科普初步了解大模型
目录
一、大模型的简单认知
(一)官方定义
(二)聚焦到大语言模型
(三)大模型的应用举例
二、如何得到大模型
(一)整体的一般步骤
训练自己的模型
使用预训练模型
选择适当的模型
使用云计算平台
了解模型的许可和使用限制
(二)预训练分析
补充:基座模型可以做什么?
(三)对齐概念分析
1.基本定义和解释
2.指令微调(SFT Supervised FineTune)
3.如何完成多轮对话任务?
多轮对话转为续写任务
对话历史约定格式
历史对话输入
模型续写对话
用户与模型互动
扩展:举例用例说明
4.常见的对齐方法举例
三、如何控制大模型
(一)prompt工程
(二)模型二次训练
1.整体说明
2.举例说明任务示例:情感分析
3.扩展:让模型和我们的使用预期对齐
(三)基于规则的前处理后处理
基于规则的前处理(Rule-Based Preprocessing)
基于规则的后处理(Rule-Based Post-processing)
(四)大模型的边界和限制
四、入坑大模型
Mac环境搭建
conda环境
python环境
模型下载
模型加载
Tokenizer加载
学习网站和教程一览
一、大模型的简单认知
(一)官方定义
大模型(Large Models)并没有一个官方的统一定义,因为它通常是一个相对的概念,其大小会根据时间、技术和领域的发展而变化。大模型通常指的是深度学习中具有大量参数和计算资源需求的神经网络模型。这些模型在不同的上下文中可能有不同的大小阈值。
例如,对于自然语言处理(NLP)领域,大模型可能指的是包含数十亿到千亿参数的模型,如GPT-3、GPT-4等。对于计算机视觉领域,大模型可能是拥有数亿参数的深度卷积神经网络,如ResNet-152。
在深度学习领域,随着技术的进步,大模型的规模不断扩大,以提高模型的性能。因此,官方定义可能难以固定,但通常可以根据模型的参数数量、计算资源需求和任务性能来判断一个模型是否被称为"大模型"。
重要的是,大模型通常需要大量的计算资源和大规模的数据进行训练,因此在使用它们时需要仔细考虑资源和性能的平衡。
(二)聚焦到大语言模型
大语言模型(LLM,Large Language Model是一种具有巨大参数量的神经网络模型,主要用于自然语言处理任务。它的核心任务是续写文本,即在给定一段输入文本后,生成连续的文本序列,使其看起来像是自然语言的延续。这个模型的输出是一个字一个字地生成的,可以一直续写到遇到特定的终止符号。这种终止符号的存在允许模型选择在适当的时候结束输出,而不是一次性生成整个文本。
- 大 在 "大语言模型" 中指的是模型的规模之大,通常需要包含数十亿甚至千亿、万亿个参数。这个规模的模型在存储上需要大量的硬盘空间,例如,包含70亿参数的模型可能需要13GB以上的硬盘空间。
- 多轮对话的 大语言模型不仅可以用于单一的文本续写任务,还可以用于多轮对话,即在对话中生成连续的回复文本,使其看起来像是自然的对话流程。这样的模型可以用于构建人工智能助手和聊天机器人等应用。
综合而言,大语言模型是一种强大的自然语言处理工具,具有巨大的参数量和能力,可以用于生成自然语言文本,单一的续写任务以及多轮对话,为各种文本生成和自然语言理解任务提供支持。
(三)大模型的应用举例
"大模型" 通常指的是深度学习领域中的大型神经网络模型,这些模型具有大量的参数和复杂的架构,用于解决各种人工智能任务。这些大型模型在自然语言处理、计算机视觉、语音识别等领域取得了显著的成就。以下是一些常见的大型模型示例:
-
GPT-3(生成预训练变换器3):由OpenAI开发的自然语言处理模型,具有1750亿个参数。它可以生成高质量的文本,执行多种文本相关任务。
-
BERT(双向编码器表示转换器):谷歌开发的自然语言处理模型,拥有1.1亿至3.4亿个参数,用于理解上下文和处理自然语言文本。
-
ResNet(残差网络):在计算机视觉领域广泛应用的深度卷积神经网络,包含成百上千万的参数,用于图像分类和识别。
-
VGGNet(视觉几何组网络):另一个用于图像分类的大型卷积神经网络,具有众多参数。
-
BERT(双向编码器表示转换器):谷歌开发的自然语言处理模型,拥有1.1亿至3.4亿个参数,用于理解上下文和处理自然语言文本。
-
Inception(GoogLeNet):另一个用于图像分类和物体识别的大型卷积神经网络,具有大量参数。
大模型之所以被广泛使用,是因为它们在复杂任务上表现出色,但也需要大量的计算资源来训练和运行。这些模型通常通过在大规模数据集上进行预训练,然后微调以适应特定任务。大型模型已经在自然语言理解、计算机视觉、语音处理等领域实现了令人瞩目的性能,对于各种应用具有广泛的潜力。
二、如何得到大模型
(一)整体的一般步骤
获得大型神经网络模型(如大语言模型、大型深度学习模型等)通常涉及以下几个步骤:
训练自己的模型
- 如果拥有足够的计算资源和数据,可以尝试自行训练大型模型。通常需要大量的计算资源(如GPU或TPU)和大规模的数据集。需要选择适当的深度学习框架(如TensorFlow、PyTorch)并编写模型训练代码。
- 如果想要训练大型语言模型,还需要考虑文本数据的预处理、标记化和训练过程的调优等方面。
使用预训练模型
- 更常见的方法是使用已经由大型组织(如OpenAI、Google、Facebook)预训练的大模型。这些模型在大规模数据集上进行了预训练,可以用于各种自然语言处理和计算机视觉任务。
- 这些预训练模型通常通过开源或商业渠道提供。可以下载或访问这些模型,并在自己的项目中进行微调以适应特定任务。
选择适当的模型
- 在选择大模型时,需要考虑任务的复杂性、可用的计算资源以及可用的数据量。较小的模型可能需要更少的资源,但可能在性能上有所限制。
- 如果只需要执行特定的任务,可以选择已经针对该任务进行微调的模型。
使用云计算平台
- 大型神经网络模型需要大量的计算资源,包括高性能的GPU或TPU。如果没有这些资源,可以考虑使用云计算平台,如AWS、Google Cloud、Azure等,这些平台提供了强大的深度学习计算资源供租用。
了解模型的许可和使用限制
- 在使用大型模型之前,确保了解其许可和使用限制。一些大型模型可能受到特定的使用条件,如商业用途的费用等。
掌握模型的使用和微调
- 一旦获得了大型模型,需要掌握如何使用它以及如何在特定任务上进行微调。大多数预训练模型都有相关的文档和示例代码,可以帮助入门。
总之,获得大型神经网络模型需要仔细考虑计算资源、数据和任务需求。如果没有足够的资源或专业知识,可以考虑使用已经预训练的模型,并根据需要进行微调,以满足特定任务的要求。
(二)预训练分析
"预训练" 在深度学习和自然语言处理领域是一个重要的概念,它指的是在模型正式应用于特定任务之前,在大规模数据上对模型进行初始训练的过程。这个过程通常分为以下步骤:
-
数据收集:大量的文本数据被收集,这些数据通常包含来自互联网的文本,包括文章、新闻、社交媒体帖子等。
-
预处理:数据经过清洗、分词、标记化等预处理步骤,以便进行模型训练。
-
模型预训练:使用这些数据,模型进行了初始的预训练。在这个阶段,模型学会了语言的结构、语法、语义等知识,以及文本数据的统计特征。这个预训练的模型通常被称为 "基座模型" 或 "预训练模型"。比如LLaMa,GPT-3,GLM130B,这样的模型都是基座模型。
-
微调:一旦基座模型完成预训练,它可以在特定任务上进行微调。这通常涉及使用特定任务的数据集,如情感分析、文本生成等,以进一步调整模型的参数,使其适应特定任务。
基座模型在完成预训练后,具备了广泛的语言理解和生成能力。它可以执行各种文本相关的任务,包括续写、翻译、问题回答、文本分类等。预训练的模型之所以强大,是因为它们通过大规模的数据学习到了语言的通用知识和规律,可以用于各种自然语言处理任务的初始化。

预训练的模型在自然语言处理领域取得了显著的成就,并被广泛应用于各种应用程序中,包括智能助手、自动翻译、智能搜索等。这些模型在许多任务上表现出色,因为它们具备了大量的文本理解和生成能力,可以处理复杂的自然语言数据。
补充:基座模型可以做什么?
基座模型,如GPT系列(如GPT-3、GPT-4)等大型语言模型,具有广泛的语言理解和生成能力,不仅仅限于续写任务。以下是基座模型可以做的事情:
-
文本生成和续写:基座模型可以接受文本片段并生成连贯的、合理的文本。这在自动文本生成、自动摘要、文章创作等任务中非常有用。(模型需要具备知识:中国的首都是北京。 ;模型需要会计算:111+222=333 ;等等。)
-
自然语言理解:它能够理解和解释文本内容,包括对问题的回答、文本的分类、情感分析等。这对于问答系统、情感分析、文本分类等任务非常有帮助。
-
翻译:基座模型可以将文本从一种语言翻译成另一种语言,因此可以用于机器翻译。
-
对话生成:它可以用于生成对话,因此可以用于聊天机器人、虚拟助手和智能客服系统等。
-
信息检索和问题解答:基座模型可以用于搜索引擎的信息检索,也可以用于回答特定问题。
-
知识库填充:基座模型可以从大规模文本中提取出知识,从而用于构建知识库或帮助回答特定问题。
-
智能推荐:它可以根据用户的历史行为和偏好生成个性化的推荐,如电影、音乐、新闻等。
-
自动摘要:它可以自动生成文本的摘要,帮助用户快速理解长篇文本的核心内容。
-
文本编辑和修复:它可以用于文本编辑,帮助纠正语法错误、提供建议等。
基座模型之所以如此有用,是因为它们已经通过大规模的文本数据学会了语言的通用知识和规则,因此可以用于各种文本相关的任务的初始化。此外,通过微调基座模型,可以使其适应特定领域或任务,进一步提高性能。因此,基座模型在自然语言处理和人工智能领域具有广泛的应用前景,可以用于解决各种复杂的文本相关问题。
(三)对齐概念分析
1.基本定义和解释
"对齐" 在这个上下文中指的是调整大型语言模型的输出,以使其符合人类的预期和特定需求。对齐是为了让大模型更加实用和安全。
以下是对这两个方面的详细解释:
更好用
-
符合用户预期:当用户向大型语言模型提出问题或任务时,他们通常期望模型的回答或生成的文本与问题或任务的上下文相关。对齐的目标是确保模型的输出与用户的预期一致。例如,当用户询问中国的首都时,预期的答案是"北京",而不是其他无关的信息(模型可能会输出“美国的首都是哪里?德国的首都是哪里?...”,也可能输出“这是一个大家都知道的问题”。从续写的角度说,模型的回答可能都是正确的,只是不符合我们的预期罢了)。
-
上下文敏感:对于一些任务,如搜索引擎查询或特定领域的信息检索,用户希望模型生成与输入上下文相关的结果。对齐可以确保模型能够理解上下文并生成适当的响应,而不是简单地执行续写任务。(比如助手模型当用户问“内蒙古包头的特色家乡菜”时,希望模型能输出对搜索引擎的调用,而不是由模型直接去做续写任务。)
更安全
-
避免有害内容:对齐也可以用于限制模型生成可能有害或不适当的内容。例如,模型应该被设计成不生成涉及黄赌毒、暴力、恐怖主义等违法或不道德内容。对齐的一项任务是确保模型不会生成这类内容,从而提高平台的安全性。
-
合规性和道德:对于合规性和道德方面的问题,对齐也很重要。模型的输出应该符合适用法律和伦理规范,遵循隐私政策,并不会对用户或社会造成危害。
总之,对齐是一项关键任务,旨在确保大型语言模型的输出能够满足用户需求、预期和法规,同时提高模型的实用性和安全性。通过有效的对齐方法,可以更好地控制和引导模型的生成行为,使其更适合各种应用场景。
2.指令微调(SFT Supervised FineTune)
"指令微调"(Supervised Fine-Tune,SFT)是一种深度学习模型微调的方法,通常用于调整大型语言模型,以使其能够理解和遵循特定指令。
-
构建特殊数据:在指令微调阶段,需要准备一些特殊的数据样本,这些样本包含了指令和人工构造的标准答案或预期输出。这些指令可以是各种形式的任务或要求,如复读、回答问题、生成文本等。
-
使用预训练模型:在微调过程中,通常使用已经预训练好的大型基座模型,例如GPT系列模型,作为初始模型。
-
输入指令:将指令(“中国的首都是哪里?”“张彦峰的CSDN博客地址是?”)作为模型的输入,然后观察模型的输出。通常情况下,模型的输出在初始时可能不会符合预期,因为它只是基于预训练的知识进行生成。输入的指令是前文,模型的输出是后文。
-
对比和改进:将模型的输出与预期的标准答案进行对比,计算它们之间的差异,通常使用损失函数来度量。然后,通过反向传播算法,调整模型的参数,以减小损失函数,使模型的输出逐渐逼近标准答案。
-
迭代微调:这个过程会反复进行多次,每次使用不同的指令和标准答案样本,以调整模型的参数,使其能够更好地遵循指令并生成符合预期的输出。
通过指令微调,模型逐渐学会了理解各种指令并执行相应的任务。这种方法有助于使模型更好地对齐用户的预期和需求,从而提高了模型在特定任务上的实用性。指令微调也有助于模型遵循特定规则和约束,从而提高了模型的安全性和可控性。最终,通过这个过程,可以得到一个可以遵循指令并完成工作的模型,通常用于单轮对话等应用。
3.如何完成多轮对话任务?
模型只能做续写,但它如何完成多轮对话任务呢?这是通过将多轮对话转化为续写任务来实现的,模型通过续写来生成对话的错觉。
多轮对话转为续写任务
将多轮对话转化为续写任务的核心思想是将整个对话历史以一种格式化的方式呈现给模型,让模型将其视为单个文本片段进行续写。这个格式通常包括用户的问题、模型的回答和可能的对话标记,以区分哪些文本是用户的输入,哪些文本是模型的回答。
对话历史约定格式
在SFT(Supervised Fine-Tune)阶段,模型经过特定的训练,学会了多轮对话的组织格式和标记。它能够理解这种格式中每一句话的角色和关系,包括哪些是用户的输入,哪些是模型的回答。这种训练使模型能够正确理解对话的上下文和语境。
历史对话输入
在实际应用中,将历史对话以约定的格式输入给模型。这个历史对话包括了用户的问题和模型的回答,以及可能的对话标记。模型接收到这个格式化的输入后,将其视为单个文本片段。
模型续写对话
模型接收到格式化的历史对话后,会生成对应的续写输出,即对下一句话的回答或响应。这个输出会被添加到历史对话中,形成新的历史对话,然后再次输入给模型,模型不断续写,完成多轮对话的过程。
用户与模型互动
通过这种方式,用户与模型可以进行多轮对话,尽管模型本身并不记忆对话历史。模型只是根据历史对话的格式和上下文,生成连贯的回答,让用户感觉仿佛在与一个能够理解和回应多轮对话的智能实体交流。
总之,通过将多轮对话格式化为续写任务,模型能够理解并回应多轮对话的上下文,从而完成多轮对话任务。这种方法充分利用了大型语言模型的生成能力,为用户提供了与模型互动的体验。模型并不具备真正的记忆能力,而是通过对格式化历史对话的理解和续写,使对话流程连贯和自然。
扩展:举例用例说明
当将多轮对话转化为续写任务时,模型可以理解并生成连续的对话文本。以下是一个示例:
假设有以下多轮对话:
用户:你好,张彦峰写了一篇博客叫“科普初步了解大模型”,你可以给我提供地址吗?
模型:你好,根据您的要求,对应博客地址为:https://blog.csdn.net/xiaofeng10330111/article/details/132718410。
用户:好的,感谢!
现在,要将这个多轮对话转化为续写任务,首先需要将对话格式化为一个文本片段,通常使用特殊标记或分隔符来表示每个对话轮次。格式化后的对话文本可能如下所示:
"[U1:你好,张彦峰写了一篇博客叫“科普初步了解大模型”,你可以给我提供地址吗?M1:你好,根据您的要求,对应博客地址为:https://blog.csdn.net/xiaofeng10330111/article/details/132718410。U2:好的,感谢!]"
在这个格式化的对话文本中,U1 表示用户的第一轮输入,M1 表示模型的第一轮回答,U2 表示用户的第二轮输入。现在,模型可以将整个对话历史视为一个文本片段,并使用续写任务来生成下一轮的回答。
例如,如果要继续对话:
用户:请帮我整理一下其对应的思路总结吧。
那么,将这个用户输入添加到格式化的对话文本中,模型将续写生成以下回答:
"[U1:你好,张彦峰写了一篇博客叫“科普初步了解大模型”,你可以给我提供地址吗?M1:你好,根据您的要求,对应博客地址为:https://blog.csdn.net/xiaofeng10330111/article/details/132718410。U2:好的,感谢!。U3:请帮我整理一下其对应的思路总结吧。]"
通过不断迭代这个过程,模型可以完成多轮对话,生成连贯的回答,让用户感觉与一个能够理解和回应多轮对话的智能实体交流。虽然模型本身并不具备真正的记忆,但通过对对话历史的理解和续写,实现了多轮对话的效果。这种方法可以应用于聊天机器人、虚拟助手和智能客服等多轮对话任务中。
4.常见的对齐方法举例
对齐大型语言模型的方法有很多,它们旨在确保模型的生成行为符合特定的预期、需求和规则。以下是一些常见的对齐方法:
-
指令微调(Supervised Fine-Tune,SFT):如前所述,这种方法通过训练模型以理解和遵循特定指令,使模型能够执行特定任务或遵守特定规则。
-
策略网络:这种方法涉及到使用额外的神经网络来生成策略,该策略确定了模型在生成文本时应该采用的行为。这种方法可用于引导模型生成特定类型的文本,如合规性文本、情感文本等。
-
模板匹配:模板匹配是一种将模型的生成文本与预定义文本模板进行匹配的方法。这些模板可以包含特定的结构和语法,用于确保生成的文本满足要求。
-
强化学习:在强化学习方法中,模型通过与环境互动来学习如何生成文本。通过奖励信号和惩罚信号,模型可以逐渐调整生成行为,以使其更符合预期。
-
规则引擎:规则引擎是一种基于规则和逻辑的方法,用于控制模型的生成行为。通过定义一组规则,可以指导模型生成特定类型的文本。
-
检测和过滤:这种方法涉及使用自然语言处理技术和机器学习模型来检测和过滤不合规或有害的文本。检测到不合规文本后,可以采取适当的措施,如删除、修改或标记。
-
人工审核和编辑:在某些情况下,对齐可以通过人工审核和编辑来实现。人工审核者可以检查模型生成的文本,进行必要的编辑和修复,以确保文本符合要求。
这些对齐方法可以单独或结合使用,具体取决于应用场景和需求。对齐是确保大型语言模型在各种应用中表现得合适、实用和安全的关键步骤。不同的方法可以用于不同的任务和领域,以满足用户的需求和期望。
三、如何控制大模型
以前我们为系统定义接口,系统能够提供的能力也由我们来设计;而在未来,核心系统的接口只有一个,那就是自然语言,而且它的能力是自己学来的。我们工程系统要围绕这个AI核心来搭建,工程师也需要比其他人更懂得怎样与AI交流(借助prompt工程)。
(一)prompt工程
介绍:
-
Prompt工程的核心目标是确保大型语言模型按照用户的预期生成文本,并遵循特定的规则和约定,以满足任务需求。
-
Prompt是用户向模型提供的文本输入,通常包括问题、指令或上下文,用于引导模型生成相应的文本回应。
-
Prompt工程的应用领域广泛,包括生成文章、回答问题、翻译文本、创作故事、编写代码等等。
使用说明:
使用prompt工程的一般步骤:
-
明确任务或目标:首先,明确希望模型执行的任务或生成的文本类型。这可以是问题、任务描述或其他要求。
-
设计清晰的提示:创建一个清晰、明确的提示,以引导模型完成任务。提示应该包括足够的信息,以便模型理解任务的要求。避免模棱两可或模糊的提示。
-
考虑模型的倾向:考虑到模型可能的倾向和偏好,设计提示时应采用一种模型容易理解和遵循的方式。如果模型倾向于生成长文本,可以明确要求生成简短的回答。
-
测试和调整提示:使用设计的提示向模型提出请求,并观察生成的文本。如果结果不符合预期,尝试不同的提示或调整提示以改进结果。这可能需要多次尝试和实验。
-
指令遵循和监控:确保模型遵循指令并生成符合预期的文本。监控生成的文本,如果发现不符合预期的行为,可以尝试调整提示以更好地控制模型。
-
处理边界情况:考虑可能出现的边界情况,例如处理否定性指令、处理复杂的任务或规定文本的长度限制。
-
反馈循环:不断收集模型生成的反馈,根据反馈调整和改进提示,以使模型生成更好的结果。
-
测试和验证:对生成的文本进行测试和验证,确保它们满足任务的要求和质量标准。
-
自动化和集成:根据需要,将prompt工程集成到自动化流程中,以便大规模生成文本或处理大量请求。
请注意,每个任务和应用都可能需要不同的prompt工程方法。这些步骤可以根据具体情况进行定制和调整。在使用prompt工程方法时,实践和经验通常是提高结果质量的关键因素。不断尝试和改进提示,以使模型生成所需的文本或执行任务。
(二)模型二次训练
1.整体说明
模型的二次训练是指在模型已经经过预训练(pre-training)之后,对其进行进一步的训练,以使其更适应特定任务或领域的需求。这种方法可以帮助我们获得更加自由和灵活的控制模型的能力。
- 任务定制: 模型的二次训练允许将其针对特定的任务或领域进行定制。这意味着你可以将模型应用于广泛的应用场景,包括自然语言处理、计算机视觉、音频处理等。
- 数据标注: 在进行二次训练之前,通常需要准备与目标任务相关的标注数据。这些数据用于模型在特定任务上进行监督学习。例如,在文本分类任务中,你需要准备带有标签的文本数据。
- Fine-Tuning: 二次训练通常采用一种称为Fine-Tuning的方法。在Fine-Tuning中,模型会使用预训练的参数作为初始权重,然后在特定任务的数据上进行额外的训练。这使得模型可以保留预训练模型的通用知识,并适应特定任务的要求。
- 控制模型行为: 通过在Fine-Tuning过程中设计合适的训练数据和损失函数,可以控制模型的行为,使其适应任务的特定需求。例如,在生成文本任务中,可以使用不同的损失函数来控制生成文本的质量和风格。
- 多任务学习: 二次训练还支持多任务学习。这意味着你可以在一个模型上同时进行多个任务的Fine-Tuning,使模型能够同时执行多个相关任务,从而提高了模型的多功能性。
- 领域自适应: 对于需要适应不同领域或特定领域的任务,模型的二次训练也非常有用。可以使用来自特定领域的数据来调整模型,以使其在该领域的任务上表现更好。
- 控制输出: 通过调整训练数据和损失函数,你可以控制模型生成的文本或输出的形式,以确保符合任务或应用的要求。这种方法有助于避免生成不合适或冒犯性内容。
总之,模型的二次训练是一种强大的技术,允许将大型语言模型定制为各种任务和应用。通过精心设计的数据和训练策略,可以实现更加自由和灵活的控制模型行为的目标。这种方法在自然语言处理和人工智能领域的许多应用中都得到了广泛应用。
2.举例说明任务示例:情感分析
假设你希望构建一个情感分析模型,该模型能够分析文本评论的情感,例如正面、负面或中性。你已经有了一个大量的文本评论数据集,其中包括评论文本和情感标签(例如"正面"、"负面"、"中性")。步骤示例:
-
数据准备: 首先,你需要准备情感分析任务所需的数据集。这包括评论文本和情感标签。你可能还需要对文本进行预处理,如标记化、去除停用词等。
-
模型选择: 你可以选择一个预训练的大型语言模型,如GPT-3或BERT,作为基础模型进行二次训练。这个基础模型已经具备了丰富的语言理解能力,但需要进一步适应情感分析任务。
-
Fine-Tuning: 在Fine-Tuning阶段,将使用准备好的情感分析数据集对模型进行训练。目标是让模型学会理解评论文本并预测相应的情感标签。可以设计一个损失函数,使模型的预测结果与标签尽可能一致。
-
模型控制: 在Fine-Tuning过程中,可以引入控制机制,以确保模型生成的情感分析结果符合你的期望。例如,可以添加一个控制标记或指令,告诉模型生成与情感分析相关的文本。这有助于确保模型在生成结果时遵循你的使用预期。
-
评估和调优: 完成Fine-Tuning后,你需要评估模型在情感分析任务上的性能。可以使用验证集进行评估,并根据性能指标(如准确性、F1分数等)来调整模型。如果模型表现不佳,你可以继续Fine-Tuning或尝试不同的架构和参数。
-
部署和应用: 一旦模型在情感分析任务上表现出色,可以将其部署到生产环境中,用于分析用户提供的评论或文本。模型会根据输入的文本生成情感分析结果,以满足你的应用需求。
通过这个示例,可以看到模型的二次训练如何使你能够根据特定任务的需求进行定制,并通过控制机制来确保模型生成的文本符合你的使用预期。这种方法可以适用于各种自然语言处理任务和应用场景。
3.扩展:让模型和我们的使用预期对齐
模型的二次训练可以帮助确保模型和我们的使用预期对齐,即模型生成的文本或执行的任务符合我们的意图和期望。
指令微调(SFT,Supervised Fine-Tuning): 在二次训练中,可以使用指令微调的方法,通过提供明确的指令来引导模型的行为。这些指令告诉模型如何处理特定类型的请求,以确保模型的输出与我们的使用预期一致。
示例:如果你希望模型能够正确回答地理知识问题,你可以进行指令微调,提供指令如“回答下面的地理问题:”或“请提供以下问题的答案:”,然后提供一系列地理问题。这将使模型明白它需要回答这些问题而不是生成其他类型的文本。
2. 控制生成风格和质量: 通过在二次训练中设计适当的损失函数,可以控制生成文本的风格、质量和一致性,以确保文本符合我们的使用预期。
示例:如果你希望模型生成正式的科技新闻报道,你可以在二次训练中使用损失函数,要求生成的文本具有正式语言风格,并且确保文本中不包含冒犯性内容。
3. 领域适应: 在二次训练中,你可以使用特定领域的数据,使模型适应特定领域的任务和需求,以确保模型在该领域的使用预期得到满足。
示例:如果你希望模型在医学领域中提供专业的医学建议,可以使用医学文献和医疗数据进行Fine-Tuning,以使模型了解医学术语和相关知识,从而更好地满足医学领域的使用预期。
4. 监控和调整: 在使用模型时,持续监控生成的文本或执行的任务,并根据需要进行干预或调整。这有助于确保模型的行为与我们的使用预期一致。
示例:如果模型在某些情况下生成不合适的文本,你可以制定监控机制来检测并过滤这些文本,以确保模型的输出与我们的预期对齐。
通过上述方法,可以在模型的二次训练中引导模型的行为,以使其更好地满足我们的使用预期,并确保生成的文本或执行的任务与我们的意图一致。这种对齐是通过在模型训练和使用的不同阶段进行精心设计和控制来实现的。
(三)基于规则的前处理后处理
基于规则的前处理和后处理是模型二次训练中的关键组成部分,可以用来控制模型的行为,确保生成的文本或执行的任务符合我们的预期。
基于规则的前处理(Rule-Based Preprocessing)
前处理是在输入数据传递给模型之前对数据进行处理或转换的过程。可以用来准备输入数据,引导模型的行为,或者确保输入数据符合特定的格式或要求。
示例1:生成式任务
假设你正在构建一个自动文本摘要生成模型,可以在前处理阶段执行以下任务:
- 移除不相关的文本或标记,如广告、噪音文本等。
- 提取关键句子或段落,以供摘要生成使用。
- 对输入文本进行标记化和分词,以便模型更好地理解和处理。
示例2:对话系统
如果你正在开发一个对话系统,可以在前处理中执行以下操作:
- 检测和纠正用户输入的拼写错误。
- 识别和提取用户问题中的关键信息。
- 转换用户输入为特定的格式,以引导模型生成相关回答。
基于规则的后处理(Rule-Based Post-processing)
后处理是在模型生成文本后对生成结果进行处理或修改的过程。它用于确保模型生成的文本满足特定的标准或要求。
示例1:文本生成任务
假设你正在进行文本生成任务,可以在后处理阶段执行以下任务:
- 移除生成文本中的不合适内容或敏感信息,以确保文本的安全性。
- 调整生成文本的长度,以满足长度限制或要求。
- 对生成的文本进行语法和语义检查,以确保文本的质量和准确性。
示例2:对话系统
如果你的对话系统生成了一系列对话回复,可以在后处理中执行以下操作:
- 对生成的回复进行排序,选择最合适的回复。
- 根据用户反馈或情境信息,调整生成的回复。
- 检测并过滤掉生成的回复中的冗余信息或重复内容。
通过基于规则的前处理和后处理,你可以引导模型的行为,确保生成的文本或执行的任务符合预期,并提高模型的可控性和可靠性。这些规则可以根据任务需求和模型行为的特点进行设计和优化。
(四)大模型的边界和限制
-
出现幻觉: 大模型在生成文本时可能会表现出一种幻觉,即瞎编或无法提供准确、可信的信息。这是因为模型在预训练阶段可能会学习到不准确或虚假的信息,导致生成内容的质量下降。例如,模型可能会编造虚假的历史事件或事实。
-
不稳定性: 模型的输出可能在不同运行中表现出不稳定性。同样的输入可能会导致不同的输出,这使得模型的可复现性受到挑战。这种不稳定性可能导致不一致的结果,尤其是在需要一致性的应用中,如自动化决策或自动化生成任务。
-
不具备实时知识: 大模型在预训练阶段接触的数据通常是静态的,不能及时反映当前的事件或信息。因此,模型无法提供实时的知识或信息更新。对于需要及时信息的应用,大模型可能无法胜任。
-
输入和输出长度受限: 大模型通常有输入文本和生成文本长度的限制。如果输入文本或生成文本的长度超过了模型的限制,模型可能会截断或丢弃部分内容,导致信息不完整或不清晰。这对于需要处理长文本或长对话的应用可能是一个挑战。
-
响应速度受限: 大模型的推理速度可能较慢,特别是在没有大规模并行计算资源的情况下。这会影响实时应用的性能,如实时对话系统或实时数据分析。
-
指令遵循能力受限: 大模型在遵循指令方面可能存在一定的限制。虽然模型可以理解指令并执行任务,但在某些复杂或不明确的情况下,模型可能无法正确理解或遵循指令。这可能导致模型生成不符合预期的结果。
综合来看,大模型在某些方面具有限制和不足,包括生成内容的质量、稳定性、实时性、输入输出限制、响应速度和指令遵循能力。在应用大模型时,需要考虑这些限制,并在必要时采取措施来解决或减轻这些问题,以确保模型能够在特定任务和场景中有效运行。同时,不同大小的模型可能在不同应用中表现不同,需要综合考虑模型大小和任务需求。
四、入坑大模型
通过一个现有的模型去感受体验一下,直接下载github上的PharMolix/OpenBioMed,这是张铁蕾团队开源的全球首个可商用多模态生物医药百亿参数大模型BioMedGPT-10B,该模型具有在生物医药专业领域比肩人类专家水平的文本生成能力,在自然语言、分子、蛋白质跨模态问答任务上达到SOTA。同时,这个repo里还开源了全球首个免费可商用、生物医药专用Llama 2大语言模型BioMedGPT-LM-7B(下面的入门教程就是以这个7B模型为例展开的)。
Mac环境搭建
conda环境
Anaconda是管理Python环境的强大工具,通过其可以创建、管理多个相互独立、隔离的Python环境,并在环境中安装、管理Python依赖。可以使用其免费、最小可用版本MiniConda。可以在Miniconda ‒ conda documentation找到对应的下载链接和安装方式。
mkdir -p ~/miniconda3
curl https://repo.anaconda.com/miniconda/Miniconda3-latest-MacOSX-arm64.sh -o ~/miniconda3/miniconda.sh
bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
rm -rf ~/miniconda3/miniconda.sh//After installing, initialize your newly-installed Miniconda. The following commands initialize for bash and zsh shells:
~/miniconda3/bin/conda init bash
~/miniconda3/bin/conda init zshpython环境
安装好miniconda以后,就可以创建一个Python环境,在这里创建了一个名为biomedgpt的python环境,并通过conda activate激活该环境。
cd /Users/zyf/miniconda3/bin./conda create -n biomedgpt python=3.10./conda activate biomedgpt为了运行BioMedGPT-LM-7B,我们需要安装pytorch和transformers。
./conda install pytorch torchvision torchaudio -c pytorch -c conda-forgepip install transformers模型下载
由于模型文件很大,还需要安装Git Large File Storage。
brew install git-lfs然后可以通过git clone的方式下载。
cd /Users/zyf/zyfcodes/jpt
git clone https://huggingface.co/PharMolix/BioMedGPT-LM-7B模型加载
BioMedGPT-LM-7B是基于meta-llama/Llama-2-7b,在生物医药语料上增量训练得到的,模型的加载方式和llama2-7B模型的加载方式一致。我们可以直接通过transformers进行模型的加载。也可以直接print(model)把模型结构打印出来,具体的模型细节可以查看llama2官网和技术报告。
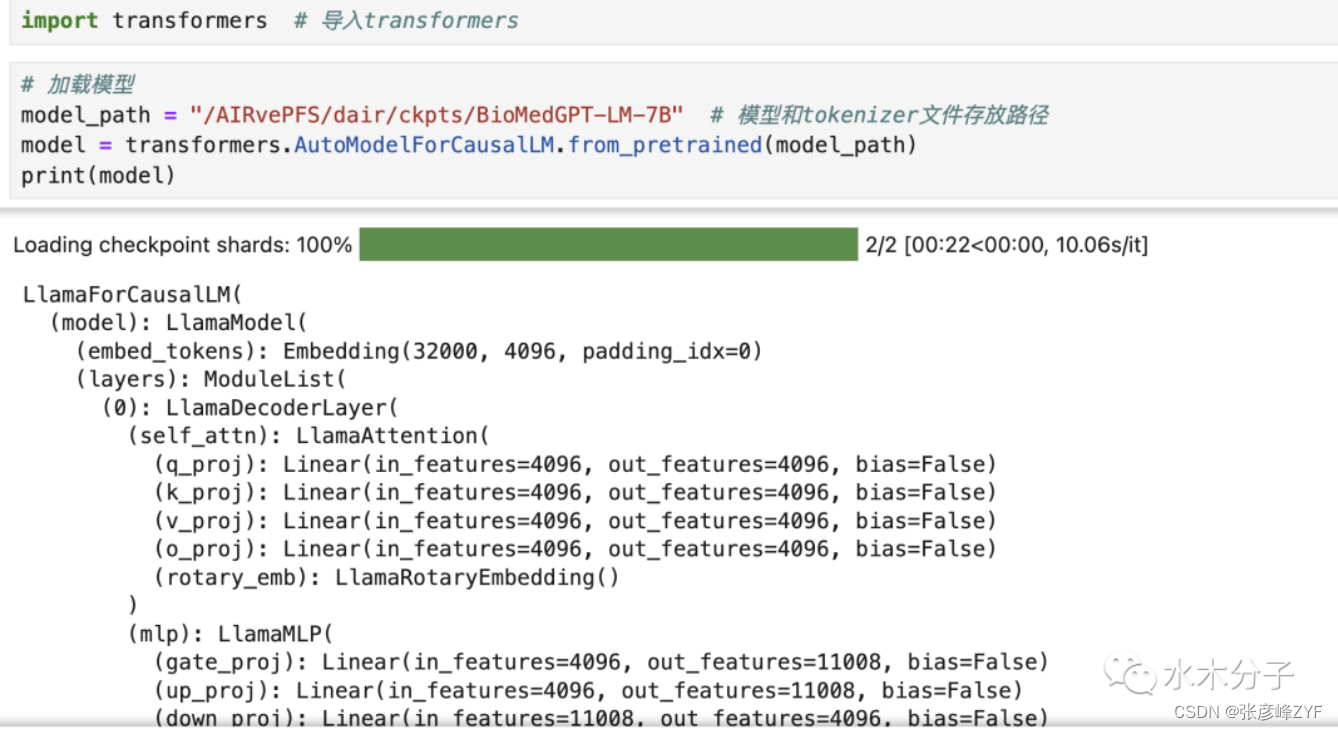
transformers.AutoModelForCausalLM的from_pretrained函数可以从huggingface仓库直接下载模型也可以加载本地下载好的模型。model_path是你存放模型和tokenizer文件的路径。运行上面的代码,我们就成功的在mac笔记本上加载了BioMedGPT-LM-7B模型,我们可以直接打印模型,查看模型的具体信息。如果提示内存不足,建议先关掉其他不需要的进程。
Tokenizer加载
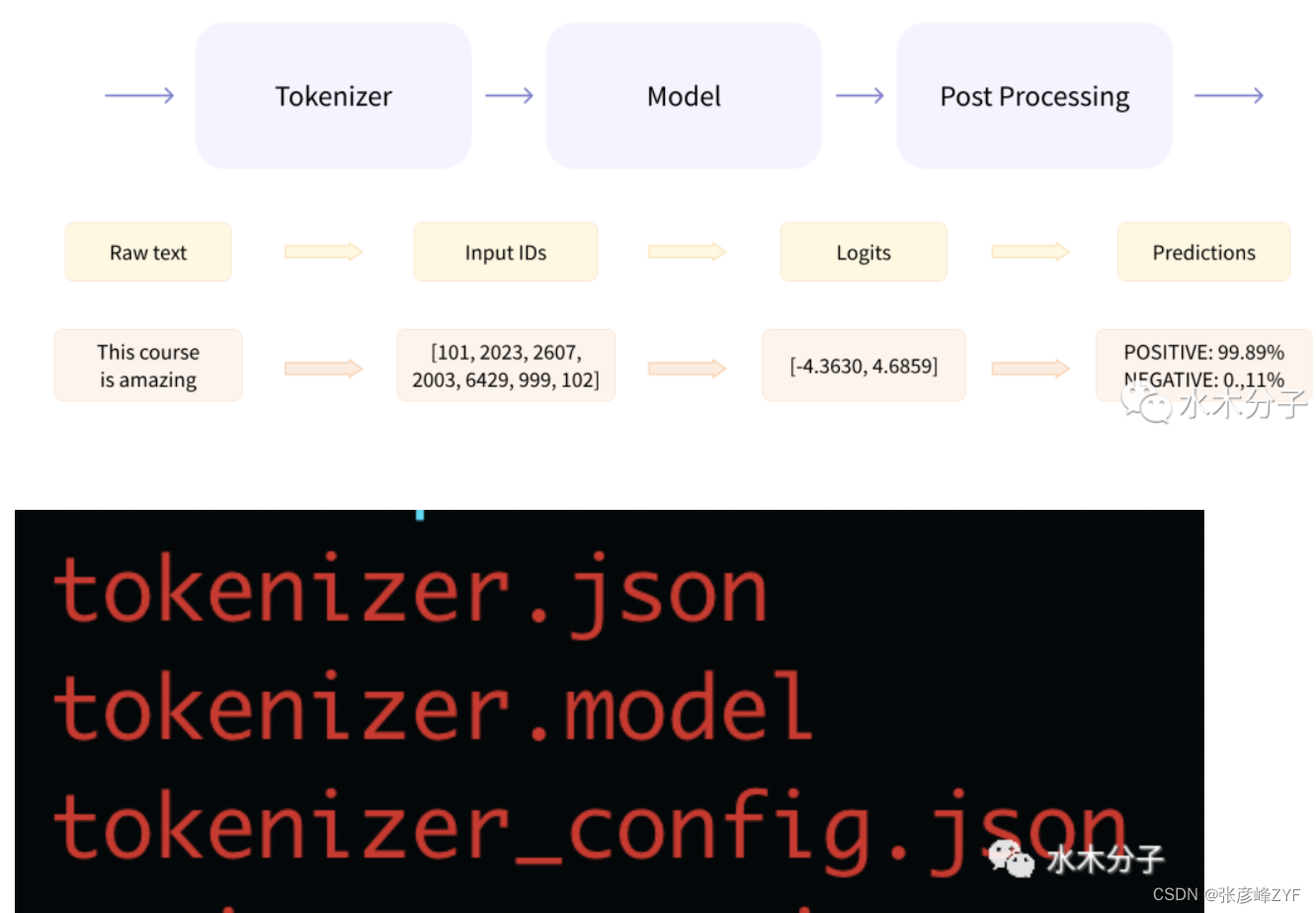
如下图所示(来源于huggingface官方文档),文本在传入到模型到输出结果,需要经过三个步骤。Tokenizer把输入的文本切分成一个一个的token,然后将token转变成向量,Model负责根据输入的变量提取语义信息,输出logits;最后Post Processing根据模型输出的语义信息,执行具体的nlp任务,比如情感分析,文本分类等。接着我们要加载模型对应的tokenizer,tokenizer相关文件和模型文件都在BioMedGPT-LM-7B/文件夹下。其中,tokenizer.json存放了tokenizer的词表,tokenizer_config.json里有tokenizer的相关参数,tokenizer.model则存放着模型参数。
使用tokenizer处理输入的文本得到模型需要的向量表示。

input_ids就是每个token对应的词表id,把其作为模型的输入,得到输出的token id,然后通过tokenizer的decoder方法将output解码成文字。
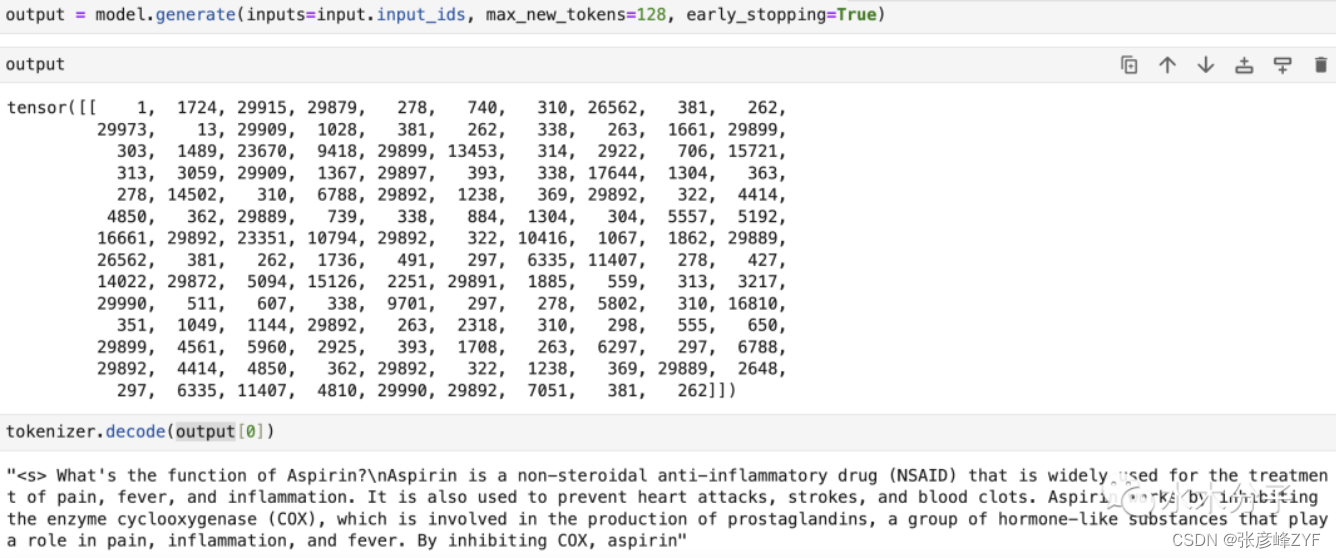
至此,我们成功地在笔记本上加载了7B的大模型,并用来生成了一段文字。注意,由于本教程在笔记本上使用CPU执行,而7B的模型有70亿参数之多,model.generate这步模型推理过程非常耗时,需要耐心等待结果输出(可能需要执行2个小时)。
该部分没有跑起来,后续在进行新的测验
推荐阅读:Spring Boot源码解读与原理剖析
本书前身是掘金社区销量TOP的小册——《Spring Boot源码解读与原理剖析》,整个社区中有3600+开发者都不约而同地选择了这本小册,也使它成为掘金社区首屈一指的王牌Spring教程,非常能打!
这本小册让作者跃居2020年度人气榜Top 40,喜提8枚荣誉勋章,站内销量遥遥领先,读者们称其为良心之作,纷纷点赞、打Call。
不过,由于小册的体量和篇幅有限,读者们纷纷表示意犹未尽,干货能够再干、再多一点就好了,希望作者能够讲得更详细、更透彻。
如果你想拥有一段相对合理、平滑、系统的学习体验,这本书简直再合适不过了。
由于本书是基于小册进行的升级,全书内容更加系统化,并且深度结合小册读者反馈给出了针对性优化,讲解更深入与详细。不仅是升级,更是焕新!
不同于小册里的集中式知识讲解,Linked-Bear将内容重新规划拆分成以下四大部分,由浅入深地讲解知识。
第1部分:Spring Boot底层依赖的核心容器
主要介绍的底层基础知识,旨在帮作者打牢基础。先从整体层面回顾Spring Boot知识,让读者快速复习Spring Boot的底层逻辑和核心知识。这些知识是后续编程和应用的基础。
第2部分:Spring Boot的生命周期原理分析
以生命周期各时期发出的Event事件为主线,结合每个生命周期内完成的大事记,让你总览Spring Boot的全貌,更深入地理解Spring Boot。
第3部分:Spring Boot整合常用开发场景
对应前两部分中核心容器讲解模块的配置,演示不同场景下的模块应用。这部分内容十分贴近实战,电商、网关服务、数据库等场景都可以用到这些技术。
第4部分:Spring Boot应用的运行
Spring Boot有多种打包方式,作者选取了两种方式通过分别讲解应用的引导启动流程,并介绍了新版本引入的优雅停机特性。学完这章,你的Spring Boot彻底就能彻底跑通!他专注于分布式系统和机器学习算法的研究,在理论、机器学习、应用和操作系统等多个领域的顶级学术会议上发表过论文。
学习网站和教程一览
网站和教程
-
OpenAI官方网站:OpenAI的官方网站通常提供了有关他们的最新研究和开发的信息,以及相关教程和文档。你可以在那里找到关于大模型的最新进展和技术。
-
Deep Learning Specialization(深度学习专项课程):Coursera上由吴恩达(Andrew Ng)教授主持的深度学习专项课程包括与大型神经网络相关的内容。这个课程提供了深度学习的基础知识,也包括自然语言处理和生成模型的内容。
-
斯坦福大学的课程:斯坦福大学开设了一些深度学习和自然语言处理相关的课程,它们的课程资料通常可以在网上免费获取,包括讲义、视频和作业。
-
GitHub:GitHub上有许多开源项目和代码库,可以让你深入了解大型模型的实现和应用。例如,你可以找到各种用于自然语言处理任务的预训练模型和工具。
书籍:
-
《Deep Learning》 by Ian Goodfellow, Yoshua Bengio, and Aaron Courville: 深度学习领域的经典之作,涵盖了深度学习的基本概念和技术,对于理解大型神经网络和语言模型非常有帮助。
-
《Natural Language Processing in Action》 by Lane, Howard, and Hapke: 介绍了自然语言处理的核心概念和技术,包括大型语言模型的应用。它提供了实际的示例和代码。
-
《BERT (Bidirectional Encoder Representations from Transformers) Explained》 by Ben Trevett: 在线教程,详细解释了BERT模型的工作原理和应用。它是一个很好的起点,用于理解预训练模型。
-
《GPT-3 and Beyond: Generative Models》 by Benjamin Obi Tayo Ph.D.: 介绍生成模型(包括GPT-3等)的书,对于深入了解大型语言模型的工作原理和应用非常有帮助。
其他:
- 55页PPT!全面了解人工智能通用大模型(ChatGPT)
- 聊聊普通工程师如何入坑大模型 | 附超详细教程!
相关文章:
科普初步了解大模型
目录 一、大模型的简单认知 (一)官方定义 (二)聚焦到大语言模型 (三)大模型的应用举例 二、如何得到大模型 (一)整体的一般步骤 训练自己的模型 使用预训练模型 选择适当的…...

Nginx 和 网关的关系是什么
分析&回答 Nginx也可以实现网关,可以实现对api接口的拦截,负载均衡、反向代理、请求过滤等。网关功能可以进行扩展,比如:安全控制,统一异常处理,XXS,SQL注入等;权限控制,黑白名…...
解决springboot项目中的groupId、package或路径的混淆问题
对于像我一样喜欢跳跃着学习的聪明人来说,肯定要学springboot,什么sevlet、maven、java基础,都太老土了,用不到就不学。所以古代的聪明人有句话叫“书到用时方恨少”,测试开源项目时,编译总是报错ÿ…...
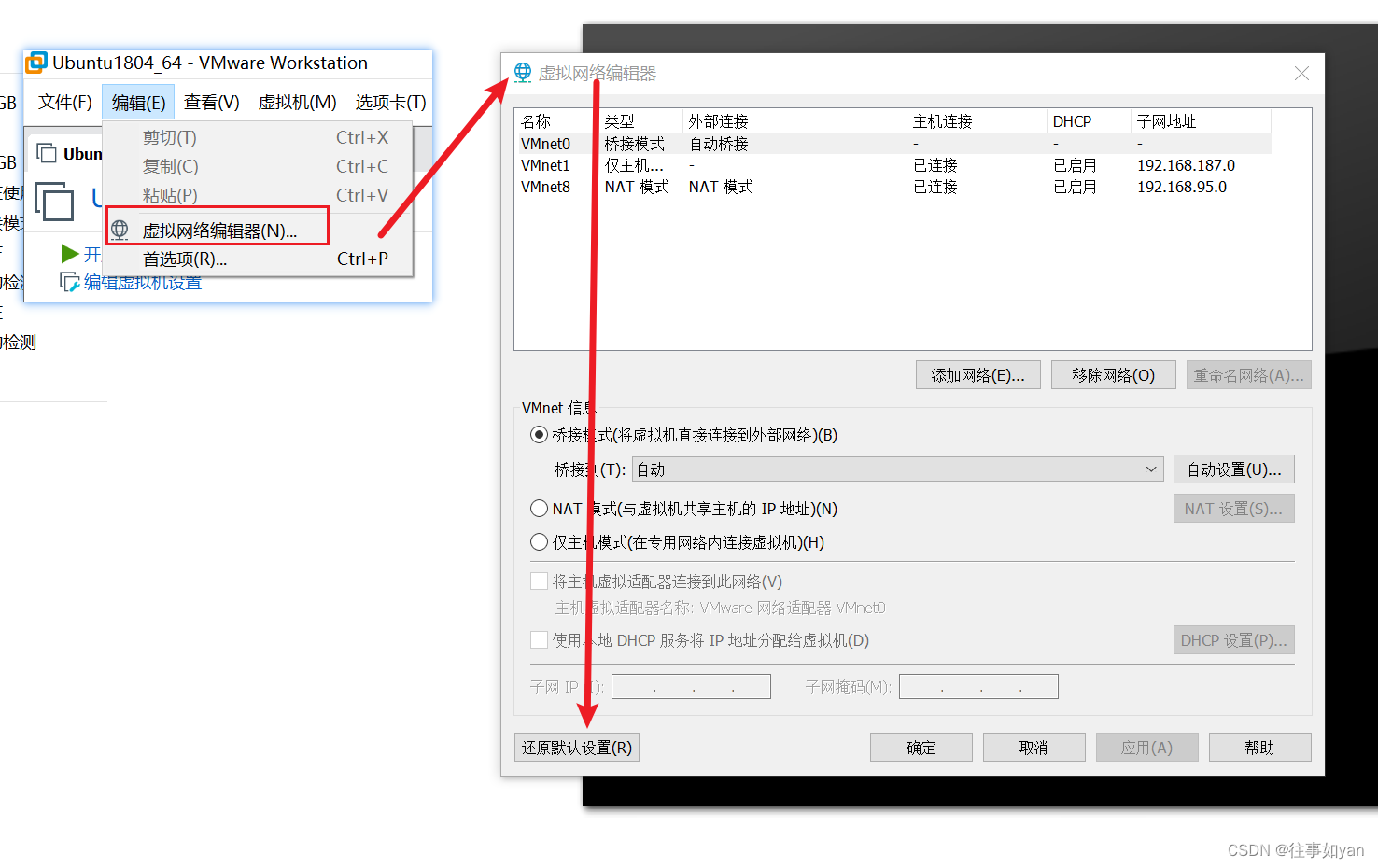
Vmware 网络恢复断网和连接
如果你的 虚拟机无法联网了,比如: vmware 无法将网络更改为桥接状态: 没有未桥接的主机网络适配器 等各种稀奇古怪的问题; 按照下面操作 还远默认设置 包你解决各种问题!...

学生来看!如何白嫖内网穿透?点进来!
文章目录 前言本教程解决的问题是:按照本教程方法操作后,达到的效果是前排提醒: 1 搭建虚拟机1.1 下载文件vmvare虚拟机安装包1.2 安装VMware虚拟机:1.3 解压虚拟机文件1.4 虚拟机初始化1.5 没有搜索到解决方式:1.6 虚…...
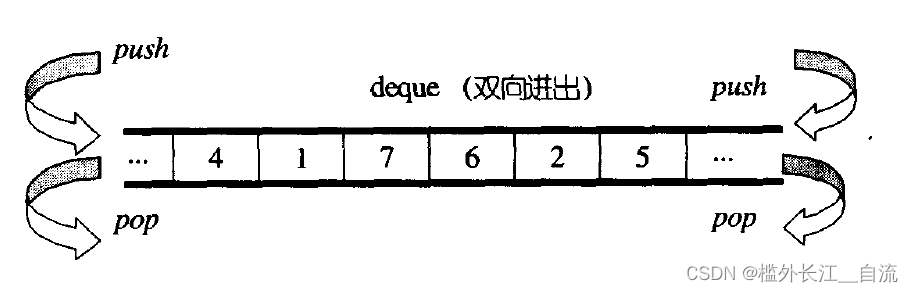
C++中的stack和queue
文章目录 1. stack的介绍和使用1.1 stack的介绍1.2 stack的使用 2. queue的介绍和使用2.1 queue的介绍2.2 queue的使用 3 priority_queue的介绍和使用3.1 priority_queue的介绍3.2 priority_queue的使用 4. 容器适配器4.1 什么是适配器4.2 STL标准库中stack和queue的底层结构4.…...
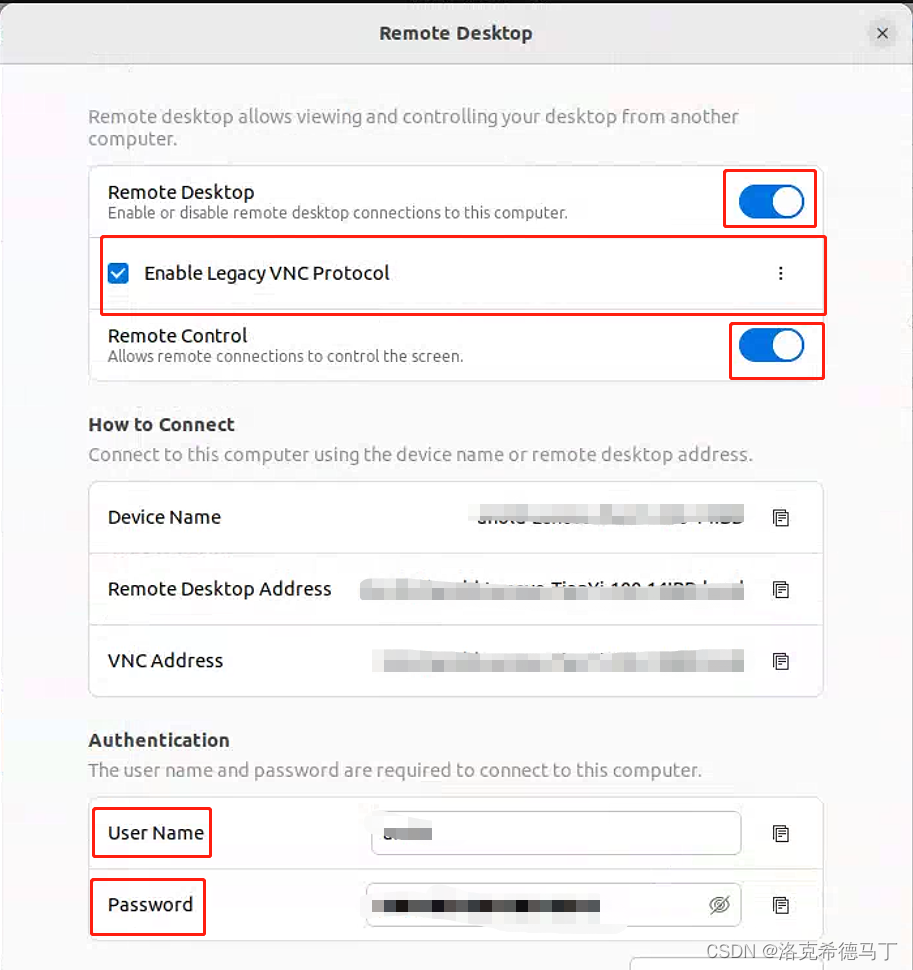
Ubuntu-22.04通过RDP协议连接远程桌面
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、RDP是什么?二、配置1.打开远程桌面功能2.验证服务3.防火墙配置4.测试效果 总结 前言 由于一些特殊需要,我需要通过远程桌面连接到U…...

20230908java面经整理
1.cpp和java的区别 cpp可以多重继承,对表java中的实现多个接口 cpp支持运算符重载、goto、默认函数参数 cpp自动强转,导致不安全;java必须显式强转 java提供垃圾回收机制,自动管理内存分配,当gc要释放无用对象时调用f…...

uniapp 开发App 网络异常如何处理
我对该问题思考的不是很清楚,目前只想到了基本的解决方案 第一、客户端的网络异常(断网) 1. 断网情况 一定要弹出信息提示,目前最好的解决方式就是在uni.request封装的统一方法中写提示 //1. 封装的网络请求 async function se…...

docker安装常用软件
Linux系统安装docker请参考:https://mp.csdn.net/mp_blog/creation/editor/128176825 docker安装mysql 1、拉镜像:docker pull mysql:8.0.26 2、创建数据目录: mkdir -p /mnt/data/mysql/data mkdir -p /mnt/data/mysql/logs mkdir -p /mn…...

CocosCreator3.8研究笔记(五)CocosCreator 脚本说明及使用(下)
在Cocos Creator中,脚本代码文件分为模块和插件两种方式: 模块一般就是项目的脚本,包含项目中创建的代码、引擎模块、第三方模块。 插件脚本,是指从 Cocos Creator 属性检查器中导入的插件,一般是引入第三方引入库文件…...
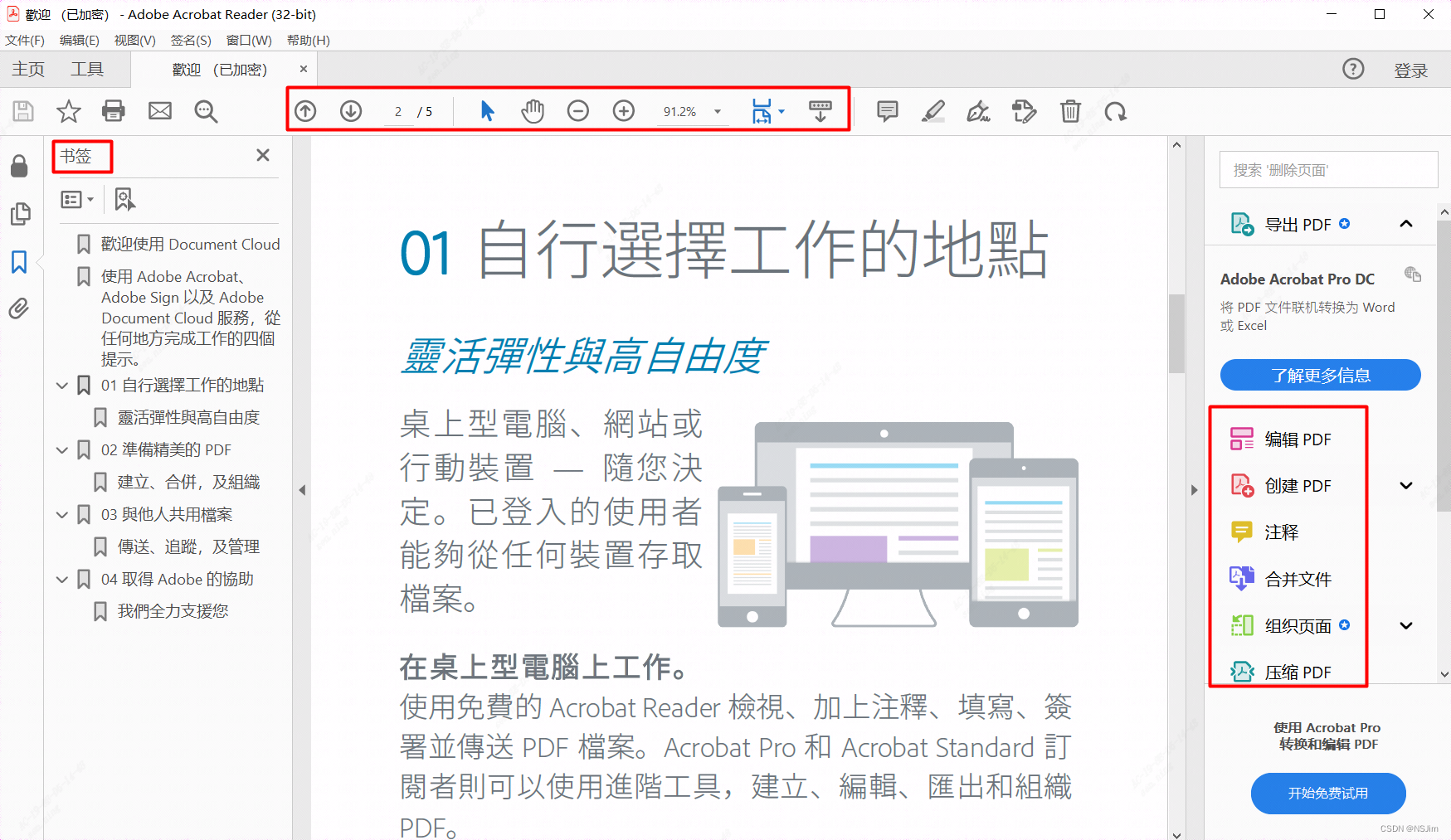
Adobe Acrobat Reader界面改版 - 解决方案
问题 日期:2023年9月 Adobe Acrobat Reader下文简称Adobe PDF Reader,此软件会自动进行更新,当版本更新至2023.003.20284版本后。 软件UI界面会大改版:书签页变成了右边、工具栏变到了左边、缩放按钮变到了右下角,如…...
)
实用调试技巧(2)
文章目录 6. 如何写出好(易于调试)的代码6.1 优秀的代码:6.2 示范:6.3 const的作用 7. 编程常见的错误7.1 编译型错误7.2 链接型错误7.3 运行时错误 附: 6. 如何写出好(易于调试)的代码 6.1 优…...

海外ASO优化之如何优化游戏应用
如果我们发布了一款手机游戏或者管理了一款手机游戏,那么需要确保我们的手机游戏对合适的人可见,目的是增加应用的下载量。 1、优化游戏元数据的关键词。 Apple和Google在应用商店中为我们提供有限的空间,来描述手机游戏及其优势。我们需要使…...

SpringMVC: Java Web应用开发的框架之选
引言 在当今的软件开发领域中,Web应用的需求不断增长。为了满足这种需求,各种Web框架应运而生。其中,SpringMVC作为一种优秀的Java Web框架,受到广泛关注和使用。本文将以文章的形式给您讲解SpringMVC的重要概念、工作原理和核心…...

【华为设备升级】AR路由器升级设备软件示例
升级设备软件示例 通过介绍设备升级的具体步骤,帮助用户顺利完成系统设备升级。 组网需求 设备当前系统软件版本已经不能满足用户需要,用户需要更大的规格和部署更多的特性,此时用户需要对系统软件进行升级。 如图1所示,网络中的某…...

Dataset 的一些 Java api 操作
文章目录 一、使用 Java API 和 JavaRDD<Row> 在 Spark SQL 中向数据帧添加新列二、foreachPartition 遍历 Dataset三、Dataset 自定义 Partitioner四、Dataset 重分区并且获取分区数 一、使用 Java API 和 JavaRDD 在 Spark SQL 中向数据帧添加新列 在应用 mapPartition…...

Vue + Element UI 前端篇(十一):第三方图标库
Vue Element UI 实现权限管理系统 前端篇(十一):第三方图标库 使用第三方图标库 用过Elment的同鞋都知道,Element UI提供的字体图符少之又少,实在是不够用啊,幸好现在有不少丰富的第三方图标库可用&…...
)
HDFS:Hadoop文件系统(HDFS)
Hadoop文件系统(HDFS)是一个分布式文件系统,主要用于存储和处理大规模的数据集。HDFS是Apache Hadoop的核心组件之一,能够支持上千个节点的集群,并能够处理PB级别的数据。 HDFS将大文件切割成小的数据块(默…...

SpringMvc--综合案例
目录 1.SpringMvc的常用注解 2.参数传递 基础类型(String) 创建一个paramController类: 创建一个index.jsp 测试结果 复杂方式 编辑 测试结果 RequestParam 测试结果 PathVariable 测试结果 RequestBody pom.xml依赖导入 输…...
)
告别低速串口:用STM32的FSMC总线驱动FPGA,实现高速数据交换的完整流程(基于STM32F407)
STM32与FPGA的高速数据通道:基于FSMC总线的实战设计指南 在嵌入式系统开发中,数据吞吐量常常成为制约系统性能的关键瓶颈。当STM32微控制器需要与FPGA进行大数据量交互时——无论是实时图像处理、高速数据采集还是复杂算法加速——传统的串行通信接口如…...

5分钟快速上手:如何为Windows安装程序添加简体中文界面支持
5分钟快速上手:如何为Windows安装程序添加简体中文界面支持 【免费下载链接】Inno-Setup-Chinese-Simplified-Translation :earth_asia: Inno Setup Chinese Simplified Translation 项目地址: https://gitcode.com/gh_mirrors/in/Inno-Setup-Chinese-Simplified-…...

【正式 v 2.7.5 版本】Windows 系统 Open Claw 搭建使用教程
✨ 核心亮点 零代码门槛|全程可视化|无需手动配环境|内置所有依赖|28 万 Tokens 额度 🔗 下载地址 https://xiake.yun/api/download/package/16?promoCodeIV8E496E2F7A 📝 前言 开源圈热门的「数字员…...

大模型岗位锐评:小白程序员转型指南 学习资源包免费领!收藏必备
本文深度剖析大模型领域的五大梯队岗位,从底层架构工程师到应用开发工程师,详细介绍了各岗位的日常工作、新手友好度、优势与避雷点。文章强调大模型领域人才缺口巨大,传统程序员具备转型优势,并提供了系统学习路线及实战资源&…...

3分钟快速上手vJoy:如何为Windows创建专业级虚拟游戏手柄
3分钟快速上手vJoy:如何为Windows创建专业级虚拟游戏手柄 【免费下载链接】vJoy Virtual Joystick 项目地址: https://gitcode.com/gh_mirrors/vj/vJoy 您是否曾经因为缺少游戏手柄而无法畅玩那些只支持手柄操作的游戏?或者需要为特殊软件设计自定…...
)
Linux mkdir、rmdir 命令详解——目录的创建与删除(新手零踩坑)
前言在Linux操作中,目录是文件的“容器”,想要管理文件,首先要学会创建和删除目录。mkdir(创建目录)和rmdir(删除目录)是最基础的目录操作命令,用法简单但有细节,尤其是r…...

Box64终极指南:如何在ARM设备上轻松运行x86程序?三个简单步骤解锁无限可能
Box64终极指南:如何在ARM设备上轻松运行x86程序?三个简单步骤解锁无限可能 【免费下载链接】box64 Box64 - Linux Userspace x86_64 Emulator with a twist, targeted at ARM64, RV64 and LoongArch Linux devices 项目地址: https://gitcode.com/gh_m…...
HSTracker:为macOS炉石传说玩家打造的数据智能助手
HSTracker:为macOS炉石传说玩家打造的数据智能助手 【免费下载链接】HSTracker A deck tracker and deck manager for Hearthstone on macOS 项目地址: https://gitcode.com/gh_mirrors/hs/HSTracker 在瞬息万变的炉石传说对局中,你是否曾因忘记对…...
)
从零搭建Perplexity增强型新闻监控系统:Python+LangChain+自定义Fact-Check插件(含GitHub可运行代码仓链接)
更多请点击: https://intelliparadigm.com 第一章:Perplexity科技新闻搜索 Perplexity 是一款以实时性、可溯源和语义理解见长的AI驱动搜索工具,专为技术从业者与研究人员优化。其“科技新闻搜索”功能并非传统关键词匹配,而是基…...

Wand-Enhancer:完全免费解锁WeMod Pro功能的终极解决方案
Wand-Enhancer:完全免费解锁WeMod Pro功能的终极解决方案 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod专业版的付费限制而烦恼…...