计算机视觉的应用12-卷积神经网络中图像特征提取的可视化研究,让大家理解特征提取的全过程
大家好,我是微学AI,今天给大家介绍一下计算机视觉的应用12-卷积神经网络中图像特征提取的可视化研究,让大家理解特征提取的全过程。
要理解卷积神经网络中图像特征提取的全过程,我们可以将其比喻为人脑对视觉信息的处理过程。就像我们看到一个物体时,大脑会通过不同的神经元来处理不同特征的信息,如轮廓、色彩和纹理等。
一、图像特征提取介绍
在CNN中,输入图像会被逐层处理,每一层都会提取不同的特征信息。这些层可以被看作是不同的“过滤器”,它们会识别图像中特定的模式和形状,比如边缘、角落和线条等。随着层数的逐渐增加,CNN能够提取越来越复杂的特征,比如图像中的纹理、形状和结构等。
假设我们的输入图像是一张猫的图片。CNN的第一层可能会检测到猫身体的边缘和角落,第二层可能会提取出猫耳朵的形状和脸部的轮廓,第三层可能会进一步分析猫毛发的纹理,眼睛,形状。这种特征提取的过程可以被可视化,让我们更好地理解CNN是如何学习和处理图像信息的。通过可视化,我们可以看到CNN不同层次提取的图像特征,可以发现低层次的特征包括边缘和纹理等,而高层次的特征包括眼睛、鼻子和嘴巴等更加抽象和语义化的信息。
二、CNN提取特征的原理
卷积神经网络通过卷积和池化操作来提取图像中的特征。其原理如下:
输入图像 I I I 经过多个卷积层和池化层的处理,得到最后的特征图 F F F。在卷积层中,使用一组可学习的滤波器 W W W 对输入图像进行卷积运算,并加上偏置 b b b,即:
C = W ∗ I + b C = W * I + b C=W∗I+b
其中, ∗ * ∗ 表示卷积运算。这样,每个滤波器在输入图像上滑动,并通过计算卷积运算,得到一个对应的特征图。
在特征图中,通过激活函数(如ReLU)进行非线性激活,得到激活特征图:
A = ReLU ( C ) A = \text{{ReLU}}(C) A=ReLU(C)
然后,通过池化层对激活特征图进行下采样操作,以减少特征图的空间维度。常用的池化操作是最大池化,它在每个池化窗口中选择最大值作为输出特征。这样可以保留最显著的特征,同时减少计算量。
经过多次卷积和池化操作,得到了一系列不同尺寸的特征图。这些特征图包含了输入图像的不同级别的特征,从低级的边缘和纹理到高级的语义信息。
这些特征图可以被传递到全连接层进行分类、检测或其他任务。全连接层将特征图展平成向量,并与权重矩阵相乘,再加上偏置,最后通过softmax函数等激活函数得到最终的输出结果。
CNN网络通过卷积和池化操作,自动学习图像中的特征,使得我们能够更好地理解和分析图像数据,并应用于各种计算机视觉任务。
三、CNN提取特征可视化过程
现在我将通过代码实现这个图像特征提取的过程:
import matplotlib.pyplot as plt
import torch
from PIL import Image
import numpy as np
import sys
sys.path.append("..")
from torchvision import transforms# 对于给定的一个网络层的输出x,x为numpy格式的array,维度为[0, channels, width, height]def draw_features(width, height, channels,x,savename):fig = plt.figure(figsize=(32,32))fig.subplots_adjust(left=0.05, right=0.95, bottom=0.05, top=0.95, wspace=0.05, hspace=0.05)for i in range(channels):plt.subplot(height,width, i + 1)plt.axis('off')img = x[0, i, :, :]pmin = np.min(img)pmax = np.max(img)img = (img - pmin) / (pmax - pmin + 0.000001)plt.imshow(img, cmap='gray')
# print("{}/{}".format(i, channels))fig.savefig(savename, dpi=300)fig.clf()plt.close()# 读取模型
def load_checkpoint(filepath):checkpoint = torch.load(filepath)model = checkpoint['model'] # 提取网络结构model.load_state_dict(checkpoint['net_state_dict']) # 加载网络权重参数for parameter in model.parameters():parameter.requires_grad = Falsemodel.eval()return modelsavepath = './'
def predict(model):# 读入模型model = load_checkpoint(model)print(model)##将模型放置在gpu上运行if torch.cuda.is_available():model.cuda()img = Image.open(img_path).convert('RGB')INPUT_SIZE =(224,224) # 根据需要调整图像的大小# 创建图像转换函数transform = transforms.Compose([transforms.Resize(INPUT_SIZE),transforms.ToTensor(),])# 对图像进行转换img = transform(img).unsqueeze(0)if torch.cuda.is_available():img = img.cuda()# 查看每一层处理的图片信息with torch.no_grad():x = model.conv1(img)x = model.bn1(x)draw_features(5,5,15, x.cpu().numpy(), "{}/f1_conv1.png".format(savepath))x = model.relu(x)draw_features(5,5,15, x.cpu().numpy(), "{}/f1_conv2.png".format(savepath))x = model.layer1(x)draw_features(5,5,15, x.cpu().numpy(), "{}/f1_conv3.png".format(savepath))x = model.layer2(x)draw_features(5,5,15, x.cpu().numpy(), "{}/f1_conv4.png".format(savepath))x = model.layer3(x)draw_features(5,5,15, x.cpu().numpy(), "{}/f1_conv5.png".format(savepath))if __name__ == "__main__":trained_model = 'resnet_model.pkl'img_path = 'cat.png'predict(trained_model)
构建模型ResNet模型:在可视化主函数的同级下创建目录:models->ClassNetwork->ResNet.py
import math
import torch
import torch.nn as nndef conv3x3(in_planes, out_planes, stride=1):"3x3 convolution with padding"return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,padding=1, bias=False)class BasicBlock(nn.Module):expansion = 1def __init__(self, inplanes, planes, stride=1, downsample=None):super(BasicBlock, self).__init__()self.conv1 = conv3x3(inplanes, planes, stride)self.bn1 = nn.BatchNorm2d(planes)self.conv2 = conv3x3(planes, planes)self.bn2 = nn.BatchNorm2d(planes)self.relu = nn.ReLU(inplace=True)self.downsample = downsampleself.stride = stridedef forward(self, x):residual = xout = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)if self.downsample is not None:residual = self.downsample(x)out += residualout = self.relu(out)return outclass Bottleneck(nn.Module):expansion = 4def __init__(self, inplanes, planes, stride=1, downsample=None):super(Bottleneck, self).__init__()self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)self.bn1 = nn.BatchNorm2d(planes)self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)self.bn2 = nn.BatchNorm2d(planes)self.conv3 = nn.Conv2d(planes, planes * Bottleneck.expansion, kernel_size=1, bias=False)self.bn3 = nn.BatchNorm2d(planes * Bottleneck.expansion)self.relu = nn.ReLU(inplace=True)self.downsample = downsampleself.stride = stridedef forward(self, x):residual = xout = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)out = self.relu(out)out = self.conv3(out)out = self.bn3(out)if self.downsample is not None:residual = self.downsample(x)#attention blockout += residualout = self.relu(out)return outclass ResNet(nn.Module):def __init__(self, dataset='cifar10', depth=18, num_classes=10, bottleneck=False):super(ResNet, self).__init__()self.dataset = datasetif self.dataset.startswith('cifar'):self.inplanes = 16# print(bottleneck)if bottleneck == True:n = int((depth - 2) / 9)block = Bottleneckelse:n = int((depth - 2) / 6)block = BasicBlockself.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=3, stride=1, padding=1, bias=False)self.bn1 = nn.BatchNorm2d(self.inplanes)self.relu = nn.ReLU(inplace=True)self.layer1 = self._make_layer(block, 16, n)self.layer2 = self._make_layer(block, 32, n, stride=2)self.layer3 = self._make_layer(block, 64, n, stride=2)self.avgpool = nn.AvgPool2d(8)self.fc = nn.Linear(64 * block.expansion, num_classes)elif dataset == 'imagenet':blocks = {18: BasicBlock, 34: BasicBlock, 50: Bottleneck, 101: Bottleneck, 152: Bottleneck, 200: Bottleneck}layers = {18: [2, 2, 2, 2], 34: [3, 4, 6, 3], 50: [3, 4, 6, 3], 101: [3, 4, 23, 3], 152: [3, 8, 36, 3],200: [3, 24, 36, 3]}assert layers[depth], 'invalid detph for ResNet (depth should be one of 18, 34, 50, 101, 152, and 200)'self.inplanes = 64self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3, bias=False)self.bn1 = nn.BatchNorm2d(64)self.relu = nn.ReLU(inplace=True)self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)self.layer1 = self._make_layer(blocks[depth], 64, layers[depth][0])self.layer2 = self._make_layer(blocks[depth], 128, layers[depth][1], stride=2)self.layer3 = self._make_layer(blocks[depth], 256, layers[depth][2], stride=2)self.layer4 = self._make_layer(blocks[depth], 512, layers[depth][3], stride=2)self.avgpool = nn.AvgPool2d(7)self.fc = nn.Linear(512 * blocks[depth].expansion, num_classes)for m in self.modules():if isinstance(m, nn.Conv2d):n = m.kernel_size[0] * m.kernel_size[1] * m.out_channelsm.weight.data.normal_(0, math.sqrt(2. / n))elif isinstance(m, nn.BatchNorm2d):m.weight.data.fill_(1)m.bias.data.zero_()def _make_layer(self, block, planes, blocks, stride=1):downsample = Noneif stride != 1 or self.inplanes != planes * block.expansion:downsample = nn.Sequential(nn.Conv2d(self.inplanes, planes * block.expansion,kernel_size=1, stride=stride, bias=False),nn.BatchNorm2d(planes * block.expansion),)layers = []layers.append(block(self.inplanes, planes, stride, downsample))self.inplanes = planes * block.expansionfor i in range(1, blocks):layers.append(block(self.inplanes, planes))return nn.Sequential(*layers)def forward(self, x):if self.dataset == 'cifar10' or self.dataset == 'cifar100':x = self.conv1(x)x = self.bn1(x)x = self.relu(x)x = self.layer1(x)x = self.layer2(x)x = self.layer3(x)x = self.avgpool(x)x = x.view(x.size(0), -1)x = self.fc(x)elif self.dataset == 'imagenet':x = self.conv1(x)x = self.bn1(x)x = self.relu(x)x = self.maxpool(x)x = self.layer1(x)x = self.layer2(x)x = self.layer3(x)x = self.layer4(x)x = self.avgpool(x)x = x.view(x.size(0), -1)x = self.fc(x)return x
四、征可视化过程运行
这里我们输入一张猫咪的图像:

程序运行我们看到ResNet的网络结构如下:
ResNet((conv1): Conv2d(3, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(layer1): Sequential((0): BasicBlock((conv1): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(1): BasicBlock((conv1): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)))(layer2): Sequential((0): BasicBlock((conv1): Conv2d(16, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(downsample): Sequential((0): Conv2d(16, 32, kernel_size=(1, 1), stride=(2, 2), bias=False)(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): BasicBlock((conv1): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)))(layer3): Sequential((0): BasicBlock((conv1): Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(downsample): Sequential((0): Conv2d(32, 64, kernel_size=(1, 1), stride=(2, 2), bias=False)(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): BasicBlock((conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)))(avgpool): AvgPool2d(kernel_size=8, stride=8, padding=0)(fc): Linear(in_features=64, out_features=100, bias=True)
)
然后会生成每一层图像处理的过程:
conv1第一层处理:

relu层处理:

layer1层处理:
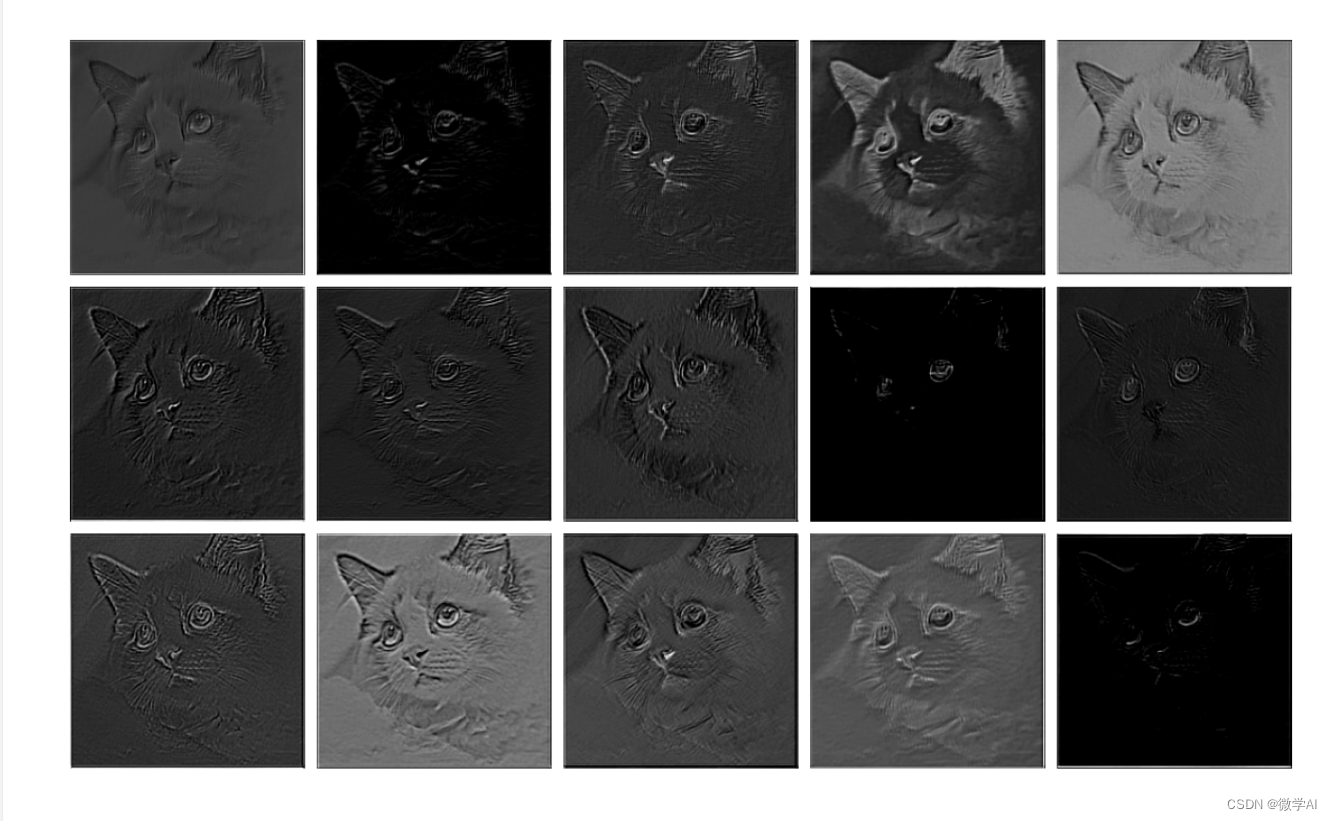
layer2层处理:

layer3层处理:
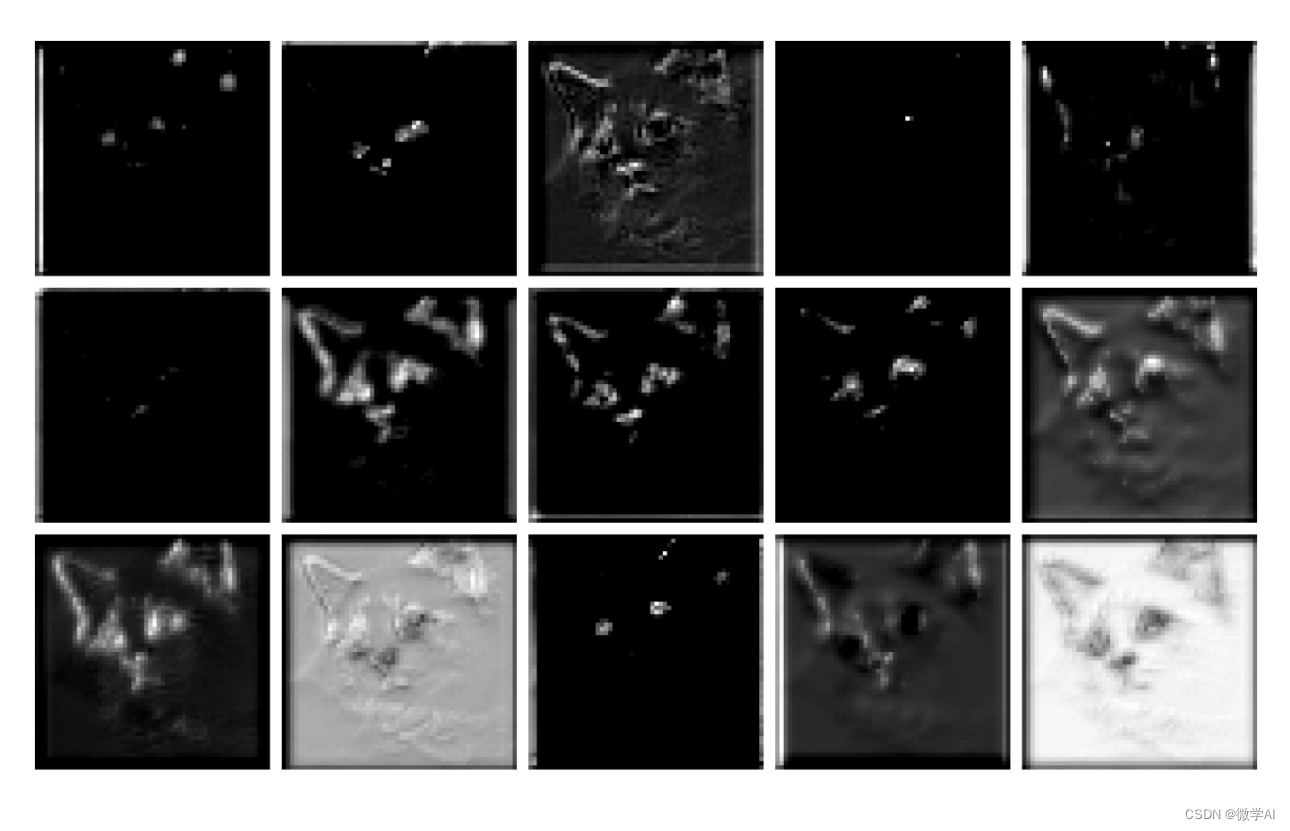
五、总结
CNN中的图像特征提取是通过模拟人类视觉系统的工作原理,逐层提取输入数据(比如图像)的不同层次的特征表示,从而实现对输入数据的深度学习和分析。通过卷积层、池化层和全连接层等组成的多层结构,CNN能够自动学习出输入数据中的抽象特征,从低级特征(如边缘、纹理)到更高级的语义概念(如物体形状、颜色、纹理等)。这种层次化的特征表达方式,使得CNN在图像分类、目标检测、人脸识别、图像生成等多种计算机视觉任务中都具有优异的性能表现。与传统的手工特征提取方法相比,CNN不需要人工设计特征,能够自动学习出最优的特征表示,因此大大减少了人工干预的成本,并且具有更好的泛化能力和鲁棒性。
相关文章:
计算机视觉的应用12-卷积神经网络中图像特征提取的可视化研究,让大家理解特征提取的全过程
大家好,我是微学AI,今天给大家介绍一下计算机视觉的应用12-卷积神经网络中图像特征提取的可视化研究,让大家理解特征提取的全过程。 要理解卷积神经网络中图像特征提取的全过程,我们可以将其比喻为人脑对视觉信息的处理过程。就像…...
el-table中点击跳转到详情页的两种方法
跳转的两种写法: 1.使用keep-alive使组件缓存,防止刷新时参数丢失 keep-alive 组件用于缓存和保持组件的状态,而不是路由参数。它可以在组件切换时保留组件的状态,从而避免重新渲染和加载数据。 keep-alive 主要用于提高页面性能和用户体验,而…...
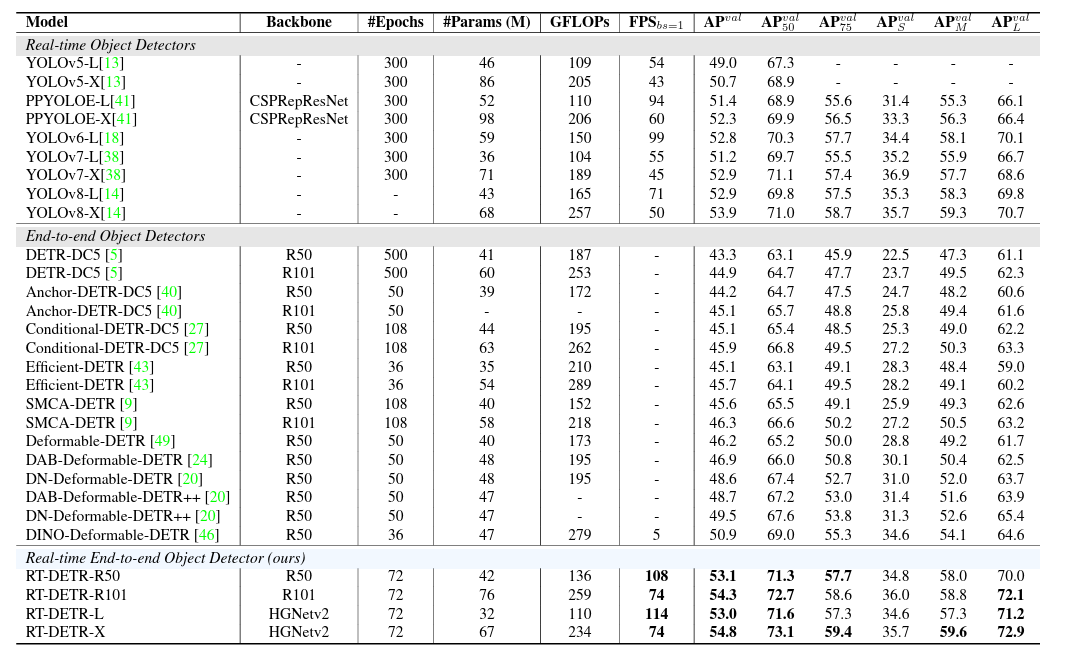
RT-DETR个人整理向理解
一、前言 在开始介绍RT-DETR这个网络之前,我们首先需要先了解DETR这个系列的网络与我们常提及的anchor-base以及anchor-free存在着何种差异。 首先我们先简单讨论一下anchor-base以及anchor-free两者的差异与共性: 1、两者差异:顾名思义&…...

易点易动库存管理系统与ERP系统打通,帮助企业实现低值易耗品管理
现今,企业管理日趋复杂,无论是核心经营还是辅助环节,都需要依靠信息化手段来提升效率。而低值易耗品作为企业日常运营中的必需品,其管理也面临诸多挑战。传统做法效率低下,容易出错。如何通过信息化手段实现低值易耗品的高效管理,成为许多企业必顾及的一个课题。 易点易动作为…...

【笔试强训选择题】Day34.习题(错题)解析
作者简介:大家好,我是未央; 博客首页:未央.303 系列专栏:笔试强训选择题 每日一句:人的一生,可以有所作为的时机只有一次,那就是现在!!!ÿ…...

“现代”“修饰”卷积神经网络,何谓现代
一、“现代” vs “传统” 现代卷积神经网络(CNNs)与传统卷积神经网络之间存在一些关键区别。这些区别主要涉及网络的深度、结构、训练技巧和应用领域等方面。以下是现代CNNs与传统CNNs之间的一些区别: 深度: 传统CNNs࿱…...

XHTML基础知识了解
XHTML是一种严格符合XML规范的标记语言,它的基本语法和HTML类似,但是更加严谨和规范。XHTML的代码结构非常清晰,方便浏览器和搜索引擎解析。下面是一些XHTML的基础知识和代码示例: 声明文档类型(DTD) 在X…...
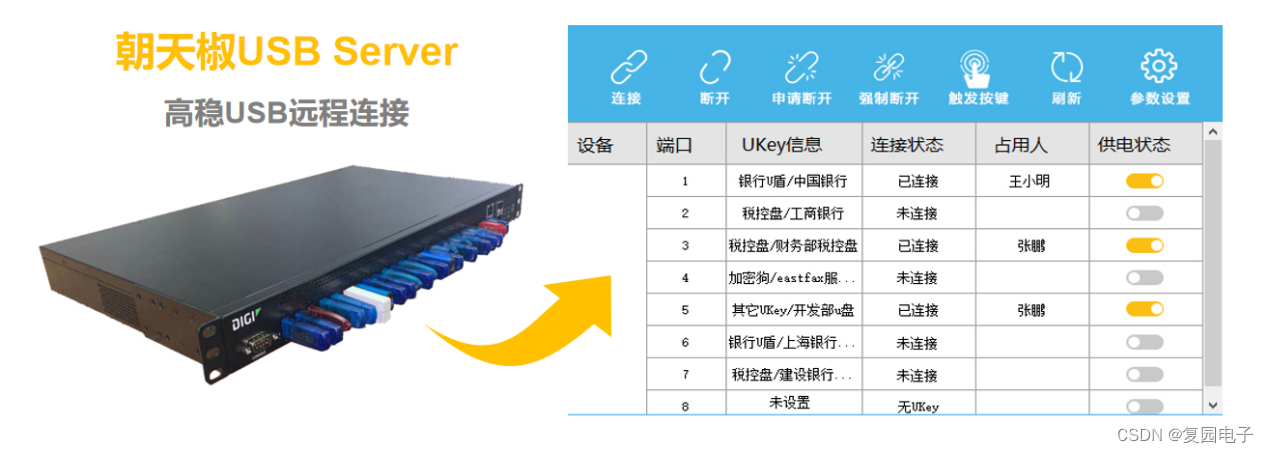
USB Server集中管控加密狗,浙江省电力设计院正在用
近日,软件加密狗的分散管理和易丢失性,给拥有大量加密狗的浙江省电力设计院带来了一系列的问题。好在浙江省电力设计院带及时使用了朝天椒USB Server方案,实现了加密狗的集中安全管控,避免了加密狗因为管理不善和遗失可能带来的巨…...

rust换源
在$HOME/.cargo/目录下建一个config文件。windows默认是C:\Users\user_name\.cargo。 config文件输入: [source.crates-io] registry "https://github.com/rust-lang/crates.io-index" # 使用 replace-with指明默认源更换为ustc源 replace-with ustc#…...

常见关系型数据库SQL增删改查语句
常见关系型数据库SQL增删改查语句: 创建表(Create Table): CREATE TABLE employees (id INT PRIMARY KEY,name VARCHAR(50),age INT,department VARCHAR(50) ); 插入数据(Insert Into): INSERT …...

OpenCV(二十七):图像距离变换
1.像素间距离 2.距离变换函数distanceTransform() void cv::distanceTransform ( InputArray src, OutputArray dst, int distanceType, int maskSize, int dstType CV_32F ) src:输入图像,数据类型为CV8U的单通道图像dst:输出图像,与输入图像…...

服务器就是一台电脑吗?服务器的功能和作用
服务器不仅仅是一台普通的电脑,它在功能和作用上有着显著的区别。下面是关于服务器的功能和作用的简要说明: 存储和共享数据:服务器可以用作数据存储和共享的中心。它们通常配备大容量的硬盘或固态硬盘,用于存储文件、数据库和其他…...

vue3实现塔罗牌翻牌
vue3实现塔罗牌翻牌 前言一、操作步骤1.布局2.操作3.样式 总结 前言 最近重刷诡秘之主,感觉里面的塔罗牌挺有意思,于是做了一个简单的塔罗牌翻牌动画(vue3vitets) 一、操作步骤 1.布局 首先我们定义一个整体的塔罗牌盒子&…...
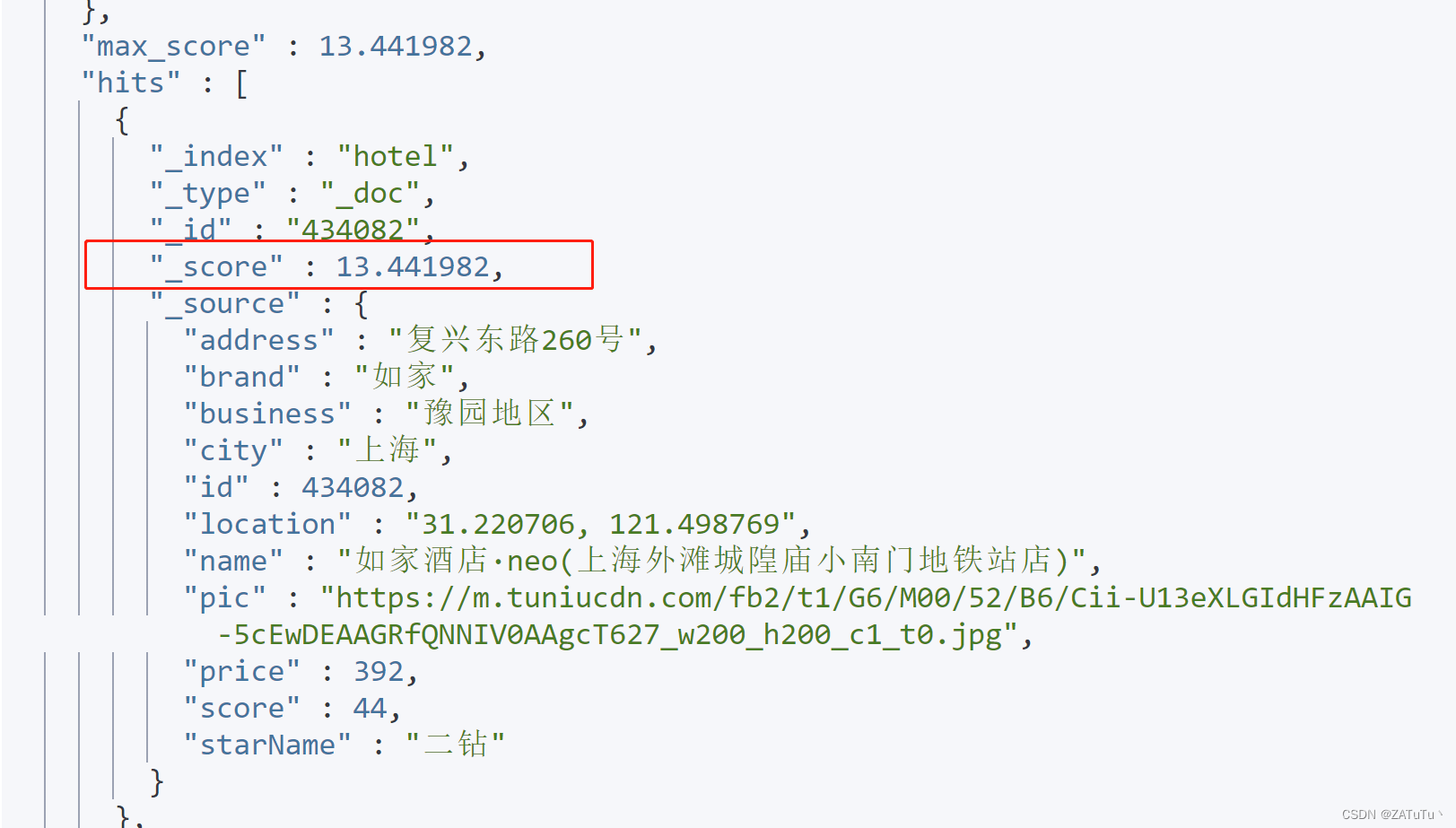
分布式搜索引擎
1 DSL查询文档 elasticsearch的查询依然是基于JSON风格的DSL来实现的。 1.1.DSL查询分类 Elasticsearch提供了基于JSON的DSL(Domain Specific Language)来定义查询。常见的查询类型包括: 查询所有:查询出所有数据,一…...
【2023最新版】腾讯云CODING平台使用教程(Pycharm/命令:本地项目推送到CODING)
目录 一、CODING简介 网址 二、CODING使用 1. 创建项目 2. 创建代码仓库 三、PyCharm:本地项目推送到CODING 1. 管理远程 2. 提交 3. 推送 4. 结果 四、使用命令推送 1. 打开终端 2. 初始化 Git 仓库 3. 添加远程仓库 4. 添加文件到暂存区 5. 提交更…...
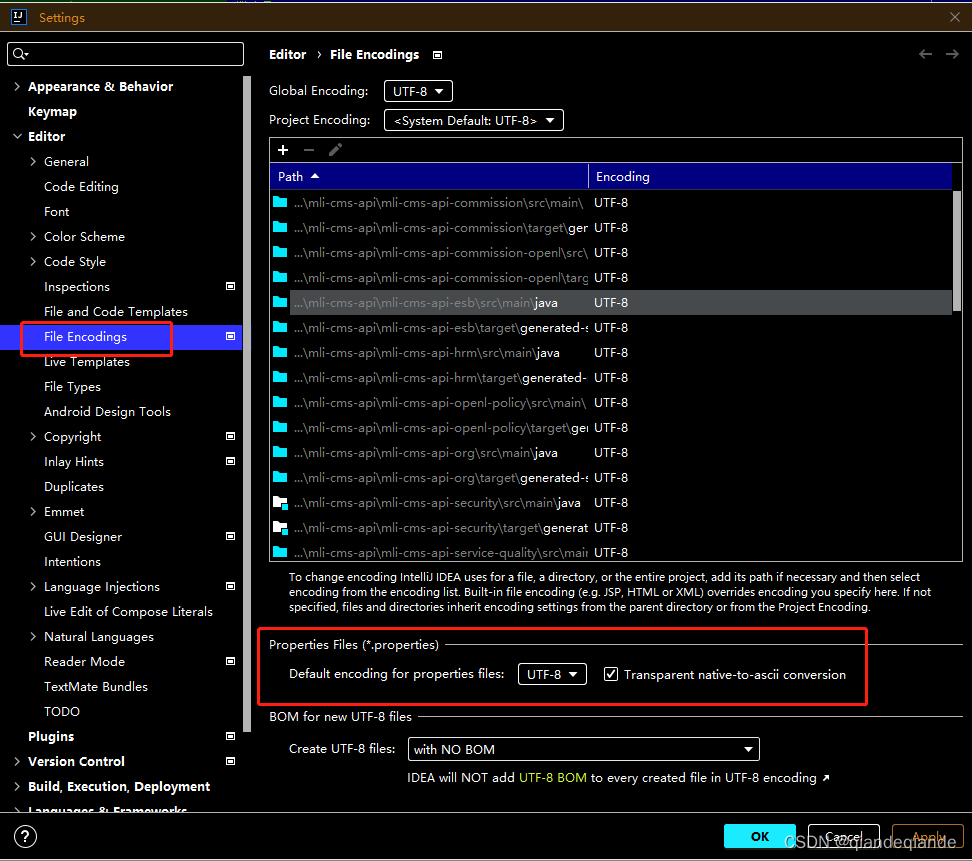
IDEA Properties 文件亂碼怎麼解決
1.FIle->Setting->Editor->File Encodings 修改Properties FIles 編碼顯示格式:UTF-8...

uniapp微信小程序用户隐私保护
使用wx.requirePrivacyAuthorize实现微信小程序用户隐私保护。 一、前言 微信小程序官方出了一个公告《关于小程序隐私保护指引设置的公告》。不处理的话,会导致很多授权无法使用,比如头像昵称、获取手机号、位置、访问相册、上传图片视频、访问剪切板…...

虚幻引擎4中关于设置关于体坐标系下的物体速度的相关问题
虚幻引擎4中关于设置关于体坐标系下的物体速度的相关问题 文章目录 虚幻引擎4中关于设置关于体坐标系下的物体速度的相关问题前言全局坐标系转体坐标系速度设置X轴方向的体坐标系速度设置Y轴方向的体坐标系速度XY轴体坐标系速度整合 Z轴速度的进一步设置解决办法 小结 前言 利…...
)
16 | Spark SQL 的 UDF(用户自定义函数)
UDF(用户自定义函数):Spark SQL 允许用户定义自定义函数,以便在 SQL 查询或 DataFrame 操作中使用。这些 UDF 可以扩展 Spark SQL 的功能,使用户能够执行更复杂的数据操作。 示例: // 注册UDF spark.udf.register("calculateDiscount", (price: Double, disc…...
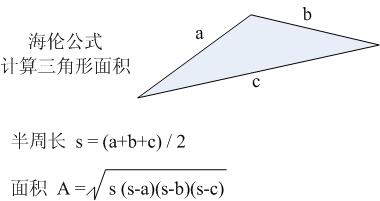
蓝桥杯官网填空题(土地测量)
题目描述 本题为填空题,只需要算出结果后,在代码中使用输出语句将所填结果输出即可。 造成高房价的原因有许多,比如土地出让价格。既然地价高,土地的面积必须仔细计算。遗憾的是,有些地块的形状不规则,比…...

Kafka压测实战:用JMeter精准诊断消息延迟与Lag根因
1. 为什么Kafka压测不能只靠“发消息看延迟”——JMeter不是万能胶,但它是唯一能说清真相的尺子很多人第一次给Kafka做负载测试,就是写个Python脚本,用confluent-kafka库往topic里狂塞10万条消息,然后看ProducerRecord的callback耗…...
)
手把手用Python实现μ律/A律压缩算法(附完整代码与波形对比)
手把手用Python实现μ律/A律压缩算法(附完整代码与波形对比) 在数字音频处理领域,动态范围压缩是一个永恒的话题。想象一下,当你录制一段包含轻柔耳语和强烈鼓声的音频时,直接使用线性PCM编码会导致要么小声部分被量化…...

到底什么是 AI 测试?AI 测试与传统测试的区别?
过去两年,AI已经从"加分项"变成了"必选项"。 不只是大厂,二线公司、甚至传统行业的测试团队都在要求:"能熟练使用AI工具提效"。 更关键的是,面试的玩法也变了。现在的技术面试早就跳出了 “考 AI 零…...

P6 马铃薯病害识别
🍨 本文为🔗365天深度学习训练营中的学习记录博客🍖 原作者:K同学啊 个人总结:了解VGG由 5 组卷积池化块堆叠构成,依靠小尺寸卷积核逐层提取图像浅层、深层特征,最后通过全连接层完成分类。&…...

AI写的小说与人类作者写的究竟有什么区别
AI写的小说与小说作者写的究竟有什么区别当2026年生成式AI的创作能力已经能做到日更百万字,当起点晋江上超过七成的网文作者都开始用AI辅助码字,当读者对着屏幕上几十万字的爽文分不清到底是人写的还是AI生成的——关于AI创作的讨论,早就从“…...

《QGIS空间数据处理与高级制图》022:融合后拓扑错误预检查
作者:翰墨之道,毕业于国际知名大学空间信息与计算机专业,获硕士学位,现任国内时空智能领域资深专家、CSDN知名技术博主。多年来深耕地理信息与时空智能核心技术研发,精通 QGIS、GrassGIS、OSG、OsgEarth、UE、Cesium、OpenLayers、Leaflet、MapBox 等主流工具与框架,兼具…...

三国杀卡牌DIY终极指南:5分钟打造你的专属武将
三国杀卡牌DIY终极指南:5分钟打造你的专属武将 【免费下载链接】Lyciumaker 在线三国杀卡牌制作器 项目地址: https://gitcode.com/gh_mirrors/ly/Lyciumaker 还在羡慕别人能设计出酷炫的三国杀武将卡牌吗?Lyciumaker这个免费开源的三国杀卡牌制作…...

BinaryBomb通关后,我总结了这6个Linux调试与逆向的‘骚操作’
BinaryBomb通关后,我总结了这6个Linux调试与逆向的‘骚操作’ 在计算机系统基础课程中,BinaryBomb实验堪称是检验学生调试与逆向能力的"试金石"。作为一位刚刚通关的"拆弹专家",我想分享那些教科书上不会教、却能让你效率…...

Taotoken用量看板与成本管理功能实操体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板与成本管理功能实操体验 在将多个大模型API集成到实际项目中时,除了对接的便利性,团队往往…...

AI绘画的三重危机:颜料、像素与剽窃
1. 这不是技术讨论,而是一场正在发生的行业地震“Paint, Pixels, and Plagiarism”——光看这个标题,你就能闻到火药味。它没说“AI绘画工具使用指南”,也没写“Stable Diffusion参数调优手册”,而是把颜料(Paint&…...