使用 Pandera 的 PySpark 应用程序的数据验证
推荐:使用 NSDT场景编辑器 快速搭建3D应用场景
本文简要介绍了 Pandera 的主要功能,然后继续解释 Pandera 数据验证如何与自最新版本 (Pandera 0.16.0) 以来使用本机 PySpark SQL 的数据处理工作流集成。
Pandera 旨在与其他流行的 Python 库配合使用,如 pandas、pyspark.pandas、Dask 等。这样可以轻松地将数据验证合并到现有数据处理工作流中。直到最近,Pandera 还缺乏对 PySpark SQL 的原生支持,但为了弥合这一差距,QuantumBlack 的一个团队,麦肯锡的 AI 由 Ismail Negm-PARI、Neeraj Malhotra、Jaskaran Singh Sidana、Kasper Janehag、Oleksandr Lazarchuk 以及 Pandera 创始人 Niels Bantilan 组成。,开发了原生的 PySpark SQL 支持并将其贡献给了 Pandera。本文的文字也是团队准备的,下面用他们的话写。
Pandera的主要特点
如果您不熟悉使用Pandera来验证数据,我们建议您查看Khuyen Tran的“使用Pandera验证您的pandas DataFrame”,其中描述了基础知识。总之,我们简要解释了简单直观的 API、内置验证功能和自定义的主要功能和优势。
简单直观的接口
Pandera 的突出特点之一是其简单直观的 API。您可以使用易于阅读和理解的声明性语法来定义数据架构。这使得编写既高效又有效的数据验证代码变得容易。
下面是 Pandera 中的架构定义示例:
class InputSchema(pa.DataFrameModel):year: Series[int] = pa.Field()month: Series[int] = pa.Field()day: Series[int] = pa.Field()内置验证函数
Pandera 提供了一组内置函数(通常称为检查)来执行数据验证。当我们调用 Pandera 模式时,它将执行模式和数据验证。数据验证将在后台调用函数。validate()check
下面是如何使用 Pandera 在数据帧对象上运行数据的简单示例。check
class InputSchema(pa.DataFrameModel):year: Series[int] = pa.Field(gt=2000, coerce=True)month: Series[int] = pa.Field(ge=1, le=12, coerce=True)day: Series[int] = pa.Field(ge=0, le=365, coerce=True)InputSchema.validate(df)如上所示,对于字段,我们定义了一个检查,强制此字段中的所有值必须大于 2000,否则 Pandera 将引发验证失败。yeargt=2000
以下是 Pandera 默认提供的所有内置检查的列表:
eq: checks if value is equal to a given literal
ne: checks if value is not equal to a given literal
gt: checks if value is greater than a given literal
ge: checks if value is greater than & equal to a given literal
lt: checks if value is less than a given literal
le: checks if value is less than & equal to a given literal
in_range: checks if value is given range
isin: checks if value is given list of literals
notin: checks if value is not in given list of literals
str_contains: checks if value contains string literal
str_endswith: checks if value ends with string literal
str_length: checks if value length matches
str_matches: checks if value matches string literal
str_startswith: checks if value starts with a string literal自定义验证函数
除了内置的验证检查之外,Pandera 还允许您定义自己的自定义验证函数。这使您能够根据用例灵活地定义自己的验证规则。
例如,您可以定义一个用于数据验证的 lambda 函数,如下所示:
schema = pa.DataFrameSchema({"column2": pa.Column(str, [pa.Check(lambda s: s.str.startswith("value")),pa.Check(lambda s: s.str.split("_", expand=True).shape[1] == 2)]),
})向 Pandera 添加对 PySpark SQL DataFrame 的支持
在添加对 PySpark SQL 的支持的过程中,我们坚持了两个基本原则:
- 界面和用户体验的一致性
- 针对 PySpark 的性能优化。
首先,让我们深入研究一致性的主题,因为从用户的角度来看,无论选择的框架如何,他们都有一组一致的 API 和一个接口,这一点很重要。由于Pandera提供了多种框架可供选择,因此在PySpark SQL API中拥有一致的用户体验更为重要。
考虑到这一点,我们可以使用 PySpark SQL 定义 Pandera 模式,如下所示:
from pyspark.sql import DataFrame, SparkSession
import pyspark.sql.types as T
import pandera.pyspark as paspark = SparkSession.builder.getOrCreate()class PanderaSchema(DataFrameModel):"""Test schema"""id: T.IntegerType() = Field(gt=5)product_name: T.StringType() = Field(str_startswith="B")price: T.DecimalType(20, 5) = Field()description: T.ArrayType(T.StringType()) = Field()meta: T.MapType(T.StringType(), T.StringType()) = Field()data_fail = [(5, "Bread", 44.4, ["description of product"], {"product_category": "dairy"}),(15, "Butter", 99.0, ["more details here"], {"product_category": "bakery"}),]spark_schema = T.StructType([T.StructField("id", T.IntegerType(), False),T.StructField("product", T.StringType(), False),T.StructField("price", T.DecimalType(20, 5), False),T.StructField("description", T.ArrayType(T.StringType(), False), False),T.StructField("meta", T.MapType(T.StringType(), T.StringType(), False), False),],)
df_fail = spark_df(spark, data_fail, spark_schema)在上面的代码中,定义了传入 pyspark 数据帧的架构。它有 5 个字段,对 and 字段进行数据检查和强制执行。 PanderaSchemadtypesidproduct_name
class PanderaSchema(DataFrameModel):"""Test schema"""id: T.IntegerType() = Field(gt=5)product_name: T.StringType() = Field(str_startswith="B")price: T.DecimalType(20, 5) = Field()description: T.ArrayType(T.StringType()) = Field()meta: T.MapType(T.StringType(), T.StringType()) = Field()接下来,我们构建了一个虚拟数据,并强制实施了 中定义的本机 PySpark SQL 架构。spark_schema
spark_schema = T.StructType([T.StructField("id", T.IntegerType(), False),T.StructField("product", T.StringType(), False),T.StructField("price", T.DecimalType(20, 5), False),T.StructField("description", T.ArrayType(T.StringType(), False), False),T.StructField("meta", T.MapType(T.StringType(), T.StringType(), False), False),],)df_fail = spark_df(spark, data_fail, spark_schema)这样做是为了模拟架构和数据验证失败。
以下是数据帧的内容:df_fail
df_fail.show()+---+-------+--------+--------------------+--------------------+| id|product| price| description| meta|+---+-------+--------+--------------------+--------------------+| 5| Bread|44.40000|[description of p...|{product_category...|| 15| Butter|99.00000| [more details here]|{product_category...|+---+-------+--------+--------------------+--------------------+接下来,我们可以调用 Pandera 的验证函数来执行模式和数据级验证,如下所示:
df_out = PanderaSchema.validate(check_obj=df)我们将很快探讨的内容。df_out
PySpark 的性能优化
我们的贡献是专门为使用 PySpark 数据帧时的最佳性能而设计的,这在处理大型数据集时至关重要,以便处理 PySpark 分布式计算环境的独特挑战。
Pandera 使用 PySpark 的分布式计算架构来高效处理大型数据集,同时保持数据的一致性和准确性。我们针对 PySpark 性能重写了 Pandera 的自定义验证函数,以便更快、更高效地验证大型数据集,同时降低数据错误和大容量不一致的风险。
全面的错误报告
我们对Pandera进行了另一项添加,以便能够以Python字典对象的形式生成详细的错误报告。这些报告可通过从验证函数返回的数据帧进行访问。它们根据用户的配置提供所有架构和数据级别验证的全面摘要。
事实证明,此功能对于开发人员快速识别和解决任何与数据相关的问题很有价值。通过使用生成的错误报告,团队可以编译其应用程序中架构和数据问题的完整列表。这使他们能够高效、精确地确定问题的优先级和解决方案。
需要注意的是,此功能目前仅适用于 PySpark SQL,为用户提供了在 Pandera 中使用错误报告时增强的体验。
在上面的代码示例中,请记住我们在 Spark 数据帧上调用过:validate()
df_out = PanderaSchema.validate(check_obj=df)它返回了一个数据帧对象。使用访问器,我们可以从中提取错误报告,如下所示:
print(df_out.pandera.errors){"SCHEMA":{"COLUMN_NOT_IN_DATAFRAME":[{"schema":"PanderaSchema","column":"PanderaSchema","check":"column_in_dataframe","error":"column 'product_name' not in dataframe Row(id=5, product='Bread', price=None, description=['description of product'], meta={'product_category': 'dairy'})"}],"WRONG_DATATYPE":[{"schema":"PanderaSchema","column":"description","check":"dtype('ArrayType(StringType(), True)')","error":"expected column 'description' to have type ArrayType(StringType(), True), got ArrayType(StringType(), False)"},{"schema":"PanderaSchema","column":"meta","check":"dtype('MapType(StringType(), StringType(), True)')","error":"expected column 'meta' to have type MapType(StringType(), StringType(), True), got MapType(StringType(), StringType(), False)"}]},"DATA":{"DATAFRAME_CHECK":[{"schema":"PanderaSchema","column":"id","check":"greater_than(5)","error":"column 'id' with type IntegerType() failed validation greater_than(5)"}]}
}如上所示,错误报告在 python 字典对象中的 2 个级别上聚合,以便下游应用程序轻松使用,例如使用 Grafana 等工具随时间推移的时间序列可视化错误:
- 验证类型 = 或
SCHEMADATA - 错误类别 = 或 等。
DATAFRAME_CHECKWRONG_DATATYPE
这种重构错误报告的新格式是在 0.16.0 中引入的,作为我们贡献的一部分。
开/关开关
对于依赖 PySpark 的应用程序,具有开/关开关是一项重要功能,可以在灵活性和风险管理方面产生重大影响。具体而言,开/关开关允许团队在生产中禁用数据验证,而无需更改代码。
这对于性能至关重要的大数据管道尤其重要。在许多情况下,数据验证可能会占用大量处理时间,这可能会影响管道的整体性能。使用开/关开关,团队可以在必要时快速轻松地禁用数据验证,而无需经历耗时的修改代码过程。
我们的团队在 Pandera 中引入了开/关开关,因此用户只需更改配置设置即可轻松关闭生产中的数据验证。这提供了在必要时确定性能优先级所需的灵活性,而不会牺牲开发中的数据质量或准确性。
要启用验证,请在环境变量中设置以下内容:
export PANDERA_VALIDATION_ENABLED=FalsePandera将选取此选项以禁用应用程序中的所有验证。默认情况下,验证处于启用状态。
目前,此功能仅适用于 0.16.0 版本的 PySpark SQL,因为它是我们的贡献引入的新概念。
对Pandera执行的精细控制
除了开/关开关功能外,我们还引入了对 Pandera 验证流程执行的更精细的控制。这是通过引入可配置的设置来实现的,这些设置允许用户在三个不同的级别控制执行:
SCHEMA_ONLY:此设置仅执行架构验证。它检查数据是否符合架构定义,但不执行任何其他数据级验证。DATA_ONLY:此设置仅执行数据级验证。它根据定义的约束和规则检查数据,但不验证架构。SCHEMA_AND_DATA:此设置同时执行架构和数据级验证。它根据架构定义以及定义的约束和规则检查数据。
通过提供这种精细控制,用户可以选择最适合其特定用例的验证级别。例如,如果主要关注点是确保数据符合定义的架构,则可以使用该设置来减少总体处理时间。或者,如果已知数据符合架构,并且重点是确保数据质量,则可以使用该设置来确定数据级验证的优先级。SCHEMA_ONLYDATA_ONLY
对 Pandera 执行的增强控制使用户能够在精度和效率之间取得微调的平衡,从而实现更有针对性和优化的验证体验。
export PANDERA_VALIDATION_DEPTH=SCHEMA_ONLY默认情况下,将启用验证,并设置深度,可以根据用例将其更改为或根据需要更改。SCHEMA_AND_DATASCHEMA_ONLYDATA_ONLY
目前,此功能仅适用于 0.16.0 版本的 PySpark SQL,因为它是我们的贡献引入的新概念。
列和数据帧级别的元数据
我们的团队为 Pandera 添加了一项新功能,允许用户在和级别存储额外的元数据。此功能旨在允许用户在其架构定义中嵌入上下文信息,以供其他应用程序利用。FieldSchema / Model
例如,通过存储有关特定列的详细信息(如数据类型、格式或单位),开发人员可以确保下游应用程序能够正确解释和使用数据。同样,通过存储有关特定用例需要架构的哪些列的信息,开发人员可以优化数据处理管道、降低存储成本并提高查询性能。
在架构级别,用户可以存储信息以帮助对整个应用程序的不同架构进行分类。此元数据可以包括架构用途、数据源或数据的日期范围等详细信息。这对于管理复杂的数据处理工作流特别有用,其中多个架构用于不同的目的,需要有效地跟踪和管理。
class PanderaSchema(DataFrameModel):"""Pandera Schema Class"""id: T.IntegerType() = Field(gt=5,metadata={"usecase": ["RetailPricing", "ConsumerBehavior"],"category": "product_pricing"},)product_name: T.StringType() = Field(str_startswith="B")price: T.DecimalType(20, 5) = Field()class Config:"""Config of pandera class"""name = "product_info"strict = Truecoerce = Truemetadata = {"category": "product-details"}在上面的示例中,我们引入了有关架构对象本身的其他信息。这在 2 个级别是允许的:字段和架构。
To extract the metadata on schema level (including all fields in it), we provide helper functions as:
PanderaSchema.get_metadata()
The output will be dictionary object as follows:
{"product_info": {"columns": {"id": {"usecase": ["RetailPricing", "ConsumerBehavior"],"category": "product_pricing"},"product_name": None,"price": None,},"dataframe": {"category": "product-details"},}
}目前,此功能是 0.16.0 中的一个新概念,已针对 PySpark SQL 和 Pandas 添加。
总结
我们引入了几个新功能和概念,包括允许团队在不更改代码的情况下禁用生产中的验证的开/关开关、对 Pandera 验证流程的精细控制,以及在列和数据帧级别存储其他元数据的能力。
原文链接:使用 Pandera 的 PySpark 应用程序的数据验证 (mvrlink.com)
相关文章:

使用 Pandera 的 PySpark 应用程序的数据验证
推荐:使用 NSDT场景编辑器 快速搭建3D应用场景 本文简要介绍了 Pandera 的主要功能,然后继续解释 Pandera 数据验证如何与自最新版本 (Pandera 0.16.0) 以来使用本机 PySpark SQL 的数据处理工作流集成。 Pandera 旨在与其他流行…...

README
一、Markdown 简介 Markdown 是一种轻量级标记语言,它允许人们使用易读易写的纯文本格式编写文档。 应用 当前许多网站都广泛使用 Markdown 来撰写帮助文档或是用于论坛上发表消息。例如:GitHub、简书、知乎等 编辑器 推荐使用Typora,官…...
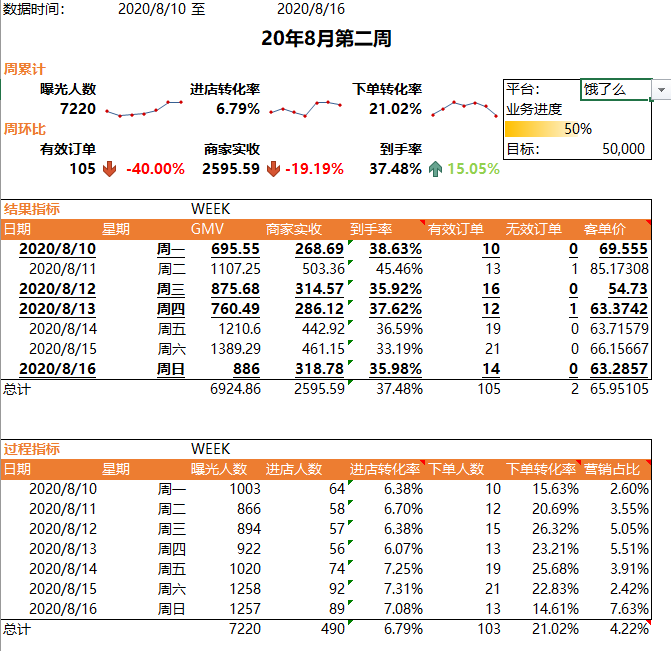
Excel周报制作
Excel周报制作 文章目录 Excel周报制作一、理解数据二、数据透视表三、常用函数1.sum-求和2.sumif-单条件求和3.sumifs-多条件求和4.sum和subtotal的区别5.if函数6.if嵌套7.vlookup函数和数据透视表聚合8.index和match函数 四、周报开发五、报表总览 一、理解数据 这是一个线上…...

Qt QtCreator 所有官方下载地址
Qt QtCreator 所有版本官方下载地址 1.所有版本QT下载地址 : Index of /archive/qt 所有Qt Creator下载地址: Index of /archive/qtcreator 所有Qt VS开发插件下载地址: Index of /archive/vsaddin 4.Qt官网镜像下载地址: Index of /…...
C++包含整数各位重组
void 包含整数各位重组() {//缘由https://bbs.csdn.net/topics/395402016int shu 100000, bs 4, bi shu * bs, a 0, p 0, d 0;while (shu < 500000)if (a<6 && (p to_string(shu).find(to_string(bi)[a], p)) ! string::npos && (d to_string(bi…...
)
数学建模--模型总结(5)
优化问题: 线性规划,半定规划、几何规划、非线性规划,整数规划,多目标规划(分层序列法),最优控制(结合微分方程组)、变分法、动态规划,存贮论、代理模型、响…...

JavaScript 中的原型到底该如何理解?
JavaScript作为一个基于原型的OOP,和我们熟知的基于类的面向对象编程语言有很大的差异。如果不理解其中的本质含义,则无法深入理解JavaScript的诸多特性,以及由此产生的诸多“坑”。在讨论“原型”的概念之前,我们先来讨论一下“类…...
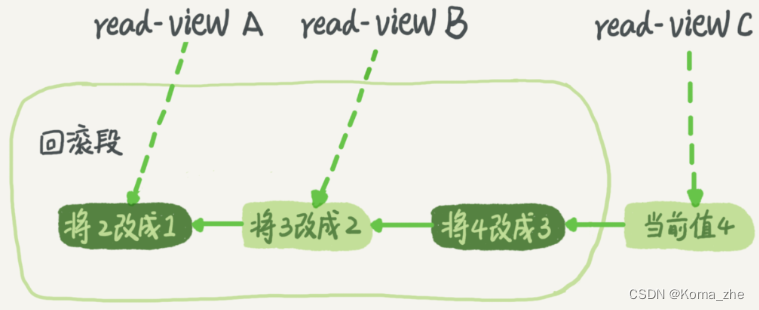
【MySQL基础】事务隔离03
目录 隔离性与隔离级别事务隔离的实现事务的启动方式MySQL事务代码示例 在MySQL中,事务支持是在引擎层实现的。MySQL是一个支持多引擎的系统,但并不是所有的引擎都支持事务。比如 MySQL 原生的 MyISAM 引擎就不支持事务,这也是 MyISAM 被 Inn…...

2023高教社杯数学建模C题思路分析 - 蔬菜类商品的自动定价与补货决策
# 1 赛题 在生鲜商超中,一般蔬菜类商品的保鲜期都比较短,且品相随销售时间的增加而变差, 大部分品种如当日未售出,隔日就无法再售。因此, 商超通常会根据各商品的历史销售和需 求情况每天进行补货。 由于商超销售的蔬菜…...

【MySQL】初见数据库
目录 什么是MySQL 为什么要使用数据库 数据库基础 数据库的本质 存储引擎 常用操作 登录mysql 创建数据库 使用数据库 查看数据库 创建数据库表 查看表 向表中插入数据 查询表中数据 什么是MySQL 🍒在我们服务器安装完 MySQL 服务之后,经…...
)
选择合适的帧率和分辨率:优化RTSP流视频抓取(java)
引言 在实时视频流应用中,选择适当的帧率和分辨率对于确保视频流的顺畅播放和图像质量至关重要。本文将向您介绍如何使用Java和JavaCV库中的FFmpegFrameGrabber来从RTSP流中抓取图像,并在抓取时设置帧率和分辨率。 一、配置开发环境 首先,…...

HTTP协议都有哪些方法?
分析&回答 HTTP1.0定义了三种请求方法: GET, POST 和 HEAD方法HTTP1.1新增了五种请求方法:OPTIONS, PUT, DELETE, TRACE 和 CONNECT 方法描述HEAD请求资源的头部信息, 并且这些头部与 HTTP GET 方法请求时返回的一致. 该请求方法的一个使用场景是在…...

数学建模--非整数规划求解的Python实现
目录 1.算法流程简介 2.算法核心代码 3.算法效果展示 1.算法流程简介 #非线性规划模型求解: #我们采用通用的minimize函数来求解 #minimize(f,x,method,bounds,contrains) #f是待求函数 #x是代求的自变量 #method是求解方法 #bounds是取值范围边界 #contrains是约束条件 &q…...
LeetCode 48题: 旋转图像
题目 给定一个 n n 的二维矩阵 matrix 表示一个图像。请你将图像顺时针旋转 90 度。 你必须在 原地 旋转图像,这意味着你需要直接修改输入的二维矩阵。请不要 使用另一个矩阵来旋转图像。 示例 1: 输入:matrix [[1,2,3],[4,5,6],[7,8,9]]…...

集成快递物流平台(快递100、快递鸟、闪送)连通多个应用
场景描述: 基于快递物流平台(快递100、快递鸟、闪送等)开放能力,无代码集成快递物流平台与多个应用互连互通。通过Aboter可搭建业务自动化流程,实现多个应用之间的数据连接。 连接器: 快递100快递鸟闪送…...
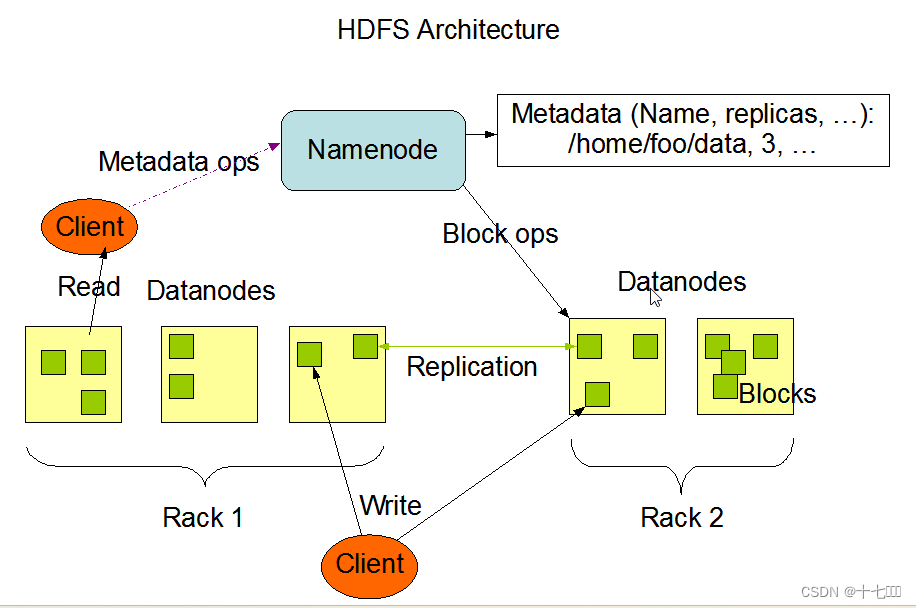
搭建hadoop集群的常见问题及解决办法
问题一: namenode -format重复初始化 出现问题的原因是重复初始化时会重新生成集群ID,而dn还是原先的集群ID,两者不匹配时无法启动相应的dn进程。 怎么查找问题原因:在logs目录下找到对应节点的.log文件,使用tail -200 文件名来查…...
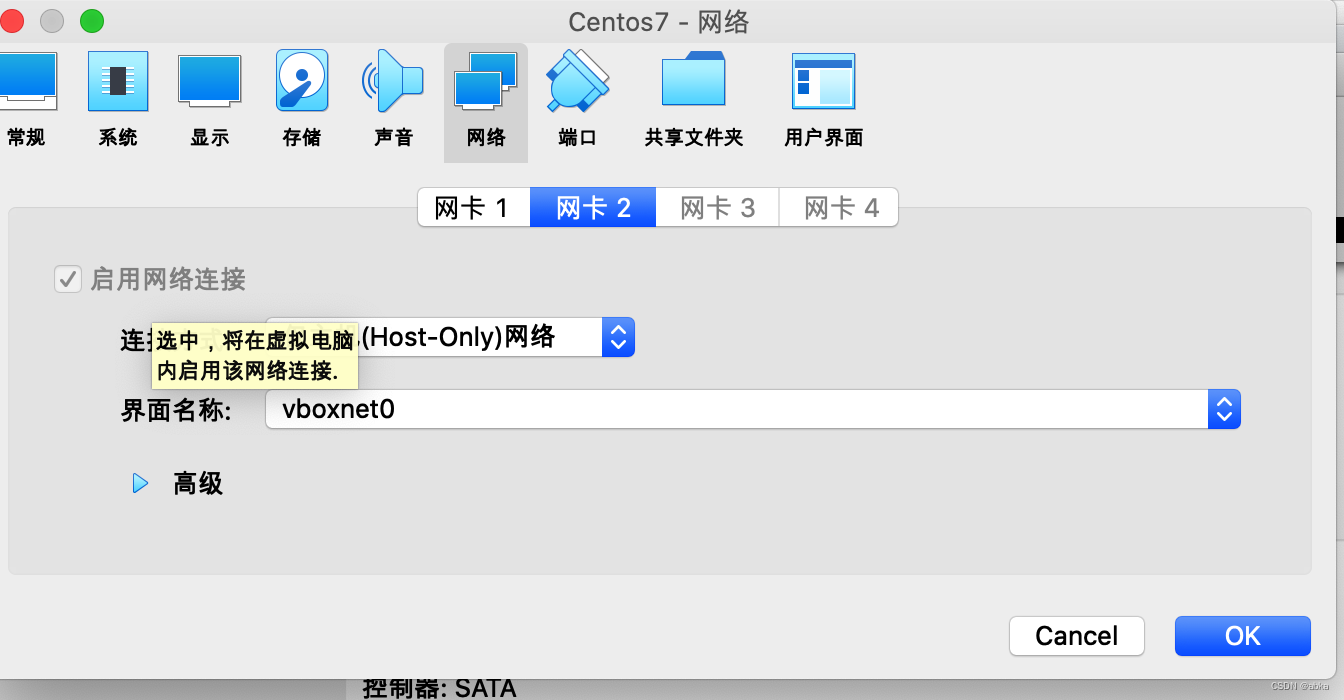
virtualbox centos 使用NAT模式上网
新安装了centos7之后,发现无法yum,无法ping外网。ping 外网域名无法ping通。 virtualbox的nat 网卡已经打开了。 需要手动打开centos7的网卡(centos7.9) 可以通过 ip addr 命令查看网卡地址 1: lo: <LOOPBACK,UP,LOWER_UP>…...
)
蓝桥杯官网填空题(梅森素数)
题目描述 本题为填空题,只需要算出结果后,在代码中使用输出语句将所填结果输出即可。 如果一个数字的所有真因子之和等于自身,则称它为“完全数”或“完美数” 例如: 6 1 2 3 28 1 2 4 7 14早在公元前 300300 多年&am…...

IBM Spectrum LSF Application Center 以应用程序为中心的工作负载提交和管理
IBM Spectrum LSF Application Center 为集群用户和管理员提供了一个灵活的、以应用为中心的界面。IBM Spectrum LSF Application Center 作为 IBM Spectrum LSF 的可选附加模块提供,使用户能够与直观、自我记录的界面进行交互。这提高了用户满意度和生产力。通过对…...

同步FIFO的verilog实现(2)——高位扩展法
一、前言 在之前的文章中,我们介绍了同步FIFO的verilog的一种实现方法:计数法。其核心在于:在同步FIFO中,我们可以很容易的使用计数来判断FIFO中还剩下多少可读的数据,从而可以判断空、满。 关于计数法实现同步FIFO的详…...

终极指南:ViGEmBus虚拟游戏控制器驱动,Windows游戏输入革命性解决方案
终极指南:ViGEmBus虚拟游戏控制器驱动,Windows游戏输入革命性解决方案 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 想要在Windows…...

CRMEB 让您的在线商城更智能:最新商品模块更新亮点一览!
为了让广大电商商家更好地管理商品、提升用户的购物体验和满意度,近日,CRMEB标准版商城系统再度发力,对商品模块进行了全面升级,新增一系列功能,期待帮助企业商家更好地管理商品,提升用户购物体验ÿ…...

GitHub中文界面插件架构解析与实战指南
GitHub中文界面插件架构解析与实战指南 【免费下载链接】github-chinese GitHub 汉化插件,GitHub 中文化界面。 (GitHub Translation To Chinese) 项目地址: https://gitcode.com/gh_mirrors/gi/github-chinese 核心问题:开发者面临的GitHub语言障…...

RK3562核心板在工业物联网与边缘AI中的实战应用解析
1. 项目概述:为什么RK3562核心板值得关注?最近在为一个工业网关项目选型,市面上主流的ARM核心板看了个遍,从全志到瑞芯微,从低功耗到高性能。当拿到迅为电子这款基于RK3562的核心板规格书时,我的第一反应是…...

液压液水解安定性检测:核心原理与全行业应用场景解析
液压系统是各类工业、工程、交通设备的动力核心,而液压液作为系统的工作介质,其性能稳定性直接决定设备的运行精度、故障率以及使用寿命。在复杂工况中,水分侵入是导致液压液失效的核心诱因之一,油液遇水发生水解反应后࿰…...

Legacy Update完整指南:让老旧Windows系统重获安全更新的5步教程
Legacy Update完整指南:让老旧Windows系统重获安全更新的5步教程 【免费下载链接】LegacyUpdate Get back online, activate, and install updates on your legacy Windows PC 项目地址: https://gitcode.com/gh_mirrors/le/LegacyUpdate 还在为Windows XP、…...

如何在Linux系统上安装Realtek RTL8125 2.5GbE网卡驱动:完整配置指南
如何在Linux系统上安装Realtek RTL8125 2.5GbE网卡驱动:完整配置指南 【免费下载链接】realtek-r8125-dkms A DKMS package for easy use of Realtek r8125 driver, which supports 2.5 GbE. 项目地址: https://gitcode.com/gh_mirrors/re/realtek-r8125-dkms …...

Ollama访问限制
发布于: Ollama访问限制 | Eucalyptushttps://blog.mingliangstar.com/2026/05/21/Ollama%E8%AE%BF%E9%97%AE%E9%99%90%E5%88%B6/ NginxBasic Auth认证 生成密码文件 # 安装工具 yum install httpd-tools -y# 创建密码文件(用户名 admin)…...

JWT密钥轮换缺陷与零停机热修复实战指南
1. 这不是一次普通升级,而是一次密钥信任体系的临界点崩塌Seedance2.0 v2.0.3发布不到72小时,我在给客户做例行安全巡检时,发现一个反直觉的现象:所有新签发的JWT令牌在旧版本客户端(v2.0.2)上验证失败&…...

Frida免Root模拟Xposed模块:原理、映射与工业级实践
1. 这不是“替代”,而是“重写”:为什么Frida能跑出Xposed的效果,却根本不需要Root“Frida vs Xposed”这个标题常被误读成一场工具对决——仿佛两者是同一赛道上的竞品,只待用户选边站队。但实操十年下来,我越来越确信…...