用huggingface.Accelerate进行分布式训练
诸神缄默不语-个人CSDN博文目录
本文属于huggingface.transformers全部文档学习笔记博文的一部分。
全文链接:huggingface transformers包 文档学习笔记(持续更新ing…)
本部分网址:https://huggingface.co/docs/transformers/main/en/accelerate
本文介绍如何使用huggingface.accelerate(官方文档:https://huggingface.co/docs/accelerate/index)进行分布式训练。
此外还参考了accelerate的安装文档:https://huggingface.co/docs/accelerate/basic_tutorials/install
一个本文代码可用的Python环境:Python 3.9.7, PyTorch 2.0.1, transformers 4.31.0, accelerate 0.22.0
parallelism能让我们实现在硬件条件受限时训练更大的模型,训练速度能加快几个数量级。
文章目录
- 1. 安装与配置
- 2. 在代码中使用
1. 安装与配置
安装:pip install accelerate
配置:accelerate config
然后它会给出一些问题,通过上下键更换选项,用Enter确定
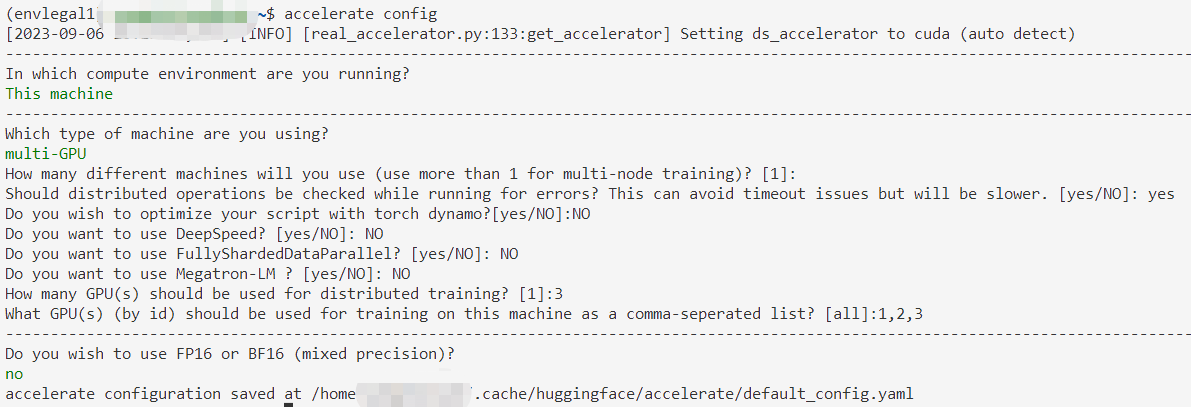
选错了也没啥关系,反正能改
用accelerate env命令可以查看配置环境。
2. 在代码中使用
用accelerate之前的脚本(具体讲解可见我之前写的博文:用huggingface.transformers.AutoModelForSequenceClassification在文本分类任务上微调预训练模型 用的是原生PyTorch那一版,因为Trainer会自动使用分布式训练。metric部分改成新版,并用全部数据来训练):
from tqdm.auto import tqdmimport torch
from torch.utils.data import DataLoader
from torch.optim import AdamWimport datasets,evaluate
from transformers import AutoTokenizer,AutoModelForSequenceClassification,get_schedulerdataset=datasets.load_from_disk("download/yelp_full_review_disk")tokenizer=AutoTokenizer.from_pretrained("/data/pretrained_models/bert-base-cased")def tokenize_function(examples):return tokenizer(examples["text"], padding="max_length",truncation=True,max_length=512)tokenized_datasets=dataset.map(tokenize_function, batched=True)#Postprocess dataset
tokenized_datasets=tokenized_datasets.remove_columns(["text"])
#删除模型不用的text列tokenized_datasets=tokenized_datasets.rename_column("label", "labels")
#改名label列为labels,因为AutoModelForSequenceClassification的入参键名为label
#我不知道为什么dataset直接叫label就可以啦……tokenized_datasets.set_format("torch") #将值转换为torch.Tensor对象small_train_dataset=tokenized_datasets["train"].shuffle(seed=42)
small_eval_dataset=tokenized_datasets["test"].shuffle(seed=42)train_dataloader=DataLoader(small_train_dataset,shuffle=True,batch_size=32)
eval_dataloader=DataLoader(small_eval_dataset,batch_size=64)model=AutoModelForSequenceClassification.from_pretrained("/data/pretrained_models/bert-base-cased",num_labels=5)optimizer=AdamW(model.parameters(),lr=5e-5)num_epochs=3
num_training_steps=num_epochs*len(train_dataloader)
lr_scheduler=get_scheduler(name="linear",optimizer=optimizer,num_warmup_steps=0,num_training_steps=num_training_steps)device=torch.device("cuda:1") if torch.cuda.is_available() else torch.device("cpu")
model.to(device)progress_bar = tqdm(range(num_training_steps))model.train()
for epoch in range(num_epochs):for batch in train_dataloader:batch={k:v.to(device) for k,v in batch.items()}outputs=model(**batch)loss=outputs.lossloss.backward()optimizer.step()lr_scheduler.step()optimizer.zero_grad()progress_bar.update(1)metric=evaluate.load("accuracy")
model.eval()
for batch in eval_dataloader:batch={k:v.to(device) for k,v in batch.items()}with torch.no_grad():outputs=model(**batch)logits=outputs.logitspredictions=torch.argmax(logits, dim=-1)metric.add_batch(predictions=predictions, references=batch["labels"])print(metric.compute())
懒得跑完了,总之预计要跑11个小时来着,非常慢。
添加如下代码:
from accelerate import Acceleratoraccelerator = Accelerator()#去掉将模型和数据集放到指定卡上的代码#在建立好数据集、模型和优化器之后:
train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(train_dataloader, eval_dataloader, model, optimizer
)#训练阶段将loss.backward()替换成
accelerator.backward(loss)
添加后的代码(我用全部数据集出来预计训练时间是4小时(3张卡),但我懒得跑这么久了,我就还是用1000条跑跑,把整个流程跑完意思一下):
用accelerate launch Python脚本路径运行
验证部分的情况见代码后面
from tqdm.auto import tqdmimport torch
from torch.utils.data import DataLoader
from torch.optim import AdamWimport datasets
from transformers import AutoTokenizer,AutoModelForSequenceClassification,get_schedulerfrom accelerate import Acceleratoraccelerator = Accelerator()dataset=datasets.load_from_disk("download/yelp_full_review_disk")tokenizer=AutoTokenizer.from_pretrained("/data/pretrained_models/bert-base-cased")def tokenize_function(examples):return tokenizer(examples["text"], padding="max_length",truncation=True,max_length=512)tokenized_datasets=dataset.map(tokenize_function, batched=True)#Postprocess dataset
tokenized_datasets=tokenized_datasets.remove_columns(["text"])
#删除模型不用的text列tokenized_datasets=tokenized_datasets.rename_column("label", "labels")
#改名label列为labels,因为AutoModelForSequenceClassification的入参键名为label
#我不知道为什么dataset直接叫label就可以啦……tokenized_datasets.set_format("torch") #将值转换为torch.Tensor对象small_train_dataset=tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
small_eval_dataset=tokenized_datasets["test"].shuffle(seed=42).select(range(1000))train_dataloader=DataLoader(small_train_dataset,shuffle=True,batch_size=32)
eval_dataloader=DataLoader(small_eval_dataset,batch_size=64)model=AutoModelForSequenceClassification.from_pretrained("/data/pretrained_models/bert-base-cased",num_labels=5)optimizer=AdamW(model.parameters(),lr=5e-5)train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(train_dataloader, eval_dataloader, model, optimizer
)num_epochs=3
num_training_steps=num_epochs*len(train_dataloader)
lr_scheduler=get_scheduler(name="linear",optimizer=optimizer,num_warmup_steps=0,num_training_steps=num_training_steps)progress_bar = tqdm(range(num_training_steps))model.train()
for epoch in range(num_epochs):for batch in train_dataloader:outputs=model(**batch)loss=outputs.lossaccelerator.backward(loss)optimizer.step()lr_scheduler.step()optimizer.zero_grad()progress_bar.update(1)
验证部分是这样的,直接用原来的验证部分就也能跑,但是因为脚本会被运行2遍,所以验证部分也会运行2遍。
所以我原则上建议用accelerate的话就光训练,验证的部分还是单卡实现。
如果还是想在训练过程中看一下验证效果,可以正常验证;也可以将验证部分限定在if accelerator.is_main_process:里,这样就只有主进程(通常是第一个GPU)会执行验证代码,而其他GPU不会,这样就只会打印一次指标了。
相关文章:
用huggingface.Accelerate进行分布式训练
诸神缄默不语-个人CSDN博文目录 本文属于huggingface.transformers全部文档学习笔记博文的一部分。 全文链接:huggingface transformers包 文档学习笔记(持续更新ing…) 本部分网址:https://huggingface.co/docs/transformers/m…...
unity 物体至视图中心以及新对象创建位置
如果游戏对象不在视野中心或在视野之外, 一种方法是双击Hierarchy中的对象名称 另一种是选中后按F 新建物体时对象的位置不是在坐标原点,而是在当前屏幕的中心...
船舶稳定性和静水力计算——绘图体平面图,静水力,GZ计算(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

Python 网页爬虫的原理是怎样的?
网页爬虫是一种自动化工具,用于从互联网上获取和提取信息。它们被广泛用于搜索引擎、数据挖掘、市场研究等领域。 网页爬虫的工作原理可以分为以下几个步骤:URL调度、页面下载、页面解析和数据提取。 URL调度: 网页爬虫首先需要一个初始的U…...

python技术面试题合集(二)
python技术面试题 1、简述django FBV和CBV FBV是基于函数编程,CBV是基于类编程,本质上也是FBV编程,在Djanog中使用CBV,则需要继承View类,在路由中指定as_view函数,返回的还是一个函数 在DRF中的使用的就是…...

【linux命令讲解大全】089.使用tree命令快速查看目录结构的方法
文章目录 tree补充说明语法选项列表选项文件选项排序选项图形选项XML / HTML / JSON 选项杂项选项 参数实例 从零学 python tree 树状图列出目录的内容 补充说明 tree 命令以树状图列出目录的内容。 语法 tree [选项] [参数]选项 列表选项 -a:显示所有文件和…...

【C++】—— 单例模式详解
前言: 本期,我将要讲解的是有关C中常见的设计模式之单例模式的相关知识!! 目录 (一)设计模式的六⼤原则 (二)设计模式的分类 (三)单例模式 1、定义 2、…...

TheRouter 框架原理
TheRouter 框架入口方法 通过InnerTheRouterContentProvider 注册在AndroidManifest.xml中,在应用启动时初始化 <application><providerandroid:name"com.therouter.InnerTheRouterContentProvider"android:authorities"${applicationId}.…...

系列十二、Java操作RocketMQ之带标签Tag的消息
一、带标签的Tag消息 1.1、概述 RocketMQ提供消息过滤的功能,通过Tag或者Key进行区分。我们往一个主题里面发送消息的时候,根据业务逻辑可能需要区分,比如带有tagA标签的消息被消费者A消费,带有tagB标签的消息被消费者B消费&…...

Java面向对象学习笔记-1
前言 “Java 学习笔记” 是为初学者和希望加深对Java编程语言的理解的人们编写的。Java是一门广泛应用于软件开发领域的强大编程语言,它的语法和概念对于初学者来说可能有些复杂。这份学习笔记的目的是帮助读者逐步学习Java的基本概念,并提供了一系列示…...

el-table根据data动态生成列和行
css //el-table-column加上fixed后会导致悬浮样式丢失,用下面方法可以避免 .el-table__body .el-table__row.hover-row td{background-color: #083a78 !important; } .el-table tbody tr:hover>td {background: #171F34 !important; }html <el-table ref&quo…...

【c++】如何有效地利用命名空间?
🌱博客主页:青竹雾色间 😘博客制作不易欢迎各位👍点赞⭐收藏➕关注 ✨人生如寄,多忧何为 ✨ 目录 前言什么是命名空间?命名空间的语法命名空间的使用避免命名冲突命名空间的嵌套总结 前言 当谈到C编…...

Go语言传参
为了让新手尽快熟悉go的使用,特记录此文,不必谢我,转载请注明! Go 语言中参数传递的各种效果,主要内容包括: 传值效果指针传递结构体传递map 传递channel 传递切片传递错误传递传递效果示例传递方式选择原文连接:https://mp.weixin.qq.com/s?__biz=MzA5Mzk4Njk1OA==&…...
SAP PI 配置SSL链接接口报错问题处理Peer certificate rejected by ChainVerifier
出现这种情况一般无非是没有正确导入证书或者证书过期的情况 第一种,如果没有导入证书的话,需要在NWA中的证书与验证-》CAs中导入管理员提供的证书,这里需要注意的是,需要导入完整的证书链。 第二种如果是证书过期的,…...

【MyBatisⅡ】动态 SQL
目录 🎒1 if 标签 🫖2 trim 标签 👠3 where 标签 🦺4 set 标签 🎨5 foreach 标签 动态 sql 是Mybatis的强⼤特性之⼀,能够完成不同条件下不同的 sql 拼接。 在 xml 里面写判断条件。 动态SQL 在数据库里…...

音视频入门基础理论知识
文章目录 前言一、视频1、视频的概念2、常见的视频格式3、视频帧4、帧率5、色彩空间6、采用 YUV 的优势7、RGB 和 YUV 的换算 二、音频1、音频的概念2、采样率和采样位数①、采样率②、采样位数 3、音频编码4、声道数5、码率6、音频格式 三、编码1、为什么要编码2、视频编码①、…...
Pytorch中如何加载数据、Tensorboard、Transforms的使用
一、Pytorch中如何加载数据 在Pytorch中涉及到如何读取数据,主要是两个类一个类是Dataset、Dataloader Dataset 提供一种方式获取数据,及其对应的label。主要包含以下两个功能: 如何获取每一个数据以及label 告诉我们总共有多少的数据 Datal…...

python如何使用打开文件对话框选择文件?
python如何使用打开文件对话框选择文件? ━━━━━━━━━━━━━━━━━━━━━━ 在Python中,可以使用Tkinter库中的filedialog子模块来打开一个文件对话框以供用户选择文件。以下是一个简单的例子,演示如何使用tkinter.filedialog打…...

虚拟化和容器
文章目录 1 介绍1.1 简介1.2 虚拟化工作原理1.3 两大核心组件:QEMU、KVMQEMUKVM 1.4 发展历史1.5 虚拟化类型1.6 云计算与虚拟化1.7 HypervisorHypervisor分为两大类 1.8 虚拟化 VS 容器 2 虚拟化应用dockerdocker 与虚拟机的区别 K8Swine 参考 1 介绍 1.1 简介 虚…...

LeetCode-78-子集
题目描述: 给你一个整数数组 nums ,数组中的元素 互不相同。返回该数组所有可能的子集(幂集)。 解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。 题目链接:LeetCode-78-子集 解题思路:递归回溯 题…...

K8s集群健康监控、Pod调度与配置存储卷
33.Kubernets对集群Pod和健康容器状态如何进行监控和检测的。 K8s通过kubelet节点监控,使用三种探针来监控和管理容器监控状态,每种探针在容器生命周期种的不同阶段发挥不同的作用。 34.解释LivenessProbes探针的作用及其适用场景。 LivenessProbes存活探…...

MASA模组汉化包技术解析:构建高效中文游戏体验的技术解决方案
MASA模组汉化包技术解析:构建高效中文游戏体验的技术解决方案 【免费下载链接】masa-mods-chinese 一个masa mods的汉化资源包 项目地址: https://gitcode.com/gh_mirrors/ma/masa-mods-chinese 在Minecraft模组生态系统中,MASA系列模组以其强大的…...

写给前端的 CANN-ops-rand:昇腾随机数生成算子库到底是啥?
之前做强化学习,兄弟问我:“哥,我想在昇腾上做蒙特卡洛模拟,随机数生成有现成的库吗?” 好问题。今天一次说清楚。 ops-rand 是啥? ops-rand Operations for Random,昇腾随机数生成算子库。 一…...

夏天来了TEMU爆单指南:我用凌风工具箱“标签模板“搞定夏季爆款
嘿,我是小彭,一个在跨境电商圈摸爬滚打的老玩家🙋♂️。这周在朋友圈晒出单周GMV破300万的成绩单,评论区直接炸了:"你这波操作可以啊""啥时候开个课教教我们"。说实话,真没什么高深技巧…...

用 Excel 手算一个 1-6-1 MLP:前向传播、损失、反向传播与参数更新
计算示例:本文用一个单输入、6 个隐藏神经元、单输出的多层感知机(MLP)作为例子,展示如何用 Excel 公式完整复现一次训练迭代。配套 Excel 文件中的“MLP计算过程”工作表已经把前向传播、损失计算、反向传播梯度和参数更新全部写…...

B站视频下载终极指南:5步掌握免费批量下载技巧
B站视频下载终极指南:5步掌握免费批量下载技巧 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirrors/bi/Bilib…...

Allegro16.6 矩形槽孔焊盘 说明
铣刀实际直径 对应 mil 值 ncroutebits.txt 写法 输出 rou 里自动变成 0.60 mm 23.62 mil 23.62 T01 T01C.02362 0.65 mm 25.59 mil 25.59 T01 T01C.02559 0.70 mm 27.56 mil 27.56 T01 T01C.02756 0.80 mm 31.50 mil 31.50 T01 …...

Verilator仿真保姆级避坑指南:从安装最新版到用GTKWave看波形的完整流程
Verilator仿真实战手册:从源码编译到波形调试的深度解析 1. 为什么选择Verilator:开源EDA工具链的新选择 在数字电路设计领域,仿真验证环节往往决定着项目成败。传统商业仿真器虽然功能强大,但高昂的授权费用和复杂的配置流程让许…...

AI多模型协同架构:破解单点依赖与技术主权困局
1. 这不是科幻讨论,而是今天必须面对的产业现实 “AI未来:一个巨无霸,还是多个巨头?”——这个标题乍看像科技媒体的年终圆桌话题,但在我过去十年跟踪AI基础设施、模型服务与企业落地的实操中,它早已不是假…...

中小型企业构建内部AI助手时如何通过Taotoken实现成本与权限的双重管控
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 中小型企业构建内部AI助手时如何通过Taotoken实现成本与权限的双重管控 应用场景类,企业部署内部AI助手需考虑成本与安…...