Intel SIMD: AVX2
AVX2
资料:
- Intel 内部指令 — AVX和AVX2学习笔记
- Intel Intrinsics — AVX & AVX2 Learning Notes
- Module x86
AVX 向量寄存器有三种:
- 128-bit (XMM forms),
AVX2支持,符号__m128,__m128d,__m128i - 256-bit (YMM forms),
AVX2支持,符号__m256,__m256d,__m256i - 512-bit 的向量寄存器,
AVX2不支持,这需要AVX-512架构
YMM 实际上是两个 XMM,在运算时会分成 2 个 128 bits 的区域。YMM 支持 16x16, 8x32, 4x64 的 SIMD,实测 add_epi16 比 a+b 快 20 倍(包括了 for 的花销)。
AVX 的数据类型包括:
- ps – packed single precision
- pd – packed double precision
- epi32 – packed 32-bit integers
- epu32 – packed 32-bit unsigned integers
- epi64 – packed 64-bit integers
一些常用指令(有些指令 __m256 不支持但 __m128 支持):
- 全局:zeroall(所有的 YMM 置零), zeroupper(所有的 YMM 高位置零)
- 加载:load, loadu, i32gather(根据索引加载), i64gather
- 存储:store(可以直接用
char*作为__m256*) - 设置:broadcast(广播), setzero, set1(复制), set(反序), setr(正序)
- 转换:cast(在
__m128, __m256之间转换), cvt(在ps, epi32之间转换) - 加减:add, sub, hadd(水平), hsub
- 乘除:mul, mullo(低位结果), mulhi(高位结果), div
- 混合运算(只有
ps, pd,不支持epi):fmadd, fmsub, fnmadd, fnmsub - 逻辑运算:cmp, cmpeq, cmpneq, cmpge(大于等于), cmpgt(严格大于), cmple, cmplt,
- 位运算:and, andnot, or, xor, sll(左移), srl(右移), slli, srli, sllv, srlv, bslli, bsrli
- 统计学:max, min, avg, ceil, floor, round, lzcnt
- 数学:abs, getexp, sqrt, rsqrt, sin, cos
- 置换:shuffle, permute(根据控制位写入), insert(根据控制位插入)
- 另外还有
mask的版本,但是AVX2似乎都不支持?
代码样例
#include <stdio.h>
#include <time.h>#include <xmmintrin.h> // __m128
#include <immintrin.h> // __m256
#include <zmmintrin.h> // __m512time_t TM_start, TM_end;#define Timer(code) TM_start = clock(); code; TM_end = clock(); printf("cpu cycles = %lld\n", TM_end - TM_start); //对code部分计时
#define Loop(loop, code) Timer(for(int ind=0; ind<loop; ind++) {code;})#define pn printf("\n\n")/*全局:zeroall, zeroupper加载:load, loadu, i32gather(根据索引加载), i64gather存储:store设置:broadcast, setzero, set1(复制), set(反序), setr(正序)转换:cast, cvt加减:add, sub, hadd(水平), hsub乘除:mul, mullo(低位结果), mulhi(高位结果), div混合运算:fmadd, fmsub, fnmadd, fnmsub逻辑运算:cmp, cmpeq, cmpneq, cmpge(大于等于), cmpgt(严格大于), cmple, cmplt,位运算:and, andnot, or, xor, sll(左移), srl(右移), slli, srli, sllv, srlv, bslli, bsrli统计学:max, min, avg, ceil, floor, round, lzcnt数学:abs, getexp, sqrt, rsqrt, sin, cos置换:shuffle, permute(根据控制位写入), insert(根据控制位插入)
*/void print_m256i_i16(__m256i* arr) {printf("[ %d", arr->m256i_i16[0]);for (int i = 1; i < 16; i++)printf(", %d", arr->m256i_i16[i]);printf(" ]\n\n");
}void print_m256i_i32(__m256i* arr) {printf("[ %d", arr->m256i_i32[0]);for (int i = 1; i < 8; i++)printf(", %d", arr->m256i_i32[i]);printf(" ]\n\n");
}int main()
{// AVX2 不支持 m512;这需要 AVX-512 指令集!/*__m512i a3;a3 = _mm512_set1_epi32(123);print_m256i_i32(&a3);*/int arr1[64], arr2[64];for (int i = 0; i < 64; i++)arr1[i] = i+1;__m256i a, b, c;printf("Test set/load/store: \n\n");a = _mm256_setzero_si256(); // 全零print_m256i_i32(&a);b = _mm256_set1_epi32(123); // Copyprint_m256i_i32(&b);/*在 m256 中,包含两个 m128。每个 m128 里,i8[15] 在最左边,i8[0] 在最右边。*/a = _mm256_set_epi32(1, 2, 3, 4, 5, 6, 7, 8); // 反序:L0 赋给 i32[7],L7 赋给 i32[0]print_m256i_i32(&a);b = _mm256_setr_epi32(1, 2, 3, 4, 5, 6, 7, 8); // 正序(reverse order)print_m256i_i32(&b);c = _mm256_load_si256(arr1); // 不必强制类型转换,直接写 32 字节数组即可print_m256i_i32(&c);_mm256_store_si256(arr2, c); // 同理,直接写 32 字节数组print_m256i_i32(arr2);printf("Test broadcast/cvt/cast: \n\n");__m256 d;float e = 123.5;float f[4] = { 1.e1,1.e2,1.e3,1.e4 };d = _mm256_broadcast_ss(&e); // m32 的广播a = _mm256_cvtps_epi32(d); // 类型转换,园整print_m256i_i32(&a);d = _mm256_broadcast_ps(&f); // m128 的广播a = _mm256_cvtps_epi32(d); // 类型转换,园整print_m256i_i32(&a);__m128i g;a.m256i_i32[0] = 123;a.m256i_i32[7] = 456;g = _mm256_castsi256_si128(a); // m256 的前一半写到 m128 上print_m256i_i32(&a);print_m256i_i32(&g);g = *(__m128i*)arr1; // 强行赋值a = _mm256_castsi128_si256(g); // m128 写到 m256 的前一半,后一半置零print_m256i_i32(&a);printf("Test gather: \n\n");__m256i index = _mm256_setr_epi32(1, 3, 5, 7, 2, 4, 6, 8);a = _mm256_i32gather_epi32(arr1, index, 4); // index 是按字节寻址的,第三个参数是每个数据项的字节长度(epi32 是 4)print_m256i_i32(&index);print_m256i_i32(arr1);print_m256i_i32(&a);printf("Test shuffle: \n\n");/*按 m128 分区,每个区的4个数置换控制位 IMM8,共4*2比特,最低的2比特控制m128[0]0b10110001:reverse(01,00,11,10)*/b = _mm256_shuffle_epi32(*(__m256i*)arr1, 0b10110001); // m128 视为 4 个 int 进行置换print_m256i_i32(arr1);print_m256i_i32(&b);b = _mm256_shufflehi_epi16(*(__m256i*)arr1, 0b10110001); // m128 的高64比特,视为 4 个 short 进行置换print_m256i_i32(arr1);print_m256i_i32(&b);b = _mm256_shufflelo_epi16(*(__m256i*)arr1, 0b10110001); // m128 的低64比特,视为 4 个 short 进行置换print_m256i_i32(arr1);print_m256i_i32(&b);printf("Test permute: \n\n");b = _mm256_permute4x64_epi64(*(__m256i*)arr1,0b00010001); // 类似 shuffle 的 IMM8 控制符print_m256i_i32(arr1);print_m256i_i32(&b);index = _mm256_setr_epi32(1, 3, 5, 7, 2, 4, 6, 10);b = _mm256_permutevar8x32_epi32(*(__m256i*)arr1, index); // 越界的 index,会自动模8(截取了低3比特)print_m256i_i32(&index);print_m256i_i32(arr1);print_m256i_i32(&b);printf("Test insert: \n\n");b = _mm256_insert_epi32(*(__m256i*)arr1, 321, 9); // 插入一个数据,index 越界则自动模8(截取低3比特)print_m256i_i32(arr1);print_m256i_i32(&b);b = _mm256_insert_epi16(*(__m256i*)arr1, 321, 17); // 插入一个数据,index 越界则自动模16(截取低4比特)print_m256i_i16(arr1);print_m256i_i16(&b);printf("Test add/sub/mul: \n\n");a = _mm256_setr_epi32(1,2,3,4,5,6,7,8);b = _mm256_setr_epi32(7,6,5,4,3,2,1,0);print_m256i_i32(&a);print_m256i_i32(&b);c = _mm256_add_epi16(a, b); // 普通的加法,会溢出print_m256i_i32(&c);a = _mm256_set1_epi16(32767);b = _mm256_set1_epi16(32767);c = _mm256_adds_epi16(a, b); // 范围受限,如果越界那么被限制在最大值上print_m256i_i16(&c);a = _mm256_setr_epi32(1, 2, 3, 4, 5, 6, 7, 8);b = _mm256_setr_epi32(7, 6, 5, 4, 3, 2, 1, 0);c = _mm256_hadd_epi32(a, b); // 水平加法,连续两个 int 相加。按照 m128,前 2 个是 a 的,后 2 个是 b 的print_m256i_i32(&c);c = _mm256_sub_epi32(a, b);print_m256i_i32(&c);c = _mm256_mul_epi32(a, b); // 连续的 8 字节,只取出第一个 4 字节的 int,将 long 的乘积结果写在对应的 8 字节里print_m256i_i32(&c);c = _mm256_mulhi_epi16(a, b); // 截取 16*2 比特结果的高 16 位print_m256i_i32(&c);c = _mm256_mullo_epi16(a, b); // 截取 16*2 比特结果的低 16 位print_m256i_i32(&c);printf("Test div/rem: \n\n");c = _mm256_div_epi32(b, a); // 整数除法print_m256i_i32(&c);__m256 rem;c = _mm256_divrem_epi32(&rem, b, a); // 带余除法print_m256i_i32(&rem);print_m256i_i32(&c);c = _mm256_rem_epi32(b, a); // 余数,b mod aprint_m256i_i32(&c);printf("Test fmadd/fnmadd: \n\n");__m256 a2 = _mm256_set1_ps(1.5);__m256 b2 = _mm256_set1_ps(1.5);__m256 c2 = _mm256_set1_ps(3);c2 = _mm256_fmadd_ps(a2,b2,c2); // a*b+c, 只有 ps/pd 有混合运算c = _mm256_cvtps_epi32(c2);print_m256i_i32(&c);c2 = _mm256_fnmadd_ps(a2, b2, c2); // -a*b+c, 只有 ps/pd 有混合运算c = _mm256_cvtps_epi32(c2);print_m256i_i32(&c);printf("Test and/or/xor: \n\n");print_m256i_i32(&a);print_m256i_i32(&b);c = _mm256_and_epi32(a, b); // bitwise ANDprint_m256i_i32(&c);c = _mm256_or_epi32(a, b); // bitwise ORprint_m256i_i32(&c);c = _mm256_xor_epi32(a, b); // bitwise XORprint_m256i_i32(&c);printf("Test sll/srl: \n\n");a = _mm256_setr_epi32(-1, -2, -3, -4, -5, -6, -7, -8);print_m256i_i32(&a);c = _mm256_slli_epi32(a, 1); // 每个 int 左移,空位补零print_m256i_i32(&c);c = _mm256_srli_epi32(a, 1); // 每个 int 右移,空位简单补零(负数也不补1)print_m256i_i32(&c);//c = _mm256_rol_epi32(a, 1); // 循环左移,AVX2 不支持:非法指令//print_m256i_i32(&c);//c = _mm256_ror_epi32(a, 1); // 循环右移,AVX2 不支持:非法指令//print_m256i_i32(&c);c = _mm256_slli_si256(a, 1); // 字节水平的左移(m256i_i8[31]在最左边,m256i_i8[0]在最右边)。按m128,空字节全零print_m256i_i32(&c);c = _mm256_srli_si256(a, 4); // 字节水平的右移。按m128,空字节全零print_m256i_i32(&c);// 这是啥?怎么结果全是 0 啊?/*__m128i offset = _mm_setr_epi32(1,2,3,4);a = _mm256_setr_epi32(1, 2, 3, 4, 5, 6, 7, 8);c = _mm256_srl_epi32(a, offset);print_m256i_i32(&a);print_m256i_i32(&c);*/// AVX2 不支持,需要 AVX-512//printf("Test mask: \n\n");//print_m256i_i16(arr1);//print_m256i_i16(&a);//print_m256i_i16(&b);//c = _mm256_mask_mullo_epi16(*(__m256i*)arr1, 0b0101010101010101, a, b); // 根据 mask16 各个比特,选择是否在 source 上写入 a*b 结果//print_m256i_i16(&c);//print_m256i_i32(arr1);//print_m256i_i32(&a);//print_m256i_i32(&b);//c = _mm256_mask_mullo_epi32(*(__m256i*)arr1, 0b01010101, a, b); // 根据 mask6 各个比特,选择是否在 source 上写入 a*b 结果//print_m256i_i32(&c);printf("Test cmp: \n\n");a = _mm256_setr_epi32(1, 2, 3, 4, 5, 6, 7, 8);b = _mm256_setr_epi32(7, 6, 5, 4, 3, 2, 1, 0);print_m256i_i32(&a);print_m256i_i32(&b);c = _mm256_cmpeq_epi32(a, b); // 满足条件,全1(-1);不满足条件,全0(0)print_m256i_i32(&c);c = _mm256_cmpgt_epi32(a, b); // 满足条件,全1(-1);不满足条件,全0(0)print_m256i_i32(&c);// AVX2 不支持/*__m128i a3 = _mm256_castsi256_si128(a);__m128i b3 = _mm256_castsi256_si128(b);int mask = _mm_cmpge_epi32_mask(a3, b3);*/return 0;
}
相关文章:

Intel SIMD: AVX2
AVX2 资料: Intel 内部指令 — AVX和AVX2学习笔记Intel Intrinsics — AVX & AVX2 Learning NotesModule x86 AVX 向量寄存器有三种: 128-bit (XMM forms),AVX2 支持,符号 __m128, __m128d, __m128i256-bit (YMM forms)&a…...
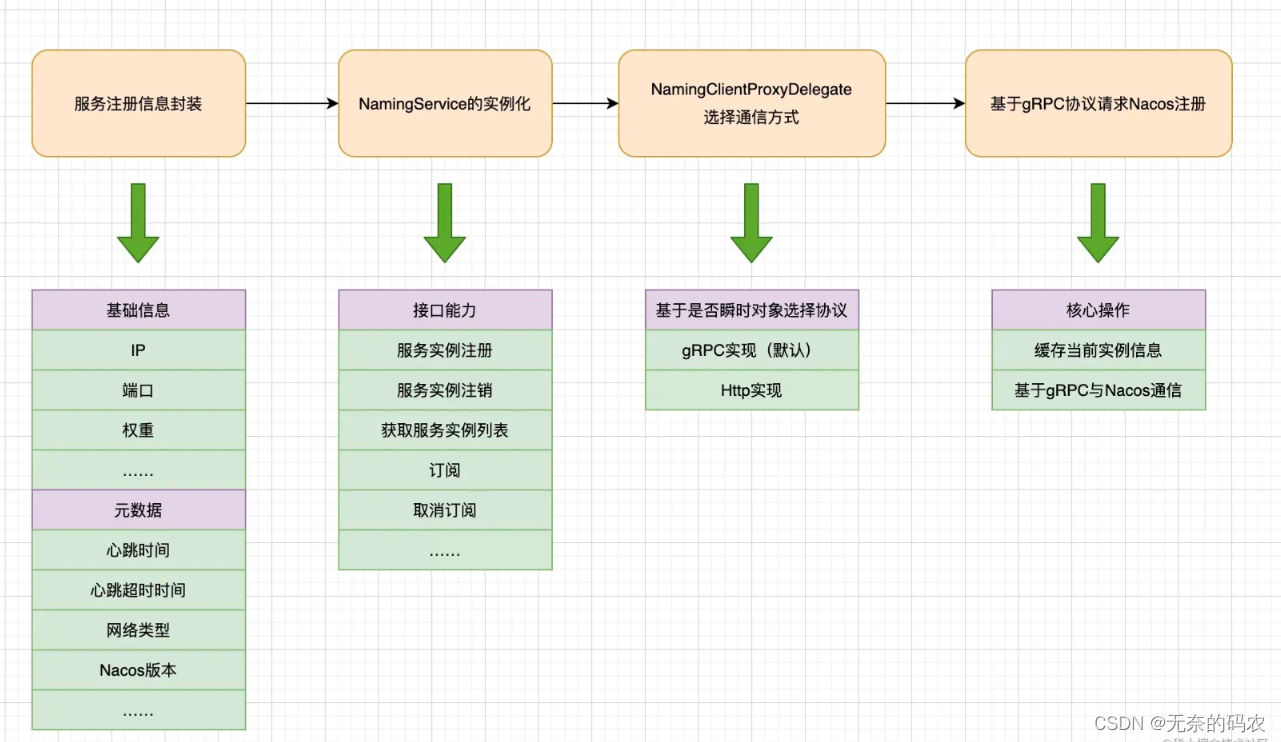
Spring Cloud Nacos源码讲解(二)- Nacos客户端服务注册源码分析
Nacos客户端服务注册源码分析 服务注册信息 我们从Nacos-Client开始说起,那么说到客户端就涉及到服务注册,我们先了解一下Nacos客户端都会将什么信息传递给服务器,我们直接从Nacos Client项目的NamingTest说起 public class NamingTest…...
 | 机试题+算法思路+考点+代码解析 【2023】)
华为OD机试 - 停车场最大距离(Python) | 机试题+算法思路+考点+代码解析 【2023】
停车场最大距离 题目 停车场有一横排车位0代表没有停车,1代表有车. 至少停了一辆车在车位上,也至少有一个空位没有停车. 为防止刮蹭,需为停车人找到一个车位 使得停车人的车最近的车辆的距离是最大的 返回此时的最大距离 输入 一个用半角逗号分割的停车标识字符串,停车标识为…...
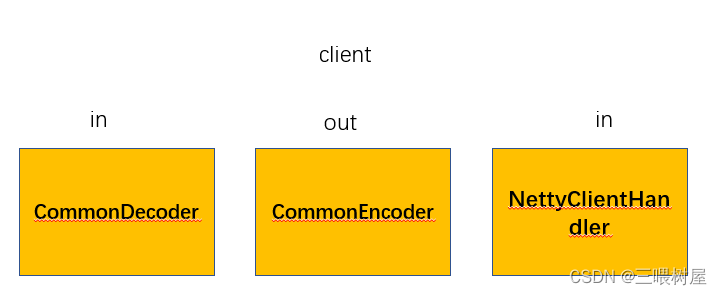
RPC(2)------ Netty(NIO) + 多种序列化协议 + JDK动态代理实现
依赖包解释 Guava 包含了若干被Google的 Java项目广泛依赖 的核心库,例如:集合 [collections] 、缓存 [caching] 、原生类型支持 [primitives support] 、并发库 [concurrency libraries] 、通用注解 [common annotations] 、字符串处理 [string process…...

CAN现场总线基础知识总结,看这一篇就理清了(CAN是什么,电气属性,CAN通协议等)
【系列专栏】:博主结合工作实践输出的,解决实际问题的专栏,朋友们看过来! 《QT开发实战》 《嵌入式通用开发实战》 《从0到1学习嵌入式Linux开发》 《Android开发实战》 《实用硬件方案设计》 长期持续带来更多案例与技术文章分享…...
盘点全网好评最多的7款团队协同软件,你用过哪款?
能亲自带团队管理项目当然是一件开心和兴奋的事,但是突然成为团队负责人后开始不大适应。如何转换角色,还有自己和团队成员之间在心理、行为等方面的互动也变得很敏感。新手领导上任的过程,是团队秩序再造的过程;是晋升者个人职业…...
Node-RED 3.0升级,新增特性介绍
前言 最近给我的树莓派上的Node-RED(以下简称NR)做了一下升级,从2.x升级到得了3.0。这是一个比较大的版本升级,在用户体验方面,NR有了有很大的提升。下面让我们一起来看一如何升级以及,3.0新增了那些特性 升级3.0 由于之前的NR是直接使用npm来进行安装的,所以此处升级…...
使用带有 Moveit 的深度相机来避免碰撞
文章目录 什么是深度相机?如何将 Kinect 深度相机添加到您的环境中在 Rviz 中可视化深度相机数据在取放场景中使用深度相机将深度相机与您的 Moveit 设置一起使用有很多优势。机器人可以避免未知环境中的碰撞,甚至可以对周围的变化做出反应。然而,将深度相机连接到您的设置并…...
干货复试详细教程——从联系导师→自我介绍的复试教程
文章目录联系导师联系之前的准备联系导师注意自我介绍教育技术领域通用的复试准备其他补充联系导师 确定出分和自己能进复试以后联系。 分两类 科研技能型 低调,如实介绍,不吹不水。就算你很牛啥都会手握核心期刊论文也不太狂 学霸高分型 不要自卑&…...

Java 优化:读取配置文件 “万能方式“ 跨平台,动态获取文件的绝对路径
Java 优化:读取配置文件 “万能方式” 跨平台,动态获取文件的绝对路径 每博一文案 往事不会像烟雾似的飘散,将永远像铅一般沉重地浇铸在心灵的深处。 不过,日常生活的纷繁不会让人专注地沉湎于自己的痛苦 不幸,即使人…...
)
华为OD机试真题Python实现【最小施肥机能效】真题+解题思路+代码(20222023)
最小施肥机能效 题目 某农场主管理了一大片果园,fields[i]表示不同果林的面积,单位:( m 2 m^2 m2),现在要为所有的果林施肥且必须在 n 天之内完成,否则影响收成。 小布是果林的工作人员,他每次选择一片果林进行施肥,且一片果林施肥完...

python基于vue健身房课程预约平台
可定制框架:ssm/Springboot/vue/python/PHP/小程序/安卓均可开发 目录 1 绪论 1 1.1课题背景 1 1.2课题研究现状 1 1.3初步设计方法与实施方案 2 1.4本文研究内容 2 2 系统开发3 2.2MyEclipse环境配置 4 2.3 B/S结构简介 4 2.4MySQL数据库 5 2.5 django框架 5 3 系统分析 6 3.1…...
Allegro无法看到金属化孔的钻孔的原因和解决办法
Allegro无法看到金属化孔的钻孔的原因和解决办法 用Allegro设计PCB的时候,希望同时看到金属化孔的盘以及钻孔,如下图 但是有时显示效果是这样的,看不到钻孔了 导致无法直观地区分是通孔是还是表贴的盘 如何解决,具体操作如下 点击Setup...

《蓝桥杯每日一题》并查集·AcWing1249. 亲戚
1.题目描述或许你并不知道,你的某个朋友是你的亲戚。他可能是你的曾祖父的外公的女婿的外甥女的表姐的孙子。如果能得到完整的家谱,判断两个人是否是亲戚应该是可行的,但如果两个人的最近公共祖先与他们相隔好几代,使得家谱十分庞…...
亚马逊云科技依托人工智能进行游戏数据分析,解决游戏行业痛点,助力游戏增长
前言 据互联网数据显示:2014 年我国游戏行业用户规模为 517.31 百万人,直至 2020 年达 554.79 百万人;同时,2020 年,我国游戏市场实际销售收入 2786.87 亿元,比 2019 年增加了478.1 亿元,…...

为什么不建议用 equals 判断对象相等?
一直以为这个方法是java8的,今天才知道是是1.7的时候,然后翻了一下源码。 这片文章中会总结一下与a.equals(b)的区别,然后对源码做一个小分析。 一,值是null的情况: 1.a.equals(b), a 是null, 抛出NullPointExcepti…...

手写线程池实例并测试
前言:在之前的文章中介绍过线程池的核心原理,在一次面试中面试官让手写线程池,这块知识忘记的差不多了,因此本篇文章做一个回顾。 希望能够加深自己的印象以及帮助到其他的小伙伴儿们😉😉。 如果文章有什么…...
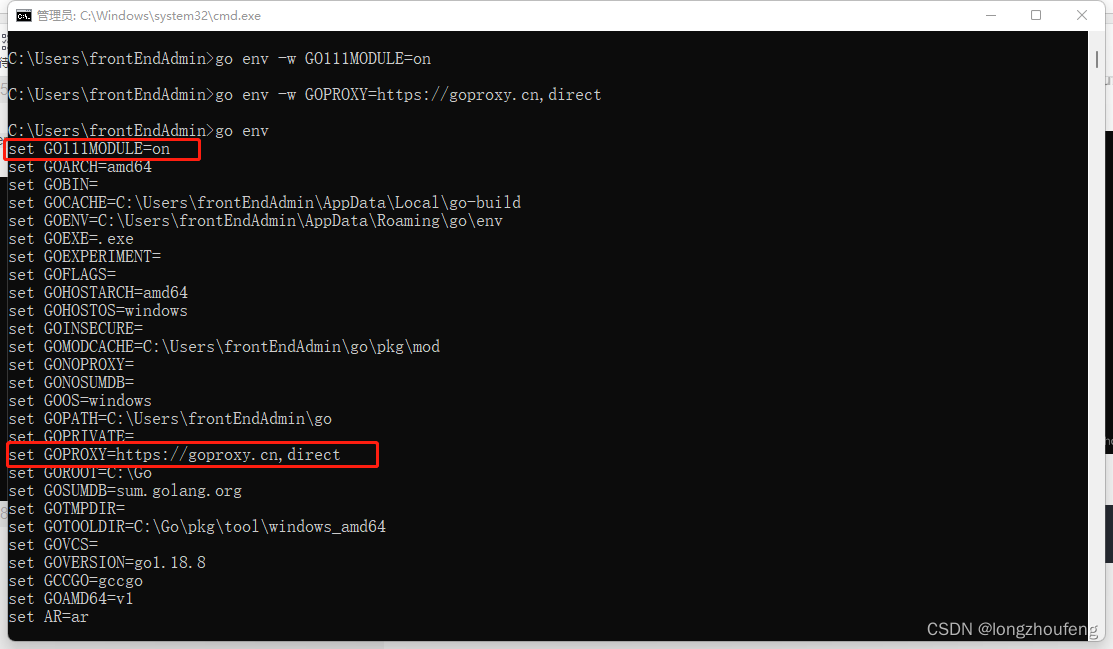
实操go开发环境的配置
1、Go 安装包下载,下载地址如下: go语言中文网下载(本人电脑的系统是Windows,这里以Windows版本的安装包为例,安装就是傻瓜式安装,只要点下一步–下一步–完成就可以了,本人安装在C盘下。 我…...
)
华为OD机试真题Python实现【匿名信】真题+解题思路+代码(20222023)
匿名信 题目 电视剧《分界线》里面有一个片段,男主为了向警察透露案件细节,且不暴露自己,于是将报刊上的字减下来,剪拼成匿名信。 现在又一名举报人,希望借鉴这种手段,使用英文报刊完成举报操作。 但为了增加文章的混淆度,只需满足每个单词中字母数量一致即可,不关注…...
)
阿里淘系面试经历(一)
文章目录 1、JVM讲一下,尽你所知道的1. 类的加载过程1.1 加载过程介绍1.2 类加载流程1.3 类加载器2. 垃圾回收2.1 如何确定对象已死2.2 垃圾回收算法2.2.1 标记--清除算法2.2.2 复制算法2.2.3 标记--整理算法2.3 垃圾收集器2.3.1 Serial 收集器2.3.2 ParNew 收集器2.3.3 Paral…...

OpenClaw 连接阿里云百炼图文教程
OpenClaw 连接阿里云百炼图文教程 前置准备 已安装并可以正常打开 OpenClaw Windows。 OpenClaw 顶部 Gateway 状态保持在线。 已准备好可正常登录的阿里云账号。 可以正常访问阿里云百炼登录地址:https://bailian.console.aliyun.com/cn-beijing#/home 建议提…...

Python基础语法:常用内置函数
round():四舍五入 # 省略 ndigits print(round(3.14)) # 输出 3(int) print(round(3.66)) # 输出 4# 指定 ndigits print(round(3.14159, 2)) # 输出 3.14(float) print(round(3.666, 2)) # 输出 3.67# …...

照着用就行:2026 最新降AIGC软件测评与推荐
2026年真正好用的AI论文降重与改写工具,核心看降重效果、去AI味、格式保留、学术适配四大指标。综合实测,千笔AI、ThouPen、豆包、DeepSeek、Grammarly 是当前最值得推荐的梯队,覆盖从免费到付费、从中文到英文、从文科到理工的全场景需求。 …...

写论文的神助攻!好用的AI写作辅助软件,逻辑清晰质量高
作为一名刚完成毕业论文的过来人,我太懂写论文的痛苦了 —— 选题迷茫、文献浩如烟海、框架混乱、逻辑不清、反复修改、查重降重反复折腾... 直到我发现了这套 AI 写作工具组合,简直是论文写作的 "开挂神器",效率直接拉满ÿ…...

自制极低频电流探头:负电阻补偿原理与低频方波测量实践
1. 项目概述:为极低频电流测量而生在电子测试领域,电流探头是个再常见不过的工具,无论是排查开关电源的纹波,还是分析电机驱动的波形,都离不开它。但如果你尝试用市面上常见的电流探头去观察一个频率低至几赫兹&#x…...

告别DLL缺失烦恼!Visual C++运行库合集一键搞定Windows应用依赖问题
告别DLL缺失烦恼!Visual C运行库合集一键搞定Windows应用依赖问题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经在打开某个软件或游戏时…...

3分钟告别英文恐惧:Android Studio中文界面轻松切换指南
3分钟告别英文恐惧:Android Studio中文界面轻松切换指南 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 你是否曾经因…...

从无线破解到PDF解密:盘点那些容易被忽略的‘非主流’密码审计场景与工具
密码安全审计的隐秘战场:从无线网络到加密文档的实战指南 当大多数人谈论密码安全时,脑海中浮现的往往是服务器登录、数据库访问这些企业级场景。然而在数字生活的每个角落,从家庭Wi-Fi到工作文档,密码保护的脆弱性同样可能成为安…...

终极STL到STEP转换指南:如何实现3D打印模型到CAD设计的无缝衔接
终极STL到STEP转换指南:如何实现3D打印模型到CAD设计的无缝衔接 【免费下载链接】stltostp Convert stl files to STEP brep files 项目地址: https://gitcode.com/gh_mirrors/st/stltostp 在数字化制造和工程设计领域,STL到STEP转换已成为连接3D…...

Metabase:零代码 BI 数据可视化工具,自建数据看板
Metabase:零代码 BI 数据可视化工具,自建数据看板 在数据驱动决策的时代,能快速看到业务数据的变化趋势至关重要。然而,专业 BI 工具(如 Tableau、Power BI)价格昂贵,而让每个业务同学都学 SQL …...