Python爬虫数据存哪里|数据存储到文件的几种方式
前言
大家早好、午好、晚好吖 ❤ ~欢迎光临本文章

爬虫请求解析后的数据,需要保存下来,才能进行下一步的处理,一般保存数据的方式有如下几种:
-
文件:txt、csv、excel、json等,保存数据量小。
-
关系型数据库:mysql、oracle等,保存数据量大。
-
非关系型数据库:Mongodb、Redis等键值对形式存储数据,保存数据量大。
-
二进制文件:保存爬取的图片、视频、音频等格式数据。
首先,获取豆瓣读书《平凡的世界》的3页短评信息,然后保存到文件中。
具体代码如下(忽略异常):
import requests
from bs4 import BeautifulSoupurls=['https://**网址不可放**/subject/1200840/comments/?start={}&limit=20&status=P&sort=new_score'.format(str(i)) for i in range(0, 60, 20)] #通过观察的url翻页的规律,使用for循环得到3个链接,保存到urls列表中
print(urls)
dic_h = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"}
comments_list = [] #初始化用于保存短评的列表for url in urls: #使用for循环分别获取每个页面的数据,保存到comments_list列表r = requests.get(url=url,headers = dic_h).textsoup = BeautifulSoup(r, 'lxml')ul = soup.find('div',id="comments")lis= ul.find_all('p')list2 =[]for li in lis:list2.append(li.find('span').string)# print(list2)comments_list.extend(list2)print(comments_list)
爬到评论数据保存到列表中:

使用open()方法写入文件‘
保存数据到txt
将上述爬取的列表数据保存到txt文件:
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:702813599
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
with open('comments.txt', 'w', encoding='utf-8') as f: #使用with open()新建对象f# 将列表中的数据循环写入到文本文件中for i in comments_list:f.write(i+"\n") #写入数据

保存数据到csv
CSV(Comma-Separated Values、逗号分隔值或字符分割值):
是一种以纯文件方式进行数据记录的存储格式,保存csv文件,需要使用python的内置模块csv。
写入列表或者元组数据:
创建writer对象,使用writerow()写入一行数据,使用writerows()方法写入多行数据。
使用writer对象写入列表数据,示例代码如下:
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:702813599
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
import csvheaders = ['No','name','age']
values = [['01','zhangsan',18],['02','lisi',19],['03','wangwu',20]
]
with open('test1.csv','w',newline='') as fp:# 获取对象writer = csv.writer(fp)# 写入数据writer.writerow(headers) #写入表头writer.writerows(values) # 写入数据
写入字典数据:
创建DictWriter对象,使用writerow()写入一行数据,使用writerows()方法写入多行数据。
使用 DictWriter 对象写入字典数据,示例代码如下:
import csvheaders = ['No','name','age']
values = [{"No":'01',"name":'zhangsan',"age":18},{"No":'02',"name":'lisi',"age":19},{"No":'03',"name":'wangwu',"age":20}]
with open('test.csv','w',newline='') as fp:dic_writer = csv.DictWriter(fp,headers)dic_writer.writeheader()# 写入表头dic_writer.writerows(values) #写入数据
将上述爬取到的数据保存到csv文件中:
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:702813599
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
import requests
import csv
from bs4 import BeautifulSoup
urls=['https://book.douban.com/subject/1200840/comments/?start={}&limit=20&status=P&sort=new_score'.format(str(i)) for i in range(0, 60, 20)] #通过观察的url翻页的规律,使用for循环得到5个链接,保存到urls列表中
print(urls)
dic_h = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"}
comments_list = [] #初始化用于保存短评的列表for url in urls: #使用for循环分别获取每个页面的数据,保存到comments_list列表r = requests.get(url=url,headers = dic_h).textsoup = BeautifulSoup(r, 'lxml')ul = soup.find('div',id="comments")lis= ul.find_all('p')list2 =[]for li in lis:list2.append(li.find('span').string)# print(list2)comments_list.extend(list2)new_list = [[x] for x in comments_list] #列表生成器,将列表项转为子列表with open("com11.csv", mode="w", newline="", encoding="utf-8") as f:csv_file = csv.writer(f) # 创建CSV文件写入对象for i in new_list:csv_file.writerow(i)

使用pandas保存数据
pandas支持多种文件格式的读写,最常用的就是csv和excel数据的操作,
因为直接读取的数据是数据框格式,所以在爬虫、数据分析中使用非常广泛。
一般,将爬取到的数据储存为DataFrame对象(DataFrame 是一个表格或者类似二维数组的结构,它的各行表示一个实例,各列表示一个变量)。
pandas保存数据到excel、csv
pandas保存excel、csv,非常简单,两行代码就可以搞定:
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:702813599
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
df = pd.DataFrame(comments_list) #把comments_list列表转换为pandas DataFrame
df.to_excel('comments.xlsx') #保存到excel表格
# df.to_csv('comments.csv')#保存在csv文件

结尾给大家推荐一个非常好的学习教程,希望对你学习Python有帮助!
48小时搞定全套爬虫教程!你和爬虫大佬只有一步之遥【python教程】
尾语
好了,今天的分享就差不多到这里了!
对下一篇大家想看什么,可在评论区留言哦!看到我会更新哒(ง •_•)ง
喜欢就关注一下博主,或点赞收藏评论一下我的文章叭!!!

相关文章:
Python爬虫数据存哪里|数据存储到文件的几种方式
前言 大家早好、午好、晚好吖 ❤ ~欢迎光临本文章 爬虫请求解析后的数据,需要保存下来,才能进行下一步的处理,一般保存数据的方式有如下几种: 文件:txt、csv、excel、json等,保存数据量小。 关系型数据库…...
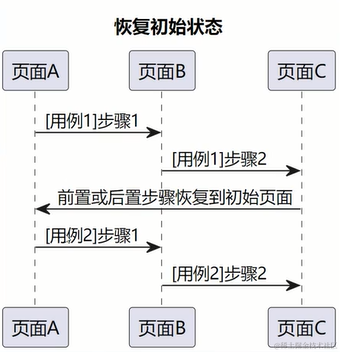
软件测试/测试开发丨Web自动化 测试用例流程设计
点此获取更多相关资料 本文为霍格沃兹测试开发学社学员学习笔记分享 原文链接:https://ceshiren.com/t/topic/27173 一、测试用例通用结构回顾 1.1、现有测试用例存在的问题 可维护性差可读性差稳定性差 1.2、用例结构设计 测试用例的编排测试用例的项目结构 1…...

git撤销修改命令
要撤销Git中尚未提交的所有修改,可以使用以下几种方法: 1、使用git checkout命令丢弃工作目录的修改,重置工作目录中所有文件的修改。 git checkout . 2、使用git reset命令重置暂存区和工作目录, 重置暂存区和工作目录,回到最后一次提交后的状态。 …...

EOCR-AR电机保护器自动复位的启用条件说明
为适用不同的现场使用需求,施耐德韩国公司推出了带有自动复位功能的模拟型电动机保护器-EOCR-AR。EOCR-AR电机保护器具有过电流、缺相、堵转保护功能,还可根据实际需要设置自动复位时间。 EOCR-AR自动复位的设置方法 如上图,R-TIME旋钮是自动…...
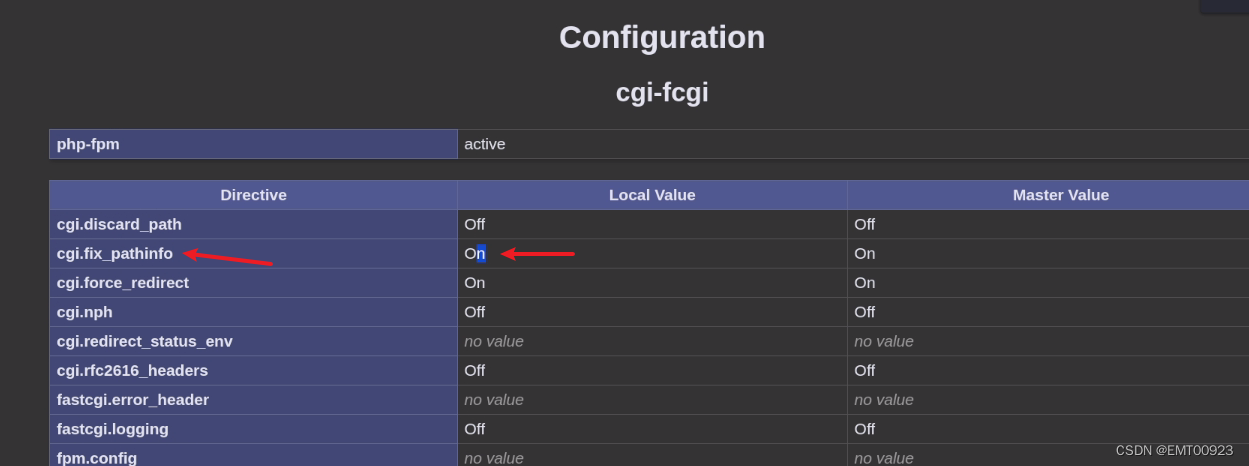
Apache nginx解析漏洞复现
文章目录 空字节漏洞安装环境漏洞复现 背锅解析漏洞安装环境漏洞复现 空字节漏洞 安装环境 将nginx解压后放到c盘根目录下: 运行startup.bat启动环境: 在HTML文件夹下有它的主页文件: 漏洞复现 nginx在遇到后缀名有php的文件时,…...
.NET之后,再无大创新
回想起来,2001年发布的.NET已经是距离最近的一次软件开发技术的整体创新了,后续的新技术就没有在各个端都这么成功的了。.NET是Windows平台下软件开发技术的巨大变革。在此之前,有VB、C(MFC)、JSP,在此之后…...

【大麦小米学量化】什么是量化交易?哪些人适合做量化交易?
系列文章目录 文章目录 系列文章目录学霸的梦想前言一、什么是量化交易?二、哪些人适合做量化交易?三、量化交易都需要掌握哪些技术和方法?总结 学霸的梦想 小米支棱着迷糊的眼睛,一脸懵逼的问大麦:“我说大麦哥哥&…...
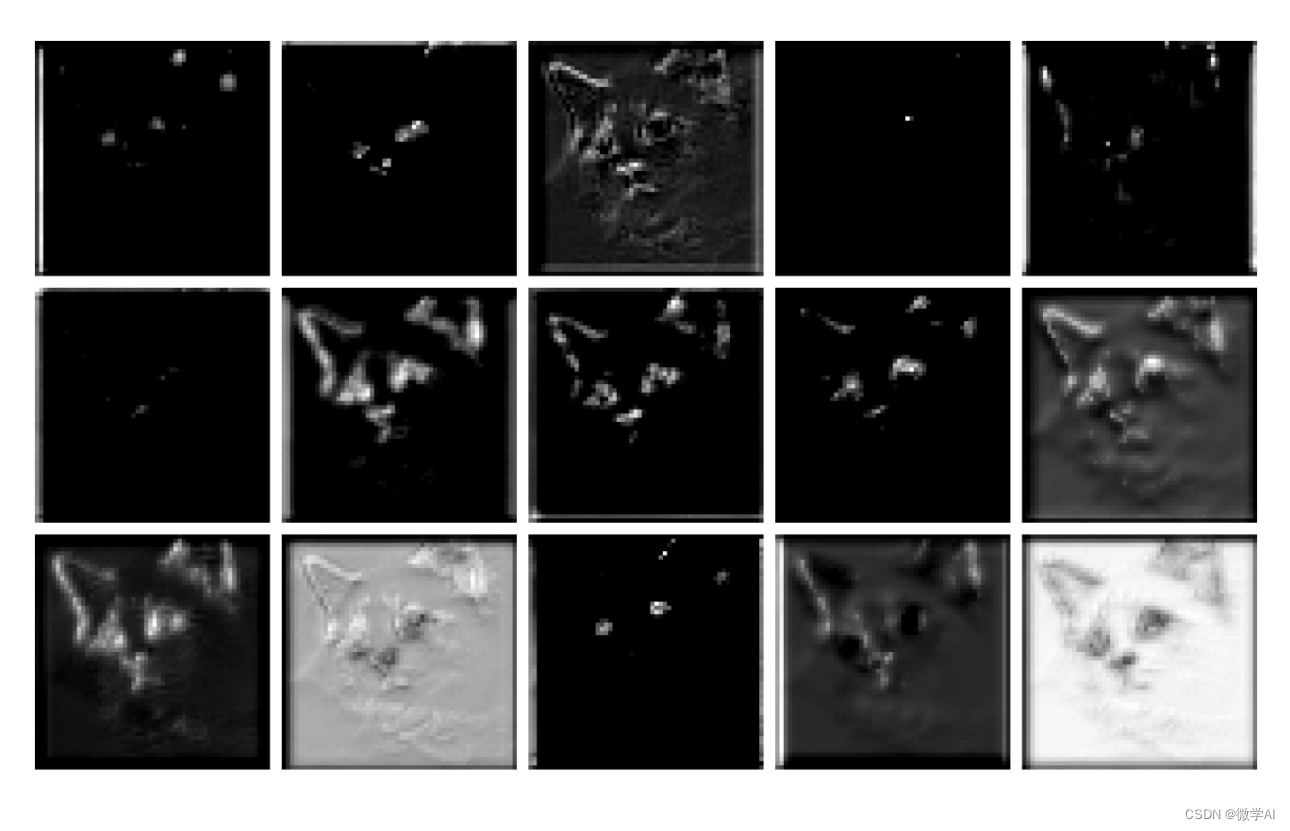
计算机视觉的应用12-卷积神经网络中图像特征提取的可视化研究,让大家理解特征提取的全过程
大家好,我是微学AI,今天给大家介绍一下计算机视觉的应用12-卷积神经网络中图像特征提取的可视化研究,让大家理解特征提取的全过程。 要理解卷积神经网络中图像特征提取的全过程,我们可以将其比喻为人脑对视觉信息的处理过程。就像…...
el-table中点击跳转到详情页的两种方法
跳转的两种写法: 1.使用keep-alive使组件缓存,防止刷新时参数丢失 keep-alive 组件用于缓存和保持组件的状态,而不是路由参数。它可以在组件切换时保留组件的状态,从而避免重新渲染和加载数据。 keep-alive 主要用于提高页面性能和用户体验,而…...
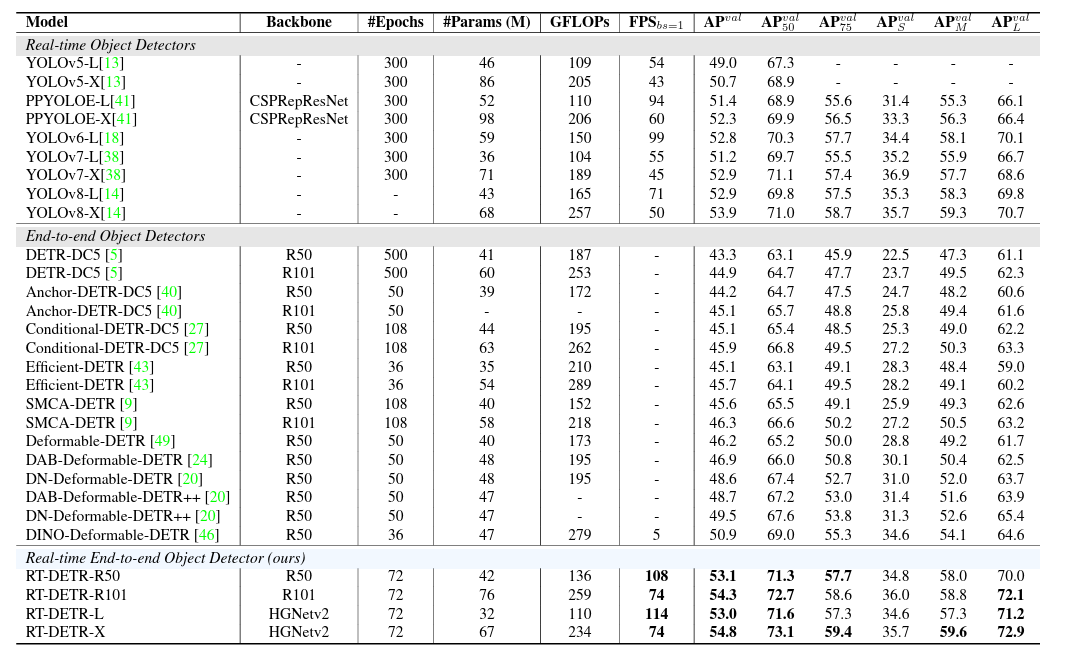
RT-DETR个人整理向理解
一、前言 在开始介绍RT-DETR这个网络之前,我们首先需要先了解DETR这个系列的网络与我们常提及的anchor-base以及anchor-free存在着何种差异。 首先我们先简单讨论一下anchor-base以及anchor-free两者的差异与共性: 1、两者差异:顾名思义&…...

易点易动库存管理系统与ERP系统打通,帮助企业实现低值易耗品管理
现今,企业管理日趋复杂,无论是核心经营还是辅助环节,都需要依靠信息化手段来提升效率。而低值易耗品作为企业日常运营中的必需品,其管理也面临诸多挑战。传统做法效率低下,容易出错。如何通过信息化手段实现低值易耗品的高效管理,成为许多企业必顾及的一个课题。 易点易动作为…...

【笔试强训选择题】Day34.习题(错题)解析
作者简介:大家好,我是未央; 博客首页:未央.303 系列专栏:笔试强训选择题 每日一句:人的一生,可以有所作为的时机只有一次,那就是现在!!!ÿ…...

“现代”“修饰”卷积神经网络,何谓现代
一、“现代” vs “传统” 现代卷积神经网络(CNNs)与传统卷积神经网络之间存在一些关键区别。这些区别主要涉及网络的深度、结构、训练技巧和应用领域等方面。以下是现代CNNs与传统CNNs之间的一些区别: 深度: 传统CNNs࿱…...

XHTML基础知识了解
XHTML是一种严格符合XML规范的标记语言,它的基本语法和HTML类似,但是更加严谨和规范。XHTML的代码结构非常清晰,方便浏览器和搜索引擎解析。下面是一些XHTML的基础知识和代码示例: 声明文档类型(DTD) 在X…...
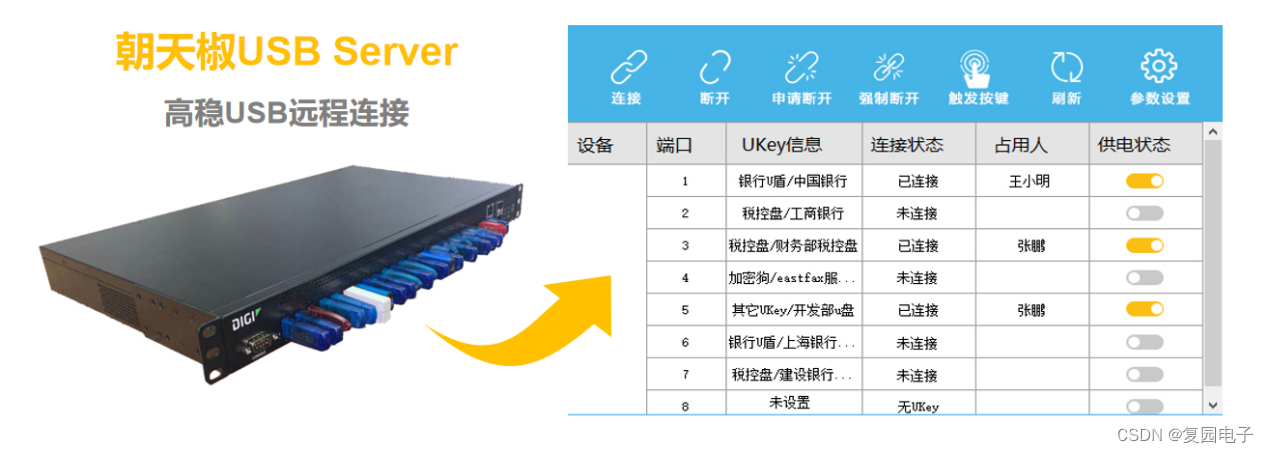
USB Server集中管控加密狗,浙江省电力设计院正在用
近日,软件加密狗的分散管理和易丢失性,给拥有大量加密狗的浙江省电力设计院带来了一系列的问题。好在浙江省电力设计院带及时使用了朝天椒USB Server方案,实现了加密狗的集中安全管控,避免了加密狗因为管理不善和遗失可能带来的巨…...

rust换源
在$HOME/.cargo/目录下建一个config文件。windows默认是C:\Users\user_name\.cargo。 config文件输入: [source.crates-io] registry "https://github.com/rust-lang/crates.io-index" # 使用 replace-with指明默认源更换为ustc源 replace-with ustc#…...

常见关系型数据库SQL增删改查语句
常见关系型数据库SQL增删改查语句: 创建表(Create Table): CREATE TABLE employees (id INT PRIMARY KEY,name VARCHAR(50),age INT,department VARCHAR(50) ); 插入数据(Insert Into): INSERT …...

OpenCV(二十七):图像距离变换
1.像素间距离 2.距离变换函数distanceTransform() void cv::distanceTransform ( InputArray src, OutputArray dst, int distanceType, int maskSize, int dstType CV_32F ) src:输入图像,数据类型为CV8U的单通道图像dst:输出图像,与输入图像…...

服务器就是一台电脑吗?服务器的功能和作用
服务器不仅仅是一台普通的电脑,它在功能和作用上有着显著的区别。下面是关于服务器的功能和作用的简要说明: 存储和共享数据:服务器可以用作数据存储和共享的中心。它们通常配备大容量的硬盘或固态硬盘,用于存储文件、数据库和其他…...

vue3实现塔罗牌翻牌
vue3实现塔罗牌翻牌 前言一、操作步骤1.布局2.操作3.样式 总结 前言 最近重刷诡秘之主,感觉里面的塔罗牌挺有意思,于是做了一个简单的塔罗牌翻牌动画(vue3vitets) 一、操作步骤 1.布局 首先我们定义一个整体的塔罗牌盒子&…...

Linux服务器安全加固实战:SSH+防火墙+权限最小化三重防护
1. 这不是“加个密码就完事”的安全,而是让服务器真正扛住真实攻击的第一道防线很多人以为 Linux 安全加固就是改个 root 密码、关掉 telnet、再装个 fail2ban 就算交差了。我去年帮一家做跨境电商 SaaS 的客户做渗透复测时,他们运维同事就是这么干的——…...
一套代码搞定 App/小程序/H5/PC,私域流量神器)
别再重复造轮子了!这个开源论坛小程序(Java+Uniapp)一套代码搞定 App/小程序/H5/PC,私域流量神器
你是否有过这些想法? 我想做个类似“知识星球”的圈子小程序,但外包报价动辄 5 万起…… 公司要做私域社区,需要同时支持微信小程序和 App,难道要养两个开发团队? 想靠“付费帖子 会员 打赏”变现,去哪…...

第一性原理计算在半导体缺陷研究中的应用:以氢掺杂氧化镓为例
1. 项目概述:从“掺杂”与“缺陷”说起在半导体材料的研究与开发中,我们常常听到“掺杂”这个词。简单来说,就像在炒菜时撒入不同的调料来改变风味,掺杂就是在纯净的半导体材料(本征材料)中,有目…...

避坑指南:Ubuntu 20.04上VINS-Fusion环境搭建,从源码修改到手机数据实测的完整流程
Ubuntu 20.04下VINS-Fusion环境搭建全流程避坑手册 当你在Ubuntu 20.04上尝试搭建VINS-Fusion环境时,可能会遇到各种令人头疼的问题。从依赖项安装到源码修改,再到手机摄像头数据的适配,每一步都可能隐藏着意想不到的"坑"。本文将带…...
:绘图模式——演示时“手写板”:标注、圈画、临时白板)
《Sysinternals实战指南》ZoomIt 学习笔记(11.9):绘图模式——演示时“手写板”:标注、圈画、临时白板
🔥个人主页:杨利杰YJlio❄️个人专栏:《Sysinternals实战教程》《Windows PowerShell 实战》《WINDOWS教程》《IOS教程》《微信助手》《锤子助手》 《Python》 《Kali Linux》 《那些年未解决的Windows疑难杂症》🌟 让复杂的事情更…...

用 shell 命令做 AI Agent 的插件系统:为什么 Hook 不是函数调用
用 shell 命令做 AI Agent 的插件系统:为什么 Hook 不是函数调用 这是 《写完一个 AI 编程助手之后,我才确定 prompt 工程不是重点》 系列的第七篇(最后一篇)。前六篇讲了进程模型、权限、并发调度、上下文压缩、记忆系统。这一篇…...

Qwen-Image-2512+LoRA:构建Godot 4.x原生像素编译工作流
1. 这不是“AI画图”,而是一次像素艺术工作流的底层重构你有没有试过在Godot 4.x里导入一张Stable Diffusion生成的“像素风”图,结果放大一看全是模糊的伪像素、边缘发虚、色阶溢出,连8-bit调色板都对不上?我去年帮三个独立游戏团…...

Spine骨骼动画集成:Unity 2D游戏性能优化实战指南
1. 为什么Spine不是“另一个动画插件”,而是2D游戏性能分水岭在Unity里做2D游戏,很多人卡在同一个地方:角色动起来很卡,美术给的PSD切图动效一多就掉帧,UI动画和角色动画抢资源,打包后APK体积暴涨——你试过…...
)
ChatGPT生成的SQL注入漏洞代码竟通过了87%静态扫描器?安全团队紧急避坑指南(含检测脚本)
更多请点击: https://codechina.net 第一章:ChatGPT生成的SQL注入漏洞代码竟通过了87%静态扫描器?安全团队紧急避坑指南(含检测脚本) 近期,某金融企业安全团队在代码审计中发现,一段由ChatGPT生…...

别再瞎找了!AI论文写作软件2026最新测评与推荐
2026年真正好用的AI论文写作软件,核心看生成的论文质量、低AI味、格式正确、学术适配四大指标。综合实测,千笔AI、ThouPen、豆包、DeepSeek、Grammarly 是当前最值得推荐的梯队,覆盖从免费到付费、从中文到英文、从文科到理工的全场景需求。 …...