FLUX查询InfluxDB -- InfluxDB笔记三
1. 入门
from(bucket: "example_query") // 没有筛选条件直接查询会报错|> range(start: -1h) // |>是管道符,后跟筛选条件2. 序列、表和表流
序列是InfluxDB的概念,一个序列是由measurement、标签集、一个字段名称
表流是FLUX为了兼容关系型数据库和InfluxDB创造的概念

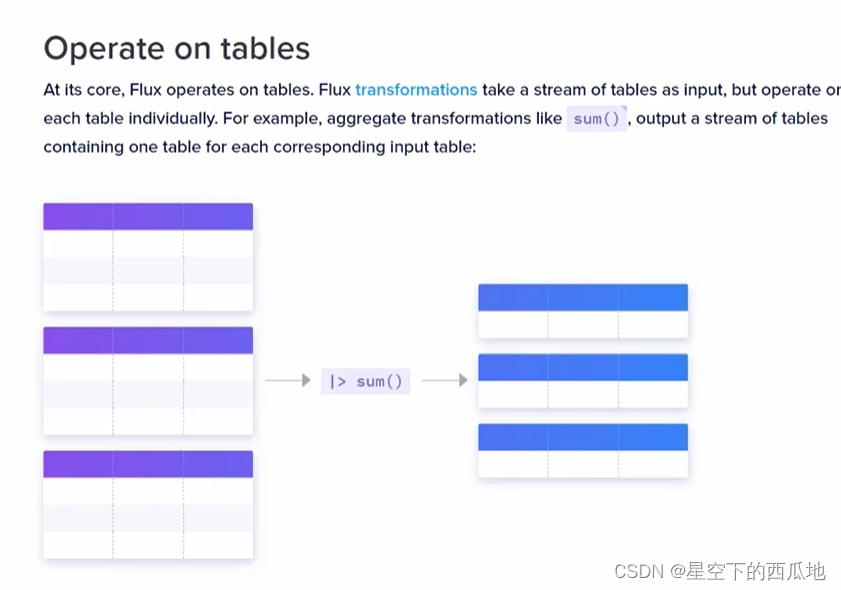
上图整体是表流,table 0、1是FLUX的两张表,对应InfluxDB的两个序列(rate、temp)
图上列名下的GROUP和NO GROUP :通过_measure、_field、code将表分组为多个子表、序列;通过Flux查询时,默认通过这三列分组
max() 最大值
|> max() // 返回结果是每个序列各一行,值为最大值
filter 过筛选滤
from(bucket: "example_query") // 没有筛选条件直接查询会报错|> range(start: -4h) // |>是管道符,后跟筛选条件,过去4小时|> filter(fn: (r) => (r:["_measurement"]=="people"))// 筛选测量名称(表名)为people的数据|> filter(fn: (r) => (r:["code"]=="02"))// 筛选标签code为02的数据|> filter(fn: (r) => (r:["_measurement"]=="people", onEmpty: "keep"))// onEmpty会让返回的table序号返回未用过的序号,比如数据存储用到0、1、2、3,则会返回4、5
_value类型不同,查询结果会分开,导致数据处理出错。一般加筛选条件过滤,来统一类型

toInt()
将查询结果的_value类型转为Long类型
原始带下划线的字段会与函数有一些约定,像_value/_time,缺失导致一些函数无法使用。
map函数
import "array"
// map函数,遍历表流里面的每一条数据
array.from(rows: [{"name": "tony"}, {"name": "jack"}])|> map(fn: (r) => {return if r["name"] == "tony" then {"_name": "tony不是jack"} else {"_name": "jack不是tony"}
})自定义管道函数
// 只能处理流数据,<-是管道函数的标识,table=<-就是流的占位符,调用时无需传入,如toInt()
big100 = (table=<-, x = 100.0) => {return table|> map(fn: (r) => ({r with "_value": r["_value"] * x}))
}from(bucket: "test_init")|> big100(x: 200.0)开窗 | window和aggregateWindow
// 30s的开窗,改变了原有序列,把整个表流 按照窗口 重新分配(查询结果会出现序号远大于原有序号)
|> window(period: 30s)
// 30s的开窗,不会改变原有序列,必须要指定一个函数
|> aggregateWindow(period: 30s, every: 30s, fn: max)
yield和join
默认返回一个_result,如果想要实现同时返回多个表,需要使用yield来区分,否则会报错
yield主要是为了支持join(.full/.inner/.left/.right/.tables/time),但是不建议使用。建议使用java等语言来处理join的逻辑 (因为InfluxDB不支持缓存,建议使用redis来缓存)
from(bucket: "example_test01")|> range(start: -4h)|> yield(name: "tom")from(bucket: "example_test02")|> range(start: -4h)|> yield(name: "jack")相关文章:
FLUX查询InfluxDB -- InfluxDB笔记三
1. 入门 from(bucket: "example_query") // 没有筛选条件直接查询会报错|> range(start: -1h) // |>是管道符,后跟筛选条件 2. 序列、表和表流 序列是InfluxDB的概念,一个序列是由measurement、标签集、一个字段名称 表流是FLUX为了…...
pico学习进程记录已经开发项目
Pico pin脚定义 Pico 运行准备 下载uf2文件 https://pico.org.cn/ (注意运行micropython的文件和运行c/c的不一样) 装载uf2文件:按住pico的按键,然后通过micro usb连接电脑(注意:如果用的线材,…...
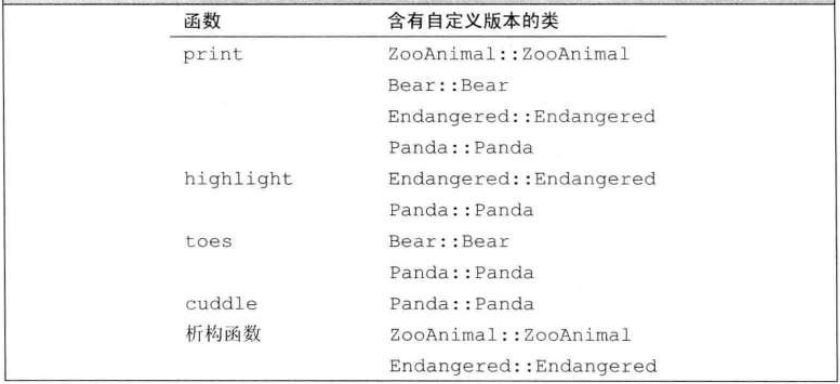
C++(20):多重继承与虚继承
多重继承 是指从多个直接基类中产生派生类的能力。多重继承的派生类继承了所有父类的属性。 多重继承 在派生类的派生列表中可以包含多个基类: class Bear : public zooAnimal { class Panda : public Bear, public Endangered{/* ...*/};每个基类包含一个可选的…...

Vue + Element UI 前端篇(一):搭建开发环境
Vue Element UI 实现权限管理系统 前端篇(一):搭建开发环境 技术基础 开发之前,请先熟悉下面的4个文档 vue.js2.0中文, 优秀的JS框架vue-router, vue.js 配套路由vuex,vue.js 应用状态管理库Element,饿…...

系统错误码指示确立+日志模块手动配置
1,系统错误码指示确立 对于前后端分离的系统设计中,后端建立错误码指示对于前端非常重要可以指示错误存在地方;以用户注册为例; public interface SystemCode{int SYSTEM_USER_ERROR_ADD_FAIL 10000;int SYSTEM_USER_INFO_ADD …...

Java入门第三季
一、异常与异常处理 1. 异常简介 在Java中,**异常是程序在执行过程中出现的问题或意外情况,导致程序无法按照预期的流程进行。**异常处理是Java中用于处理程序中出现的异常的一种机制。 Java中的异常可以分为两大类:受检查的异常ÿ…...

【linux命令讲解大全】056.updatedb命令:创建或更新slocate数据库文件
文章目录 updatedb补充说明语法选项实例 从零学 python updatedb 创建或更新slocate命令所必需的数据库文件 补充说明 updatedb命令用来创建或更新slocate命令所必需的数据库文件。updatedb命令的执行过程较长,因为在执行时它会遍历整个系统的目录树,…...
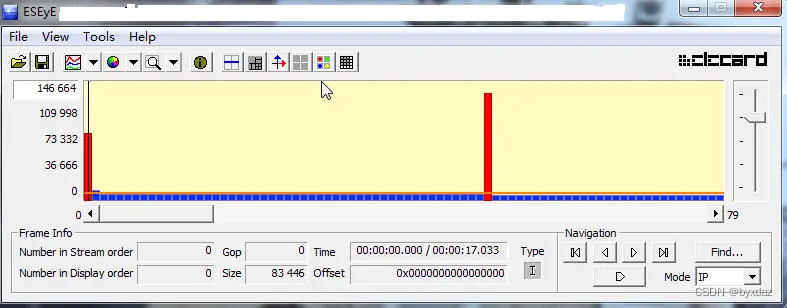
查看视频文件关键帧间隔
一、Elecard StreamEye Tools拖放视频文件查看。 红的是I帧;蓝的是P帧;绿的是B帧。 二、ffprobe -show_streams统计。 1、统计视频关键帧、非关键帧 ffprobe.exe -i 1.mp4 -show_streams v -show_packets -print_format json > d:\1.json 再统计1.j…...
如何在mac上安装多版本python并配置PATH
摘要 mac 默认安装的python是 python3,但是如果我们需要其他python版本时,该怎么办呢? 例如:需要python2 版本,如果使用homebrew安装会提示没有python2。同时使用python --version 会发现commond not found。 所以本…...

GPT-人工智能如何改变我们的编码方式
在本文中,您将找到我对人工智能和工作的最新研究的总结(探索人工智能对生产力的影响,同时开启对长期影响的讨论),一个准实验方法的示例(通过 ChatGPT 和 Stack Overflow 进行说明,了解如何使用简…...
)
混淆技术研究-混淆技术简介(1)
背景 在实际的移动安全分析过程中,遇到的混淆防护技术越来越多,因此分析难度逐渐增大,本系列技术研究主要通过对目前已有的混淆技术进行详细的技术分析,包括原理分析、反混淆技术等。本文是此系列的第一篇,主要是介绍目前市场上存在的混淆技术及其简单原理概述。 混淆技…...

HTML5+CSS3+JS小实例:科技感满满的鼠标移动推开粒子特效
实例:科技感满满的鼠标移动推开粒子特效 技术栈:HTML+CSS+JS 效果: 源码: 【html】 <!DOCTYPE html> <html><head><meta http-equiv="content-type" content="text/html; charset=utf-8"><meta name="viewport&qu…...
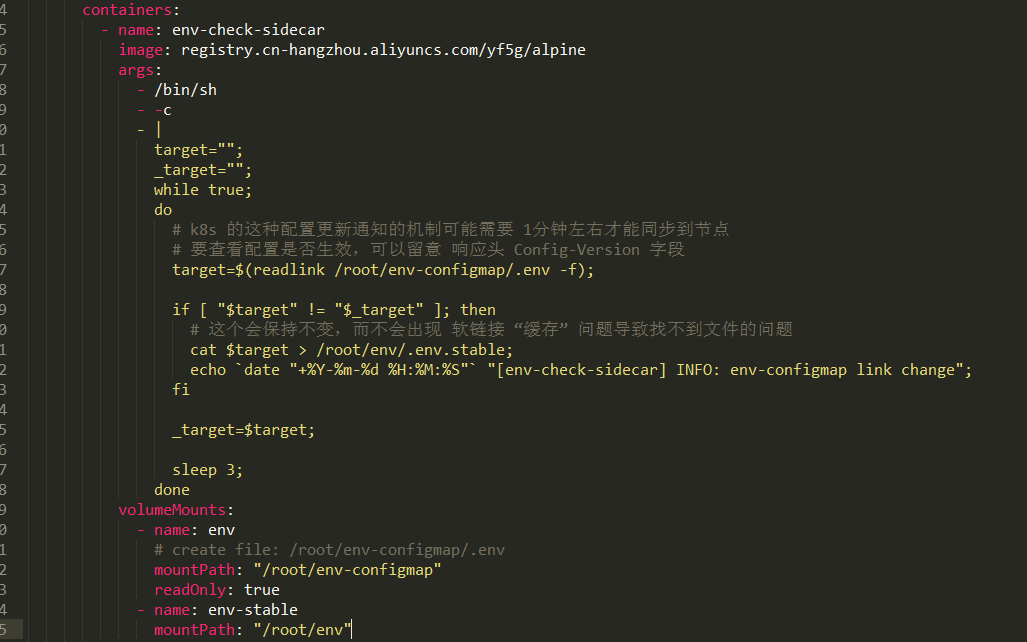
某物联网数智化园区行业基于 KubeSphere 的云原生实践
公司简介 作为物联网 数智化园区一体化解决方案提供商,我们致力于为大中型园区、停车场提供软硬件平台,帮助园区运营者实现数字化、智能化运营。 在使用 K8s 之前我们使用传统的方式部署上线,使用 spug(一款轻量级无 Agent 的自…...

MySQL查询数据库所有表名及其注释
1 查询 数据库 所有表 select table_name from information_schema.tables where table_schemasdam 2 查询数据库所有表 和表的 注释 SELECT TABLE_NAME, TABLE_COMMENT from information_schema.tables WHERE TABLE_SCHEMA dam ORDER BY TABLE_NAME; 3 查询数据库 单…...

8月31日-9月1日 第六章 案例:MySQL主从复制与读写分离(面试重点,必记)
本章结构 案例概述 案例前置知识点 详细图示 1、什么是读写分离? 读写分离,基本的原理是让主数据库处理事务性增、改、删操作(INSERT、UPDATE、DELETE),而从数据库处理SELECT查询操作。数据库复制被用来把事务性操作导…...

Oracle RAC 删除CRS集群配置失败
1.错误现象 [gridrac1~]$ /u01/app/11.2.0/grid/crs/install/rootcrs.pl -deconfig -force -verbose Cant locate Env.pm in INC (INC contains: /usr/local/lib64/perl5 /usr/local/share/perl5 /usr/lib64 /app/11.2.0/grid/crs/install) at /u01/app/11.2.0/grid/crs/insta…...

Kafka3.0.0版本——消费者(消费者总体工作流程图解)
一、消费者总体工作流程图解 角色划分:生产者、zookeeper、kafka集群、消费者、消费者组。如下图所示: 生产者发送消息给leader,followerr主动从leader同步数据,一个消费者可以消费某一个分区数据或者一个消费者可以消费多个分区数据。如下图…...
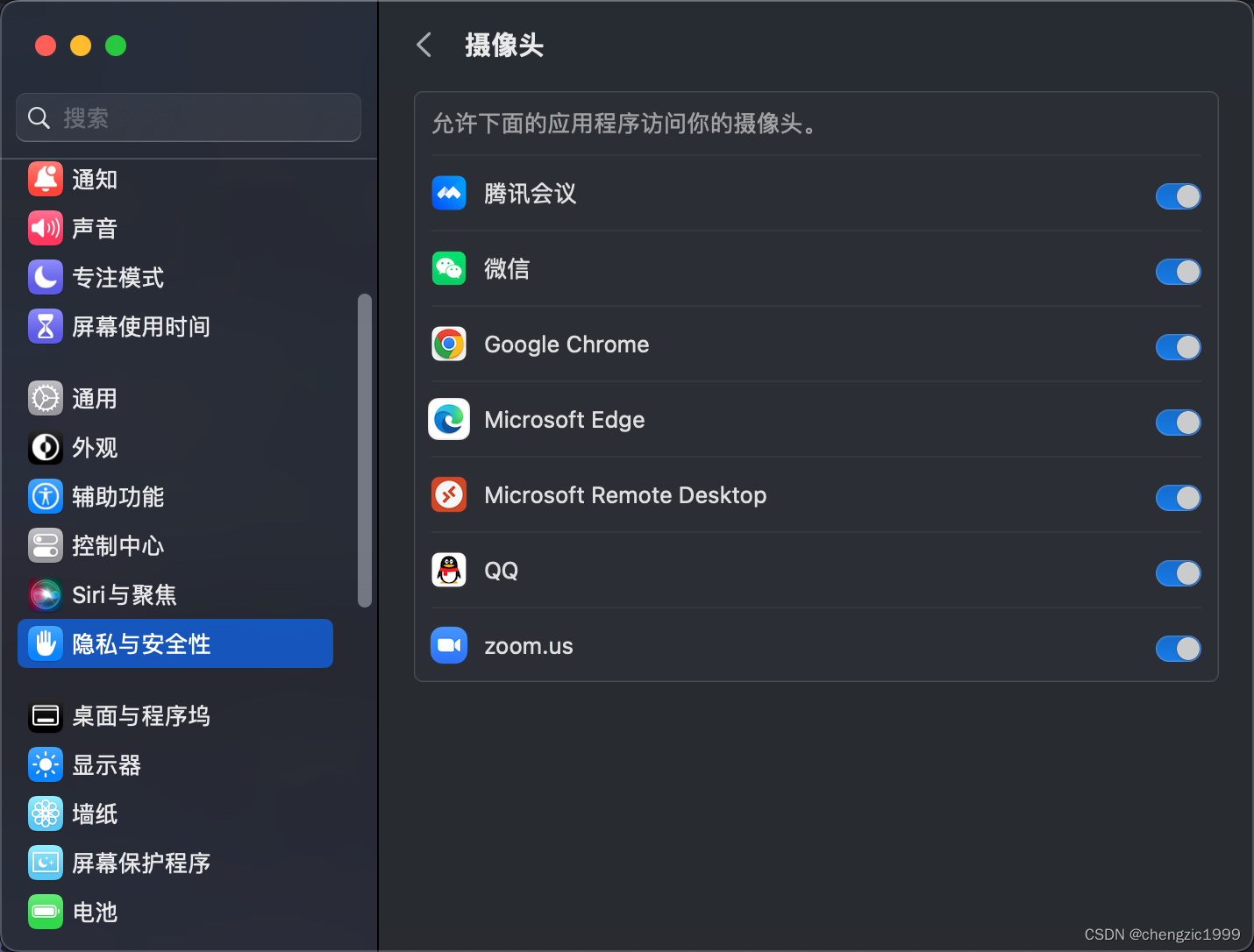
MacOS 为指定应用添加指定权限(浏览器无法使用摄像头、麦克风终极解决方案)
起因:需要浏览器在线做一些测评,但我的 Chrome 没有摄像头/麦克风权限,并且在设置中是没有手动添加按钮的。 我尝试了重装软件,更新系统(上面的 13.5 就是这么来的,我本来都半年懒得更新系统了)…...

Mysql 流程控制
简介 我们可以在存储过程和函数中实现比较复杂的业务逻辑,但是需要对应的流程控制语句来控制,就像Java中分支和循环语句一样,在MySQL中也提供了对应的语句,接下来就详细的介绍下。 1.分支结构 1.1 IF语句 IF 表达式1 THEN 操作1…...

Java学习笔记之----I/O(输入/输出)二
【今日】 孩儿立志出乡关,学不成名誓不还。 文件输入/输出流 程序运行期间,大部分数据都在内存中进行操作,当程序结束或关闭时,这些数据将消失。如果需要将数据永久保存,可使用文件输入/输出流与指定的文件建立连接&a…...

软考高项案例分析8:项目风险管理
软考高项案例分析8:项目风险管理 一、项目风险管理过程 1、规划风险管理; 2、识别风险; 3、实施定性风险分析; 4、实施定量风险分析; 5、规划风险应对; 6、实施风险应对; 7、监督风险; 二、案例分析知识点 1. 风险应对措施 威胁应对策略:上报、规避、转移、…...

TV Bro:终极智能电视浏览器解决方案 - 让大屏上网变得简单快速
TV Bro:终极智能电视浏览器解决方案 - 让大屏上网变得简单快速 【免费下载链接】tv-bro Simple web browser for android optimized to use with TV remote 项目地址: https://gitcode.com/gh_mirrors/tv/tv-bro 您是否曾经对着智能电视的浏览器感到沮丧&…...

网页端嵌入 Agent 对接前端方案
本文将深入探讨「网页端嵌入AI」的核心概念与实战技巧,帮助你快速掌握关键要点。让我们开始吧! 网页端嵌入 Agent 对接前端方案 1. 引言 当前前端项目正从被动展示走向主动交互,AI Agent 嵌入网页端可自动化 UI 操作、优化布局并辅助编码。…...

奇迹 MU 荣耀出征 新区开区 最新地址官方正版下载
《奇迹 MU 荣耀出征》是正版授权的复古魔幻 MMORPG 手游,完美复刻端游 1.03H 黄金版本核心玩法,逐光娱手游官网https://www.gw648.com提供官方正规下载渠道,带你重回艾瑞西亚大陆,再续荣耀传奇。 官方正版下载渠道 《奇迹 MU 荣耀…...

番茄小说下载器终极指南:三步打造你的私人数字图书馆
番茄小说下载器终极指南:三步打造你的私人数字图书馆 【免费下载链接】fanqienovel-downloader 下载番茄小说 项目地址: https://gitcode.com/gh_mirrors/fa/fanqienovel-downloader 你是否曾在深夜追更小说时突然断网?或者想在地铁上继续阅读却发…...

从零到出版级作品,包豪斯风格AI绘图全流程拆解,含12个可复用提示模板与字体/网格参数表
更多请点击: https://kaifayun.com 第一章:包豪斯设计哲学与AI绘图的底层耦合 包豪斯学派所倡导的“形式追随功能”“少即是多”“艺术与技术统一”三大信条,并非仅属于20世纪的工艺宣言,而是深度嵌入现代生成式AI模型的架构基因…...

宣传片微电影制作拍摄
荣誉见证实力・匠心铸就品牌|国隆映像传媒,6 年深耕乌鲁木齐,斩获全国影像盛典、脱贫攻坚、文旅代言等多项大奖,为企事业单位提供一站式影视制作服务。...

配置openclaw使用taotoken作为其底层大模型供应商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 配置 OpenClaw 使用 Taotoken 作为其底层大模型供应商 基础教程类,引导使用 OpenClaw 这类 Agent 框架的开发者&#x…...

从装饰器原理到实战:手把手教你用TypeScript为NestJS方法实现一个‘网络代理’
从装饰器原理到实战:手把手教你用TypeScript为NestJS方法实现一个‘网络代理’ 在Node.js生态中,装饰器(Decorator)作为一种元编程工具,正逐渐从实验性特性转变为现代框架的核心支柱。NestJS正是这一趋势的典型代表—…...
:声调准确率92.6%、连读自然度行业首破88分)
ElevenLabs湖南话TTS深度评测(2024真实场景压测报告):声调准确率92.6%、连读自然度行业首破88分
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs湖南话语音技术概览 ElevenLabs 作为全球领先的语音合成平台,其多语言支持能力持续扩展,但需明确指出:截至 2024 年底,ElevenLabs 官方模型库*…...