【AI理论学习】语言模型:从Word Embedding到ELMo
语言模型:从Word Embedding到ELMo
- ELMo原理
- Bi-LM
- 总结
- 参考资料
本文主要介绍一种建立在LSTM基础上的ELMo预训练模型。2013年的Word2Vec及2014年的GloVe的工作中,每个词对应一个vector,对于多义词无能为力。ELMo的工作对于此,提出了一个较好的解决方案。不同于以往的一个词对应一个向量,是固定的。 在ELMo世界里,预训练好的模型不再只是向量对应关系,而是一个训练好的模型。使用时, 将一句话或一段话输入模型,模型会根据上线文来推断每个词对应的词向量。这样做之后明显的好处之一就是对于多义词,可以结合前后语境对多义词进行理解。比如apple,可以根据前后文语境理解为苹果公司或一种水果。可以说,ELMo的提出意味着从词嵌入(Word Embedding)时代进入了语境词嵌入(Contextualized Word-Embedding)时代。
ELMo原理
ELMo来自论文Deep contextualized word representations,它是”Embeddings from Language Models“的简称。从论文题目看,ELMo的核心思想主要体现在深度上下文(Deep Contextualized )上。与静态的词嵌入不同,ELMo除提供临时词嵌入之外,还提供生成这些词嵌入的预训练模型,所以在实际使用时,ELMo可以基于预训练模型,根据实际上下文场景动态调整单词的Word Embedding表示,这样经过调整后的Word Embedding更能表达在这个上下文中的具体含义,自然也就解决了多义词的问题。所以ELMo实现了一个由静态到动态的飞跃。
ELMo的实现主要涉及语言模型,当然,它使用的语言模型有点特别,因为它首先把输入转换为字符级别的Embedding,根据字符级别的Embedding来生成上下文无关的Word Embedding,然后使用双向语言模型(如Bi-LM)生成上下文相关的Word Embedding。
ELMo的整体模型结果如下图所示:

从上图中可以看出,ELMo模型的处理流程可分为如下
-
输入句子
句子维度为 B × W × C B\times W\times C B×W×C,其中B表示批量大小(batch_size),W表示一句话中的单词数num_words,C表示每个单词的最大字符数目(max_characters_per_token),可设置为某个固定值(如50或60)。在一个批量中,语句有长短,可以采用Padding方法对齐。 -
字符编码层
输入语句首先经过一个字符编码层(Char Encoder Layer),ELMo实际是对字符进行编码,它会对每个单词中所有字符进行编码,得到这个单词的表示。输入维度是 B × W × C B\times W\times C B×W×C,经过字符编码层后的数据维度为 B × W × D B\times W\times D B×W×D。这里展开进一步说明:
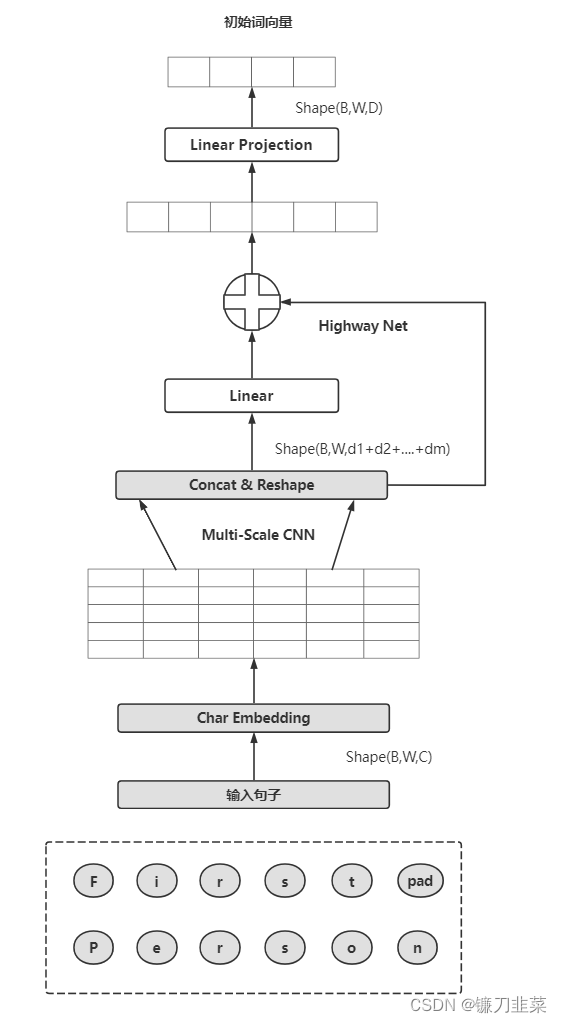
如上图所示:- Char Embedding
对每个字符进行编码,包括一些特殊字符,如单词的开始<bow>、单词的结束<eow>、句子的开始符<bos>、句子的结束符<eos>、单词补齐符<pow>和句子补齐符<pos>等,维度会变为 B ∗ W ∗ C ∗ d B*W*C*d B∗W∗C∗d,这里d表示字符的Embedding维度(char_embed_dim) - Multi-Scale CNN
Char Embedding通过不同规模的一维卷积、池化等作用后,再经过激活层,最后进入拼接和修改状态层(Concat&Reshape) - Concat&Reshape
把卷积后的结果进行拼接,使其形状变为 ( B , W , d 1 + . . . + d m ) (B,W,d1+...+dm) (B,W,d1+...+dm),di表示第i个卷积的通道数 - Highway Net
Highway Net类似残差连接,这里有2个Highway层 - Linear Projection
该层为线性映射层:上一层得到的维度d1+…+dm比较长,经过该层后将维度映射到D,作为词嵌入输入后续的层中,这里输出维度为 B ∗ W ∗ D B*W*D B∗W∗D
- Char Embedding
注意:输入度量是字符而不是词汇,以便模型能捕捉词的内部结构信息。比如beauty和beautiful,即使不了解这两个词的上下文,双向语言模型也能够识别出它们在一定程度上的相关性。
- 双向语言模型
对字符级语句编码后,该句子会经过双向语言模型(Bi-LM),模型内部先分开训练了两个正向和反向的语言模型,而后将其表征进行拼接,最终得到输出维度 ( L + 1 ) ∗ B ∗ W ∗ 2 D (L+1)*B*W*2D (L+1)∗B∗W∗2D,这里+1是加上最初的Embedding层,类似残差连接。
ELMo采用双向语言模型,即同时结合正向和反向的语言模型,其目标是最大化如下的log似然值:
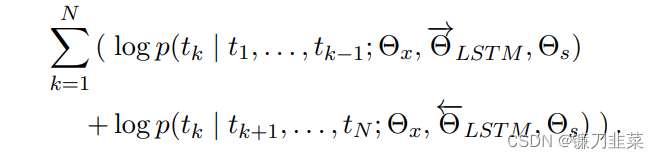

然后,分别训练正向和反向的两个LM,最后把结果拼接起来。词向量层的参数 Θ x \Theta_x Θx和Softmax层参数 Θ \Theta Θ在前向和后向语言模型中是共享的,但LM正向与反向的参数是分开的。如下图所示:
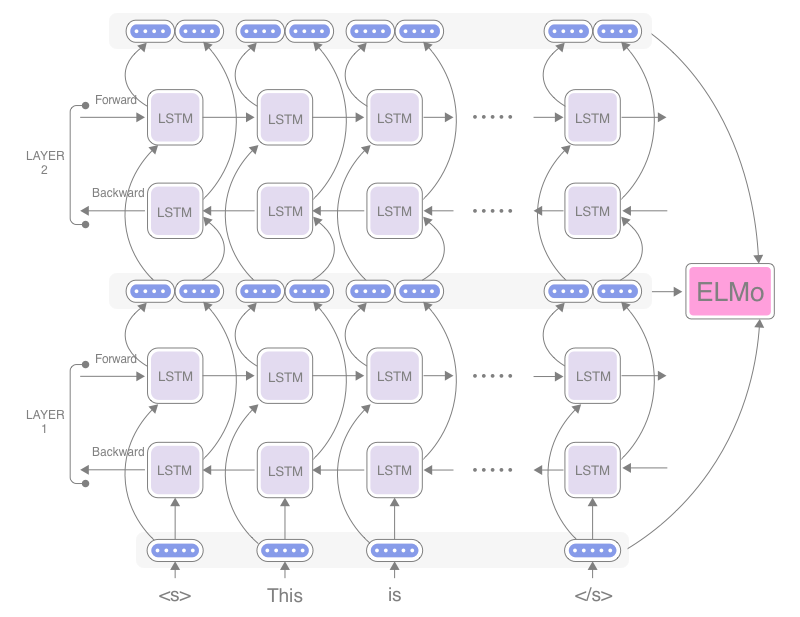
ELMo 利用正向和反向扫描句子计算单词的词向量,并通过级联的方式产生一个中间向量(下面会给出具体的级联方式)。通过这种方式得到的词向量可以捕获到当前句子的结构和该单词的使用方式。
值得注意是,ELMo 使用的 Bi-LM 与 Bi-LSTM 不同,虽然长得相似,但是 Bi-LM 是两个 LM 模型的串联,一个向前,一个向后;而 Bi-LSTM 不仅仅是两个 LSTM 串联,Bi-LSTM 模型中来自两个方向的内部状态在被送到下层时进行级联(注意下图的 out 部分,在 out 中进行级联),而在 Bi-LM 中,两个方向的内部状态仅从两个独立训练的 LM 中进行级联。

- 混合层
得到各层的表征后,会经过一个混合层(Scalar Mixer),它会对前面这些层的表示进行线性融合,得出最终的ELMo向量,维度为 B ∗ W ∗ 2 D B*W*2D B∗W∗2D。·
Bi-LM
设一个序列有N个 token ( t 1 , t 2 , . . . , t N ) (t_1,t_2,...,t_N) (t1,t2,...,tN)(这里说 token 是为了兼容字符和单词,如上文所说,EMLo使用的是字符级别的Embedding)
对于一个前向语言模型来说,是基于先前的序列来预测当前 token: p ( t 1 , t 2 , . . . , t N ) = ∏ k = 1 N p ( t k ∣ t 1 , t 2 , . . . , t k − 1 ) p (t_1 ,t_2 ,...,t_N )=\prod_{k=1}^{N}{p( t_k|t_1 ,t_2 ,...,t_{k-1} )} p(t1,t2,...,tN)=k=1∏Np(tk∣t1,t2,...,tk−1)
而对于一个后向语言模型来说,是基于后面的序列来预测当前 token: p ( t 1 , t 2 , . . . , t N ) = ∏ k = 1 N p ( t k ∣ t k + 1 , t k + 2 , . . . , t N ) p (t_1 ,t_2 ,...,t_N )=\prod_{k=1}^{N}{p( t_k|t_{k+1} ,t_{k+2} ,...,t_{N} )} p(t1,t2,...,tN)=k=1∏Np(tk∣tk+1,tk+2,...,tN)可以用 h k , j → \overrightarrow{h_{k,j}} hk,j 和 h k , j ← \overleftarrow{h_{k,j}} hk,j分别表示前向和后向语言模型。
ELMo 用的是多层双向的 LSTM,所以我们联合前向模型和后向模型给出对数似然估计:
∑ k = 1 N ( log p ( t k ∣ t 1 , . . . , t k − 1 ; Θ x , Θ → L S T M , Θ s ) + log p ( t k ∣ t k + 1 , . . . , t N ; Θ x , Θ ← L S T M , Θ s ) ) \sum_{k=1}^{N}(\log p(t_k | t_1,...,t_{k-1}; \Theta_x, \overrightarrow{\Theta}_{LSTM},\Theta_s) + \log p(t_k | t_{k+1},...,t_{N}; \Theta_x, \overleftarrow{\Theta}_{LSTM},\Theta_s)) k=1∑N(logp(tk∣t1,...,tk−1;Θx,ΘLSTM,Θs)+logp(tk∣tk+1,...,tN;Θx,ΘLSTM,Θs))其中, Θ x \Theta_x Θx表示 token 的向量, Θ s \Theta_s Θs表示 Softmax 层对的参数, Θ → L S T M \overrightarrow{\Theta}_{LSTM} ΘLSTM和 Θ ← L S T M \overleftarrow{\Theta}_{LSTM} ΘLSTM表示前向和后向的LSTM 的参数。
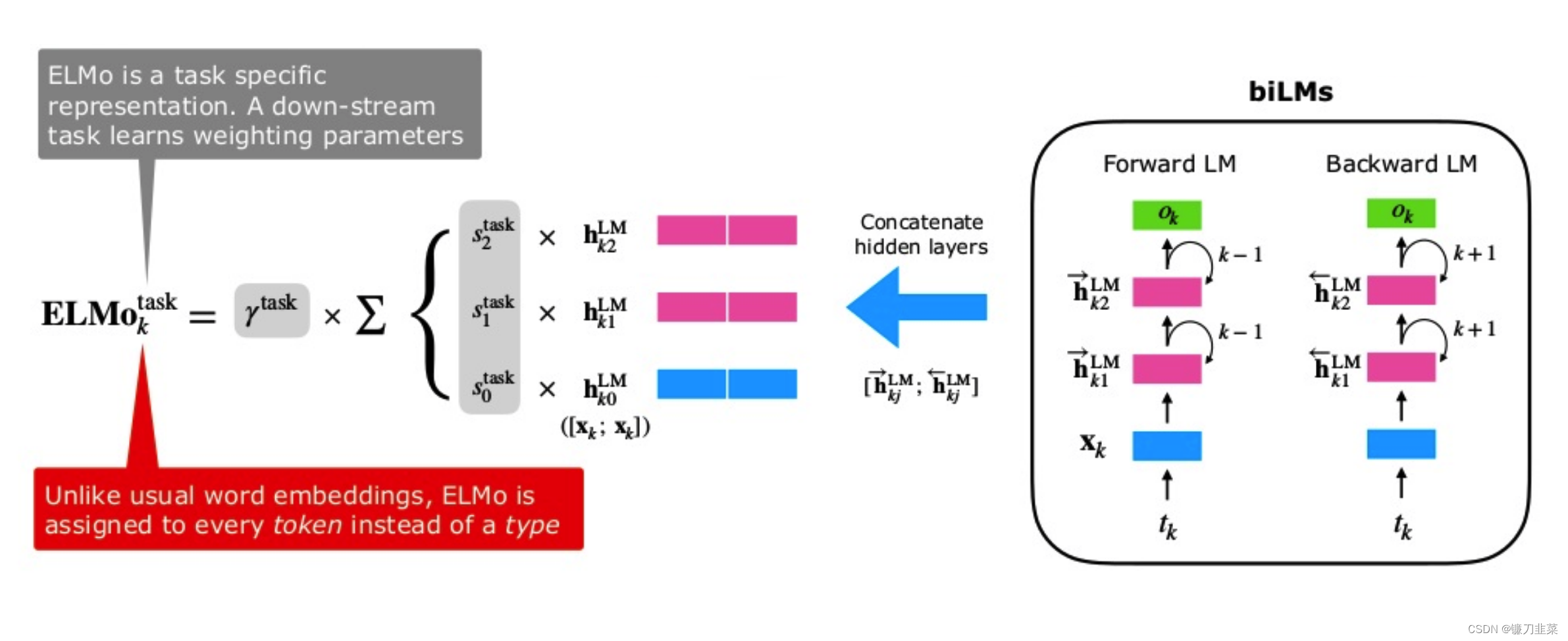
我们刚说 ELMo 通过级联的方式给出中间向量(这边要注意两个地方:一个是级联,一个是中间向量),现在给出符号定义:对每一个 token t k t_k tk来说,一个 L 层的 ELMo 的 2L + 1 个表征: R k = { x k L M , h k , j → , h k , j ← ∣ j = 1 , . . , L } = { h k , j ∣ j = 0 , . . . , L } R_k=\{x_k^{LM},\overrightarrow{h_{k,j}},\overleftarrow{h_{k,j}} | j=1,..,L\} \\ =\{h_{k,j}| j=0,...,L\} Rk={xkLM,hk,j,hk,j∣j=1,..,L}={hk,j∣j=0,...,L}其中, h k , 0 h_{k,0} hk,0表示输入层, h k , j = [ h k , j → ; h k , j ← ] h_{k,j} = [\overrightarrow{h_{k,j}}; \overleftarrow{h_{k,j}}] hk,j=[hk,j;hk,j]。(之所以是 2L + 1 是因为把输入层加了进来)
对于下游任务来说,ELMo 会将所有的表征加权合并为一个中间向量:
E L M o k = E ( R k ; Θ ) = γ ∑ j = 0 L s j h k , j L M ELMo_k=E(R_k;\Theta) = \gamma\sum_{j=0}^{L}s_jh_{k,j}^{LM} ELMok=E(Rk;Θ)=γj=0∑Lsjhk,jLM其中, s s s 是 Softmax 的结果,用作权重; γ \gamma γ 是常量参数,允许模型缩放整个 ELMo 向量,考虑到各个 Bi-LSTM 层分布不同,某些情况下对网络的 Layer Normalization 会有帮助。
总结
ELMo预训练模型采用双向语言模型,该预训练模型能够随着具体语言环境更新词向量表示,即更新对应词的Embedding。当然,由于ELMo采用LSTM架构,因此,模型的并发能力、关注语句的长度等在大的语料库面前,不能完全适用。而且通过拼接(word embedding,Forward hidden state,backward hidden state)方式融合特征的方式,削弱了语言模型特征抽取的能力。
参考资料
- ELMo (Embeddings from Language Models)
- ELMo原理解析及简单上手使用
- Deep contextualized word representations(ELMO词向量理解)
相关文章:
【AI理论学习】语言模型:从Word Embedding到ELMo
语言模型:从Word Embedding到ELMo ELMo原理Bi-LM总结参考资料 本文主要介绍一种建立在LSTM基础上的ELMo预训练模型。2013年的Word2Vec及2014年的GloVe的工作中,每个词对应一个vector,对于多义词无能为力。ELMo的工作对于此,提出了…...

多功能透明屏,在智能家居领域中,有哪些功能特点?显示、连接
多功能透明屏是一种新型的显示技术,它能够在透明的表面上显示图像和视频,并且具有多种功能。 这种屏幕可以应用于各种领域,如商业广告、智能家居、教育等,为用户提供更加便捷和多样化的体验。 首先,多功能透明屏可以…...
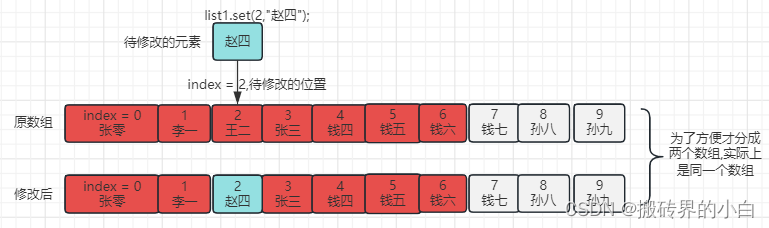
【List篇】ArrayList 详解(含图示说明)
Java中的ArrayList是一个动态数组,可以自动扩展容量以适应数据的添加和删除。它可以用来存储各种类型的数据,例如String,Integer,Boolean等。ArrayList实现了List接口,可以进行常见的List操作,例如添加、插…...

SSL证书只有收费的吗?有没有免费使用的?
首先明白SSL证书是什么SSL英文全称:英文全称: Secure Socket Layer Certificate,中文全称:安全套接字层证书。 SSL是一种由数字证书颁发机构(CA) 签发的数字证书。它用于建立安全的加密连接,确保通过网络传输的数据在客户端和服务器之间的安全性和完整性…...

48V轻混技术
文章目录 48V轻混技术的主要特点和优势48V轻混技术的优缺点优点:缺点: 48V轻混技术的主要特点和优势 48V轻混技术(48V Mild Hybrid Technology)是一种汽车动力系统技术,它结合了内燃机和电动机的优势,以提…...

机器学习基础算法--回归类型和评价分析
目录 1.数据归一化处理 2.数据标准化处理 3.Lasso回归模型 4.岭回归模型 5.评价指标计算 1.数据归一化处理 """ x的归一化的方法还是比较多的我们就选取最为基本的归一化方法 x(x-x_min)/(x_max-x_min) """ import numpy as np from sklea…...

MATLAB 软件功能简介
MATLAB 的名称源自 Matrix Laboratory,1984 年由美国 Mathworks 公司推向市场。 它是一种科学计算软件,专门以矩阵的形式处理数据。MATLAB 将高性能的数值计算和可 视化集成在一起,并提供了大量的内置函数,从而被广泛的应用于科学计算、控制…...
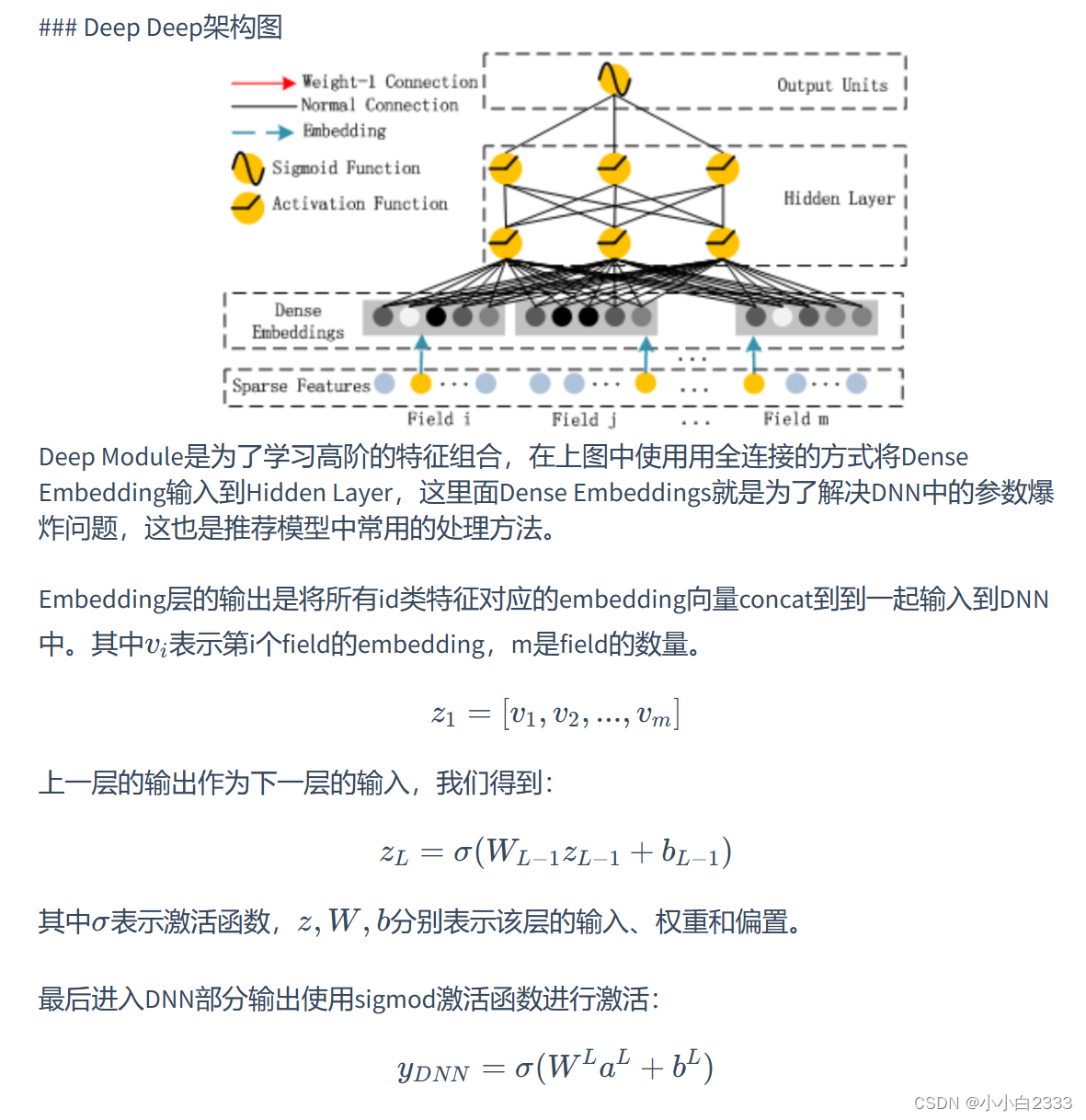
deepfm内容理解
对于CTR问题,被证明的最有效的提升任务表现的策略是特征组合(Feature Interaction); 两个问题: 如何更好地学习特征组合,进而更加精确地描述数据的特点; 如何更高效的学习特征组合。 DNN局限 :当我们使…...
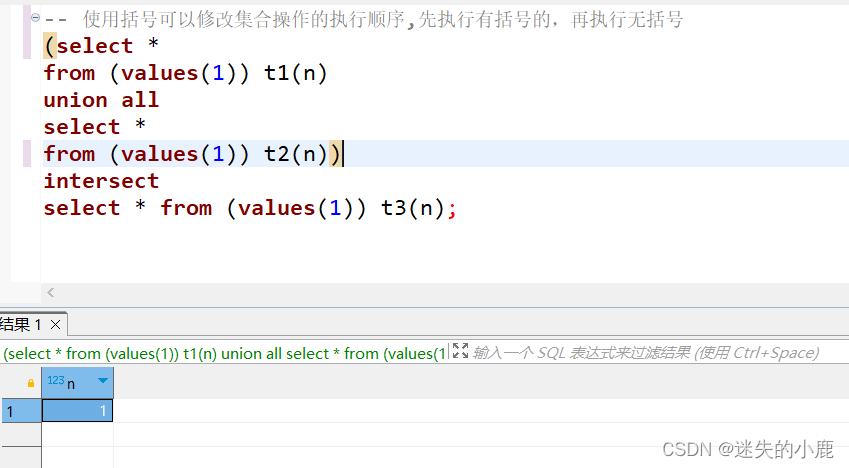
postgresql-集合运算
postgresql-集合运算 并集交集差集集合运算符的优先级 并集 create table excellent_emp( year int not null, emp_id integer not null, constraint pk_excellent_emp primary key(year,emp_id) );insert into excellent_emp values(2018,9); insert into excellent_emp value…...

[持续更新]计算机经典面试题基础篇Day2
[通用]计算机经典面试题基础篇Day2 1、单例模式是什么,线程安全吗 单例模式是一种设计模式,旨在确保一个类只有一个实例,并提供全局访问点。通过使用单例模式,可以避免多次创建相同的对象,节省内存资源,同…...

C++:类和对象(二)
本文主要介绍:构造函数、析构函数、拷贝构造函数、赋值运算符重载、const成员函数、取地址及const取地址操作符重载。 目录 一、类的六个默认成员函数 二、构造函数 1.概念 2.特性 三、析构函数 1.概念 2.特性 四、拷贝构造函数 1.概念 2.特征 五、赋值…...
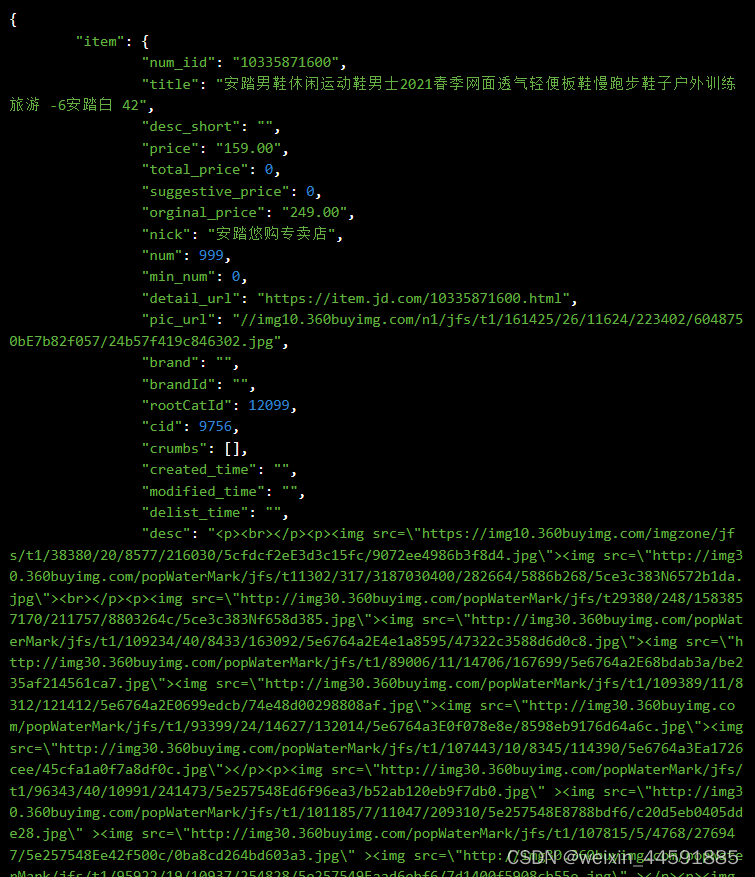
Java“牵手”京东商品详情数据,京东商品详情API接口,京东API接口申请指南
京东平台商品详情接口是开放平台提供的一种API接口,通过调用API接口,开发者可以获取京东商品的标题、价格、库存、月销量、总销量、库存、详情描述、图片等详细信息 。 获取商品详情接口API是一种用于获取电商平台上商品详情数据的接口,通过…...

Fluidd摄像头公网无法正常显示修复一例
Fluidd摄像头在内网正常显示,公网一直无法显示,经过排查发现由于url加了端口号引起的,摄像头url中正常填写的是/webcam?actionsnapshot,或者/webcam?actionstream。但是由于nginx跳转机制,会被301跳转到/webcam/?ac…...
【C++ 学习 ⑳】- 详解二叉搜索树
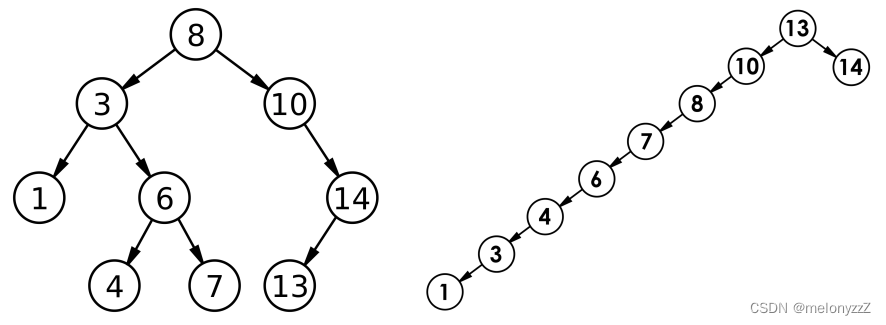
目录 一、概念 二、实现 2.1 - BST.h 2.2 - test.cpp 三、应用 四、性能分析 一、概念 二叉搜索树(BST,Binary Search Tree),又称二叉排序树或二叉查找树。 二叉搜索树是一棵二叉树,可以为空;如果不…...
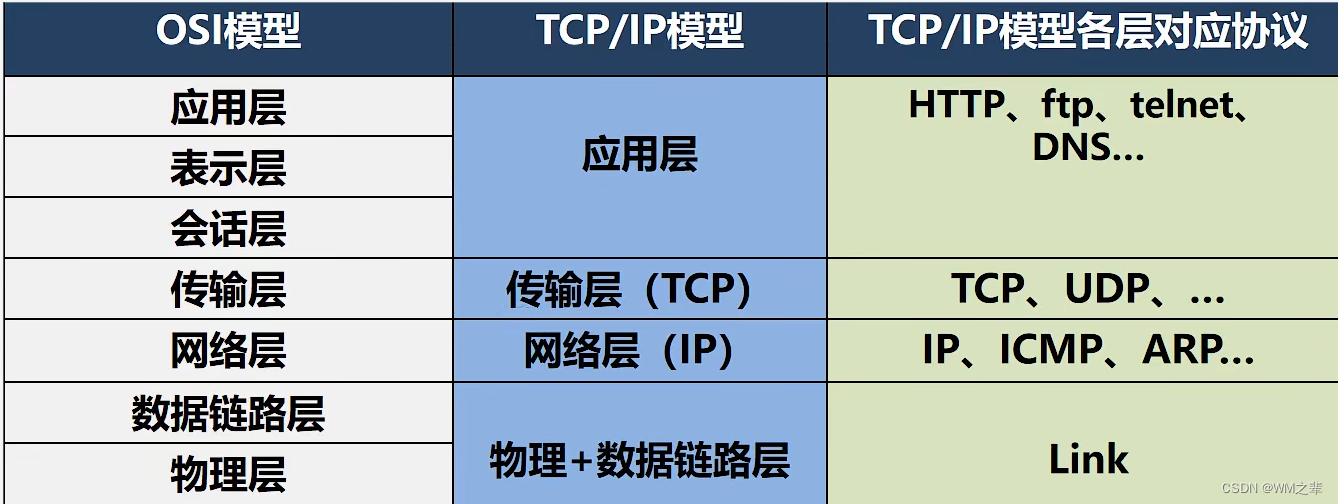
Java中网络的基本介绍。网络通信,网络,ip地址,域名,端口,网络通信协议,TCP/IP传输过程,网络通信协议模型,TCP协议,UDP协议
- 网络通信 概念:网络通信是指通过计算机网络进行信息传输的过程,包括数据传输、语音通话、视频会议等。在网络通信中,数据被分成一系列的数据包,并通过网络传输到目的地。在数据传输过程中,需要确保数据的完整性、准…...

【Qt】总体把握文本编码问题
在项目开发中,经常会遇到文本编码问题。文本编码知识非常基础,但对于新手来说,可能需要花费较长的时间去尝试,才能在脑海中建立对编码的正确认知。文本编码原理并不难,难的是在项目实践中掌握正确处理文本编码的方法。…...
之curl)
Linux命令(77)之curl
linux命令之curl 1.curl介绍 linux命令之curl是一款强大的http命令行工具,它支持文件的上传和下载,是综合传输工具。 2.curl用法 curl [参数] [url] curl参数 参数说明-C断点续传-o <filename>把输出写到filename文件中-x在给定的端口上使用HT…...

详解 sudo usermod -aG docker majn
这个命令涉及到几个 Linux 系统管理的基础概念,包括 sudo、usermod 和用户组管理。我们可以逐一地解析它们: sudo: sudo(superuser do)允许一个已经被授权的用户以超级用户或其他用户的身份执行一个命令。当使用 sudo 前缀一个命令…...
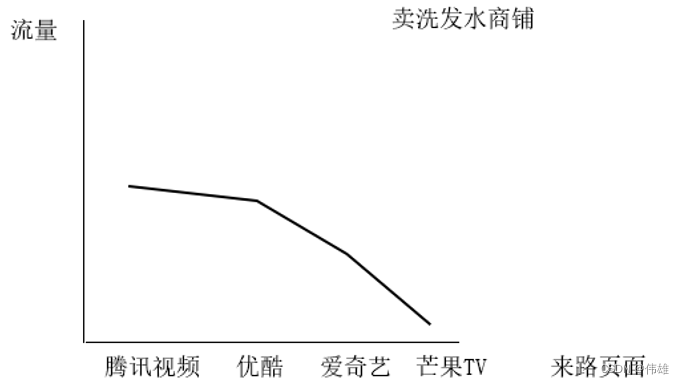
大数据课程L2——网站流量项目的算法分析数据处理
文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州 ▲ 本章节目的 ⚪ 了解网站流量项目的算法分析; ⚪ 了解网站流量项目的数据处理; 一、项目的算法分析 1. 概述 网站流量统计是改进网站服务的重要手段之一,通过获取用户在网站的行为,可以分析出哪些内…...
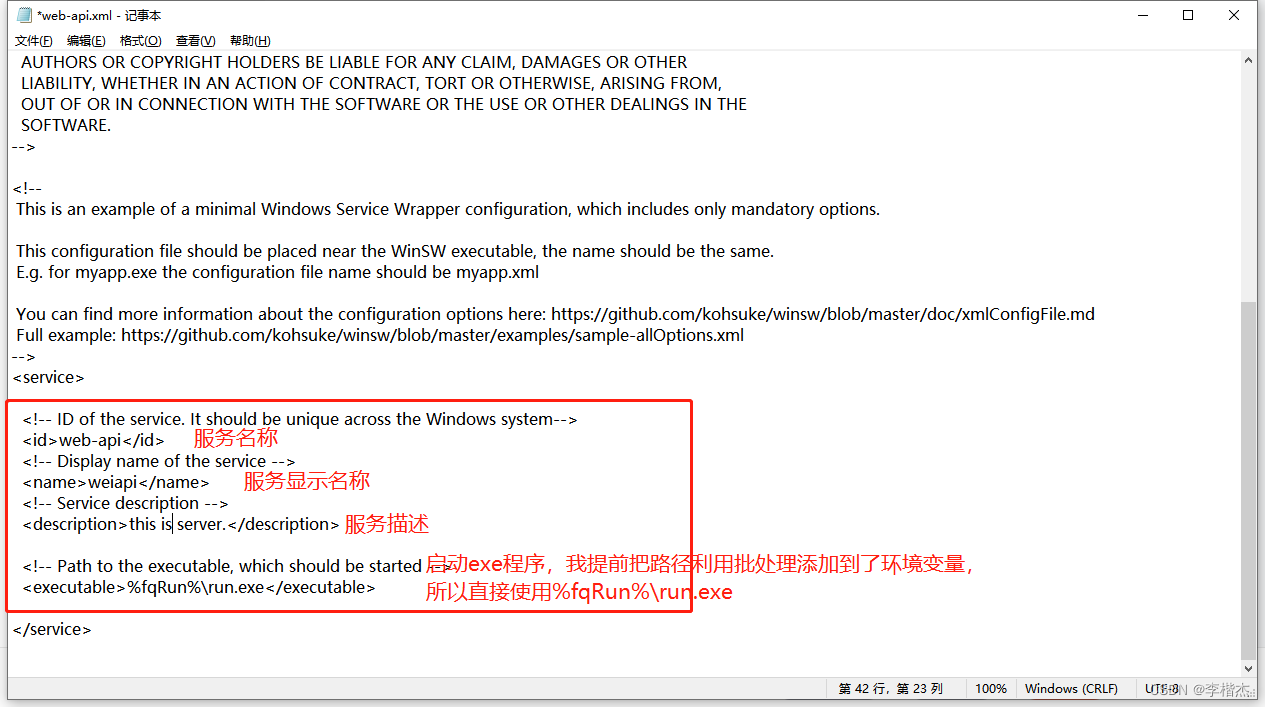
jar包或exe程序设置为windows服务
最近在使用java和python制作客户端时突发奇想,是否能够通过一种方法来讲jar包和exe程序打包成windows服务呢?简单了解了一下是可以的。 首先要用到的是winSW,制作windows服务的过程非常简单,仅需几步制作完成,也不需要…...

基于Rust和Axum的高性能静态文件服务器架构设计与实现
基于Rust和Axum的高性能静态文件服务器架构设计与实现 【免费下载链接】simple-http-server Simple http server in Rust (Windows/Mac/Linux) 项目地址: https://gitcode.com/gh_mirrors/si/simple-http-server 在现代化开发工作流中,高效的文件共享与静态资…...

5步解锁Total War模组制作:用RPFM编辑器从新手到专家的完整指南
5步解锁Total War模组制作:用RPFM编辑器从新手到专家的完整指南 【免费下载链接】rpfm Rusted PackFile Manager (RPFM) is a... reimplementation in Rust and Qt6 of PackFile Manager (PFM), one of the best modding tools for Total War Games. 项目地址: ht…...

终极指南:如何使用Play Integrity API检查器确保Android设备安全
终极指南:如何使用Play Integrity API检查器确保Android设备安全 【免费下载链接】play-integrity-checker-app Get info about your Device Integrity through the Play Intergrity API 项目地址: https://gitcode.com/gh_mirrors/pl/play-integrity-checker-app…...

网易2026年Q1财报:游戏增长背后,AI、跨端与全球化面临哪些挑战?
网易发布2026年Q1财报5月21日,网易发布2026年第一季度财报。大体上,网易呈现出基本面企稳、公司效率提升以释放利润的态势。财报显示,网易Q1净收入306亿元,同比增长6.1%,Non - GAAP归母净利润为107亿元。游戏及相关增值…...
Extracting and saving responses)
第七章 指令微调学习(五)Extracting and saving responses
第七章 指令微调学习(五) 7.7 Extracting and saving responses 在对指令数据集的训练部分完成LLM的微调后,现在评估其在保留测试集上的性能。首先,我们提取测试集中每个输入对应的模型生成响应并进行人工分析;随后通过…...

FastMamba:边缘计算中的Mamba2高效部署方案
1. FastMamba项目概述在深度学习领域,状态空间模型(State Space Models, SSMs)正逐渐成为处理长序列任务的新范式。Mamba2作为SSM家族的最新成员,通过状态空间对偶性框架和半可分离矩阵分解技术,在保持模型精度的同时&…...

洛雪音乐音源:如何免费畅享全网无损音乐的终极指南
洛雪音乐音源:如何免费畅享全网无损音乐的终极指南 【免费下载链接】lxmusic- lxmusic(洛雪音乐)全网最新最全音源 项目地址: https://gitcode.com/gh_mirrors/lx/lxmusic- 还在为音乐会员费烦恼吗?洛雪音乐音源为你提供完美的免费音乐解决方案&a…...

告别手速焦虑:大麦抢票自动化系统全攻略
告别手速焦虑:大麦抢票自动化系统全攻略 【免费下载链接】ticket-purchase 大麦自动抢票,支持人员、城市、日期场次、价格选择 项目地址: https://gitcode.com/GitHub_Trending/ti/ticket-purchase 还在为抢不到演唱会门票而烦恼吗?每…...

如何用Happy Island Designer免费打造你的梦幻岛屿:终极完整指南
如何用Happy Island Designer免费打造你的梦幻岛屿:终极完整指南 【免费下载链接】HappyIslandDesigner "Happy Island Designer (Alpha)",是一个在线工具,它允许用户设计和定制自己的岛屿。这个工具是受游戏《动物森友会》(Animal…...

终极指南:在Windows上完美使用苹果触控板的完整配置方案
终极指南:在Windows上完美使用苹果触控板的完整配置方案 【免费下载链接】mac-precision-touchpad Windows Precision Touchpad Driver Implementation for Apple MacBook / Magic Trackpad 项目地址: https://gitcode.com/gh_mirrors/ma/mac-precision-touchpad …...