小白备战大厂算法笔试(四)——哈希表
文章目录
- 哈希表
- 常用操作
- 简单实现
- 冲突与扩容
- 链式地址
- 开放寻址
- 线性探测
- 多次哈希
哈希表
哈希表,又称散列表,其通过建立键 key 与值 value 之间的映射,实现高效的元素查询。具体而言,我们向哈希表输入一个键 key ,则可以在 O(1) 时间内获取对应的值 value 。
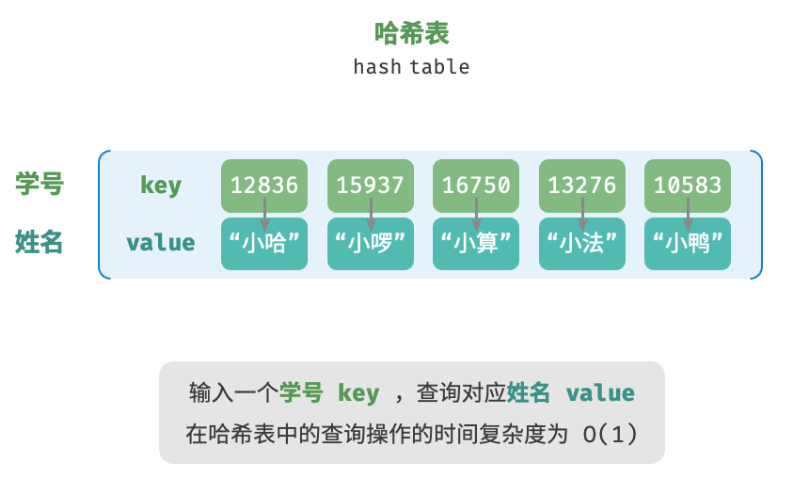
除哈希表外,数组和链表也可以实现查询功能,它们的效率对比如下所示。
- 添加元素:仅需将元素添加至数组(链表)的尾部即可,使用 O(1) 时间。
- 查询元素:由于数组(链表)是乱序的,因此需要遍历其中的所有元素,使用 O(n) 时间。
- 删除元素:需要先查询到元素,再从数组(链表)中删除,使用 O(n) 时间。
| 数组 | 链表 | 哈希表 | |
|---|---|---|---|
| 查找元素 | O(n) | O(n) | O(1) |
| 添加元素 | O(1) | O(1) | O(1) |
| 删除元素 | O(n) | O(n) | O(1) |
在哈希表中进行增删查改的时间复杂度都是 O(1) ,非常高效。
常用操作
Python:
# 初始化哈希表
hmap: dict = {}# 添加操作
# 在哈希表中添加键值对 (key, value)
hmap[12836] = "小哈"
hmap[15937] = "小啰"
hmap[16750] = "小算"
hmap[13276] = "小法"
hmap[10583] = "小鸭"# 查询操作
# 向哈希表输入键 key ,得到值 value
name: str = hmap[15937]# 删除操作
# 在哈希表中删除键值对 (key, value)
hmap.pop(10583)# 遍历哈希表
# 遍历键值对 key->value
for key, value in hmap.items():print(key, "->", value)
# 单独遍历键 key
for key in hmap.keys():print(key)
# 单独遍历值 value
for value in hmap.values():print(value)Go:
/* 初始化哈希表 */
hmap := make(map[int]string)/* 添加操作 */
// 在哈希表中添加键值对 (key, value)
hmap[12836] = "小哈"
hmap[15937] = "小啰"
hmap[16750] = "小算"
hmap[13276] = "小法"
hmap[10583] = "小鸭"/* 查询操作 */
// 向哈希表输入键 key ,得到值 value
name := hmap[15937]/* 删除操作 */
// 在哈希表中删除键值对 (key, value)
delete(hmap, 10583)/* 遍历哈希表 */
// 遍历键值对 key->value
for key, value := range hmap {fmt.Println(key, "->", value)
}
// 单独遍历键 key
for key := range hmap {fmt.Println(key)
}
// 单独遍历值 value
for _, value := range hmap {fmt.Println(value)
}
简单实现
先考虑最简单的情况,仅用一个数组来实现哈希表。在哈希表中,我们将数组中的每个空位称为桶,每个桶可存储一个键值对。因此,查询操作就是找到 key 对应的桶,并在桶中获取 value 。
那么,如何基于 key 来定位对应的桶呢?这是通过「哈希函数 hash function」实现的。哈希函数的作用是将一个较大的输入空间映射到一个较小的输出空间。在哈希表中,输入空间是所有 key ,输出空间是所有桶(数组索引)。换句话说,输入一个 key ,我们可以通过哈希函数得到该 key 对应的键值对在数组中的存储位置。
输入一个 key ,哈希函数的计算过程分为以下两步。
- 通过某种哈希算法
hash()计算得到哈希值。 - 将哈希值对桶数量(数组长度)
capacity取模,从而获取该key对应的数组索引index。
index = hash(key) % capacity
随后,我们就可以利用 index 在哈希表中访问对应的桶,从而获取 value 。
设数组长度 capacity = 100、哈希算法 hash(key) = key ,易得哈希函数为 key % 100 。以 key 学号和 value 姓名为例,展示哈希函数的工作原理:
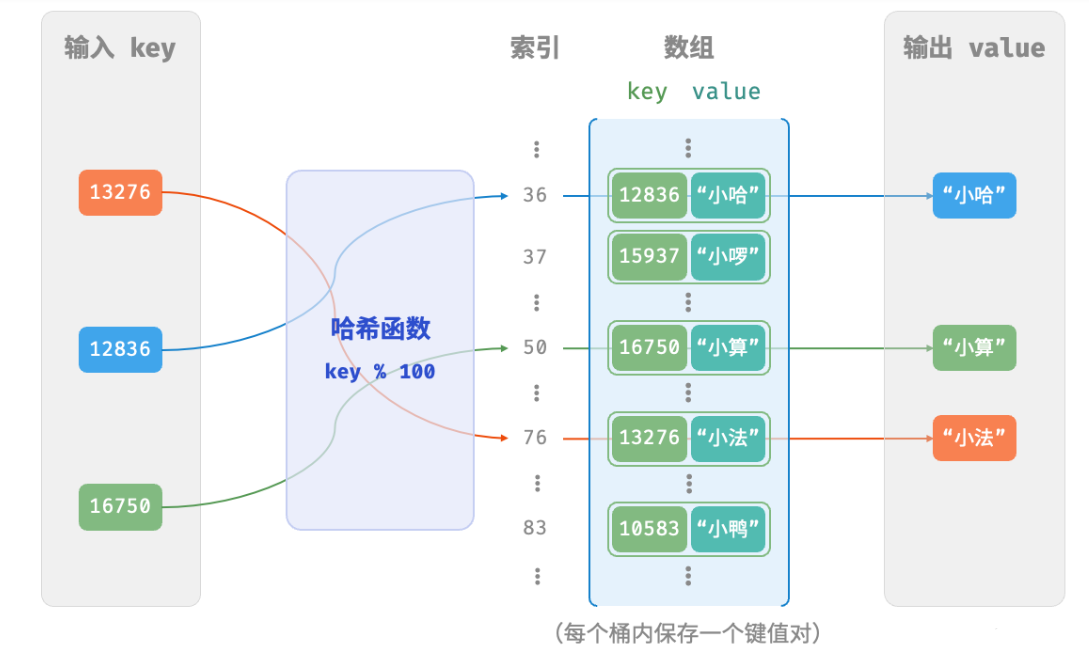
以下代码实现了一个简单哈希表。其中,我们将 key 和 value 封装成一个类 Pair ,以表示键值对。
Python:
class Pair:"""键值对"""def __init__(self, key: int, val: str):self.key = keyself.val = valclass ArrayHashMap:"""基于数组简易实现的哈希表"""def __init__(self):"""构造方法"""# 初始化数组,包含 100 个桶self.buckets: list[Pair | None] = [None] * 100def hash_func(self, key: int) -> int:"""哈希函数"""index = key % 100return indexdef get(self, key: int) -> str:"""查询操作"""index: int = self.hash_func(key)pair: Pair = self.buckets[index]if pair is None:return Nonereturn pair.valdef put(self, key: int, val: str):"""添加操作"""pair = Pair(key, val)index: int = self.hash_func(key)self.buckets[index] = pairdef remove(self, key: int):"""删除操作"""index: int = self.hash_func(key)# 置为 None ,代表删除self.buckets[index] = Nonedef entry_set(self) -> list[Pair]:"""获取所有键值对"""result: list[Pair] = []for pair in self.buckets:if pair is not None:result.append(pair)return resultdef key_set(self) -> list[int]:"""获取所有键"""result = []for pair in self.buckets:if pair is not None:result.append(pair.key)return resultdef value_set(self) -> list[str]:"""获取所有值"""result = []for pair in self.buckets:if pair is not None:result.append(pair.val)return resultdef print(self):"""打印哈希表"""for pair in self.buckets:if pair is not None:print(pair.key, "->", pair.val)
Go:
/* 键值对 */
type pair struct {key intval string
}/* 基于数组简易实现的哈希表 */
type arrayHashMap struct {buckets []*pair
}/* 初始化哈希表 */
func newArrayHashMap() *arrayHashMap {// 初始化数组,包含 100 个桶buckets := make([]*pair, 100)return &arrayHashMap{buckets: buckets}
}/* 哈希函数 */
func (a *arrayHashMap) hashFunc(key int) int {index := key % 100return index
}/* 查询操作 */
func (a *arrayHashMap) get(key int) string {index := a.hashFunc(key)pair := a.buckets[index]if pair == nil {return "Not Found"}return pair.val
}/* 添加操作 */
func (a *arrayHashMap) put(key int, val string) {pair := &pair{key: key, val: val}index := a.hashFunc(key)a.buckets[index] = pair
}/* 删除操作 */
func (a *arrayHashMap) remove(key int) {index := a.hashFunc(key)// 置为 nil ,代表删除a.buckets[index] = nil
}/* 获取所有键对 */
func (a *arrayHashMap) pairSet() []*pair {var pairs []*pairfor _, pair := range a.buckets {if pair != nil {pairs = append(pairs, pair)}}return pairs
}/* 获取所有键 */
func (a *arrayHashMap) keySet() []int {var keys []intfor _, pair := range a.buckets {if pair != nil {keys = append(keys, pair.key)}}return keys
}/* 获取所有值 */
func (a *arrayHashMap) valueSet() []string {var values []stringfor _, pair := range a.buckets {if pair != nil {values = append(values, pair.val)}}return values
}/* 打印哈希表 */
func (a *arrayHashMap) print() {for _, pair := range a.buckets {if pair != nil {fmt.Println(pair.key, "->", pair.val)}}
}
冲突与扩容
本质上看,哈希函数的作用是将所有 key 构成的输入空间映射到数组所有索引构成的输出空间,而输入空间往往远大于输出空间。因此,理论上一定存在“多个输入对应相同输出”的情况。
对于上述示例中的哈希函数,当输入的 key 后两位相同时,哈希函数的输出结果也相同。例如,查询学号为 12836 和 20336 的两个学生时,我们得到:
12836 % 100 = 36
20336 % 100 = 36
两个学号指向了同一个姓名,这显然是不对的。我们将这种多个输入对应同一输出的情况称为哈希冲突 。
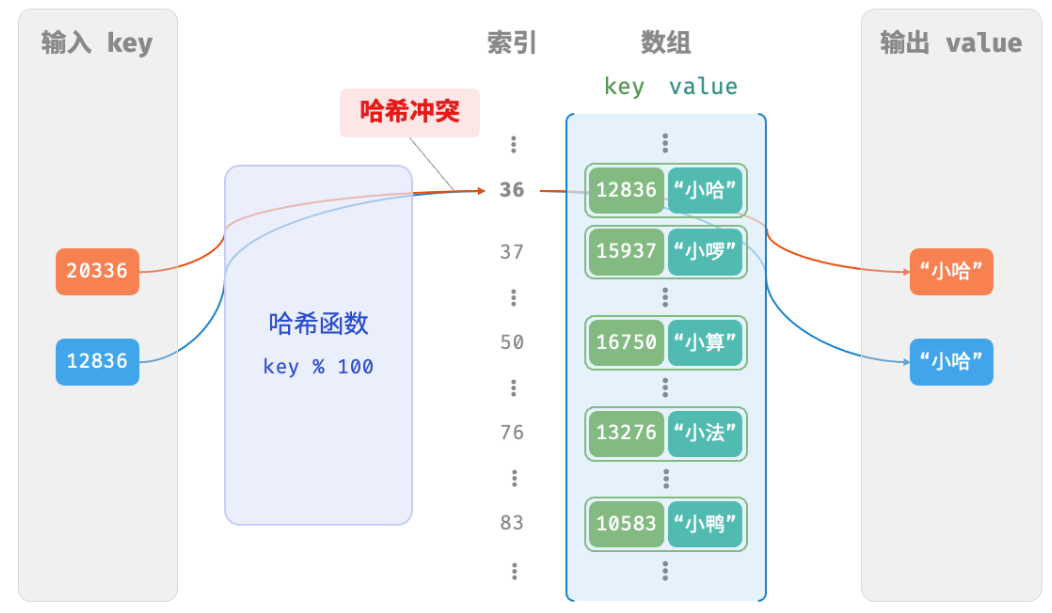
容易想到,哈希表容量n越大,多个 key 被分配到同一个桶中的概率就越低,冲突就越少。因此,我们可以通过扩容哈希表来减少哈希冲突。
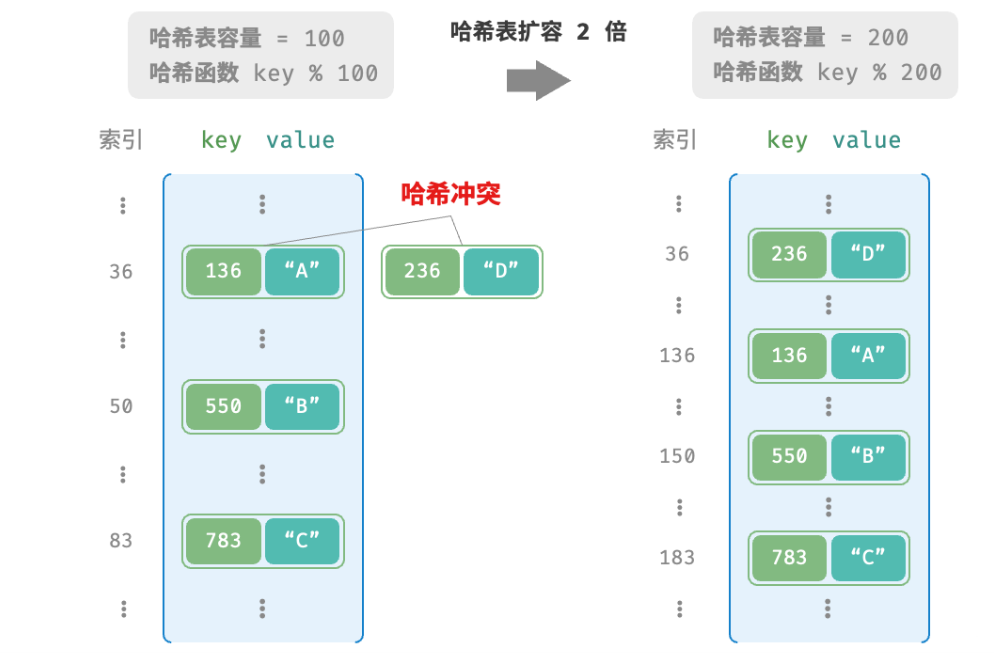
类似于数组扩容,哈希表扩容需将所有键值对从原哈希表迁移至新哈希表,非常耗时。并且由于哈希表容量 capacity 改变,我们需要通过哈希函数来重新计算所有键值对的存储位置,这进一步提高了扩容过程的计算开销。为了提升效率,我们可以采用以下策略。
- 改良哈希表数据结构,使得哈希表可以在存在哈希冲突时正常工作。
- 仅在必要时,即当哈希冲突比较严重时,才执行扩容操作。
哈希表的结构改良方法主要包括“链式地址”和“开放寻址”。
负载因子是哈希表的一个重要概念,其定义为哈希表的元素数量除以桶数量,用于衡量哈希冲突的严重程度,也常被作为哈希表扩容的触发条件。例如在 Java 中,当负载因子超过 0.75 时,系统会将哈希表容量扩展为原先的 2 倍。
链式地址
在原始哈希表中,每个桶仅能存储一个键值对。链式地址将单个元素转换为链表,将键值对作为链表节点,将所有发生冲突的键值对都存储在同一链表中。
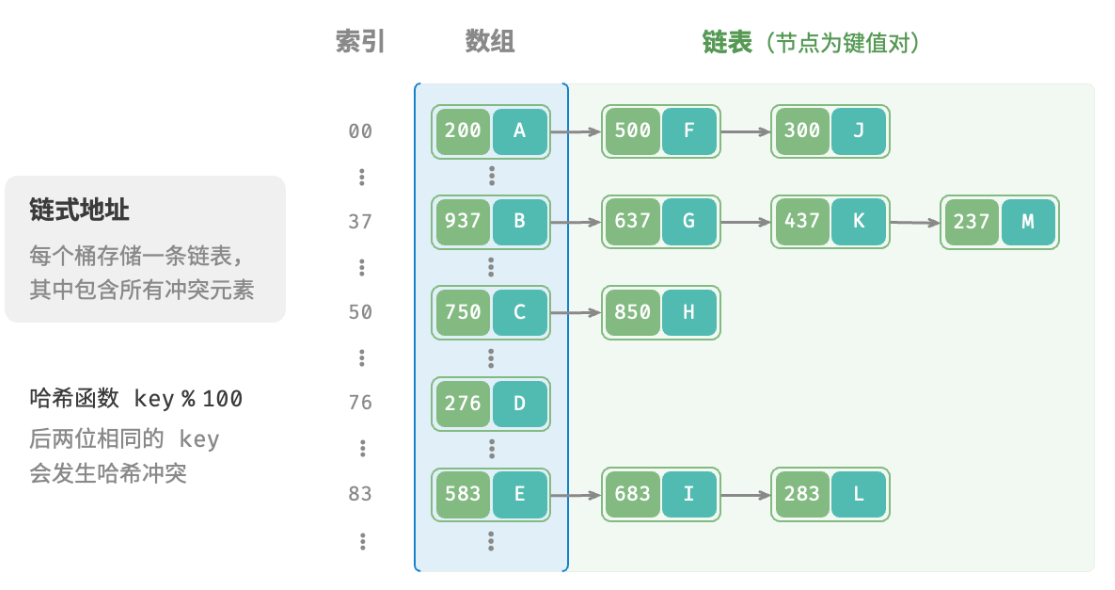
哈希表在链式地址下的操作方法发生了一些变化。
- 查询元素:输入
key,经过哈希函数得到数组索引,即可访问链表头节点,然后遍历链表并对比key以查找目标键值对。 - 添加元素:先通过哈希函数访问链表头节点,然后将节点(即键值对)添加到链表中。
- 删除元素:根据哈希函数的结果访问链表头部,接着遍历链表以查找目标节点,并将其删除。
链式地址存在以下局限性。
- 占用空间增大,链表包含节点指针,它相比数组更加耗费内存空间。
- 查询效率降低,因为需要线性遍历链表来查找对应元素。
以下代码给出了链式地址哈希表的简单实现,需要注意两点。
- 使用列表(动态数组)代替链表,从而简化代码。在这种设定下,哈希表(数组)包含多个桶,每个桶都是一个列表。
- 以下实现包含哈希表扩容方法。当负载因子超过 0.75 时,我们将哈希表扩容至 2 倍。
Python:
class HashMapChaining:"""链式地址哈希表"""def __init__(self):"""构造方法"""self.size = 0 # 键值对数量self.capacity = 4 # 哈希表容量self.load_thres = 2 / 3 # 触发扩容的负载因子阈值self.extend_ratio = 2 # 扩容倍数self.buckets = [[] for _ in range(self.capacity)] # 桶数组def hash_func(self, key: int) -> int:"""哈希函数"""return key % self.capacitydef load_factor(self) -> float:"""负载因子"""return self.size / self.capacitydef get(self, key: int) -> str:"""查询操作"""index = self.hash_func(key)bucket = self.buckets[index]# 遍历桶,若找到 key 则返回对应 valfor pair in bucket:if pair.key == key:return pair.val# 若未找到 key 则返回 Nonereturn Nonedef put(self, key: int, val: str):"""添加操作"""# 当负载因子超过阈值时,执行扩容if self.load_factor() > self.load_thres:self.extend()index = self.hash_func(key)bucket = self.buckets[index]# 遍历桶,若遇到指定 key ,则更新对应 val 并返回for pair in bucket:if pair.key == key:pair.val = valreturn# 若无该 key ,则将键值对添加至尾部pair = Pair(key, val)bucket.append(pair)self.size += 1def remove(self, key: int):"""删除操作"""index = self.hash_func(key)bucket = self.buckets[index]# 遍历桶,从中删除键值对for pair in bucket:if pair.key == key:bucket.remove(pair)self.size -= 1breakdef extend(self):"""扩容哈希表"""# 暂存原哈希表buckets = self.buckets# 初始化扩容后的新哈希表self.capacity *= self.extend_ratioself.buckets = [[] for _ in range(self.capacity)]self.size = 0# 将键值对从原哈希表搬运至新哈希表for bucket in buckets:for pair in bucket:self.put(pair.key, pair.val)def print(self):"""打印哈希表"""for bucket in self.buckets:res = []for pair in bucket:res.append(str(pair.key) + " -> " + pair.val)print(res)
Go:
/* 链式地址哈希表 */
type hashMapChaining struct {size int // 键值对数量capacity int // 哈希表容量loadThres float64 // 触发扩容的负载因子阈值extendRatio int // 扩容倍数buckets [][]pair // 桶数组
}/* 构造方法 */
func newHashMapChaining() *hashMapChaining {buckets := make([][]pair, 4)for i := 0; i < 4; i++ {buckets[i] = make([]pair, 0)}return &hashMapChaining{size: 0,capacity: 4,loadThres: 2 / 3.0,extendRatio: 2,buckets: buckets,}
}/* 哈希函数 */
func (m *hashMapChaining) hashFunc(key int) int {return key % m.capacity
}/* 负载因子 */
func (m *hashMapChaining) loadFactor() float64 {return float64(m.size / m.capacity)
}/* 查询操作 */
func (m *hashMapChaining) get(key int) string {idx := m.hashFunc(key)bucket := m.buckets[idx]// 遍历桶,若找到 key 则返回对应 valfor _, p := range bucket {if p.key == key {return p.val}}// 若未找到 key 则返回空字符串return ""
}/* 添加操作 */
func (m *hashMapChaining) put(key int, val string) {// 当负载因子超过阈值时,执行扩容if m.loadFactor() > m.loadThres {m.extend()}idx := m.hashFunc(key)// 遍历桶,若遇到指定 key ,则更新对应 val 并返回for _, p := range m.buckets[idx] {if p.key == key {p.val = valreturn}}// 若无该 key ,则将键值对添加至尾部p := pair{key: key,val: val,}m.buckets[idx] = append(m.buckets[idx], p)m.size += 1
}/* 删除操作 */
func (m *hashMapChaining) remove(key int) {idx := m.hashFunc(key)// 遍历桶,从中删除键值对for i, p := range m.buckets[idx] {if p.key == key {// 切片删除m.buckets[idx] = append(m.buckets[idx][:i], m.buckets[idx][i+1:]...)m.size -= 1break}}
}/* 扩容哈希表 */
func (m *hashMapChaining) extend() {// 暂存原哈希表tmpBuckets := make([][]pair, len(m.buckets))for i := 0; i < len(m.buckets); i++ {tmpBuckets[i] = make([]pair, len(m.buckets[i]))copy(tmpBuckets[i], m.buckets[i])}// 初始化扩容后的新哈希表m.capacity *= m.extendRatiom.buckets = make([][]pair, m.capacity)for i := 0; i < m.capacity; i++ {m.buckets[i] = make([]pair, 0)}m.size = 0// 将键值对从原哈希表搬运至新哈希表for _, bucket := range tmpBuckets {for _, p := range bucket {m.put(p.key, p.val)}}
}/* 打印哈希表 */
func (m *hashMapChaining) print() {var builder strings.Builderfor _, bucket := range m.buckets {builder.WriteString("[")for _, p := range bucket {builder.WriteString(strconv.Itoa(p.key) + " -> " + p.val + " ")}builder.WriteString("]")fmt.Println(builder.String())builder.Reset()}
}
开放寻址
「开放寻址 open addressing」不引入额外的数据结构,而是通过“多次探测”来处理哈希冲突,探测方式主要包括线性探测、平方探测、多次哈希等。
线性探测
线性探测采用固定步长的线性搜索来进行探测,其操作方法与普通哈希表有所不同。
- 插入元素:通过哈希函数计算数组索引,若发现桶内已有元素,则从冲突位置向后线性遍历(步长通常为 1 ),直至找到空位,将元素插入其中。
- 查找元素:若发现哈希冲突,则使用相同步长向后线性遍历,直到找到对应元素,返回
value即可;如果遇到空位,说明目标键值对不在哈希表中,返回 None 。
下图展示了一个在开放寻址(线性探测)下工作的哈希表。

然而,线性探测存在以下缺陷。
- 不能直接删除元素。删除元素会在数组内产生一个空位,当查找该空位之后的元素时,该空位可能导致程序误判元素不存在。为此,通常需要借助一个标志位来标记已删除元素。
- 容易产生聚集。数组内连续被占用位置越长,这些连续位置发生哈希冲突的可能性越大,进一步促使这一位置的聚堆生长,形成恶性循环,最终导致增删查改操作效率劣化。
以下代码实现了一个简单的开放寻址(线性探测)哈希表。
- 我们使用一个固定的键值对实例
removed来标记已删除元素。也就是说,当一个桶内的元素为 None 或removed时,说明这个桶是空的,可用于放置键值对。 - 在线性探测时,我们从当前索引
index向后遍历;而当越过数组尾部时,需要回到头部继续遍历。
Python:
class HashMapOpenAddressing:"""开放寻址哈希表"""def __init__(self):"""构造方法"""self.size = 0 # 键值对数量self.capacity = 4 # 哈希表容量self.load_thres = 2 / 3 # 触发扩容的负载因子阈值self.extend_ratio = 2 # 扩容倍数self.buckets: list[Pair | None] = [None] * self.capacity # 桶数组self.removed = Pair(-1, "-1") # 删除标记def hash_func(self, key: int) -> int:"""哈希函数"""return key % self.capacitydef load_factor(self) -> float:"""负载因子"""return self.size / self.capacitydef get(self, key: int) -> str:"""查询操作"""index = self.hash_func(key)# 线性探测,从 index 开始向后遍历for i in range(self.capacity):# 计算桶索引,越过尾部返回头部j = (index + i) % self.capacity# 若遇到空桶,说明无此 key ,则返回 Noneif self.buckets[j] is None:return None# 若遇到指定 key ,则返回对应 valif self.buckets[j].key == key and self.buckets[j] != self.removed:return self.buckets[j].valdef put(self, key: int, val: str):"""添加操作"""# 当负载因子超过阈值时,执行扩容if self.load_factor() > self.load_thres:self.extend()index = self.hash_func(key)# 线性探测,从 index 开始向后遍历for i in range(self.capacity):# 计算桶索引,越过尾部返回头部j = (index + i) % self.capacity# 若遇到空桶、或带有删除标记的桶,则将键值对放入该桶if self.buckets[j] in [None, self.removed]:self.buckets[j] = Pair(key, val)self.size += 1return# 若遇到指定 key ,则更新对应 valif self.buckets[j].key == key:self.buckets[j].val = valreturndef remove(self, key: int):"""删除操作"""index = self.hash_func(key)# 线性探测,从 index 开始向后遍历for i in range(self.capacity):# 计算桶索引,越过尾部返回头部j = (index + i) % self.capacity# 若遇到空桶,说明无此 key ,则直接返回if self.buckets[j] is None:return# 若遇到指定 key ,则标记删除并返回if self.buckets[j].key == key:self.buckets[j] = self.removedself.size -= 1returndef extend(self):"""扩容哈希表"""# 暂存原哈希表buckets_tmp = self.buckets# 初始化扩容后的新哈希表self.capacity *= self.extend_ratioself.buckets = [None] * self.capacityself.size = 0# 将键值对从原哈希表搬运至新哈希表for pair in buckets_tmp:if pair not in [None, self.removed]:self.put(pair.key, pair.val)def print(self):"""打印哈希表"""for pair in self.buckets:if pair is not None:print(pair.key, "->", pair.val)else:print("None")
Go:
/* 链式地址哈希表 */
type hashMapOpenAddressing struct {size int // 键值对数量capacity int // 哈希表容量loadThres float64 // 触发扩容的负载因子阈值extendRatio int // 扩容倍数buckets []pair // 桶数组removed pair // 删除标记
}/* 构造方法 */
func newHashMapOpenAddressing() *hashMapOpenAddressing {buckets := make([]pair, 4)return &hashMapOpenAddressing{size: 0,capacity: 4,loadThres: 2 / 3.0,extendRatio: 2,buckets: buckets,removed: pair{key: -1,val: "-1",},}
}/* 哈希函数 */
func (m *hashMapOpenAddressing) hashFunc(key int) int {return key % m.capacity
}/* 负载因子 */
func (m *hashMapOpenAddressing) loadFactor() float64 {return float64(m.size) / float64(m.capacity)
}/* 查询操作 */
func (m *hashMapOpenAddressing) get(key int) string {idx := m.hashFunc(key)// 线性探测,从 index 开始向后遍历for i := 0; i < m.capacity; i++ {// 计算桶索引,越过尾部返回头部j := (idx + 1) % m.capacity// 若遇到空桶,说明无此 key ,则返回 nullif m.buckets[j] == (pair{}) {return ""}// 若遇到指定 key ,则返回对应 valif m.buckets[j].key == key && m.buckets[j] != m.removed {return m.buckets[j].val}}// 若未找到 key 则返回空字符串return ""
}/* 添加操作 */
func (m *hashMapOpenAddressing) put(key int, val string) {// 当负载因子超过阈值时,执行扩容if m.loadFactor() > m.loadThres {m.extend()}idx := m.hashFunc(key)// 线性探测,从 index 开始向后遍历for i := 0; i < m.capacity; i++ {// 计算桶索引,越过尾部返回头部j := (idx + i) % m.capacity// 若遇到空桶、或带有删除标记的桶,则将键值对放入该桶if m.buckets[j] == (pair{}) || m.buckets[j] == m.removed {m.buckets[j] = pair{key: key,val: val,}m.size += 1return}// 若遇到指定 key ,则更新对应 valif m.buckets[j].key == key {m.buckets[j].val = val}}
}/* 删除操作 */
func (m *hashMapOpenAddressing) remove(key int) {idx := m.hashFunc(key)// 遍历桶,从中删除键值对// 线性探测,从 index 开始向后遍历for i := 0; i < m.capacity; i++ {// 计算桶索引,越过尾部返回头部j := (idx + 1) % m.capacity// 若遇到空桶,说明无此 key ,则直接返回if m.buckets[j] == (pair{}) {return}// 若遇到指定 key ,则标记删除并返回if m.buckets[j].key == key {m.buckets[j] = m.removedm.size -= 1}}
}/* 扩容哈希表 */
func (m *hashMapOpenAddressing) extend() {// 暂存原哈希表tmpBuckets := make([]pair, len(m.buckets))copy(tmpBuckets, m.buckets)// 初始化扩容后的新哈希表m.capacity *= m.extendRatiom.buckets = make([]pair, m.capacity)m.size = 0// 将键值对从原哈希表搬运至新哈希表for _, p := range tmpBuckets {if p != (pair{}) && p != m.removed {m.put(p.key, p.val)}}
}/* 打印哈希表 */
func (m *hashMapOpenAddressing) print() {for _, p := range m.buckets {if p != (pair{}) {fmt.Println(strconv.Itoa(p.key) + " -> " + p.val)} else {fmt.Println("nil")}}
}
多次哈希
顾名思义,多次哈希方法是使用多个哈希函数 f1(x)、f2(x)、f3(x)、… 进行探测。
- 插入元素:若哈希函数 f1(x) 出现冲突,则尝试 f2(x) ,以此类推,直到找到空位后插入元素。
- 查找元素:在相同的哈希函数顺序下进行查找,直到找到目标元素时返回;或遇到空位或已尝试所有哈希函数,说明哈希表中不存在该元素,则返回 None 。
与线性探测相比,多次哈希方法不易产生聚集,但多个哈希函数会增加额外的计算量。
Python 采用开放寻址。字典 dict 使用伪随机数进行探测。
Golang 采用链式地址。Go 规定每个桶最多存储 8 个键值对,超出容量则连接一个溢出桶;当溢出桶过多时,会执行一次特殊的等量扩容操作,以确保性能。
相关文章:
小白备战大厂算法笔试(四)——哈希表
文章目录 哈希表常用操作简单实现冲突与扩容链式地址开放寻址线性探测多次哈希 哈希表 哈希表,又称散列表,其通过建立键 key 与值 value 之间的映射,实现高效的元素查询。具体而言,我们向哈希表输入一个键 key ,则可以…...

云原生Kubernetes:pod基础
目录 一、理论 1.pod 2.pod容器分类 3.镜像拉取策略(image PullPolicy) 二、实验 1.Pod容器的分类 2.镜像拉取策略 三、问题 1.apiVersion 报错 2.pod v1版本资源未注册 3.取行显示指定pod信息 四、总结 一、理论 1.pod (1) 概念 Pod是ku…...
Ansys Zemax | 手机镜头设计 - 第 3 部分:使用 STAR 模块和 ZOS-API 进行 STOP 分析
本文是 3 篇系列文章的一部分,该系列文章将讨论智能手机镜头模组设计的挑战,从概念、设计到制造和结构变形的分析。本文是三部分系列的第三部分。它涵盖了使用 Ansys Zemax OpticStudio Enterprise 版本提供的 STAR 技术对智能手机镜头进行自动的结构、热…...

CSP-J初赛复习大题整理笔记
本篇全是整理,为比赛准备. 在这里插入代码片 #include<cstdio> using namespace std; int n, m; int a[100], b[100];int main() {scanf_s("%d%d", &n, &m);for (int i 1; i < n; i)a[i] b[i] 0;//将两个数组清0,这…...
面试题 ⑤
1、TCP与UDP的区别 UDPTCP是否连接无连接,即刻传输面向连接,三次握手是否可靠不可靠传输,网络波动拥堵也不会减缓传输可靠传输,使用流量控制和拥塞控制连接对象个数支持一对一,一对多,多对一和多对多交互通…...

硅谷课堂1
文章目录 P1 项目概述P2—P12 MybatisPlus知识回顾P8 MybatisPlus实现逻辑删除P9 QueryWrapper使用P14 项目后端模块介绍P15 项目后端环境搭建P50—P53 整合腾讯云对象存储1、整合腾讯2、腾讯云示例3、讲师头像上传-后端代码P54—P60 课堂分类管理1、课堂分类查询2、课程分类导…...

第6节-PhotoShop基础课程-认识选区
文章目录 前言1.认识选区1.选区原理1.普通选区2.高级选区 2.功能用途1.抠图2.修图3.调色 3.关键操作(手术与屠宰的区别)2.加选(shift 是快捷键)3.减选(Alt是快捷键)4.交集(2,3合起来…...

SQLServer如何获取客户端IP
SQLServer如何获取客户端IP 很多用户询问如何通过SQLServer获取客户端IP从而定位一些问题,比如链接泄露,其实主要是利用几个相关视图,如下给出一些SQL方便用户排查 当前链接 SELECT CONNECTIONPROPERTY(PROTOCOL_TYPE) AS PROTOCOL_TYPE,CO…...

爬虫数据清洗可视化实战-就业形势分析
基于采集和分析招聘网站的数据的芜湖就业形势的调查研究 一、引言 本报告旨在分析基于大数据的当地就业形势,并提供有关薪资、工作地点、经验要求、学历要求、公司行业、公司福利以及公司类型及规模的详细信息。该分析是通过网络爬虫技术对招聘网站的数据进行采集…...
Python - 队列【queue】task_done()和join()基本使用
一. 前言 task_done()是Python中queue模块提供的方法,用于通知队列管理器,已经处理完了队列中的一个项目。 queue.task_done()是Queue对象的一个方法,它用于通知Queue对象,队列中的某一项已经被处理完毕。通常在使用Queue对象时…...

springboot web 增加不存在的url返回200状态码 vue 打包设置
spring boot项目增加 html web页面访问 1. 首先 application.properties 文件中增加配置,指定静态资源目录(包括html的存放) spring.resources.static-locationsclasspath:/webapp/,classpath:/webapp/static/ 2. 项目目录 3. 如果有实现 …...

JavaWeb_LeadNews_Day11-KafkaStream实现实时计算文章分数
JavaWeb_LeadNews_Day11-KafkaStream实现实时计算文章分数 KafkaStream概述案例-统计单词个数SpringBoot集成 实时计算文章分值来源Gitee KafkaStream 概述 Kafka Stream: 提供了对存储与Kafka内的数据进行流式处理和分析的功能特点: Kafka Stream提供了一个非常简单而轻量的…...

python tcp server client示例代码
功能: 实现基本的tcp server端、client端,并引入threading, 保证两端任意链接、断链接,保证两端的稳定运行 IP说明: server不输入IP,默认为本机的IP,client需要输入要链接的server端的IP 端口说明&#x…...
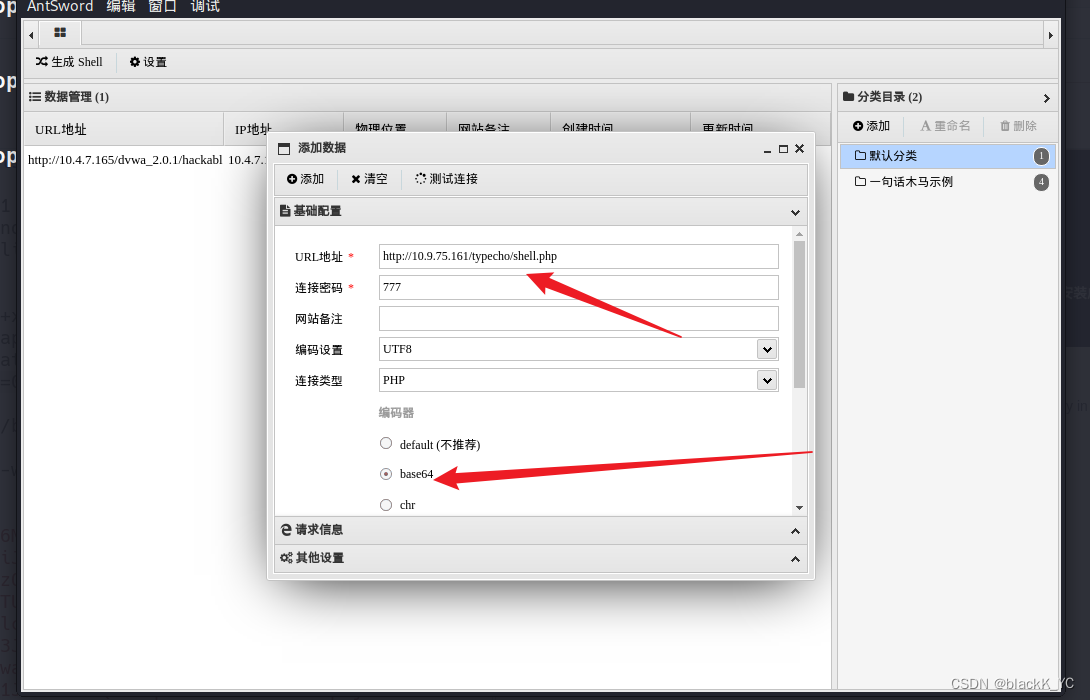
typecho 反序列化漏洞复现
环境搭建 下载typecho14.10.10 https://github.com/typecho/typecho/tags 安装,这里需要安装数据库 PHPINFO POC.php <?php class Typecho_Feed { const RSS1 RSS 1.0; const RSS2 RSS 2.0; const ATOM1 ATOM 1.0; const DATE_RFC822 r; const DATE_W3…...

Python实现SSA智能麻雀搜索算法优化LightGBM分类模型(LGBMClassifier算法)项目实战
说明:这是一个机器学习实战项目(附带数据代码文档视频讲解),如需数据代码文档视频讲解可以直接到文章最后获取。 1.项目背景 麻雀搜索算法(Sparrow Search Algorithm, SSA)是一种新型的群智能优化算法,在2020年提出&a…...
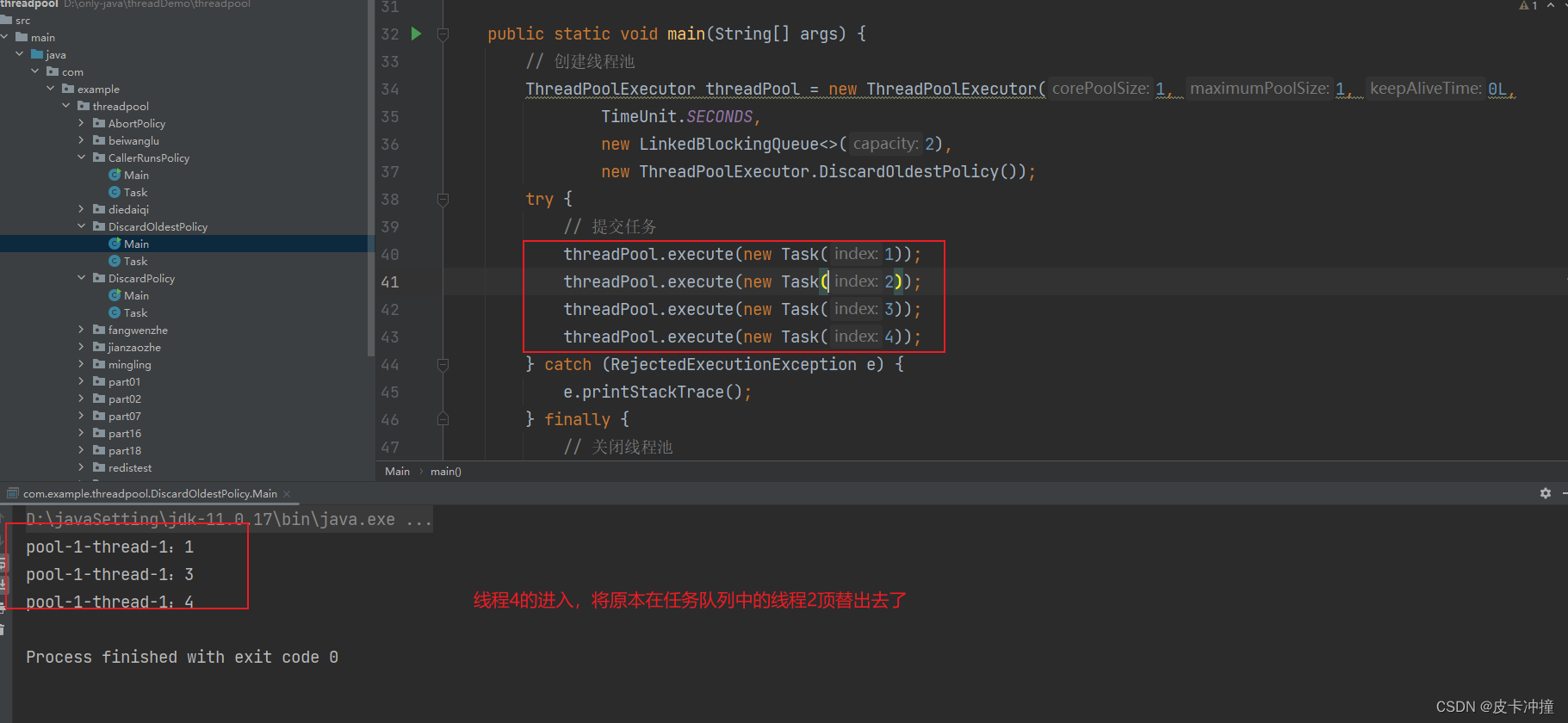
Java多线程4种拒绝策略
文章目录 一、简介二、AbortPolicy拒绝策略A. 概述B. 拒绝策略实现原理C. 应用场景D. 使用示例 三、CallerRunsPolicy拒绝策略A. 概述B. 拒绝策略实现原理C. 应用场景D. 使用示例 四、DiscardPolicy拒绝策略A. 概述B. 拒绝策略实现原理C. 应用场景D. 使用示例 五、DiscardOldes…...

MySQL的MHA
1.什么是 MHA MHA(MasterHigh Availability)是一套优秀的MySQL高可用环境下故障切换和主从复制的软件。 MHA 的出现就是解决MySQL 单点的问题。 MySQL故障切换过程中,MHA能做到0-30秒内自动完成故障切换操作。 MHA能在故障切换的过…...

Java实现链表
在Java中,可以使用类来定义链表的节点,并使用引用数据类型(即类名)来模拟指针进而构建链表。下面是一个简单的示例。 首先,创建一个节点类 Node,它包含一个值和指向下一个节点的引用: public …...
SpringCloud Alibaba(2021.0.1版本)微服务-OpenFeign以及相关组件使用(保姆级教程)
💻目录 前言一、简绍二、代码实现1、搭建服务模块1.1、建立父包1.2、建立两个子包(service-order、service-product)1.3、添加util 工具类 2、添加maven依赖和yml配置文件2.1、springcloud-test父包配置2.2、服务模块配置2.2.1、service-orde…...

豆制品废水处理设备源头厂家方案
豆制品废水处理设备源头厂家方案 豆制品生产过程中产生的废水含有有机物、悬浮物、油脂等污染物,需要经过合理的处理才能达到排放标准或循环再利用。以下是一个可能的豆制品废水处理设备及方案: 1.初步处理: 格栅:用于去除大颗粒的…...

win-acme证书自动续期架构深度解析:从故障排查到高可用部署
win-acme证书自动续期架构深度解析:从故障排查到高可用部署 【免费下载链接】win-acme Automate SSL/TLS certificates on Windows with ease 项目地址: https://gitcode.com/gh_mirrors/wi/win-acme 技术背景与挑战 在当今云原生和微服务架构盛行的时代&am…...

FanControl:Windows系统下深度自定义风扇控制的终极指南
FanControl:Windows系统下深度自定义风扇控制的终极指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/…...

MegSpot专业视觉分析工具:从基础操作到高级应用全指南
MegSpot专业视觉分析工具:从基础操作到高级应用全指南 【免费下载链接】MegSpot MegSpot是一款高效、专业、跨平台的图片&视频对比应用 项目地址: https://gitcode.com/gh_mirrors/me/MegSpot 在数字媒体创作与分析领域,如何高效对比图片细节…...

数字记忆保护新方案:GetQzonehistory让QQ空间数据备份不再困难
数字记忆保护新方案:GetQzonehistory让QQ空间数据备份不再困难 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 在数字时代,我们的个人记忆越来越多地以数据形式存…...

找不到msvcr120.dll解决方法:2026年有效的一键修复与手动安装步骤
正玩着游戏或做着设计图,屏幕突然弹出“找不到msvcr120.dll”的提示,相信很多Windows用户都遇到过这种令人抓狂的时刻。这个错误意味着你的电脑缺少了某个软件或游戏运行所必需的“零件”。别担心,这个零件就是Microsoft Visual C 2013运行库…...

3步打造智能家居音乐自由:给爱好者的开源方案详解
3步打造智能家居音乐自由:给爱好者的开源方案详解 【免费下载链接】xiaomusic 使用小爱音箱播放音乐,音乐使用 yt-dlp 下载。 项目地址: https://gitcode.com/GitHub_Trending/xia/xiaomusic 在智能家居的日常使用中,许多用户都面临着…...

港科喜讯|[港科百创]参赛项目上市!视觉语言大模型第一股诞生!
2026年3 月 30 日,山东极视角科技股份有限公司(股票代码:6636.HK)在香港联合交易所主板正式上市。这家曾斩获香港科技大学第六届百万奖金国际创业大赛深圳赛区一等奖的科创企业,同时也是香港科大"创科行"(第…...

忍者像素绘卷代码实例:Python调用Z-Image-Turbo-rinaiqiao模型避坑指南
忍者像素绘卷代码实例:Python调用Z-Image-Turbo-rinaiqiao模型避坑指南 1. 环境准备与快速部署 在开始使用忍者像素绘卷之前,我们需要先搭建好Python环境并安装必要的依赖库。这个模型基于Z-Image-Turbo深度优化,特别适合生成16-Bit复古风格…...

Clipboard命令行参数完整指南:掌握所有可用选项的终极手册
Clipboard命令行参数完整指南:掌握所有可用选项的终极手册 【免费下载链接】Clipboard 😎🏖️🐬 Your new, 𝙧𝙞𝙙𝙤𝙣𝙠𝙪𝙡…...

Flux Sea Studio 极限测试:生成8K超高清巨幅海景壁纸的技术挑战与实现
Flux Sea Studio 极限测试:生成8K超高清巨幅海景壁纸的技术挑战与实现 最近在折腾AI生成图片,发现一个挺有意思的挑战:用Flux Sea Studio这类模型,能不能做出那种能铺满整块大屏幕的、细节拉满的8K超高清壁纸?特别是海…...