将遍历指针p置空
void PostOrder(BiTree T) {Stack S;//定义栈 S InitStack(S);//初始化栈 S BiTNode* p = T;//定义遍历指针 p,初始时指向根结点 BiTNode* r = NULL;//定义记录指针 r,负责记录上一个打印的结点位置 while (p || !IsEmpty(S)) {//若 p 指针不为空或栈不为空则继续循环 if (p != NULL) {//若 p 指针不为空 Push(S, p);//将所处理结点压入栈中 p = p->lchild;//p 继续遍历此结点左子树 }else {GetTop(S, p);//若 p 指针为空则 p 指向栈顶结点 if (p->rchild && p->rchild != r)//判断此结点是否有右孩子以及是否遍历 p = p->rchild;//若结点有右孩子且未被遍历则 p 继续遍历其右子树 else {//若结点没有右子树或者右子树已被遍历过 Pop(S, p);//出栈,并让 p 指向其出栈结点 printf("%d", p->data);//打印此结点数据域中的数据 r = p;//更新记录指针 p = NULL;//将遍历指针置空 }}}
}
对于后续非递归遍历算法,当你遍历打印某个结点时,栈中的结点就是该结点的根,也就是遍历某个结点时候栈中的元素都是其祖先,后续打印某结点的祖先结点,打印根节点到某结点的路径,都是后续非递归遍历算法的改写。
22 在二叉树中查找值为 x 的结点,试编写算法打印值为 x 的结点的所有祖先,假设值为 x 的结点不多于一个。
- 后序非递归遍历,栈里面的就是x及其所有祖先结点,因此写这类求祖先结点,实质就是写后序遍历的非递归版本,只是将打印操作变成判断值是否为x,相等则出栈打印其祖先结点。
void Search_x_father(BiTree T,int x) {Stack S;InitStack(S);BiTNode* p = T;BiTNode* r = NULL;while (p || !IsEmpty(S)) {if (p != NULL) {Push(S, p);p = p->lchild;}else {GetTop(S, p);//p 指向栈顶结点但不出栈if (p->rchild && p->rchild != r) {//若该结点有右子树且未被访问p = p->rchild;}else {//若该结点无右子树或者右子树已经被访问Pop(S, p);//出栈并让 p 指向出栈结点if (p->data == x) {//是我们要找的值while (!IsEmpty(S)) {//打印栈中的元素Pop(S, p);//出栈并让 p 指向出栈结点printf("%d", p->data);}}else {//不是我们要找的值r = p;//更新记录指针位置p = NULL;//将指针 p 置空进行下一次循环判断}}}}
}
23 p 和 q 分别为指向一棵二叉树中任意两个结点的指针,试编写算法找到p 和 q 最近公共结点并返回。
- 思路就是分别找两个结点的所有祖先节点,然后比较,这里采用后序非递归遍历(每次遍历过程中,栈中的元素就是该结点的所有祖先);
- 具体就是先找到p或者q(谁先找到都没事),找到后将栈中内容复制一份到新创建的栈1,然后继续找还没找到的p/q,然后找到后再复制一份内容到新创建的栈2,因为涉及到栈的复制,因此这里使用数组,方便复制(使用标准的栈需要出入栈,比较复杂,数组复制就使用一个for循环就好);
- 注意这里是查找公共结点并返回,因此函数类型需要注意。
- 后序非递归执行完后,需要找最近公共结点(从下往上,从叶子结点到最祖先节点)
- 复制栈后别忘了更新栈顶指针。
BiTNode* FindAncestor(BiTree T, BiTNode* p, BiTNode* q) {BiTNode* bt = T;BiTNode* r = NULL;//定义三个栈,因为要复制BiTNode* S[MaxSize];BiTNode* S1[MaxSize],* S2[MaxSize];int top = -1, top1 = -1, top2 = -1;int temp;//复制元素时使用while (bt || top!=-1) {//栈不为空if (bt != NULL) {S[++top] = bt;//入栈bt = bt->lchild;}else {//若遍历指针为空bt = S[top];//bt 指向栈顶结点但不出栈if (bt->rchild && bt->rchild != r) {//若该结点有右孩子且未被访问bt = bt->rchild;//bt 遍历该结点右子树}else {//若该结点没有右孩子或者右孩子已经被访问bt = S[top];top--;//出栈bt指向出栈结点if (bt == p) {//如果该节点是p结点,复制栈S到栈S1for (temp = 0; temp <= top; temp++) {S1[temp] = S[temp];}top1 = top;//更新 S1 栈顶指针}if (bt == q) {for (temp = 0; temp <= top; temp++) {S2[temp] = S[temp];}top2 = top;}//更新r和btr = bt;//更新记录指针bt = NULL;//bt 指针置空}}}//查找最近公共结点for (int i = top1; i >= 0; i--) {for (int j = top2; j >= 0; j--) {if (S1[i] == S2[j]) {return S1[i];//若找到即返回指向最近公共结点的指针变量 }}}return NULL;
}
24 假设一棵二叉树以二叉链表存储方式存储,请设计一个算法,输出根结点到每个叶子结点的路径。
- 输出路径也使用后序非递归遍历,定义辅助栈S,这里判断一下每次的结点是不是叶子节点;
- 由于这里需要输出根节点到每个叶子结点的路径,如果采用伪代码中调用栈的话,每次打印路径需要出栈,打印,出栈,打印,比较麻烦,此外,由于是根->叶子结点,在栈中是从下往上打印,因此可以定义数组类型的栈,方便遍历打印(for循环从下标0处开始打印就是从下网上打印);
- 这里定义的栈存储的元素是结点类型,有data域,因此代码第23行为S[i]->data,且需要打印叶子结点(因为这个结点是先出栈,然后打印的,栈中只有其祖先结点);
- 这类题目首先看是后续非递归遍历的体型,因此一般是19行开始,最内部的else的代码的改写,因为进入这个循环才要准备对结点进行相关操作了,在此之前的都是为了让其进入对应的“路”。
void AllPath(BiTree T) {//改写后序非递归遍历BiTNode* p = T;BiTNode* r = NULL;//定义遍历指针 p,记录指针 rBiTNode* S[MaxSize];//定义栈 Sint top = -1;//定义栈顶指针while (p != NULL || top != -1) {if (p != NULL) {S[++top] = p;//让 p 所指结点入栈 p = p->lchild;}else {p = S[top];//p 指向栈顶结点但不出栈 if (p->rchild && p->rchild != r) {//若 p 所指结点有右子树且未被访问 p = p->rchild;}else {p = S[top--];//出栈,并让 p 指向其出栈结点if (p->lchild == NULL && p->rchild == NULL) {for (int i = 0; i <= top; i++) {printf("%d", S[i]->data);//打印栈中所有结点数据}printf("%d", p->data);//打印此叶子结点数据}r = p;//更新记录指针 r p = NULL;//将 p 指针置空 }}}
}
25 设计一个算法将二叉树的叶子结点按从左到右的顺序连成一个单链表,表头指针为 head。二叉树按二叉链表方式存储,链接时用叶子结点的右指针域来存放单链表指针。
- 从左到右链接,头指针head指向最左边的叶子节点;
- 少不了遍历,先序(根左右)中序(左根右)后序(左右根),不看根的位置,这三种发现都是以左->右遍历的,因此这三种遍历方式遍历叶子结点都可以,这里通过改写中序遍历(左根右);
- 由题意,先定义一个表头指针head,然后由于需要将叶子结点链接起来,需要定义一个pre指针,指向最近已经链接的叶子结点(记录上一次遍历到的叶子结点),若新找到叶子结点,可以用pre->rchild=新找到的叶子结点,然后更新pre指针;
- 判断是否是第一个叶子结点可以判断pre是否为NULL。
BiTNode* head = NULL, * pre = NULL;//定义头指针 head 和记录指针 pre
void Link(BiTree& T) {if (T != NULL) {//改写中序递归遍历算法 Link(T->lchild);//递归遍历左子树//判断此结点为叶子结点 if (T->lchild == NULL && T->rchild == NULL) {if (pre == NULL) {//判断此结点是否为访问到的第一个叶子结点 head = T;//若为第一个叶子结点则让头指针 head 指向它 pre = T;//pre 负责记录上一次处理的叶子结点,所以进行更新 }else {//若此结点不是第一个叶子结点 pre->rchild = T;//直接让上一个访问的叶子结点指向此结点 pre = T;//更新 pre 指针位置 }}Link(T->rchild);//递归遍历右子树 }
}
26 表达式(a-(b+c))*(d/e)存储在如下图所示的一棵以二叉链表为存储结构的二叉树中(二叉树结点的 data 域为字符型),编写程序求出该表达式的值。(表达式中的操作数都是一位的整数)
说明:函数 int op(int A,int B,char C)返回的是以 C 为运算符,以 A、B 为操作数的算式的数值,例如,若 C 为‘+’,则返回 A+B 的值。

- 表达式中包括操作数和运算符,叶子结点都是操作数,双分支结点是操作符,对于双分支结点,采用递归方式求其左右子树的值,对于叶子结点(结点的data域是字符型,如’0’‘1’‘2’,不能直接参与计算,计算机存的是ASCII码,将字符型转化为整型,可以采用将其对应的ASCII码减去’0’的ASCII码),然后return就是对应的0-9的数字;
- 递归方式,将其分为左右子树,分别计算,调用op函数;
int Compute(BiTree T) {if (T == NULL) {return 0;}int A, B;//定义两个变量分别接受左右子树计算的结果if (T->lchild != NULL && T->rchild != NULL) {//若结点为双分支结点 A = Compute(T->lchild);//递归计算左子树的值并用 A 接收 B = Compute(T->rchild);//递归计算右子树的值并用 B 接收 return op(A, B, T->data);//计算左右子树运算结果并返回 }else {//若结点为叶子结点 return T->data - '0';//将字符型变量转换为数值(ASCII 码)return T->data是错的 }
}
27 试设计判断两棵二叉树是否相似的算法。所谓二叉树 T1 和 T2 相似,指的是 T1 和 T2 都是空的二叉树或都只有一个根结点;或者 T1 的左子树和 T2 的左子树是相似的,且 T1 的右子树和 T2 的右子树是相似的。
- 这题的相似指的是,不管数据如何,只管二叉树的结构是否相同;
- 使用递归,分别判断左右子树是否相似;
- 递归边界:这里给出两个,两棵树都为空,相似,一棵树为空、另一棵树不为空,说明不相似。
int Similar(BiTree T1, BiTree T2) {//结点结构一样即为相似 定义两个变量分别用于接收左右子树是否相似 int left, right;if (T1 == NULL && T2 == NULL) {return 1;}else if (T1 == NULL || T2 == NULL) {return 0;}else {//递归式left = Similar(T1->lchild, T2->lchild);//递归判断两棵树左子树是否相似 right = Similar(T1->rchild, T2->rchild);//递归判断两棵树右子树是否相似 //return left && right;//若左右子树都相似则两棵树相似,返回 1 if (left == 1 && right == 1) {return 1;//相似}else {return 0;}}
}
28 在二叉树的二叉链表存储结构中,增加一个指向双亲结点的 parent 指针,设计一个算法,给这个指针赋值,并输出所有结点到根结点的路径。
- 修改原先树结点的结构体,增加parent指针,然后赋值,最后输出所有结点到根结点的路径。
- 赋值时,采用先序遍历(根左右),先处理根,然后在左右结点,因此可以较好的从孩子结点-父亲结点,定义一个q指针,每次让结点的parent指针指向q,就实现了赋值;但是代码中,需要注意的是根结点没有双亲结点,需要将其置空,且初始时应该为空,因此调用Func()函数时候,传入的参数应该为NULL;
- 输出所有结点到根结点的路径,可以先写一个结点到根节点的路径的函数,然后对所有结点(遍历)调用该函数。
- 根节点的parent置空,这是判断循环结束的条件;
- 遍历树的时候,可以采用任何遍历方式,因为只要遍历就行。
typedef struct BiTNode {int data;struct BiTNode* lchild;struct BiTNode* rchild;struct BiTNode* parent;
}BiTNode,*BiTree;
//对parent指针赋值
void Func(BiTree& T, BiTNode* q) {//指针 q 用来记录T的双亲结点 if (T != NULL) {//改写先序递归遍历 T->parent = q;//遍历结点的 parent 指针指向双亲结点 q = T;//更新指针 q 的位置 Func(T->lchild, q);//递归遍历左子树 Func(T->rchild, q);//递归遍历右子树 }
}
//打印单个结点到根结点的路径
void PrintPath(BiTNode* p) {while (p != NULL) {//只要 p 不为空则继续循环 printf("%d", p->data);//打印结点数据域中数据 p = p->parent;//p 顺着 parent 指针遍历 }
}
//打印所有结点到根结点的路径
void AllPath(BiTree T) {if (T != NULL) {//只要 p 不为空则继续循环 PrintPath(T);//打印所处理结点到根结点路径 AllPath(T->lchild);//递归遍历左子树 AllPath(T->rchild);//递归遍历右子树 }
}
29 有一棵二叉树以顺序存储的方式存在一维数组 A 中,树中结点存储数据为字符型,空指针域在数组中以字符’#'表示,请设计一个算法将其改为二叉链表的存储方式。(假设数组 A 中元素个数为 n,从下标1处开始存储)
- 普通二叉树存在数组中,需要将二叉树补成完全二叉树,题目中给出NULL指针域用#表示;
- 二叉链表由左指针域,数据域,右指针域,由于这里是下标为1开始,数组下标和结点存在关系,根结点下标为i,左孩子结点位置为2i,右孩子节点位置2i+1;
- 函数类型BiTree,每次创建完新的结点后,返回新创建结点的位置;
- 为何会涉及到i>n呢,比如当i是5时候,进入下次递归,去它左子树处,此时i=10>n,因此返回NULL。

BiTree Create(char A[], int i, int n) {//i 为索引,n 为数组中元素个数 if(i>n||A[i]=='#'){return NULL;//若 i≥n 则代表后续已无结点则返回 NULL }else{//只有 i<n 才有意义 BiTNode* p = (BiTNode*)malloc(sizeof(BiTNode));//申请内存空间 p->data = A[i];//给结点数据域赋值 p->lchild = Create(A, 2*i, n);//递归处理左子树 p->rchild = Create(A, 2*i+1, n);//递归处理右子树 return p; //返回结点位置}
}
30 设一棵二叉树中各结点的值互不相同,其先序遍历序列和中序遍历序列分别存于两个一维数组 A[1…n]和 B[1…n]中,试编写算法建立该二叉树的二叉链表。
先序:ABCDE
中序:BCAED
建立的二叉树如下:
A
B D
NULL C E NULL
-
写代码时,和我们自己手动确定二叉树结构类似,拿到先序和中序序列时候,先找到先序递归遍历的第一个结点,该结点是整棵树的根结点,此时确定好整棵树的根节点了,可以创建该节点,然后在中序遍历序列中找到这个根节点,将序列分为左右两块,也就是左子树和右子树;
-
先序遍历序列(根左右)和中序遍历序列(左根右)可以确定唯一的二叉树,且先序遍历序列的第一个结点是整棵树的根结点;
-
需要在中序遍历序列中将结点分为左右两块;
-
代码中low和high指的是数组中最左边和最右边是谁,根节点确定好后,B数组也需要到根结点处,方便后续将树分为左子树和右子树,因此有个for循环;
-
由于题目中数组下标从1开始,因此记录左右子树结点个数 llen = i - low2;rlen = high2 - i
-
递归创建左子树时候(左半段),对于A数组,最开始的是根,在递归时需要排出(已经使用过了),结束位置是low1 + llen,这里不是low1+1 + llen(可以自己动手试一试)对于B数组,最开始的就是最左边的,结束位置是根节点前一个
p->lchild = Create(A, low1 + 1, low1 + llen, B, low2, low2 + llen - 1); -
递归创建右子树时,同样可以自己模拟一下哦
BiTree Create(char A[], int low1, int high1, char B[], int low2, int high2) {BiTNode* p = (BiTNode*)malloc(sizeof(BiTNode));//给根结点分配内存空间p->data = A[low1];//为根结点数据域赋值int i;//定义变量 i,记录中序序列中根结点的位置for (i = low2; B[i] != p->data; i++);//循环使变量 i 指向中序序列中根结点的位置int llen = i - low2;//llen 记录左子树结点个数int rlen = high2 - i;//rlen 记录右子树结点个数if (llen) {//若左子树有结点则递归创建左子树p->lchild = Create(A, low1 + 1, low1 + llen, B, low2, low2 + llen - 1);}else {//若左子树已无结点则让其左指针域赋 NULLp->lchild = NULL;}if (rlen) {//若右子树有结点则递归创建右子树p->rchild = Create(A, high1 - rlen + 1, high1, B, high2 - rlen + 1, high2);}else {//若右子树已无结点则让其右指针域赋 NULLp->rchild = NULL;}return p;//最后返回所创建树的根结点
}
31 设有一棵满二叉树(所有结点值均不同),已知其先序序列为 pre,设计一个算法求其后序序列 post。
- 先序序列的第一个结点,就是根节点,也是后序序列的最后一个结点;
- 满二叉树特点:如果不看根节点,其左右子树的结点数量是一样的,可以将除根节点以外的结点一分为二,然后分出来的两块,左边的就是左子树,右边的就是右子树,然后递归。
- l1和h1是先序序列最左边的位置和最右边的位置(所有h1>=l1时才有意义),l2和h2是后序序列最左边的位置和最右边的位置(所有h1>=l1时才有意义)
- 代码中给post数组赋值的根节点的操作。
void PreToPost(char pre[], int l1, int h1, char post[], int l2, int h2) {int half;//定义 half 变量记录左子树(右子树)结点个数if (h1 >= l1) {//h1≥l1 才有意义(先序遍历)post[h2] = pre[l1];//后序序列最后一个即为根结点,也就是先序序列第一个half = (h1 - l1) / 2;//因为是满二叉树,所以左右子树结点个数相等PreToPost(pre, l1 + 1, l1 + half, post, l2, l2 + half - 1);//递归处理左子树PreToPost(pre, l1 + 1 + half, h1, post, l2 + half, h2 - 1);//递归处理右子树}
}
/llen 记录左子树结点个数
int rlen = high2 - i;//rlen 记录右子树结点个数
if (llen) {//若左子树有结点则递归创建左子树
p->lchild = Create(A, low1 + 1, low1 + llen, B, low2, low2 + llen - 1);
}
else {//若左子树已无结点则让其左指针域赋 NULL
p->lchild = NULL;
}
if (rlen) {//若右子树有结点则递归创建右子树
p->rchild = Create(A, high1 - rlen + 1, high1, B, high2 - rlen + 1, high2);
}
else {//若右子树已无结点则让其右指针域赋 NULL
p->rchild = NULL;
}
return p;//最后返回所创建树的根结点
}
##### 31 设有一棵满二叉树(所有结点值均不同),已知其先序序列为 pre,设计一个算法求其后序序列 post。1. 先序序列的第一个结点,就是根节点,也是后序序列的最后一个结点;
2. ==**满二叉树特点**:如果不看根节点,其左右子树的结点数量是一样的==,可以将除根节点以外的结点一分为二,然后分出来的两块,左边的就是左子树,右边的就是右子树,然后递归。
3. l1和h1是先序序列最左边的位置和最右边的位置(所有h1>=l1时才有意义),l2和h2是后序序列最左边的位置和最右边的位置(所有h1>=l1时才有意义)
4. 代码中给post数组赋值的根节点的操作。~~~cpp
void PreToPost(char pre[], int l1, int h1, char post[], int l2, int h2) {int half;//定义 half 变量记录左子树(右子树)结点个数if (h1 >= l1) {//h1≥l1 才有意义(先序遍历)post[h2] = pre[l1];//后序序列最后一个即为根结点,也就是先序序列第一个half = (h1 - l1) / 2;//因为是满二叉树,所以左右子树结点个数相等PreToPost(pre, l1 + 1, l1 + half, post, l2, l2 + half - 1);//递归处理左子树PreToPost(pre, l1 + 1 + half, h1, post, l2 + half, h2 - 1);//递归处理右子树}
}
相关文章:
数据结构例题代码及其讲解-递归与树
树 树的很多题目中都包含递归的思想 递归 递归包括递归边界以及递归式 即:往下递,往上归 递归写法的特点:写起来代码较短,但是时间复杂度较高 01 利用递归求解 n 的阶乘。 int Func(int n) {if (n 0) {return 1;}else …...

Jenkins | 流水线构建使用expect免密交互时卡住,直接退出
注意: expect 脚本必须以 interact 或 expect eof 结束。 原因: interact:使用interact会保持在终端而不会退回到原终端,所以就卡在这里。 expect eof:expect脚本默认的是等待10s,当执行完命令后,自动切回…...

git修改默认分支
git checkout 分支 切换到当前分支 git branch --set-upstream-toorigin/complete(远程分支名) 设置当前分支的上游分支为远程分支complete git branch --unset-upstream master 取消master上游分支的身份 现在,使用git commit,git push 命令可以直接…...
Android Studio开发入门教程:如何更改APP的图标?
更改APP的图标(安卓系统) 环境:Windows10、Android Studio版本如下图、雷电模拟器。 推荐图标库 默认APP图标 将新图标拉进src/main/res/mipmap-hdpi文件夹(一般app的icon图标是存放在mipmap打头的文件夹下的) 更改sr…...

MATLAB/Python的编程教程: 匹配滤波器的实现
MATLAB/Python的编程教程: 匹配滤波器的实现 注1:本文系“MATLAB/Python的编程教程”系列之一,致力于使用Python和Matlab实现特定的功能。本次要实现的功能是:匹配滤波器的实现。 匹配滤波器,这是一个在信号处理领域常见的主题,主要用于增强特定信号的检测性能,特别是在噪…...
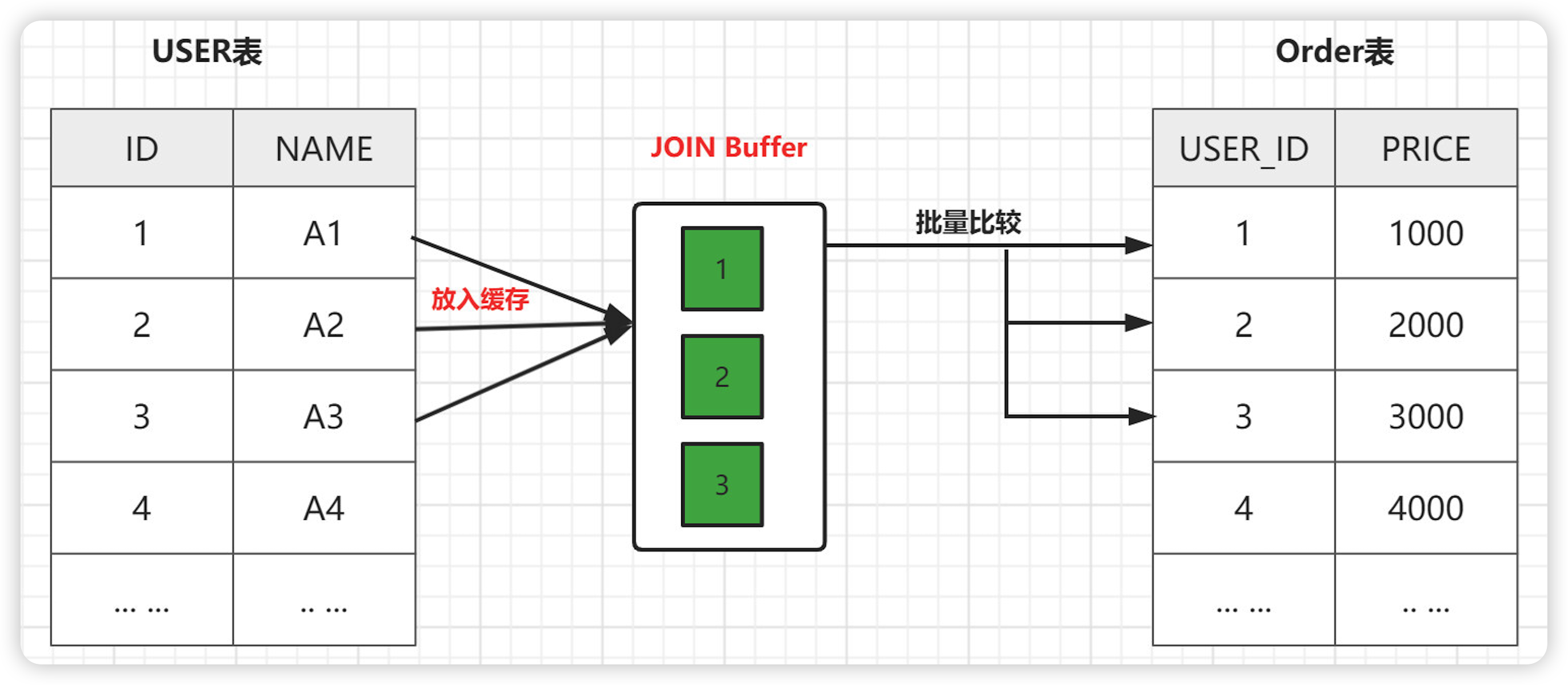
java八股文面试[数据库]——JOIN优化
JOIN 是 MySQL 用来进行联表操作的,用来匹配两个表的数据,筛选并合并出符合我们要求的结果集。 JOIN 操作有多种方式,取决于最终数据的合并效果。常用连接方式的有以下几种: 什么是驱动表 ? 多表关联查询时,第一个被处理的表就是驱动表,使用…...
Java语法中一些需要注意的点(仅用于个人学习)
1.当字符串和其他类型相加时,基本都是字符串,这与运算顺序有关。 2.Java中用ctrl d 来结束循环输入。 3.nextLine() 遇到空格不会结束。 4.方法重载 4.1. 方法名必须相同 4.2. 参数列表必须不同(参数的个数不同、参数的类型不同、类型的次序必须不…...

golang 线程 定时器 --chatGPT
问:线程函数write(ch,timer),功能为启动一个线程,循环执行打印,打印条件为触发ch chane 或 timer定时器每隔一段时间会触发 GPT:以下是一个示例Golang代码,其中有一个名为 write 的线程函数,它会在触发ch通道或每隔一…...

java 编程 7个简单的调优技巧
你的Java性能调优有救了!分享7个简单实用的Java性能调优技巧 一、以编程方式连接字符串 在Java中有很多不同的连接字符串的选项。比如,可以使用简单的或、良好的旧StringBuffer或StringBuilder。 那么,应该选择哪种方法? 答案取…...

03-Dockerfile
Dockerfile简介 Dockerfile是什么? Dockerfile是用来构建Docker镜像的文本文件,是由一条条构建镜像所需的指令和参数构成的脚本 Dockerfile官网 https://docs.docker.com/engine/reference/builder/ Dockerfile构建三步曲 编写Dockerfile文件docke…...

【AI】机器学习——朴素贝叶斯
文章目录 2.1 贝叶斯定理2.1.1 贝叶斯公式推导条件概率变式 贝叶斯公式 2.1.2 贝叶斯定理2.1.3 贝叶斯决策基本思想 2.2 朴素贝叶斯2.2.1 朴素贝叶斯分类器思想2.2.2 条件独立性对似然概率计算的影响2.2.3 基本方法2.2.4 模型后验概率最大化损失函数期望风险最小化策略 2.2.5 朴…...

数学建模:模糊综合评价分析
🔆 文章首发于我的个人博客:欢迎大佬们来逛逛 数学建模:模糊综合评价分析 文章目录 数学建模:模糊综合评价分析综合评价分析常用评价方法一级模糊综合评价综合代码 多级模糊综合评价总结 综合评价分析 构成综合评价类问题的五个…...

智能小车—PWM方式实现小车调速和转向
目录 1. 让小车动起来 2. 串口控制小车方向 3. 如何进行小车PWM调速 4. PWM方式实现小车转向 1. 让小车动起来 电机模块开发 L9110s概述 接通VCC,GND 模块电源指示灯亮, 以下资料来源官方,具体根据实际调试 IA1输入高电平,…...

Getx其他高级API
// 给出当前页面的args。 Get.arguments//给出以前的路由名称 Get.previousRoute// 给出要访问的原始路由,例如,rawRoute.isFirst() Get.rawRoute// 允许从GetObserver访问Rounting API。 Get.routing// 检查 snackbar 是否打开 Get.isSnackbarOpen// 检…...

npm/yarn link 测试包时报错 Warning: Invalid hook call. Hooks can only be called ...
使用 dumi 开发 React 组件库时,为避免每次修改都发布到 npm,需要在本地的测试项目中使用 npm link 为组件库建立软连接,方便本地调试。 结果在本地测试项目使用 $ npm link 组件库 后,使用内部组件确报错: react.dev…...
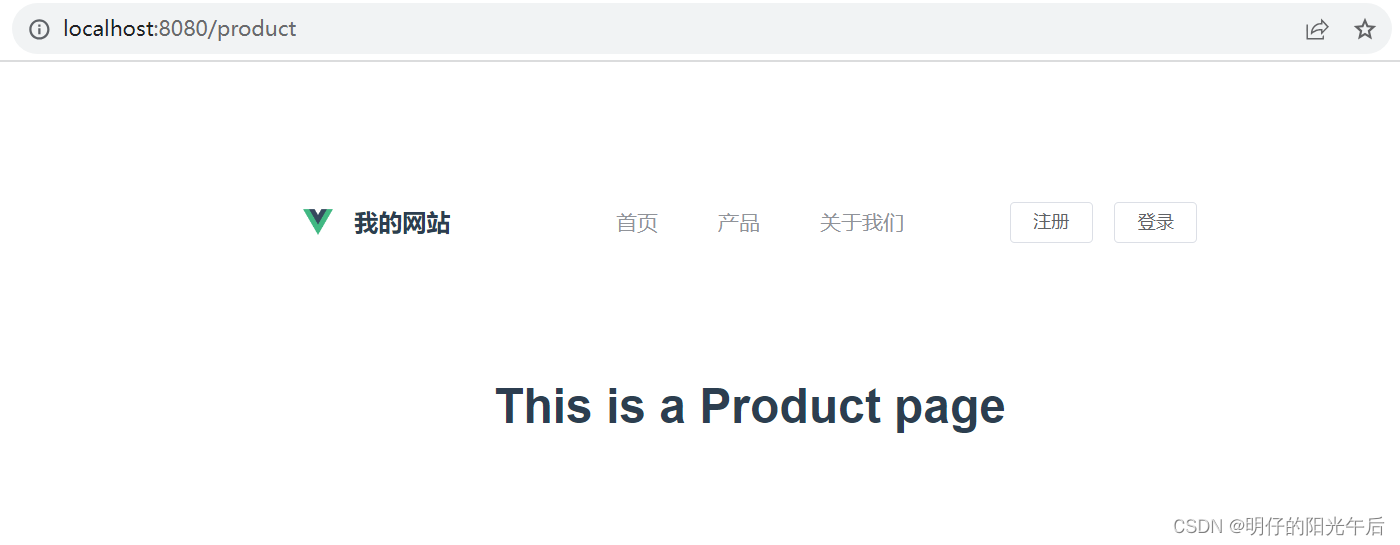
「网页开发|前端开发|Vue」06 公共组件与嵌套路由:让每一个页面都平等地拥有导航栏
本文主要介绍在多个页面存在相同部分时,如何提取公共组件然后在多个页面中导入组件重复使用来减少重复代码。在这基础上介绍了通过嵌套路由的方式来避免页面较多或公共部分较多的情况下,避免不断手动导入公共组件的麻烦,并且加快页面跳转的速…...

leetcode687. 最长同值路径(java)
最长同值路径 题目描述DFS 深度遍历代码演示 题目描述 难度 - 中等 LC - 687. 最长同值路径 给定一个二叉树的 root ,返回 最长的路径的长度 ,这个路径中的 每个节点具有相同值 。 这条路径可以经过也可以不经过根节点。 两个节点之间的路径长度 由它们之…...
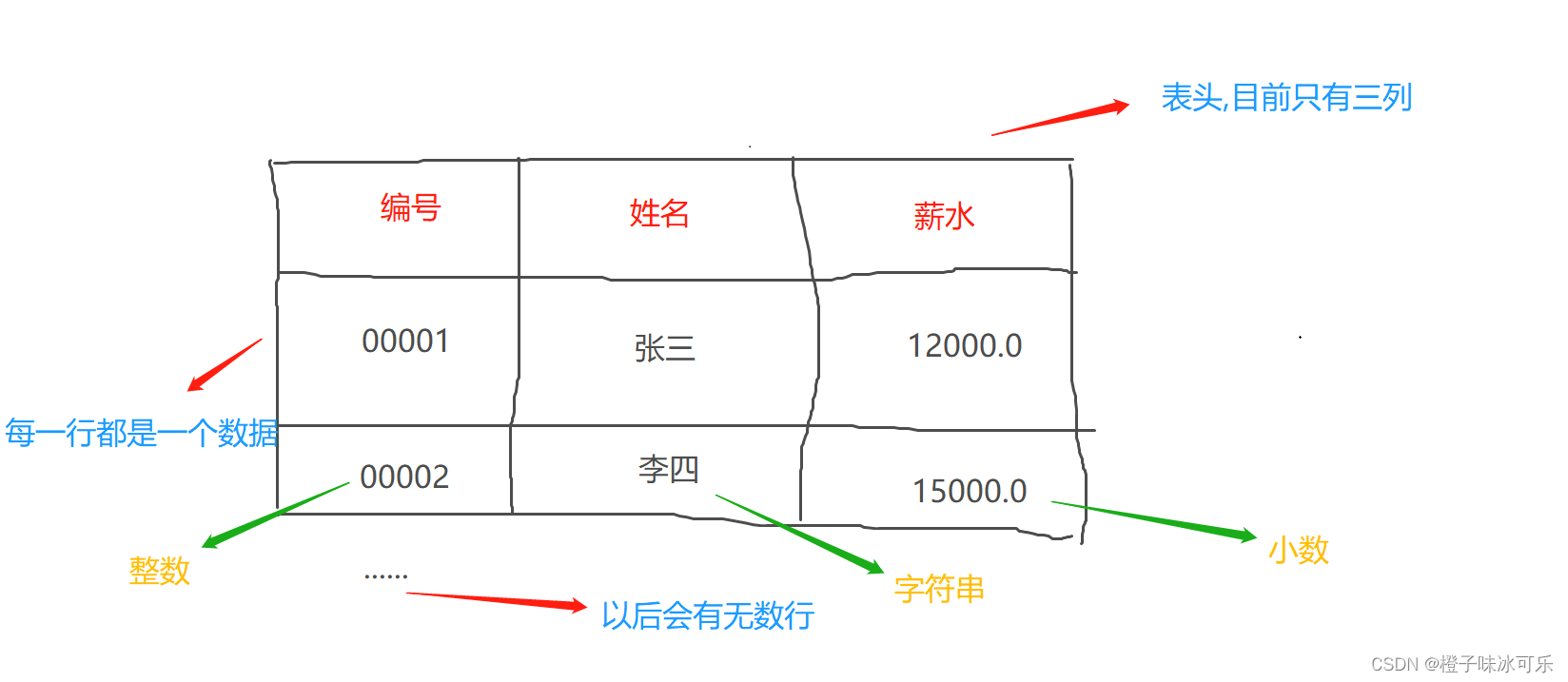
MySQL的常用术语
目录 1.关系 2.元组 3.属性 MySQL从小白到总裁完整教程目录:https://blog.csdn.net/weixin_67859959/article/details/129334507?spm1001.2014.3001.5502 1.关系 前面的博客有说到,MySQL是一款关系型数据库管理软件,一个关系就是 一张二维表(表) 我想大家都知道表格怎么…...
机器学习的特征工程
字典特征提取 def dict_demo():"""字典特征提取:return:"""data [{city: 北京, temperature: 100}, {city: 上海, temperature: 60}, {city: 深圳, temperature: 30}]# data [{city:[北京,上海,深圳]},{temperature:["100","6…...
python3 修改nacos的yaml配置
一、安装nacos库 pip install nacos-sdk-python 二、代码如下 import nacos import yaml# 连接地址 NACOS_SERVER_ADDRESSES "192.168.xx.xx" NACOS_SERVER_PORT 替换为你的端口号,如8848# 命名空间 NACOS_NAMESPACE "your_namespace"# 账…...

CCPD车牌数据集预处理避坑指南:透视变换原理详解与OpenCV实战
CCPD车牌数据集预处理避坑指南:透视变换原理详解与OpenCV实战 车牌识别系统中,数据预处理的质量直接影响模型性能。CCPD作为目前最全面的中文车牌数据集,其四点标注特性为透视变换提供了基础,但也暗藏诸多陷阱。本文将手把手带您穿…...

终极指南:10分钟掌握SPT-AKI存档编辑器完整使用教程
终极指南:10分钟掌握SPT-AKI存档编辑器完整使用教程 【免费下载链接】SPT-AKI-Profile-Editor Программа для редактирования профиля игрока на сервере SPT-AKI 项目地址: https://gitcode.com/gh_mirrors/sp/…...

【ZYNQ】AXI4总线协议实战:从握手时序到PS-PL高效通信
1. AXI4总线协议基础:从握手信号到通道架构 第一次接触ZYNQ的PS-PL通信时,我被AXI4协议里那些VALID/READY信号搞得头晕眼花。直到在示波器上抓到真实的握手波形,才突然理解这个看似复杂的协议其实像极了我们日常的对话机制——只有当说话方准…...

从零到一:Android Studio集成Uniapp离线SDK打包实战
1. 环境准备:工具选择与版本匹配 第一次接触Uniapp离线打包时,最让我头疼的就是工具版本匹配问题。记得去年接手一个混合开发项目时,因为HBuilderX和SDK版本不兼容,整整浪费了两天时间排查问题。为了避免大家重蹈覆辙,…...

进化算法驱动机械爪设计优化:从原理到EvoClaw项目实践
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“EvoClaw”。光看这个名字,可能有点摸不着头脑,但点进去一看,发现这是一个关于“进化算法驱动的机械爪设计优化”的开源项目。简单来说,就是利用计算机…...

ADXL335模拟传感器读数不稳?手把手教你用Arduino进行软件滤波与校准
ADXL335模拟传感器读数不稳?手把手教你用Arduino进行软件滤波与校准 当你把ADXL335加速度计接入Arduino,兴奋地跑起第一个测试程序时,那些跳动的数字可能很快会浇灭你的热情。原始读数像得了疟疾般颤抖,静止时本该稳定的1g重力加速…...

ncmdumpGUI:3分钟解锁网易云音乐ncm格式,让你的音乐无处不在
ncmdumpGUI:3分钟解锁网易云音乐ncm格式,让你的音乐无处不在 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 还在为网易云音乐下载的nc…...

5步实现AutoHotkey脚本独立运行:Ahk2Exe编译实战指南
5步实现AutoHotkey脚本独立运行:Ahk2Exe编译实战指南 【免费下载链接】Ahk2Exe Official AutoHotkey script compiler - written itself in AutoHotkey 项目地址: https://gitcode.com/gh_mirrors/ah/Ahk2Exe 你是否遇到过这样的困扰?精心编写的A…...

Go语言缓存雪崩:防止缓存失效
Go语言缓存雪崩:防止缓存失效 1. 雪崩防护 type CacheWithProtection struct {cache *RedisCachemu sync.Mutexlocks map[string]*sync.Mutex }func NewCacheWithProtection(cache *RedisCache) *CacheWithProtection {return &CacheWithProtect…...

基于MCP协议的AI Agent远程SSH安全操作实践指南
1. 项目概述与核心价值最近在折腾AI Agent的开发,发现一个挺有意思的现象:很多开发者都卡在了“如何让AI安全、可控地操作远程服务器”这一步。你可能会想到直接给AI一个SSH私钥,但这无异于把自家大门的钥匙扔给一个还在学习走路的机器人&…...